statistical methods bayesian methods daniel thorburn stockholm university 2012-03-20
TRANSCRIPT

Statistical Methods Bayesian methods
Daniel Thorburn
Stockholm University
2012-03-20

2
Outline
1. Background to Bayesian statistics2. Two simple rules3. Why not design-based?4. Bayes´ theorem and likelihood5. Binomial and Normal observations

1. Background to Bayesian statistics

• Mathematically:
– Probability is a positive, finite, normed, additive measure defined on a algebra (Kolmogorovs axioms)
• But what does that correspond to in real life?

What is the probability of heads in the following sequence?
Does it change? And when?
– This is a fair coin– I am now going to toss it in the corner – I have tossed it but noone has seen the result– I have got a glimpse of it but you have not– I know the result but you don´t– I tell you the result
5

What is the probability that Mitt Romney will be the next president
of the USA?
• If I offer you 10 Swedish kronor if you guess right, which alternative would yo choose (Yes or No)? – p < or > ½
• If I offer you 15 Swedish kronor if you correctly says yes and 5 if correctly no. What would you choose?– p < or > ¾
• If I offer you 17 Swedish kronor if you correctly says yes and 3 if correctly no. What would you choose?– p < or > 0,85
• A.s.o.

Prior probability
• In this way you can decide your prior probability.
• It varies between different persons depending on their knowledge
• Also your opinion will change over time as you get more knowledge (e.g. the result from upcoming primaries)

• Laplace definition. ”All outcomes are equally probable if there is no information to the contrary”. (number of positive elementary events/number of possible elementary events)
• Choose heads and bet on it, with your neighbour. You get one krona if you are right and lose one if you are wrong. When should you change from indifference?
• Frequency interpretation. (LLN). If there is an infinite sequence of independent experiments then the relative frequency converges a.s. towards the true value. Cannot be used as a definition for two reasons – It is a vicious circle. Independence is defined in terms of
probability– It is logically impossible to define over-countably many quantities
by a countable procedure.
8

Probabilities do not exist (de Finetti)
• They only describe your lack of knowledge• If there is a God almighty, he knows everything
now, in the past and in the future. (God does not play dice, (Einstein))
• But lack of knowledge is personal, thus probability is subjective
• Kolmogorovs axioms only does not say anything about the relation to reality
9

10
• Probability is the language which describes uncertainty
• If you do not know a quantity you should describe your opinion in terms of probability (or equivalently odds =p/(1-p))
• Probability is subjective and varies between persons and over time, depending on the background information.

The distribution of foreign students in this group
• My prior – before going here
• See Excel sheet!
• Posterior after getting more and more observations

2. Two simple requirements for rational inference
12

13
Rule 1
• What you know/believe in advance + The information in the data = What you know/believe afterwards

14
Rule 1
• What you know/believe in advance + The information in the data = What you know/believe afterwards
• This is described by Bayes’ Formula:
• P(P(XPX,K)

15
Rule 1
• What you know/believe in advance + The information in the data = What you know/believe afterwards
• This is described by Bayes’ Formula:
• P(P(XPX,K)
• or in terms of the likelihood
• P(LXPX,K)

16
Rule 1 corrolarium
• What you believe afterwards + the information in a new study = What you believe after both studies

17
Rule 1 corrolarium• What you believe afterwards +
the information in a new study = What you believe after both studies
• The result of the inference should be possible to use as an input to the next study
• It should thus be of the same form!• Note that hypothesis testing and confidence
intervals can never appear on the left hand side so they do not follow rule 1

18
Rule 2
• Your knowledge must be given in a form that can be used for deciding actions. (At least in a well-formulated problem with well-defined losses/utility).

19
Rule 2
• Your knowledge must be given in a form that can be used for deciding actions. (At least in a well-formulated problem with well-defined losses/utility).
• If you are rational, you must use the rule which minimizes expected ”losses” (maximizes utility)
• Dopt = argmin E(Loss(D, )|X,K) = argmin Loss(D,) P( |X,K) d

20
Rule 2
• Your knowledge must be given in a form that can be used. (At least in a well-formulated problem with well-defined losses/utility.
• If you are rational, you must use the rule which minimizes expected ”losses” (maximizes utility)
• Dopt = argmin E(Loss(D, )|X,K)
= argmin Loss(D,) P( |X,K) d• Note that classical design-based inference has no
interface with decisions.

Statistical tests are useless
• They cannot be used to combine with new data.
• They cannot be used even in simple decision problems.
• They can be compared to a blunt plastic knife given to a three year old child– He cannot do much sensible with it– But he cannot harm himself either

3. An example of the the stupidity of frequency-based
methods

23
N=4, n=2, SRS. Dichotomous data, black or white. The variable is known to come in pairs, i.e. the total is T=0, 2 or 4.
Probabilities:
Population\outcome 0 white 1 white 2 white
No white T=0 1
2 white T=2 1/6 2/3 1/6
All white T=4 1
If you observe 1 white you know for sure that the population contains 2 white.
If you observe 0 or 2 white the only unbiased estimate is T*= 0 resp. 4 (Prove it)
The variance of this estimate is 4/3 if T=2 (=1/6*4+4/6*0+1/6*4) and 0 if T=0 or 4
So if you know the true value the variance is 4/3 and if you are uncertain, variance is 0. (Standard unbiased variance estimates are 2 resp. 0)

Bayesian analysis works OK
– We saw the Bayesian analysis when t=1, (T*=2).
– If all possibilities are equally likely à priori, the posterior estimates of T when t = 0 (2) is T* = 2/7 (26/7) and the posterior variance is 24/49.
24

25
Always stupid?
• It is stupid to believe that the variance of an estimator is a measure of precision in one particular case. (It is defined as a long run average for many repetitions if the parqameter has a specified value)
• But it is not always so obvious and so stupid as in this example.
• Is this a consequence of the unusual prior where T must be even?
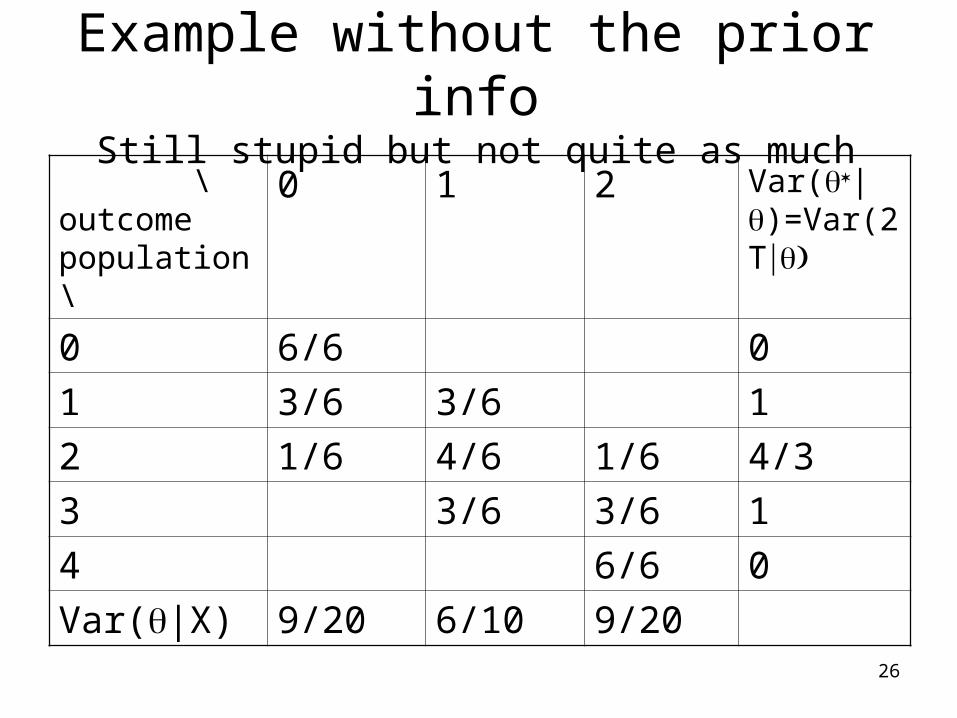
26
Example without the prior infoStill stupid but not quite as much
\outcome population\
0 1 2 Var(|)=Var(2T
0 6/6 0
1 3/6 3/6 1
2 1/6 4/6 1/6 4/3
3 3/6 3/6 1
4 6/6 0
Var(|X) 9/20 6/10 9/20

27
Example without the prior infoStill stupid but not quite as much
\outcome population\
0 1 2 Var(|)=Var(2T
0 6/6 0
1 3/6 3/6 1
2 1/6 4/6 1/6 4/3
3 3/6 3/6 1
4 6/6 0
Var(|X) 9/20 6/10 9/20If you observe 1, the true error is never larger than 1, but the standard deviation is always larger than (or equal to) 1 for all possible parameter values.

28
Always stupid?• It is always stupid to assume that the variance of
an estimator is a measure of precision in one particular case. (It is defined as a long run property for many repetitions)
• But it is not always so obvious and stupid as in these examples.
• Under suitable regularity conditions designbased methods are asymptotically as efficient as Bayesian methods
nasXpsaXVar
Varn
n
),(..1)|(
)|*(

29
• Many people say that one should choose the approach that is best for the problem at hand. Classical or Bayesian.

30
• Many people say that one should choose the approach that is best for the problem at hand. Classical or Bayesian.
• So do Bayesians.
• But they also draw the conclusion:

31
• Many people say that one should choose the approach that is best for the problem at hand. Classical or Bayesian.
• So do Bayesians.
• But they also draw the conclusion:
• Always use Bayesian methods!

32
• Many people say that one should choose the approach that is best for the problem at hand. Classical or Bayesian.
• So do Bayesians.
• But they also draw the conclusion:
• Always use Bayesian methods!
• Classical methods can sometimes be seen as quick and dirty approximations to Bayesian methods.
• Then you may use them.

4. Bayes´ theorem and likelihood

Bayes´ theorem: Let A be an event and B a partition of the sample space
),()()|()()|(
)|()()|(
)|()(
)|()()|(
)|()()|(
)|()(
)|()()|(
xLfxffxXf
yYxfyfxXyf
dssYxfsf
yYxfyfxXyf
ABPAPBAP
ABPAP
ABPAPBAP
X
XYY
s
XY
XYY
ii
jj
ii
where Y and X are random variables, with the joint distribution fYX (y,x) = fX(x)fY(y|X=x) =fY(y)fX(x|Y=y)

Likelihood
• You have heard about the likelihood. • What does it mean? • Does it in some way reflect how likely
different values are?• The maximum likelihood is often a good
estimate but otherwise? • Are those values with smaller values less
likely than those with higher likelihood values?

Likelihood
• Yes and No• The probability depends also on what else you
know• But given that you have a uniform prior reflecting
”no prior information” (sometimes called a ”vague prior”), it describes how likely differen parameter values are.
• If you have another prior the probability increases most where the likelihood is high.

5. Binomial and Normal distributions

Binomial
• Likelihood pk(1-p)n-k
• Possible prior: Beta distribution
• Se Excel sheet• This is a common prior but there are many
other which are possible.
11 )1()1()1(
)(

Binomial
• Likelihood pk(1-p)n-k
• Possible prior: Beta distribution
• Posterior: Beta distributed with parameters kand +n-k
• Proof: …
• Prior has a weight corresponding to (/(n+
11 )1()1()1(
)(

Example
• A manufacturer gets mail in large shipments. He knows from previous experience that the shipments vary in quality. The proportion of units with quality under the specified level is around 15 percent with a standard error of 10 percental unit.
• He tests some units in a new shipment and wants to assess the quality of the shipment.
• He selects a prior with the known properties

• Beta variable mean • Variance • Solving for the parameters gives that the prior
corresponds to a Beta distribution with =1.763 and b= 9.99
• He first tests 10 units and finds 2 under specification. – Here the prior information and data weights equally)
• In the following 90, there are 25 under the specification– Here the data dominates and the likelihood and
posterior are almost equal– It is seen that the posterior distribution in this case
converges to normality

• Note that you could look at the data during the study and see and stop testing when the estimate or the estimated precision is good enough.
• (which may depend on the outcome. Very few under the specified limits may mean that you can stop early since you are certain that the shipment has good quality. Many under the limits may also lead to a quick stop.)
• This is not allowed for standard statistics, where it is important to specify the sampling plan in advance. In Bayesian theory you just have to specify your prior in advance.

• What is the probability that the next unit will be under the specified limits?
• The expected value of the posterior is
• And the probability that the following two units both are under the specified value
n
k
1
1
n
k
n
k

Normal distribution with known variance
• x1, x2, … are i.i.d. N(, 2)
• Prior: m € N(m0, 2)
• X-bar: N(, 2/n) • Posterior: Normal with
220
2
220
220
0
11
1
nn
xnm
m nn

Precision
• Precision is sometimes defined as 1/variance.
• The posterior mean is the prior mean and the data mean weighted with their precision
• And the posterior precision is the sum of the prior precision and the data precision

A vague prior
• If you do not know anything in advance the prior variance,
2, is large.
• And the precision -2 is small and thus the weight of
the prior• Sometimes one lets the precision tend to 0
• i.e. N(m0, ).
• This corresponds to a prior uniform on the real line, which is mathematically impossible (since you cannot get the area under the curve to be 1). But it is possible to do many of the usual calculations anyway

47
Thank you for your attention!