superlu_dist on gpu cluster sherry li fastmath meeting, oct. 1-2, /2014 “a distributed cpu-gpu...
TRANSCRIPT

SuperLU_DIST on GPU Cluster
Sherry Li
FASTMath Meeting, Oct. 1-2, /2014
“A distributed CPU-GPU sparse direct solver”, P. Sao, R. Vuduc and X.S. Li, Euro-Par 2014, LNCS Vol. 8632. Porto, Portugal, August 25-29, 2014.

SuperLU_DIST : Algorithm and data distribution• 2D-data distribution
• Owner update policy
• L and U are stored in different sparse format
• Right looking
Euro-Par 2014

Schur complement update
Schur Complement update is done in three step
1. Gather : Packing operands into dense BLAS compliant format
2. GEMM :
3. Scatter : Scatter the dense output into the sparse format
Euro-Par 2014
3

Euro-Par 2014
4
Offloading BLAS calls to GPU
Considerations1. Smaller operand sizes for BLAS
2. PCI-e latencies and transfer cost is high
3. Cost of Scatter phase is significant
4. Device/PCI-e resource contention

5
Euro-Par 2014
Aggregating BLAS calls
• Aggregating BLAS calls increases the operand size
• Require fewer transfers to device and back. May not increases arithmetic intensity
• Requires a buffer for temporary product.
• GPU memory may be limited; in which case we slices the matrix so that it fits into GPU/CPU memory.
6
Euro-Par 2014
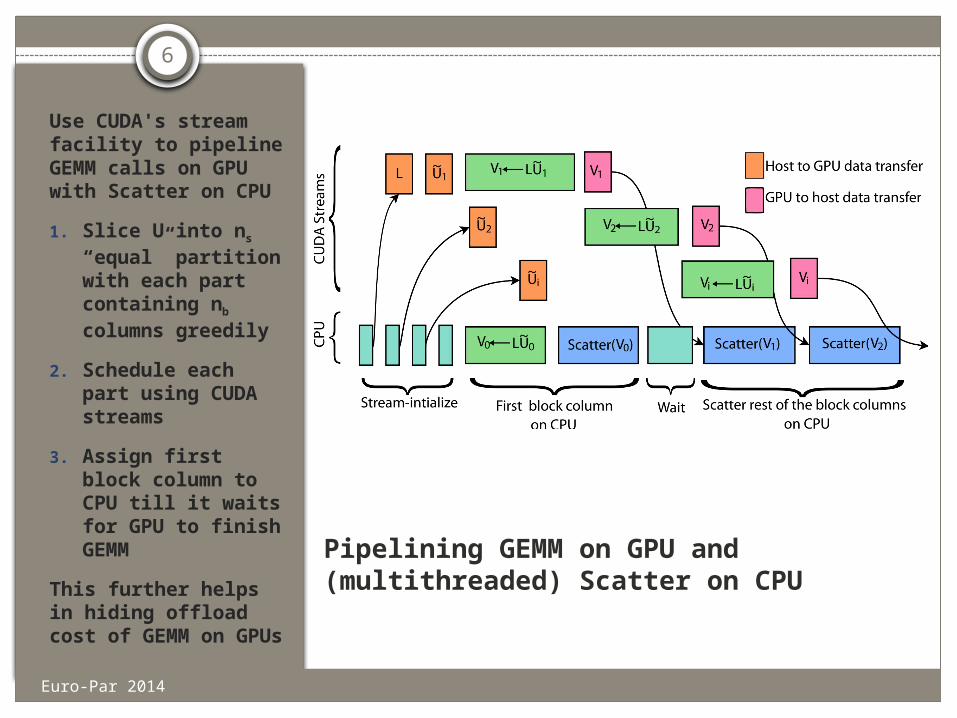
Pipelining GEMM on GPU and (multithreaded) Scatter on CPU
Use CUDA's stream facility to pipeline GEMM calls on GPU with Scatter on CPU
1. Slice U into ns “equal” partition with each part containing nb columns greedily
2. Schedule each part using CUDA streams
3. Assign first block column to CPU till it waits for GPU to finish GEMM
This further helps in hiding offload cost of GEMM on GPUs

Programming
Code complexityAt each step of Schur complement update:• Gemm_division_cpu_gpu()• Decide how many CUDA streams to use:
For each CUDA stream:• cudaMemcpyAsync(…, HostToDevice)• cublasDgemm()• cudaMemcpyAsync(…, DeviceToHost)
• CPU performs Scatter to destination
Programming, productivity, portabilityCan a single programming model capture all the Abstract machine models?
7
Euro-Par 2014
8
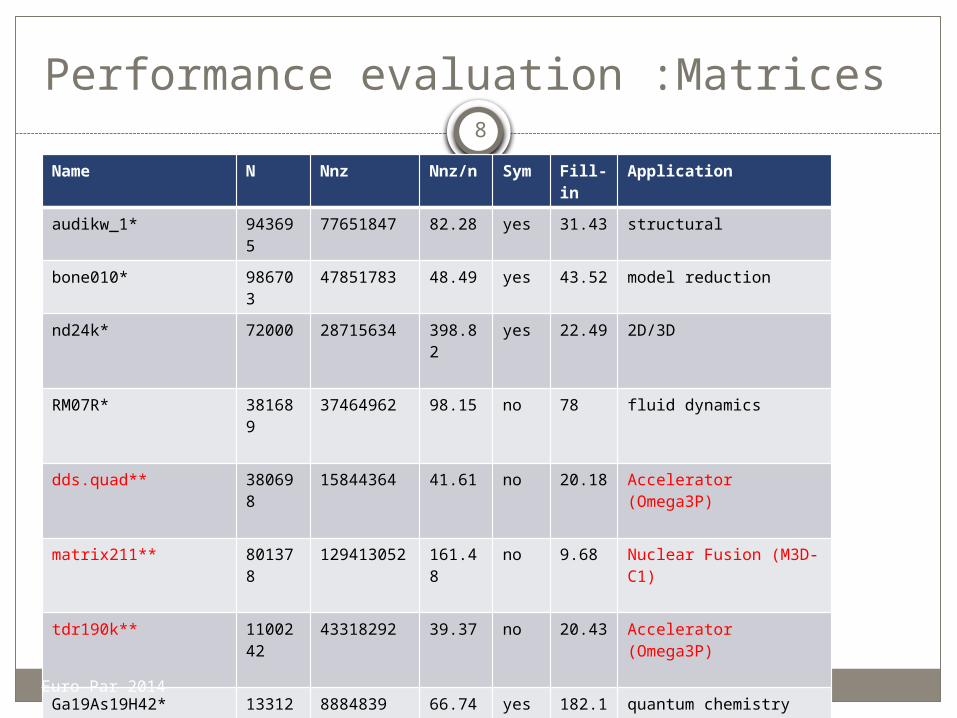
Performance evaluation :Matrices
Name N Nnz Nnz/n Sym Fill-in Application
audikw_1* 943695 77651847 82.28 yes 31.43 structural
bone010* 986703 47851783 48.49 yes 43.52 model reduction
nd24k* 72000 28715634 398.82 yes 22.49 2D/3D
RM07R* 381689 37464962 98.15 no 78 fluid dynamics
dds.quad** 380698 15844364 41.61 no 20.18 Accelerator (Omega3P)
matrix211** 801378 129413052 161.48 no 9.68 Nuclear Fusion (M3D-C1)
tdr190k** 1100242
43318292 39.37 no 20.43 Accelerator (Omega3P)
Ga19As19H42* 133123 8884839 66.74 yes 182.16 quantum chemistry
TSOPF_RS_b2383_c1 * 38120 16171169 424.21 no 3.44 power network
dielFilterV2real * 1157456
48538952 41.93 yes 22.39 electromagnetics
Euro-Par 2014
9
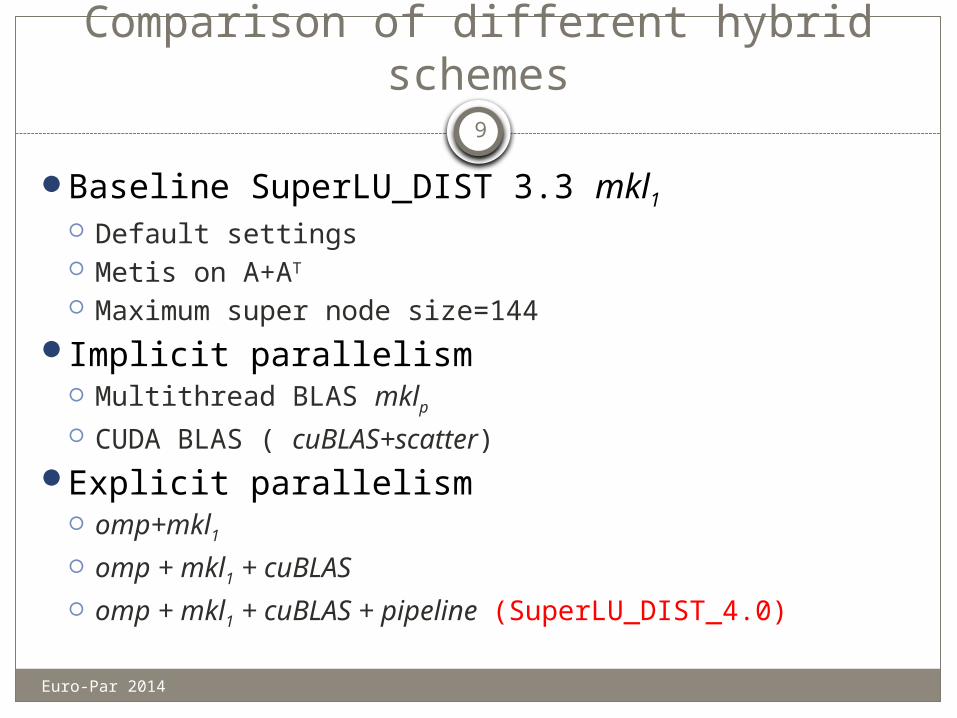
Comparison of different hybrid schemes
Baseline SuperLU_DIST 3.3 mkl1
Default settings Metis on A+AT Maximum super node size=144
Implicit parallelism Multithread BLAS mklp CUDA BLAS ( cuBLAS+scatter)
Explicit parallelism omp+mkl1
omp + mkl1 + cuBLAS
omp + mkl1 + cuBLAS + pipeline (SuperLU_DIST_4.0)

Euro-Par 2014
10
Performance on Dirac Cluster at NERSC 2xNodes x 2x4 “Nehalem” @2.4GHz+1 Tesla C2040
icc+mkl (11.1) + CUDA 5.5
Euro-Par 2014
11
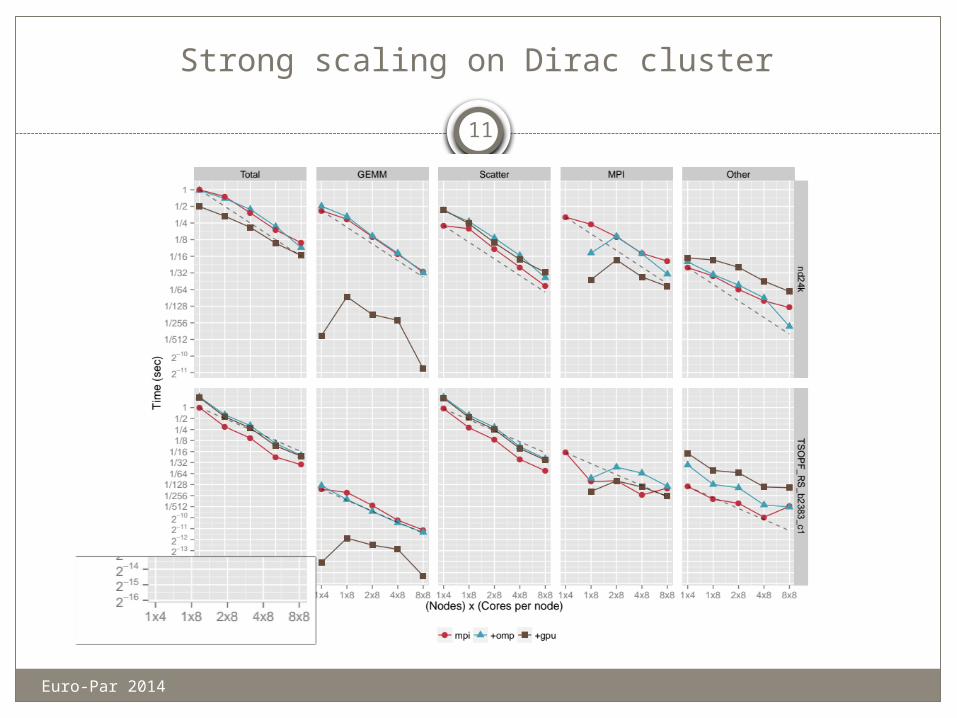
Strong scaling on Dirac cluster
Euro-Par 2014
12
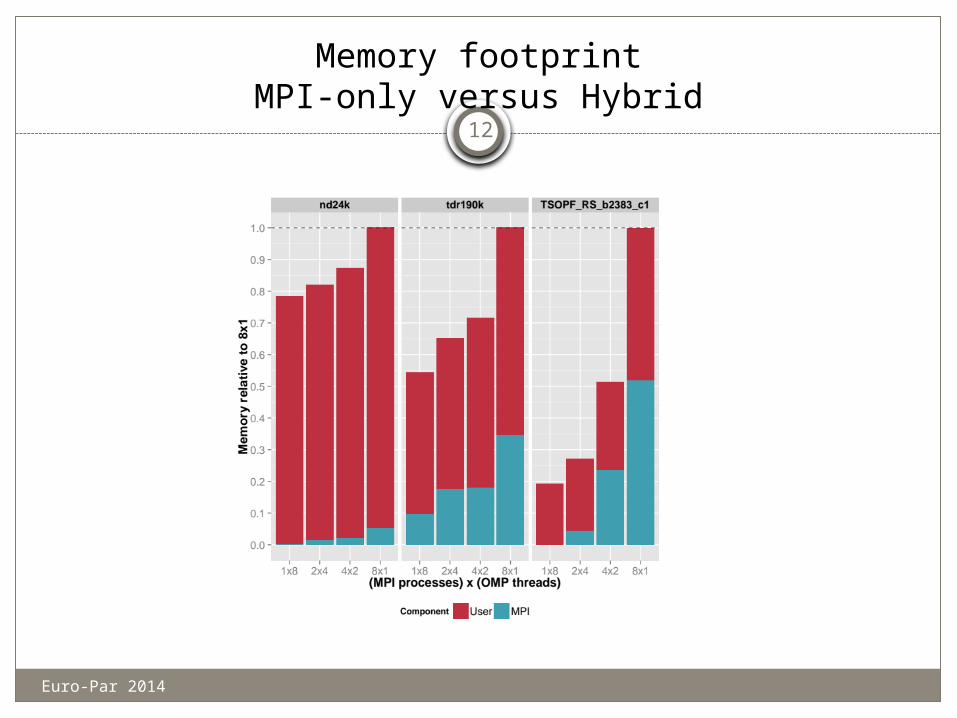
Memory footprintMPI-only versus Hybrid

Euro-Par 2014
13
Conclusions
BLAS only GPU acceleration can give up to 2-3x speed up on "denser" matrices
Slow down may occur for sparser matricesBLAS acceleration leaves Scatter as bottleneck CPU-threaded BLAS (implicit parallelism) may not be
sufficient : Utilizing all resources is important
Hybrid always reduces memory footprint, up to 5x

Euro-Par 2014
14
Ongoing and future work
Optimizing Scatter phase on CPU and accelerators1. Utilizing high bandwidth of GPU
Accelerating Scatter phase of the computation using a hybrid data structure1. New algorithm tried on many-core Xeon-Phi;
2. Same algorithm may work for GPUs
Using accelerators to aggressively overlap computation with MPI communication