scaling mongodb
TRANSCRIPT


Achieving Scale with MongoDB
Thomas Boyd
Director, Solutions Architecture, MongoDB
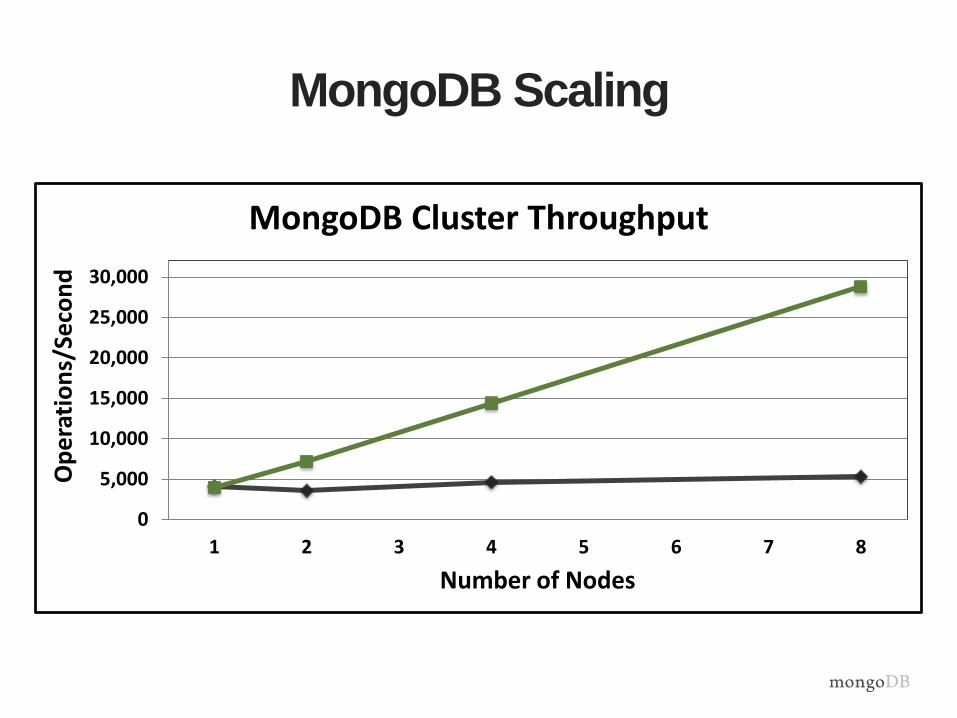
MongoDB Scaling
0
5,000
10,000
15,000
20,000
25,000
30,000
1 2 3 4 5 6 7 8
Op
era
tio
ns/
Seco
nd
Number of Nodes
MongoDB Cluster Throughput

Agenda
• Optimization Tips
– Schema Design
– Indexes
– Monitoring
– WiredTiger
• Vertical Scaling
• Horizontal Scaling
• Scaling your Operations Team

Optimization Tips: Schema Design

Document Model
• Matches Application
Objects
• Flexible
• High performance
{ "customer_id" : 123,
"first_name" : ”John",
"last_name" : "Smith",
"address" : {
"street": "123 Main Street",
"city": "Houston",
"state": "TX",
"zip_code": "77027"
}
policies: [ {
policy_number : 13,
description: “short term”,
deductible: 500
},
{ policy_number : 14,
description: “dental”,
visits: […]
} ]
}

The Importance of Schema Design
• Very different from RDBMS schema design
• MongoDB Schema:
– denormalize the data
– create a (potentially complex) schema with
prior knowledge of your actual (not just
predicted) query patterns
– write simple queries

Real World Example
Product catalog for retailer selling in 20 countries
{
_id: 375,
en_US: { name: …, description: …, <etc…> },
en_GB: { name: …, description: …, <etc…> },
fr_FR: { name: …, description: …, <etc…> },
fr_CA: { name: …, description: …, <etc…> },
de_DE: …,
<… and so on for other locales …>
}

Not a Good Match for Access Pattern
Actual application queries:
db.catalog.find( { _id: 375 }, { en_US: true } );
db.catalog.find( { _id: 375 }, { fr_FR: true } );
db.catalog.find( { _id: 375 }, { de_DE: true } );
… and so forth for other locales

Inefficient use of resources
Data in RED are being
used. Data in BLUE
take up memory but
are not in demand.
{
_id: 375,
en_US: { name: …, description: …, <etc…> },
en_GB: { name: …, description: …, <etc…> },
fr_FR: { name: …, description: …, <etc…> },
fr_CA: { name: …, description: …, <etc…> },
de_DE: …,
de_CH: …,
<… and so on for other locales …>
}
{
_id: 42,
en_US: { name: …, description: …, <etc…> },
en_GB: { name: …, description: …, <etc…> },
fr_FR: { name: …, description: …, <etc…> },
fr_CA: { name: …, description: …, <etc…> },
de_DE: …,
de_CH: …,
<… and so on for other locales …>
}

Consequences of Schema Redesign
• Queries induced minimal memory overhead
• 20x as many products fit in RAM at once
• Disk IO utilization reduced
• Application latency reduced
{
_id: "375-en_GB",
name: …,
description: …,
<… the rest of the document …>
}

Schema Design Patterns
• Pattern: pre-computing interesting
quantities, ideally with each write operation
• Pattern: putting unrelated items in different
collections to take advantage of indexing
• Anti-pattern: appending to arrays ad
infinitum
• Anti-pattern: importing relational schemas
directly into MongoDB

Schema Design Resources
• Data Modeling Deep Dive, 2pm
Robertston Auditorium 1
• Blog series, "6 rules of thumb"
– Part 1: http://goo.gl/TFJ3dr
– Part 2: http://goo.gl/qTdGhP
– Part 3: http://goo.gl/JFO1pI
• Webinars, training, consulting,
etc…

Optimization Tips: Indexing

B-Tree Indexes
• Tree-structured references to your documents
• Single biggest tunable performance factor
• Indexing and schema design go hand in hand

Indexing Mistakes and Their Fixes
• Failing to build necessary indexes
– Run .explain(), examine slow query log, mtools,
system.profile collection
• Building unnecessary indexes
– Talk to your application developers about usage
• Running ad-hoc queries in production
– Use a staging environment, use secondaries

mongod log files
Sun Jun 29 06:35:37.646 [conn2]
query test.docs query: {
parent.company: "22794",
parent.employeeId: "83881" }
ntoreturn:1 ntoskip:0
nscanned:806381 keyUpdates:0
numYields: 5 locks(micros)
r:2145254 nreturned:0 reslen:20
1156ms

mtools
• http://github.com/rueckstiess/mtools
• log file analysis for poorly performing queries
– Show me queries that took more than 1000 ms
from 6 am to 6 pm:
– mlogfilter mongodb.log --from 06:00 --to 18:00 --slow 1000 > mongodb-filtered.log

Indexing Strategies
• Create indexes that support your queries!
• Create highly selective indexes
• Eliminate duplicate indexes with compound
indexes
– db.collection.ensureIndex({A:1, B:1, C:1})
– allows queries using leftmost prefix
• Order index columns to support scans & sorts
• Create indexes that support covered queries
• Prevent collection scans in pre-production
environmentsdb.getSiblingDB("admin").runCommand( {
setParameter: 1, notablescan: 1 } )

Optimization Tips: Monitoring

JUST DO IT
NOW
IN PRE-PROD/STRESS
MongoDB Management Services (MMS)
Backup
Monitoring
Automation

MMS: Database Metrics
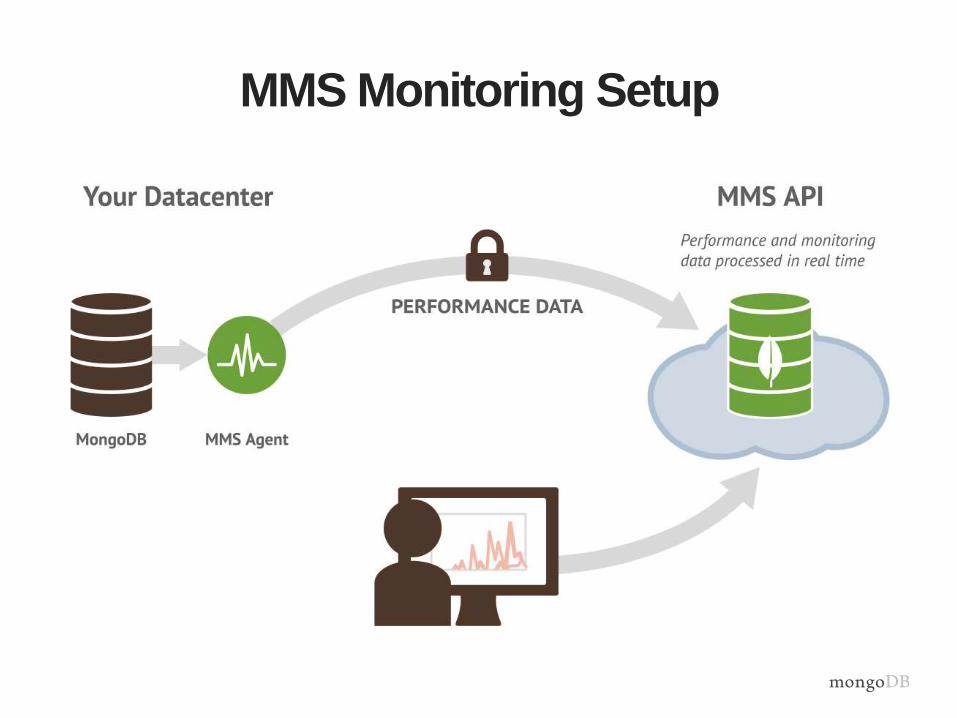
MMS Monitoring Setup
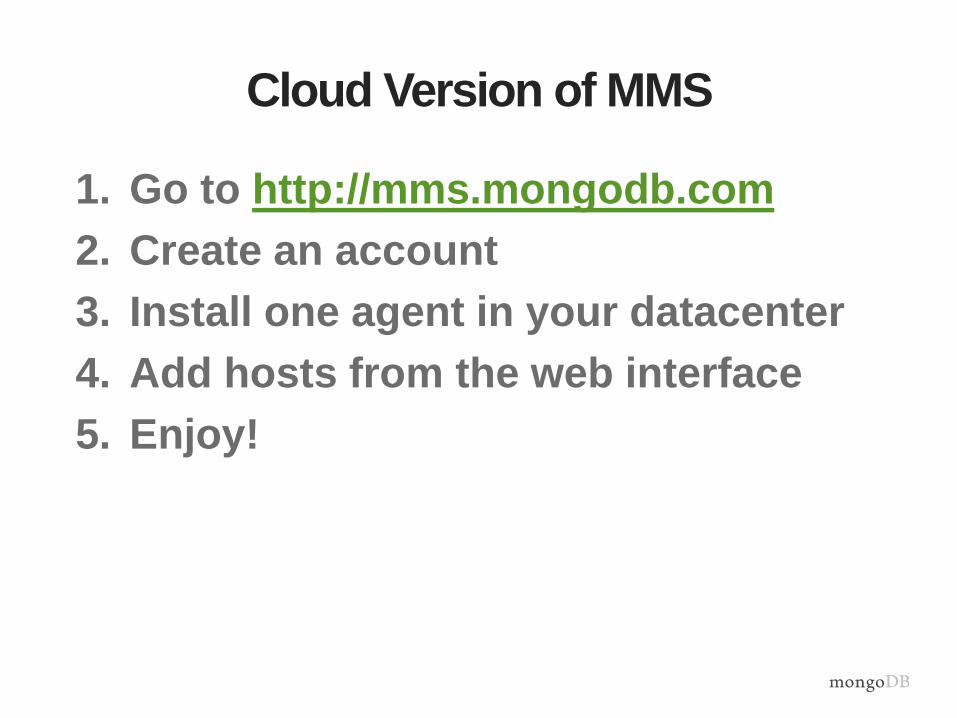
Cloud Version of MMS
1. Go to http://mms.mongodb.com
2. Create an account
3. Install one agent in your datacenter
4. Add hosts from the web interface
5. Enjoy!

WiredTiger Storage Engine

7x-10x Performance, 50%-80% Less Storage
How: WiredTiger Storage Engine
• Same data model, same query
language, same ops
• Write performance gains driven
by document-level concurrency
control
• Storage savings driven by native
compression
• 100% backwards compatible
• Non-disruptive upgradeMongoDB 3.0MongoDB 2.6
Performance

Vertical Scaling

Factors:
– RAM
– Disk
– CPU
– Network
We are Here to Pump you Up
Primary
Secondary
Secondary
Replica Set Primary
Secondary
Secondary
Replica Set
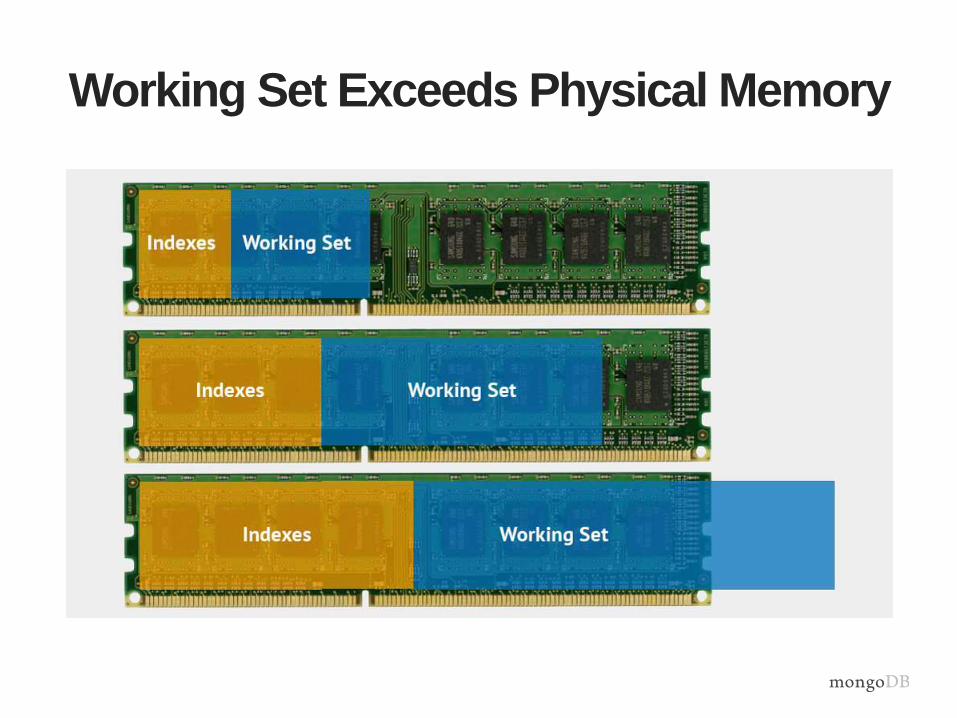
Working Set Exceeds Physical Memory

Real world Example
• Status changes for entities in the business
• State changes happen in batches
– sometimes 10% of entities get updated
– sometimes 100% get updated

Initial Architecture
Sharded Cluster, 4 shards backed by spinning disk
Application / mongosmongod

Horizontal Scaling
Rapidly growing business means more
shards
Application / mongos
…16 more shards…
mongod
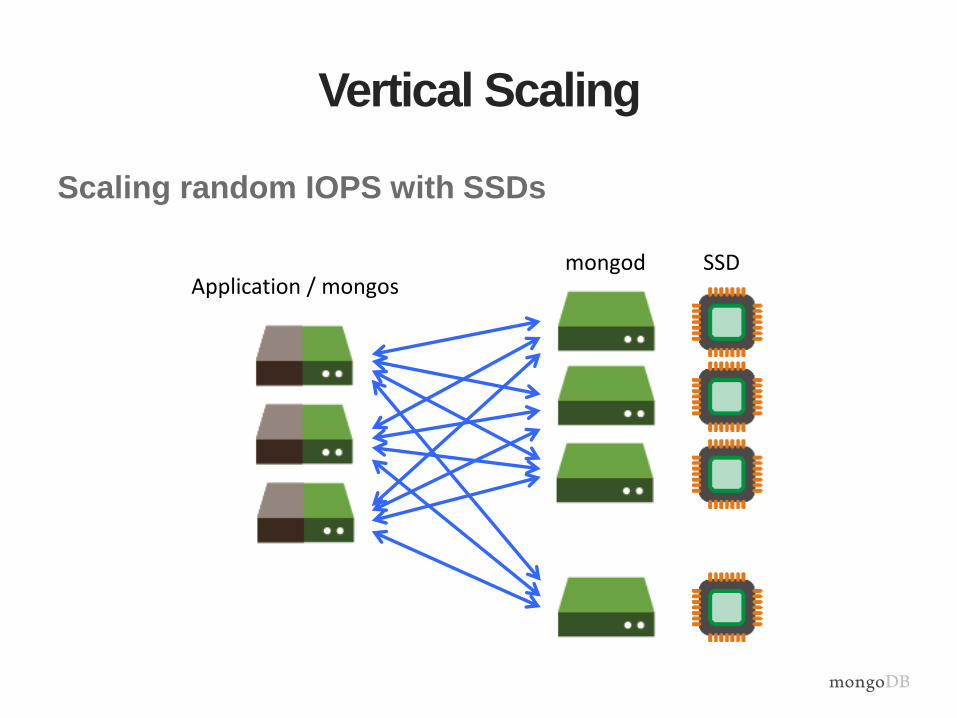
Vertical Scaling
Scaling random IOPS with SSDs
Application / mongosmongod SSD

Before you add hardware....
• Make sure you are solving the right scaling problem
• Remedy schema and index problems first
– schema and index problems can look like hardware
problems
• Tune the Operating System
– ulimits, swap, NUMA, NOOP scheduler with hypervisors
• Tune the IO subsystem
– ext4 or XFS vs SAN, RAID10, readahead, noatime
• See MongoDB "production notes" page
• Heed logfile startup warnings

Horizontal Scaling

Sharding Overview
Primary
Secondary
Secondary
Shard 1
Primary
Secondary
Secondary
Shard 2
Primary
Secondary
Secondary
Shard 3
Primary
Secondary
Secondary
Shard N
…
Query
Router
Query
Router
Query
Router
……
Driver
Application

Range Sharding
mongod
Read/Write Scalability
Key Range
0..100
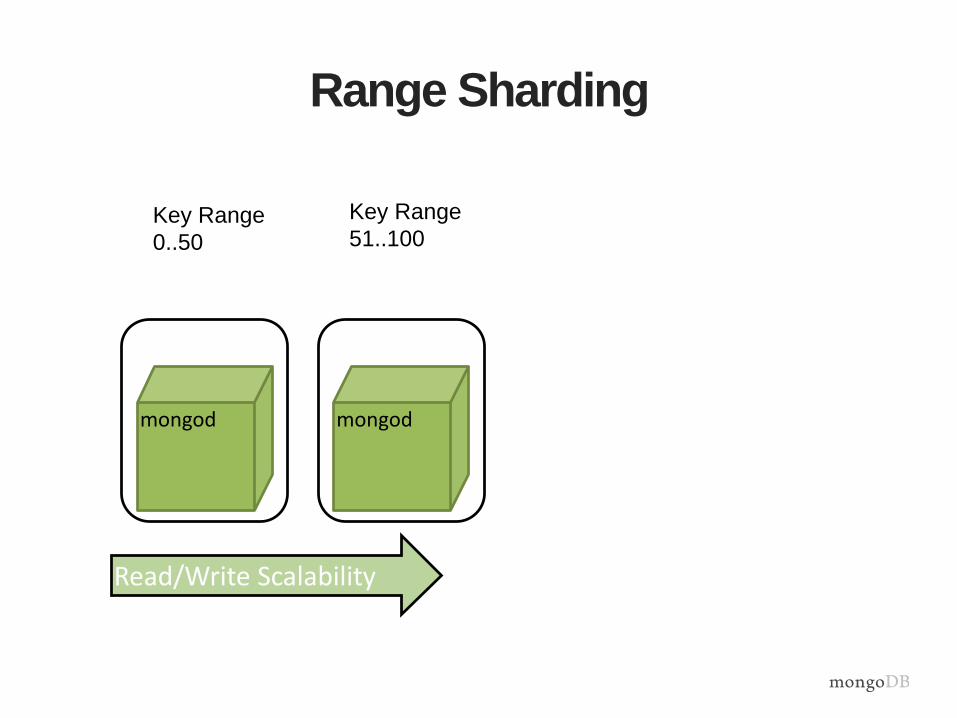
Range Sharding
Read/Write Scalability
mongod mongod
Key Range
0..50
Key Range
51..100
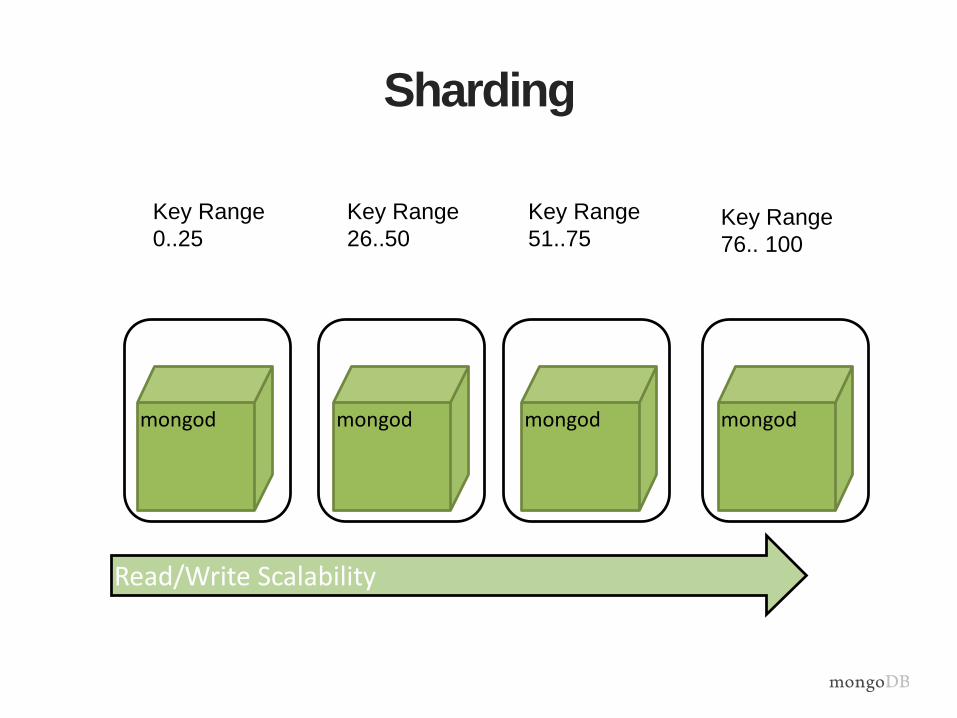
Sharding
mongod mongod mongod mongod
Key Range
0..25
Key Range
26..50
Key Range
51..75Key Range
76.. 100
Read/Write Scalability
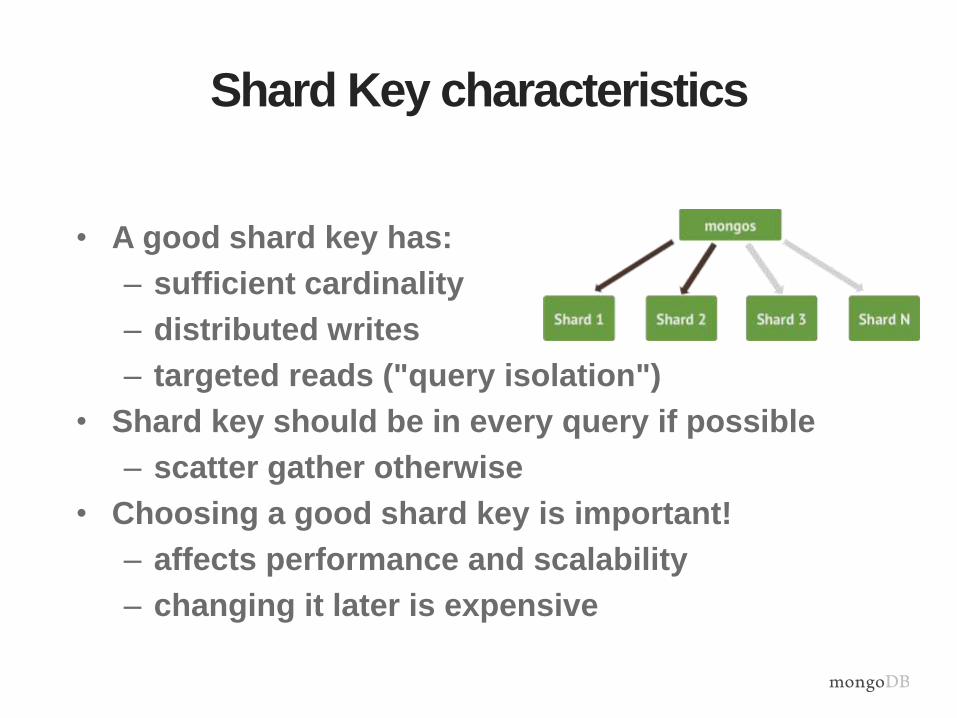
Shard Key characteristics
• A good shard key has:
– sufficient cardinality
– distributed writes
– targeted reads ("query isolation")
• Shard key should be in every query if possible
– scatter gather otherwise
• Choosing a good shard key is important!
– affects performance and scalability
– changing it later is expensive
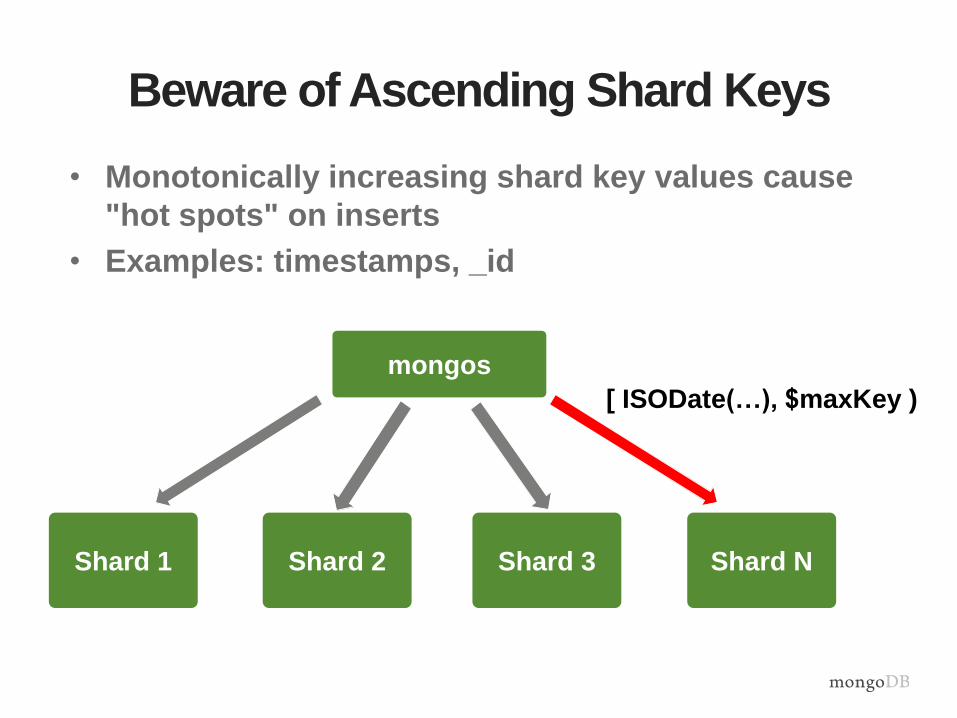
Beware of Ascending Shard Keys
• Monotonically increasing shard key values cause
"hot spots" on inserts
• Examples: timestamps, _id
Shard 1
mongos
Shard 2 Shard 3 Shard N
[ ISODate(…), $maxKey )

Scaling your Operations Team

MongoDB Management Service (MMS)
Scale EasilyMeet SLAs
Best Practices, Automated
Cut Management Overhead

Without MMS
Example Deployment – 12 Servers
Install, Configure
150+ steps
…Error handling, throttling, alerts
Scale out, move servers, resize oplog, etc.
10-180+ steps
Upgrades, downgrades
100+ steps
With MMS

Common Tasks, Performed in Minutes
• Deploy – any size, most topologies
• Upgrade/Downgrade – with no downtime
• Scale – add/remove shards or replicas, with no
downtime
• Resize Oplog – with no downtime
• Specify users, roles, custom roles
• Provision AWS instances and optimize for MongoDB
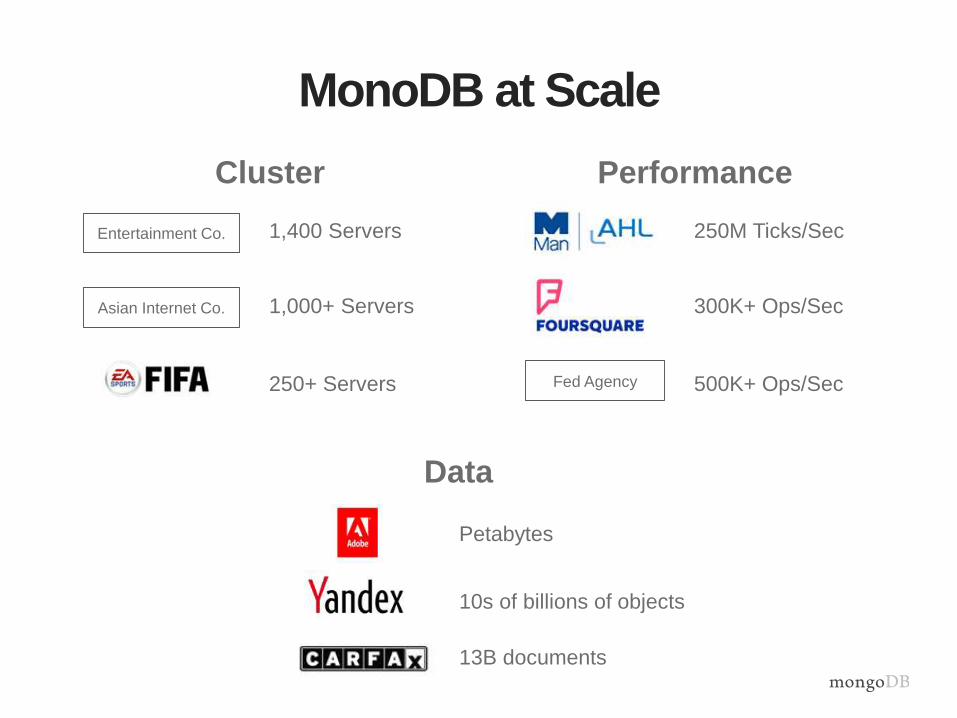
MonoDB at Scale
250M Ticks/Sec
300K+ Ops/Sec
500K+ Ops/SecFed Agency
Performance
1,400 Servers
1,000+ Servers
250+ Servers
Entertainment Co.
Cluster
Petabytes
10s of billions of objects
13B documents
Data
Asian Internet Co.
