storing and accessing information. databases and queries (ueb-uat bioinformatics course - session...
DESCRIPTION
Course: Bioinformatics for Biomedical Research (2014). Session: 1.2- Storing and Accessing Information. Databases and Queries. Statistics and Bioinformatisc Unit (UEB) & High Technology Unit (UAT) from Vall d'Hebron Research Institute (www.vhir.org), Barcelona.TRANSCRIPT

Hospital Universitari Vall d’Hebron Institut de Recerca - VHIR
Institut d’Investigació Sanitària de l’Instituto de Salud Carlos III (ISCIII)
Bioinformàtica per la Recerca Biomèdica http://ueb.vhir.org/2014BRB
Alex Sánchez
[email protected] 13/05/2014
STORING AND ACCESSING INFORMATION DATABASES AND QUERIES

1. Data banks and databases ● Information in the genomics era ● Distinct DB usages ● To take into account ● Main resources providers
2. Types of databases ● EMBL vs NCBI ● Bibliography DB ● Taxonomy DB ● Nucleotide DB ● Genome DB ● Protein DB ● Microarray DB ● Other DB ● Lists of DB
PRESENTATION OUTLINE
2 13/05/2014
3. Structure and formats of the databases ● Structure of the DB ● Formats of the DB ● Sequence FASTA format ● GenBank entry example ● EMBL entry example
4. Submitting data
● Submitting sequences ● Submitting expression data
5. Tools for DB exploitation ● ENTREZ ● Cross-search tables ● Entrez queries ● Entrez fields ● Help system

Data banks and databases
3 13/05/2014

INFORMATION IN THE GENOMICS ERA
4
• Genomics era: huge amount of data
• To be able to use this information, it should be properly stored
• The access to that info
– Must be quick
– Has to be done in a flexible way
• That is possible thanks to the
– Creation of databases
– It’s online availability
13/05/2014

DISTINCT DB USAGES
5
• Information search – By keyword, accession number, authors…
• Homology search – Is there any sequence identical or similar to that mine?
• Pattern search – Has my sequence any known pattern?
• Predictions – Can I find proteins, with already known function, similar to
mine?
13/05/2014

Bioinformatics reagent: Databases
Organized array of information
Place where you put things in, and (if all is well) you should be able to get them out again.
Resource for other databases and tools.
Simplify the information space by specialization.
Bonus: Allows you to make discoveries.
Important question to ask: what is the data model?

7
Bioinformatics experiments:
BLAST search Sequence Alignment
Reagents:
•Sequence •Databases
Method: •P-P BLASTP •N-P BLASTX •P-N TBLASTN •N-N BLASTN •N (P) – N (P) TBLASTX
Interpretation:
•Similarity •Hypothesis testing
Know your reagents
Know your methods
Do your controls

8
Nature 409:452
Bioinformatics Citizenship: What it means, and what does it cost?

Databases
Information system
Query system
Storage System
Data

Databases
Information system
Query system
Storage System
Data
GenBank flat file COSMIC record Interaction Record Title of a book Book

Databases
Information system
Query system
Storage System
Data
Boxes
Oracle
MySQL
PC binary files
Unix text files
Bookshelves

Databases
Information system
Query system
Storage System
Data
A List you look at A catalogue indexed files SQL grep

The library of Congress Google Entrez EnsEMBL UCSC gemome browser
Databases
Information system
Query system
Storage System
Data

TO TAKE INTO ACCOUNT
14 13/05/2014
Information organization
Resources providers Databases Tools
Organizations or centers devoted to the offer and maintain the databases
To find/check/export information into/from DB
Diverse and very different information

MAIN RESOURCES PROVIDERS
15 13/05/2014
• The National Center for Biotechnology Information (NCBI) offers data banks, databases and tools at the USA
• The European Bioinformatics Institute (EBI) does a similar function in Europe
• GenomeNet gathers several databases from Japan

Types of databases
16 13/05/2014

TYPES OF DB
17 13/05/2014
• There are hundreds of BD, so it is not feasible to enumerate them (but they have tried here)
• We can classify them by multiple criteria
• The structural organization of the EMBL and the NCBI resources is radically different

EMBL vs NCBI
18 13/05/2014
• EMBL – Bibliographic DB
– Taxonomic DB
– Nucleotide DB
– Genomic BD
– Protein BD
– Microarrays DB
…
• NCBI – PubMed
– Entrez
– OMIM
– Books
– TaxBrowser
– Structure
…

BIBLIOGRAPHY DB
19 13/05/2014
• Collection of papers published in scientific journals
– Pubmed (NCBI)
– Medline (EBI)
– Biocatalog: papers organized by concrete molecular biology topics

TAXONOMY DB
20 13/05/2014
• Information on the classification of living things
– basically hierarchical
– and based on molecular evidences
• To classify any organism from which at least one nucleic acid sequence has been determined
• There is indeed some controversy in the scientific community

NUCLEOTIDE DB
21 13/05/2014
• Sequences from experimental laboratories
• Daily updated
• Daily exchanging of its contents
– Genbank (NCBI)
– EMBL (EBI)
– KEGG (Genome net)

Sequences NOT in NucleotideDB
• WGS: whole genome shotgun
• TPA: third party annotations
• SNPs
• SAGE tags (serial analysis of gene expression)
• RefSeq (Genomic, mRNA, or protein)
• Consensus sequences

GENOME DB
23 13/05/2014
• Sequences and annotations of whole genomes
– Ensembl (EBI)
– Genome viewer (NCBI)
– Goldenpath (UCSC)
• Specialized genomic resources
– Transfact
– EST
– UTRDB
– SpliceSitesDB
…

PROTEIN DB (I)
24 13/05/2014
• Aminoacids primary sequences
– Without human revision
• Trembl (EBI)
• NR (NCBI)
– With annotation’s curation
• Uniprot (EBI)
– Proteome DB
• Proteome analysis (EBI)

PROTEIN DB (II)
25 13/05/2014
• Secondary structures or protein domains
• They depend on the protein source and the analysis perfomed on them
– PROSITE: Regular Expressions over Swiss-Prot
– PRINTS: Set of motifs that define a family over Swiss-Prot/TrEMBL
– BLOCKS: Aligned motifs from PROSITE/PRINTS
– PFAM: Markov Modelos over Swiss-Prot
– INTERPRO: Integrates information from several domain-focused data bases.

PROTEIN DB (III)
26 13/05/2014
• 3D structures with coordinates of each atom
– PDB: Reference protein 3D
structure (x-ray, NMR) database
– CATH: Classification of the PDB in different functional and structural groups
– MMDB: subset de PDB maintained by the NCBI
– MSD: subset of the PDB maintained by the EBI

MICROARRAY DB
27 13/05/2014
• Expression arrays results
– ArrayExpress
– caArray
– Gene Expression Omnibus

OTHER DB (1)
28 13/05/2014
• Biological Annotations
– Gene Ontology
– KEGG
– Gene Cards
• Therapeutic targets
– Therapeutic targets database
– PharmGKB
…

Historical perspective on the Human Genome Data
Human Expressed Seq Tags (mRNA) sequencing
Human genome mapping and sequencing
Population analysis and polymorphism measurements
Genome Wide Association Studies
<the Homer paper>
The Cancer Genome Atlas pilot
The 1000 genome project
The Cancer Genome Atlas
The International Cancer Genome Consortium

• Detailed Phenotype and Outcome data • Region of residence • Risk factors • Examination • Surgery • Drugs • Radiation • Sample • Slide • Specific histological features • Analyte • Aliquot • Donor notes
• Gene Expression (probe-level data) • Raw genotype calls • Gene-sample identifier links • Genome sequence files
ICGC Controlled Access Datasets
• Cancer Pathology Histologic type or subtype Histologic nuclear grade
• Patient/Person Gender Age range
• Gene Expression (normalized) • DNA methylation • Genotype frequencies • Computed Copy Number and Loss of Heterozygosity • Newly discovered somatic variants
ICGC OA Datasets
http://goo.gl/w4mrV
Main source of Cancer Data: ICGC

http://dcc.icgc.org/

Module 2a bioinformatics.ca

Another source of important Cancer Data:
:
http://www.sanger.ac.uk/genetics/CGP/cosmic/

Module 2a bioinformatics.ca
What is Cancer Data? Structured Clinical Data about the patient
Structured Clinical Data about the treatment
Structured Clinical Data about the tumor
Associated with a number of positions (hundreds, if not thousands) of nucleotide coordinate system on one reference genome.

ICGC is implementing NCBI’s bioprojects http://www.ncbi.nlm.nih.gov/bioproject

LISTS OF BD
36 13/05/2014
Nucleic Acids Research Database Listing
– Annual Database issue http://www.oxfordjournals.org/nar/database/c/
– Suplement that comes with each year’s January issue
– 2009 2013 describes 179 1512 databases, sorted into 14 categories and 41 subcategories.
– They ara added to the list of Nucleic Acids Research online Molecular Biology Database Collection
– Good starting point for selecting the appropriate DB

LISTS OF BD
37 13/05/2014

Structure and formats of the DB
38 13/05/2014
STRUCTURE OF THE DB
39 13/05/2014
• The way of organizing data in any DB depends mainly in the model or architecture in which it is based on
• There are multiple models
Relational, Hierarchical, Network-based…
but the most usual relational
– Several tables, that could have relationships between them
– The relationships are done through key fields

FORMATS OF THE DB
40 13/05/2014
• To work with relational DB implies the use of plane data formats
– Text files
– Some kind of labels to specify the contents of every line or region of the file
• There are multiple formats, so a good program or application should be able to recognize (and even interchange) them.

SEQUENCE FASTA FORMAT
41 13/05/2014
Identifier Additional info
se
qu
ence
1st lin
e
>gi|15341523|gb|AF405321.1| Human echovirus 29 strain JV-10 5' UTR, partial
sequence CAAGCACTTCTGTTTCCCCGGACTGAGTATCAATAGACTGCTCACGCGGTTGAAGGAGAAAACGTTCGTT
ATCCGGCCAACTACTTCGAGAAACCTAGTAACGCCATGGAAGTTGTGGAGTGTTTCGCTCAGCACTACCC
CAGTGTAGATCAGGTTGATGAGTCACCGCATTCCCCACGGGTGACCGTGGCGGTGGCTGCGTTGGCGGCC
TGCCCATGGGGAAACCCATGGGACGCTCTTATACAGACATGGTGCGAAGAGTCTATTGAGCTAGTTGGTA
GTCCTCCGGCCCCTGAATGCGGCTAATCCCAACTGCGGAGCATACACTCTCAAGCCAGAGGGTAGTGTGT
CGTAATGGGCAACTCTGCAGCGGAACCGACTACTTTGGGT
>gi|15341527|gb|AF405325.1| Human echovirus 6 strain D' Amori 5' UTR, partial
sequence
CAAGCACTTCTGTTTCCCCGGACCGAGTATCAATAAGCTGCTCACGCGGCTGAAGGAGAAAGTGTTCGTT
ACCCGGCTAGTTACTTCGAGAAACCTAGTACCACCATGAAGGTTGCGCAGCGTTTCGCTCCGCACAACCC
CAGTGTAGATCAGGTCGATGAGTCACCGCGTTCCCCACGGGCGACCGTGGCGGTGGCTGCGTTGGCGGCC
TGCCCATGGGGCAACCCATGGGACGCTTCAATACTGACATGGTGCGAAGAGTCTATTGAGCTAACTAGTA
GTCCTCCGGCCCCTGAATGCGGATAATCTTAACTGCGGAGCAGGTGCTCACAATCCAGTGGGTGGCCTGT
CGTAACGGGCAACTCTGCAGCGGAACCGACTACTTTGGGT

GENBANK ENTRY EXAMPLE
42 13/05/2014

EMBL ENTRY EXAMPLE
43 13/05/2014

Submitting data
44 13/05/2014

SUBMITTING DATA
45 13/05/2014
• Several biological databases are public, so any (properly identified) user can contribute uploading new data
• There are multiple types of data to upload, but the most usual are
– Sequencies
– Expression data (from microarrays)

SUBMITTING SEQUENCES
46 13/05/2014
How to submit your sequences to…
• EMBL
– http://www.ebi.ac.uk/embl/Submission/
• GeneBank
– http://www.nlm.nih.gov/pubs/factsheets/sdgenbk.html

SUBMITTING EXPRESSION DATA
47 13/05/2014
And your expression data to…
• ArrayExpress (EBI)
– http://www.ebi.ac.uk/microarray/submissions.html
• Gene Expression Omnibus (NCBI)
– https://www.ncbi.nlm.nih.gov/geo/info/faq.html

Tools for DB exploitation
48 13/05/2014

ENTREZ
49 13/05/2014
• It is the NCBI’s searching system
• Great power and versatility, but less intuitive than SRS
• It doesn’t provide forms for each field
• Usually used in a “Top Bottom” manner
– Perform a first query
– Refine the results until reaching what you are looking for.

CROSS-SEARCH TABLES
50 13/05/2014

ENTREZ QUERIES
51 13/05/2014
• Boolean operators: AND, OR, NOT, “”, *
• AND applied by default
• Query by Accession Numbers (AC) in
– Genbank / EMBL / DDBJ:
• 1 char. + 5 nums. (U12345)
• 2 char. + 6 nums. (AF123456)
– SwissProt / PIR:
• 1 char. + 5 nums. (P12345)
• Refine queries with the reserved word LIMITS
• Combine queries with HISTORY

ENTREZ AVAILABLE FIELDS
52 13/05/2014

HELP AND INFORMATION SYSTEM
53 13/05/2014

Estamos interesados en el gen MLH1 humano, implicado en el cáncer de colon
– Separar el grano de la paja: identificar una secuencia de mRNA representativa y bien anotada del gen MLH1.
– Obtener literatura asociada y su secuencia protéica.
– Identificar proteínas similares.
– Identificar dominios conservados dentro de la proteína.
– Identificar mutaciones conocidas en el gen o la proteína.
– Encontrar la estructura tridimensional de la proteína, si esta es conocida, o si no es así, identificar estructuras de secuencia homóloga.
– Ver el contexto genómico del gen y descargar la región que lo contiene.
Vall d'Hebron Institut de Recerca 21/06/2011
Ejemplos de búsqueda con Entrez

Vall d'Hebron Institut de Recerca 21/06/2011
Consulta directa (1.1)

Vall d'Hebron Institut de Recerca 21/06/2011
Consulta directa (1.2) Límites
Vall d'Hebron Institut de Recerca 21/06/2011
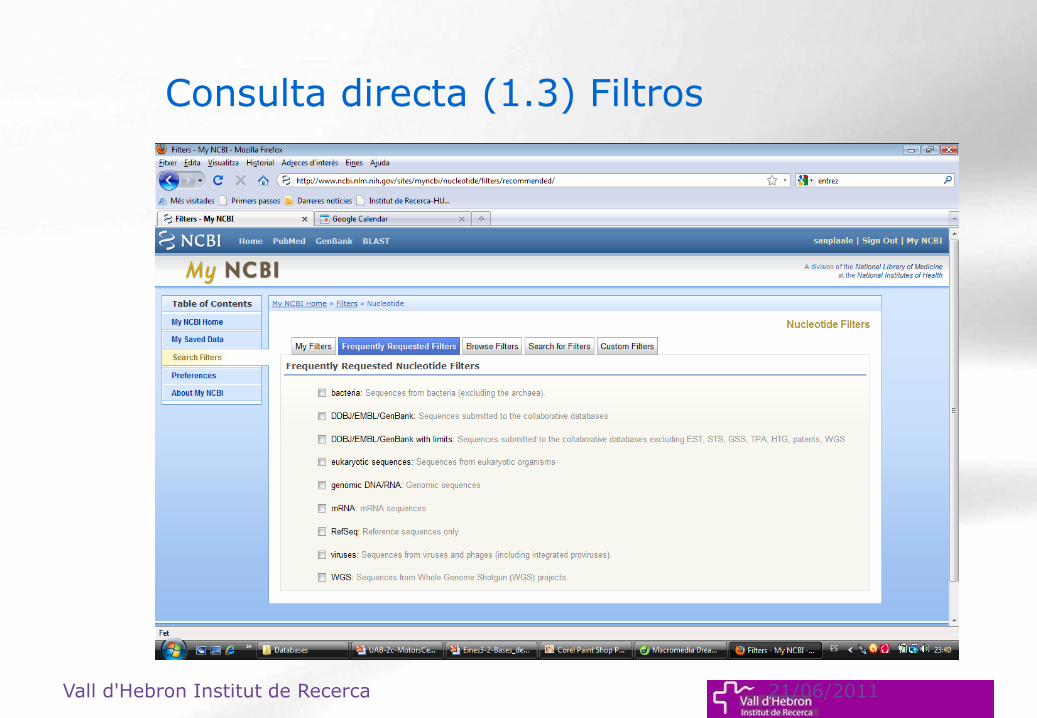
Consulta directa (1.3) Filtros

Vall d'Hebron Institut de Recerca 21/06/2011
Consulta directa (1.4) Registro

Vall d'Hebron Institut de Recerca 21/06/2011
Consulta (2) Enlaces a otras BD

Vall d'Hebron Institut de Recerca 21/06/2011
Consulta (3) Secuencias

Vall d'Hebron Institut de Recerca 21/06/2011
Consulta (4) Proteína

Vall d'Hebron Institut de Recerca 21/06/2011
Consulta (5.1) Mutaciones

Vall d'Hebron Institut de Recerca 21/06/2011
Consulta (5.2) SNPs
Vall d'Hebron Institut de Recerca 21/06/2011
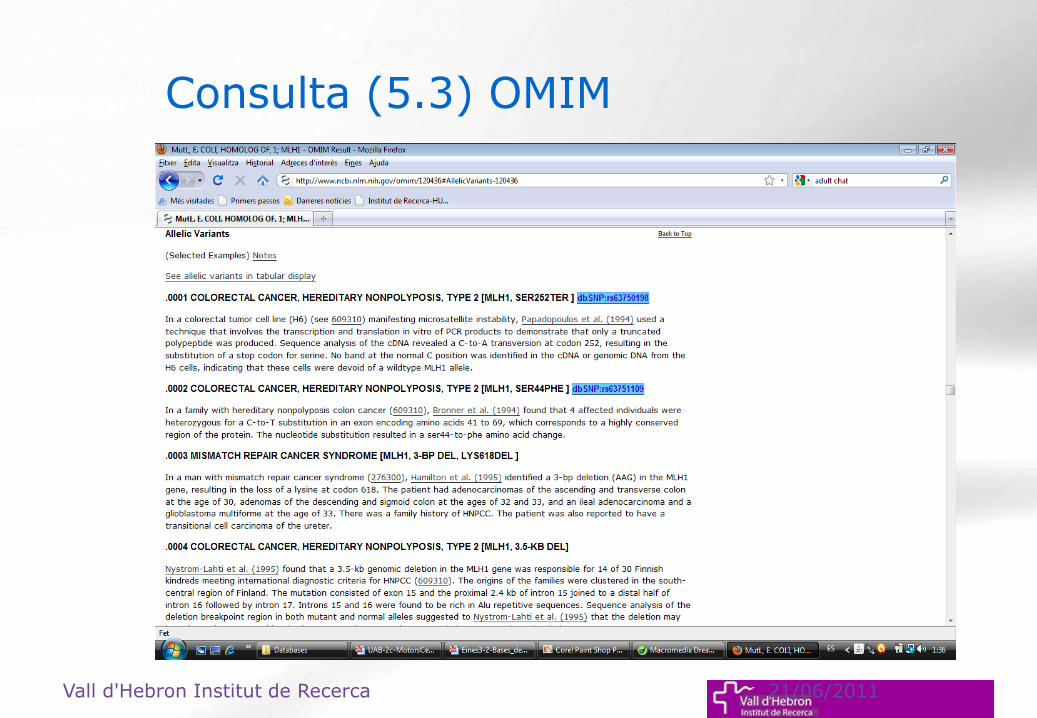
Consulta (5.3) OMIM

Vall d'Hebron Institut de Recerca 21/06/2011
Consulta (6.1) Estructuras

Mouse over the residues of NP_000240 until the grey footer bar shows ‘gi 4557757, loc 67’ (Glycine). Click on the corresponding Glycine residue in 1H7U_A (loc 74) to highlight it.
In the structure window use the left mouse button to spin the 3D structure until you can clearly see and identify the highlighted residue. Is it possibly in the active site? For example, is it within 5 Ä of the ATPS molecule?
Double click on the Mg-complexed ATPS to highlight it. Then use the menu bar option called ‘Show/Hide|Select By Distance|Residues Only’ to highlight all residues within 5 Ä of the ATPS. Indeed, the Glycine at position #74 is within 5 Ä and is likely part of the active site for this energy-producing domain. This hints at the possible problems a Gly Trp mutation might cause at that position.
Vall d'Hebron Institut de Recerca 21/06/2011
Consulta (6.2) Alineamiento de secuencia y estructura
Vall d'Hebron Institut de Recerca 21/06/2011
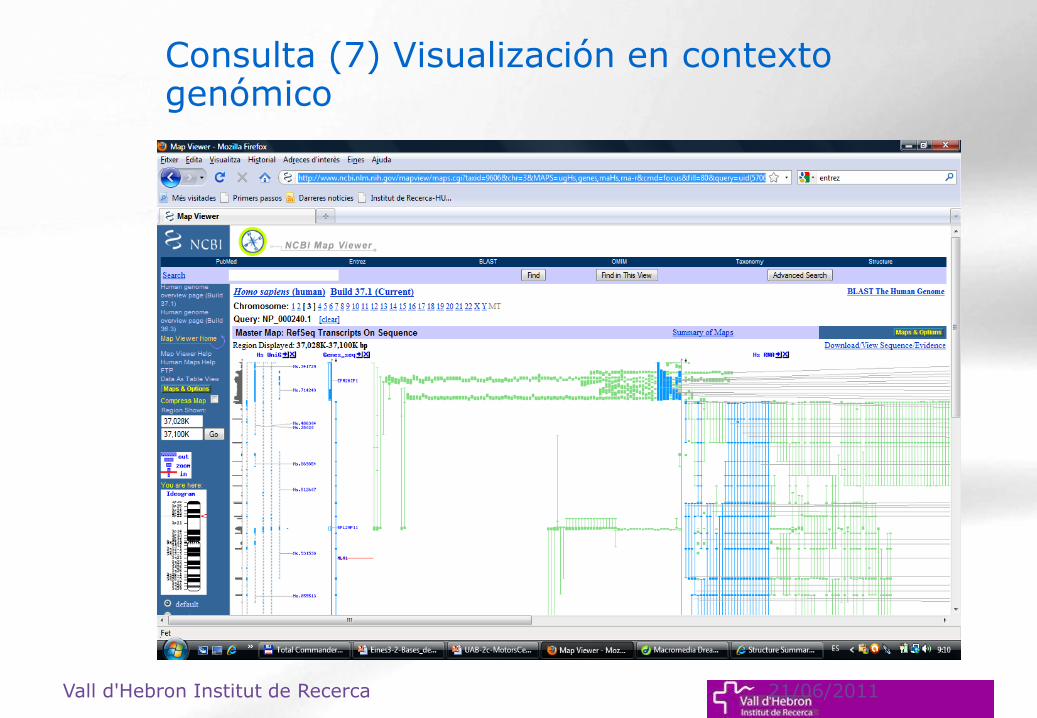
Consulta (7) Visualización en contexto genómico