spark, spark streaming & tachyon
TRANSCRIPT

Spark, Spark Streaming & Tachyon
Solving big data problem without programming for big data

Who am I? What do we do?
• Name: Johan Hong [email protected]
• Software Architect work for Pearson Higher Education
• Deliver personalized and connected learning at scale
• Build assessment platform with micro-services to serve internal and public services and applications

Definitions
Apache Spark™ is a fast and general engine for large-scale data processing.
Apache Spark is a cluster computing platform designed to be fast and general-purpose.
Spark Streaming makes it easy to build scalable fault-tolerant streaming applications.
Tachyon is a memory-centric distributed file system enabling reliable file sharing at memory-speed across cluster frameworks
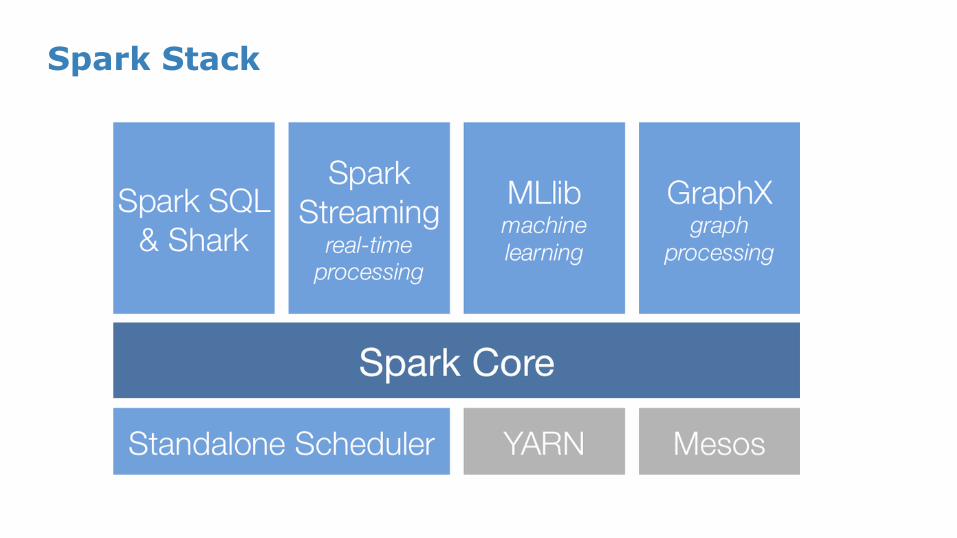
Spark Stack
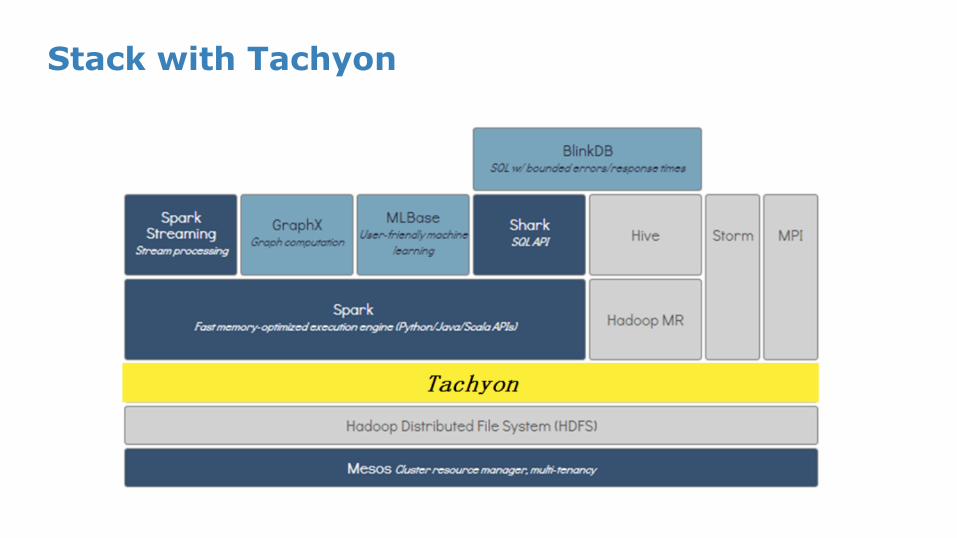
Stack with Tachyon

Distributed Execution
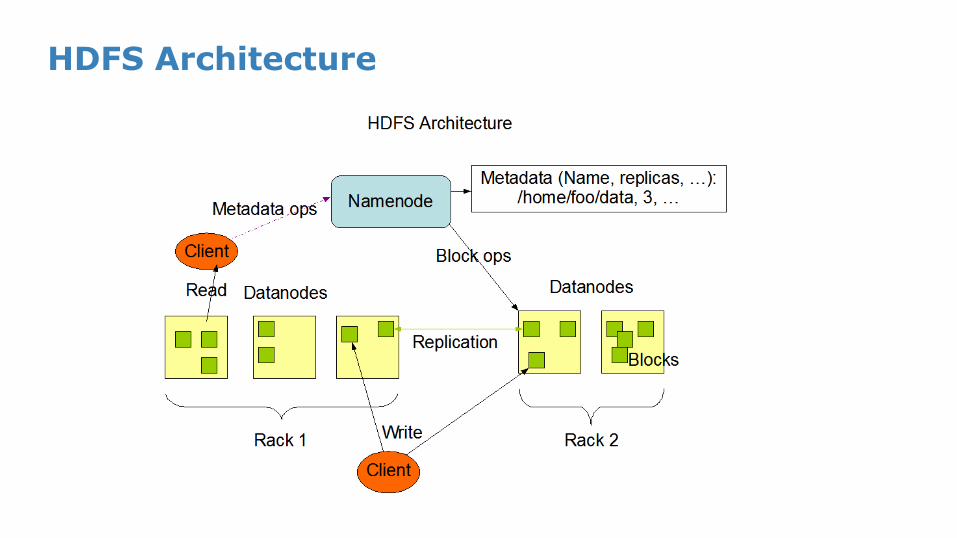
HDFS Architecture
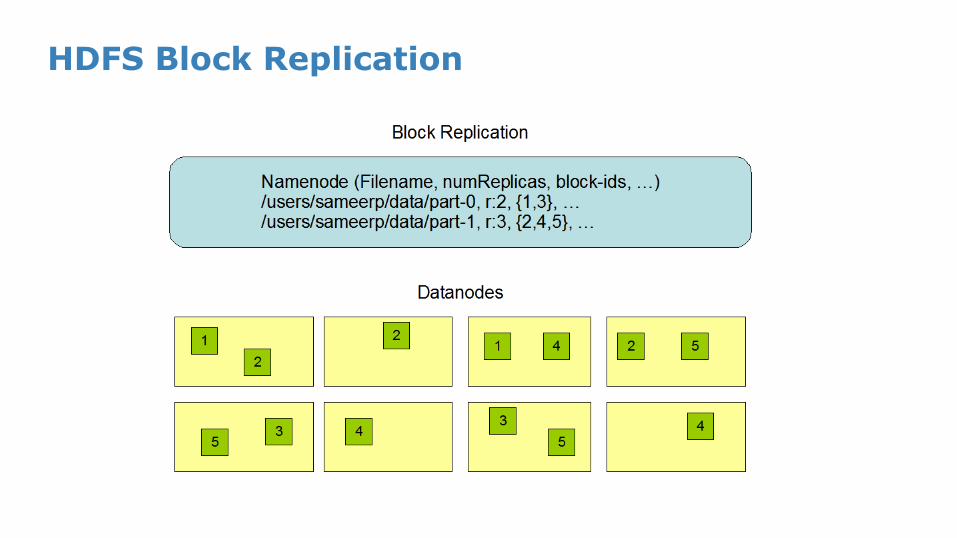
HDFS Block Replication
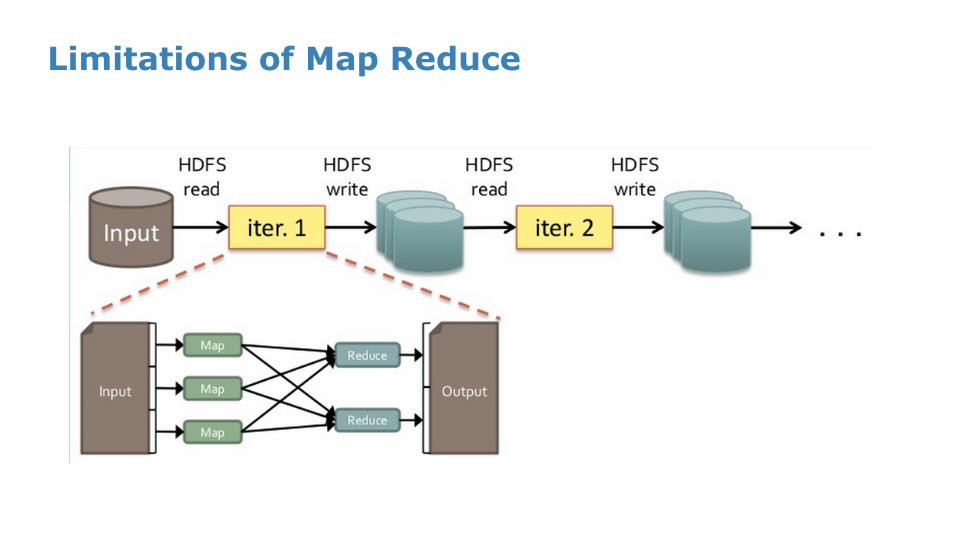
Limitations of Map Reduce
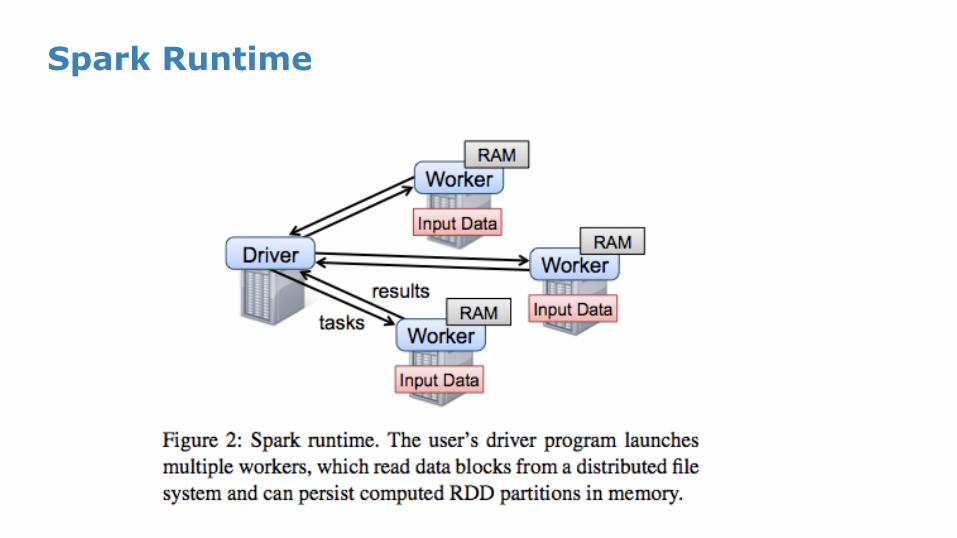
Spark Runtime
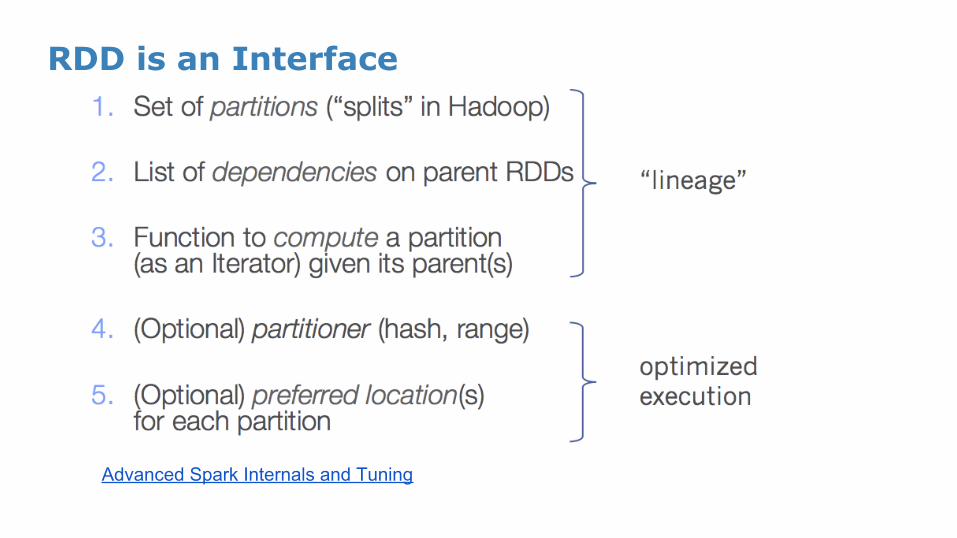
RDD is an Interface
Advanced Spark Internals and Tuning

Sample Application
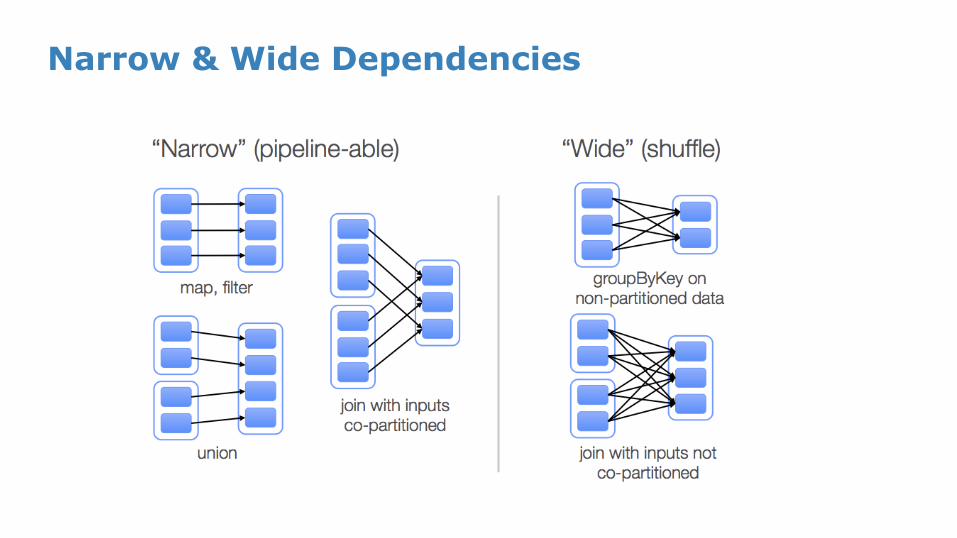
Narrow & Wide Dependencies
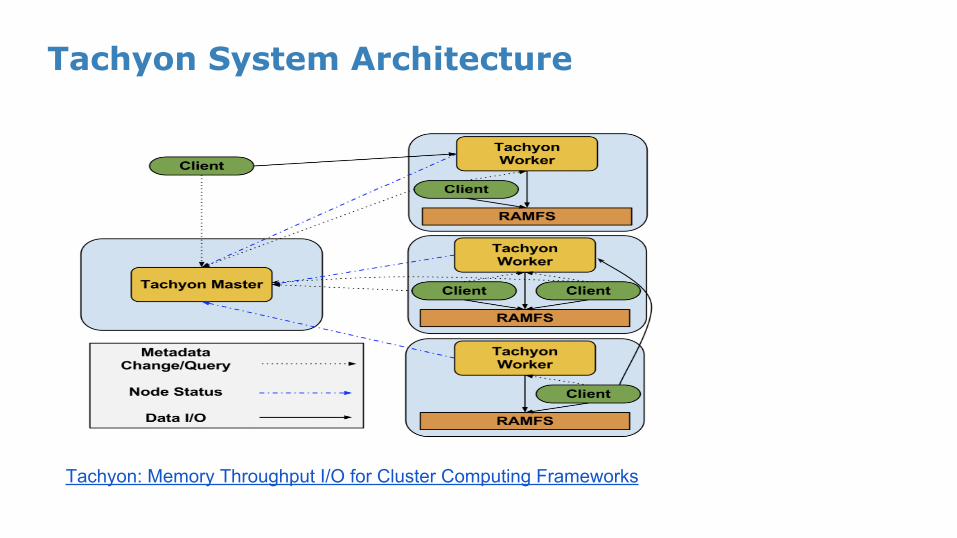
Tachyon System Architecture
Tachyon: Memory Throughput I/O for Cluster Computing Frameworks
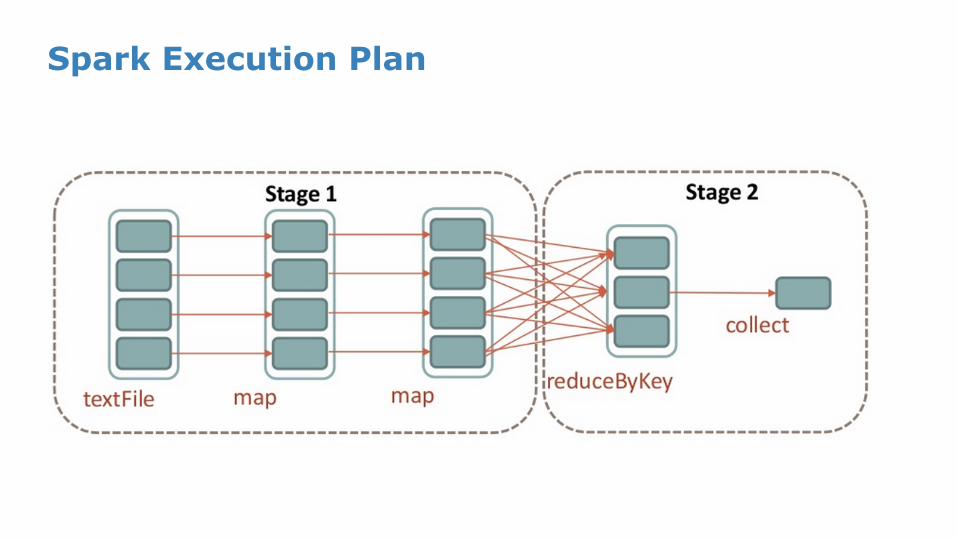
Spark Execution Plan
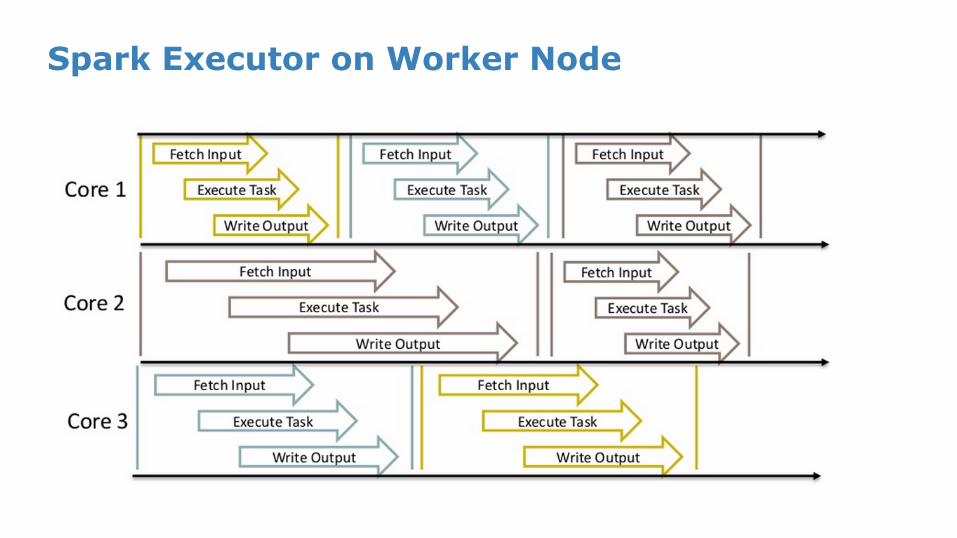
Spark Executor on Worker Node

Fault-Tolerant in Spark Streaming
Could data be lost if the receiving node crashes before it replicates incoming data to other data node(s)?
It happens. Ooyala loses 1% of their data but it is considered as acceptable.
What can we do to prevent data loss?
We could persist events before they reach Spark Streaming Receiver, replay the events/messages after receiver crashes and recovers.
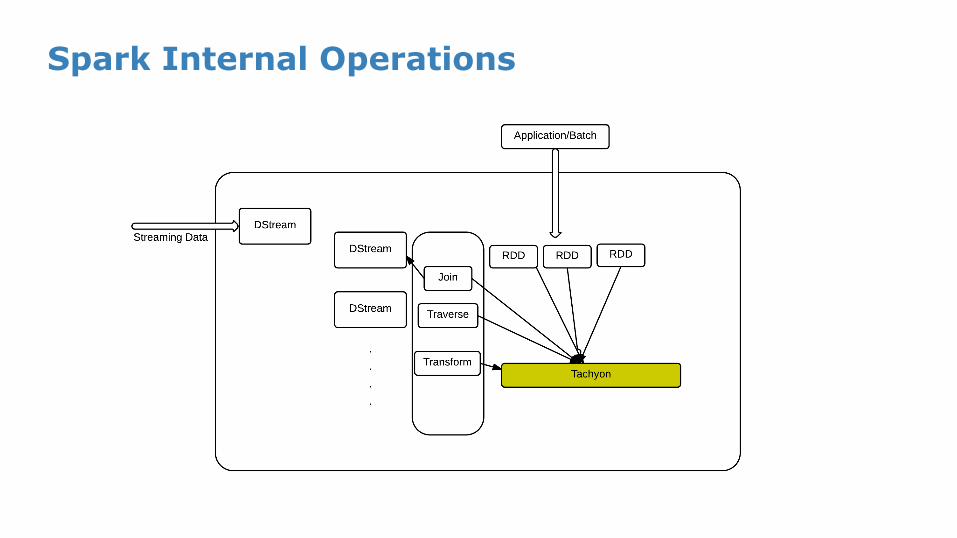
Spark Internal Operations
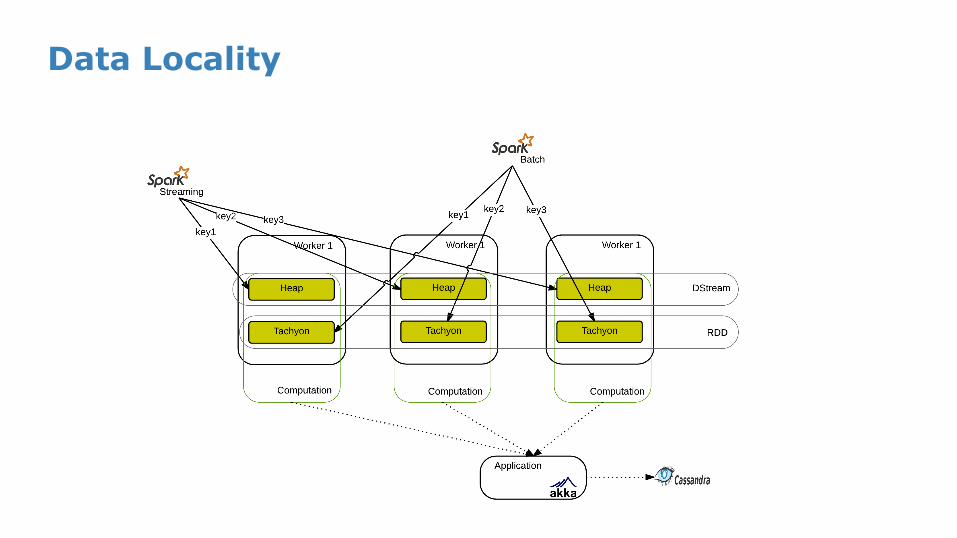
Data Locality