spring 2015 mathematics in management science binary linear codes two examples
TRANSCRIPT

Spring 2015Mathematics in
Management Science
Binary Linear Codes
Two Examples

ExampleConsider the code C = {0000000, 0010111, 0101101, 0111010,1001011, 1011100, 1100110, 1110001}
Use nearest-neighbor method to decode w = 1010100:
So, w decodes to 1011100.
Code word 0000000 0010111 0101101 0111010
W 1010100 1010100 1010100 1010100
Bit sum 1010100 1000011 1111001 1101110
Distance 3 3 5 5
Code word 1001011 1011100 1100110 1110001
W 1010100 1010100 1010100 1010100
Bit sum 0011111 0001000 0110010 0100101
Distance 5 1 3 3

ExampleGiven the code C = {0000000, 0010111, 0101101, 0111010, 1001011, 1011100, 1100110, 1110001}.
Can W = 1000001 be decoded?
This cannot be decoded because there is no one closest code word.
Code word 0000000 0010111 0101101 0111010
W 1000001 1000001 1000001 1000001
Bit sum 1000001 1010110 1101100 1111011
Distance 2 4 4 6
Code word 1001011 1011100 1100110 1110001
W 1000001 1000001 1000001 1000001
Bit sum 0001010 0011101 0100111 0110000
Distance 2 4 4 2

Spring 2015Mathematics in
Management Science
Data Compression
Huffman CodesCode Trees
Encoding & Decoding
Constructing

Types of Codes
Error Detection/Correction Codes
for accuracy of data
Data Compression Codes
for efficiency
Cryptography
for security

Error Correcting Codes
In error correction we expand the data (through redundancy, check digits, etc.) to be able to detect and recover from errors.

Data Compression
Here want to use less space to express (approximately) same info.
Reduced size of data (fewer data bits) means reduced costs for both storage and transmission.

Data Compression
Data compression is the process of encoding data so that the most frequently occurring data are represented by the fewest symbols.

Sources of Compressibility
RedundancyRecognize repeating patterns
Exploit usingDictionary
Variable length encoding
Human perceptionLess sensitive to some information
Can discard less important data

Compression Algorithms
Can be lossless – meaning that original data can be reconstructed exactly – or lossy – meaning only get approximate reconstruction of the data.
Examples
ZIP and GIF are lossless
JPEG and MPEG are lossy

Types of Compression
LosslessPreserves all information
Exploits redundancy in data
Applied to general data
LossyMay lose some information
Exploits redundancy & human perception
Applied to audio, image, video

Lossy Data Compression
Frequently used for images where an exact reproduction may not be required.
Many different shades of gray could be converted to just a few.
Many different colors could be changed to just a few.

Run-Length Encoding (RLE)
Simple form of data compression (introduced very early, but still in use).
Only useful where there are long runs of same data (e.g., black and white images).
Repeated symbols (runs) are replaced by a single symbol and a count.

Run-Length Encoding (RLE)
Repeated symbols (runs) are replaced by a single symbol and a count.
For example, we could replace
aaaaaaaaaAAaaaaaAAAAAAAA
with just 9a2A5a8A.
Simplistic, but still commonly used.
Only effective when have long runs of symbols (e.g., images with small color palettes).

Run-Length Encoding (RLE)
Repeated symbols (runs) are replaced by a single symbol and a count.
Example Suppose in a B/W image
‘.’ represents a white pixel
‘*’ represents a black pixel
One row of pixels has the form
...............*......***..................**.....

Run-Length Encoding (RLE)
Repeated symbols (runs) are replaced by a single symbol and a count.
One row of pixels has the form
...............*......***..................**.....These 50 characters could be replaced by the 16 characters
15.1*6.3*18.2*5.


ABACABADABACABAD
In ABACABADABACABAD (16 chars),
A appears 8 times,
B appears 4 times,
C & D each appear twice.
Standard ASCII codes this by using
8 ×16 = 128 bits.

ABACABADABACABAD
In ABACABADABACABAD (16 chars),A 8 times, B 4 times, C & D each twice.
Can label 4 chars with 2 bits:
A → 00, B → 01, C → 10, D → 11
Now get 16 chars → 2 ×16 = 32 bits to represent the sequence.
Here used fixed length labels.

ABACABADABACABAD
In ABACABADABACABAD (16 chars),
A 8 times, B 4 times, C & D each twice.
Use variable length labels instead, based on idea that most frequent chars get the shortest labels. So, use codes
A → 0, B → 10, C → 110, D → 111
Get message
0100110010011101001100100111
which is just 28 bits.

Uncompressing Data
Data must be recoverable!
Compression algorithms must be reversible (up to some accepted loss in lossy algorithms).
In previous ex, how do we decode
0100110010011101001100100111 ?
Where do labels end??

Uncompressing Data
How do we decode
0100110010011101001100100111 ?
Where do labels end? Labels given by
A → 0, B → 10, C → 110, D → 111
Every 0 terminates a label.
Only D does not end with 0; it is the only label with three 1’s.

Uncompressing Data
How do we decode
0100110010011101001100100111 ?
Labels given by
A → 0, B → 10, C → 110, D → 111
So rule is: read from left and break when see 0 or three consecutive 1’s.

Uncompressing Data
Decode 111110000011001100010
Labels given by
A → 0, B → 10, C → 110, D → 111
Rule: read from left and break when see 0 or three consecutive 1’s.
Get 111,110,0,0,0,0,110,0,110,0,0,10
which translates as DCAAAACACAAB.


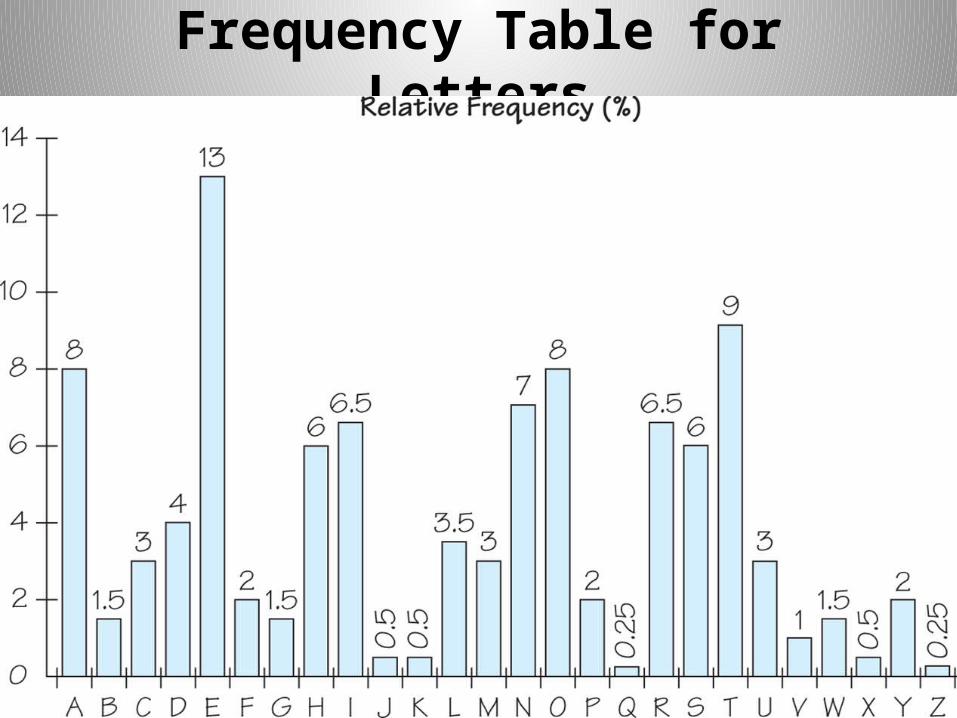
Morse Code
Ternary code (uses short & long marks, and spaces) invented in early 1840s.
Widely used until mid 20th century.

Frequency Table for Letters

Huffman Encoding
A general lossless compression method.
Developed by David Hu man in 1951 (while ffa grad student at MIT).
Encodes single chars using variable length labels.
Hu man codes are ff the most e cient ffiamong compression methods that assign strings of bits to individual source symbols.

Huffman Encoding
ApproachVariable length encoding of chars
Exploit statistical frequency of chars
Efficient when char freqs vary widely
PrincipleUse fewer bits for frequent symbols
Use more bits for infrequent symbols

Huffman Encoding
Code created using so-called code tree by arranging chars from top to bottom according to increasing probabilities.
The code tree is used to both encode and decode.
Must know:
How to create the code tree.
How to use code tree to encode/decode.

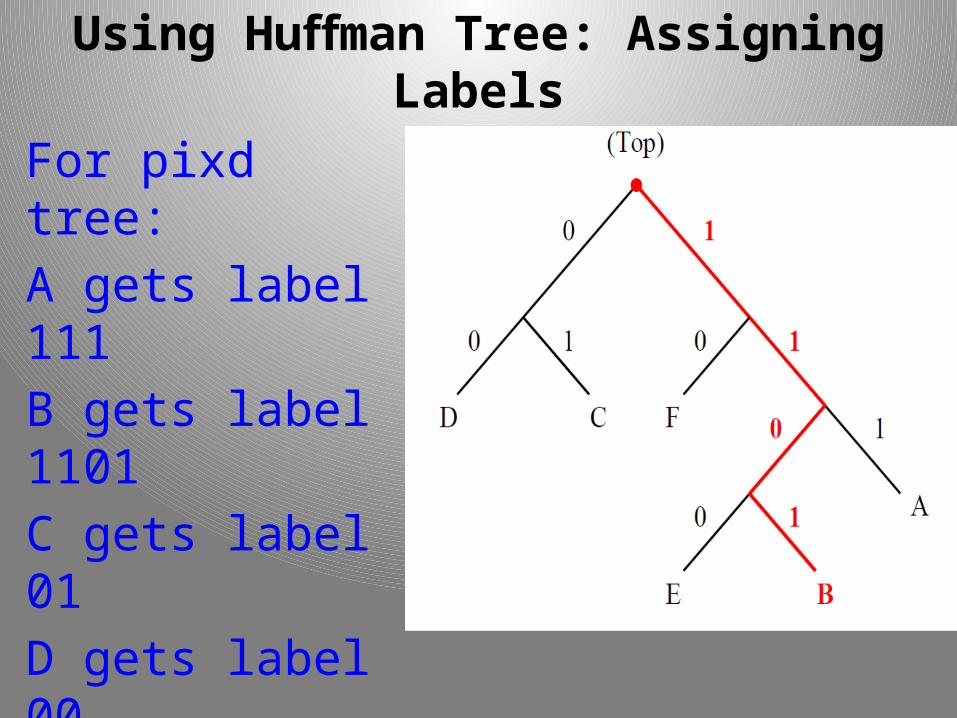
Using Hu man Tree: Assigning Labelsff
The label that gets assigned to a letter is the sequence of binary digits along the path connecting the top to the desired letter.

Using Hu man Tree: Assigning Labelsff
For pixd tree:
A gets label 111
B gets label 1101
C gets label
D gets label
E gets label
F gets label
Using Hu man Tree: Assigning Labelsff
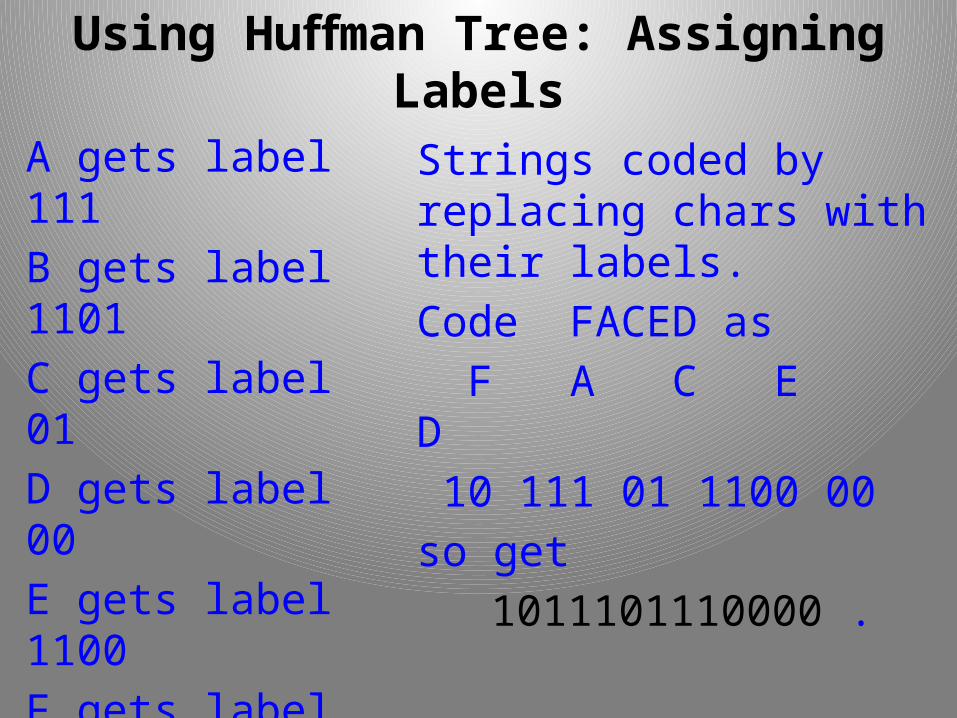
For pixd tree:
A gets label 111
B gets label 1101
C gets label 01
D gets label 00
E gets label 1100
F gets label 10
Using Hu man Tree: Assigning Labelsff
A gets label 111
B gets label 1101
C gets label 01
D gets label 00
E gets label 1100
F gets label 10
Strings coded by replacing chars with their labels.
Code FACED as
F A C E D
10 111 01 1100 00
so get
1011101110000 .

Using Hu man Tree: Decodingff
The digits “walk” you down the tree to the correct letter.
Read digits from left side of code string.When see 0, take left branch.
When see 1, take right branch.
Continue until you terminate at a letter.
Replace digits read so far with letter and repeat from the top of the tree with the next digit.
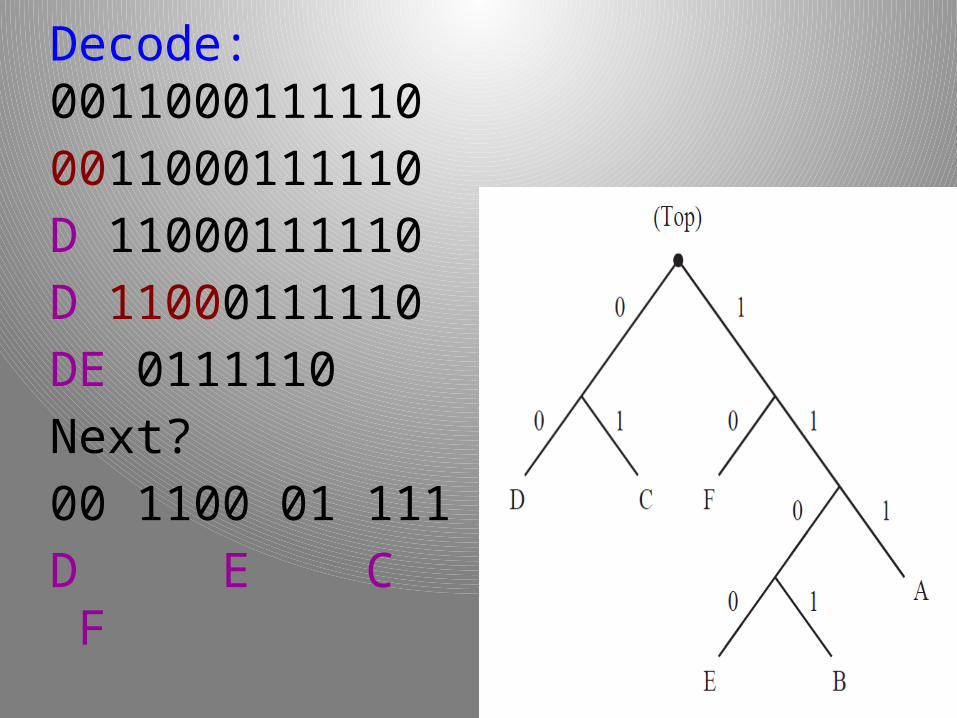
Decode: 0011000111110
0011000111110
D 11000111110
D 11000111110
DE 0111110
Next?
00 1100 01 111 10
D E C A F

Creating a Huffman Code Tree
Constructed from a frequency table.
Freq table shows number of times (as a fraction of the total) that each char occurs in the document.
Freq table specific to the document being compressed, so
every doc has its own code tree!

Frequency Table Example
“PETER PIPER PICKED A PECK OF PICKLED PEPPERS”

Creating a Huffman Code Tree
Start with freq table:
A 0.190
B 0.085
C 0.220
D 0.205
E 0.070
F 0.230
Sort freq table:
E 0.070
B 0.085
A 0.190
D 0.205
C 0.220
F 0.230

Creating a Huffman Code TreeMerge top (smallest) two values, put char with smaller value on left, and sort again.
E 0.070
B 0.085
A 0.190
D 0.205
C 0.220
F 0.230
EB 0.155
A 0.190
D 0.205
C 0.220
F 0.230
Repeat Process

Creating a Huffman Code TreeMerge top (smallest) two values, put char with smaller value on left, and sort again.
EB 0.155
A 0.190
D 0.205
C 0.220
F 0.230
Repeat Process
D 0.205
C 0.220
F 0.230
EBA 0.345

Creating a Huffman Code TreeMerge top (smallest) two values, put char with smaller value on left, and sort again.
D 0.205
C 0.220
F 0.230
EBA 0.345
Repeat Process
F 0.230
EBA 0.345
DC 0.425

Creating a Huffman Code TreeMerge top (smallest) two values, put char with smaller value on left, and sort again.
F 0.230
EBA 0.345
DC 0.425
DCFEBA 1.000
DC 0.425
FEBA 0.575
Now gotta build Code Tree.

Creating a Huffman Code Tree
Construct tree from top down by reversing all merges.
Insert branch when symbols (re)split.
Left branch labeled 0, right branch 1.
First split (last merge) is
DCFEBA into DC + FEBA



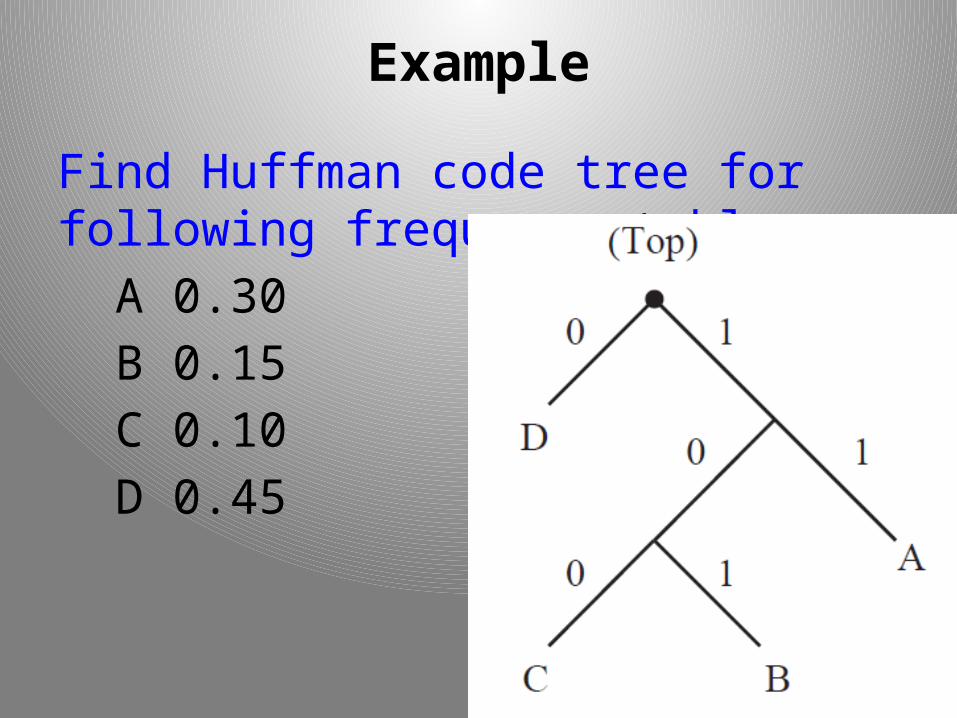
Example
Find Huffman code tree for following frequency table.
A 0.30
B 0.15
C 0.10
D 0.45