serial code accelerators for heterogeneous multicores...
TRANSCRIPT

"Serial Code Accelerators for Heterogeneous Multicores, Employing SiGe HBT BiCMOS - and 3D Memory for Memory Wall Mitigation”
J. F. McDonald, Philip Jacobs, Alexey Gutin, Aamir Zia, Sherry Liu, and Russ Kraft
Electrical Systems and Computer Engineering
Center for Integrated Electronics Rensselaer Polytechnic Institute
Troy, NY 12180
Abstract Moore’s “Law” [1] was an empirical observation enunciated in 1965 by Gordon Moore that the number of FET transistors implemented on an integrated circuit doubled roughly every 18 month essentially by a 33% lithographic scaling per generation. Moore’s Law is not a law of physics. Rather it is a statement of economic imperative. Initially this was accompanied by increasing clock rates, which were enabled by scaling. The progress was codified in the Dennard rules [2], which linked device, voltage, and interconnection scaling strategies. However, even at the outset, wire parasitics were a known challenge to continuation of this clock race. In 2000 clock rates had risen to 1GHz. It is now 2009, which is six 18-month clock-doubling times. We should have computers at 64GHz clock rate by now. Instead, around 2004 the clock rate progression noticeably slowed and saturated (Figure 1) and may actually be in decline.
Figure 1. CMOS Microprocessor Clock Rate Trends [Slide Published in 2008 IBM TAPO Advanced Technology Workshop by Wilfried Haensch].
Initially additional performance improvements beyond scaling were needed through the years, one of which was instruction level parallelism. However, notably the introduction of additional layers of interconnections and lower dielectric constant interlayer dielectrics helped keep the clock race alive. These additional layers and dielectrics were forced due

to the fact that wire does not scale well. Wires and contacts increased in resistance. To combat this, repeaters were introduced [3] to help reshape resistance-capacitance limited charging events. However, the number of these repeaters is now increasing at an alarming rate as shown in this slide presented by IBM’s Ruchir Puri at SEMATECH [4]. At least part of this problem is due to the TaN-Ru clad barrier for Cu diffusion, which is no less than 4nm to be effective. This means that at 8nm for the outer width of the wire there would be NO copper left. Consequently, unless there is a breakthrough in carbon nano-tubes, graphenes, or high temperature superconductors, this becomes one of the ultimate defining limitations of scaling.
Figure 2. Exploding CMOS Repeater Count Growth [Slide Presented by Ruchir Puri at the Albany Sematech 3D Workshop 2008]
This repeater explosion has resulted in the introduction of multiple cores at modest clock rate. While appealing, it is not without its own problems. In this paper we will focus on a few of these issues, one of which has to do with the so-called Memory Wall problem [5]. Whether continued progress in computing results from higher clock rates, or multiple cores (or both), memory starvation of the processors is becoming more evident. One anomaly of the multiple core evolution has been that the additional transistors provided by continued Moore’s law improvements, have not been used for implementation of mass 2D memory within the processor chip, but rather for more cores. The success of this approach then depends greatly on the footprint of data and instructions in memory. When this footprint exceeds internal cache sizes there is a competition for access to memory through the limited pin-out and per pin bandwidth of the processor package and the large external capacitance needed to access additional memory. In addition, memory itself is a product of scaling, and wire resistance is even more of a problem for this type of circuit. Use of 3D memory over the processor is the only way to mitigate memory starvation. Another problem is the implication of Amdahl’s Law [6]. Amdahl’s law: Amdahl’s law originally discusses the performance improvement that can be achieved in a system by speeding up a certain factor. This law was extended to apply to evaluate the amount of performance benefits that one can achieve from parallelization of code. As discussed in the Project Summary microprocessor system now have fully embraced the multicore approach to

continuing the processor throughput issue in an era where the scaling limits for wiring, repeater quantities and associated power dissipation have forced this paradigm change. The objective of the multi-core approach was that code that can be parallelized can be sped up by introducing more processor nodes to execute them. However most code have a serial component and a parallel component. Forty years ago Amdahl [6] created a figure of merit (or FOM) given by
Performance =S + P
S +P
n
Where P is the fraction of the code that can be parallelized, and S is the fraction that cannot be parallelized, and n is the number of cores. As n goes to infinity the figure of merit becomes 1 + P/S. So if S is 33% as Amdahl claimed, the FOM is limited to 3.00, and this only for an infinite number of cores. However there are notable applications where S is 4% (the FOM rises to 25.00) or even lower values for S. However, the plot of the FOM versus P reveals just how challenging the problem can be.
Figure 3. Plot of Amdahl’s Figure of Merit versus P for n = 16, 32, 64, 128 and 512. Essentially S must be smaller than about 4% to show large improvements in run time. More significantly though, is the steep slope of the curve near 4%, which reveals how sensitive the FOM can be to various assumptions. Of particular interest in this proposal is the fact that the Amdahl FOM assumes ideal parallelism, in which there is no penalty to be paid in actually implementing parallelism. In reality when devising hardware (and software) to implement parallel code execution there are inevitably lost cycles, L, which are due to memory latency, multithread and multitask code management, inter-processor communication, and memory management among others. Comparing the total code cycles without parallelization and code cycles with lost cycles in parallelization we obtain a modified Amdahl figure of merit:
If we divide L by n and define this ratio as an average “burden” per core for parallelization

then if B tends to be a constant not dependent on n for a given problem, then B masquerades as serial code
If B is moderately large, then from Figure 3 one can see that these lost cycles can easily push the performance down the steep curve shown there from its ideal. This makes it worthwhile to consider a heterogeneous power managed system in which during serial code operation the clock rate for that core can be higher by a factor of say m. The appropriately changed Amdahl FOM would then be
If m = n then this figure of merit is n/[1 + B/{n(S+P)}], for large enough n (or small enough B), would give a Figure of merit of n. How to make S code go n times faster is the question? Evidently CMOS is not the answer. The clock race is over for CMOS. Although CMOS has been clocked at 5 GHz (A Quad Opteron attained this) Liquid Nitrogen Temperature is required to reduce wire resistance and enhance carrier mobility. A single core 4.7 GHz Power PC has been obtained at Room Temperature, but it required 120 watts of power dissipation. If we let n go to infinity even if m is not equal to n then this figure of becomes m[(S+P)/(S+B)], which is the product of the Figure of Merit obtained without serial code enhancement, and the clock rate enhancement factor. In other words, if BOTH parallelization and serial code speed-up (by clock rate enhancement) strategies are employed, they complement each other. For example, if we ignore B for simplicity, the figure of merit for an infinite number of course asymptotically approaches (1+P/S). For P=66%, and S=33%, this is just 3.000. But if the residual 33% of serial code is also sped up by the clock rate improvement, m, then the figure of merit is m (1+P/S), i.e. the product of the parallelization and serial acceleration gains, and for the same S and P if m is say 10, then the total improvement is 30, not just 3.
Figure 4. Pictorial Representation of both Parallel and Serial Speed-up.

This suggests that the multicore system of the future should in fact be quite heterogeneous, including at least one High Clock Rate Unit (HCRU) to accelerate serial code. The higher the clock rate, the higher the gain, since in theory with an infinite number of parallelizing cores, the only code left is serial code.
Figure 5. High Clock Rate Unit as an embedded accelerator for executing serial code. The question remaining is what technology should be used to implement the HCRU. To be practical, the technology should remain compatible with CMOS and could be a CMOS processor tuned for as much speed as is possible. One observes the two outlier-points in Figure 1 at 4.7GHz. But as shown in Figure 2, wire resistance will increasingly limit this path, with one possible exception, cryogenic operation. But the high thermal dissipation of the HCRU would make that approach problematic. For room temperature operation one alternative might well be IBM’s SiGe HBT BiCMOS process [27]. As shown in Figure 6 the SiGe HBT offers extremely high device speed, with may chances for trading off some of this speed for lower power.
Figure 6. Three Generations of IBM SiGe HBT including 8XP (a Precursor for 9HP). The stars mark positions realizable in 8XP with higher speed or lower power.

By “regressing” to less ambitious wire scaling geometries (where wire resistance is less of a problem), and obtaining speed from some other method (vertical scaling of the HBT device) some new and possibly overlooked high clock rate opportunities may be found. Figure 7 illustrates the cross section of a SiGe HBT showing how vertical base and collector engineering may be used to continue the vertical scaling for a number of generations. Wire dimensions used for bipolar design are much larger than for CMOS due to the different way that bipolar scales compared with CMOS and these largely capacitive parasitics are well driven by the low ON-resistance of the bipolar device, which is also a feature of the vertical current flow.
Figure 7. Cross section of IBM SiGe HBT illustrating one of the larger feature sizes of the technology, the Deep Trench Isolation or (DTI).
With a view towards exploring this opportunity several small demonstration chips have been designed in 7HP and 8HP. One of these is shown in Figure 8. However, while these do illustrate the possibility of still higher clock rates, memory speeds remain a problem.
Figure 8. Small RISC Demonstrator employing IBM’s 7HP Process at 16 GHz. To mitigate the memory wall problem 3D memory chip stacking on top of the processor appears to offer significant improvement, although other internal architecture and circuit
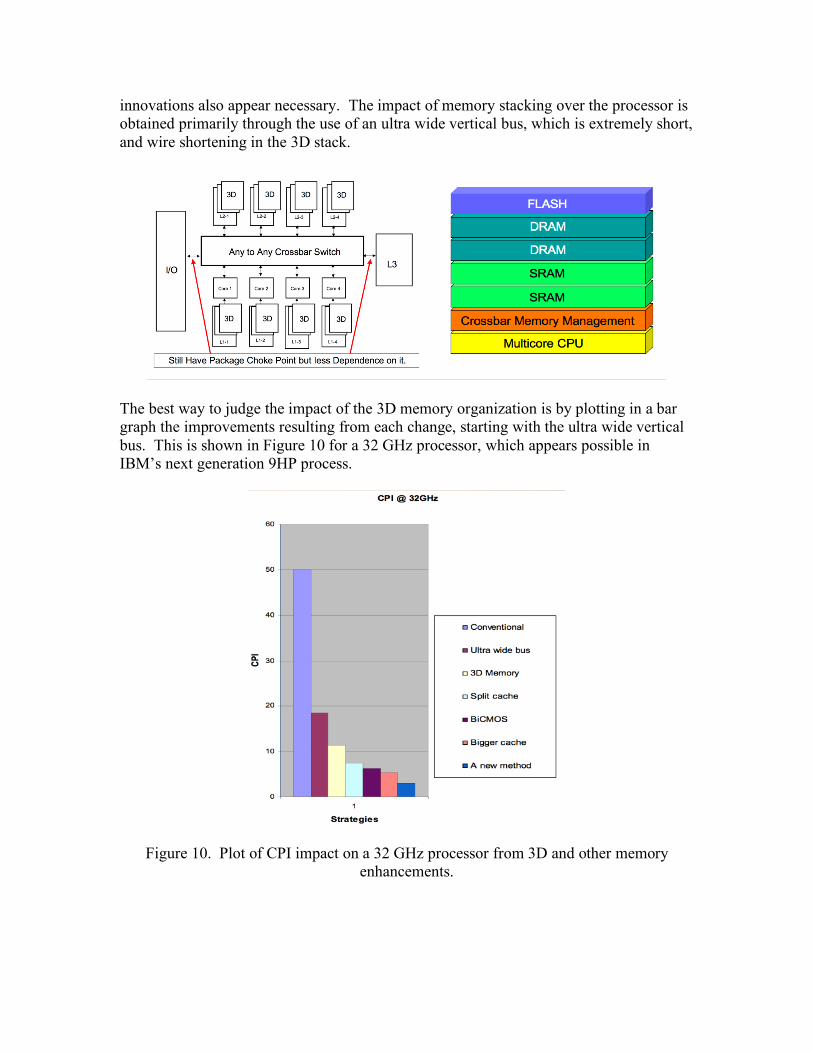
innovations also appear necessary. The impact of memory stacking over the processor is obtained primarily through the use of an ultra wide vertical bus, which is extremely short, and wire shortening in the 3D stack.
The best way to judge the impact of the 3D memory organization is by plotting in a bar graph the improvements resulting from each change, starting with the ultra wide vertical bus. This is shown in Figure 10 for a 32 GHz processor, which appears possible in IBM’s next generation 9HP process.
Figure 10. Plot of CPI impact on a 32 GHz processor from 3D and other memory enhancements.

References Cited
[1] G. Moore, “Cramming more components onto Integrated Circuits,“ Electronics, Vol 38, pp. 114-117, April 19, 1965.
[2] R.H. Dennard, F.H. Gaensslen, V.L. Rideout, E. Bassous, and A.R. LeBlanc, “Design of Ion-Implanted MOSFET's with Very Small Physical Dimensions,” IEEE Journal of Solid-State Circuits, Oct. 1974.
[3] H. B. Bakoglu and J. D. Meindl, "Optimal interconnection circuits for VLSI," IEEE Trans. Electron Dev., vol. ED-32, pp. 903-909, May 1985.
[4] K. Bernstein, P. Andry, J. Cann, P. Emma, D. Greenberg, W. Haensch, M. Ignatowski, S. Koester, J. Magerlein, R. Puri, A. Young, “Interconnects in the Third Dimension: Design Challenges for 3D ICs,” 44th Design Automation Conference, 2007, pp. 562-567.
[5] J. Hennessy and D. Patterson, “Computer Architecture: A Quantitative Approach,” 3rd, Elsevier, Jan. 2003.
[6] Amdahl, G.M., "Validity of the single-processor approach to achieving large scale computing capabilities," Proceedings of AFIPS Conference, 1967, pp. 483-485.
[7] Krishnaprasad, S., “Uses and Abuses of Amdahl’s Law,” Proc. CCSC: Southeastern Conference, reprinted in JCSC 17(#2), Dec. 2001, pp. 288-293.
[8] O'Neal, David, "On Microprocessors, Memory Hierarchies and Amdahl's Law," Carnegie Mellon University, Pittsburgh Supercomputing Center, Pittsburgh, PA. See web link http://archive.ncsa.uiuc.edu/EP/CSM/presentations, November 1999.
[9] P. Jacob, A. Zia, J.F. McDonald, and R.P. Kraft, “Predicting the Performance of a 3D Processor-Memory Chip Stack,” IEEE Design & Test of Computers, Vol. 22, No. 6, pp. 540-547, Nov. 2005.
[10] Jacob, P., Zia, A., Erdogan, O., Belemjian, P. M. Kim, J.-W., Chu, M., Kraft, R.P., McDonald, J. F., and Bernstein, K., “Mitigating Memory Wall Effects in High-Clock-Rate and Multicore CMOS 3-D Processor Memory Stacks” Proceedings of the IEEE,, Sp. Issue on 3D Electronics, Vol. 97, No. 1, January 2009 pp. 109-122. [11] Emma, P.G., “How Bandwidth Works in Computers,” Chapter 11 in High Performance
Energy Efficient Microprocessor Design, edited by V.G. Oklobdzija and R. Krishnamurthy, published by Springer, Feb., 2006.
[12] P. Pujare, and A. Aggarwal, “Cache Noise Prediction,” IEEE Trans. on Computers, , 57(#10), October 2008, pp;. 1372-1384.
[13] J. Edler, M.D. Hill, “Dinero IV: Trace-Driven Uniprocessor cache simulator” http://www.cs.wisc.edu/~markhill/DineroIV/ [14] C.J. Hughes, V.S. Pai , P. Ranganathan ,S.V. Adve , “RSIM: simulating shared memory
multiprocessors with ILP processors”, Feb 2002, vol. 35, Issue: 2, pp.40. [15] R. Fernandez , J. M.García. RSIM x86: A cost-effective performance simulator. In 19th
European Conference on Modelling and Simulation, June 2005, pp 774-779. [16] T. H. Ning, P. M. Solomon and D. D. Tang, Scaling properties of Bipolar Devices,
Electron Devices Meeting, 1980 International Volume 26, Issue , 1980 Page(s): 61 - 64 [17] P. M. Belemjian, O. Erdogan, R. P. Kraft, and J. F. McDonald, "SiGe HBT
Microprocessor Core Test Vehicle," Proc. IEEE [Special Issue on SiGe Technology Guest Editors, R. Singh, D. Harame, and B. Meyerson], Vol. 93(#9), Sept. 2005, pp. 1669-1678.
[18] H. J. Greub, J. F, McDonald, T. Yamaguchi, and T. Creedon), "Cell Library for Current Mode Logic using an Advanced Bipolar Process," (with H. J. Greub, T. Yamaguchi, and T. Creedon), I.E.E.E. J. Sol. State Cir., Special issue on VLSI, (D. Bouldin, guest

editor), I.E.E.E. Trans. on Solid State Circuits, Vol. JSSC-26 (#5), pp. 749-762, May, 1991.
[19] C. L., Ratzlaff and L. T. Pillage, "RICE: Rapid Interconnect Circuit Evaluation Using AWE" IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 13, no. 6, June 1994, pages 763--776.
[20] Bard, K.; Dewey, B.; Hsu, M.-T.; Mitchell, T.; Moody, K.; Rao, V.; Rose, R.; Soreff, J.; Washburn, S., Transistor-Level Tools for High-End Processor Custom Circuit Design at IBM. Proceedings of the IEEE, Volume 95, Issue 3, March 2007 pp. 530 – 554.
[21] Hill, M. D. and Murty, M. R. “Amdahl’s Law in the Multicore Era,” http://www.cs.wisc.edu/multifacet/papers/tr1593_amdahl_multicore.pdf [22] J.A. Kahl, M.N. Day, H.P. Hofstee, C.R. Johns, T.R. Maeurer, and D. Shippy. Introduction to the Cell Multiprocessor. IBM Journal of Research and Development, 49(4), 2005. [23] Morad, T. Y. Weiser, U. C. Kolodny, A. Valero, M. Ayguadé, E., “Performance, Power Efficiency and Scalability of Asymmetric Cluster Chip Multiprocessors,” IEEE Computer Architecture Letters [1556-6056] Morad 2006 vol:5 iss:1 pg:14. [24] D. Moncrieff, R. E. Overill, and S. Wilson. “Heterogeneous Computing Machines and Amdahl's Law.” Parallel Computing, vol. 22, 1996. [25] F. Pollack. "New Microarchitecture Challenges in the ComingGenerations of CMOS Process Technologies." Micro 32, 1999, http://www.intel.com/research/mrl/Library/micro32Keynote.pdf [26] Y. Taur, and T. H,. Ning, “Fundamentals of Modern VLSI Devices,” Cambridge University Press, 2001. [27] J.-S. Rieh, D. Greenberg, A. Strickler, and G. Freeman, “Scaling of SiGe Heterojunction
Bipolar Transistors,” Proc. IEEE [Special Issue on SiGe Technology Guest Editors, R. Singh, D. Harame, and B. Meyerson], Vol. 93(#9), Sept. 2005, pp. 1522-1538.