self taught clustering
TRANSCRIPT

Self-taught ClusteringWenyuan Dai, Qiang Yang, Gui-Rong Xue, Yong Yu
ICML 2008

A good data representation can make the cluster-ing much easier
Self-taught clustering

Self-taught clustering
auxiliary data
target data
Very sparse !
A transfer unsupervised learning
These data should be in a good representation to be clustered

Transfer learning can help• makes use of knowledge gained from one learning task to im-
prove the performance of another
Self-taught clustering
auxiliary data
target data
separate the auxiliary data via transforma-
tion
A transfer unsupervised learning

Transfer learning
training data auxiliary data test data
(Raina et al., ICML 2006)

Self-taught learning
training data auxiliary data test data
(Raina et al., ICML 2007)

Self-taught clustering
auxiliary data target data
A transfer unsupervised learning

Target Data• a small collection; to be clustered
Auxiliary Data• a large amount of; be irrelevant to the target
data Objective• enhance the clustering performance on the
target data by making use of the auxiliary un-labeled data
Self-taught clusteringA transfer unsupervised learning
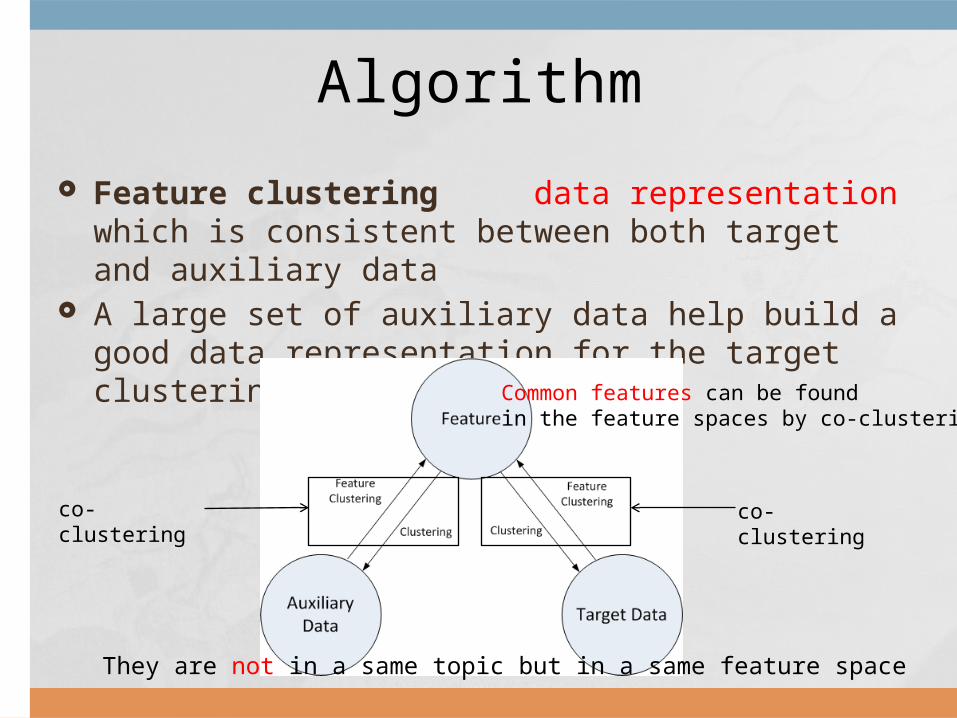
Feature clustering data representation which is consistent between both target and aux-iliary data
A large set of auxiliary data help build a good data representation for the target clustering
Algorithm
co-cluster-ing
co-cluster-ing
They are not in a same topic but in a same feature space
Common features can be foundin the feature spaces by co-clustering

Notations• X = {x1, . . . , xn} and Y ={y1, . . . , ym} : X and Y corre-
spond to the target and auxiliary data. • Z = {z1, . . . , zk} corresponds to the common fea-
ture space of both target and auxiliary data.• and represent the clusterings on X, Y and Z
Algorithm

Notations• X = {x1, . . . , xn} and Y ={y1, . . . , ym} : X and Y correspond to
the target and auxiliary data. • Z = {z1, . . . , zk} corresponds to the common feature space
of both target and auxiliary data.• and represent the clusterings on X, Y and Z
Objective function for self-taught clustering:
Algorithm
Information Theoretic Co-clustering (Dhillon et al., KDD 2003) minimizes the information loss in mutual information before and after co-clustering
The two co-clusterings are optimized simulta-neously

To optimize the objective function, the informa-tion loss can be reformulated in the form of KL-divergence
Algorithm
choose the best cluster for each z to minimize

Objective: minimizes the objective function by it-eratively choosing the best cluster and for each target instance x, auxiliary instance y and fea-ture z
Algorithm
target data
auxiliary data
features

Caltech-256 image corpus• 20 categories• eyeglass, sheet-music, airplane, ostrich,
fern, starfish, guitar, laptop, hibiscus, ketch, cake, harp, car-side, tire, frog, cd, comet, vcr, diamond-ring, and skyscraper• 70 images for each category
Data is represented using “bag-of-words” model with SIFT descriptor
Data set

For each clustering task, • Target unlabeled data:
• Eyeglass vs sheet-music• Airplane vs ostrich• Fern vs starfish• guitar vs laptop• Hibiscus vs ketch• Cake vs harp• Car-side, tire, frog (3-way)• Cd, comet, vcr, diamond-ring, skyscraper (5-way)
• Auxiliary unlabeled data: • the remaining categories excluding categories of
target data
Data setfern starfish

Entropy• The entropy for a cluster is defined as
• The total entropy is defined as the weighted sum of the entropy with re-spect to all the clusters
Evaluation

Experimental Results
7

This paper investigates the transfer unsupervised learning problem, called self-taught clustering.• Use irrelevant auxiliary unlabeled data to help the target cluster-
ing.
This paper develops a co-clustering based self-taught clus-tering algorithm.• Two co-clusterings are performed simultaneously between target
data and features, and between auxiliary data and features.• The two co-clusterings share a common feature clustering.
The experiments show that this algorithm can improve clus-tering performance using irrelevant auxiliary unlabeled data.
Conclusion

Thank you !
Q&A