semi-supervised information extraction in semantical vector space - jelena milovanovic
TRANSCRIPT

Ugradjivanje reči i fraza u vektorske prostore i polu-nadgledano otkrivanje
semantičkih sličnosti
Jelena Milovanović , asistent u istraživanju
Istraživačko razvojni institut NIRI



cat
dog

PregledPregled
● Uvod● Detekcija fraza● Ugradjivanje reči i fraza u vektorske prostore● Obrada podataka● Zaključak

● Osvežavanje ontologije poslovnih veština
Uvod: Uvod: PrimenaPrimena

● Osvežavanje ontologije poslovnih veština
● presentional_skills● comunication_skills
Uvod: Uvod: PrimenaPrimena

● Osvežavanje ontologije poslovnih veština
● presentional_skills● comunication_skills● inter_personal_skills● influencing_skills● organisational_skills● problem_solving_skills● analitical_skills
Uvod: Uvod: PrimenaPrimena

Uvod: Metod polu-nadgledanog Uvod: Metod polu-nadgledanog dobijanja informacijadobijanja informacija
Pedloženi metod sastoji se iz dva osnovna koraka i koristi:
● Grupu modela poznatu pod skraćenicom Word2Vec za ugrađivanje reči i fraza u vektorske prostore
● Hijerarhijsko aglomerativno klasterovanje za dobijanje informacija

● Jedan-od reprezentacija reči (One-hot)
House [0 0 0...0 1 0...0 0 0 0 0 0 0 0 0 ]
Cottage [0 1 0...0 0 0...0 0 0 0 0 0 0 0 0 ]
Moon [0 0 0...0 0 0...0 0 0 0 0 0 0 0 1 ]
Vektorska reprezentacija reči Vektorska reprezentacija reči

● Jedan-od reprezentacija reči (One-hot)
House [0 0 0...0 1 0...0 0 0 0 0 0 0 0 0 ]
Cottage [0 1 0...0 0 0...0 0 0 0 0 0 0 0 0 ]
Moon [0 0 0...0 0 0...0 0 0 0 0 0 0 0 1 ]
Vektorska reprezentacija reči Vektorska reprezentacija reči
I live in the house I live in the ?

Vektorska reprezentacija reči Vektorska reprezentacija reči

Vektorska reprezentacija reči Vektorska reprezentacija reči
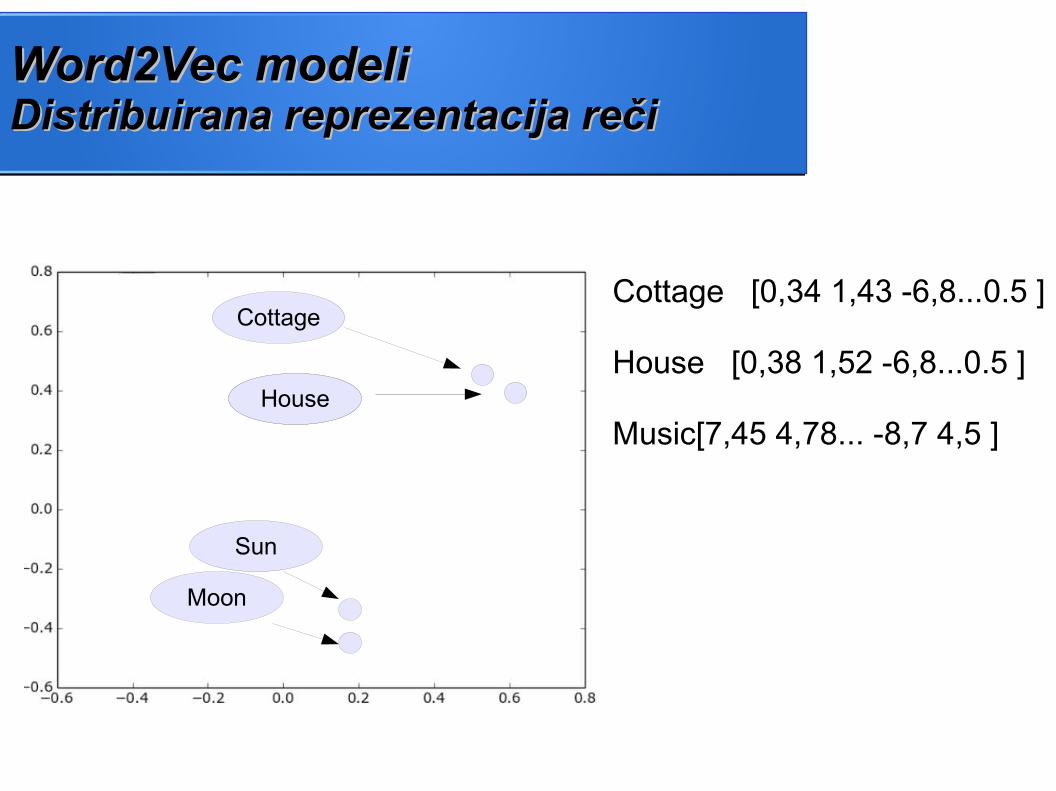
Word2Vec modeli Word2Vec modeli Distribuirana reprezentacija rečiDistribuirana reprezentacija reči
Cottage [0,34 1,43 -6,8...0.5 ]
House [0,38 1,52 -6,8...0.5 ]
Music[7,45 4,78... -8,7 4,5 ]
Cottage
DOG
Moon
Sun
House

Distributivna hipoteza:
Reči i fraze koje se javljaju u istim kontekstima teže da imaju isto značenje
Fert, 1957
Word2Vec modeliWord2Vec modeli: : Distributivna hipotezaDistributivna hipoteza

Word2Vec modeliWord2Vec modeli: : Distributivna hipotezaDistributivna hipoteza
I have built a house for my family.
I have built a cottage for my family.
It takes the Moon 28 days to make a complete orbit of the Earth

Word2Vec modeliWord2Vec modeli: : Relacije izmedju vektoraRelacije izmedju vektora

Word2Vec modeliWord2Vec modeli: : Relacije izmedju vektoraRelacije izmedju vektora

Word2Vec modeliWord2Vec modeli: : Relacije izmedju vektoraRelacije izmedju vektora

Word2Vec modeliWord2Vec modeli: : Relacije izmedju vektoraRelacije izmedju vektora
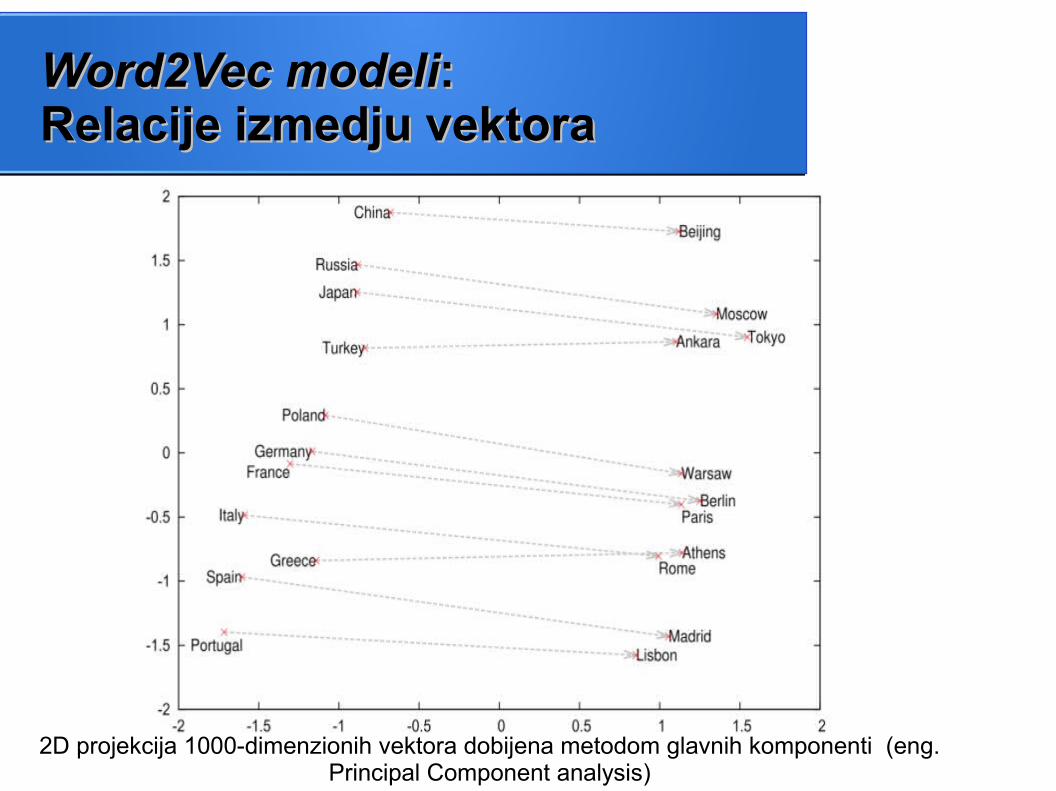
2D projekcija 1000-dimenzionih vektora dobijena metodom glavnih komponenti (eng.
Principal Component analysis)
Word2Vec modeliWord2Vec modeli: : Relacije izmedju vektoraRelacije izmedju vektora

vec(''king'') - vec(''man'') + vec(''woman'') = vec(''queen'')
Word2Vec modeliWord2Vec modeli: : Relacije izmedju vektoraRelacije izmedju vektora
vec(''king'') - vec(''man'') = vec(''queen'') - vec(''woman'')

athens : greece
= baghdad :
?
bulgaria : lev
= sweden : ?
boy : girl
= brother : ?
amazing : amazingly
= apparent : ?
acceptable
: unacceptable
= aware : ?
bad : worse
= big : ?
Word2Vec modeliWord2Vec modeli: : Relacije izmedju vektoraRelacije izmedju vektora
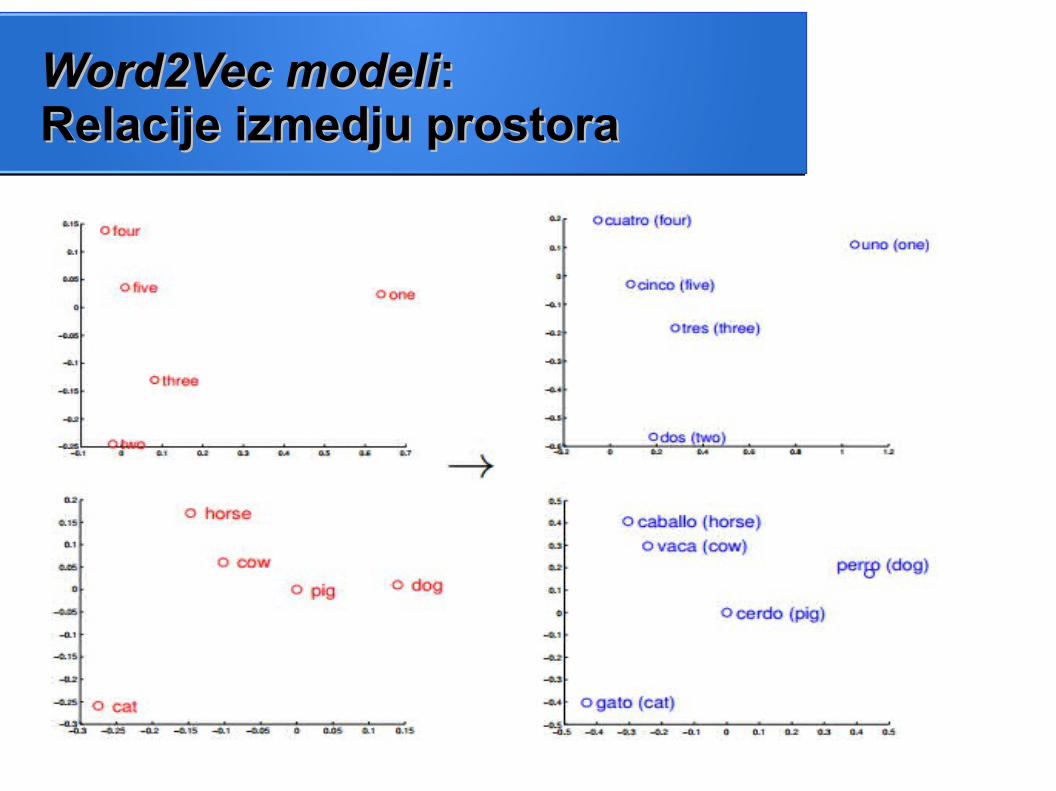
Word2Vec modeliWord2Vec modeli: : Relacije izmedju prostoraRelacije izmedju prostora

Word2Vec modeliWord2Vec modeli: : Relacije izmedju prostoraRelacije izmedju prostora
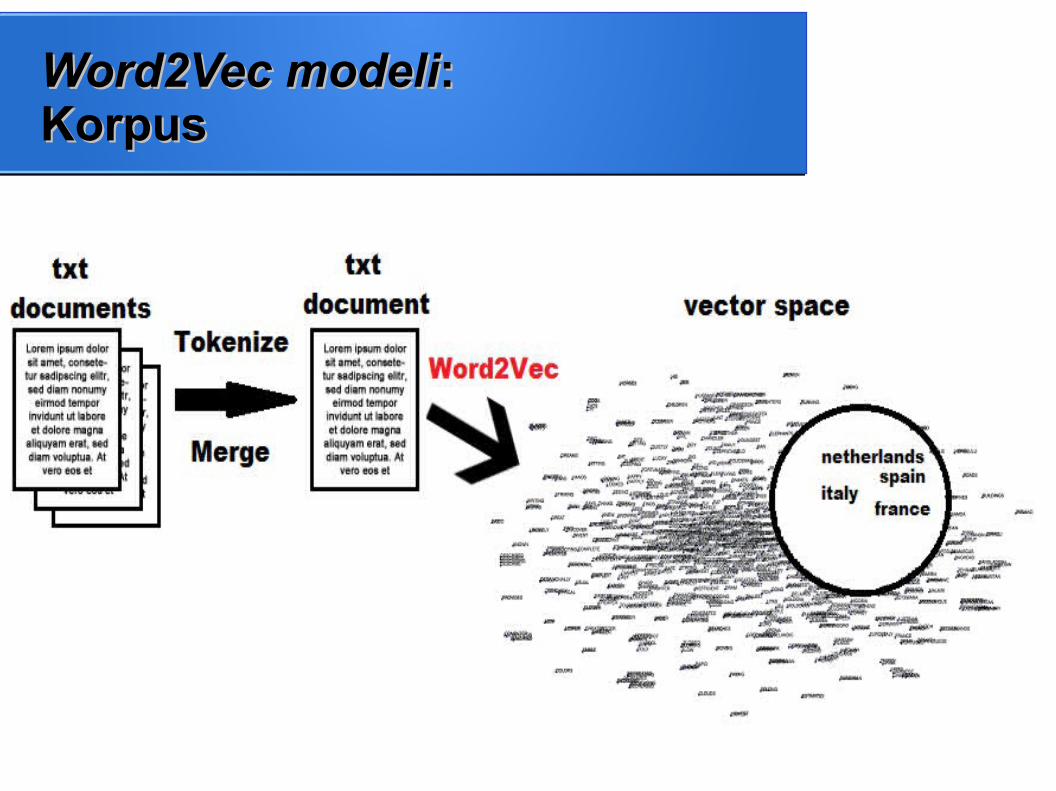
Word2Vec modeliWord2Vec modeli: : KorpusKorpus

● Nenadgledano učenje
● Za treniranje se koriste tekstualni dokumenti koji se sastoji od reči i fraza
● Radi sa velikim korpusima
● Vektori semantički sličnih reči nalaze se u blizini
● Dobijeni vektorski prostor sadrži sintaksne i semantičke relacije koje su uslovljene relativnim položajem vektora
Word2Vec modeliWord2Vec modeli: : KarakteristikeKarakteristike

Uvod: Uvod: Obrada podataka Obrada podataka
● Polu-nadgledano dobijanje informacija
● Upit se sastoji od poznatih termina koje nazivamo semenima
● Cilj: Izdvajanje termina koji imaju slično semantičko značenje kao i semena

Uvod: Uvod: Obrada podataka Obrada podataka
● Korišćen algoritam hijerarhijskog aglomerativnog klasterovanja
● Reči i fraze predstavljene listovima
● Odsecanje stabla u u čvoru koji je semenima najbliži zajednički predak
● Dobijeni klasteri pored semena sadrže reči i fraze semantički slične semenima

OOdsecanje stabla u čvoru koji je najbliži dsecanje stabla u čvoru koji je najbliži zajednički predak semenimazajednički predak semenimaOOdsecanje stabla u čvoru koji je najbliži dsecanje stabla u čvoru koji je najbliži zajednički predak semenimazajednički predak semenima

OOdsecanje stabla u čvoru koji je najbliži dsecanje stabla u čvoru koji je najbliži zajednički predak semenimazajednički predak semenima

OOdsecanje stabla u čvoru koji je najbliži dsecanje stabla u čvoru koji je najbliži zajednički predak semenimazajednički predak semenima

● Luxemburg● Estonia● Sloavakia● Croatia● Latvia● Lithuania● Slovenia● Belgium● Denmark● Netherlands● Switzerland
OOdsecanje stabla u čvoru koji je najbliži dsecanje stabla u čvoru koji je najbliži zajednički predak semenimazajednički predak semenima

Proces dobijanja Proces dobijanja informacijainformacija
1. Prikupljanje dokumentata2. Procesiranje korpusa (izbacivanje znakova interpunkcije)
3. Detekcija fraza4. Treniranje Word2Vec modela5. Aglomerativno hijerarhijsko klasterovanje dobijenih vektora
6. Odsecanje stabla pomoću semena i dobijanje podataka

Detekcija frazaDetekcija fraza
● Kao mera povezanosti reči koristi se uzajamno pojavljivanje tačaka (eng. Pointwise Mutual Pointwise Mutual InformationInformation)
● PMI je jedinica povezanosti dva događaja i dobija se

Detekcija frazaDetekcija fraza
● Kao mera povezanosti reči koristi se uzajamno pojavljivanje tačaka (eng. Pointwise Mutual Pointwise Mutual InformationInformation)
● PMI je jedinica povezanosti dva događaja i dobija se

Detekcija frazaDetekcija fraza
● Kao mera povezanosti reči koristi se uzajamno pojavljivanje tačaka (eng. Pointwise Mutual Pointwise Mutual InformationInformation)
● PMI je jedinica povezanosti dva događaja i dobija se
● Dužina fraza uslovljena je brojem iteracija

Detekcija frazaDetekcija fraza
● working_class● french_revolution● should_be● google_maps● adobe_photoshop● classical_guitar● kennedy_space_center● artificial_intelligence_laboratory● american_central_intelligence_agency● british_prime_minister_winston_churchill

Word2Vec modeliWord2Vec modeli
● Model Kontinualne grupe reči (eng. Continuous bag of words - CBOW)
● Model preskakanja reči (eng. Skip-gram)

Word2Vec modeliWord2Vec modeli

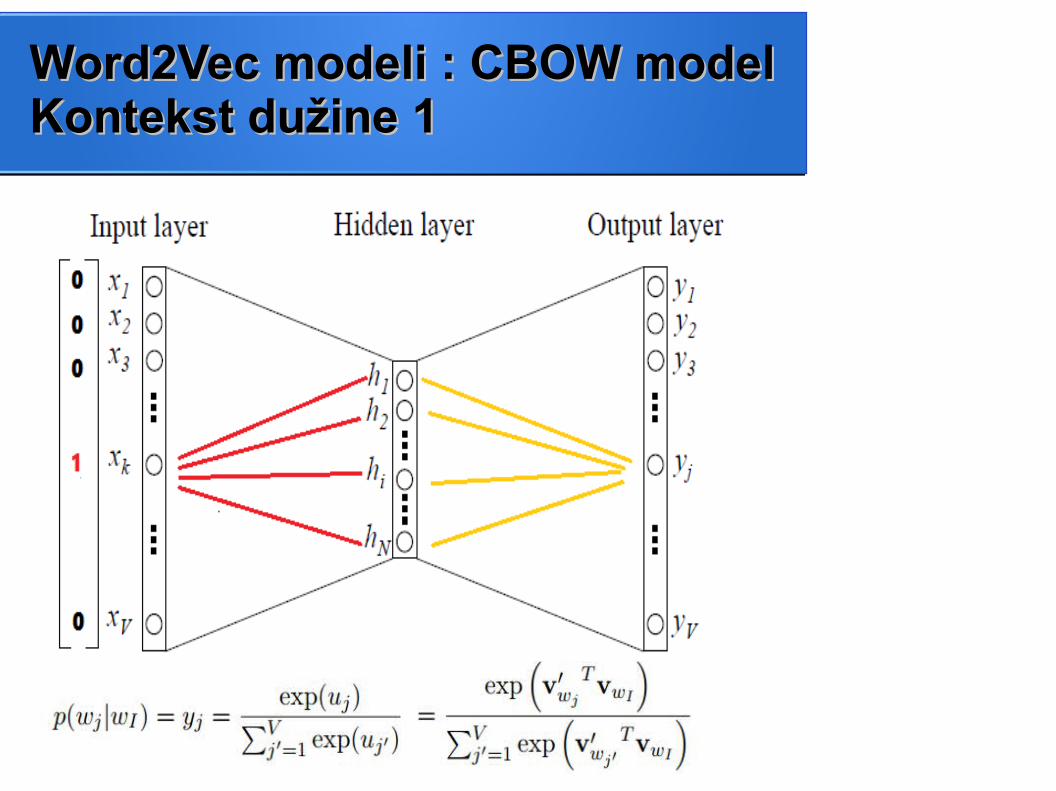
Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW model
● Model kontinualne grupe (vreće) reči● Opisuje kako neuronska mreža uči vektorske reprezentacije reči

Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW modelKontekst dužine 1Kontekst dužine 1
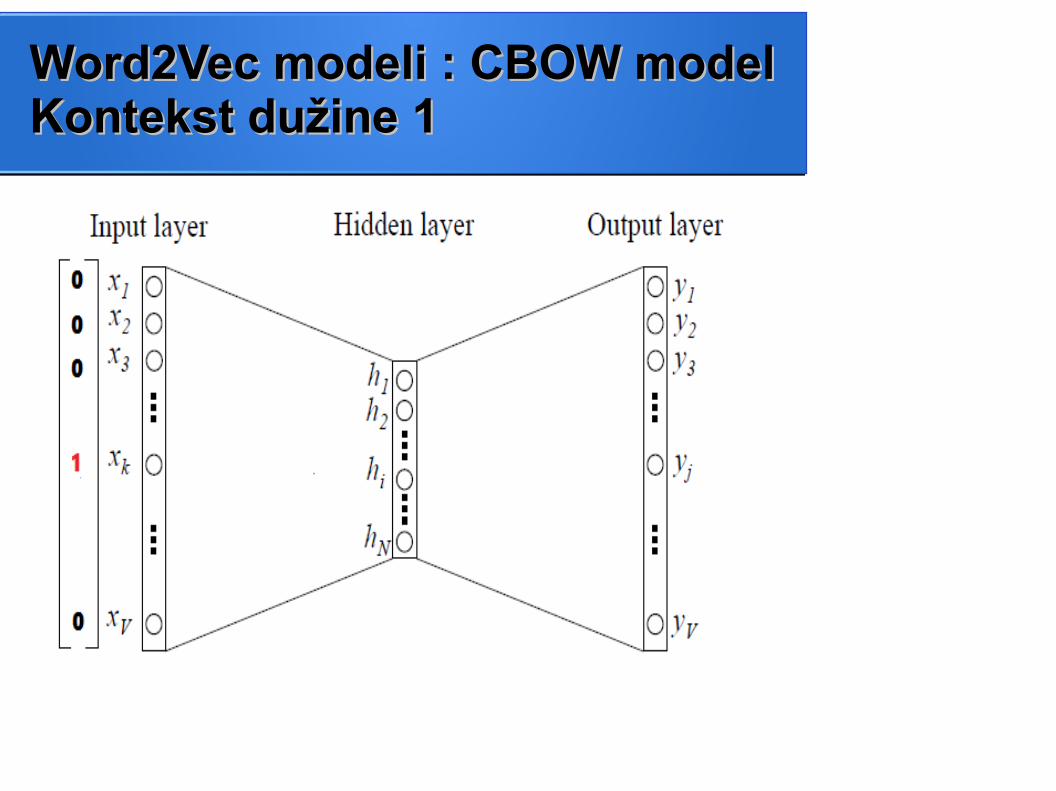
Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW modelKontekst dužine 1Kontekst dužine 1

Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW modelKontekst dužine 1Kontekst dužine 1

Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW modelKontekst dužine 1Kontekst dužine 1

● Linearna aktivaciona funkcija skrivenog sloja
● Softmax sloj izlaznih neurona
Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW modelKontekst dužine 1Kontekst dužine 1
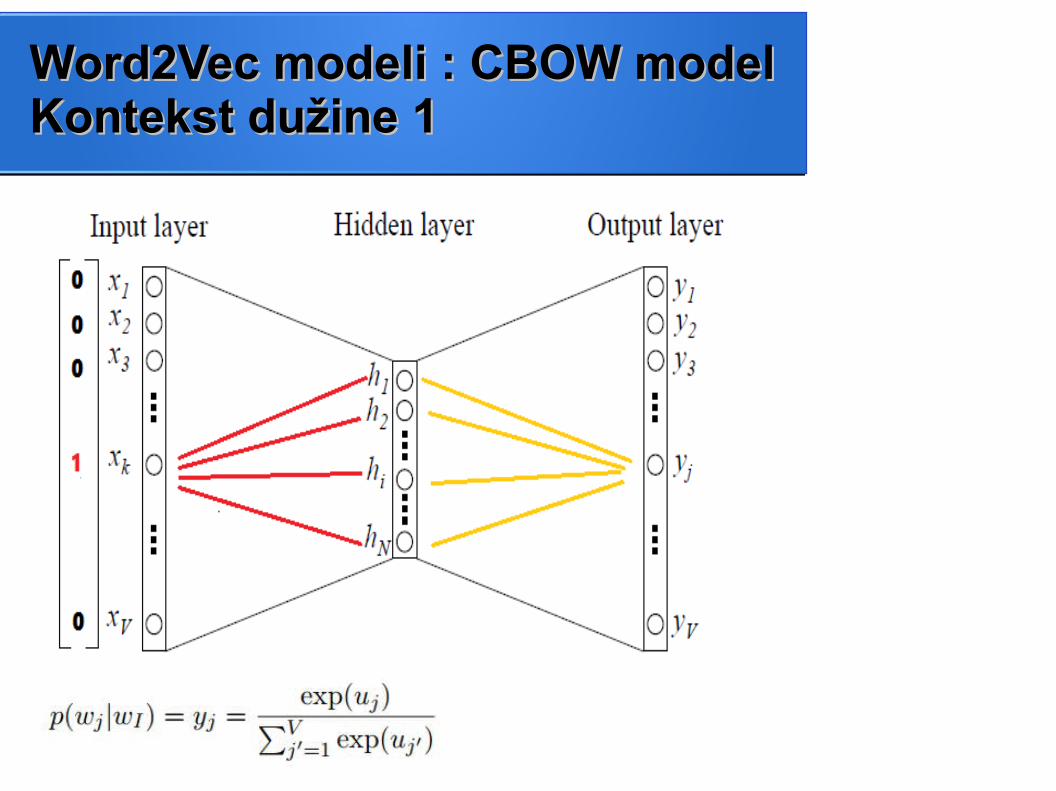
Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW modelKontekst dužine 1Kontekst dužine 1
Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW modelKontekst dužine 1Kontekst dužine 1
Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW modelKontekst dužine 1Kontekst dužine 1

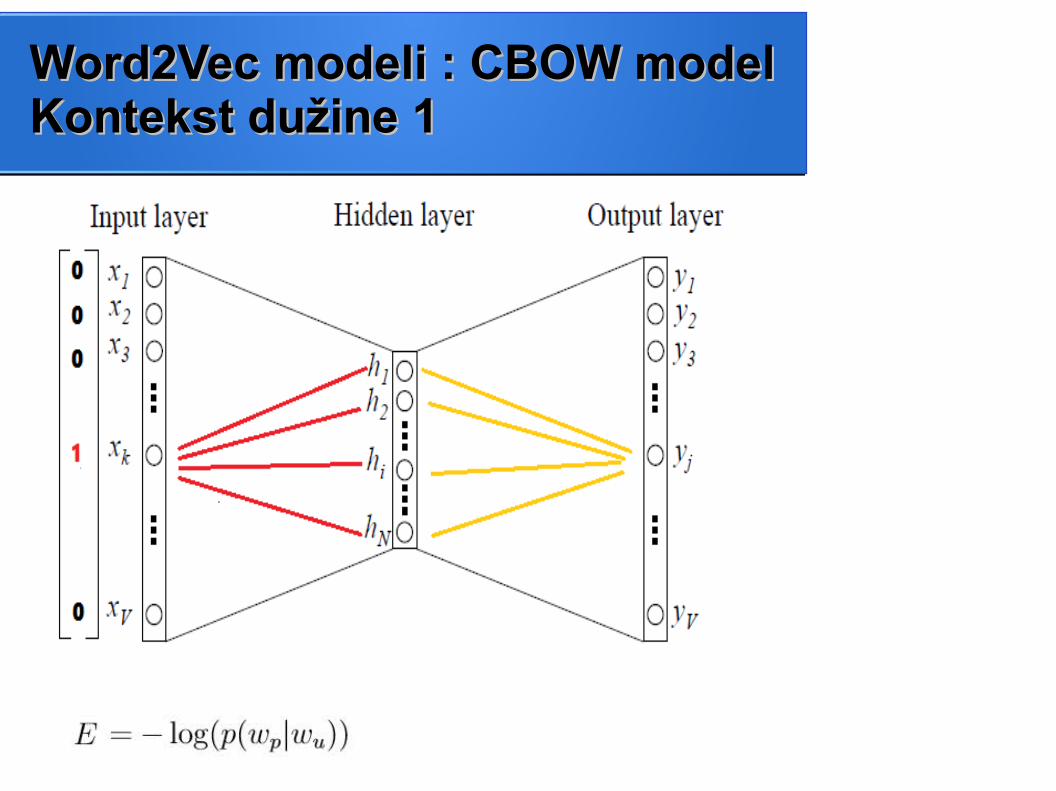
Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW modelKriterijumska funkcijaKriterijumska funkcija
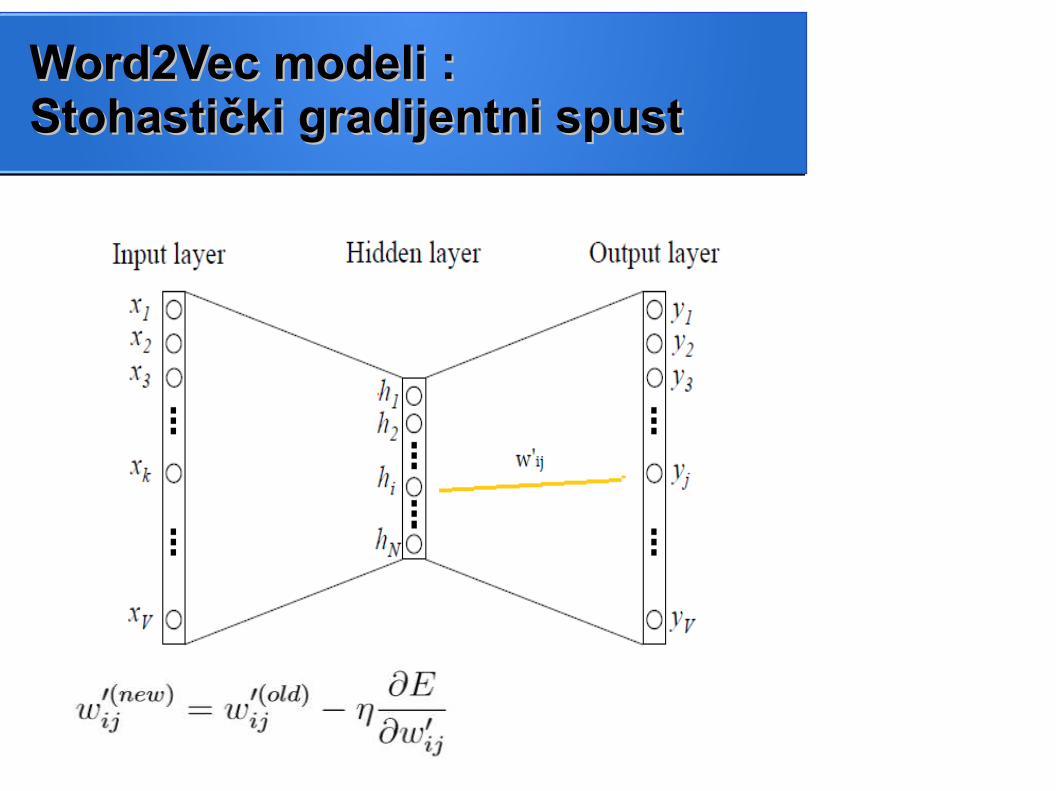
Word2Vec modeli : Word2Vec modeli : Stohastički gradijentni spustStohastički gradijentni spust

Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW modelKontekst dužine 1Kontekst dužine 1

Tehnika propagiranja greške Tehnika propagiranja greške u nazadu nazad
wki w'ki

Tehnika propagiranja greške Tehnika propagiranja greške unazadunazad
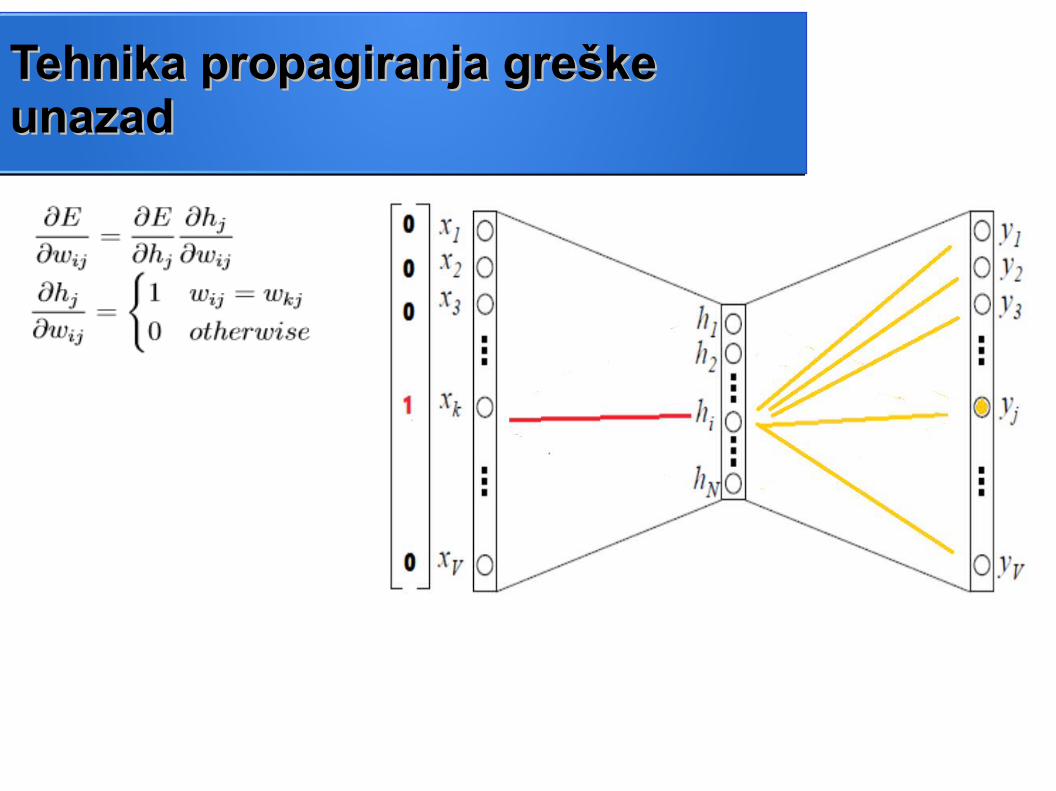
Tehnika propagiranja greške Tehnika propagiranja greške unazadunazad

Tehnika propagiranja greške Tehnika propagiranja greške unazadunazad
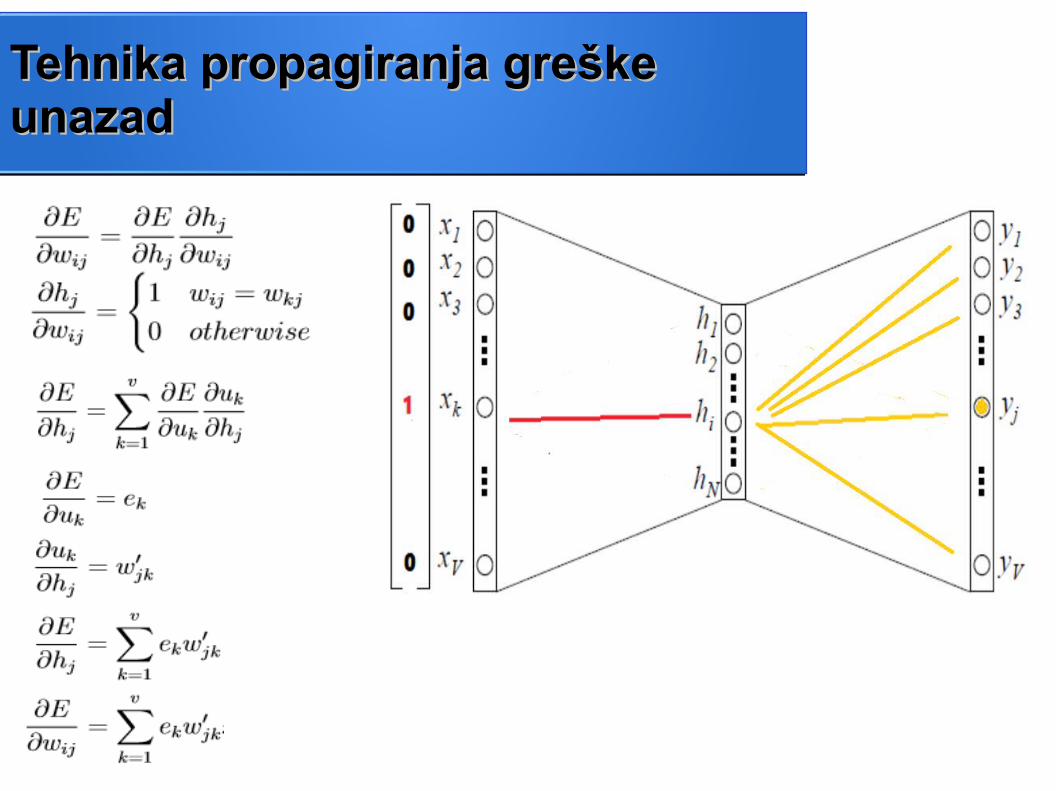
Tehnika propagiranja greške Tehnika propagiranja greške unazadunazad

Tehnika propagiranja greške Tehnika propagiranja greške unazadunazad
v
v'V

Word2Vec modeli : CBOW modelWord2Vec modeli : CBOW model

Word2Vec modeli : Skip-gramWord2Vec modeli : Skip-gram

Word2Vec modeli : Skip-gramWord2Vec modeli : Skip-gram

Word2Vec modeli : Skip-gramWord2Vec modeli : Skip-gram

Word2Vec modeli : OptimizacijaWord2Vec modeli : Optimizacija
● Hijerarhijski sloj izlaznih neurona (eng. Hierarchical softmax)
● Uzimanje negativnih uzoraka (eng. Negative Sampling)

● Koristi se hijerarhijski sloj umesto softmax sloja
● Reči se predstavljaju binarnim stablom gde je broj listova jednak dužini rečnika
● Svaka reč predstavljna je jednim listom
● Verovatnoća pojavljivanja reči u datom kontekstu računa se na osnovu puta od korena do lista kojim je predstavljena
Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax

Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax
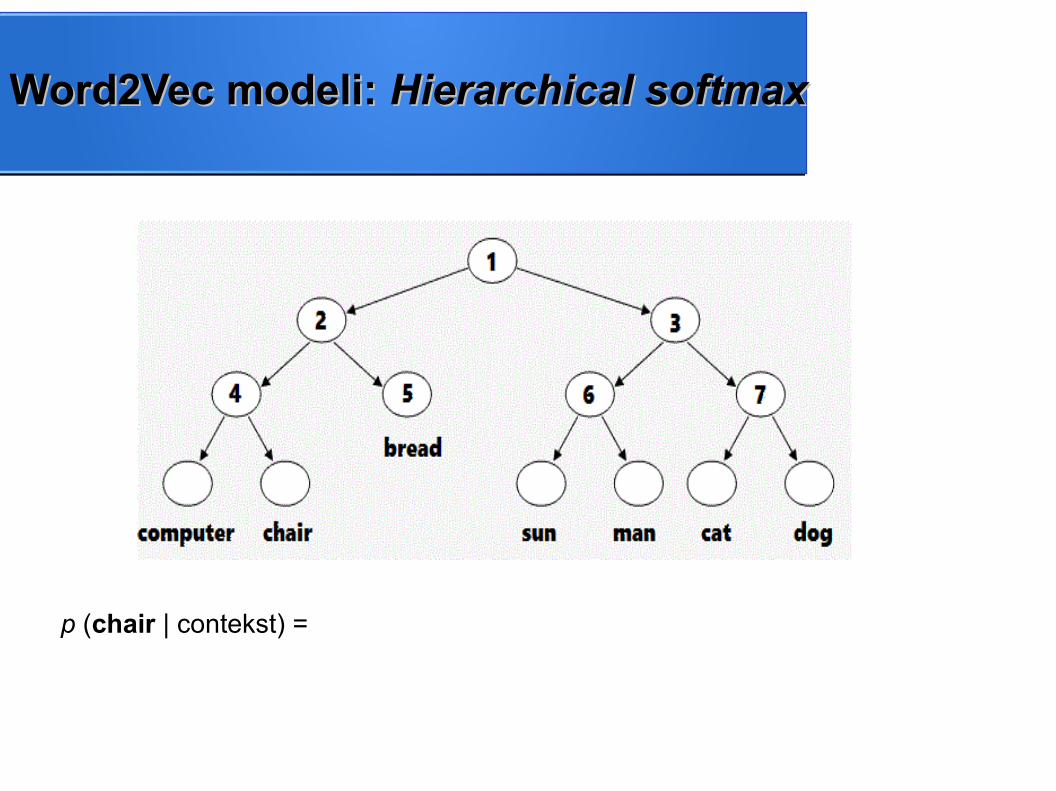
p (chair | contekst) =
Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax

p (chair | contekst) = p ( skretanje levo u čvoru 1)
Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax

p (chair | contekst) = p ( skretanje levo u čvoru 1) * p ( skretanje levo u čvoru 2)
Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax
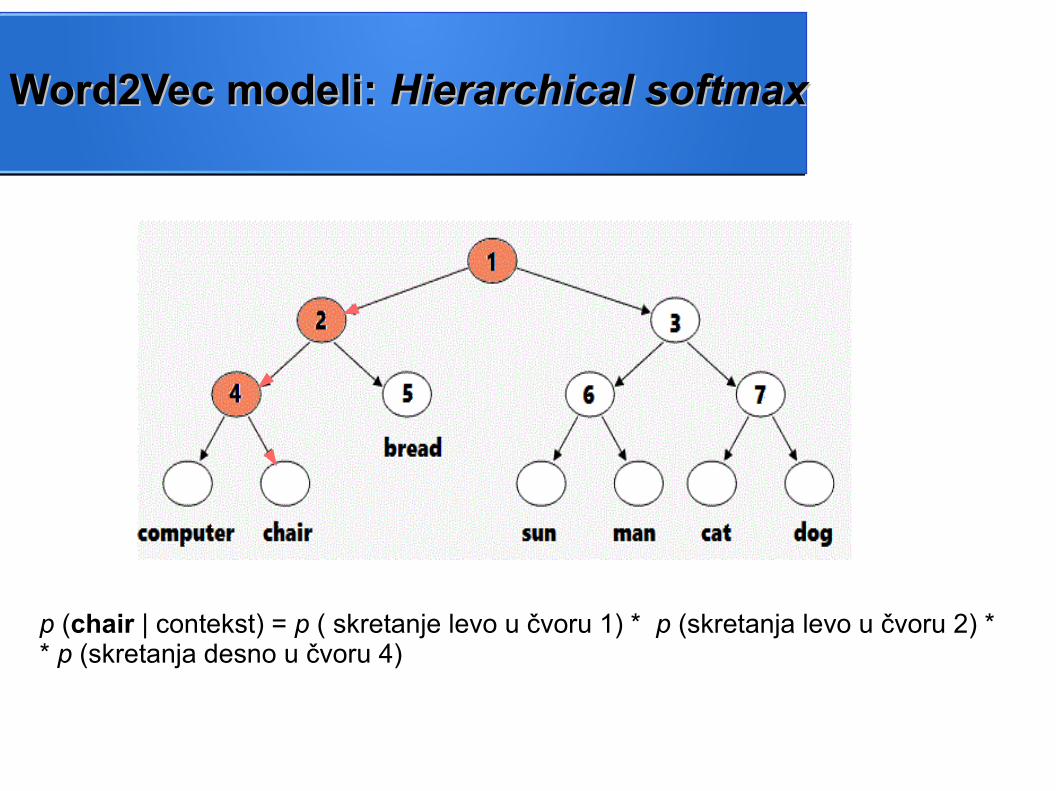
p (chair | contekst) = p ( skretanje levo u čvoru 1) * p (skretanja levo u čvoru 2) * * p (skretanja desno u čvoru 4)
Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax

● Izlazni sloj je sloj sigmoidalnih neurona koji odgovaraju unutrašnjim čvorovima stabla
Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax
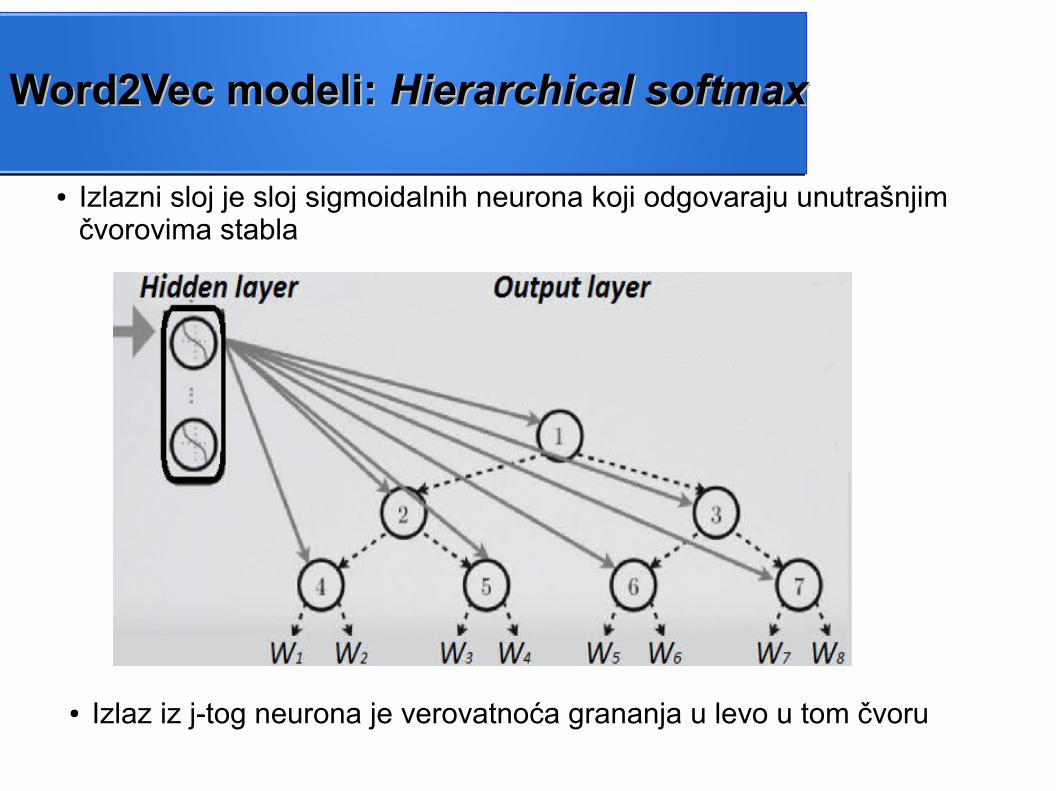
● Izlazni sloj je sloj sigmoidalnih neurona koji odgovaraju unutrašnjim čvorovima stabla
Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax
● Izlaz iz j-tog neurona je verovatnoća grananja u levo u tom čvoru

Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax
● P(w) skup čvorova na putu od korena do lista
● Verovatnoća grananja u pravcu reči u čvoru j
● Ako se put grana u levo jednaka (izlaz iz j-tog
nerona) u suprotnom
Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax
●
●

Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax
● P(w) skup čvorova na putu od korena do lista
● Verovatnoća grananja u pravcu reči u čvoru j
● Ako se put grana u levo jednaka (izlaz iz j-tog
nerona) u suprotnom
Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax
●
●

Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmaxWord2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax

Word2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmaxWord2Vec modeli: Word2Vec modeli: Hierarchical softmaxHierarchical softmax
● Najbolji rezultati se postižu kada se reči predstavljaju Huffman-ovim stablom

Word2Vec modeli: Word2Vec modeli: Negative samplingNegative sampling
● Ne moraju da se koriste neuronske mreže
● Problem estimacije verovatnoća posmatra se kao klasifikacioni i rešava uz pomoć Logističke regresije

Word2Vec modeli: Word2Vec modeli: Negative samplingNegative sampling
● D – skup pozitivnih primera(svih parova (reč,kontekst) koji su se javili u korpusu)
● D' – skup negativnih primera(svih parova (reč,kontekst) koji se nisu javili u korpusu)
● Cilj da dobijemo klasifikator koji dodeljuje labelu Z = 1 (par pripada skupu D) ili Z = 0 (ne pripada skupu D)
●
●
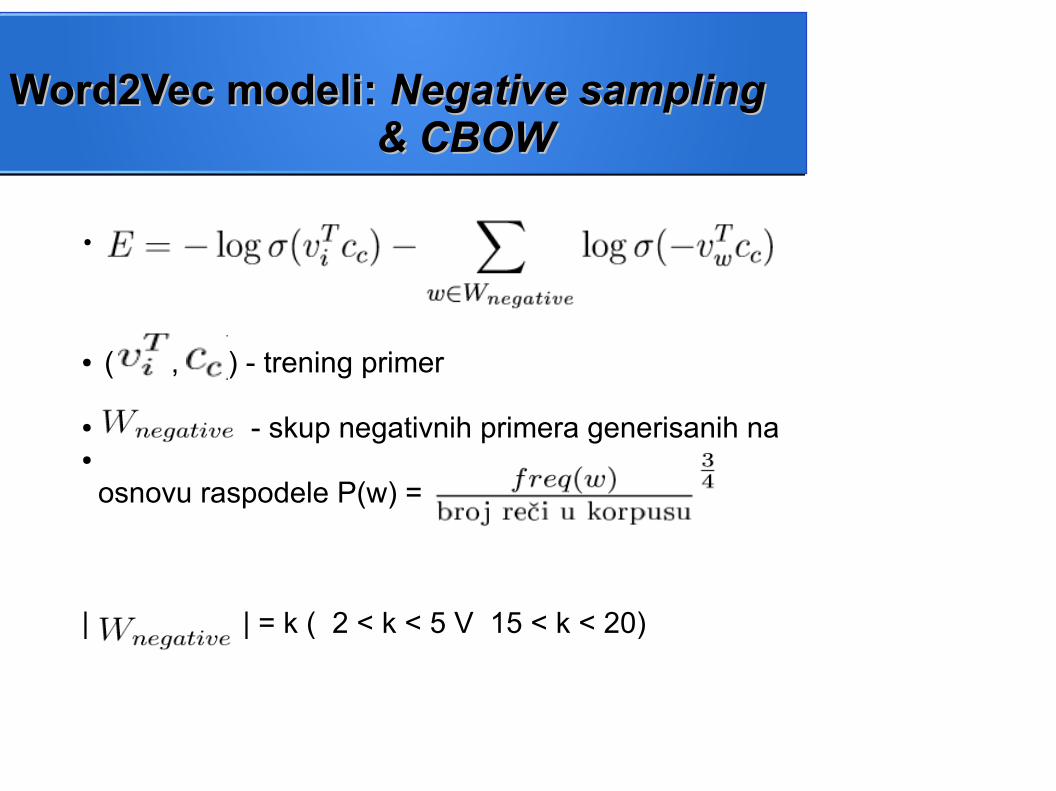
Word2Vec modeli: Word2Vec modeli: Negative sampling Negative sampling & CBOW& CBOW
●
● ( , ) - trening primer
● - skup negativnih primera generisanih na ●
osnovu raspodele P(w) =
| | | = k ( 2 < k < 5 V 15 < k < 20)

Word2Vec modeli: Word2Vec modeli: Negative sampling Negative sampling & CBOW& CBOW

Testovi analogijskog povezivanja
germany
: berlin
= france : paris
Word2Vec modeli: Word2Vec modeli: Merenje kvalitetaMerenje kvalitetavektoravektora

Testovi analogijskog povezivanja
germany
: berlin
= france : paris
germany
: berlin
= france : ?
Word2Vec modeli: Word2Vec modeli: Merenje kvalitetaMerenje kvalitetavektoravektora

Testovi analogijskog povezivanja
vec(paris) - vec (france) ≈ vec (germany) – vec (berlin)
germany
: berlin
= france : paris
germany
: berlin
= france : ?
Word2Vec modeli: Word2Vec modeli: Merenje kvalitetaMerenje kvalitetavektoravektora

Testovi analogijskog povezivanja
germany
: berlin
= france : paris
germany
: berlin
= france : x
vec(paris) - vec (france) ≈ vec (germany) – vec (berlin) vec(x) ≈ vec (germany) – vec (berlin) + vec (france)
Word2Vec modeli: Word2Vec modeli: Merenje kvalitetaMerenje kvalitetavektoravektora

Testovi analogijskog povezivanja
germany
: berlin
= france : paris
germany
: berlin
= france : x
vec(paris) - vec (france) ≈ vec (germany) – vec (berlin) vec(x) ≈ vec (germany) – vec (berlin) + vec (france)
x = paris ✔
Word2Vec modeli: Word2Vec modeli: Merenje kvalitetaMerenje kvalitetavektoravektora

Word2Vec modeli: TestiranjeWord2Vec modeli: Testiranje
● 5 tipova semantičkih relacija● 9 tipova sintaksičkih relacija● 8869 semantičkih pitanja● 10 675 sintaksičkih pitanja

Word2Vec modeli: TestiranjeWord2Vec modeli: Testiranje

Word2Vec modeli: Word2Vec modeli: Mere sličnostiMere sličnosti
a : b
= a* : b*
vec(b*) ≈ vec(a) – vec(b) + vec(a*)

Word2Vec modeli: Word2Vec modeli: Mere sličnostiMere sličnosti
a : b
= a* : b*
vec(b*) ≈ vec(a) – vec(b) + vec(a*)

Word2Vec modeli: Word2Vec modeli: Mere sličnostiMere sličnosti
log log log

Word2Vec modeli: Word2Vec modeli: Mere sličnostiMere sličnosti
log log log
london : england
= baghdad :
?
cos similarity : mosulcos mul : iraq

Word2Vec modeli: Word2Vec modeli: NedostaciNedostaci
● Dvosmislenost
● Korpus je niz tokena

Obrada podatakaObrada podataka
● Hijerarhijsko aglomerativno klasterovanje

Obrada podatakaObrada podataka
● Hijerarhijsko aglomerativno klasterovanje
● Problem:

Obrada podatakaObrada podataka
● Hijerarhijsko aglomerativno klasterovanje
● Problem: Složenost izračunavanja i memorijskih zahteva

Obrada podatakaObrada podataka
● Hijerarhijsko aglomerativno klasterovanje
● Problem:Složenost izračunavanja i memorijskih zahteva
● Ne može se koristiti standardni algoritam za klasterovanje rečnika koji sadrže više od 30 000 reči

Obrada podataka: Obrada podataka: Hibridni algoritamHibridni algoritam
● Hibridni algoritam

Obrada podataka: Obrada podataka: Hibridni algoritamHibridni algoritam
● Hibridni algoritam
Kombinuje:
A) Metod sredjih vrednosti (eng. K-means)
B) Hijerarhijsko aglomerativno klasterovanje

Obrada podataka: Obrada podataka: Hibridni algoritamHibridni algoritam

Obrada podataka: Obrada podataka: Hibridni algoritamHibridni algoritam

Obrada podataka: Obrada podataka: Hibridni algoritamHibridni algoritam

Obrada podataka: Obrada podataka: Hibridni algoritamHibridni algoritam

Obrada podataka: Obrada podataka: Hibridni algoritamHibridni algoritam

Obrada podataka: Obrada podataka: Hibridni algoritamHibridni algoritam

Obrada podataka: Obrada podataka: Hibridni algoritamHibridni algoritam

Dobijanje informacijaDobijanje informacija
● Iz stabla se podaci dobijaju polu-nadgledano● Sečenje stabla u najbližem zajedničkom pretku● Dobijaju se klasteri koji sadrže semena i njima semantički
slične termine

ZaključakZaključak
● Metod se može koristiti za izdvajanje sličnih termina● Za izdvajanje isith termina neophodna je kontrola od
strane korisnika

ZaključakZaključak
● C++● Java● Perl● Cobol● Assembler● Pascal● Visual Basic

ZaključakZaključak
● C++● Java● Perl● Cobol● Assembler● Pascal● Visual Basic● Visual c++● Eclipse● Programming language

Zaključak: Zaključak: Vektorski prostori Vektorski prostori
● Korišćenjem različitih mera za upoređivanje vektora otkrivaju se različite sličnosti između reči
● Za otkrivanje semantičkih sličnosti potrebno je detaljno istražitivanje prostora pa čak i unapređenje prostora i prilagođavanje konkretnom zahtevu korisnika

HVALA NA PAŽNJI!