solving big data problems
TRANSCRIPT

PRESENTATION TITLE GOES HERE
Solving Big Data Problems: Storage to the Rescue?
John Webster
Evaluator Group

22015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
Agenda
Big Data Analytics Storage Maxims
The Fundamental JBOD and DAS Architecture
Overview of Disk-based Alternatives
What are the Advantages and Disadvantages?
The Solid State and In-memory Alternatives
Summary and Q&A
Note: References to specific vendors and products are used as real-world examples and do not imply an endorsement
04/15/23 2

32015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
Big Data Storage Maxim #1
Deliver storage performance at large scale and at low cost, and all at the same time(Think early stage Google, Facebook, Twitter)
04/15/23 3

42015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
Big Data Storage Maxim #2
Minimize the “distance” between processing and data storage
04/15/23 4

52015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
Big Data Storage Maxim #3
Big Data analytics is dominated by open source
04/15/23 5

62015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
Big Data Storage Maxim #4
Big Data analytics software developers manage data at the clustered server level. Storage vendors
manage data at the storage system level.
04/15/23 6

72015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
Shared Nothing, Asymmetrical Distributed Computing
NODE 1
NODE 2
NODE 3
NODE n
DAS DAS DAS DAS
1 2 3 4 5 6 7 8
B8
GM
R3 Link
Active
Link
Active
Link
Active
ConsolePwr
Active
Link
Active
CONTROL
DAS
Network Layer
1 Gb Ethernet
Compute Layer
Commodity Servers
Storage Layer
6-12 disks in each server
typically JBOD
Scale to thousands
of nodes
Only the Ethernet network is shared
In Hadoop, Control = Name Node; Node 1,2… = Data Node

82015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
Apache Hadoop: A Platform for All Applications?
Presentation & ApplicationEnable both existing and new applications to provide
value to the organization
OperationsEmpower existing operations and security tools to manage Hadoop
Metadata ManagementHCatalog
Batch Online Real-Time
In-Memory
OthersSQLScript
Map Reduce Pig Hive
HbaseAccumulo Storm Spark
Multitenant Processing: YARN(Hadoop Operating System)
Storage: HDFS(Hadoop Distributed File System)
DataAccess
DataManagement
Data Integration & Governance
Data WorkflowData Lifecycle
Falcon
Real-time and Batch Ingest
FlumeSqoop
WebHDFSNFS
AuthenticationAuthorizationAccountabilityData Protection
AcrossStorage: HDFS
Resources: YARN
Access: Hive,…
Pipeline: Falcon
Cluster: Knox
Provision, Manage & Monitor
Ambari
Scheduling
Oozie
Linux WindowsEnvironment
On Premise Virtualize
Commodity HWAppliance
Cloud/Hosted
Security Operations
Source: Hortonworks

92015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
HDFS as a Persistent Storage Layer
AdvantagesStorage performance at large scale and low costMinimize distance between data and computeNode failures toleratedOpen Source
DisadvantagesHadoop NameNode lacks active/active failover (i.e. it’s a SPOF)For data integrity and protection, HDFS creates three full clone copies of data
3x the storage for each file – slow and inefficientIf all three copies are corrupted, you’re still hosed (reload and start over)
No storage tiering (recognition of different storage types now available in 2.3)Limited ways to respond to corporate security and data governance policiesData in/out processes can take longer than the actual query processWhat is the single source of the truth?Inability to dis-aggregate storage from compute so that the two can be scaled
independently

102015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
NODE 1
NODE 2
NODE 3
NODE n
1 2 3 4 5 6 7 8
B8
GM
R3 Link
Active
Link
Active
Link
Active
ConsolePwr
Active
Link
Active
CONTROL
Network Layer
Compute Layer
Storage Layer SAN or NAS, but more commonly Scale-out
NAS
Shared Storage as Primary Storage
04/15/23 10

112015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
NODE 1
NODE 2
NODE 3
NODE n
1 2 3 4 5 6 7 8
B8
GM
R3 Link
Active
Link
Active
Link
Active
ConsolePwr
Active
Link
Active
CONTROL
Network Layer
Compute Layer
Storage Layer
Shared Storage as Secondary Storage
04/15/23 11
SAN/NAS/Object Storage

122015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
Hadoop On Scale-out Storage
Scale-out storage replaces node-level DASHDFS implemented as “over the wire” protocol or CDMI interface to underlying FSNameNode SPOF eliminatedDecoupled storage and compute layersData services, data protection, and DR by storage-resident servicesExamples include EMC Isilon, IBM Elastic Storage, Ceph
04/15/23 12

132015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
Shared Primary/Secondary Storage
Advantages
Addresses the enterprise storage management requirements
Data protection/disaster recovery/business continuance Data governance/compliance/archiving Single source of the truth
Disadvantages
Additional cost
Potential performance impact
Using a vendor specific solution introduces proprietary data/storage management software
04/15/23 13
142015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
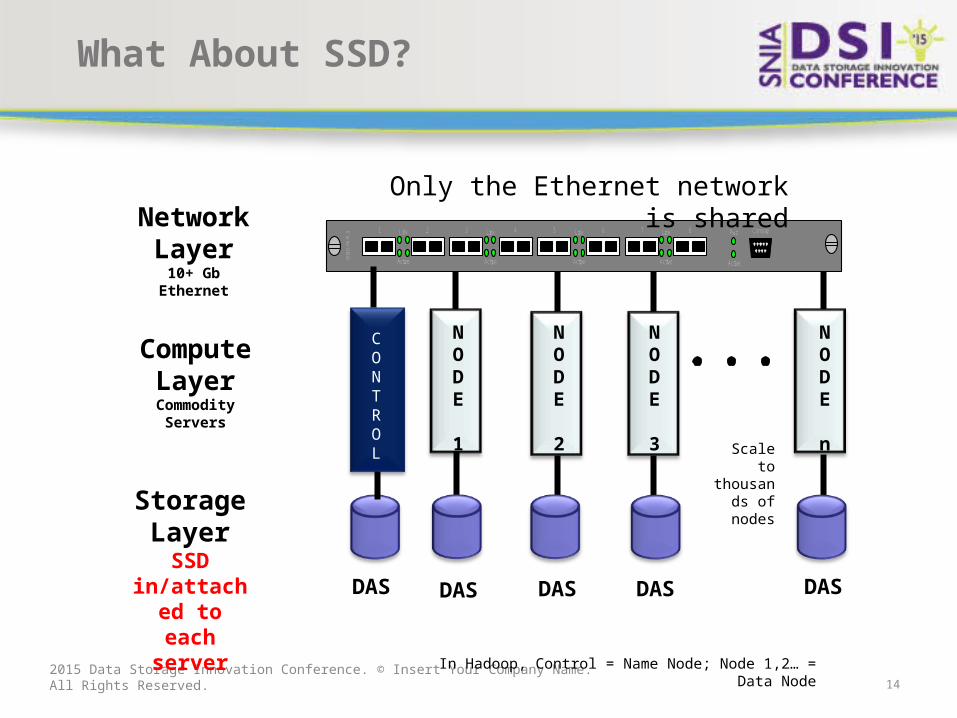
What About SSD?
NODE 1
NODE 2
NODE 3
NODE n
DAS DAS DAS DAS
1 2 3 4 5 6 7 8
B8
GM
R3 Link
Active
Link
Active
Link
Active
ConsolePwr
Active
Link
Active
CONTROL
DAS
Network Layer
10+ Gb Ethernet
Compute Layer
Commodity Servers
Storage Layer
SSD in/attached
to each server
Scale to thousands
of nodes
Only the Ethernet network is shared
In Hadoop, Control = Name Node; Node 1,2… = Data Node

152015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
NODE 1
NODE 2
NODE 3
NODE n
1 2 3 4 5 6 7 8
B8
GM
R3 Link
Active
Link
Active
Link
Active
ConsolePwr
Active
Link
Active
CONTROL
Network Layer
Compute Layer
Storage Layer Scale-out Flash Storage
What About SSD?
04/15/23 15

162015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
What About In-Memory Computing?
TachyonUC Berkeley Amp Lab project
“Reliable, memory-centric storage for Big Data Analytics clusters” (i.e. memory as persistent data store across cluster nodes)
One in-memory data copy inside JVM, use operation “lineage” to re-compute data if failure
Initial use in Apache Spark environments
04/15/23 16

172015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
What About In-memory Computing?
Apache IgniteIn-memory “data fabric”
Distributed in-memory platform for computing and transacting on large-scale data sets in real-time
“Orders of magnitude faster than possible with traditional disk-based or flash technologies.”
Tier -1 storage?
Originated as GridGain Data Fabric
In-Memory Computing Summit 6/29-30 imcsummit.org
04/15/23 17

182015 Data Storage Innovation Conference. © Insert Your Company Name. All Rights Reserved.
Summary and Q&A
The need for a longer-term, persistent storage layer is now recognized
For Hadoop, HDFS may or may not be that storage layer
Enterprise storage architects and administrators will be more directly involved in managing Big Data analytics storage over time
Now is the time to research and understand the options
04/15/23 18