state-space synthesis of virtual auditory space
TRANSCRIPT

IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 5, JULY 2008 881
State-Space Synthesis of Virtual Auditory SpaceNorman H. Adams, Member, IEEE, and Gregory H. Wakefield, Member, IEEE
Abstract—Binaural displays for immersive listening must modelrealistic acoustic environments, multiple sound sources, and ac-commodate source and head motion. Many displays accomplishthis by convolving collections of spatially distributed point sourceswith head-related transfer functions (HRTFs). The computationalload of such a system scales linearly with the number of HRTFsmodeled by the display. Realistic scenes often require a largenumber of HRTFs, and this framework is computationally bur-densome. We propose a method that significantly eases this load byformulating the HRTF filter array as a state-space system. Threestate-space architectures are explored. The performance of themost general architecture is found to suffer due to the interauraltime delay (ITD). This problem may be circumvented with twoalternative architectures, although the ideal choice depends on thespecific display application. For each architecture, two order-re-duction techniques are explored. Both techniques are based on theHankel operator; one is ad hoc and simple to implement whereasthe other is optimal in the Hankel norm. The two methods yieldsimilar auditory performance, although the optimal method maybe desirable for HRTF approximation.
Index Terms—Acoustic signal processing, Hankel matrices,headphones, multiple-input multiple-output (MIMO) systems,reduced-order systems.
I. INTRODUCTION
B INAURAL displays seek to immerse a listener in a 3-D vir-tual auditory scene (VAS) using only a pair of conventional
headphones [1]. The synthesis of perceptually convincing VASrequires the modeling of complex physical phenomena. Typ-ical physical acoustic scenes contain multiple sound sources,interactions with the environment such as reflections and scat-tering, as well as source and listener motion [2]. Methods havebeen proposed for modeling such physical phenomena in bin-aural displays, but with a formidable computational burden. Nu-merous emerging applications have shown interest in binauraldisplay technology, from video games and virtual reality to soni-fication and musical composition. However, the computationalefficiency of flexible and low-latency binaural displays must beimproved in order for the technology be broadly accepted.
The present work considers a framework for the display ofa wide variety of acoustic scenes and proposes an efficient im-plementation of this framework. The framework filters sourcesignals with numerous head-related transfer functions (HRTFs)simultaneously. A naive implementation of this frameworkis untenable, as the computational cost scales linearly withthe number of HRTFs included, and the number of HRTFs
Manuscript received April 13, 2007; revised February 21, 2008. This workwas supported in part by a Rackham Predoctoral Fellowship. The associate ed-itor coordinating the review of this manuscript and approving it for publicationwas Dr. Rudolf Rabenstein.
The authors are with the Electrical Engineering and Computer ScienceDepartment, University of Michigan, Ann Arbor MI 48109 USA (e-mail:[email protected]; [email protected]).
Digital Object Identifier 10.1109/TASL.2008.924151
required for a “realistic” acoustic scene is often large. Toaddress this problem, we explore reduced-order multiple-inputmultiple-output (MIMO) state-space systems for the HRTFfilter array and find that state-space systems offer substantialcomputational improvements relative to standard time-domainapproaches. Previous research has considered state-spaceapproaches for low-order filter design [3]–[6]; however, theauthors are unaware of any studies that directly compare thenet computational cost of a state-space implementation to thatof a conventional filter array.
The remainder of this section gives background on binauraldisplays, as well as reports on previous studies that employstate-space methods for binaural displays. Section II formulatesthe HRTF filter array in the state-space and describes three state-space architectures. Multiple architectures are considered be-cause the performance of the simplest architecture suffers dueto the interaural time delay (ITD) between ipsilateral and con-tralateral HRTFs. For this reason, two alternative architecturesare considered that circumvent the ITD problem. For each ar-chitecture, high-order state-space systems are constructed frommeasured HRTFs. Two order-reduction methods are then em-ployed to reduce the cost of the systems. One method is ad hocand relatively simple to implement, whereas the other is optimalin the Hankel sense. The two methods have been compared ex-tensively for single-input single-output (SISO) systems [7], butnot for large MIMO systems [8]. Section III reports on an empir-ical experiment in which state-space systems, with various ar-chitectures and order-reduction methods, are compared to trun-cated finite-impulse response (FIR) arrays of equal net cost. Re-sults are discussed with respect to Hankel and errors, as wellas a perceptually motivated error.
A. Virtual Auditory Scene Synthesis
An auditory scene that consists of a single stationary soundsource in the far-field of a listener in an anechoic environmentcan be displayed using a single pair of HRTFs [9]. The HRTFrepresents the acoustic filtering of a plane wave enroute to a lis-tener’s two ears due to the head, pinna, and torso of the listener,and is unique to each listener. Such transfer functions can be im-plemented using appropriately measured head related impulseresponses (HRIRs), which, empirically, require approximately200 FIR filter coefficients at a sampling rate of 44.1 kHz. Abinaural display that operates in this manner, by convolving amonaural source with two FIR filters, requires about18 million multiplication and addition operations per second.Because this is a substantial computational load, considerableeffort has been made to find low-order approximations to mea-sured HRIRs [10].
However, it is well known that binaural displays, as describedabove, are perceptually unsatisfying [2]. Virtual sound sourcesare often localized inside the listener’s head. Virtual auditory
1558-7916/$25.00 © 2008 IEEE

882 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 5, JULY 2008
Fig. 1. A complex auditory scene, with reflections and motion, may be modeledas a collection of stationary free-space point sources.
Fig. 2. Naive implementation of a virtual auditory scene with multiple head-related transfer functions (HRTFs).
scenes presented over headphones often lack presence. Local-ization errors, such as front–back reversals, are common. Thesedeficiencies are often attributed in the literature to the assump-tions that underly conventional binaural displays: sound sourcesare stationary, located in the far-field, and in free space. Sincewe rarely experience such primitive auditory scenes, it is notsurprising that virtual auditory scenes based on these assump-tions are inadequate for an immersive experience.
Recently, binaural displays have been designed that accountfor reflective environments [11]–[16], source and listener mo-tion [11]–[14], [17], and spatially extended sources [18]. Theseexamples share a similar framework: monaural source signalsare filtered with multiple HRTF pairs instead of a single HRTFpair. That is, a monaural source is rendered at directions si-multaneously, and the binaural signals are then combinedso as to model the desired auditory scene. This framework al-lows us to model reflections with image sources [19] or rays[20], source and listener motion with dynamic amplitude pan-ning [21], and spatially extended sources with a collection ofpoint sources. An example arrangement of directions1
is shown in Fig. 1. A common architecture for such binaural dis-plays is shown in Fig. 2. This architecture allows for the displayof a wide variety of auditory scenes without the need to updatethe HRTF model itself. Hence, only one fixed HRTF array needsto be implemented, and the “Room model and dynamics” block
1For clarity, only the directions in the median plane and to the right of thelistener are shown. The collection of directions shown in Fig. 1 is a subset ofthe 253 directions included in HRTF datasets used in the present study, see Sec-tion III-A.
accounts for any changes to the virtual environment and sourceand listener positions. This architecture compounds the com-putational burden however, as the overall computational costscales linearly with if individual filters are employed for eachHRTF. Acoustic reflections, in particular, are problematic, asrigid enclosures result in an exponential growth in reflectionnumber with reflection order.
B. State-Space Models of HRTFs
HRTFs measured for different directions are locally redun-dant. A system that models HRTFs at many directions simul-taneously may be able to utilize this redundancy to reduce thenet cost of the system. Numerous studies have found that col-lections of HRTFs can be reasonably represented in low-dimen-sional spaces. In [22], it is shown that most of the variance of anHRTF dataset can be accounted for with the first five principalcomponents. However, principal component analysis yields ahigh-order FIR structure for filter implementation. Filters thatdo not restrict the system poles to the origin, such as IIR fil-ters, are known to yield substantial cost savings for individualHRTFs [10], [23], [24]. We seek an analogous structure thatmodels multiple HRTFs. It has been shown that HRTFs can beaccurately modeled with common pole locations [25]. This im-plies that a collection of HRTFs can be reasonably approximatedusing a single MIMO state-space system, as the rational transferfunctions between each input and output of the system share thesame poles.
At first glance, modeling HRTFs with a state-space systemmay not appear computationally efficient. Any orderstate-space system can be converted to an equivalent array oforder IIR filters. For SISO systems, an IIR implementationis guaranteed to be lower cost than a equivalent state-spacesystem. Nonetheless, state-space techniques have been used todesign low-order IIR filters from measured HRIRs [4], [18],[26]. These studies do not consider MIMO state-space systemshowever, the computational cost still scales linearly with thenumber of directions .
Three recent studies propose state-space systems that modelHRTFs at multiple directions simultaneously. In [5], multiple-input single-output (MISO) systems are designed that modelmultiple HRTFs for each ear. HRTF redundancy is not fullyexploited in this paper however, as separate state-space sys-tems are designed for each HRTF individually and then com-bined into one large system. In contrast, [27] constructs a MISOsystem from a PCA reconstruction of a collection of HRTFs. AMIMO state-space design that models HRTFs in the horizontalplane is proposed in [6]. It was shown that for sufficiently largesystem order, the localization performance with a state-spacesystem was similar to the performance with an array of mea-sured HRIRs [6]. However, neither study considered the com-putational advantages of state-space implementations. Below,we consider the cost of low-order state-space implementationsrelative to common FIR arrays and show that system orders wellbelow those found in [6] may be perceptually adequate in manycases.
C. Time- Versus Frequency-Domain Implementations
The state-space HRTF models that we describe below aretime-domain systems. To lower the computational cost, HRTFs

ADAMS AND WAKEFIELD: STATE-SPACE SYNTHESIS OF VIRTUAL AUDITORY SPACE 883
are sometimes implemented in the frequency-domain using theoverlap-and-add method [28]. This technique is often employedin software-based displays. Comparing time- and frequency-domain approaches is difficult however, because the cost2 islimited by different factors, and the two approaches have dif-ferent hardware requirements. In practice, the cost of frequency-domain HRTF implementations is determined by latency andmemory constraints, whereas the cost of time-domain HRTFimplementations is determined by the order of the filters. Forfrequency-domain systems, low computational cost is achievedwith relatively long frame lengths, e.g., 1000 samples or more.Long frame lengths require additional memory and incur la-tency, which can be problematic for real-time applications [1],[11]. Furthermore, if the frame length is 1000 samples or more,then there is no computational benefit to reducing the order ofthe HRTF. Accordingly, we compare state-space HRTF systemsto another time-domain system, an array of truncated FIR filters.Both time-domain systems incur no latency and require verylittle memory.
II. STATE-SPACE MODELING
Consider a stable, causal, discrete-time MIMO state-spacesystem3
(1)
where is the state vector of size , is the input vectorof size , and is the output vector of size . To simplifynotation, let represent the state-space system.The matrix impulse response of is
.... . .
...
(2)
It is straightforward to implement any collection of measuredHRTFs exactly with a state-space system , using the controllercanonical form [30]. For example, the HRTF array shown in thegray box in Fig. 2 can be implemented with a single MIMOsystem with inputs and outputs. Other architec-tures are possible, and, as will be shown below, may be prefer-able. Because such systems are necessarily high order
, we seek a low-order approximant withorder . In the following, we consider two order-reduc-tion techniques that are based on the Hankel operator.
A. Order Reduction
The Hankel operator is often employed for state-space orderreduction, as optimal solutions are known for this operator. The
2As defined in Section II-D.3For convenience, the systems considered here have no feed-through term
(Du[n]), similar to [5] and [6]. The Hankel operator is not dependent on D;hence, we let D = 0. The interested reader is referred to [29] for a detaileddiscussion.
Hankel operator is related to the convolution operator with re-stricted domain and range: the Hankel operator maps past in-puts to future outputs [31]. Two reduction techniques based onthe Hankel operator are balanced model truncation (BMT) [32]and Hankel-norm optimal approximation (HOA) [29]. BMT haspreviously been applied in several HRTF studies [4]–[6], [18],[26], [27].
Balanced state-space systems are a special form that allowfor convenient order reduction [3]. In this form, any statethat results in a “small” amount of energy output (with the inputset to zero) also requires a “large” amount of energy at the inputto move the system from zero to state . Such states contributelittle to the input–output behavior of the system and can be trun-cated without greatly affecting the transfer function. BMT op-erates by first applying a balancing similarity transform toand then discarding all but the largest Hankel singular valuesof the system. For HRTF modeling, the BMT solution can becomputed directly from the sample Hankel matrix, without con-structing and balancing the high-order . A complete algorithmis given in [32].
While BMT is convenient, it is not optimal in any specificsense. The HOA method is also based on the theory of balancedsystems. However, rather than simply truncate the leastsignificant states, the th state is removed by means of anall pass dilation, and the remaining states are trans-formed so as to be both antistable and anticausal, in which casethey no longer influence the Hankel operator of the system. Acomplete algorithm is given in [29]. The order stable sub-system is then extracted, yielding an approximant with min-imal Hankel error
where is the th largest Hankel singular value of. The Hankel error is a lower bound to the spectral error
where is the maximum singular value, and arethe transfer function matrices of [31]. In practice, forapproximants designed using BMT and HOA, the Hankel erroris often found to be a tight lower bound on the error [8].
B. ITD Modeling
The binaural time-delay between ipsilateral and contralateralHRTFs is perceptually critical, although the monaural phase re-sponse of HRTFs is not [33]. Human listener’s are sensitive tochanges in the interaural time delay (ITD) as small as severalmicroseconds [1]. This perceptual sensitivity presents a diffi-culty in the design of low-order MIMO state-space systems.
Hankel methods are known to well approximate transfer func-tions that are minimum phase, or nearly so [3]. However, in-cluding time-delay terms in the transfer functions introduceszeros outside the unit circle. Cancelling these zeros with state-space poles during order reduction distorts the phase response ofthe approximant. For contralateral HRTFs, the time-delay termsintroduce up to 40 zeros, at 44.1-kHz sampling rate, outside theunit circle. In order to retain the contralateral time-delays in the
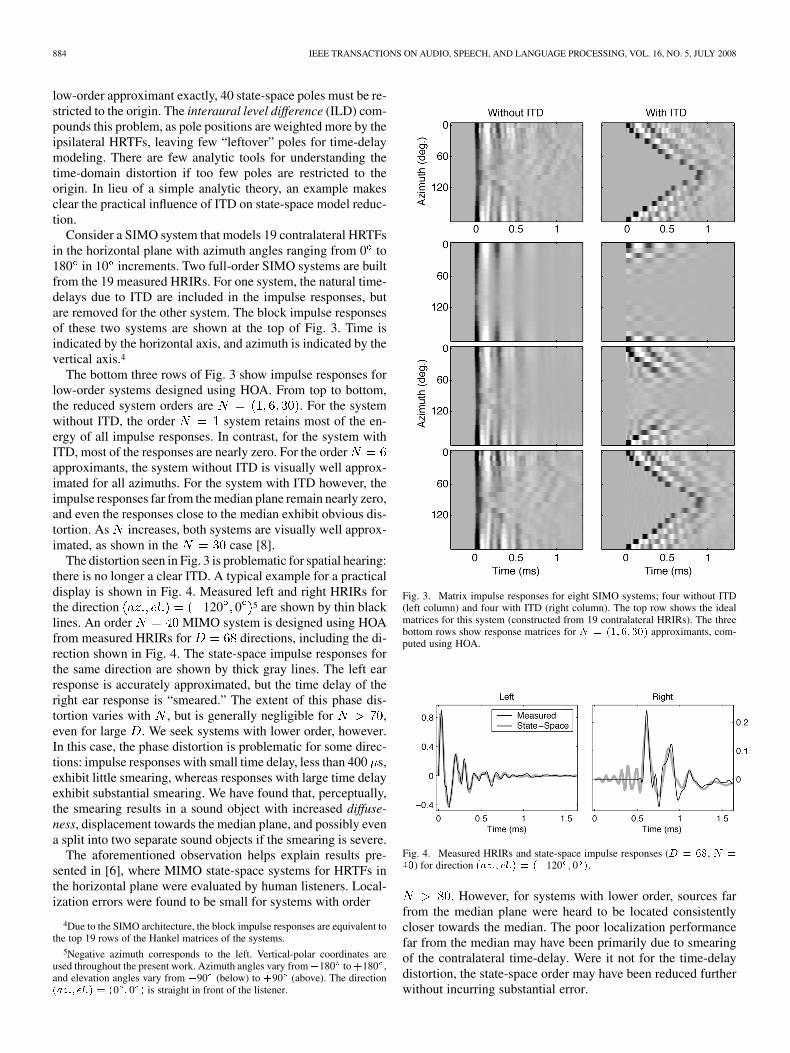
884 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 5, JULY 2008
low-order approximant exactly, 40 state-space poles must be re-stricted to the origin. The interaural level difference (ILD) com-pounds this problem, as pole positions are weighted more by theipsilateral HRTFs, leaving few “leftover” poles for time-delaymodeling. There are few analytic tools for understanding thetime-domain distortion if too few poles are restricted to theorigin. In lieu of a simple analytic theory, an example makesclear the practical influence of ITD on state-space model reduc-tion.
Consider a SIMO system that models 19 contralateral HRTFsin the horizontal plane with azimuth angles ranging from 0 to180 in 10 increments. Two full-order SIMO systems are builtfrom the 19 measured HRIRs. For one system, the natural time-delays due to ITD are included in the impulse responses, butare removed for the other system. The block impulse responsesof these two systems are shown at the top of Fig. 3. Time isindicated by the horizontal axis, and azimuth is indicated by thevertical axis.4
The bottom three rows of Fig. 3 show impulse responses forlow-order systems designed using HOA. From top to bottom,the reduced system orders are . For the systemwithout ITD, the order system retains most of the en-ergy of all impulse responses. In contrast, for the system withITD, most of the responses are nearly zero. For the orderapproximants, the system without ITD is visually well approx-imated for all azimuths. For the system with ITD however, theimpulse responses far from the median plane remain nearly zero,and even the responses close to the median exhibit obvious dis-tortion. As increases, both systems are visually well approx-imated, as shown in the case [8].
The distortion seen in Fig. 3 is problematic for spatial hearing:there is no longer a clear ITD. A typical example for a practicaldisplay is shown in Fig. 4. Measured left and right HRIRs forthe direction 120 0 5 are shown by thin blacklines. An order MIMO system is designed using HOAfrom measured HRIRs for directions, including the di-rection shown in Fig. 4. The state-space impulse responses forthe same direction are shown by thick gray lines. The left earresponse is accurately approximated, but the time delay of theright ear response is “smeared.” The extent of this phase dis-tortion varies with , but is generally negligible for ,even for large . We seek systems with lower order, however.In this case, the phase distortion is problematic for some direc-tions: impulse responses with small time delay, less than 400 s,exhibit little smearing, whereas responses with large time delayexhibit substantial smearing. We have found that, perceptually,the smearing results in a sound object with increased diffuse-ness, displacement towards the median plane, and possibly evena split into two separate sound objects if the smearing is severe.
The aforementioned observation helps explain results pre-sented in [6], where MIMO state-space systems for HRTFs inthe horizontal plane were evaluated by human listeners. Local-ization errors were found to be small for systems with order
4Due to the SIMO architecture, the block impulse responses are equivalent tothe top 19 rows of the Hankel matrices of the systems.
5Negative azimuth corresponds to the left. Vertical-polar coordinates areused throughout the present work. Azimuth angles vary from�180 to +180 ,and elevation angles vary from �90 (below) to +90 (above). The direction(az:; el:) = (0 ; 0 ) is straight in front of the listener.
Fig. 3. Matrix impulse responses for eight SIMO systems; four without ITD(left column) and four with ITD (right column). The top row shows the idealmatrices for this system (constructed from 19 contralateral HRIRs). The threebottom rows show response matrices for N = (1; 6; 30) approximants, com-puted using HOA.
Fig. 4. Measured HRIRs and state-space impulse responses (D = 68, N =40) for direction (az:; el:) = (�120 ; 0 ).
. However, for systems with lower order, sources farfrom the median plane were heard to be located consistentlycloser towards the median. The poor localization performancefar from the median may have been primarily due to smearingof the contralateral time-delay. Were it not for the time-delaydistortion, the state-space order may have been reduced furtherwithout incurring substantial error.

ADAMS AND WAKEFIELD: STATE-SPACE SYNTHESIS OF VIRTUAL AUDITORY SPACE 885
Fig. 5. Three state-space architectures for binaural display.
We have explored multiple techniques to address thisproblem, including time-delay systems [31] and hybridstate-space/FIR systems [34]. In practice, these methods werefound to be computationally prohibitive, however. Below, wedescribe alternative system architectures that circumvent theITD problem without incurring a large computational cost.
C. State-Space Architectures
Let and be the HRIRs for the left and right earsfor direction . A MIMO system that models the arrangementof HRTFs shown in Fig. 2 has matrix impulse response
(3)
Clearly, the ITD must be included in the transfer functions thatthe MIMO system models. Due to the time-delay smearing ex-hibited by reduced-order systems, we consider two alternativearchitectures.
If the architecture of the binaural display is changed such thatthe state-space system has either a single input or a single output,then the time-delays can be factored out of the contralateralHRTFs and implemented externally. This approach was takenin the design of MISO systems in [5]. In the present work, weconsider both SIMO and MISO architectures. Block diagramsof binaural displays with the three architectures are shown inFig. 5.
Environment modeling does not necessarily need to be per-formed prior to HRTF filtering; changing the order of linear,time-invariant blocks does not change the overall response. ASIMO architecture may be used, with input andoutputs, and matrix impulse response
(4)
Alternatively, the two outputs of the MIMO architecture can besplit into two MISO systems, with inputs each. In this case,the matrix impulse responses are
(5)
While all three architectures can be used for binaural environ-ment modeling, there are significant differences between them.The SIMO architecture has the disadvantage that multiplesource signals at different locations cannot be presented simul-taneously. Hence, the SIMO architecture only solves a subsetof the general binaural-display problem. The MISO architec-ture has the disadvantage of requiring two separate systemsthat model similar transfer functions, due to symmetry of thehead. This redundancy would seem to limit the computationalefficiency of the MISO architecture. It is unclear a priori whicharchitecture yields the best balance of approximation qualityand computational savings.
D. Computational Cost
In the next section, state-space systems are compared to FIRfilter arrays of equal computational cost. We define the costas the number of multiplication operations required per sampleperiod, or equivalently, the total number of coefficients in thesystem. This measure of computational cost is common in filterdesign applications when comparing FIR and IIR filters [10],[18], [28]. An FIR filter array of order with inputs and
outputs requires multiplies per sampleperiod. For example, consider a ten-input and two-output FIRfilter array that models HRIRs with order .The cost of this array is .
For state-space systems, the computational cost depends onthe choice of system realization, as there are an infinite numberof state-space systems with the same input–output behavior. Ingeneral, a state-space system of order with inputs and
outputs, and no feed-through path, requiresmultiplies per time step. However, after a low-order
state-space system has been designed, it is possible to applya similarity transform to the system matrices to re-duce the number of nonzero elements in . We employ a Schurdecomposition to triangularize the matrix. Because we seeksystem matrices that are strictly real, the new matrix is onlyquasitriangular. In this case, the cost of the final state-spacesystem is not greater than . Thisformula is used to determine the cost of the state-space systemsevaluated next.
III. PERFORMANCE CHARACTERIZATION
The number of directions that are required for a binauraldisplay depends upon the application. For some applications,such as displays that allow restricted motion, only a smallnumber of directions need to be included [17], [18]. However,modeling acoustic reflections often requires a large number ofdirections surrounding the listener [11], [12]. Hence, we view
as an independent variable. To characterize the performanceof the state-space systems described above, a numerical ex-periment is conducted in which multiple HRTF systems are

886 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 5, JULY 2008
constructed with fixed cost . We vary from 1 to 110, andfor every chose the largest system order suchthat the total computational cost of the system, as defined inSection II-D, does not exceed some bound .
For a fixed number of directions, there are many possible ar-rangements of directions around the listener. In the main ex-periment below, we report aggregate statistics on the quality ofthe HRTF approximation. We use a simple rule for selectingdirections that is both practical for modeling common auditoryscenes and limits the redundancy in the transfer function matrix.For every system constructed, directions are chosen randomlyfrom the grid of 253 measured directions, subject to a constraintthat they be approximately uniformly arranged around listenerwithout left–right or front–back symmetry.
An FIR filter array is used as a practical baseline for com-parison with the state-space systems. For any given cost bound,two FIR arrays are constructed, one with cost bound by ,and the other with cost bound by . The “double-cost”FIR array is included to gauge the significance of the improve-ment in the approximation quality of the state-space systems. Inso doing, we will demonstrate that for some configurations, astate-space system not only outperforms an FIR array of equalcost, but also outperforms an FIR array of twice the cost. FIRfilters of order are constructed by truncating all but the first
samples of minimum-phase HRIRs. Hence, the FIR fil-ters are optimal FIR approximations in terms of error [28].
A. HRTF Measurements
The HRTFs of eight individuals were measured at the NavalSubmarine Medical Research Laboratory in Groton, CT. Themeasurement process is described in detail in [9]. At a samplingrate of 44.1 kHz, the measured HRIRs have length 256, order
. The measured HRIRs are nearly minimum-phase, ex-cluding the ITD. To simplify the analysis, and to guarantee theperformance of the truncated FIR filters, all HRIRs are trans-formed so as to be strictly minimum-phase for this experiment.6
HRTFs were measured in 10 increments in azimuth aroundthe listener, and in 18 increments in elevation from 36 to
90 , yielding a total of 253 pairs of HRTFs for each listener.In the experiment below, systems are designed using each ofthe eight HRTF datasets. We found that results varied little withthe choice of HRTF dataset. Below, we report results averagedacross the eight individuals.
B. Main Experiment
For the main experiment, a cost bound of isused, which is approximately the cost of eight full-order HRIRpairs. At 44.1-kHz sampling rate, this cost requires 176.4 mil-lion multiplies per second, which is a significant computationalcost, but within reach of modern hardware considering that thisis the net cost for the entire collection. State-space systemsare designed that meet this bound for a varying number ofdirections7 . Three architectures are considered:MIMO, SIMO, and MISO, as described in Section II-C. The
6Discarding all but the N + 1 first coefficient of a minimum-phase impulseresponse yields an order N FIR approximant with minimum L error [28].
7For D > 100, the density of direction surrounding the listener is highenough that we can easily interpolate between directions for any additional di-rections that we may need.
Fig. 6. System order for five systems as a function of the number of directionsD. The system labeled “FIR �2” has a cost bound of 8000, and the remainingfour have a cost bound of 4000.
ITD is included in the MIMO system, but not by the SIMOor MISO systems. Systems are designed using both BMT andHOA, as described in Section II-A. Hence, for every , sixstate-space systems are designed. Two FIR arrays are designedfor each as well.
Fig. 6 shows the order for five systems: MIMO, SIMO,and MISO state-space systems with cost , an FIRarray with cost , and a second FIR array with cost
. For the MISO architecture, is the order of eachstate-space system. Note that for the FIR filter arrays, it is notnecessary to truncate the measured HRIRs if inorder to satisfy the cost constraint. Hence, the approximationerror for the two FIR arrays will be zero for .
C. Hankel and Results
The Hankel error is defined as the largest Hankel singularvalue of the error system [29], [31], and computation isstraightforward. The spectral error is estimated by findingthe maximum largest singular value of the transfer function errormatrix over a finely sampled frequency grid.
Fig. 7 shows the Hankel and errors of state-space and FIRsystems with order given by Fig. 6. Each panel corresponds toone architecture, from top to bottom: MIMO, SIMO, and MISO.The error is shown with black lines, and the Hankel error isshown with gray lines. Note that the truncated FIR filters are,individually, identical for all three architectures, but that theHankel and errors depend on the architecture.
Both errors increase monotonically as a function of for allsystems. The performance trends are very similar for all threearchitectures. As expected, the Hankel error lower bounds the
error in all cases. For the FIR systems, the Hankel error isa loose bound on the error for . In contrast, forthe state-space systems, the Hankel error is a relatively tightbound for all . Both state-space designs, BMT and HOA, out-perform both FIR systems for . The two state-spacereduction methods show similar performance, although HOAyields lower Hankel and errors than BMT. These resultsare promising, but system theoretic measures of performanceare not necessarily suitable for auditory applications. Next, weconsider a modified error as a simple model of auditory per-ception.

ADAMS AND WAKEFIELD: STATE-SPACE SYNTHESIS OF VIRTUAL AUDITORY SPACE 887
Fig. 7. Hankel (gray) and L (black) error as a function of D. Errors are re-ported separately for each architecture: MIMO (top), SIMO (middle), and MISO(bottom). The Hankel error of the BMT systems is approximately equal to, andis hidden by, the L error of the HOA systems for all architectures.
D. Auditory Results
The “auditory” error that we report has been previouslyemployed in HRTF approximation studies [10]. This error mea-sure is computed by warping the log-magnitude response of theideal and low-order systems to a log-frequency scale. A fifth-oc-tave smoothing filter is then applied to both responses to modelthe critical bands of the auditory system. The error (RMSE)between the two modified responses is then computed over therange 300 Hz to 16 kHz. For systems with multiple inputs oroutputs, the auditory error is computed for each input–outputpair and averaged.
The lower bound of the integration is lower than in [10].In free-field conditions, ILD cues below 1 kHz do not domi-nate the localization of sound sources [1]. However, it has beenshown that low-pass sources can be localized in elevation [35].Furthermore, studies have shown that sensitivity to ILD cuesextends below 1 kHz in the presence of reflecting surfaces [36],and that the sense of “externalization” is affected by ILD cuesbelow 1 kHz [37]. In fact, recently it has been shown for gerbilsthat the presence of a reflecting surface introduces perceptuallysalient magnitude features for localization as low as 500 Hz,whereas such features only appear above 10 kHz in the free-fieldcase [38]. Because we are interested in low-cost systems for bin-aural environment modeling, we include frequencies as low as300 Hz in the auditory error.
Fig. 8 shows the auditory error for eight systems: sixstate-space and two FIR. Naturally, the auditory error of theFIR systems does not change with architecture. For this error
Fig. 8. AuditoryL error as a function ofD. The auditoryL error is computedfor each input–output pair and averaged and is independent of architecture forthe FIR arrays.
measure, the results of the different architectures can be directlycompared and are shown in a single panel. For , theSIMO and MISO architectures yield lower approximation errorthan the FIR array, and for the SIMO and MISO archi-tectures outperform the “double-cost” FIR array as well. TheSIMO architecture yields slightly lower error than the MISOarchitecture, although this difference vanishes as approaches100. Furthermore, the BMT systems yield slightly lower errorthan the HOA systems for .
In contrast to the SIMO and MISO architectures, the MIMOarchitecture does not perform well, for both BMT and HOA.For , the state-space systems yield slightly lowererror than the FIR array, but greater error for other . This isdiscussed in greater detail below.
E. Local Structure
In addition to the aggregate statistics reported above, it is in-teresting to consider individual local characteristics. Consideran example SIMO system that models HRTF pairs( , ). One direction included in this system isdirection 120 0 . The HRTF magnitude re-sponses for this direction are shown in Fig. 9. Two low-costsystems are constructed from the 88 transfer functions: a state-space system designed using the HOA method, and an arrayof FIR filters.8 Both systems are designed not to exceed a costbound of . For the state-space system, order
is chosen, yielding a net system cost of . For theFIR array, order is chosen, yielding a net system costof .
The magnitude responses of the two approximants at120 0 are shown in Fig. 9. At low frequencies, the
response of the FIR filters diverge from the desired response,especially below 300 Hz. Although, it is unclear if accuratelow-frequency magnitude modeling is perceptually critical forspatial listening. Fig. 10 shows the same responses as Fig. 9
8A state-space system designed with BMT was also considered. The magni-tude response of the BMT and HOA systems was very similar; only the HOAresponse is shown here.

888 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 5, JULY 2008
Fig. 9. Magnitude responses for direction � = 120 and � = 0 , for the rightear (top) and left ear (bottom). The measured HRTF responses are shown witha thin black line. The magnitude responses of anN = 33 FIR filters are shownwith a dashed line. The magnitude responses of an N = 28 SIMO state-spacesystem are shown with a thick gray line. The vertical dotted lines indicate thebounds of the responses shown in Fig. 10.
Fig. 10. Detail plots of the responses shown in Fig. 9 for the right ear (top) andleft ear (bottom).
over high frequencies. The spectral notches in the measuredHRTF are more accurately modeled by the state-space systemthan the FIR array. For the right ear response, the shallow notchat 4.5 kHz is well approximated by the state-space system, butis shifted by the FIR array. A more significant difference is seenat 8.5 kHz, where the measured HRTF exhibits a sharp, lopsidednotch. The state-space system also exhibits a lopsided notch atthe same frequency, whereas the FIR array exhibits two notcheswith the same depth ( 18 dB), one at 8.5 kHz, and anotherat 9.7 kHz. The deep notch in the left ear response at 2.5 kHzis well approximated by the state-space systems, whereas theFIR array exhibits only a shallow dip at this frequency. Thistrend is seen throughout the results: spectral notches are moreaccurately modeled by the state-space systems than the FIRarrays, particularly notches below 5 kHz.
Fig. 11. AuditoryL error as a function ofD, ipsilateral, and median responsesonly. See Fig. 12 for legend.
Fig. 12. Auditory L error as a function of D, contralateral responses only.
F. Discussion
BMT and HOA have been employed in numerous studiesof SISO filters [7], although less is known about their relativestrengths in the MIMO case [8]. From Figs. 7 and 8 it can beseen that HOA yields lower error, whereas BMT yieldslower auditory error. This disparity is due to the differencein the -norm and the 2-norm. HOA is known to distributeerror uniformly across frequency, whereas BMT concentrateserror near the transition bands and notches. The average spec-tral error across all frequencies is often lower with BMT, butthe maximum spectral error is lower with HOA. Because of theperceptual importance of spectral notches, HOA may be prefer-able for spatial hearing applications, although we found that theerror peaks near HRTF notches when using BMT were typicallysmall. The two methods are compared in greater detail in [31].
The poor performance of the MIMO state-space systems,which include ITD, is clearly reflected in the auditoryerror, but not in the error. This is explained by consideringthe auditory error for ipsilateral and contralateral HRTFsseparately, as shown in Figs. 11 and 12. The MIMO state-spacesystems approximate the ipsilateral HRTFs relatively well,but the contralateral HRTFs are poorly approximated. Due tothe ILD, the poor approximation of the contralateral HRTFs

ADAMS AND WAKEFIELD: STATE-SPACE SYNTHESIS OF VIRTUAL AUDITORY SPACE 889
has little impact on the error. The auditory error iscomputed from the log magnitude spectra; hence, the ipsilateraland contralateral approximations influence the error equally.Studies have shown that, perceptually, the ipsilateral magnituderesponses are more important than contralateral responses [39].It may therefore be desirable to weight the ipsilateral responsesmore than contralateral responses.
In addition to weighting ipsilateral versus contralateralHRTFs, it is also possible to weight some directions morethan others. For example, weighting across direction has beenproposed in modeling reflective environments [15]. The audi-tory system gives precedence to the direct wave in perceivingthe location of a sound source [40]. Precedence argumentsmight suggest that some directions be weighted more thanothers, although the weighting must be time-varying if motionis included. Furthermore, localization performance alone maynot be a suitable criteria for the design of a binaural display, asa listener may be able to correctly “localize” a sound sourcewithout being perceptually immersed in the auditory scene.9 Inthe interest of flexibility and generality, a uniform weight forboth ears and all directions may be preferable.
Informal listening tests confirm the numerical results pre-sented above: for a fixed we construct state-space systemsthat are less discriminable from measured HRIRs than FIR ar-rays of equal cost . A formal experiment is currently beingconducted in which state-space approximants are evaluated bothfor free-space conditions, and in reflective enclosures. The au-dible artifacts that sometimes appear in the design of low-orderIIR filters for audio applications [5], [18] are not apparent in anyof the state-space HRTF systems considered here.
IV. CONCLUSION
The present work explores low-cost state-space models ofHRTFs. Many contemporary binaural environment models areimplemented with an array of HRTF filters. If more than tendirections are included, a single state-space system with lowercomputational cost and equivalent approximation quality maybe used in place of the filter array.
Three state-space architectures are considered: MIMO,SIMO, and MISO. All three architectures are suitable forbinaural environment modeling, although each presents relativestrengths. The MIMO architecture is the most general, butperformance suffers due to modeling ITD in the state-spacesystem. The SIMO architecture yields the lowest approximationerror; however, this architecture only allows a single monauralsource to be rendered. Overall, the MISO architecture, firstproposed in [5], may be the best compromise, as multiplemonaural sources can be rendered simultaneously and the ITDcan be modeled externally.
Two order-reduction techniques are compared, BMT andHOA. The two methods yield similar performance; both aresuitable for HRTF approximation if linear-phase terms are re-moved. BMT tends to cluster error near spectral notches in theoriginal transfer functions. This behavior is obvious for idealnotch filters, although for measured HRTFs the error peaks
9For example, studies have shown instances in which a listener correctly lo-calizes a virtual far-field sound source (i.e., its direction), but still perceives thevirtual source as being inside the head [11].
were typically small. Nonetheless, the perceptual importanceof notches for spatial hearing may favor HOA.
ACKNOWLEDGMENT
The authors would like to thank to thank Dr. T. Santoro of theNSMRL for his assistance with HRTF measurement.
REFERENCES
[1] J. Blauert, Spatial Hearing: The Psychophysics of Human Sound Lo-calization. Cambridge, MA: MIT Press, 1997.
[2] B. Shinn-Cunningham and A. Kulkarni, “Recent developments in vir-tual auditory space,” in Virtual Auditory Space: Generation and Appli-cations, S. Carlile, Ed. Berlin, Germany: Springer-Verlag, 1996.
[3] B. Beliczynski, I. Kale, and G. Cain, “Approximation of FIR by IIRdigital filters: An algorithm based on balanced model truncation,” IEEETrans. Signal Process., vol. 40, no. 3, pp. 532–542, Mar. 1992.
[4] J. Mackenzie, J. Huopaniemi, V. Välimäki, and I. Kale, “Low-ordermodeling of head-related transfer functions using balanced model trun-cation,” IEEE Signal Process. Lett., vol. 4, no. 2, pp. 39–41, Feb. 1997.
[5] P. Georgiou and C. Kyriakakis, “Modeling of head related transferfunctions for immersive audio using a state-space approach,” inProc. IEEE Asilomar Conf. Signals, Syst., Comput., 1999, vol. 1, pp.720–724.
[6] D. Grantham, J. Willhite, K. Frampton, and D. Ashmead, “Reducedorder modeling of head related impulse responses for virtual acousticdisplays,” J. Acoust. Soc. Amer., vol. 117, no. 5, pp. 3116–3125, May2005.
[7] I. Kale, J. Gryka, G. Cain, and B. Beliczynski, “FIR filter order reduc-tion: Balanced model truncation and Hankel-norm optimal approxima-tion,” Proc. Inst. Elect. Eng.-Vis. Image Signal Process., vol. 141, no.3, pp. 168–174, Jun. 1994.
[8] A. Antoulas, D. Sorensen, and S. Gugergin, “A survey of model reduc-tion methods for large-scale systems,” Contemporary Math., vol. 280,pp. 193–219, 2001.
[9] C. Cheng and G. Wakefield, “Introduction to Head-Related TransferFunctions (HRTFs): Representations of HRTFs in time, frequency, andspace,” J. Audio Eng. Soc., vol. 49, no. 4, pp. 231–249, 2001.
[10] J. Huopaniemi, N. Zacharov, and M. Karjalainen, “Objective and sub-jective evaluation of head-related transfer function filter design,” J.Audio Eng. Soc., vol. 47, no. 4, pp. 218–239, 1999.
[11] D. Begault and E. Wenzel, “Direct comparison of the impact of headtracking, reverberation, and individualized head-related transfer func-tions on spatial perception of a virtual speech source,” J. Audio Eng.Soc., vol. 49, no. 10, pp. 904–916, Oct. 2001.
[12] D. Zotkin, R. Duraiswami, and L. Davis, “Rendering localized spatialaudio in a virtual auditory space,” IEEE Trans. Multimedia, vol. 6, no.4, pp. 553–564, Aug. 2004.
[13] L. Savioja, J. Huopaniemi, T. Lokki, and R. Väanänen, “Creating inter-active virtual acoustic environments,” J. Audio Eng. Soc., vol. 47, no.9, pp. 675–705, Sep. 1999.
[14] S. Takane, Y. Suzuki, T. Miyajime, and T. Sone, “ADISE: A newmethod for high definition virtual acoustic display,” in Proc. Int. Conf.Auditory Display, Kyoto, Japan, 2002, pp. 213–218.
[15] H. Hacihabiboglu, “A fixed-cost variable-length auralization filtermodel utilizing the precedence effect,” in Proc. IEEE Workshop Appl.Signal Process. Audio Acoust., New Paltz, NY, 2003, pp. 1–4.
[16] R. Heinz, “Binaural room simulation based on an image source modelwith addition of statistical methods to include the diffuse sound scat-tering of walls and to predict the reverberant tail,” Appl. Acoust., vol.38, pp. 145–159, 1993.
[17] V. Algazi, R. Duda, and D. Thompson, “Motion tracked binauralsound,” J. Audio Eng. Soc., vol. 52, no. 11, pp. 1142–1156, Nov. 2004.
[18] N. Adams and G. Wakefield, “The binaural display of clouds of pointsources,” in Proc. IEEE Workshop Appl. Signal Process. Audio Acoust.,New Paltz, NY, Oct. 2005, pp. 126–129.
[19] J. Allen and D. Berkley, “Image method for efficiently simulatingsmall-room acoustics,” J. Acoust. Soc. Amer., vol. 65, no. 4, pp.943–950, Apr. 1979.
[20] A. Krokstad, S. Strøm, and S. Sørsdal, “Calculating the acoustical roomresponse by the use of a ray tracing technique,” J. Sound Vibr., vol. 8,no. 1, pp. 118–125, 1968.
[21] V. Pulkki, “Virtual sound source positioning using vector base ampli-tude panning,” J. Audio Eng. Soc., vol. 45, no. 6, pp. 456–466, Jun.1997.

890 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 5, JULY 2008
[22] D. Kistler and F. Wightman, “A model of head-related transfer func-tions based on principal components analysis an minimum-phase re-construction,” J. Acoust. Soc. Amer., vol. 91, no. 3, pp. 1637–1647,Mar. 1992.
[23] M. Blommer and G. Wakefield, “Pole-zero approximations for head-related transfer functions using a logarithmic error criterion,” IEEETrans. Speech Audio Process., vol. 5, no. 3, pp. 278–287, May 1997.
[24] A. Kulkarni and H. Colburn, “Infinite-impulse-response models of thehead-related trasnfer function,” J. Acoust. Soc. Amer., vol. 115, no. 4,pp. 1714–1728, Apr. 2004.
[25] Y. Haneda, S. Makino, Y. Kaneda, and N. Kitawaki, “Common-acous-tical-pole and zero modeling of head-related transfer functions,” IEEETrans. Speech Audio Process., vol. 7, no. 2, pp. 188–196, Mar. 1999.
[26] F. Freeland, L. Biscainho, and P. Diniz, “Interpositional transfer func-tion for 3D-sound generation,” J. Audio Eng. Soc., vol. 52, no. 9, pp.915–930, Sep. 2004.
[27] P. Chanda, S. Park, and T. Kang, “A binaural synthesis with multiplesound sources based on spatial features of head-related transferfunctions,” in Proc. IEEE Int. Joint Conf. Neural Netw., 2006, pp.1726–1730.
[28] A. Oppenheim and R. Schafer, Discrete-Time Signal Processing. En-glewood Cliffs, NJ: Prentice-Hall, 1989.
[29] K. Glover, “All optimal Hankel-norm approximations of linear multi-variable systems and their L -error bounds,” Int. J. Control, vol. 39,pp. 1115–1193, 1984.
[30] D. Luenberger, “Canonical forms for linear multivariable systems,”IEEE Trans. Auto. Control, pp. 290–293, Jun. 1967.
[31] N. Adams, “A model of head-related transfer functions based ona state-space analysis,” Ph.D. dissertation, Univ. of Michigan, AnnArbor, 2007.
[32] S. Kung, “A new identification and model reduction algorithm via sin-gular value decompositions,” in Proc. IEEE Asilomar Conf. Signals,Syst., Comput., 1978, pp. 705–714.
[33] A. Kulkarni, S. Isabelle, and H. Colburn, “Sensitivity of human subjectsto head-related transfer-function phase spectra,” J. Acoust. Soc. Amer.,vol. 105, no. 5, pp. 2821–2840, May 1999.
[34] N. Adams and G. Wakefield, “Efficient binaural display using MIMOstate-space systems,” in Proc. IEEE Int. Conf. Acoust., Speech, SignalProcess., Honolulu, HI, Apr. 2007, pp. I-169–I-172.
[35] V. Algazi, C. Avendano, and R. Duda, “Elevation localization andhead-related transfer functions analysis at low frequencies,” J. Acoust.Soc. Amer., vol. 109, no. 3, pp. 1110–1122, Mar. 2001.
[36] B. Rakerd and W. Hartmann, “Localization of sound in rooms II: Theeffect of a single reflecting surface,” J. Acoust. Soc. Amer., vol. 78, no.2, pp. 524–533, Aug. 1985.
[37] W. Hartmann and A. Wittenberg, “On the externalization of sound im-ages,” J. Acoust. Soc. Amer., vol. 99, no. 6, pp. 3678–3688, Jun. 1996.
[38] K. Maki, S. Furukawa, and T. Hirahara, “Acoustical cues for local-ization by gerbils in an ecologically realistic environment,” Assoc. forResearch in Otolaryncology, 2003, abstract 26, Poster 352.
[39] E. Macpherson and J. Middlebrooks, “Listener weighting of cues forlateral angle: The duplex theory of sound localization revisited,” J.Acoust. Soc. Amer., vol. 111, p. 2219, 2002.
[40] R. Litovsky, H. Colburn, W. Yost, and S. Guzman, “The precedenceeffect,” J. Acoust. Soc. Amer., vol. 106, no. 4, pp. 1633–1654, Oct.1999.
Norman H. Adams (M’96) received the B.S. degreein electrical engineering and music and the M.S. de-gree in electrical engineering from the University ofVirginia, Charlottesville, in 2000 and 2001, respec-tively, and the Ph.D. degree in electrical engineeringfrom the University of Michigan, Ann Arbor, in 2007,where he is pursuing the M.A. degree in media art.
His research interests include statistical andacoustic signal processing. In particular, he has pub-lished in spatial sound, music information retrieval,and time–frequency analysis/synthesis. Currently, he
is a Signal and Image Processing Engineer for forensic applications at QuantumSignal, LLC, Ann Arbor.
Gregory H. Wakefield (M’85) received the B.A. de-gree in mathematics and psychology, the M.S. andPh.D. degrees in electrical engineering, and the Ph.D.degree in psychology, all from the University of Min-nesota, Minneapolis, in 1978, 1982, 1985, and 1988,respectively.
In 1986, he joined the faculty of the ElectricalEngineering and Computer Science Department,University of Michigan, Ann Arbor, where he iscurrently an Associate Professor. His research inter-ests are drawn from time–frequency representations,
music signal processing, auditory systems modeling, psychoacoustics, sensoryprosthetics, and sound quality engineering. He serves as consultant to variousindustries in sound quality engineering and time–frequency representations.
Dr. Wakefield received the NSF Presidential Young Investigator Award in1987 and the IEEE Millennium Award in 2000.