spark overview - oleg mürk
TRANSCRIPT

Oleg Mürk October 2016
Spark Overview
Oleg MürkFounding Engineer

2 October 2016
Big Data: Volume & Velocity
10s of Terabytes up to Petabytes
Scales to 100s computing nodes
Examples: Hadoop, Spark, Flink, Google Dataflow, H2O, Dato/Turi, etc
Volume (Batch Computations)
100K+ msg/sec/node
Latency: 100ms - 1 sec
Scales to 100s computing nodes
Examples: Storm, Spark Streaming, Flink,
Google Dataflow, Kafka Streams, etc
Velocity (Streaming Computions)

3 October 2016
Hadoop Stack
Key Value Store HBase
Computation MapReduce, Spark, Flink
Filesystem HDFS
Scheduler YARN
Coordination Zookeeper

4 October 2016
SMACK Stack
Computation Spark
Scheduler Mesos
Reactive Akka
Key Value Store Cassandra
Event Streaming Kafka

5 October 2016
PANCAKE STACK

6 October 2016
Hadoop MapReduce: Word Count
Input
Deer Bear RiverCar Car RiverDeer Car Bear
Deer Bear River
Car Car River
Deer Car Bear
Splitting Mapping Shuffling Reducing Final Result
Deer, 1Bear, 1River, 1
Car, 1Car, 1
River, 1
Deer, 1Car, 1Bear, 1
Bear, 1Bear, 1
Car, 1Car, 1Car, 1
Deer, 1Deer, 1
River, 1River, 1
Bear, 2
Car, 3
Deer, 2
River, 2
Bear, 2Car, 3Deer, 2River, 2

7 October 2016
Hadoop/MapReduce Problems
Writing MapReduce jobs is very verbose
High overhead when starting jobs (seconds)
Many real-world computations are iterative
Each phase writes output to disk (HDFS)
Intermediate results are not cached in RAM
Hadoop is written in unoptimized Java :)

8 October 2016
Spark 1.x Improvements over Hadoop
Productivity: up to 10x less lines of code Similar API for batch and stream processingFunctional programming (Scala, Python)
… but also works well with plain Java
Computations are defined as transformations of datasets (RDDs)
Can develop from REPL (read-eval-print loop)
Performance: up to 10x faster In-memory computations when possible
Optimized computation graph (DAG)

9 October 2016
Word Count in Spark and PySpark

10 October 2016
Word Count in MapReduce
11 October 2016
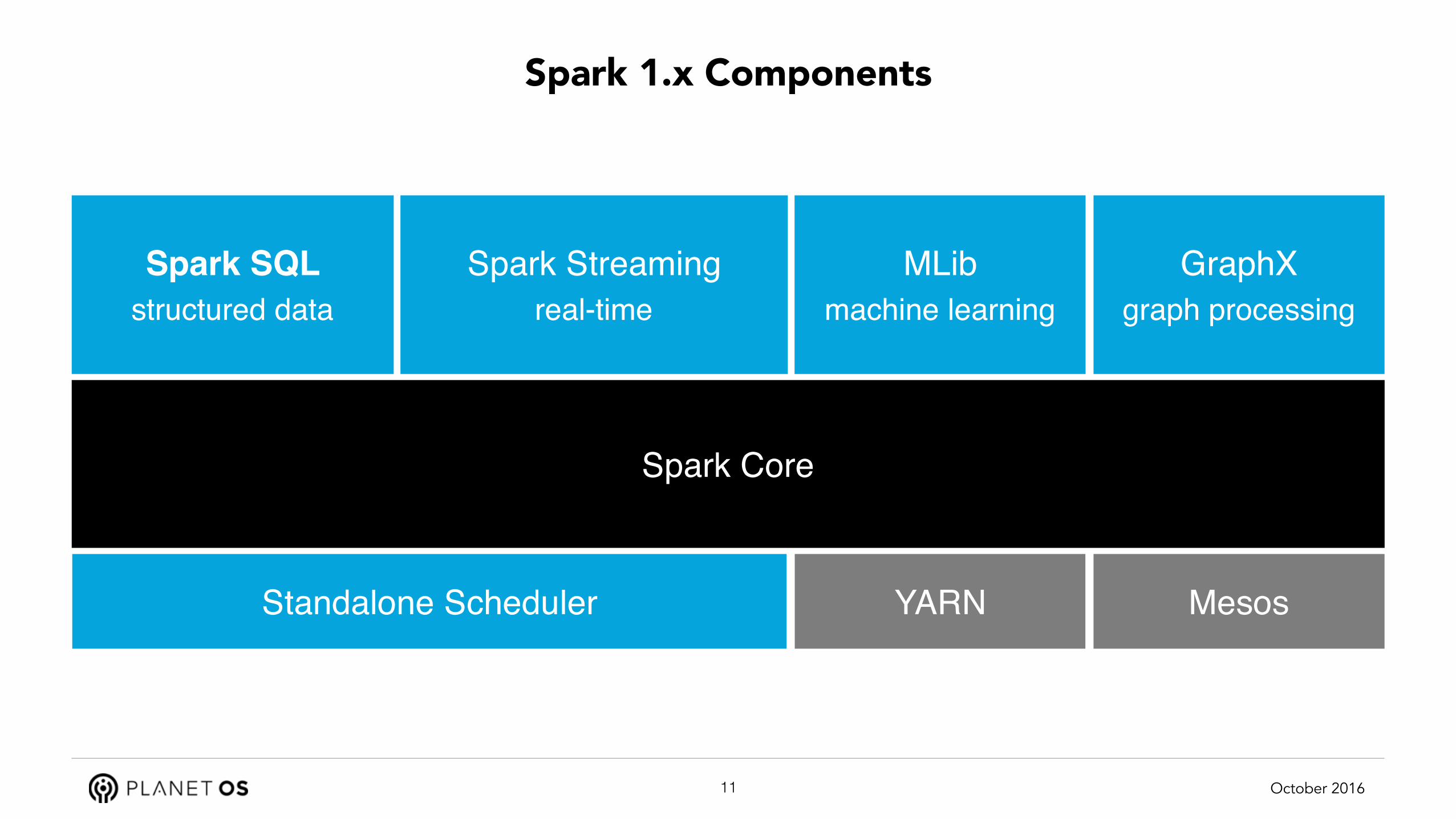
Spark 1.x Components
Spark SQLstructured data
Standalone Scheduler
Spark Streamingreal-time
MLibmachine learning
GraphXgraph processing
Spark Core
YARN Mesos

12 October 2016
Resilient Distributed Datasets (RDD)
RDDs are read-only collection of values
Transformations: map, filter, flatMap, join, etc Can be re-executed and should not have side-effects.
Actions: reduce, collect, save, foreach
Can have side-effects and are executed exactly once.
Transformations are lazy Computations are triggered by actions

13 October 2016
Word Count in Spark (again)

14 October 2016
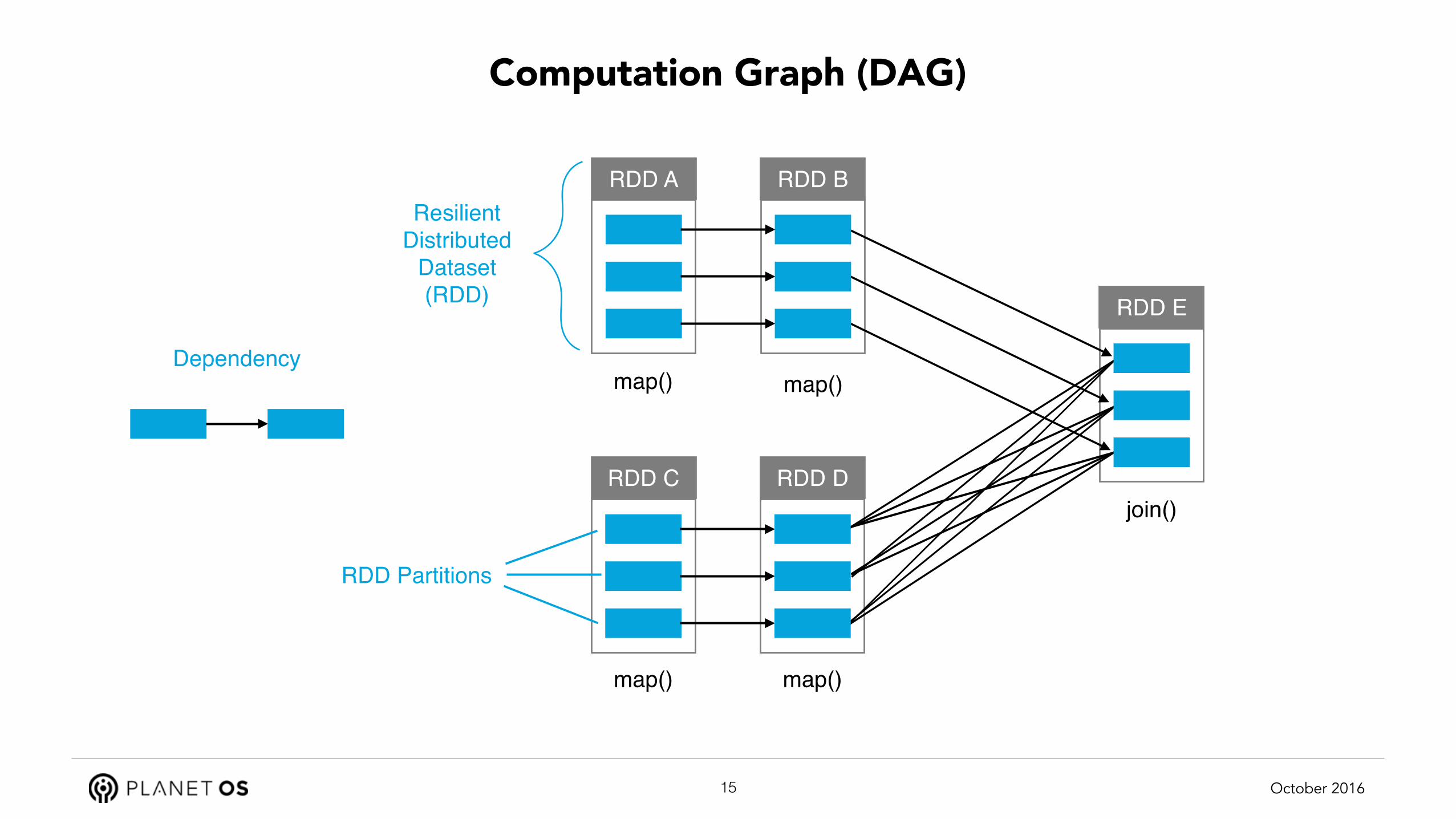
RDD Partitions
RDDS are partitioned, potentially across nodes
Partitioning scheme can be customized
Partitions can be recomputed from input partitions
… this is called lineage
Partition dependencies form a DAG
… DAG = Directed Acyclic Graph
Partition dependencies can be narrow or wide
15 October 2016
Computation Graph (DAG)
RDD BRDD A
RDD DRDD C
RDD E
map() map()
map() map()
join()
Resilient Distributed
Dataset (RDD)
RDD Partitions
Dependency

16 October 2016
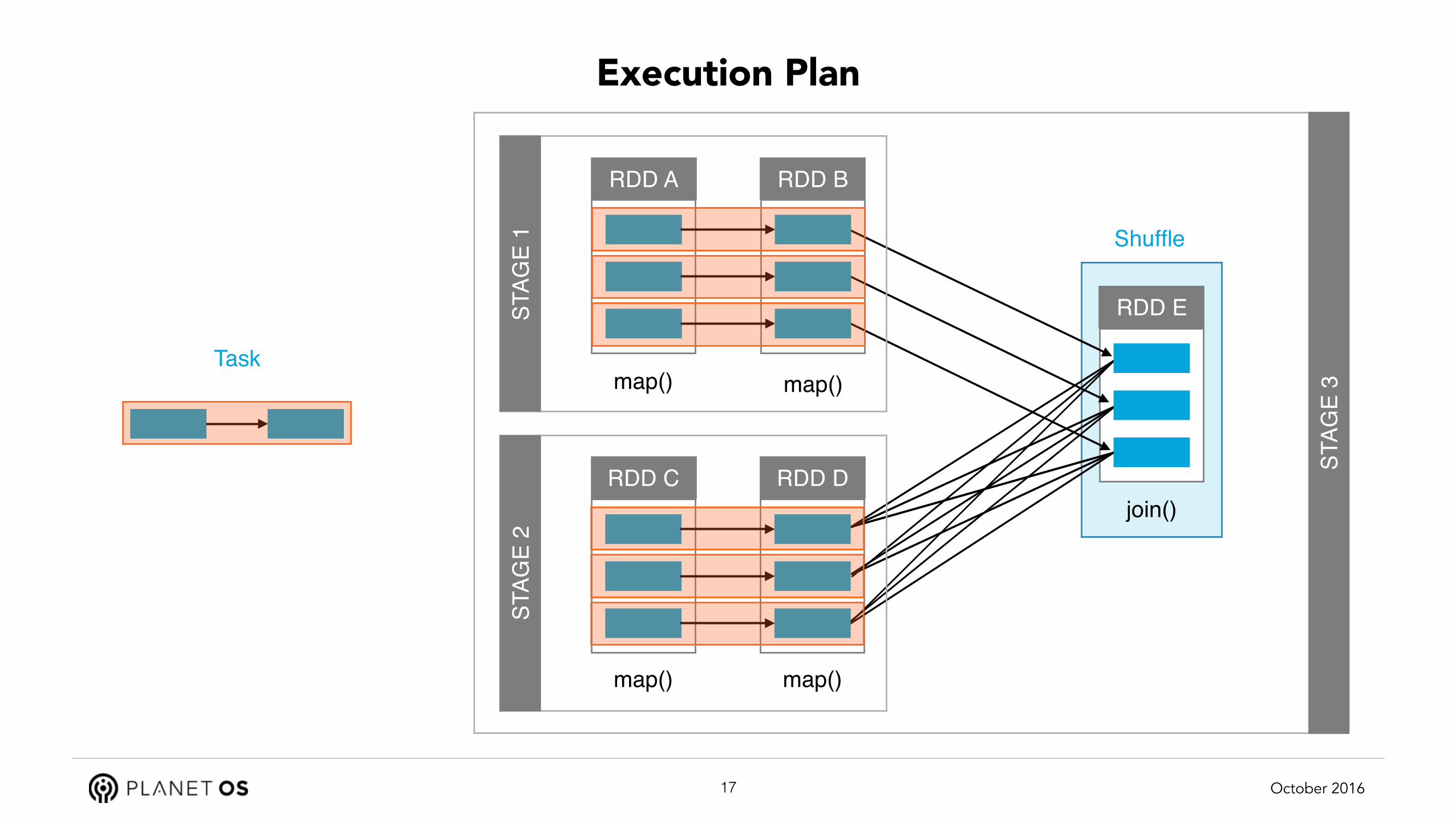
RDD DAG Execution
DAG is compiled into Execution Plan
Partitions are kept in-memory and spilled to disk
Lost / slow partitions can be recomputed
Unneeded partitions are freed
Unless explicitly marked as cached/persistent
… either in ram or on disk
17 October 2016
STAG
E 3
Execution Plan
RDD BRDD A
RDD DRDD C
RDD E
map() map()
map() map()
join()
STAG
E 1
STAG
E 2
Task
Shuffle

18 October 2016
Spark Streaming
Processing event streams from: Kafka, ZeroMQ, TCP, and various other sources Can output results to: Kafka, HDFS, KV-Stores, Databases, Dashboards and various other sinks Developer productivity Syntax very similar to Spark Core Reliability: Can recover from crashes via RDD snapshots and lineage Throughput: 100K+ events/sec per cpu core, scales to 100s of nodes
Latency: ~500 ms micro-batches

19 October 2016
Word Count in Spark Streaming
20 October 2016
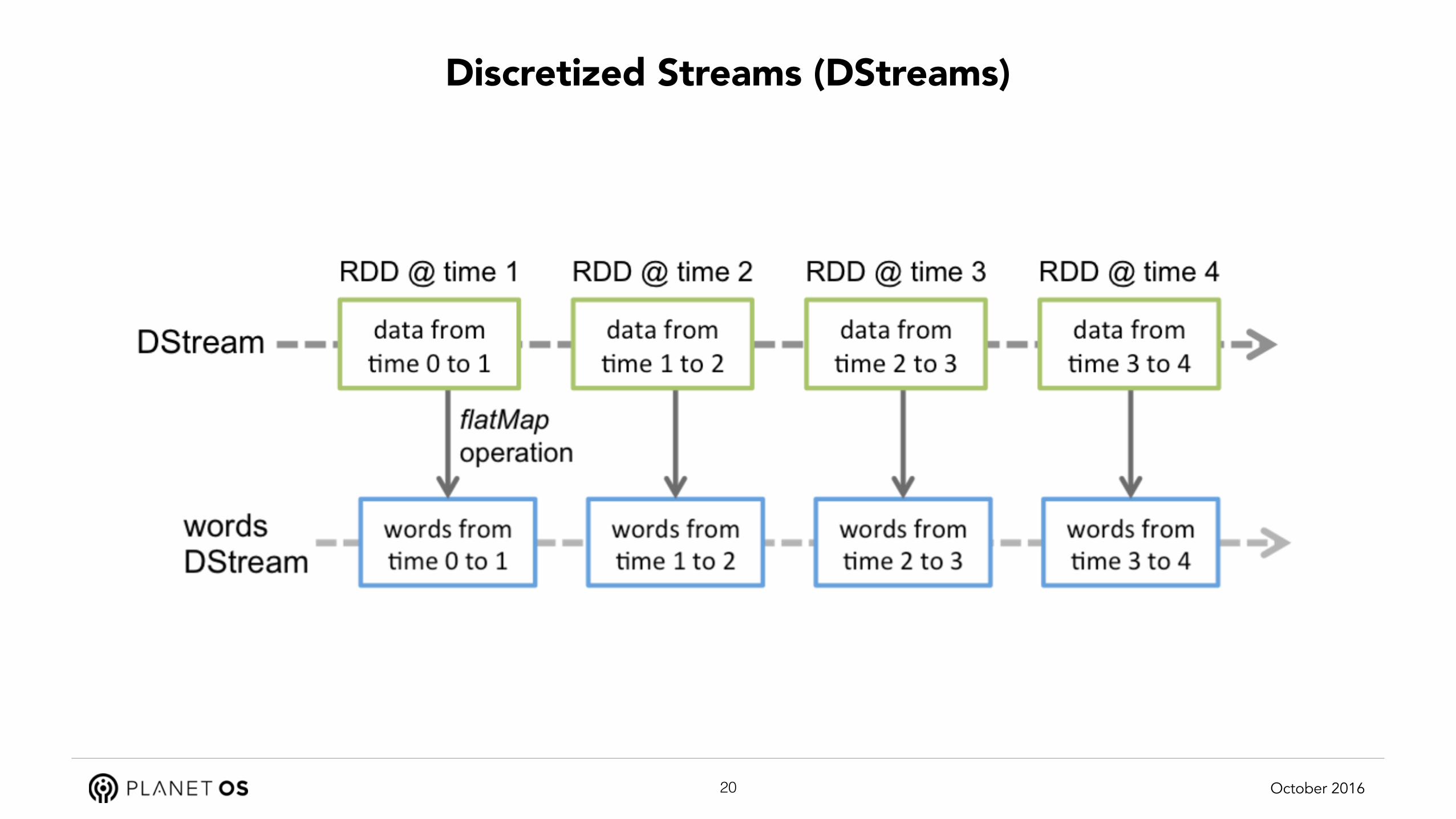
Discretized Streams (DStreams)

21 October 2016
Stateful Spark Streaming: updateStateByKey

22 October 2016
Spark SQL
Analytical SQL queries
Unified Data Source API
File formats: CSV, JSON
Columnar files: Parquet, RCFile, ORC
Key-value stores: HBase, Cassandra
Databases: JDBC
Can do predicate pushdown to data sources
… ie SQL where clauses can be passed to data sources

23 October 2016
Spark SQL Example

24 October 2016
DataFrames API
DataFrames API is a typed DSL equivalent to Spark SQL
Query result is a DataFrame
Intermediate result is a DataFrame
DataFrames can be cached in columnar compressed format
External table can be cached as a DataFrame

25 October 2016
Data Frame API Example

26 October 2016
Columnar Table Representation
Split table rows into chunks … can skip chunks based on precomputed column min/max values
Store each table column separately … can read only needed columns
Columns compress better than rows
Better CPU cache utilization
Better CPU vectorization
Off-heap Java storage
Examples: Parquet, RCFile, ORC

27 October 2016
Analytical Databases (OLAP)
Also called data warehouses
Support large batch inserts & deletes
Support long-running analytical queries
Often organize tables in columns
Examples: Redshift, Vertica, Greenplum, HIVE

28 October 2016
HIVE on MapReduce vs Spark
Data warehousing system (OLAP)
Used to manage PetaBytes of event logs
Table data stored in partitions on HDFS
Optimized Row Columnar Format (ORC)
Table Metadata stored in HCatalog
HiveQL originally executed using MapReduce
Now 10x faster on Spark

29 October 2016
Spark ML(Lib)
Algorithms: classification, regression, clustering, collab. filtering
Featurization: feature extraction, transformation, dim. reduction
Pipelines: constructing, evaluating, and tuning ML Pipelines
Persistence: saving and load algorithms, models, and Pipelines
Utilities: linear algebra, statistics, data handling, etc.
Spark ML: based on DataFrames

30 October 2016
Spark GraphX & GraphFrames
Vertex & Edge RDDs
Edge RDD partitioning is essential
… in Power-law graphs with highly skewed edge distributions
Common algorithms
PageRank, Connected components, Label propagation, SVD++,
Strongly connected components, Triangle count
GraphX exposes a variant of the Google Pregel API
GraphFrames: based on DataFrames

31 October 2016
Spark 2.0 Components
Spark SQLstructured data
Standalone Scheduler
Spark Streamingreal-time
MLilbmachine learning
GraphXgraph processing
Spark Core (RDDs, etc)
YARN Mesos
Tungsten (Binary Representation & Code Generation)
Catalyst (Query Planner)
DataFrame / Dataset
Incrementalization

32 October 2016
Catalyst + Tungsten Pipeline

33 October 2016
Incrementalization: Structured Streaming
Identical API for Batch and Streaming
Auto-incrementalizing DataFrame / SQL queries
Prefix consistency on input stream
Transactional consistency on output sinks
