scalable trusted computing engineering challenge, or something more fundamental? ken birman cornell...
Post on 22-Dec-2015
214 views
TRANSCRIPT

Scalable Trusted Computing
Engineering challenge, or something more
fundamental?
Ken BirmanCornell University

Cornell Quicksilver Project Krzys Ostrowski: The key player Ken Birman, Danny Dolev:
Collaborators and research supervisors Mahesh Balakrishnan, Maya Haridasan,
Tudor Marian, Amar Phanishayee, Robbert van Renesse, Einar Vollset, Hakim Weatherspoon: Offered valuable comments and criticisms

Trusted Computing A vague term with many meanings…
For individual platforms, integrity of the computing base
Availability and exploitation of TPM h/w Proofs of correctness for key components Security policy specification, enforcement
Scalable trust issues arise mostly in distributed settings

System model
A world of Actors: Sally, Ted, … Groups: Sally_Advisors = {Ted, Alice, …} Objects: travel_plans.html,
investments.xls Actions: Open, Edit, … Policies:
(Actor,Object,Action) { Permit, Deny } Places: Ted_Desktop, Sally_Phone, ….

Rules
If Emp.place Secure_Place and Emp Client_Advisors thenAllow Open Client_Investments.xls
Can Ted, working at Ted_Desktop, open Sally_Investments.xls? … yes, if Ted_Desktop Secure_Places

Miscellaneous stuff
Policy changes all the time Like a database receiving updates E.g. as new actors are added, old
ones leave the system, etc … and they have a temporal scope
Starting at time t=19 and continuing until now, Ted is permitted to access Sally’s file investments.xls

Order dependent decisions Consider rules such as:
Only one person can use the cluster at a time.
The meeting room is limited to three people While people lacking clearance are present,
no classified information can be exposed These are sensitive to the order in which
conflicting events occur Central “clearinghouse” decides what to
allow based on order in which it sees events

Goal: Enforce policy
Policy Database
investments.xls
investments.xls
Read
(data)

… reduction to a proof Each time an action is attempted,
system must develop a proof either that the action should be blocked or allowed
For example, might use the BAN logic
For the sake of argument, let’s assume we know how to do all this on a
single machine

Implications of scale
We’ll be forced to replicate and decentralize the policy enforcement function For ownership: Allows “local policy” to
be stored close to the entity that “owns” it
For performance and scalability For fault-tolerance

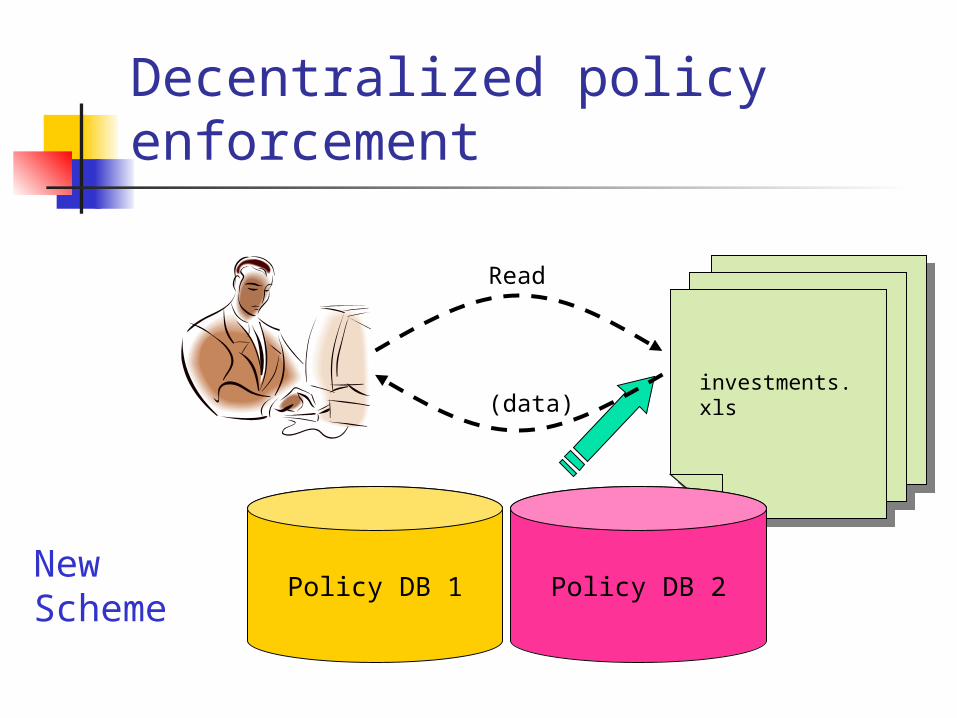
Decentralized policy enforcement
Policy Database
investments.xls
investments.xls
Read
(data)
Original Scheme
Decentralized policy enforcement
investments.xls
investments.xls
Read
(data)
Policy DB 1 Policy DB 2New Scheme

So… how do we decentralize?
Consistency: the bane of decentralization We want a system to behave as if all
decisions occur in a single “rules” database Yet want the decisions to actually occur in
a decentralized way… a replicated policy database
System needs to handle concurrent events in a consistent manner

So… how do we decentralize?
More formally:
Analogy: database 1-copy serializability
Any run of the decentralized system should be
indistinguishable from some run of a centralized system

But this is a familiar problem! Database researchers know it as
the atomic commit problem. Distributed systems people call it:
State machine replication Virtual synchrony Paxos-style replication
… and because of this we know a lot about the question!

… replicated data with abcast Closely related to the “atomic broadcast”
problem within a group Abcast sends a message to all the members
of a group Protocol guarantees order, fault-tolerance Solves consensus…
Indeed, a dynamic policy repository would need abcast if we wanted to parallelize it for speed or replicate it for fault-tolerance!

A slight digression
Consensus is a classical problem in distributed systems N processes They start execution with inputs {0,1} Asynchronous, reliable network At most 1 process fails by halting (crash) Goal: protocol whereby all “decide” same
value v, and v was an input

Distributed Consensus
Jenkins, if I want another yes-man, I’ll build one!
Lee Lorenz, Brent Sheppard

Asynchronous networks
No common clocks or shared notion of time (local ideas of time are fine, but different processes may have very different “clocks”)
No way to know how long a message will take to get from A to B
Messages are never lost in the network

Fault-tolerant protocol
Collect votes from all N processes At most one is faulty, so if one doesn’t
respond, count that vote as 0 Compute majority Tell everyone the outcome They “decide” (they accept
outcome) … but this has a problem! Why?

What makes consensus hard?
Fundamentally, the issue revolves around membership In an asynchronous environment, we can’t
detect failures reliably A faulty process stops sending messages
but a “slow” message might confuse us Yet when the vote is nearly a tie, this
confusing situation really matters

Some bad news FLP result shows that fault-tolerant
consensus protocols always have non-terminating runs.
All of the mechanisms we discussed are equivalent to consensus
Impossibility of non-blocking commit is a similar result from database community

But how bad is this news? In practice, these impossibility results
don’t hold up so well Both define “impossible not always
possible” In fact, with probabilities, the FLP scenario is
of probability zero … must ask: Does a probability zero result
even hold in a “real system”? Indeed, people build consensus-based
systems all the time…

Solving consensus Systems that “solve” consensus often
use a membership service This GMS functions as an oracle, a trusted
status reporting function Then consensus protocol involves a kind
of 2-phase protocol that runs over the output of the GMS
It is known precisely when such a solution will be able to make progress

More bad news Consensus protocols don’t scale!
Isis (virtual synchrony) new view protocol Selects a leader; normally 2-phase; 3 if leader dies Each phase is a 1-n multicast followed by an n-1
convergecast (can tolerate n/2-1 failures) Paxos decree protocol
Basic protocol has no leader and could have rollbacks with probability linear in n
Faster-Paxos is isomorphic to the Isis view protocol (!) … both are linear in group size.
Regular Paxos might be O(n2) because of rollbacks

Work-arounds?
Only run the consensus protocol in the “group membership service” or GMS It has a small number of members, like 3-5 They run a protocol like the Isis one Track membership (and other “global”
state on behalf of everything in the system as a whole”
Scalability of consensus won’t matter

But this is centralized
Recall our earlier discussion Any central service running on behalf
of the whole system will become burdened if the system gets big enough
Can we decentralize our GMS service?

GMS in a large system
GMS
Global events are inputs to the GMS
Output is the official record of
events that mattered to the
system

Hierarchical, federated GMS
Quicksilver V2 (QS2) constructs a hierarchy of GMS state machines
In this approach, each “event” is associated with some GMS that owns the relevant official record
GMS0
GMS2GMS1

Delegation of roles One (important) use of the GMS is to
track membership in our rule enforcement subsystem
But “delegate” responsibility for classes of actions to subsystems that can own and handle them locally GMS “reports” the delegation events In effect, it tells nodes in the system about
the system configuration – about their roles And as conditions change, it reports new
events

DelegationIn my capacity as President of the
United States, I authorize John Pigg to oversee this nation’s
banks
Thank you, sir! You can trust me

Delegation
GMS0
GMS1
Policysubsystem

Delegation example
IBM might delegate the handling of access to its Kingston facility to the security scanners at the doors
Events associated with Kingston access don’t need to pass through the GMS
Instead, they “exist” entirely within the group of security scanners

… giving rise to pub/sub groups
Our vision spawns lots and lots of groups that own various aspects of trust enforcement The scanners at the doors The security subsystems on our
desktops The key management system for a VPN … etc
A nice match with publish-subscribe

Publish-subscribe in a nutshell Publish(“topic”, message) Subscribe(“topic”, handler)
Basic idea: Platform invokes handler(message)
each time a topic match arises Fancier versions also support history
mechanisms (lets joining process catch up)

Publish-subscribe in a nutshell Concept first mentioned by Willy
Zwaenepoel in a paper on multicast in the V system
First implementation was Frank Schmuck’s Isis “news” tool
Later re-invented in TIB message bus
Also known as “event notification”… very popular

Other kinds of published events
Changes in the user set For example, IBM hired Sally. Jeff left his
job at CIA. Halliburton snapped him up Or the group set
Jeff will be handling the Iraq account Or the rules
Jeff will have access to the secret archives Sally is no longer allowed to access them

But this raises problems
If “actors” only have partial knowledge E.g. the Cornell library door access
system only knows things normally needed by that door
… then we will need to support out-of-band interrogation of remote policy databases in some cases

A Scalable Trust Architecture
GMS
GMSGMS
GMS hierarchy tracks configuration events
Masterenterprisepolicy DB
Central database tracks overall policy
Roledelegation
Pub/sub framework
Slave systemapplies policy
Knowledge limited to locally useful policy
Enterprise policy system for some company or entity

A Scalable Trust Architecture
Enterprises talk to one-another when decisions require non-local information
FBI
Cornell University
PeopleSoft
Inquiry
(policy)

www.zombiesattackithaca.com

Open questions? Minimal trust
A problem reminiscent of zero-knowledge Example:
FBI is investigating reports of zombies in Cornell’s Mann Library… Mulder is assigned to the case.
The Cornell Mann Library must verify that he is authorized to study the situation
But does FBI need to reveal to Cornell that the Cigarette Man actually runs the show?

Other research questions
Pub-sub systems are organized around topics, to which applications subscribe
But in a large-scale security policy system, how would one structure these topics? Topics are like file names – “paths” But we still would need an agreed upon
layout

Practical research question “State transfer” is the problem of
initializing a database or service when it joins the system after an outage
How would we implement a rapid and secure state transfer, so that a joining security policy enforcement module can quickly come up to date? Once it’s online, the pub-sub system
reports updates on topics that matter to it

Practical research question
Designing secure protocols for inter-enterprise queries
This could draw on the secured Internet transaction architecture A hierarchy of credential databases Used to authenticate enterprises to one-
another so that they can share keys They employ the keys to secure “queries”

Recap?
We’ve suggested that scalable trust comes down to “emulation” of a trusted single-node rule enforcement service by a distributed service
And that service needs to deal with dynamics such as changing actor set, object set, rule set, group membership

Recap?
Concerns that any single node Would be politically unworkable Would impose a maximum capacity limit Won’t be fault-tolerant
… pushed for a decentralized alternative
Needed to make a decentralized service emulate a centralized one

Recap? This led us to recognize that our
problem is an instance of an older problem: replication of a state machine or an abstract data type
The problem reduces to consensus… and hence is impossible
… but we chose to accept “Mission Impossible: V”

… Impossible? Who cares! We decided that the impossibility
results were irrelevant to real systems Federation addressed by building a
hierarchy of GMS services Each supported by a group of servers Each GMS owns a category of global events
Now can create pub/sub topics for the various forms of information used in our decentralized policy database
… enabling decentralized policy enforcement

QS2: A work in progress We’re building Quicksilver, V2 (aka QS2)
Under development by Krzys Ostrowski at Cornell, with help from Ken Birman, Danny Dolev (HUJL)
Some parts already exist and can be downloaded now: Quicksilver Scalable Multicast (QSM). Focus is on reliable and scalable message
delivery even with huge numbers of groups or severe stress on the system

Quicksilver Architecture
Our solution: Assumes low latencies, IP multicast A layered platform, native hosting
on .NET
Quicksilver Scalable Multicast (C# / .NET)
Strongly-typed .NET group endpoints
Quicksilver pub-sub API
Properties Framework endows groups with stronger properties
Applications (any language)
our platform
GMS

Quicksilver: Major ideas
Maps overlapping groups down to “regions” Engineering challenge: application may belong to
thousands of groups; efficiency of mapping is key Multicast is doing by IP multicast, per-region
Discovers failures using circulating tokens Local repair avoids overloading sender Eventually will support strong reliability model too
Novel rate limited sending scheme

Protocol 1
Protocol 3
Node
Protocol 2
Region
inter-regionprotocol
intra-regionprotocol
Groups A1..A100
Groups B1..B100
Groups C1..C100
in 300 groups
sendingmessagesin multiple
groups
Signed up to 100 groups
ABC
B
A
AB
AC C
B
BC
A
C
Members of a region have “similar” group membership
In traditional group multicast systems, groups run
independently
QSM runs protocols that aggregate over regions,
improving scalability
Hierarchical aggregation used for groups that span multiple
regions

0
2000
4000
6000
8000
10000
0 10 20 30 40 50 60 70 80 90 100 110
thro
ughp
ut (
pack
ets/
s)
number of nodes
Throughput (1 group, 1000-byte messages)
QSM (1 sender)
QSM (2 senders)
JGroups
QSM’s network bandwidth utilization 1 sender - 80% 2 senders - 90%
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 1000 2000 3000 4000 5000 6000 0
50
100
150
200
thro
ughp
ut (
pack
ets/
s)
mem
ory
usag
e (m
egab
ytes
)
number of groups
Throughput (1 sender, 1000-byte messages)
QSM throughput (110 nodes)
JGroups throughput (8 nodes)
QSM memory usage
crashed with 512 groups
880 890 900 910 920 930 940 950
nu
mb
er
of
pa
cke
ts
time (s)
Reaction to a 10-second freeze (110 nodes, rate 7500/s)
sentreceived (undisturbed)
received (disturbed)completed
one node freezes
node resumes
sender detects delays, suspends sending
node catching up,sender resumes
all nodesback
in sync
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0.0001 0.001 0.01 0.1 1 10
fra
ctio
n o
f tim
e sm
alle
r th
an th
is
latency (s)
QSM latency (110 nodes) – Cumulative Distribution
send to receive send to ack
average ≈ 19ms median ≈ 17ms
maximum ≈ 340ms
average ≈ 2.6s median ≈ 2.3s maximum ≈ 6.9s

Connections to type theory We’re developing a new high-level language
for endowing groups with “types” Such as security or reliability properties Internally, QS2 will “compile” from this language
down to protocols that amortize costs across groups Externally, we are integrating QS2 types with types
in the operating system / runtime environment (right now, Windows .net)
Many challenging research topics in this area!
http://www.cs.cornell.edu/projects/quicksilver/

Open questions?
Not all policy databases are amenable to a decentralized enforcement Must have “enough” information at the
point of enforcement to construct proofs Is this problem tractable? Complexity?
More research is needed on the question of federation of policy databases with “minimal disclosure”

Open questions?
We lack a constructive logic of distributed, fault-tolerant systems Part of the issue is exemplified by the
FLP problem: logic has yet to deal with the pragmatics of real-world systems
Part of the problem resides in type theory: we lack true “distributed” type mechanisms