sql language guide - online documentation - raima
TRANSCRIPT

RDM SQL Language Guide
1
Raima Database Manager 11.0
RDM SQL Language Guide

RDM SQL Language Guide
2
Trademarks
Raima Database Manager® (RDM®), RDM Embedded® and RDM Server® are trademarks of Raima Inc. and may be registered in the United States of America and/or other countries. All other names may be trademarks of their respective owners.
This guide may contain links to third-party Web sites that are not under the control of Raima Inc. and Raima Inc. is not responsible for the content on any linked site. If you access a third-party Web site mentioned in this guide, you do so at your own risk. Inclusion of any links does not imply Raima Inc. endorsement or acceptance of the content of those third-party sites.

RDM SQL Language Guide
Contents 3
ContentsContents 3
Introduction 10
Operational Overview 11
How this Book is Organized 14
A Language for Describing a Language 16
A Simple Interactive SQL Scripting Utility 18
Interface and Scripting Commands 18
Defining a Database 25
Create Database 25
Create Domain 26
Create Table 27
Standard Database Table 27
Virtual Table 30
Compiling a DDL Specification 32
Example Databases 32
National Science Foundation Awards Database 33
Antiquarian Bookshop Database 35
Retrieving Data from a Database 40
Simple Queries 40
Column Expressions 41
Conditional Queries 46
Retrieving Data from Multiple Tables 50
Sorting Query Results 55
Performing Result Set Aggregate Calculations 58
NSF Gender Study Example 63
Inserting Data into a Database 67
Transactions 67
Insert Values 68

RDM SQL Language Guide
Contents 4
Insert From Select 70
Import 70
Changing and Deleting Data in a Database 73
Searched Delete Statement 73
Searched Update Statement 75
Writing and Using Stored Procedures 79
Concurrent Database Access 83
Locking In RDM SQL 84
Read Only Transactions 85
Modification Stored Procedures 86
Avoiding Deadlock 86
Concurrent Database Access Use in Static SQL Applications 87
How Queries are Processed by RDM SQL 89
Overview of the Query Optimization Process 89
Cost-Based Optimization 93
Restriction Factors 94
Table Access Methods 94
Sequential Table Scan 95
Hashed Access Retrieval 95
Index Access Retrieval 95
Joins Involving Primary and Foreign Keys 96
Optimizable Expressions 97
Access Plan Determination 98
Selecting From Alternative Access Methods 98
Selecting the Access Order 98
Sorting and Grouping Operations 100
Outer Join Processing 100
Returning the Number of Rows in a Table 100
Query Construction Guidelines 101

RDM SQL Language Guide
Contents 5
Controlling Optimizer with a User-Specified Restriction Factor 102
Using SQL in an Application Program 103
Native SQL API Basics 103
Comparing the ODBC API with the Native RSQL API 105
Connection Handles 107
Statement Handles 107
Header Files 109
API Function Parameters 109
SQL Data Types and Values 110
Structure of an RDM SQL Application 113
Hello World! 114
Initializing and Terminating TFS operation 118
Connecting to a TFS and Opening Databases 119
Database Unions 121
Compiling and Executing SQL Statements 122
Retrieving Select Statement Results 128
Basic Retrieval 128
Retrieving Blob Data Values 128
Fetching Results From Retrieval Stored Procedures 130
Positioned Update and Delete Statements 135
User-Defined Functions (UDFs) in SQL 138
UDF Load Table Definition and Registration 138
UDF Type Checking Function: udfCheck 142
UDF Initialization Function: udfInit 145
UDF Termination Function: udfTerm 146
Scalar Call Function: udfScalarCall 147
Aggregate UDF Call Function: udfAggCall 148
Aggregate UDF Result Function: udfAggResult 150
Aggregate UDF Reset Function: udfAggReset 151

RDM SQL Language Guide
Contents 6
Calling RSQL API Functions from a UDF 152
Using Virtual Tables to Access Any Data 154
Virtual Table Load Table Definition and Registration 155
Thread-safe Access to Global Data Used by a Virtual Table Interface 158
Virtual Table Execution Function: vtInsert 160
Virtual Table Row Count Function: vtRowCount 164
Virtual Table Row Count Function: vtSelectCount 164
Virtual Table Select Open Function: vtSelectOpen 166
Virtual Table Fetch Function: vtFetch 168
Virtual Table Select CloseFunction: vtSelectClose 170
Virtual Table Usage 170
Accessing a Core (non-SQL) Database in RDM SQL 173
How Core Database Record Types are Mapped to SQL Tables 173
Mapping Core Keys to SQL Keys 174
Mapping Core Sets to SQL Foreign Keys 175
Multi-Member Sets and Explicit Locking 176
Order of Columns in the Table 176
Null Values 176
Adding Column Information and Creating a Catalog 176
SQL Built-In Function Reference 179
Aggregate Functions 179
Scalar Functions 179
Mathematical Functions 179
Date and Time Functions 180
String Functions 180
abs 182
acos 183
age 184
asin 185

RDM SQL Language Guide
Contents 7
atan 186
atan2 187
avg 188
ceiling 189
convert 190
cos 193
cot 194
count 195
curdate 197
curtime 198
dayofmonth 199
dayofweek 200
dayofyear 201
exp 202
floor 203
hour 204
if 205
ifnull 206
log 207
max 208
min 209
minute 210
mod 211
month 212
pi 213
quarter 214
query 215
rand 216
second 217

RDM SQL Language Guide
Contents 8
sign 218
sin 219
sqrt 220
sum 221
tan 223
week 224
year 225
SQL Language Syntax Summary 226
RDM DDL Statements 226
RDM DML Statements 228
RDM Procedure Statements 234
SQL Reserved Words for RDM 235
SQL Statement Reference 237
close 238
commit 239
create catalog 240
create database 241
create domain 243
create procedure 245
create table 247
create virtual table 252
delete 254
drop database 256
drop procedure 257
end read only transaction 258
execute 259
export 261
import 262
initialize 265

RDM SQL Language Guide
Contents 9
insert 266
lock table 268
open 270
release 272
rollback 273
savepoint 274
select 275
set 281
set column 283
start 285
unlock table 287
update 288
SQL UDF Reference 290
udfAggCall 291
udfAggReset 293
udfAggResult 295
udfCheck 297
udfInit 300
udfScalarCall 302
udfTerm 305
SQL Virtual Table Function Reference 307
vtFetch 308
vtInsert 311
vtRowCount 315
vtSelectClose 317
vtSelectCount 319
vtSelectOpen 321
Glossary 324
Index 335

RDM SQL Language Guide
Introduction 10
Introduction"The days just prior to marriage are like
a snappy introduction to a tedious book."- Wilson Mizner,
US Screenwriter (1876-1933)
According to Wikipedia's entry entitled "Elephant Joke", there's an old one that goes like this:
Q. How many elephants will fit into a Mini?
A. Four: two in the front, two in the back.
Q. How many giraffes will fit into a Mini?
A. None. It's full of elephants.
Of course, if it is possible to get four elephants into a Mini then it must be pretty easy to get one in. In which case, there must also be no problem using SQL in an embedded computer application! But, even if one does succeed in getting the elephant into the car, the added weight will certainly have a significant negative impact on its speed. Such is the case on the advisability of using SQL in an embedded database application. The 2008 edition of Vol-ume 2 of the ANSI/ISO SQL standard is over 1300 pages long. That's about twice the size of the 1992 standard which itself was considerably larger than the original 1989 standard. A fully-compliant implementation of SQL (which may not actually exist) is indeed a monster. For any SQL database management system (DBMS) imple-menter, just the effort involved to understand the standard in order to construct a commercially-viable, fully-compliant implementation is immense.
Nevertheless, SQL has become the industry standard database access language. As such, there are many soft-ware developers who know how to use SQL. Because of this vast availability of SQL database skills, many com-panies that are involved in the development of embedded computer applications with database management requirements would like to be able to use SQL to access and manipulate that database information.
The DBMS capabilities that are needed in embedded computing applications are not nearly as broad as those needed in enterprise systems. RDM SQL has been designed specifically for embedded systems applications. As such, it provides a subset of the ANSI/ISO standard SQL that is suitable for running on a wide variety of com-puters and embedded operating systems many of which have limited computing resources. Some non-standard features are also included that are designed specifically for the needs of embedded computing applications.
RDM SQL is built on top of the RDM database system and thus provides all of its replication and mirroring capabilities. However, it is important to note that RDM SQL is not designed to provide an SQL interface to exist-ing RDM applications but to be the primary database access interface for the application. Of course, the ability to use the core-level RDM API is available to the RDM SQL user but the need to utilize the lower-level record-oriented API would be the exception and not the rule. On a practical level what this means is that the application database can only be defined through the RDM SQL DDL which does not expose all of the DDL capabilities avail-able in the non-SQL RDM DDL.
Features of SQL that are not all that useful in embedded applications and, when implemented, can consume a significant amount of computing resources have not been implemented in RDM SQL. Those features include: database views (create view) and security (grant and revoke), check clause integrity constraints, triggers (create trigger), and dynamic DDL (alter table).

RDM SQL Language Guide
Introduction 11
Non-standard features that have been added based on embedded application requirements include the ability to:
l include compiled C modules containing statically initialized database catalog tables and SQL stored pro-cedures,
l include compiled C modules containing statically initialized, pre-compiled SQL stored procedure def-initions,
l define user-defined SQL functions in C, l define virtual tables that allow any kind of data source (e.g., real-time sensor network data) to be accessed
through SQL, l limit the number of returned rows from a select statement by number or time, l produce a target SQL application that does not need to perform any dynamic compilation of SQL state-
ments.
This manual uses standard database and SQL terminology such as DDL (database definition language), DML (database manipulation language), etc. If there is a term that you do not understand simply refer to the glossary toward the end of the manual for a definition.
Operational OverviewRDM SQL is designed to be used in a C language application program and execute on virtually any operating sys-tem and hardware platform. While many platforms are supported, a given database application must only use platforms that are architecturally identical (e.g., same endianess).
Input and output to an RDM database is managed by an RDM Transactional File Server (TFS). The RDM SQL application makes calls to the RDM SQL application program interface (API) functions which can compile and/or execute SQL statements embedded in the application program. Figure 1
Figure 1 shows a typical RDM SQL application that includes the ability to dynamically compile and execute SQL statements.

RDM SQL Language Guide
Introduction 12
Figure 1 - Dynamic RDM SQL Application
Embedded applications, however, typically have well-defined data access and manipulation requirements and so they usually do not need to have the ability to support ad hoc query processing. As much as 25-30% of an SQL implementation goes to the support of dynamic compilation. Thus, if this can be eliminated from the embed-ded application code, a not insignificant amount of memory can be saved.
In order to do this, RDM SQL provides the ability to define a basic stored procedure that can contain either one or more select statements or one or more insert, update, or delete statements. These statements are compiled on a host development computer system. The compiled form of the stored procedure is stored in both a C file and a binary file. The C file can be compiled and linked in with the application and the procedures executed through a specific RDM SQL API function call (rsqlExecProc). When all of the SQL statements used by an application are encapsulated this way in pre-compiled stored procedures then the compilation component of RDM SQL is no longer needed and can be omitted from the application. Figure 2 depicts this situation.
Notice that an RDM application program can access databases from any number of TFSs and that those TFSs can be running on any computer that is accessible to the application's computer through TCP/IP. A feature of RDM SQL is the ability to open multiple instances of the same database running on separate TFSs as a single database that is a union of the separate instances. This allows the database to be separated into independent partitions on which queries can be performed across all partitions. The Concurrent Database Access section will describe this feature in more detail.
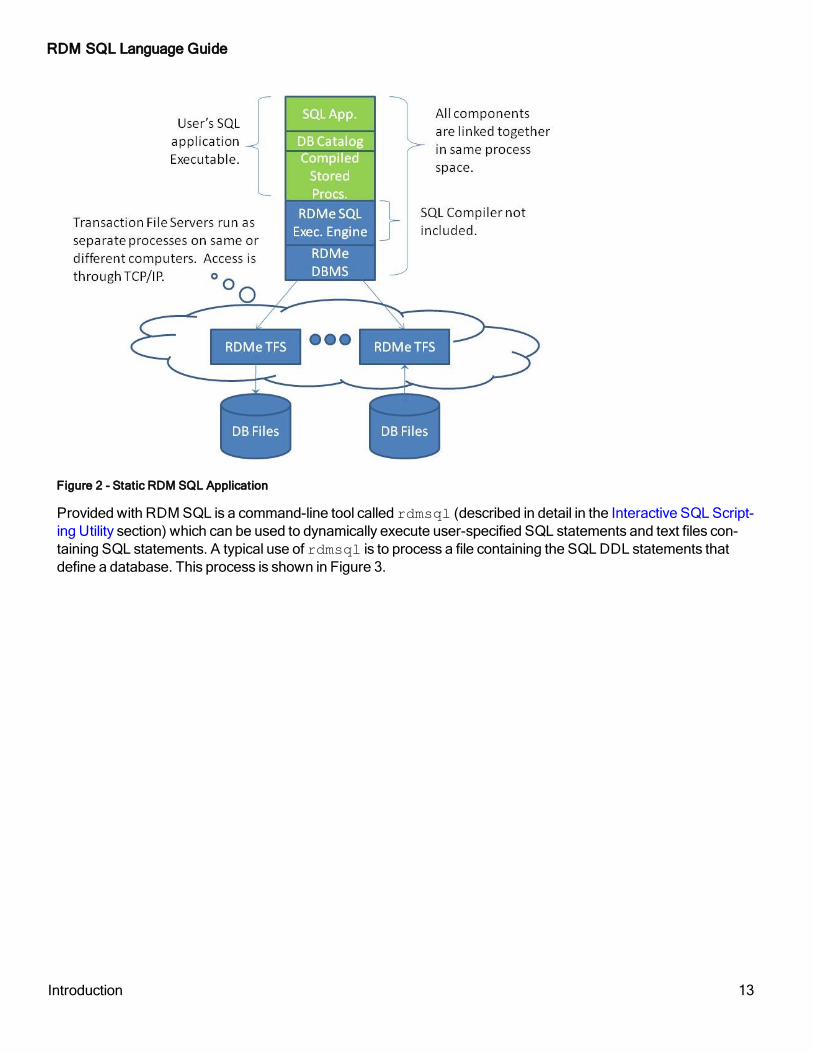
RDM SQL Language Guide
Introduction 13
Figure 2 - Static RDM SQL Application
Provided with RDM SQL is a command-line tool called rdmsql (described in detail in the Interactive SQL Script-ing Utility section) which can be used to dynamically execute user-specified SQL statements and text files con-taining SQL statements. A typical use of rdmsql is to process a file containing the SQL DDL statements that define a database. This process is shown in Figure 3.

RDM SQL Language Guide
Introduction 14
Figure 3 - How RDM SQL Processes a DDL File
Embedded development often involves doing development on a host system and deploying the application on a target system. Catalogs and stored procedures that are created on the host platform can only be used on a tar-get platform that is architecturally identical to the host. However, if the catalogs and stored procedures were created by an RDM SQL running under a target simulator on the host system, then they will be output in a target-compatible format.
Besides the native RDM SQL API, standard ODBC and JDBC interfaces are also provided. Two forms of each are available. A client-server version allows an ODBC or JDBC application to interact with an RDM SQL data-base engine running as a server on a separate computer. This allows, for example, third-party ODBC-based tools to access an RDM SQL database without having to execute on the same computer. A situation which may not even be possible on some embedded systems. Alternatively, if you prefer to program using a standard SQL interface, you can link your target computer C/C++ (or Java) application directly with our ODBC (or JDBC) library.
How this Book is OrganizedThe sections in this book are designed as a tutorial that incrementally introduces you to SQL in general and its use in RDM specifically. Rather than just repeat here what's also in the Table of Contents, I recommend that you check it out to see how the book is organized.
Following the chapters, the appendices which comprise a significant amount of the book provide a reference manual for the system. If you already know SQL then you can skip most of the chapters and go right to the appen-dices. However, I would strongly suggest that you read through Chapters 3, 4, 8, 9, 10, 12, and 13 because they describe important features that are unique to RDM SQL. Okay, so you don't really get to skip much at all.

RDM SQL Language Guide
Introduction 15
We here at Raima have worked hard to make this manual both easy-to-read and easy-to-use as well as accu-rate. Any errors are the responsibility of the primary author and if you find any we would greatly appreciate your letting us know which you can easily do through our web site at http://www.raima.com.

RDM SQL Language Guide
A Language for Describing a Language 16
A Language for Describing a LanguageWorks of imagination should be
written in very plain language;
the more purely imaginative they are
the more necessary it is to be plain.- Samuel Taylor Coleridge
SQL stands for "Structured Query Language". You have probably seen many different methods used in pro-gramming manuals to show how to use a specific programming language. The two most common methods use syntax flow diagrams and what is known as Backus-Naur Form (BNF) which is a formal language for describing a programming language. In this document we use a simplified BNF method that seeks to represent the lan-guage in a way that closely matches the way you will code your own SQL statements for your application.
For example, the following select statement:
select sale_name, company, city, state
from salesperson natural join customer;
can be described by this syntax rule:
select_stmt:
select identifier[, identifier]… from identifier [natural join identifier] ;
where "select_stmt" is the name of the rule (sometimes called a non-terminal); the bold-faced identifiers select, from, natural, and join are key words (sometimes called terminal symbols); identifier is like a function argument that stands in place of a user-specified value (technically, it too is the name of a rule that is matched by any user-specified value that begins with a letter followed by any sequence consisting of letters, digits, and the underscore ("_") character). Rule names are identifiers and their definitions are specified by giving the rule name beginning in column 1 and terminating the rule with a colon (":") as shown above.
There are also special meta-symbols that are part of the syntax descriptor language. Two are shown in the above select_stmt syntax rule. The brackets ("[" and "]") enclose optional elements. The ellipsis ("…") specifies that the preceding item can be repeated zero or more times. Other meta-symbols include a vertical bar (i.e., an "or" symbol) that is used to separate alternative elements and braces ("{" and "}") which enclose a set of alter-natives from which one must always be matched. All other special characters (e.g., the "," and ";" in the select_stmt rule) are considered to be part of the language definition. Meta-symbols that are themselves part of the lan-guage will be enclosed in single quotes (e.g., '[') in the syntax rule.
Rule names can be used in other rules. For example, the syntax for a stored procedure that can contain multiple select statements could be described by the following rule:
create_proc:
create procedure identifier as
select_stmt[; select_stmt]…
end proc;

RDM SQL Language Guide
A Language for Describing a Language 17
In order to make the syntax more readable, any non-bold, italicized name is considered to be matched as an iden-tifier. Thus, the select_stmt rule can also be written as follows…
select_stmt:
select column_name[, column_name]… from table_name [natural join table_name] ;
where column_name represents identifiers that correspond to table column names and table_name represents identifiers that correspond to table names.
Some italicized terms are used to match specific text patterns. E.g., number matches any text pattern that can be used to represent a number (either integer or decimal) and integer matches any pattern that represents an integer number.
These rules are summarized in the table below.
Syntax Element Description
keyword Bold-faced words that identify the special words used in the language that specify actions and usage. Sometimes called reserved words. Examples, select, insert, create, using.
identifier Italicized word corresponding to an identifier: sequences of letters, digits, and "_" that begin with a letter.
number Any text that corresponds to an integer or decimal number.
integer Any text that corresponds to an integer.
[option1 | option2] A selection in which either nothing or option1 or option2 is specified.
{option1 | option2} Either option1 or option2 must be specified.
element… Repeat element zero or more times.
identifier Normal-faced identifiers correspond to the names of syntax rules. Syntax rules are defined by the name starting in column 1 and ending with a ":".
Table 1. Syntax Description Language Elements
RDM SQL Language Guide
A Simple Interactive SQL Scripting Utility 18
A Simple Interactive SQL Scripting UtilityBeauty of style and harmony
and grace and good rhythm
depends on simplicity.- Plato
Okay, I know that this is the world of point-and-click, easy-to-use applications. In fact, many abound for doing just that with SQL. So what value can there possibly be in providing a text-based, command-line-oriented, interactive SQL scripting utility? Well, for one thing, you can keep both hands on the keyboard and never have to touch the mouse! Novel concept isn't it? It also has provided us here at Raima with something that was easy to write and is easily ported to any platform. Hence, the interface works identically on all platforms. It also provides us (and, pre-sumably, you as well) with the ability to generate test cases that can be easily and automatically executed. You will more effectively learn how to properly formulate SQL statements by actually typing them in than by simply pointing to icons that do the job for you.
The name of this program is rdmsql. To start rdmsql, open an OS command window and enter a command that conforms to the following syntax.
rdmsql
When started rdmsql will display its startup banner (unless the –B option was specified) and an input prompt.
Enter ? for list of interface commands.
001 rdmsql:
The number in the command prompt above (001 rdmsql:) is a SQL statement number which is incremented for each SQL statement executed.
Interface and Scripting CommandsThe list of rdmsql interface commands are given in the following table.
Command Description? Display the list of commands available.-- Comment delimiter. Lines beginning with "--" will be ignored.
-- Script File Example
-- Open bookshop database and wait for input
.c 1
open bookshop;
Running the above script will open the bookshop database and then wait for input..c [n srv port] Select connection handle "n". By default there are 5 connection handles available. If "n" is
not provided, the current connection information is displayed.

RDM SQL Language Guide
A Simple Interactive SQL Scripting Utility 19
Command DescriptionIf the remote connection option is selected on the command line, the "srv" parameter specifies the host name where rdmsqlserver is running and "port" specifies the anchor port number (default is port number 21553),
.d * | n [,n] Disconnect all connections (*) or specific connections by connection number.
.q Exit the rdmsql utility. The process of exiting will rollback any uncommitted transactions and disconnect connections before exiting.
.r filespec Read and execute statements from filespec.!oscmd Execute the specified OS command. For example, the following shows executing a
"dir" command:
001 rdmsql: !dir *.txt /b
acctmgrs.txt
authors.txt
bnotelines.txt
bnotes.txt
bookgens.txt
books.txt
booksubs.txt
genres.txt
names.txt
patrons.txt
pnotelines.txt
pnotes.txt
sales.txt
subjects.txt
001 rdmsql:
<return> Display the current statement.; Resubmit current statement.* Display statement history (default 25).-[n] Retreat current statement n lines (default 1)+[n] Advance current statement n lines (default 1)#n Make statement number n the current statement./old/new/[g] Substitute 'new' for 'old' in current statement. Specify 'g' to replace all occurrences.
In the example below, the current statement is statement 002. The substitution command (/091/081/) replaces the matching text in the calculation and redisplays the modified statement. The modified current statement is then resubmitted using the ";" command.
002 rdmsql: select bookid, price, price*0.091 tax from book
where bookid like "carl%";
bookid price tax
carlyle01 125 11.375
carlyle02 1385 126.035
carlyle03 995 90.545
carlyle04 3750 341.25
carlyle05 5750 523.25

RDM SQL Language Guide
A Simple Interactive SQL Scripting Utility 20
Command Description
003 rdmsql: /091/081/
rdmsql: select bookid, price, price*0.081 tax from book where
bookid like "carl%"
+ 003 rdmsql: ;
bookid price tax
carlyle01 125 10.125
carlyle02 1385 112.185
carlyle03 995 80.595
carlyle04 3750 303.75
carlyle05 5750 465.75
004 rdmsql:
.T [start|stop] Start / stop timer. Displays elapsed time between start and stop in seconds and outputs to stdout.
.e [on|off] Turn on/off echo of executing statements. If on/off is not specified, the current echo mode is displayed.
.t [on|off] Turn on/off table display mode. If on/off is not specified, the current table display mode is displayed.
.n Display next row if table display mode is off.
The example below shows the usage of the display table mode:
116 rdmsql: .t on
*** table mode is on
116 rdmsql: select name, age(hire_date) from acctmgr where age
(hire_date) = 12;
name age(hire_date)
Fox, Joe 12
Kelly, Kathleen 12
117 rdmsql: .t off
*** table mode is off
117 rdmsql: select name, age(hire_date) from acctmgr where age
(hire_date) = 12;
name : Fox, Joe
age(hire_date) : 12
118 rdmsql: .n
name : Kelly, Kathleen
age(hire_date) : 12
118 rdmsql: .n
*** no more rows
118 rdmsql:
.l [n] Set output page length to n lines. If n is not specified, the current page length is displayed. (default 50)
.w [n] Set output page width to n columns. If n is not specified, the current page width is dis-played. (default 4096)
.C Execute commit (alternative to "commit;").
.R Execute rollback (alternative to "rollback;").
RDM SQL Language Guide
A Simple Interactive SQL Scripting Utility 21
Command Description
005 rdmsql: select avg(price) from book;
avg(price)
7200.48012232416
006 rdmsql: update book set price = 100;
*** 327 rows affected
007 rdmsql: select avg(price) from book;
avg(price)
100
008 rdmsql: .R
008 rdmsql: select avg(price) from book;
avg(price)
7200.48012232416
.i Display current transaction status.
.m message Display message on stdout.
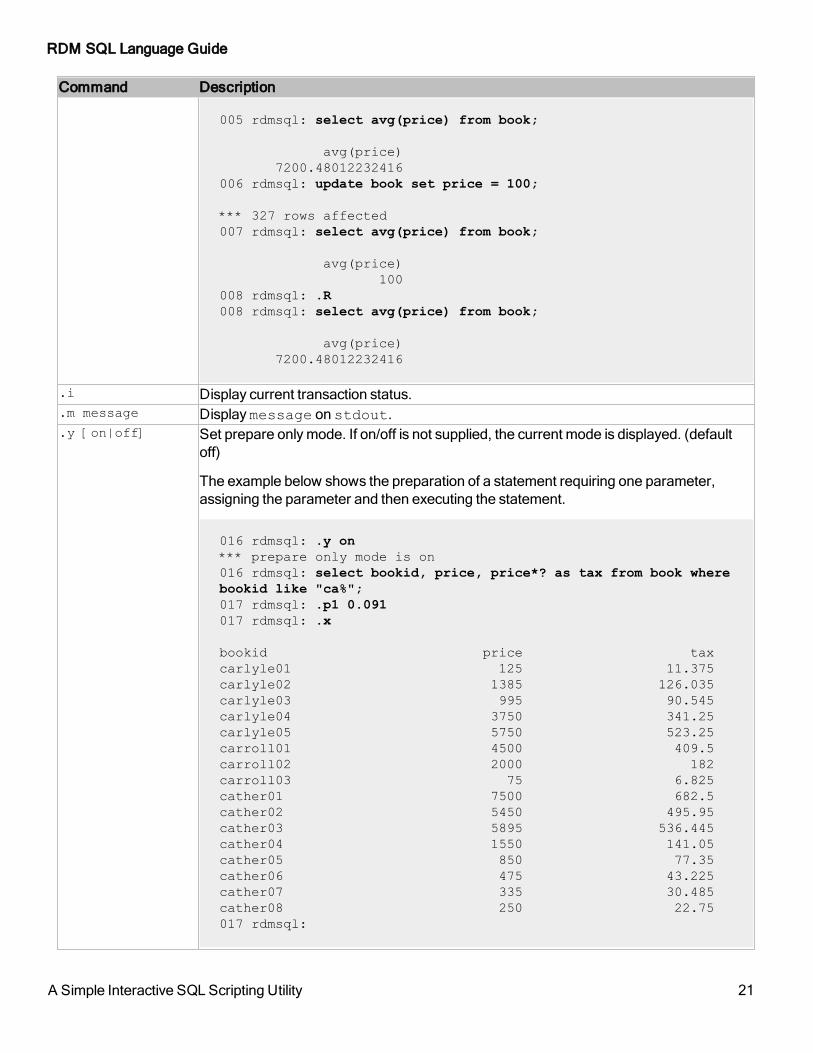
.y [on|off] Set prepare only mode. If on/off is not supplied, the current mode is displayed. (default off)
The example below shows the preparation of a statement requiring one parameter, assigning the parameter and then executing the statement.
016 rdmsql: .y on
*** prepare only mode is on
016 rdmsql: select bookid, price, price*? as tax from book where
bookid like "ca%";
017 rdmsql: .p1 0.091
017 rdmsql: .x
bookid price tax
carlyle01 125 11.375
carlyle02 1385 126.035
carlyle03 995 90.545
carlyle04 3750 341.25
carlyle05 5750 523.25
carroll01 4500 409.5
carroll02 2000 182
carroll03 75 6.825
cather01 7500 682.5
cather02 5450 495.95
cather03 5895 536.445
cather04 1550 141.05
cather05 850 77.35
cather06 475 43.225
cather07 335 30.485
cather08 250 22.75
017 rdmsql:

RDM SQL Language Guide
A Simple Interactive SQL Scripting Utility 22
Command DescriptionThe parameter value can be changed and the current statement re-executed:
017 rdmsql: .p1 0.092
017 rdmsql: .x
.o [on|off] Set autocommit mode. If on/off not specified, the current mode will be displayed. (default off)
.s filespec Save entered commands to filespec. File will be saved and closed on exit.
.f getcursor Get the a cursor name associated with the current statement handle.
The following example illustrates using a cursor to update a specific row in a table.
002 rdmsql: .t off
*** table mode is off
002 rdmsql: select bookid, price from book for update;
bookid : alcott01
price : 1200
003 rdmsql: .n
bookid : alcott02
price : 1075
003 rdmsql: .f getcursor
*** cursor = SQL_CUR_2108_41d8
003 rdmsql: .h 2
*** using statement handle 2 of connection 1
003 rdmsql: update book set price=1076 where current of SQL_CUR_
2108_41d8;
*** 1 rows affected
004 rdmsql: select bookid, price from book;
bookid : alcott01
price : 1200
005 rdmsql: .n
bookid : alcott02
price : 1076
005 rdmsql:
Once a connection has been opened, you can submit SQL statements by simply typing in the statement from the command prompt. Statements can span multiple input lines and are terminated with a semicolon (";"). At this point, rdmsql will compile and execute the statement. Any errors detected during compilation or execution will be displayed. If the statement was a select statement then the result set will be displayed and paginated accord-ing to the .l and .w settings. A sample session is shown below. User input is shown in bold-faced text.
RDMSQL Utility
Raima Database Manager 11.0.0 Build 412 [2-15-2012] http://www.raima.com/
Copyright © 2012, Raima Inc. All rights reserved.
Enter ? for list of interface commands.

RDM SQL Language Guide
A Simple Interactive SQL Scripting Utility 23
001 rdmsql: .c 1
*** using statement handle 1 of connection 1
001 rdmsql: .l 50
*** lines per page = 50
001 rdmsql: .w 132
*** columns per page = 132
001 rdmsql: open bookshop;
002 rdmsql: select full_name, gender, yr_born, yr_died from author;
FULL_NAME GENDER YR_BORN YR_DIED
Alcott, Louisa May M 1832 1888
Austen, Jane F 1775 1817
Bacon, Francis M 1561 1626
Barrie, J. M. (James Matthew) M 1860 1937
Baum, L. Frank (Lyman Frank) M 1856 1919
Bronte, Charlotte F 1816 1855
Bronte, Emily F 1818 1848
Burns, Robert M 1759 1796
Burroughs, Edgar Rice M 1875 1950
Carlyle, Thomas M 1795 1881
Carroll, Lewis M 1832 1898
Cather, Willa F 1873 1947
Chaucer, Geoffrey M 1343 1400
Chesterton, G. K. (Gilbert Keith) M 1874 1936
Coleridge, Samuel Taylor M 1772 1834
Conrad, Joseph M 1857 1924
Cooper, James Fenimore M 1789 1851
Crane, Stephen M 1871 1900
Descartes, Rene M 1596 1650
Defoe, Daniel M 1661 1731
Dickens, Charles M 1812 1870
Dostoyevsky, Fyodor M 1821 1881
Doyle, Arthur Conan, Sir M 1859 1930
Dumas, Alexandre M 1802 1870
Eliot, George F 1819 1880
Faulkner, William M 1897 1962
Ferber, Edna F 1887 1968
Franklin, Benjamin M 1706 1790
Gaskell, Elizabeth Cleghorn F 1810 1865
Hardy, Thomas M 1840 1928
Hawthorne, Nathaniel M 1804 1864
Hemingway, Ernest M 1899 1961
Hobbes, Thomas M 1588 1679
Hugo, Victor M 1802 1885
Irving, Washington M 1783 1859
James, Henry M 1843 1916
Flaubert, Gustave M 1821 1880
Johnson, Samuel M 1709 1784
Kipling, Rudyard M 1865 1936
Lewis, Sinclair M 1885 1951
London, Jack M 1876 1916
Longfellow, Henry Wadsworth M 1807 1882
Milton, John M 1608 1674

RDM SQL Language Guide
A Simple Interactive SQL Scripting Utility 24
Muir, John M 1838 1914
Paine, Thomas M 1737 1809
Poe, Edgar Allan M 1809 1849
Potter, Beatrix F 1866 1943
Raleigh, Walter, Sir M 1552 1618
Scott, Walter, Sir M 1771 1832
Shakespeare, William M 1564 1616
**** press <enter> to continue or s to stop here
FULL_NAME GENDER YR_BORN YR_DIED
Shelley, Mary Wollstonecraft F 1797 1851
Sinclair, Upton M 1878 1968
Steinbeck, John M 1902 1968
Stevenson, Robert Louis M 1850 1894
Stowe, Harriet Beecher F 1811 1896
Swift, Jonathan M 1667 1745
Tennyson, Alfred, Baron M 1809 1892
Thoreau, Henry David M 1817 1862
Tolstoy, Leo M 1828 1910
Trollope, Anthony M 1815 1882
Twain, Mark M 1835 1910
Verne, Jules M 1828 1905
Wells, H. G. (Herbert George) M 1866 1946
Wharton, Edith F 1862 1937
Whitman, Walt M 1819 1892
Wilde, Oscar M 1854 1900
Woolf, Virginia F 1882 1941
003 rdmsql: .q
The –b startupfile command line option can be used to run the script file startupfile in batch mode in which rdmsql will automatically open a connection and process each statements in order. When the last one has been executed rdmsql will automatically compile and execute a commit statement to ensure that all of the work has completed and data stored and then the program will terminate. Error messages associated with any errors that are encountered will be output to stdout.
This option is useful for processing files containing a SQL DDL specification. It is also good to use when import-ing data into database tables.

RDM SQL Language Guide
Defining a Database 25
Defining a DatabaseBut Vronsky felt that now especially it
was essential for him to clear up
and define his position if he were
to avoid getting into difficulties.- Leo Tolstoy, Anna Karenin
A poorly designed database can create all kinds of difficulties for the user of a database application. Unfor-tunately, the blame for those difficulties are often laid at the feet of the database management system which, try as it might, simply cannot use non-existent access paths to quickly get at the needed data. Good database design is as much of an art as it is engineering and a solid understanding of the application requirements is a nec-essary prerequisite. However, it is not the purpose of this document to teach you how to produce good database designs. But you do need to understand that designing a database is a complex task and that the quality of the application in which it is to be used is highly dependent on the quality of the database design. If you are not expe-rienced in designing databases then it is highly recommended that you first consult any number of good books on that subject before setting out to develop your RDM SQL database.
A database schema is the definition of what kind of data is to be stored and how that data is to be organized in the database. The Database Definition Language (DDL) consists of the SQL statements that are used to describe a particular database schema (also called the database definition). Three DDL statements are provided in RDM SQL: create database (schema), create domain, and create table. The create database (schema) statement names the database that will be defined by the create domain and create table statements that follow it. The create domain statement allows you to define a special-purpose data type that can be used by a subsequent create table statement in the declaration of a table column. The create table statement is used to define the char-acteristics of a table that will be stored in the database. Each of these DDL statements are described in detail in the following sections.
Create DatabaseThe create database statement must be the first DDL statement issued for a new database specification. The syntax for this statement is as follows.
create_schema_stmt:
create {schema | database} db_name
[pagesize = num] [inmemory [persistent | volatile | read]]
Use of "schema" (instead of "database") follows the ISO/ANSI SQL standard convention. The pagesize and inmemory options are RDM SQL extensions. The pagesize option sets the default page size for all of the data-base files. If not specified, the default page size is 1024 bytes. The inmemory option indicates that the database is to be kept entirely in memory. The read, persistent, and volatile options control whether the database files are read from disk when the database is opened (read, persistent), and whether they are written to the disk when the database is closed (persistent). The default inmemory option is volatile which means that the database is created empty the first time it is opened and will cease to exist either after the last application closes the database (e.g. Windows) or when the system is rebooted (Unix). The read option means that the entire database is read from the files when the database is opened, changes to the data are allowed but are not written back to the files

RDM SQL Language Guide
Defining a Database 26
on closing. The persistent option means that the entire database is read on opening and all changes that were made while the database was open are written when the database is closed.
The database consists of all of the tables that are declared in the create table statements that are issued after the create database statement.
Examples
create database sales;
create database usage_stats no nulls pagesize = 512;
Create DomainA "domain" is simply a user-defined and named data type which can then be specified as the data type for col-umns that are declared in a create table statement. The syntax for the create domain statement is shown below.
create_domain_stmt:
create domain domain_name [as] data_type
[default {constant | null}]
The name of the domain is specified as the domain_name. The data_type specifies the base type for the domain. A constant value or null can be specified as the default.
The distinct values clause specifies the number of distinct values that will be stored in columns of this type. The range clause specifies the minimum and maximum values that will be stored in columns of this type. These two clauses provide important information that is only used by the RDM SQL query optimizer to determine the best possible execution plan for a query. Note that these clauses do not specify column validation checks. It will still be possible to store values that are outside of the specified range.
The data types that are available in RDM SQL are given in the following syntax specification.
data_type:
base_type | blob_type
base_type:
{character | char } [(length)]
| {{character | char} varying | varchar } (length)
| {binary [(length)]
| {double [precision] | float | real }
| { tinyint | smallint | int | integer | long | bigint}
| date | time | timestamp

RDM SQL Language Guide
Defining a Database 27
blob_type:
{{character | char} large object | long varchar | clob} [(length)] file_option
| {binary large object | large varbinary | blob} [(length)] file_option
file_option:
[pagesize = num] [inmemory [persistent | volatile | read]]
Each specific blob instance is stored in a separate set of blob file pages using only as many pages as are needed to store the entire blob. If the size of the blob data is less than a page the unused space on that page will remain unused. Hence, you should probably supply a pagesize value that will minimize the amount of unused page space based on the average size of your blob data.
Examples
create domain birth_date as
date range date "1900-01-01" to date "2011-01-01";
create domain gender as
char distinct values = 2;
create domain us_state as
char(2) distinct values = 53
Create Table
Standard Database Table
The create table statement is used to define a table to be included in the database. Create table statements can only be issued after the create database statement and before issuing any other non-DDL statements. Any domain types that are used in column declarations included in the create table statement must have already been declared through the issuance of a prior create domain statement. The syntax for the create table state-ment is as follows.
standard_table:
create [circular] table table_name (
column_def[, column_def]...
[, key_def[, key_def]...]
) [pagesize = num] [inmemory [persistent | volatile | read]]
[maxpgs = num] [maxrows = num]

RDM SQL Language Guide
Defining a Database 28
column_def:
column_name {type_spec | domain_name}
[distinct values = num] [range constant to constant]
[not null] [key_spec] [refs_spec]
type_spec:
data_type [default {constant | null}]
key_spec:
[primary | unique] key ['['keysize']']
| {primary | unique} key [hash { (num) | of num rows}] ['['keysize']']
refs_spec:
references table_name[.column_name] [triggered_action]
key_def:
[primary | unique] key [hash {(num) | of num rows}] ['['keysize']'] [key_name]
(column_name[asc | desc] [, column_name[asc | desc] ]...)
[pagesize = num] [inmemory [persistent | volatile | read]] [maxpgs = num]
| foreign key [set_name] (column_name[, column_name]...
references table_name[(column_name[, column_name]...)]
[triggered_action]
triggered_action:
on update action_spec [on delete action_spec]
| on delete action_spec [on update action_spec]
action_spec:
cascade | restrict | set null
The table_name is a user-specified identifier that names the table. The contents of the table is comprised of the columns that are declared within it. Columns are declared to be of a specific data type which is either explicitly given or specified through use of a previously declared domain name. A default value and display format can also optionally be specified unless the column was declared with a domain type.
The distinct values clause specifies the number of distinct values that will be stored in this column. The range clause specifies the minimum and maximum values that will be stored in the column. These two clauses provide important information that is only used by the RDM SQL query optimizer to determine the best possible execution plan for a query. Note that these clauses do not specify column validation checks. It will still be possible to store values that are outside of the specified range.
Columns can be specified with one or more constraints which declare the column to be:
l not null—null values are not allowed for the column, l a primary/unique or non-unique key—on which an index will be automatically created, l a foreign key that references the primary/unique key of the specified table.

RDM SQL Language Guide
Defining a Database 29
Foreign key references are automatically implemented using RDM sets. The name of the column becomes the name of the RDM set. The RDM record type into which the SQL table is mapped will not contain a data field for this column. The SQL column value is retrieved through the owner of the set—i.e., the primary key column's value. A triggered_action can be specified with foreign key columns in order to specify what should happen when the referenced row (the owner record instance) is updated or deleted. The default action is restrict meaning that primary key rows that have existing foreign key references cannot be updated/deleted. If on ... cascade is spec-ified, then all of the referenced rows are updated or deleted when the primary key row is updated (i.e., the pri-mary key column value) or deleted. Note that the referencing table may itself have a primary key declared that is referenced by foreign keys in other tables that may not have a cascade triggered action specified. Thus, a delete of the referenced row of a cascade delete allowed table may be denied due to a restrict foreign key on a row of a referencing table.
A key_def on a table is used to declare multi-column primary/unique/non-unique keys and foreign keys. The [pri-mary | unique] key clause is used to identify the columns from the table on which a key is to be formed. You can specify the sort order for each column to be either ascending (default) or descending. A table can have only one primary key. If a key_name is specified then that will be the name of the RDM compound key. If not specified a unique system-generated name will be used.
Each table is contained in a separate RDM data file. Each key is contained in a separate RDM key file. The values for each blob type column is stored in a separate RDM blob file. The file_option can optionally be specified to provide RDM-specific file characteristics.
Examples
create table sales_office(
office_id char(3) primary key,
city char(24),
state char(2)
);
create table salesperson(
sale_id integer primary key,
name char(38) not null,
sex gender,
dob birth_date,
hired_on date default today,
sales_tot double,
office char(3) references outlet,
mgr_id integer references salesperson,
unique key sale_key(name, office)
);
create table customer(
cust_id integer primary key,
name char(38),
sale_id integer not null
references salesperson
on update cascade
on delete restrict
);

RDM SQL Language Guide
Defining a Database 30
Virtual Table
An RDM SQLvirtual table is defined through a combination of the create virtual table statement and a set of user-written C functions that conform to a particular interface specification. A pointer to a pre-defined structure array that contains an entry for each virtual table with the addresses of each of the virtual table interface functions is passed into SQL before the database is opened. These functions are then called by SQL at the appropriate times during the execution of any SQL statement that references the virtual table. This interaction is depicted in Figure 4 which shows SQL calling the function in the application's virtual table function module to fetch a row of weather data from a wireless sensor network (WSN). Note that in this example by storing the data retrieved from the virtual table in a standard table, RDM can then replicate that data to an outside host DBMS (e.g., RDM Server or some other well-known SQL DBMS). Also note that the green boxes represent code that is compiled as part of the user's application while the blue boxes represent RDM systems code.
The syntax for the create virtual table statement is given below.
virtual_table:
create virtual [read only] table table_name (
vcolumn_def[, vcolumn_def]…
)
vcolumn_def:
column_name base_type
[distinct values = num] [range constant to constant]
[primary key]
base_type:
{character | char } [(length)]
| {{character | char} varying | varchar } (length)
| {binary [(length)]
| {double [precision] | float | real }
| { tinyint | smallint | int | integer | long | bigint}
| date | time | timestamp

RDM SQL Language Guide
Defining a Database 31
Figure 4. Virtual Tables in RDM SQL
No create virtual table statement for a given database can be submitted until all standard create table state-ments have first been submitted. In other words, the create virtual table statements must all come at the end of your database schema specification. Only one primary key column declaration can appear in a create virtual table statement. Values for this column must be unique and will be used by SQL in calls to the user-function in the virtual table interface API to find the row for a specified value.
The DDL schema specification for the aforementioned wireless weather sensor database is given in the fol-lowing example.
create database weather_db;
create table location( /* location of weather sensor */
longitude integer,
latitude integer,
sensor_id bigint,
descr char(48),
county char(24),
state char(2),
primary key loc_id(longitude, latitude)
);

RDM SQL Language Guide
Defining a Database 32
create table weather_summary(
longitude integer,
latitude integer,
rdg_date date,
hour_of_day smallint,
avg_temp smallint,
avg_ press smallint,
avg_hum smallint,
avg_lumens smallint,
foreign key (longitude, latitude) references location
);
create virtual readonly table weather_data(
sensor_id bigint primary key,
loc_long integer,
loc_lat integer,
rdg_time timestamp,
temperature smallint,
pressure smallint,
humidity smallint,
light smallint,
power integer
);
Compiling a DDL SpecificationOf course, you can interactively enter your DDL statements using rdmsql (or any other ODBC-based SQL util-ity) but you will normally create the DDL specification for your database using a text editor and storing it in a text file. A good convention is to store SQL scripts in files with a ".sql" extension. A convention that I like to use is to name the DDL specification file "dbname.sql". For example, the DDL files for the two example databases described in the next section are "nsfawards.sql" and "bookshop.sql".
Assuming you too use the same convention. you can use rdmsql to compile an SQL DDL file as follows.
rdmsql –b [@hostname:port] dbname.sql
If the @hostname:port is not specified, @localhost:21553 will be used. Errors will be reported to stdout and iden-tify the file and line number of the offending SQL statement. A successful compilation of a DDL specification will produce the dbname_cat.c and dbname_cat.h files in the current directory (when the "generate C files" option is enabled -see rsqlSetGenCFiles) and the database dictionary file (dbname.dbd), catalog file (dbname.cat), data files (dbname.d*), and key files (dbname.k*) in a directory named dbname on the TFS. The database will be initialized and ready for use.
Example DatabasesTwo example databases are provided with RDM SQL that facilitate learning how to use RDM SQL and will be used in most of the examples given in this book. This section describes the two databases by presenting the DDL

RDM SQL Language Guide
Defining a Database 33
specifications along with an explanation of how that data would be used in a SQL application. The first database contains actual data derived from over 130,000 National Science Foundation (USA) research grants that were awarded during the years 1990 through 2003. The second database is for a hypothetical bookshop that only sells high-end, rare antiquarian books.
National Science Foundation Awards Database
The data used in this example has been extracted from the University of California Irvine Knowledge Discovery in Databases Archive (http://kdd.ics.uci.edu/). The original source data can be found at http://kdd.ics.uci.-edu/databases/nsfabs/nsfawards.html. The data was processed by a Raima-developed RDM SQL program that, in addition to pulling out the data from each award document, converted all personal names to a "last name, first name, …" format and, where possible, identified each person's gender from the first name. The complete DDL specification for the NSF awards database is shown below.
NOTE: The NSF Awards example is a large database and may take a few minutes to create and pop-ulate.
create database nsfawards;
create table person(
name char(35) primary key,
gender char(1) distinct values = 3,
jobclass char(1) distinct values = 2
);
create table sponsor(
name char(50) primary key,
addr char(40),
city char(20),
state char(2) distinct values = 100,
zip char(5)
);
create table nsforg(
orgid char(3) primary key,
name char(40)
);
create table nsfprog(
progid char(4) primary key,
descr char(40)
);
create table nsfapp(
appid char(10) primary key,
descr char(40)
);
create table award(
awardno integer primary key,
title char(200),
award_date date key,
instr char(3) distinct values = 11,
start_date date,
exp_date date key,
amount double key,
RDM SQL Language Guide
Defining a Database 34
abstract long varchar,
prgm_mgr char(35) references person,
sponsor_nm char(50) references sponsor,
orgid char(3) references nsforg
);
create table investigator(
awardno integer references award,
name char(35) references person
);
create table field_apps(
awardno integer references award,
appid char(10) references nsfapp
);
create table progrefs(
awardno integer references award,
progid char(4) references nsfprog
);
Descriptions for each of the tables declared in the nsfawards database are given in the following table.
Table Name Descriptionperson Contains one row for each investigator or NSF program manager. An investigator
(jobcclass = "I") is a person who is doing the research. The NSF program manager (jobcclass = "P") oversees the research project on behalf of the NSF. An award can have more than one investigator but only one program manager. The gender col-umn is derived from the first name but has three values "M", "F", and "U" for "unknown" when the gender based on the first name could not be determined (about 13%).
sponsor Institution that is sponsoring the research. Usually where the principal investigator is employed. Each award has a single sponsor.
nsforg NSF organization. The highest level NSF division or office under which the grant is awarded.
nsfprog Specific NSF programs responsible for funding research grants.nsfapp NSF application areas that the research impacts.award Specific data about the research grant. The columns are fairly self-explanatory. For
clarity the exp_data column contains the award expiration data (i.e., when the money runs out). The amount column contains the total funding amount. The instr column is a code indicating the award instrument (e.g., "CTG" = "continuing", "STD" = "standard", etc.).
investigator The specific investigators responsible for carrying out the research. This table is used to form a many-to-many relationship between the person and award tables.
field_apps NSF application areas for which the research is intended. This table is used to form a many-to-many relationship between the nsfapp and award tables.
progrefs Specific programs under which the research is funded. This table is used to form a many-to-many relationship between the nsfprog and award tables.
Table 4. NSF Awards Database Table Descriptions
Note that the interpretations given in the above descriptions are my own and may not be completely accurate (e.g., it could be that NSF programs are not actually responsible for funding research grants). However, my

RDM SQL Language Guide
Defining a Database 35
intent is to simply use this data for the purpose of illustration (although we will later delve into an interesting gender analysis).
Note the use of the distinct values clause in the DDL specification. In particular, where the number of actual dis-tinct values is significantly less than the total number of rows in the table it is important to indicate this so that the SQL query optimizer can make better choices as to access method. The Concurrent Database Access section explains in greater detail how the RDM query optimizer works.
A schema diagram for the nsfawards database is shown below. Each box represents a table and each arrow represents a one-to-many relationship between two tables. The arrow label is the foreign key column (declared using the references clause in the DDL specification) in the target (i.e. the "many" side) table on which the rela-tionship is formed.
Figure 5 - NSF Awards Database Schema Diagram
Antiquarian Bookshop Database
Our fictional bookshop is located in Hertford, England (a very real and charming town north of London). It is located in a building constructed around 1735 and has two rather smallish rooms on two floors with floor-to-ceil-ing bookshelves throughout. Upon entering, one is immediately transported to a much earlier era being quite overwhelmed by the wonderful sight and odor of the ancient mahogany wood in which the entire interior is lined along with the rare and ancient books that reside on them. There is a little bell that announces one's entrance into the shop but it is not really needed, as the delightfully squeaky floor boards quite clearly makes your presence known.
In spite of the ancient setting and very old and rare books, this bookshop has a very modern Internet storefront through which it sells and auctions off its expensive inventory. A computer system contains a database describ-ing the inventory and manages the sales and auction processes. The database schema for our bookshop is given below.
create database bookshop;

RDM SQL Language Guide
Defining a Database 36
create table author(
last_name char(13) primary key,
full_name char(35),
gender char(1) distinct values = 2,
yr_born smallint,
yr_died smallint,
short_bio varchar(250)
);
create table genres(
text char(31) primary key
);
create table subjects(
text char(51) primary key
);
create table book(
bookid char(14) primary key,
last_name char(13)
references author on delete cascade on update cascade,
title varchar(255),
descr char(61),
publisher char(136),
publ_year smallint key,
lc_class char(33),
date_acqd date,
date_sold date,
price double,
cost double
);
create table related_name(
bookid char(14)
references book on delete cascade on update cascade,
name char(61)
);
create table genres_books(
bookid char(14)
references book on delete cascade on update cascade,
genre char(31)
references genres
);
create table subjects_books(
bookid char(14)
references book on delete cascade on update cascade,
subject char(51)
references subjects
);

RDM SQL Language Guide
Defining a Database 37
create table acctmgr(
mgrid char(7) primary key,
name char(24),
hire_date date,
commission double
);
create table patron(
patid char(3) primary key,
name char(30),
street char(30),
city char(17),
state char(2),
country char(2),
pc char(10),
email char(63),
phone char(15),
mgrid char(7)
references acctmgr
);
create table note(
noteid integer primary key,
bookid char(14)
references book on delete cascade on update cascade,
patid char(3)
references patron on delete cascade on update cascade
);
create table note_line(
noteid integer
references note on delete cascade on update cascade,
text char(61)
);
create table sale(
bookid char(14)
references book on delete cascade on update cascade,
patid char(3)
references patron on delete cascade on update cascade
);
create table auction(
aucid integer primary key,
bookid char(14)
references book on delete cascade on update cascade,
mgrid char(7)
references acctmgr,
start_date date,
end_date date,
reserve double,
curr_bid double

RDM SQL Language Guide
Defining a Database 38
);
create table bid(
aucid integer
references auction on delete cascade on update cascade,
patid char(3)
references patron on delete cascade on update cascade,
offer double,
bid_ts timestamp
);
Descriptions for each of the above tables are given below.
Table Name Descriptionauthor Each row contains biographical information about a renowned author.book Contains information about each book in the bookshop inventory. The last_name
column associates the book with its author. Books with a non null date_sold are no longer available.
genres Table of genre names (e.g., "Historical fiction") with which particular books are asso-ciated via the genres_books table.
subjects Table of subject names (e.g., "Cape Cod") with which particular books are asso-ciated via the subjects_books table.
related_name Related names are names of individuals associated with a particular book. The names are usually hand-written in the book's front matter or on separate pages that were included with the book (e.g., letters) and identify the book's provenance (own-ers). Only a few books have related names. However, their presence can sig-nificantly increase the value of the book.
genres_books Used to create a many-to-many relationship between genres and books.subjects_books Used to create a many-to-many relationship between subjects and books.note Connects each note_line to its associated book. Notes include edition info and other
comments (often coded) relating to its condition.note_line One row for each line of text in a particular note.acctmgr Account manager are the bookshop employees responsible for servicing the
patrons and managing auctions.patron Bookshop customers and their contact info. Connected to their purchases/bids
through their relationship with the sale and auction tables.sale Contains one row for each book that has been sold. Connects the book with the
patron who acquired through the bookid and patid columns.auction Some books are auctioned. Those that have been (or currently being) auctioned
have a row in this table that identifies the account manager who oversees the auc-tion. The reserve column specifies the minimum acceptable bid, curr_bid contains the current amount bid.
bid Each row provides the bid history for a particular auction.
Table 5. Bookshop Database Table Descriptions

RDM SQL Language Guide
Defining a Database 39
Foreign keys are declared using the references clause. Many are specified with the on delete/update cascade option indicating that deletions or updates to the referenced rows will cause the referencing row to automatically be deleted or updated as well.
A schema diagram depicting the inter-table relationships is shown below. As was mentioned above for the NSF awards database, the arrows represent a one-to-many relationship between the source and target tables and labels on the arrows identify the foreign key in the target table on which the relationship is formed.
Figure 6 - Bookshop Database Schema Diagram
The sample data that is included with this example contains book descriptions that were obtained from the United States Library of Congress online card catalog: http://catalog.loc.gov. The short biographical sketches included with each author entry are condensed descriptions from information about each author contained on Wikipedia: http://www.wikipedia.org. The use of the Wikipedia information is governed by the Creative Com-mons Attribution-ShareAlike license: http://creativecommons.org/licenses/by-sa/3.0/. Pricing information and the JPEG files of photographs of some of the books in the database were obtained from the website for Peter Harrington Antiquarian Bookseller in Chelsea London, http://www.peterharrington.co.uk, which is a perfect real-world example of the kind of bookshop depicted in this example.
RDM SQL Language Guide
Retrieving Data from a Database 40
Retrieving Data from a DatabaseYou can use all the quantitative data you can get,
but you still have to distrust it and use your own
intelligence and judgment.- Alvin Toffler
The reason data is stored in a database is so that it can be later retrieved and looked at. However, in order to do something intelligent with that data it must first intelligently be retrieved. This is often much easier to say than to do and that is particularly true with a language like SQL.
Data is retrieved from RDM databases using the SQL select statement. This section will explain how to properly formulate select statements to view data contained in one or more RDM databases.
A completely specified select statement is commonly referred to as a query. The complete set of rows that are returned by a select statement is called the result set.
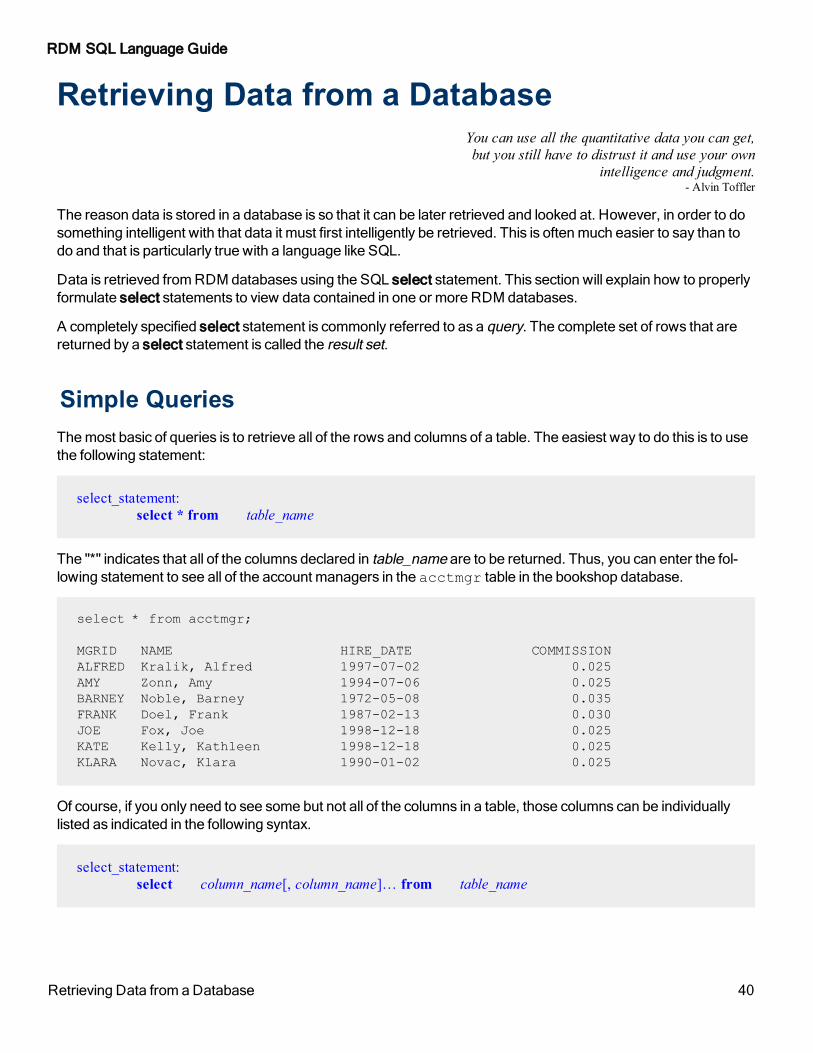
Simple QueriesThe most basic of queries is to retrieve all of the rows and columns of a table. The easiest way to do this is to use the following statement:
select_statement:
select * from table_name
The "*" indicates that all of the columns declared in table_name are to be returned. Thus, you can enter the fol-lowing statement to see all of the account managers in the acctmgr table in the bookshop database.
select * from acctmgr;
MGRID NAME HIRE_DATE COMMISSION
ALFRED Kralik, Alfred 1997-07-02 0.025
AMY Zonn, Amy 1994-07-06 0.025
BARNEY Noble, Barney 1972-05-08 0.035
FRANK Doel, Frank 1987-02-13 0.030
JOE Fox, Joe 1998-12-18 0.025
KATE Kelly, Kathleen 1998-12-18 0.025
KLARA Novac, Klara 1990-01-02 0.025
Of course, if you only need to see some but not all of the columns in a table, those columns can be individually listed as indicated in the following syntax.
select_statement:
select column_name[, column_name]… from table_name

RDM SQL Language Guide
Retrieving Data from a Database 41
Each specified column_name must identify a column that is declared in table_name. The next example retrieves the name, city, and email address of each bookshop patron.
select name, city, email from patron;
NAME CITY EMAIL
Carlos Slim Helu Acapulco [email protected]
William Gates, III Redmond [email protected]
Warren Buffett Omaha [email protected]
Mukesh Ambani Mumbai [email protected]
Bernard Arnult Cannes [email protected]
Stephen Jobs Cupertino [email protected]
Scrooge McDuck Anaheim [email protected]
Richie Rich San Diego [email protected]
Jed Clampett Beverly Hills [email protected]
Bruce Wayne Gotham City [email protected]
Thurston Howell III Newport [email protected]
Artimis Fowel II Dublin [email protected]
Charles Montgomery Burns Springfield [email protected]
Jay Gatsby West Egg [email protected]
Lucille Bluth Newport Beach [email protected]
Chatsworth Osborne Jr. Haddonfield [email protected]
Jean Luc Picard San Francisco [email protected]
Jeffrey Bezos Seattle [email protected]
Giorgio Armani Piacenza [email protected]
Column ExpressionsBesides retrieving the values of individual columns, a select statement allows you to specify expressions that can perform arithmetic operations on the columns in a table. The normal arithmetic operators (+, -, *, /) along with a wide range of scalar functions can be included in a select column expression. The complete syntax for column expressions is given below.
select_statement:
select expression [column_alias] [, expression [column_alias] ]… fromtable_name
expression:
operand [arith_operator operand]...
operand:
constant | param_ref | column_ref | function | (expr)
param_ref:
? | :param_name

RDM SQL Language Guide
Retrieving Data from a Database 42
column_ref:
[{table_name | correlation_name}.]column_name
arith_operator:
+ | - | * | /
function:
aggregate_fcn | scalar_fcn
aggregate_fcn:
{sum | avg | max | min} (expression)
| count ({* | column_ref })
| aggregate_udf_name ([expression][, expression]...)
scalar_fcn:
| if (conditional_expr, expression, expression)
| numeric_function | datetime_function | string_function
| scalar_udf_name ([expression][, expression]...)
numeric_function:
abs(arith_expr)
| acos(arith_expr)
| asin(arith_expr)
| atan(arith_expr)
| atan2(arith_expr)
| {ceil | ceiling}(arith_expr)
| cos(arith_expr)
| cot(arith_expr)
| exp(arith_expr)
| floor(arith_expr)
| {ln | log}(arith_expr)
| mod(arith_expr)
| pi()
| rand(num)
| sign(arith_expr)
| sin(arith_expr)
| sqrt(arith_expr)
| tan(arith_expr)
datetime_function:
age(dt_expr)
| {curdate | current_date}()
| {curtime | current_time}()
| dayofmonth(dt_expr)
| dayofyear(dt_expr)
| hour(dt_expr)

RDM SQL Language Guide
Retrieving Data from a Database 43
| minute(dt_expr)
| month(dt_expr)
| quarter(dt_expr)
| second(dt_expr)
| week(dt_expr)
| year(dt_expr)
string_function:
ascii(string_expr)
| char(num)
| concat(string_expr, string_expr)
| convert(expression, {convert_type | {char}, width, convert_format})
| lcase(string_expr)
| left(string_expr, num)
| length(string_expr)
| locate(string_expr, string_expr, num)
| ltrim(string_expr)
| repeat(string_expr, num)
| replace(string_expr, string_expr, string_expr)
| right(string_expr, num)
| rtrim(string_expr)
| substring(string_expr, num, num)
| ucase(string_expr)
| unicode(string_expr)
convert_type:
char |smallint | integer | real
| double | date | time | timestamp | tinyint | bigint
convert_format:
numeric_format | datetime_format
numeric_format:
"[<< | >> | ><]['text' | $][- | (][#,]#[.#[#]...][e | E]['text' | $ | %]"
datetime_format:
"[<< | >> | ><]['text' | spchar | date_code | time_code]..."
date_code:
m | mm | mmm | mon | mmmm | month
| d | dd | ddd | dddd | day
| yy | yyyy
time_code:
h | hh | m | mm | s | ss | .f[f]... | [a/p | am/pm | A/P | AM/PM]
The built-in numeric functions that are available in RDM SQL are listed in the following table.

RDM SQL Language Guide
Retrieving Data from a Database 44
Function Descriptionabs Returns the absolute value of an expression.acos Returns the arccosine of an expression.asin Returns the arcsine of an expression.atan Returns the arctangent of an expression.atan2 Returns the arctangent of an x-y coordinate pair.ceil | ceiling Finds the upper bound for an expression.cos Returns the cosine of an angle.cot Returns the cotangent of an angle.exp Returns the value of an exponential function.floor Finds the lower bound for an expression.ln | log Returns the natural logarithm of an expression.mod Returns the remainder of arith_expr1/arith_expr2.pi Returns the value of pi.rand Returns next random floating-point number. Non-zero num is seed.sign Returns the sign of an expression (-1, 0, +1).sin Returns the sine of an angle.sqrt Returns the square root of an expression.tan Returns the tangent of an angle.
Table 6. Built-in Numeric Functions
The RDM SQL data and time manipulation functions are listed below. Note that dt_expr is an arith_expr that involves only date, time, and timestamp columns and values.
Function Descriptionage Returns the age (in full years).curdate
current_date
Returns the current date.
curtime
current_time
Returns the current time.
current_timestamp Returns the current date and timedayofmonth Returns the day of the month.dayofweek Returns the day of the week.dayofyear Returns the day of the year.hour Returns the hour.minute Returns the minute.month Returns the month.quarter Returns the quarter.second Returns the second.week Returns the week.year Returns the year.
Table 7. Built-in Date and Time Functions
The RDM SQL string manipulation functions are listed below.

RDM SQL Language Guide
Retrieving Data from a Database 45
Function Descriptionascii Returns the numeric ASCII value of a characterchar Returns the ASCII character with numeric value numconcat Concatenates two stringsconvert Convert an expression to a data type or a character stringinsstr Replace num2 chars from string_expr2 in string_expr1 beginning at position num1
(1st position is 1 not 0)lcase Converts a string to lowercaseleft Returns the leftmost num characters from the stringlength Returns the length of the stringlocate Locate string_expr1 from position num in string_expr2ltrim Removes all leading spaces from stringrepeat Repeats string num timesreplace Replace string_expr2 with string_expr3 in string_expr1right Returns the rightmost num characters from stringrtrim Removes all trailing spaces from stringsubstring Returns num2 characters from string_expr beginning at position num1.ucase Convert string to uppercaseunicode Returns the numeric Unicode value of a characterwchar(num) Returns a Unicode character with numeric value num.
Table 8. Built-in String Functions
Arithmetic operators that are specified in an expression are evaluated based on the precedence given in the fol-lowing table.
Priority Operator Use
Highest () Parenthetical expressions
High + Unary plus
High - Unary minus
Medium * Multiplication
Medium / Division
Lowest + Addition
Lowest - Subtraction
Table 9. Precedence of Arithmetic Operators
Okay, I know. That's a lot of detail to have to wade through but you're through it now and so we'll illustrate column expressions with a couple of examples. More sophisticated examples will be given in subsequent sections.
The following query computes the sales tax based on a rate of 9.2% for each book.
select bookid, price, price*0.091 tax from book;
BOOKID PRICE TAX
alcott01 1200.00 109.20
alcott02 1075.00 97.82

RDM SQL Language Guide
Retrieving Data from a Database 46
alcott03 1550.00 141.05
alcott04 1250.00 113.75
alcott05 850.00 77.35
alcott06 875.00 79.62
austen01 12500.00 1137.50
austen02 13500.00 1228.50
...
wilde04 22500.00 2047.50
wilde05 2000.00 182.00
woolf01 3250.00 295.75
woolf02 1750.00 159.25
woolf03 32500.00 2957.50
The next query computes both the raw profit and the percentage profit margin for each book based on the price and cost columns in each row of the book table.
select bookid, price, cost, price-cost profit, ((price-cost)/cost)*100 margin from
book;
BOOKID PRICE COST PROFIT MARGIN
alcott01 1200.00 960.00 240.00 25.00
alcott02 1075.00 860.00 215.00 25.00
alcott03 1550.00 1240.00 310.00 25.00
alcott04 1250.00 1000.00 250.00 25.00
alcott05 850.00 708.00 142.00 20.00
alcott06 875.00 729.00 146.00 20.00
austen01 12500.00 9615.00 2885.00 30.00
austen02 13500.00 10384.00 3116.00 30.00
...
wilde04 22500.00 17307.00 5193.00 30.00
wilde05 2000.00 1600.00 400.00 25.00
woolf01 3250.00 2600.00 650.00 25.00
woolf02 1750.00 1400.00 350.00 25.00
woolf03 32500.00 25000.00 7500.00 30.00
Notice any pattern when you compare the profit margin percentage with the price? The higher the price, the larger the profit margin.
Conditional QueriesWhile there are times when one needs to see all of the rows in a table, by far the more common situation is that only some rows of a table are needed. In order to restrict the rows to be returned by a select statement you can specify a conditional expression in a select statement where clause which specifies that only those rows for which the conditional expression is true are to be retrieved. The syntax for the select statement containing the where clause is as follows.

RDM SQL Language Guide
Retrieving Data from a Database 47
select_statement:
select expression [column_alias] [, expression [column_alias] ]… from table_name
where conditional_expr
conditional_expr:
rel_expr [bool_oper rel_expr]...
rel_expr:
expression [not] rel_oper expression
| expression [not] between constant and constant
| expression [not] in (constant[, constant]...)
| column_ref is [not] null
| string_expr [not] like "string"
| not rel_expr
| ( conditional_expr )
rel_oper:
= | ==
| <
| >
| <=
| >=
| <> | != | /=
bool_oper:
& | && | and
| "|" | "||" | or
The like operation can be used to perform simple pattern matching. SQL defines two pattern matching symbols. The "%" can be specified to match zero or more characters. The "?" can be specified to match any single char-acter.
For example, most of the short biographical sketches (column short_bio) contained in the author table spec-ifies the nationality of the author. Hence, for example, the following query will retrieve only those authors in which "English" is included somewhere in the short_bio column.
select full_name from author where short_bio like "%English%";
FULL_NAME
Austen, Jane
Bacon, Francis
Bronte, Charlotte
Bronte, Emily
Carroll, Lewis
Chaucer, Geoffrey
Chesterton, G. K. (Gilbert Keith)

RDM SQL Language Guide
Retrieving Data from a Database 48
Coleridge, Samuel Taylor
Conrad, Joseph
Defoe, Daniel
Dickens, Charles
Eliot, George
Hardy, Thomas
Hobbes, Thomas
Johnson, Samuel
Milton, John
Potter, Beatrix
Raleigh, Walter
Scott, Walter
Shakespeare, William
Tennyson, Alfred
Trollope, Anthony
Wells, H. G. (Herbert George)
Woolf, Virginia
The next query returns those books that are priced over £100,000.
select bookid, price, title from book where price > 100000.00;
BOOKID PRICE TITLE
shakespeare01 175000.00 The Tragicall Historie of Hamlet, Prince of Den-
marke.
shakespeare02 135000.00 Midsummer night's dream
shakespeare04 250000.00 Plays
shakespeare05 225000.00 Romeo and Juliet
Books that have not been sold have a null date_sold column value. Issue the following query to list all those books that have sold.
select bookid, date_sold, price, title from book where date_sold is not null;
BOOKID DATE_SOLD PRICE TITLE
alcott01 2010-05-04 1200.00 Moods
alcott04 2010-01-11 1250.00 Little men : life at Plumfield with Jo's boys
alcott05 2010-08-14 850.00 Eight cousins;
alcott06 2010-01-06 875.00 Rose in bloom. A sequel to 'Eight cousins.'
austen03 2009-10-28 13500.00 Mansfield Park: a novel. In three volumes.
bacon03 2010-04-01 5000.00 Sylva sylvarum. French
bacon04 2010-02-13 2500.00 History natural and experimental, of life and
death.
burns01 2009-07-12 1250.00 Poems, chiefly in the Scottish dialect...
carlyle03 2009-12-13 995.00 Chartism.
...
wells04 2006-12-15 3000.00 The war of the worlds,
wells05 2010-01-02 25000.00 The first men in the moon, by H.G. Wells ...
wharton03 2009-03-20 3250.00 Crucial instances,
wharton05 2010-04-04 4000.00 The descent of man, and other stories

RDM SQL Language Guide
Retrieving Data from a Database 49
wharton08 2010-07-13 2500.00 Ethan Frome
wharton09 2008-12-20 2500.00 The age of innocence
wharton11 2007-08-08 1500.00 The buccaneers
wilde04 2007-12-23 22500.00 The ballad of Reading gaol.
Note that the following query does not return any rows even though you might think that it should.
select bookid, date_sold, title from book where date_sold != null;
SQL uses three-valued conditional results: a condition can be true, or false, or indeterminate. The processing details are too complicated to get into here but in order to do null value comparisons you must use the is null and is not null operators.
The in operator will return all rows in which the left hand expression evaluates to one of the values specified in the list as in the next example which lists those patrons from California and Washington.
select name, city, email from patron where state in ("CA","WA");
NAME CITY EMAIL
William Gates, III Redmond [email protected]
Stephen Jobs Cupertino [email protected]
Scrooge McDuck Anaheim [email protected]
Richie Rich San Diego [email protected]
Jed Clampett Beverly Hills [email protected]
Lucille Bluth Newport Beach [email protected]
Jean Luc Picard San Francisco [email protected]
Jeffrey Bezos Seattle [email protected]
The between operator returns those rows where the left hand expression inclusively evaluates to a value between the two values on the right.
select last_name, publ_year, title from book where publ_year between 1810 and
1820;
LAST_NAME PUBL_YEAR TITLE
AustenJ 1813 Pride and prejudice: a novel ...
AustenJ 1813 Sense and sensibility: a novel.
AustenJ 1814 Mansfield Park: a novel. In three volumes.
AustenJ 1816 Emma: a novel. In three volumes.
CooperJ 1820 Precaution; a novel...
IrvingW 1814 Biographical memoir of Capt-David Porter.
ScottW 1810 The lady of the lake. A poem.
ScottW 1811 The vision of Don Roderick: a poem.
ScottW 1815 The field of Waterloo; a poem.

RDM SQL Language Guide
Retrieving Data from a Database 50
Retrieving Data from Multiple TablesI am a lover of historical fiction. Suppose I wanted to see all of the books of that genre. You will note that there is nothing in the book table which identifies the genre. However, there is a table called genres_books that con-tains a bookid column and a genre column. The declaration of bookid in genres_books indicates that it ref-erences the book table. So, one could issue the following query to list the bookid for each book that has a genre equal to "Historical fiction".
select bookid from genre_books where genre = "Historical fiction";
BOOKID
cather03
cather07
cooper03
cooper04
defoe02
eliot04
hawthorne03
hawthorne04
scott01
scott07
stevenson06
twain05
twain09
Unfortunately, this does not tell you very much about the book. What you really need is to see the information in the particular row from the book table that has the same bookid listed in the genres_books table. You can do this using a query that specifies a join operation on the two tables as shown in the following example.
select last_name, title from book, genre_books
where book.bookid = genre_books.bookid and genre = "Historical fiction";
LAST_NAME TITLE
CatherW O pioneers! By Willa Sibert Cather ...
CatherW Shadows on the rock.
CooperJ The last of the Mohicans; a narrative of 1757.
CooperJ The prairie : a tale
DefoeD Memoirs of a cavalier:
EliotG Romola.
HawthorneN The scarlet letter, a romance.
HawthorneN The house of the seven gables, a romance.
ScottW Rob Roy.
ScottW Ivanhoe; a romance,
StevensonR Kidnapped : being memoirs of the adventures of David Balfour
TwainM The prince and the pauper : a tale for young people of all ages
TwainM Connecticut Yankee in King Arthur's court
The join is specified by listing each table in the from clause and then including in the where clause an equals oper-ation between the bookid columns in each table. When designing a database (see Defining a Database), as much as possible you will want to use the same column names between tables which are related in this way.

RDM SQL Language Guide
Retrieving Data from a Database 51
These relationships can (and should) be explicitly declared through the foreign and primary key specifications in the create table statement. When you use the same column names in the two tables, the join operation based on those columns containing the same values is called a natural join. SQL provides a simpler syntax for specifying natural joins. For example, the above query can also be specified as follows.
select last_name, title from book natural join genre_books
where genre = "Historical fiction";
Join processing is a fundamental feature of all relational database systems. As such, SQL defines a rich set of join specification options. The syntax for specifying joins is given below.
select_statement:
select expression [column_alias] [, expression [column_alias] ]…
from table_ref [, table_ref]… [where conditional_expr]
table_ref:
table_primary | table_join
table_primary:
table_spec | ( table_join )
table_spec:
[db_name.]table_name [[as] correlation_name]
table_join:
table_ref natural [inner | {left | right} [outer]] join table_primary
| table_ref [inner | {left | right} [outer]] join table_primary
[using ( column_name[, column_name]...) | on conditional_expr]
The natural join specification indicates that the join is to be performed based on the common columns (names and types) from the two tables. The join is formed from the columns from the table (or tables) specified on the left side of "natural … join" that have identical values with those columns from the table (or tables) on the right side that have the same name. Since common column names are used to form the join, sometimes you may not get the expected results because the tables may have unrelated columns that happen to have the same name. Thus, if you desire to make extensive use of the natural join, care must be taken in naming the columns in your table definitions so that common column names between related tables are only those upon which the joins are based. It is also best to explicitly declared the relationship using the primary key and foreign key/references clauses in your create table declarations.
By default, a natural join specification performs an inner join between two tables. An inner join is a join between those tables that have matching values in the join columns. However, sometimes it is possible to have values in one table that have no matching entry in the other. An outer join allows one to see those unmatched rows as wells. For example, the following query will return the list of all the books in the inventory for each author as well as those authors for which no books are available.
select bookid, full_name, title from author natural left outer join book;

RDM SQL Language Guide
Retrieving Data from a Database 52
FULL_NAME TITLE
Alcott, Louisa May Moods
Alcott, Louisa May On picket duty, and other tales.
Alcott, Louisa May Little women, or, Meg, Jo, Beth, and Amy
...
Eliot, George Middlemarch: a study of provincial life.
Faulkner, William *NULL*
Ferber, Edna Dawn O'Hara, the girl who laughed,
Ferber, Edna Show boat; a novel by Edna Ferber.
Ferber, Edna American beauty,
Franklin, Benjamin Advice to a young tradesman
Gaskell, Elizabeth Cleghorn Mary Barton: a tale of Manchester life ...
Gaskell, Elizabeth Cleghorn North and South.
Gaskell, Elizabeth Cleghorn The life of Charlotte Bronte, by E.C. Gaskell.
Gaskell, Elizabeth Cleghorn Wives and daughters. A novel.
Gaskell, Elizabeth Cleghorn Cranford.
Hardy, Thomas A pair of blue eyes; a novel by Thomas Hardy ...
Hardy, Thomas Under the greenwood tree
Hardy, Thomas Far from the madding crowd,
Hardy, Thomas A Laodicean. A novel.
Hawthorne, Nathaniel Fanshawe, a tale ...
Hawthorne, Nathaniel Twice-told tales.
Hawthorne, Nathaniel The scarlet letter, a romance.
Hawthorne, Nathaniel The house of the seven gables, a romance.
Hemingway, Ernest *NULL*
Hobbes, Thomas Leviathan
...
A left outer join will include those rows from author (full_name is a column of author) that do not have a corresponding row in book (author is the left-side table in the join clause). In this example, our bookshop evidently does not have a book by Faulkner or Hemingway. To see only the authors that do not have a book in the inventory, enter the query below.
select full_name, title from author natural left join book where title is null;
FULL_NAME TITLE
Faulkner, William *NULL*
Hemingway, Ernest *NULL*
Steinbeck, John *NULL*
When there are common columns between two tables in which some of the columns should not be included in the join you can specify a qualified join where you explicitly identify the join columns. For example, each book-shop patron is serviced by one account manager. The account manager is identified by the mgrid column in the patron table. However, both tables also have a name column but clearly that column should not be used in the join. So, to see a list of account managers and the patrons each one services, enter the following select state-ment.
select acctmgr.name, patron.name from acctmgr inner join patron using(mgrid);

RDM SQL Language Guide
Retrieving Data from a Database 53
ACCTMGR.NAME PATRON.NAME
Fox, Joe Bernard Arnult
Fox, Joe Chatsworth Osborne Jr.
Fox, Joe Giorgio Armani
Kelly, Kathleen Stephen Jobs
Kelly, Kathleen Scrooge McDuck
Kelly, Kathleen Jay Gatsby
Doel, Frank Warren Buffett
Doel, Frank Artimis Fowel II
Kralik, Alfred William Gates, III
Kralik, Alfred Thurston Howell III
Kralik, Alfred Charles Montgomery Burns
Kralik, Alfred Jean Luc Picard
Novac, Klara Mukesh Ambani
Novac, Klara Richie Rich
Novac, Klara Lucille Bluth
Noble, Barney Carlos Slim Helu
Noble, Barney Bruce Wayne
Zonn, Amy Jed Clampett
Zonn, Amy Jeffrey Bezos
The "inner" does not actually have to be specified as the default is to perform an inner join. Also notice that the col-umns in the select expression list are qualified by table name to differentiate the account manager name from the patron name.
Where the join columns between the tables do not have the same name use the on clause to provide the join con-ditions. Issue the following query on the NSF awards database to list the 2001 NSF grants awards to those spon-sors located in North Dakota.
select name, award_date, title from sponsor join award on(sponsor_nm = name)
where state = "ND" and award_date between date "2001-01-01" and date "2001-12-
31"
NAME AWARD_DATE TITLE
Bismarck St Coll 2001-07-10 Energy Technology Education Project
Cankdeska Cikana Community 2001-07-23 Cankdeska Cikana Community College Rural..
Dakota Technologies, Inc. 2001-06-22 SBIR Phase I: Novel Ultrasensitive Gas..
North Dakota State U Fargo 2001-06-11 Optics for Scientists and Engineers Lab..
North Dakota State U Fargo 2001-04-19 GOALI: Sequencing the Assembly Line and
Anal..
North Dakota State U Fargo 2001-08-06 US-Egypt Cooperative Research: Development
of..
North Dakota State U Fargo 2001-05-31 SGER: Evaluation and Modeling of Inter-
layer..
North Dakota State U Fargo 2001-09-25 Mathematics and Engineering Scholarships
North Dakota State U Fargo 2001-11-26 Developing and Assessing Impact of Prob-
lem-..
North Dakota State U Fargo 2001-12-26 Novel Instrumentation and Experimental for
..
North Dakota State U Fargo 2001-09-26 High Performance Network Connection in
Suppo..

RDM SQL Language Guide
Retrieving Data from a Database 54
North Dakota State U Fargo 2001-05-11 Molecular Basis of Substrate Specificity,
..
North Dakota State U Fargo 2001-04-18 Statics: The next generation
SMC 2001-11-15 SBIR Phase I: Protective Metal Foam
Hybrid..
Sitting Bull College 2001-03-07 Sitting Bull College Rural Systemic Ini-
tiative
Turtle Mountain Cmty Col 2001-09-20 Rural Systemic Initiatives in Science,
Math..
U of North Dakota 2001-04-26 Red River Geoscience Education Pilot
Project
U of North Dakota 2001-04-10 CAREER: Thermoeconomic Modeling as a Tool
for..
U of North Dakota 2001-08-30 Acquisition of a Variable Temperature
Automa..
U of North Dakota 2001-07-28 Acquisition of an Automated Sequencer
U of North Dakota 2001-05-02 CAREER: Protein Export in Escherichia coli
U of North Dakota 2001-02-20 REU Site: Research Experience for Under-
gradu..
U of North Dakota 2001-04-27 CAREER: Environmental Heterogeneity,
Populat..
U of North Dakota 2001-11-19 University of North Dakota Computer
Science,..
United Tribes Tech College 2001-07-20 United Tribes- Rural Systemic Initiative
The above examples all involve joins between just two tables. However, a select statement can involve joins between more than two tables. Joins still occur in pairs. The result of a single join operation is a virtual table that is then joined with another table. Join processing proceeds in a left-to-right manner. Thus, the left-hand "table" for the second join is the result of the previous join and is joined to the next table. In the above syntax specification note that a table_ref on the left hand side of the join operator can be a fully specified join whereas the right-hand side is table_primary—a table name. This processing order can be altered (or clarified) using parentheses. For example, the query below will return the investigator name and the research title for all NSF awards granted to the University of Colorado at Denver.
select person.name, title
from (award natural join investigator natural join person)
join sponsor on (sponsor_nm = sponsor.name)
where sponsor.name = "U of Colorado Denver";
PERSON.NAME TITLE
Hirshman, Elliot Using Midazolam to Explore the Nature of Implicit Memory
Zapien, Donald C. RUI: Investigation of the Relationship of Ferritin's
Struct..
Mandel, Jan Scalable Submesh Computing
Andrew., Andrew Acquisition of a High-Performance Parallel Computer for..
Mandel, Jan Acquisition of a High-Performance Parallel Computer for..
Bennethum, Lynn S. Acquisition of a High-Performance Parallel Computer for..
Russell, Thomas F. Acquisition of a High-Performance Parallel Computer for..
Billups, Stephen C. Acquisition of a High-Performance Parallel Computer for..
Stith, Bradley J. Lipid Signaling During Fertilization

RDM SQL Language Guide
Retrieving Data from a Database 55
Zamudio, Stacy Ancestry, Altitude and Placental Development in Highlands
..
Charles.§, Charles M. REU Site: American Economic Association Summer Training
Pr..
Andrew., Andrew Preconditioned Algorithms for Large Eigenvalue Problems..
Sievering, Herman Sea-Salt Aqueous Phase SO2 Oxidation: Contribution to
Mari..
Tracer, David P. Breast Feeding Structure and Parental Investment in
Papua..
Jenkins, Peter E. Toward T3 Tetherless Communications Workshop, Uni-
versity..
Sanders, Nancy M. School District Capacity to Support the Mathematics
Standar..
Billups, Stephen C. Algorithms for Nonsmooth Equations
Weaver, Gabriela C. Proof of Concept Proposal for Physical Chemistry in
Practi..
Rens, Kevin L. Concrete Maturity: A Quantitative Understanding of How..
Notice that both the person and sponsor tables have a column called name. Thus, references to each name must be qualified with the table name to ensure that SQL uses the correct name.
Sorting Query ResultsSuppose I want to see just the names of the investigators from the University of Colorado at Denver who have been awarded NSF grants. Scanning the result set for familiar names would be much easier if the results were returned sorted by the person's name. The order by clause of the select statement allows you to specify the col-umn or columns on which to sort the result set. The syntax is given below.
select_statement:
select [distinct] expression [column_alias] [, expression [column_alias] ]…
from table_ref [, table_ref]… [where cond_expr]
order by {num | column_name} [asc | desc] [,{num | column_name} [asc | desc]]…
The num is the ordinal position of the select expression on which to sort where num = 1 refers to the first expres-sion. The column_name is either the specified column_alias or the column name when expression is simply a table column name. The default sort order is asc (ascending) but desc can be specified to reverse the order. If more than one order by column is specified each subsequent column specifies a sort order within each value from the outer sort column(s). If select distinct is specified, duplicate rows in the result set will be eliminated. All of this is actually easier to show than to explain.
The next query will return the list of all investigators from the University of Colorado Denver that have been awarded NSF grants.
select person.name
from award natural join investigator natural join person
join sponsor on (sponsor_nm = sponsor.name)
where sponsor.name = "U of Colorado Denver"

RDM SQL Language Guide
Retrieving Data from a Database 56
order by 1;
PERSON.NAME
Alaghband, Gita
Altman, Tom
Andrew., Andrew
Andrew., Andrew
Andrew., Andrew
Andrew., Andrew
Banks, David L.
Beekman, Christopher S.
Beekman, Christopher S.
...
Stith, Bradley J.
Stith, Bradley J.
Stith, Bradley J.
Tagg, Randall P.
Tagg, Randall P.
Tagg, Randall P.
Tang, Michael S.
Tracer, David P.
Walker, Kenneth
Weaver, Gabriela C.
Weaver, Gabriela C.
Weaver, Gabriela C.
Zamudio, Stacy
Zapien, Donald C.
This list includes some duplicate entries. To eliminate them add distinct to the select as shown below.
select distinct person.name
from award natural join investigator natural join person
join sponsor on (sponsor_nm = sponsor.name)
where sponsor.name = "U of Colorado Denver"
order by 1;
PERSON.NAME
Alaghband, Gita
Altman, Tom
Andrew., Andrew
Banks, David L.
Beekman, Christopher S.
Bennethum, Lynn S.
Billups, Stephen C.
...
Stith, Bradley J.
Tagg, Randall P.
Tang, Michael S.
Tracer, David P.
Walker, Kenneth
Weaver, Gabriela C.

RDM SQL Language Guide
Retrieving Data from a Database 57
Zamudio, Stacy
Zapien, Donald C.
The next example will show the list of awards for each investigator in order of when the grant was issued with the most recent listed first.
select person.name, award_date, title
from award natural join investigator natural join person
join sponsor on (sponsor_nm = sponsor.name)
where sponsor.name = "U of Colorado Denver"
order by 1, 2 desc;
PERSON.NAME AWARD_DATE TITLE
Alaghband, Gita 1993-08-16 RIA: Parametric Modeling Tools for Performance
Altman, Tom 1992-09-04 Elimination of Certain Ambiguity Causing Con-
stru..
Andrew., Andrew 2002-08-28 Preconditioned Algorithms for Large Eigenvalue
Andrew., Andrew 2002-07-30 Sixth IMACS International Symposium on Iter-
ative
Andrew., Andrew 2000-08-28 Acquisition of a High-Performance Parallel
Compu..
Andrew., Andrew 1995-06-26 Mathematical Sciences: Preconditioned Parallel
Banks, David L. 1998-09-11 Group Travel Award to Support U.S Par-
ticipation in
Beekman, Christopher S. 2002-11-06 The Articulation of Political Strategies and
Reg..
Beekman, Christopher S. 2002-06-12 The Articulation of Political Strategies and
Reg.. ...
Stein, Fredrick M. 2002-01-28 Energy 2020: A Teacher Enhancement Workshop To
Stith, Bradley J. 2002-04-30 Lipid Signaling During Fertilization
Stith, Bradley J. 1999-03-22 RUI: Lipid Signaling During Fertilization
Stith, Bradley J. 1996-05-15 RUI: Induction of Cell Division by Protein
Kinas..
Tagg, Randall P. 2002-01-28 Energy 2020: A Teacher Enhancement Workshop To
Tagg, Randall P. 1995-06-30 Course Modules in Apparatus Design and Exper-
ime..
Tagg, Randall P. 1995-06-08 Mathematical Sciences: Patterns, Chaos, and ..
Tang, Michael S. 1995-02-02 Engineering, Technology and Culture: with an
Em..
Tracer, David P. 1999-12-20 Breast Feeding Structure and Parental Invest-
ment..
Walker, Kenneth 1995-02-02 Engineering, Technology and Culture: with an
Em..
Weaver, Gabriela C. 2002-01-28 Energy 2020: A Teacher Enhancement Workshop To
Weaver, Gabriela C. 1999-12-14 Proof of Concept Proposal for Physical Chem-
istry..
Weaver, Gabriela C. 1996-05-10 Integration of Novel Laser-Spectroscopy
Experim..
Zamudio, Stacy 2002-07-17 Ancestry, Altitude and Placental Development
in

RDM SQL Language Guide
Retrieving Data from a Database 58
Zapien, Donald C. 2002-02-11 RUI: Investigation of the Relationship of
Ferri..
Performing Result Set Aggregate CalculationsAll of the select statements shown thus far have produced detail rows where each row of the result set cor-responds to a single row from the table (a base table or table formed from the set of joined tables in the from clause). There are often times when you want to perform a calculation on one or more columns from a related set of rows returning only a summary row that includes the calculation result. The set of rows over which the cal-culations are performed is called the aggregate. The select statement group by clause is used to identify the col-umn or columns that define each aggregate—those rows that have identical group by column values. Five built-in aggregate functions are provided in SQL as defined in the table below.
Function Descriptioncount Returns the number (distinct) of rows in the aggregate.sum Returns the sum of the (distinct) values of expression in the aggregate.avg Returns the average of the (distinct) values of expression in the aggregate.min Returns the minimum expression value in the aggregate.max Returns the maximum expression value in the aggregate.
Table 10. Built-in Aggregate Functions
The complete syntax for the select statement including group by is as follows.
select_stmt:
select [first] [all | distinct] {* | select_item[, select_item]...}
from table_ref[, table_ref]...
[where conditional_expr]
[grouping | sorting | grouping sorting]
[limit (num {rows | mins | secs | msecs})]
[for {read only | update [of column_name[, column_name]...]}]
grouping:
group by sort_col[, sort_col]... [having conditional_expr]
sorting:
order by sort_col [asc | desc][, sort_col [asc | desc]]...
sort_col:
num | column_name
select_item:
expression [alias_name | "column heading"]

RDM SQL Language Guide
Retrieving Data from a Database 59
table_ref:
table_primary | table_join
table_primary:
table_spec | ( table_join )
table_spec:
[db_name.]table_name [[as] correlation_name]
table_join:
natural_join | qualified_join | cross_join
natural_join:
table_ref natural [inner | {left | right} [outer]] join table_primary
qualified _join:
table_ref [inner | {left | right} [outer]] join table_primary
[using (column_name[, column_name]...) | on conditional_expr]
cross_join:
table_ref cross join table_primary
arith_expr:
expression /* involving only numeric operands and operations */
dt_expr:
expression /* involving only date/time/timestamp operands and operations */
string_expr:
expression /* involving only string operands and operations */
expression:
operand [arith_operator operand]...
operand:
constant | param_ref | column_ref | function | (expr)
param_ref:
? | :param_name
column_ref:
[{table_name | correlation_name}.]column_name

RDM SQL Language Guide
Retrieving Data from a Database 60
arith_operator:
+ | - | * | /
function:
aggregate_fcn | scalar_fcn
aggregate_fcn:
{sum | avg | max | min} (expression)
| count ({* | column_ref })
| aggregate_udf_name ([expression][, expression]...)
scalar_fcn:
| if (conditional_expr, expression, expression)
| numeric_function | datetime_function | string_function
| scalar_udf_name ([expression][, expression]...)
numeric_function:
abs(arith_expr)
| acos(arith_expr)
| asin(arith_expr)
| atan(arith_expr)
| atan2(arith_expr)
| {ceil | ceiling}(arith_expr)
| cos(arith_expr)
| cot(arith_expr)
| exp(arith_expr)
| floor(arith_expr)
| {ln | log}(arith_expr)
| mod(arith_expr)
| pi()
| rand(num)
| sign(arith_expr)
| sin(arith_expr)
| sqrt(arith_expr)
| tan(arith_expr)
datetime_function:
age(dt_expr)
| {curdate | current_date}()
| {curtime | current_time}()
| dayofmonth(dt_expr)
| dayofyear(dt_expr)
| hour(dt_expr)
| minute(dt_expr)
| month(dt_expr)
| quarter(dt_expr)
| second(dt_expr)

RDM SQL Language Guide
Retrieving Data from a Database 61
| week(dt_expr)
| year(dt_expr)
string_function:
ascii(string_expr)
| char(num)
| concat(string_expr, string_expr)
| convert(expression, {convert_type | {char}, width, convert_format})
| lcase(string_expr)
| left(string_expr, num)
| length(string_expr)
| locate(string_expr, string_expr, num)
| ltrim(string_expr)
| repeat(string_expr, num)
| replace(string_expr, string_expr, string_expr)
| right(string_expr, num)
| rtrim(string_expr)
| substring(string_expr, num, num)
| ucase(string_expr)
| unicode(string_expr)
convert_type:
char |smallint | integer | real
| double | date | time | timestamp | tinyint | bigint
convert_format:
numeric_format | datetime_format
numeric_format:
"[<< | >> | ><]['text' | $][- | (][#,]#[.#[#]...][e | E]['text' | $ | %]"
datetime_format:
"[<< | >> | ><]['text' | spchar | date_code | time_code]..."
date_code:
m | mm | mmm | mon | mmmm | month
| d | dd | ddd | dddd | day
| yy | yyyy
time_code:
h | hh | m | mm | s | ss | .f[f]... | [a/p | am/pm | A/P | AM/PM]
To illustrate the basic operation of aggregate calculations, consider the following example which computes the total sales for each bookshop account manager.
select name, count(*), sum(price)
from (acctmgr join patron using(mgrid)) natural join sale natural join book

RDM SQL Language Guide
Retrieving Data from a Database 62
group by 1;
NAME COUNT(*) SUM(PRICE)
Doel, Frank 5 31745
Fox, Joe 19 95500
Kelly, Kathleen 14 67350
Kralik, Alfred 18 72685
Noble, Barney 6 234700
Novac, Klara 21 221650
Zonn, Amy 9 15660
The from clause needs a little explanation. A natural join between acctmgr and patron cannot be used because besides the mgrid column which is the correct join column both tables have a column called name which is not a legitimate join column as they never contain the same value. So the using clause is specified to identify the par-ticular common column name on which to form the join.
The count(*) give the number of detail rows (i.e., sold books) in the aggregate for each account manager. The sum(price) gives the total of all of the price values in the aggregate for each account manager.
You can see all of the detail rows that were used in the aggregate calculations by issuing the following query.
select name, price
from (acctmgr join patron using(mgrid)) natural join sale natural join book
order by 1;
NAME PRICE
Doel, Frank 25000
Doel, Frank 750
Doel, Frank 2500
Doel, Frank 995
Doel, Frank 2500
Fox, Joe 3500
Fox, Joe 12500
Fox, Joe 750
Fox, Joe 1200
...
Zonn, Amy 1250
Zonn, Amy 1200
Zonn, Amy 4375
Zonn, Amy 750
Zonn, Amy 325
Figure 7 illustrates how aggregate calculations are performed on the detail rows that are retrieved.

RDM SQL Language Guide
Retrieving Data from a Database 63
Figure 7 - Group By Aggregate Calculations
NSF Gender Study Example
The next example is from the NSF awards database. This is a rather involved example that shows how you can use SQL to do analytical studies based on historical data contained in a database. The conclusions that are given are the author's own based on his interpretation of the results of the queries given below.
The person table contains a list of all of the individual research investigators (jobclass = "I") and NSF pro-gram managers (jobclass = "P"). The gender of each person was not included in the original data but was deduced from the person's first name based on a modified version of the list of names available from the fol-lowing web site:
http://www.gpeters.com/names/baby-names.php?report=pop_all&showcount=10000
Not all first names in the person table were in this list and hence the gender could not be deduced. Thus, the gender column values can be "M", "F", or "U". You can issue the following queries to see the totals for each gender.
select count(*) from person where gender = "M";
COUNT(*)
57386
select count(*) from person where gender = "F";
COUNT(*)
17537
select count(*) from person where gender = "U";
COUNT(*)
10983
Alternatively, the next query can be used to compute the same results in one pass through the person table.

RDM SQL Language Guide
Retrieving Data from a Database 64
select sum(if(gender="F",1,0)) female,
sum(if(gender="M",1,0)) male,
sum(if(gender="U",1,0)) unknown from person;
FEMALE MALE UNKNOWN
17537 57386 10983
It might be interesting to see what difference there is between the ratio of male to female investigators and the ratio of male to female program managers. The following query uses a group by to group the totals by job-class.
select jobclass, sum(if(gender="F",1,0)) female, sum(if(gender="M",1,0)) male
from person where gender != "U"
group by 1;
JOBCLASS FEMALE MALE
I 17197 56813
P 340 573
The ratio of male to female investigators is 3.3 while the ratio for program managers is 1.7. Assuming that the pro-gram managers are NSF employees, it appears that, on a percentage basis, they hire significantly more women to oversee NSF research grants than women to whom they award the grants.
To see if there is any trend in the percentage of women granted NSF awards, you can issue the query below to see the percentage of women who were awarded NSF grants by year.
select year(award_date), 100.*sum(if(gender="F",1,0))/count(gender) pct_females
from award natural join investigator natural join person
where gender != "U" group by 1;
YEAR(AWARD_DATE) PCT_FEMALES
1989 21.74
1990 22.21
1991 19.79
1992 17.90
1993 18.81
1994 17.69
1995 19.91
1996 18.82
1997 19.52
1998 20.85
1999 19.61
2000 20.02
2001 20.94
2002 21.04
2003 21.93
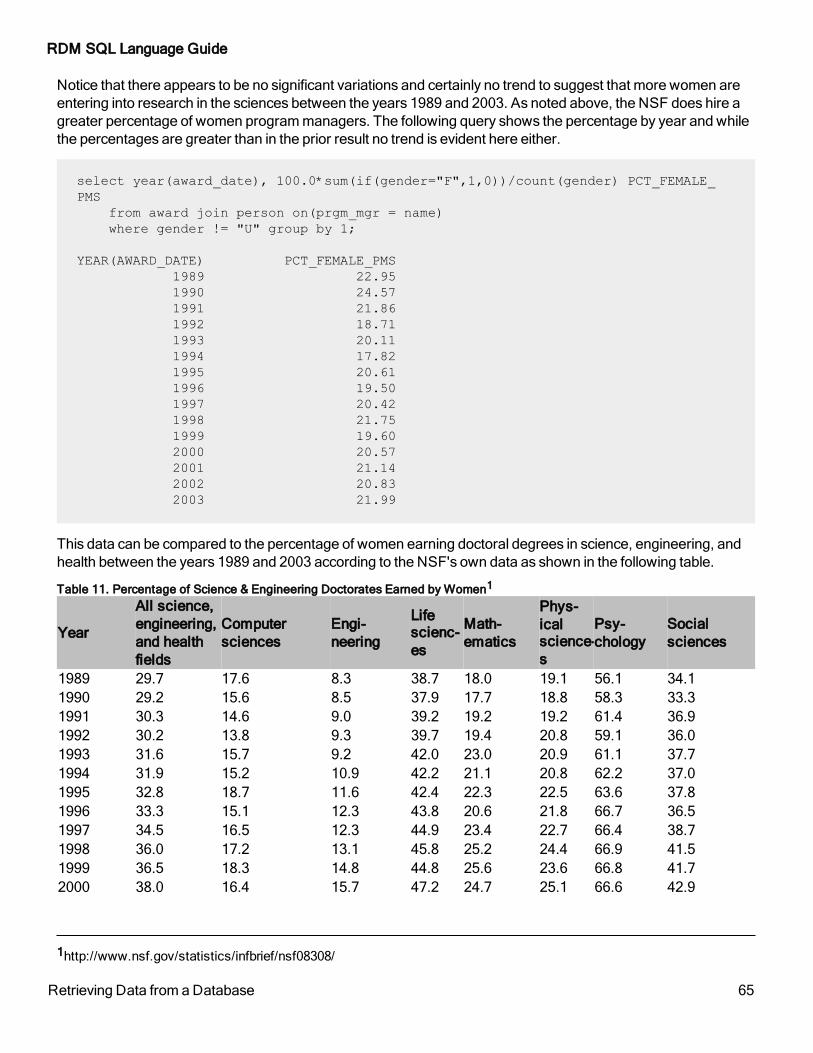
RDM SQL Language Guide
Retrieving Data from a Database 65
Notice that there appears to be no significant variations and certainly no trend to suggest that more women are entering into research in the sciences between the years 1989 and 2003. As noted above, the NSF does hire a greater percentage of women program managers. The following query shows the percentage by year and while the percentages are greater than in the prior result no trend is evident here either.
select year(award_date), 100.0*sum(if(gender="F",1,0))/count(gender) PCT_FEMALE_
PMS
from award join person on(prgm_mgr = name)
where gender != "U" group by 1;
YEAR(AWARD_DATE) PCT_FEMALE_PMS
1989 22.95
1990 24.57
1991 21.86
1992 18.71
1993 20.11
1994 17.82
1995 20.61
1996 19.50
1997 20.42
1998 21.75
1999 19.60
2000 20.57
2001 21.14
2002 20.83
2003 21.99
This data can be compared to the percentage of women earning doctoral degrees in science, engineering, and health between the years 1989 and 2003 according to the NSF's own data as shown in the following table.
Year
All science,engineering,and healthfields
Computer sciences
Engi-neering
Life scienc-es
Math-ematics
Phys-ical science-s
Psy-chology
Social sciences
1989 29.7 17.6 8.3 38.7 18.0 19.1 56.1 34.11990 29.2 15.6 8.5 37.9 17.7 18.8 58.3 33.31991 30.3 14.6 9.0 39.2 19.2 19.2 61.4 36.91992 30.2 13.8 9.3 39.7 19.4 20.8 59.1 36.01993 31.6 15.7 9.2 42.0 23.0 20.9 61.1 37.71994 31.9 15.2 10.9 42.2 21.1 20.8 62.2 37.01995 32.8 18.7 11.6 42.4 22.3 22.5 63.6 37.81996 33.3 15.1 12.3 43.8 20.6 21.8 66.7 36.51997 34.5 16.5 12.3 44.9 23.4 22.7 66.4 38.71998 36.0 17.2 13.1 45.8 25.2 24.4 66.9 41.51999 36.5 18.3 14.8 44.8 25.6 23.6 66.8 41.72000 38.0 16.4 15.7 47.2 24.7 25.1 66.6 42.9
Table 11. Percentage of Science & Engineering Doctorates Earned by Women1
1http://www.nsf.gov/statistics/infbrief/nsf08308/

RDM SQL Language Guide
Retrieving Data from a Database 66
2001 38.0 18.7 16.9 47.2 27.3 25.5 66.7 42.92002 39.2 20.6 17.6 47.8 28.9 27.3 66.6 44.52003 39.4 20.3 17.3 48.5 26.6 27.8 68.1 44.8
Here trends that show an increasing percentage of women who've earned doctorates in every field are clearly evident. What isn't clear is why these same trends are not also represented in the NSF research grant awards. Now I suppose that it is possible that those person table rows in which the gender was not deducible could be a higher percentage of female than male but that does not strike me as likely. One might even ask why the researcher's gender was not included in the data collection. Perhaps it was but it was not included in the report data in order to avoid just this kind of analysis. But that is mere speculation. The culprits, if there really are any, could be anywhere not just who at NSF decides who is awarded research grants. Other data that could be sig-nificant requires tracking the gender of the proposed investigators for all grant requests including those that are rejected. If that data were to show a trend that corresponds to that in the above table then it would seem that the fault lies in the grant awards process. However, if no such trend is evident, it is possible that the problem could be inside the grant requesting institutions where the authority for approving grant requests resides with senior research management. However, other NSF data1 does show an historical increase in the percentage of women in senior faculty positions. So, since we evidently do not have all of the data, it would be "a capital mistake to theorize before one has data."
1http://www.nsf.gov/statistics/seind10/pdf/c05.pdf

RDM SQL Language Guide
Inserting Data into a Database 67
Inserting Data into a Database"I never guess. It is a capital mistake to theorize
before one has data. Insensibly one begins to twist
facts to suit theories, instead of theories to suit facts".- Sherlock Holmes
In this section you will learn how to put data into an RDM SQL database. Three methods are available to you for doing this. The most common is through the insert values statement that stores a single row into a table. Another is to use the insert select statement that lets you store all of the rows returned from a select statement into a table. The select retrieves rows from other tables in the same database or in another database but can also retrieve data from a non-SQL data source that you can make available to RDM SQL through the create vir-tual table feature. The third method is through the use of the non-standard import statement. This statement can insert new rows into a table from data stored in a comma-delimited or XML text file.
When making modifications to database content it is vitally important to maintain the logical integrity of the data. Logical integrity means that all the related rows from multiple tables, as defined by the foreign and primary key relationships in the DDL, always exist. That means, for example, that for every book stored in the bookshop data-base the referenced author row exists as do all of its related names, notes, sales and auctions. Logical integrity is achieved through the use of transactions. This section will also show you how to use SQL transactions to ensure that the logical integrity of your database remains intact and it is with that subject that we begin.
TransactionsIt is very important that any database management system (DBMS) ensures that the data that is stored in a data-base satisfies the ACID criteria: Atomicity, Consistency, Isolation, and Durability. Atomicity means that a set of interrelated database modifications all be made together at the same time. If one modification from the set fails then all fail. Consistency means that a database never contains errant data or relationships and that a trans-action always transforms the database from one consistent state into another. Consistency is something that is primarily the responsibility of the application because the database cannot be certain that all of the necessary modifications have been properly included in any given transaction. In RDM SQL, consistency rules are specified through the foreign and primary key declarations and RDM SQL does ensure that those relationships are con-sistent. Isolation means that the changes that are being made during a transaction are only visible to the user (program task) making them. Not until the transaction's changes have been committed to the database are other users (tasks) able to see them. Durability refers to the DBMS's ability to ensure that the changes made by all transactions that have committed survive any kind of system failure.
The work necessary to ensure that a DBMS supports "ACIDicity" makes it among the most complex of all system software components. The challenge being to maintain ACIDicity and yet allow the database data to be easily accessed by as many users as possible, as fast as possible. However, there is an unavoidable and severe neg-ative performance impact caused by the need to maintain an ACID compliant database. When enforcement of these properties is relaxed, data can be updated and accessed much more quickly but the consistency and integ-rity of the data will certainly be impaired should a system failure occur.
Three statements are used for transaction processing. The start transaction statement does just that. The com-mit statement will write to the database all of the changes made since the last start transaction. The rollback statement will undo all of the changes made since the last start transaction. The syntax for each of these state-ments is shown below.

RDM SQL Language Guide
Inserting Data into a Database 68
start_stmt:
{start trans[action] | begin [work] [trans[action]]} [read only]
commit_stmt:
{commit [work] | end [trans[action]]}
release_stmt:
release savepoint savepoint_id]
rollback_stmt:
rollback [work] [[to savepoint] savepoint_id]
If no start transaction statement has been executed prior to the execution of an insert, update, or delete state-ment, the system will automatically start a transaction for you.
The read only transaction was described in detail in the Retrieving Data from a Database section. Examples showing how to use transactions with the insert statement are provided in the following sections.
Insert ValuesThe insert values statement is used to insert a new row into a table. Its syntax is as shown in the box below.
insert_values_stmt:
insert into [db_name.]table_name [( column_name[, column_name]... )]
values simple_expr[, simple_expr]...
simple_expr:
simple_operand [+ | - | * | / | % | simple_operand]…
| ( simple_expr )
simple_operand:
constant | column_name | arg_name | ? | scalar_fcn
scalar_fcn:
numeric_function | datetime_function | string_function | system_function
| udf_name ([simple_expr][, simple_expr]...)
The insert values statement is used to insert a single row into the table table_name. If a column_name list is specified it must include every column which requires that a value be specified (a primary key column or one which does not have a default value but does have a not null declared). For each column, there must be a value specified in the same corresponding position in the values list. If no column_name list is specified then there must be a value listed for each column declared in the table in the order in which the columns were declared in the create table statement for table_name.

RDM SQL Language Guide
Inserting Data into a Database 69
The values specified in the values list will usually simply be a constant of a data type that is compatible with the data type of its corresponding column. However, simple expressions can be used and besides constant values can include a reference to another column value in the list (column_name) , parameter marker references (des-ignated by a "?") or, if the insert statement is contained within a create procedure statement, procedure argu-ment names (arg_name). Expressions can also include calls to the built-in SQL functions or to a user-defined function. Use of functions will be described in detail in the Changing and Deleting Data in a Database section and in the User-Defined Functions (UDFs) in SQL section. The arithmetic operations that are supported include the usual addition (+), subtraction (-), multiplication (*), and division (/) as well as modulo (%). If a values list entry includes a column_name it must reference another column in the table and the values list entry for that column cannot itself include a column_name reference.
Here are some example insert statements:
start transaction;
insert into author values "DescartesR", "Descartes, Rene", "M", 1596, 1650,
"French philosopher, mathematician, physicist, and writer";
insert into book values "descartes01", "DescartesR", "Principia philosophiae",
"12 p.l., 310 p. illus., diagrs. 21 cm.",
"Amstelodami, apud Ludovicum Elzevirium",
1644, "B1860 1644", date "2010-09-22", null, 1.20*cost, 12750.0;
insert into related_name values "descartes01", "Lessing J. Rosenwald Collection";
insert into related_name values "descartes01", "John Davis Batchelder Collection";
insert into note(noteid, bookid) values nextnote(), "descartes01";
insert into note_line values thisnote(), "Title vignette: device of Louis
Elzevir.";
insert into note_line values thisnote(), "Last preliminary leaf (sig. b[4])
blank.";
commit;
There are several things to notice from this example. The first is the presence of the start transaction and commit statements that enclose the seven insert statements. As was discussed in the last section, since all of the data being inserted into the database is interrelated, by placing it inside a single transaction unit, the system guar-antees that either all of the data will be reliability stored in the database or, in the event of a system failure during the transaction, none of it will. If each insert statement was individually committed then, should a failure occur, some of the data would be missing. Therefore, it is always best to enclose all related database modification state-ments (i.e., insert, update, and delete) in a transaction.
The value associated with the price column in the second insert statement (i.e., the next to last entry in the values list) is an expression that references the cost column (the last entry in the list). In this example, the asking price for the book is calculated as a 20% markup over the cost of the book.
The final three insert statements illustrate how RDM user-defined functions (UDF) can be used to implement an "auto-increment" integer primary key. UDFs will be explained in detail in the User-Defined Functions (UDFs) in SQL section but here all you need to know is that the call to nextnote() returns the next higher noteid value and the call to thisnote() returns the current value (i.e., that just returned by nextnote() when the pre-vious insert statement was executed). This allows the foreign key value for column noteid in table note_line to reference the note row that was just entered.

RDM SQL Language Guide
Inserting Data into a Database 70
Insert From SelectYou can also insert new rows into a table from another table using insert from select statement. The syntax for the insert from select statement is given below. The select statement was described in detail in the Retrieving Data from a Database section and its use with the insert statement will show the basics of how the two can be used together.
insert_select_stmt:
insert into table_name [( column_name[, column_name]... )]
from select_stmt
The number of result columns returned from the select_stmt must equal the number of columns specified in the colum_name list or, if not specified, the number of columns declared in the table. The data type of each result column must also be compatible with its corresponding table column.
The following example uses the weather sensor database example discussed in the Defining a Database sec-tion. The select statement retrieves data from the various weather sensors and stores the results in the weather_summary table. It uses the limit clause to specify that the data is to be accumulated and summarized every 60 minutes. Even though only the SQL statements are shown, the execution of the statement would be per-formed inside a loop in the application program. One row per longitude and latitude, date, and hour of the day is stored in the weather_summary table. Note that the execution time for this statement is one hour.
insert into weather_summary from
select loc_long, loc_lat, curdate(), hour(rdg_time)
avg(temperature), avg(pressure), avg(humidity), avg(light) from weather_data
group by 1, 2, 3, 4 limit(60 mins);
ImportData from non-database sources that are contained in text files can be loaded into a database table by using the import statement as shown in the syntax specification below.
import_stmt:
import into table_name from [char | wchar | xml] file "filename"
The data must either be stored in a comma-delimited or XML format. A comma-delimited format requires that each column value be specified in the order in which the columns are declared in the table. Absence of a column value is indicated by a blank or empty entry (e.g., ",,"). Specify wchar if the text is stored with wide-characters.
The following statements are used to load the sample data contained in comma-delimited text files into bookshop example database.
import into author from file "authors.txt";
import into book from file "books.txt";

RDM SQL Language Guide
Inserting Data into a Database 71
import into genres from file "genres.txt";
import into subjects from file "subjects.txt";
import into related_name from file "names.txt";
import into genres_books from file "bookgens.txt";
import into subjects_books from file "booksubs.txt";
import into acctmgr from file "acctmgrs.txt";
import into patron from file "patrons.txt";
import into note from file "bnotes.txt";
import into note_line from file "bnotelines.txt";
import into note from file "pnotes.txt";
import into note_line from file "pnotelines.txt";
import into sale from file "sales.txt";
import into auction from file "auctions.txt";
In XML format the column values are identified using XML attributes or tags to identify the column name with which the tagged value is associated. The columns can be in any order but all necessary columns must be included (i.e., columns declared as not null without a default value or which are declared as a primary or unique key). Each row is bracketed between pairs of <ROW> and </ROW> tags. For each row column values are spec-ified between pairs of <column_name> and </column_name> tags. The file begins with a <RAIMA-SQL> tag and ends with a </RAIMA-SQL> tag. A portion of file sponsors.xml which can be used to load the sponsor table in the nsfawards database is shown below.
<RAIMA-SQL>
...
<ROW>
<name>UNAVCO, Inc.</name>
<addr>3360 Mitchell Lane</addr>
<city>Boulder</city>
<state>CO</state>
<zip>80301</zip>
</ROW>
<ROW>
<name>UNIAX Corporation</name>
<addr>6780 Cortona Drive</addr>
<city>Santa Barbara</city>
<state>CA</state>
<zip>93117</zip>
</ROW>
<ROW>
<name>UNIVERSITY OF MICHIGAN</name>
<addr>2455 Hayward Street</addr>
<city>Ann Arbor</city>
<state>MI</state>
<zip>48109</zip>
</ROW>
<ROW>
<name>UNIVERSITY OF WISCONSIN MA</name>
<addr></addr>
<city></city>
<state> </state>
<zip> / </zip>

RDM SQL Language Guide
Inserting Data into a Database 72
</ROW>
<ROW>
<name>UNT Hlth Sci Ctr at Fort W</name>
<addr>Camp Bowie at Montgomery</addr>
<city>Fort Worth</city>
<state>TX</state>
<zip>76107</zip>
</ROW>
<ROW>
<name>URS Group, Inc.</name>
<addr>566 El Dorado Street - 2nd Floor</addr>
<city>Pasadena</city>
<state>CA</state>
<zip>91101</zip>
</ROW>
<ROW>
<name>US Army Corps of Engineers</name>
<addr>Transatlantic Programs Center</addr>
<city>Winchester</city>
<state>VA</state>
<zip>22601</zip>
</ROW>
...
</RAIMA-SQL>
The following statement loads the sponsor table in the nsfawards database from the above file.
import into sponsor from xml file "sponsors.xml";

RDM SQL Language Guide
Changing and Deleting Data in a Database 73
Changing and Deleting Data in a DatabasePoliticians are like diapers. They both need
changing regularly and for the same reason.- Unknown
As I write this sentence and look up and see the quote at the top of the page which I found several weeks ago, I note that today is election day in the USA. Interesting coincidence. However, what you will learn about changing and deleting data in a database using SQL in this section will be much easier than changing politicians!
The SQL update statement is used to change the value of one or more columns in the rows of a particular table. The SQL delete statement can be used to delete one or more rows from a particular table. Two forms are pro-vided for each statement. A searched update or delete contains a where clause that is used to determine which rows of the table are to be updated or deleted. Searched updates and deletes are designed to be used inter-actively although they are also easily used in an application program. A positioned update or delete is used in con-junction with a select statement that is being processed under a separate statement handle and is only used within an application program. For that reason, the discussion on positioned updates and deletes will be dis-cussed in the Using SQL in an Application Program section.
Searched Delete StatementThe syntax for the delete statement is as follows.
delete_stmt:
delete from [db_name.]table_name
[where {conditional_expr | current of cursor_name}]
If no where clause is specified then all of the rows in the table are deleted. If a where clause is specified then only those rows for which the conditional expression is true will be deleted. If a referential integrity violation occurs on any row during the execution of the delete statement, then the delete fails with no rows deleted. A referential integrity violation occurs when there is a foreign key reference to a row to be deleted and the foreign key/ref-erences declaration does not include on delete cascade. All foreign key/references declarations that do include on delete cascade will cause the referencing rows from those tables to be deleted as well.
Our antiquarian bookshop has a limited first edition, first impression copy of Jacob's Room by Virginia Woolf worth 32,500 pounds. The owner has loaned this copy to the British Library for an upcoming Virginia Woolf exhi-bition. Hence, it needs to be removed from the inventory. The following queries show the pertinent information from the book table as well as the entries in all the tables that reference the book.
select bookid, publ_year, price, title from book where bookid = "woolf03";
BOOKID PUBL_YEAR PRICE TITLE
woolf03 1922 32500.00 Jacob's room [by] Virginia Woolf.
select * from related_name where bookid = "woolf03";
BOOKID NAME
woolf03 Hogarth Press, publisher.

RDM SQL Language Guide
Changing and Deleting Data in a Database 74
select * from genre_books where bookid = "woolf03";
BOOKID GENRE
woolf03 Psychological fiction
woolf03 Experimental fiction
select * from subjects_books where bookid = "woolf03";
BOOKID SUBJECT
woolf03 World War, 1914-1918
woolf03 Young men
woolf03 England
select text from note natural join note_line where bookid = "woolf03";
TEXT
First edition, first impression. One of probably
40 'A' subscribers copies.
Because all of the references to this particular book have foreign keys that specify on delete cascade, all that is needed to remove the book and its references is to issue the following statement.
delete from book where bookid = "woolf03";
The previous four select statements will now not return any results. Now suppose you want to delete the genre "Gothic fiction." You might first attempt the direct approach as follows.
delete from genres where text = "Gothic fiction";
**** referential integrity error: row to be deleted is referenced
The referential integrity error results from the fact that the foreign key references to this table are by default on delete restrict which prevents the deletion of rows from a table where references exist. The genres table is ref-erenced by only one other foreign key: the genre column of the genres_books table. You can use the following query to list all of the rows in genres_books that reference "Gothic fiction."
select * from genres_books where genre = "Gothic fiction";
BOOKID GENRE
austen06 Gothic fiction
There is only one reference which is Jane Austen's Northanger Abbey. So to delete "Gothic fiction" from the gen-res table you must first delete the reference in genres_books (which is appropriate considering the book is not gothic fiction but is, in fact, a parody of gothic fiction).
delete from genres_books where genre = "Gothic fiction";
**** 1 rows affected
delete from genres where text = "Gothic fiction";
**** 1 rows affected

RDM SQL Language Guide
Changing and Deleting Data in a Database 75
At this point, since these are only examples, I suggest that you issue a rollback to restore the database back to its original state.
select * from genres where text = "Gothic fiction";
TEXT
select * from genres_books where genre = "Gothic fiction";
BOOKID GENRE
rollback;
select * from genres where text = "Gothic fiction";
TEXT
Gothic fiction
select * from genres_books where genre = "Gothic fiction";
BOOKID GENRE
austen06 Gothic fiction
Searched Update StatementThe syntax for the searched update statement is given below.
update_stmt:
update [db_name.]table_name
set column_name = expression[, column_name = expression]...
[where {conditional_expr | current of cursor_name}]
The values to which the named columns in the set clause are assigned are the evaluated results of the specified column expressions. The column values in [db_name.]table_name referenced by the expressions are the pre-updated column values. The rows that are updated are those for which conditional_expr is true. If the update of any of the selected rows results in an referential integrity violation (i.e., a foreign key column in the table is changed to a value that does not exist in the referenced table), the update is aborted and the changes to the rows that had already been modified are discarded. If the where clause is not specified, all of the rows in the spec-ified table are updated.
If one of the columns specified in the set clause is a primary key that is referenced by one or more foreign key ref-erences in other tables then one of two results can occur. If the foreign key declaration in the create table state-ment of the referencing table is specified with on update cascade then the update will succeed and the column values of all referencing rows will automatically (and instantly) be updated accordingly. If no on clause is spec-ified or if on update restrict is specified, the update will be rejected with a referential integrity error.
The following query lists the unsold books priced at £25,000 and above in the order in which the books were acquired.
select bookid, date_acqd, price, title from book
where date_sold is null and price >= 25000.00

RDM SQL Language Guide
Changing and Deleting Data in a Database 76
order by date_acqd;
BOOKID DATE_ACQD PRICE TITLE
shakespeare01 2006-01-02 175000.00 The Tragicall Historie of Hamlet,
Prince...
poe02 2006-02-14 25000.00 Tales of the grotesque and arabesque
decartes01 2006-03-09 75000.00 Principia philosophiae
twain01 2006-08-06 32500.00 The celebrated jumping frog of Calaveras
...
shakespeare07 2006-10-26 25000.00 Works. 1709
shakespeare03 2007-05-22 75000.00 Macbeth, a tragedy.
shakespeare06 2007-08-22 34500.00 King Richard II
twain03 2007-09-17 67500.00 The adventures of Tom Sawyer,
potter04 2007-12-19 80000.00 The tale of Peter Rabbit
shakespeare04 2008-02-09 250000.00 Plays
wells02 2009-03-24 30000.00 The island of Doctor Moreau,
woolf03 2009-08-10 32500.00 Jacob's room [by] Virginia Woolf.
shelley01 2009-11-26 25000.00 Frankenstein; or, The modern Prometheus.
raleigh01 2010-01-12 32500.00 The history of the world.
Given the difficult economic conditions and because they have been sitting in inventory unsold for some time, the shop owner has decided to lower the price by 15% on the most expensive books that were acquired prior to 2007. The following update statement will do this.
Note that the values in the date_acqd and date_sold columns in your installation of the bookshop database example will be comprised of dates later than those shown here.
update book set price = price - price*0.15
where date_sold is null and date_acqd < date "2007-01-01" and price >=
25000.00;
**** 5 rows affected
select bookid, date_acqd, price, title from book
where date_sold is null and price >= 25000.00 order by date_acqd;
BOOKID DATE_ACQD PRICE TITLE
shakespeare01 2006-01-02 148750.00 The Tragicall Historie of Hamlet,
Prince...
decartes01 2006-03-09 63750.00 Principia philosophiae
twain01 2006-08-06 27625.00 The celebrated jumping frog of Calaveras
...
shakespeare03 2007-05-22 75000.00 Macbeth, a tragedy.
shakespeare06 2007-08-22 34500.00 King Richard II
twain03 2007-09-17 67500.00 The adventures of Tom Sawyer,
potter04 2007-12-19 80000.00 The tale of Peter Rabbit
shakespeare04 2008-02-09 250000.00 Plays
wells02 2009-03-24 30000.00 The island of Doctor Moreau,
woolf03 2009-08-10 32500.00 Jacob's room [by] Virginia Woolf.
shelley01 2009-11-26 25000.00 Frankenstein; or, The modern Prometheus.
raleigh01 2010-01-12 32500.00 The history of the world.

RDM SQL Language Guide
Changing and Deleting Data in a Database 77
It was also noticed that the bookid values in the book table all begin with the author's last name followed by a two-digit ordered sequence. However, two authors share the same last name: Emily and Charlotte Bronte. The bookid values for the two sisters begin with the first initial to differentiate between the authors. The shop owner was to change this so that the initial follows the last name in order to preserve the last name bookid convention. Since all foreign key references to bookid have been declared with the on update cascade specification, it is possible to update the bookid column even though it is the book table's primary key. The following example shows the update statements that do this. Notice the use of the built-in string function replace.
select bookid, last_name, title from book where last_name like "Bronte%";
BOOKID LAST_NAME TITLE
cbronte01 BronteC Jane Eyre. An autobiography. Ed. by Currer Bell
[pseud.]
cbronte02 BronteC Villette.
cbronte03 BronteC Jane Eyre.
ebronte01 BronteE Wuthering Heights. A novel.
update book set bookid = replace(bookid, "cbronte", "brontec")
where last_name = "BronteC";
*** 3 rows affected
update book set bookid = replace(bookid, "ebronte", "brontee")
where last_name = "BronteE";
*** 1 rows affected
select bookid, last_name, title from book where last_name like "Bronte%";
BOOKID LAST_NAME TITLE
brontec01 BronteC Jane Eyre. An autobiography. Ed. by Currer Bell
[pseud.]
brontec02 BronteC Villette.
brontec03 BronteC Jane Eyre.
brontee01 BronteE Wuthering Heights. A novel.
One final comment. Notice that in none of the above examples was a commit statement issued. Hence, the changes made by the foregoing update statements have not yet been permanently stored in the database. Since, these were just examples, let's just go ahead and issue a rollback statement to discard them.
rollback;
select bookid, date_acqd, price, title from book
where date_sold is null and price >= 25000.00 order by date_acqd;
BOOKID DATE_ACQD PRICE TITLE
shakespeare01 2006-01-02 175000 The Tragicall Historie of Hamlet, Prince...
poe02 2006-02-14 25000 Tales of the grotesque and arabesque
decartes01 2006-03-09 75000 Principia philosophiae
twain01 2006-08-06 32500 The celebrated jumping frog of Calaveras ...

RDM SQL Language Guide
Changing and Deleting Data in a Database 78
shakespeare07 2006-10-26 25000 Works. 1709
shakespeare03 2007-05-22 75000 Macbeth, a tragedy.
shakespeare06 2007-08-22 34500 King Richard II
twain03 2007-09-17 67500 The adventures of Tom Sawyer,
potter04 2007-12-19 80000 The tale of Peter Rabbit
shakespeare04 2008-02-09 250000 Plays
wells02 2009-03-24 30000 The island of Doctor Moreau,
woolf03 2009-08-10 32500 Jacob's room [by] Virginia Woolf.
shelley01 2009-11-26 25000 Frankenstein; or, The modern Prometheus.
raleigh01 2010-01-12 32500 The history of the world.
select bookid, last_name, title from book where last_name like "Bronte%";
BOOKID LAST_NAME TITLE
cbronte01 BronteC Jane Eyre. An autobiography. Ed. by Currer Bell
[pseud.]
cbronte02 BronteC Villette.
cbronte03 BronteC Jane Eyre.
ebronte01 BronteE Wuthering Heights. A novel.

RDM SQL Language Guide
Writing and Using Stored Procedures 79
Writing and Using Stored ProceduresThere is no procedure for learning to write.
What you must do, is learn to think.- S. Leonard Rubenstein, Pennsylvania State University
classroom lecture, 1980.
A stored procedure is a named and possibly parameterized collection of one or more SQL statements that are precompiled and executed together as a group. In RDM SQL, stored procedures are defined using the create procedure statement as shown in the syntax specification given below.
create_proc_stmt:
create {proc | procedure} proc_name [(arg_name arg_type[, arg_name arg_type]...)] as
{select_stmt... |
[start_stmt] {insert_stmt | update_stmt | delete_stmt}... [commit_stmt]}
end {proc | procedure}
arg_type:
{character | char }
| {double [precision] | float | real }
| {tinyint | smallint | int | integer long | bigint}
| date | time | timestamp
You will notice that you can either include one or more select statements or you can only include one or more database modification statements optionally as a transaction. Stored procedures, therefore, can be used to spec-ify the precompiled queries and the precompiled database modifications needed by an application. However, RDM SQL stored procedures do not allow you to specify a single procedure that does both. The limitations are designed to keep the RDM SQL implementation as efficient and as small as possible because of the resource lim-itations of many embedded computing environments.
The names used for stored procedure arguments must not conflict with column names that are declared in any of the tables that are referenced in the SQL statements contained in the stored procedure. The argument data types must be compatible with how they are used in the SQL statements specified in the procedure.
When a stored procedure has been successfully compiled by RDM SQL, the compiled code is stored in a file named proc_name.ssp on the database's TFS. Also created and stored in the current directory is a file named proc_name_ssp.c containing statically initialized C data structures that contain the compiled stored procedure information and a file named proc_name_ssp.h which is a C header file to be included in any program that will directly execute the stored procedure by calling function rsqlExecProc. This process is illustrated in Figure 8.

RDM SQL Language Guide
Writing and Using Stored Procedures 80
Figure 8 - How Create Procedure is Processed
There are two ways to execute a stored procedure. If all of your SQL database access is through pre-compiled stored procedures (i.e., use of the proc_name_ssp.c module), then as mentioned above, the application, calls rsqlExecProc. This will be explained in detail in the Using SQL in an Application Program section. The other way to execute a stored procedure is by compiling and executing an execute statement as shown in the fol-lowing syntax.
execute_stmt:
[exec[ute] | run] proc_name [(constant[, constant]...)]
The next example creates and executes a stored procedure that will retrieve some of the columns in the book table for a specific bookid value that is passed in as an argument.
create proc getbook(bid char) as
select last_name, publ_year, price, title from book
where bookid = bid
end proc;
execute getbook("austen03");
LAST_NAME PUBL_YEAR PRICE TITLE
AustenJ 1814 13500.00 Mansfield Park: a novel. In three volumes.

RDM SQL Language Guide
Writing and Using Stored Procedures 81
Now suppose we really want to see the author's full name along with the selected book information. You can do this by including two select statements: one that returns the full_name column from the author row that's joined with the book and another that returns the book data. Note also that the execute key word is optional.
create proc getbook(bid char) as
select full_name from author natural join book where bookid = bid
select publ_year, price, title from book where bookid = bid
end proc;
getbook("austen03");
FULL_NAME
Austen, Jane
PUBL_YEAR PRICE TITLE
1814 13500.00 Mansfield Park: a novel. In three volumes.
The next example shows how to modify the database contents using a stored procedure. The newpatron pro-cedure inserts a new row into the patron table.
create procedure newpatron(
pid char, nm char, cty char, str char, st char,
cntry char, zip char, em char, tel char, mid char) as
insert into patron values pid, nm, str, cty, st, cntry, zip, em, tel, mid
end proc;
newpatron("RLM", "Randy Merilatt", "720 3rd Ave Suite 1100", "Seattle", "WA",
"US", "98104", "[email protected]","206-748-5200","BARNEY");
select name, city, state, mgrid, email from patron where patid = "RLM";
NAME CITY STATE MGRID EMAIL
Randy Merilatt Seattle WA BARNEY [email protected]
The above version of newpatron does encapsulate the insert inside a transaction. So in order to make the new patron permanent, a commit needs to be separately executed. Normally, you would not use a transaction inside a stored procedure when there is more than one modification stored procedure that you want to have as part of a single transaction. The version of newpatron that uses a transaction is defined below.
create procedure newpatron(
pid char, nm char, cty char, str char, st char,
cntry char, zip char, em char, tel char, mid char) as
start transaction
insert into patron values pid, nm, str, cty, st, cntry, zip, em, tel, mid
commit
end proc;
A modification stored procedure can contain more than one statement. The next example records a book sale.

RDM SQL Language Guide
Writing and Using Stored Procedures 82
create procedure sold(b_id char, p_id char, amt double) as
start transaction
insert into sale values b_id, p_id
update book set price = amt, date_sold = curdate() where bookid = b_id
commit
end proc;
To record the sale of Jane Austen's Emma to Lucille Bluth for £12,500 enter the following.
select last_name, price, date_sold, title from book where bookid = "austen04";
LAST_NAME PRICE DATE_SOLD TITLE
AustenJ 13500 *NULL* Emma: a novel. In three volumes.
exec sold("austen04","BLU", 12500.00);
*** 1 rows affected
*** 1 rows affected
select last_name, price, date_sold, title from book where bookid = "austen04";
LAST_NAME PRICE DATE_SOLD TITLE
AustenJ 12500 2010-11-18 Emma: a novel. In three volumes.
If an error occurs during the execution of any of the SQL statements in a stored procedure, any changed made by that statement are aborted and the stored procedure will immediately exist leaving any remaining statements unexecuted. If the stored procedure is a modification procedure any changes made by the stored procedure prior to the attempted execution of the offending statement are automatically rolled back. If no transaction was spec-ified in the stored procedure, any changes made during the active transaction but prior to the execution of the stored procedure remain intact and can either be committed or rolled back as desired.
In RDM SQL, stored procedures are not intended to be an alternative way to program. They simply provide the ability to pre-compile the SQL statements that are needed to access and manipulate the database so that an application does not incur the cost of either having to compile the statements dynamically at runtime.

RDM SQL Language Guide
Concurrent Database Access 83
Concurrent Database AccessThe test of a first-rate intelligence is the ability
to hold two opposed ideas in the mind at the
same time, and still retain the ability to function.- F. Scott Fitzgerald , "The Crack-Up" (1936)
Concurrent database access refers to the situation where the database is being accessed from more than one connection (user) at a time. Without the database system exerting some control over what gets updated by who and when, all kinds of data integrity and consistency problems can arise. This can be illustrated with the simple example given below in Table 12 which shows what can happen when the database system does not provide some kind of concurrent access protection.
Time Connection 1 Connection 2T1 select price from book where bookid =
"cbronte03";
PRICE
12500.00
T2 select price from book where bookid =
"cbronte03";
PRICE
12500.00
T3 update book set price=14500.00 where
bookid "cbronte03";
T4 update book set price=10500.00 where
bookid "cbronte03";
T5 select price from book where bookid =
"cbronte03";
PRICE
10500.00
select price from book where bookid =
"cbronte03";
PRICE
10500.00
Table 12. Concurrent Update Problem
At time T1 connection 1 executes a select that returns the price of the books as 12,500. At time T2 connection 2 executes the same select and gets the same result. Then at time T3 connection 2 issues an update changing the price to 14,500 while at time T4 connection one changes the price to 10,500 overwriting the change just made by connection 2. At time T5 both connections issue the same select with connection 1 getting the expected result while the user on connection 2 wonders if there is something wrong with her keyboard!
One of the most common ways for a DBMS to prevent these kinds of problems is to use locking in order to pre-vent other connections from accessing the data being updated. So, in the above example, if at time T1 con-nection 1 places a lock on the book table then the lock request issued by connection 2 at T2 will wait until connection 1 releases the lock which will occur when the update completes and the lock is freed. Then con-nection 2's lock request will be granted and the select statement will now return the value of price as 10,500 and connection 2's update can proceed with no anomalies.
Time Connection 1 Connection 2T1 Request book table lock
T2 Lock granted Request book table lock
T3 select price from book where bookid =
Table 13. Locking Solution to Concurrent Update Problem

RDM SQL Language Guide
Concurrent Database Access 84
Time Connection 1 Connection 2"cbronte03";
PRICE
12500.00
T4 update book set price=10500.00 where
bookid "cbronte03";
T5 Free book table lock Lock granted
T6 select price from book where bookid =
"cbronte03";
PRICE
10500.00
T7 update book set price=14500.00 where
bookid "cbronte03";
T8 Free book table lock;
Locking In RDM SQLRDM SQL provides two types of locks. A read (share) lock locks a table for read-only access. Any number of dif-ferent connections can have a read lock on a table. During the time that a table is read locked, no modifications can occur on the table. A write (exclusive) lock locks a table for exclusive access by the connection which was granted the write lock. When one connection has been granted a write lock on a table, lock requests from other connections are queued and granted on a first-come, first-served basis.
Queued lock requests do not wait forever. When a lock request has waited for 10 seconds, it will be deleted from the queue and a timeout status code (errTIMEOUT) will be returned. The timeout value for a connection can be changed using the set timeout statement as shown below or through a call to function rsqlSetTimeout.
set_timeout_stmt:
set timeout {to | =} integer
A timeout value equal to -1 disables timeout checking so that lock calls will wait indefinitely. Timeouts should only be disabled when you are certain that there is no possibility of a deadlock situation arising (see deadlock dis-cussion below). Any non-negative value specifies the number of seconds to wait for the requested table lock(s) to be granted. Setting the timeout to zero means that a lock request will return immediately if the lock cannot be granted.
Only table-level locking is provided in RDM SQL. Table locking is simple and is therefore very efficient but because an entire table is locked at a time, it works best in applications where there are a limited number of con-current connections. If, however, you keep the duration of your transactions as short as possible good through-put is achievable for most embedded systems applications.
Lock requests are automatically issued by RDM SQL when needed (implicit locking). For example, read locks are requested for each table that is accessed by a select statement. When the locks on all of the needed tables have been granted then statement execution will proceed. If the select statement was executed outside a trans-action, the locks are held until the statement handle on which the select is associated (i.e., the cursor) is closed which occurs automatically after the last row has been fetched. If the select was executed after a transaction has started then the locks will be held until the transaction is either committed or rolled back.
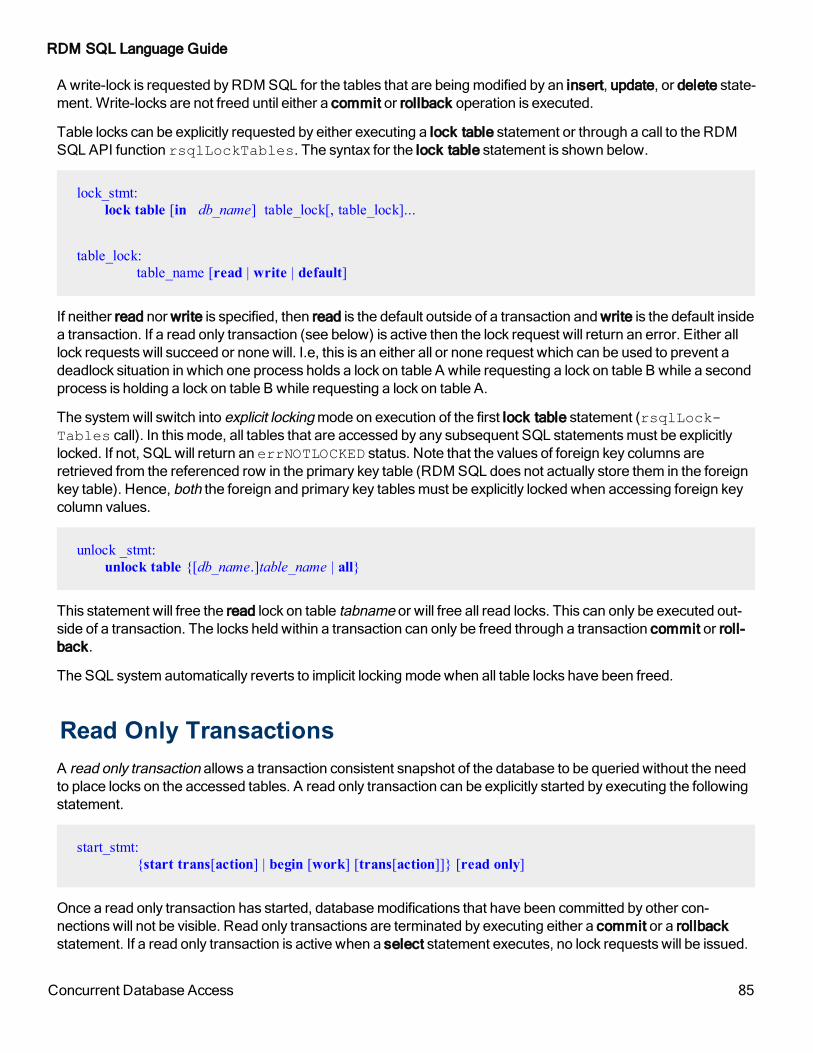
RDM SQL Language Guide
Concurrent Database Access 85
A write-lock is requested by RDM SQL for the tables that are being modified by an insert, update, or delete state-ment. Write-locks are not freed until either a commit or rollback operation is executed.
Table locks can be explicitly requested by either executing a lock table statement or through a call to the RDM SQL API function rsqlLockTables. The syntax for the lock table statement is shown below.
lock_stmt:
lock table [in db_name] table_lock[, table_lock]...
table_lock:
table_name [read | write | default]
If neither read nor write is specified, then read is the default outside of a transaction and write is the default inside a transaction. If a read only transaction (see below) is active then the lock request will return an error. Either all lock requests will succeed or none will. I.e, this is an either all or none request which can be used to prevent a deadlock situation in which one process holds a lock on table A while requesting a lock on table B while a second process is holding a lock on table B while requesting a lock on table A.
The system will switch into explicit locking mode on execution of the first lock table statement (rsqlLock-Tables call). In this mode, all tables that are accessed by any subsequent SQL statements must be explicitly locked. If not, SQL will return an errNOTLOCKED status. Note that the values of foreign key columns are retrieved from the referenced row in the primary key table (RDM SQL does not actually store them in the foreign key table). Hence, both the foreign and primary key tables must be explicitly locked when accessing foreign key column values.
unlock _stmt:
unlock table {[db_name.]table_name | all}
This statement will free the read lock on table tabname or will free all read locks. This can only be executed out-side of a transaction. The locks held within a transaction can only be freed through a transaction commit or roll-back.
The SQL system automatically reverts to implicit locking mode when all table locks have been freed.
Read Only TransactionsA read only transaction allows a transaction consistent snapshot of the database to be queried without the need to place locks on the accessed tables. A read only transaction can be explicitly started by executing the following statement.
start_stmt:
{start trans[action] | begin [work] [trans[action]]} [read only]
Once a read only transaction has started, database modifications that have been committed by other con-nections will not be visible. Read only transactions are terminated by executing either a commit or a rollback statement. If a read only transaction is active when a select statement executes, no lock requests will be issued.

RDM SQL Language Guide
Concurrent Database Access 86
By default, RDM SQL automatically requests read locks on the tables that are accessed by a select statement. However, an option is available that will cause SQL to automatically initiate a read only transaction instead of requesting locks. The read only transaction will be terminated when the select statement completes (i.e., cursor is closed). The mode is controlled using the statement given in the following syntax.
read_only_trmode_stmt:
set read only trans[action] mode [to | =] {auto | manual}
When this mode is set to manual (default), SQL will issue lock requests on the tables to be accessed by a select statement. When this mode is set to auto, SQL will executed each select statement within its own read only trans-action.
You can also explicitly indicate that a select is to use a read only transaction instead of locks by adding the for read only clause to the end of your select statement.
Read only transactions are very useful in concurrent database access applications because they do not block access to the database from other connections. However, these do not come free. Long running read only trans-actions will eventually seriously degrade system performance. Therefore, it is best that read only transactions be kept as short as possible.
Modification Stored ProceduresRDM SQL automatically places write locks on the tables that are being modified in an insert, update, or delete statement. If you encapsulate all of your database modifications in stored procedures that includes an opening start transaction and a closing commit statement—a transactional stored procedure—then the system will issue a grouped lock request at the start of execution of the stored procedure to acquire all of the locks on all of the tables involved in the modification. The execute statement (or call to rsqlExecProc) will return status errTIMEOUT when one or more of the requested locks could not be acquired within the timeout window.
Transactional stored procedures can modify only one database at a time. If you use more than one database at a time, then the modifications for each must be made in separate transactions.
Avoiding DeadlockA deadlock (also known as deadly embrace) is an egregious situation that can arise in any system that involves concurrent access to shared data from multiple processes. In its simplest form, process 1 holds an exclusive lock on data item A and is requesting a lock on data item B while at the same time process 2 holds an exclusive lock on data item B while requesting a lock on data item A. As you can easily see, both processes will wait forever unless one or the other releases the lock it holds. Of course, much more complex deadlock scenarios exist that involve multiple processes.
The primary application programming technique available in RDM that can be used to avoid deadlock is the time-out. A lock request will fail if the lock is not granted within the time duration specified by the connection's timeout value. The default timeout is set to 10 seconds. As noted above, this value can be changed using either the set timeout statement or through a call to the rsqlSetTimeout function.

RDM SQL Language Guide
Concurrent Database Access 87
While timeouts can be used to avoid deadlock, a related condition known as a livelock can still occur in which, in the example above both of process 1's and process 2's lock requests timeout at the same time, causing each to free the other lock as well and then restart their respective transactions with the timing of the operations such that the same situation continues to repeat itself.
Both livelock and deadlock can be avoided by including in a single request locks on all of the tables (i.e., a grouped lock request) that will potentially be modified by a transaction. As noted in the last section, a trans-actional stored procedure performs a grouped lock request for all needed locks at the beginning of the trans-action, before any modification statements have executed. The table locks included in grouped lock requests made by RDM SQL are always specified in the same order. While a timeout can still certainly occur, neither a deadlock nor livelock situation will occur.
However, if you are issuing dynamic SQL transactions that include multiple database modification statements, you need to explicitly lock all tables that can be modified in the transaction immediately following the start trans-asction statement. While not strictly necessary, it is also best to specify the tables in the lock table statement in the order in which they are declared in your DDL specification (this is the order in which SQL automatically issues the grouped lock request when a transactional stored procedure is executed). If you do not explicitly lock the tables in a dynamic SQL transaction, SQL will automatically make the lock requests for each statement. If a time-out occurs during execution of a database modification statement, the correct response is to roll back the trans-action and then restart it.
It is highly recommended that you encapsulate all of your transactions in transactional stored procedures in order to ensure that deadlock and livelock situations are avoided. It is also recommended that you use read only trans-actions as much as possible as these will not block other updating processes. Both regular and read only trans-actions should execute in as short a time frame as possible.
Concurrent Database Access Use in Static SQL ApplicationsThese statements are only available through dynamic SQL—they cannot be included in stored procedures. Explicit locking within a static SQL application that uses only pre-compiled stored procedures must be done through calls to the RDM SQL API locking functions as shown in the table below. The Using SQL in an Appli-cation Program section will describe in detail the use of these functions in an RDM SQL C application program.
SQL Statement RDM SQL API Function
lock table rsqlLockTables
unlock table rsqlUnlockTable
set timeout rsqlSetTimeout
set read only transaction mode rsqlSetReadOnlyTrmode
start transaction [ read only ] rsqlTransStart or rsqlTransStartReadOnly
savepoint rsqlTransSavepoint
release savepoint rsqlTransRelease
rollback rsqlTransRollback or rsqlTransEndReadOnly
commit rsqlTransCommit or rsqlTransEndReadOnly
Table 14. RDM SQL API Functions that Correspond to SQL Locking Statements

RDM SQL Language Guide
Concurrent Database Access 88
Examples
If a timeout occurs at any time during the execution of a statement within a transaction, the transaction should be rolled back and restarted.

RDM SQL Language Guide
How Queries are Processed by RDM SQL 89
How Queries are Processed by RDM SQLArtificial Intelligence is no match for natural stupidity.
- Unknown
A query optimizer is the component of an SQL system that attempts to determine the best way to retrieve the data that is needed to produce the results specified by a given select statement. The problem with the term "query optimizer" is that it makes it sound like it can take a stupidly formulated query and turn it into one that executes at optimal performance. The fact is, query optimizers are just not that smart. So, it is important that que-ries be reasonably formulated and the more you understand how the optimizer goes about its business the better equipped you will be to do just that. That is what this section is all about. Here you will …
l learn how the RDM SQL optimizer works, l learn the different ways in which data can be retrieved from a database, l be given guidelines on how to construct fast-performing queries, and l learn how to retrieve and interpret a query's access plan.
Overview of the Query Optimization ProcessIn SQL, queries are specified using the select statement, and many methods (or query execution plans) exist for processing a query. The goal of the optimizer is to discover, among potentially many possible options, which plan will execute in the shortest amount of time. Of course, the only way to guarantee a specific plan is optimal is to execute every possibility and then choose the fastest one. As this clearly defeats the purpose of optimization, other methods must be devised.
The query optimizer must resolve two interrelated issues: how it will access each table referenced in the query, and in what order. To access requested rows in a table, the optimizer can choose from a variety of access meth-ods. It determines the best execution plan by estimating the cost associated with each access method and by fac-toring in the constraints on these methods imposed by each possible access ordering. Note that the decisions made by the optimizer are independent of the listed order of the tables in the from clause or the location of the expressions in the where clause.
To illustrate consider the declarations for the two tables defined below.
create table customer(
cust_id char(3) primary key,
company char(30) not null,
street char(30),
city char(17),
state char(2),
key cust_geo(state, city)
);
create table sales_order(
cust_id char(3) references customer,
ord_num smallint primary key,
ord_date date key,
amount double
);

RDM SQL Language Guide
How Queries are Processed by RDM SQL 90
RDM SQL will generate two indexes for each table. The customer table has an index on cust_id and a com-pound index for cust_geo on state and city. The sales_order table has an index on ord_num and another on ord_date. With this in mind, consider the following query.
select company, ord_num, ord_date, amount from customer natural join sales_order
where state = "CO" and ord_date = date "2010-11-23";
Note that this is functionally identical to the query...
select company, ord_num, ord_date, amount from customer, sales_order
where customer.cust_id = sales_order.cust_id and
state = "CO" and ord_date = date "2010-11-23";
In this second form, two tables will be accessed: customer and sales_order. T he first relational expression in the where clause specifies the join predicate, which relates the two tables based on their declared foreign and primary keys. RDM SQL implements foreign and primary key relationships using a bi-directional, direct access method. This means that it is possible to quickly go from 1) the foreign key row to the referenced primary key row and 2) from the primary key row to each row that references it. Note also that the state column in the cus-tomer table is the first column in the cust_geo key, and the ord_date column in the sales_order table is the first column in the order_key key. Thus the optimizer has choices of which index to use. All possible execution plans considered by the RDM Server query optimizer for this query are listed in the following table.
Plan Description
1 Scan customer table (i.e., read all rows) to locate rows where state = "CO", then for each matching customer row, scan sales_order table to locate rows that match customer's cust_id and have ord_date = 2010-11-23.
2 Scan customer table to locate rows where state = "CO", then for each customer row, read each sales_order row through the primary to foreign key join, and return only those that have ord_date = 2010-11-23.
3 Use the cust_geo index to find the customer rows where state = "CO", then for each cus-tomer row, scan sales_order table to locate rows that match customer's cust_id and have ord_date = 2010-11-23.
4 Use the cust_geo index to find the customer rows where state = "CO", then for each cus-tomer row, read each sales_order row through the primary to foreign key join, and return only those that have ord_date = 2010-11-23.
5 Scan sales_order table to locate rows where ord_date = 2010-11-23, then for each sales_order row, scan customer table to locate rows that match sales_order's cust_id and have state = "CO".
6 Scan sales_order table to locate rows where ord_date = 2010-11-23, then for each sales_order row, read the customer row through the foreign to primary key join, and return only those that have state = "CO".
7 Use the order_ndx index to find the sales_order rows where ord_date = 2010-11-23, then for each sales_order row, scan customer table to locate rows that match sales_order's cust_id and have state = "CO".
Table 15. Possible Execution Plans for Example Query

RDM SQL Language Guide
How Queries are Processed by RDM SQL 91
Plan Description
8 Use the order_ndx index to find the sales_order rows where ord_date = 2010-11-23, then for each sales_order row, read the customer row through the foreign to primary key join, and return only those that have state = "CO".
Because the time (based on the number of disk accesses) required to scan an entire table is generally much greater than the time needed to locate a row through an index, plans 4 and 8 seem the best. However, it is unclear which of the two plans is optimal. In fact, both are probably good enough to obtain acceptable per-formance.
Additional information to help you make the best choice includes the number of rows in each table, the number of customers from Colorado, and the number of orders for November 23, 2010. Let's assume that there are 1000 customers and 20,000 sales orders. Thus there is an average of 20 sales orders per customer. Of the 1000 cus-tomers, 25 are located in Colorado and 8 sales orders were made on 2010-11-23.
Now let's estimate the number of disk accesses for plan 4. Since all 25 Colorado customers are grouped together in the index for cust_geo (state is the first column in the index) it is likely that no more than 3 index reads are needed to locate them but each of the 25 rows need to be read and then for each customer row its related sales_order rows (average of 20) need to be read and the ord_date checked. That gives a total number of disk accesses as…
Plan 4 Cost Estimate = 3 + 25*20 = 503.
To estimate the number of disk accesses for plan 8 all of the 8 sales_order rows with an ord_date of 2010-11-23 can be retrieved in 1 index read plus 8 reads for each row. Then the associated customer row is found through the foreign to primary key join (1 read) and the state column value is checked. That gives a total number of disk accesses...
Plan 8 Cost Estimate = 1 + 8 + 8*1 = 17.
Clearly, plan 8 is the better choice.
Note that plans 1 and 5 perform what is called a Cartesian or cross-product—for each row of the first table accessed, all rows of the second table are retrieved. Thus given that the customer table contained 1000 rows and the sales_order table contained 20,000 rows, the query would need to read a total of 20,000,000 rows! Cross-products are extremely inefficient and will never be considered by the optimizer except when a necessary join predicate has been omitted from the query. In our example, this would occur if the relational expression, "customer.cust_id = sales_order.cust_id" was not specified. Necessary join predicates are often erroneously omitted when four or more tables are listed in the from clause and/or when multi-column join pred-icates (for compound foreign and primary keys) are required. To avoid this, it is best to use explicit join spec-ification in the from clause as was shown in the first select statement in the above example. It is also important when defining foreign and primary keys that there be no other columns in the two tables that have the same name other than the foreign and primary key columns because the SQL standard defines a natural join as being based not on the declared foreign and primary keys (which is how it should define it) but based on the commonly named columns.
The optimization process is depicted below in Figure 9. The green boxes represent internal data structures and the blue boxes represent processes.

RDM SQL Language Guide
How Queries are Processed by RDM SQL 92
Figure 9 - RDM SQL Query Optimization Process
Using the information in the catalog, the select statement is parsed, validated, and represented in a set of easily processed query description tables. These tables include a tree representation of the where clause expressions (called the expression tree) and information about the tables, columns, and keys in the database.
The system then analyzes those tables, and constructs both the access rule table and the expression table. For table that is referenced in the from clause, the analysis process uses information in the catalog and other data related statistics such as then number of rows in each table, blocking factors, and user-specified column sta-tistics. The access rule table contains a rule entry for each possible access method (for example, table scan or index lookup) for each table. The expression table has one entry for each conditional expression specified in the where clause. These tables drive the actual optimization process.
Finally, the optimizer determines the plan with the lowest total cost. An execution plan basically consists of a series of steps (one step for each table listed in the from clause), of how the table in that particular plan step will be accessed. The possible access rules that can be applied at that step are sorted by their cost so that the first candidate rule is the cheapest. The optimizer's goal is to select one access rule for each step that minimizes the total cost of the complete execution plan. As the optimizer iterates through the steps, the cost of the candidate plan is updated. As soon as a candidate plan's cost exceeds the cost of the currently best complete plan, the can-didate plan is abandoned at its current step and the next rule for that step is then tested. Conditional expressions that are incorporated into the plan are deleted from the expression tree so that they are not redundantly executed.

RDM SQL Language Guide
How Queries are Processed by RDM SQL 93
Cost-Based OptimizationThe cost to determine the execution plan is the time it takes the optimizer to find the "optimal" plan. An execution plan consists of n steps where n is the number of tables listed in the from clause. Each step of the plan specifies the table to be accessed and the method to be used to access rows from that table. The cost increases factorially to the number of tables listed in the from clause (n!). Performance impact start to become noticeable for queries that reference more than about 10-12 tables. This is due to the increasing number of combinations of access orderings that must be considered (2 tables have 2 possible orderings, 3 have 6, 4 have 24, etc.). The cost to esti-mate each candidate plan also includes a linear factor of the number of access methods available at each step in a plan from which the optimizer must choose. More access methods means the optimizer must do more work, but the odds of finding a good plan improve.
The cost to carry out an execution plan is the total number of file reads required to access the necessary data-base information. Because it is extremely difficult to accurately estimate the effects caused by caching per-formance and diverse database page sizes, physical disk read estimates are not possible. Hence, the system estimates the number of logical file read based on an analysis of the number of reads required to read a row for each access method. There is also a CPU computation component but that it much more difficult to estimate and is controlled by a constant that is somewhat akin to Einstein's infamous cosmological constant. More on this later.
The statistics maintained for use by cost-based optimizers are used to: 1) guide the choice between alternative access methods derived from the relational expressions specified in the where clause, 2) estimate the number of output rows that result from each plan step, and 3) estimate the number of logical reads incurred by each pos-sible access method.
The statistics used by the RDM cost-based optimizer include:
l Number of rows in a table l Number of rows per page in a table (database I/O is performed a page at a time) l Depth of an index's B-tree l Number of keys per page in an index l The range of possible values in a column l The number of distinct values in a column
The last two stats can be specified by the user through distinct values and range clauses of the create domain and create table statements or the set column stats statement.
Most SQL implementations adopt a cost-based approach because the quality of the execution plan that is chosen is not all that sensitive to how a particular query is formulated. Another optimization approach is called rule-based optimization which access the tables in the order in which the tables are specified which places a greater responsibility on the part of the query formulator to understand the best way for the query to be proc-essed. This is not to suggest that cost-based optimization frees the query developer of having to put any thought into how the query should be constructed (re: opening paragraph of this section). If that were so then this dis-cussion would not be necessary. Nevertheless, cost-based optimizers will more reliably produce higher quality query execution plans but no optimization strategy is perfect.

RDM SQL Language Guide
How Queries are Processed by RDM SQL 94
Restriction FactorsA restriction factor is associated with each relational expression that is specified in the where clause and is an estimate of the ratio of number of rows for which the expression is true to the total number of candidate rows. A candidate row is a row of the table being produced by the select statement before the where clause is evaluated. Restriction factors are used by the optimizer to decide between alternative access methods. Restriction factors are floating point values between 0 and 1 and are computed based on the kind of relational expression as fol-lows.
Relational Expression Restriction Factor Estimate
column = value 1/number of distinct values of column
column in (value[, value]…) number of values in list * (1/number of distinct values of column)
column >[=] value (max(column) – value) / (max(column) – min(column))
column <[=] value (value - min(column)) / (max(column) – min(column))
column between loval and hival (hival – loval) / (max(column) – min(column))
Table 16. Restriction Factor Computations
Table Access MethodsRDM SQL provides a variety of methods for retrieving the rows in a table. Each of these access methods is described below, including how cost is estimated for each method. The cost estimate equations use the above statistics as represented by the following parameters.
Parameter Definition
P The number of pages in the file in which the table's rows are stored.
D The depth of the B-tree index.
C The cardinality of the table being accessed (that is, the number of rows in the table).
Cf
The cardinality of the table containing the referenced foreign key.
Cp
The cardinality of the table containing the referenced primary key.
K The maximum number of key values per index page.
R The restriction factor, an estimate (between 0 and 1) of the percentage of the rows of the table that satisfy the conditional expression. The restriction factor for a conditional expression is the product of the restriction factors for each relational expression in the conditional expression's boolean prod-uct (i.e., rel_expr and rel_expr …)
Table 17. Table Access Method Cost Estimation Parameters
Database access is performed by reading data and index file pages. A data file page contains at least one (usually more) table row so each physical disk read will read that number of rows. An index file page contains many keys per page depending on the size of the page and the size of the index values. RDM uses a B-tree struc-ture for its indexes, which guarantees that each index page is at least half full. On the average, index pages are about 60-70% full. The depth of a B-tree indicates the number of index pages that must be read to locate a par-ticular key value. Most B-trees have a depth of from 4 to 7 levels. A hash index can usually locate a key value in 1 to 3 reads depending on the quality of the hash and the number of key values (rows).

RDM SQL Language Guide
How Queries are Processed by RDM SQL 95
Sequential Table Scan
Each row of a table is stored as a record in a file. A data file can contain the rows from one or more tables. The most basic access method is to perform a sequential scan of a file where the table's rows are retrieved by sequen-tially reading through the file. Thus, the cost (measured in logical disk accesses) to perform a sequential scan of a table is equal to the number of pages in the file:
Escan
= Cost of sequential file scan = P
A sequential file scan is used in queries where the where clause contains no optimizable conditional expressions that reference foreign key, primary key, or indexed columns.
Hashed Access Retrieval
Hashed access retrieval accesses an individual row based on the hashed key value. Typically more than 1 page read is required but usually less than 2 or 3 additional reads. Hence, the optimizer assumes that the cost of a hashed retrieval is 2.
Ehash
=Cost of hashed access retrieval = 2
Index Access Retrieval
The cost of an indexed access retrieval depends on the relational expression on which the access is based. The cost estimate computations for the each of the optimizable relational expressions are as follows.
l Equality Conditionals
Indexed access retrieval allows retrieval of an individual row or set of matching rows, based on the value of one or more columns contained in a single index. These values can be specified in the query directly or through a join predicate.
For a unique index, the cost to access a single row is equal to the depth of the index's B-tree (seldom more than 4 ) + 1 (to read the row from the data file). For a non-unique index, the cost is based on an estimate of the average number of rows having the same index value derived from number of distinct column values. The percentage of the table's rows that match the specified equality constraint is the restriction factor (R). Thus, the estimate of number of matching rows is equal to the cardinality of the table multiplied by the restriction factor, or:
number of matching rows = C * R
The cost estimate (in logical page reads) of an indexed access retrieval is equal to the number of index pages that must be accessed plus the number of matching rows (1 logical page read per row), or:
Eeq = Cost of index access for column = value
= D + (C * R)/(.7 * K) + (C * R)

RDM SQL Language Guide
How Queries are Processed by RDM SQL 96
This assumes that each index page is an average of 70% full (D = depth of B-tree, K = maximum number of keys per index page). Note that this formula works for both unique and non-unique indexes (for unique indexes, R = 1/C).
l In Conditionals
When the in operator is used, the restriction factor is equal to the sum of the equality restriction factors for each of the listed values. Thus, the cost is simply the sum of the costs of the individual values.
Elist
= Cost of index access for column in (v1, v2, ..., vn)
= SUM(cost(column = vi)) for all i: 1..n
l Inequality Conditionals
Indexed scans use an index to access the rows satisfying an inequality relational expression involving the major column in the index. The estimate of the cost of an index scan is calculated exactly the same as the indexed access method. The restriction factor is calculated as given in Table 15.
Eineq
= Cost of index access for inequality relational expressions
= D + (C * R)/(.7 * K) + (C * R)
l Like Conditionals
[TBD] Need to check the code.
Elike
=
Joins Involving Primary and Foreign Keys
Foreign and primary key relationships are implemented in RDM by internally maintaining rowid pointers that are used to optimally access the related rows and to easily ensure that referential integrity is enforced. A one-to-many relationship is created between the referenced primary key table and the referencing foreign key table. Thus, only 1 read is needed to access the related row in the primary key table from the referencing row in the for-eign key table. This is summarized below.
Efp
= Cost of a foreign key to primary key access = 1
The number of reads needed to access the foreign key table rows that reference a particular primary key table row is computed by dividing the cardinality of the primary key table by the cardinality of the foreign key table as fol-lows.
Epf
= Cost of a primary key to foreign key access = Cf / C
p
One additional optimization occurs when a foreign key table contains a foreign_key_column = value condition. Since the related primary key is indexed and the related foreign key table rows can be directly accessed from the referenced primary key row the foreign key table rows can quickly be found through an index access to the pri-mary key row and then directly accessing each of the referencing foreign key table rows. The cost for this is sum-marized below.
Epk
= Eeq
+ Epf

RDM SQL Language Guide
How Queries are Processed by RDM SQL 97
All of these formulas are summarized below in Table 17.
Access Method Cost Estimate Computation
sequential file scan Escan
= P
direct access Edirect
= 1
hashed access Ehash
= 2
index access for column = value Eeq
= D + (C * R)/(.7 * K) + (C * R)
index access for column in (v1, v2, ..., vn) Elist
= SUM(cost(column = vi)) for all i: 1..n
index access for inequalities Eineq
= D + (C * R)/(.7 * K) + (C * R)
index access for like with prefix Elike
= D + ((C * R)/(.7 * K)) + (C * R)
foreign key to primary key Efp
= 1
primary key to foreign key Epf
= Cf / Cp
to foreign key through primary key Epk
= Eeq
+ Epf
Table 18. Table Access Method Cost Estimation Formulas
Optimizable ExpressionsThe RDM SQL query optimizer is able to optimize a restricted set of relational expressions that are specified in the where clause of a select statement. Simple expressions involving a comparison between a simple column and a literal constant value (or parameter marker or stored procedure argument) can be analyzed by the opti-mizer to determine if any access methods exist that can retrieve rows satisfying that particular conditional. Expressions for potential use by the optimizer in an execution plan are referred to as optimizable. Table 18 sum-marizes the optimizable relational expressions.
1 KeyCol1 = constant [and KeyCol
2 = constant]...
2 FkCol1 = constant [and FkCol
2 = constant]...
3 FkCol1 = PkCol
1 [and FkCol
2 = PkCol
2]...
4 KeyCol1 = Col
a [and KeyCol
2 = Col
b]...
5 KeyCol1in (constant[, constant]...)
6 KeyCol1 {> | >= | < | <=} constant
7 KeyCol1 {> | >=} constant [and KeyCol
1 {< | <=} constant]
8 KeyCol1between constant and constant
9 KeyCol1like "pattern"
Table 19. Optimizable Relational Expressions
The constant is either a literal, a parameter marker ('?'), or a stored procedure argument (if statement is con-tained in a stored procedure declaration). The KeyColi's refer to the i'th declared column in a given key. The FkCol i's (PkCol i's) refer to the i'th declared column in a foreign (primary) key. An equality comparison must be provided for all multi-column foreign and primary key columns in order for the optimizer to recognize a join pred-icate. Col
a, Col
b, etc., are columns from the same table that match (in type and length) KeyCol
1 , KeyCol
2, etc.,
respectively.

RDM SQL Language Guide
How Queries are Processed by RDM SQL 98
These expressions are all written in the following form: ColumnName relop expression. Note that expressions of the form: expression relop ColumnName are recognized and transformed by the optimizer so that the Col-umnName is always listed on the left hand side. This transformation may require modification of the relational operator. For example,
select … from … where 1000 > colname
Is changed to
select … from … where colname < 1000
Depending on how the where clause is organized, an expression may or may not be optimizable. Conditional expressions composed in conjunctive normal form are optimizable. In conjunctive normal form, the where clause is constructed as follows:
C1 and C
2 and ... C
n
Each Ci is a conditional expression comprised of a single or multiple or'ed relational comparisons. Only those C
i's that consist of a single optimizable relational expression are optimizable. In other words, relational expres-
sions that are sub-branches of an or'ed conditional expression are not optimizable. The best possible opti-mization results are obtained when the desired conditions use and. The optimizer can recognize a sequence of or'ed equality comparisons referencing the same KeyCol
1 and will convert it into an in comparison. For example,
the optimizer will convert…
select … from book
where bookid = "austen02" or bookid = "cbronte01" or bookid = "dickens07";
into…
select … from book
where bookid in ("austen02", "cbronte01", "dickens07");
Access Plan Determination
Selecting From Alternative Access Methods
Consider the following query from the NSF database.
Selecting the Access Order
When a query references more than one table, the optimization process becomes more complex, because the optimizer must choose between different methods to access each table, and the order in which to access them. Many access methods rely only on the values specified in the conditional expression for the needed data.

RDM SQL Language Guide
How Queries are Processed by RDM SQL 99
However, some access methods (those associated with join predicates) require that other tables have already been accessed. This places constraints on the possible orderings. Access methods available at the first step in the plan are those that do not depend on any other tables.
For possible access methods at the first plan step, the optimizer chooses the method with the lowest cost from a list of possible methods sorted by cost. The accessed table is then marked as bound. The access methods avail-able at the next step in the plan include the choices from the first step for the other tables, plus those methods that depend on the table bound by the first step. These too are ordered by cost. The optimizer continues in this manner until methods have been chosen for all steps in the plan. It then selects the method with the next highest cost and recursively evaluates a new plan. At any point in the process, if the plan being evaluated exceeds the total cost of the current best complete plan, that plan is abandoned and another is chosen. A flowchart of the opti-mizer algorithm is given in Figure 10.
Figure 10 - Optimizer Algorithm Flowchart

RDM SQL Language Guide
How Queries are Processed by RDM SQL 100
Sorting and Grouping Operations
For select statements that include a group by or order by specification, the SQL optimizer performs two sep-arate optimization passes. The first pass restricts the choice of usable access methods to only those that produce or maintain the specified ordering. For example, an index scan retrieves its results in the order specified in the key declaration. If the results match the specified ordering, they are included as a usable access method. This optimization pass is fast because, typically, very few plans produce the desired ordering without performing an external sort of the result set.
If a plan is produced by the first pass, it is saved (along with its cost estimate), and a second optimization is per-formed without the ordering restriction. An estimate of the cost required to sort the result set, based on the opti-mizer's estimate of the result set's size, is added to the cost of the plan produced by the unrestricted pass. From the two plans, the optimizer will choose the one with the lowest cost.
The estimate of the sort cost is based on the optimizer's cardinality estimate, the length of the sort key, and the sort index page size. The optimizer will calculate the number of I/Os as two times the number of index pages to store the sort index (one pass to create the page and another to read each page in order) and add the number of result rows.
Note that if both the group by and order by clauses are specified, only the group by ordering can be satisfied by existing indexes and joins. A separate sort of the result set will always be required for the order by clause. If there is no index to satisfy the specified group by, then two sort passes will be needed.
Outer Join Processing
The optimizer processes outer joins by forcing all outer joins into left outer joins (right outer joins are converted into left outer joins by simply reversing the order). It then will disable all access paths that require the right hand table to be accessed before the left hand table. If there is no access path (that is, through an index or declared for-eign key) from the left hand table to the right hand table, the optimizer will simply perform an inner join (rather than doing a potentially very expensive cross-product).
Returning the Number of Rows in a Table
The row counts for each table in a database are maintained by the RDM runtime. SQL recognizes queries of the following form:
select count(*) from tablename
and generates a special execution plan that returns the current row count value for the specified table. No table or index scan is needed. However, if the query is specified as shown below, the optimizer performs a scan of the table or index (if colname is indexed) and counts the rows.
select count(columnname) from tablename
Thus, if you need the row count of the entire table, use the first form and not the second.

RDM SQL Language Guide
How Queries are Processed by RDM SQL 101
Query Construction GuidelinesSome systems perform a great deal of work to convert poorly written queries into well written queries before sub-mitting the query to the optimizer. This is particularly useful in systems where ad hoc querying (such as in enter-prise environments) is performed by non-technical people. SQL is less user friendly, so often this work is performed by front-end tools. RDM SQL does not perform complex query transformation analysis (it will do sim-ple things such as converting expressions like "10 = quantity" into "quantity = 10"). Therefore, a thorough under-standing of the information provided here will assist you in formulating queries that can be optimized efficiently by RDM Server SQL. Guidelines for writing efficient RDM Server SQL queries are listed below.
l Formulate where clauses in conjunctive normal form. Avoid using or. l Formulate conditional expressions according to the forms listed in Table 18. Use literal constants as often
as possible. The compile-time for most queries is insignificant compared to their execution time. Thus, dynamically constructing and compiling queries containing literal constants (as opposed to parameter markers or stored procedures) will allow the optimizer to make more intelligent access choices.
l Make sure that the only columns that have the same name in tables that are related through foreign and pri-mary keys are the foreign and primary key columns themselves. Then use the natural join clause when formulating queries that join the two tables.
l Include more (not fewer) conditional expressions in the where clause, and include redundant expressions. For example, foreign and primary keys exist between tables A and B, B and C, and A and C. Even though it is not strictly necessary (mathematically) to include a join predicate between A and C, doing so provides the optimizer with additional access path choices. Also, assuming that join predicates exist and a simple conditional is specified for the primary key, you can include the same conditional on the foreign key as well. Look at the following query:
select ... from A,B where A.pkey = B.fkey and A.pkey = 1000
You can improve this query by adding the conditional shown in an equivalent version below.
select ... from A,B where A.pkey = B.fkey and A.pkey = 1000 and B.fkey =
1000
l If you are not using SQL's extended join syntax in the from clause of your select statements, make certain join predicates exist for all pairs of referenced tables that are related through foreign and primary keys.
l Avoid sorting queries with large result sets in which no index is available to produce the desired ordering. If you have heavy report writing requirements, consider using the replication or mirroring feature to maintain a redundant, read-only copy of the database on a separate TFS and run your reports from there. This will allow the primary system to provide the best response to update requests without blocking or being blocked by a high level of query activity.
l In defining your DDL, explicitly declare the foreign and primary key relationships. You can still do joins between tables even when the relationships are not declared but optimum join performance is guaranteed when you declare those relationships in your create table DDL statements.
l Do not include conditional expressions in the having clause that belong in the where clause. Conditional expressions contained in the having clause should always include an aggregate function reference. Note that expressions in the having clause are not taken into consideration by the optimizer.

RDM SQL Language Guide
How Queries are Processed by RDM SQL 102
l Use the distinct values and range clauses in either the create table or the set column stats state-ments to provide more statistical information to the optimizer. The distinct values clause is particularly important for equality conditions. Do not declare a key on a column that has only a few distinct values. For example, never declare a key on a column that contains a person's gender. If no distinct values clause is specified, the optimizer will use the current number of rows in the table. The range clause is used with inequality conditions.
l Only declare keys that you actually need to get the needed performance in your embedded application. More keys increases the time to insert new rows in a table besides consuming more storage.
Controlling Optimizer with a User-Specified Restriction Fac-torThe restriction factor is the fraction of a table between 0 and 1 that is returned as a result of the application of a specific where condition. The lower the value, the greater the likelihood that the access method associated with that condition will be chosen by the optimizer. This factor is computed by the optimizer based on the type of rela-tional expression and the range values for the column, if specified. Note that you can override the optimizer's esti-mate by using a non-standard RDM SQL feature. A relational expression, relexpr, can be written as "(relexpr, factor)", where factor is a decimal fraction between 0 and 1 indicating the percentage of the file restricted by rel-expr.
For example, in the following query from the NSF database, where the optimizer would normally access the data using the awardno key, the specified restriction factors will actually cause the optimizer to use the award_date key.
select * from award
where (awardno = 70246, 1.0)
and (award_date > date "2002-07-01", 0.00001);
When statistics used by the optimizer are not accurate enough for a given query and the result is unsatisfactory, you can use this feature to override the stats-based restriction factor and substitute your own value. However, your use of this feature renders the query independent of future changes to the data distribution statistics.

RDM SQL Language Guide
Using SQL in an Application Program 103
Using SQL in an Application ProgramSome people like my advice so much that
they frame it upon the wall instead of using it.- Gordon R. Dickson
The previous sections have described how to use SQL as a database language. While some programming con-siderations necessarily were involved with the operational aspects of the SQL language itself, how to actually use RDM SQL from an application program is the subject of this section.
There are several different application programming interfaces (API) available for use with RDM SQL. The nativeRDM SQL API is designed for use with C application programs. Raima also provides an API that conforms to Microsoft's ODBC (Open Data Base Connectivity) API specification which is also designed for use with C application programs. Programs written in Java can access RDM SQL through the JDBC (Java Data Base Con-nectivity) API that is also provided by Raima. Both the ODBC and JDBC APIs have been implemented using the RDM native API so those of you who are familiar with ODBC or JDBC will see close similarities with them.
If you are an experienced ODBC programmer, you will have little difficulty in learning how to use the native API. However, while there are many similarities, there are also some significant differences so you will want to do a careful reading of this section and do not assume that just because ODBC does something a certain way that the native API does it the same way. In fact, we've designed the native API to be simpler and easier to use than ODBC.
Native SQL API BasicsA complete, alphabetical list of the functions provided in the RDM SQL API is given below.
Function DescriptionrsqlAllocConn Allocate a new connection handlersqlAllocStmt Allocate a new statement handlersqlBindNamedParam Bind a data value to a named parameter markerrsqlBindParam Bind a data value to a parameter markerrsqlCancelRow Cancel (discard) column value changes to current rowrsqlCloseDB Close a databasersqlCloseDBAll Close all databases that are open on a connectionrsqlCloseStmt Close the open select statement cursorrsqlDropDB Drop (delete) a databasersqlExecDirect Prepare and execute a SQL statementrsqlExecProc Directly execute a pre-compiled SQL stored procedurersqlExecute Execute a compiled SQL statementrsqlFetch Fetch the next row of the select statement result setrsqlFreeConn Free a connection handlersqlFreeStmt Free a statement handlersqlGetAutoCommit Get the connection handle's current auto commit statusrsqlGetColDescr Get description information for a select statement result column
Table 1. RDM SQL API Functions

RDM SQL Language Guide
Using SQL in an Application Program 104
Function DescriptionrsqlGetConnHandle Get connection handle associated with specified statement handlersqlGetCursorName Get the cursor name associated for the specified statement handlersqlGetData Get data value for one select statement result columnrsqlGetDateFormat Get the current date format settingrsqlGetDateSeparator Get the current date separator characterrsqlGetDBNames Get a list of the names of the currently opened databasesrsqlGetDeferBlobMode Get the current deferred blob reading mode settingrsqlGetErrorInfo Get the message associated with the current error codersqlGetErrorMsg Get the message associated with a specific error codersqlGetGenCFiles Get the connection handle's "generate C files" modersqlGetNumParams Get the number of parameter markers in the compiled statementrsqlGetNumResultCols Get the number of result columns in the compiled select statementrsqlGetParamDescr Get description information for a SQL statement parameter markerrsqlGetReadOnlyTrmode Get the current read only transaction modersqlGetRowCount Get the count of the # of rows affected by the executed statementrsqlGetSelectType Get the statement handle's select statement typersqlGetStmtState Get the statement handle's statement statersqlGetStmtString Return the SQL statement string for a statement handlersqlGetStmtType Get the statement type of the prepared statementrsqlGetTableName Get result column's table namersqlGetTimeout Get a connection's lock request timeout valuersqlInitDB Initialize a databasersqlLockTables Issue an explicit lock request for one or more database tablesrsqlMoreResults Execute next statement in the currently executing stored procedurersqlOpenCat Open a database through its compiled catalog modulersqlOpenDB Open a database by namersqlPackDate Pack a CAL_DATE into a binary DATE_VALrsqlPackTime Pack a CAL_TIME into a binary TIME_VALrsqlPackTimestamp Pack a CAL_TIMESTAMP into a binary TIMESTAMP_VALrsqlParamData Check for and initialize rsqlPutData for next data-at-exec parameterrsqlPrepare Compile an SQL statementrsqlPutData Put a data value for a data-at-exec blob parameterrsqlRegisterProc Register a compiled stored procedurersqlRegisterUDFs Register C-based user-defined functionsrsqlRegisterVirtualTablesRegister C-based virtual tablesrsqlSetAutoCommit Set the auto commit status for the specified connectionrsqlSetCursorName Set the cursor name for the specified statement handlersqlSetDateFormat Set the date constant format for the connectionrsqlSetDateSeparator Set the current date constant separator character for the connectionrsqlSetDeferBlobMode Set a statement's deferred reading mode for blob datarsqlSetErrorCallback Set an error callback user functionrsqlSetGenCFiles Set the connection handle's "generate C files" mode

RDM SQL Language Guide
Using SQL in an Application Program 105
Function DescriptionrsqlSetReadOnlyTrmode Set the current read only transaction modersqlSetTimeout Set lock wait timeout in seconds for the connectionrsqlShowPlan Show a query's execution plan as a result setrsqlTFSInit Initialize RDM SQL TFST or TFSS operationrsqlTFSTerm Terminate RDM SQL TFST or TFSS operationrsqlTransCommit Commit a transactionrsqlTransEndReadOnly End a read only transactionrsqlTransRelease Release a transaction savepointrsqlTransRollback Rollback to transaction savepoint or startrsqlTransSavepoint Mark a transaction savepointrsqlTransStart Start a transactionrsqlTransStartReadOnly Start a read only transactionrsqlTransStatus Return the current transaction state for the specified connectionrsqlUnlockTable Free a read lock on a database tablersqlUnlockTableAll Unlock all read locked tablesrsqlUnpackDate Unpack a binary DATE_VAL into a CAL_DATE structurersqlUnpackTime Unpack a binary TIME_VAL into a CAL_TIME structurersqlUnpackTimestamp Unpack a binary TIMESTAMP_VAL into a CAL_TIMESTAMP structurersqlUpdateCol Update a column value of current rowrsqlUpdateRow Store the updated column values for the current row
Comparing the ODBC API with the Native RSQL API
The following table provides a mapping of the ODBC API functions with the RSQL API functions. Not all ODBC functions have an equivalent RSQL API function. Some, (e.g., SQLTables, SQLColumns, etc) are imple-mented in the RDM ODBC layer as select statements on built-in virtual system catalog tables which are described later in this section. Also note that those functions that do have a RSQL API equivalent do not have the same function arguments. However, the basic operational approach (e.g., function calling sequence) that is used in an ODBC application is also needed in a RSQL application. ODBC API functions that are not listed do not have a RSQL API counterpart.
ODBC API Function RSQL Function CommentsSQLAllocHandle rsqlAllocConn
rsqlAllocStmt
Allocation of connection and statement handles are made through separated functions. There is no environment handle.
SQLBindCol n/a Column result values are not bound but are returned by rsqlFetch or rsqlGetData.
SQLBindParameter rsqlBindParam SQLCancel n/a Call rsqlCloseStmt to cancel statement processing.SQLCloseCursor rsqlCloseStmt SQLColAttribute rsqlGetColDescr SQLColumns n/a Database meta-data information is available by executing select
statements on the appropriate syscat virtual tables.SQLConnect n/a Connections are initiated when rsqlAllocConn is called. Data-
bases are opened through calls to rsqlOpenDB or rsqlO-
Table 2. ODBC to RDM SQL API Function Mapping

RDM SQL Language Guide
Using SQL in an Application Program 106
ODBC API Function RSQL Function CommentspenCat.
SQLDescribeCol rsqlGetColDescr SQLDescribeParam rsqlGetParamDescr SQLDescribeStmt rsqlGetStmtDescr SQLDescribeStmt is a Raima Inc. extension.SQLDisconnect n/a Connections are closed when rsqlFreeConn is called.SQLEndTran rsqlTransCommit rsqlTransRollback SQLExecDirect rsqlExecDirect SQLExecute rsqlExecute SQLExtendedTran rsqlTransStart
rsqlTransSavepoint
rsqlTransRelease
rsqlTransCommit
rsqlTransRollback
We believe that separate calls represent a better API design than a single call with a control variable
SQLFetch rsqlFetch Note that the rsqlFetch returns the column result values-no bound columns.
SQLForeignKeys n/a Database meta-data information is available by executing select statements on the appropriate syscat virtual tables.
SQLFreeHandle rsqlFreeConn
rsqlFreeStmt
SQLGetConnectAttr rsqlGetAutoCommit
rsqlGetDateFormat
rsqlGetDateSeparator
rsqlGetDeferBlobMode
rsqlGetReadOnlyTrmode
Not all ODBC connection attributes have a RDM equivalent. Not all RDM connection attributes have an ODBC equivalent.
SQLGetCursorName rsqlGetCursorName SQLGetData rsqlGetData SQLMoreResults rsqlMoreResults SQLNumParams rsqlGetNumParams SQLNumResultCols rsqlGetNumResultCols SQLPrepare rsqlPrepare SQLPrimaryKeys n/a Database meta-data information is available by executing select
statements on the appropriate syscat virtual tables.SQLProcedures n/a Database meta-data information is available by executing select
statements on the appropriate syscat virtual tables.SQLPutData rsqlPutData SQLRowCount rsqlGetRowCount SQLSetConnectAttr rsqlSetAutoCommit
rsqlSetDateFormat
rsqlSetDateSeparator
rsqlSetDeferBlobMode
rsqlSetReadOnlyTrmode
Not all ODBC connection attributes have a RDM equivalent. Not all RDM connection attributes have an ODBC equivalent.
SQLSetCursorName rsqlSetCursorName SQLSetError rsqlSetErrorCallback SQLSetError is a Raima Inc. extension.SQLSpecialColumns n/a Database meta-data information is available by executing select
statements on the appropriate syscat virtual tables.SQLTables n/a Database meta-data information is available by executing select

RDM SQL Language Guide
Using SQL in an Application Program 107
ODBC API Function RSQL Function Commentsstatements on the appropriate syscat virtual tables.
SQLTransactStatus rsqlTransStatus
The advantage of using the native API instead of ODBC is that it is simpler and more efficient with a smaller foot-print. However, ODBC is available and can certainly be used if DBMS independence and/or use of a standard SQL API is needed.
Connection Handles
Almost all of these functions require the use of either a connection handle or a statement handle. A connection provides single-threaded access to the RDM SQL database engine. A connection handle is used to keep all of the data used in all of the SQL calls for that connection thread safe. This means that each connection from a given RDM SQL program can be executed in its own thread. A single connection typically connects to one or more databases that are controlled by a single RDM Transactional File Server (TFS). However, a single con-nection can open a union of two or more instances of a database schema that are each running under a separate TFS.
Statement Handles
A statement handle keeps track of all of the data involved in the compilation and execution of a single SQL state-ment. Each statement handle is associated with a single connection but a single connection can have multiple statement handles.
The functions listed in Table 3 are those that deal with system-wide issues and, therefore, require neither a con-nection nor a statement handle.
Usage Function DescriptionStartup rsqlTFSInit Initialize RDM SQL TFST or TFSS operationStatus rsqlGetErrorMsg Get error message for a specific error codeShutdown rsqlTFSTerm Terminate RDM SQL TFST or TFSS operation
Table 3. RDM SQL API Functions that Do Not Need a Handle
The functions that use a connection handle are listed below in Table 4 along with an indication as to how each function is used.
Usage Function DescriptionStartup rsqlAllocConn Allocate a connection handle and open the connection rsqlAllocStmt Allocate a statement handle rsqlDropDB Drop (delete) a database rsqlOpenDB Open one or more databases by name rsqlOpenCat Open a database through the provided catalog rsqlRegisterProc Register a compiled stored procedure rsqlRegisterUDFs Register user-defined functions table rsqlRegisterVirtualTables Register virtual tables in databases to be opened rsqlSetAutoCommit Set auto-commit mode.
Table 4. RDM SQL API Functions that Use a Connection Handle
RDM SQL Language Guide
Using SQL in an Application Program 108
Usage Function Description rsqlGetTimeout Get a connection's lock request timeout value rsqlSetTimeout Set a connection's lock request timeout value rsqlSetDateFormat Set the date constant format rsqlSetDateSeparator Set the current date constant separator character rsqlSetReadOnlyTrmode Set the current read only transaction modeStatus rsqlGetDBNames Get a list of the names of currently opened databases rsqlGetAutoCommit Get the current auto-commit mode setting rsqlTransStatus Return the transaction state for the specified con-
nection rsqlGetReadOnlyTrmode Get the current read only transaction mode rsqlGetDateFormat Get the current date format setting rsqlGetDateSeparator Get the current date separator characterOperation rsqlLockTables Issue lock request for one or more database tables rsqlUnlockTable Free a read lock on a database table rsqlUnlockTableAll Unlock all read locked tables rsqlTransStart Start a transaction rsqlTransSavepoint Mark a transaction savepoint rsqlTransRelease Release a transaction savepoint rsqlTransRollback Rollback to transaction savepoint or start rsqlTransCommit Commit a transaction rsqlTransStartReadOnly Start a read only transaction rsqlTransEndReadOnly End a read only transaction rsqlGetErrorInfo Get connection related error infoShutdown rsqlCloseDB Close a database rsqlCloseDBAll Close all open databases rsqlFreeConn Free the connection handle
The functions that use a statement handle are shown below in Table 5 together with an indication of how each function is used.
Usage Function DescriptionSetup rsqlAllocStmt Allocate a statement handle rsqlGetDeferBlobMode Get the current deferred blob reading mode setting rsqlSetDeferBlobMode Set the current deferred blob reading mode setting rsqlInitDB Initialize a databaseCompile rsqlPrepare Compile an RDM SQL statement rsqlGetColDescr Get result set column description rsqlBindNamedParam Bind value variables to a named parameter marker rsqlBindParam Bind value variables to a parameter marker rsqlGetParamDescr Get description of parameter rsqlGetCursorName Get statement's cursor name rsqlSetCursorName Set statement's cursor name rsqlGetNumParams Get number of parameter markers in statement
Table 5. RDM SQL API Functions that Use a Statement Handle

RDM SQL Language Guide
Using SQL in an Application Program 109
Usage Function Description rsqlGetNumResultCols Get number of select statement result columns rsqlGetTableName Get result column's table name rsqlGetStmtString Return the SQL statement string for a statement handle rsqlGetStmtState Get the statement handle's statement state rsqlGetStmtType Get statement type rsqlShowPlan Show a query's execution plan as a result setExecute rsqlCancelRow Cancel (discard) column value changes to current row rsqlExecute Execute compiled SQL statement rsqlExecDirect Compile and execute SQL statement rsqlExecProc Execute stored procedure rsqlFetch Fetch next row from result set rsqlGetData Get data value for one select statement result column rsqlParamData Set up next data-at-exec parameter rsqlPutData Put a data value for a data-at-exec blob parameter rsqlGetRowCount Get # of rows affected by just executed statement rsqlMoreResults Execute next statement in stored procedure rsqlCloseStmt Close select statement cursor rsqlUpdateCol Update a column value of current row rsqlUpdateRow Store the updated column values for the current rowErrors rsqlGetErrorInfo Get statement's error informationShutdown rsqlFreeStmt Free statement handle
Header Files
There is one standard header file that must be #include'd in each module of your application that calls an RDM API SQL function: rsql.h. It is contained in the standard RDM include directory. This file will itself include all other RDM header files that are needed. Of particular importance is header file rsqltypes.h which includes all of the type and macro definitions used by the native RSQL API.
API Function Parameters
As noted above, most functions take either a connection handle or a statement handle. Other needed arguments are specified in the reference manual entries for each function. A connection handle is declared as type HCONN. A statement handle is declared as type HSTMT. The typedef for each is void * and is declared in header file rsqltypes.h.
All character string arguments are assumed to be C-based, null-terminated character strings.
Output arguments are passed as pointers and, unless otherwise noted, can be NULL when there is no interest in that particular result value.

RDM SQL Language Guide
Using SQL in an Application Program 110
SQL Data Types and Values
SQL data types are identified in the API functions by use of the SQL_T enumeration type declared in header file rsqltypes.h. The table below lists each of the SQL data types that are supported in RDM SQL along with its SQL_T value and its equivalent C data type (includes some possibly RDM-declared types such as uint8_t).
SQL Data Type SQL_T value C Data Typechar tCHAR char
varchar tVARCHAR char
binary tBINARY uint8_t
varbinary tVARBINARY uint8_t
boolean tBOOL int8_t
tinyint tTINYINT int8_t
smallint tSMALLINT int16_t
integer tINTEGER int32_t
bigint tBIGINT int64_t
real tREAL float
float, double tFLOAT, tDOUBLE double
date tDATE int32_t
time tTIME int32_t
timestamp tTIMESTAMP int64_t
long varchar tCLOB char
long varbinary tBLOB uint8_t
Table 6. SQL Data Type Values
Data values such as select statement result column values and stored procedure argument values are provided in RSQL-specific generic data value containers of type RSQL_VALUE. The declaration for this struct type is contained in header file rsqltypes.h as shown below.
/* container for blob (long var...) data values */
typedef struct {
void *buf; /* ptr to blob data (VALUE.len==amount of blob data in
buf) */
uint32_t pos; /* current position==total bytes read so far */
} LONGVAR;
typedef union _value {
int8_t tv; /* tTINYINT, tBOOL */
int16_t sv; /* tSMALLINT */
int32_t lv; /* tINTEGER */
int64_t llv; /* tBIGINT */
float fv; /* tREAL */
double dv; /* tFLOAT, tDOUBLE */
char *cv; /* tCHAR, tVARCHAR */
void *pv; /* tBINARY, tVARBINARY */
LONGVAR lvv; /* tCLOB, tWCLOB, tBLOB */
TIMESTAMP_VAL ts; /* tDATE, tTIME, tTIMESTAMP */
DB_ADDR dbal /* tROWID (internal use only) */

RDM SQL Language Guide
Using SQL in an Application Program 111
} VALUE;
typedef enum _val_status {
vsOKAY = 0,
vsTRUNCATE = 1, /* string truncation */
vsNOVAL = 2
} VAL_STATUS;
/* general purpose SQL data value container */
typedef struct _rsql_value {
SQL_T type; /* internal data type code */
uint32_t len; /* # of bytes of var-length data (e.g., strlen+1) else 0
*/
VAL_STATUS status; /* operation status code */
VALUE vt; /* generic data type container */
} RSQL_VALUE;
Since the TIMESTAMP_VAL struct in used by both the RSQL API and the RDM Core API it is declared in a separate header (base.h) as given below.
/* Date, time, and timestamp definitions */
typedef uint32_t DATE_VAL;
typedef uint32_t TIME_VAL;
typedef struct {
DATE_VAL date;
TIME_VAL time;
} TIMESTAMP_VAL;
Functions rsqlFetch and rsqlGetData return select statement column result values using the RSQL_VALUE container. Stored procedure arguments must be specified using the RSQL_VALUE container when call-ing function rsqlExecProc. Access to the value in the RSQL_VALUE container is given in the table below for each possible data type.
HSTMT hstmt;
RSQL_VALUE *ResultRow;
uint16_t nocols, cno;
while ( rsqlFetch(hstmt &ResultRow, &nocols) == errSUCCESS )
for ( cno = 0; cno < nocols; ++cno )
/* access the result column value as follows... */
ResultRow[cno].type ResultRow[cno].vt ResultRow[cno].len vt Field C Type
tCHAR .cv# of bytes (including
null)char *
tVARCHAR .cv# of bytes (including
null)char *
tBINARY .pv # of bytes void *
tVARBINARY .pv # of bytes void *
Table 7. RSQL_VALUE Container Access

RDM SQL Language Guide
Using SQL in an Application Program 112
ResultRow[cno].type ResultRow[cno].vt ResultRow[cno].len vt Field C Type
tBOOL .tv 0 int8_t
tTINYINT .tv 0 int8_t
tSMALLINT .sv 0 int16_t
tINTEGER .lv 0 int32_t
tBIGINT .llv 0 int64_t
tREAL .fv 0 float
tFLOAT .dv 0 double
tDOUBLE .dv 0 double
tDATE .dtv 0 DATE_VAL
tTIME .tmv 0 TIME_VAL
tTIMESTAMP .tsv 0 TIMESTAMP_VAL
tCLOB .lvv.buf # of bytes void *
tBLOB .lvv.buf # of bytes void *
Note that the ResultRow[cno].len field only contains the length of variable-length data types and is zero for scalar data types.
Basic access of the data values stored in RSQL_VALUE containers is illustrated in the example C program snip-pet below.
HSTMT hstmt;
uint16_t cno, nocols;
RSQL_VALUE *ResultRow;
...
while ( rsqlFetch(hstmt, &ResultRow, &nocols) == errSUCCESS ) {
/* display result row values */
for ( cno = 0; cno < norows; ++cno ) {
switch ( pRow[cno].type ) {
case tCHAR:
case tVARCHAR: printf("%s", pRow[cno].vt.cv); break;
case tBOOL: printf("%s", pRow[cno].vt.tv ? "True" : "False");
break;
case tSMALLINT: printf("%d", pRow[cno].vt.sv); break;
...
}
}
}
...
Note that the pointers to variable-length data returned from an SQL API function call (e.g., rsqlFetch) may not survive the next call and so you may need to copy the data if it needs to survive the next call (e.g., to rsqlFetch).
It is important that you properly initialized all of the fields of the RSQL_VALUE structure when using it to pass values to the RSQL native SQL API. For scalar (non-char/binary types-i.e. those whose lengths never vary), the len field must be zero. The status field is ignored for input RSQL_VALUE arguments. Of course, the actual data value (or pointer) needs to be assigned to the proper field in the vt union. Copies of any variable-length data passed through a pointer field will be made by the SQL system from input RSQL_VALUE pointers.

RDM SQL Language Guide
Using SQL in an Application Program 113
Other RSQL_VALUE usage issues are addressed in the remaining examples in this section as well as in the func-tion description entries in the RDM SQL API Reference.
Structure of an RDM SQL ApplicationAn RDM SQL C application program consists of a set of calls to the RDM SQL API functions in a particular sequence as outlined below.
1. Set up and initialize your application's use of RDM SQL as follows. a. Call rsqlTFSInit if you're using the directly-linked Transactional File Server (TFS). b. Call rsqlAllocConn to allocate a connection handle and open the connection. All of the SQL
calls for a given connection must be made from a single thread. Other threads can have their own connections as well.
c. Call rsqlSetErrorCallback if you want to have your own error handling routine automatically called by RDM SQL.
d. Call rsqlRegisterUDFs to register any user-defined functions for your application. e. Call rsqlRegisterVirtualTables to register the virtual tables that are defined in the data-
base(s) to be opened in the next step. f. Open the needed database(s) by calling either rsqlOpenDB or rsqlOpenCat (alternatively you
can open database(s) by executing the open databaseRDM SQL statement after step i below). g. Call rsqlRegisterProc for each directly linked stored procedure C module (i.e., procname_
ssp.c) that is used in your application. h. Call any rsqlSet* functions (e.g., rsqlSetDateFormat, rsqlSetTimeout) to set up any
needed operational parameters. i. Call rsqlAllocStmt to allocate a statement handle that you will use to compile and execute SQL
statements. Allocate as many statement handles as you will need. If you intend to do positioned updates and/or deletes then you will need at least two statement handles. Typically, you will need a statement handle for each statement that will be compiled once but potentially executed multiple times.
2. Prepare your application to execute SQL statements as follows. a. Call rsqlPrepare to compile each of the statements that will need to executed by your appli-
cation. b. Call rsqlBindParam to bind your application's variables to any parameter markers that were
specified in the SQL statements prepared in the prior step. 3. At this point your application is execution ready. That means that your application will...
a. Call rsqlExecute to execute the appropriate statements that implement the database access needs for each particular function. Alternatively, you can call rsqlExecDirect to both compile and execute a statement in a single call. Usually, you would only do this for statements that only need to be executed once.
b. Possibly call rsqlParamData and rsqlPutData to process any needed data-at-exec blob parameters specified in insert and update statements.
c. Call transaction statements (e.g., rsqlTransStart, rsqlTransCommit) to encapsulate related database modifications within transactions.

RDM SQL Language Guide
Using SQL in an Application Program 114
d. Call rsqlFetch to retrieve the result rows from an executed select statement. You may also need to call rsqlGetData to retrieve blob data results a block at a time. Alternatively, if the select is updateable, you may need to call rsqlGetCursorName or rsqlSetCursorName associated with a related positioned update or delete statement to change the current row returned from the call to rsqlFetch. You will need to call rsqlCloseStmt on a select for which you do not call rsqlFetch through to the end of the result set.
e. Possibly call rsqlExecProc to execute any stored procedures. 4. When your application is ready to terminate you need to ...
a. Call rsqlFreeStmt for each statement handle allocated in step 1j. b. Call rsqlFreeConn for each allocated connection which automatically closes all open databases
and terminates the connection and frees the connection handle and all its associated dynamically allocated memory.
c. If you're using the directly-linked TFS, call rsqlTFSTerm to terminated TFS processing.
Hello World!
The most basic of the above steps are illustrated below in an RDM SQL version of the ubiquitous "Hello World!" C program. Now, granted, this is a little bit more complex than a simple printf statement. But it should serve well to show the basic approach needed to use the RDM SQL API.
In the first version of the program, the return values from the SQL API functions are mostly ignored. This is per-fectly okay in this case because I know what I'm doing and I know that there are no errors or unusual statuses that are going to be returned (of course, if you take this code and try it yourself and get errors then I am going to be really embarrassed!).
By the way, all of the example programs referred to throughout this section are available under the Get-tingStarted\examples\sql_db directory.
Example Program: hello1Example_main.c
#include "rsql.h"
/* =======================================================================
Simple RDM SQL "Hello World!" Example #1
*/
int main()
{
const RSQL_VALUE *row;
HCONN hdbc;
HSTMT hstmt;
rsqlAllocConn(&hdbc);
rsqlAllocStmt(hdbc, &hstmt);
/* create the database */
rsqlExecDirect(hstmt, "create database hellodb");
rsqlExecDirect(hstmt, "create table hellotab(txtln char(24))");
stat = rsqlTransCommit(hdbc);

RDM SQL Language Guide
Using SQL in an Application Program 115
if ( stat != errSUCCESS ) {
printf("*** unable to connect to TFS\n");
exit((int)stat);
}
/* insert a couple of rows into hellotab */
rsqlExecDirect(hstmt, "insert into hellotab values \"Hello\"");
rsqlExecDirect(hstmt, "insert into hellotab values \"World!\"");
rsqlTransCommit(hdbc);
/* retrieve and display the rows */
rsqlExecDirect(hstmt, "select txtln from hellotab");
while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS )
printf("%s\n", row->vt.cv);
rsqlFreeStmt(hstmt);
rsqlFreeConn(hdbc);
}
Executing this program will produce the following output:
Hello
World!
In this example the program is creating the database that will be used and so the first TFS communication does not occur until the call to rsqlTransCommit following the create statement calls to rsqlExecDirect. When the database already exists (which will typically be the case), the startup calls would be as follows.
rsqlAllocConn(&hdbc);
/* open database hellodb in shared mode */
stat = rsqlOpenDB(hdbc, "hellodb", "s");
if ( stat != errSUCCESS ) {
printf("*** unable to open the database\n");
exit((int)stat);
}
rsqlAllocStmt(hdbc, &hstmt);
/* insert a couple of rows into hellotab */
...
Now, good programming means that one should not just go around ignoring the status codes returned from func-tion calls. However, checking every function for an unpleasant status code and then doing something appro-priate with it adds a lot of code to the program that is not directly related to the important work being performed. For example, doing this to this program would make the code look something like the following snippet.
RSQL_ERRCODE stat;
...

RDM SQL Language Guide
Using SQL in an Application Program 116
/* create the database */
stat = rsqlExecDirect(hstmt, "create database hellodb");
if ( stat != errSUCCESS ) return report_error(NULL, hstmt, stat);
stat = rsqlExecDirect(hstmt, "create table hellotab(txtln char(24))");
if ( stat != errSUCCESS ) return report_error(NULL, hstmt, stat);
stat = rsqlExecDirect(hstmt, "commit");
if ( stat != errSUCCESS ) return report_error(NULL, hstmt, stat);
/* insert a couple of rows into hellotab */
stat = rsqlExecDirect(hstmt, "insert into hellotab values \"Hello\"");
if ( stat != errSUCCESS ) return report_error(NULL, hstmt, stat);
stat = rsqlExecDirect(hstmt, "insert into hellotab values \"World!\"");
if ( stat != errSUCCESS ) return report_error(NULL, hstmt, stat);
stat = rsqlExecDirect(hstmt, "commit");
if ( stat != errSUCCESS ) return report_error(NULL, hstmt, stat);
Isn't it just a little difficult to see what is really happening? We'll be discussing how to handle errors later on in this section. However, a little introduction of a simple technique using the RDM SQLrsqlSetErrorCallback function with use of C's setjmp and longjmp functions will illustrate how you can properly handle errors and have readable code all at the same time.
The rsqlSetErrorCallback function arguments include the pointer to the callback function and a pointer to an application data area. In our example, this is going to be a pointer to a struct of type ERR_DATA as shown below.
/* error data structure */
typedef struct {
jmp_buf errexit;
HCONN hdbc;
HSTMT hstmt;
int erractive;
} ERR_DATA;
The hdbc and hstmt handles will be saved in this struct so that the error handling function can use them in calls to rsqlTransRollback and rsqlGetErrorInfo. The errexit jmp_buf will contain the setjmp location that will be set by the main program prior to calling rsqlSetErrorCallback. The erractive flag will prevent looping in case rsqlTransRollback generates an error (e.g., "transaction not active"). The complete program is given below.
Example Program: hello2Example_main.c
#include "rsql.h"
/* error data structure */
typedef struct {
jmp_buf errexit;
HCONN hdbc;
HSTMT hstmt;
int erractive;

RDM SQL Language Guide
Using SQL in an Application Program 117
} ERR_DATA;
/* =======================================================================
Report error
*/
RSQL_ERRCODE EXTERNAL_FCN report_error(
HRSQL hrsql,
RSQL_ERRCODE stat,
ERR_DATA *errdata)
{
char errmsg[133], *emsg = errmsg;
if ( errdata->erractive ) {
errdata->erractive = 0;
return stat;
}
if ( errdata && errdata->hstmt ) {
errdata->erractive = 1;
rsqlGetErrorInfo(errdata->hstmt, errmsg, 132);
printf("*** error: %s\n", emsg);
rsqlTransRollback(errdata->hdbc, NULL);
longjmp(errdata->errexit, (int32_t)stat);
}
rsqlGetErrorMsg(stat, &emsg);
printf("*** error: %s\n", emsg);
return stat;
}
/* =======================================================================
Simple RDM SQL "Hello World!" Example #2
*/
int main()
{
const RSQL_VALUE *row;
RSQL_ERRCODE stat;
HCONN hdbc = NULL;
HSTMT hstmt = NULL;
ERR_DATA errdata;
errdata.erractive = 0;
if ( stat = (RSQL_ERRCODE)setjmp(errdata.errexit) )
return stat;
stat = rsqlAllocConn(&hdbc);
if ( stat != errSUCCESS ) return report_error(stat, NULL);
errdata.hdbc = hdbc;
rsqlSetErrorCallback(hdbc, report_error, &errdata);
rsqlAllocStmt(hdbc, &hstmt);

RDM SQL Language Guide
Using SQL in an Application Program 118
errdata.hstmt = hstmt;
/* create the database */
rsqlExecDirect(hstmt, "create database hellodb");
rsqlExecDirect(hstmt, "create table hellotab(txtln char(24))");
rsqlTransCommit(hdbc);
/* insert a couple of rows into hellotab */
rsqlExecDirect(hstmt, "insert into hellotab values \"Hello\"");
rsqlExecDirect(hstmt, "insert into hellotab values \"World!\"");
rsqlTransCommit(hdbc);
/* retrieve and display the rows */
rsqlExecDirect(hstmt, "select txtln from hellotab");
while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS )
printf("%s\n", row->vt.cv);
rsqlFreeStmt(hstmt);
rsqlFreeConn(hdbc);
}
The call to rsqlSetErrorCallback passes in the address of function report_error along with a pointer to the errdata struct variable. When any SQL error occurs, the RDM SQL system will call function report_error which will print the error message and then do a longjmp to the setjmp called at the beginning of the pro-gram. So, errors are properly caught without the need to pollute the important calls with a lot of status checking code.
Initializing and Terminating TFS operation
If you are building your application to function as a server application that is integrated directly with the RDM Transactional File Server (through use of the TFST configuration option), then you will need to include calls to functions rsqlTFSInit and rsqlTFSTerm to initialize and terminate TFS operation. These calls are unnec-essary if your application will only use the TFSR configuration in which one or more TFSs execute as separate processes or if your application will only use the standalone TFS (TFSS).
Function rsqlTFSInit initializes the TFS. It takes two arguments. The first argument, docroot, is a string that specifies the path name of the "root database directory" into which database directories will be stored. If docroot is NULL then the root database directory will be the current directory. The second argument, tparams, is a pointer to a struct variable containing elements that specify various TFS operational parameters. If tparams is NULL then the system default values will be used for the TFS operational parameters. Note that even if both arguments are NULL, this function must still be called when using the TFST configuration. The table below describes the elements in the TFS_PARAMS struct that are relevant for RDM SQL.
Element Declaration Default Descriptionport uint16_t 21553 TCP/IP port number on which the TFS will be listening for remote connections.no_disk uint32_t 0 Set this flag to 1 to indicate that the TFS is to run diskless.rd_only uint32_t 0 Set this flag to 1 to indicate that the databases controlled by this TFS are read-
only.

RDM SQL Language Guide
Using SQL in an Application Program 119
As the TFS_PARAMS struct has elements besides the ones described above, it is always best to clear your TFS_PARAMS variable first (see example below). Refer to function d_tfsinit for more details about use of all of the TFS_PARAMS struct elements.
So code fragment below shows the calls to rsqlTFSInit and rsqlTFSTerm.
#include "rsql.h"
int main()
{
RSQL_ERRCODE stat;
HCONN hdbc = NULL;
HSTMT hstmt = NULL;
TFS_PARAMS tfs;
/* clear the tfs params struct: this is necessary */
memset(&tfs, 0, sizeof(tfs));
/* assign the tfs param values */
tfs.port = 21553;
/* Initialize this program to be the TFS */
stat = rsqlTFSInit("c:\tfs_dbs", (const TFS_PARAMS *)&tfs);
if ( stat != errSUCCESS ) {
printf("unable to start TFS, status code = %d\n", stat);
return stat;
}
stat = rsqlAllocConn(&hdbc);
... do the database stuff
rsqlFreeConn(hdbc);
/* terminate TFS operation */
rsqlTFSTerm();
return 0;
}
Connecting to a TFS and Opening Databases
Opening a database and connecting to a TFS occurs when calling either rsqlOpenDB or rsqlOpenCat. Func-tion rsqlOpenDB specifies one or more databases to be opened from the binary catalog files (e.g., book-shop.cat) stored in the database directory on the TFS. Function rsqlOpenCat specifies a database to open using the catalog structure from the C catalog module (e.g., bookshop_cat.c). You need to call rsqlO-penCat for each database that is to be opened.
The database name(s) argument given in the call to rsqlOpenDB or rsqlOpenCat can specify the TFS on which that particular database is located as given in the following syntax.

RDM SQL Language Guide
Using SQL in an Application Program 120
"dbname[@TFSComputerName[:port]]"
where:
dbname the name of the database to be opened
TFSComputerName the name of the computer on which the TFS is running (default is localhost),
port the TCP/IP port number on which the TFS is listening (default is 21553)
More than one database can be specified in the rsqlOpenDB function call by separating each database spec-ification with a semi-colon (";"). For example, the following code segment opens the bookshop and nsfa-wards databases each running on a separate TFS on different computers.
#include "rsql.h"
static char sel_acctmgr[] = "select mgrid, commission from acctmgr";
static char sel_sponsor[] = "select name, city from sponsor where state = 'WA'";
main()
{
HCONN hdbc;
HSTMT hstmt;
RSQL_ERRCODE stat;
RSQL_VALUE *row;
rsqlAllocConn(&hdbc);
rsqlOpenDB(hdbc, "bookshop@RaimaSrvr1:1650;nsfawards@RaimaSvr2:21553", "s");
rsqlAllocStmt(hdbc, &hstmt);
stat = rsqlExecDirect(hstmt, sel_acctmgr);
if ( stat != errSUCCESS )
return stat;
printf("**** %s\n", sel_acctmgr);
while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS ) {
printf("%s, %f\n", row[0].vt.cv, row[1].vt.dv);
}
stat = rsqlExecDirect(hstmt, sel_sponsor);
if ( stat != errSUCCESS )
return stat;
printf("**** %s\n", sel_sponsor);
while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS ) {
printf("%s, %s\n", row[0].vt.cv, row[1].vt.cv);
}
rsqlFreeConn(hdbc);
}
Use of function rsqlOpenCat is shown in the following version of the previous example.

RDM SQL Language Guide
Using SQL in an Application Program 121
#include "rsql.h"
#include "bookshop_cat.h"
#include "nsfawards_cat.h"
static char sel_acctmgr[] = "select mgrid, commission from acctmgr";
static char sel_sponsor[] = "select name, city from sponsor where state = 'WA'";
main()
{
HCONN hdbc;
HSTMT hstmt;
RSQL_ERRCODE stat;
RSQL_VALUE *row;
rsqlAllocConn(&hdbc);
rsqlOpenCat(hdbc, &bookshop_cat, "@localhost:21553", "s");
rsqlOpenCat(hdbc, &nsfawards_cat, "@localhost:21555", "s");
rsqlAllocStmt(hdbc, &hstmt);
stat = rsqlExecDirect(hstmt, sel_acctmgr);
if ( stat != errSUCCESS )
return stat;
printf("**** %s\n", sel_acctmgr);
while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS ) {
printf("%s, %f\n", row[0].vt.cv, row[1].vt.dv);
}
stat = rsqlExecDirect(hstmt, sel_sponsor);
if ( stat != errSUCCESS )
return stat;
printf("**** %s\n", sel_sponsor);
while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS ) {
printf("%s, %s\n", row[0].vt.cv, row[1].vt.cv);
}
rsqlFreeConn(hdbc);
}
Database Unions
A database union allows multiple instances of the same database running on different TFSs to be opened and accessed as though they were just a single database. The database names can be different but they must all have identical DDL schema definitions (hence, identical catalogs). Database unions allow you to partition a data-base among multiple TFSs running on separate computers (or as separate processes on the same multi-core/multi-processor computer) in order to take advantage of the performance benefits from truly parallel data-base access.

RDM SQL Language Guide
Using SQL in an Application Program 122
You can call either rsqlOpenCat or rsqlOpenDB to open a union of two or more databases. The specification for each database and TFS combination is separated using the vertical bar symbol, "|". The following examples show the calls needed for the case where the NSF awards database was partitioned between three TFSs.
rsqlOpenCat(hdbc, @nsfawards_cat,
"nsfawards@NSF1:21553|nsfawards@NSF2:21555|nsfawards@NSF3:21557", "s");
or,
rsqlOpenDB(hdbc,
"nsfawards@NSF1:21553|nsfawards@NSF2:21555|nsfawards@NSF3:21557", "s");
Compiling and Executing SQL StatementsAs SQL is a database language, statements coded in SQL need to be compiled in order to be executed. The func-tion that needs to be called in order to compile an SQL statement is rsqlPrepare. The function that needs to be called in order to executed a compiled SQL statement is rsqlExecute. A statement can be compiled once and executed multiple times. In fact, except for a few situations described later on in this section, it is best to com-pile most of your statements once when the program starts and then execute them as needed. You can also com-pile and execute a statement in a single call using function rsqlExecDirect.
The SQL statement to be compiled is passed to rsqlPrepare as a standard null-terminated string. The status returned from the call to rsqlPrepare will indicate any error encountered during compilation. Several func-tions can be called in order to discover information about the compiled statement. You can call function rsqlGetStmtType in order to discover the type of statement just compiled. Function rsqlGet-NumResultCols can be called to retrieve the number of select statement result columns. Function rsqlGet-ColDescr can be called to retrieve information about a particular select statement result column.
Parameters are specified within an SQL statement string using a question mark character ('?') and can appear in any context in which a literal constant value is allowed. Parameters are identified as ordinals beginning at 1 and proceeding in left-to-right order in the statement string. Function rsqlBindParam must be called before the statement is executed in order to provide to SQL the type and location information in the user application where a parameter value can be found.
Once all of the specified parameter markers have been bound to the application variables containing their values, function rsqlExecute can be called to execute the compiled SQL statement.
The following program shows the basic sequence of compiling and executing a simple SQL select statement with parameter markers. Note that the checking of the status codes returned from most of the RSQL API func-tion calls has been left out for readability. The bold-faced lines are discussed below.
Example Program: params1Example_main.c
1 #include "rsql.h"
2
3 static void gettext(
4 const char *prompt,

RDM SQL Language Guide
Using SQL in an Application Program 123
5 char *text,
6 size_t len)
7 {
8 printf("%s ", prompt);
9 if (fgets(text, len, stdin) == NULL )
10 text[0] = '\0';
11 else {
12 char *nl = strchr(text, '\n');
13 if ( nl )
14 *nl = '\0';
15 }
16 }
17
18 /* =======================================================================
19 Simple RDM SQL parameter markers example 1
20 */
21 int main()
22 {
23 const RSQL_VALUE *row;
24 RSQL_ERRCODE stat;
25 HCONN hdbc;
26 HSTMT hstmt;
27 char buf[250];
28 int16_t lo_born = 0, hi_born = 0;
29 char gender[2] = "";
30 char stmt[] = "select full_name, yr_born, yr_died from author "
31 "where gender = ? and yr_born between ? and ?";
32
33 rsqlAllocConn(&hdbc);
34 rsqlAllocStmt(hdbc, &hstmt);
35 stat = rsqlOpenDB(hdbc, "bookshop", "s");
36 if ( stat != errSUCCESS ) {
37 printf("unable to open bookshop database\n");
38 rsqlFreeConn(hdbc);
39 exit((int)stat);
40 }
41 rsqlPrepare(hstmt, stmt);
42 rsqlBindParam(hstmt, 1, tCHAR, gender, NULL);
43 rsqlBindParam(hstmt, 2, tSMALLINT, &lo_born, NULL);
44 rsqlBindParam(hstmt, 3, tSMALLINT, &hi_born, NULL);
45
46 for ( ; ; ) {
47 /* get parameter values from user */
48 gettext("\nenter gender (M/F):", gender, sizeof(gender));
49 if ( gender[0] != 'M' && gender[0] != 'F' ) {
50 printf("gender must be a M or F\n");
51 continue;
52 }
53
54 gettext("\nenter low year born:", buf, sizeof(buf));
55 lo_born = (int16_t)atoi(buf);
56 if ( lo_born == 0 )

RDM SQL Language Guide
Using SQL in an Application Program 124
57 break;
58
59 gettext("enter high year born:", buf, sizeof(buf));
60 hi_born = (int16_t)atoi(buf);
61 if ( hi_born == 0 )
62 break;
63
64 if ( lo_born > hi_born ) {
65 printf("low year born must be less or equal to high!\n");
66 continue;
67 }
68 /* execute select statement */
69 rsqlExecute(hstmt);
70
71 /* fetch result set */
72 printf("NAME YR_BORN YR_DIED\n");
73 printf("----------------------------------- ------- -------\n");
74 while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS )
75 printf("%-35.35s %4d %4d\n",
76 row[0].vt.cv, row[1].vt.sv, row[2].vt.sv);
77 }
78 rsqlFreeStmt(hstmt);
79 rsqlFreeConn(hdbc);
80 exit(0);
81 }
The select statement specified at lines 30 and 31 in stmt contains three parameters. The first is the comparison value for the gender column of type char and the second and third specify the low and high comparison values for the smallint column yr_born. The statement is compiled by the call to rsqlPrepare at line 41. The three calls to rsqlBindParam associate each parameter with the local variable that will contain its value at execution time. The final argument to rsqlBindParam is not used because it is only needed for parameters that need to specify a length (e.g., tBINARY) or to indicate that a parameter value is to be specified at execution time (e.g., a blob data-at-exec parameter).
The actual parameter values are assigned inside the for loop at line 48 for the gender parameter, line 55 for the low yr_born parameter, and at line 60 for the high yr_born parameter. Note that while the gender column was declared as a single character column (see bookshop.sql for the bookshop database DDL), the param-eter value for it must be a null-terminated string. The C data type for the variable that is associated with a given parameter must be as indicated in Table 6.
The call to rsqlExecute at line 69 executes the select statement with the specified parameter values and the rsqlFetch while loop at line 74 retrieves all of the rows that satisfy the where clause with the current set of parameter values.
RDM SQL also provides the ability to specify named parameter markers and then call rsqlBindNamedParam to bind the parameter values. Named parameter markers are specified by a colon followed by an identifier that serves as the parameter name. Referring to the above example, the following changes modify the program to use named parameters.

RDM SQL Language Guide
Using SQL in an Application Program 125
30 char stmt[] = "select full_name, yr_born, yr_died from author "
31 "where gender = :gen and yr_born between :lo and :hi";
...
42 rsqlBindNamedParam(hstmt, "gen", tCHAR, gender, NULL, NULL);
43 rsqlBindNamedParam(hstmt, "hi", tSMALLINT, &hi_born, NULL, NULL);
44 rsqlBindNamedParam(hstmt, "lo", tSMALLINT, &lo_born, NULL, NULL);
Use of parameter markers with an insert statement is shown in the example program below which inserts new rows into the author table of the bookshop database.
Example Program: params2Example_main.c
1 #include "rsql.h"
2
3 static void gettext(
...
17
18 /* =======================================================================
19 Simple RDM SQL parameter markers example 2 including blobs
20 */
21 int main()
22 {
23 HCONN hdbc;
24 HSTMT hstmt;
25
26 char last_name[14] = "";
27 char full_name[35] = "";
28 int32_t full_name_len = 0;
29 char gender[2] = " ";
30 int32_t gender_len = 0;
31 int16_t yr_born = 0;
32 int32_t yr_born_len = 0;
33 int16_t yr_died = 0;
34 int32_t yr_died_len = 0;
35 char year[5];
36 char bio[132] = "";
37 int32_t data_at_exec = -2;
38 uint32_t short_bio_len;
39
40 char stmt[] = "insert into author values ?, ?, ?, ?, ?, ?";
41
42 rsqlAllocConn(&hdbc);
43 rsqlAllocStmt(hdbc, &hstmt);
44 rsqlOpenDB(hdbc, "bookshop", "s");
45
46 rsqlPrepare(hstmt, stmt);
47
48 /* bind all 6 parameters */
49 rsqlBindParam(hstmt, 1, tCHAR, last_name, NULL);
50 rsqlBindParam(hstmt, 2, tCHAR, full_name, &full_name_len);

RDM SQL Language Guide
Using SQL in an Application Program 126
51 rsqlBindParam(hstmt, 3, tCHAR, gender, &gender_len);
52 rsqlBindParam(hstmt, 4, tSMALLINT, &yr_born, &yr_born_len);
53 rsqlBindParam(hstmt, 5, tSMALLINT, &yr_died, &yr_died_len);
54 rsqlBindParam(hstmt, 6, tCLOB, bio, &data_at_exec);
55
56 for ( ; ; ) {
57 /* get parameter values from user */
58 gettext("enter last_name:", last_name, sizeof(last_name));
59 if ( !last_name[0] ) break;
60
61 gettext("enter full_name:", full_name, sizeof(full_name));
62 full_name_len = full_name[0] ? 0 : -1;
63
64 gettext("enter gender (M/F):", gender, sizeof(gender));
65 if ( !gender[0] )
66 gender_len = -1;
67 else if ( gender[0] == 'M' || gender[0] == 'F' )
68 gender_len = 0;
69 else {
70 printf("gender must be a M or F\n");
71 continue;
72 }
73
74 gettext("enter year born:", year, sizeof(year));
75 if ( year[0] ) {
76 yr_born = (int16_t)atoi(year);
77 yr_born_len = 0;
78 }
79 else
80 yr_born_len = -1;
81
82 gettext("enter year died:", year, sizeof(year));
83 if ( year[0] ) {
84 yr_died = (int16_t)atoi(year);
85 yr_died_len = 0;
86 }
87 else
88 yr_died_len = -1;
89
90 rsqlTransStart(hdbc, NULL);
91
92 /* execute select statement */
93 if ( rsqlExecute(hstmt) != errNEEDDATA )
{
94 printf("rsqlExecute did NOT return errNEEDDATA!!\n");
95 break;
96 }
97 while ( rsqlParamData(hstmt, NULL, NULL) == errNEEDDATA )
{
98 for ( ; ; ) {
99 gettext("enter short_bio:", bio, sizeof(bio));
100 if ( !bio[0] )

RDM SQL Language Guide
Using SQL in an Application Program 127
101 break;
102 short_bio_len = (uint32_t)strlen(bio);
103 rsqlPutData(hstmt, bio, short_bio_len);
104 }
105 /* add a null terminator */
106 rsqlPutData(hstmt, "", 1);
107 }
108 rsqlTransCommit(hdbc);
109 }
110 rsqlFreeStmt(hstmt);
111 rsqlFreeConn(hdbc);
112 exit(0);
113 }
The insert statement at line 40 (compiled at line 46) contains a parameter marker for each of the author table's six columns. The author table's declaration is shown below for easy reference.
create table author(
last_name char(13) primary key,
full_name char(35),
gender char distinct values = 2,
yr_born smallint,
yr_died smallint,
short_bio long varchar,
key yob_gender_key(yr_born, gender)
);
To specify a null column value for a parameter the parameter length variable pointed to by the pLenValue (final) argument to rsqlBindParam must be set to -1 at the time rsqlExecute is called. Line 62 shows how this is done for the full_name_len variable that was specified in the rsqlBindParam call at line 50. Nulls are allowed for all of the author table columns except last_name. Hence, the pLenValue argument is not needed (i.e., it is NULL) in its call to rsqlBindParam at line 49.
Use of data-at-exec parameters is designed to provide the ability to store blob (i.e., columns of type long varchar, or long varbinary) data values in sets of fixed-length blocks in order to minimize the amount of needed memory. Data-at-exec parameters are parameter values that will be supplied by the application program after rsqlExecute is called to execute the statement. A data-at-exec parameter is specified by setting the length variable specified through the pLenValue argument to rsqlBindParam to -2(see lines 37 and 54).. When executing an SQL statement for which one or more data-at-exec parameters have been specified, rsqlEx-ecute will return status errNEEDDATA to indicate that it is ready for the application to supply the blob data values. The program then calls rsqlParamData to set up the subsequent calls to rsqlPutData that store the parameter's blob value. Lines 93 to 107 show how this is done for the long varchar column short_bio in the author table.
It is important to note that character blob data is considered to be one long null terminated string. If multiple calls to rsqlPutData are used to store its value it is important that the terminating null byte only be included on the final rsqlPutData call. Hence, short_bio_len is set to the string length at line 102, excluding the null byte, in the intermediate rsqlPutData calls at line 103. The additional call at line 106 ensures that the blob is ter-minated by a null byte..

RDM SQL Language Guide
Using SQL in an Application Program 128
Retrieving Select Statement Results
Basic Retrieval
Retrieving the result set rows of a select statement is quite simple. After successfully compiling and executing a select statement through calls to rsqlPrepare and rsqlExecute (or rsqlExecDirect), the program can retrieve the result set one row at a time by calling rsqlFetch. After the last row has been fetched the next call to rsqlFetch will return status errNOMOREDATA. A number of examples that do just that have already been given.
Function rsqlFetch must be called to retrieve the next row of a select statement's result set. The values of each result column are returned through the pResult argument. You can also access a column's result value using function rsqlGetData. In fact, you can call fetch passing NULL for the pResult argument and then call rsqlGetData to retrieve the value for a specific result column. For example, you could replace lines 59-61 of the params1Example_main.c example program given earlier with the following code to do the same thing.
while ( rsqlFetch(hstmt, NULL, NULL) == errSUCCESS ) {
RSQL_VALUE *pColval;
rsqlGetData(hstmt, 1, &pColval, 0, NULL);
printf("%-35.35s ", pColval->vt.cv);
rsqlGetData(hstmt, 2, &pColval, 0, NULL);
printf("%4d ", pColval->vt.sv);
rsqlGetData(hstmt, 3, &pColval, 0, NULL);
printf("%4d\n", pColval->vt.sv);
}
While you can use rsqlGetData to do this it is primarily intended as a way to retrieve blob column values in chunks -i.e., a block at a time. The basic approach for doing just that is shown in the following example program.
Retrieving Blob Data Values
Example Program: getdataExample_main.c
1 #include "rsql.h"
2
3 static void gettext(
...
17
18 /* =======================================================================
19 Simple RDM SQL example retrieving blob data using rsqlGetData
20 */
21 int main()
22 {
23 const RSQL_VALUE *pColval;
24 RSQL_ERRCODE stat;

RDM SQL Language Guide
Using SQL in an Application Program 129
25 HCONN hdbc;
26 HSTMT hstmt;
27 char last_name[40] = "";
28 char short_bio[81];
29 uint32_t remlen;
30 char stmt[] = "select full_name, short_bio from author"
31 " where last_name like ? for read only";
32
33 rsqlAllocConn(&hdbc);
34 rsqlAllocStmt(hdbc, &hstmt);
35 stat = rsqlOpenDB(hdbc, "bookshop", "s");
36 if ( stat != errSUCCESS ) {
37 printf("unable to open bookshop database\n");
38 rsqlFreeConn(hdbc);
39 exit((int)stat);
40 }
41 rsqlPrepare(hstmt, stmt);
42 rsqlBindParam(hstmt, 1, tCHAR, last_name, NULL);
43
44 for ( ; ; ) {
45 /* get parameter value from user */
46 gettext("\nenter author's last_name:", last_name, sizeof(last_name)-1);
47 if (!last_name[0]) break;
48 strcat(last_name, "%");
49
50 /* execute select statement */
51 rsqlExecute(hstmt);
52 stat = rsqlFetch(hstmt, NULL, NULL);
53 if ( stat != errSUCCESS ) {
54 printf("author %s not in database\n", last_name);
55 continue;
56 }
57 /* author's full_name */
58 rsqlGetData(hstmt, 1, &pColval, 0, NULL);
59 printf("%s:\n", pColval->vt.cv);
60
61 /* fetch short_bio blob data */
62 while ( rsqlGetData(hstmt, 2, &pColval, 80, &remlen) == errSUCCESS ) {
63 if ( pColval->type == tNULL || remlen == 0 )
{
64 printf("No short_bio has been entered\n");
65 break;
66 }
67 /* copy blob data block and add null terminator */
68 memcpy(short_bio, pColval->vt.lvv.buf, pColval->len);
69 short_bio[pColval->len] = '\0';
70 printf("%s\n", short_bio);
71 }
72 rsqlCloseStmt(hstmt);
73 }
74 rsqlFreeStmt(hstmt);
75 rsqlFreeConn(hdbc);

RDM SQL Language Guide
Using SQL in an Application Program 130
76 exit(0);
77 }
The select statement is shown in lines 30-31. The code that retrieves the blob value for the short_bio long varchar column is given in while loop at lines 62 to 71. As a NULL could have been stored for the blob value that is checked at line 63 (the test for remlen == 0 will probably never occur as that would mean that a zero length blob value was stored -but it doesn't hurt to check). The value containing pColval->len bytes is memcpy'd from the blob data buffer pointer (pColval->vt.lvv.buf into the local char array named short_bio (line 68) and a null string terminator byte is added at the end (line 69). Remember that character blobs are treated as a single character string so there is only the one null-byte terminator as the last character stored in the blob.
Fetching Results From Retrieval Stored Procedures
Recall that a retrieval stored procedure was one that contained one or more select statements. To retrieve the results from the select statements contained in a stored procedure you can either compile and execute an execute statement that invokes the procedure or call function rsqlExecProc to directly execute the stored pro-cedure. For example, the following script creates a stored procedure that returns the author name and list of titles of books by that author.
create procedure books_by_author(name char) as
select full_name, title from author natural join book
where last_name like name
end procedure;
Note that the where clauses uses the like operator so that you can issue the following execute to retrieve the books written by both Bronte sisters:
execute books_by_author("Bront%");
FULL_NAME TITLE
Bronte, Charlotte Jane Eyre. An autobiography. Ed. by Currer Bell [pseud.]
Bronte, Charlotte Villette.
Bronte, Charlotte Jane Eyre.
Bronte, Emily Wuthering Heights. A novel.
The example program given below prompts the user (lines 41-43) for the author's last name (wild cards allowed), generates an execute statement string that passes that name into the books_by_author procedure (line 46) and then calls rsqlExecDirect to compile and execute it (line 49). After that, the result set is retrieved just as if the stored procedure's select statement was itself compiled and executed (lines 57-58),.
Example Program: procs1Example_main.c
1 #include "rsql.h"
2
3 static void gettext(
...
17

RDM SQL Language Guide
Using SQL in an Application Program 131
18 /* =======================================================================
19 Simple RDM SQL stored proc execution example 1
20 */
21 int main()
22 {
23 const RSQL_VALUE *row;
24 RSQL_ERRCODE stat;
25 HCONN hdbc;
26 HSTMT hstmt;
27 char last_name[35];
28 char stmt[81];
29
30 rsqlAllocConn(&hdbc);
31 rsqlAllocStmt(hdbc, &hstmt);
32 stat = rsqlOpenDB(hdbc, "bookshop", "s");
33 if ( stat != errSUCCESS ) {
34 printf("unable to open bookshop database\n");
35 rsqlFreeConn(hdbc);
36 exit((int)stat);
37 }
38
39 for ( ; ; ) {
40 /* get parameter values from user */
41 gettext("\nenter author's last_name:", last_name, sizeof(last_name));
42 if ( !last_name[0] )
43 break;
44
45 /* construct execute statement */
46 sprintf(stmt, "execute books_by_author(\"%s\")", last_name);
47
48 /* execute the execute statement */
49 stat = rsqlExecDirect(hstmt, stmt);
50 if ( stat != errSUCCESS ) {
51 printf("error in execute statement\n");
52 continue;
53 }
54 /* fetch result set */
55 printf("NAME TITLE\n");
56 printf("----------------------------------- -----\n");
57 while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS )
58 printf("%-35.35s %s\n", row[0].vt.cv, row[1].vt.cv);
59 }
60 rsqlFreeStmt(hstmt);
61 rsqlFreeConn(hdbc);
62 exit(0);
63 }
The second approach is actually a better solution because it does not incur the cost of recompiling an execute statement each time. This is shown in the following example program.
Example Program: procs2Example_main.c

RDM SQL Language Guide
Using SQL in an Application Program 132
1 #include "rsql.h"
2
3 static void gettext(
...
17
18 /* =======================================================================
19 Simple RDM SQL stored proc execution example 2
20 */
21 int main()
22 {
23 const RSQL_VALUE *row;
24 RSQL_VALUE arg;
25 RSQL_ERRCODE stat;
26 HCONN hdbc;
27 HSTMT hstmt;
28 char last_name[35];
29
30 rsqlAllocConn(&hdbc);
31 rsqlAllocStmt(hdbc, &hstmt);
32 stat = rsqlOpenDB(hdbc, "bookshop", "s");
33 if ( stat != errSUCCESS ) {
34 printf("unable to open bookshop database\n");
35 rsqlFreeConn(hdbc);
36 exit((int)stat);
37 }
38 /* set up argument value container */
39 arg.type = tCHAR;
40 arg.status = vsOKAY;
41 arg.len = 0;
42 arg.vt.cv = last_name;
43
44 for ( ; ; ) {
45 /* get parameter values from user */
46 gettext("\nenter author's last_name:", last_name, sizeof(last_name));
47 if ( !last_name[0] )
48 break;
49
50 /* execute the execute statement */
51 stat = rsqlExecProc(hstmt, "books_by_author", 1, &arg);
52 if ( stat != errSUCCESS ) {
53 printf("error attempting to execute proc\n");
54 continue;
55 }
56 /* fetch result set */
57 printf("NAME TITLE\n");
58 printf("----------------------------------- -----\n");
59 while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS )
60 printf("%-35.35s %s\n", row[0].vt.cv, row[1].vt.cv);
61 }
62 rsqlFreeStmt(hstmt);
63 rsqlFreeConn(hdbc);
64 exit(0);

RDM SQL Language Guide
Using SQL in an Application Program 133
65 }
Lines 39-42 sets up the argument value container (line 24) that will be passed into rsqlExecProc at line 51 that executes the books_by_author stored procedure. At that point, retrieval of the result set proceeds in the usual manner.
Stored procedures can contain more than one select statement as shown in the following version of books_by_author.
create procedure books_by_author(name char) as
select full_name, yr_born, short_bio from author where last_name = name
select title from book where last_name = name
end procedure;
Two select statements are contained in this procedure. After executing the stored procedure and fetching the result rows from the first, in order to retrieve the results of the second the application needs to call function rsqlMoreResults which will return status errSUCCESS when there is another select statement to be executed or errNOMOREDATA after the last select has been processed. This is shown in the following example.
Example Program: procs3Example_main.c
1 #include "rsql.h"
2
3 static void gettext(
...
17
18 /* =======================================================================
19 Simple RDM SQL stored proc execution example 3
20 */
21 int main()
22 {
23 const RSQL_VALUE *row, *pColval;
24 RSQL_VALUE arg;
25 RSQL_ERRCODE stat;
26 HCONN hdbc;
27 HSTMT hstmt;
28 uint32_t remlen;
29 char short_bio[81];
30 char last_name[35];
31
32 rsqlAllocConn(&hdbc);
33 rsqlAllocStmt(hdbc, &hstmt);
34 stat = rsqlOpenDB(hdbc, "bookshop", "s");
35 if ( stat != errSUCCESS ) {
36 printf("unable to open bookshop database\n");
37 rsqlFreeConn(hdbc);
38 exit((int)stat);
39 }
40 /* set up argument value container */

RDM SQL Language Guide
Using SQL in an Application Program 134
41 arg.type = tCHAR;
42 arg.status = vsOKAY;
43 arg.len = 0;
44 arg.vt.cv = last_name;
45
46 /* turn on deferred blob reading mode */
47 rsqlSetDeferBlobMode(hstmt, 1);
48
49 for ( ; ; ) {
50 /* get parameter values from user */
51 gettext("\nenter author's last_name:", last_name, sizeof(last_name));
52 if ( !last_name[0] )
53 break;
54
55 /* execute the execute statement */
56 stat = rsqlExecProc(hstmt, "books_by_author", 1, &arg);
57 if ( stat != errSUCCESS ) {
58 printf("error attempting to execute proc\n");
59 continue;
60 }
61 /* fetch 1st select's result set */
62 while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS ) {
63 printf("\nauthor : %s\n", row[0].vt.cv);
64 printf("year of birth: %d\n", row[1].vt.sv);
65 printf("------------------------------------------------------\n");
66
67 /* fetch short_bio blob data */
68 while (rsqlGetData(hstmt, 3, &pColval, 80, &remlen) == errSUCCESS)
{
69 if ( pColval->type == tNULL || remlen == 0 ) {
70 printf("None\n");
71 break;
72 }
73 /* copy blob data block and add null terminator */
74 memcpy(short_bio, pColval->vt.lvv.buf, pColval->len);
75 short_bio[pColval->len] = '\0';
76 printf("%s\n", short_bio);
77 }
78 }
79 /* execute and fetch 2nd select's result set */
80 if ( rsqlMoreResults(hstmt) != errSUCCESS )
{
81 printf("Second SELECT not in books_by_author\n");
82 break;
83 }
84 printf("\ntitles in stock\n---------------\n");
85 while ( rsqlFetch(hstmt, &row, NULL) == errSUCCESS )
86 printf("%s\n", row[0].vt.cv);
87 }
88 rsqlFreeStmt(hstmt);
89 rsqlFreeConn(hdbc);
90 exit(0);

RDM SQL Language Guide
Using SQL in an Application Program 135
91 }
The call to rsqlMoreResults in line 80 executes the second select statement and its result set is returned in the rsqlFetch while loop at line 85.
This example also includes a call to rsqlSetDeferBlobMode to turn on deferred reading of blob data (line 47) which is performed by the rsqlGetData while loop at line 68 (identical to that shown earlier in get-dataExample_main.c example). Note that without having made that call, the rsqlGetData loop would never exit as it would be returning the entire blob value in the single call. In getdataExample_main.c deferred blob mode was automatically set when rsqlFetch was called with a NULL second argument.
Positioned Update and Delete StatementsA positioned update/delete statement updates/deletes the current row of an updateable select statement that is currently being fetched on a separate statement handle within the same connection. Executing a select opens what is commonly referred to as a cursor which can be thought of as an indicator of the current row in the select statement's result set. After calling rsqlExecute the cursor is positioned before the first row. A call to rsqlFetch advances the cursor to the next row if one exists. Associated with each statement handle is a unique cursor name. This can be set by a call to function rsqlSetCursorName to specify your own cursor name or you can call function rsqlGetCursorName to get the name automatically assigned by RDM SQL. Cursor names are not case-sensitive.
The syntax for an updateable select and positioned update and delete statements is shown below.
updateable_select:
select { * | column_name [, column_name]...} from table_spec
[where conditional_expr]
for update [of column_name [, column_name]...]
positioned_update_stmt:
update [db_name.]table_name
set column_name = expression[, column_name = expression]...
where current of cursor_name
positioned_delete_stmt:
delete from [db_name.]table_name
where current of cursor_name
Only an updateable select statement can be used with a positioned update/delete. An updateable select must adhere to the following rules:
1. Only one table can be listed in the from clause. 2. Result columns must not contain any expressions. 3. No distinct, order by or group by is allowed. 4. The for update clause must be specified. 5. 4.5. If an of clause is specified then each of the specified column names must also appear in the select
result set.

RDM SQL Language Guide
Using SQL in an Application Program 136
For a positioned update the columns that can be assigned new values in the set clause must be specified in the corresponding select statement's result set and, if specified, listed in the for update of clause. Any columns declared in the table can be referenced in the update (i.e., used in the set assignment of one of the updateable columns).
A simple example program which performs a positioned delete is shown below. A positioned update would be done similarly.
Example Program: pos_delExample_main.c
1 #include "rsql.h"
2
3 static void gettext(
...
17
18 /* =======================================================================
19 RDM SQL positioned delete example
20 */
21 int main()
22 {
23 RSQL_ERRCODE stat;
24 HCONN hdbc;
25 HSTMT sel_hstmt, del_hstmt;
26 const RSQL_VALUE *row;
27 char reply[30];
28
29 rsqlAllocConn(&hdbc);
30 stat = rsqlOpenDB(hdbc, "bookshop", "s");
31 if ( stat != errSUCCESS ) {
32 printf("unable to open bookshop database\n");
33 rsqlFreeConn(hdbc);
34 exit((int)stat);
35 }
36 /* set up select statement cursor */
37 rsqlAllocStmt(hdbc, &sel_hstmt);
38 rsqlSetCursorName(sel_hstmt, "book_cursor");
39 rsqlPrepare(sel_hstmt, "select bookid, last_name, title from book for
update");
40
41 /* set up delete statement */
42 rsqlAllocStmt(hdbc, &del_hstmt);
43 rsqlPrepare(del_hstmt, "delete from book where current of book_cursor");
44
45 rsqlTransStart(hdbc, NULL);
46
47 rsqlExecute(sel_hstmt);
48
49 while ( rsqlFetch(sel_hstmt, &row, NULL) == errSUCCESS )
{
50 printf("bookid : %s\n", row[0].vt.cv);
51 printf("last_name: %s\n", row[1].vt.cv);
52 printf("title : %s\n", row[2].vt.cv);
53 gettext("do you want to delete this book (y|n)?", reply, sizeof

RDM SQL Language Guide
Using SQL in an Application Program 137
(reply));
54 if ( reply[0] == 'y' )
55 rsqlExecute(del_hstmt);
56
57 gettext("continue (y|n)?", reply, sizeof(reply));
58 if ( reply[0] != 'y' )
59 break;
60 }
61 rsqlTransCommit(hdbc);
62
63 rsqlFreeStmt(sel_hstmt);
64 rsqlFreeStmt(del_hstmt);
65 rsqlFreeConn(hdbc);
66
67 exit(0);
68 }
Two statement handles are allocated on the same connection handle: sel_hstmt (line 37) is used for the select statement and del_stmt (line 42) is used for the delete. After allocating sel_hstmt function rsqlSet-CursorName is called to set the cursor name to "book_cursor". This called could have been made after the call to rsqlPrepare but must be made before the call to rsqlExecute. The select is compiled at lines 39. Note that the for update clause must be specified. The delete statement at lines 43. The where current of clause iden-tifies this as a positioned delete. Function rsqlTransStart is called at line 45 before the select is executed at line 47. The rsqlFetch while loop retrieves and displays each row and gives the user the option of deleting that row. If the reply begins with 'y' (so, "yes", "yo", "yea", "ya", "you better not", etc. all will delete the book from the database) then that row is deleted. The process continues as long as the reply to the prompt at lines 57-58 is 'y'. When the loop exits the rsqlTransCommit will commit the changes to the database. Note that rsqlClo-seStmt is not explicitly called. This is because the rsqlFreeStmt will close the cursor automatically. How-ever, if more processing is to be done with sel_hstmt then rsqlCloseStmt must be called before proceeding. That's really all there is to it. Of course, a real application would probably have a more user-friendly interface and properly handle the return codes from the function calls!

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 138
User-Defined Functions (UDFs) in SQLCivilization advances by extending the
number of important operations which
we can perform without thinking about them.- Alfred North Whitehead, Introduction to Mathematics (1911)
A User-Defined Function (UDF) is an application-specific function used just like the RDM SQL scalar and aggre-gate functions as described in the Retrieving Data from a Database section, but developed to meet the specific needs of your application. UDFs are created in a C program module that conforms to a pre-defined API that will be called by the SQL runtime system whenever the specific function is used in an SQL statement.
Your UDF can be either a scalar or an aggregate function. A scalar UDF operates on a single row and retrieves a single value. An aggregate function is used with the group by clause of a select statement and performs com-putations on sets of rows that result from the select statement.
This section will show you how to write a RDM SQL UDF in C through two simple example UDFs: a scalar UDF that implements a soundex code for names, and an aggregate UDF that counts the number of occurrences of a column (or expression) of type character that match a specified string.
The soundex function takes a single character string argument that should contain the name of a person begin-ning with the last name. It returns the 4 character soundex code based on the rules given in the Wikipedia article "soundex" (http://en.wikipedia.org/wiki/Soundex). If the string does not conform to a name, the function returns code "xERR". For example, the following query returns the name and soundex code for each row of the person table in the nsfawards database.
select name, soundex(name) from person;
The example aggregate UDF is called matchcount and takes two character arguments. The first is a column or string expression and the second is a character column or string expression that the first is to match. The func-tion tracks the count of the number of matches that are encountered in each group. For example, the query below returns the counts of the number of person table rows in the nsfawards database of male, female, and unknown gender.
select matchcount(gender,"F"), matchcount(gender,"M"), matchcount(gender,"U")
from person;
matchcount(gender, "F") matchcount(gender, "M") matchcount(gender, "U")
17537 57385 10982
UDF Load Table Definition and RegistrationA UDF implementation consists of the seven C functions described in the following table.
Function Entry Description When Called by SQLudfCheck Checks argument types and returns result
data type.When SQL statement is compiled.
Table 1. UDF Implementation Functions

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 139
Function Entry Description When Called by SQLudfInit Initializes a given execution of the UDF usually
needed to allocate memory for any needed UDF context data.
When SQL statement is executed.
udfTerm Performs any needed cleanup—usually to free any memory allocated by the udfInit or udfCall functions.
When execution completes or when the cursor is closed (on a select statement).
udfScalarCall Performs one execution of the scalar function. When next row is processed.udfAggCall Performs one execution of the aggregate func-
tion for each row of the groupWhen next row of group is processed.
udfAggResult Called to return the aggregate computation value.
Either during or after aggregate accumulation.
udfAggReset Resets the aggregate calculation. When group changes.
The entry points for these functions are provided through a UDF load table that is passed from your application to the RDM SQL system by calling function rsqlRegisterUDFs. This table is an array of type UDFLOADTABLE defined in header file rsqltypes.h (automatically included with header file rsql.h) and shown below.
typedef struct udfloadtable {
char udfName[NAMELEN]; /* name of user function */
SQL_T udfType; /* data type of return value */
PUDFCHECK udfCheck; /* address of arg type checking function */
PUDFINIT udfInit; /* address of initialization function */
PUDFINIT udfTerm; /* address of termination function */
PUDFSCALARCALL udfScalarCall; /* address of user function */
PUDFAGGCALL udfAggCall; /* address of user function */
PUDFAGGRESULT udfAggResult; /* address of user function */
PUDFRESET udfAggReset; /* address of aggregate reset function */
} UDFLOADTABLE;
The first field in the table, udfName, is a char string containing the name of the UDF that will be used in SQL statements. The second field, udfType, is the data type of the value returned by the function. If the return type of the function depends on the type of its argument then this should be set to tNOVAL. In any case, the data type returned by function udfCheck is the type that is used by SQL during compilation. The other fields in UDFLOAD-TABLE contain pointers to the functions that implement the UDF. Note that udfInit, udfTerm, udf-ScalarCall, udfAggCall, udfAggResult and udfAggReset can all be NULL. However, udfScalarCall must be specified and all three udfAgg functions must be NULL for a scalar UDF. Similarly, all three udfAgg functions must be specified and udfScalarCall must be NULL for an aggregate UDF. Each of the seven implementation functions must conform to its prototype definition given in header file rsqltypes.h as follows.
typedef RSQL_ERRCODE (EXTERNAL_FCN UDFCHECK)( /* udfCheck */
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to registration context */
uint16_t noargs, /* in: number of arguments */
const RSQL_VALUE *pArgs, /* in: ptr to array of arg values (types) */
SQL_T *pType, /* out: result data type */
int16_t *pDeterm); /* out: deterministic fcn flag (0 or 1) */

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 140
typedef RSQL_ERRCODE (EXTERNAL_FCN UDFINIT)( /* udfInit */
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to registration context */
void *pFcnCtx); /* in: ptr to fcn execution context data area */
typedef void (EXTERNAL_FCN UDFTERM)( /* udfTerm */
HSTMT hstmt, /* in: statement handle */
void *pFcnCtx); /* in: ptr to fcn execution context data area */
typedef RSQL_ERRCODE (EXTERNAL_FCN UDFSCALARCALL)( /* udfScalarCall */
HSTMT hstmt, /* in: statement handle */
void *pFcnCtx, /* in: ptr to fcn execution context data area */
uint16_t noargs, /* in: number of arguments */
const RSQL_VALUE *pArgs, /* in: ptr to array of argument values */
RSQL_VALUE *pResult); /* out: ptr to function result value */
typedef RSQL_ERRCODE (EXTERNAL_FCN UDFAGGCALL)( /* udfAggCall */
HSTMT hstmt, /* in: statement handle */
void *pFcnCtx, /* in: ptr to fcn execution context data area */
uint16_t noargs, /* in: number of arguments */
const RSQL_VALUE *pArgs); /* in: ptr to array of argument values */
typedef RSQL_ERRCODE (EXTERNAL_FCN UDFAGGRESULT)( /* udfAggResult */
HSTMT hstmt, /* in: statement handle */
void *pFcnCtx, /* in: ptr to fcn execution context data area */
RSQL_VALUE *pResult); /* out: ptr to function result value */
typedef RSQL_ERRCODE (EXTERNAL_FCN UDFAGGRESET)( /* udfAggRest */
HSTMT hstmt, /* in: statement handle */
void *pFcnCtx); /* in: ptr to fcn execution context data area */
The function names are italicized to indicate that they can be named whatever you like. Note that the first argu-ment to each function is a statement handle. This is the statement handle of the SQL statement that contains the reference to the UDF. You will only need to use this argument when your UDF needs to make calls to the RDM SQL functions. Details on how to do this will be discussed later on in this section.
The code snippet below is from the example UDF C module udf.c (contained in the Get-tingStarted\examples\sqlUDF directory) and shows the definition of the UDFLOADTABLE for the soun-dex and matchcount functions. Each uses a predefined prototype (e.g., UDFCHECK) to ensure that the arguments are properly defined.
/* UDF functions for soundex */
static UDFCHECK SndxCheck;

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 141
static UDFSCALARCALL SndxCall;
/* user function for matchcount */
static UDFCHECK CntCheck;
static UDFAGGCALL CntCall;
static UDFAGGRESULT CntResult;
static UDFAGGRESET CntReset;
/*--------------------------------------------------------------------------
Table of user-defined functions for this module
---------------------------------------------------------------------------*/
/* table of user functions callable from within an sql expression */
const UDFLOADTABLE UdfTable[] = {
/* Scalar Aggregate--------------- */
/* Name Type Check Init Term Call Call Result Reset */
/* -------- ------- --------- ---- ---- -------- ------- --------- ------ */
{"soundex", tCHAR, SndxCheck,NULL,NULL,SndxCall,NULL, NULL, NULL},
{"matchcount",tBIGINT,CntCheck, NULL,NULL,NULL, CntCall,CntResult,CntReset}
};
RDM SQL is informed about the existence of these functions by the application through a call to function rsqlRe-gisterUDFs (which must occur before compiling/executing any SQL statement that references them).
The code snippet below shows how this is done.
extern const UDFLOADTABLE UdfTable[];
extern const size_t szUdfCtx;
MyApplication()
{
HCONN hdbc;
if ( rsqlAllocConn(&hdbc) == errSUCCESS ) {
rsqlRegisterUDFs(hdbc, 2, UdfTable, NULL, szUdfCtx);
...
}
Five arguments are passed into function rsqlRegisterUDFs: the connection handle, the number of entries in the UDF load table, the address of the UDF load table, a pointer to a user registration context data area (which can be NULL if unnecessary), and the maximum size that is needed for a UDF execution context (e.g., aggregate functions in particular will use this space to keep track of computationally important data from each detail row of the set of rows comprising each aggregate). The prototype for rsqlRegisterUDFs is given below. Note that only one call to this function is allowed for any given connection.
RSQL_ERRCODE EXTERNAL_FCN rsqlRegisterUDFs(
HCONN hConn, /* in: connection handle */
uint16_t noudfs, /* in: number of UDFs */
const UDFLOADTABLE *udftab, /* in: ptr to UDF load table */
void *pRegCtx, /* in: ptr to user's registration context */

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 142
const size_t szFcnCtx) /* in: size of function context space to be
alloc'd */
The pRegCtx can be used by the application program to pass in any application-specific, execution-inde-pendent data that will be needed by one or more UDFs. If no registration context is needed the pRegCtx argu-ment should be NULL. The specified pRefCtx pointer is passed to the udfCheck and udfInit functions.
The szFcnCtx needs to be set to the largest context data area used for all of the UDFs. This space will be auto-matically allocated by the RDM SQL engine and passed to the execution-time UDF functions (all but udfCheck). If no function context is needed then szFcnCtx should be 0.
UDF Type Checking Function: udfCheckThis function is called by SQL during compilation (i.e. rsqlPrepare) of a SQL statement that contains a ref-erence to the UDF. Six arguments are passed into the udfCheck function as described in the following table.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement referencing this UDFpRegCtx void * Pointer to the user program allocated registration context data area that
was originally passed in through the call to rsqlRegisterUDFs.noargs uint16_t Number of arguments specified in SQL statement's UDF callargs RSQL_VALUE * Array of noargs argument value entries. The first argument is contained in
args[0]. As this function is called during compilation, only the data type specified in each args entry should be referenced as the actual data value will only be present for literal constant arguments.
fcntype SQL_T * The data type of the value that will be returned by the UDF is returned in this output variable.
pDeterm int16_t * Set to 1 to indicate that the function is deterministic otherwise set to 0. A function is deterministic if it always returns the same value for the same arguments. SQL will call deterministic functions at compile time when all of the argument values are known (i.e., literals) and replace the call with the result value in the compiled code.
Table 2. Function udfCheck Argument Descriptions
If no errors are detected the function needs to return status errSUCCESS. If an error is detected, then the status code associated with that particular error needs to be returned by the udfCheck function. The specific error code that is returned can be any of the RDM SQL codes but it is recommended that the following codes be used.
Error Code DescriptionerrUDFNOARGS Incorrect number of function argumentserrUDFARG Invalid function argument typeerrUDF Other UDF error
Table 3. UDF Error Return Codes
Most of the time only the data type from the the args RSQL_VALUE array (e.g., args[0].type) needs to be inspected as the actual data value will only be present when a literal constant value is being passed to the func-tion. In order to know which arguments have a literal value, the status field of RSQL_VALUE can be checked (e.g., args[0].status). When a value is present the status will be set to vsOKAY, if no value is present the

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 143
status will be set to vsNOVAL. You can use this, for example, when you want to define an argument for a par-ticular function that is only allowed to take a literal constant.If an argument was specified using a parameter marker then its corresponding type will be tPARAMREF or if the argument is a stored procedure argument the type will be tPROCVAR. In either case, the actual type checking will need to be done at execution time by the udf-ScalarCall/udfAggCall function.
The data type returned by the UDF is returned through the pType argument. The valid RDM SQL_T data type values that can be returned by a UDF are specified in the table below.
SQL Data Type SQL_T value C Data Typechar tCHAR char
varchar tVARCHAR char
wchar tWCHAR wchar_t
wvarchar tWVARCHAR wchar_t
binary tBINARY uint8_t
varbinary tVARBINARY uint8_t
boolean tBOOL int8_t
tinyint tTINYINT int8_t
smallint tSMALLINT int16_t
integer tINTEGER int32_t
bigint tBIGINT int64_t
real tREAL float
float, double tFLOAT, tDOUBLE double
date tDATE int32_t
time tTIME int32_t
timestamp tTIMESTAMP int64_t
Table 4. SQL Data Type Values
The udfCheck implementation for the soundex UDF is given below.
/* ======================================================================
Soundex - type checking function (1 argument == name to be encoded)
*/
static RSQL_ERRCODE EXTERNAL_FCN SndxCheck(
HSTMT hStmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to registration context */
uint16_t noargs, /* in: number of arguments to function */
const RSQL_VALUE *args, /* in: array of argument values */
SQL_T *fcntype, /* out: result data type */
int16_t *pDeterm) /* out: = 1 deterministic */
{
RSQL_ERRCODE status;
UNREF_PARM(hStmt)
UNREF_PARM(pRegCtx)
if ( !args || noargs != 1 )
status = errUDFNOARGS;
else if ( args->type != tNOVAL && args->type !=tCHAR && args->type !=tVARCHAR
)

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 144
status = errUDFARG;
else {
status = errSUCCESS;
*fcntype = tCHAR;
*pDeterm = 1;
}
return status;
}
When an argument has been specified with a parameter marker, SQL will not know its data type at compilation time. In those situations, the argument type will be tNOVAL and it is therefore a good idea to allow this by the udfCheck function. So you can see that both tNOVAL and tCHAR/tVARCHAR are allowed in the soundex type checking function. This also means that the udfScalarCall function will also need to validate the argument type.
The soundex function is deterministic (i.e., always computes the same value for a particular set of argument values), so it sets *pDeterm to 1. This means that when all of the argument values for a particular call are lit-erals then SQL will call udfInit, udfScalarCall, and udfTerm when the statement that references the UDF is compiled and then replace the call with the literal result value in the compiled statement code.
The udfCheck function for the matchcount UDF is as follows.
/* ======================================================================
Type checking call, used for matchcount() UDF
*/
static RSQL_ERRCODE EXTERNAL_FCN CntCheck (
HSTMT hStmt, /* in: system handle */
void *pRegCtx, /* in: ptr to registration context */
uint16_t noargs, /* in: number of arguments to function */
const RSQL_VALUE *args, /* in: array of argument values */
SQL_T *fcntype, /* out: result data type */
int16_t *pDeterm) /* out: = 0: not deterministic */
{
RSQL_ERRCODE stat;
UNREF_PARM(hStmt)
UNREF_PARM(pRegCtx)
if ( noargs != 2 )
stat = errUDFNOARGS;
else if ( args[0].type != tNOVAL
&& args[0].type != tCHAR && args[0].type != tVARCHAR
&& args[1].type != tNOVAL
&& args[1].type != tCHAR && args[1].type != tVARCHAR )
stat = errUDFARG;
else {
stat = errSUCCESS;
*fcntype = tBIGINT;
*pDeterm = 0;
}

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 145
return stat;
}
UDF Initialization Function: udfInitThe udfInit function is called by RDM SQL when the SQL statement containing the UDF call is executed (rsqlExecute). This function is used to initialize data that needs to survive multiple calls to the udf-ScalarCall or udfAggCall functions during the processing of the SQL statement. The pointer to this allo-cated memory is called the function context pointer and is passed to the udfInit function (as well as each of the other execution-time functions) through the pFcnCtx argument. If no initialization is needed then this func-tion is unnecessary and its entry in the UDFLOADTABLE can be assigned to NULL (as is the case with both the soundex and matchcount UDFs).
The three arguments that are passed to the udfInit function are described below.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement referencing this UDFpRegCtx void * Pointer to the user program allocated registration context data area that
was originally passed in through the call to rsqlRegisterUDFs.pFcnCtx void * Pointer to the user function context data area.
Table 5. Function udfInit Argument Descriptions
The context data is typically defined as a struct type with fields defined for any of the data that needs to survive the calls to the udfScalarCallor udfAggCall functions. For example, the context declarations for the soun-dex and matchcount functions' context is given below.
/* Soundex UDF data context packet */
typedef struct sndx_ctx {
char sndx[5]; /* code buffer needs to survive each soundex() call */
} SNDX_CTX;
/* Matchcount UDF data context packet */
typedef struct count_cxt {
RSQL_ERRCODE stat; /* CntCall error status */
int64_t count; /* Current match count */
} COUNT_CTX;
const size_t szUdfCtx = RDM_MAX(sizeof(SNDX_CTX), sizeof(COUNT_CTX));
Note how the szUdfCtx variable is initialized to the maximum of the sizes of the two struct typedefs. This is the variable that is passed in to rsqlRegisterUDFs to specify the amount of space the RDM SQL system will allocate for the UDF function context.
The sndx field will contain the last soundex code returned by the udfScalarCall function. It is placed in the UDF context so that repeated allocations for the code string do not have to occur on each call. The count field of COUNT_CTX keeps track of the match count for the current aggregate set. The stat field is simply used by the udfAggCall function to inform the udfAggResult function of an argument error.
As initialization functions are not needed for the two example UDFs as stub version is given below.

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 146
/* ======================================================================
Initialization function for generic UDF
*/
static RSQL_ERRCODE EXTERNAL_FCN MyUdfInit (
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to registration context */
void *pFcnCtx); /* in: ptr to fcn execution context data area */
{
MYUDF_CTX *pCtx = (MYUDF_CTX *)pFcnCtx;
UNREF_PARM(hStmt)
UNREF_PARM(pRegCtx)
/* do needed initialization of pCtx */
return errSUCCESS;
}
UDF Termination Function: udfTermThe udfTerm function is called after the SQL statement containing the UDF reference has completed executing which, in the case of a select, means when the cursor has been closed either through the call to rsqlFetch that returns status errNOMOREDATA (automatically closing the cursor) or through a call to rsqlCloseStmt which is used to close a cursor before having scrolled completely through it.
The two arguments that are passed to the udfterm function are described below.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement referencing this UDFpFcnCtx void * Pointer to the user function context data area.
Table 6. Function udfTerm Argument Descriptions
This function is called to perform any needed termination processing when the SQL statement containing the UDF reference has completed its execution. For example, any memory allocated by the udfInit function would be freed by udfTerm.
As termination functions are not needed for the two example UDFs as stub version is given below.
/* ======================================================================
Termination function for generic UDF
*/
static void EXTERNAL_FCN MyUdfTerm (
HSTMT hstmt, /* in: statement handle */
void *pFcnCtx); /* in: ptr to fcn execution context data area */
{
MYUDF_CTX *pCtx = (MYUDF_CTX *)pFcnCtx;
UNREF_PARM(hStmt)

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 147
/* do needed termination from pCtx */
}
Scalar Call Function: udfScalarCallThe udfScalarCall function is called by RDM SQL during execution of the SQL statement containing the UDF function reference to perform the desired calculation/evaluation. The five arguments to udfScalarCall are described in the following table.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement referencing this UDFpFcnCtx void * A pointer to the UDF function context pointeruint16_t noargs Number of arguments (i.e., size of args array)args const RSQL_VALUE * Pointer to an array of noargs argument value entries. The first argument is
contained in args[0]. The argument value is contained in the vt field of RSQL_VALUE.
result RSQL_VALUE * Pointer to the output RSQL_VALUE variable that will contain the function result value.
Table 7. Function udfScalar Call Argument Descriptions
The udfScalarCall implementation for the soundex UDF is given below.
1 /* ======================================================================
2 Soundex() UDF - return soundex code for specified name
3 */
4 static RSQL_ERRCODE EXTERNAL_FCN SndxFunc (
5 HSTMT hStmt, /* in: system handle */
6 void *cxtp, /* in: UDF context pointer */
7 uint16_t noargs, /* in: number of arguments to function */
8 const RSQL_VALUE *args, /* in: array of arguments */
9 RSQL_VALUE *result) /* out: result value */
10 {
11 /* Soundex conversion table. See Wikipedia "Soundex" page */
12 static char *codes[] = {"bfpv", "cgjkqsxz", "dt", "l", "mn", "r", "hw",
NULL};
13 static char sndxerr[] = "xERR";
14 int cpos, cndx;
15 char cur_c, last_c;
16 SNDX_CTX *scp = (SNDX_CTX *)cxtp;
17 char *sndx = &scp->sndx[0];
18 char *name = args->vt.cv;
19
20 UNREF_PARM(hStmt)
21 UNREF_PARM(noargs)
22
23 result->type = tCHAR;
24 result->len = 0;
25

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 148
26 if ( !name || !isalpha(*name)
27 || (args->type != tCHAR && args->type != tVARCHAR) ) {
28 result->vt.cv = sndxerr;
29 return errSUCCESS;
30 }
31 sndx[0] = toupper(*name++);
32 strcpy(&sndx[1], "000");
33
34 for (last_c = 0, cpos = 1; cpos < 4 && isalpha(*name); ++name) {
35 for (cndx = 0; codes[cndx]; ++cndx) {
36 if ( strchr(codes[cndx], tolower(*name)) ) {
37 if ( cndx < 6 ) { /* "hw" */
38 cur_c = '1' + cndx;
39 if ( cur_c != last_c ) {
40 sndx[cpos++] = cur_c;
41 last_c = cur_c;
42 }
43 }
44 break;
45 }
46 }
47 if ( !codes[cndx] )
48 last_c = 0;
49 }
50 result->vt.cv = sndx;
51
52 return errSUCCESS;
53 }
Function SndxFunc will never be called by SQL without having executed a prior successful call to SndxCheck. Hence it is certain that noargs is equal to 1 and does not need to be checked. However, it is possible that the argument type not be equal to tCHAR (or tVARCHAR) because it may have been specified with a parameter marker that was assigned to a non-tCHAR (or tVARCHAR) variable. Lines 26 to 30 contain a check of the argu-ment types and if they are not correct, rather than returning an error code, SndxFunc returns a special code that indicates that an error for that particular row occurred. If an actual error code is returned then SQL will abort the processing at that point, returning the error to the application program. Of course, for many UDFs that will be exactly the correct thing to do. Note that in this case, the type of the argument could be valid but if the character string does not begin with a letter then it cannot be a name (the isalpha test at line 26).
The details of the soundex algorithm are not particularly important except to note that the code is a four char-acter code where the first is the upper-case first letter of the name followed by three digits. The result is stored in the context field, sndx (see lines 17, 31-32, and 40). The result type field is tCHAR (line 23) and the result len field is zero (line 24) indicating that this is not an SQL allocated string. The pointer to the result string is assigned to field vt.cv at line 50.
Aggregate UDF Call Function: udfAggCallThe udfAggCall function is called by RDM SQL for each detail row from the current set of aggregate rows to perform the detail calculations needed by the aggregate function. The four arguments to udfAggCall are

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 149
described in the following table.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement referencing this UDFpFcnCtx void * A pointer to the UDF function context pointeruint16_t noargs Number of arguments (i.e., size of args array)args const RSQL_VALUE * Pointer to an array of noargs argument value entries. The first argument is
contained in args[0]. The argument value is contained in the vt field of RSQL_VALUE.
Table 8. Function udfAggCall Argument Descriptions
Note that a locally-declared 5 character array variable could not be used to contain the resulting soundex code and assigned to result->vt.cv because it would go out of context when the function returns. This is why it is necessary to the UDF function context to contain the buffer. Moreover, a global variable cannot be used as that is not thread safe should the function be called from another thread from the same program.
The udfAggCall implementation for the matchcount UDF is shown below.
1 /* ======================================================================
2 User function for matchcount() UDF
3 */
4 static RSQL_ERRCODE EXTERNAL_FCN CntCall (
5 HSTMT hStmt, /* in: system handle */
6 void *cxtp, /* in: UDF context pointer */
7 uint16_t noargs, /* in: number of arguments to function */
8 const RSQL_VALUE *args) /* in: array of arguments */
9 {
10 COUNT_CTX *ccp = cxtp;
11
12 UNREF_PARM(hStmt)
13 UNREF_PARM(noargs)
14
15 if ( args[0].type != tNOVAL && args[1].type != tNOVAL ) {
16 if (args[0].type != tNULL) {
17 if ( (args[0].type != tCHAR && args[0].type != tVARCHAR)
18 ||(args[1].type != tCHAR && args[1].type != tVARCHAR) )
19 ccp->stat = errUDFARG;
20 else {
21 ccp->stat = errSUCCESS;
22 if ( strstr(args[0].vt.cv, args[1].vt.cv) )
23 ++ccp->count;
24 }
25 }
26 }
27 return errSUCCESS;
28 }
The count field of the UDF context COUNT_CTX is declared as type int64_t (the _t integer types are defined in the RDM header files). It is used to contain the count of the number of calls to CntFunc when the two argu-ments match. There are two points that need to be made from this example to which you will want to pay par-ticular attention.

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 150
First, notice the checks for tNOVAL at line 15 and the check for tNULL in line 16. In the implementation of an aggregate function, the tNOVAL types will be passed in on the initial call to the function for each aggregate set so they should not be considered erroneous but no computation needs to occur. It is also possible that a null argu-ment can be passed in and this too needs to be allowed. Note that in standard SQL aggregate computations are supposed to ignore nulls. In this example that has no effect on the result. However, it does matter with any com-putation that depends on the number of candidate rows.
Lines 17-20 show how error handling from within the udfAggCall function needs to be done. It is not quite the same as in the udfCheck function where a simple status code is returned. Two methods for returning an error can be used. In this example, result->type is set to tSMALLINT and result->vt.sv is set to the desired error code (errUDFARG) and status errSQLERROR is returned by the function. SQL will then return the spec-ified status along with the name of the UDF to the application from the invoking function (either rsqlExecute or rsqlFetch). Another method is to set result->type to tCHAR and assign a pointer to a static char string error message to result->vt.cv. SQL will then return that message along with the UDF name in the error info buffer associated with that statement (retrievable through a call to function rsqlGetErrorInfo) and return error code errUDF to the application from the invoking function (rsqlExecute or rsqlFetch). This alternative approach could be coded for CntFunc as follows.
17 if ( args[0].type != tCHAR || args[1].type != tCHAR ) {
18 result->type = tCHAR;
19 result->vt.cv = "invalid argument type";
20 return errSQLERROR;
Aggregate UDF Result Function: udfAggResultThe udfAggResult function is called by RDM SQL during execution of the SQL statement containing the UDF function reference to perform and return the desired aggregate calculation result. This function is designed to be called once after all of the detail rows have been processed. However, at this time, RDM SQL actually calls this function after each detail row has been fetched and after the udfAggCall function has been called. So, this function should never reset the aggregate computational value—that is the job of the udfAggReset function described in the next section. The three arguments to udfAggResult are described in the following table.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement referencing this UDFpFcnCtx void * A pointer to the UDF function context pointerresult RSQL_VALUE * Pointer to the output RSQL_VALUE variable the will contain the function
result value.
Table 9. Function udfAggResult Argument Descriptions
The udfAggResult implementation for the matchcount UDF is given below.
/* ======================================================================
User function for matchcount() UDF
*/
static RSQL_ERRCODE EXTERNAL_FCN CntResult (
HSTMT hStmt, /* in: system handle */
void *cxtp, /* in: UDF context pointer */

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 151
RSQL_VALUE *result) /* out: result value */
{
RSQL_ERRCODE stat;
COUNT_CTX *ccp = (COUNT_CTX *)cxtp;
UNREF_PARM(hStmt)
if ( ccp->stat != errSUCCESS ) {
result->type = tSMALLINT;
result->vt.sv = (int16_t) ccp->stat;
stat = errSQLERROR;
}
else {
result->type = tBIGINT;
result->vt.llv = ccp->count;
stat = errSUCCESS;
}
return stat;
}
Aggregate UDF Reset Function: udfAggResetThe udfAggReset function is only used with aggregate UDFs. Its function is to reset the aggregated com-putational result to its initial value. The function is called by SQL each time the group by column values change.
The two arguments that are passed to the udfReset function are described below.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement referencing this UDFctxp void * A pointer to the allocated UDF context pointer containing the aggregated
computational result value.
Table 10. Function udfReset Argument Descriptions
The udfReset implementation for the matchcount UDF is shown below. As it is quite trivial no further com-ment is needed.
/* ======================================================================
Reset function for matchcount() UDF
*/
static RSQL_ERRCODE EXTERNAL_FCN CntReset(
HSTMT hStmt, /* in: system handle */
void *cxtp) /* in: UDF context pointer */
{
COUNT_CTX *ccp = (COUNT_CTX *)cxtp;
UNREF_PARM(hStmt)
ccp->count = 0;

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 152
return errSUCCESS;
}
Calling RSQL API Functions from a UDFIf your UDF needs to make calls to the RDM SQL API functions there are some important things that you need to know. The statement handle that is passed into each of the UDF implementation functions is the one associated with the statement containing the call to the UDF. There are only a limited number of functions that can be safely called using this statement handle as listed in the table below.
Function DescriptionrsqlGetColDescr Get description information for a select statement result columnrsqlGetConnHandle Get connection handle associated with specified statement handlersqlGetCursorName Get the cursor name associated for the specified statement handlersqlGetNumParams Get the number of parameter markers in the compiled statementrsqlGetNumResultCols Get the number of result columns in the compiled select statementrsqlGetParamDescr Get description information for a SQL statement parameter markerrsqlGetRowCount Get the count of the # of rows affected by the executed statementrsqlGetSelectType Get the type of select statementrsqlGetStmtState Get the statement handle's statement statersqlGetStmtString Get the SQL statement stringrsqlGetStmtType Get the statement type of the prepared statementrsqlGetTableName Get result column’s table name
Table 11. Function Calls that Can Be Made Using hStmt
Calls to any other RDM SQL API function into which you pass hStmt will return error code errNOTINUDF.
Most often you will want to allocate a new statement handle to use within the UDF. Function rsqlGet-ConnHandle must be called to retrieve the connection handle associated with the calling statement handle. You can then pass this into rsqlAllocStmt in order to allocate a statement handle for use within the UDF.
If the UDF is deterministic, it may be important to know whether the UDF is being called during compilation or execution. This can be discovered via a call to function rsqlGetStmtState using the original statement han-dle. Note that when called during compilation, the locks that are needed by the invoking statement cannot be guaranteed to be in place when the UDF is called. If the UDF relies on those locks then udfCheck needs to indi-cate that the UDF is not deterministic.
You can also use the connection handle returned from the call to rsqlGetConnHandle to call some, but not all, connection-related RDM SQL API calls. The following table lists those functions which can be called.
Function DescriptionrsqlAllocStmt Allocate a statement handlersqlCloseDB Close a databasersqlGetAutoCommit Get the connection handle’s current auto commit statusrsqlGetDateFormat Get the current date format setting
Table 12. Function Calls that Can Be Made Using hStmt's Connection Handle

RDM SQL Language Guide
User-Defined Functions (UDFs) in SQL 153
Function DescriptionrsqlGetDateSeparator Get the current date separator characterrsqlGetDBNames Get a list of the names of the currently opened databasesrsqlGetDBTask Get the RDM task handle associated with a connection handlersqlGetGenCFiles Get the connection handle's "generate C files" modersqlGetTimeout Get lock wait timeout in seconds for the connectionrsqlLockTables Issue an explicit lock request for one or more database tablesrsqlOpenCat Open a database through its compiled catalog modulersqlOpenDB Open a database by namersqlSetDateFormat Set the date constant format for the connectionrsqlSetDateSeparator Set the current date constant separator character for the connectionrsqlSetTimeout Set lock wait timeout in seconds for the connectionrsqlTransStatus Return the current transaction state for the specified connectionrsqlUnlockTable Free a read lock on a database table
Calls to any other RDM SQL API function into which you pass the connection handle associated with hStmt will return error code errNOTINUDF.
All of the connection's open databases and locks are inherited by the UDF. You can call rsqlGetDBNames to get a semi-colon separated list of the names of the open databases. If rsqlOpenDB (rsqlOpenCat) is called then the UDF needs to make sure that those databases are closed in udfCleanup. If you call rsqlAl-locStmt to allocate a separate statement handle on the connection handle returned from the call to rsqlGet-ConnHandle you can use it with any RDM SQL API call that takes a statement handle.
You can allocate a separate connection handle with no restrictions on the calls that can be made. Note, however, that the open databases and locks held by the original connection are not inherited and you will need to be very careful not to attempt to lock a table that is blocked by a lock held by the original connection because it will not regain control (and free the lock) until the UDF returns. Because of this we recommend that you never call rsqlAllocConn from a UDF.

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 154
Using Virtual Tables to Access Any Data'Virtual Reality' is a name being slapped on
almost anything these days, especially if it's lame.- Mark Hamilton
A virtual table provides the ability to present any kind of data to SQL as a table. . It is important to recognize that virtual tables do not behave like standard database tables. RDM SQL does not lock a virtual table. Virtual tables are not transactional—you cannot commit or rollback an insert statement. The data in a virtual table is not nec-essarily persistent. A virtual table's implementation of an insert statement may not actually store a new "row" into the table but might actually be used to simply provide data that is used to control an embedded device. Some vir-tual tables may have an unlimited number of rows as in, for example, a virtual table that returns the status data from sensors in an embedded system that varies over time. The virtual table implementation described in this sec-tion is quite basic supporting only insert and select statements yet that is sufficient to allow you to interface SQL with just about any kind of non-SQL data from your embedded systems application.
A virtual table is defined through a combination of the create virtual table DDL statement and a set of user-written C functions that conform to a pre-defined function call interface specification. A pointer to a pre-defined structure array that contains an entry for each virtual table with the addresses of each of the virtual table interface functions is passed into SQL before the database is opened by calling the rsqlRegisterVirtualTables function. The virtual table interface functions are then called by SQL at the appropriate times during the execution of any SQL statement that references the virtual table. This interaction is depicted in the figure below which shows SQL calling the function in the application's virtual table function module to fetch a row of weather data from a wireless sensor network (WSN).
Figure 1. Virtual Table Operation

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 155
This section will show you how to develop a virtual table implementation through the use of a simple example. Vir-tual tables are defined using the create virtual table SQL DDL statement described in the Defining a Database section and implemented in a C program module that conforms to a pre-defined API that will be called by the SQL runtime system in order to process any insert (or import) and select statements that access the virtual table (note that at the present time update and delete statements are not allowed on a virtual table). The example vir-tual table is defined as follows in the vtabs example database DDL specification (file vtabs.sql).
create database vtabs;
create table stdtab(
pkey integer primary key,
name char(24) key,
addr char(32),
city char(24),
state char(2),
zip char(10)
);
create virtual table virtab(
pkey integer primary key,
name char(24),
addr char(32),
city char(24),
state char(2),
zip char(10)
);
Note that two identical tables are defined except for the defined keys. One is a standard table and one is a virtual table. A database must contain at least one standard table. Of course, it is not required that you have an identical standard table for each virtual table. The purpose of the example is to demonstrate how easy it is to load a stand-ard table from a virtual table using the insert into table from select statement.
Virtual Table Load Table Definition and RegistrationA virtual table implementation consists of the six C functions described in the table below.
Function Entry Description When Called by SQL
vtInsert Executes an insert statement which "inserts" the specified data values.
When SQL insert statement is executed (rsqlExecute). Can be NULL.
vtRowCount Returns an estimate of the current number of rows contained in the virtual table.
When SQL statement is compiled (rsqlPre-pare).
vtSelectCount Returns the actual current number of rows contained in the virtual table.
When "select count(*)" is executed on the vir-tual table.
vtSelectOpen Executes a select statement which performs any needed initialization for subsequent calls to vtFetch.
When SQL select statement is executed (rsqlExecute).
vtFetch Fetches the next row in the virtual table. When rsqlFetch is called.
vtSelectClose Performs any needed cleanup—e.g., to free When select execution completes (e.g., when
Table 1. Virtual Table Implementation Functions

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 156
Function Entry Description When Called by SQL
any memory allocated by the vtSe-lectOpen or vtFetch functions.
the cursor is closed). Can be NULL.
The entry points for these functions are provided through a virtual table load table that is passed from your appli-cation to the RDM SQL system by calling function rsqlRegisterVirtualTables before processing any SQL statements that reference a virtual table. This table is an array of type VTLOADTABLE defined in header file rsqltypes.h (automatically included with header file rsql.h) and shown below.
typedef struct vtfloadtable {
char vtName[NAMELEN]; /* name of the virtual table */
PVTINSERT vtInsert; /* ptr to INSERT execution function */
PVTROWCOUNT vtRowCount; /* ptr to row count est. function*/
PVTSELECTCOUNT vtSelectCount; /* ptr to actual row count function */
PVTSELECTOPEN vtSelectOpen; /* ptr to SELECT init function */
PVTFETCH vtFetch; /* ptr to fetch next row function */
PVTSELECTCLOSE vtSelectClose; /* ptr to SELECT term function */
} VTFLOADTABLE;
The first field in the table, vtName, is a char string containing the name of the virtual table and must be the same as that specified in its corresponding create virtual table statement (case insensitive). The remaining fields in VTLOADTABLE contain pointers to the functions that implement the virtual table. Each of the six implementation functions must conform to its prototype definition given in header file rsqltypes.h as follows.
typedef RSQL_ERRCODE (EXTERNAL_FCN VTINSERT)( /* vtInsert() */
HSTMT hstmt, /* in: statement handle */
uint16_t nocols, /* in: no. of ref'd columns */
VCOL_INFO *colsvals, /* in: array of ref'd column value containers */
void *pRegCtx) /* in: ptr to user's registration context */
typedef RSQL_ERRCODE (EXTERNAL_FCN VTROWCOUNT)( /* vtRowCount() */
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to user's registration context */
uint64_t *pNoRows) /* out: ptr to row count value */
typedef RSQL_ERRCODE (EXTERNAL_FCN VTSELECTCOUNT)( /* vtSelectCount() */
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to user's registration context */
void *pFetchCtx, /* in: ptr to fetch context */
uint64_t *pNoRows) /* out: ptr to row count value */
typedef RSQL_ERRCODE (EXTERNAL_FCN VTSELECTOPEN)( /* vtSelectOpen() */
HSTMT hstmt, /* in: statement handle */
uint16_t nocols, /* in: no. of ref'd columns */
VCOL_INFO *colsvals, /* in: array of ref'd column value containers */

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 157
void *pRegCtx, /* in: ptr to registration context */
void *pFetchCtx, /* in: ptr to fetch context */
RSQL_VALUE *pkeyval) /* in: ptr to primary key value */
typedef RSQL_ERRCODE (EXTERNAL_FCN VTFETCH)( /* vtFetch() */
HSTMT hstmt, /* in: statement handle */
uint16_t nocols, /* in: no. of ref'd columns */
VCOL_INFO *colsvals, /* in: array of ref'd column value containers */
void *pRegCtx, /* in: ptr to registration context */
void *pFetchCtx) /* in: ptr to fetch context */
typedef void (EXTERNAL_FCN VTSELECTCLOSE)( /* vtSelectClose() */
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to registration context */
void *pFetchCtx) /* in: ptr to fetch context */
The function names are italicized to indicate that they can be named whatever you like. Note that the first argu-ment to each function is a statement handle. This is the statement handle of the SQL statement that contains the reference to the virtual table. In general you do not need to use this argument. If the implementation of your vir-tual table needs to make calls to the RDM SQL functions you can use the statement handle to retrieve its asso-ciated connection handle by calling rsqlGetConnHandle which can then be used to call rsqlAllocStmt to allocate a new statement handle that could be used by the virtual table implementation functions.
The code snippet below is from the example virtual table C module vtabfcns.c (contained in the Get-tingStarted\examples\sqlVT directory) and shows the definition of the VTLOADTABLE for the virtab table.
static VTINSERT vtInsert;
static VTROWCOUNT vtRowCount;
static VTSELECTCOUNT vtSelectCount;
static VTSELECTOPEN vtSelectOpen;
static VTFETCH vtFetch;
const VTFLOADTABLE vtFcnTable[] = {
{"virtab",vtInsert,vtRowCount,vtSelectCount,vtSelectOpen,vtFetch,NULL}
};
const size_t vtFetchSz = sizeof(VTAB_CTX);
RDM SQL is informed about the existence of these functions by the application through a call to function rsqlRe-gisterVirtualTables which must occur before opening the database in which they are declared. The code snippet below shows how this is done.
extern const UDFLOADTABLE vtFcnTable[];
extern const size_t vtFetchSz;
MyApplication()

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 158
{
HCONN hdbc;
if ( rsqlAllocConn(&hdbc) == errSUCCESS ) {
rsqlRegisterVirtualTables(hdbc, "vtabs", 1, vtFcnTable, NULL, vtFetchSz);
if ( rsqlOpenDB(hdbc, "vtabs", "s") != errSUCCESS )
...
}
Six arguments are passed to rsqlRegisterVirtualTables: the connection handle, the name of the data-base containing the declarations of the virtual tables, the number of virtual tables in the load table, the address of the virtual table load table, a pointer to a user registration context data area (which can be NULL if unnec-essary)), and the maximum size that is needed for the fetch context data area. The prototype for rsqlRe-gisterVirtualTables is given below.
RSQL_ERRCODE EXTERNAL_FCN rsqlRegisterVirtualTables(
HCONN hConn, /* in: connection handle */
const char *dbname, /* in: name of db */
uint16_t novts, /* in: number of virtual tables */
const VTFLOADTABLE *vtftab, /* in: ptr to VTF load table */
void *pRegCtx, /* in: ptr to user's registration context */
const size_t szFetchCtx) /* in: size of fetch context to be alloc'd */
The pRegCtx can be used by the application program to allocate the space for the data to be manipulated by the virtual table interface in order for the interface functions to operate reentrantly without having to use the syn-chronization functions described in the next section. Of course, this only works when the data to be accessed does not need to be shared by multiple connections in which case the technique described in the next section must still be used. The pRegCtx pointer is passed all of the virtual table functions by the RDM SQL engine. If no registration context is needed the pRegCtx should be NULL.
The szFetchCtx needs to be set to the largest fetch context data area used for all the virtual tables in database dbname. This space will be automatically allocated by the RDM SQL engine and passed to the execution-time functions (all but vtRowCount) through the pFetchCtx argument. If no context is needed then szFetchCtx should be 0.
Thread-safe Access to Global Data Used by a Virtual Table InterfaceThe virtual table example provided in this section stores its data in a global table. As such, access to that data needs to be done in a safe manner when used in multi-threaded applications. RDM's platform support package (PSP) includes a set of synchronization functions that can be used to serialize access to the shared data. These functions are described in the table below.
Function Descriptionpsp_enterCritSec Enter a process-wide critical section. This function blocks execution of all other threads
running in the application's process except the calling one until psp_exitCritSec is
Table 2. RDM PSP Synchronization Functions

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 159
Function Descriptioncalled.
psp_exitCritSec Exits the critical section started by the last call to psp_enterCritSec allowing other threads to execute.
psp_syncCreate Creates a semaphore that can be used with psp_syncEnterExcl to serialize access to the shared data that is to be protected by that semaphore.
psp_syncEnterExcl Enter exclusive, one-thread-at-a-time access controlled by the specified semaphore. The calling thread will block until all other threads that have already called psp_syn-cEnterExcl on that semaphore have exited.
psp_syncExitExcl Exits the exclusive access section controlled by the specified semaphore.
The shared data used by the virtab table interface is declared in module vtabfcns.c and is shown below.
struct virtab {
int32_t pkey;
char name[25];
char addr[33];
char city[24];
char state[3];
char zip[10];
int8_t is_null[6];
};
static PSP_SEM vtsem = NO_PSP_SEM;
static const uint32_t maxrows = 1000;
static struct virtab *vtrows = NULL;
static uint32_t norows = 0;
The PSP_SEM variable vtsem is the semaphore that will be used to serialize access to the vtrows array and the norows variable. The two functions that are included in the vtabfcns.c module that encapsulate the calls to the PSP synchronization functions are shown below.
1 /* ========================================================================
2 Enter serialized access to vtrows data
3 */
4 static void vtEnter()
5 {
6 if ( vtsem == NO_PSP_SEM ) {
7 psp_enterCritSec();
8 if ( vtsem == NO_PSP_SEM )
9 vtsem = psp_syncCreate(PSP_MUTEX_SEM);
10 psp_exitCritSec();
11 }
12 psp_syncEnterExcl(vtsem);
13 }
14
15 /* ========================================================================
16 Exit serialized access to vtrows data
17 */

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 160
18 static void vtExit()
19 {
20 psp_syncExitExcl(vtsem);
21 }
Note that the call to psp_enterCritSec at line 7 will only be called once and that the recheck of the vtsem value at line 8 is a common method to guard against one thread having created the vtsem semaphore between another thread's execution at line 6 and its successful return from the call at line 7. The call to psp_syn-cEnterExcl at line 12 will serialize access to the shared data. Hence, the virtual functions will call vtEnter() before accessing vtrows and/or norows and then call vtExit() when the needed access is finished.
Virtual Table Execution Function: vtInsertThis function is called by SQL to execute the SQL insert statement that references the virtual table. Four argu-ments are passed into the vtInsert function as described in the following table.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement containing the virtual table reference.nocols uint16_t Number of referenced columns (size of colsvals array).colsvals VCOL_INFO * Array of referenced column value containers.pRegCtx void * Pointer to the user program allocated context data area that was originally
passed in through the call to rsqlRegisterVirtualTables.
Table 3. Function vtInsert Argument Descriptions
Each entry of the colsvals array contains information about a virtual table column that is referenced in the SQL statement. This information is contained in the VCOL_INFO struct type whose fields are described in the following table.
Field Name Data Type Descriptioncolno int16_t Ordinal position of column in table declaration: 0 (first column) to # of col-
umns in table – 1 (last column).len uint32_t Column length in bytes.is_null int16_t * Pointer to variable containing the null indicator flag: *is_null = 0 => not null,
*is_null = 1 => is null.data void * Pointer to the buffer containing the column value.
Table 4. VCOL_INFO Description
Note that the is_null field is a pointer to the int16_t variable that is used by SQL system to indicate that a column value is null. By assigning this through the pointer it eliminates the need for the SQL system to perform an extra loop through the colsvals array.
The values contained in the colsvals array are those specified in the values clause of the associated insert statement. The vtInsert implementation for the virtab table is given below.
1 /* ========================================================================
2 Virtual table INSERT execution function
3 */

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 161
4 static RSQL_ERRCODE EXTERNAL_FCN vtInsert( /* vtInsert() */
5 HSTMT hstmt, /* in: statement handle */
6 uint16_t nocols, /* in: no. of ref'd columns */
7 VCOL_INFO *colsvals, /* in: array of ref'd column value containers
*/
8 void *pRegCtx) /* in: unused */
9 {
10 int32_t lv;
11 uint32_t rowno;
12 int16_t pkno = -1;
13 RSQL_ERRCODE stat = errSUCCESS;
14
15 UNREF_PARM(hstmt)
16 UNREF_PARM(pRegCtx)
17
18 vtEnter();
19
20 if ( !vtrows ) {
21 /* allocate virtab data area */
22 vtrows = calloc(maxrows, sizeof(struct virtab));
23 }
24 /* locate specified primary key value, if any */
25 for (pkno = 0; pkno < nocols; ++pkno) {
26 if ( colsvals[pkno].colno == 0 ) {
27 /* locate row with matching primary key */
28 memcpy(&lv, colsvals[pkno].data, sizeof(int32_t));
29 for ( rowno = 0; rowno < norows; ++rowno ) {
30 if ( vtrows[rowno].pkey == lv ) {
31 vtExit();
32 return errDUPLICATE;
33 }
34 }
35 }
36 }
37 stat = vtStoreRow(norows, nocols, colsvals);
38 if ( stat == errSUCCESS )
39 ++norows;
40
41 vtExit();
42
43 return stat;
44 }
The colsvals array contains the values of the table columns to be inserted. The nocols argument specifies the number of entries in the colsvals array which could be less than the number of columns declared in the table.
Since the virtab table has a primary key, the function needs to locate the primary key value in the colsvals array so that its uniqueness can be checked. This is work is done at lines 24 to 36. Since the primary key is declared on the first column of the table, its value is located in the colsvals entry that has colno equal to 0 (line 26). Once found, the value is copied into the local int32_t variable lv. If a matching row is found the func-

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 162
tion returns status errDUPLICATE indicate that an attempt was made to insert a row with a duplicate primary key value (lines 30-33).
If no duplicate is found, function vtStoreRow (shown below) is called to add the new row to the vtrows array.
1 /* ========================================================================
2 Store column values in specified row (0 = first row)
3 */
4 static RSQL_ERRCODE vtStoreRow(
5 uint32_t rowno, /* in: row number into which store col vals */
6 uint16_t nocols, /* in: no. of ref'd columns */
7 const VCOL_INFO *colsvals) /* in: array of ref'd column value containers
*/
8 {
9 uint16_t cno;
10 const VCOL_INFO *pCol;
11 struct virtab *pRow;
12
13 if ( rowno >= maxrows )
14 return errVTSPACE;
15
16 pRow = &vtrows[rowno];
17
18 for (pCol = colsvals, cno = 0; cno < nocols; ++cno, ++pCol ) {
19 if ( *pCol->is_null )
20 pRow->is_null[pCol->colno] = 1;
21 else {
22 pRow->is_null[pCol->colno] = 0;
23 switch (pCol->colno) {
24 case 0: memcpy(&pRow->pkey, pCol->data, sizeof(int32_t));
break;
25 case 1: strncpy(pRow->name, (char *)pCol->data, 24);
break;
26 case 2: strncpy(pRow->addr, (char *)pCol->data, 32);
break;
27 case 3: strncpy(pRow->city, (char *)pCol->data, 24);
break;
28 case 4: strncpy(pRow->state, (char *)pCol->data, 2);
break;
29 case 5: strncpy(pRow->zip, (char *)pCol->data, 9);
break;
30 } /*lint !e744 */
31 }
32 }
33 return errSUCCESS;
34 }
The rowno argument is index into vtrows into which the row will be stored. The pRow pointer (assigned at line 16) is simply used to derefence that row in the code which follows. Lines 18-32 loop through the colsvals array in order to assign the values for each individual column into its field in the vtrows struct array entry. It is important to note that the table column number is not cno but pCol->colno (lines 20, 22, and 23). Also note that in this example the len field of VCOL_INFO is not used but it could (should!) have been used to, for

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 163
example, check for a possible truncation (i.e., where pCol->len is greater than the declared size of the col-umn).

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 164
Virtual Table Row Count Function: vtRowCountThis function is called by SQL during compilation of a SQL select statement that contains a reference to the vir-tual table in order to fetch an estimate of the number of rows in the table. Three arguments are passed into the vtRowCount function as described in the following table.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement containing the virtual table reference.pRegCtx void * Pointer to the user program allocated registration context data area that
was originally passed in through the call to rsqlRe-gisterVirtualTables.
pNoRows uint64_t * Pointer to the output variable into which the estimate of the number of rows in the table is to be returned.
Table 5. Function vtRowCount Argument Descriptions
The vtRowCount implementation for the virtab table is provided below.
/* ========================================================================
Virtual table row count function
*/
static void EXTERNAL_FCN vtRowCount( /* vtRowCount() */
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: unused */
uint64_t *pNoRows) /* out: ptr to row count value */
{
UNREF_PARM(hstmt)
UNREF_PARM(pRegCtx)
vtEnter();
*pNoRows = (uint64_t)norows;
vtExit();
}
The UNREF_PARM macro is provided in RDM to indicate that a particular argument is unused and to avoid the associated compiler warning. Note the necessary absence of the terminating semi-colon (";").
Here you can clearly see how access to the norows variable is protected by the bracketing calls to functions vtEnter and vtExit.
If an exact row count value cannot be determined at compilation time then the vtRowCount function should return an estimate of the number of rows. It does not have to be an exact value.
Virtual Table Row Count Function: vtSelectCountThis function is only called by SQL during execution of a SQL "select count(*) from virtab" statement in order to fetch the actual number of rows in the table. Four arguments are passed into the vtRowCount function as described in the following table.

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 165
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement containing the virtual table reference.pRegCtx void * Pointer to the user program allocated registration context data area that
was originally passed in through the call to rsqlRegisterVirtualTables.pFCtx void * Pointer to the fetch context data area.pNoRows uint64_t * Pointer to the output variable into which the number of rows in the table is
to be returned.
Table 6. Function vtSelectCount Argument Descriptions
The vtSelectCount implementation for the virtab table is almost identical to the vtRowCount and is pro-vided below.
/* ========================================================================
Virtual table select count function
*/
static void EXTERNAL_FCN vtSelectCount( /* vtSelectCount() */
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: unused */
void *pFCtx, /* in: fetch context pointer */
uint64_t *pNoRows) /* out: ptr to row count value */
{
UNREF_PARM(hstmt)
UNREF_PARM(pRegCtx)
UNREF_PARM(pFCtx)
vtEnter();
*pNoRows = (uint64_t)norows;
vtExit();
}
If an exact row count value cannot be determined at compilation time then the vtRowCount function should return an estimate of the number of rows. It does not have to be an exact value.

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 166
Virtual Table Select Open Function: vtSelectOpenThis function is called by SQL to initialize execution of the SQL select statement that references the virtual table. Six arguments are passed into the vtSelectOpen function as described in the following table.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement containing the virtual table reference.nocols uint16_t Number of referenced columns (size of colsvals array).colsvals VCOL_INFO * Array of referenced column value containers.pRegCtx void * Pointer to the user program allocated context data area that was originally
passed in through the call to rsqlRegisterVirtualTables.pFCtx void * Pointer to the fetch context data area.pkeyval RSQL_VALUE * Pointer to specified primary key value (NULL if not specified).
Table 7. Function vtSelectOpen Argument Descriptions
Each entry of the colsvals array contains information about a virtual table column that is referenced in the SQL statement. This information is contained in the VCOL_INFO struct type whose fields are described in the following table.
Field Name Data Type Descriptioncolno int16_t Ordinal position of column in table declaration: 0 (first column) to # of col-
umns in table – 1 (last column).len uint32_t Column length in bytes.is_null int16_t * Pointer to variable containing the null indicator flag: *is_null = 0 => not null,
*is_null = 1 => is null.data void * Pointer to the buffer containing the column value.
Table 8. VCOL_INFO Description
Note that the is_null field is a pointer to the int16_t variable that is used by SQL system to indicate that a column value is null. By assigning this through the pointer it eliminates the need for the SQL system to perform an extra loop through the colsvals array.
The implementation of vtSelectOpen for the virtab virtual table example is given below. Note the calls to vtEnter and the reciprocal call to vtExit. As stated above, this serializes thread access to the shared vtrows and norows variables.
1 /* ========================================================================
2 Virtual table SELECT execution function
3 */
4 static RSQL_ERRCODE EXTERNAL_FCN vtSelectOpen( /* vtSelectOpen() */
5 HSTMT hstmt, /* in: statement handle */
6 uint16_t nocols, /* in: no. of ref'd columns */
7 VCOL_INFO *colsvals, /* in: array of ref'd column value containers
*/
8 void *pRegCtx, /* in: ptr to registration context */
9 void *pFCtx, /* in: ptr to fetch context */
10 RSQL_VALUE *pkeyval) /* in: ptr to primary key value */
11 {
12 RSQL_ERRCODE stat = errSUCCESS;
13 uint32_t rowno;

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 167
14 VTAB_CTX *pCtx = (VTAB_CTX *)pFCtx;
15
16 UNREF_PARM(hstmt)
17 UNREF_PARM(pRegCtx)
18
19 pCtx->rowcnt = 0;
20 pCtx->rowno = rowno = 0;
21 pCtx->pkeyval = pkeyval;
22
23 vtEnter();
24
25 if ( !vtrows ) {
26 vtrows = calloc(maxrows, sizeof(struct virtab));
27 }
28 else if ( pkeyval ) {
29 /* locate row with matching primary key */
30 for ( rowno = 0; rowno < norows; ++rowno ) {
31 if ( pkeyval->vt.lv == vtrows[rowno].pkey )
32 break;
33 }
34 pCtx->rowno = rowno;
35 }
36 vtExit();
37
38 return stat;
39 }
It is important to note that any dynamic allocations that need to be made for any of the shared data will nec-essarily live for the life of the invoking process (unless, for some reason, it is explicitly freed in the vtSe-lectOpen function).
The select statement operational requirements for the vtSelectOpen function to set the rowno variable to the first row to be fetched.
The fetch context that is passed to vtSelectOpen must be used to save any information that will be used by vtFetch to control the fetching of rows from the virtual table. The context used in the virtab example is defined by the VTAB_CTX struct typedef declaration given below.
typedef struct vtab_ctx {
uint64_t rowcnt; /* count of rows fetched */
uint64_t rowno; /* number of next row to be fetched */
RSQL_VALUE *pkeyval; /* ptr to primary key's value */
} VTAB_CTX;
The rowno contains the vtrows index of the next row to be returned by vtFetch. The rowcnt and a non-NULL pkeyval is used to ensure that only one row is returned when the select statement included the "where pkey = value" clause.
If a primary key value is specified then vtSelectOpen needs to locate the row with that value (lines 30-34) and set pCtx->rowno to it. If it is not found then pCtx->rowno is set to norows which will cause vtFetch to return errNOMOREDATA.

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 168
Virtual Table Fetch Function: vtFetchThis function is called by SQL to fetch the next row from the virtual table. Five arguments are passed into the vtFetch function as described in the following table.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement containing the virtual table reference.nocols uint16_t Number of referenced columns (size of colsvals array).colsvals VCOL_INFO * Array of referenced column value containers.pRegCtx void * Pointer to the user program allocated context data area that was originally
passed in through the call to rsqlRegisterVirtualTables.pFCtx void * Pointer to the fetch context data area.
Table 9. Function vtFetch Argument Description
The fetch context pointer, pFCtx, references the fetch context data area containing any virtual table specific data needed for processing the fetch (e.g., current row number). If a primary key lookup value was specified, then only one row should be retrieved. If not, then all rows in the table should be retrieved with status errNO-MOREDATA being returned on the first call after the last row has been fetched. The necessary programming logic is best explained through the virtab example as shown below.
1 /* ========================================================================
2 Virtual table fetch function
3 */
4 static RSQL_ERRCODE EXTERNAL_FCN vtFetch( /* vtFetch() */
5 HSTMT hstmt, /* in: statement handle */
6 uint16_t nocols, /* in: no. of ref'd columns */
7 VCOL_INFO *colsvals, /* in: array of ref'd col value containers */
8 void *pRegCtx, /* in: ptr to registration context */
9 void *pFCtx) /* in: ptr to fetch context */
10 {
11 int16_t cno;
12 VTAB_CTX *pCtx = (VTAB_CTX *)pFCtx;
13 uint32_t rno = (uint32_t)pCtx->rowno;
14
15 vtEnter();
16
17 if ( rno == norows || (pCtx->pkeyval && pCtx->rowcnt) ) {
18 pCtx->rowno = 0;
19 vtExit();
20 return errNOMOREDATA;
21 }
22 for (cno = 0; cno < nocols; ++cno) {
23 const VCOL_INFO *pCVal = &colsvals[cno];
24 if ( vtrows[rno].is_null[pCVal->colno] )
25 *pCVal->is_null = 1;
26 else {
27 *pCVal->is_null = 0;
28 switch ( pCVal->colno ) {
29 case 0:
30 memcpy(pCVal->data, &vtrows[rno].pkey, sizeof(int32_t));
31 break;

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 169
32 case 1:
33 strcpy(pCVal->data, vtrows[rno].name);
34 break;
35 case 2:
36 strcpy(pCVal->data, vtrows[rno].addr);
37 break;
38 case 3:
39 strcpy(pCVal->data, vtrows[rno].city);
40 break;
41 case 4:
42 strcpy(pCVal->data, vtrows[rno].state);
43 break;
44 case 5:
45 strcpy(pCVal->data, vtrows[rno].zip);
46 break;
47 } /*lint !e744 */
48 }
49 }
50 ++pCtx->rowcnt;
51 ++pCtx->rowno;
52
53 vtExit();
54
55 return errSUCCESS;
56 }
As with vtSelectOpen, note here as well the call to vtEnter at line 15 and its reciprocal calls to vtExit at lines 19 and 53 serializing access to the norows and vtrows variables. The if statement at line 17 tests the two conditions under which an errNOMOREDATA status code is to be returned.
The loop at lines 22 to 49 is used to copy the fetched row's information for each column in the colsvals array. This involves setting the correct null value indicator (lines 24-25) and, for the non-null columns, copying its value into the column's data buffer pointed to by the VCOL_INFO data field (lines 30, 33, 36, 39, 42, and 45).
Finally, the row count and row number values are incremented (lines 50-51).

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 170
Virtual Table Select CloseFunction: vtSelectCloseThis function is called by SQL when the application has completed its processing of the statement containing the virtual table reference in order to terminate the select statement access to the virtual table. Any memory that was allocated by vtSelectOpen for the vtFetch calls would need to be freed by this function. Three arguments are passed into the vtSelectClose function as described in the following table.
Argument Type DescriptionhStmt HSTMT Statement handle of SQL statement containing the virtual table reference.pRegCtx void * Pointer to the user program allocated context data area that was originally
passed in through the call to rsqlRegisterVirtualTables.pFCtx void * Pointer to the fetch context data area.
Table 10. Function vtSelectCClose Argument Descriptions
No vtSelectClose function is needed for the virtab virtual table implementation. But an example stub is shown below.
/* ========================================================================
Virtual table close function
*/
typedef void EXTERNAL_FCN vtSelectClose(
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to registration context */
void *pFetchCtx) /* in: ptr to fetch context */
/*
Called by SQL when SELECT statement containing virtual table reference
completes execution (i.e., when cursor is closed).
Use this function to do any needed cleanup and device termination actions.
*/
{
/* code to free any allocated memory or, perhaps
to power down virtual table device. */
}
Virtual Table Usage
Virtual Tables Are Not Transaction Sensitive
An insert on a virtual table cannot be committed nor can it be rolled-back. In fact, an insert doesn't even have to do an "insert". It simply sends a set of data values to the vtInsert function for the specified virtual table. What that function actually does with the data is up to it. For example, in a wireless sensor network (WSN) application an insert could be used to send control settings to a sensor.

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 171
Some Virtual Tables May Have an Unlimited Number of Rows
Only a little imagination is needed to see that data from sources such as a WSN have no natural end. As long as the sensors continue to operate, data will always be available. This presents a particularly difficult problem when the data needs to be summarized over some aggregate collection. Consider the following two tables shown below from the weather data WSN application database from the Defining a Database section.
create table weather_summary(
longitude integer,
latitude integer,
rdg_date date,
hour_of_day smallint,
avg_temp smallint,
avg_ press smallint,
avg_hum smallint,
avg_lumens smallint,
foreign key (longitude, latitude) references location
);
create virtual readonly table weather_data(
sensor_id bigint primary key,
loc_long integer,
loc_lat integer,
rdg_time timestamp,
temperature smallint,
pressure smallint,
humidity smallint,
light smallint,
power integer
);
The weather_summary table contains the averages of the readings from each sensor as collected over each hour of the day. In order to compute these aggregated values, SQL needs to sort the fetched rows by sensor_id and rdg_time (timestamp when the sensor data was read). But any sort needs to have a fixed number of rows. How is this done when there is an unlimited number of rows?
To address this problem, the select statement includes a non-standard clause that can limit the number of rows that are returned as specified in the following syntax.
select_stmt:
select … from table where … limit( num limit_unit)
limit_unit:
rows | hours | mins | secs | msecs
The limit clause limits either the number of rows that are returned or the amount of time the select statement is allowed to run. The following example shows a select statement that stores the averages per hour from each weather sensor in the weather_summary table.

RDM SQL Language Guide
Using Virtual Tables to Access Any Data 172
insert into weather_summary
select loc_long, loc_lat, convert(rdg_time,date), hour(rdg_time),
avg(temperature), avg(pressure), avg(humidity), avg(light) from weather_data
group by 1,2,4 limit(4 hours);
Each row is fetched and sorted over each four hour span of time. At the end of that time, the sorted data is scanned and the aggregate calculations performed and the resulting rows are then stored in the weather_sum-mary table. The time limit can be shorter but, in this case, not any less than an hour as that is the smallest unit over which the aggregation is made (of course, this assumes that the select is synchronized to execute at the start of an hour).
It is important to note that even though the virtual table has no fixed number of rows, the vtRowCount function still needs to return a value. Based on how you choose to limit the select statements that retrieve data from your virtual table just have vtRowCount return an estimate of the average number of rows that will be returned from any given execution of the select. It does not have to be an exact value.
Virtual Table Data Is Not Necessarily Persistent
The data contained in the example virtab virtual table is clearly not persistent. The stdtab table can be used to save a persistent copy of the data as shown in the following SQL statements.
insert into stdtab from select * from virtab;
commit;
Then, when the application is restarted, virtab can be reloaded by simply doing the reverse (only without the commit).
insert into virtab from select * from stdtab;

RDM SQL Language Guide
Accessing a Core (non-SQL) Database in RDM SQL 173
Accessing a Core (non-SQL) Database in RDM SQL
I am as vulnerable and fragile as it is
possible to be. I am shredded to the core.
I am at the point where I am stripped bare.- Rachel Hunter,
New Zealand model (1968 - )
RDM SQL allows opening a RDM core database (i.e., a native, non-SQL, database) in read only mode. Besides providing the ability to perform SQL queries using the native RDM SQL API it also allows access to RDM core databases from ODBC, JDBC, or ADO.NET clients.
A core database is one for which the schema was created using the core API instead of through SQL. SQL will internally create a compatible catalog based on the database dictionary contents. However, RDM core data-bases have features that are not available through SQL. This section will describe how core databases are mapped into a SQL database. Knowledge of both RDM native and SQL database definition is assumed through-out this section.
How Core Database Record Types are Mapped to SQL TablesEach core record type will map directly into an SQL table that will have the same name. This includes the system record even though it will not have any columns and is not used in SQL.
Each data field in a core record type will map into its equivalent SQL column. However, since SQL does not sup-port unsigned integer types, unsigned integers map into the signed integer type of the same size. Grouped (struct) fields, array fields and DB_ADDR fields will map into a SQL binary array of the appropriate size.
Note that meaningful access to the binary form can only occur when the computer on which the data is returned through SQL has the same native architecture as the computer on which the database is stored because of byte ordering and alignment differences that necessarily exist between different computers. This is only possible when using remote access to the database through rdmsqlserver.
Fields of type blob_id will map into SQL long varbinary columns.
The table below summarizes the core data type mappings into SQL.
Core Data Type Mapped SQL Data Typechar char
uint8_t tinyint
[unsigned] short, uint16_t,
int16_t
smallint
[unsigned] int, uint32_t, int32_
t
integer
[unsigned] long integer
uint64_t, int64_t bigint
Table 1. Core Data Type SQL Mappings

RDM SQL Language Guide
Accessing a Core (non-SQL) Database in RDM SQL 174
Core Data Type Mapped SQL Data Typefloat real
double float (double)
[unsigned] char[33] char(32)1
wchar, wchar_t wchar
varchar[256] varchar(255)
varwchar wvarchar
blob_id long varbinary
int32_t[10] binary(40)2
char[2][10] binary(20)
struct { int32_t, char[20]} binary(24)
DB_ADDR binary(8)
Mapping Core Keys to SQL KeysKey fields and compound keys map directly into SQL keys. Unique keys will map into a primary key. Where a rec-ord type has more than one unique key, SQL will identify which one will serve as the primary key based on the fol-lowing criteria in order of priority.
1. The first declared hash key. 2. The smallest, single field key (i.e., not compound key). 3. The smallest key.
If two or more candidate keys have the same length then the first declared key is chosen as primary.
Core DDL SnippetCore DDL Snippet Mapped SQL DDL Snippet
record recname {
unique key char name[25];
hash[1000] int32_t code;
char text[81];
}
create table recname(
name char(24) unique key,
code integer primary key hash
[1000],
text char(80)
);
record recname {
char name[25];
int32_t code;
unique key char soundex[5];
compound unique key name_code {
code; name;
}
}
create table recname(
name(24),
code integer,
soundex char(4) primary key,
unique key name_code(code, name)
);
Table 2. Example Core Keys to SQL Mappings
1Note that the core char array size includes the null byte whereas the SQL declared size does not (but internally it does). Same is true for varchar, etc. 2The actual binary column size depends on computer alignment issues. True for all of the following binary mappings.

RDM SQL Language Guide
Accessing a Core (non-SQL) Database in RDM SQL 175
Since SQL does not support unsigned integer types, core keys on unsigned integer fields cannot be used except for equality lookups due to the potential problem that can occur should an unsigned value map into a signed neg-ative value. If the values actually stored in the unsigned data field can never be that large then simply removing the unsigned attribute from the core DDL field declaration will allow SQL to use the key. Core unique keys on unsigned integer fields are treated by SQL as if it were a hash key which allows the key to be used for equality lookups.
Mapping Core Sets to SQL Foreign KeysSets map into SQL foreign keys but only when the owner record type has a unique key. Foreign key columns are added to the SQL table that corresponds to the set member record type. These columns match their primary key counterparts in the SQL table that corresponds to the set owner record type. The values for foreign key columns will be retrieved by SQL via the set from the primary key (i.e. set owner) table.
The names of the foreign key columns will be assigned the same name as its corresponding field in the owner rec-ord. However, if the member record already has a field with that same name then the name will be appended with "$r" followed by a number to make the column name unique.
Table 3 below gives two examples of how core sets map into SQL foreign keys.
Core DDL SnippetCore DDL Snippet Mapped SQL DDL Snippet
record info {
unique key varchar id_code[48];
varchar info_title[80];
char publisher[32];
char pub_date[12];
int16_t info_type;
}
record key_word {
unique key char kword[32];
}
record intersect {
int16_t int_type;
}
set key_to_info {
order last;
owner key_word;
member intersect;
}
set info_to_key {
order last;
owner info;
member intersect;
}
create table info(
id_code char(47) primary key,
info_title char(79),
publisher char(31),
pub_date char(11),
info_type smallint
);
create table key_word(
kword char(31) primary key
);
create table intersect(
int_type smallint,
kword char(31) references key_
word,
id_code char(47) references info
);
record ownrec {
unique key char idcode[9];
char title[33];
create table ownrec(
idcode char(8) primary key,
title char(32)
Table 3. Example Core Set to Foreign Key Mappings

RDM SQL Language Guide
Accessing a Core (non-SQL) Database in RDM SQL 176
Core DDL SnippetCore DDL Snippet Mapped SQL DDL Snippet
}
record memrec {
key int32_t idcode;
char txtln[81];
}
set notes {
order last;
owner ownrec;
member memrec;
}
);
create table memrec(
idcode integer,
txtln char(80),
idcode$r1 char(8) references own-
rec
);
Multi-Member Sets and Explicit LockingMulti-member sets can be declared in the core level database. These present no problem for SQL except in the event that explicit table is being used (see Locking in RDM SQL). If locks are being explicitly issue through use of the lock table statement then it will be necessary to lock all of the tables that participate as a member of a set that may be used to access one of the member tables. An errNOTLOCKED status will be returned when SQL attempts to access the next member of a multi-member set that is a row from an alternate member table that has not been explicitly locked.
Order of Columns in the TableThe fields declared in the core record type map directly into columns of its corresponding SQL table in exactly the same order. These are followed by the virtual columns for each foreign key which are created in the order in which the sets in which the record type is a member are declared in the core DDL specification (e.g., see "create table intersect" above in Table 3).
Null ValuesRDM core databases do not support null data field values. Note that this does not mean that null values can not occur. Foreign key references can still be null and outer joins can produce null values.
Adding Column Information and Creating a CatalogTwo RDM-specific SQL statements can be used in conjunction with core databases. The set column statement can be used to specify the SQL data type for certain core data fields that contained SQL-understandable data (e.g., long varchar). It can also be used to specify the number of distinct values and/or the range values used by the SQL query optimizer. Once all of the needed set column statements have been processed for a given core database, the create catalog statement can be executed which will create and store the SQL catalog file for the core database.
The syntax for the set column statement is given below.

RDM SQL Language Guide
Accessing a Core (non-SQL) Database in RDM SQL 177
set_column_stmt:
set column [db_name.]table_name.column_name
[type [to | =] {date | time | timestamp | long | {varchar | wvarchar}}]
[distinct values = num]
[range constant to constant]
| set column stats [db_name.]table_name.column_name
[distinct values = num]
[range constant to constant]
The type clause can be used to specify an SQL-specific data type for a core database field. You can specify date for an (32-bit) integer field but it must contain a valid DATE_VAL value (the number of elapsed days since Jan 1, 1 AD which has a value 1). You can specify time for an (32-bit) integer field but it must contain a valid TIME_VAL value (the number of elapsed seconds since midnight times 10,000). You can specify timestamp for a (64-bit) bigint field but it must contain a valid TIMESTAMP_VAL value (DATE_VAL and TIME_VAL combined). Since core databases do not differentiate between binary and character blob fields, you can also specify long varchar or long wvarchar for a blob field.
Two types of statistics can be specified. The number of distinct values specifies the approximate number of dif-ferent values stored in the column. For example, a column of type smallint can theoretically contain 65,535 dif-ferent values. If, however, the actual number of different values is considerably smaller then that can have an important impact on the access choices the optimizer might be inclined to make. Similarly, the range clause is used to identify the range of values that the column can contain. Note that specifying the range only affects the optimizer. It does not mean that the SQL system will check to ensure that only those values are stored in the col-umn. The values specified in these two clauses are understood to be estimates and no problems are created when, for example, a column value actually falls outside the specified range. The database in which the table col-umn is declared must be opened when set column is called.
The syntax for the create catalog statement is as follows.
create_catalog_stmt:
create catalog for dbname
The database must be opened in exclusive access mode in order to execute the create catalog statement.
For example, the following snippet shows a portion of a core DDL version of the bookshop database definition.
record author {
unique key char last_name[14];
char full_name[36];
char gender[2];
int16_t yr_born;
int16_t yr_died;
blob_id short_bio;
compound key yob_gender_key {
yr_born ascending;
gender ascending;
}
}

RDM SQL Language Guide
Accessing a Core (non-SQL) Database in RDM SQL 178
record book {
unique key char bookid[15];
key varchar title[256];
char descr[62];
varchar publisher[137];
key int16_t publ_year;
char lc_class[34];
int32_t date_acqd;
int32_t date_sold;
double price;
double cost;
}
The following SQL statement script shows how the set column statement is used to specify the needed data types and stats as specified in its SQL DDL counterpart (see "Antiquarian Bookshop Database" in the "Example Databases" section in the Defining a Database section).
open database bookshop in exclusive mode;
set column author.gender distinct values = 2;
set column author.short_bio type to long varchar;
set column book.publ_year range 1500 to 1980;
set column book.date_acqd type to date;
set column book.date_sold type to date;
create catalog for bookshop;

RDM SQL Language Guide
SQL Built-In Function Reference 179
SQL Built-In Function ReferenceRDM provides many built-in functions that you can use in queries to return data or perform operations on data.
Aggregate FunctionsAggregate functions perform a calculation on a set of values and return a single value. Except for COUNT, aggre-gate functions ignore null values. Aggregate functions are frequently used with the GROUP BY clause of the SELECT statement.
Function Descriptioncount Returns the number (distinct) of rows in the aggregate.sum Returns the sum of the (distinct) values of expression in the aggregate.avg Returns the average of the (distinct) values of expression in the aggregate.min Returns the minimum expression value in the aggregate.max Returns the maximum expression value in the aggregate.
Table 10. Built-in Aggregate Functions
Scalar Functions
Mathematical Functions
The following scalar functions perform a calculation, usually based on input values that are provided as argu-ments, and return a numeric value:
Function Descriptionabs Returns the absolute value of an expression.acos Returns the arccosine of an expression.asin Returns the arcsine of an expression.atan Returns the arctangent of an expression.atan2 Returns the arctangent of an x-y coordinate pair.ceil | ceiling Finds the upper bound for an expression.cos Returns the cosine of an angle.cot Returns the cotangent of an angle.exp Returns the value of an exponential function.floor Finds the lower bound for an expression.ln | log Returns the natural logarithm of an expression.mod Returns the remainder of arith_expr1/arith_expr2.pi Returns the value of pi.rand Returns next random floating-point number. Non-zero num is seed.sign Returns the sign of an expression (-1, 0, +1).
Table 6. Built-in Numeric Functions

RDM SQL Language Guide
SQL Built-In Function Reference 180
Function Descriptionsin Returns the sine of an angle.sqrt Returns the square root of an expression.tan Returns the tangent of an angle.
Date and Time Functions
The data type 'date' assumes the Gregorian calendar even for dates prior to the introduction of the Gre-gorian calendar. This means that databases that store historical dates prior to the introduction of the Gregorian calendar may not compute select with date ranges, dayofweek, and week correctly.
Function Descriptionage Calculate number of whole years from date_expr to current datecurdate Retrieve the current datecurtime Retrieve the current timedayofmonth Retrieve the day of the monthdayofweek Retrieve the day of the weekdayofyear Retrieve the day of the yearhour Retrieve the hourminute Retrieve the minutemonth Retrieve the monthquarter Retrieve the quartersecond Retrieve the secondweek Retrieve the weekyear Retrieve the year
Table 7. Date/Time Functions
String Functions
The following scalar functions perform an operation on a string input value and return a string or numeric value:
Function Descriptionascii Returns the numeric ASCII value of a characterchar Returns the ASCII character with numeric value numconcat Concatenates two stringsconvert Convert an expression to a data type or a character stringinsstr Replace num2 chars from string_expr2 in string_expr1 beginning at position num1
(1st position is 1 not 0)lcase Converts a string to lowercaseleft Returns the leftmost num characters from the stringlength Returns the length of the stringlocate Locate string_expr1 from position num in string_expr2ltrim Removes all leading spaces from string
Table 8. Built-in String Functions
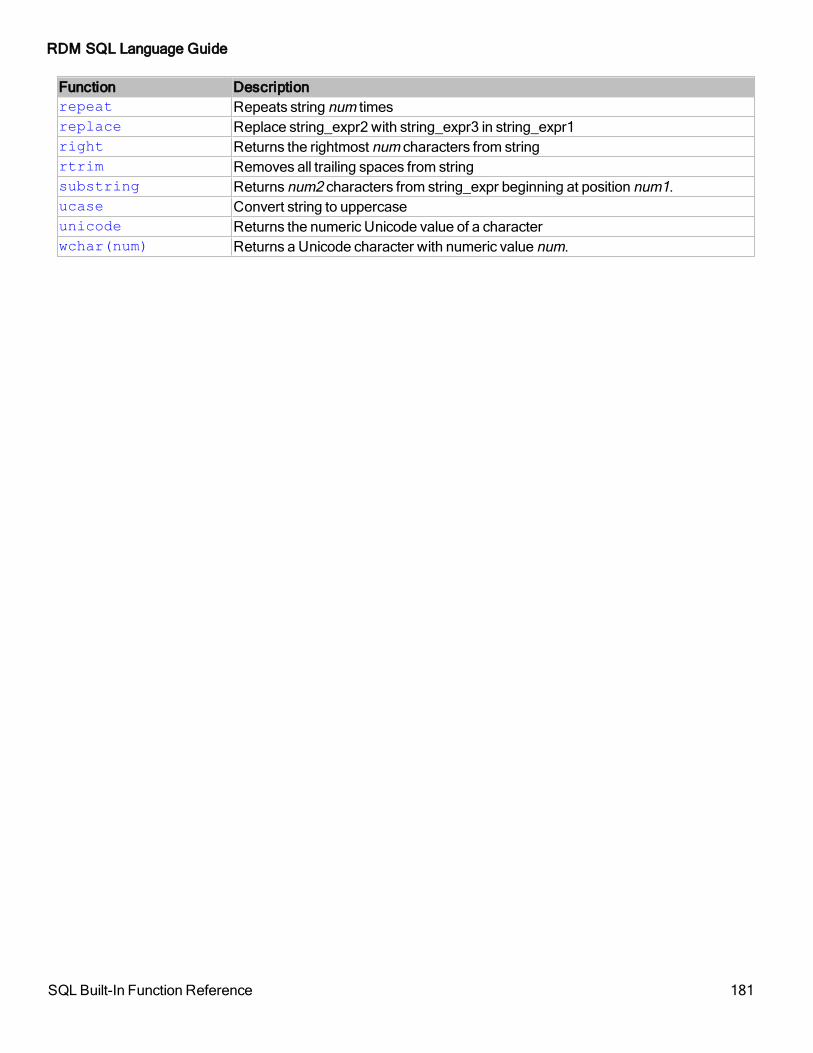
RDM SQL Language Guide
SQL Built-In Function Reference 181
Function Descriptionrepeat Repeats string num timesreplace Replace string_expr2 with string_expr3 in string_expr1right Returns the rightmost num characters from stringrtrim Removes all trailing spaces from stringsubstring Returns num2 characters from string_expr beginning at position num1.ucase Convert string to uppercaseunicode Returns the numeric Unicode value of a characterwchar(num) Returns a Unicode character with numeric value num.

RDM SQL Language Guide
SQL Built-In Function Reference 182
abs
Retrieve the absolute value of an expression
Syntax
abs(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves the absolute value of the specified arithmetic expression.
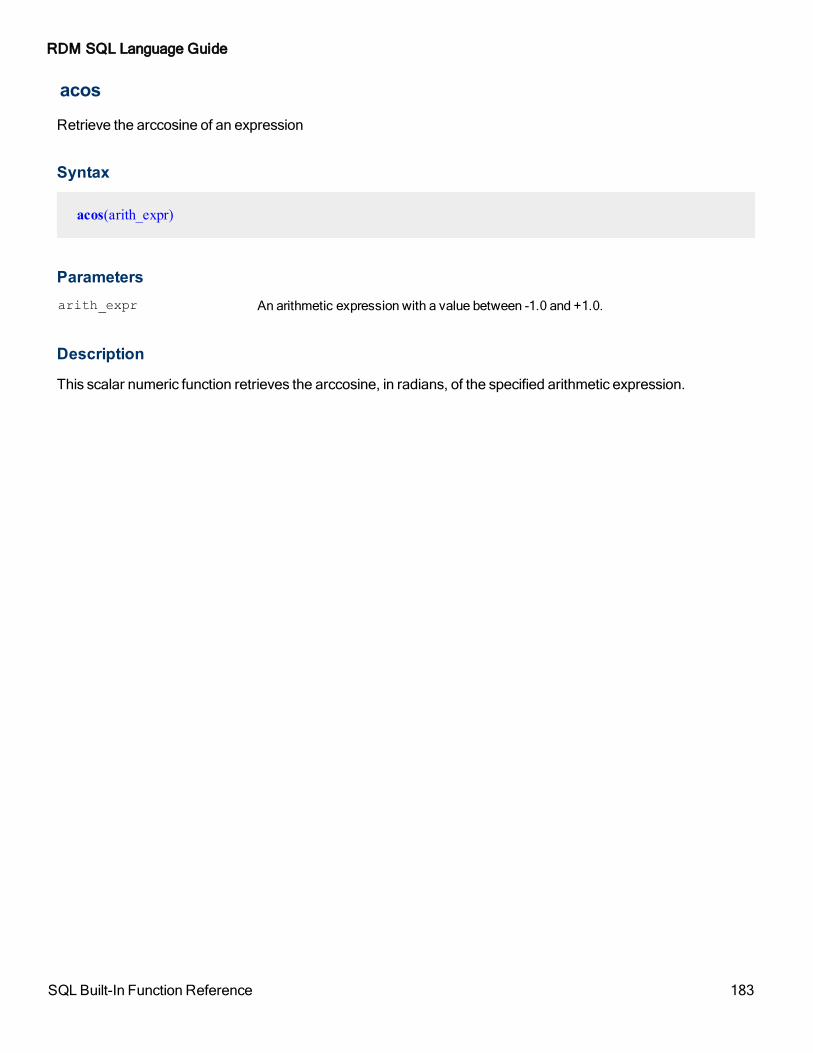
RDM SQL Language Guide
SQL Built-In Function Reference 183
acos
Retrieve the arccosine of an expression
Syntax
acos(arith_expr)
Parametersarith_expr An arithmetic expression with a value between -1.0 and +1.0.
Description
This scalar numeric function retrieves the arccosine, in radians, of the specified arithmetic expression.

RDM SQL Language Guide
SQL Built-In Function Reference 184
age
Returns the age (in full years)
Syntax
age(date_expr)
Parametersdate_expr A date expression from which the age will be calculated
Description
Return the number of years from the date_expr to the current date.
The data type 'date' assumes the Gregorian calendar even for dates prior to the introduction of the Gre-gorian calendar. This means that databases that store historical dates prior to the introduction of the Gregorian calendar may not compute select with date ranges, dayofweek, and week correctly.

RDM SQL Language Guide
SQL Built-In Function Reference 185
asin
Retrieve the arcsine of an expression
Syntax
asin(arith_expr)
Parametersarith_expr An arithmetic expression with a value between -1.0 and +1.0.
Description
This scalar numeric function retrieves the arcsine, in radians, of the specified arithmetic expression.

RDM SQL Language Guide
SQL Built-In Function Reference 186
atan
Retrieve the arctangent of an expression
Syntax
atan(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves the arctangent, in radians, of the specified arithmetic expression.

RDM SQL Language Guide
SQL Built-In Function Reference 187
atan2
Retrieve the arctangent of an x-y coordinate pair
Syntax
atan2(arith_expr_X, arith_expr_Y)
Parametersarith_expr_X An arithmetic expression providing the x coordinate.arith_expr_Y An arithmetic expression providing the y coordinate.
Description
This scalar numeric function retrieves the arctangent, in radians, of the specified x and y coordinates.

RDM SQL Language Guide
SQL Built-In Function Reference 188
avg
Compute the average of the results for an aggregate result set
Syntax
avg(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This aggregate (calculation) function computes the average of the results of the specified expression for all rows of an aggregate result set.
Example
select sale_name,
convert(avg(amount), char, 10, "$#,#.##") "avg sale amt"
from salesperson natutal join customer natural join sales_order
group by 1;
sale_name avg sale amt
Flores, Bob $19,233.56
Jones, Walter $28,170.70
Kennedy, Bob $61,362.11
McGuire, Sidney $18,948.37
Nash, Gail $34,089.70
Porter, Greg $87,869.30
Robinson, Stephanie $24,993.63
Stouffer, Bill $3,631.66
Warren, Wayne $21,263.85
Williams, Steve $27,464.44
Wyman, Eliska $23,617.38

RDM SQL Language Guide
SQL Built-In Function Reference 189
ceiling
Find the upper bound for an expression
Syntax
ceiling(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves an upper bound (ceiling) for the specified arithmetic expression. The ceil-ing is the smallest integer greater than or equal to the expression.

RDM SQL Language Guide
SQL Built-In Function Reference 190
convert
Convert an expression to a data type or a character string
Syntax
convert(expression, convert_type_type)
convert(expression, {char | wchar}, width, format_spec)
convert_type:
char |smallint | integer | real
| double | date | time | timestamp | tinyint | bigint
convert_format:
numeric_format | datetime_format
numeric_format:
"[<< | >> | ><]['text' | $][- | (][#,]#[.#[#]...][e | E]['text' | $ | %]"
datetime_format:
"[<< | >> | ><]['text' | spchar | date_code | time_code]..."
date_code:
m | mm | mmm | mon | mmmm | month
| d | dd | ddd | dddd | day
| yy | yyyy
time_code:
h | hh | m | mm | s | ss | .f[f]... | [a/p | am/pm | A/P | AM/PM]
Parametersexpr The expression to be converted.arg_type Specifies the data type into which the expression is to be converted.char | wchar Specifies the character type of the result when using the second form of the convert
function specified above.width The maximum width, in characters, of the result string.fmt The specification of the format of the result character string into which the numeric or
date/time values will be converted. The individual elements of the format specifiers are described in the Numeric Format Specifier and Date/Time Format Specifier tables below.
Description
This system function converts an expression to a different type or string representation. There are two forms of this function.

RDM SQL Language Guide
SQL Built-In Function Reference 191
The first form of this function, shown above, converts an expression to the specified data type. The second form converts an expression to a character string in the specified format.
Numeric Format Specifier
The format specifier for numeric values is represented as shown in the box below. The minimum specifier that must be used for a numeric format is "#". If the display field width (width parameter) is too small to contain a numeric value, the convert function formats the value in exponential format (for example, 1.759263e08).
The elements for this specifier are explained in the following table.
ElementDescription[<< | >> | ><]
The justification specifier. You can specify left-justified text (<<), right-justified text (>>), or centered text (><). The default for numeric values is right-justified.
['text' | $]A text character or string to use as a prefix for the result string. You must enclose the character or text with single quotation marks unless the prefix is one dollar sign.
[- | (]The display specifier for negative values. You can show negative values with a minus sign or with paren-theses around the value. If parentheses are used, positive values are shown with an ending space to ensure alignment of the decimal point.
[#,]#[.#[#]...]
The numeric format specifier. You can specify whether to show commas every third place before the decimal point. Also, you can specify how many digits (if any) to show after the decimal point.
[e | E]Whether to use exponential format to show numeric values. If this option is omitted, exponential format is used only when the value is too large or small to be shown otherwise. You can specify display of an lowercase or uppercase exponent indicator.
['text' | $ | %]
A text character or string to use as a suffix for the result string. You must enclose the character or text with single quotation marks unless the suffix is one dollar or percent sign.
Numeric Format Specifier Elements
Formatting Date/Time Values
The format specifier for date/time values is given in the above syntax box. The date/time format specifier can con-tain any number of text items or special characters that are interspersed with the date or time codes. You can arrange these items in any order, but a time specifier must adhere to the ordering rules described in the syntax under "time_code". For the minute codes to be interpreted as minutes (and not months) they must follow the hour codes. You cannot specify the minutes of a time value without also specifying the hour. You can specify the hour by itself. Similarly, you cannot specify the seconds without having specified minutes and you cannot specify fractions of a second without specifying seconds. Thus, the order "hours, minutes, seconds, fractions" must be preserved.
General Formatting ElementsElement Description
[<< | >> | ><]The justification specifier. You can specify left-justified text (<<), right-justified text (>>), or cen-tered text (><). The default for numeric values is left-justified.
'text' | spcharA string or a special character (for example, "-", "/", or ".") to be copied into the result string. The special character is often useful in separating the entities within a date and time.
Date-Specific Formatting ElementsElement Descriptionm Month number (1-12) without a leading zero.
Date and Time Format Specifier Elements

RDM SQL Language Guide
SQL Built-In Function Reference 192
mm Month number with a leading zero.mmm Three-character month abbreviation (e.g., "Jan").mon Same as mmm.mmmm Fully spelled month name (e.g., "January").month Same as mmmm.d Day of month (1-31) without leading zero.dd Day of month with leading zero.ddd Three character day of week abbreviation (e.g., "Wed").dddd Fully spelled day of week (e.g., "Wednesday").day Same as dddd.yy Two-digit year AD with leading zero if year between 1950 and 2049; otherwise same as yyyy.yyyy Year AD up to four digits without leading zero. Time-Specific Formatting ElementsElement Descriptionh Hour of day (0-12 or 23) without leading zero.hh Hour of day with leading zero.m Minute of hour (0-59) without leading zero (only after h or hh).mm Minute of hour with leading zero (only after h or hh).s Second of minute (0-59) without leading zero (only after m or mm).ss Second of minute with leading zero (only after m or mm)..f[f]... Fraction of a second: four decimal place accuracy (only after s or ss).a/p | am/pm | A/P | AM/PM
Hour of day is 0-12; AM or PM indicator will be output to result string (only after last time code ele-ment).
Example
The following examples show numeric format specifiers and their results.
Function Result
convert(14773.1234, char, 10, "#.#") " 14773.1"
convert(736620.3795, char, 12, "#,#.###") "736,620.380"
convert(736620.3795, char, 12, "$#,#.##") "$736,620.38"
convert(736620.3795, char, 12, "<<#.######e") "7.366204e05"
convert(56.75, char, 8, "#.##%") " 56.75%"
convert(56.75, char, 8, "#.##' percent'") " 56.75 percent"
The examples below show date/time format specifiers and corresponding results. These examples show how Tuesday, October 23, 1951 at 4:42:27.1750 a.m. can be returned. The format specifier, rather than the entire function, is shown here in the left column.
Format Spec. Result
mmm dd, yyyy Oct 23, 1951
hh'hours' on ddd month dd, yyyy 04hours on Tue October 23, 1951
dd 'of' month 'of the year' yyyy 23 of October of the year 1951
dddd hh.mm.ss.ffff mm-dd-yyyy Tuesday 04.42.27.1750 10-23-1951
'date:'yyyy.mm.dd 'at' hh:mm A/P date:1951.10.23 at 04:42 AM

RDM SQL Language Guide
SQL Built-In Function Reference 193
cos
Retrieve the cosine of an angle
Syntax
cos(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves the cosine of the specified arithmetic expression. Cosine operations return values between -1.0 and +1.0.

RDM SQL Language Guide
SQL Built-In Function Reference 194
cot
Retrieve the cotangent of an angle
Syntax
cot(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves the cotangent of the specified arithmetic expression.

RDM SQL Language Guide
SQL Built-In Function Reference 195
count
Count the rows of an aggregate result set
Syntax
count({* | column_name})
Parameters* All columns of the result set.column_name A column name.
Description
This aggregate (calculation) function returns the total number of rows of an aggregate.
Example
select company, count(ord_num) from customer natural join sales_order
group by 1;
COMPANY COUNT(ORD_NUM)
"Bills We Pay" Financial Corp. 5
Bears Market Trends, Inc. 5
Bengels Imports 5
Broncos Air Express 7
Browns Kennels 7
Bucs Data Services 4
Cardinals Bookmakers 5
Chargers Credit Corp. 3
Chiefs Management Corporation 5
Colts Nuts & Bolts, Inc. 8
Cowboys Data Services 3
Dolphins Diving School 2
Eagles Electronics Corp. 5
Falcons Microsystems, Inc. 3
Forty-Niners Venture Group 3
Giants Garments, Inc. 2
Jets Overnight Express 4
Lions Motor Company 5
Oilers Gas and Light Co. 3
Packers Van Lines 4
Patriots Computer Corp. 6
Raiders Development Co. 4
Rams Data Processing, Inc. 8
Redskins Outdoor Supply Co. 4
Saints Software Support 3

RDM SQL Language Guide
SQL Built-In Function Reference 196
Seahawks Data Services 6
Steelers National Bank 2
Vikings Athletic Equipment 6

RDM SQL Language Guide
SQL Built-In Function Reference 197
curdate
Retrieve the current date
Syntax
curdate()
Description
This scalar date/time function retrieves the current date. You can also use today as a literal for the current date.
See Also
curtime

RDM SQL Language Guide
SQL Built-In Function Reference 198
curtime
Retrieve the current time
Syntax
curtime()
Description
This scalar date/time function retrieves the current local (server) time.
See Also
curdate

RDM SQL Language Guide
SQL Built-In Function Reference 199
dayofmonth
Retrieve the day of the month
Syntax
dayofmonth(date_expr)
Parametersdate_expr A date expression from which the day of the month will be extracted.
Description
This scalar date/time function retrieves the day of the month in the specified date expression as a number between 1 and 31.
The data type 'date' assumes the Gregorian calendar even for dates prior to the introduction of the Gre-gorian calendar. This means that databases that store historical dates prior to the introduction of the Gregorian calendar may not compute select with date ranges, dayofweek, and week correctly.

RDM SQL Language Guide
SQL Built-In Function Reference 200
dayofweek
Retrieve the day of the week
Syntax
dayofweek(date_expr)
Parametersdate_expr A date expression from which the day of week will be extracted.
Description
This scalar date/time function retrieves the day of the week in the specified date expression as a number between 1 and 7, where 1 is Sunday.
The data type 'date' assumes the Gregorian calendar even for dates prior to the introduction of the Gre-gorian calendar. This means that databases that store historical dates prior to the introduction of the Gregorian calendar may not compute select with date ranges, dayofweek, and week correctly.

RDM SQL Language Guide
SQL Built-In Function Reference 201
dayofyear
Retrieve the day of the year
Syntax
dayofyear(date_expr)
Parametersdate_expr A date expression from which the day of the year will be extracted.
Description
This scalar date/time function retrieves the day of the year in the specified date expression as a number between 1 and 366.
The data type 'date' assumes the Gregorian calendar even for dates prior to the introduction of the Gre-gorian calendar. This means that databases that store historical dates prior to the introduction of the Gregorian calendar may not compute select with date ranges, dayofweek, and week correctly.

RDM SQL Language Guide
SQL Built-In Function Reference 202
exp
Retrieve the value of an exponential function
Syntax
exp(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves the value of an exponential function with the specified arithmetic expres-sion as an exponent (that is, earith_expr).

RDM SQL Language Guide
SQL Built-In Function Reference 203
floor
Find the lower bound for an arithmetic expression
Syntax
floor(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves the lower bound (floor) for the specified arithmetic expression. The floor is the largest integer less than or equal to the expression.

RDM SQL Language Guide
SQL Built-In Function Reference 204
hour
Retrieve the hour
Syntax
hour(time_expr)
Parameterstime_expr An expression representing either a time or a timestamp value.
Description
This scalar date/time function retrieves the hour in the specified time expression as a number between 0 and 23.

RDM SQL Language Guide
SQL Built-In Function Reference 205
if
Implement a conditional selection
Syntax
if(cond_expr,expression1,expression2)
Parameterscond_expr The conditional expression.expression1 The expression to be evaluated and returned if the conditional expression evaluates to
TRUE.expression2 The expression to be evaluated and returned if the conditional expression evaluates to
FALSE.
Description
This function conditionally evaluates one of two expressions for each row of the select statement in which it is used. The expression to be evaluated and returned is based on the value of the specified conditional expression for each row. If the conditional expression evaluates to TRUE, the if evaluates and retrieves the value of the first expression (expression1). If the conditional expression evaluates to FALSE, the function evaluates and returns the value of the second expression (expression2). Both expressions must return values of identical data types.
Example
select quantity, prod_id, prod_desc,
if(quantity > 20, .8*price, if(quantity > 5, .9*price, price)) "PRICE"
from item natural join product;
update sales_order
set tax = if(state="WA", amount*0.085, if(state="CO", amount*0.062, 0.0))
where state in ("CA","WA");
select
sum(if(prod_id=10320, quantity, 0)) "386/20",
sum(if(prod_id=10333, quantity, 0)) "386/33",
sum(if(prod_id=10433, quantity, 0)) "486/33",
sum(if(prod_id=10450, quantity, 0)) "486/50",
from item;

RDM SQL Language Guide
SQL Built-In Function Reference 206
ifnull
Retrieve an expression if another expression is null
Syntax
ifnull(expr1, expr2)
Parametersexpr1 The expression to be evaluated and, if not null, returned.expr2 The expression to be evaluated and returned if expr1 is null.
Description
This system function retrieves the value of the first specified expression (expr1) if it is not null. If expr1 is null, the ifnull function returns the value of second expression (expr2). The two expressions must be of compatible data types.

RDM SQL Language Guide
SQL Built-In Function Reference 207
log
Retrieve the natural logarithm of an expression
Syntax
log(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves the natural logarithm of the specified arithmetic expression.

RDM SQL Language Guide
SQL Built-In Function Reference 208
max
Compute the maximum of the results for an aggregate
Syntax
max(expression)
Parametersexpression The expression from which the maximum value is to be determined.
Description
This aggregate (calculation) function computes the maximum value for the specified expression for all rows of an aggregate.
Example
set double display(12, "#,#.##");
select month(ord_date), max(amount) from sales_order group by 1;
month(ord_date) max(amount)
1 274,375.00
2 124,660.00
3 143,375.00
4 252,425.00
5 39,675.95
6 104,019.50
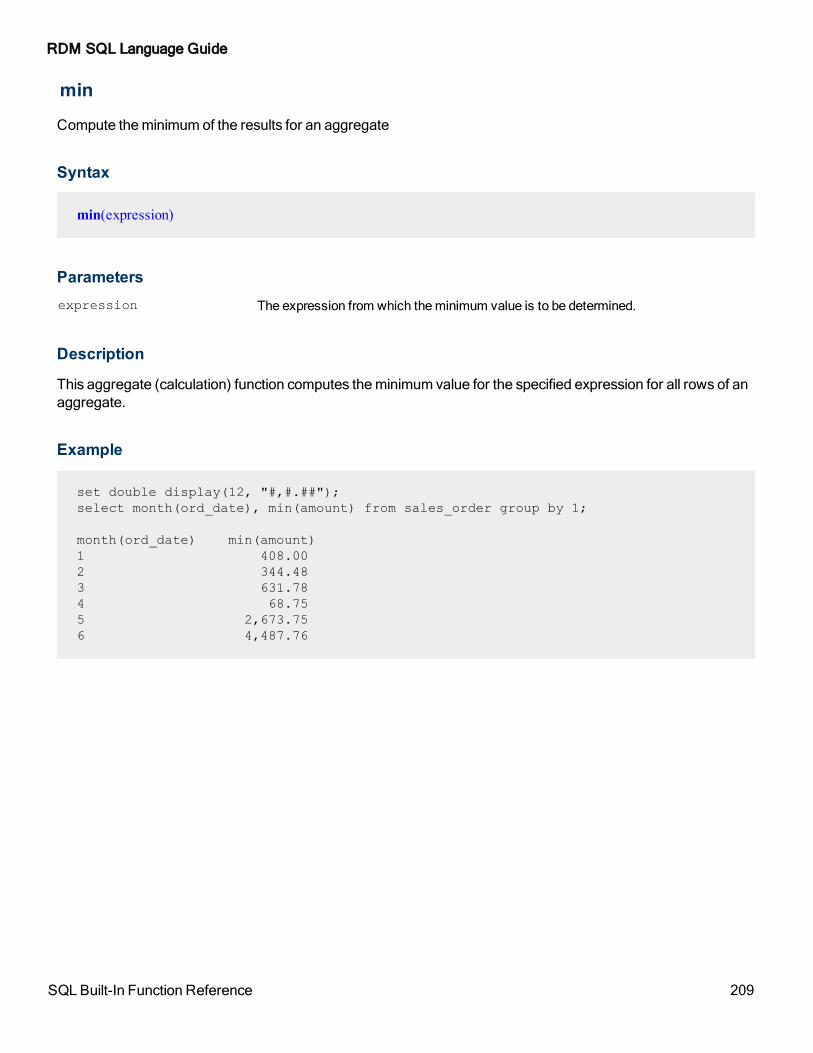
RDM SQL Language Guide
SQL Built-In Function Reference 209
min
Compute the minimum of the results for an aggregate
Syntax
min(expression)
Parameters expression The expression from which the minimum value is to be determined.
Description
This aggregate (calculation) function computes the minimum value for the specified expression for all rows of an aggregate.
Example
set double display(12, "#,#.##");
select month(ord_date), min(amount) from sales_order group by 1;
month(ord_date) min(amount)
1 408.00
2 344.48
3 631.78
4 68.75
5 2,673.75
6 4,487.76

RDM SQL Language Guide
SQL Built-In Function Reference 210
minute
Retrieve the minute
Syntax
minute(time_expr)
Parameterstime_expr An expression representing either a time or a timestamp value.
Description
This scalar date/time function returns the minute in the specified time expression as a number between 0 and 59.

RDM SQL Language Guide
SQL Built-In Function Reference 211
mod
Perform a modulo arithmetic operation
Syntax
mod(arith_expr1,arith_expr2)
Parametersarith_expr1 The expression to divide.arith_expr2 The expression that is used as the divisor.
Description
This scalar numeric function performs a modulo arithmetic operation of the form arith_expr1 modulo arith_expr2. In other words, the function retrieves the remainder resulting from dividing arith_expr1 by arith_expr2.

RDM SQL Language Guide
SQL Built-In Function Reference 212
month
Retrieve the month
Syntax
month(date_expr)
Parametersdate_expr A date expression.
Description
This scalar date/time function retrieves the number of the month in the specified date expression as a number between 1 and 12.
Example
set double display(12, "#,#.##");
select month(ord_date), min(amount) from sales_order group by 1;
month(ord_date) min(amount)
1 408.00
2 344.48
3 631.78
4 68.75
5 2,673.75
6 4,487.76
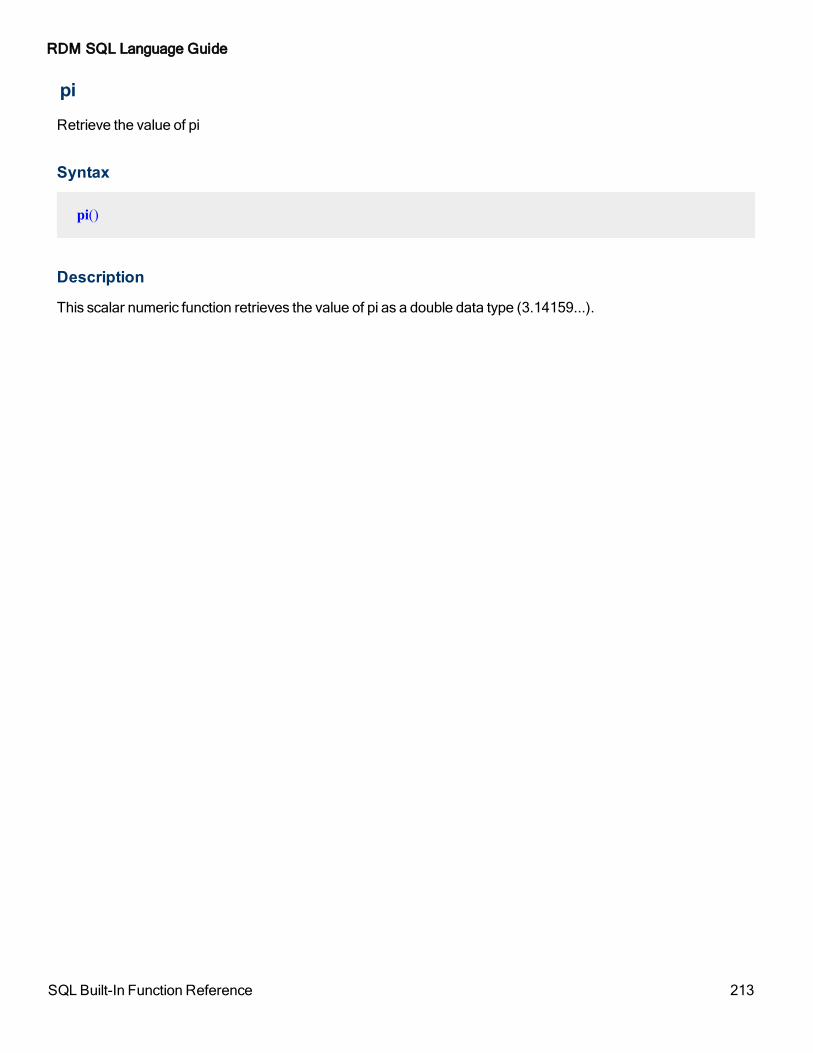
RDM SQL Language Guide
SQL Built-In Function Reference 213
pi
Retrieve the value of pi
Syntax
pi()
Description
This scalar numeric function retrieves the value of pi as a double data type (3.14159...).

RDM SQL Language Guide
SQL Built-In Function Reference 214
quarter
Retrieve the quarter
Syntax
quarter(date_expr)
Parametersdate_expr A date expression.
Description
This scalar date/time function retrieves the number of the quarter in the specified date expression as a number between 1 and 4.

RDM SQL Language Guide
SQL Built-In Function Reference 215
query
Evaluate a single-row query
Syntax
query(select_stmt_str[, param_value]...)
Parametersselect_stmt_str A string which specifies the select statement to be executed. The select statement
must only return at most one row. If no rows are returned then the function returns a null value. The select statement can contain parameter markers.
param_val Provides the value of a parameter marker specified the corresponding parameter marker in select_stmt_str. For each parameter marker specified in the select statement there must be a param_val argument specified as well and the param_val argu-ments must be listed in the same order as the parameter markers in the select state-ment.
Description
This scalar function executes the select statement specified in the select_stmt_str argument. The select statement must select only one column and return only one row. Parameter markers (indicated by a '?') can be specified in the select statement string. For each one that is specified, a param_val argument that supplies the value of the parameter marker must be provided.
This function allows single-valued queries to be specified in expression evaluation contexts where normal sub-queries are not allowed.
Example
update customer set sales_tot =
query("select sum(amount) from sales_order where cust_id=?", cust_id);
select sale_name,
query("select city from outlet where loc_id=?", office) office
from salesperson;

RDM SQL Language Guide
SQL Built-In Function Reference 216
rand
Retrieve a random floating-point number
Syntax
rand(num)
Parametersnum An integer to use as the seed for the floating-point number.
Description
This scalar numeric function retrieves a random floating-point number (between 0.0 and 1.0) using the specified integer as the seed. If 0 is specified, the rand function retrieves the next random floating-point number for the cur-rent seed.

RDM SQL Language Guide
SQL Built-In Function Reference 217
second
Retrieve the second
Syntax
second(time_expr)
Parameterstime_expr An expression that is either a time or a timestamp value.
Description
This scalar date/time function returns the second in the specified time expression as a number between 0 and 59.
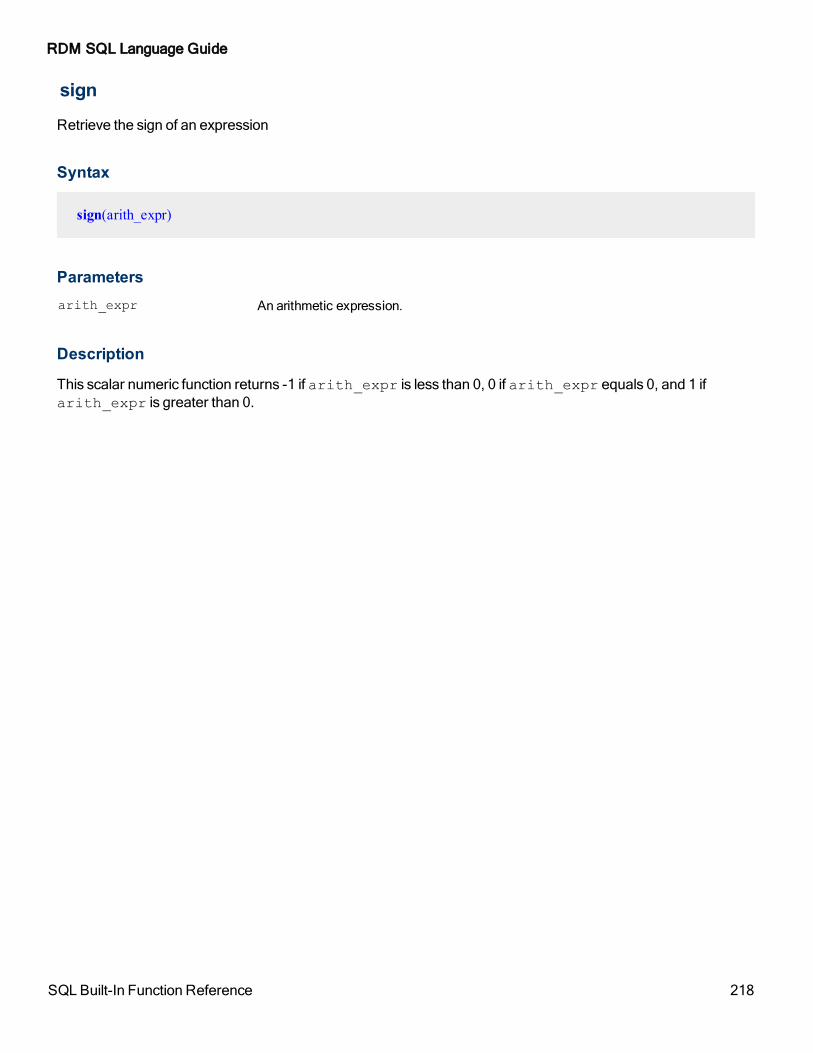
RDM SQL Language Guide
SQL Built-In Function Reference 218
sign
Retrieve the sign of an expression
Syntax
sign(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function returns -1 if arith_expr is less than 0, 0 if arith_expr equals 0, and 1 if arith_expr is greater than 0.

RDM SQL Language Guide
SQL Built-In Function Reference 219
sin
Retrieve the sine of an angle
Syntax
sin(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves the sine of the specified arithmetic expression. Sine operations return values between -1.0 and +1.0.

RDM SQL Language Guide
SQL Built-In Function Reference 220
sqrt
Retrieve the square root of an expression
Syntax
sqrt(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves the square root of the specified arithmetic expression.

RDM SQL Language Guide
SQL Built-In Function Reference 221
sum
Compute the sum of the results for an aggregate
Syntax
sum(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This aggregate (calculation) function computes the sum of results of the specified expression for each row of an aggregate.
Example
set double display(12, "#,#.##");
select cust_id, company, sum(amount) from customer natural join sales_order
group by 1;
cust_id company sum(amount)
ATL Falcons Microsystems, Inc. 113,659.75
BUF 'Bills We Pay' Financial Corp. 263,030.36
CHI Bears Market Trends, Inc. 160,224.65
CIN Bengels Imports 120,800.56
CLE Browns Kennels 43,284.54
DAL Cowboys Data Services 43,392.40
DEN Broncos Air Express 498,952.76
DET Lions Motor Company 439,346.50
GBP Packers Van Lines 163,177.30
HOU Oilers Gas and Light Co. 77,781.36
IND Colts Nuts & Bolts, Inc. 29,053.30
KCC Chiefs Management Corporation 141,535.34
LAA Raiders Development Co. 167,411.68
LAN Rams Data Processing, Inc. 172,936.31
MIA Dolphins Diving School 29,481.99
MIN Vikings Athletic Equipment 49,461.20
NEP Patriots Computer Corp. 120,184.69
NOS Saints Software Support 185,633.50
NYG Giants Garments, Inc. 15,829.64
NYJ Jets Overnight Express 124,487.78
PHI Eagles Electronics Corp. 130,006.17
PHO Cardinals Bookmakers 237,392.56
PIT Steelers National Bank 15,386.04
SDC Chargers Credit Corp. 34,556.48

RDM SQL Language Guide
SQL Built-In Function Reference 222
SEA Seahawks Data Services 60,756.36
SFF Forty-niners Venture Group 112,345.66
TBB Bucs Data Services 104,038.25
WAS Redskins Outdoor Supply Co. 63,039.90

RDM SQL Language Guide
SQL Built-In Function Reference 223
tan
Retrieve the tangent of an angle
Syntax
tan(arith_expr)
Parametersarith_expr An arithmetic expression.
Description
This scalar numeric function retrieves the tangent of the specified arithmetic expression.

RDM SQL Language Guide
SQL Built-In Function Reference 224
week
Retrieve the week
Syntax
week(date_expr)
Parametersdate_expr A date expression.
Description
This scalar date/time function retrieves the number of the week of the year in the specified date expression as a number between 1 and 53.
The data type 'date' assumes the Gregorian calendar even for dates prior to the introduction of the Gre-gorian calendar. This means that databases that store historical dates prior to the introduction of the Gregorian calendar may not compute select with date ranges, dayofweek, and week correctly.

RDM SQL Language Guide
SQL Built-In Function Reference 225
year
Retrieve the year
Syntax
year(date_expr)
Parametersdate_expr A date expression.
Description
This scalar date/time function retrieves the number of the year in the specified date expression.

RDM SQL Language Guide
SQL Language Syntax Summary 226
SQL Language Syntax SummaryThe syntax for the SQL statements that are implemented in RDM SQL is given below. Note that those items in red have not yet been implemented. Refer to "A Language for Describing a Language" for a description of how to read the syntax specification. C-style comments are explanatory and not part of the syntax.
RDM_SQL:
RDM_ddl_stmts | RDM_dml_stmts | RDM_proc_stmts
RDM DDL Statements
RDM_ddl_stmts:
create_schema_stmt
{create_domain_stmt | create_table_stmt}...
{create_catalog_stmt}
create_schema_stmt:
create {schema | database} db_name
[pagesize = num] [inmemory [persistent | volatile | read]]
create_domain_stmt:
create domain domain_name [as] data_type
[default {constant | null}]
create_catalog_stmt:
create catalog for dbname
create_table_stmt:
standard_table | virtual_table
virtual_table:
create virtual [read only] table table_name (
vcolumn_def[, vcolumn_def]…
)
vcolumn_def:
column_name base_type
[distinct values = num] [range constant to constant]
[primary key]

RDM SQL Language Guide
SQL Language Syntax Summary 227
standard_table:
create [circular] table table_name (
column_def[, column_def]...
[, key_def[, key_def]...]
) [pagesize = num] [inmemory [persistent | volatile | read]]
[maxpgs = num] [maxrows = num]
column_def:
column_name {type_spec | domain_name}
[distinct values = num] [range constant to constant]
[not null] [key_spec] [refs_spec]
type_spec:
data_type [default {constant | null}]
data_type:
base_type | blob_type
base_type:
{character | char } [(length)]
| {{character | char} varying | varchar } (length)
| {binary [(length)]
| {double [precision] | float | real }
| { tinyint | smallint | int | integer | long | bigint}
| date | time | timestamp
blob_type:
{{character | char} large object | long varchar | clob} [(length)] file_option
| {binary large object | large varbinary | blob} [(length)] file_option
file_option:
[pagesize = num] [inmemory [persistent | volatile | read]]
key_spec:
[primary | unique] key ['['keysize']']
| {primary | unique} key [hash { (num) | of num rows}] ['['keysize']']
refs_spec:
references table_name[.column_name] [triggered_action]
key_def:
[primary | unique] key [hash {(num) | of num rows}] ['['keysize']'] [key_name]
(column_name[asc | desc] [, column_name[asc | desc] ]...)
[pagesize = num] [inmemory [persistent | volatile | read]] [maxpgs = num]

RDM SQL Language Guide
SQL Language Syntax Summary 228
| foreign key [set_name] (column_name[, column_name]...
references table_name[(column_name[, column_name]...)]
[triggered_action]
triggered_action:
on update action_spec [on delete action_spec]
| on delete action_spec [on update action_spec]
action_spec:
cascade | restrict | set null
RDM DML Statements
RDM_dml_stmt:
db_stmt | select_stmt | mod_stmt
| trans_stmt | lock_stmt | set_stmt
db_stmt:
open_db_stmt | close_db_stmt | init_db_stmt
mod_stmt:
insert_stmt | update_stmt | delete_stmt | import_stmt | export_stmt
trans_stmt:
start_stmt | savepoint_stmt | release_stmt
| rollback_stmt | commit_stmt | end_trans_stmt
lock_stmt:
lock_stmt | unlock_stmt
open_db_stmt:
open [database] db_spec
[[in] {share | read only | exclusive} [mode] | as union of tfs_spec[, tfs_spec]...]
db_spec:
db_name | "[pathspec/]db_name"
close_db_stmt:
close [database] db_name

RDM SQL Language Guide
SQL Language Syntax Summary 229
init_db_stmt:
initialize [database] db_name
dropdb_stmt:
drop database {db_name | "db_name@tfs_spec"}
tfs_spec:
"HostComputerName[:ddddd]"
select_stmt:
select [first] [all | distinct] {* | select_item[, select_item]...}
from table_ref[, table_ref]...
[where conditional_expr]
[grouping | sorting | grouping sorting]
[limit (num {rows | mins | secs | msecs})]
[for {read only | update [of column_name[, column_name]...]}]
grouping:
group by sort_col[, sort_col]... [having conditional_expr]
sorting:
order by sort_col [asc | desc][, sort_col [asc | desc]]...
sort_col:
num | column_name
select_item:
expression [alias_name | "column heading"]
table_ref:
table_primary | table_join
table_primary:
table_spec | ( table_join )
table_spec:
[db_name.]table_name [[as] correlation_name]
table_join:
natural_join | qualified_join | cross_join

RDM SQL Language Guide
SQL Language Syntax Summary 230
natural_join:
table_ref natural [inner | {left | right} [outer]] join table_primary
qualified _join:
table_ref [inner | {left | right} [outer]] join table_primary
[using (column_name[, column_name]...) | on conditional_expr]
cross_join:
table_ref cross join table_primary
arith_expr:
expression /* involving only numeric operands and operations */
dt_expr:
expression /* involving only date/time/timestamp operands and operations */
string_expr:
expression /* involving only string operands and operations */
expression:
operand [arith_operator operand]...
operand:
constant | param_ref | column_ref | function | (expr)
param_ref:
? | :param_name
column_ref:
[{table_name | correlation_name}.]column_name
arith_operator:
+ | - | * | /
function:
aggregate_fcn | scalar_fcn
aggregate_fcn:
{sum | avg | max | min} (expression)
| count ({* | column_ref })
| aggregate_udf_name ([expression][, expression]...)
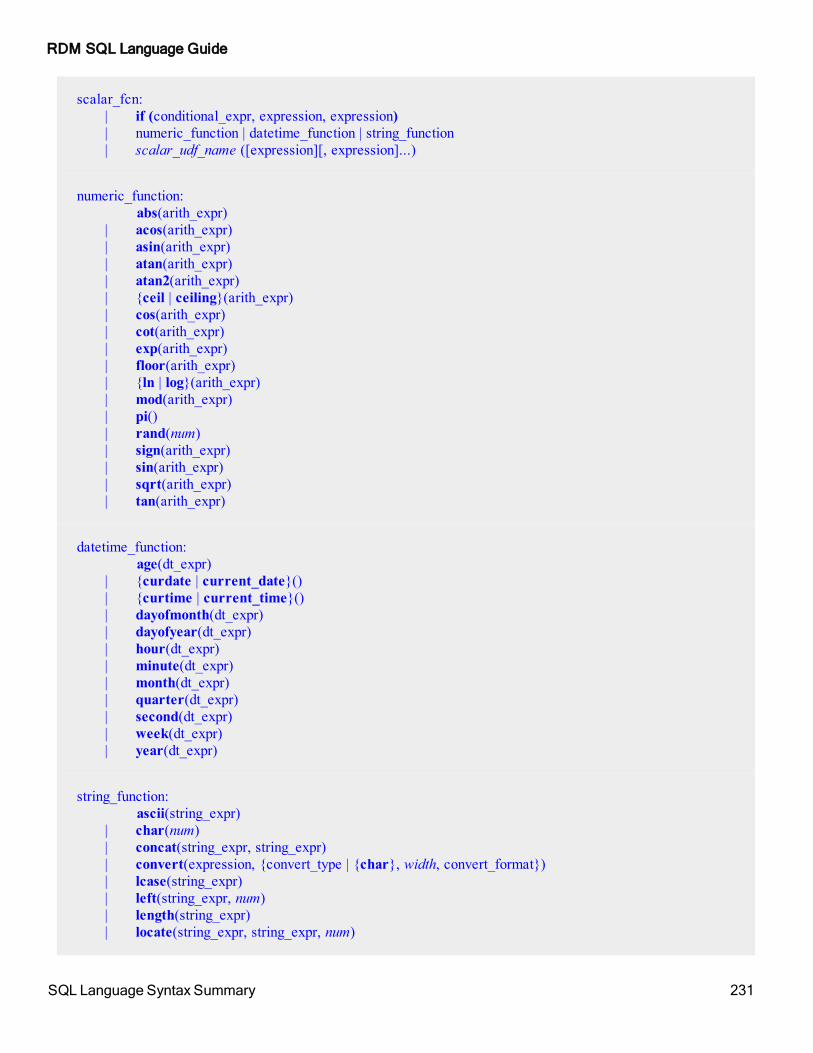
RDM SQL Language Guide
SQL Language Syntax Summary 231
scalar_fcn:
| if (conditional_expr, expression, expression)
| numeric_function | datetime_function | string_function
| scalar_udf_name ([expression][, expression]...)
numeric_function:
abs(arith_expr)
| acos(arith_expr)
| asin(arith_expr)
| atan(arith_expr)
| atan2(arith_expr)
| {ceil | ceiling}(arith_expr)
| cos(arith_expr)
| cot(arith_expr)
| exp(arith_expr)
| floor(arith_expr)
| {ln | log}(arith_expr)
| mod(arith_expr)
| pi()
| rand(num)
| sign(arith_expr)
| sin(arith_expr)
| sqrt(arith_expr)
| tan(arith_expr)
datetime_function:
age(dt_expr)
| {curdate | current_date}()
| {curtime | current_time}()
| dayofmonth(dt_expr)
| dayofyear(dt_expr)
| hour(dt_expr)
| minute(dt_expr)
| month(dt_expr)
| quarter(dt_expr)
| second(dt_expr)
| week(dt_expr)
| year(dt_expr)
string_function:
ascii(string_expr)
| char(num)
| concat(string_expr, string_expr)
| convert(expression, {convert_type | {char}, width, convert_format})
| lcase(string_expr)
| left(string_expr, num)
| length(string_expr)
| locate(string_expr, string_expr, num)

RDM SQL Language Guide
SQL Language Syntax Summary 232
| ltrim(string_expr)
| repeat(string_expr, num)
| replace(string_expr, string_expr, string_expr)
| right(string_expr, num)
| rtrim(string_expr)
| substring(string_expr, num, num)
| ucase(string_expr)
| unicode(string_expr)
convert_type:
char |smallint | integer | real
| double | date | time | timestamp | tinyint | bigint
convert_format:
numeric_format | datetime_format
numeric_format:
"[<< | >> | ><]['text' | $][- | (][#,]#[.#[#]...][e | E]['text' | $ | %]"
datetime_format:
"[<< | >> | ><]['text' | spchar | date_code | time_code]..."
date_code:
m | mm | mmm | mon | mmmm | month
| d | dd | ddd | dddd | day
| yy | yyyy
time_code:
h | hh | m | mm | s | ss | .f[f]... | [a/p | am/pm | A/P | AM/PM]
conditional_expr:
rel_expr [bool_oper rel_expr]...
rel_expr:
expression [not] rel_oper expression
| expression [not] between constant and constant
| expression [not] in (constant[, constant]...)
| column_ref is [not] null
| string_expr [not] like "string"
| not rel_expr
| ( conditional_expr )
rel_oper:
= | ==
| <
| >
| <=

RDM SQL Language Guide
SQL Language Syntax Summary 233
| >=
| <> | != | /=
bool_oper:
& | && | and
| "|" | "||" | or
insert_stmt:
insert into [db_name.]table_name [(column_name[, column_name]... )] data_source
data_source:
values value_expr[, value_expr]...
| [from] select_stmt
value_expr:
value_operand [{+ | - | * | /} value_operand]…
value_operand:
constant | arg_name | column_name | ? | scalar_fcn | ( value_expr )
update_stmt:
update [db_name.]table_name
set column_name = expression[, column_name = expression]...
[where {conditional_expr | current of cursor_name}]
delete_stmt:
delete from [db_name.]table_name
[where {conditional_expr | current of cursor_name}]
import_stmt:
import into table_name from [char | wchar | xml] file "filename"
export_stmt:
export into [char | wchar | xml] file "filename" from select_stmt
start_stmt:
{start trans[action] | begin [work] [trans[action]]} [read only]
savepoint_stmt:
savepoint savepoint_id
release_stmt:
release savepoint savepoint_id]

RDM SQL Language Guide
SQL Language Syntax Summary 234
rollback_stmt:
rollback [work] [[to savepoint] savepoint_id]
commit_stmt:
{commit [work] | end [trans[action]]}
end_trans_stmt:
end read only trans[action]
lock_stmt:
lock table [in db_name] table_lock[, table_lock]...
table_lock:
table_name [read | write | default]
unlock _stmt:
unlock table {[db_name.]table_name | all}
set_stmt:
set_option_stmt | set_column_stmt
set_option_stmt:
set timeout [to | =] constant
| set autocommit [to | =] {on | off}
| set read only trans[action] mode [to | =] {auto | manual}
| set debug [to | =] {0 | 1}
set_column_stmt:
set column [db_name.]table_name.column_name
[type [to | =] {date | time | timestamp | long | {varchar | wvarchar}}]
[distinct values = num]
[range constant to constant]
| set column stats [db_name.]table_name.column_name
[distinct values = num]
[range constant to constant]
RDM Procedure Statements
RDM_proc_stmts:
create_proc_stmt | drop_proc_stmt | execute_stmt

RDM SQL Language Guide
SQL Language Syntax Summary 235
create_proc_stmt:
create {proc | procedure} proc_name [(arg_name arg_type[, arg_name arg_type]...)] as
{select_stmt... |
[start_stmt] {insert_stmt | update_stmt | delete_stmt}... [commit_stmt]}
end {proc | procedure}
arg_type:
{character | char }
| {double [precision] | float | real }
| {tinyint | smallint | int | integer long | bigint}
| date | time | timestamp
arg_type:
{character | char }
| {double [precision] | float | real }
| {tinyint | smallint | int | integer long | bigint}
| date | time | timestamp
drop_proc_stmt:
drop proc[edure] proc_name
execute_stmt:
[exec[ute] | run] proc_name [(constant[, constant]...)]
SQL Reserved Words for RDMThe table below lists reserved words that cannot be used when creating your SQL schema, except when used for their intended purpose (i.e., the reserved word "DATABASE" cannot be used as your database name because it is used in the SQL grammar "CREATE DATABASE ...").
Note: * Represents reserved words that are not reserved in the SQL Standard but are reserved in the underlying Native DDL.
BS DAYOFWEEK LEFT ROLLBACK
ACOS DAYOFYEAR LENGTH ROUND
AGE DB_ADDR LIMIT ROWID
ALL DBA4 LN RTRIM
*ASC DBA8 LOCALTIME SECOND
*ASCENDING DELETE LOCALTIMESTAMP SELECT
ASCII *DESC LOCATE *SET
ASIN *DESCENDING LOG SHORT
ATAN DISTINCT LONG SIGN
ATAN2 DOUBLE LOWER SIN
AVG END LTRIM SMALLINT

RDM SQL Language Guide
SQL Language Syntax Summary 236
BEGIN EXP MAX SQRT
BIGINT EXPORT *MAXPGS *STATIC
BIT FALSE *MAXSLOTS *STRUCT
*BLOB *FILE *MEMBER SUBSTRING
BOOLEAN FIRST MIN SUM
*BY FLOAT MINUTE TAN
CEIL FLOOR MOD *THRU
CEILING FOR MONTH TIME
CHAR FOREIGN NAT TIMESTAMP
CHARACTER FROM NATURAL TINYINT
CHARACTER_LENGTH FULL *NEXT TRUE
*CIRCULAR GROUP NOT TYPE
COMMIT HASH NOW *TYPEDEF
*COMPACT HOUR NULL TYPEOF
*COMPOUND IF *NULLABLE UCASE
CONCAT IFNULL OCTET_LENGTH UNICODE
*CONST IMPORT ON UNIQUE
*CONTAINS IN *OPT UNLOCK
CONVERT INDEX *OPTIONAL *UNSIGNED
COS *INITIAL *ORDER UPDATE
COT INNER *OWNER UPPER
COUNT INSERT *PAGESIZE USING
CROSS INSSTR *PCTINCREASE *VARDATA
CURDATE INT *PERSISTENT *VOLATILE
CURRENT_DATE *INT16_T PI WCHAR
CURRENT_TIME *INT32_T QUARTER WCHARACTER
CURRENT_TIMESTAMP *INT64_T RAND WEEK
CURTIME *INMEMORY *READ WHERE
DATA INTEGER REAL WORK
DATABASE JOIN *RECORD(S) YEAR
DATE KEY REPEAT
DATETIME *LAST REPLACE
DAYOFMONTH LCASE RIGHT

RDM SQL Language Guide
SQL Statement Reference 237
SQL Statement ReferenceThe primary purpose of the Data statement is to give names to constants;
instead of referring to pi as 3.141592653589793 at every appearance,
the variable Pi can be given that value with a Data statement and used
instead of the longer form of the constant. This also simplifies
modifying the program, should the value of pi change.- Fortran manual for Xerox Computers
Each individual SQL statement is described in this section. The descriptions are listed in alphabetical order by statement. Oh, and sorry, we don't have a data statement (but we do have pi, however, our version requires that it never changes value!).
The following table summarizes each RDM SQL statement.
Statement Descriptionclose Close an open databasecommit / end Commit transaction's changes to the databasecreate catalog Create a new catalog filecreate database Create a database definitioncreate domain Create a column domain specificationcreate procedure Create a stored procedurecreate table Create a table definitioncreate virtual table Create a virtual table for an external data sourcedelete Delete one or more rows from a tabledrop database Drop (delete) a databasedrop procedure Drop a stored procedureend read only trans-
action
Terminate a read only transaction
execute Execute a stored procedureexport Export select results to an external fileimport Import data into a table from an external fileinitialize Initialize a databaseinsert Insert a row or rows into a tablelock table Explicitly lock one or more tablesopen Open a databaserelease Release a transaction savepointrollback Rollback (undo) a transaction's changessavepoint Mark a transaction savepointselect Retrieve a set of rows of data from the databaseset Set an SQL operational parameter valueset column Set column statistics or SQL type for core database columnstart/ begin Start a transactionunlock table Unlock (all) read-locked table(s)update Update one or more rows in a table
Table 23. RDM SQL Statement Summary

RDM SQL Language Guide
SQL Statement Reference 238
close
Close an open database
Syntax
close_db_stmt:
close [database] db_name
Description
The close statement can be used to close any open database. Attempts to execute a close statement when a transaction is active will result in an error.
Example
open bookshop;
...access bookshop database
close bookshop;
open database nsfawards;
...access nsfawards database
close database nsfawards;
See Also
open

RDM SQL Language Guide
SQL Statement Reference 239
commit
Commit transaction's changes to the database
Syntax
commit_stmt:
{commit [work] | end [trans[action]]}
Description
The commit statement causes all database modifications that have been made since the beginning of the trans-action to be permanently written to the database. Upon successful return the transaction's changes are guar-anteed to be in the database and all locks are freed.
A transaction is explicitly started through execution of a start transaction statement or implicitly through the execution of the first database modification statement (insert, update, or delete). It is recommended that you always use the start transaction statement to mark the beginning of a transaction.
RDM SQL also provides the ability to run in auto-commit mode in which each insert, update, and delete state-ment is automatically committed. This mode is made available to support some third-party ODBC tools. How-ever, the use of auto-commit mode is not recommended as transactions are designed to allow the grouping of related database changes and that is not possible when running with auto-commit enabled.
Execution of a commit statement when a transaction is not currently active will free all of the read locks held by the connection.
Example
start transaction;
... insert, update, and/or delete statements
commit;
See Also
start
rollback
set autocommit

RDM SQL Language Guide
SQL Statement Reference 240
create catalog
Create a new catalog file
Syntax
create_catalog_stmt:
create catalog for dbname
Description
The create catalog statement is used to either create a catalog file for a RDM core (i.e., non-SQL) database or to update the catalog of a RDM SQL database in order to store column statistics updated through prior calls to the set column statement.
When a core database is opened in SQL, the RDM SQL engine creates an internal catalog from the core data-base dictionary. Once opened, since the database dictionary does not contain the range and distinct values that in SQL can be specified for table columns, the set column statement can be used to provide this information. Moreover, as core databases also do not distinguish between character and binary blob data, the set column statement can be used to specify a blob column to be either a long varchar or long wvarchar. Having done so, a catalog containing the SQL version of the core database along with the additional information provided in pre-viously executed set column statements can be permanently stored in a catalog by executing the create catalog statement.
For an SQL database, this statement can be used to update the column statistics specified in previously executed set column statements contained in the catalog for the specified database.
Execution of this statement requires that the database has been opened in exclusive access mode. This state-ment is not transactional. Hence, once executed it cannot be undone.
Example
open database mycoredb in exclusive mode;
set column geosensor.descr to long varchar;
set column geosensor.type distinct values 20;
... other set column statements
create catalog for mycoredb;
See Also
open
set column

RDM SQL Language Guide
SQL Statement Reference 241
create database
Create a database definition
Syntax
create_schema_stmt:
create {schema | database} db_name
[pagesize = num] [inmemory [persistent | volatile | read]]
Description
The create database statement is used to introduce the database definition for a new database. The definition is contained in the sequence of DDL statements (create domain or create table) that are submitted immediately following this statement. The name of the database is specified by the db_name identifier.
The system stores the rows of each database table in a separate system file. It also stores the indexes asso-ciated with keys in separate system files as well. The default page size for the database files is 1024 bytes but can be changed by the pagesize option. This will be the default page size used for each database file created for the database. Specific page sizes for tables and keys that override the default can be specified in the create table statement.
You can specify that all database files are to be stored in shared memory by including the inmemory option. The read, persistent, and volatile options control whether the database files are read from disk when the database is opened (read, persistent), and whether they are written to the disk when the database is closed (persistent). The default is volatile meaning that the database is created empty each time it is opened. The read option means that the entire database is read from the files when the database is opened, changes to the data are allowed but are not written back to the files on closing. The persistent option means that the entire database is read on opening and all changes that were made while the database was open are written when the database is closed. As with the pagesize option, the create table statement allows specific tables and/or keys to be inmem-ory.
The database is automatically created and initialized upon the successful compilation of all of its subsequent DDL statements and execution of the first non-DDL statement (usually commit) that follows the DDL state-ments. At that point, the database is open and ready for use.Example
Only one create database can be issued in a given connection and no other databases can be opened when the create database is issued.
Example
create database bookshop pagesize=4096;
create table author(
last_name char(11) primary key,
full_name char(35),

RDM SQL Language Guide
SQL Statement Reference 242
gender char(1),
yr_born smallint,
yr_died smallint,
short_bio varchar(250)
);
... other DDL statements for the bookshop database
commit;
See Also
create domain
create table

RDM SQL Language Guide
SQL Statement Reference 243
create domain
Create a column domain specification
Syntax
create_domain_stmt:
create domain domain_name [as] data_type
[default {constant | null}]
data_type:
base_type | blob_type
base_type:
{character | char } [(length)]
| {{character | char} varying | varchar } (length)
| {binary [(length)]
| {double [precision] | float | real }
| { tinyint | smallint | int | integer | long | bigint}
| date | time | timestamp
blob_type:
{{character | char} large object | long varchar | clob} [(length)] file_option
| {binary large object | large varbinary | blob} [(length)] file_option
file_option:
[pagesize = num] [inmemory [persistent | volatile | read]]
Description
A "domain" is simply a user-defined and named data type which can then be specified as the data type for col-umns declared in a create table statement. The create domain statement must be submitted before any create table statements that reference it.
The name of the domain is specified as the domain_name. The data_type specifies the base type for the domain. A constant value or null can be specified as the default.
Example
create database bookshop;
create domain money as double
default null;

RDM SQL Language Guide
SQL Statement Reference 244
create table book(
bookid char(14) primary key,
last_name char(11) references author,
title varchar(255),
descr char(61),
publisher char(136),
publ_year smallint,
lc_class char(33),
date_acqd date,
date_sold date,
price money,
cost money
);
See Also
create database
create table

RDM SQL Language Guide
SQL Statement Reference 245
create procedure
Create a stored procedure
Syntax
create_proc_stmt:
create {proc | procedure} proc_name [(arg_name arg_type[, arg_name arg_type]...)] as
{select_stmt... |
[start_stmt] {insert_stmt | update_stmt | delete_stmt}... [commit_stmt]}
end {proc | procedure}
arg_type:
{character | char }
| {double [precision] | float | real }
| {tinyint | smallint | int | integer long | bigint}
| date | time | timestamp
Description
Stored procedures that execute one or more basic SQL statements can be created with the create procedure statement. A stored procedure can either contain one or more select statements (retrieval procedure) or a sequence of insert, update, and/or delete statements (modification procedure) optionally enclosed in a trans-action (transactional procedure). The name of the stored procedure is specified by the identifier procname which can be executed using the execute statement.
Any number of arguments can be declared with the stored procedure. Each arg_name must be an identifier than is not an SQL reserved word or the name of any table or column in the database. The type of the argument must also be specified as shown in the above syntax. Argument values of type char represent a (null-terminated) char-acter string of any length. Each arg_name can be simply referenced by name in any of the stored procedures SQL statements in any context in which a value of that data type can be specified.
The additional result sets from a retrieval procedure that contains more than one select statement are accessed by the application through a call to the rsqlMoreResults function after the last call to rsqlFetch on the prior select statement has returned errNOMOREDATA. Function rsqlMoreResults itself will return errNO-MOREDATA after the last row of the last result set has been returned.
It is recommended that you use transactional procedures for all of your transactions that involve the execution of more than one insert, update, and/or delete statement involving modifications to more than one table. Execution of a modification or transactional procedure will issue a single grouped lock request for all of the referenced tables at the start of execution so that either all or none of the locks are granted. Grouped locking in this way guar-antees that the application is deadlock free. Use of a transactional procedure ensures that either all or none of the changes are committed to the database.
Execution of a modification procedure when auto-commit mode is enabled, behaves the same as a transactional procedure. This provides a way to ensure that the modifications from more than one statement are committed together even in auto-commit mode.

RDM SQL Language Guide
SQL Statement Reference 246
An inherited read lock is a read lock that is active at the time a transaction begins (e.g., locks that may be held by an active cursor on another statement handle in the same connection). In auto-commit mode, all inherited read locks remain in place after the changes are committed (or rolled back, in the event that one of the modification (or transactional) procedure's statements encounter an execution error such as a referential integrity violation). When auto-commit is not active, all transaction commits (or rollbacks) free all locks.
The advantage of using stored procedures is that the cost of compiling the stored procedure statements is incurred only once. Compiled stored procedures are stored in the referenced database's directory on the TFS in a file named procname.ssp. An embeddable (through #include directives) C module containing statically initial-ized tables comprising the compiled form of the procedure is also created. This file along with a companion header file is named procname_ssp.c (or .h). It can be compiled with your C application and directly execute through a call to function rsqlExecProc.
Examples
create proc authors_books(lastnm char) as
select publ_yr, title from book where last_name = lastnm
end proc;
...
authors_books("PotterB");
PUBL_YR TITLE
1903 The Tailor of Gloucester
1903 The tale of Squirrel Nutkin
1904 The tale of Benjamin Bunny
1904 The tale of Peter Rabbit; thirty-one illustrations.
1905 The pie and the patty-pan.
1905 The tale of Mrs. Tiggy-Winkle
1906 The tale of Mr. Jeremy Fisher
1908 The tale of Jemima Puddle-Duck
1907 The tale of Tom Kitten
1911 The tale of Timmy Tiptoes
1912 The tale of Mr. Tod
1913 The tale of Pigling Bland
1918 The tale of Johnny Town-mouse
...
create procedure sold(pid char, bid char, offer double, sale_date char) as
start transaction
update book set price = offer, date_sold = sale_date where bookid = bid
insert into sale values bid, pid
commit
end proc;
...
execute sold("SMD", "potter08", 750.0, date "2011-04-03");
...
See Also
execute
rsqlExecProc

RDM SQL Language Guide
SQL Statement Reference 247
create table
Specifies a file to contain blob field data
Syntax
standard_table:
create [circular] table table_name (
column_def[, column_def]...
[, key_def[, key_def]...]
) [pagesize = num] [inmemory [persistent | volatile | read]]
[maxpgs = num] [maxrows = num]
column_def:
column_name {type_spec | domain_name}
[distinct values = num] [range constant to constant]
[not null] [key_spec] [refs_spec]
type_spec:
data_type [default {constant | null}]
data_type:
base_type | blob_type
base_type:
{character | char } [(length)]
| {{character | char} varying | varchar } (length)
| {binary [(length)]
| {double [precision] | float | real }
| { tinyint | smallint | int | integer | long | bigint}
| date | time | timestamp
blob_type:
{{character | char} large object | long varchar | clob} [(length)] file_option
| {binary large object | large varbinary | blob} [(length)] file_option
file_option:
[pagesize = num] [inmemory [persistent | volatile | read]]
key_spec:
[primary | unique] key ['['keysize']']
| {primary | unique} key [hash { (num) | of num rows}] ['['keysize']']

RDM SQL Language Guide
SQL Statement Reference 248
refs_spec:
references table_name[.column_name] [triggered_action]
key_def:
[primary | unique] key [hash {(num) | of num rows}] ['['keysize']'] [key_name]
(column_name[asc | desc] [, column_name[asc | desc] ]...)
[pagesize = num] [inmemory [persistent | volatile | read]] [maxpgs = num]
| foreign key [set_name] (column_name[, column_name]...
references table_name[(column_name[, column_name]...)]
[triggered_action]
triggered_action:
on update action_spec [on delete action_spec]
| on delete action_spec [on update action_spec]
action_spec:
cascade | restrict | set null
Description
The create table statement is used to define a table to be included in the database. Create table statements can only be issued after the create database statement and before issuing any other non-DDL statements. Any domain types that are used in column declarations included in the create table statement must have already been declared through the issuance of a prior create domain statement.
The table_name is a user-specified identifier that names the table. The contents of the table is comprised of the columns that are declared within it. Columns are declared to be of a specific data type which is either explicitly given or specified through use of a previously declared domain name. A default value can also optionally be spec-ified unless the column was declared with a domain type.
The distinct values clause specifies the number of distinct values that will be stored in this column. The range clause specifies the minimum and maximum values that will be stored in the column. These two clauses provide important information that is only used by the RDM SQL query optimizer to determine the best possible execution plan for a query. Note that these clauses do not specify column validation checks. It will still be possible to store values that are outside of the specified range.
Columns can be specified with one or more constraints which declare the column to be:
l not null—null values are not allowed for the column, l a primary/unique or non-unique key—on which an index will be automatically created, l a foreign key that references the primary/unique key of the specified table.
Columns declared as not null will cause any insert or update statement that attempts to assign a null value to that column to return an error.

RDM SQL Language Guide
SQL Statement Reference 249
Foreign key references are automatically implemented by RDM SQL for quick access and maintenance of ref-erential integrity1 . A triggered_action can be specified with foreign key columns in order to indicate what should happen when the referenced row is updated or deleted. The default action is restrict meaning that primary key rows that have existing foreign key references cannot be updated/deleted. If on ... cascade is specified, then all of the referenced rows are updated or deleted when the primary key row is updated (i.e., the primary key column value) or deleted. Note that the referencing table may itself have a primary key declared that is referenced by for-eign keys in other tables that may not have a cascade triggered action specified. Thus, a delete of the referenced row of a cascade-delete-allowed table may be denied due to a restrict foreign key on a row of a referencing table. If on ... set null is specified, then all of the referencing foreign key columns will be set to null. This option is not allowed when the foreign key column has been declared as not null.
A key_def on a table is used to declare primary/unique/non-unique keys and foreign keys on one or more col-umns. The [primary | unique] key clause is used to identify the columns from the table on which a key is to be formed. A table can have only one primary key. Keys that include the keysize clause will index a maximum of only keysize number of bytes of the column values. By default keys are maintained in a B-tree index file which maintains the keys in sorted order based on the data type of the columns comprising the key. You can also spec-ify that a key be stored in a hash index which is designed for very fast lookups of specific keys but cannot be used for sorting or range searches. The hash specification must include an estimate of the number of rows on which the hash is to be based.
The contents (rows) of each table is contained in a separate RDM data file. Each key is contained in a separate RDM key file. The values for each blob type column is stored in a separate RDM blob file.
A pagesize value that differs from the default pagesize (see create database) can be specified. You can also specify that the table's file is inmemory. The read, persistent, and volatile options control whether the table is read from disk when the database is opened (read, persistent), and whether changes to the table are written to the disk when the database is closed (persistent). The default is volatile meaning that the table is created empty each time it is opened. The read option means that the entire table is read from the file when the database is opened, changes to the table are allowed but are not written back to the file on closing. The persistent option means that the entire table is read on opening and all changes that were made while the database was open are written back to the table's file when the database is closed.
A circular table is one which has a fixed number of rows as specified by the maxrows clause (which is required when circular is specified). An insert into a circular table inserts the specified row into the next row position in the table. When maxrows have been inserted the next row will be written to the first row in the table overwriting the original row value. Circular tables are useful for storing time-dependent information such as log entries, oper-ational status records, and so on. Note that foreign key references to a circular table are not allowed.
The data type 'date' assumes the Gregorian calendar even for dates prior to the introduction of the Gre-gorian calendar. This means that databases that store historical dates prior to the introduction of the Gregorian calendar may not compute select with date ranges, dayofweek, and week correctly.
Example
create database sales;
1Declared foreign and primary key relationships are implemented using RDM core-level sets.

RDM SQL Language Guide
SQL Statement Reference 250
create domain money as double;
create table product
(
prod_id smallint primary key,
prod_desc char(39) not null,
price money range 11.95 to 12495.00,
cost money range 5.5 to 8800.00,
key prod_pricing(price, prod_id)
);
create table outlet
(
loc_id char(3) primary key,
city char(17) not null,
state char(2) distinct values = 11 range "AZ" to "WA" not null,
region smallint distinct values = 4 range 0 to 3 not null,
key loc_geo(state, city)
);
create table on_hand
(
loc_id char(3) not null
references outlet(loc_id),
prod_id smallint not null
references product,
quantity smallint not null,
primary key(loc_id, prod_id)
);
create table salesperson
(
sale_id char(3) primary key,
sale_name char(30) not null,
dob date,
commission double,
region smallint distinct values = 4 range 0 to 3 not null,
sales_tot money,
office char(3) distinct values = 12,
mgr_id char(3)
references salesperson on delete set null on update cascade,
key sales_region (region, office)
);
create table customer
(
cust_id char(3) primary key,
company char(30) not null,
contact char(30),
street char(30),
city char(17),
state char(2) distinct values = 50,
zip char(5),
orders_tot money,
sale_id char(3)
references salesperson on delete set null on update cascade

RDM SQL Language Guide
SQL Statement Reference 251
);
create table sales_order
(
cust_id char(3)
references customer on delete set null on update cascade,
ord_num smallint primary key,
ord_date date,
ord_time time,
amount money,
tax double default 0.0,
key order_ndx(ord_date, amount, ord_time)
);
create table item
(
ord_num smallint not null
references sales_order on delete cascade on update cascade,
prod_id smallint not null
references product on update cascade,
loc_id char(3) distinct values = 12 not null
references outlet on update cascade,
quantity smallint not null
);
create table note
(
note_id char(12) not null,
note_date date not null,
sale_id char(3) distinct values = 14 not null,
cust_id char(3)
references customer on delete cascade on update cascade,
unique key(sale_id, note_id, note_date)
);
create table note_line
(
note_id char(12) not null,
note_date date not null,
sale_id char(3) distinct values = 14 not null,
txtln char(81) not null,
foreign key(sale_id, note_id, note_date)
references note(sale_id, note_id, note_date)
on delete cascade on update cascade
);
See Also
create database

RDM SQL Language Guide
SQL Statement Reference 252
create virtual table
Create a virtual table for an external data source
Syntax
virtual_table:
create virtual [read only] table table_name (
vcolumn_def[, vcolumn_def]…
)
vcolumn_def:
column_name base_type
[distinct values = num] [range constant to constant]
[primary key]
base_type:
{character | char } [(length)]
| {{character | char} varying | varchar } (length)
| {binary [(length)]
| {double [precision] | float | real }
| { tinyint | smallint | int | integer | long | bigint}
| date | time | timestamp
Description
An RDM SQLvirtual table is a feature that allows just about any kind of external data to be accessed as an SQL table. It is defined through a combination of the create virtual table statement and a set of user developed C func-tions that conform to a particular interface specification. A pointer to a pre-defined structure array that contains an entry for each virtual table with the addresses of each of the virtual table interface functions is passed into SQL through a call to rsqlRegisterVirtualTables before the database is opened. These functions are then called by SQL at the appropriate times during the execution of any SQL statement that references the virtual table.
The read only option indicates that the table can only be referenced in a select statement.
Only single-column primary keys are allowed and only one column in the table can be declared to be the primary key. SQL will call the vtLookup virtual table interface function to handle single-valued lookups from a where con-ditional of the form "pkeycol = value".
In a DDL specification, all create virtual table statements must come after all standard create table statements for the database have been submitted.

RDM SQL Language Guide
SQL Statement Reference 253
Example
create database weather_db;
create table sensor_location(
longitude integer,
latitude integer,
sensor_id bigint,
descr char(48),
county char(24),
state char(2),
primary key loc_id(longitude, latitude)
);
create table weather_summary(
longitude integer,
latitude integer,
rdg_date date,
hour_of_day smallint,
avg_temp smallint,
avg_ press smallint,
avg_hum smallint,
avg_lumens smallint,
foreign key (longitude, latitude) references sensor_location
);
create virtual readonly table weather_data(
sensor_id bigint primary key,
loc_long integer,
loc_lat integer,
rdg_time timestamp display(19, "yyyy-mon-dd hh:mm:ss"),
temperature smallint range -10 to 100,
pressure smallint,
humidity smallint,
light smallint,
power integer
);
See Also
rsqlRegisterVirtualTables

RDM SQL Language Guide
SQL Statement Reference 254
delete
Delete one or more rows from a table
Syntax
delete_stmt:
delete from [db_name.]table_name
[where {conditional_expr | current of cursor_name}]
conditional_expr:
rel_expr [bool_oper rel_expr]...
rel_expr:
expression [not] rel_oper expression
| expression [not] between constant and constant
| expression [not] in (constant[, constant]...)
| column_ref is [not] null
| string_expr [not] like "string"
| not rel_expr
| ( conditional_expr )
rel_oper:
= | ==
| <
| >
| <=
| >=
| <> | != | /=
bool_oper:
& | && | and
| "|" | "||" | or
Description
This statement deletes one or more rows from table table_name. Two types of delete are supported. In a searched delete, the delete statement deletes all rows of the table that satisfy the conditional expression (con-ditional_expr) specified in the where clause. In a positioned delete, the delete statement deletes the current row associated with the specified cursor (cursor_name) in the where current of clause. The cursor_name must have been established through a prior call to either rsqlGetCursorName or rsqlSetCursorName on a com-piled, updateable select statement associated with a separate statement handle.
Deleting rows that have referencing foreign keyed rows will either succeed or fail based on the cascade or restrict settings associated with the related foreign key specifications. If all referenced rows specify cascade

RDM SQL Language Guide
SQL Statement Reference 255
then all of the referencing rows will be deleted in addition to the rows from this particular table. However, if the restrict option is specified and referencing rows exist, then the delete will fail with a referential integrity error. Note also that while a foreign key to this table may have cascade set a foreign key to the referencing table may itself have restrict set and thus the cascaded deletion could cause the delete to fail due to a referential integrity constraint violation.
A call to rsqlGetRowCount after a successful execution of delete will return the count of all rows from all affected (i.e., cascaded) tables that were deleted.
Example
delete from book where date_sold < date "2003-01-01";
...
delete from sponsor where state < "A" or state > "Z";
...
delete from person where current of SQL_CUR_f3f0_08b0;
See Also
select
update
rsqlGetCursorName
rsqlSetCursorName
rsqlGetRowCount

RDM SQL Language Guide
SQL Statement Reference 256
drop database
Drop (delete) a database
Syntax
dropdb_stmt:
drop database {db_name | "db_name@tfs_spec"}
tfs_spec:
"HostComputerName[:ddddd]"
Description
The drop database statement can be used to drop (i.e., delete) the database named db_name. The string form must be used if it is necessary to identify the TFS on which the database is located. The tfs_spec is a string specifying the location on the network of the TFS where HostComputerName is just that and ddddd is the five digit TCP/IP port number on which that TFS is listening (default is 21553).
If the database is open you only need to specify the db_name and then execution of the drop database state-ment will close it. The database remains closed even when the drop database statement fails (except for err-TRACTIVE).
Status errNODB is returned if the database cannot be found. Status errDBINUSE is returned if another task or user has the database open. Status errTFSFAILURE is returned when a connection to the specified TFS can-not be made.
Execution of a drop database completely deletes the database and is irrecoverable (i.e., a rollback statement cannot undo a drop database).
Example
open bookshop;
drop database bookshop;
drop database "nsfawards@nsfTFS:21695";
See Also
initialize
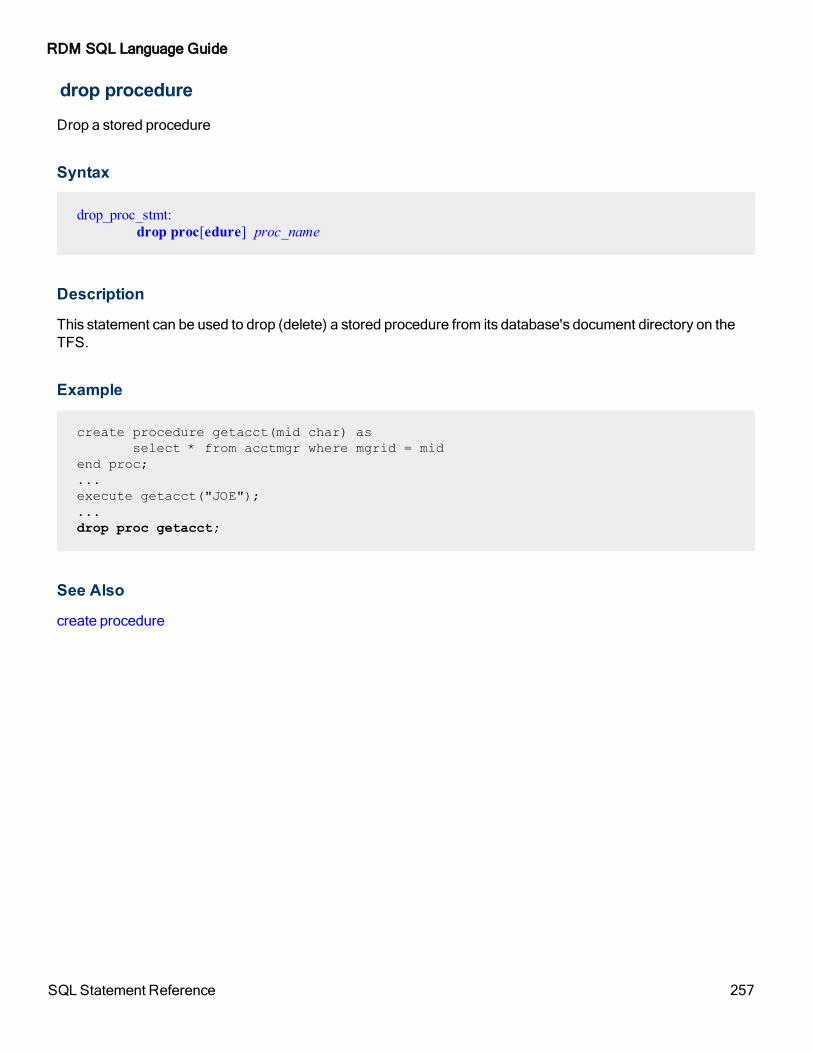
RDM SQL Language Guide
SQL Statement Reference 257
drop procedure
Drop a stored procedure
Syntax
drop_proc_stmt:
drop proc[edure] proc_name
Description
This statement can be used to drop (delete) a stored procedure from its database's document directory on the TFS.
Example
create procedure getacct(mid char) as
select * from acctmgr where mgrid = mid
end proc;
...
execute getacct("JOE");
...
drop proc getacct;
See Also
create procedure
RDM SQL Language Guide
SQL Statement Reference 258
end read only transaction
End a read only transaction
Syntax
end_trans_stmt:
end read only trans[action]
Description
This statement is used to terminate a read only transaction.
Example
start transaction read only;
select * from book;
end read only trans;
See Also
commit
rollback
start transaction

RDM SQL Language Guide
SQL Statement Reference 259
execute
Execute a stored procedure
Syntax
execute_stmt:
[exec[ute] | run] proc_name [(constant[, constant]...)]
Description
The execute statement will execute the stored procedure named proc_name. An argument value, constant, of the proper data type must be specified for each argument that was declared in the create procedure statement for proc_name. Specification of the execute keyword is optional. Thus, the procedure can be invoked simply by specifying proc_name followed by the argument values enclosed in parentheses.
When executing a modification or transactional stored procedure, either all or none of the changes by the pro-cedure's insert, update, and delete statements will be made. If an error occurs (e.g., a referential integrity error) during execution of any one of the included statements then all changes made since the start of the procedure will be discarded.
For retrieval stored procedures that contain more than one select statement, rsqlMoreResults must be called to execute each subsequent select after the first. After the last select has returned errNOMOREDATA, a call to rsqlMoreResults will also return errNOMOREDATA indicating that the last select has been executed.
Example
create proc authors_books(lastnm char) as
select publ_yr, title from book where last_name = lastnm
end proc;
...
authors_books("PotterB");
PUBL_YR TITLE
1903 The Tailor of Gloucester
1903 The tale of Squirrel Nutkin
1904 The tale of Benjamin Bunny
1904 The tale of Peter Rabbit; thirty-one illustrations.
1905 The pie and the patty-pan.
1905 The tale of Mrs. Tiggy-Winkle
1906 The tale of Mr. Jeremy Fisher
1908 The tale of Jemima Puddle-Duck
1907 The tale of Tom Kitten
1911 The tale of Timmy Tiptoes
1912 The tale of Mr. Tod
1913 The tale of Pigling Bland
1918 The tale of Johnny Town-mouse
...

RDM SQL Language Guide
SQL Statement Reference 260
create procedure sold(pid char, bid char, offer double, sale_date char) as
start transaction
update book set price = offer, date_sold = sale_date where bookid = bid
insert into sale values bid, pid
commit
end proc;
...
execute sold("SMD", "potter08", 750.0, date "2011-04-03");
...
See Also
create procedure

RDM SQL Language Guide
SQL Statement Reference 261
export
Export select statement result rows into a file
Syntax
export_stmt:
export into [char | wchar | xml] file "filename" from select_stmt
Description
The export statement is used to store the result rows from a select statement in either a comma-delimited char-acter (file, char file) or wide character (unicode) file (wchar file) or into an XML formatted file (xml file).
The file identified by filename will be created on the remote SQL server if the application is connected to a remote SQL server. Otherwise it will be created locally.
In XML format (xml file) the result column values are identified using XML attributes or tags to identify the col-umn name with which the tagged value is associated. The columns can be in any order but all necessary col-umns must be included (i.e., columns declared as not null without a default value or which are declared as a primary or unique key). Each row is bracketed between pairs of <ROW> and </ROW> tags. For each row col-umn values are specified between pairs of <column_name> and </column_name> tags. The file begins with a <RAIMA-SQL> tag and ends with a </RAIMA-SQL> tag.
Exporting to a comma separated file can be done for any select statement where for example columns may be reordered or expressions is used instead of column. When importing such files the actual order in the table must match the order of the columns for the table they are imported into.
Exporting to a XML file can also be done for any select statement. However where expressions is used instead of column the column name will not be meaningful. Such files can not be imported without manually editing the col-umn names.
Example
export into file "acctmgrs.txt" from select * from acctmgr;
export into xml file "books.xml" from select * from book;
See Also
import

RDM SQL Language Guide
SQL Statement Reference 262
import
Import rows into a table from a file
Syntax
import_stmt:
import into table_name from [char | wchar | xml] file "filename"
Description
The import statement is used to insert new rows into table table_name in database db_name. If db_name is not specified, then the first table named table_name found in the set of currently opened databases will be used. The file identified by filename must exist and be accessible on the remote SQL server if the application is connected to a remote SQL server. Otherwise it must exist and be accessible locally.
The data must either be stored in a comma-delimited or XML format. A comma-delimited format (file, char file, or wchar file) requires that each column value be specified in the order in which the columns are declared in the table. Absence of a column value is indicated by a blank or empty entry (e.g., ",,"). Specify wchar if the file is stored with wide characters. If either 'char', 'wchar', 'xml' is specified it defaults to 'char'.
In XML format (xml file) the column values are identified using XML attributes or tags to identify the column name with which the tagged value is associated. The columns can be in any order but all necessary columns must be included (i.e., columns declared as not null without a default value or which are declared as a primary or unique key). Each row is bracketed between pairs of <ROW> and </ROW> tags. For each row column values are specified between pairs of <column_name> and </column_name> tags. The file begins with a <RAIMA-SQL> tag and ends with a </RAIMA-SQL> tag.
Exporting to a comma separated file can be done for any select statement where for example columns may be reordered or expressions is used instead of column. When importing such files the actual order in the table must match the order of the columns for the table they are imported into.
Exporting to a XML file can also be done for any select statement. However where expressions is used instead of column the column name will not be meaningful. Such files can not be imported without manually editing the col-umn names.
Example
The following statements are used to load the sample data contained in comma-delimited text files into book-shop example database.
open database bookshop exclusive;
import into author from file "c:\bookshop\authors.txt";
import into book from file "c:\bookshop\books.txt";
import into genres from file "c:\bookshop\genres.txt";
import into subjects from file "c:\bookshop\subjects.txt";
import into related_name from file "c:\bookshop\names.txt";

RDM SQL Language Guide
SQL Statement Reference 263
import into genres_books from file "c:\bookshop\bookgens.txt';
import into subjects_books from file "c:\bookshop\booksubs.txt";
import into acctmgr from file "c:\bookshop\acctmgrs.txt";
import into patron from file "c:\bookshop\patrons.txt";
import into note from file "c:\bookshop\bnotes.txt";
import into note_line from file "c:\bookshop\bnotelines.txt";
import into note from file "c:\bookshop\pnotes.txt";
import into note_line from file "c:\bookshop\pnotelines.txt";
import into sale from file "c:\bookshop\sales.txt";
commit;
A portion of file sponsors.xml which can be used to load the sponsor table in the nsfawards database is shown below.
<RAIMA-SQL>
...
<ROW>
<name>UNAVCO, Inc.</name>
<addr>3360 Mitchell Lane</addr>
<city>Boulder</city>
<state>CO</state>
<zip>80301</zip>
</ROW>
<ROW>
<name>UNIAX Corporation</name>
<addr>6780 Cortona Drive</addr>
<city>Santa Barbara</city>
<state>CA</state>
<zip>93117</zip>
</ROW>
<ROW>
<name>UNIVERSITY OF MICHIGAN</name>
<addr>2455 Hayward Street</addr>
<city>Ann Arbor</city>
<state>MI</state>
<zip>48109</zip>
</ROW>
<ROW>
<name>UNIVERSITY OF WISCONSIN MA</name>
<addr></addr>
<city></city>
<state> </state>
<zip> / </zip>
</ROW>
<ROW>
<name>UNT Hlth Sci Ctr at Fort W</name>
<addr>Camp Bowie at Montgomery</addr>
<city>Fort Worth</city>
<state>TX</state>
<zip>76107</zip>
</ROW>

RDM SQL Language Guide
SQL Statement Reference 264
<ROW>
<name>URS Group, Inc.</name>
<addr>566 El Dorado Street - 2nd Floor</addr>
<city>Pasadena</city>
<state>CA</state>
<zip>91101</zip>
</ROW>
<ROW>
<name>US Army Corps of Engineers</name>
<addr>Transatlantic Programs Center</addr>
<city>Winchester</city>
<state>VA</state>
<zip>22601</zip>
</ROW>
...
</RAIMA-SQL>
See Also
export

RDM SQL Language Guide
SQL Statement Reference 265
initialize
Initialize database
Syntax
init_db_stmt:
initialize [database] db_name
Description
The initialize statement can be used to (re)initialize the database named db_name. Execution of this statement requires that the database has been opened in exclusive access mode and that it is the only database that is open.
Note that this statement will delete the entire contents of the specified database so be sure you know what you're doing before you execute this statement!
Note that the initialize statement is not transactional - i.e., you cannot rollback the changes made by this statement.
Example
open database bookshop exclusive;
initialize bookshop;
...import bookshop tables
See Also
open

RDM SQL Language Guide
SQL Statement Reference 266
insert
Insert a row or rows into a table
Syntax
insert_stmt:
insert into [db_name.]table_name [(column_name[, column_name]... )] data_source
data_source:
values value_expr[, value_expr]...
| [from] select_stmt
value_expr:
value_operand [{+ | - | * | /} value_operand]…
value_operand:
constant | arg_name | column_name | ? | scalar_fcn | ( value_expr )
Description
The insert statement is used to insert new rows into table table_name in database db_name. If db_name is not specified, then the first table named table_name found in the set of opened databases starting from the most recently opened will be used.
If a column_name list is not specified, the values must be listed in the same order as the columns have been declared in the create table statement for table_name.
Two forms of the insert statement are available. Use of the values clause specifies the values of the columns of the single row to be inserted into table_name. If a select_stmt is specified, it must return the number of result col-umns that match either the specified column_name list or the columns in the order declared in the table. The data type of each expression result in the values list or the select statement result columns must be commensurate with the corresponding table column's data type.
Column names can be referenced in a values expression but only one column reference in a value_expr is allowed and the referenced column's value_expr itself cannot contain a column reference.
The arg_name value_operand only applies if the insert statement is part of a create procedure statement.
Example
insert into author values "BarrieJ", "Barrie, J. M. (James Matthew)", "M", 1860,
1937,
"Scottish author and dramatist, best remembered today as the creator of Peter
Pan.";
insert into book values "descartes01", "DescartesR", "Principia philosophiae",

RDM SQL Language Guide
SQL Statement Reference 267
"12 p.l., 310 p. illus., diagrs. 21 cm.", "Amstelodami, apud Ludovicum Elzev-
irium",
1644, "B1860 1644", date "2010-09-22", null, 1.20*cost, 12750.0;
...
insert into se_tfs.nsforg select * from ne_tfs.nsforg;
...
insert into person(name) values "Unknown, Manager";
See Also
delete
update

RDM SQL Language Guide
SQL Statement Reference 268
lock table
Explicitly lock one or more database tables
Syntax
lock_stmt:
lock table [in db_name] table_lock[, table_lock]...
table_lock:
table_name [read | write | default]
Description
The lock table statement can be used to explicitly lock one or more tables contained in any of the databases cur-rently open in the connection in which this statement is executed. The in db_name clause can be specified to identify the specific database that contains the listed tables in the event that more than one database is open that have duplicate table names.
If neither read nor write is specified, then read is the default outside of a transaction and write is the default inside a transaction. Either all lock requests will succeed or none will. I.e., this is an either all or none request which can be used to prevent a deadlock situation in which one process holds a lock on table A while requesting a lock on table B while a second process is holding a lock on table B while requesting a lock on table A.
Write lock requests issued when a transaction is not active will return an error. If a read only transaction is active then the lock request will also return an error.
The system will switch into explicit locking mode on execution of the first lock table statement. In this mode, all tables that are accessed by any subsequent SQL statements must be explicitly locked. If not, SQL will return an errNOTLOCKED status. Note that the values of foreign key columns are retrieved from the referenced row in the primary key table (RDM SQL does not actually store them in the foreign key table). Hence, both the foreign and primary key tables must be explicitly locked when accessing foreign key column values. Once all explicitly lock tables have been freed, the system will switch back into implicit locking mode.
Read-locked tables can be freed by the unlock table statement. Write-locked tables can only be freed by a com-mit or rollback. Execution of a commit or rollback statement outside a transaction can also be used to free all read-locked tables.
Explicit locking allows you to issue a single grouped lock request at the beginning of a transaction that involves modifications to more than one table in order to ensure that the transaction will not cause a deadlock situation to arise. With implicit locking, the lock requests are made by execution of each insert, update, and delete statement which can potentially create a deadlock situation. Alternatively, you can use transactional stored procedures with implicit locking to achieve the same deadlock free guarantee.
NOTE: When using the Standalone TFS Configuration, lock requests are treated ignored as the data-base is opened exclusively

RDM SQL Language Guide
SQL Statement Reference 269
Example
start trans;
lock table acctmgr, patron;
insert into patron values "RLM","Merilatt, Randy", ..., "KATE";
commit;
See Also
unlock table
create procedure

RDM SQL Language Guide
SQL Statement Reference 270
open
Open a database
Syntax
open_db_stmt:
open [database] db_spec
[[in] {share | read only | exclusive} [mode] | as union of tfs_spec[, tfs_spec]...]
db_spec:
db_name | "[pathspec/]db_name"
tfs_spec:
"HostComputerName[:ddddd]"
Description
Databases are normally intended to be opened through calls to the RDM SQL API function rsqlOpenDB. The open statement provides an alternative that can be helpful when doing ad hoc testing using a utility such as rdmsql. The database to be opened in specified by the identifier db_name. The string form of the db_spec can have a path (subdirectory or IP address) prefixed to the db_name. If no other options are specified, the database is opened in shared mode on the default Transaction File Server (TFS). The open mode can be explicitly spec-ified as share or exclusive. If exclusive then the open only succeeds when no other tasks have the database open. If read only then the database can only be accessed by select statements and any attempt to start a trans-action or execute an insert, update, or delete statement will return an error.
Difference instances of database db_name that are stored on separate TFSs can be opened as a union by spec-ifying the host computer and port numbers of each TFS. The tfs_spec is a string specifying the location on the net-work of the TFS where HostComputerName is just that and dddd is the four digit TCP/IP port number on which that TFS is listening. Each database is opened in read-only mode. Access to the content of the databases must be made through normal select statements that are executed inside a read-only transaction. Note that a data-base union is a union of different instances of the same database schema (i.e., definition) contained on separate TFSs. This is not to be confused with the standard SQL union of select statements operation.
NOTE: If the pathspec or HostComputerName is specified, the database specification must be quoted.
Example
open bookshop exclusive;
insert into author values "BarrieJ", "Barrie, J. M. (James Matthew)", "M", 1860,
1937,
RDM SQL Language Guide
SQL Statement Reference 271
"Scottish author and dramatist, best remembered today as the creator of Peter
Pan.";
...
open nsfawards as union of "Northeast_TFS:1650", "Southeast_TFS:1650",
"Midwest_TFS:1650", "West_TFS:1650";
start read only transaction;
select state, sum(amount) from award join sponsor on sponsor_nm = name group by
state;
See Also
start transaction

RDM SQL Language Guide
SQL Statement Reference 272
release
Release a transaction savepoint
Syntax
release_stmt:
release savepoint savepoint_id]
Description
The release statement is used to release a transaction savepoint identified by savepoint_id that was established by a prior execution of a savepoint statement. Once a savepoint is released, all of the changes made since that savepoint can only be discarded by a rollback of the entire transaction.
Of course, this statement requires that a transaction has been started and that a savepoint has been executed for the specified savepoint_id.
Savepoints are also discarded through execution of a rollback to a prior savepoint, or a rollback or commit of the transaction.
Example
start trans;
insert into acctmgr ... new account manager
savepoint new_patron;
insert into patron ... new patron for new acct manager
insert into patron ... another for the new acct manager
... no problems encountered
release savepoint new_patron;
... other changes
commit;
See Also
savepoint

RDM SQL Language Guide
SQL Statement Reference 273
rollback
Rollback (undo) a transaction's changes
Syntax
rollback_stmt:
rollback [work] [[to savepoint] savepoint_id]
Description
The rollback statement discards (undoes) all changes that have been made to any open databases since the most recent start transaction statement or, if no start was issued, since the last commit or rollback statement was executed, or, if neither a start, commit, or rollback have been issued, since the start of the session.
This statement can also used to rollback the changes that have been made since the savepoint specified by save-point_id was issued.
This statement is also used to terminate a read only transaction.
Example
start transaction;
... /* make some changes to the database */
... /* system detects invalid data */
rollback;
See Also
commit
start transaction
rsqlTransRollback
rsqlTransEndReadOnly

RDM SQL Language Guide
SQL Statement Reference 274
savepoint
Mark a transaction savepoint
Syntax
savepoint_stmt:
savepoint savepoint_id
Description
The savepoint statement is used to mark a transaction savepoint identified by savepoint_id that can be the target of a subsequently executed rollback [to savepoint] savepoint_id statement which will cause all of the database modifications made after this savepoint to be discarded while keeping intact all changes made in the transaction prior to this savepoint.
Of course, this statement requires that a transaction has been started.
Savepoints are discarded through execution of a release savepoint statement, a rollback to a prior savepoint, or a rollback or commit of the transaction.
Example
start trans;
insert into acctmgr ... new account manager
savepoint new_patron;
insert into patron ... new patron for new acct manager
insert into patron ... another for the new acct manager
... discover problem with new patrons
rollback savepoint to new_patron;
commit;
See Also
release
rollback

RDM SQL Language Guide
SQL Statement Reference 275
select
Retrieve a set of rows of data from the database
Syntax
select_stmt:
select [first] [all | distinct] {* | select_item[, select_item]...}
from table_ref[, table_ref]...
[where conditional_expr]
[grouping | sorting | grouping sorting]
[limit (num {rows | mins | secs | msecs})]
[for {read only | update [of column_name[, column_name]...]}]
grouping:
group by sort_col[, sort_col]... [having conditional_expr]
sorting:
order by sort_col [asc | desc][, sort_col [asc | desc]]...
sort_col:
num | column_name
select_item:
expression [alias_name | "column heading"]
table_ref:
table_primary | table_join
table_primary:
table_spec | ( table_join )
table_spec:
[db_name.]table_name [[as] correlation_name]
table_join:
natural_join | qualified_join | cross_join
natural_join:
table_ref natural [inner | {left | right} [outer]] join table_primary

RDM SQL Language Guide
SQL Statement Reference 276
qualified _join:
table_ref [inner | {left | right} [outer]] join table_primary
[using (column_name[, column_name]...) | on conditional_expr]
cross_join:
table_ref cross join table_primary
arith_expr:
expression /* involving only numeric operands and operations */
dt_expr:
expression /* involving only date/time/timestamp operands and operations */
string_expr:
expression /* involving only string operands and operations */
expression:
operand [arith_operator operand]...
operand:
constant | param_ref | column_ref | function | (expr)
param_ref:
? | :param_name
column_ref:
[{table_name | correlation_name}.]column_name
arith_operator:
+ | - | * | /
function:
aggregate_fcn | scalar_fcn
aggregate_fcn:
{sum | avg | max | min} (expression)
| count ({* | column_ref })
| aggregate_udf_name ([expression][, expression]...)
scalar_fcn:
| if (conditional_expr, expression, expression)
| numeric_function | datetime_function | string_function
| scalar_udf_name ([expression][, expression]...)

RDM SQL Language Guide
SQL Statement Reference 277
numeric_function:
abs(arith_expr)
| acos(arith_expr)
| asin(arith_expr)
| atan(arith_expr)
| atan2(arith_expr)
| {ceil | ceiling}(arith_expr)
| cos(arith_expr)
| cot(arith_expr)
| exp(arith_expr)
| floor(arith_expr)
| {ln | log}(arith_expr)
| mod(arith_expr)
| pi()
| rand(num)
| sign(arith_expr)
| sin(arith_expr)
| sqrt(arith_expr)
| tan(arith_expr)
datetime_function:
age(dt_expr)
| {curdate | current_date}()
| {curtime | current_time}()
| dayofmonth(dt_expr)
| dayofyear(dt_expr)
| hour(dt_expr)
| minute(dt_expr)
| month(dt_expr)
| quarter(dt_expr)
| second(dt_expr)
| week(dt_expr)
| year(dt_expr)
string_function:
ascii(string_expr)
| char(num)
| concat(string_expr, string_expr)
| convert(expression, {convert_type | {char}, width, convert_format})
| lcase(string_expr)
| left(string_expr, num)
| length(string_expr)
| locate(string_expr, string_expr, num)
| ltrim(string_expr)
| repeat(string_expr, num)
| replace(string_expr, string_expr, string_expr)
| right(string_expr, num)
| rtrim(string_expr)
| substring(string_expr, num, num)

RDM SQL Language Guide
SQL Statement Reference 278
| ucase(string_expr)
| unicode(string_expr)
convert_type:
char |smallint | integer | real
| double | date | time | timestamp | tinyint | bigint
convert_format:
numeric_format | datetime_format
numeric_format:
"[<< | >> | ><]['text' | $][- | (][#,]#[.#[#]...][e | E]['text' | $ | %]"
datetime_format:
"[<< | >> | ><]['text' | spchar | date_code | time_code]..."
date_code:
m | mm | mmm | mon | mmmm | month
| d | dd | ddd | dddd | day
| yy | yyyy
time_code:
h | hh | m | mm | s | ss | .f[f]... | [a/p | am/pm | A/P | AM/PM]
conditional_expr:
rel_expr [bool_oper rel_expr]...
rel_expr:
expression [not] rel_oper expression
| expression [not] between constant and constant
| expression [not] in (constant[, constant]...)
| column_ref is [not] null
| string_expr [not] like "string"
| not rel_expr
| ( conditional_expr )
rel_oper:
= | ==
| <
| >
| <=
| >=
| <> | != | /=
bool_oper:
& | && | and
| "|" | "||" | or

RDM SQL Language Guide
SQL Statement Reference 279
Description
The select statement retrieves a subset of data (the result set) from a table or tables. The result set contains rows that satisfy a conditional expression (where clause). If there is no condition for the where clause, the select statement retrieves all rows from the table or tables. If the select statement includes a group by clause, only rows that satisfy the where clause are reflected in grouping calculations.
A select first only returns the first row of the result set. A select distinct will eliminate duplicate rows from the result set. Note that this necessarily requires that the rows first be sorted and can be quite an expensive (i.e., time consuming) operation and should be avoided unless absolutely necessary. The default behavior is select all which returns all of the rows of the result set.
The select_item expressions can optionally be given an alias or alternate column heading.
The natural join specification indicates that the join is to be performed based on the common columns (names and types) from the two tables. The join is based on the columns from the table (or tables) specified on the left side of "natural … join" with those columns from the table (or tables) on the right side that have the same name. A natural left (right) outer join includes the results of the inner join plus those rows of the left (right) table that do not have a corresponding matching row in the joined table. An inner join is the default so that the specification of "nat-ural join" produces a natural inner join. For outer joins, "outer" does not need to be specified.
A qualified join is like a natural join except that it requires that the columns on which the join is to be formed be explicitly specified. Two specification methods are provided. The using clause requires you to name the common column names between the joined tables which are to be used to form the join allowing you to choose only the matching columns on which you want the join formed. The on clause requires you to specify the join predicates as conditional expressions exactly as they would be specified in the where clause. The on clause is necessary whenever the join is to be performed between columns that do not have the same name.
A cross join is simply a cross product of the two tables where each row of the left table is joined with each row of the right table so that the cardinality of the result (i.e., the number of result rows) is equal to the product of the car-dinalities of the two tables. An on clause cannot be specified with a cross join. However, there is nothing that restricts including join conditions in the where clause. In practice, there are very few times when a cross join is needed and since it can be a very expensive operation that can potentially produce huge result sets, its use should be avoided.
Parentheses are sometimes needed to be used to group joins when more than two tables are involved in the from clause. They are required when one table needs to be joined with two or more tables.
The group by clause defines a set of aggregate rows upon which computations are to be made. An aggregate consists of those rows that have identical values in the columns that are named in the group by specification. Each of the other selected columns should either have a unique value within each aggregate or be a computation that uses of one or more aggregate functions (sum, avg, min, max, count, or an aggregate UDF). Only one row is reported for each aggregate resulting from the select.
The having clause is similar to the where clause in that it is used to conditionally select which resultant rows will be reported. However, the having conditional expression is not evaluated until after the group by processing has been performed. The conditional expression will include comparisons that typically involve the aggregate func-tions in the select column list.
The limits clause can be specified to limit either the number of rows that are returned or the amount of time the select statement is allowed to run. This feature is particularly useful when retrieving data from a virtual table which may represent a never-ending source of data (such as from a weather sensor network).

RDM SQL Language Guide
SQL Statement Reference 280
The for read only clause will cause RDM SQL to execute the select statement within its own read only trans-action which accesses a static, transaction-consistent version of the database at the time the select statement executes and does not require any locking to be performed.
The for update clause indicates that the select statement is updateable by a positioned update on a separate statement handle in the same connection that references the cursor name associated with this select.. An updateable select is one for which the select result expressions are only simple column names, only one table is listed in the from clause, and no order by clause is specified. If an of column name list clause is specified then only those select result columns can be updated. If the of column name list clause is not specified then any of the select result columns can be updated. Any columns declared in the table can be referenced in the associated update (i.e., used in the set assignment of one of the updateable columns). The cursor name associated with the select statement can be set by a call to function rsqlSetCursorName or the system-generated cursor name can be retrieved through a call to rsqlGetCursorName. The cursor name needs to be specified in the where current of clause of the related positioned update statement.
Example
select name, sum(amount) from sponsor join award on sponsor_nm = name
group by name order by 2 desc;
...
select sum(if(gender="M",1,0)) men, sum(if(gender="F",1,0)) women
from award natural join investigator natural join person;
...
select loc_long, loc_lat, convert(rdg_time,date), hour(rdg_time),
avg(temperature), avg(pressure), avg(humidity), avg(light) from weather_data
group by 1,2,4
limit(4 hours);
...
select bookid, publ_year, last_name, title from book where publ_year < 1800;
...
select aucid, count(*) from auction natural join bid where start_date = curdate()
group by 1;
...
See Also
set read only transaction mode
update

RDM SQL Language Guide
SQL Statement Reference 281
set
Set an SQL operational parameter value
Syntax
set_option_stmt:
set timeout [to | =] constant
| set autocommit [to | =] {on | off}
| set read only trans[action] mode [to | =] {auto | manual}
| set debug [to | =] {0 | 1}
Description
The set statement is used to set a variety of different RDM SQL operational parameters. The set currency, thou-sands, and decimal statements set the currency, thousands separator, and decimal symbols to be used in the format_spec of the display clause of the create domain and create table statements and the convert string func-tion. All of the parameter settings apply to the connection handle and, thus, all of the statement handles that have been allocated on that connection.
The set timeout sets the number of seconds to wait for a locked table to become available. The default is 30 sec-onds. Setting timeout to -1 will disable timeouts which we do not recommend doing. A timeout value of 0 will cause lock requests to timeout immediately when the requested lock is not available.
The set autocommit can be used to turn on or off autocommit mode. When autocommit is on, each insert, update, and delete statement will automatically issue a transaction commit at the end of the statement unless a transaction was explicitly started by the application prior to the statement's execution.
The read only transaction mode is set to manual by default. In manual mode, each select statement will issue read lock requests on the tables to be accessed. In this mode, execution of a select statement can return an errTIMEOUT status. When read only transaction mode is set to auto, select statements that are executed out-side of a transaction will automatically execute a start transaction read only marking the beginning of a group of related database reads in which the data being read has been "frozen" to its state at the time the transaction was started. Changes made after this by other connections are not blocked but they are also not visible. When the select statement completes (i.e., the cursor is closed), the read only transaction is automatically terminated.
The set debug statement can be used to enable the writing of files named "debug.ddd" into the current direc-tory where ddd begins with "000" and increases monotonically. Each file contains information for a single com-piled SQL select, update, or delete that is used by the RDM SQL query optimizer. At this time, this information is only of particular use to Raima support engineers and its use is, therefore, discouraged.
Example
set read only transaction mode to auto;
set timeout to 5;

RDM SQL Language Guide
SQL Statement Reference 282
See Also
create table
start transaction
rsqlSetAutoCommit
rsqlSetReadOnlyTrmode

RDM SQL Language Guide
SQL Statement Reference 283
set column
Set column statistics or SQL type for core database column
Syntax
set_column_stmt:
set column [db_name.]table_name.column_name
[type [to | =] {date | time | timestamp | long | {varchar | wvarchar}}]
[distinct values = num]
[range constant to constant]
| set column stats [db_name.]table_name.column_name
[distinct values = num]
[range constant to constant]
Description
The set column statement is used to specify an SQL-specific data type for a core (non-SQL) database and/or specify table column statistics that can be used by the RDM SQL optimizer to make better access method choices. (Note that the set column stats syntax is provided for compatibility with the earlier version of RDM SQL.)
Two types of statistics can be specified. The number of distinct values specifies the approximate number of dif-ferent values stored in the column. For example, a column of type smallint can theoretically contain 65,535 dif-ferent values. If, however, the actual number of different values is considerably smaller then that can have an important impact on the access choices the optimizer might be inclined to make. Similarly, the range clause is used to identify the range of values that the column can contain. Note that specifying the range only affects the optimizer. It does not mean that the SQL system will check to ensure that only those values are stored in the col-umn. The values specified in these two clauses are understood to be estimates and no problems are created when, for example, a column value actually falls outside the specified range. The database in which the table col-umn is declared must be opened when set column is called. The assigned values are only active for the duration of the connection. However, you can use the create catalog statement to update the catalog with the new values.
The type clause can be used to specify an SQL-specific data type for a core database field. You can specify date for an (32-bit) integer field but it must contain a valid DATE_VAL value (the number of elapsed days since Jan 1, 1 AD which has a value 1). You can specify time for an (32-bit) integer field but it must contain a valid TIME_VAL value (the number of elapsed seconds since midnight times 10,000). You can specify timestamp for a (64-bit) bigint field but it must contain a valid TIMESTAMP_VAL value (DATE_VAL and TIME_VAL combined). Since core databases do not differentiate between binary and character blob fields, you can also specify long varchar or long wvarchar for a blob field.
Example
open nsfawards;
set column nsfawards.person.gender distinct values = 3;
set column nsfawards.person.jobclass distinct values = 2;

RDM SQL Language Guide
SQL Statement Reference 284
...
open mycoredb;
set column coretab.blobfield type to long varchar;
See Also
create table
create catalog
rsqlPackDate
rsqlPackTime
rsqlPackTimestamp

RDM SQL Language Guide
SQL Statement Reference 285
start
Start a transaction
Syntax
start_stmt:
{start trans[action] | begin [work] [trans[action]]} [read only]
Description
The start transaction statement does just that: it begins a transaction. A transaction is defined as a group of related database changes that are either committed (made permanent) or rolled-back (discarded) as a group. This is necessary in order to maintain the logical consistency of the database content in case the system fails (e.g., power failure) in the middle of the transaction. All database changes (insert, update, delete statement executions) made after start are written in a single atomic operation upon execution of the commit statement. The changes made after start can be discarded (e.g., in the event of a user input error) upon execution of the roll-back statement.
Note that SQL will automatically start a transaction upon execution of the first insert, update, or delete statement where a start transaction has not already been executed.
The read only option extends the transaction concept beyond being just "a group of related database changes" to being "a group of related database operations." A read only transaction marks the beginning of a group of related database reads in which the data being read has been "frozen" to its state at the time the transaction was started. Changes made by other connections are not blocked but they are also not visible to the connection issu-ing the start transaction read only statement until it is terminated by an end read only transaction, commit or rollback (any of which can be used to end a read only transaction) statement. Read only transactions improve total system throughput because they do not block (i.e., by issuing locks) database writers. However, is it impor-tant that read only transactions be short-lived as, due to implementation necessities, performance can degrade over time.
Issuing a start transaction when a transaction is already active is not allowed.
If autocommit is enabled, the execution of a start transaction will disable autocommit until the next commit or rollback is executed.
Example
...connection alpha...
start trans read only;
... issue a series of select statements
...meanwhile, over at connection omega...
start trans;
... issue a series of related insert, update, and delete statements

RDM SQL Language Guide
SQL Statement Reference 286
commit; -- alpha cannot see omega's changes
...back at alpha...
commit; -- ends alpha's read only transactions
... subsequent reads can now see omega's changes
See Also
commit
rollback
end read only transaction

RDM SQL Language Guide
SQL Statement Reference 287
unlock table
Explicitly unlock one or all read-locked database tables
Syntax
unlock _stmt:
unlock table {[db_name.]table_name | all}
Description
This statement will free the read lock on table table_name or will free all read locks from previously executed lock table statements. This statement can only be executed outside of a transaction. The locks held within a trans-action can only be freed through a transaction commit or rollback.
Example
lock table acctmgr, patron;
select * from acctmgr;
unlock table acctmgr;
select * from patron;
unlock table patron;
See Also
lock table

RDM SQL Language Guide
SQL Statement Reference 288
update
Update one or more rows in a table
Syntax
update_stmt:
update [db_name.]table_name
set column_name = expression[, column_name = expression]...
[where {conditional_expr | current of cursor_name}]
conditional_expr:
rel_expr [bool_oper rel_expr]...
rel_expr:
expression [not] rel_oper expression
| expression [not] between constant and constant
| expression [not] in (constant[, constant]...)
| column_ref is [not] null
| string_expr [not] like "string"
| not rel_expr
| ( conditional_expr )
rel_oper:
= | ==
| <
| >
| <=
| >=
| <> | != | /=
bool_oper:
& | && | and
| "|" | "||" | or
Description
The update statement modifies the column values in one or more rows from the specified table table_name. The statement sets the column values to the results of the specified expressions or null. Table columns that are ref-erenced in the conditional_expr and in each expression can only come from table_name.
The update statement is capable of two types of updates: searched updates and positioned updates. In a searched update, the update statement modifies all rows of the table that satisfy the specified conditional expres-sion. A positioned update is specified using the where current of cursor_name clause. The cursor_name must be that associated with an updateable select statement on another statement handle in the same connection

RDM SQL Language Guide
SQL Statement Reference 289
that has been compiled, executed, and fetched so that it is positioned on a valid row of its result set when the posi-tioned update is executed. The columns that can be updated are only those that are specified in the select state-ment's for update clause. If no of column name list was specified there, then any of the select statement result columns can be updated. Any columns declared in the table can be referenced in the associated update (i.e., used in the set assignment of one of the updateable columns). The cursor name associated with the select state-ment can be retrieved by a call to rsqlGetCursorName or set by the application through a call to rsqlSet-CursorName in the RDM SQL API.
If a primary or unique key is referenced by foreign keys, the behavior of the update statement is determined based on the on update clause specified in the create table. The default action (no on update clause specified) is to restrict (i.e. disallow) updates on a primary or unique key column in which there exists one or more rows in the referencing table with matching foreign key values. The on update restrict option explicitly specifies this same behavior. If the foreign key is declared with on update cascade then the values of all matching foreign key rows will be changed to the new primary or unique key value. Note that in RDM SQL this happens automatically with very little negative performance impact.
Example
start trans;
update author set last_name = "BronteE" where last_name = "Bronte";
insert into author values "BronteC", "Bronte, Charlotte", "F", 1816, 1855,
"English novelist, one of the 3 sisters whose novels are English lit. stand-
ards.";
commit;
See Also
create table
select
rsqlGetCursorName
rsqlSetCursorName

RDM SQL Language Guide
SQL UDF Reference 290
SQL UDF ReferenceFunction DescriptionudfInit Initialize execution of a user-defined functionudfTerm Terminate execution of a user-defined functionudfCheck Check user-defined function argument types and return result typeudfScalarCall Process call to a scalar user-defined functionudfAggCall Process call to an aggregate user-defined functionudfAggResult Fetch aggregate user-defined function result calculationudfAggReset Reset aggregate user-defined function grouping calculations

RDM SQL Language Guide
SQL UDF Reference 291
udfAggCall
Process call to an aggregate user-defined function
Prototype
RSQL_ERRCODE EXTERNAL_FCN udfAggCall(
HSTMT hstmt,
void *pFcnCtx,
uint16_t noargs,
const RSQL_VALUE *pArgs)
ArgumentshStmt (input) Statement handle of SQL statement referencing this UDF.pFcnCtx (input) Pointer to the user program allocated registration context data area.noargs (input) Number of arguments specified in SQL statement's UDF call.pArgs (input) Array of noargs argument value entries.
Description
The udfAggCall function is called by RDM SQL for each detail row from the current set of aggregate rows to per-form the detail calculations needed by the aggregate function.
The hStmt argument is the statement handle of the SQL statement that contains a reference to the UDF. It can be used by any of the UDF implementation functions to discover any needed information about the invoking state-ment (e.g., rsqlGetStmtType).
The pArgs argument is a pointer to an RSQL_VALUE array of noargs elements containing the value for each argument. The first argument value is contained in pArgs[0]. Refer to the SQL Data Types and Values section for details on the use of the RSQL_VALUE struct.
Example
#include "rsql.h"
...
/* ======================================================================
User function for matchcount() UDF
*/
static RSQL_ERRCODE EXTERNAL_FCN CntCall (
HSTMT hStmt, /* in: system handle */
void *cxtp, /* in: UDF context pointer */
uint16_t noargs, /* in: number of arguments to function */
const RSQL_VALUE *args) /* in: array of arguments */
{
COUNT_CTX *ccp = cxtp;

RDM SQL Language Guide
SQL UDF Reference 292
UNREF_PARM(hStmt)
UNREF_PARM(noargs)
if ( args[0].type != tNOVAL && args[1].type != tNOVAL ) {
if (args[0].type != tNULL) {
if ( (args[0].type != tCHAR && args[0].type != tVARCHAR)
||(args[1].type != tCHAR && args[1].type != tVARCHAR) )
ccp->stat = errUDFARG;
else {
ccp->stat = errSUCCESS;
if ( strstr(args[0].vt.cv, args[1].vt.cv) )
++ccp->count;
}
}
}
return errSUCCESS;
}
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected83 errUDF RX011 user-defined function error86 errUDFARG 21000 invalid funtion argument type
See Also
rsqlRegisterUDFs
udfCheck
udfInit
udfTerm
udfScalarCall
udfAggResult
udfAggReset

RDM SQL Language Guide
SQL UDF Reference 293
udfAggReset
Reset aggregate user-defined function grouping calculations
Prototype
RSQL_ERRCODE EXTERNAL_FCN udfAggReset(
HSTMT hStmt,
void *pFcnCtx)
ArgumentshStmt (input) Statement handle of SQL statement referencing this UDF.pFcnCtx (input) Pointer to the user program allocated registration context data area.
Description
The udfAggReset function is only used with aggregate UDFs. Its function is to reset the aggregated com-putational result to its initial value. The function is called by SQL at the beginning of execution and each time the group by column values change.
Example
#include "rsql.h"
...
/* ======================================================================
Reset function for matchcount() UDF
*/
static RSQL_ERRCODE EXTERNAL_FCN CntReset(
HSTMT hStmt, /* in: system handle */
void *cxtp) /* in: UDF context pointer */
{
COUNT_CTX *ccp = (COUNT_CTX *)cxtp;
UNREF_PARM(hStmt)
ccp->count = 0;
return errSUCCESS;
}
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected

RDM SQL Language Guide
SQL UDF Reference 294
See Also
rsqlRegisterUDFs
udfCheck
udfInit
udfTerm
udfScalarCall
udfAggCall
udfAggResult

RDM SQL Language Guide
SQL UDF Reference 295
udfAggResult
Fetch aggregate user-defined function result calculation
Prototype
RSQL_ERRCODE EXTERNAL_FCN udfAggResult(
HSTMT hStmt,
void *pFcnCtx,
RSQL_VALUE *pResult)
ArgumentshStmt (input) Statement handle of SQL statement referencing this UDF.pFcnCtx (input) Pointer to the user program allocated registration context data area.pResult (output) Pointer to the RSQL_VALUE variable to contain the result value.
Description
The udfAggResult function is called by RDM SQL during execution of the SQL statement containing the UDF function reference to perform and return the desired aggregate calculation result. This function is designed to be called once after all of the detail rows have been processed. However, at this time, RDM SQL actually calls this function after each detail row has been fetched and after the udfAggCall function has been called. So, this func-tion should never reset the aggregate computational value—that is the job of the udfAggReset function.
The result value needs to be returned in the RSQL_VALUE variable pointed to by the pResult output argument. Note that for tCHAR/tVARCHAR result values the pResult->vt.cv is assigned to a pointer to a null-ter-minated char array for a character string result value. The memory containing the string must not be local to the udfAggResult function as it will go out of scope as soon as the function returns. The memory needed for results that are dynamic (e.g., character strings, binary arrays, etc.) will normally be contained or managed in the func-tion context data area (pFcnCtx). Refer to the SQL Data Types and Values section for details on the use of the RSQL_VALUE struct.
Example
#include "rsql.h"
. . .
/* ======================================================================
User function for matchcount() UDF
*/
static RSQL_ERRCODE EXTERNAL_FCN CntResult (
HSTMT hStmt, /* in: system handle */
void *cxtp, /* in: UDF context pointer */
RSQL_VALUE *result) /* out: result value */
{
RSQL_ERRCODE stat;

RDM SQL Language Guide
SQL UDF Reference 296
COUNT_CTX *ccp = (COUNT_CTX *)cxtp;
UNREF_PARM(hStmt)
if ( ccp->stat != errSUCCESS ) {
result->type = tSMALLINT;
result->vt.sv = (int16_t) ccp->stat;
stat = errSQLERROR;
}
else {
result->type = tBIGINT;
result->vt.llv = ccp->count;
stat = errSUCCESS;
}
return stat;
}
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected-2 errSQLERROR RX002 internal SQL error
See Also
rsqlRegisterUDFs
udfCheck
udfInit
udfTerm
udfScalarCall
udfAggCall
udfAggReset

RDM SQL Language Guide
SQL UDF Reference 297
udfCheck
Check user-defined function argument types and return result type
Prototype
RSQL_ERRCODE EXTERNAL_FCN udfCheck(
HSTMT hStmt,
void *pRegCtx,
uint16_t noargs,
const RSQL_VALUE *pArgs,
SQL_T *pType,
int16_t *pDeterm)
ArgumentshStmt (input) Statement handle of SQL statement referencing this UDF.pRegCtx (input) Pointer to the user program allocated registration context data area.noargs (input) Number of arguments specified in SQL statement's UDF call.pArgs (input) Array of noargs argument value entries.pType (output) Pointer to variable to contain the data type of the UDF result value.pDeterm (output) Pointer to int16_t variable to contain the deterministic UDF indicator flag.
Description
This function is called by SQL during compilation (i.e. rsqlPrepare) of a SQL statement that contains a ref-erence to the user-defined function (UDF) for which this particular udfCheck function has been associated in the UDFLOADTABLE specified in a prior call to the rsqlRegisterUDFs function. The function can have any name you choose.
The hStmt argument is the statement handle of the SQL statement that contains a reference to the UDF. It can be used by any of the UDF implementation functions to discover any needed information about the invoking state-ment (e.g., rsqlGetStmtType).
The pRegCtx is the registration context pointer that was passed by the application to the rsqlRegisterUDFs function. This can be used to pass any necessary application-specific control information that may be needed by any of the UDFs (e.g., a random number seed for any function that generates random numbers).
The pArgs argument is a pointer to an RSQL_VALUE array of noargs elements. The first argument is con-tained in pArgs[0]. Most of the time, only the data type from the pArgs RSQL_VALUE array (e.g., args[0].type) needs to be inspected as the actual data value will only be present when a literal constant value is being passed to the function. In order to know which arguments have a literal value, the status field of RSQL_VALUE can be checked (e.g., args[0].status). When a value is present the status will be set to vsOKAY, if no value is present the status will be set to vsNOVAL. You can use this, for example, when you want to define an argument for a particular function that is only allowed to take a literal constant. If an argument was specified using a parameter marker or the argument is a stored procedure argument the type will be tNOVAL. In which case, the actual type checking will need to be done at execution time by the udfScalarCall/udfAggCall function.

RDM SQL Language Guide
SQL UDF Reference 298
The data type returned by the UDF is returned through the pType argument. The valid RDM SQL_T data type values that can be returned by a UDF are specified in the table below.
SQL Data Type SQL_T value C Data Typechar tCHAR char
varchar tVARCHAR char
wchar tWCHAR wchar_t
wvarchar tWVARCHAR wchar_t
binary tBINARY uint8_t
varbinary tVARBINARY uint8_t
boolean tBOOL int8_t
tinyint tTINYINT int8_t
smallint tSMALLINT int16_t
integer tINTEGER int32_t
bigint tBIGINT int64_t
real tREAL float
float, double tFLOAT, tDOUBLE double
date tDATE int32_t
time tTIME int32_t
timestamp tTIMESTAMP int64_t
Table 1. SQL Data Type Values
The pDeterm argument is returned from udfCheck to indicate whether or not the function is deterministic. Set-ting *pDeterm to 1 indicates that the function is deterministic. Setting *pDeterm to 0 indicates that it is not. A deterministic function always returns the same value for all calls that pass the same argument values. This means that when all of the argument values for a particular call are literals then SQL will call udfInit, udf-ScalarCall, and udfTerm when the statement that references the UDF is compiled and then replace the call with the literal result value in the compiled statement code.
Example
#include "rsql.h"
...
/* ======================================================================
Soundex - type checking function (1 argument == name to be encoded)
*/
static RSQL_ERRCODE EXTERNAL_FCN SndxCheck(
HSTMT hStmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to registration context */
uint16_t noargs, /* in: number of arguments to function */
const RSQL_VALUE *args, /* in: array of argument values */
SQL_T *fcntype, /* out: result data type */
int16_t *pDeterm) /* out: = 1 deterministic */
{
RSQL_ERRCODE status;
UNREF_PARM(hStmt)
UNREF_PARM(pRegCtx)

RDM SQL Language Guide
SQL UDF Reference 299
if ( !args || noargs != 1 )
status = errUDFNOARGS;
else if ( args->type != tNOVAL && args->type !=tCHAR && args->type !=tVARCHAR
)
status = errUDFARG;
else {
status = errSUCCESS;
*fcntype = tCHAR;
*pDeterm = 1;
}
return status;
}
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected83 errUDF RX011 user-defined function error86 errUDFARG 21000 invalid funtion argument type
See Also
rsqlRegisterUDFs
udfInit
udfTerm
udfScalarCall
udfAggCall
udfAggResult
udfAggReset

RDM SQL Language Guide
SQL UDF Reference 300
udfInit
Initialize execution of a user-defined function
Prototype
RSQL_ERRCODE EXTERNAL_FCN udfInit(
HSTMT hStmt,
void *pRegCtx,
void *pFcnCtx)
ArgumentshStmt (input) Statement handle of SQL statement referencing this UDF.pFcnCtx (input) Pointer to the user program allocated registration context data area.pResult (output) Pointer to the RSQL_VALUE variable to contain the result value.
Description
The udfInit function is called by RDM SQL when the SQL statement containing the UDF call is executed (rsqlExecute). This function is used to initialize data that needs to survive multiple calls to the udfScalarCall or udfAggCall functions during the processing of the SQL statement. The pointer to this allocated memory is called the function context pointer and is passed to the udfInit function (as well as each of the other execution-time func-tions) through the pFcnCtx argument. If no initialization is needed then this function is unnecessary and its entry in the UDFLOADTABLE can be assigned to NULL.
The hStmt argument is the statement handle of the SQL statement that contains a reference to the UDF. It can be used by any of the UDF implementation functions to discover any needed information about the invoking state-ment (e.g., rsqlGetStmtType).
The pRegCtx argument is the registration context pointer that was passed by the application to the rsqlRe-gisterUDFs function. This can be used to pass any necessary application-specific control information that may be needed by any of the UDFs (e.g., a random number seed for any function that generates random numbers).
The pFcnCtx argument is a pointer to the function context data area and is typically defined as a struct type with fields defined for any of the data that needs to survive the calls to the udfScalarCall or udfAggCall functions. RDM SQL will allocate and clear this memory based on the size (in bytes) specified in the call to rsqlRe-gisterUDFs (argument szFcnCtx).
Example
#include "rsql.h"
...
/* ======================================================================
Initialization function for generic UDF
*/

RDM SQL Language Guide
SQL UDF Reference 301
static RSQL_ERRCODE EXTERNAL_FCN MyUdfInit (
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to registration context */
void *pFcnCtx); /* in: ptr to fcn execution context data area */
{
MYUDF_CTX *pCtx = (MYUDF_CTX *)pFcnCtx;
UNREF_PARM(hStmt)
UNREF_PARM(pRegCtx)
/* do needed initialization of pCtx */
. . .
return errSUCCESS;
}
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected
See Also
rsqlRegisterUDFs
udfCheck
udfTerm
udfScalarCall
udfAggCall
udfAggResult
udfAggReset

RDM SQL Language Guide
SQL UDF Reference 302
udfScalarCall
Process call to a scalar user-defined function
Prototype
RSQL_ERRCODE EXTERNAL_FCN udfScalarCall(
HSTMT hstmt,
void *pFcnCtx,
uint16_t noargs,
const RSQL_VALUE *pArgs,
RSQL_VALUE *pResult)
ArgumentshStmt (input) Statement handle of SQL statement referencing this UDF.pFcnCtx (input) Pointer to the user program allocated registration context data area.noargs (input) Number of arguments specified in SQL statement's UDF call.pArgs (input) Array of noargs argument value entries.pResult (output) Pointer to the RSQL_VALUE variable to contain the result value.
Description
The udfScalarCall function is called by RDM SQL (usually) during execution of the SQL statement containing the user-defined function (UDF) reference to perform the desired calculation. It can also be called at compilation time when 1) the function is deterministic (as indicated by the pDeterm output argument from a prior call to the udfCheck function), and 2) when all of the argument values are literal constants.
The hStmt argument is the statement handle of the SQL statement that contains a reference to the UDF. It can be used by any of the UDF implementation functions to discover any needed information about the invoking state-ment (e.g., rsqlGetStmtType).
The pArgs argument is a pointer to an RSQL_VALUE array of noargs elements containing the value for each argument. The first argument value is contained in pArgs[0]. The result value needs to be returned in the RSQL_VALUE variable pointed to by the pResult output argument. Note that for tCHAR/tVARCHAR result values the pResult->vt.cv is assigned to a pointer to a null-terminated char array for a character string result value. The memory containing the string must not be local to the udfScalarCall function as it will go out of scope as soon as the function returns. The memory needed for results that are dynamic (e.g., character strings, binary arrays, etc.) will normally be contained or managed in the function context data area (pFcnCtx). Refer to the SQL Data Types and Values section for details on the use of the RSQL_VALUE struct.
Example
#include "rsql.h"
...

RDM SQL Language Guide
SQL UDF Reference 303
/* ======================================================================
Soundex() UDF - return soundex code for specified name
*/
static RSQL_ERRCODE EXTERNAL_FCN SndxCall (
HSTMT hStmt, /* in: system handle */
void *cxtp, /* in: UDF context pointer */
uint16_t noargs, /* in: number of arguments to function */
const RSQL_VALUE *args, /* in: array of arguments */
RSQL_VALUE *result) /* out: result value */
{
/* Soundex conversion table. See Wikipedia "Soundex" page */
static const char *const codes[] = {"bfpv","cgjkqsxz","dt","l","mn","r","hw",
NULL};
static const char *const sndxerr = "xERR";
int32_t cpos = 1;
int32_t cndx;
char cur_c;
char last_c = '\0';
SNDX_CTX *scp = cxtp;
char *sndx = &scp->sndx[0];
const char *name = args->vt.cv;
UNREF_PARM(hStmt)
UNREF_PARM(noargs)
result->type = tCHAR;
result->len = 0;
if ( !name || !isalpha(*name)
|| (args->type != tCHAR && args->type != tVARCHAR) ) {
result->vt.cv = sndxerr;
return errSUCCESS;
}
sndx[0] = (char) toupper(*name++);
strcpy(&sndx[1], "000");
for ( ; cpos < 4 && isalpha(*name); ++name) {
for (cndx = 0; codes[cndx] && cpos < 4; ++cndx) {
if ( strchr(codes[cndx], tolower(*name)) ) {
if ( cndx < 6 ) { /* "hw" */
cur_c = (char) ('1' + cndx);
if ( cur_c != last_c ) {
sndx[cpos++] = cur_c;
last_c = cur_c;
}
}
break;
}
}
if ( !codes[cndx] )
last_c = 0;
}

RDM SQL Language Guide
SQL UDF Reference 304
result->vt.cv = sndx;
return errSUCCESS;
}
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected83 errUDF RX011 user-defined function error86 errUDFARG 21000 invalid funtion argument type
See Also
rsqlRegisterUDFs
udfCheck
udfInit
udfTerm
udfAggCall
udfAggResult
udfAggReset

RDM SQL Language Guide
SQL UDF Reference 305
udfTerm
Terminate execution of a user-defined function
Prototype
void EXTERNAL_FCN udfTerm(
HSTMT hStmt,
void *pFcnCtx)
ArgumentshStmt (input) Statement handle of SQL statement referencing this UDF.pFcnCtx (input) Pointer to the user program allocated registration context data area.
Description
The udfAggResult function is called after the SQL statement containing the UDF reference has completed executing which, in the case of a select, means when the cursor has been closed either through the call to rsqlFetch that returns status errNOMOREDATA (automatically closing the cursor) or through a call to rsqlCloseStmt which is used to close a cursor before having scrolled completely through it.
The hStmt argument is the statement handle of the SQL statement that contains a reference to the UDF. The pFcnCtx argument is a pointer to the function context data area and is typically defined as a struct type with fields defined for any of the data that needs to survive the calls to the udfScalarCall or udfAggCall functions. RDM SQL will allocate and clear this memory based on the size (in bytes) specified in the call to rsqlRe-gisterUDFs (argument szFcnCtx).
Example
/* ======================================================================
Termination function for generic UDF
*/
static void EXTERNAL_FCN MyUdfTerm (
HSTMT hstmt, /* in: statement handle */
void *pFcnCtx); /* in: ptr to fcn execution context data area */
{
MYUDF_CTX *pCtx = (MYUDF_CTX *)pFcnCtx;
UNREF_PARM(hStmt)
/* do needed termination from pCtx */
. . .
}

RDM SQL Language Guide
SQL UDF Reference 306
See Also
rsqlRegisterUDFs
udfCheck
udfInit
udfScalarCall
udfAggCall
udfAggResult
udfAggReset

RDM SQL Language Guide
SQL Virtual Table Function Reference 307
SQL Virtual Table Function ReferenceFunction DescriptionvtFetch Fetch the next row in the virtual tablevtInsert Process execution of an insert statement into a virtual tablevtRowCount Return estimate of number of rows in virtual tablevtSelectClose Close select statement execution access to virtual tablevtSelectCount Return actual number of rows in virtual tablevtSelectOpen Process execution of SQL statement access to virtual table

RDM SQL Language Guide
SQL Virtual Table Function Reference 308
vtFetch
Fetch the next row in the virtual table
Prototype
RSQL_ERRCODE EXTERNAL_FCN vtFetch(
HSTMT hstmt,
uint16_t nocols,
VCOL_INFO *colsvals,
void *pRegCtx,
void *pFetchCtx)
Argumentshstmt (input) Statement handle of SQL statement containing the virtual table reference.nocols (input) Number of referenced columns (size of colsvals array).colsvals (input) Array of referenced column value containers.pRegCtx (input) Pointer to the user program allocated context data area that was originally passed in
through the call to rsqlRegisterVirtualTables.pFetchCtx (input) Pointer to the fetch context data area.
Description
This function is called by SQL to fetch the next row from the virtual table. The fetch context pointer, pFCtx, ref-erences the fetch context data area containing any virtual table specific data needed for processing the fetch (e.g., current row number). If a primary key lookup value was specified, then only one row should be retrieved. If not, then all rows in the table should be retrieved with status errNOMOREDATA being returned on the first call after the last row has been fetched. The necessary programming logic is best explained through the virtab example as shown below.
Example
1 /* ========================================================================
2 Virtual table fetch function
3 */
4 static RSQL_ERRCODE EXTERNAL_FCN vtabFetch( /* vtFetch() */
5 HSTMT hstmt, /* in: statement handle */
6 uint16_t nocols, /* in: no. of ref'd columns */
7 VCOL_INFO *colsvals, /* in: array of ref'd col value containers */
8 void *pRegCtx, /* in: ptr to registration context */
9 void *pFCtx) /* in: ptr to fetch context */
10 {
11 int16_t cno;
12 VTAB_CTX *pCtx = (VTAB_CTX *)pFCtx;
13 uint32_t rno = (uint32_t)pCtx->rowno;

RDM SQL Language Guide
SQL Virtual Table Function Reference 309
14
15 vtabEnter();
16
17 if ( rno == norows || (pCtx->pkeyval && pCtx->rowcnt) ) {
18 pCtx->rowno = 0;
19 vtabExit();
20 return errNOMOREDATA;
21 }
22 for (cno = 0; cno < nocols; ++cno) {
23 const VCOL_INFO *pCVal = &colsvals[cno];
24 if ( vtabrows[rno].is_null[pCVal->colno] )
25 *pCVal->is_null = 1;
26 else {
27 *pCVal->is_null = 0;
28 switch ( pCVal->colno ) {
29 case 0:
30 memcpy(pCVal->data, &vtabrows[rno].pkey, sizeof(int32_t));
31 break;
32 case 1:
33 strcpy(pCVal->data, vtabrows[rno].name);
34 break;
35 case 2:
36 strcpy(pCVal->data, vtabrows[rno].addr);
37 break;
38 case 3:
39 strcpy(pCVal->data, vtabrows[rno].city);
40 break;
41 case 4:
42 strcpy(pCVal->data, vtabrows[rno].state);
43 break;
44 case 5:
45 strcpy(pCVal->data, vtabrows[rno].zip);
46 break;
47 } /*lint !e744 */
48 }
49 }
50 ++pCtx->rowcnt;
51 ++pCtx->rowno;
52
53 vtabExit();
54
55 return errSUCCESS;
56 }
Note the call to vtabEnter at line 15 and its reciprocal calls to vtabExit at lines 19 and 53 serializing access to the norows and vtabrows variables. The if statement at line 17 tests the two conditions under which an errNOMOREDATA status code is to be returned.
The loop at lines 22 to 49 is used to copy the fetched row's information for each column in the colsvals array. This involves setting the correct null value indicator (lines 24-25) and, for the non-null columns, copying its value into the column's data buffer pointed to by the VCOL_INFO data field (lines 30, 33, 36, 39, 42, and 45).

RDM SQL Language Guide
SQL Virtual Table Function Reference 310
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected-1 errNOMOREDATA 02000 no more data
See Also
rsqlRegisterVirtualTables
vtRowCount
vtSelectCount
vtSelectOpen
vtSelectClose

RDM SQL Language Guide
SQL Virtual Table Function Reference 311
vtInsert
Process execution of an insert statement into a virtual table
Prototype
RSQL_ERRCODE EXTERNAL_FCN vtInsert(
HSTMT hstmt,
uint16_t nocols,
VCOL_INFO *colsvals,
void *pRegCtx)
Argumentshstmt (input) Statement handle of SQL statement containing the virtual table reference.nocols (input) Number of referenced columns (size of colsvals array).colsvals (input) Array of referenced column value containers.pRegCtx (input) Pointer to the user program allocated context data area that was originally passed in
through the call to rsqlRegisterVirtualTables.
Description
This is a callback function, implemented by you, that is called by SQL to execute the SQL insert statement that references the virtual table. The name of the function can be anything as the RDM SQL system only calls this function through a pointer to it contained in the VTFLOADTABLE struct entry for its associated virtual table.
Each entry of the colsvals array contains information about a virtual table column that is referenced in the SQL statement. This information is contained in the VCOL_INFO struct type whose fields are described in the following table.
Field Name Data Type Descriptioncolno int16_t Ordinal position of column in table declaration: 0 (first column) to # of col-
umns in table – 1 (last column).len uint32_t Column length in bytes.is_null int16_t * Pointer to variable containing the null indicator flag: *is_null = 0 => not null,
*is_null = 1 => is null.data void * Pointer to the buffer containing the column value.
Table 4. VCOL_INFO Description
Note that the is_null field is a pointer to the int16_t variable that is used by SQL system to indicate that a column value is null. By assigning this through the pointer it eliminates the need for the SQL system to perform an extra loop through the colsvals array.
All of the information needed to do the insert is provided in the vtInsert arguments. The colsvals array con-tains the values of the table columns to be inserted. The nocols argument specifies the number of entries in the colsvals array which could be less than the number of columns declared in the table.

RDM SQL Language Guide
SQL Virtual Table Function Reference 312
If the associated virtual table has a primary key then it is the responsibility of this function to ensure that any spec-ified primary key column value is unique. If a duplicate entry is found then the function needs to return status errDUPLICATE.
Example
1 /* ========================================================================
2 Virtual table INSERT execution function
3 */
4 static RSQL_ERRCODE EXTERNAL_FCN vtabInsert( /* vtInsert() */
5 HSTMT hstmt, /* in: statement handle */
6 uint16_t nocols, /* in: no. of ref'd columns */
7 VCOL_INFO *colsvals, /* in: array of ref'd column value containers
*/
8 void *pRegCtx) /* in: unused */
9 {
10 int32_t lv;
11 uint32_t rowno;
12 int16_t pkno = -1;
13 RSQL_ERRCODE stat = errSUCCESS;
14
15 UNREF_PARM(hstmt)
16 UNREF_PARM(pRegCtx)
17
18 vtabEnter();
19
20 if ( !vtabrows ) {
21 /* allocate virtab data area */
22 vtabrows = calloc(maxrows, sizeof(struct virtab));
23 }
24 /* locate specified primary key value, if any */
25 for (pkno = 0; pkno < nocols; ++pkno) {
26 if ( colsvals[pkno].colno == 0 ) {
27 /* locate row with matching primary key */
28 memcpy(&lv, colsvals[pkno].data, sizeof(int32_t));
29 for ( rowno = 0; rowno < norows; ++rowno ) {
30 if ( vtabrows[rowno].pkey == lv ) {
31 vtabExit();
32 return errDUPLICATE;
33 }
34 }
35 }
36 }
37 stat = vtabStoreRow(norows, nocols, colsvals);
38 if ( stat == errSUCCESS )
39 ++norows;
40
41 vtabExit();
42
43 return stat;
44 }

RDM SQL Language Guide
SQL Virtual Table Function Reference 313
Since the virtab table has a primary key, the function needs to locate the primary key value in the colsvals array so that its uniqueness can be checked. This is work is done at lines 24 to 36. Since the primary key is declared on the first column of the table, its value is located in the colsvals entry that has colno equal to 0 (line 26). Once found, the value is copied into the local int32_t variable lv. If a matching row is found the func-tion returns status errDUPLICATE indicate that an attempt was made to insert a row with a duplicate primary key value (lines 30-33).
1 /* ========================================================================
2 Store column values in specified row (0 = first row)
3 */
4 static RSQL_ERRCODE vtabStoreRow(
5 uint32_t rowno, /* in: row number into which store col vals */
6 uint16_t nocols, /* in: no. of ref'd columns */
7 const VCOL_INFO *colsvals) /* in: array of ref'd column value containers
*/
8 {
9 uint16_t cno;
10 const VCOL_INFO *pCol;
11 struct virtab *pRow;
12
13 if ( rowno >= maxrows )
14 return errVTSPACE;
15
16 pRow = &vtabrows[rowno];
17
18 for (pCol = colsvals, cno = 0; cno < nocols; ++cno, ++pCol ) {
19 if ( *pCol->is_null )
20 pRow->is_null[pCol->colno] = 1;
21 else {
22 pRow->is_null[pCol->colno] = 0;
23 switch (pCol->colno) {
24 case 0: memcpy(&pRow->pkey, pCol->data, sizeof(int32_t));
break;
25 case 1: strncpy(pRow->name, (char *)pCol->data, 24);
break;
26 case 2: strncpy(pRow->addr, (char *)pCol->data, 32);
break;
27 case 3: strncpy(pRow->city, (char *)pCol->data, 24);
break;
28 case 4: strncpy(pRow->state, (char *)pCol->data, 2);
break;
29 case 5: strncpy(pRow->zip, (char *)pCol->data, 9);
break;
30 } /*lint !e744 */
31 }
32 }
33 return errSUCCESS;
34 }
The rowno argument is index into vtabrows into which the row will be stored. The pRow pointer (assigned at line 16) is simply used to derefence that row in the code which follows. Lines 18-32 loop through the colsvals array in order to assign the values for each individual column into its field in the vtabrows struct array entry.

RDM SQL Language Guide
SQL Virtual Table Function Reference 314
It is important to note that the table column number is not cno but pCol->colno (lines 20, 22, and 23). Also note that in this example the len field of VCOL_INFO is not used but it could (should!) have been used to, for example, check for a possible truncation (i.e., where pCol->len is greater than the declared size of the col-umn).
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected90 errDUPLICATE 42000 duplicate primary/unique key value
See Also
rsqlRegisterVirtualTables
vtRowCount
vtSelectCount
vtSelectOpen
vtFetch
vtSelectClose

RDM SQL Language Guide
SQL Virtual Table Function Reference 315
vtRowCount
Return estimate of number of rows in virtual table
Prototype
RSQL_ERRCODE EXTERNAL_FCN vtRowCount(
HSTMT hstmt,
void *pRegCtx,
uint64_t *pNoRows)
Argumentshstmt (input) Statement handle of SQL statement containing the virtual table reference.pRegCtx (input) Pointer to the user program allocated context data area that was originally passed in
through the call to rsqlRegisterVirtualTables.pNoRows (output) Pointer to the variable to contain the number of rows.
Description
This is a callback function that implemented by you that is called by SQL during compilation of a SQL select state-ment that contains a reference to the virtual table in order to fetch an estimate of the number of rows in the table. The name of the function can be anything as the RDM SQL system only calls this function through a pointer to it contained in the VTFLOADTABLE struct entry for its associated virtual table.
The function is always called during compilation of a select statement. The returned number of rows does not need to be exact as it is only being used by the query optimizer to get an estimate of the number of rows in the table.
Some virtual tables (e.g., those that map to real-time sensors) may have an unlimited number of rows. Nev-ertheless, a value does need to be returned so you can set it to whatever makes the most sense for your appli-cation.
The pRegCtx pointer is that which was given in the call to rsqlRegisterVirtualTables which registered the VTFLOADTABLE for the database containing the definition for this particular virtual table.
The function must return status code errSUCCESS unless some application-dependent error has occurred which needs to be reported.
Example
/* ========================================================================
Virtual table 'virtab' row count function
*/
static RSQL_ERRCODE EXTERNAL_FCN vtabRowCount( /* vtRowCount() */
HSTMT hstmt, /* in: statement handle */
RDM SQL Language Guide
SQL Virtual Table Function Reference 316
void *pRegCtx, /* in: unused */
uint64_t *pNoRows) /* out: ptr to row count value */
{
UNREF_PARM(hstmt)
UNREF_PARM(pRegCtx)
vtabEnter();
*pNoRows = (uint64_t)norows;
vtabExit();
return errSUCCESS;
}
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected
See Also
rsqlRegisterVirtualTables
vtSelectCount
vtSelectOpen
vtFetch
vtSelectClose

RDM SQL Language Guide
SQL Virtual Table Function Reference 317
vtSelectClose
Close select statement execution access to virtual table
Prototype
RSQL_ERRCODE EXTERNAL_FCN vtSelectClose(
HSTMT hstmt,
void *pRegCtx,
void *pFetchCtx)
Argumentshstmt (input) Statement handle of SQL statement containing the virtual table reference.pRegCtx (input) Pointer to the user program allocated context data area that was originally passed in
through the call to rsqlRegisterVirtualTables.pFetchCtx (input) Pointer to the fetch context data area.
Description
This is a callback function, implemented by you, that is called by SQL when execution of the select statement con-tains a reference to the virtual table is closed. The name of the function can be anything as the RDM SQL system only calls this function through a pointer to it contained in the VTFLOADTABLE struct entry for its associated virtual table.
The pRegCtx pointer is that which was given in the call to rsqlRegisterVirtualTables which registered the VTFLOADTABLE for the database containing the definition of this particular virtual table.
The pFetchCtx points to the fetch context data area. Any additional allocated memory contained in pointers stored in this data area to support processing of the select statement referencing the virtual table should be freed by this function.
The function must return status code errSUCCESS unless some application-dependent error has occurred which needs to be reported.
Example
/* ========================================================================
Virtual table close function
*/
typedef void EXTERNAL_FCN vtabSelectClose(
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: ptr to registration context */
void *pFetchCtx) /* in: ptr to fetch context */
/*
Called by SQL when SELECT statement containing virtual table reference

RDM SQL Language Guide
SQL Virtual Table Function Reference 318
completes execution (i.e., when cursor is closed).
Use this function to do any needed cleanup and device termination actions.
*/
{
/* code to free any allocated memory or, perhaps
to power down virtual table device. */
}
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected
See Also
vtRowCount
vtSelectCount
vtSelectOpen
vtFetch

RDM SQL Language Guide
SQL Virtual Table Function Reference 319
vtSelectCount
Return actual number of rows in virtual table
Prototype
RSQL_ERRCODE EXTERNAL_FCN vtSelectCount(
HSTMT hstmt,
void *pRegCtx,
void *pFetchCtx,
uint64_t *pNoRows)
Argumentshstmt (input) Statement handle of SQL statement containing the virtual table reference.pRegCtx (input) Pointer to the user program allocated context data area that was originally passed in
through the call to rsqlRegisterVirtualTables.pFetchCtx (input) Pointer to the fetch context data area.pNoRows (output) Pointer to the variable to contain the number of rows.
Description
This is a callback function, implemented by you, that is called by SQL during compilation of a SQL select state-ment that contains a reference to the virtual table in order to fetch the count of the actual number of rows in the table. The name of the function can be anything as the RDM SQL system only calls this function through a pointer to it contained in the VTFLOADTABLE struct entry for its associated virtual table.
It is only called during the execution of a "select count(*) from virtab" statement in order to return the current actual number of rows in the virtual table.
Some virtual tables (e.g., those that map to real-time sensors) may have an unlimited number of rows. Nev-ertheless, a value does need to be returned. For the "select count(*)" the value returned still needs to be a fixed value so you can set it to whatever makes the most sense for your application.
The pRegCtx pointer is that which was given in the call to rsqlRegisterVirtualTables which registered the VTFLOADTABLE for the database containing the definition of this particular virtual table.
The function must return status code errSUCCESS unless some application-dependent error has occurred which needs to be reported.
Example
/* ========================================================================
Virtual table 'virtab' select count function
*/
static RSQL_ERRCODE EXTERNAL_FCN vtabSelectCount( /* vtSelectCount() */

RDM SQL Language Guide
SQL Virtual Table Function Reference 320
HSTMT hstmt, /* in: statement handle */
void *pRegCtx, /* in: unused */
void *pCtx, /* in: unused */
uint64_t *pNoRows) /* out: ptr to row count value */
{
vtabEnter();
*pNoRows = (uint64_t)norows;
vtabExit();
return errSUCCESS;
}
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected
See Also
rsqlRegisterVirtualTables
vtSelectCount
vtSelectOpen
vtFetch
vtSelectClose

RDM SQL Language Guide
SQL Virtual Table Function Reference 321
vtSelectOpen
Process execution of SQL statement access to virtual table
Prototype
RSQL_ERRCODE EXTERNAL_FCN vtSelectOpen(
HSTMT hstmt,
uint16_t nocols,
VCOL_INFO *colsvals,
void *pRegCtx,
void *pFetchCtx,
RSQL_VALUE *pkeyval)
Argumentshstmt (input) Statement handle of SQL statement containing the virtual table reference.nocols (input) Number of referenced columns (size of colsvals array).colsvals (input) Array of referenced column value containers.pRegCtx (input) Pointer to the user program allocated context data area that was originally passed in
through the call to rsqlRegisterVirtualTables.pFetchCtx (input) Pointer to the fetch context data area.pkeyval (input) Pointer to specified primary key value. Non-NULL only when executing "select ...
from virtab where pkey = value" statement.
Description
This is a callback function, implemented by you, that is called by SQL to execute a select statement that ref-erences the virtual table. The name of the function can be anything as the RDM SQL system only calls this func-tion through a pointer to it contained in the VTFLOADTABLE struct entry for its associated virtual table.
Each entry of the colsvals array contains information about a virtual table column that is referenced in the SQL statement. This information is contained in the VCOL_INFO struct type whose fields are described in the following table.
Field Name Data Type Descriptioncolno int16_t Ordinal position of column in table declaration: 0 (first column) to # of col-
umns in table – 1 (last column).len uint32_t Column length in bytes.is_null int16_t * Pointer to variable containing the null indicator flag: *is_null = 0 => not null,
*is_null = 1 => is null.data void * Pointer to the buffer containing the column value.
Table 4. VCOL_INFO Description
Note that the is_null field is a pointer to the int16_t variable that is used by SQL system to indicate that a column value is null. By assigning this through the pointer it eliminates the need for the SQL system to perform an extra loop through the colsvals array.

RDM SQL Language Guide
SQL Virtual Table Function Reference 322
The fetch context pointer contains the address of a data area that is be used by vtFetch to control the fetching of rows from the virtual table. The context used in the virtab example is defined by the VTAB_CTX struct typedef declaration given below.
typedef struct vtab_ctx {
uint64_t rowcnt; /* count of rows fetched */
uint64_t rowno; /* number of next row to be fetched */
RSQL_VALUE *pkeyval; /* ptr to primary key's value */
} VTAB_CTX;
The rowno contains the vtabrows index of the next row to be returned by vtFetch. The rowcnt and a non-NULL pkeyval is used to ensure that only one row is returned when the select statement included the "where pkey = value" clause.
If a primary key value is specified then vtSelectOpen needs to locate the row with that value (lines 30-34) and set pCtx->rowno to it. If it is not found then pCtx->rowno is set to norows which will cause vtFetch to return errNOMOREDATA.
Example
1 /* ========================================================================
2 Virtual table SELECT execution function
3 */
4 static RSQL_ERRCODE EXTERNAL_FCN vtabSelectOpen( /* vtSelectOpen() */
5 HSTMT hstmt, /* in: statement handle */
6 uint16_t nocols, /* in: no. of ref'd columns */
7 VCOL_INFO *colsvals, /* in: array of ref'd column value containers
*/
8 void *pRegCtx, /* in: ptr to registration context */
9 void *pFCtx, /* in: ptr to fetch context */
10 RSQL_VALUE *pkeyval) /* in: ptr to primary key value */
11 {
12 RSQL_ERRCODE stat = errSUCCESS;
13 uint32_t rowno;
14 VTAB_CTX *pCtx = (VTAB_CTX *)pFCtx;
15
16 UNREF_PARM(hstmt)
17 UNREF_PARM(pRegCtx)
18
19 pCtx->rowcnt = 0;
20 pCtx->rowno = rowno = 0;
21 pCtx->pkeyval = pkeyval;
22
23 vtabEnter();
24
25 if ( !vtabrows ) {
26 vtabrows = calloc(maxrows, sizeof(struct virtab));
27 }
28 else if ( pkeyval ) {
29 /* locate row with matching primary key */

RDM SQL Language Guide
SQL Virtual Table Function Reference 323
30 for ( rowno = 0; rowno < norows; ++rowno ) {
31 if ( pkeyval->vt.lv == vtabrows[rowno].pkey )
32 break;
33 }
34 pCtx->rowno = rowno;
35 }
36 vtabExit();
37
38 return stat;
39 }
Return Codes
Error Code Enum Identifier SQL State Description0 errSUCCESS 00000 no error was detected
See Also
rsqlRegisterVirtualTables
vtRowCount
vtSelectCount
vtFetch
vtSelectClose

RDM SQL Language Guide
Glossary 324
Glossary
B
B-treeAlso called a multiway tree, a B-tree is a fast data-indexing method that organizes the index into a multi-level set of nodes. Each node contains a sorted array of key values (the indexed data). Two important properties of a B-tree are that all nodes are at least half-full and that the tree is always balanced (that is, an identical number of nodes must be read in order to locate all keys at any given level in the tree). A well-organized B-tree will have only three or four levels.
bufferAn in-memory store of data read from a disk file, in which database operations are per-formed.
C
cacheA set of buffers used to optimize database input and output operations. All RDM Embedded database input and output is performed using a cache.
combineThe concatenation of the members of two or more set types into one set type.
commitThe point at which database changes made during a single transaction are actually written to the database files.
compound keyA key field composed of any combination of fields (not necessarily contiguous) from a rec-ord. Each field of a compound key may be stored in ascending or descending order.
connectThe process of inserting a member record occurrence into a set occurrence.
currency tablesA table of database addresses maintained by the RDM Embedded runtime system for con-trolling record access and set navigation. The currency tables consist of the current member table, current owner table, and the current record.

RDM SQL Language Guide
Glossary 325
current databaseThe database that is currently accessible by the RDM Embedded runtime functions when multiple databases have been opened. The current database is changed by the database number function argument or by function d_setdb.
current memberContains, for each set, the database address of a record occurrence that is a valid member of that set. Usually, the current member of a set is the last record accessed using a set navi-gation function (d_findfm, d_findlm, d_findnm, or d_findpm).
current ownerContains for each set, the database address of a record occurrence that is a valid owner of that set. Usually, the current owner of a set is established using the set navigation function d_findco or by using a currency manipulation function.
current recordContains the database address of the most recently accessed record instance.
D
data fieldA field represents the basic unit of information storage in a database and is always defined to be an element of a record. A field has associated with it attributes such as name, type (for example, char or int), and length. Other terms used for field include: attribute, entity, or col-umn.
data fileAn RDM Embedded file defined in a DDL specification that contains occurrences of one or more record types.
databaseAn organized collection of related files.
database addressThe location in the database of a record occurrence, frequently referred to as a DB_ADDR. Composed of two numbers: the file index and the slot within the file. Either 4 or 8 bytes long.
database definition languageA programming-like language used to define the structure and content of a database. RDM Embedded's Database Definition Language has been designed to be used with the C pro-gramming language.

RDM SQL Language Guide
Glossary 326
DDLA programming-like language used to define the structure and content of a database. RDM Embedded's Database Definition Language has been designed to be used with the C pro-gramming language.
deadlockA situation in which multiple processes accessing the same database each hold locks needed by the other processes in such a way that none of the processes can proceed. Sometimes called deadly embrace.
delete chainA linked list containing deleted records or nodes to be reused when a new record or node is created.
derived revisionA revision that can be derived from a comparison of the source and destination database dic-tionary files.
destimation databaseThe db_REVISE-created database that stores the specified revisions.
dictionaryA repository containing a definition of the content and structure of a database. It is used by the RDM Embedded runtime library functions for accessing and manipulating information from that database.
disconnectThe process of removing a member record from a set occurrence.
document rootThe path to the directory under which all files will be stored. Within the domain of one TFS, no files outside of this path may be accessed.
domain nameThe "name" of a computer which has visibility to another computer. This may be a published name available on DNS servers and across the Internet, or an internal network name visible only within a workgroup. The "ping" utility must be able to locate the IP address associated with this name. In RDM Embedded, a server (tfserver, dbmirror, dbrep, or dbrepsql) may be located through the domain name of the computer it is running on, together with the port on which it is listening. A special domain name, "localhost" always refers to the same computer as the application is running on (IP address is always 127.0.0.1).

RDM SQL Language Guide
Glossary 327
E
environment variableA programmer-specified operating system parameter that is used to identify configuration information to the runtime system.
F
fieldA field represents the basic unit of information storage in a database and is always defined to be an element of a record. A field has associated with it attributes such as name, type (for example, char or int), and length. Other terms used for field include: attribute, entity, or col-umn.
fileThe primary physical storage unit into which a database is organized. In RDM Embedded, files are used to store records and keys.
H
hierarchical database modelA data representation in which the relationships between record types are formed from par-ent-child structures, such that a record type may have many child relationships but only one parent relationship.
I
indexA set of key values through which rapid retrieval of a record is provided, similar to the index of a book. The term is often used synonymously with key file.
J
joinThe creation of one record type from a hierarchy of record types.
K
keyA field through which rapid and/or sorted access to a record is desired.

RDM SQL Language Guide
Glossary 328
key fileA file that only contains keys. It may, in fact, contain more than one index because multiple key types can be contained in a single RDM Embedded key file.
key scanThe process of performing an ordered traversal through all (or a subset of all) occurrences of a given key field.
L
localhostA special Domain Name that always refers to the computer on which the application soft-ware is running. It is the default domain name used by RDM Embedded utilities and runtime library.
lockA multi-user database synchronization mechanism, used to prevent simultaneous updates to shared data. Locks can be applied to the entire database or to files.
loggingThe process of making a copy of the database changes made during a transaction prior to a commit. Logging is used to support the ability to perform a recovery in the event a failure occurs during a commit.
M
many-to-many relationshipA relationship between two record types, A and B, such that for each occurrence of type A, there are many related occurrences of type B and, for each occurrence of type B, there are many related occurrences of type A. In RDM Embedded, many-to-many relationships can be implemented using two one-to-many sets through a third, intersection record type.
member of setSpecifies a one-to-many relationship between record types. One occurrence of the owner record type is related to many occurrences of a member record type. Also called a set type.
member pointerStores set membership linkage information. There is one member pointer stored with a rec-ord per set for which the record is a member. Each one contains the database addresses of the owner record, previous member in the set, and next member in the set.

RDM SQL Language Guide
Glossary 329
N
navigationThe process of retrieving records from a database by moving through various navigational methods. Methods include set navigation, key scanning, and record-type scanning.
network database modelA data representation in which the relationships are explicitly defined and maintained through sets of owner/members, where any given record type may be the owner of multiple types of sets and the member of multiple types of sets. Multiple set membership dis-tinguishes the Network database model from the Hierarchical database model.
nodeA component of a B-tree, consisting of a page of sorted keys stored in a key file.
normalizeThe elimination of redundant record instances that own a new set, resulting in a one-to-many relationship.
O
occurrenceOne record instance within a record type, specifically associated with record type scanning (d_recfrst, d_recnext, d_recprev, d_reclast), where the current occurrence of a record type is used to bookmark the position on a record type scan. Record occurrences are ordered by their physical appearance in a data file. The current occurrence is not the same as the cur-rent record, although the current record will also be set by the scanning functions.
owner of setSpecifies a one-to-many relationship between record types. One occurrence of the owner record type is related to many occurrences of a member record type. Also called a set type.
P
pageFiles are blocked into contiguous fixed-length segments called pages. A page is the unit of database I/O performed in RDM Embedded.
path nameThe sequence of directories in a hierarchical file system that must be traversed to locate a particular file.

RDM SQL Language Guide
Glossary 330
pointerIn a database, a pointer is data stored in a record occurrence that provides the necessary information for locating related record occurrences. In a C program, a pointer is a variable that contains a memory address.
portTogether with an IP address, a port number uniquely identifies an endpoint by which a TCP/IP connection can be made to another program. In RDM Embedded, each server (tfserver, dbmirror, dbrep or dbrepsql) identifies the port number that should be used to locate it. The IP address is normally obtained through a domain name lookup (e.g. tfs.raima.com is a domain name, and its IP address is 198.168.140.200).
processAn independently executing task or program. An individual execution of an RDM Embedded application program.
projectionThe placement of fields from one record type into one or more new record types.
Q
queueA first-in-first-out waiting list. Lock requests for a locked resource will be placed at the end of a queue. When the locked resource becomes available, the first lock request on the queue will be granted.
R
recordUsed synonymously with record type or record occurrence depending on the context in which the term is used.
record occurenceOne individual instance in a database of a record of a particular type. A database consists of many occurrences of many different record types. For example, an employee record type may consist of the fields name, employee_id, job_title, and pay. An employee record occur-rence could be "name: Jones, Jim; employee_id: c87101, job_title: engr, pay: 3400".
recoveryThe process of completing the transaction of a process that failed during a commit.

RDM SQL Language Guide
Glossary 331
redundant dataIdentical data that is stored in multiple locations in a database. Typically used to form rela-tionships between tables in a relational database management system.
relational database modelA data representation in which a database is viewed as consisting of two-dimensional tables, each composed of one or more columns. Inter-table relationships are defined through use of common column names and data. Tables and columns are analogous to RDM Embedded records and fields, respectively.
remote procedure callA programming mechanism that makes a library call appear to operate in the program space of an application, even though the actual function exists in the program space of another pro-gram (called a "server"). A client application places a function identifier and parameter con-tents into a packet that is first transferred to the server, with results (return code, return parameter values) transferred back to the caller.
Revision Definition LanguageThe RDL supplies information to db_REVISE that cannot be derived from a comparison of the source and destination dictionary files.
root nodeThe top or start node of a B-tree.
RPCA programming mechanism that makes a library call appear to operate in the program space of an application, even though the actual function exists in the program space of another pro-gram (called a "server"). A client application places a function identifier and parameter con-tents into a packet that is first transferred to the server, with results (return code, return parameter values) transferred back to the caller.
runtime systemThe RDM Embedded C language library functions that perform all of the database access required by an application program while it is executing.
S
schemaA conceptual model of the structure of a database that defines the data contents and rela-tionships. A database definition language specification is an implementation of a particular schema.

RDM SQL Language Guide
Glossary 332
setSpecifies a one-to-many relationship between record types. One occurrence of the owner record type is related to many occurrences of a member record type. Also called a set type.
set occurenceAn individual instance of a set in which one owner record occurrence has one or more member record occurrences connected to it.
set pointerStores set ownership linkage information. There is one set pointer stored with a record per set for which the record is an owner. Each one contains a count of the number of members in the set, the database address of the first member record occurrence, and the database address of the last member record occurrence in the set.
set scanThe process of performing an ordered traversal through all (or a subset of all) member rec-ord occurrences of a given set occurrence.
slotA position in a data or key file for storage of a single record or key occurrence.
source databaseThe database containing the data that is to be revised. This database is used in a read-only manner.
specified revisionA revision requiring specification by an RDL statement.
splitThe separation of a multiple-member set type into two or more set types.
static revisionA revision that can be performed without changing the existing database content or struc-ture.
synchronizationThe process of ensuring that, in a multi-user database environment, updates to shared data are performed serially, one user at a time.
system recordA special record type used to define the "top" record in a network database. There is only one occurrence of the system record in a database. It is defined by naming "system" as a set owner in one or more set definitions in the DDL. When a database is opened, the system

RDM SQL Language Guide
Glossary 333
record, if it exists, is set as the current owner of all sets for which it is named as owner. It may not be a set member.
T
taskIn an RDM Embedded Application, a task is a block of allocated memory that stores the com-plete database context for a thread of execution. It must be allocated through the d_open-task function and closed through the d_closetask function. A task represents one user in a multi-user environment. A task can also represent one database transaction, with all locks and database updates associated with the transaction.
TFSA software component within the RDM Embedded system that maintains safe multi-user transactional updates to a set of files, and responds to page requests. The tfserver utility links to the TFS to allow it to run as a separate utility. The TFS may also be linked directly into an application in order to avoid the RPC overhead of calling a separate server.
threadAn independent flow of control within a computer operating system. Differentiated from a Process in that a process may contain one or more threads. Threads within the same proc-ess share common (or global) data but have their own stacks, which keeps track of the thread's context. In RDM Embedded Applications, each thread must be associated with its own task variable, and is treated as a separate user in a multi-user environment.
timeoutAn event that occurs when a lock request has waited on a queue longer than a pre-deter-mined amount of time. It is used to avoid deadlock.
transactionA group of related database changes that are written to the database as a single unit during a commit. The logical consistency of a database is maintained by placing all related updates within transactions.
transactional file serverA software component within the RDM Embedded system that maintains safe multi-user transactional updates to a set of files, and responds to page requests. The tfserver utility links to the TFS to allow it to run as a separate utility. The TFS may also be linked directly into an application in order to avoid the RPC overhead of calling a separate server.

RDM SQL Language Guide
Glossary 334
W
working databaseA temporary database created by db_REVISE for use only during the database revision process. db_REVISE removes the working database when the revision process is com-plete.

RDM SQL Language Guide
Index 335
Index
S
SQL
begin 285
close 238
commit 239
create catalog 240
create database 241
create domain 243
create procedure 245
create table 247
create virtual table 252
delete 254
drop database 256
drop procedure 257
end 239, 258
end read only transaction 258
exec 259
execute 259
export 261
import 262
initialize 265
insert 266
lock table 268
open 270
release 272
rollback 273
run 259

RDM SQL Language Guide
Index 336
savepoint 274
select 275
set 281
set column 283
start 285
unlock table 287
update 288
U
udfAggCall 148, 291
udfAggReset 151, 293
udfAggResult 150, 295
udfCheck 142, 297
udfInit 145, 300
udfScalarCall 147, 302
udfTerm 146, 305
V
vtFetch 168, 308
vtInsert 160, 311
vtRowCount 164, 315
vtSelectClose 170, 317
vtSelectCount 164, 319
vtSelectOpen 166, 321