speaker and speech recognition for secured smart home applications
DESCRIPTION
The paper published in discusses implementation of a robust text-independent speaker recognition system using MFCC extraction of feature vectors its matching using VQ and optimization using LBG, further a text dependent speech recognition system using the DTW algorithm's implementation is discussed in the context of home automation.TRANSCRIPT

International Conference on Advance Research in Computer Science, Electrical and Electronics Engineering
Sep 7, 2013 Pattaya
5
SPEAKER AND SPEECH RECOGNITION FOR SECURED SMART
HOME APPLICATION
R. Gomes1, S. Shaji
2, L. Nadar
2, V. Vincent
2
Dept. of Electronics and Telecommunication
Xavier Institute of Engineering, University of Mumbai
Mahim (W), Mumbai-400016, Maharashtra, India [email protected]
S. Patnaik
Dept. of Electronics and Telecommunication
Xavier Institute of Engineering, University of Mumbai
Mahim (W), Mumbai-400016, Maharashtra, India
ABSTRACT
The concept of a smart home refers to the idea of
having intelligent devices surrounding us responding to
our various needs as and when the situation arises for
e.g. switching on/off of lights and fans when an
individual enters or leaves a room, automatic
adjustment of the temperature of a room depending on
the ambient temperature etc. In the context of a smart
home an individual’s interaction with all the electrical
appliances is crucial giving him complete control and
freedom to control all the devices at home. However,
with this control a question of security arises. An
individual at his home would want access to all the
devices restricted to only his family members and
friends. To address the above simultaneous demand of
security (e.g. operation by family members only) and
automation (remote operation of multiple devices), in
this paper we present a concept of speaker recognition
for security and speech recognition for home
appliances automation. The goal is design and
implementation of a text independent speaker
recognition based on Mel-frequency Cepstrum
Coefficients (MFCCs) and Vector Quantization (VQ)
algorithm for security integrated with a speaker
independent speech recognition using Dynamic time
warping (DTW) algorithm for home appliances
automation.
KEYWORDS: Automation, Security, Speaker
Recognition, Speech Recognition, Mel Frequency
Cepstrum Coefficients (MFCCs), Vector Quantization
(VQ), Dynamic Time Warping (DTW)
I. INTRODUCTION
The human speech signal contains many discriminative
features. These features are unique to every individual
and serve as a biometric parameter which can be used
by robust voice based biometric systems to correctly
verify an individual‟s identity [1]. Unlike other
biometric parameters like fingerprint and iris, voice
based biometrics presents the advantage of remotely
accessing systems through the telephone network, this
makes it quite valuable in real time applications of
authentication and authorization over a large distance
[2]. Speaker recognition typically is the process of
automatically recognizing who is speaking on the basis
of information obtained from his speech. This technique
will make it possible to verify the identity of a person
accessing the system [2]. In the context of automation
in a smart home only an authorized user must be given
access to control all the devices and appliances at home.
In this case, for authenticating a user we use text
independent speaker recognition. Once access to the
system has been granted to the authenticated user, all
the appliances and device connected to the system must
be under his control. In order to accomplish this task we
use isolated word speech recognition for correctly
identifying the uttered words by matching it with the
reference templates stored in the database.
The proposed system in this paper involves three
phases. The first phase is the speaker recognition phase
to authenticate the user, the second phase is the speech
recognition phase to identify the word spoken by the
user for the purpose of automation and the third phase is
the device control phase which involves serially
communicating the results of identification to
PIC16F676 to toggle the status of the devices connected
to it.
II. SPEAKER RECOGNITION
Speaker recognition is the method of automatically
identify who is speaking on the basis of individual
information integrated in speech waves [2]. The process
of speaker recognition involves two phases, the testing
and the training phase. Both these phases involve
extracting the features vectors and its matching. This is
possible using MFCC algorithm and feature matching
using VQ and its optimization with Linde, Buzo and
Gray (LBG) algorithm.
Fig. 1 Block Diagram of MFCC Processor [3]
A. Mel-frequency Cepstrum Coefficients
The Mel-Frequency Cepstrum (MFC) is a
representation of short-term power spectrum of a sound.
The MFCCs are coefficients that collectively make up
an MFC. They are derived from a type of cepstral
representation of the audio clip (a nonlinear "spectrum-
of-a-spectrum") [3]. The difference between the

6
cepstrum and the mel-frequency cepstrum is that in the
MFC, the frequency bands are equally spaced on the
mel scale, which approximates the human auditory
system's response more closely than the linearly-spaced
frequency bands used in the normal cepstrum [1].
1) Frame Blocking: It has been assumed that over a
long interval of time speech signal is not stationary,
however over a sufficiently short interval of time
say 10-30ms it can be considered stationary. In
frame blocking, the continuous speech signal is
blocked into frames of N samples, with adjacent
frames being separated by M (M < N).The first
frame consists of the first N samples. The second
frame begins M samples after the first frame, and
overlaps it by N - M samples [3]. Similarly, the
third frame begins 2M samples after the first frame
(or M samples after the second frame) and overlaps
it by N - 2M samples. Typical values for N and M
are N = 256 (which is equivalent to ~ 30ms
windowing and facilitate the fast radix-2 FFT) and
M = 100 [1, 3].
2) Windowing: To minimize the signal discontinuities
at the beginning and end of each frame the concept
of windowing is used to minimize the spectral
distortion to taper the signal to zero at the
beginning and end of each frame. In other words,
when we perform Fourier Transform, it assumes
that the signal repeats, and the end of one frame
does not connect smoothly with the beginning of
the next one. In this process, we multiply the given
signal (frame in this case) by a so called Window
Function [3, 11]. There are many „soft windows‟
which can be used, but in our system Hamming
window has been used, which has the form
( )
(
) ( )
3) Fast Fourier Transform (FFT): The next
processing step is the Fast Fourier Transform,
which converts each frame of N samples from the
time domain into the frequency domain [3]. The
FFT is a fast algorithm to implement the Discrete
Fourier Transform (DFT) which is defined on the
set of N samples
∑
( )
The result after this step is often referred to as spectrum
or periodogram [5, 3].
4) Mel-frequency wrapping: Psychophysical studies
have shown that human perception of the frequency
contents of sounds for speech signals does not
follow a linear scale. Thus for each tone with an
actual frequency, f, measured in Hz, a subjective
pitch is measured on a scale called the „mel‟ scale.
The mel-frequency scale is linear frequency
spacing below 1000 Hz and a logarithmic spacing
above 1000 Hz. As a reference point, the pitch of a
1 kHz tone, 40dB above the perceptual hearing
threshold, is defined as 1000 mels [1, 3]. Therefore
we can use the following approximate formula to
compute the mels for a given frequency f in Hz:
( )
(
) ( )
5) Cepstrum: In this final step, we convert the log mel
spectrum back to time. The result is called the mel
frequency cepstrum coefficients (MFCC). The
cepstral representation of the speech spectrum
provides a good representation of the local spectral
properties of the signal for the given frame
analysis. Because the mel spectrum coefficients
(and so their logarithm) are real numbers, we can
convert them to the time domain using the Discrete
Cosine Transform (DCT). Therefore if we denote
those mel power spectrum coefficients that are the
result of the last step are
, K (4)
We calculate the mfcc‟s as
∑ ( ) [ (
)
]
( )
By applying the procedure described above, for each
speech frame of around 30msec with overlap, a set of
mel-frequency cepstrum coefficients is computed [3, 4].
These are result of a cosine transform of the logarithm
of the short-term power spectrum expressed on a mel-
frequency scale. This set of coefficients is called an
acoustic vector. Therefore each input utterance is
transformed into a sequence of acoustic vectors.
B. Feature matching using VQ
The state-of-the-art in feature matching techniques used
in speaker recognition includes DTW, Hidden Markov
Modelling (HMM), and VQ. In this paper, the VQ
approach is used, due to ease of implementation and
high accuracy [2]. Vector Quantization is the classical
quantization technique from signal processing which
allows the modelling of probability density functions by
the distribution of prototype vectors. It works by
dividing a large set of points into groups having
approximately the same number of points closest to
them. Each group is represented by its centroid point.
The density matching property of vector quantization is
powerful, especially for identifying the density of large
and high-dimensioned data. Since data points are
represented by the index of their closest centroid,
commonly occurring data have low error [1].

7
A vector quantizer maps k-dimensional vectors in the
vector space Rk into a finite set of vectors Y = {yi : i =
1, 2,….N}. Each vector yi is called a code vector or a
codeword and the set of all the code words is called a
codebook. Associated with each codeword, yi, is a
nearest neighbour region called Voronoi region, and it
is defined by
{ }
( )
Given an input vector, the codeword that is chosen to
represent it is the one in the same Voronoi region.
Fig. 2 Codewords in 2-dimensional space. Input
vectors are marked with an x, codewords are
marked with circles, and the Voronoi regions are
separated with boundary lines [1]
The representative codeword is determined to be the
closest in Euclidean distance from the input vector. The
Euclidean distance is defined by
( )
√∑( )
( )
where, xj is the jth
component of the input vector, and
yij is
the jth
is component of the codeword yi [1].
C. Clustering of Training Vectors using LBG
algorithm
After the enrolment session, the acoustic vectors
extracted from input speech of a speaker provide a set
of training vectors. As described above, the next
important step is to build a speaker-specific VQ
codebook for this speaker using those training vectors.
There is a well-known algorithm, namely LBG
algorithm [Linde, Buzo and Gray, 1980], for clustering
a set of L training vectors into a set of M codebook
vectors [3]. The algorithm is formally implemented by
the following recursive procedure:
1. Design a 1-vector codebook; this is the centroid of
the entire set of training vectors (hence, no iteration
is required here).
2. Double the size of the codebook by splitting each
current codebook yn according to the rule
( )
( )
Where n varies from 1 to the current size of the
codebook, and ε is a splitting parameter (we choose
ε=0.01).
3. Nearest-Neighbor Search: for each training vector,
find the codeword in the current codebook that is
closest (in terms of similarity measurement), and
assign that vector to the corresponding cell
(associated with the closest codeword).
4. Centroid Update: update the codeword in each cell
using the centroid of the training vectors assigned
to
that cell.
5. Iteration 1: repeat steps 3 and 4 until the average
distance falls below a preset threshold.
6. Iteration 2: repeat steps 2, 3 and 4 until a codebook
size of M is designed [3].
III. SPEECH RECOGNITION
Speech Recognition is the ability of a computer to
recognize general, naturally flowing utterances from a
wide variety of users [10]. Speaker independent isolated
word recognition for the purpose of automation in a
smart home has been described in this paper. The
process of isolated word recognition involves
acquisition of the speech sequence of the word uttered
by the user. This then followed by the extraction of
MFCC‟s or the acoustic feature vectors which is exactly
similar to the processes employed in speaker
recognition described in the above section. This then
followed by the DTW algorithm to identify the
correctly uttered word.
A. Dynamic Time Warping
DTW algorithm is based on Dynamic Programming
techniques as described in [10]. This algorithm is for
measuring similarity between two time series which
may vary in time or speed. This technique also used to
find the optimal alignment between two times series if
one time series may be “warped” non-linearly by
stretching or shrinking it along its time axis. This
warping between two time series can then be used to
find corresponding regions between the two time series
or to determine the similarity between the two time
series [11]. The principle of DTW is to compare two
dynamic patterns and measure its similarity by
calculating a minimum distance between them. The
classic DTW is computed as below. Suppose we have
two time series Q and C, of length n and m respectively,
where:
Q= q1,q2,q3….qi….qn (8)
C=c1,c2,c3.....cj…...cm, (9)
To align two sequences using DTW, an n-by-m matrix
where the (ith
, jth
) element of the matrix contains the
distance d (qi, cj) between the two points qi and cj is
constructed [10]. Then, the absolute distance between

8
the values of two sequences is calculated using the
Euclidean distance computation:
d (qi , cj) = (qi - cj)2 (10)
Each matrix element (i, j) corresponds to the alignment
between the points qi and cj. Then, accumulated
distance is measured by:
D(i, j) =min[ D(i-1, j-1), D(i-1, j) ,D(i, j-1) ] + d(i, j)
(11)
Using dynamic programming techniques, the search for
the minimum distance path can be done in polynomial
time P(t), using equation below:
P(t)=O(N2 V) (12)
where, N is the length of the sequence, and V is the
number of templates to be considered [11].
Theoretically, the major optimizations to the DTW
algorithm arise from observations on the nature of good
paths through the grid. These are outlined in Sakoe and
Chiba [11,12] and can be summarized as: Monotonic
condition, Continuity Condition, Boundary Condition,
Adjustment window condition and Slope constraint
condition.
IV. SYSTEM ARCHITECTURE
The application of speaker and speech recognition in
our proposed smart home system is shown in figure 7.
Fig. 3 Process flow of the proposed smart home
system
As described in figure 7 a prospective user must first be
authenticated to use the system, his speech sequences
are first acquired and analyzed using MFCC and VQ
LBG if it matches with the speaker templates then the
user is granted access. The next phase is the automation
phase, the authenticated user utters the name of the
device/appliance he wants to use, provided the
reference template of the word is stored and the device
is connected to the system. DTW algorithm insures
robust matching with the reference templates and on
correct recognition passes on the results acquired to the
PIC16F676 microcontroller using the RS232 standard
communication protocol. On receiving the appropriate
signals of the correctly recognized device/appliance, its
current status would be toggled.
A. Experimental Setup
As it can be seen from figure 7, the basic experimental
setup consists of mic which captures the utterances from
the user. Processing of the speech is done by the Matlab
Scripts which involves feature extraction using MFCC,
Feature matching and optimization using VQ and LBG
respectively, followed by isolated word recognition using
DTW. The phases of speaker and speech recognition are
carried out in Matlab following which the results of
authentication and identification are serially
communicated to the PIC16F676 microcontroller.
Computer mic Light Bulb PIC16F676 based RS232
Relay board
Fig. 4 Experimental set up for speaker and speech
recognition based device control
B. PIC16F676 based RS232 Relay Board
The PIC16F676 microcontroller has been used in our
system for communicating with Matlab to acquire the
results of the recognized word using the RS232
communications protocol. Interfacing with various
devices in our system has been accomplished by
making provisions for an array of relays.
Acquisition of Speech Sequence from the prospective
user
Analysis of the Speech Sequence for
Authentication
Speech Feature Extraction using MFCC
Speech Feature matching with the models in the
database using VQ LBG
Perform Speech Recognition using DTW
Grant of access to the authenticated user for
controlling devices using speech recognition
Acquire uttered speech sequence and extraction
of acoustic feature vectors(MFCC)
Recognition of the uttered word using DTW
Serially communicate the recognized word to
PIC16F676 using RS232 communication
protocol
Toggle the current status of the corresponding
device connected to the microcontroller via a
relay
9
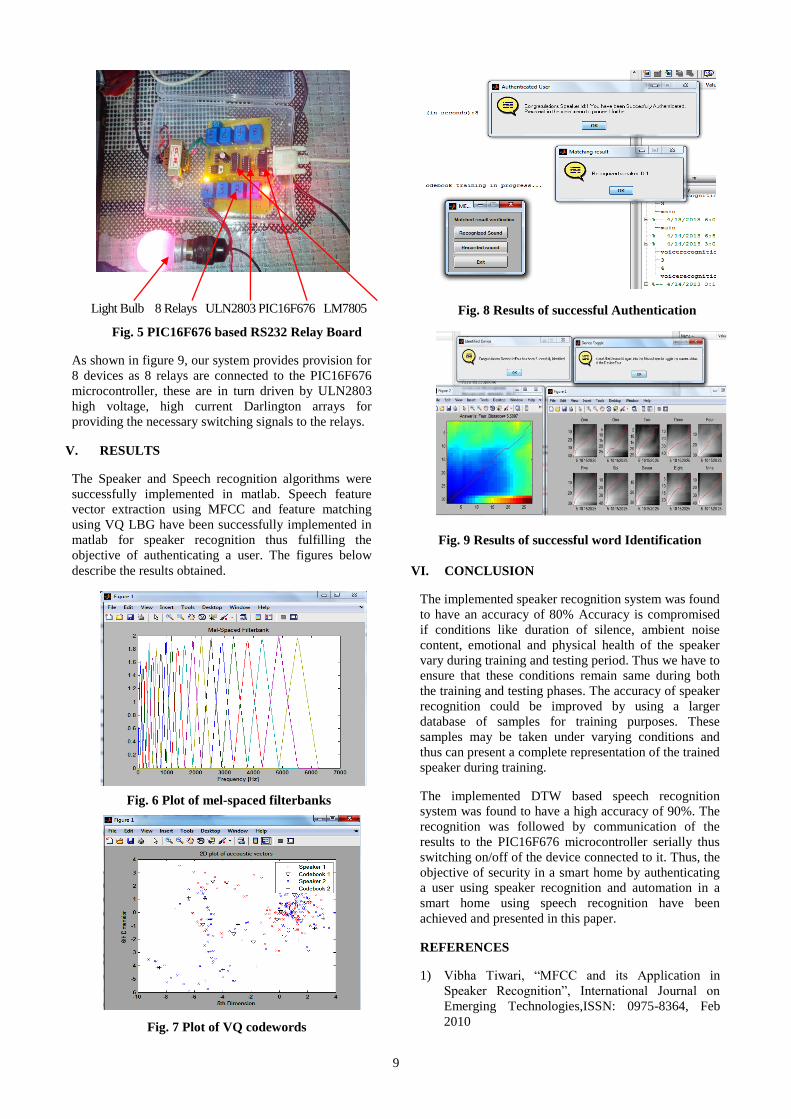
Light Bulb 8 Relays ULN2803 PIC16F676 LM7805
Fig. 5 PIC16F676 based RS232 Relay Board
As shown in figure 9, our system provides provision for
8 devices as 8 relays are connected to the PIC16F676
microcontroller, these are in turn driven by ULN2803
high voltage, high current Darlington arrays for
providing the necessary switching signals to the relays.
V. RESULTS
The Speaker and Speech recognition algorithms were
successfully implemented in matlab. Speech feature
vector extraction using MFCC and feature matching
using VQ LBG have been successfully implemented in
matlab for speaker recognition thus fulfilling the
objective of authenticating a user. The figures below
describe the results obtained.
Fig. 6 Plot of mel-spaced filterbanks
Fig. 7 Plot of VQ codewords
Fig. 8 Results of successful Authentication
Fig. 9 Results of successful word Identification
VI. CONCLUSION
The implemented speaker recognition system was found
to have an accuracy of 80% Accuracy is compromised
if conditions like duration of silence, ambient noise
content, emotional and physical health of the speaker
vary during training and testing period. Thus we have to
ensure that these conditions remain same during both
the training and testing phases. The accuracy of speaker
recognition could be improved by using a larger
database of samples for training purposes. These
samples may be taken under varying conditions and
thus can present a complete representation of the trained
speaker during training.
The implemented DTW based speech recognition
system was found to have a high accuracy of 90%. The
recognition was followed by communication of the
results to the PIC16F676 microcontroller serially thus
switching on/off of the device connected to it. Thus, the
objective of security in a smart home by authenticating
a user using speaker recognition and automation in a
smart home using speech recognition have been
achieved and presented in this paper.
REFERENCES
1) Vibha Tiwari, “MFCC and its Application in
Speaker Recognition”, International Journal on
Emerging Technologies,ISSN: 0975-8364, Feb
2010

10
2) S. J. Abdallaha, I. M. Osman, M. E. Mustafa,
“Text-Independent Speaker Identification Using
Hidden Markov Model” World of Computer
Science and Information Technology Journal
(WCSIT) , ISSN: 2221-0741, Vol. 2, No. 6, 203-
208, 2012
3) Ch.Srinivasa Kumar et al., “Design Of An
Automatic Speaker Recognition System Using
MFCC, Vector Quantization And LBG Algorithm”,
International Journal on Computer Science and
Engineering (IJCSE), ISSN: 0975-3397, Vol 3 No:
8, August 2011
4) Srinivasan,”Speaker Identification and Verification
using Vector Quantization and Mel Frequency
Cepstral Coefficients” Research Journal of Applied
Sciences, Engineering and Technology, ISSN:2040-
7467, 4(1): 33-40, 2012
5) Anjali Bala et al. , ”Voice Command recognition
system on MFCC and DTW”, International Journal
of Engineering Science and Technology,
ISSN:0975-5462, Vol. 2 (12), 2010,
6) D. Subudhi, A.K. Patra, N. Bhattacharya, and P.
Kuanar, “Embedded System Design of a Remote
Voice Control and Security System”, TENCON
2008-2008 Region 10 Conference
7) Ian McLoughlin, “Applied Speech and Audio
Signal Processing”, Cambridge University Press,
2009
8) Jacob Benesty, M. Mohan Sondhi, Yiteng
Huang(Eds.),”Springer Handbook of Speech
Processing”
9) A Thakur, “Design of a Matlab based Automatic
Speaker Recognition and Control System”,
International journal of Advanced engineering
Sciences and Technologies, ISSN: 2230-7818, Vol
no 8, Issue no 1, 100-1
10) B Plannener, “Introduction to Speech Recognition”
March 2005, www.speech-recognition .de accessed
on 25th
April 2013
11) L Muda, M Begam and L Elamvazuthi, “Voice
Recognition Algorithms using MFCC and DTW
Techniques” Journal of Computing, volume 2 ,
issues 3, March 2010
12) Steve Cassidy, “Speech Recognition: Chapter 11:
Pattern Matching in Time”,
http://web.science.mq .edu.au/~cassidy/comp449/ht
ml/ch11s02.html, Accessed on 24th
April 2013

11