seminar(pattern recognition)
TRANSCRIPT

Pattern Recognition
with
Semi-Supervised Learning
Algorithm
Presented By:-
Anurodh Kumar Sinha
2ND Year MSLIS Student
DRTC,ISI Bangalore
2012-2013
12/3/2012 1

Agenda
• What is Pattern Recognition?
• What is Machine Learning n why we
need..?
• Types of Learning Algorithm
• Need for Semi-Supervised Learning
• Conclusion
2 12/3/2012

What is a Pattern…. ?
• An entity, vaguely defined, that could be
given a name,
• e.g.:
– handwritten word,
– human face,
– fingerprint image,
– speech signal, 3 12/3/2012

What is Feature….?
• A Feature is an individual measurable heuristic property
of a phenomenon being observed
• Examples
• In speech recognition, features for recognizing
phonemes can include noise ratios, length of sounds,
relative power, filter matches and many others.
• In spam detection algorithms, features may include
whether certain email headers are present or absent,
whether they are well formed, what language the email
appears to be, the grammatical correctness of the text
4 12/3/2012

What is Pattern Recognition.. ?
• Pattern recognition is the study of how
machines can:
– observe the environment,
– learn to distinguish patterns of interest,
– make sound and reasonable decisions about
the categories of the patterns.
“The assignment of a physical object or event to
one of several prespecified categories” -- Duda
& Hart
5 12/3/2012

What is Pattern Recognition… ?
• Some Applications:
6 12/3/2012

Motivation For The Study
of
Pattern Recognition It is threefold.
• In Artificial Intelligence, which is concerned with techniques, that enable
computers to do things, that seem intelligent when done by people.
• It is an important aspect of applying computers to do analysis and
classification of measurements, from its data observation.
• Pattern Recognition techniques provide a unified frame work to study a
variety of techniques with use of mathematics and computer science, which
helps the machine to make decision
7 12/3/2012

Methodology
of
Pattern Recognitions
It consists of the following:
1.We observe patterns
2.We study the relationships between the various
patterns.
3.We study the relationships between patterns and
ourselves and thus arrive at situations
4.We study the changes in situations and come to know
about the events.
5.We study events and thus find rule behind the events.
6. Using the rule, we can predict future events.
8 12/3/2012

An Example
• Suppose that: – A fish packing plant
wants to automate the process of sorting incoming fish on a conveyor belt according to species,
– There are two species: • Sea bass,
• Salmon.
9 12/3/2012

An Example
10 12/3/2012

An Example
How to distinguish one specie from the other ?
(length, width, weight, number and shape of fins,
tail shape,etc.)
11 12/3/2012

An Example
• Suppose we also know that:
– Sea bass are typically wider than salmon.
– But it may happen that decision can‟t be
made on single feature
• We can use more than one feature for our
decision:
– Lightness (x1) and width (x2)
12 12/3/2012

Components of a typical Pattern Recognition System
Pattern Recognition Systems
13 12/3/2012

Examples of applications
• Optical Character
Recognition (OCR)
• Biometrics
• Diagnostic systems
• Military applications
• Handwritten: sorting letters by postal code, input device for PDA‘s.
• Printed texts: reading machines for blind people, digitalization of text documents.
• Face recognition, verification, retrieval.
• Finger prints recognition.
• Speech recognition.
• Medical diagnosis: X-Ray, EKG analysis.
• Machine diagnostics, waster detection.
• Automated Target Recognition (ATR).
• Image segmentation and analysis (recognition from aerial or satelite photographs).
14 12/3/2012

What is Machine Learning….?
• Machine Learning algorithms discover the relationships
between the variables of a system (input, output and
hidden) from direct samples of the system
• These algorithms originate form many fields:
– Statistics, mathematics, theoretical computer science,
physics, neuroscience, etc
15 12/3/2012

16
Why Learning algorithms needed….?
• When the relationships between all system variables (input,
output, and hidden) is completely understood!
• This is NOT the case for almost any real system!
• Growing flood of online data
• Computational power is available
• progress in algorithms and theory
12/3/2012

Learning Algorithm Application
• Data mining: using historical data to improve decision
– medical records ⇒ medical knowledge
– log data to model user
• Software applications we can‟t program by hand
– autonomous driving
– speech recognition
• Self customizing programs
– Newsreader that learns user interests
17 12/3/2012

Typical Example
• 9714 patient records, each describing a pregnancy and birth
• Each patient record contains 215 features
• Classes of future patients at high risk for Emergency Cesarean Section
Learn to predict:
Given:
18 12/3/2012

19
The Sub-Fields
of
Machine Learning
• Supervised Learning
• Unsupervised Learning
• Semi-Supervsed Learning
12/3/2012

Supervised Learning
20 12/3/2012

Supervised Learning
• Supervised learning is the machine learning task of inferring a function from labeled training data.
• In training data each pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal).
• A supervised learning algorithm analyzes the training data and produces an inferred function, which is called a classifier (if the output is discrete) or a regression function (if the output is continuous).
• The inferred function should predict the correct output value for any valid input object. This requires the learning algorithm to generalize from the training data to unseen situations in a "reasonable" way.
21 12/3/2012

Supervised Learning Process: two
Steps Learning (training): Learn a model using the training data
Testing: Test the model using unseen test data to assess the model accuracy
,cases test ofnumber Total
tionsclassificacorrect ofNumber Accuracy
12/3/2012 22

Example • A credit card company receives thousands of
applications for new cards. Each application contains information about an applicant, – age
– Job
– House
– credit rating
– etc.
• Problem: to decide whether an application should approved, or to classify applications into two categories, approved and not approved.
12/3/2012 23

An example: Data (Loan
Application)
24 12/3/2012

25
An example: The Learning Task
• Learn a classification model from the data
• Use the model to classify future loan applications
into
– Yes (approved) and
– No (not approved)
• What is the class for following case/instance?

Bayesian Classifier
• The Simple Bayesian Classifier (SBC) uses probabilistic
methods for classification
• The basis of bayesian classifier is: The probability of document
„d‟ being in class „c‟ is computed as-
where P(tk|c) is the conditional probability of term occurring in a
document of class c .Where,
26 12/3/2012

Simple Bayes Classifier
27 12/3/2012

12/3/2012 28

Unsupervised Learning
29 12/3/2012

• Organizing data into classes such that there is Inter-clusters distance maximized Intra-clusters distance minimized
• Finding the class labels and the number of classes directly from the data
(in contrast to classification).
• More informally, finding natural groupings among objects.
What is Unsupervised
Learning….? • Unsupervised learning refers to the problem of trying to
find hidden structure in unlabeled data
• Sometimes it is also referred as Clustering
30 12/3/2012

What is a natural grouping among these objects?
31 12/3/2012

School Employees Simpson's Family Males Females
Clustering is subjective
What is a natural grouping among these objects?
32 12/3/2012

What is clustering for….? Let us see some real-life examples
• Example 1: Groups people of similar sizes together to
make “small”, “medium” and “large” T-Shirts.
– Tailor-made for each person: too expensive
– One-size-fits-all: does not fit all.
• Example 2: Given a collection of text documents, we want to organize them according to their content similarities,
– To produce a topic hierarchy
12/3/2012 33

What is clustering for? (cont…) In fact, clustering is one of the most utilized data mining techniques
– It has a long history, and used in almost every field,
e.g., medicine, psychology, botany, sociology, biology, archeology, marketing, insurance, libraries, etc.
– In recent years, due to the rapid increase of online documents, text clustering becomes important.
12/3/2012 34

K-means algorithm
12/3/2012 35

36
An example
+ +
12/3/2012

37
An example (cont …)
12/3/2012

Semi-Supervised learning
12/3/2012 38

Supervised Learning
versus
Unsupervised Learning
• Unsupervised clustering Group similar objects together
to find clusters • Minimize intra-class distance
• Maximize inter-class distance
• Supervised classification Class label for each training
sample is given
– Build a model from the training data
– Predict class label on unseen future data points
39 12/3/2012

However, for many problems, labeled
data can be rare or expensive.
Unlabeled data is much cheaper.
Speech
Images
Medical outcomes
Customer modeling
Protein sequences
Web pages
Need to pay someone to do it, requires special testing,…
40 12/3/2012

Why Semi-Supervised Learning…?
• Why not clustering?
– The clusters produced may not be the ones required.
– Sometimes there are multiple possible groupings.
• Why not classification?
– Sometimes there are insufficient labeled data.
41 12/3/2012

Semi-Supervised Learning
• Combines labeled and unlabeled data
during training to improve performance: – Semi-supervised classification: Training on labeled data exploits
additional unlabeled data, frequently resulting in a more accurate
classifier.
– Semi-supervised clustering: Uses small amount of labeled data to
aid and bias the clustering of unlabeled data.
Unsupervised clustering
Semi-supervised learning
Supervised classification
42 12/3/2012

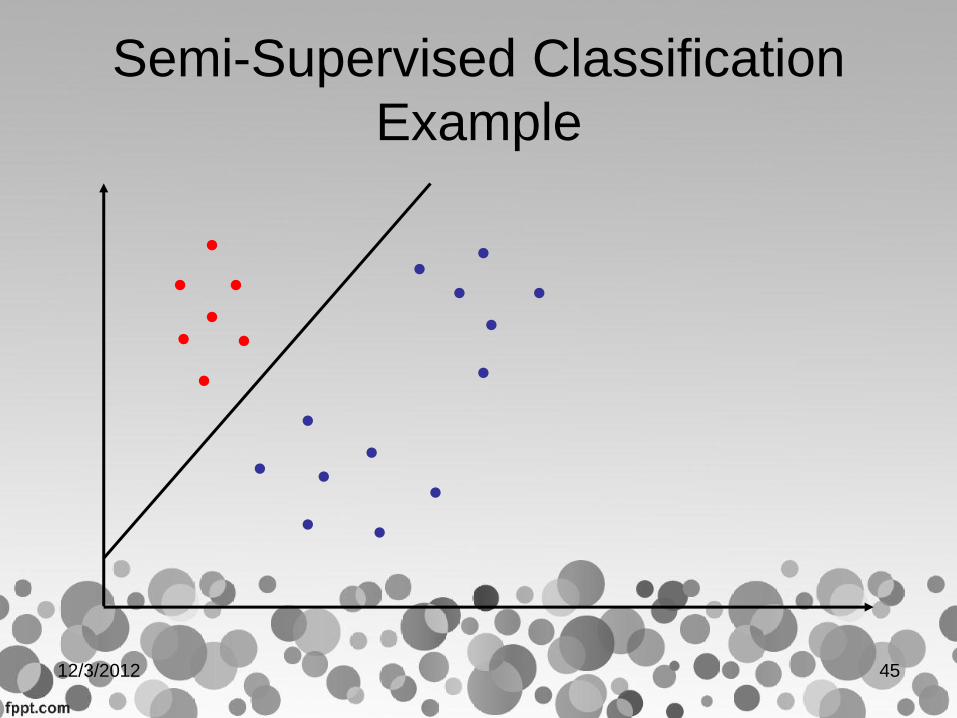
Semi-Supervised Classification
• An initial classifier is designed using the labeled data set D(l).
This classifier is then used to assign class labels to examples
in D(u). Then the classifier is re-trained using D(l) U D(u).
• The last two steps are usually repeated for a given number of
times or until some criterion is satisfied
43 12/3/2012

.
Semi-Supervised Classification
Example
.
. . .
. . . . .
.
.
. . .
.
.
. . .
44 12/3/2012
.
Semi-Supervised Classification
Example
.
. . .
. . . . .
.
.
. . .
.
.
. . .
45 12/3/2012

Semi-Supervised Classification
• Algorithms:
– Semisupervised EM
[Ghahramani:NIPS94,Nigam:ML00].
– Co-training [Blum:COLT98].
– Transductive SVM‟s [Vapnik:98,Joachims:ICML99].
– Graph based algorithms
• Assumptions:
– Known, fixed set of categories given in the labeled
data.
– Goal is to improve classification of examples into
these known categories. 46 12/3/2012

Semi-Supervised clustering • Input:
– A set of unlabeled objects, each described by a set of attributes
(numeric and/or categorical)
– A small amount of domain knowledge
• Output:
– A partitioning of the objects into k clusters (possibly with some
discarded as outliers)
• Objective:
– Maximum intra-cluster similarity
– Minimum inter-cluster similarity
– High consistency between the partitioning and the domain
knowledge
47 12/3/2012

How Semi-Supervised Clustering done?
• In addition to the similarity information used by unsupervised
clustering, in many cases a small amount of knowledge is available
concerning either pairwise (must-link or cannot-link) constraints
between data items or class labels for some items.
• Instead of simply using this knowledge for the external validation of
the results of clustering, one can imagine letting it “guide” or “adjust”
the clustering process, i.e. provide a limited form of supervision. The
resulting approach is called semi-supervised clustering
48 12/3/2012

Illustration
x x
Must-link
Determine its label
Assign to the red class
49 12/3/2012

Illustration
x x
Cannot-link
Determine its label
Assign to the red class
50 12/3/2012

• According to different given domain knowledge: – Users provide class labels (seeded points) a priori to
some of the documents
-Users know about which few documents are related
(must-link) or unrelated (cannot-link)
Semi-Supervised Clustering
Seeded points
Must-link
Cannot-link
51 12/3/2012

Semi-supervised Clustering Algorithm
• Semi-supervised Clustering with labels (Partial label information is given ) : – SS-Seeded-Kmeans ( Sugato Basu, et al. ICML 2002)
- SS-Constraint-Kmeans ( Sugato Basu, et al. ICML 2002)
• Semi-supervised Clustering with Constraints (Pairwise Constraints (Must-link, Cannot-link) is given): – SS-COP-Kmeans (Wagstaff et al. ICML01)
– SS-HMRF-Kmeans (Sugato Basu, et al. ACM SIGKDD 2004)
– SS-Kernel-Kmeans (Brian Kulis, et al. ICML 2005)
– SS-Spectral-Normalized-Cuts (X. Ji, et al. ACM SIGIR 2006)
52 12/3/2012

Co-Training Algorithm
53 12/3/2012

Conclusions
• Semi-supervised learning is an area of increasing
importance in Machine Learning.
• Automatic methods of collecting data make it more
important than ever to develop methods to make use
of unlabeled data.
• Several promising algorithms (only discussed a few).
Also new theoretical framework to help guide further
development.
54 12/3/2012

Reference
• Duda, Heart: Pattern Classification and Scene Analysis. J. Wiley &
Sons, New York, 1982. (2nd edition 2000).
• Fukunaga: Introduction to Statistical Pattern Recognition. Academic
Press, 1990.
• Sergios Theodoridis, Konstantinos Koutroumbas , pattern recognition
, Pattern Recognition ,Elsevier(USA)) ,1982
• K. Nigam and R. Ghani. Analyzing the effectiveness and applicability
of co-training. In Proceedings of the ninth international conference on
Information and knowledge management, pages 86{93. ACM, 2000.
• http://nlp.stanford.edu/IR-book/html/htmledition/naive-bayes-text-
classification-1.html
• http://home.dei.polimi.it/matteucc/Clustering/tutorial_html/kmeans.htm
l
12/3/2012 55

Any
•
•
Question…..Suggestion….Feedback….???
56 12/3/2012

Thank You
57 12/3/2012