scalable many-core acceleration for image understanding - is cpu+gpu the answer?
TRANSCRIPT

Luca Benini - Chief Architect,DEIS Università di Bologna & STMicroelectronics
Scalable Many -core Acceleration for Image Understanding - is CPU+GPU the answer?
1

The Dawn of IOT
IN-Stat: Growth of mobile App Procs in 2011 exceeded 43% and is forecast to grow at a 22% CAGR through 2016… and IOT is next!
2

STM “Platform 2012” ���� STHORM
1 > 1003 6
CPU GPGPU HW IP
GOPS/mm 2 – GOPS/W
Platform 2012
SW HWMixed
ThroughputComputing
General-purposeComputing
Closing The Accelerator Efficiency Gap
3
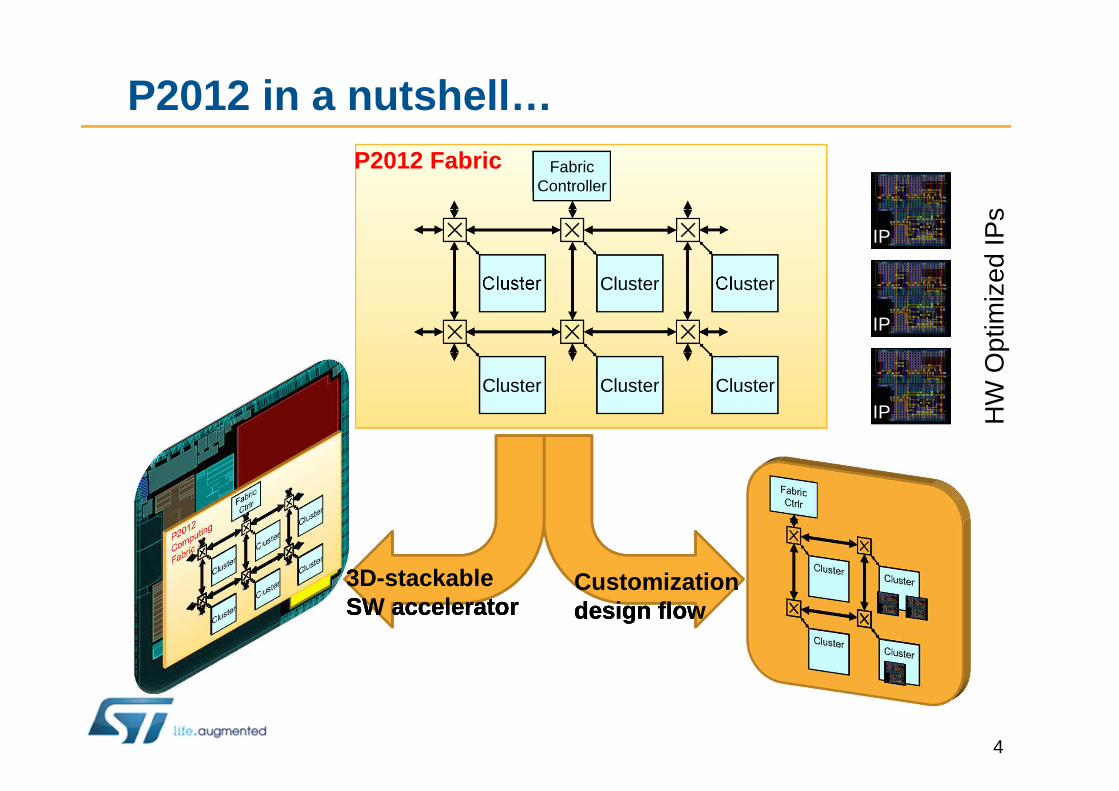
P2012 in a nutshell…
SoC
FabricController
ClusterCluster
Cluster
Cluster
Cluster Cluster
IPIPIP
IPIPIP
IPIPIP
Customization design flowCustomization design flowCustomization design flow
HW
Opt
imiz
edIP
s
P2012 Fabric
3D-stackableSW accelerator3D-stackableSW accelerator3D-stackableSW accelerator
4
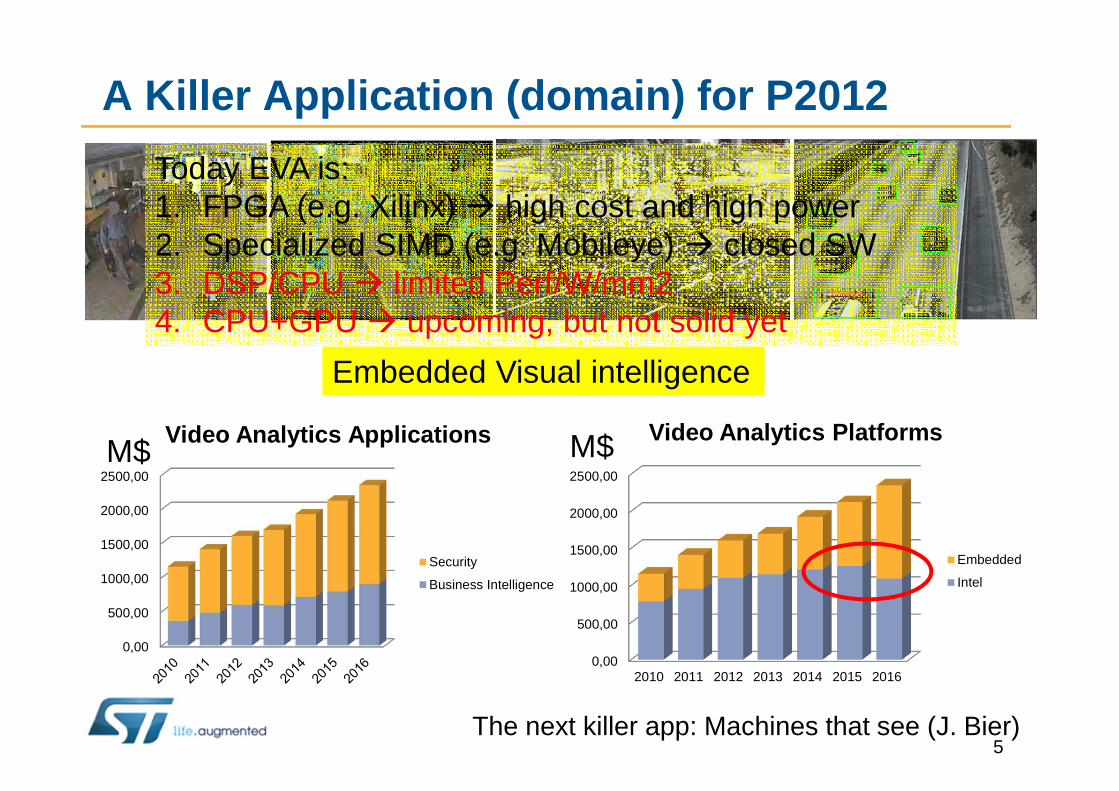
A Killer Application (domain) for P2012
0,00
500,00
1000,00
1500,00
2000,00
2500,00
Video Analytics Applications
Security
Business Intelligence
M$
0,00
500,00
1000,00
1500,00
2000,00
2500,00
2010 2011 2012 2013 2014 2015 2016
Video Analytics Platforms
Embedded
Intel
M$
Embedded Visual intelligence
The next killer app: Machines that see (J. Bier)5
Today EVA is:1. FPGA (e.g. Xilinx) � high cost and high power2. Specialized SIMD (e.g. Mobileye) � closed SW3. DSP/CPU � limited Perf/W/mm24. CPU+GPU � upcoming, but not solid yet

P2012 SoC in 28nm
• 4 Clusters, 69 processors
• 80 GOPS• 1MB L2 mem• 2D flip chip or 3D stacked
• 600 MHz typ• < 2 W• 3.7 mm2 per cluster
Energy efficiency 40GOPS/W �0,04GOPS/mW
Taped out 3/12 ↓
Samples back from fab 6/12
6

Designing the P2012 SoC
Communication challenge
7
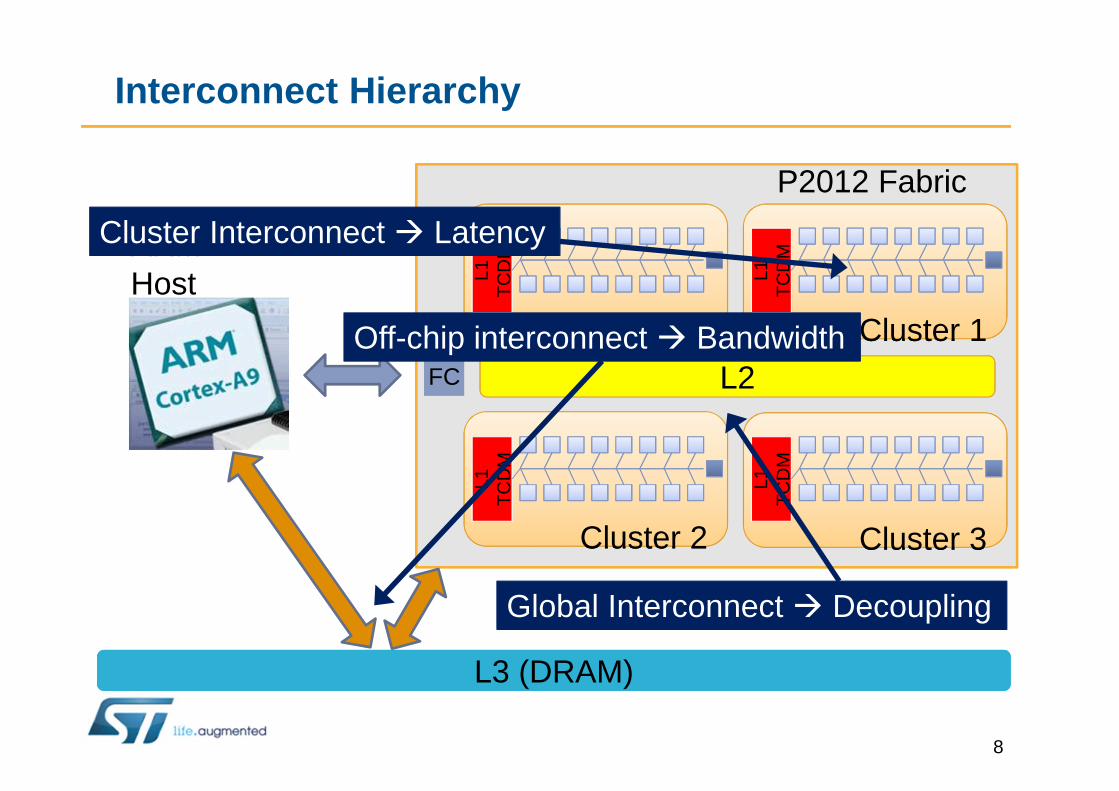
Interconnect Hierarchy
P2012 Fabric
L2
L3 (DRAM)L3 (DRAM)
Cluster 0Cluster 0
L1
TC
DM
L1
TC
DM
Cluster 1Cluster 1
L1
TC
DM
L1
TC
DM
Cluster 2Cluster 2
L1
TC
DM
L1
TC
DM
Cluster 3Cluster 3
L1
TC
DM
L1
TC
DM
ARM Host
FCFC
Cluster Interconnect � Latency
Global Interconnect � Decoupling
Off-chip interconnect � Bandwidth
8

P2012 Fabric Memory Map� Up to 32 clusters
� 544 processors
� 256 Mbyte ENCoreMemory � up to 4 Mbyte/cluster; today256 KB/cluster
� GAS-NUMA architecture
� No caches!
0x8000_0000
0xFFFF_FFFF
L3
Clust00x4000_0000
Clust10x4010_0000
Clust31
Clust0
Fabric NI0x6000_0000
0x6000_3000
Fabric Controller
0x5000_0000
0x4200_0000Cluster
Peripheral0x4000_0000
ENcore Memory0x1000_0000
0x0000_0000
0x4020_0000
0x41F0_0000
0x4200_0000
0x1000_0000
0x1080_0000
0x1F80_0000
0x2000_0000
Clust1
Clust31
0x2000_0000
ENCorePeripheral0x3E00_0000
Clust00x3E00_0000
Clust10x3E10_0000
Clust31
0x3E20_0000
0x3FF0_0000
0x4000_0000L2
0x5800_0000
0x5810_0000
NI-L20x5FFF_C000
9

Cluster interconnect
10

The cluster
Cluster Controller
Debug & Test Unit BOUTBIN
ENCore<N>
TMS TCK TDI TD0 BI BOTMS TCK TDI TD0 BI BO
CC
Int
erfa
ce
EN
Cor
eIn
terf
ace
N:1 Mux/Arbiter
DMAsub-system
CC interconnect, CCI
CP Sub-System
CVP
STxP70-basedCluster
Processor, CP
32K I$,16K TCDM, 32-entry ITC
CC-Peripherals
DMAChannel #0
BI
JTAG
BO
HardWare Synchronizer, HWS
Shared 256-KB, 2xN-bank TCDM
… x N…PE#0
I$
PE#1
PE#N-1
I$ I$
DMAChannel #1
DMAChannel # P-1
…N
I64
TMS TCK TDI TD0 BI BO
GIC
GA
LS I/
F
M/S
T3
Configurable(N, EFUs, banking factor, …)
“Computing Farm”
ClusterControl
ENCoreBoot,
HWPE control,etc…
DMAControlL3 � L1,L1 � L1
Debug Multicore Debug
11

P2012 Cluster Main Features� HW Support for synchronization:
� Fast barrier (within a cluster only) in ~4 Cycles for 16 processors� Flexible barrier ~20 cycles for 16 processors
� High level of customization though:� The number of STxP70 processing elements� The STxP70 extensions (ISA customization)� Memory sizes + Banking factor of the shared memory
12

ENCore16
DEMUX
Low-Latency Interconnect
8-KBMem
#0
8-KBMem
#1
8-KBMem #32
HWS
ENC2EXT Bridge
128-bit
64-bit
64-bit
32-bit
DEMUX DEMUX
STxP70#0 + FPx
16K I$
32-bit
STxP70#1 + FPx
16K I$
32-bit
STxP70#15 + FPx
16K I$
32-bit
64-bit
Per
iph.
Inte
rcon
nect
Timer
EXT2MEM Bridge
EXT2PER Bridge
SlaveMaster T3 T1 Log-Interc. Interrupt Control
IT
It_wdt
It_hws
IT
CTL
ITC ITC ITC
64-bit 64-bit
OCE OCE OCE
BI BOJTAG BI BOJTAG BI BOJTAG
STBus T3 N:1 Node
DDATA
CC
DMA
IDATA
Features:• 2/3 cycles latency
� 0/1 pipe stalls• Non-blocking• Parametric soft IP
14

Shared Memory
P1 P2 P3 P4
B2
B3
B4
B5
B6
B7
B8
B1
Routing Tree
Arbitration Tree
Processors
Memory Banks
15

P2012 Cluster Overview
Shared Memory Conflicts
1 1.0328 1.07211.1329
1.2536
0
0.2
0.4
0.6
0.8
1
1.2
1.4
0% 35.70% 50% 66.70% 100%
LD/ST %
Com
puta
tion
Tim
e
Theoretical
Measured
Typical case
16

Inter-cluster interconnect
18

� Each cluster has its ownoperating point tunable to the right energy budget
� Inter cluster communication must support cluster decoupling
Cluster Decoupling
F1 F2
F3 F4
19

Decoupling ����GALS
� Several synchronous clock domains (Synchronous Blocks) communicate through asynchronous channels
� Each SB can be clocked independently for local needs
DataHandshake
CLK1
SB1
CLK2
SB2
CLK3
SB3
� Pros� Reduced average frequency� Reduced global power� Globally skew tolerant� No global clock in GALS: easier
local clock design
� Cons� Global communication overhead
from handshake protocol� Total area, average wirelength
and power penalty from protocol� Local clock overhead
20

Fully asynchronous network on chip
IPa IPb IPc
IPd IPe IPf
R L
G
GALS SoC: IndependentTime & power domains suitable for DVFS
Network on Chip:Flexible packet-switched interconnect
Fully asynchronousrouters & links: clocklesshigh performance & low-power
Standard-cell based hierarchical implementation with top-level pseudo-synchronous constraints
Low latency / low areaGALS interface
21

P2012 SoC GANoC
SoC ports
64-bit G-ANoC-L3
L2 tile (1MB)
64-bit G-ANoC-L2
STxP70-V4B
ITC
32-KB TCDM
16-KB I$
Fabric Controller
OC
E
FC PERIPHERAL
STM
JTAG
External ITs fromI/O Peripherals
rst_n, anoc_rst_n
ref_clk (100MHz)
FC ITs for host
Sys_clk
360
DMA
Trace5
2
3
8
1
1
5
CVP4pad_en
Slave
MasterIOs
CCCVP
Cluster Processor
CC-Peripherals
DMA
EN
Cor
e16
CCIGALSI/F
CCCVP
Cluster Processor
CC-Peripherals
DMA
EN
Cor
e16
CCIGALSI/F
CCCVP
Cluster Processor
CC-Peripherals
DMA
EN
Cor
e16
CCIGALSI/F
CCCVP
Cluster Processor
CC-Peripherals
DMA
EN
Cor
e16
CCIGALSI/F
std_config_n2
tst_mode
1
360 360
Topology is tailored to architecture
System plug: asymmetric bandwidth
Sideband signaling: events, debug
22

System interconnect
23
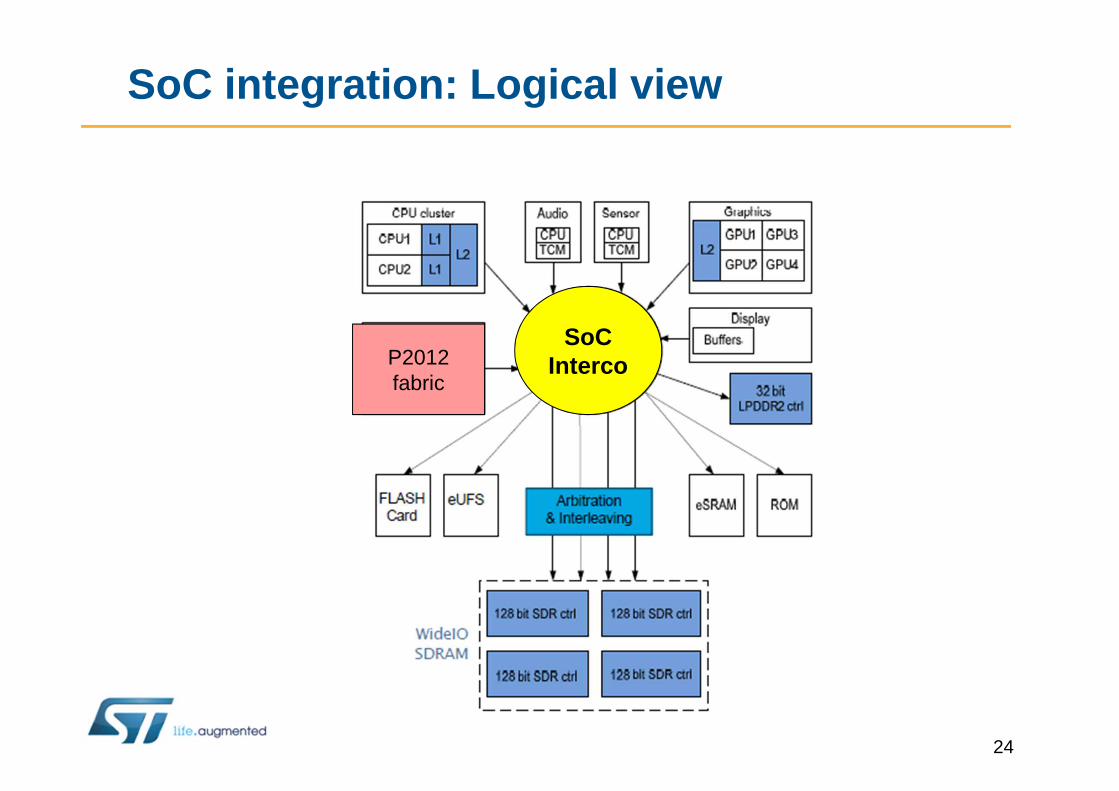
SoC integration: Logical view
P2012fabric
SoCInterco
24

3D: the die to die challenge
V1, F1
V2, F2Die 2
Die 1
You need a Phy and at 500MHz to 1GHz thisis tough, time consumming and expensive
Alternative: Asynchronous Link (QDI implementation)
Micro Pipeline Stages
Pro:•No more Phy ☺☺☺☺
Cons:•Async logic on both sides
•Challenge:•Micro pipe stages need to be as close as they can befrom micro bumps on bothsides
Die 1
Die
2
26
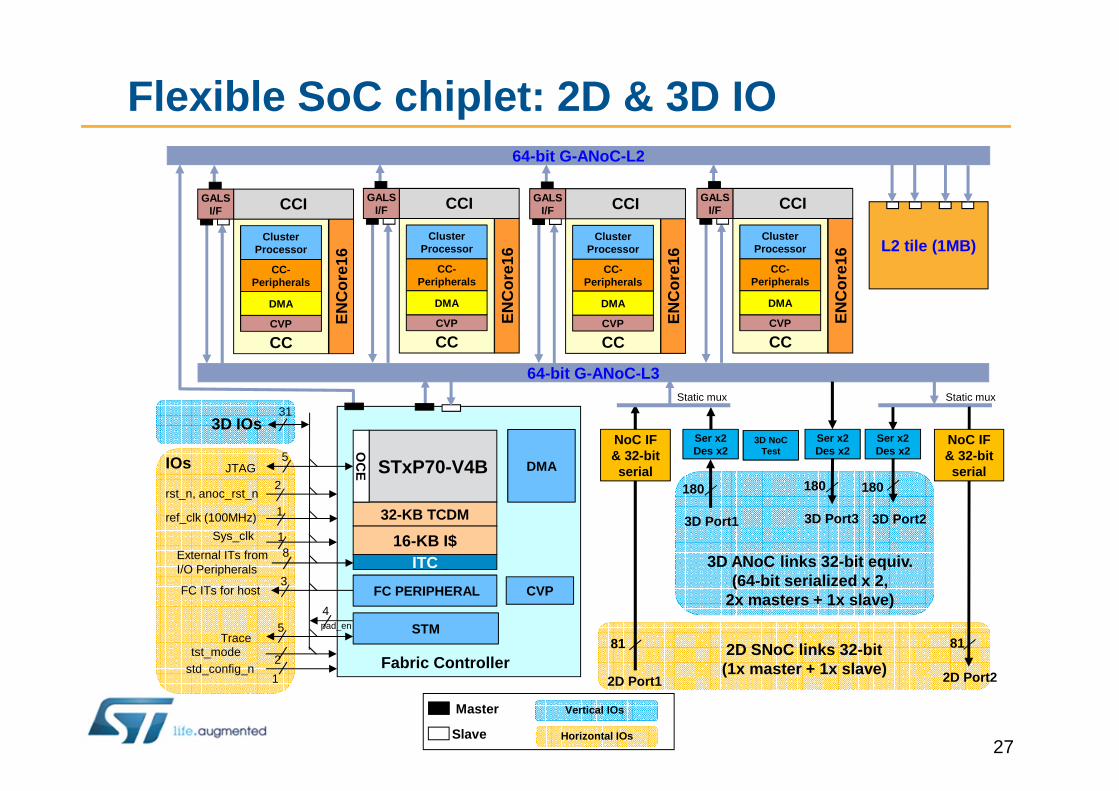
Flexible SoC chiplet: 2D & 3D IO
64-bit G-ANoC-L3
L2 tile (1MB)
64-bit G-ANoC-L2
STxP70-V4B
ITC
32-KB TCDM
16-KB I$
Fabric Controller
OC
E
FC PERIPHERAL
STM
JTAG
External ITs fromI/O Peripherals
rst_n, anoc_rst_n
ref_clk (100MHz)
FC ITs for host
Sys_clk
3D ANoC links 32-bit equiv.(64-bit serialized x 2,
2x masters + 1x slave)
2D SNoC links 32-bit(1x master + 1x slave)
180 180 180
81 81
DMA
Trace5
2
3
8
1
1
5
Static muxStatic mux31
3D IOsNoC IF& 32-bit serial
CVP4pad_en
Ser x2Des x2
Ser x2Des x2
Ser x2Des x2
NoC IF& 32-bit serial
Slave
Master Vertical IOs
Horizontal IOs
IOs
CCCVP
Cluster Processor
CC-Peripherals
DMA
EN
Cor
e16
CCIGALSI/F
CCCVP
Cluster Processor
CC-Peripherals
DMA
EN
Cor
e16
CCIGALSI/F
CCCVP
Cluster Processor
CC-Peripherals
DMA
EN
Cor
e16
CCIGALSI/F
CCCVP
Cluster Processor
CC-Peripherals
DMA
EN
Cor
e16
CCIGALSI/F
std_config_n2
tst_mode
1 2D Port1 2D Port2
3D Port1 3D Port23D Port3
3D NoC Test
27

Programming the P2012 Fabric
SW Ecosystem & Efficiency challenge
28

OpenCL Standard
Multi-core CPU GPUMany-core
RogueP2012
More programmabilityMore parallelism
Task Parallelism(run-to-completion)
Data Parallelism(with some-synchro)
Coretex-A15
29

P2012 ≠ GPU: Kernel level parallelism
Independent Clusters + Independent processor IF� Work-item divergence is not an issue� P2012 supports more complex OpenCL task
graph than GPUs. Both task-level and data-level (ND-Range) are possible
P2012 cores are not HW-multithreaded� P2012 OCL runtime does not accept
more than 16 work-items per work group when creating an ND-Range.
� But you can chose which work to do (e.g. using “case”) in each WI
30
GPU P2012
NO!t t OK!
P1P2P3
… …P6P7
P8
P1P2P3 P6P7 P8
Full thread divergence
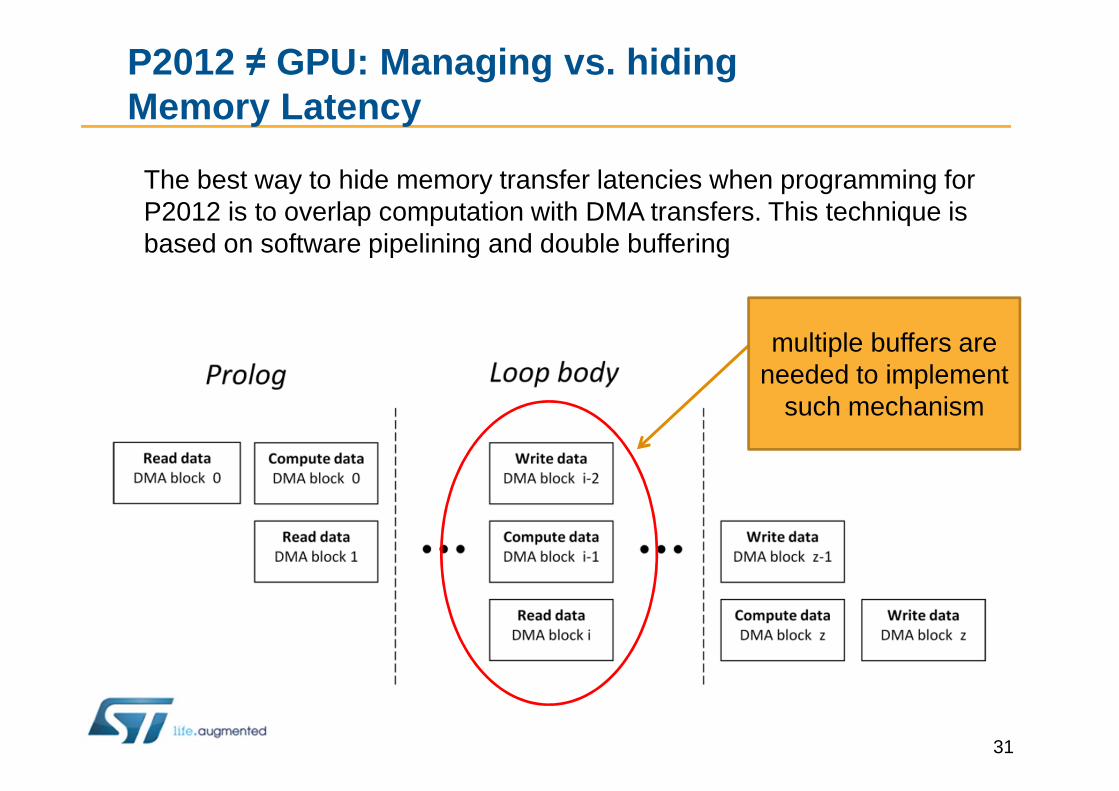
The best way to hide memory transfer latencies when programming for P2012 is to overlap computation with DMA transfers. This technique is based on software pipelining and double buffering
multiple buffers are needed to implement
such mechanism
P2012 ≠ GPU: Managing vs. hiding Memory Latency
31

Memory Mapping and Data Movements
L3Global Memory (buffers)
Local Memory (shared)Private Memory(kernel stacks)
Constant MemoryL1
shared256KB
>200cycles
Scalar/Vector load/storeasync_work_group_copy
Cluster
The compiler can
compute accurately
OpenCL-C kernel
stack size !async_work_group_2d_copyasync_work_item_[2d]_copy
32

P2012 OpenCL Programming Summary
1. Fill processors/clusters with processing� Fully with data parallelism when available� Task parallelism otherwise (mid-coarse grain)
2. Optimize the data locality� Use local & private as user managed cache� Minimize global ↔ local/private
3. Parallelize memory transfers & computation� Use asynchronous copies (DMA)
33

Peformance Assessment
34

OpenCV on P2012
FAST: key point detection
AR
M F
MP
osix
Linux (+Android)
P2012 Linux driver
P2012 OpenCL 1.1
OpenCV library
App
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernel
FAST kernelH
ost
P20
12
X
fb
CC
OCV functions accelerated with P2012 (transparently for the Appprogrammer) � Standard domain specific APIs
35
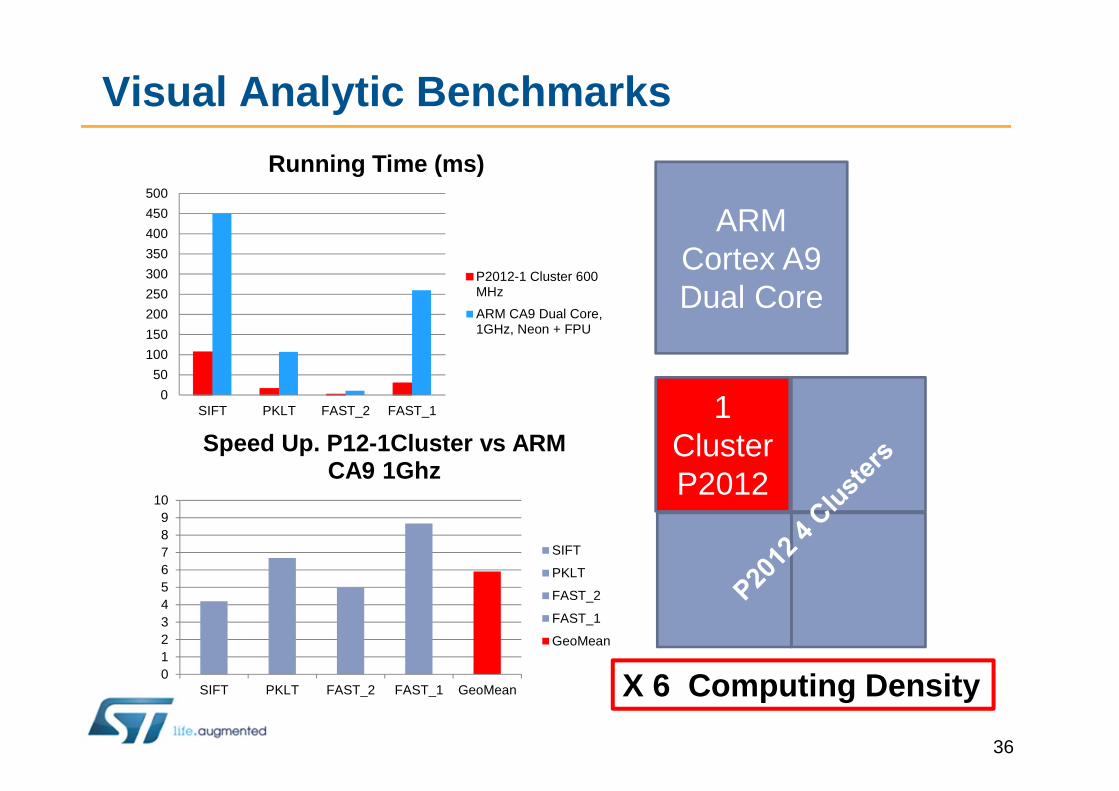
Visual Analytic Benchmarks
0
50
100
150
200
250
300
350
400
450
500
SIFT PKLT FAST_2 FAST_1
Running Time (ms)
P2012-1 Cluster 600MHz
ARM CA9 Dual Core,1GHz, Neon + FPU
0123456789
10
SIFT PKLT FAST_2 FAST_1 GeoMean
Speed Up. P12-1Cluster vs ARM CA9 1Ghz
SIFT
PKLT
FAST_2
FAST_1
GeoMean
ARM Cortex A9Dual Core
1 ClusterP2012
X 6 Computing Density
36

Scalability (PKLT)
50
2716
9
107
0
20
40
60
80
100
120
P2012- 4cores
P2012 -8cores
P2012 -16cores
P2012 -32cores
ARM CA9 -1GHz
2,1
4,0
6,7
11,9
0,0
2,0
4,0
6,0
8,0
10,0
12,0
14,0
P2012- 4cores
P2012 -8cores
P2012 -16cores
P2012 -32cores
Running time [ms] Speedup vs ARM CA9
1 cluster: varying ND range
2 clusters
37

P2012 vs. GPU
Resolution: 640 x 480 pixelsSystem: Quadro NVS3100M, NVIDIA GTX280, STHORM (P2012)
0
100
200
300
400
500
600
700
800
STHORM16
cores - 600
MHz
Quadro
NVS3100M -
1.5 GHz
STHORM 4
clusters 64
cores - 600
Mhz
Nvidia
GeForce GTX
280 (240
Processors) -
1.5 GHz
Frame/sec detection Kernel - VGA
Image - 777 Keypoints
0
10
20
30
40
50
60
70
80
90
STHORM16 cores
- 600 MHz
Quadro
NVS3100M - 1.5
GHz
STHORM 4
clusters 64 cores -
600 Mhz
Nvidia GeForce
GTX 280 (240
Processors) - 1.5
GHz
Frame/sec/W - VGA Image - 777 Keypoints
38

From prototype to product
Go to market challenge
39

P2012 in GOPS/mm 2
1 > 1003 6
CPU GP-GPU HW IP
P2012 SpaceThroughputComputing
General-purposeComputing
SW HWHW/SW
CO HC
40

Opportunities
� Natural selection� Develop 10 apps� Succeed with 1 or 2 � Go to market at
premium on success
� Low-cost, power, high-volume� Quick derivative� Some flexibility to
adapt to market and standard changes
PE0
…
Shared L1 MEM
PE1
PEn/2
PEj
…PEk
PEn
PE0
…
Shared L1 MEM
PE1
PEn/2
PEj
…PEk
PEn
PE0 …
Shared L1 M
PE1
PEn
HWPE HWPEPU1 PU2 PUn-1 PUn
COM
XP70
STBUS
PU3
StreamerDelay lines
Mail Box
Register Bank
1x5x~10x 1.2x~3x
X41

Summing Up
0
0,5
1Peak Perf
Peak Perf vsAvg Perf
Perf perpower unit
Perf per costunit
Flexibility
GP-SMP
GP-GPU
HW-PipelineP2012-SW
P2012-HWSW
IPs for SoCs
P2012
•Video Codecs•Imaging•Base Band•IQI•…
X GopsSmall
LowPower
Standalone SoC
•Eco System•Analytics•Fragmented Mkts
?
?
Heterogeneous Computing
Homogeneous Computing 42