software-defined networks - inet: internet network …stefan/sdn-panopticon-dist… · ·...
TRANSCRIPT

Software-Defined Networks: How to deploy them. How to update them. How to distribute them.
1
Stefan Schmid (TU Berlin & T-Labs)

2 Stefan Schmid (T-Labs)
3 Stefan Schmid (T-Labs)
I SDN! Where can I get it, how can I deploy it?

Prologue
4

Context: Network Virtualization
5 Stefan Schmid (T-Labs)

Context: Flexible Allocation and Migration of Resources
6 Stefan Schmid (T-Labs)
Physical infrastructure
(e.g., accessed by mobile clients)
Specification:
1. close to mobile clients
2. >100 kbit/s bandwidth for synchronization
Provider 1
Provider 2
CloudNet requests
VNet 2: Mobile service w/ QoS VNet 1: Computation
Specification:
1. > 1 GFLOPS per node
2. Monday 3pm-5pm
3. multi provider ok
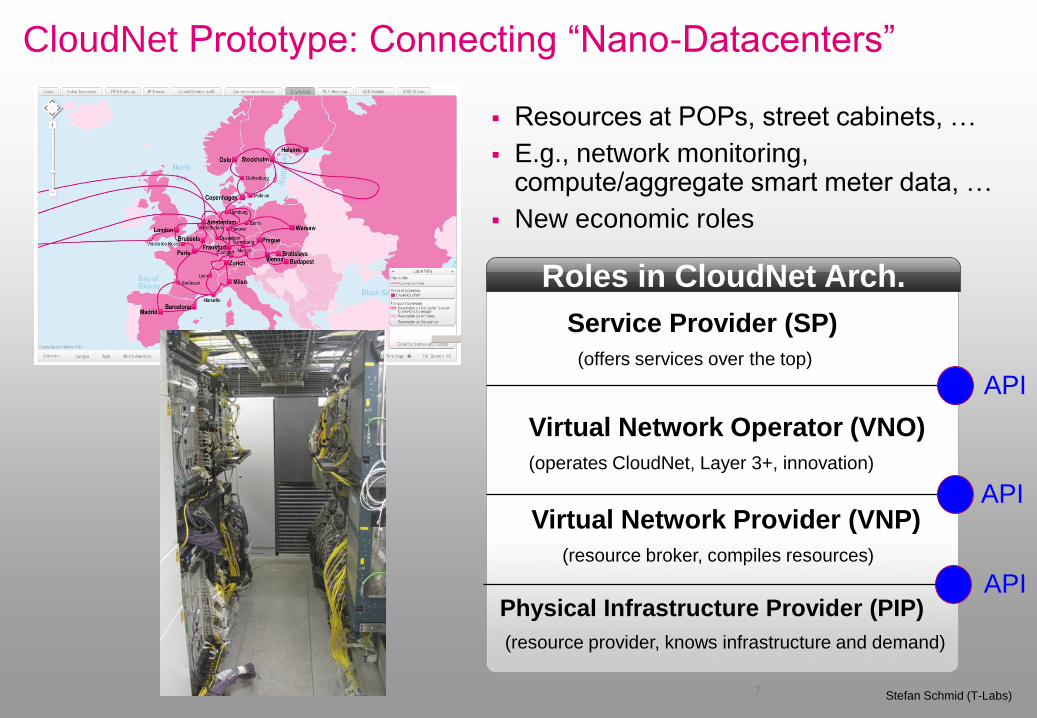
CloudNet Prototype: Connecting “Nano-Datacenters”
7 Stefan Schmid (T-Labs)
API
API
API
Roles in CloudNet Arch.
Service Provider (SP)
(offers services over the top)
Virtual Network Operator (VNO)
(operates CloudNet, Layer 3+, innovation)
Physical Infrastructure Provider (PIP)
(resource provider, knows infrastructure and demand)
Virtual Network Provider (VNP)
(resource broker, compiles resources)
Resources at POPs, street cabinets, …
E.g., network monitoring, compute/aggregate smart meter data, …
New economic roles
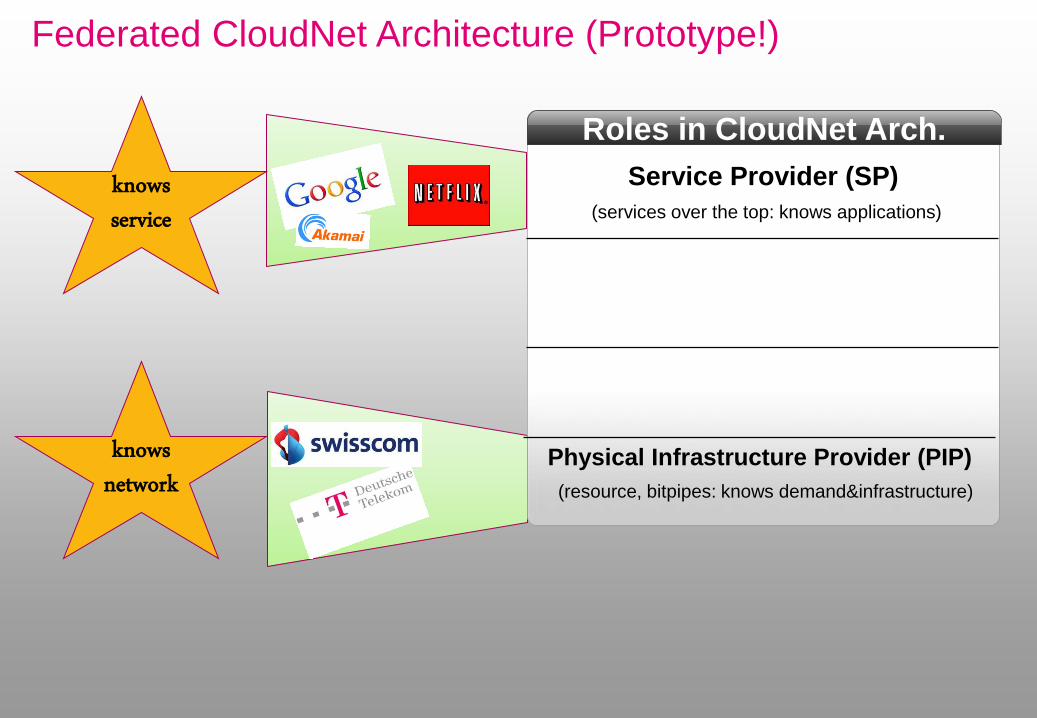
Federated CloudNet Architecture (Prototype!)
Roles in CloudNet Arch.
Service Provider (SP)
(services over the top: knows applications)
Physical Infrastructure Provider (PIP)
(resource, bitpipes: knows demand&infrastructure)
knows service
knows network

Federated CloudNet Architecture
Roles in CloudNet Arch.
Service Provider (SP)
(services over the top: knows applications)
Physical Infrastructure Provider (PIP)
(resource, bitpipes: knows demand&infrastructure)
Provide L2 topology: resource and management interfaces, provides indirection layer, across PIPs!
Can be recursive.
Virtual Network Provider (VNP)
(resource broker, compiles resources)
CloudNet

Federated CloudNet Architecture
Roles in CloudNet Arch.
Service Provider (SP)
(services over the top: knows applications)
Physical Infrastructure Provider (PIP)
(resource, bitpipes: knows demand&infrastructure)
Virtual Network Provider (VNP)
(resource broker, compiles resources)
Build upon layer 2: clean slate!
Tailored towards application (OSN, …): routing, addressing, multi-path/redundancy…
E.g., today’s Internet.
Virtual Network Operator (VNO)
(operates CloudNet, Layer 3+, triggers migration)
Innovation!

Federated CloudNet Architecture
API
API
API
AP
Is: e
.g., p
rovis
ion
ing
inte
rfa
ce
s (
mig
ratio
n)
Roles in CloudNet Arch.
Service Provider (SP)
(offers services over the top)
Virtual Network Operator (VNO)
(operates CloudNet, Layer 3+, triggers migration)
Physical Infrastructure Provider (PIP)
(resource and bit pipe provider)
Virtual Network Provider (VNP)
(resource broker, compiles resources)
Embed!
Embed!
Embed!

Prototype
12 Stefan Schmid (T-Labs)
Open source, testbed in Berlin and Munich
Entire pipeline: from specification over solving to resource signalling
service and resource specification: FleRD
two stage embedding: heuristic and optimization of heavy-hitters
respect privacy, keep spec flexibility, non-topological aspects
signaling to allocation resources VLANs, SDN paths, …
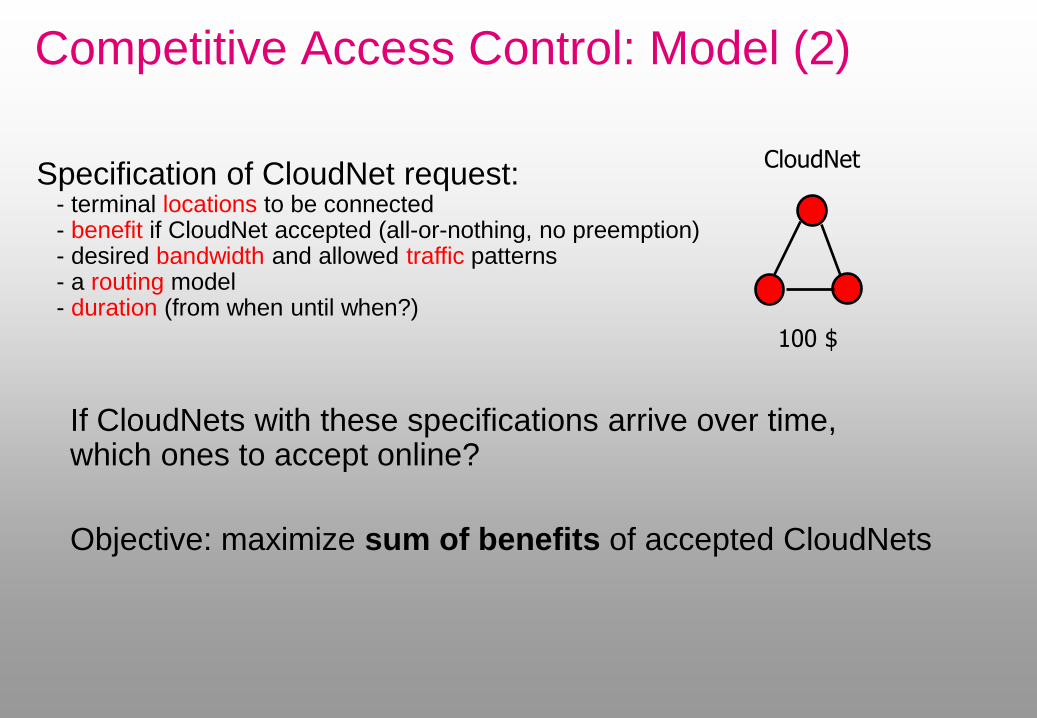
CloudNet
100 $
Specification of CloudNet request: - terminal locations to be connected - benefit if CloudNet accepted (all-or-nothing, no preemption) - desired bandwidth and allowed traffic patterns - a routing model - duration (from when until when?)
If CloudNets with these specifications arrive over time, which ones to accept online?
Competitive Access Control: Model (2)
Objective: maximize sum of benefits of accepted CloudNets

Competitive Access Control: Model (3)
Which ones to accept?
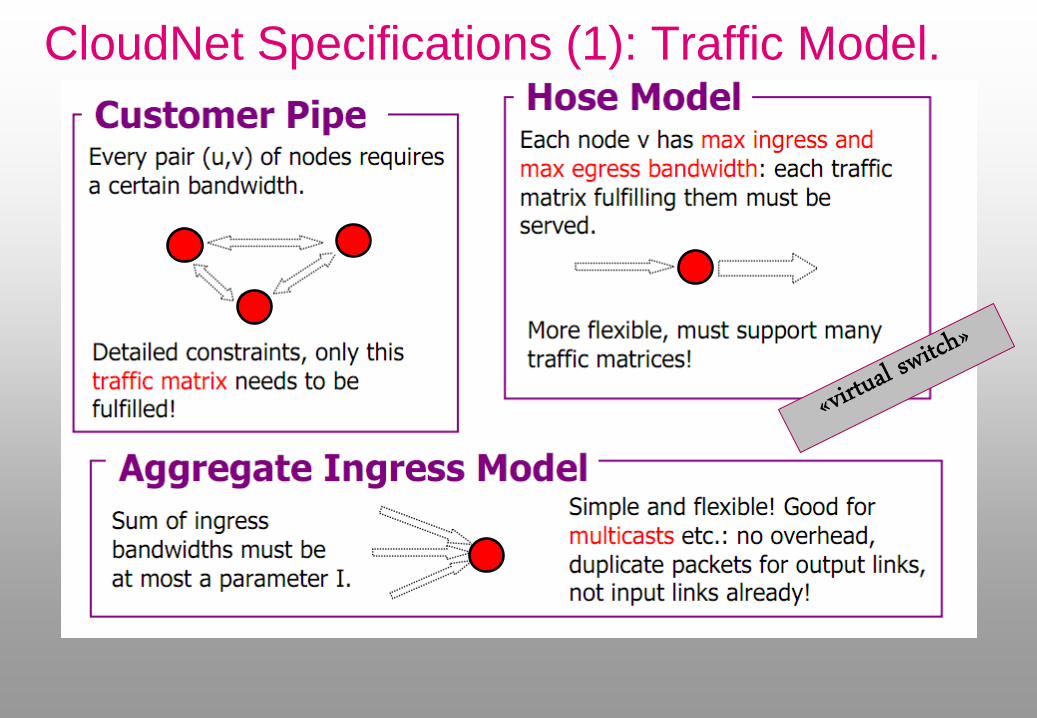
CloudNet Specifications (1): Traffic Model.

CloudNet Specifications (2): Routing Model.

CloudNet Specifications (2): Routing Model.
Relay nodes may add to embedding costs! (resources depend, e.g., on packet rate)

Why SDN and how to get it?
18 Stefan Schmid (T-Labs)

Where is SDN useful? And for what? Examples of Deployment?
19 Stefan Schmid (T-Labs)

Where is SDN useful? And for what? Examples of Deployment?
20 Stefan Schmid (T-Labs)
Datacenter
Inter-Datacenter WANs
IXP/ISP
Enterprise Networks
Wireless
… and more

Where is SDN useful? And for what? Examples of Deployment?
21 Stefan Schmid (T-Labs)
Datacenter
Inter-Datacenter WANs
IXP/ISP
Enterprise Networks
Wireless
… and more

SDN in Datacenter (1)
What is SDN used for?
Virtualize: decouple applications from the physical infrastructure (e.g., to migrate VMs)
Isolate: e.g., different customers can use same virtual addresses
Performance: Higher utilization in Ethernet-based architectures
Characteristics and Problems
Fat-tree networks
Quite homogenous (hardware, software), even clean-slate
Already quite virtualized (e.g., OpenVSwitch’s run on servers, realizes
the fabric abstraction) The Clos Topology
Decoupling

SDN in Datacenter (2)
Examples of “Deployments”
PAST: more utilization for Ethernet-based architectures
SPAIN, VL2, NVP, …
Often cleanslate architectures (possible in datacenters)
E.g. PAST
Implements a Per-Address Spanning Tree routing algorithm
Network architecture for datacenter Ethernet networks
Preserves Ethernet’s self-configuration and mobility support while increasing its scalability and usable bandwidth
Performance comparable to or greater than Equal-Cost Multipath (ECMP) forwarding, which is currently limited to layer-3 IP networks, without any multipath hardware support
OpenFlow-based implementation

SDN for Inter-Datacenter WAN (1)
24
What is SDN used for?
Improve link utilization
Prioritize traffic (bulk vs priority traffic: not possible in conventional
control plane)
Characteristics and Problems
Wide-area: bandwidth precious (WAN traffic grows at fastest rate)
Latency
Probably not so many sites
Many different applications and requirements

SDN for Inter-Datacenter WAN (2)
25 Stefan Schmid (T-Labs)
Examples of “Deployments”
Google B4:
own hardware
implement own routing control plane protocol
application classes:
i) user data copies (e.g., email, documents, audio/video) to remote data centers for availability/-durability: highly latency senstive!
ii) remote storage access for computation over inherently distributed data sources
iii) large-scale data push synchronizing state across multiple data centers (high-volume)
Ordered in increasing volume, decreasing latency sensitivity, and decreasing
overall priority.
Vol
Latency
sensitive

SDN for IXP/ISP (1)
26 Stefan Schmid (T-Labs)
Characteristics and Problems
IXP: layer-2 internet exchange points (multiple providers)
ISP: wide-area carrier network, dumb bit-pipe providers?
Today’s inter-domain routing protocol BGP: inflexible, difficult to manage, troubleshoot, and secure

SDN for IXP/ISP (2)
27 Stefan Schmid (T-Labs)
What is SDN used for?
ISP
introduce new services
e.g., based on multiple header fields
e.g. video over better paths, traffic differentiation, QoS, …: CloudNets
manage traffic directly (not via weights and logging into devices)
IXP
More expressive policies
from multiple ISPs, depending on application, etc.
implementing business contracts (more than hop-by-hop forwarding)
distant networks can exercise “remote control” over packet handling
And and and: inbound traffic engineering, redirection of traffic to middleboxes, wide-area server load balancing, blocking of unwanted traffic, etc.
Examples of “Deployments”
SDX

SDN for Enterprise Networks (1)
28 Stefan Schmid (T-Labs)
Characteristics and Problems
Organically grown, “unstructured” (not clean-slate!)
Complex management: 1000s of config files distributed over devices)
Utilization often low
Many legacy devices
Outages costly (and not business expertise!)
Automated
Troubleshooting Automated Network
Management
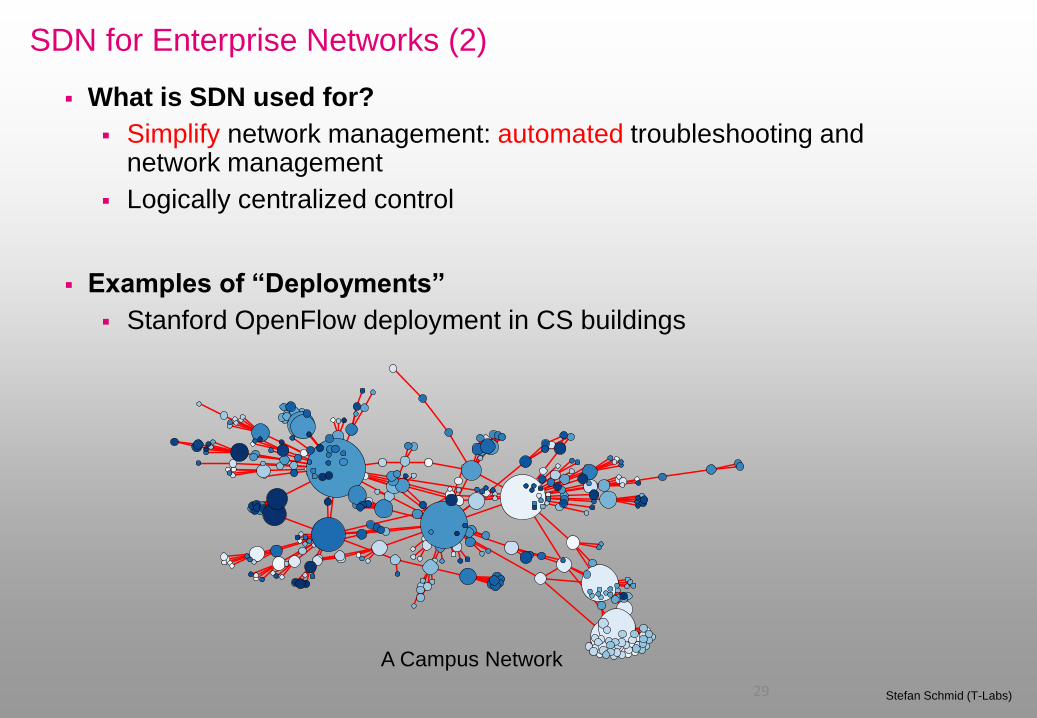
SDN for Enterprise Networks (2)
29 Stefan Schmid (T-Labs)
Examples of “Deployments”
Stanford OpenFlow deployment in CS buildings
What is SDN used for?
Simplify network management: automated troubleshooting and network management
Logically centralized control
A Campus Network

How to Introduce SDN (and Operate as a Hybrid Network)?
30 Stefan Schmid (T-Labs)
Datacenter
Inter-Datacenter WANs
IXP/ISP
Enterprise Networks

Deploy SDN in Datacenter
Where to deploy?
Usually deployed on (software) edge only: there translate logical to physical addresses, use access control mechanism, etc.
OpenVSwitch, run on servers (can terminate links at VM hypervisor)
Inside the network: e.g., simple “fabric” (forwarding only), classic multipath-equal cost control platform, etc.
How to deploy?
Software update in the hypervisor (e.g. OpenVSwitch)

Deploy SDN in Inter-Datacenter WAN
Where to deploy?
At IP “core” routers (running BGP) at border of datacenter (end of long-haul fiber)
How to deploy?
Gradually replace routers
However, benefits arise only after complete hardware overhaul of network (after years)
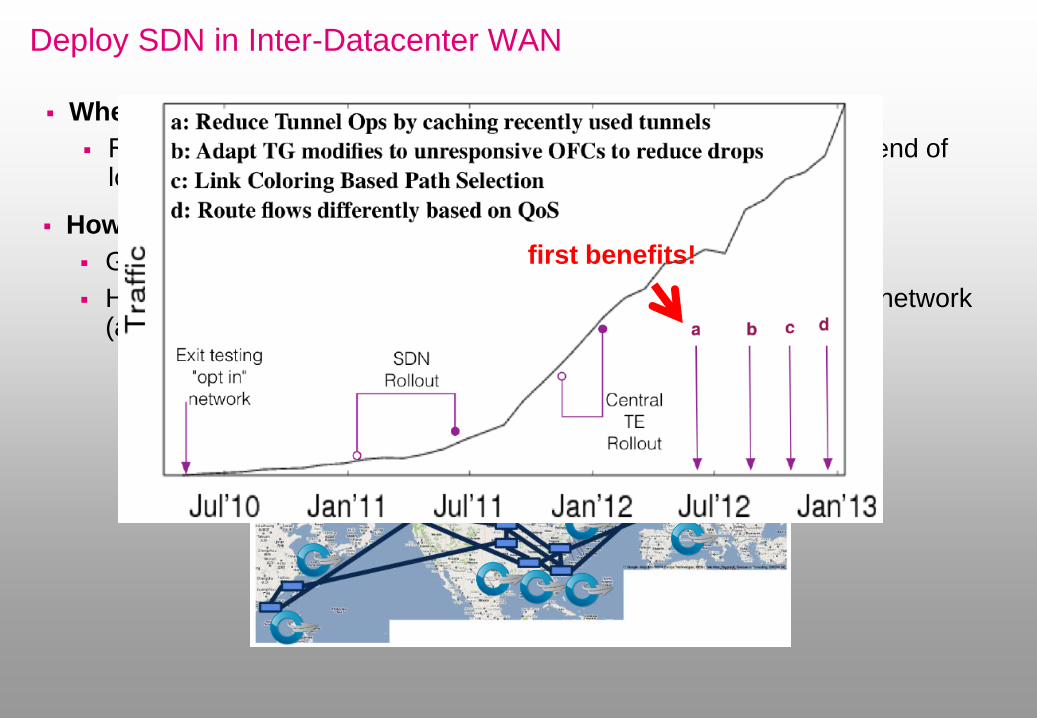
Deploy SDN in Inter-Datacenter WAN
Where to deploy?
Replace IP “core” routers (running BGP) at border of datacenter (end of long-haul fiber)
How to deploy?
Gradually replace routers
However, benefits arise only after complete hardware overhaul of network (after years)
first benefits!

Deploy SDN in IXP and ISP
Deployment options?
Single-site deployment (SDN controller = “smart route server” on behalf of the participating ASes at the exchange)
Or multi-site deployment: SDN controllers across multiple exchange points coordinate to enable more sophisticated wide-area policies

Deploy SDN in Enterprise Network
Let’s shift gears and focus on enterprise network in more detail!
How to deploy SDN it in enterprise?
A real large-scale campus network

Deploy SDN in Enterprise Network
Let’s shift gears and focus on enterprise network in more detail!
How to deploy SDN it in enterprise?
First idea: Full deployment (replace all legacy devices)
Migros-budget idea: Edge deployment, like in datacenter
Pro and Cons?

First Option: Full Upgrade (Of All Devices)
37 Stefan Schmid (T-Labs)
A real large-scale campus network
Full
SDN
Too expensive! Must upgrade to SDN incrementally…

Second Option: Edge-Based Approach
38 Stefan Schmid (T-Labs)
Legacy Mgmt
SDN Platform
App 1
App 2
App 3
Police traffic at all (SDN) ingress ports, then “tunnel” through legacy network
Full control over access policy
New network functionality at edge
Bad for enterprise networks:
Unlike datacenters, edge does not terminate at VM hypervisor but at access switch
Hundreds of switches at edge!

The Enterprise Network…: Where the heck is the edge?!
39 Stefan Schmid (T-Labs)
A real large-scale campus network

The Enterprise Network…: Where the heck is the edge?!
40 Stefan Schmid (T-Labs)
A real large-scale campus network
Still too expensive! Many legacy devices, large edge, …

Reasons Incremental Deployment in Enterprise
41 Stefan Schmid (T-Labs)
Several reasons for gradual deployment:
Budget constraints
Confidence building: gradually open scope rather than flag-day event
Want to benefit from SDN already after buying the first switch: unrealistic?
We want more flexible and even more incremental deployment!
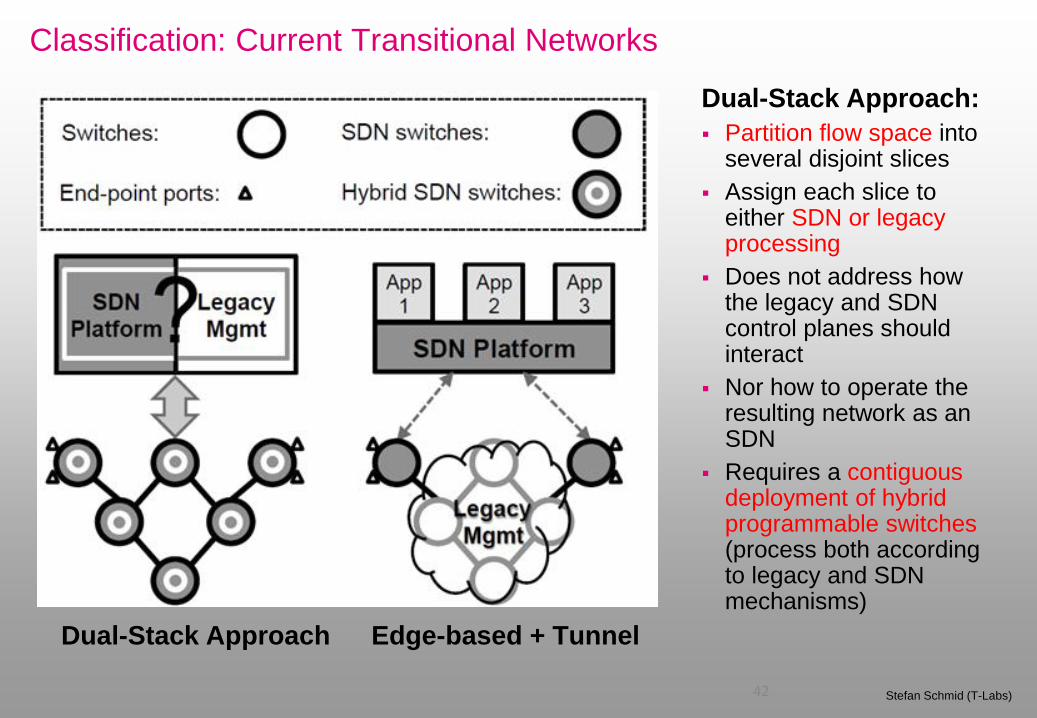
Classification: Current Transitional Networks
42 Stefan Schmid (T-Labs)
Dual-Stack Approach
Edge-based + Tunnel
Dual-Stack Approach:
Partition flow space into several disjoint slices
Assign each slice to either SDN or legacy processing
Does not address how the legacy and SDN control planes should interact
Nor how to operate the resulting network as an SDN
Requires a contiguous deployment of hybrid programmable switches (process both according to legacy and SDN mechanisms)

Classification: Current Transitional Networks
43 Stefan Schmid (T-Labs)
Dual-Stack Approach
Edge-based + Tunnel
Edge-based + Tunnel
High cost of deployment
Impairs the ability to control forwarding decisions within the core of the network (e.g., load balancing, waypoint routing)
Management benefits do not extend to legacy devices

Classification: Current Transitional Networks
44
Dual-Stack Approach
Edge-based + Tunnel
Panopticon
Panopticon realizes full SDN from partial SDN deployment!

Classification: Current Transitional Networks
45
Dual-Stack Approach
Edge-based + Tunnel
Panopticon
Panopticon realizes full SDN from partial SDN deployment!
Transition to SDN control plane before hardware is fully installed.
I.e., (1) integrates legacy and SDN switches, (2) exposes an SDN control plane on an abstract network view, (3) supports arbitrary deployment!

Talk Overview: Incremental SDN Deployment in Enterprise
46 Stefan Schmid (T-Labs)
Deployment Planning
Determine efficient partial SDN deployment
Hybrid Operation Operate the network as
a (nearly) full SDN
published at Open Networking Summit 2013

Talk Overview: Incremental SDN Deployment in Enterprise
47 Stefan Schmid (T-Labs)
Deployment Planning
Determine efficient partial SDN deployment
Hybrid Operation Operate the network as
a (nearly) full SDN
published at Open Networking Summit 2013

How to realize a full SDN from a partial SDN deployment?
A
B
C
D
E
F
Match-Action
Semantics
Match-Action
Semantics
48
Given: partially upgraded network (hybrid SDN+legacy switches).
How to realize full SDN from partial SDN deployment?
What is it used for / what functionality needs to be introduced and how?

How to realize a full SDN from a partial SDN deployment?
A
B
C
D
E
F
Match-Action
Semantics
Match-Action
Semantics
49 Stefan Schmid (T-Labs)
SDN functionality: policy enforcement, middlebox traversals, access control, …

The Notion of SDN Ports
A
B
C
D
E
F
Match-Action
Semantics
Match-Action
Semantics
Choice: want to upgrade all or a subset of ports! (E.g., semantics: flow with at least one SDN-endpoints needs to be SDNed.)
Stefan Schmid (T-Labs)
SDN Port
SDN Port
SDN Port
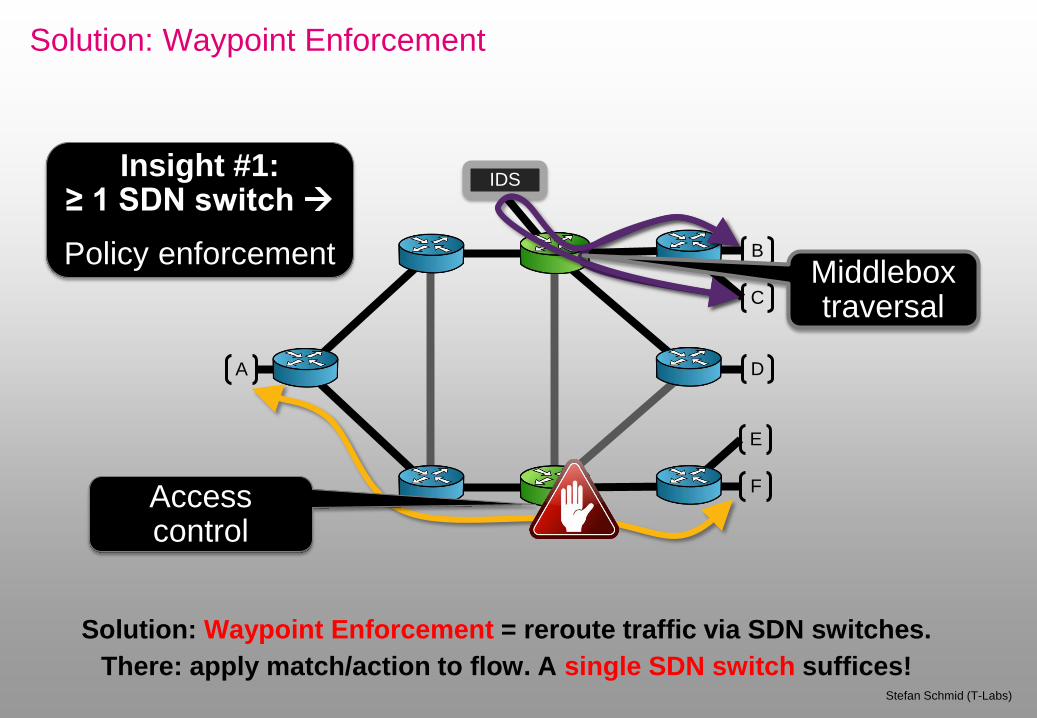
Solution: Waypoint Enforcement
Stefan Schmid (T-Labs)
A
B
C
D
E
F Access control
Insight #1: ≥ 1 SDN switch
Policy enforcement
IDS
Middlebox traversal
Solution: Waypoint Enforcement = reroute traffic via SDN switches.
There: apply match/action to flow. A single SDN switch suffices!

Get flexibility with more SDN switches
Stefan Schmid (T-Labs)
A
B
C
D
E
F
Traffic load-
balancing Insight #2: ≥ 2 SDN switch
Fine-grained control
Also: capacity beyond trees!

How to realize a full SDN from a partial SDN deployment?
Stefan Schmid (T-Labs)
SDN Waypoint Enforcement
Insight #1: ≥ 1 SDN switch
Policy enforcement
Insight #2: ≥ 2 SDN switch
Fine-grained control
Ensure that all traffic to/from an SDN-controlled port always traverses
at least one SDN switch

How to realize a full SDN from a partial SDN deployment?
Stefan Schmid (T-Labs)
SDN Waypoint Enforcement
Insight #1: ≥ 1 SDN switch
Policy enforcement
Insight #2: ≥ 2 SDN switch
Fine-grained control
Must isolate traffic across legacy devices: How?
Ensure that all traffic to/from an SDN-controlled port always traverses
at least one SDN switch
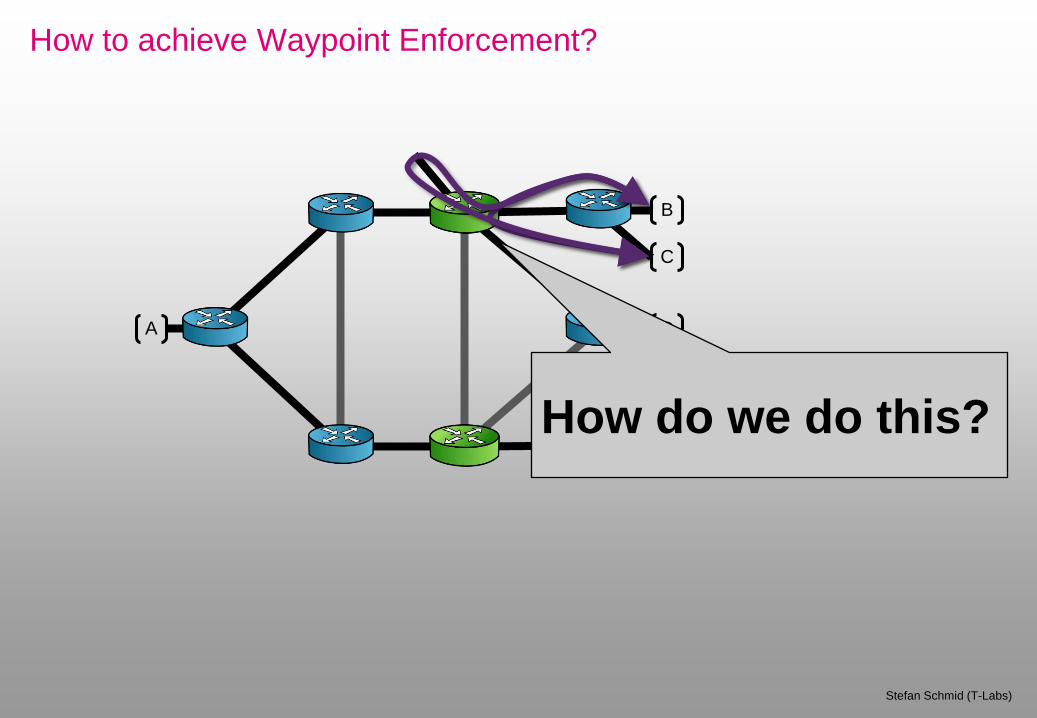
How to achieve Waypoint Enforcement?
Stefan Schmid (T-Labs)
A
B
C
D
E
F How do we do this?

How to achieve Waypoint Enforcement?
Stefan Schmid (T-Labs)
A
B
C
D
E
F How do we do this?
Use per-port VLANs to isolate traffic!
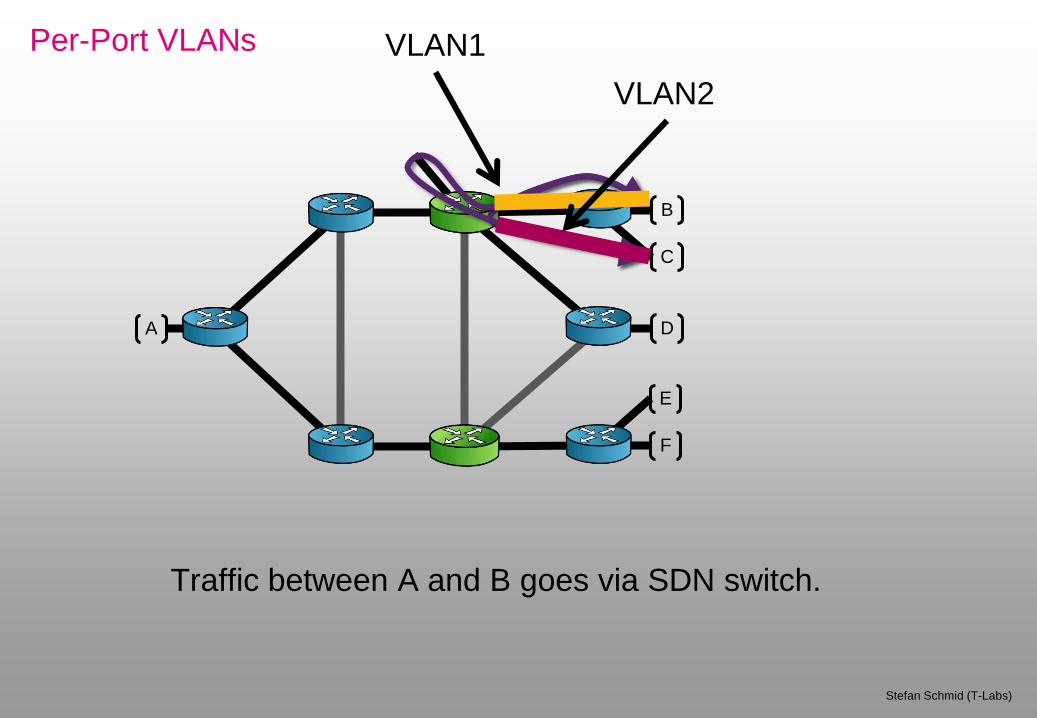
Per-Port VLANs
Stefan Schmid (T-Labs)
A
B
C
D
E
F
VLAN1
VLAN2
Traffic between A and B goes via SDN switch.
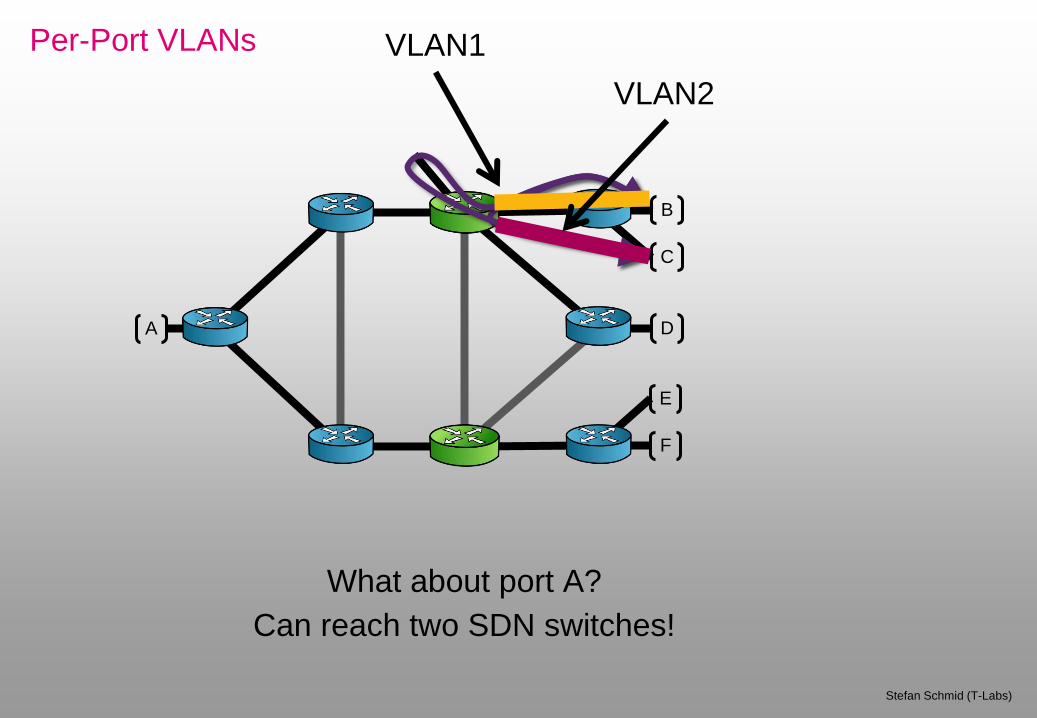
Per-Port VLANs
Stefan Schmid (T-Labs)
A
B
C
D
E
F
VLAN1
VLAN2
What about port A?
Can reach two SDN switches!
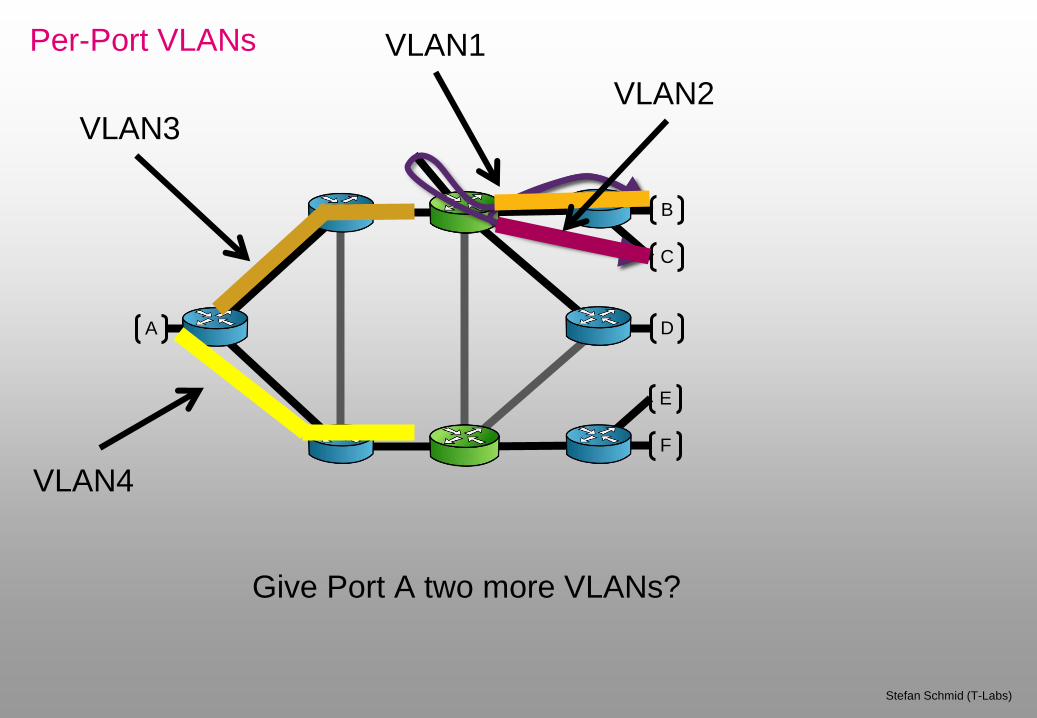
Per-Port VLANs
Stefan Schmid (T-Labs)
A
B
C
D
E
F
VLAN1
VLAN2
VLAN4
VLAN3
Give Port A two more VLANs?

Per-Port VLANs
Stefan Schmid (T-Labs)
A
B
C
D
E
F
VLAN1
VLAN2
VLAN1
VLAN1
Idea:
1. Can reuse VLANs: different domain/“island”!
2. Can use single VLAN for port A: still full flexibility.
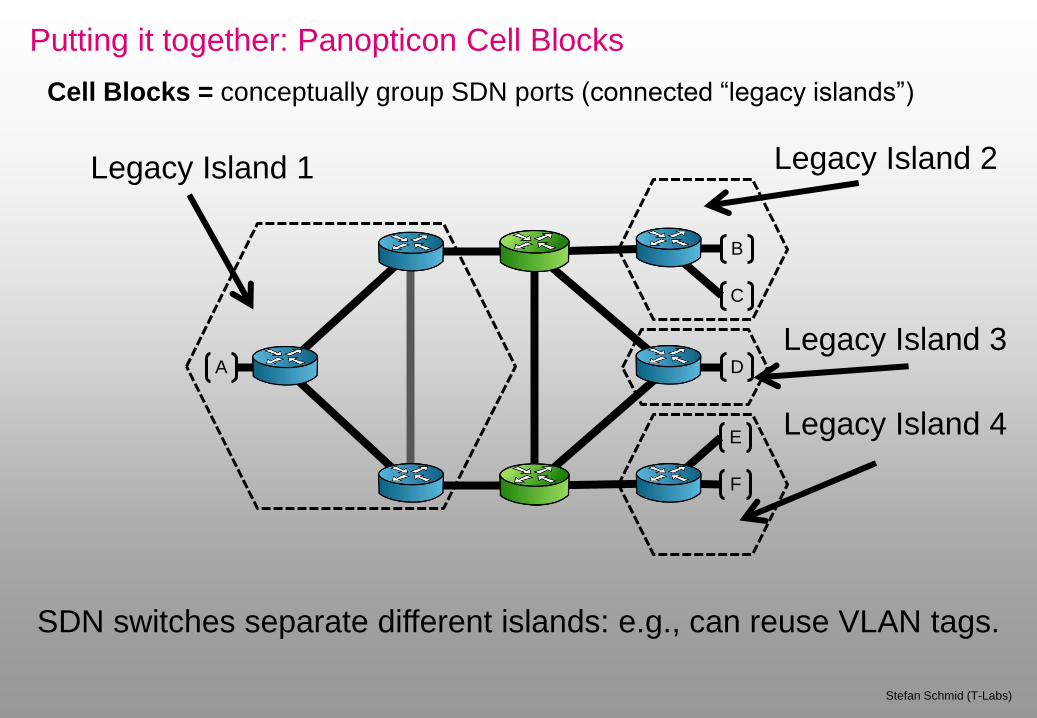
Putting it together: Panopticon Cell Blocks
Stefan Schmid (T-Labs)
A
B
C
D
E
F
Cell Blocks = conceptually group SDN ports (connected “legacy islands”)
SDN switches separate different islands: e.g., can reuse VLAN tags.
Legacy Island 1 Legacy Island 2
Legacy Island 3
Legacy Island 4

Putting it together: Panopticon Solitary Confinement Trees
Stefan Schmid (T-Labs)
A
B
C
D
E
F
Per-port spanning tree (VLAN) to entire SDN frontier: ensures waypoint enforcement and traffic isolation. Larger frontier = more choice (MAC learning inside)

Stefan Schmid (T-Labs)
SDN Platform
App 1
App 2
App 3
B C D E F
A
A
B
C
D
E
F
: Physical SDN
: Logical SDN only SDN switches, or even one single “big switch”

Talk Overview: Incremental SDN Deployment in Enterprise
64 Stefan Schmid (T-Labs)
Deployment Planning
Determine efficient partial SDN deployment
Hybrid Operation Operate the network as
a (nearly) full SDN
published at Open Networking Summit 2013

Where to Deploy SDN Switches?
Stefan Schmid (T-Labs)
What if you could choose where to place SDN switches?
1. What is the “price of Panopticon”?
2. Optimization criteria?
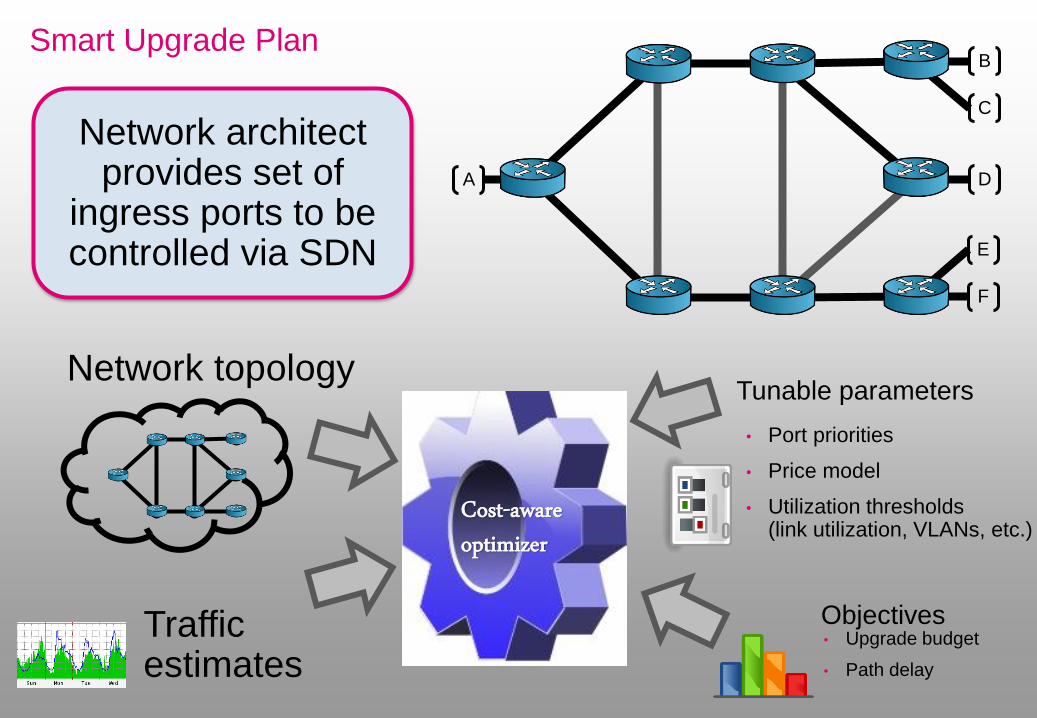
Smart Upgrade Plan
66
A
B
C
D
E
F
Network architect provides set of
ingress ports to be controlled via SDN
Tunable parameters
• Port priorities
• Price model
• Utilization thresholds (link utilization, VLANs, etc.)
Network topology
Cost-aware optimizer
Objectives • Upgrade budget
• Path delay
Traffic estimates

High-Level Results
Stefan Schmid (T-Labs)
Evaluated architecture on a large campus network (1713 L2 and L3 switches)
Traffic matrix derived from LBNL traces
Upgrading 6% of distribution switches
100% SDN-controlled ports
avg. path stretch < 50%
max. link util. < 70%

A strength of SDN: flexible traffic management! So how to update network configuration?
68 Stefan Schmid (T-Labs)

First: A Simplistic Model for SDN
69
Stefan Schmid (T-Labs)
SDN
Control of (forwarding) rules in network from simple, logically centralized vantage point
Flow concept: install rules (“matches”) to define flow (match L2 to L4)
Match-Action concept: apply actions to packet (forward to port A, add tag, …)
Allows to express global network policies, e.g., load-balancing, adaptive monitoring / heavy hitter detection, …
How to install a new policy “consistently”?

But what about multi-author policies?
Stefan Schmid (T-Labs)
vs
E.g., Alice in charge of setting up tunnels, Bob in charge of ACLs, …

But what about distributed control planes?
Stefan Schmid (T-Labs)
fully central fully local SPECTRUM
e.g., small network e.g., routing control
platform
e.g., FIBIUM

Use Case: Network Updates
72 Stefan Schmid (T-Labs)
How to do network updates in this model? Network update (here): change path of packet class (e.g., header).
Possible criteria?

Abstractions for Consistent Network Update
Goals
Per-packet consistency: per packet only one policy applied (during journey through network)
Per-flow consistency: all packets of a given flow see only one policy
Definition
Policy: Here, path to be traversed by packet (of certain header)
Why per-flow?

Abstractions for Consistent Network Update
Goals
Per-packet consistency: per packet only one policy applied (during journey through network)
Per-flow consistency: all packets of a given flow see only one policy
Definition
Policy: Here, path to be traversed by packet (of certain header)
Why per-flow? E.g., packets of same TCP should reach same server.

Installation: 2-Phase Update Protocol
75 Stefan Schmid (T-Labs)
ingress port
internal ports How to guarantee per-packet consistency but still update network paths eventually?
Transmissions asynchronous…

Installation: 2-Phase Update Protocol
76 Stefan Schmid (T-Labs)
ingress port
internal ports SDN Match-Action
Match header (define flow)
Execute action (e.g., add tag or forward to port)
Consistent Update: 2-phase
At internal ports: add new rules for new policy with new tag
Then at ingress ports: start tagging packets with new tag

2-Phase Update Protocol
77 Stefan Schmid (T-Labs)
ingress port
internal ports
SDN Match-Action
Match header (define flow)
Execute action (e.g., add tag or forward to port)
Consistent Update: 2-phase
At internal ports: add new rules for new policy with new tag
Then at ingress ports: start tagging packets with new tag
add tag:
forward ac- cording to tag:
Initially

2-Phase Update Protocol
78 Stefan Schmid (T-Labs)
ingress port
internal ports
SDN Match-Action
Match header (define flow)
Execute action (e.g., add tag or forward to port)
Consistent Update: 2-phase
At internal ports: add new rules for new policy with new tag
Then at ingress ports: start tagging packets with new tag
add tag:
forward ac- cording to tag:
Phase 1

2-Phase Update Protocol
79 Stefan Schmid (T-Labs)
ingress port
internal ports
SDN Match-Action
Match header (define flow)
Execute action (e.g., add tag or forward to port)
Consistent Update: 2-phase
At internal ports: add new rules for new policy with new tag
Then at ingress ports: start tagging packets with new tag
add tag:
forward ac- cording to tag:
Phase 2
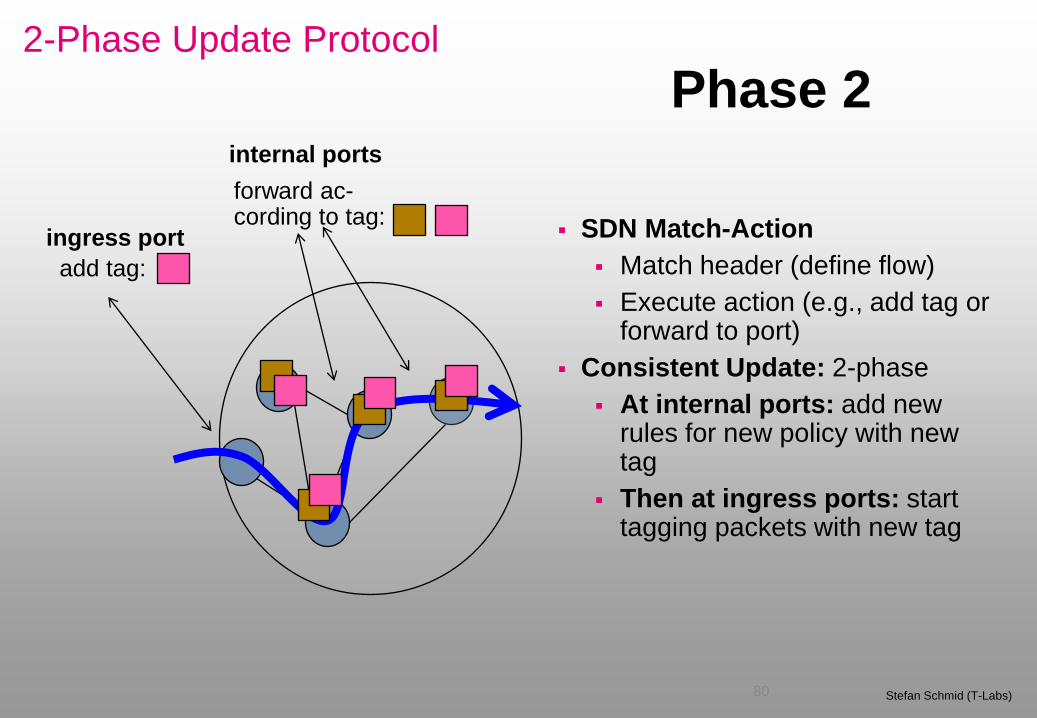
2-Phase Update Protocol
80 Stefan Schmid (T-Labs)
ingress port
internal ports
SDN Match-Action
Match header (define flow)
Execute action (e.g., add tag or forward to port)
Consistent Update: 2-phase
At internal ports: add new rules for new policy with new tag
Then at ingress ports: start tagging packets with new tag
add tag:
forward ac- cording to tag:
Phase 2

Abstractions for Consistent Network Update
Goals
Per-packet consistency: per packet only one policy applied (during journey through network)
Per-flow consistency: all packets of a given flow see only one policy
Definition
Policy: Here, path to be traversed by packet (of certain header)
Number of tags?
One per policy update.
Do I need FIFO?
Homework.

Abstractions for Consistent Network Update
Goals
Per-packet consistency: per packet only one policy applied (during journey through network)
Per-flow consistency: all packets of a given flow see only one policy
Definition
Policy: Here, path to be traversed by packet (of certain header)
How to do it per-flow?
Preinstall new policy at lower priority, but keep tagging packets of old flows. Idea: let old microflows expire (via timeout). But need to identify active flows, and do not want too many rules for each individual flow. Alternative: end-host feedback…
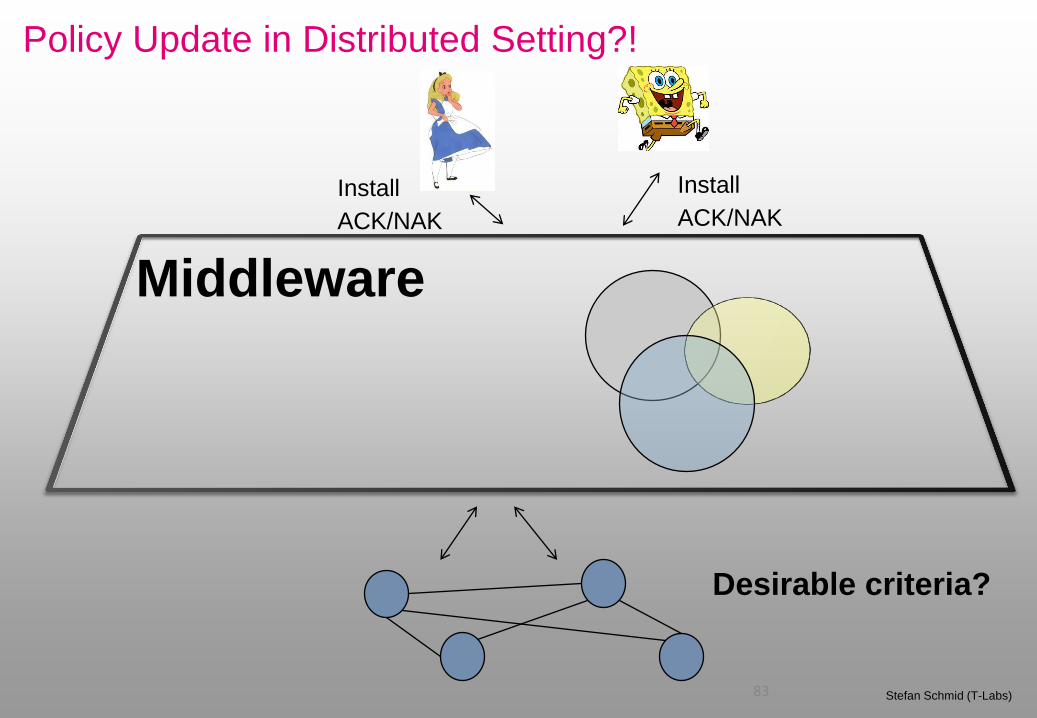
Policy Update in Distributed Setting?!
83 Stefan Schmid (T-Labs)
Middleware
Install
ACK/NAK
Install
ACK/NAK
Desirable criteria?

What about failures?
84 Stefan Schmid (T-Labs)
Middleware
Install
ACK/NAK
Install
ACK/NAK
may even fail…
Desirable criteria?

Policy Update: Goals
85 Stefan Schmid (T-Labs)
Goals
All-or-nothing: policy fully installed or not at all
Conflict-free: never two conflicting policies
Progress: non-conflicting policy eventually installed; and: at least one conflicting policy
Per-packet consistency: per packet only one policy applied (during journey through network)
… despite failures!
Definition
Policy: Here, path to be traversed by packet (of certain header)
Definition
How to realize?

Policy Update: Goals
86
Goals
All-or-nothing: policy fully installed or not at all
Conflict-free: never two conflicting policies
Progress: non-conflicting policy eventually installed; and: at least one conflicting policy
Per-packet consistency: per packet only one policy applied (during journey through network)
… despite failures!
Definition
Policy: Here, path to be traversed by packet (of certain header)
Definition
How to realize? Need to (1) compose, (2) install,
(3) make fault-tolerant! How?

Policy Update: Goals
87
Goals
All-or-nothing: policy fully installed or not at all
Conflict-free: never two conflicting policies
Progress: non-conflicting policy eventually installed; and: at least one conflicting policy
Per-packet consistency: per packet only one policy applied (during journey through network)
… despite failures!
Definition
Policy: Here, path to be traversed by packet (of certain header)
Definition
How to realize? Need to (1) compose, (2) install,
(3) make fault-tolerant! How?

Install and Compose!
Stefan Schmid (T-Labs)
compose and install concurrent policies,
with redundancy/”helping”
Middleware
Install
ACK/NAK
Install
ACK/NAK

compose and install concurrent policies,
with redundancy/”helping”
Install and Compose!
Stefan Schmid (T-Labs)
Middleware
Install
ACK/NAK
Install
ACK/NAK

Building Blocks: Installation and Composition
90 Stefan Schmid (T-Labs)
Centralized installation:
2-phase consistent policy installation protocol
Designed with centralized controller in mind
Policy Composition Language:
Frenetic/Pyrethic: policy composition
Parallel composition “|” enough

Remark: Composition Semantics External
Stefan Schmid (T-Labs)
Policy: here defined over (header) domain (“flow space”)
Policy priority
Implies rules on switch ports
Conflict = overlapping domains, different treatment
Policy composition = combined policy
Semantics for intersection: do one, none, or both?
Or composition by priorities or most specific?
src=*
dst=10*
to port A
prio=1
src=10*
dst=*
to port B
prio=1
?
Assume: Composition semantics given!

Distributed Systems Issues: What does it require?
92 Stefan Schmid (T-Labs)
vs
Goals
All-or-nothing: policy fully installed or not at all
Conflict-free: never two conflicting policies
Progress: non-conflicting policy eventually installed; and: at least one conflicting policy
Per-packet consistency: per packet only one policy applied (during journey through network)

Distributed Systems Issues: What does it require?
93 Stefan Schmid (T-Labs)
Goals
All-or-nothing: policy fully installed or not at all
Conflict-free: never two conflicting policies
Progress: non-conflicting policy eventually installed; and: at least one conflicting policy
Per-packet consistency: per packet only one policy applied (during journey through network)
= processes need to help each other!
= need to agree on tags and compose!
= no locking!
vs

Distributed Systems Issues: What does it require?
94 Stefan Schmid (T-Labs)
Goals
All-or-nothing: policy fully installed or not at all
Conflict-free: never two conflicting policies
Progress: non-conflicting policy eventually installed; and: at least one conflicting policy
Per-packet consistency: per packet only one policy applied (during journey through network)
= processes need to help each other!
= need to agree on tags and compose!
= no locking!
vs
What else do you always want in distributed systems?

Distributed Systems Issues: What does it require?
95 Stefan Schmid (T-Labs)
Goals
All-or-nothing: policy fully installed or not at all
Conflict-free: never two conflicting policies
Progress: non-conflicting policy eventually installed; and: at least one conflicting policy
Per-packet consistency: per packet only one policy applied (during journey through network)
= processes need to help each other!
= need to agree on tags and compose!
= no locking!
vs
What else do you always want in distributed systems?
Linearizability…
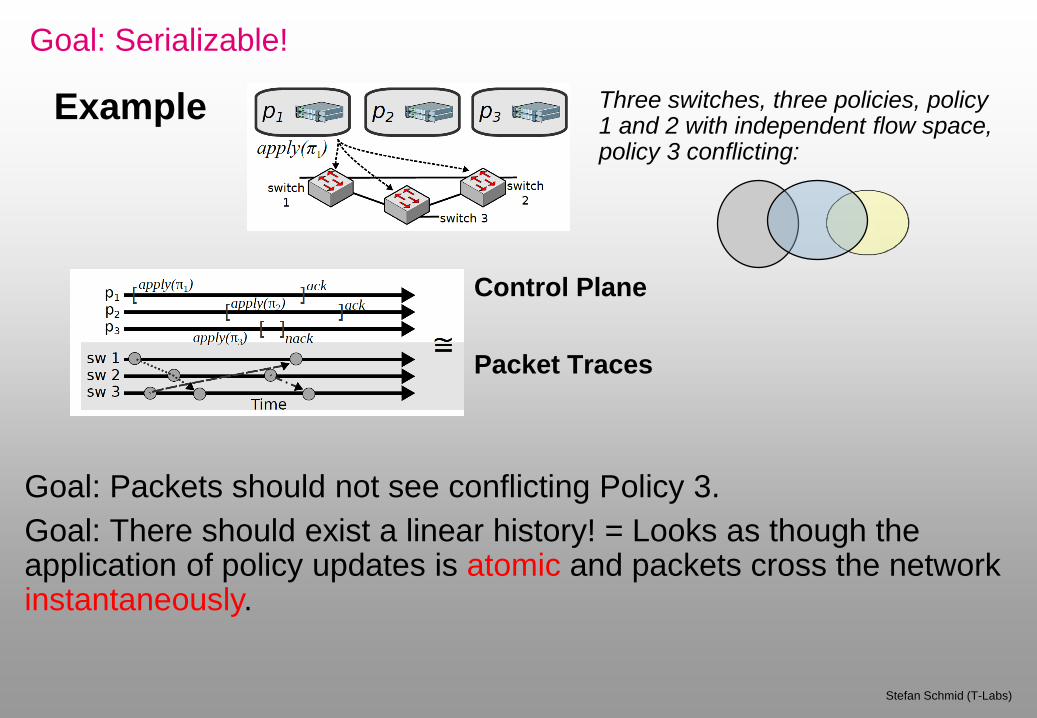
Goal: Serializable!
Stefan Schmid (T-Labs)
Goal: Packets should not see conflicting Policy 3.
Goal: There should exist a linear history! = Looks as though the application of policy updates is atomic and packets cross the network instantaneously.
Control Plane
Packet Traces
Example Three switches, three policies, policy 1 and 2 with independent flow space, policy 3 conflicting:

Goal: Serializable!
Stefan Schmid (T-Labs)
Left: Concurrent history: 3rd policy aborted due to conflict.
Right: In the sequential history, no two requests applied concurrently. No packet is in flight while an update is being installed.
Control Plane
Packet Traces
Example Three switches, three policies, policy 1 and 2 with independent flow space, policy 3 conflicting:
No packet can distinguish the two histories!

Remark: Impossible Without Atomic Read-Modify-Write Ports
Stefan Schmid (T-Labs)
Thm: Without atomic rmw-ports, per-packet consistent network update is impossible if
a controller may crash-fail.
Proof: Consensus not always possible!
QED

Remark: Impossible Without Atomic Read-Modify-Write Ports
Stefan Schmid (T-Labs)
Thm: Without atomic rmw-ports, per-packet consistent network update is impossible if
a controller may crash-fail.
Proof: May install a conflicting policy without noticing!
π1
Single port already!
π1 and π2 are conflicting
Descendant of state σ is extension of execution of σ.
State σ is i-valent if all descendants of σ are processed according to πi. Otherwise it is undecided.
Initial state is undecided, and in undecided state nobody can commit its request and at least one process cannot abort its request.
There must exist a critical undecided state after which it’s univalent if a process not longer proceeds.
Difference cannot be observed: overriding violates consistency (sequential composition).
π2
π0
QED
Solutions?
Stefan Schmid (T-Labs)

The TAG Solution
Stefan Schmid (T-Labs)
Atomic RMW ports: “see before write!”
Naïve solution: pre-install tags for each possible path internally, only need to tag packets at ingress port with path-tag! Can synchronize “globally” at ingress port: not a distributed problem anymore…
If policy involves multiple ingress ports, go through ingress ports in pre-defined order. Copy rules where needed (if process died)
ingress port add tag:
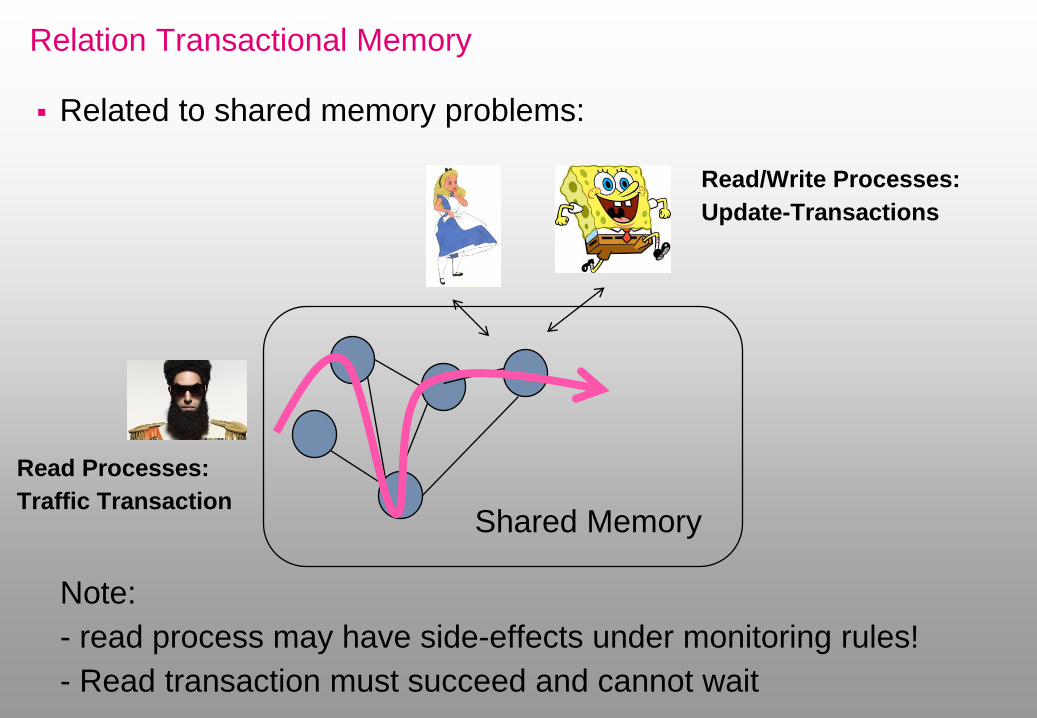
Relation Transactional Memory
Related to shared memory problems:
Shared Memory
Read/Write Processes:
Update-Transactions
Note:
- read process may have side-effects under monitoring rules!
- Read transaction must succeed and cannot wait
Read Processes:
Traffic Transaction

Efficient Solution
Less then n tags? Processes must share: Consensus?!
With n tags: Replicated State Machine, distributed counter to get next tag…

Conclusion
Stefan Schmid (T-Labs)
SDN: How to get it?
Distributed control
Own literature:
Optimizing Long-Lived CloudNets with Migrations Gregor Schaffrath, Stefan Schmid, and Anja Feldmann. 5th IEEE/ACM International Conference on Utility and Cloud Computing (UCC), Chicago, Illinois, USA, November 2012.
Toward Transitional SDN Deployment in Enterprise Networks Dan Levin, Marco Canini, Stefan Schmid, and Anja Feldmann. Open Networking Summit (ONS), Santa Clara, California, USA, April 2013.
Exploiting Locality in Distributed SDN Control Stefan Schmid and Jukka Suomela. ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking (HotSDN), Hong Kong, China, August 2013.
Sofftware Transactional Networking: Concurrent and Consistent Policy Composition Marco Canini, Petr Kuznetsov, Dan Levin, and Stefan Schmid. ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking (HotSDN), Hong Kong, China, August 2013.
Thank you! But wait! Next slide!

Internship in Berlin? We are hiring…!
105 Stefan Schmid (T-Labs)
Also help with open-source
CloudNet prototype welcome

Backup Slides

Policy Composition
107 Stefan Schmid (T-Labs)

The Problem of Policy Composition
Stefan Schmid (T-Labs)
Task 1: fwd traffic based on IPdst
Task 2: monitor traffic based on IPsrc
Existing controller platforms: “northbound API” forces programmers to reason manually about low-level dependencies between different parts of their code
Multiple tasks (e.g., routing, monitoring, …): how to ensure that packet-processing rules installed to perform one task do not override the functionality of another? Monolithic applications…
Want to do both for traffic matched by the two tasks!
Solution: modularity! Programmer constructs complex application out of multiple modules that each partially specify the handling of the traffic.
Modules that need to process the same traffic could run in parallel or in series.
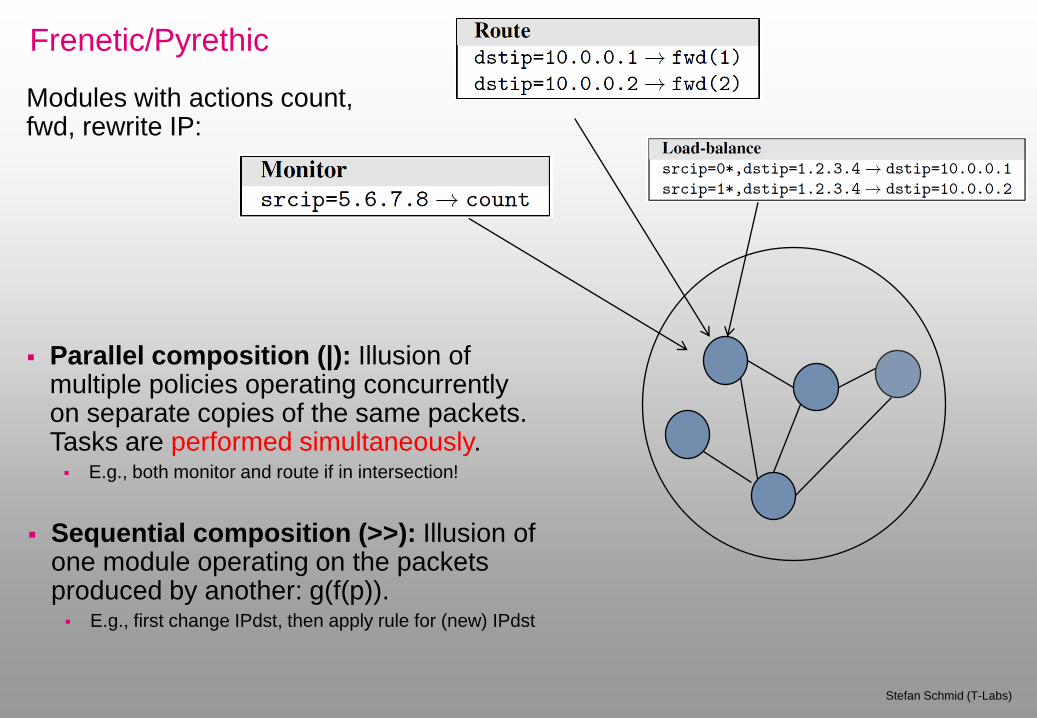
Frenetic/Pyrethic
Stefan Schmid (T-Labs)
Modules with actions count, fwd, rewrite IP:
Parallel composition (|): Illusion of multiple policies operating concurrently on separate copies of the same packets. Tasks are performed simultaneously. E.g., both monitor and route if in intersection!
Sequential composition (>>): Illusion of one module operating on the packets produced by another: g(f(p)). E.g., first change IPdst, then apply rule for (new) IPdst

Frenetic/Pyrethic
Stefan Schmid (T-Labs)
Modules with actions count, fwd, rewrite IP:
Parallel composition: Monitor and Route
Automatically composed (ordered wrt priorities):

Frenetic/Pyrethic
Stefan Schmid (T-Labs)
Modules with actions count, fwd, rewrite IP:
Sequential composition: Balance and Route
Automatically composed (ordered wrt priorities):

Topology Abstraction with Network Objects
Stefan Schmid (T-Labs)
Network Object consists of an abstract topology and a policy function applied to the abstract topology.
For example, the abstract topology could be a subgraph of the real topology, one big virtual switch, or anything in between.
May consist of a mix of physical and virtual switches, and even be nested!
Example: MAC learning switch
Modular programming requires way to constrain what each module can see (information hiding) and do (protection)
Network Objects (NO): Give familiar abstraction of a network topology to each module.

Distributed Control
113 Stefan Schmid (T-Labs)

1st Dimension of Distribution: Flat SDN Control (“Divide Network”)
114 Stefan Schmid (T-Labs)
fully central fully local SPECTRUM
e.g., small network e.g., routing control platform
e.g., SDN router (FIBIUM)

2nd Dimension of Distribution: Hierarchical SDN Control (“Flow Space”)
115 Stefan Schmid (T-Labs)
e.g., handle frequent events close to data path, shield global controllers (Kandoo)
local
glo
bal
SP
EC
TR
UM
e.g., r
outin
g, spa
nning
tree
e.g., l
ocal p
olicy
enfor
cer,
eleph
ant fl
ow de
tectio
n

Questions Raised
116 Stefan Schmid (T-Labs)
How to control a network if I have “local view” only?
How to design distributed control plane (if I can), and how to divide it among controllers?
Where to place controllers? (see Brandon!) Which tasks can be solved locally, which tasks need global control? …

Generic SDN Tasks: Load-Balancing and Ensuring Loop-free Paths
Stefan Schmid (T-Labs)
SDN for TE and Load-Balancing: Re-Route Flows
Compute and Ensure Loop-Free Forwarding Set
OK
not OK
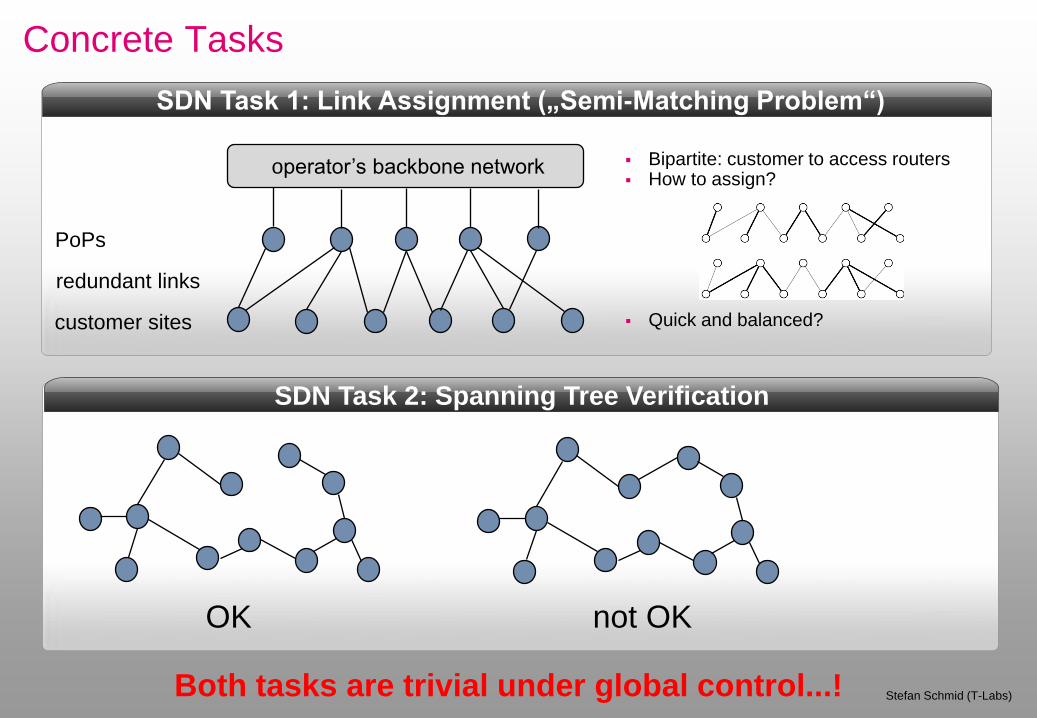
Concrete Tasks
Stefan Schmid (T-Labs)
SDN Task 1: Link Assignment („Semi-Matching Problem“)
SDN Task 2: Spanning Tree Verification
operator’s backbone network
redundant links
OK
not OK
PoPs
customer sites
Bipartite: customer to access routers How to assign?
Quick and balanced?
Both tasks are trivial under global control...!

… but not for distributed control plane!
119 Stefan Schmid (T-Labs)
Hierarchical control:
Flat control:
root controller
local controller
local controller

Local vs Global: Minimize Interactions Between Controllers
120 Stefan Schmid (T-Labs)
Global task: inherently need to
respond to events occurring at
all devices.
u
u
Local task: sufficient to respond to events occurring in vicinity!
Objective: minimize interactions (number of involved controllers and communication)
Useful abstraction and terminology: The “controllers graph”

Take-home 1: Go for Local Approximations!
121 Stefan Schmid (T-Labs)
backbone
V
A semi-matching problem: Semi-matching
If a customer u connects to a POP with c clients connected to it, the customer u costs c.
Minimize the average cost of customers!
The bad news: Generally the problem is inherently global e.g.,
The good news: Near-optimal semi-matchings can be found efficiently and locally! Runtime independent of graph size and local communication only. (How? Paper! )
U
= 6 = 5 ??
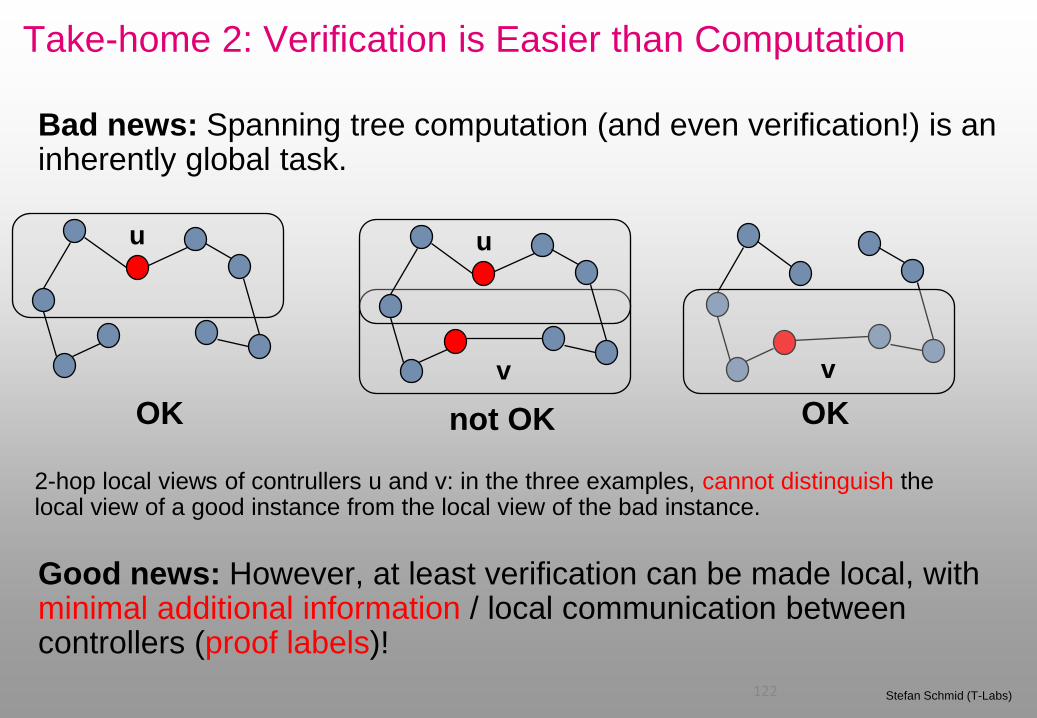
Take-home 2: Verification is Easier than Computation
122 Stefan Schmid (T-Labs)
Bad news: Spanning tree computation (and even verification!) is an inherently global task.
u
OK
u
not OK
v
OK
2-hop local views of contrullers u and v: in the three examples, cannot distinguish the local view of a good instance from the local view of the bad instance.
Good news: However, at least verification can be made local, with minimal additional information / local communication between controllers (proof labels)!
v

f( ) = No
Proof Labeling Schemes
123 Stefan Schmid (T-Labs)
Idea: For verification, it is often sufficient if at least one controller notices local inconsistency: it can then trigger global re-computation!
Requirements:
Controllers exchange minimal amount of information (“proofs labels”)
Proof labels are small (an “SMS”)
Communicate only with controllers with incident domains
Verification: if property not true, at least one controller will notice…
… and raise alarm (re-compute labels)
Yes
Yes
Yes
Yes
Yes
Yes
Yes
Yes
No

Examples
124 Stefan Schmid (T-Labs)
Euler Property: Hard to compute Euler
tour (“each edge exactly once”), but
easy to verify! 0-bits (= no communication) :
output whether degree is even.
(r,1)
r
(r,1)
(r,2)
(r,2)
(r,3)
(r,3)
(r,4)
(r,4)
Neighbor with same distance alert!
No
No
Spanning Tree Property: Label encodes root node plus distance & direction to root. At least one node notices that root/distance not consistent! Requires O(log n) bits.
No
Any (Topological) Property: O(n2) bits.
Maybe also known from databases: efficient ancestor query! Given two log(n) labels.

Take-home 3: Not Purely Local, Pre-Processing Can Help!
125
Example: Local Matchings
(M1) Maximal matching (only because of symm!)
(M2) Maximal matching on bicolored graph
(M3) Maximum matching (symm+opt!)
(M4) Maximum matching on bicolored graph
(M5) Fractional maximum matching
Optimization:
(M1, M2): only need to find feasible solution!
(M1, M2, M3): need to find optimal solution!
Symmetry breaking:
(M1, M3): require symmetry breaking
(M2, M4): symmetry already broken
(M5): symmetry trivial
Idea: If network changes happen at different time scales (e.g., topology vs traffic), pre-processing “(relatively) static state” (e.g., topology) can improve the performance of local algorithms (e.g., no need for symmetry breaking)!
Local problems often face two challenges: optimization and symmetry breaking.
The latter may be overcome by pre-processing.
E.g., (M1) is simpler if graph can be pre-colored! Or Dominating Set (1. distance-2 coloring then 2. greedy [5]) , MaxCut, … The “supported locality model”.
bipartite (like PoP assignment)
packing LP
* impossible, approx ok, easy
Stefan Schmid (T-Labs)

Take-home >3: How to Design Control Plane
126 Stefan Schmid (T-Labs)
Make your controller graph low-degree if you can!
…

Conclusion
127 Stefan Schmid (T-Labs)
Local algorithms provide insights on how to design and operate distributed control plane. Not always literally, requires emulation! (No communication over customer site!)
Take-home message 1: Some tasks like matching are inherently global if they need to be solved optimally. But efficient almost-optimal, local solutions exist.
Take-home message 2: Some tasks like spanning tree computations are inherently global but they can be locally verified efficiently with minimal additional communication!
Take-home message 3: If network changes happen at different time scales, some pre-processing can speed up other tasks as well. A new non-purely local model.
More in paper…
And there are other distributed computing techniques that may be useful for SDN! See e.g., the upcoming talk on “Software Transactional Networking”

Backup: Locality Preserving Simulation
128 Stefan Schmid (T-Labs)
Controllers simulate execution on graph:
local controllers at PoPs
backbone
backbone
Algorithmic view:
distributed computation of the best matching
Reality:
controllers V simulate execution; each node v in V simulates its incident nodes in U
U U
V V
Locality: Controllers only need to communicate with controllers within 2-hop distance in matching graph.

Backup: From Local Algorithms to SDN: Link Assignment
129 Stefan Schmid (T-Labs)
backbone
U
V
A semi-matching problem: Semi-matching
Connect all customers U: exactly one incident edge. If a customer u connects to a POP with c clients connected to it, the customer u costs c (not one: quadratic!).
Minimize the average cost of customers!
The bad news: Generally the problem is inherently global (e.g., a long path that would allow a perfect matching).
The good news: Near-optimal solutions can be found efficiently and locally! E.g., Czygrinow (DISC 2012): runtime independent of graph size and local communication only.
1 1 1 1+2+3=6

Robust Failover
130 Stefan Schmid (T-Labs)

SDN Local Fast Failover
131 Stefan Schmid (T-Labs)
Failures: a disadvantage of OpenFlow?
Indirection via controller (reactive control) an overhead?
Or even full disconnect from controller?
Local fast failover
E.g., since OpenFlow 1.1 (but already MPLS, …)
Failover in data plane: given failed incident links, decide what to do with flow
<header, failed links> <backup port>
React quickly, controller can improve later!
Threat: local failover may introduce loop or be inefficient in other ways (high load)
How not to shoot in your foot?!
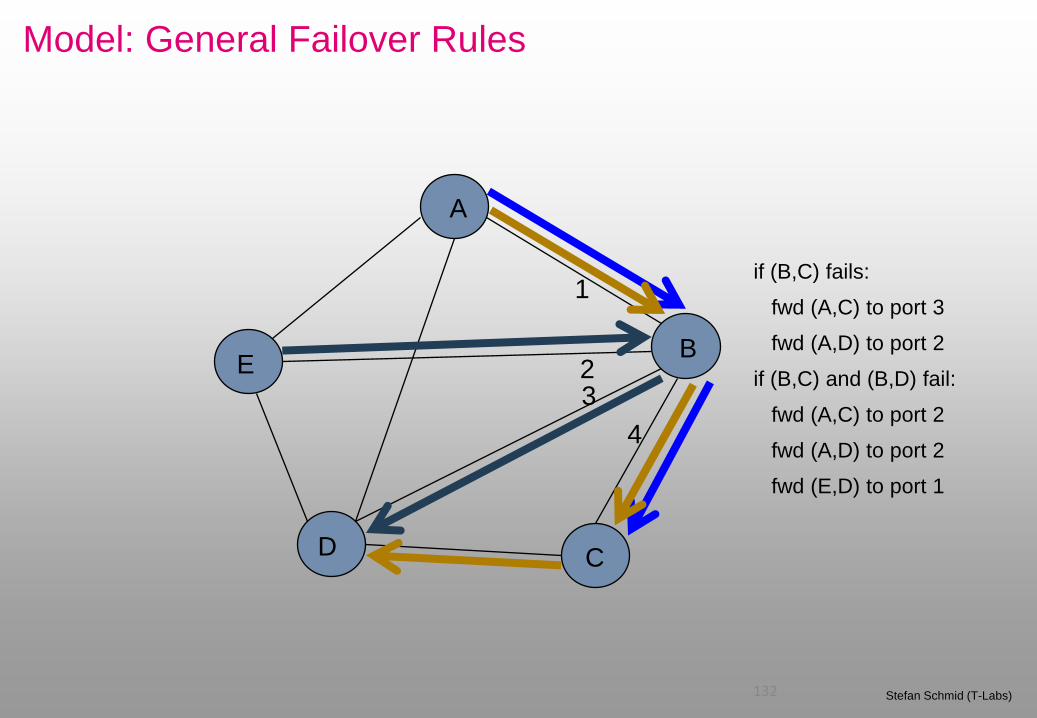
Model: General Failover Rules
132 Stefan Schmid (T-Labs)
A
B
C D
E
if (B,C) fails:
fwd (A,C) to port 3
fwd (A,D) to port 2
if (B,C) and (B,D) fail:
fwd (A,C) to port 2
fwd (A,D) to port 2
fwd (E,D) to port 1
1
2 3
4

Model: General Failover Rules
133 Stefan Schmid (T-Labs)
A
B
C D
E
if (B,C) fails:
fwd (A,C) to port 3
fwd (A,D) to port 2
if (B,C) and (B,D) fail:
fwd (A,C) to port 2
fwd (A,D) to port 2
fwd (E,D) to port 1
1
2 3
4

Model: General Failover Rules
134 Stefan Schmid (T-Labs)
A
B
C D
E
if (B,C) fails:
fwd (A,C) to port 3
fwd (A,D) to port 2
if (B,C) and (B,D) fail:
fwd (A,C) to port 2
fwd (A,D) to port 2
fwd (E,D) to port 1
1
2 3
4
Flows can be treated individually!

Model: General Failover Rules
135 Stefan Schmid (T-Labs)
A
B
C D
E
if (B,C) fails:
fwd (A,C) to port 3
fwd (A,D) to port 2
if (B,C) and (B,D) fail:
fwd (A,C) to port 2
fwd (A,D) to port 2
fwd (E,D) to port 1
1
2 3
4

Model: General Failover Rules
136 Stefan Schmid (T-Labs)
A
B
C D
E
if (B,C) fails:
fwd (A,C) to port 3
fwd (A,D) to port 2
if (B,C) and (B,D) fail:
fwd (A,C) to port 2
fwd (A,D) to port 2
fwd (E,D) to port 1
1
2 3
4
Depending on failure set, (A,C) is forwarded differently!
Model: Destination-Based Failover Rules
137 Stefan Schmid (T-Labs)
A
B
C D
E
if (B,C) fails:
fwd (A,C) to port 3
fwd (A,D) to port 2
if (B,C) and (B,D) fail:
fwd (A,C) to port 2
fwd (A,D) to port x
fwd (E,D) to port x
1
2 3
4

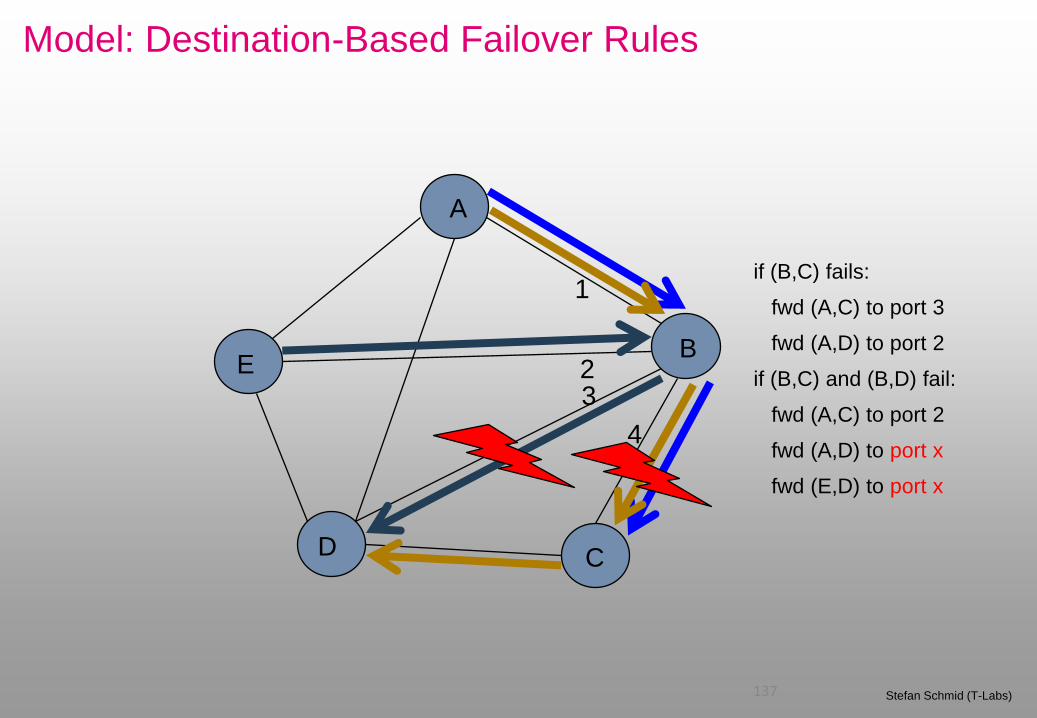
Model: Destination-Based Failover Rules
138 Stefan Schmid (T-Labs)
A
B
C D
E
if (B,C) fails:
fwd (A,C) to port 3
fwd (A,D) to port 2
if (B,C) and (B,D) fail:
fwd (A,C) to port 2
fwd (A,D) to port x
fwd (E,D) to port x
1
2 3
4
Same destination requires same forwarding port.

Negative Result: You must shoot in your foot!
139 Stefan Schmid (T-Labs)
A simple example: full mesh (“clique”) & all-to-one communication

Negative Result: You must shoot in your foot!
140 Stefan Schmid (T-Labs)
A
B
C D
E
A simple example: full mesh (“clique”) & all-to-one communication

Negative Result: You must shoot in your foot!
141 Stefan Schmid (T-Labs)
A simple example: full mesh (“clique”) & all-to-one communication

Negative Result: You must shoot in your foot!
142 Stefan Schmid (T-Labs)
A simple example: full mesh (“clique”) & all-to-one communication
if «Event» then try other port (set of failures, per flow, ...)

Negative Result: You must shoot in your foot!
143 Stefan Schmid (T-Labs)
A simple example: full mesh (“clique”) & all-to-one communication
if «Event» then try other port (set of failures, per flow, ...)

Negative Result: You must shoot in your foot!
144 Stefan Schmid (T-Labs)
A simple example: full mesh (“clique”) & all-to-one communication
if «Event» then try other port (set of failures, per flow, ...)

Negative Result: You must shoot in your foot!
145 Stefan Schmid (T-Labs)
A simple example: full mesh (“clique”) & all-to-one communication
Loop!

Negative Result: You must shoot in your foot!
146 Stefan Schmid (T-Labs)
A simple example: full mesh (“clique”) & all-to-one communication
Loop!
Unnecessary: Many paths left!
But do not know remote state...

Negative Result: You must shoot in your foot!
147 Stefan Schmid (T-Labs)
How bad can it get?
Thm: Can tolerate at most n-1 link failures, even if graph still n/2-connected.
Proof Idea?

Negative Result: You must shoot in your foot!
148 Stefan Schmid (T-Labs)
Fail any link which would directly lead to destination node v
Until n/2-1 links failed
Fail also links from x to n-n/2 other nodes
x only has links to already visited nodes left: loop unavoidable!
But all nodes still have degree at least n/2-1 (node x has lowest)
n/2-1 failures
v
u
x
n-n/2 failures
Thm: Can tolerate at most n-1 link failures, even if graph still n/2-connected.
How bad can it get?

Negative Result: You must shoot in your foot!
149 Stefan Schmid (T-Labs)
Another consequence: high load!
Thm: Any failover scheme tolerating Φ failures (0<Φ<n) without disconnecting src-
dst pairs, can yield a link load λ ≥ √Φ,
although mincut is still at least n-Φ-1.
If rules failover destination-based only, the load is much higher.
Thm: Any destination-based failover scheme yields a link load λ ≥ Φ,
although mincut is still at least n-Φ-1.

Negative Result: You must shoot in your foot!
150 Stefan Schmid (T-Labs)
Proof Idea.
Consider what happens on failover
For any failures, there will be failover paths of the form:
First generated when vi-vn fails, second if vi(1)-vn fails, etc.
vi(j) for j Є [1,Φ] must be unique otherwise we have a loop!
Consider the failover sets Ai = {vi, vi(j) , …, vi
(√ Φ) }
For all sources, we have n* (√ Φ +1) elements∪ Ai .
Counting argument: there is a x that appears in √ Φ sets Ai
For each such Ai , the adversary can route vi via x. Link (x,v) has load at least √ Φ
This can be achieved by failing links to vn in each such set Ai.
Thus, the adversary fails at most √ Φ links in each Ai, so √ Φ * √ Φ in total.
Clique stays highly connected: mincut reduced by one per failure.

Negative Result: You must shoot in your foot!
151 Stefan Schmid (T-Labs)
Why worse for destination-based? Intuition:
B
C
A
At B, flow (A,C) gets combined with flow (B,C) and never splits again. Etc.!

Positive Result: Make the best out of the situation!
152 Stefan Schmid (T-Labs)
A general failover scheme:
Matrix dij: if node vi cannot reach destination directly, try node di1; if not reachable either, try node di2, ...
Choosing random permutations:
Thm: RAND tolerates Φ/log(n) failures (0<Φ<n) with load λ ≤ √Φ.

Positive Result: Make the best out of the situation!
153 Stefan Schmid (T-Labs)
Can also be achieved deterministically, as long as number of failures bounded by log n:
Thm: DET tolerates Φ failures (0<Φ<n) with load λ ≤ √Φ if Φ < log n.

Simulations
154 Stefan Schmid (T-Labs)
Better in reality (i.e., under random failures):
Only small fraction of links highly loaded:

Discussion and Extensions
155 Stefan Schmid (T-Labs)
Thm: Under random failures, at least Ω(Φ) links need to be failed to creat a λ ≥ √Φ for RAND.
Thm: For all-to-all communication, θ(Φ) links need to be failed to create a load λ ≥ Φ. (All-
to-all only as bad as destination-based!)

Churn-Aware FIB Aggregation
156 Stefan Schmid (T-Labs)
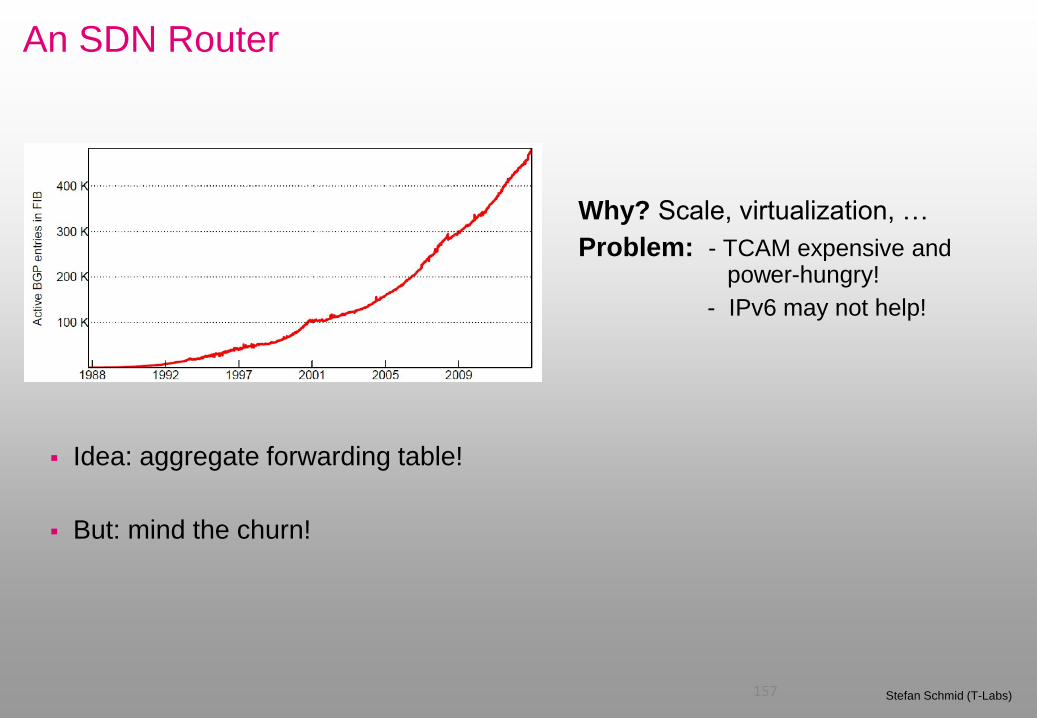
An SDN Router
157 Stefan Schmid (T-Labs)
Idea: aggregate forwarding table!
But: mind the churn!
Why? Scale, virtualization, …
Problem: - TCAM expensive and power-hungry!
- IPv6 may not help!

Local FIB Compression: 1-Page Overview
158 Stefan Schmid (T-Labs)
Model FIB: Forwarding Information Base
FIB consists of
set of <prefix, next-hop>
IP only: most specific IP prefix
Control: (1) RIB or (2) SDN Controller (s. picture)
Routers or SDN Switches:
RIB or SDN Controller
Basic Idea Dynamically aggregate FIB
“Adjacent” prefixes with same next-hop (= color): one rule only!
But be aware that BGP updates (next-hop change, insert, delete) may change forwarding set, need to de-aggregate again
Benefits Only single router affected
Aggregation = simple software update

Local FIB Compression: 1-Page Overview
159 Stefan Schmid (T-Labs)
Model FIB: Forwarding Information Base
FIB consists of
set of <prefix, next-hop>
IP only: most specific IP prefix
Control: (1) RIB or (2) SDN Controller (s. picture)
Routers or SDN Switches:
RIB or SDN Controller
Basic Idea Dynamically aggregate FIB
“Adjacent” prefixes with same next-hop (= color): one rule only!
But be aware that BGP updates (next-hop change, insert, delete) may change forwarding set, need to de-aggregate again
Benefits Only single router affected
Aggregation = simple software update
Memory!
Update!

Setting: A Memory-Efficient Switch/Router
160 Stefan Schmid (T-Labs)
Route processor
(RIB or SDN controller)
FIB (e.g., TCAM on SDN switch)
BGP updates
updates 0
0 1
1 0 1
full list of forwarded prefixes: (prefix, port)
compressed list
Goal: keep FIB small but consistent!
Without sending too many additional updates.
tra
ffic

Setting: A Memory-Efficient Switch/Router
161 Stefan Schmid (T-Labs)
Route processor
(RIB or SDN controller)
FIB (e.g., TCAM on SDN switch)
BGP updates
updates 0
0 1
1 0 1
full list of forwarded prefixes: (prefix, port)
compressed list
Goal: keep FIB small but consistent!
Without sending too many additional updates.
tra
ffic
Expensive! Memory
constraints?

Setting: A Memory-Efficient Switch/Router
162 Stefan Schmid (T-Labs)
Route processor
(RIB or SDN controller)
FIB (e.g., TCAM on SDN switch)
BGP updates
updates 0
0 1
1 0 1
full list of forwarded prefixes: (prefix, port)
compressed list
Goal: keep FIB small but consistent!
Without sending too many additional updates.
tra
ffic
Update Churn?
Data structure,
networking, …

Motivation: FIB Compression and Update Churn
163 Stefan Schmid (T-Labs)
Benefits of FIB aggregation Routeview snapshots indicate 40%
memory gains
More than under uniform distribution
But depends on number of next hops
Churn Thousands of routing updates per second
Goal: do not increase more

Model: Online Perspective
164 Stefan Schmid (T-Labs)
Online algorithms make decisions at time t without any knowledge of inputs at times t’>t.
Online Algorithm
Competitive analysis framework:
An r-competitive online algorithm ALG gives a worst-case performance guarantee: the performance is at most a factor r worse than an optimal offline algorithm OPT!
Competitive Analysis
Competitive ratio r, r = Cost(ALG) / cost(OPT) The price of not knowing the future!
Competitive Ratio
No need for complex predictions but still good!

Model: Online Input Sequence
165 Stefan Schmid (T-Labs)
Route processor
(RIB or SDN controller)
BGP updates 0
0 1
1
full list of forwarded prefixes: (prefix, port)
Update: Color change
0
0 1
1 0
0 1
1
Update: Insert/Delete
0
0 1
1 0
1
1

Model: Costs
166 Stefan Schmid (T-Labs)
Route processor
(RIB or SDN controller)
FIB (e.g., TCAM on SDN switch)
BGP updates
updates 0
0 1
1 0 1
full list of forwarded prefixes: (prefix, port)
compressed list
tra
ffic
online and worst-case
arrival consistent at any time!
(rule: most specific)
Cost = α (# updates to FIB) + ∫ memory t
Ports = Next-Hops = Colors
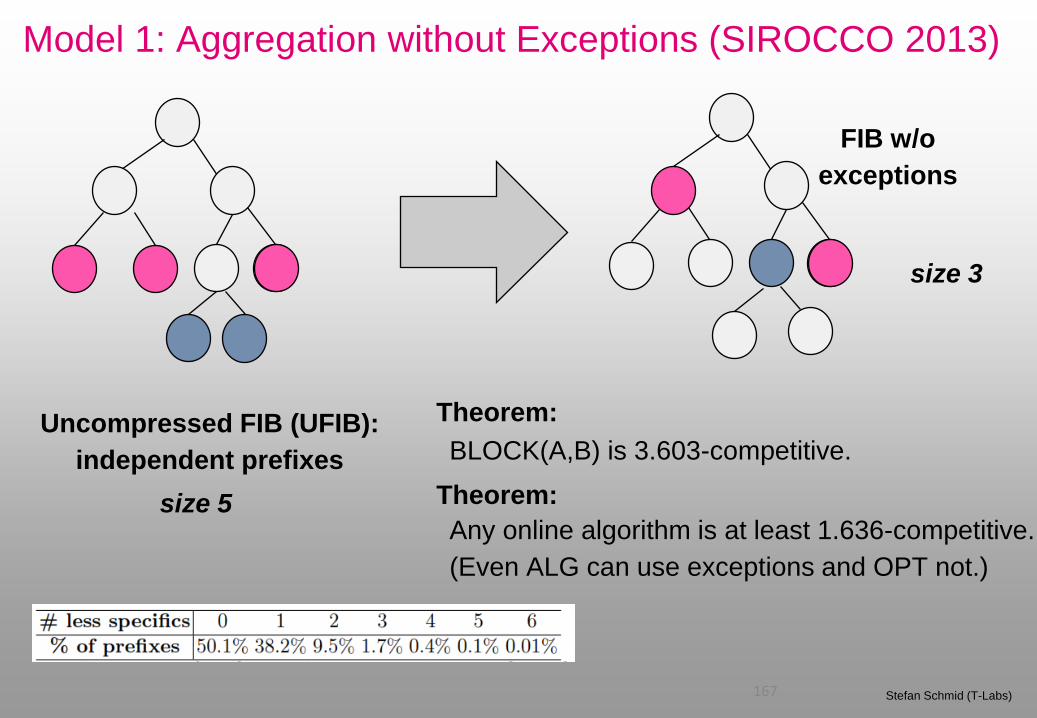
Model 1: Aggregation without Exceptions (SIROCCO 2013)
167 Stefan Schmid (T-Labs)
Uncompressed FIB (UFIB):
independent prefixes
size 5
size 3
FIB w/o
exceptions
Theorem:
BLOCK(A,B) is 3.603-competitive.
Theorem:
Any online algorithm is at least 1.636-competitive.
(Even ALG can use exceptions and OPT not.)

Model 1: Aggregation without Exceptions (SIROCCO 2013)
168 Stefan Schmid (T-Labs)
BLOCK(A,B) operates on trie:
Two parameters A and B for amortization (A ≥ B)
Definition: internal node v is c-mergeable if subtree T(v) only constains color c leaves
Trie node v monitors: how long was subtree T(v) c-mergeable without interruption? Counter C(v).
If C(v) ≥ A α, then aggregate entire tree T(u) where u is furthest ancestor of v with C(u) ≥ B α. (Maybe
v is u.)
Split lazily: only when forced.
Nodes with square inside: mergeable. Nodes with bold border: suppressed for FIB1.

Model 1: Aggregation without Exceptions (SIROCCO 2013)
169 Stefan Schmid (T-Labs)
BLOCK(A,B) operates on trie:
Two parameters A and B for amortization (A ≥ B)
Definition: internal node v is c-mergeable if subtree T(v) only constains color c leaves
Trie node v monitors: how long was subtree T(v) c-mergeable without interruption? Counter C(v).
If C(v) ≥ A α, then aggregate entire tree T(u) where u is furthest ancestor of v with C(u) ≥ B α. (Maybe
v is u.)
Split lazily: only when forced.
Nodes with square inside: mergeable. Nodes with bold border: suppressed for FIB1.
BLOCK:
(1) balances memory and update costs
(2) exploits possibility to merge multiple tree nodes simultaneously at lower price (threshold A and B)

Analysis
170 Stefan Schmid (T-Labs)
Theorem:
Proof idea (a bit technical):
Time events when ALG merges k nodes of T(u) at u
Upper bound ALG cost:
k+1 counters between B α and A α
Merging cost at most (k+3) α: remove k+2 leaves, insert one root
Splitting cost at most (k+1) 3α: in worst case, remove-insert-remove individually
Lower bound OPT cost:
Time period from t- α to t
If OPT does not merge anything in T(u) or higher: high memory costs
If OPT merges ancestor of u: counter there must be smaller than B α, memory and update costs
If OPT merges subtree of T(u): update cost and memory cost for in- and out-subtree
Optimal choice: A = √13 - 1 , B = (2√13)/3 – 2/3
Add event costs (inserts/deletes) later!
BLOCK(A,B) is 3.603-competitive.
QED
u
T(u):

Lower Bound
171 Stefan Schmid (T-Labs)
Theorem:
Proof idea:
Simple example:
Any online algorithm is at least 1.636-competitive.
00 1
01 1 1 00
1 01 0
Adversary Adversary
00 01
Ɛ ALG
do nothing!
(1) If ALG does never changes to single entry, competitive ratio is at least 2 (size 2 vs 1).
(2) If ALG changes before time α, adversary immediately forces split back! Yields costly inserts...
(3) If ALG changes after time α, the adversary resets color as soon as ALG for the first time has a
single node. Waiting costs too high.

Note on Adding Insertions and Deletions
172 Stefan Schmid (T-Labs)
Algorithm can be extended to insertions/deletions
Insert:
u u u becomes mergeable!
Delete:
u u u no longer mergeable!

Model 2: Aggregation with Exceptions (DISC 2013)
173 Stefan Schmid (T-Labs)
Uncompressed FIB (UFIB):
dependent prefixes
size 4
size 2
FIB w/
exceptions
Theorem:
HIMS is O(w)-competitive, w = address length.
Theorem:
Asymptotically optimal for general class of online algorithms.
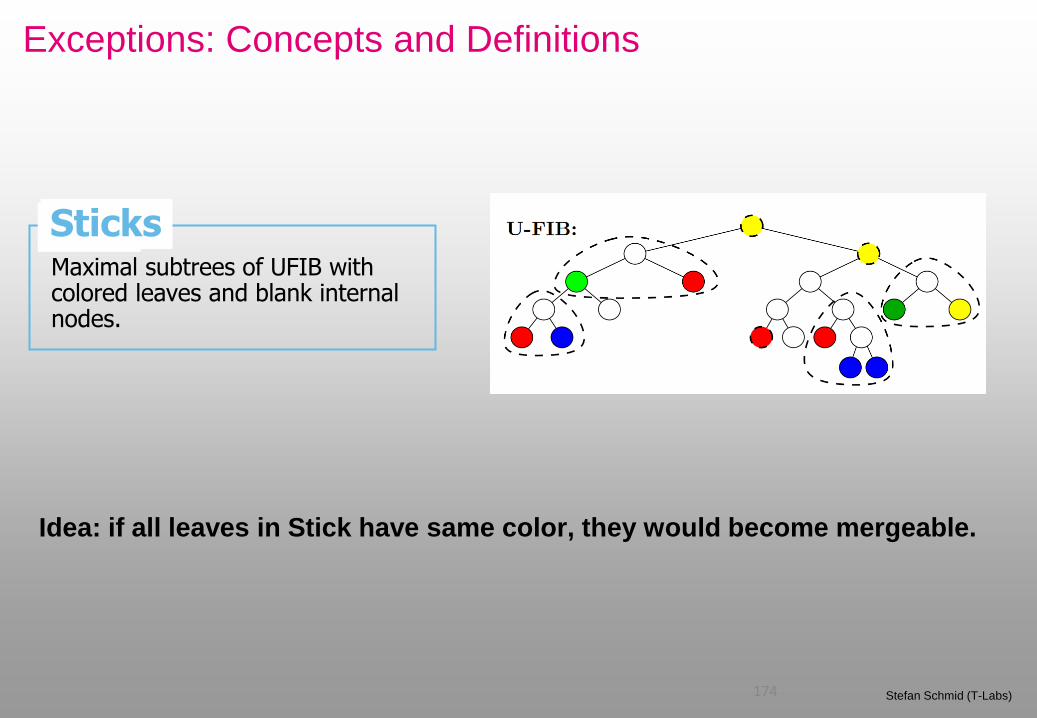
Exceptions: Concepts and Definitions
174 Stefan Schmid (T-Labs)
Maximal subtrees of UFIB with colored leaves and blank internal nodes.
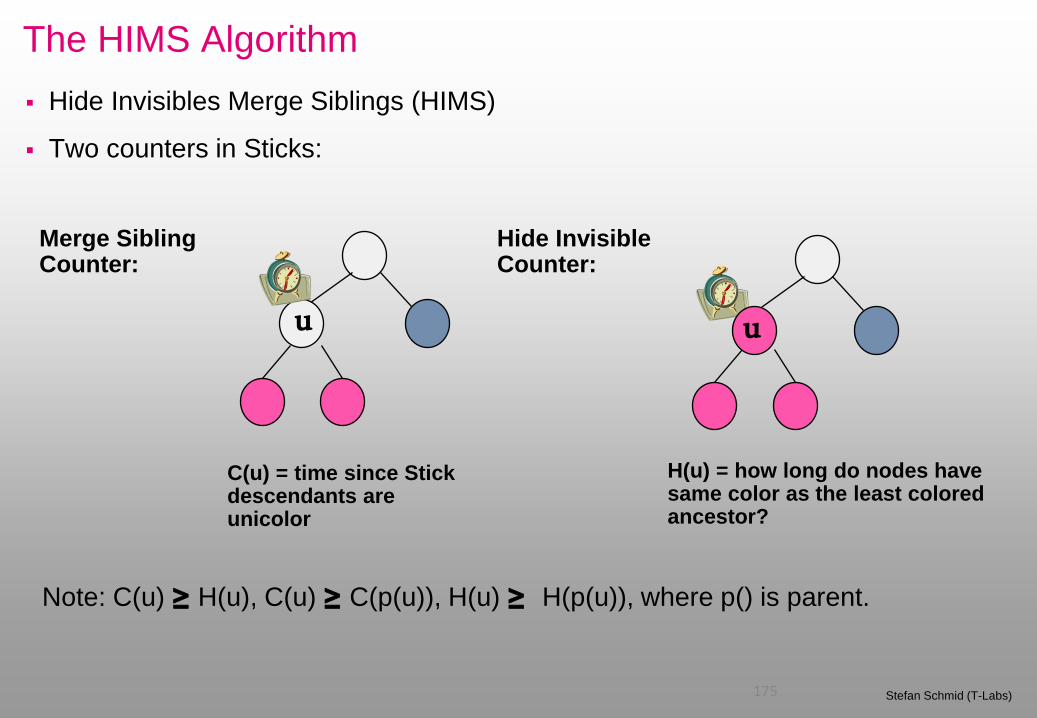
Sticks
Idea: if all leaves in Stick have same color, they would become mergeable.
The HIMS Algorithm
175 Stefan Schmid (T-Labs)
Hide Invisibles Merge Siblings (HIMS)
u
Two counters in Sticks:
u
C(u) = time since Stick descendants are unicolor
H(u) = how long do nodes have same color as the least colored ancestor?
Hide Invisible Counter:
Merge Sibling Counter:
Note: C(u) ≥ H(u), C(u) ≥ C(p(u)), H(u) ≥ H(p(u)), where p() is parent.
u
The HIMS Algorithm
176 Stefan Schmid (T-Labs)
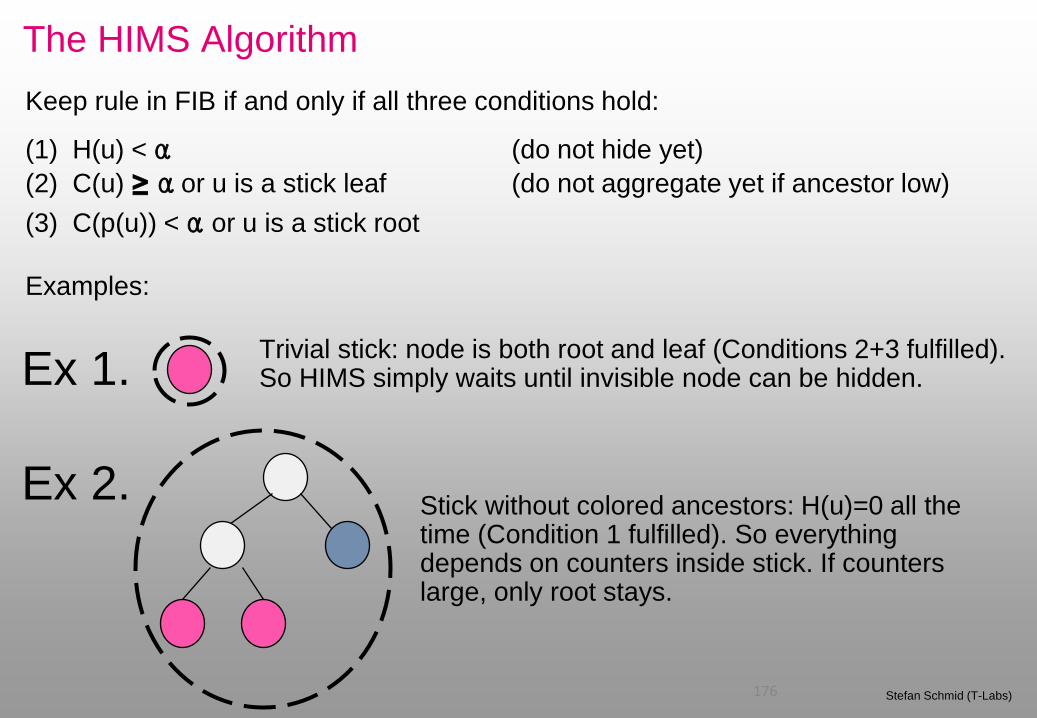
Keep rule in FIB if and only if all three conditions hold:
(1) H(u) < α (do not hide yet)
(2) C(u) ≥ α or u is a stick leaf (do not aggregate yet if ancestor low)
(3) C(p(u)) < α or u is a stick root
Examples:
Trivial stick: node is both root and leaf (Conditions 2+3 fulfilled). So HIMS simply waits until invisible node can be hidden. Ex 1.
Ex 2. Stick without colored ancestors: H(u)=0 all the time (Condition 1 fulfilled). So everything depends on counters inside stick. If counters large, only root stays.

Analysis
177 Stefan Schmid (T-Labs)
Theorem:
HIMS is O(w) -competitive.
Proof idea:
In the absence of further BGP updates
(1) HIMS does not introduce any changes after time α
(2) After time α, the memory cost is at most an factor O(w) off
In general: for any snapshot at time t, either HIMS already started aggregating or changes are quite new
Concept of rainbow points and line coloring useful
A rainbow point is a “witness” for a FIB rule
Many different rainbow points over time give lower bound
addresses
rainbow point rainbow point
0 2w-1

Lower Bound
178 Stefan Schmid (T-Labs)
Theorem:
Any (online or offline) Stick-based algo is Ω(w) -competitive.
Proof idea:
Stick-based: (1) never keep a node outside a stick
(2) inside a stick, for any pair u,v in ancestor- descendant relation, only keep one
Consider single stick: prefixes representing lengths 2w-1, 2w-2, ..., 21, 20, 20
Cannot aggregate stick!
But OPT could do that:
QED

LFA: A Simplified Implementation
179 Stefan Schmid (T-Labs)
LFA: Locality-aware FIB aggregation
Combines stick aggregation with offline optimal ORTC
Parameter α: depth where aggregation starts
Parameter β: time until aggregation
LFA Simulation Results
180 Stefan Schmid (T-Labs)
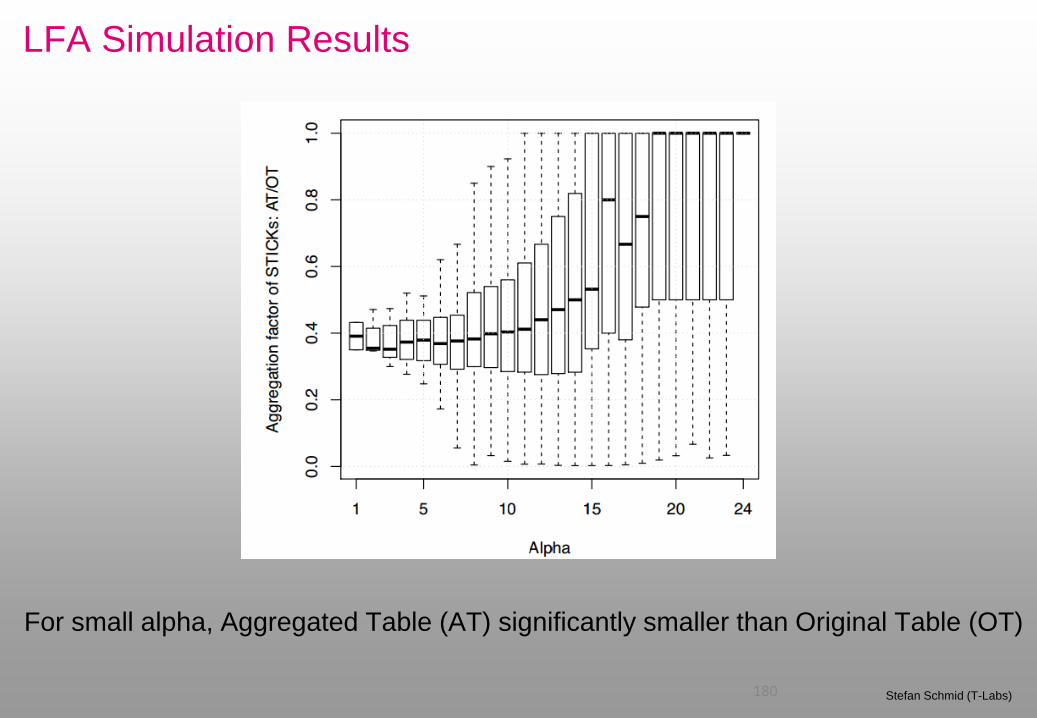
For small alpha, Aggregated Table (AT) significantly smaller than Original Table (OT)