spark under the hood - meetup @ data science london
TRANSCRIPT

Under the Hood Meetup @ Data Science London Aug 27, 2015

Who are we?
Sameer Farooqui Doug Bateman Jon Bates
• Dir of Training @ NewCircle
• Spark Trainer for Databricks
• 800+ trainings on Java, Python, Android, Hibernate, Spring, etc
• Trainer @ Databricks • 150+ trainings on Hadoop,
C*, HBase, Couchbase, NoSQL, etc
• Data Scientist
• Consultant for Databricks
• EdX assistant instructor on Scalable ML w/ Spark

Agenda: Talks
Sameer Farooqui Doug Bateman Jon Bates
15 mins: • Intro & Spark Overview
25 mins: • Power Plant Demo
• ETL + Linear Regression
25 mins: • Iris Flower Demo
• Model Parallel w/ sci-kit learn

Agenda: Q & A 30 mins
+
• Consulting Architect for Cloudera
• Cluster setup, Security/Kerberos, Hive, Impala, HBase, Spark
• Based in Germany
• R, Sci-Kit Learn, Spark, Mahout, HBase, Hive, Pig
• Senior Data Scientist @ Big Data Partnership + Spark Trainer for DB
• Based in London
Stephane Rion
Lars Francke

Who are you?
1) I have used Spark hands on before…
2) I have more than 1 year hands on experience with ML…
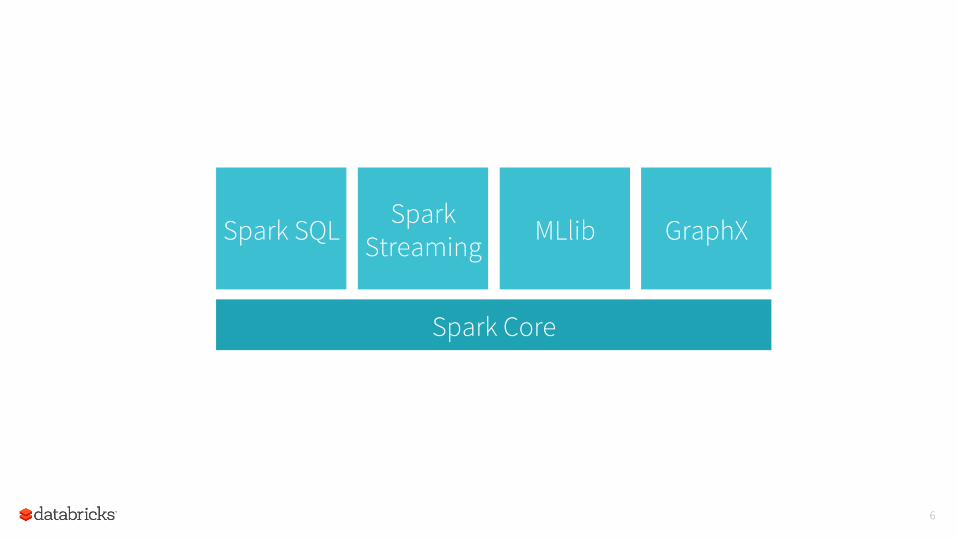
6
Spark Core
Spark Streaming
Spark SQL MLlib GraphX
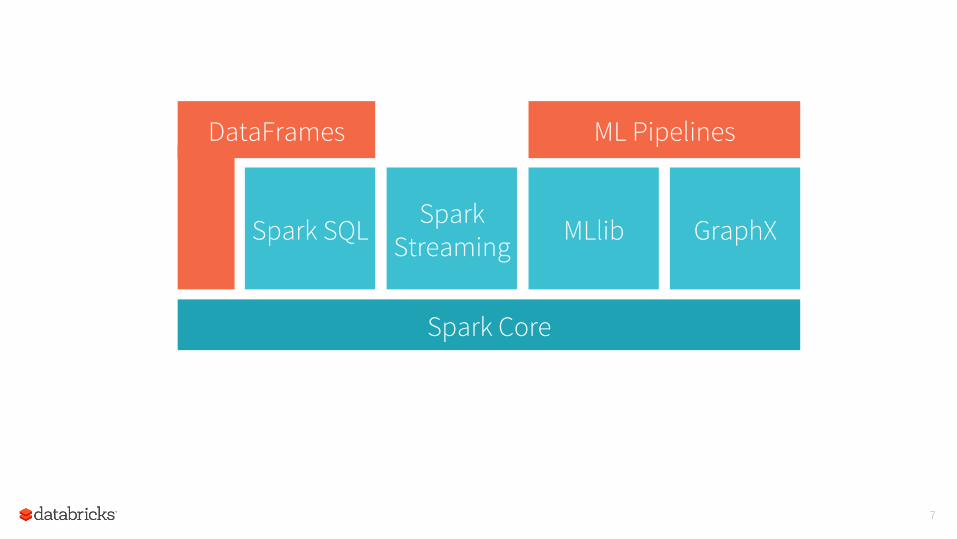
7
Spark Core
DataFrames ML Pipelines
Spark Streaming
Spark SQL MLlib GraphX
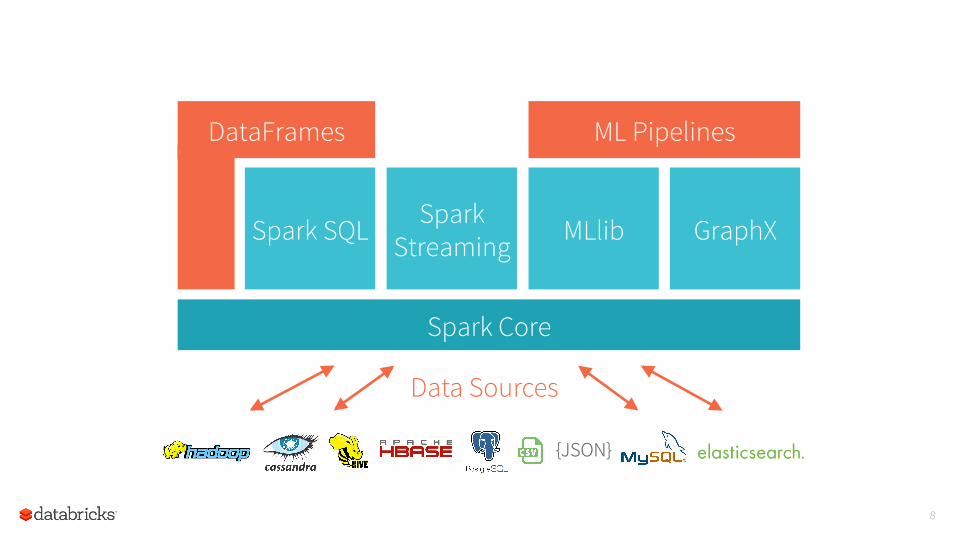
8
{JSON}
Data Sources
Spark Core
DataFrames ML Pipelines
Spark Streaming
Spark SQL MLlib GraphX
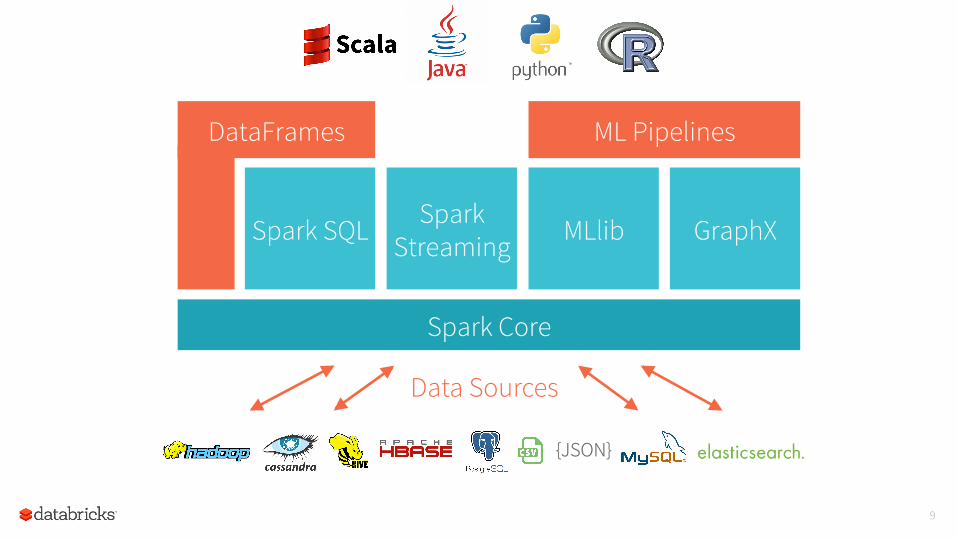
9
{JSON}
Data Sources
Spark Core
DataFrames ML Pipelines
Spark Streaming
Spark SQL MLlib GraphX

10
Goal: unified engine across data sources, workloads and environments

Spark – 100% open source and mature Used in production by over 500 organizations. From fortune 100 to small innovators
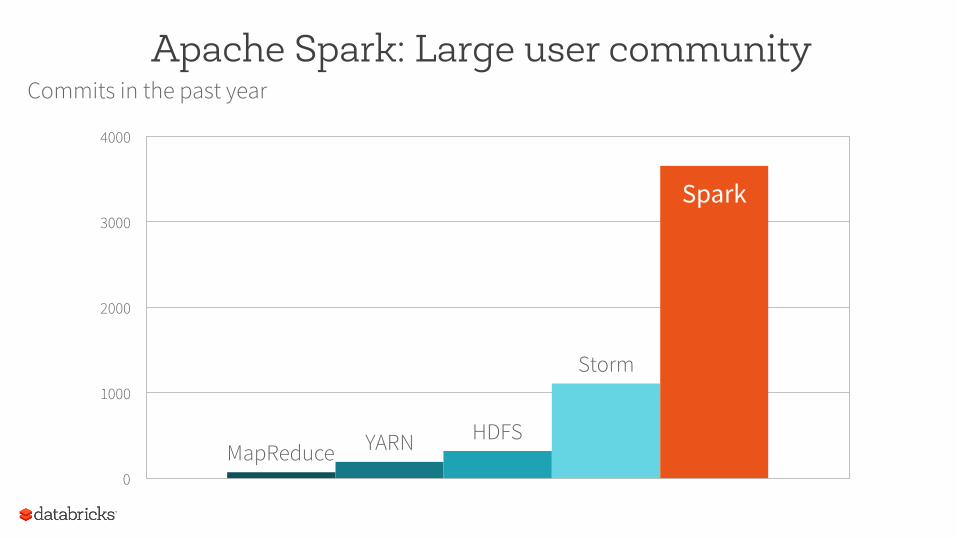
Apache Spark: Large user community
MapReduce YARN HDFS
Storm
Spark
0
1000
2000
3000
4000
Commits in the past year
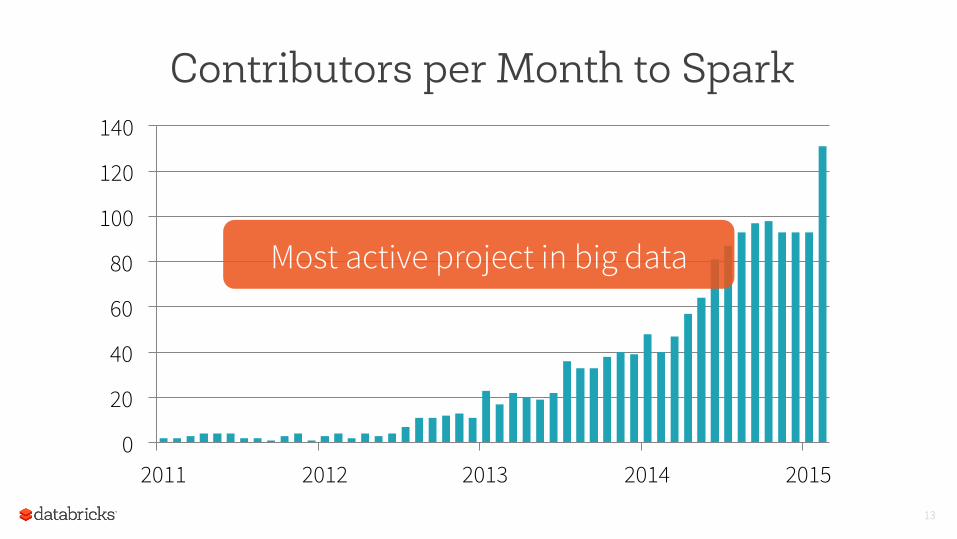
0
20
40
60
80
100
120
140
2011 2012 2013 2014 2015
Contributors per Month to Spark
Most active project in big data
13

Large-Scale Usage
Largest cluster: 8000 nodes
Largest single job: 1 petabyte
Top streaming intake: 1 TB/hour
2014 on-disk 100 TB sort record

15
On-Disk Sort Record: Time to sort 100TB
Source: Daytona GraySort benchmark, sortbenchmark.org
2100 machines 2013 Record: Hadoop
72 minutes
2014 Record: Spark
207 machines
23 minutes

2014: an Amazing Year for Spark
Total contributors: 150 => 500
Lines of code: 190K => 370K
500+ active production deployments
16

The Databricks team contributed more than 75% of the code added to Spark in the past year
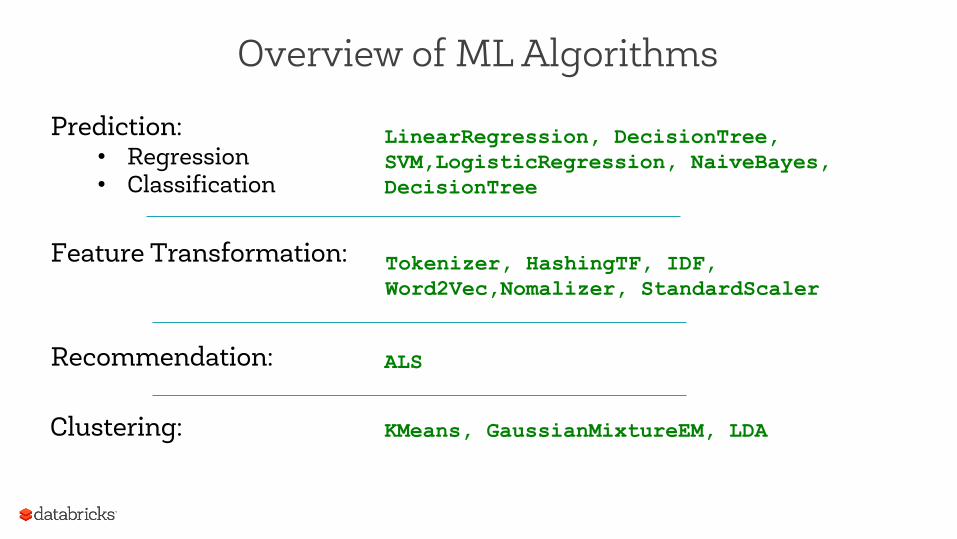
Overview of ML Algorithms
Prediction: • Regression • Classification
Tokenizer, HashingTF, IDF, Word2Vec,Nomalizer, StandardScaler
LinearRegression, DecisionTree, SVM,LogisticRegression, NaiveBayes, DecisionTree
Feature Transformation:
Recommendation: ALS
Clustering: KMeans, GaussianMixtureEM, LDA

Overview of ML Algorithms
Other: • Statistics • Linear Algebra
• Optimization
Clustering Other:
• Statistics • Linear Algebra • Optimization
Correlation, ChiSqTest, Statistics, MultivariateOnlineSummarizer
RowMatrix, EigenValueDecomposition, Matrix, Vector
GradientDescent, LBFGS
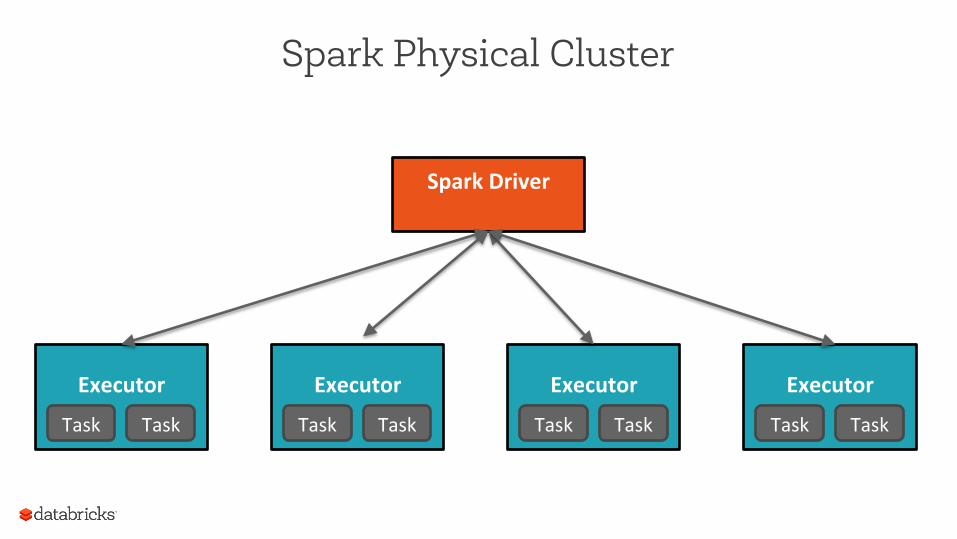
Spark Driver
Executor Task Task
Executor Task Task
Executor Task Task
Executor Task Task
Spark Physical Cluster

Spark Data Model
Error, ts, msg1 Warn, ts, msg2 Error, ts, msg1
RDD / DataFrame with 4 partitions
Info, ts, msg8 Warn, ts, msg2 Info, ts, msg8
Error, ts, msg3 Info, ts, msg5 Info, ts, msg5
Error, ts, msg4 Warn, ts, msg9 Error, ts, msg1
logLinesRDD
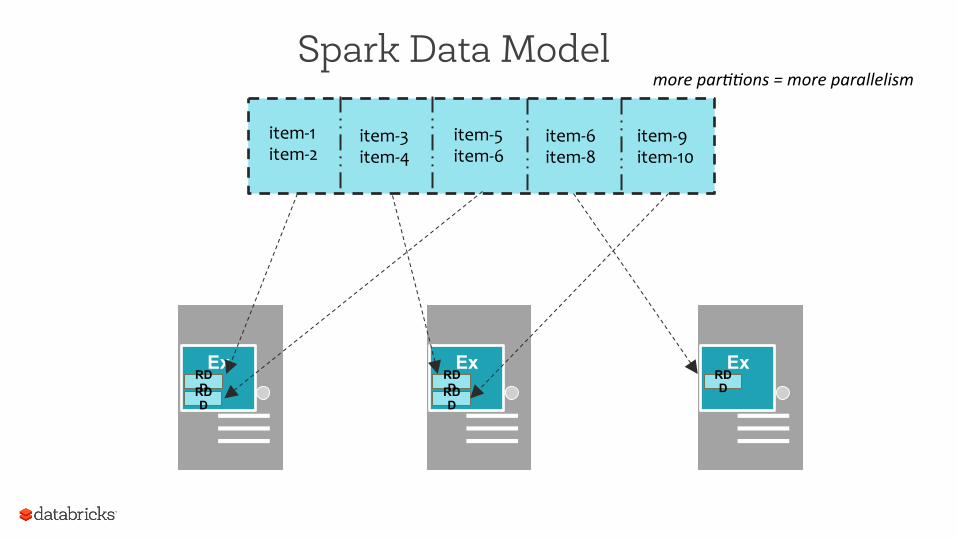
Spark Data Model
item-‐1 item-‐2
item-‐3 item-‐4
item-‐5 item-‐6
item-‐6 item-‐8
item-‐9 item-‐10
Ex RDD RDD
Ex RDD RDD
Ex RDD
more par((ons = more parallelism

Power Plant Demo

Use Case: predict power output given a set of readings from various sensors in a gas-fired power generation plant
Schema Definition:
AT = Atmospheric Temperature in C V = Exhaust Vacuum Speed AP = Atmospheric Pressure RH = RelaCve Humidity PE = Power Output (value we are trying to predict)

1. ETL
2. Explore + Visualize Data
3. Apply Machine Learning
Steps:

Iris Flower Demo

Use Case: Link legacy code to Spark

Different ways to parallelize ML
• Model Parallelism
• Divide & Conquer
• Data Parallelism

Model Parallelism
• Model stored across workers
• Communicate data to all workers
• Examples: • Grid search • Cross validation • Ensemble

Divide & Conquer
• Minimizes communication
• Leads to approximate solutions

Data Parallelism
• Data stored across workers
• Communicate model to all workers
• Examples: • MLLib Linear models • Matrix outer products
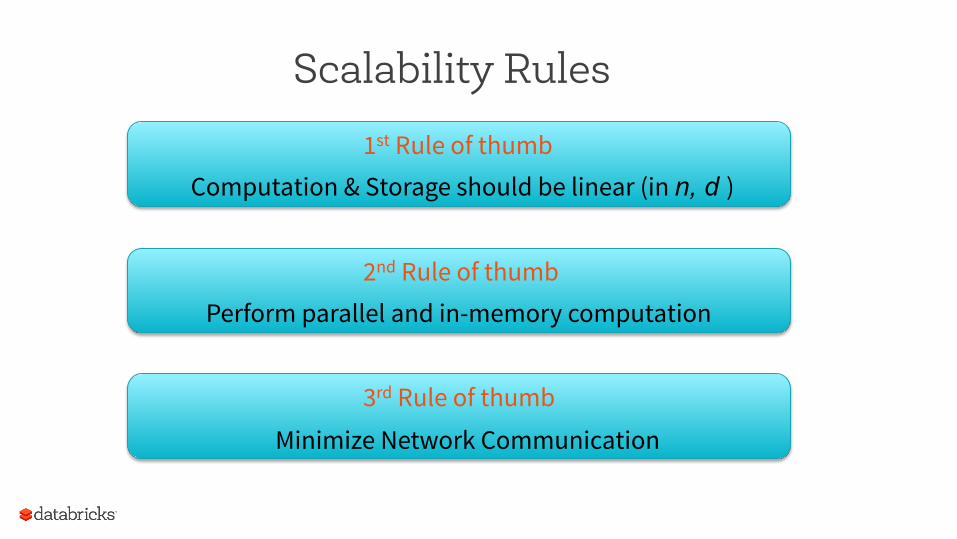
Scalability Rules
1st Rule of thumb Computation & Storage should be linear (in n, d )
2nd Rule of thumb Perform parallel and in-memory computation
3rd Rule of thumb Minimize Network Communication

Agenda: Q & A 30 mins
Stephane Rion
Lars Francke Sameer Farooqui
Doug Bateman
Jon Bates