statistical analysis sc504/hs927 spring term 2008 week 17 (25th january 2008): analysing data
Post on 21-Dec-2015
215 views
TRANSCRIPT

Statistical AnalysisSC504/HS927
Spring Term 2008Week 17 (25th January 2008):
Analysing data

Recap
• Why
• How
• What

Questions to consider
• What is my question / interest?• Can the sample tell me about it?• What are the relevant variables, what are their
characteristics – are they in the form I want them? (If not, change them into that form).
• What is the most appropriate method to use?• If it works what will / might it show me? NB
negative results are not necessarily uniformative• If it doesn’t work – why might that be?

Levels of measurement
• Nominal e.g., colours numbers are not meaningful
• Ordinal e.g., order in which you finished a race numbers don’t indicate how far ahead the winner of the race was
• Interval e.g., temperature equal intervals between each number on the scale but no absolute zero
• Ratio e.g., time equal intervals between each number with an absolute zero.

Univariate analysis
• Measures of central tendency– Mean=– Median= midpoint of
the distribution– Mode= most common
value
n
xxxxx n...4321

Mode – value or category that has the highest frequency (count)
age frequency (count)
sex frequency (count)
16-25 12 male 435
26-35 20 female 654
36-45 32
46-55 27
56+ 18

Median – value that is halfway in the distribution (50th percentile)
age 12 14 18 21 36 41 42
median
age 12 14 18 21 36 41
median= (18+21)/2 =19.5

Mean – the sum of all scores divided by the number of scores
• What most people call the average
• Mean: ∑x / N

Which One To Use?
Mode Median Mean
Nominal
Ordinal
Interval

Measures of dispersion
– Range= highest value-lowest value– variance, s2=
– standard deviation, s (or SD)=
The standard error of the mean and confidence intervals
– SE
1
)( 2_
n
YYi = 1
)(...()( 2_2_
22
_
1 )
n
YYYYYY n
n
s
2s

Definitions: Measures of Dispersion
• Variance: indicates the distance of each score from the mean but in order to account for both + and – differences from the mean (so they don’t just cancel each other out) we square the difference and add them together (Sum of Squares). This indicates the total error within the sample but the larger the sample the larger the error so we need to divide by N-1 to get the average error.

Definitions: Measures of Dispersion
• Standard deviation: due to the fact that we squared the sums of the error of each score the variance actually tells us the average error². To get the SD we need to take the square root of the variance. The SD is a measure of how representative the mean is. The smaller the SD the more representative of your sample the mean is.

Definitions: Measures of Dispersion
• Standard error: the standard error is the standard deviation of sample means. If you take a lot of separate samples and work out their means the standard deviation of these means would indicate the variability between the means of different samples. The smaller the standard error the more representative your sample mean is of the population mean.

Definitions: Measures of Dispersion
• Confidence Intervals: A 95% confidence interval means that if we collected 100 samples and calculated the means and confidence intervals 95 of those confidence intervals would contain the population mean.

Describing data
• Numbers / tables– Analyze – Descriptive Statistics-
Frequencies / Descriptives
• Charts / graphs– Graphs – Pie / Histogram / Bar– Using excel for charts

E.g.Descriptive Statistics
3880 18.00 12.00 30.00 21.2317 6.20229 38.468
3880
@/what is your exact age?
Valid N (lis twise)
N Range Minimum Maximum Mean Std. Deviation Variance
Highest Qualification
387 38.7 38.7 38.7
346 34.6 34.6 73.3
267 26.7 26.7 100.0
1000 100.0 100.0
NONE
VOC & O LEVEL
A LEVEL & ABOVE
Total
ValidFrequency Percent Valid Percent
CumulativePercent
Statistics
Highest Qualification1000
0
1.0000
.00
Valid
Missing
N
Median
Mode
Descriptive Statistics
3880 12.00 30.00 21.2317 .09957 6.20229
3880
@/what is your exact age?
Valid N (listwise)
Statistic Statistic Statistic Statistic Std. Error Statistic
N Minimum Maximum Mean Std.Deviation

Bivariate relationships
• Asking research questions involving two variables:– Categorical and interval– Interval and interval– Categorical and Categorical
• Describing relationships
• Testing relationships

Interval and interval
• Correlation– To be covered next week with OLS

Categorical (dichotomous) and interval
• T-tests– Analyze – compare means – independent
samples t-test – check for equality of variances
– t value= observed difference between the means for the two groups divided by the standard error of the difference
– Significance of t statistic, upper and lower confidence intervals based on standard error

E.g. (with stats sceli.sav)
• Average age in sample=37.34• Average age of single=31.55• Average age of partnered=39.45• t=7.9/.74• Upper bound=-7.9+(1.96*.74)• Lower bound=-7.9-(1.96*.74)
Independent Samples Test
.026 .872 -10.721 998 .000 -7.905 .737 -9.352 -6.458
-10.661 470.095 .000 -7.905 .741 -9.362 -6.448
Equal variancesassumed
Equal variancesnot assumed
ageF Sig.
Levene's Test forEquality of Variances
t df Sig. (2-tailed)Mean
DifferenceStd. ErrorDifference Lower Upper
95% ConfidenceInterval of the
Difference
t-tes t for Equality of Means

Categorical and Categorical
• Chi Square Test– Tabulation of two variables– What is the observed variation compared to what
would be expected if equal distributions?– What is the size of that observed variation compared
to the number of cells across which variation could occur? (the chi-square statistic)
– What is its significance? (the chi square distribution and degrees of freedom)
fe
fefo 2)(2
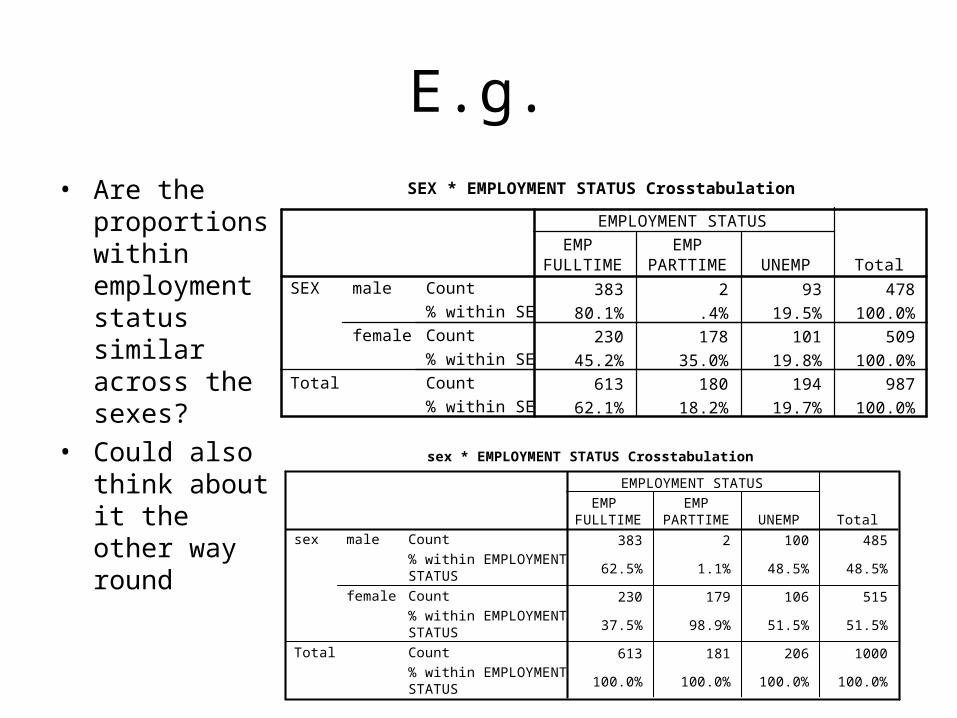
E.g.
• Are the proportions within employment status similar across the sexes?
• Could also think about it the other way round
SEX * EMPLOYMENT STATUS Crosstabulation
383 2 93 478
80.1% .4% 19.5% 100.0%
230 178 101 509
45.2% 35.0% 19.8% 100.0%
613 180 194 987
62.1% 18.2% 19.7% 100.0%
Count
% within SEX
Count
% within SEX
Count
% within SEX
male
female
SEX
Total
EMP FULLTIME
EMPPARTTIME UNEMP
EMPLOYMENT STATUS
Total
sex * EMPLOYMENT STATUS Crosstabulation
383 2 100 485
62.5% 1.1% 48.5% 48.5%
230 179 106 515
37.5% 98.9% 51.5% 51.5%
613 181 206 1000
100.0% 100.0% 100.0% 100.0%
Count
% within EMPLOYMENTSTATUS
Count
% within EMPLOYMENTSTATUS
Count
% within EMPLOYMENTSTATUS
male
female
sex
Total
EMP FULLTIME
EMPPARTTIME UNEMP
EMPLOYMENT STATUS
Total
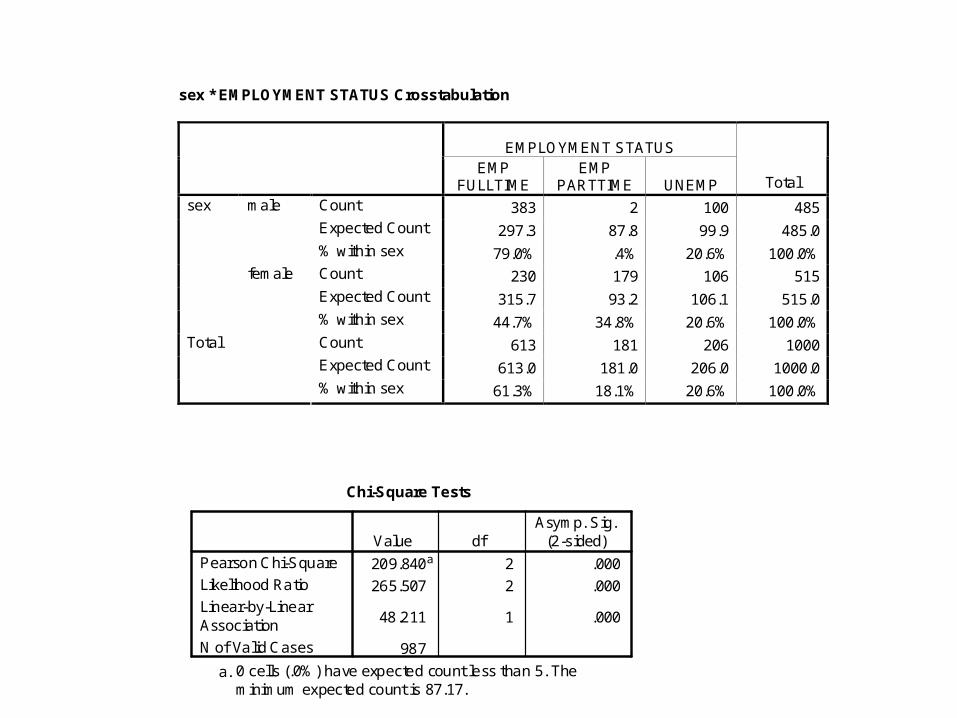
sex * EMPLOYMENT STATUS Crosstabulation
EMPLOYMENT STATUS
EMP
FULLTIME EMP
PARTTIME UNEMP Total
Count 383 2 100 485 Expected Count 297.3 87.8 99.9 485.0
male
% within sex 79.0% .4% 20.6% 100.0% Count 230 179 106 515 Expected Count 315.7 93.2 106.1 515.0
sex
female
% within sex 44.7% 34.8% 20.6% 100.0% Count 613 181 206 1000 Expected Count 613.0 181.0 206.0 1000.0
Total
% within sex 61.3% 18.1% 20.6% 100.0%
Chi-Square Tests
209.840a 2 .000
265.507 2 .000
48.211 1 .000
987
Pearson Chi-Square
Likelihood Ratio
Linear-by-LinearAssociation
N of Valid Cases
Value dfAsymp. Sig.
(2-sided)
0 cells (.0%) have expected count less than 5. Theminimum expected count is 87.17.
a.

Now look through your background notes before starting
the exercises…