stats 330: lecture 30
DESCRIPTION
Stats 330: Lecture 30. Association Reversal and Simpson's Paradox. Plan of the day. In today’s lecture we continue our discussion of contingency tables. Topics Simpson’s Paradox Collapsing tables Adequacy of the chi-square approximation See also Tutorial 10 (can download). - PowerPoint PPT PresentationTRANSCRIPT

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 1
Stats 330: Lecture 30

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 2
Plan of the dayIn today’s lecture we continue our discussion of contingency tables.Topics
– Simpson’s Paradox
– Collapsing tables
– Adequacy of the chi-square approximation
See also Tutorial 10 (can download)

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 3
Example: Florida murders
If we “collapse” the table over victim, we get the 2x 2 table of defendant by death penalty:
Odds of being black for “no DP group” are 149/141Odds of being black for “DP group” is 17/19
OR = (149/141)/(17/19) = (149*19)/(141*17) = 1.181The odds of being black are 18% higher for the no DP group than for the DP group i.e. blacks favoured
Death
= N
Death
= Y
Defendant = black 149 17
Defendant = white 141 19

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 4
Example: Florida murders
The tables conditional on victim are
Death
= N
Death
= Y
Defendant = black
97 6
Defendant = white
9 0
Death
= N
Death
= Y
Defendant = black
52 11
Defendant = white
132 19
Victim=black, OR =0.79 (add 0.5 to each cell)
Victim=white, OR =0.67
Now odds of being black are greater in the DP group!

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 5
Association Reversal
In our regression lectures, we saw that regression coefficients could change sign when new variables were added to the model.
i.e. the coefficient of x1 in the model
y ~ x1
can have the opposite sign to the coefficient of x1 in the model
y ~ x1 + x2– See e.g. Lecture 5, Slides 12 and 13.

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 6
The reason
• The coefficient of x1 in the model y~x1 is the slope of the fitted line in the scatter plot, summarising the marginal relationship between y and x1
• The coefficient of x1 in the model y~x1+x2 is the slope of the line in the coplot, which summarises the relationship between y and x1, conditional on x2

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 7
Marginal and conditional association
• In the first case, we are looking at association between y and x1
• In the second case, we are looking at the association between y and x1, with x2 held fixed (conditional on x2)
• We can do the same sort of thing in contingency tables

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 8
Association in contingency tables
• In 2 x 2 tables, we measure association using the odds ratio.
• If we have 3 factors A, B and C, each at 2 levels, we can look at the marginal odds ratio of A and B, using the AB table, ignoring C.
• Or, the 2 conditional odds ratios, one the AB table corresponding to C=1, and the other corresponding to C=2.

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 9
When will these be the same?
• In ordinary regression, the coefficient of x1 in the model y~x1 will be the same as the coefficient of x1 in the model y~x1+x2 if and only if x1 and x2 are uncorrelated.
• In contingency tables, the marginal and conditional population OR’s for the AB tables will be the same if– A and C are independent, given B, or,– B and C are independent, given A.
• Thus, we can collapse the table over C if – The ABC interaction is zero, and either the AC interaction is zero,
or the BC interaction is zero.
• If this is not the case, association reversal ( Simpson’s paradox) may occur. The more associated A and/or B is with C, the more likely it is to happen.

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 10
Florida data:• Very strong association between DP and race of
victim: if victim is black, small chance of DP
• Very strong association between race of victim and race of defendant
• Since blacks murder blacks, (and whites murder whites), not so many DPs for black defendants overall

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 11
When can we collapse?
• Thus, we can collapse the table over C if – The ABC interaction is zero, and
• Either the AC interaction is zero, or• The BC interaction is zero.
If these conditions are not met, then the marginal and conditional tables may have different (even reversed) degrees of association

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 12
Florida dataRecall that there are significant interactions between Race of victim and race of defendantRace of victim and death penalty
Thus, can’t collapse over race of victim
Call:glm(formula = counts ~ defendant * dp * victim, family = poisson,
data = murder.df)Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 5.27300 0.07161 73.633 < 2e-16 ***defendantw -2.32856 0.24033 -9.689 < 2e-16 ***dpy -2.70805 0.28645 -9.454 < 2e-16 ***victimw -0.61904 0.12105 -5.114 3.15e-07 ***defendantw:dpy -0.23639 1.06521 -0.222 0.82438 defendantw:victimw 3.25433 0.26657 12.208 < 2e-16 ***dpy:victimw 1.18958 0.36750 3.237 0.00121 ** defendantw:dpy:victimw -0.16131 1.10322 -0.146 0.88375

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 13
In graphical form
B
CA
Can collapse over B or C but not A
© Department of Statistics 2012 STATS 330 Lecture 30: Slide 14
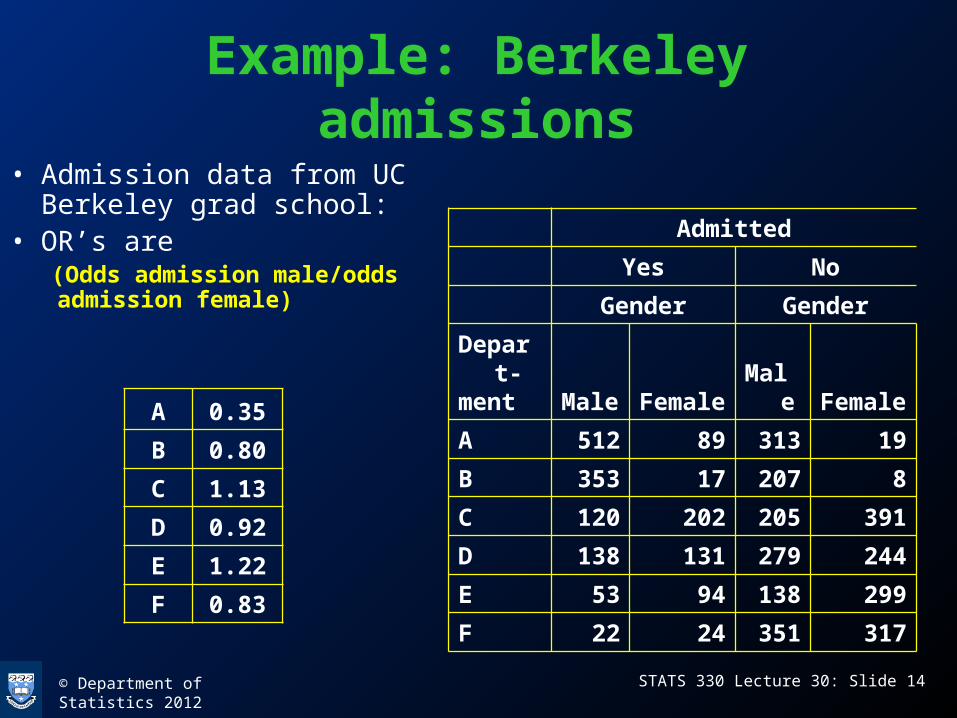
Example: Berkeley admissions
• Admission data from UC Berkeley grad school:
• OR’s are(Odds admission male/odds admission female)
Admitted
Yes No
Gender Gender
Depart-ment Male Female Male Female
A 512 89 313 19
B 353 17 207 8
C 120 202 205 391
D 138 131 279 244
E 53 94 138 299
F 22 24 351 317
A 0.35
B 0.80
C 1.13
D 0.92
E 1.22
F 0.83

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 15
Collapse over departments
Admitted
Gender Yes No
Male 1198 1493
Female 557 1278
• OR = 1.84 (odds admission male/ odds admission female)
• Seems to be strong evidence of bias against women
• Reason: females apply for programs that have low admission rates, males for programs that have high admission rates, so strong dependence between dept and the other 2 factors

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 16
Anova Table Df Deviance Resid. Df Resid. Dev P(>|Chi|)NULL 23 2650.10
Dept 5 159.52 18 2490.57 1.251e-32
Gender 1 162.87 17 2327.70 2.665e-37
Admit 1 230.03 16 2097.67 5.879e-52
Dept:Gender 5 1220.61 11 877.06 1.006e-261
Dept:Admit 5 855.32 6 21.74 1.242e-182
Gender:Admit 1 1.53 5 20.20 0.22
Dept:Gender:Admit 5 20.20 0 7.239e-14 1.144e-03

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 17
Thus
• 3 factor interaction is significant, so
– Dept is not conditionally independent of admission, given gender
– Dept is not conditionally independent of gender, given admission
• Collapse over Dept at your peril!

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 18
Moral: Collapsing tables
• Dangerous to collapse tables when factor being collapsed over (eg victim’s race, Berkeley department) is strongly associated with the other factors
• Marginal (collapsed) tables may give a very misleading picture, need to look at conditional tables

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 19
How good is chi-square?
• The bigger the cell counts, the better the chi-square approximation to the deviance
• The smaller the number of cells, the better the approximation
• But approximation is often OK even if some cells counts are small: our next example illustrates this.

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 20
The Dayton Study
The data in this case study were gathered by researchers investigating teenage substance abuse in a community near Dayton, Ohio in 1992.
• The researchers asked 2276 high school students if they had ever used alcohol, cigarettes or marijuana.

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 21
The dataA 3-dimensional contingency table:
Used marijuana
Yes No
Used cigarettes Used cigarettes
Used alcohol Yes No Yes No
Yes 911 44 538 456
No 3 2 43 279

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 22
Making the data frame:
> counts = c(911,3,44,2,538,43,456,279) > ACM.df = data.frame(counts,expand.grid(A=c("Yes","No"), C=c("Yes","No"), M=c("Yes","No")))> ACM.df counts A C M1 911 Yes Yes Yes2 3 No Yes Yes3 44 Yes No Yes4 2 No No Yes5 538 Yes Yes No6 43 No Yes No7 456 Yes No No8 279 No No No

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 23
Fitting modelsham.glm = glm(counts~A*C*M, family=poisson, data=ACM.df) > anova(ACM.glm, test="Chisq")Analysis of Deviance Table Df Deviance Resid. Df Resid. Dev P(>|Chi|)NULL 7 2851.46 A 1 1281.71 6 1569.75 1.064e-280C 1 227.81 5 1341.93 1.787e-51M 1 55.91 4 1286.02 7.575e-14A:C 1 442.19 3 843.83 3.607e-98A:M 1 346.46 2 497.37 2.504e-77C:M 1 497.00 1 0.37 4.283e-110A:C:M 1 0.37 0 2.509e-14 0.54

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 24
Try the indicated homogeneous association
model> ham.glm = glm(counts~A*C+A*M+C*M, family=poisson, data=ACM.df)> summary(ham.glm)Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 6.81387 0.03313 205.699 < 2e-16 ***ANo -5.52827 0.45221 -12.225 < 2e-16 ***CNo -3.01575 0.15162 -19.891 < 2e-16 ***MNo -0.52486 0.05428 -9.669 < 2e-16 ***ANo:CNo 2.05453 0.17406 11.803 < 2e-16 ***ANo:MNo 2.98601 0.46468 6.426 1.31e-10 ***CNo:MNo 2.84789 0.16384 17.382 < 2e-16 ***
Null deviance: 2851.46098 on 7 degrees of freedomResidual deviance: 0.37399 on 1 degrees of freedom

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 25
Summary• The model counts~ A*C + C*M + A*M
seems to fit well
• This is the homogeneous association model, can write
counts~ (C+A+M)^2
Or counts~ A*C*M – A:C:M
with all possible 2-way interactions but no 3-way interaction

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 26
Is Chi-square adequate?• Consider the 3-dimensional table: it had two
small counts• We fitted a model to these data having all 2
factor interactions but no 3-factor interactions.• We can estimate the Poisson means using
predict
> means = predict(ham.glm, type="response")> means 1 2 3 4 5 6 7 8 910.383170 3.616830 44.616830 1.383170 538.616830 42.383170 455.383170 279.616830

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 27
Is Chisquare adequate (2)• Assuming these estimated means are the true ones, we
can simulate a table by generating 8 new table entries.• Thus, for example, if cell 1 has assumed mean 910.383,
we generate an entry for cell 1 by selecting a value at random from a Poisson distribution with mean 910.38
> rpois(1, 910.38)[1] 969• Repeat for every cell, get a simulated table• Calculate the deviance of the model for the simulated
table• Repeat for 10000 tables, record deviance each time.
© Department of Statistics 2012 STATS 330 Lecture 30: Slide 28
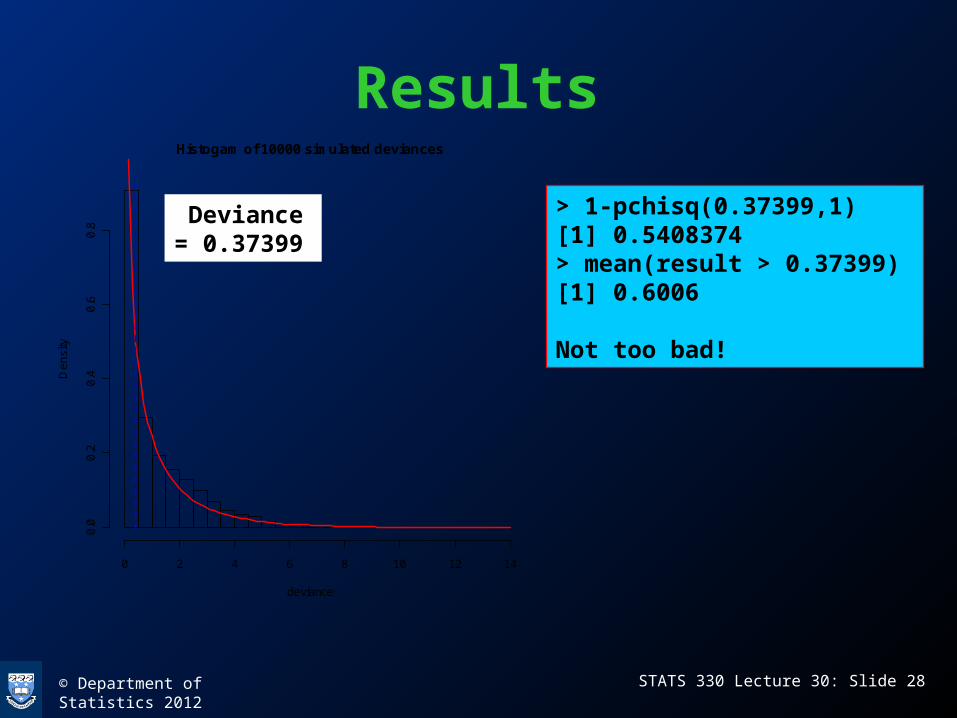
Results
> 1-pchisq(0.37399,1)[1] 0.5408374> mean(result > 0.37399)[1] 0.6006
Not too bad!
Histogam of 10000 simulated deviances
deviance
De
nsi
ty
0 2 4 6 8 10 12 14
0.0
0.2
0.4
0.6
0.8
Deviance = 0.37399

© Department of Statistics 2012 STATS 330 Lecture 30: Slide 29
Codemeans = predict(ham.glm, type="response")Nsim=10000# generate 10000 tablesdata<-matrix(rpois(Nsim*8, means), 8, Nsim)
result<-numeric(Nsim)for(i in 1:Nsim)result[i]<-deviance(glm(data[,i]~ A*C + C*M + A*M , family=poisson, data=ACM.df))# draw a picture of the resultshist(result, nclass=30, freq=F, xlab="deviance",main="Histogam of 10000 simulated deviances")# add chisquare 1 densityxx<-seq(0,14,length=100)lines(xx,dchisq(xx,1), lwd=2, col="red")