school of eecs penn state universityduk17/slides/tpdp2017.pdf · format. utility-firstconstraints:...
TRANSCRIPT

Challenges of Differential Privacy in Practice
Daniel Kifer
School of EECSPenn State University
Collaborators:Penn State: Danfeng ZhangCensus: John Abowd, Robert Ashmead, Phil Leclerc, Brett Moran,Edward Porter, William SextonFriends of Census: Michael Hay, Ashwin Machanavajjhala, GeromeMiklau, Jerry Reiter

Differential Privacy in Practice
Outline
1 Differential Privacy in Practice
2 Census Data
3 Imposed Constraints
4 Defining and Explaining Privacy
5 Postprocessing, Sparsity, Dimensionality
6 Relational Data
7 Big Data Problems
8 Program Verification
(TPDP Workshop) Challenges of DP 2 / 66

Differential Privacy in Practice
Note
Part of this talk is about Differential privacy experience related to U.S.Census Bureau projects and other real-world applicationsDisclaimer:
Sabbatical at CensusFormer employee, current contractorThe statements made in this presentation represent my views and arenot necessarily the views of the U.S. Census Bureau
(TPDP Workshop) Challenges of DP 3 / 66

Differential Privacy in Practice
Major Public Deployments of Differential Privacy
2008 Census Bureau LODES/OnTheMap [MKA+08]Public release of differentially private dataCentral data collector model
2014 Google Chrome [EPK14]First major commercial application of differential privacyPrivacy in the local model
2016 Apple2016 Harvard Privacy Tools project2020 Goal:
Decennial CensusRelease Differentially Private dataRelease source code
(TPDP Workshop) Challenges of DP 4 / 66

Census Data
Outline
1 Differential Privacy in Practice
2 Census Data
3 Imposed Constraints
4 Defining and Explaining Privacy
5 Postprocessing, Sparsity, Dimensionality
6 Relational Data
7 Big Data Problems
8 Program Verification
(TPDP Workshop) Challenges of DP 5 / 66

Census Data
U.S. Census Bureau
Part of Department of Commerce.Census is early adopter of differential privacy technology.Major push to incorporate formal privacy confidentiality protection inmore Census products:
Economic CensusAmerican Community Survey (ACS)Decennial Census
(TPDP Workshop) Challenges of DP 6 / 66

Census Data
Legal Framework
Title 13 of U.S. CodeAuthorizes data collection and publication of statistics by CensusBureauSection 9: requires privacy protections
Neither the Secretary, nor any other officer or employee ofthe Department of Commerce or bureau or agency thereof,... may ... Make any publication whereby the data furnishedby any particular establishment or individual under thistitle can be identified;
Section 214 outlines penalties:
shall be fined not more than $5,000 or imprisoned not morethan 5 years, or both.
per incident (data item), up to $250,000
Title 26 also applies when linking with IRS data.
(TPDP Workshop) Challenges of DP 7 / 66

Census Data
Supreme Court Decisions
Department of Commerce v. United States House, 1999Certain sub-populations are difficult to enumerate and have beenunder-counted.Affects apportionment (determining number of CongressionalRepresentatives for each state).Statistical sampling is one way to address undercounts.Sampling for the purposes of apportionment was prohibited by thisdecision.
Utah v. Evans, 2002Not everyone responds to Census questionnaire.Even after field visit, population in a household may be unknown.Used hot deck imputation (infer characteristics based on neighbors).Result: Utah lost 1 representative and North Carolina gained 1.Supreme Court upheld use of hot-deck imputation.
Take-home message: some quantities are too important to be left tochance.
(TPDP Workshop) Challenges of DP 8 / 66

Census Data
2010 Census Geography Lattice
Complex LatticeMain hierarchyState
52 entities
50 statesPuerto RicoWashington, D.C.
County3,124 entities
Tract74,002 entities
Block Group220,334 entities
Block11,155,486 entities
(TPDP Workshop) Challenges of DP 9 / 66

Census Data
Geography Data
Geography tableGeoIDType
RuralUrban ClusterUrbanized Area
Block boundariesDefined with help of statesMay be based on “private” data
(TPDP Workshop) Challenges of DP 10 / 66

Census Data
2010 Decennial Census Questionnaire - Household
Households tableHousehold IDTenureGeography
(TPDP Workshop) Challenges of DP 11 / 66

Census Data
Group Quarters
Census collects information about group quartersGQ table:
GQ IDGeography (geoid)GQ Type:
Institutional Group QuartersCorrectional Facilities for Adults (+6 sub-sub-categories)Juvenile Facilities (+3 sub-sub-categories),Nursing Facilities/Skilled-Nursing FacilitiesOther Institutional Facilities (+5 sub-sub-categories)
Noninstitutional Group QuartersCollege/University Student HousingMilitary Quarters (+2 sub-sub-categories)Other Noninstitutional Facilities (+10 sub-sub-categories)
(TPDP Workshop) Challenges of DP 12 / 66
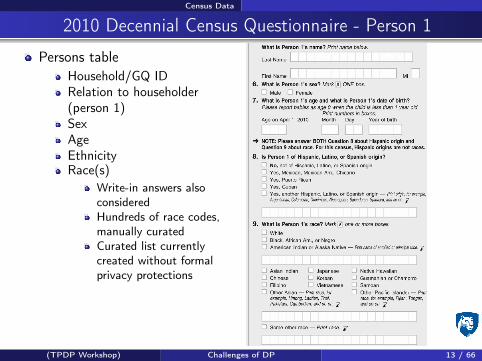
Census Data
2010 Decennial Census Questionnaire - Person 1
Persons tableHousehold/GQ IDRelation to householder(person 1)SexAgeEthnicityRace(s)
Write-in answers alsoconsideredHundreds of race codes,manually curatedCurated list currentlycreated without formalprivacy protections
(TPDP Workshop) Challenges of DP 13 / 66

Census Data
2010 Decennial Census Questionnaire - Others
Persons tableHousehold/GQ IDRelation to householder(person 1)SexAgeEthnicityRace(s)
Write-in answers alsoconsideredHundreds of race codes,manually curatedNo formal privacy on thiscurated list
(TPDP Workshop) Challenges of DP 14 / 66

Census Data
Edit and Imputation Phase
What if age does not match DOB?What if householder is 2 years old?What if no race provided?What if nothing is checked for sex? What if both M and F arechecked?Is write-in race valid (e.g., "Jedi Knight")?This data cleaning is not formally private
(TPDP Workshop) Challenges of DP 15 / 66

Census Data
Types of queries: Linear
For each block, population counts by:Ethnicity (2 values)
HispanicNot hispanic
Powerset of major race categories (63 values)WhiteBlack or African AmericanAmerican Indian and Alaska NativeAsianNative Hawaiian and Other Pacific IslanderSome Other Race
Histogram size: ≈ 11, 000, 000 ∗ 2 ∗ 63 = 1, 386, 000, 0002010 U.S. Population: ≈ 309, 000, 0002010 Number of households: ≈ 116, 000, 000Also need estimates for each tract, county, state, etc.
For each block, sex by age by races, etc.
(TPDP Workshop) Challenges of DP 16 / 66

Census Data
Decennial Publications
PL94counts of population and voting age population by races and ethnicityUsed for redistricting
Summary File 1 (SF1)Much larger set of tablesDemographics about individualsInformation about households and group quarters
(TPDP Workshop) Challenges of DP 17 / 66

Census Data
Types of Queries: Low sensitivity joins (1)
For each level of geography:
(TPDP Workshop) Challenges of DP 18 / 66

Census Data
Types of Queries: Low sensitivity joins (2)
For each level of geography:
(TPDP Workshop) Challenges of DP 19 / 66

Census Data
Types of Queries: High sensitivity joins
For each level of geography:
(TPDP Workshop) Challenges of DP 20 / 66

Imposed Constraints
Outline
1 Differential Privacy in Practice
2 Census Data
3 Imposed Constraints
4 Defining and Explaining Privacy
5 Postprocessing, Sparsity, Dimensionality
6 Relational Data
7 Big Data Problems
8 Program Verification
(TPDP Workshop) Challenges of DP 21 / 66

Imposed Constraints
Data Workflow
Integration of formal privacy impacts system architectureImpacts policy decisions on accuracy vs. privacyImpacts prioritization of some queries over othersImpacts changes to query specificationsPrivacy wall
(TPDP Workshop) Challenges of DP 22 / 66

Imposed Constraints
Constraints
System architecture, software engineering standards imposeconstraints on privacy module.Query answers should be consistent.Tabulated queries are complex, heavily tested, and can change.
⇒ Formal privacy module should not tabulate data.⇒ System should be able to work with and without privacy module.⇒ Privacy module should output microdata. Input format == outputformat.
Utility-first constraints:DoC v United States House ⇒ population in each block is exact.Other exact statistics, like voting age populations, must also bemaintained.Structural zeroes:
No 3-year-olds can be householders.Household cannot contain 5 grandparents of householder.Many, many others – they are difficult to enumerate.
Auxiliary data: GQ block locations are already known.
(TPDP Workshop) Challenges of DP 23 / 66

Defining and Explaining Privacy
Outline
1 Differential Privacy in Practice
2 Census Data
3 Imposed Constraints
4 Defining and Explaining Privacy
5 Postprocessing, Sparsity, Dimensionality
6 Relational Data
7 Big Data Problems
8 Program Verification
(TPDP Workshop) Challenges of DP 24 / 66

Defining and Explaining Privacy
Defining Privacy
Popular privacy definitions:Differential Privacy [DMNS06]Approximate: (ε, δ)-Differential PrivacyzCDP (zero-mean concentrated differential privacy) [BS16]
Can they be supported by policy?Have they withstood deep scrutiny?Personal opinion:
yes for differential privacycurrently unknown for the rest
Exciting technologies.If you are confident, propose the Title 13, Section 214 challenge.
Privacy in practice even more complicated.
(TPDP Workshop) Challenges of DP 25 / 66

Defining and Explaining Privacy
Defining Privacy
Popular privacy definitions:Differential Privacy [DMNS06]Approximate: (ε, δ)-Differential PrivacyzCDP (zero-mean concentrated differential privacy) [BS16]
Can they be supported by policy?Have they withstood deep scrutiny?Personal opinion:
yes for differential privacycurrently unknown for the rest
Exciting technologies.If you are confident, propose the Title 13, Section 214 challenge. Ifanyone finds a privacy flaw in your favorite privacy definition, they get$5k and you report to a federal correctional facility for 5 years.
Privacy in practice even more complicated.
(TPDP Workshop) Challenges of DP 25 / 66

Defining and Explaining Privacy
Privacy Complications
3 types of entitiesPeopleHouseholdsGroup Quarters
Each have their own attributes, privacy requirementsEach have links to other entities (correlations)Additional constraints:
Population subtotals at block levelsPublic group quarters counts by blockMinimum household and GQ sizes
Result in Pufferfish [KM14] and Blowfish [HMD14] style privacydefinitions
e.g., differential privacy conditioned on exact informationHow does differential privacy compose with non-differentially privateinformation?
(TPDP Workshop) Challenges of DP 26 / 66

Defining and Explaining Privacy
Problems with Perception
In 2010: approximately 309 million peopleNumber of populated blocks: approximately 6 millionAverage number of people per block is about 51.5Many blocks have very few peopleSuppose, in a sparsely population block, we have
A synthetic person closely matching a real personLay person may conclude there is a privacy violation
A synthetic person clearly very different from everyone in blockFor example, the race may be differentLay person may conclude the data are junk
(TPDP Workshop) Challenges of DP 27 / 66

Defining and Explaining Privacy
Challenges
Explain privacy definition to policy people and end-usersExplain how to set parameters
Practical ε values [EPK14, MKA+08, TKB+17, ACG+16] of 6,10 orhigher often resist "textbook" explanations.
Output probability barely changes due to one person?Odds ratio about one person changes by factor ≤ e6?
Explain how to evaluate privacy tradeoffPart of difficulty is utility evaluationHow to evaluate effect of ε on redistricting?How to evaluate effect on analyses of other stakeholders?
Allocation of federal funds?Study of Native American populations?Social science research?
Security of implementation (e.g., floating point attacks)
(TPDP Workshop) Challenges of DP 28 / 66

Postprocessing, Sparsity, Dimensionality
Outline
1 Differential Privacy in Practice
2 Census Data
3 Imposed Constraints
4 Defining and Explaining Privacy
5 Postprocessing, Sparsity, Dimensionality
6 Relational Data
7 Big Data Problems
8 Program Verification
(TPDP Workshop) Challenges of DP 29 / 66

Postprocessing, Sparsity, Dimensionality
A Simple Problem
Based on 2010 schema (2020 is schema is not currently available)National-level demographics histogram (i.e. no geography)
Age: 0-113 (upper bound is a separate issue)Sex: 2 valuesEthnicity: 2 values, 5 subcategories + write-inRace powerset of 6 major categories, 15 subcategories + 3 write-inRelation to householder/ gq type (institutionalized or not): ≈ 17 values
Total size: at least 114× 2× 2× 63× 17 ≈ 500, 000Very sparse:
How many people nationally are aged 105+How many people are mixture of 5 or more races?Sounds like a job for data-dependent algorithms!(?)
(TPDP Workshop) Challenges of DP 30 / 66

Postprocessing, Sparsity, Dimensionality
Goals
Accurate and realistic synthetic microdataAccuracy:
L1/L2/L∞ error on query workloadVariances of error measures
Realistic:Nonnegative integersAvoid artifacts
e.g., many demographics categories have exactly the same countsstatistically suspicious if occurs in real dataUsed data visualizations to "eyeball" differences (which algorithmsproduce data that look more like the original?)Artifacts decrease trust in dataObjective functions do not consider artifacts
Privacy consistency [HMM+16]: as ε→∞, do we get back originaldata?Running time
(TPDP Workshop) Challenges of DP 31 / 66

Postprocessing, Sparsity, Dimensionality
Data dependent methods we tried
MWEM [HLM12]Maintains differentially private database estimateIteratively find queries with (probably) large errorsUpdate database estimate
DAWA [LHMW14] (on age for each demographic combination)Use private dynamic programming step to find sparse regions.Carefully choose query set
AHP [ZCX+14]Use privacy budget to find regions with similar countsUse more privacy budget to estimate totals within each region
PrivTree [ZXX16]Hierarchical decomposition of space into sparse and non-sparse regionsIntricate composition between correlated queries
Plus many combinations and variants
(TPDP Workshop) Challenges of DP 32 / 66

Postprocessing, Sparsity, Dimensionality
General Results
Data dependent methods can perform well, but are not the bestAllocation of privacy budget between learning structure and answeringqueries
pros: learn “structure” of datacons: less accurate query answers (less budget allocated to them)observation: improvements due to structural knowledge did notoutweigh loss of accuracy in query answers
Generally slowHampers parameter tuning and experimentation/variations
Output data generally not realisticEstimation of bias and variance (and other uncertainty measures) ofquery answers is more complexConclusion: promising but more research needed for practical use
(TPDP Workshop) Challenges of DP 33 / 66

Postprocessing, Sparsity, Dimensionality
Data independent methods
Laplace mechanism on histogram.Geometric mechanism on histogram [GRS09] (discrete and moresecure than Laplace).HB−Trees [QYL13] on age for each demographic
Tree with carefully chosen branching factor and height.Matrix mechanism [LMH+15]
Original matrix mechanism is too slow to optimizeStructure of queries can be exploited (in development by collaborators)Allows for tradeoff between various queriesMost promising approach so far.
(TPDP Workshop) Challenges of DP 34 / 66

Postprocessing, Sparsity, Dimensionality
Postprocessing
Biggest impact on accuracy is not choice of algorithm (in general).Postprocessing, when done incorrectly, could blow up error by factor of10-100.
Take noisy query answersStructural informationConvert into histogram that with properties:
NonnegativeIntegerSatisfies constraints (e.g., total population)
Surprise: this didn’t workSelect nonnegative histogram that minimizes error to noisy queryanswers.Inaccurate even when integrality constraints are relaxed
Still open problemBest current approach
Variant of nonnegative workload least squares [LMH+15]Careful randomized rounding for integralityIn some cases linear programming can also generate integer solutions
(TPDP Workshop) Challenges of DP 35 / 66

Relational Data
Outline
1 Differential Privacy in Practice
2 Census Data
3 Imposed Constraints
4 Defining and Explaining Privacy
5 Postprocessing, Sparsity, Dimensionality
6 Relational Data
7 Big Data Problems
8 Program Verification
(TPDP Workshop) Challenges of DP 36 / 66

Relational Data
Relational Data
Most important tables (PL94) are simple demographics counts from 1table.Most common tables (SF1) deal with household structure andrelationships.
# of multi-generational householdsFamily typesProperties of households by race/age of householder
Join queriesJoin with households to get geography and tenureMultiple self-joins:
Husband-wife family type: 1 join on household id to findhouseholder/spouse combinationNon-family: multiple joins on household id to make sure no one isrelated to householderOpen-ended: no a priori maximum on household size
(TPDP Workshop) Challenges of DP 37 / 66

Relational Data
Open Questions
Exploring privacy in correlated settingsHousehold tenure attribute (rented, owned, etc.)All people in household share same householder race
Workload aware querying of household structure.Mechanisms for nonlinear queries.Strategies for multiple nonlinear queries.
Synthesizing tablesCreating tables from nonlinear queries (objective functions?)Synthesizing join keys
Structural zeros (illegal join combinations)No more than 2 grandparents of householderChildren cannot be older than parents
(TPDP Workshop) Challenges of DP 38 / 66

Big Data Problems
Outline
1 Differential Privacy in Practice
2 Census Data
3 Imposed Constraints
4 Defining and Explaining Privacy
5 Postprocessing, Sparsity, Dimensionality
6 Relational Data
7 Big Data Problems
8 Program Verification
(TPDP Workshop) Challenges of DP 39 / 66

Big Data Problems
Big Data Problems
Consider just demographics histogram (≈ 500, 000 cells)Geography hierarchy
National level52 state-like entities3,124 counties74,002 tracts220,334 block groups11,155,486 blocks (roughly 6 million populated blocks)
So actual problem is ≈ 500, 000× 6, 000, 000 = 3× 1012
Highly parallelizable due to parallel composition (e.g., 6 million parallelblocks).
optimistically assuming 1 minute processing per blockNeed 6 million distributed minutesAssuming 1, 000 node cluster: approximately 4 days.
In practice:MWEM: over 30 min on smaller problemsCommercial optimizers: minutes
(TPDP Workshop) Challenges of DP 40 / 66

Big Data Problems
Big Data Tradeoffs
Open questions (that we are exploring):Data-dependent processing of hierarchies
Take advantage of sparsity to reduce computation costSparsity learned at higher levels helps accuracy at lower levels too
Accuracy vs. computation vs. privacy consistencySome asymptotically optimal algorithms are superlinear or have largeconstants.Sparse biased representations (e.g., identfiy a few peaks and assumeuniformity elsewhere)
Expected to increase accuracy (doesn’t generate many randomvariables in sparse regions)Increases bias while reducing varianceReducing bias while reducing variance requires more computation (e.g.,finding more heavy hitters)Adds visual artifacts (due to uniformity many counts are the same)
(TPDP Workshop) Challenges of DP 41 / 66

Program Verification
Outline
1 Differential Privacy in Practice
2 Census Data
3 Imposed Constraints
4 Defining and Explaining Privacy
5 Postprocessing, Sparsity, Dimensionality
6 Relational Data
7 Big Data Problems
8 Program Verification
(TPDP Workshop) Challenges of DP 42 / 66

Program Verification
The Correctness Challenge
According to Google Scholar:
Experience when evaluating algorithms for the Decennial Censusproblem:
Many algorithms are correctMany algorithms have subtle bugsMany algorithms have obvious bugsSome correct algorithms have incorrect implementations(without even counting floating point bugs and timing attacks)Problem is not going away
Source code must be releasedDue to high-stakes nature of the data, bugs are a big deal!(TPDP Workshop) Challenges of DP 43 / 66

Program Verification
Programming with DP Correctly
Programming Language Support. e.g.:DFuzz [GHH+13]:
Type system tracks sensitivity of computationEquivalent to proof by composition theorems
Probabilistic coupling/lifting [BGG+16]Probabilistic coupling/lifting is general proof techniqueProgram proof written in extension of relational Hoare logic
Programming platforms (e.g,. [RSK+10, McS09, MTS+12])Programming language support + proof inference support (e.g,[AH17, ZK17]). Goals of LightDP [ZK17]:
Expressive programsMinimize burden on programmer
Reduce annotation burdenType inferenceInfer parameters (e.g., privacy budget allocation) to achieve privacytarget.
(TPDP Workshop) Challenges of DP 44 / 66

Program Verification
Prototypical Case Study
Sparse Vector TechniqueSubtle proofMany incorrect variants in literature [CM15].
Setup:List of queries q1, q2, . . .
When a record is added or deleted,Each qi can change by at most 1.
Threshold TParameter NAssumption (for utility only): very few qi are above T .Goal: for as many qi as possible, answer whether qi ≥ T or qi < T .Magic: for fixed ε, algorithm can answer "above" at most N times andarbitrarily many "below" answers.
(TPDP Workshop) Challenges of DP 45 / 66

Program Verification
Sparse Vector Method
(TPDP Workshop) Challenges of DP 46 / 66

Program Verification
A formal proof
(TPDP Workshop) Challenges of DP 47 / 66

Program Verification
A simple proof technique
Randomness Alignment.Given two parallel executions of M on "neighboring" databases D1,D2
There are two sets of random variablesR.V.s x1, . . . , xk created in execution under D1, and associatedε1, . . . , εk .R.V.s y1, . . . , yk created in execution under D2
Randomness alignment φω : Rk → Rk
Maps random variables x1, . . . , xk to y1, . . . , ykOne-to-one mapping (but not necessarily onto)If M(D1, x1, . . . , xk) = ω then M(D2, φω(x1, . . . , xk)) = ωCost:
∑i |xi − φ(xi )| ∗ εi
LemmaIf for all possible outputs ω, ∃φω with cost ≤ ε for all neighboring pairsD1,D2, then algorithm satisfies ε-differential privacy.
(TPDP Workshop) Challenges of DP 48 / 66

Program Verification
Example
φ(x0) = x0 + 1 (using ε/2 budget)φ(xi ) = xi if below, xi + 2 if above (using ε/(4N) budget)Red noisy answers are above noisy threshold.
Execution under D1 Execution under D2
T q1 q̃1 = q1 + x1 T q1 q̃1 = q1 + x1
T̃ = T + x0 q2 q̃2 = q2 + x2 T̃ = T + x0 + 1 q2 q̃2 = q2 + x2 + 2q3 q̃3 = q3 + x3 q3 q̃3 = q3 + x3q4 q̃4 = q4 + x4 q4 q̃4 = q4 + x4q5 q̃5 = q5 + x5 q5 q̃5 = q5 + x5 + 2q6 q̃6 = q6 + x6 q6 q̃6 = q6 + x6
(TPDP Workshop) Challenges of DP 49 / 66

Program Verification
Example
φ(x0) = x0 + 1 (using ε/2 budget)φ(xi ) = xi if below, xi + 2 if above (using ε/(4N) budget)Red noisy answers are above noisy threshold.
Execution under D1 Execution under D2
T q1 q̃1 = q1 + x1 T q1 q̃1 = q1 + x1
T̃ = T + x0 q2 q̃2 = q2 + x2 T̃ = T + x0 + 1 q2 q̃2 = q2 + x2 + 2q3 q̃3 = q3 + x3 q3 q̃3 = q3 + x3q4 q̃4 = q4 + x4 q4 q̃4 = q4 + x4q5 q̃5 = q5 + x5 q5 q̃5 = q5 + x5 + 2q6 q̃6 = q6 + x6 q6 q̃6 = q6 + x6
Can these distances (xi − φ(xi )) be tracked using PL techniques?
(TPDP Workshop) Challenges of DP 49 / 66

Program Verification
Dependent Type System
Variables have a dependent type that tracks distance (in subscript)T̃ : num1
Noisy thresholdReal number that must differ by 1 in neighboring executions
i : num0
Loop counterReal number that must be the same in neighboring executions
out: list bool0out the list of "above" (true) or "below" (false) answersDistance is 0, so they must be identical
η2: numq[i ]+η2≥T̃?2:0Noise added to queryDistance depends on whether main execution is above threshold
(TPDP Workshop) Challenges of DP 50 / 66

Program Verification
Sparse Vector Method
(TPDP Workshop) Challenges of DP 51 / 66

Program Verification
Dependent Type System
Type checking is done staticallyA few programmer annotationsType inference for the restSyntax directed translation creates a new program
New variable keeps track of costsStatements about distances translated directly into costsFormat allows SMT solver to check if cost is bounded by ε (with smallamount of programmer annotation)Translated program is not intended to be executed.
(TPDP Workshop) Challenges of DP 52 / 66

Program Verification
Type-directed Program Transformation
(TPDP Workshop) Challenges of DP 53 / 66

Program Verification
Dependent Type System
Type checking is done staticallyA few programmer annotationsType inference for the restSyntax directed translation creates a new program
New variable keeps track of costsStatements about distances translated directly into costsFormat allows SMT solver to check if cost is bounded by ε (with smallamount of programmer annotation)Translated program is not intended to be executed.
Type checking sets up variable alignment.SMT solver checks for boundedness.Allows free parameters in type expression that SMT solver canoptimize to find better privacy bound.
(TPDP Workshop) Challenges of DP 54 / 66

Program Verification
Sparse Vector Method
(TPDP Workshop) Challenges of DP 55 / 66

Program Verification
Limitations and Future Directions
Currently randomness alignment in LightDP requires programs underrelated executions to go through same control flow.
Overestimates impact of Noisy Max algorithm:Add Laplace(2/ε) noise to each query and select index of largest noisyvalue.
Still requires some programmer annotationType annotations to specify how inputs can differ between neighboringexecutionsType annotations on some variables for distanceLoop invariant annotation (progress made by [AH17])
(TPDP Workshop) Challenges of DP 56 / 66

Conclusions
Conclusions
Lot of research remains even for pure differential privacyData dependent algorithmsVerification of correctnessPost-processingPractical EngineeringLarge-scale algorithmsPolicyVisualization/diagnostics of errorMaking privatized data realistic
(TPDP Workshop) Challenges of DP 57 / 66

Conclusions
Questions
(TPDP Workshop) Challenges of DP 58 / 66

References
References I
Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, IlyaMironov, Kunal Talwar, and Li Zhang.Deep learning with differential privacy.In CCS, 2016.
Aws Albarghouthi and Justin Hsu.Synthesizing coupling proofs of differential privacy.https://arxiv.org/abs/1709.05361, 2017.
Gilles Barthe, Marco Gaboardi, Benjamin GrÃľgoire, Justin Hsu, andPierre-Yves Strub.Proving differential privacy via probabilistic couplings.In LICS, 2016.
(TPDP Workshop) Challenges of DP 59 / 66

References
References II
Mark Bun and Thomas Steinke.Concentrated differential privacy: Simplifications, extensions, and lowerbounds.In TCC, 2016.
Yan Chen and Ashwin Machanavajjhala.On the privacy properties of variants on the sparse vector technique.https://arxiv.org/abs/1508.07306, 2015.
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith.Calibrating noise to sensitivity in private data analysis.In TCC, 2006.
Úlfar Erlingsson, Vasyl Pihur, and Aleksandra Korolova.Rappor: Randomized aggregatable privacy-preserving ordinal response.In CCS, 2014.
(TPDP Workshop) Challenges of DP 60 / 66

References
References III
Marco Gaboardi, Andreas Haeberlen, Justin Hsu, Arjun Narayan, andBenjamin C. Pierce.Linear dependent types for differential privacy.In Proceedings of the 40th Annual ACM SIGPLAN-SIGACTSymposium on Principles of Programming Languages, POPL ’13,pages 357–370, 2013.
Arpita Ghosh, Tim Roughgarden, and Mukund Sundararajan.Universally utility-maximizing privacy mechanisms.In STOC, 2009.
Moritz Hardt, Katrina Ligett, and Frank McSherry.A simple and practical algorithm for differentially private data release.In NIPS, 2012.
(TPDP Workshop) Challenges of DP 61 / 66

References
References IV
Xi He, Ashwin Machanavajjhala, and Bolin Ding.Blowfish privacy: Tuning privacy-utility trade-offs using policies.In Proceedings of the 2014 ACM SIGMOD International Conference onManagement of Data, 2014.
Michael Hay, Ashwin Machanavajjhala, Gerome Miklau, Yan Chen, andDan Zhang.Principled evaluation of differentially private algorithms using dpbench.In SIGMOD, 2016.
Daniel Kifer and Ashwin Machanavajjhala.Pufferfish: A framework for mathematical privacy definitions.ACM Trans. Database Syst., 39(1):3:1–3:36, 2014.
(TPDP Workshop) Challenges of DP 62 / 66

References
References V
Chao Li, Michael Hay, Gerome Miklau, and Yue Wang.A data- and workload-aware algorithm for range queries underdifferential privacy.VLDB, 7(5), 2014.
Chao Li, Gerome Miklau, Michael Hay, Andrew Mcgregor, and VibhorRastogi.The matrix mechanism: Optimizing linear counting queries underdifferential privacy.The VLDB Journal, 24(6), 2015.
Frank D. McSherry.Privacy integrated queries: An extensible platform forprivacy-preserving data analysis.In SIGMOD, pages 19–30, 2009.
(TPDP Workshop) Challenges of DP 63 / 66

References
References VI
Ashwin Machanavajjhala, Daniel Kifer, John M. Abowd, JohannesGehrke, and Lars Vilhuber.Privacy: Theory meets practice on the map.In ICDE, 2008.
Prashanth Mohan, Abhradeep Thakurta, Elaine Shi, Dawn Song, andDavid Culler.Gupt: Privacy preserving data analysis made easy.In Proceedings of the ACM SIGMOD International Conference onManagement of Data, 2012.
Wahbeh Qardaji, Weining Yang, and Ninghui Li.Understanding hierarchical methods for differentially privatehistograms.VLDB, 2013.
(TPDP Workshop) Challenges of DP 64 / 66

References
References VII
Indrajit Roy, Srinath Setty, Ann Kilzer, Vitaly Shmatikov, and EmmettWitchel.Airavat: Security and privacy for MapReduce.In NSDI, 2010.
Jun Tang, Aleksandra Korolova, Xiaolong Bai, Xueqiang Wang, andXiaofeng Wang.Privacy loss in apple’s implementation of differential privacy on macos10.12.https://arxiv.org/abs/1709.02753, 2017.
Xiaojian Zhang, Rui Chen, Jianliang Xu, Xiaofeng Meng, and YingtaoXie.Towards accurate histogram publication under differential privacy.In SDM, 2014.
(TPDP Workshop) Challenges of DP 65 / 66

References
References VIII
Danfeng Zhang and Daniel Kifer.Lightdp: Towards automating differential privacy proofs.In POPL, 2017.
Jun Zhang, Xiaokui Xiao, and Xing Xie.Privtree: A differentially private algorithm for hierarchicaldecompositions.In SIGMOD, 2016.
(TPDP Workshop) Challenges of DP 66 / 66