syntactic reap.pt - inesc-id
TRANSCRIPT

Syntactic REAP.PT
Cristiano Jose Lopes Marques
Dissertation for obtaining the Master’s Degree inInformation Systems and Computer Engineering
Jury
President: Professor Joao Antonio Madeiras PereiraAdvisor: Professor Nuno Joao Neves Mamede
Professor Jorge Manuel Evangelista BaptistaEvaluation Jury: Professor Bruno Emanuel da Graca Martins
2011


Acknowledgements
First of all I would like to thank Prof. Nuno Mamede and Prof. Jorge Baptista for providing
me with this opportunity and for his excellent guidance, support, motivation, and knowledge
sharing. I would also like to thank Andre Silva and Joana Barracosa, for their optimistic support
and for the many conversations, work meetings and helpful insights along the course of this work.
Their help and collaboration strongly improved the journey. Furthermore, my thanks go to every
author for their work and contribution with inestimable background knowledge. To my friends,
a special thank you, for helping and providing their own knowledge and expertise, even when it
was not related with this work. To Fernando Pardelhas, Pedro Ruivo and Joao Dias, for their
continuous help, valuable feedback, support, motivation and and dedication firmly encouraged
me to move on. Lastly, but definitely not least, to my parents and family, a special thank you
very much for all these years of comfort and encouragement that made this work possible.
This work was supported by project CMU- PT/HuMach/0053/2008, sponsored by FCT.
Lisboa, 2011
Cristiano Jose Lopes Marques


To my parents, Jose and Cidalina.
To my brother, Nuno,


Resumo
Ensino da lıngua assistido por computador e uma area de pesquisa que se foca no desen-
volvimento de ferramentas que melhorem o processo de aprendizagem da lıngua. REAP.PT
(REAder-specific Practice Portuguese) e um exemplo destes sistemas, em que o objectivo e aju-
dar a ensinar a lıngua portuguesa de uma forma apelativa, abordando temas que sao do interesse
dos utilizadores.
Esta tese foca-se na geracao automatica de exercıcios sintacticos e de vocabulario. Para
tentar cumprir esses objectivo, um conjunto de tarefas foram desenvolvidas: um estudo de
formatos de questoes pertinentes e quais os sistemas que criavam estes exercıcios; um estudo
de sistemas CALL com exercıcios sintacticos e semanticos; e modelacao/desenvolvimento de
um solucao arquitectural para o problema, incluindo diferentes recursos: filtros, classificadores,
tabelas com informacao lexical adicional e geradores automaticos de distractores.
Outro objectivo deste trabalho e incluir este modulo no sistema CALL - REAP.PT.


Abstract
Computer-Aided Language Learning (CALL) is an area of research that focuses on devel-
oping tools to improve the process of learning a language. REAP.PT (REAder-specific Practice
Portuguese) is a system that aims to teach Portuguese in an appealing way, addressing issues
that the user is interested in.
This thesis focuses on the topic of automatic generation of syntactic and vocabulary ques-
tions. In trying to successfully accomplish this goal, there are several tasks that were developed:
a study on the format of pertinent questions and which existing systems create these exercises;
a study of some CALL systems with syntactic and semantic exercises; and the modeling of an
architectural solution of the problem, including other resources such as filters and automatic
distractors generation.
Another goal of the present work is to be able to include this feature in the tutoring system
– REAP.PT.


Palavras Chave
Keywords
Palavras Chave
Ensino da lıngua Assistido por Computador
Geracao Automatica de Exercıcios
Exercıcios Sintacticos
Exercıcios Semanticos
Geracao Automatica de Distractores
Lıngua Portuguesa
Keywords
Computer Assisted Language Learning
Automatic Exercise Generation
Syntactic Exercises
Semantic Exercises
Automatic Distractors Generation
Portuguese


Contents
1 Introduction 1
1.1 Goals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Requirements of Syntactic REAP.PT . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Computer-Aided Language Learning . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Structure of this Document . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 REAP 7
2.1 Architecture of REAP.PT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3 State of the art 13
3.1 Syntactic-Semantic Exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.1.1 Crosswords . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.1.2 Correspondence Exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.3 “True” or “False” exercises . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.1.4 Multiple choice exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.1.5 Fill in the blank exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.6 Word Sorting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1.7 Short Answer Exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.1.8 Open Answer Exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.1.9 Alphabet Soup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2 Automatic Exercise Generation Systems . . . . . . . . . . . . . . . . . . . . . . . 21
i

3.2.1 Working With Real English Text . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.2 TAGARELA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.2.3 ALPHEIOS PROJECT . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4 Our Approach 25
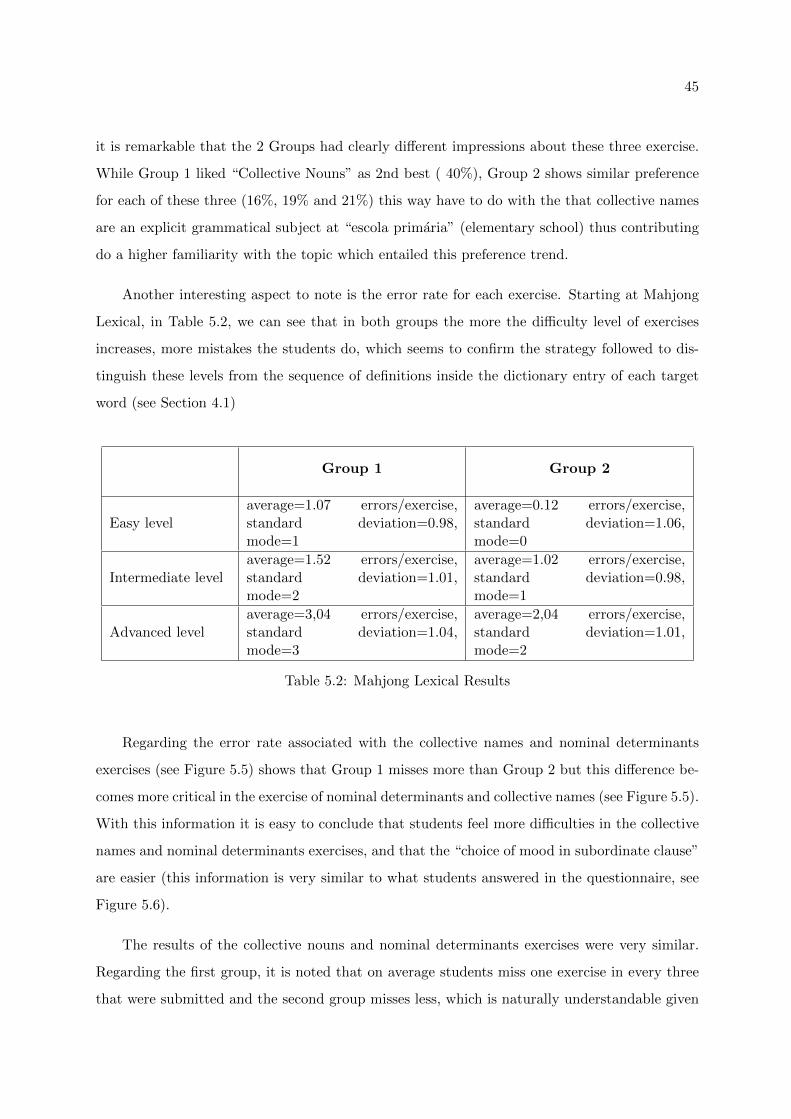
4.1 Mahjong Lexical . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.1.1 Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.2 Choice of mood in subordinate clause . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2.1 Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.3 Collective Names and Nominal Determinants . . . . . . . . . . . . . . . . . . . . 34
4.3.1 Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.4 Teacher Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4.1 Mahjong Lexical . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4.2 Choice of mood in subordinate clause . . . . . . . . . . . . . . . . . . . . 38
4.4.3 Collective Names and Names determinative . . . . . . . . . . . . . . . . . 39
5 Evaluation 41
6 Conclusion and Future Work 49
Bibliography 55
A 5th Grade P–AWL 57
B Number of exercises for each nominal determinant 59
B.1 Collective names . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
B.2 Nominal Determinants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
C Initial Form 61
ii

D Questionnaire 63
iii

iv

List of Figures
2.1 Architecture of REAP.PT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Vocabulary Exercise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3 Example of Cloze Question . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.1 Crossword (taken from http://www.prof2000.pt/users/amsniza/) . . . . . . . . . 15
3.2 Correspondence (taken from http://www.prof2000.pt/users/amsniza/) . . . . . . 16
3.3 Fill in the blank exercises (taken from http://guida.querido.net/jogos/) . . . . . 18
3.4 Word Sorting (taken from http://guida.querido.net/jogos/) . . . . . . . . . . . . 19
3.5 Alphabet Soup (taken from http://cvc.instituto-camoes.pt/sopa-de-letras.html) . 21
4.1 Mahjong Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.2 HTML structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.3 Filters and Classifiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.4 Mahjong Table and Mahjong Evaluation . . . . . . . . . . . . . . . . . . . . . . . 28
4.5 Mechanism to award points . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.6 Filters’s Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.7 Example “ate” (until) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.8 Chunk Subclause . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.9 Example of Exercise of Nominal Determinant . . . . . . . . . . . . . . . . . . . . 34
4.10 QUANTD dependency . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.11 Teacher Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
v

5.1 The system was quick in giving an answer . . . . . . . . . . . . . . . . . . . . . . 43
5.2 The system was easy to use . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.3 The help menu contains useful information presented in a concise and clear manager 44
5.4 Which exercise did you like best . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.5 Error rate by exercise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.6 Which exercise was the easiest . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.7 System’s global appreciation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
C.1 Initial Form . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
D.1 Questionnaire - 1st Part . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
D.2 Questionnaire - 2nd Part . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
vi

List of Tables
1.1 Functional Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Non-Functional Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
3.1 Exercises and language skills . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.1 Collective names and nominal determinants . . . . . . . . . . . . . . . . . . . . . 36
5.1 Test Users . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.2 Mahjong Lexical Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.3 Average test duration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
A.1 5th Grade P–AWL (1st Part) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
A.2 5th Grade P–AWL (2nd Part) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
B.1 Collective names . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
B.2 Nominal determinants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
vii

viii

1IntroductionThe field of Education is certainly one of the most important and discussed topics in the
world. During the past two decades, the exercise of spoken language skills has received increasing
attention among educators. According to the Lisbon Summit (Lisbon European Council 2010),
learning a foreign language is extremely important for the curriculum enrichment of any person
and is considered, by the same entity, as one of five key skills of a successful professional. With
the advancement of technologies for information systems, the use of CALL has emerged as a
tempting alternative to traditional modes of supplementing or replacing direct student-teacher
interaction, such as the language laboratory or audio-tape-based self-study. This context is the
starting point of the REAP1 project and also of the REAP.PT2 project.
1.1 Goals
The main goal of the REAP.PT system is to present to the students rich and authentic
study material (texts, exercises, etc) that is deemed interesting by the students (based on their
topics of interest), and adequate to their learning needs and current skills, thus being able to
advance their learning process.
The aim of this work is to develop a module of REAP.PT to help learning the syntactic-
semantic component of the language, through the development of automatic exercises drawn
from actual texts taken from the Internet, and according to the topic preferences of the student.
This module can use features already present in the REAP.PT system (see Section 2.1)
While the main focus of the original REAP project has been the acquisition of vocabulary,
the exercises to be present by this module of REAP.PT will focus too on aspects of syntax that
are especially problematic for students of Portuguese as a second language, for example, the
1http://reap.cs.cmu.edu (last visited in December 2010)2http://call.l2f.inesc-id.pt/ (last visited in December 2010)

2 CHAPTER 1. INTRODUCTION
placement of clitic pronouns, adjectives or adverbs, formation of interrogatives, the alternation
between direct speech and indirect speech, between active/passive sentence structure or nomi-
nalizations. Because the exercises are generated automatically, careful design of the generation
process is necessary in order to assure the linguistic adequacy and the relevance of the question.
Above all, the exercises automatically generated by the system should not present ambiguous
solutions. For example: in the case of gap-filling exercises, it is important that there is not more
than one possible solution so that the system does not invalidate the answer given by the user
just because this was simply not the expected input.
Additionally, it is necessary to create an interface for teachers and another for students.
The teacher will have permissions to see the answers given by students, save all the answers and
editing/viewing the exercises. The student interface will give him access to available exercises
and allow him to solve them. From a technical point of view, special care must be taken in
the development of both interfaces (teacher and student) so that it is not necessary to install
plugins on the client browser.
1.2 Requirements of Syntactic REAP.PT
This section defines the requirements of the problem, for adequate project planning and
management in the presence of changing requirements. Defining requirements precisely is im-
portant to identify what exactly should the system do. Requirements can be divided in two
groups (Rost 2005): functional requirements (see Table 1.1) and non-functional requirements
(see Table 1.2). The main requirements for this module of REAP are thus defined as:

1.3. COMPUTER-AIDED LANGUAGE LEARNING 3
Requirement Description
Automatic Exercise GenerationThe exercise generation must be done with-out human intervention
Different types of exercises
Clitic pronouns, adjectives or adverbs, for-mation of interrogatives, the alternationbetween direct speech and indirect speech,active/passive or nominalizations
Teacher permission Teacher can see students’ result
Students inputStudents can answer questions through abrowser
Table 1.1: Functional Requirements
Requirement Description
High AccuracyGenerated exercises don’t have ambiguoussolutions
SecurityDifferent permissions for teachers and stu-dents
Persistence Save students’ answers and results
UsabilityUsers do not need to have advanced knowl-edge in Technology
Table 1.2: Non-Functional Requirements
1.3 Computer-Aided Language Learning
Currently, CALL can be seen as an approach to language teaching and learning in which
computer technology is used as an aid to the presentation, reinforcement and assessment of
material to be learned, usually including a substantial interactive element. It also includes
the search and the investigation of applications in language teaching and learning (Hacken
2003). Gamper and Knapp (2002) define CALL as “a research field which explores the use of
computational methods and techniques as well as new media for language learning and teaching”
(Gamper & Knapp 2002).
However, various difficulties have to be overcome in order to developed CALL systems,
namely: the financial barrier resulting from the need of strong financial support required to
obtain human and technological resources; availability and access conditions to hardware and
software in the teaching institutions; and the reluctance – still quite strong – from many people,
both teachers and students, in using new technologies, specially in language learning.

4 CHAPTER 1. INTRODUCTION
One of the most important requirements for this CALL system is the ability to retrieve and
use texts with updated information, as well as to present correct and appropriate content.
This goal has already been achieved as a result form previous research (Marujo 2009) (Cor-
reia 2010).
The motivation for this requirements can be summarized as follows:
• Experiential learning: it is easier for the user to learn gradually from their mistakes;
• Motivation: generally speaking, the use of technology both inside and outside the class-
room, tends to make the learning process more interesting. However, certain design issues
may affect the way a particular tool creates influences motivation;
• Enhance student achievement: if texts shown to the student are to be selected according to
their topic preferences, it is then likely that their motivation be enhanced, thus improving
their learning performance;
• Greater interaction: computers can adapt to students; adapting to a student usually means
that the student controls the pace of the learning but it also means that the student can
make choices regarding the content and the manner of learning, skipping unnecessary
items or doing remedial work on difficult concepts; such control makes students feel more
competent in their learning (Okan );
• Completeness: a fully-fledged CALL systems provides the student the opportunity to
interact using one or more of the four basic languages skills (reading, writing, listening
and speaking).
1.4 Structure of this Document
The present thesis consists in 6 chapters, and it is structured as follows:
• Overview of the REAP.PT is described in Chapter 2
• Chapter 3 describes the work related to the theme of this thesis: Portuguese language
syntax exercises and automatic question generation systems;

1.4. STRUCTURE OF THIS DOCUMENT 5
• The solution proposed is presented in Chapter 4;
• Chapter 5 introduces how the system here developed will be evaluated;
• Chapter 6 presents the conclusion and future work.

6 CHAPTER 1. INTRODUCTION

2REAPREAding-Practice1 (REAP) project was initially developed by the Language Technologies
Institute (LTI) of Carnegie Mellon University2 (CMU). It is a system that implements the main
ideas of CALL and it is specifically focused on vocabulary learning.
The goal behind REAP, as described by Michael Heilman and Maxine Eskenazi “is to furnish
appropriate, authentic texts to students to help in reading and vocabulary learning. In REAP,
a student sees short reading passages that contain a number of words (usually ranging from two
to four) from his or her list of target words to be learned from context. The passages are Web
documents of about one to two pages in length, covering a wide variety of topics” (Heilman &
Eskenazi 2006). This reading is complemented by practice in series of automatically generated
exercises.
In April 2009, a Portuguese version of REAP - REAP.PT3 begun being implemented. The
target audience for this system is primarily students who want to learn Portuguese as a foreign
language.
2.1 Architecture of REAP.PT
In order to understand how the current work is integrated in the remaining modules already
developed within the REAP.PT project. This section describes the current system architecture
(see Figure 2.1) (Correia 2010)(Marujo 2009):
• Web Interface: Two interfaces, one for student and other for teacher have already been
implemented (Marujo 2009). These can be accessed through any web browser. The web
interface is also responsible for the communication between the database and the DIXI
1http://reap.cs.cmu.edu (last visited in June 2011)2http://www.cmu.edu/index.shtml (last visited in June 2011)3http://call.l2f.inesc-id.pt/ (last visited in June 2011)

8 CHAPTER 2. REAP
Figure 2.1: Architecture of REAP.PT
software (Paulo, Oliveira, Mendes, Figueira, Cassaca, Viana, & Moniz 2008). This software
is a system for automatic speech generation from text which uses the most advanced
techniques of speech production. It enables audio playback of text from any document
(text-to-speech). An example of a direct application of this software is the possibility of
listening to words that are marked as focus word (words considered important and that
students should learn) or, for that matter, of any words in the text, sequences of words,
phrases and even entire sentences;
• REAP.PT Database: It consists of two databases. The first one is used to maintain the
state of the system during execution and use (profile’s information of each user, keeping
track of exercises for each user, questions that will be solved, etc). The second database
contains references to the Andrew File System (AFS) (Howard, Kazar, Menees, Nichols,
Satyanarayanan, Sidebotham, & West 1988) which is responsible for storing the content
of the lexical resources (like list of words, dictionary, texts) (Correia 2010);

2.1. ARCHITECTURE OF REAP.PT 9
• Nutch Crawler: When building ClueWeb094 (see below), a crawler was necessary. In
this case, the Nutch Crawler was used, wich aims at indexing and automatically browse
the World Wide Web, and extracting updated information (in this case, texts) (Moreira,
Michael, da Silva, Shiloach, Dube, & Zhang 2007);
• ClueWeb09: Is a collection of over 1 billion web pages (5 TB compressed, 25 TB uncom-
pressed) created by the LTI at CMU. This corpus contains texts in 10 different languages
(like Arabic, English, Portuguese or Spanish), compiled for the research on speech and lan-
guage technology. In the specific case of the Portuguese section of this corpus, it includes
37,578,858 pages, retrieved in 2009. This subset of documents from ClueWeb09 (about
160 GB compressed) constitutes the corpus currently being used in the REAP.PT project;
• Filter Chain: In spite of its size, only a subset of this corpus of texts is selected for use
in REAP.PT, if they don’t violate the following constraints or filters: text cannot have
less then 300 words (short texts are excluded); HTML format; only texts with words from
the Portuguese Academic List (P–AWL, see below) (Baptista, Costa, Guerra, Zampieri,
Cabral, & Mamede ) are kept; texts with profanity words are rejected;
• Topic Classifier: The texts considered valid by the filtering system are classified according
to topic and reading level, and them stored in the database (Correia 2010);
• Readability Classifier: Texts are classified according to the Collins-Thompson and Callan
algorithm (Collins-Thompson & Callan 2005);
• Question Generation: This module is responsible for creating the exercises that are given
to students at the end of each reading – definition question, synonym/antonym question,
hyperonym/hyponym question, cloze question and open cloze question.
• P-AWL: Ensures the quality of the vocabulary that students have to learn. To achieve this
objective, the REAP.PT use Portuguese Academic Word List (P-AWL), which can be de-
fined as a “general purpose vocabulary, with current (but not colloquial) words, which has
been designed for immediate application on a CALL web-based environment, currently de-
voted to improve students’ reading practice and vocabulary acquisition” (Baptista, Costa,
Guerra, Zampieri, Cabral, & Mamede ).
4http://boston.lti.cs.cmu.edu/Data/clueweb09/ (last visited in December 2010)

10 CHAPTER 2. REAP
• Infopedia5, PAPEL6 (Oliveira, Santos, Gomes, & Seco 2008), TemaNet7 and MWN.PT8:
Are resources used to implement the automatic question generation system.
In the next section, some of these components of the REAP.PT are presented in greater
detail.
Portuguese Academic Word List
It is important that a system meant for language learning ensures the quality of the vo-
cabulary that students have to learn. To achieve this objective, the REAP.PT use Portuguese
Academic Word List (P-AWL), which can be defined as a “general purpose vocabulary, with cur-
rent (but not colloquial) words, which has been designed for immediate application on a CALL
web-based environment, currently devoted to improve students’ reading practice and vocabulary
acquisition” (Baptista, Costa, Guerra, Zampieri, Cabral, & Mamede ). P-AWL consists of 1823
lemmas (and over 33k inflected forms associated to them). This list defines the focus words that
students should learn.
To implement the automatic question generation system, the following resources have been
used: TemaNet9, PAPEL10 (Oliveira, Santos, Gomes, & Seco 2008) and MWN.PT11. Another
feature important is the dictionary of Porto Editora, the Infopedia12 that contains 920,000
entries.
Language Proficiency and Preferences
The level of language proficiency of the students is calculated through the resolution of a
set of exercises presented to students when they are first introduced to REAP.PT. Based on this
level, each student is assigned a set of P-AWL words that they must learn when interacting with
5http://www.infopedia.pt/ (last visited in December 2010)6http://www.linguateca.pt/PAPEL/ (last visited in December 2010)7http://www.instituto-camoes.pt/temanet/ (last visited in December 2010)8http://mwnpt.di.fc.ul.pt/index.html (last visited in December 2010)9http://www.instituto-camoes.pt/temanet/ (last visited in December 2010)
10http://www.linguateca.pt/PAPEL/ (last visited in December 2010)11http://mwnpt.di.fc.ul.pt/index.html (last visited in December 2010)12http://www.infopedia.pt/ (last visited in December 2010)

2.1. ARCHITECTURE OF REAP.PT 11
the system (Correia 2010). There is a direct correlation between the current level of student
and the keywords is supposed to learn.
When the students enter their personal area, they have the opportunity to choose which
topics they find more or less interesting, so that later the texts and exercises presented by the
system may be more suitable to their topic preferences.
Listening Module
Listening comprehension is a complex but critical process to the development of the skills
necessary to learn a foreign language. This module in particular can be viewed as the result
of integrating two components: Software Text-to-Speech and Multimedia Documents. The first
component is the software DIXI (see Section 2.1), through which students have the opportunity
to hear the words or word sequences (phrases) that they have previously selected. According
(O’Malley, Chamot, & Kupper 1989) listening helps to discriminate sounds, understand the
vocabulary, acquire grammatical structures, and to interpret intentions. All these factors are
responsible for the preeminence of listening comprehension, especially in the early stages of the
language acquisition (Stern ).
The second module, Multimedia Documents, complements the speech synthesis software. A
type of multimedia documents presented in REAP.PT and that has been already implemented
is the digital talking books. These are an excellent tool to improve language proficiency since
it allows students to follow the oral reading of a text by a nature speaker, thus being able to
associate the sounds to words, learn prosody and other speech features.
Another feature that is available in Listening Module is the broadcast news (BN) stories,
which consists of news subtitles from television through an automatic speech recognition system
(ASR). ASR, the AUDIMUS (Meinedo, Caseiro, Neto, & Trancoso 2003) “combines the temporal
modelling capabilities of Hidden Markov Models with the pattern discriminative classification
capabilities of multilayer perceptrons”. In short, AUDIMUS converts an acoustic signal to text,
allowing the processing of sound produced by one or more speakers (Meinedo & Neto 2003).
The news stories are presented in small sized videos (one of news piece) along with the subtitles
produced by AUDIMUS.
Although it is not the main objective of this module, the use of BN can also help students

12 CHAPTER 2. REAP
learn facial expressions, gestures and emotions, witch are essential elements of oral, face-to-face
communication. This is a side effect of the visual training implicit in the BN, which becomes
especially important for people with hearing difficulties, but who have the ability to interpret
facial expressions and lip movements.
Exercises
The development of (semi-)automatically built exercises has been the focus of much research
(L2F) in the improvement of the REAP.PT system. Initially a set of cloze questions have been
manually built by a team of teachers and linguists (Marujo 2009). Later on, automatic generation
of questions has been introduced (Correia 2010) like vocabulary exercises (see Figure 2.2) and
cloze question (see Figure 2.3) cases.
Qual das seguintes e uma definicao da palavra criar?; Which of the following is adefinition of the word create?
a) conceber algo original; design something originalb) coser a orla de um tecido para que nao se desfie; sew the hem ofa cloth so as not to shredc) temperar em vinha-d’alho com o intuito de aromatizar a comida,conserva-la e torna-la mais terra; had garlic wine in order to flavorthe food, keep it and make it more landd) causar a morte; cause death
Figure 2.2: Vocabulary Exercise
O livro e tao extenso e tao complexo que o editor decidiu que nao era para umtradutor e contratou dois profissionais para o fazer.; The book is so extensive andso complex that the editor decided it was not for a translator and hired twoprofessionals to do it.
a) palestra; lectureb) assunto; subjectc) receita; reciped) tarefa; task
Figure 2.3: Example of Cloze Question
The goal of this thesis is to continue the work already done, including more types of exercises
in REAP.PT.

3State of the art
3.1 Syntactic-Semantic Exercises
The literature review in this area is extremely important to ensure that the implemented
exercises are consistent with what is taught and practised by Portuguese students in their first
years of school. Thus, it will be ensured that this thesis focuses on the really important and
interesting exercises for learning the language.
In Table 3.1, a match is made between the skills explored and the exercises’ formats that
are presented in this thesis. These exercises are available in format in digital format (such as
software applications, online exercises) and on paper (such as grammars, books).
Skills were divided into four groups:
• Reading Comprehension - Ability to understand and interpret what you read;
• Syntactic knowledge of language - Ability to apply the language rules to construct sen-
tences;
• Semantic Knowledge of Language (Lexicon) - Knowledge of word meaning;
• Meta-Linguistic Knowledge - Knowledge about the language used to describe the natural
language.
It is important to mention that with a small amount of imagination, each exercise format
can explore other skills that are not represented in Table 3.1. Essentially this table reflects the
skills exercised by the systems presented in this work.
In the following sections, several syntactic exercises are presented.

14 CHAPTER 3. STATE OF THE ART
Reading Com-prehension
Syntacticknowledge oflanguage
SemanticKnowledgeof Language(Lexicon)
Meta-LinguisticKnowledge
Crosswords X X X
Fill-in-the-blanks
X X X
Correspon-dence Exer-cise
X X
”Right” or”Wrong”
X X
MultipleChoice
X X X
Short Answer X X
Word Sorting X X X
Identificationof Grammati-cal Category
X
Open Re-sponse
X X X
AlphabetSoup
X
Table 3.1: Exercises and language skills
3.1.1 Crosswords
Crosswords (see figure 3.1) are usually done on paper, but there are also computer versions.
Words must be discovered (remembered or guessed) following tips provided by the exercise.
The most common use of crosswords consists in identifying a word from its definition (e.g.
“profissional da area de ensino”/“professor” ; professional in the field of education/teacher).
Other tips may involve metalinguistic knowledge (e.g “verbo casar no gerundio”/“casando” ;
verb married in the gerund/married).
There is already a system (Aherne & Vogel 2006) developed by the Computational Lin-
guistics Group – University of Dublin1 that automatically generates crossword puzzles, using a
pre-installed database with the target clues/words pair needed to these exercises. This database
was obtained with the support of the information contained in WordNet (Stark & Riesenfeld
1http://www.scss.tcd.ie/disciplines/intelligent systems/clg/clg web/ (last visited in December 2010)

3.1. SYNTACTIC-SEMANTIC EXERCISES 15
Figure 3.1: Crossword (taken from http://www.prof2000.pt/users/amsniza/)
1998). Besides these systems, there are tools that do not allow the automatic generation, but
nevertheless help the user in the creation of the exercise in a digital format, such as the Jcross2,
Instant Online Crossword Puzzle Maker3 or the Crossword Generator for Teachers4, where the
clues and the words have to be inserted manually into the system by the user. There are other
systems that search the web for definitions of words and then through a program of constraint
satisfaction (CSP) constructs the puzzle (Anbulagan & Botea 2008).
Some characteristics of this exercise format:
• difficulties on producing automatically the word grid;
• the ludic aspect oh the exercise is a motivator;
• students may take advantage from the crossing of words to guess the missing words so
indirect help way be available and direct assessment of language skill being tested may be
hindered.
3.1.2 Correspondence Exercises
Correspondence exercises consist of two columns of items that are to be aligned by appealing
to a single linguistic relation (meaning, syntactic transformation, etc.). They aim at simulating
the student’s ability to differentiate between several concepts being presented, or to systematize
2http://hotpot.uvic.ca/ (last visited in December 2010)3http://www.varietygames.com/CW/ (last visited in December 2010)4http://www.theteacherscorner.net/printable-worksheets/make-your-own/crossword/crossword-puzzle-
maker.php (last visited in December 2010)

16 CHAPTER 3. STATE OF THE ART
the concepts involved in the linguistic relation under study. One of the most common uses of this
exercise format is to make the correspondence between the word and its definition. (example:
phone/mobile phone).
For example, in Figure 3.2, a correspondence exercise is shown, aimed at drilling the pro-
nounning of different noun phrases, in several syntactic functions (subject, object, beneficiary,
etc.).
Figure 3.2: Correspondence (taken from http://www.prof2000.pt/users/amsniza/)
To create exercises in this format there is JMatch, although it does not manage the exercise
automatically, it only allows teachers to build these exercises in digital format. Regarding the
(semi-)automatic generation:
• working the other way around (from pronouns to full-hedged Prepositional Phrases or
Nominal Phrases) raises the problem of anaphora resolution (Carbonell & Brown 1988), a
natural language processing (NLP) task that still has a limited success.
• the exercise may be automatically generated, depending on the more or less complexity
on the relation being tested. In this case, automatic identification of Nominal Phrase
(NP)/Prepositional Phrase(PP) and their function is likely to produce incorrect results
because, among other factors, the yet unsolved problem of PP attachment and the conse-
quent incomplete delimitation of the constituent being pronominalized.

3.1. SYNTACTIC-SEMANTIC EXERCISES 17
3.1.3 “True” or “False” exercises
True-or-false exercises are often used in text comprehension. They have the great advantage
of being aplicable in many other areas of language learning as well. For example, agreement
between nouns and adjectives can be tested, given the following instruction/example pair:
“Marca “correcto” or “incorrecto” as frases seguintes: Sempre julguei competente o gerente
e a directora” (Mark as “correct” or “incorrect” the following sentences: I have always considered
competent the manager and the director).
The main disadvantage of this type of exercises is the loss of specificity for each question,
since it may not reveal exactly the knowledge that has been activated to answer.
The most common systems for creating this type of exercise have a similar architecture to
(Bastos, Berardi, & Silveira 2004) where there is a database with a set of questions and answers
previously defined by a teacher.
3.1.4 Multiple choice exercises
Multiple-choice or cloze questions is probably the most widely used type of automatically
generated exercises. In their most basic form, they consist of a sentence (the stem), which is
provided with a blank space from where a word or string of words has been removed; and a set of
possible answers. Usually, the correct word is randomly placed among several incorrect choices
(distractors or foils) and while ideally only one possible solution exists, the set of distractors
are carefully designed to engage different linguistic strategies in order to pinpoint the language
knowledge that the student is supposed to have acquired and is being tested for. Much research
has already been devoted to the theoretical, psychological, cognitive and educational aspects
involved in the making of cloze question (Armand 2001), while several systems have been built to
automatically generate cloze question (Correia 2010) (Aldabe, de Lacalle, Maritxalar, Martinez,
& Uria ).
The distractors have a very important role in the automatic generation of these exercises.
Distractors can be extracted from several sources. They can be, for instance, random words,
phonetically similar words, antonyms or variations of the correct word (Correia 2010).
There are already some solutions in REAP.PT and ArikIturri

18 CHAPTER 3. STATE OF THE ART
(Aldabe, de Lacalle, Maritxalar, Martinez, & Uria ). The first system, focuses pri-
marily on vocabulary and is based on distractors that were implemented using a
set of existing resources (like PAPEL, TemaNet and MWN.PT). The second system
“uses techniques of replacement and duplication of declension cases (inessive, abla-
tive, dative...), number (singular/plural) or the inflection paradigm (finite, indefinite)”
(Aldabe, de Lacalle, Maritxalar, Martinez, & Uria ).
3.1.5 Fill in the blank exercises
This type of exercise consists of blank spaces and words. The student has to match the
words with the blank spaces. The linguistic context of the blanks consist of real utterances so
they work both as clue and as conveyor of language knowledge.
Another version of this exercise is when students instead of having the words to fill the
blank spaces, only have tips for each blank space. Both versions are a powerful way to practice
various syntactic aspects of the language.
In Figure 3.3, an example of this exercise format can be seen, where each space has to be
filled by an adjective.
Figure 3.3: Fill in the blank exercises (taken from http://guida.querido.net/jogos/)
Another version of this exercise may be used for learning word inflection, for example, the
student only knows which is the verb to apply. The verbal agreement, mode and tense are
implicit in the exercise, e.g. “O Pedro queria que o Joao (ir) a Lisboa” / “Peter wanted
that John (go) to Lisbon”.
JCloze5 is a tool that facilitates the creation of these exercises in digital format, but it
requires that all information is entered by the user.
5http://hotpot.uvic.ca/ (last visited in December 2010)

3.1. SYNTACTIC-SEMANTIC EXERCISES 19
(Semi-)automatically generation of this type of exercises, is difficult since seldom is a word
so narrowly constraint in its use that its use that exactly same syntactic slot; secondly, automatic
slotting of syntactic structures is often too imprecise to be effective (except for simple cases)
(Correia 2010) and (Curto 2010).
This exercise format can shares several characteristics with the previous format: the gen-
eration of wrong answers for each space to be filled can also be generated by distractors; the
systems presented above may also be used to generate this exercise format.
There are other systems (Goto, Kojiri, Watanabe, Iwata, & Yamada 2010) that use a slightly
different approach from the previous ones:
• the system extracts sentences based on machine learning;
• estimates a blank part based on discriminative model;
• Generates distractors based on statistical patterns of existing question.
3.1.6 Word Sorting
These exercises consist of sentences whose words have been scrambled so that the student’s
may drag-and-drop them in the correct order.
Figure 3.4: Word Sorting (taken from http://guida.querido.net/jogos/)
The easiest way to generate these exercises automatically is to take a phrase from the corpus
and randomly change their word order. The difficulty is in assessing the response because the
sentence can be constructed in different ways and still be right.
Despite not having found any system that generates this format of exercises, this is exten-
sively used in text books and language materials to emphasize students’ grasp of the meaning
and the relationships between words.

20 CHAPTER 3. STATE OF THE ART
3.1.7 Short Answer Exercises
This type of questions is used to test the knowledge of different fields, making questions
where the answer is just a word or a small set of words. The great advantage of these exercises
is that instead of the exercises presented above, these are the ones where the answer depends
only on the students’ knowledge, because they do not contain any help. But one disadvantage,
is the great difficulty in carrying out the automatic correction because the student can write the
answer in different ways, including with spelling errors that do not necessarily indicate that the
student does not know the answer.
These exercises are not usually associated with syntax exercises, al-
though they are still used in some fields: singular/plural, masculine/feminine
(Costa & Traca 2010) (Costa & Mendonca 2010) (Seixas & Castanheira 2010). Exam-
ple: “Qual o plural de imagem?” (Costa & Traca 2010).
There are already some applications that allow teachers to create short-answer tests in digital
format (Jquiz), but in these cases teachers must first insert the questions and the corresponding
answers. (Semi-)Automatic generation systems available for this exercises’ format (Siddiqi,
Harrison, & Siddiqi 2010) are based on syntactic and semantic features, which introduced by the
processing chain, and in accordance with a set of preprogrammed rules, are generated questions.
3.1.8 Open Answer Exercises
Exercises where there are no restrictions on possible answers to a question. Each student
structures the response in the way that seems to be more appropriate. It may be exercises that
require some imagination (example: “Write a text that uses direct speech” ) or direct questions
about a specific topic.
For this reason, the automatic generation of these exercises is more complex. Nevertheless,
there is already some work done in this field (Sukkarieh, Pulman, & Raikes 2003) (Pulman &
Sukkarieh ), using the following tools:
• Modules to normalize students’ answers;
• Neural Networks and Machine Learnings, which attempt to calculate the similarity ratio
between the student’s answer and the correct answer.

3.2. AUTOMATIC EXERCISE GENERATION SYSTEMS 21
3.1.9 Alphabet Soup
This game can be used as an exercise. The goal is to the students find the answer to certain
questions or tips that are given along with to the alphabet soup. This exercise combines learning
with entertainment to teach the language.
Figure 3.5: Alphabet Soup (taken from http://cvc.instituto-camoes.pt/sopa-de-letras.html)
The difficulty of creating the table is one of the biggest drawbacks in the automatic gener-
ation of this exercise. Subsequently, there are other drawbacks:
• People with dyslexia can not do these exercises;
• The time to resolve the exercise is not related to the linguistic profienciency.
JClic6 is a tool that can create alphabet soups in digital format. The big drawback is that
all the information needed to create this format exercise has to be entered manually.
3.2 Automatic Exercise Generation Systems
Currently there are several tools which aim is to help students/teachers in their lessons.
Systems performing exercises generation are usually domain-specific because of the complex-
ity of the operations required for this task. For example, in the domain of Mathematics (Costa
2003) it is possible to mention the Computer Aided Generation and Solving of Math Exercises
6https://launchpad.net/jclic/ (last visited in December 2010)

22 CHAPTER 3. STATE OF THE ART
(Tomas & Leal 2003), AGILMAT (Tomas, Leal, & Domingues ) and others; in the area of music
exercises, there is the i-maestro(Ng 2008); and in the domain electric ac circuits analysis
(Cristea & Tuduce 2005), adpatative e-learning system developed by
(Holohan, Melia, McMullen, & Pahl 2006). System that include automatic generation of
syntactic exercises are not very common but the offer, if limited, already exists, especially for
English. In the next sections, some of these systems will be presented.
3.2.1 Working With Real English Text
The Working With Real English Text (WERTI) system (Dimitrov 2008), presents several
features that are interesting for the purpose of this work.
This system incorporates a chain of NLP, which filters real texts in order to generate various
syntactic exercises for English. In summary, this processing is divided into three phases:
• HTML processing (Pre-Processing): Removes the pages’ contents that surrounds the text
(tags, links), returning only the relevant text
• Linguistic Processing: responsible for tokenization, sentence boundary detection and part-
of-speech tagging.
• Enhancement Processing (Post-Processing): Performs the necessary operations to the cre-
ation of the exercise (it is different for each type of exercise).
The exercises produced by this system are generated with the help of a set of rules imple-
mented in the NLP chain, for example:
Gerunds vs Infinitives – In the presence of certain prepositions, it is required the application
of the gerund. These rules are in NLP grammar and they hide the tenses so that later students
can fill them in adequately - the verb to use is shown next to each space.
Wh-Questions – 126 standard rules are identified to formulate questions from the texts.
While these exercises way appear as too simple for a native speaker, they correspond to
syntactic topics where second language learners and known to have difficulty in learning English.
Color Different colors identify the words that match with the grammatical category that it is
being practised. These colors are accompanied with a caption.

3.2. AUTOMATIC EXERCISE GENERATION SYSTEMS 23
Click Students click on the words that they think can match to the grammatical category. If
it is correct the word turns green, otherwise it turns red.
Multiple Choice For each blank space in a text, several words of the same grammatical are
given, and the student has to choose the right one.
Category In the case of determinants, gerunds vs. infinitives, phrasel verbs and prepositions,
blank spaces appear so that students fill them properly. In the Wh-Question case, the
student must arrange the words given by the system to create a question.
3.2.2 TAGARELA
TAGARELA System (Bailey & Meurers 2008) is an intelligent computer-assisted language
learning that provides opportunities to practice reading, listening and writing skills. This sys-
tem can be accessed through a web browser and has the ability to offer individualized feedback
on speeeling, morphological, syntactic and semantic errors. Architecture of this system is di-
vided into two main components, which aim to make the syntactic and semantic analysis of the
students’ answers. The first component – Form Analysis – consists by four modules:
• Tokenizer: have special attention to cliticization, contractions, abbreviations;
• Lexical/Morphological Lookup: returns multiple analysis based on CURUPIRA lexicon
(Martins, Nunes, & Hasegawa );
• Disambiguator: set of rules for disambiguation;
• Parser: syntactic analyzer ascending.
The second component of the architecture – Content Analysis – tries to establish a semantic
agreement between the student’s answer and the correct answer.
This architecture supports different formats of exercises: fill gaps, vocabulary, description
of pictures and text description of the student hears.

24 CHAPTER 3. STATE OF THE ART
3.2.3 ALPHEIOS PROJECT
This software’s7 aim is to support the learning of two extinct languages - Latin and Ancient
Greek. To do so, this application provides: word definitions, word morphology, links to sections
of grammar considered relevant, manager of learned words and words left to be learned by each
user, automatic translator.
Regarding syntactic exercises, the application provides a specific tool - “My Diagrams”:
when a sentence is selected, this tool allows the student to create a dependency tree, analysing
each word according to its syntax; it also provides a set of questions for which the student must
classify each POS that is shown.
Although this software is being used as a browser plug-in, and the learning is being made
through the text of web pages, Alpheios also provides enriched texts, which allows the full use
of all the potential of this application.
Briefly, all systems presented in this work are composed of a processing chain that en-
riches the text with syntactic and semantic information. This information is useful for
generating exercises at a later stage. The major constraints consist of a limited number of
different types of exercises that are available on each system and also in small percentages of
exercises with errors due to problems with semi-automatic generation.
7http://alpheios.net/ (last visited in December 2010)

4Our Approach
To achieve the goals previously defined, it is expected that the developed module can gen-
erate three different types of exercises, wich are presented in this chapter.
4.1 Mahjong Lexical
In these exercises the student has to make a correspondence between the lemma and the
definition of a word.
This section describes the solution architecture adopted to automatically generate these
exercises (see Figure 4.1).
Figure 4.1: Mahjong Architecture
The words and their definitions will be taken from the Porto Editora dictionary. To represent
words and their definitions, the dictionary uses an HTML structure based on <span> and <div>
that group inline-elements and block-elements. Figure 4.2 shows an example of the HTML
structure for the word correr “run”, where each grouping <span> indicates a grammatical
category (transitive verb, intransitive verb) and also indicates the origin of the word (from

26 CHAPTER 4. OUR APPROACH
Latin). Each <span> element is composed ofs several <div> tags that group all information
needed (e.g. definitions).
Figure 4.2: HTML structure
The second step is to filter the definitions (see Figure 4.3), since only a subset of the
definitions is going to be classified later.
The filters’ module performs the following selection procedures:
• Cognate Words - Ideally, definitions containing words cognate to the target word should
be discarded, since this an obvious cue to the correspondence between a lemma and a
definition. As an approximation to this concept the Levenshtein distance was used, where
the algorithm implemented in this filter verifies if there is any word in the definition with
a high level of similarity with the target word. For example, for the target word “escrever”
(to write) the following definition is rejected “passar a escrito” (passing to the writing)
since “escrito” is cognate to “escrever”;
• Length - Only definitions of more than one word (to avoid similarities with synonyms’
exercises) and less than 150 words (to avoid very long definitions) are considered;
• Characters - characters that might hinder the understanding of a given definition are
removed. Examples: numbering of definitions, semicolon, cardinal, etc.

4.1. MAHJONG LEXICAL 27
Figure 4.3: Filters and Classifiers
A set of classifiers is also applied to the definitions:
• Difficulty - Usually, basic and more current meanings are shown first in dictionary’s defi-
nition, while more specialized or rarer meanings appear later.
For example: Target word – “caneta” (pen)
1. Beginners level - “utensılio que contem tinta e serve para escrever ou desenhar” (tool
that contains ink and is used to write or draw)
2. Intermediate level - “tubo ou cabo que se encaixa um aparo para escrever ou desenhar”
(pipe or cable that fits a nib to write or draw)
3. Advanced level - “especie de cabo ou pinca com que segura um cauterio” (kind of
cable or clamp that holds a cautery)
• Specific Domain - several definitions are very specific to a given field or profession. These
are classified as “advanced level” since they requires a deeper knowledge of the language.
Example: Target word – “relogio” (watch)
definition – BOTANICA termo com que se designam diversas malvaceas (BOTANICS
term with which several Malvaceae are designated)
The pre-processing steps here described are required to be performed once for each word,
and the results are stored in the REAP.PT database, in Mahjong table (see figure 4.4).

28 CHAPTER 4. OUR APPROACH
Figure 4.4: Mahjong Table and Mahjong Evaluation
The REAP.PT system is student-oriented, and the word-definition pairs are chosen by the
system developed in this work according to the student profile, therefore:
• Student’s level - influences the number of word-definition pairs that are presented to the
student; it also determines the difficulty level of the definitions presented;
• Student’s history - influences which words are selected by Syntactic REAP.PT to be present
to the student, showing words that the student doesn’t know yet. Words are considered
unknow if they were never searched by the student in the dictionary; or if the student
never matched them correctly with their definition; or if the students indicated that they
did not know them.
In each exercise of Mahjong Lexical, at least one pair word-definition will be repeated;
meaning that in each exercise there will be a word-definition pair that has already been presented
to the student in previous exercises. This feature serves to:
1. Avoid “forgetting” the definition of a new learned word, for it will be submitted periodically
in exercises;
2. Outwit cases where students hit a pair by luck and not through their knowledge;
3. Try to teach a new word, when students systematically miss the definition of that word.
Students’ performance before the repeated word-definition pair, will directly influence the rate
of students’ retention. The more times the student hit repeated words, the higher will be the
retention rate, otherwise it decreases. Only students with high retention rates in the words
repeated can claim to know the words’ meaning, while for students who only hit once, nothing
can be said about this learning aspect.

4.1. MAHJONG LEXICAL 29
Additionally, a scoring mechanism was added (see Figure 4.5). Initially a set of points is
given to the student, where each word-definition pair is worth 20 points. During the resolution
of the exercise, the student may be penalized according to following the set of rules: for each
wrong word-definition correspondence s/he loses 10 points; and for each minute passed without
the solution s/he loses 10 points with a maximum of 30 points.
Figure 4.5: Mechanism to award points
There will be also a word-definition pair with a difficulty level higher than the current
student’s level. If a student hit in this pair, they will receive 40 bonus points to their score.
The implementation of this scoring’ system tries to accomplish several objectives: to provide
greater feedback about student performance; to keep the student motivated in the exercise;
to prevent the student from solving the exercise by repeating his/her tries; and to provide a
“summary” of the student’s performance to the teacher.
The evaluation module, apart from the scoring’ system, also checks if the student hits/misses
a given word-definition correspondence and if the student has finished the exercise. The result
of this evaluation is stored in the REAP.PT database (see Figure 4.4) and it will be used later
to analyze the student’s learning progress.
The automatic correction of the exercise locks only the right answers, keeping the wrong

30 CHAPTER 4. OUR APPROACH
answers still selectable for further tries, and giving the student more opportunities to solve the
exercise correctly. Thus, we try to motivate the student to solve the exercise and to make
him/her learn the definitions he/she still doesn’t know.
4.1.1 Data
Figure 4.6: Filters’s Results
The results for this exercise are directly dependent on the words that teachers want to teach.

4.1. MAHJONG LEXICAL 31
For illustrative purposes, in this section we used the list of P-AWL words (5th grade) (see annex
A), that students have to know.
For the set of 167 words, there are 554 definitions available in Porto Editora dictionary (see
picture 4.6). From these definitions, only a subset of 439 definitions respect the “filter size”
and, of these, only 431 are considered by the filter that removes the definitions with invalid
characters.
Finally the definitions go through a third and final filter that removes definitions that contain
cognate words of the target word. In this last filter, 419 definitions are properly classified
according to their difficulty level. Completing this process, we get 222 definitions of basic level,
148 definitions of intermediate level, 49 definitions of advanced level and 135 definitions were
rejected from the initial set of 554 definitions (see Figure 4.6).

32 CHAPTER 4. OUR APPROACH
4.2 Choice of mood in subordinate clause
Learning the vocabulary of subordinating conjunctions and conjunctive phrases implies the
acquisition of syntactic restrictions imposed to the mode of the subordinate clause they intro-
duce. These constraints are also related with the tense and mood of the main clause. These
cloze questions allow students to practice reading comprehension while enhancing the syntactic
knowledge of the language. Thus, for example, “ate que” (until) imposes the infinitive or the
subjunctive mode, but does not accept the indicative mode (see Figure 4.7).
Figure 4.7: Example “ate” (until)
For the automatic generation of the exercise, the CETEMPublico Corpus (Santos & Rocha
2001) is used, after being processed by the STRING processing chain of L2F (Hagege, Baptista,
& Mamede 2010). A large set of conjunctions and conjunctive locutions have been registered in
the system lexicon. A very general set of rules creates a SC (subclause) chunk that links these
expressions to the first verb of the subordinate clause (see Figure 4.8). To run the filters that
generate the potential stems for this exercise, the distributed computing platform Hadoop is
used to process this large corpus.
Figure 4.8: Chunk Subclause
To generate the wrong answers, the L2F verbs’ generator (Hagege, Baptista, & Mamede
2010) was used. Furthermore, in order to avoid ambiguity in the wrong responses generated, we
added the following set of restrictions:
• if the verb is in the indicative (present, imperfect, perfect, pluperfect, future) — generate
verbs in subjunctive (present or imperfect);

4.2. CHOICE OF MOOD IN SUBORDINATE CLAUSE 33
• if the verb is in the subjunctive (present or imperfect) — generate verbs in indicative
(present, imperfect, perfect, pluperfect, future);
• if the verb is in the infinitive — randomly pick one of the tenses of the indicative or the
subjunctive;
• in the selection of distractors the homographs of the target word should not be used.
4.2.1 Data
To generate the stems for this exercise, the corpus CETEMPublico (Santos & Rocha 2001)
was used, which contains over 190 million words and 7 million setences. In order to extract
the candidate sentences in a fast and expedient way1, the Hadoop2 plataform for distributed
computing was used. This platform is based on MapReduce and uses a cluster to process
large amounts of data. In this way, was possible to extract 720,784 sentences and generate the
corresponding exercises of this type.
1Initial experiments showed a 95,6% reduction of processing time using Hadoop against a sequential executionof the processes. Even so, it took about 1h30m to process the entire corpus.
2http://hadoop.apache.org/ (visited in Jul. 2011)

34 CHAPTER 4. OUR APPROACH
4.3 Collective Names and Nominal Determinants
The purpose of this exercise is to learn the subtle distributional constraints observed between
a determinative noun (Dnom) and the noun it determines (see Figure 4.9). This exercise also
serves to teach the classifying relationship between collective names and common names, since
collectives often function as Dnom on common nouns.
Figure 4.9: Example of Exercise of Nominal Determinant
These exercises are generated from real sentences, taken from the corpus. In these sentences,
a quantifying dependency (QUANTD) (see Figure 4.10) has been extracted by the syntactic
parser XIP (Hagege, Baptista, & Mamede 2010). This dependency holds between a Dnom
functioning as the head of a nominal or prepositional phrase (NP or PP) and the head oh the
immediately subsequent PP introduced by preposition “de” (of).
Again, the distributed computing platform Hadoop is used to retrieve from the large-sized
corpus the sentences that can be potential stems for this exercise.
Figure 4.10: QUANTD dependency
A new set of lexical information was added to the lexicon in order to generate adequate
distractors for the exercises. To do that, a list of determinative and collective names was added.
A set of semantic features was defined and accorded to these words. These semantic features
consist on the following categories: Human, Animal, Food, Organization/Institutions, Object,
Nature, Military and Local. By using these features, potential distractors that share the same
traits as the target word are never select, thus avoiding to generate unwanted correct solutions

4.3. COLLECTIVE NAMES AND NOMINAL DETERMINANTS 35
as foils. An additional set of constraints was also added to prevent the generation of distractors
that, in a figurative use, would be possible solutions. For example, Dnom associated to the
“Animal” feature (alcateia, “pack”, speaking of wolves) are not used for human nouns (e.g.
uma alcateia de polıticos “a pack of politicians”) since this combination might be used in a
ironic formulation.
To make the exercise more interesting, in the generation of distractors the same number
and gender of the target word is kept.
One of the important points in the CALL system is that the application is able to provide
feedback to the student. When the student incorrectly chooses a given word-definition pair, s/he
is given some feedback by the system. This feedback consists of three parts:
• the definition of the wrong answer;
• a real sentence as an example of the correct use of the selected word;
• pictures of the word selected.
This feedback system gives the indication that the student missed a question, and tries to
teach the meaning of the given nominal determinant and also its proper use (giving examples of
images, definitions, and uses the correct given determinative noun).
The illustrative images of the nominal determinant that appear on the feedback system
were selected in advance and stored in the REAP.PT database. To select these images was
necessary to retrieve the first ten images available in google images for each determinative noun.
Subsequently, through a voting system, the two most voted images (in 10 possible) are selected
and used by the REAP.PT system.
Following the same logic of the Mahjong Lexical exercise, it is important that there is some
repetition in the nominal determinants presented to the student. The Syntactic REAP.PT
presents sentences that are different but whose correct nominal determinant used to fill the
sentence has appeared in previous exercises. If the student hits the nominal determinant in
different contexts it means that s/he knows its meaning and knows how to make a proper use
of it.

36 CHAPTER 4. OUR APPROACH
4.3.1 Data
The syntactic REAP was able to extract from the corpus approximately 19,000 sentences,
of which 46,61% involve determinative nouns exercises and 53.39% correspond to the collective
names (see table 4.1). It should also be noted that determinatives names that appear more
frequently (see annex B) in the exercises are “percentagem”, “pacote” e “pedaco” and the
most common collective name (see annex B) in the generated exercises are “equipa”, “album”
e “comissao”. Although some nominal determinants /collective names do not appear in the
correct answers generated by this module, they are used as a distractors.
Exercise Number of exercises %
Collective names 9,035 46.61%
Nominal determinants 1,0345 53.39%
Table 4.1: Collective names and nominal determinants
The Hadoop3 plataform was used to process the corpus with the filters in order to generate
the exercise, in a similar way as with the previous game.
3http://hadoop.apache.org/ (visited in Jul. 2011)

4.4. TEACHER INTERFACE 37
4.4 Teacher Interface
This section presents the work developed in the teacher interface for the REAP.PT system.
At this stage, we felt the need to create an interface that would be simple and intuitive but
at the same time could give all the information needed by the teacher in order to assess the
learning process of each individual student and the class in general. This interface assumes
particular relevance because if teachers feel they can not control the progress of the students
(given answers, questions presented, results, etc.) they will not use the system. To avoid this
situation it is interesting that the system, in addition to providing a general feedback about the
students’ performance, may also give all relevant data to the teacher if s/he wishes to validate
any particular information or make an assessment using her/his own criteria.
The pages that allow the visualisation of the students’ results are composed of two parts:
the first entitled “General Information”, where the teacher a general overview of the current
status of the student. The second, called “Detailed Information”, which contains all data of
all exercises solved by student, separated by exercise. Thus, teachers can see the evolution of
students over the use of Syntactic REAP.
4.4.1 Mahjong Lexical
In the General Information screen, teachers can view the summary of a student’s perfor-
mance in percentage (0% to 100%). This performance is the weighted value between the number
of points earned versus the maximum number of points that the student could obtain.
In order to complement and help understanding this performance, the percentage is pre-
sented in different colors: red (poor performance), orange (can improve), blue (successful out-
come) and green (good result). On this page the teacher can also check:
• number of exercises solved;
• time spent solving exercises;
• number of errors;
• words whose meaning the student already knows;
• words whose meaning the student does not seem to know.

38 CHAPTER 4. OUR APPROACH
In the Detailed Information screen the teachers can view the student’s history. For each
exercise, the teacher can check the performance of the student, the mistakes, the points obtained,
and the retention rate associated with each exercise. In order to be simpler to understand, these
results are presented in a graphic and a table format. The graphics (see figure 4.11) show
the oscillations of student performance and the retention rate. As in the General Information
screen, graphics are colored with: red (bad performance), orange (can improve), blue (successful
outcome) and green (good result).
Figure 4.11: Teacher Interface
4.4.2 Choice of mood in subordinate clause
In the Detailed Information screen the teacher can analyze the results of the student for
each exercise, namely:
• the number of errors committed;
• the answers submitted by the student;
• check if the student failed to respond properly to the exercise.

4.4. TEACHER INTERFACE 39
4.4.3 Collective Names and Names determinative
On the page General Information screen the teacher sees an overview of the student
performance. Here it is possible to view:
• number of exercises presented;
• number of errors;
• number of correct answers;
• determinative names / collective names that the student already knows how to use cor-
rectly;
• determinative names / collective names that the student still does not know how to use
correctly;
On the Detailed Information page the teacher can monitor the answers given by the
students in each exercise (the system indicates the correct answer for each exercise). It is also
possible to view the question presented in each exercise, the number of wrong answers, the
retention rate and the associated information if the student successfully solved the exercise.

40 CHAPTER 4. OUR APPROACH

5EvaluationTo assess the performance of the Syntactic REAP.PT, two groups of students were given
the system to try it and comment on its use. This evaluation consisted in a Syntactic REAP.PT
Session, composed of three parts:
• initial form (see annex C): tracing the students’ profile (e.g. age, native language, etc.);
• exercises: three mahjong lexical exercises are presented (one for each difficulty level), three
mood selection for subclause verbs exercises, three nominal determinants exercises, and
three collective names exercises;
• final questionnaire (see annex D): aimed at qualitative assessment of the system (e.g.
system case of use, which exercises are most relevant or appealing, etc).
The exercises generated by the Syntactic REAP require some knowledge of Portuguese as
they call upon more advanced language contents. In this way, to evaluate the system, it is
required that the subjects of the evaluation comply with this condition: if they are non-native
Portuguese speakers, they already should have an elementary knowledge of the language. Due to
the impossibility of gathering a group with the characteristics described in time for this exercise,
the tests were conducted on a group with relatively similar characteristics - Portuguese native
speakers in the 3rd and 4th grade. In order be able to contrast this group performance, the same
test was also performed with another group of native speakers with at least a college degree.
Test Users
Therefore, 45 subjects performed this exercise, 18 in Group 1 and 31 in Group 2. A brief
overview of these two groups in presented in Table 5.1. Naturally, while de age of Group 1
subjects is quite homogeneous, Group 2 varied from 19 to 70, the average age being 24. Most
subjects from Group 2 know other languages (such as english, french, spanish, italian and

42 CHAPTER 5. EVALUATION
german). The choice of Group 1 can be justified by their knowledge of Portuguese as mother
language but their still limited vocabulary - this being one of REAP.PT main learning targets.
GroupNumber ofusers
% Average age Other languages
1 18 37% 8 –
2 31 63% 24 english, french, spanish, ital-ian, german
Table 5.1: Test Users
As we can see in the table, the nationality of the group differs between the portuguese and
brazilian, and most of the people that belong to the Group 2 (with college degree) speak other
languages such as english, french, spanish, italian and/or german.
Assessment – Test Environment
The testing environment was different for each group. Group 1 did the exercises one at time
in the room’s computer, and a team member of REAP.PT project helped them to access the
starting page and occasionally had to explain the exercises or some unknown word since some
children still hadn’t fully mastered their reading skills. Each child took about 26 minutes to
complete the exercises and the questionnaire.
Users from Group 2 did the test at their own homes, without the aid of any element of the
REAP.PT project.

43
Figure 5.1: The system was quick in giving an answer
Results and Discussion
As shown in Figure 5.2, move than 77% of the users found the system easy to use. In this
way we can say that one of the goals of this project was achieved, namely, to create a system
with a simple and easy to use interface, so that all users (even some inexperienced users) were
able to use the Syntactic REAP.PT. In Table 5.3 we can see that only 39% needed to use the
“Help” button.
Figure 5.2: The system was easy to use
The pre-processing of the exercises is made in advance and stored in the REAP.PT database.
Thus, the generation stage, which is the most time-consuming step of the processing, is already

44 CHAPTER 5. EVALUATION
Figure 5.3: The help menu contains useful information presented in a concise and clear manager
done when the user access the system. This is why the system is so quick when responding to
requests from users as is a reflect in their answer to the question shown in Figure 5.1.
Figure 5.4: Which exercise did you like best
Regarding the results obtained in the three Mahjong Lexical exercises that were presented,
Group 2 obtained better results with a performance of 84% (standard deviation = 6,6%), while
the users from Group 1 made more errors and obtained a performance of 54% (standard deviation
= 12,4%).
Users from both group reported that the exercise they liked most (44%) was the Mahjong
Lexical (see Figure 5.4), the next most enjoyed exercise was the “Collective Nouns” (27%) fol-
lowed by “Nominal Determinants” (17%) and the “mood of subordinate clause” (12%). However
45
it is remarkable that the 2 Groups had clearly different impressions about these three exercise.
While Group 1 liked “Collective Nouns” as 2nd best ( 40%), Group 2 shows similar preference
for each of these three (16%, 19% and 21%) this way have to do with the that collective names
are an explicit grammatical subject at “escola primaria” (elementary school) thus contributing
do a higher familiarity with the topic which entailed this preference trend.
Another interesting aspect to note is the error rate for each exercise. Starting at Mahjong
Lexical, in Table 5.2, we can see that in both groups the more the difficulty level of exercises
increases, more mistakes the students do, which seems to confirm the strategy followed to dis-
tinguish these levels from the sequence of definitions inside the dictionary entry of each target
word (see Section 4.1)
Group 1 Group 2
Easy levelaverage=1.07 errors/exercise,standard deviation=0.98,mode=1
average=0.12 errors/exercise,standard deviation=1.06,mode=0
Intermediate levelaverage=1.52 errors/exercise,standard deviation=1.01,mode=2
average=1.02 errors/exercise,standard deviation=0.98,mode=1
Advanced levelaverage=3,04 errors/exercise,standard deviation=1.04,mode=3
average=2,04 errors/exercise,standard deviation=1.01,mode=2
Table 5.2: Mahjong Lexical Results
Regarding the error rate associated with the collective names and nominal determinants
exercises (see Figure 5.5) shows that Group 1 misses more than Group 2 but this difference be-
comes more critical in the exercise of nominal determinants and collective names (see Figure 5.5).
With this information it is easy to conclude that students feel more difficulties in the collective
names and nominal determinants exercises, and that the “choice of mood in subordinate clause”
are easier (this information is very similar to what students answered in the questionnaire, see
Figure 5.6).
The results of the collective nouns and nominal determinants exercises were very similar.
Regarding the first group, it is noted that on average students miss one exercise in every three
that were submitted and the second group misses less, which is naturally understandable given

46 CHAPTER 5. EVALUATION
Figure 5.5: Error rate by exercise
Figure 5.6: Which exercise was the easiest
the age difference and educational level of the subjects from each group.
In relation to the overall assessment of the system, 50% of the subjects classify it as “very
good”, 17% as “good”, 9% as “acceptable” and the remaining 18% classified it as “bad” or “very
bad” (see Figure 5.7). In this way a global positive appreciation was achieved (67% good or
very good). Group 2 is more critical about the system: only 41% found it very good against
55% from Group 1.
The most critical opinion relates to the high repetition of the infinitive in the “‘mood of
subordinate clauses” exercises. This is due to the fact that most of the stems found in the
CETEMPublico corpus contain the verb in the infinitive, which makes the correct tense for
these exercises also the infinitive. This can lead the users to sense that this exercise is the

47
Figure 5.7: System’s global appreciation
easiest (see Figure 5.6), due to repetition, but also the less interesting one.
One of the ways we can use to help improve this situation, is to create a new condition
during the automatic generation of the exercise that would provide greater variety in the mood
of the stem target verb and thus prevent the exercises selected to users to have always the correct
verb in the infinitive.
Finally, Table 5.3 presents the tests duration. We can verify that Group 1 takes on average
more 5 minutes than the Group 2 to take the test, the Mahjong Lexical being the game that
takes the longest time to complete. Notice that for each exercise in Mahjong 4 pairs are involved,
however in the remaining exercises it is only necessary to select a single answer.

48 CHAPTER 5. EVALUATION
GroupMahjongLexical
Choice ofmood insubordinateclause
CollectiveNames
NominalDetermi-nants
Total
1Average:8m46s;Standard de-viation:0m56s
Average:4m38s;Standard de-viation:1m23s
Average:4m27s;Standard
devia-tion:1m12s;
Average:3m03s;Standard de-viation:1m45s
Average:21m03s;Standard
deviation:1m56s
2Average:7m34s;Standard de-viation:1m45s
Average:3m56s;Standard de-viation:0m46s
Average:3m37s;Standard de-viation:1m09s
Average:2m45s;Standard de-viation:1m24s
Average:15m59s;Standard
deviation:1m46s
Table 5.3: Average test duration

6Conclusion and Future
Work
CALL systems emerged in the context of a growing need for multilingual proficiency in a
globalized world, as a way of providing a fast and appealing tool to learn foreign languages.
This work presented the development of syntatic-semantic module for the REAP.PT system,
able to generate exercises for vocabulary acquisition in a (semi-)automatic way. These exercises
focus on semantic definitions (Mahjong Lexical), on the mood selection for subclause verbs and
on the distributional constraints between Dnom and their heads.
It is important to note that the exercises presented here are especially designed for people
who want to learn Portuguese but that already have a reasonable level of knowledge of the
language, because the generated exercises require the understanding of phrases and definitions
that are difficult concepts for people who have not had contact with the Portuguese.
Regarding the future work, we intend to integrate this system with the DIXI software
(Paulo, Oliveira, Mendes, Figueira, Cassaca, Viana, & Moniz 2008) so that students have the
opportunity to hear the exercises. It is also an objective of this study to make an assessment
of knowledge acquisition by comparing this system with the traditional exercise of textbooks.
Two groups will be used for that - one group uses this system and the others solves written
assignments - at the end we will analyze which group of students obtains better results.
Looking a little more to REAP.PT as a whole, it is important to note that there is still
interesting future work:
• Interface and Portability – The simplicity of the current REAP.PT interface may not
be an attractive point to some students. For that reason, REAP.PT needs to meet the
students’ interests and be adapted to new technologies – devices that the students use in
their everyday life (such as iPhone and iPad) (Correia 2010);
• Games – Carnegie Mellon University started to develop games for inclusion in the REAP
system. The main goal of this proposed future research topic is to make the learning

50 CHAPTER 6. CONCLUSION AND FUTURE WORK
process more attractive and appealing for the students (Correia 2010).

Bibliography
Aherne, A. & C. Vogel (2006). Wordnet enhanced automatic crossword generation. In P. So-
jka, K.-S. Choi, C. Fellbaum, & P. Vossen (Eds.), Proceedings of the Third International
Wordnet Conference, pp. 139 – 145.
Aldabe, I., M. de Lacalle, M. Maritxalar, E. Martinez, & L. Uria. ArikIturri: An Automatic
Question Generator Based on Corpora and NLP Techniques. In M. Ikeda, K. Ashley, & T.-
W. Chan (Eds.), Intelligent Tutoring Systems, Volume 4053 of Lecture Notes in Computer
Science, pp. 584–594. Springer Berlin / Heidelberg.
Anbulagan & A. Botea (2008). Crossword puzzles as a constraint problem. In Proceedings of
the 14th international conference on Principles and Practice of Constraint Programming,
CP ’08, Berlin, Heidelberg, pp. 550–554. Springer-Verlag.
Armand, F. (2001). Learning from expository texts: Effects of the interaction of prior knowl-
edge and text structure on responses to different question types. European Journal of
Psychology of Education 16, pp. 67–86.
Bailey, S. & D. Meurers (2008). Diagnosing meaning errors in short answers to reading com-
prehension questions. In Proceedings of the Third Workshop on Innovative Use of NLP
for Building Educational Applications, EANL’08, Morristown, NJ, USA, pp. 107–115. As-
sociation for Computational Linguistics.
Baptista, J., N. Costa, J. Guerra, M. Zampieri, M. Cabral, & N. Mamede. P-AWL: Academic
word list for portuguese. In T. Pardo, A. Branco, A. Klautau, R. Vieira, & V. Lima (Eds.),
Computational Processing of the Portuguese Language, Volume 6001 of Lecture Notes in
Computer Science, pp. 120 – 123. Springer Berlin / Heidelberg.
Bastos, A., R. Berardi, & R. Silveira (2004). Webduc: Uma proposta de ferramenta de
avaliacao formativa no ambiente TelEduc. In RENOTE Revista Novas Tecnologias na
Educacao, Porto Alegre, v.2, n.1, pp. 161–169.
Carbonell, J. & R. Brown (1988). Anaphora resolution: a multi-strategy approach. In Pro-
51

52 CHAPTER 6. CONCLUSION AND FUTURE WORK
ceedings of the 12th conference on Computational linguistics - Volume 1, Morristown, NJ,
USA, pp. 96–101. Association for Computational Linguistics.
Collins-Thompson, K. & J. Callan (2005). Predicting reading difficulty with statistical lan-
guage models. Journal of the American Society for Information Science and Technol-
ogy 56 (13), pp. 1448–1462.
Correia, R. (2010). MSc Thesis, Automatic Question Generation for REAP.PT Tutoring Sys-
tem, Instituto Superior Tecnico - Universidade Tecnica de Lisboa.
Costa, F. & L. Mendonca (2010). Na Ponta da Lıngua - Lıngua Portuguesa - 6.o Ano. Porto
Editora.
Costa, M. & M. Traca (2010). Passa Palavra - Lıngua Portuguesa - 5.o Ano. Porto Editora.
Costa, R. (2003). Geracao automatica de exercıcios de matematica. Master’s thesis, Departa-
mento de Matematica Pura - Faculdade de Ciencias da Universidade do Porto.
Cristea, P. & R. Tuduce (2005). Automatic generation of exercises for selftesting in adaptive
e-learning systems. In 3rd Workshop on Adaptive and Adaptable Educational Hypermedia
at the AIED’05 conference, (A3EH).
Curto, S. (2010). MSc Thesis, automatic generation of multiple-choice tests , Instituto Supe-
rior Tecnico - Universidade Tecnica de Lisboa.
Dimitrov, A. (2008). Rebuilding WERTi: Providing a platform for second language acquisition
assistance. In Seminar fur Sprachwissenschaft, Universitat Tubingen.
Gamper, J. & J. Knapp (2002). A review of intelligent CALL systems. In J. Gamper &
J. Knapp (Eds.), Computer Assisted Language Learning, Volume 15 of Lecture Notes in
Computer Science, pp. 329–342. Springer-Verlag.
Goto, T., T. Kojiri, T. Watanabe, T. Iwata, & T. Yamada (2010). Automatic generation
system of multiple-choice cloze questions and its evaluation. In International Journal on
Knowledge Management and E-Learning, Volume 2, pp. 210–224.
Hacken, P. T. (2003). Computer-assisted language learning and the revolution in Computa-
tional Linguistics. Journal Linguistik online, Volume 17, pp. 23-39.
Hagege, C., J. Baptista, & N. Mamede (2010). Caracterizacao e processamento de expressoes
temporais em portugues. Linguamatica 2, pp. 63–76.

53
Heilman, M. & M. Eskenazi (2006). Language learning: Challenges for intelligent tutoring
systems. In Proceedings of the Workshop of Intelligent Tutoring Systems for Ill-Defined
Domains. 8th International Conference on Intelligent Tutoring Systems, Volume 8th In-
ternational, pp. 20 – 28.
Holohan, E., M. Melia, D. McMullen, & C. Pahl (2006). The generation of e-learning exercise
problems from subject ontologies. Advanced Learning Technologies, IEEE International
Conference on, pp. 967–969.
Howard, J., M. Kazar, S. Menees, D. Nichols, M. Satyanarayanan, R. Sidebotham, & M. West
(1988). Scale and performance in a distributed file system. ACM Trans. Comput. Syst. 6,
pp. 51–81.
Lisbon European Council (2010). Employment, Economic Reform and Social Cohesion- to-
wards a Europe based on innovation and knowledge. Confederation of British Industry.
Martins, R., G. Nunes, & R. Hasegawa. Curupira: A functional parser for brazilian por-
tuguese. In N. Mamede, I. Trancoso, J. Baptista, & M. das Gracas Volpe Nunes (Eds.),
Computational Processing of the Portuguese Language, Volume 2721 of Lecture Notes in
Computer Science, pp. 195–195. Springer Berlin / Heidelberg.
Marujo, L. (2009). MSc Thesis, REAP em portugues, Instituto Superior Tecnico - Universi-
dade Tecnica de Lisboa.
Meinedo, H., D. Caseiro, J. a. Neto, & I. Trancoso (2003). AUDIMUS : A broadcast news
speech recognition system for the european portuguese language. In N. Mamede, I. Tran-
coso, J. Baptista, & M. das Gracas Volpe Nunes (Eds.), Computational Processing of the
Portuguese Language, Volume 2721 of Lecture Notes in Computer Science, pp. 196–196.
Springer Berlin / Heidelberg.
Meinedo, H. & J. a. Neto (2003). Automatic speech annotation and transcription in a broad-
cast news task. In Proc. ISCA ITRW on Multilingual Spoken Document Retrieval, Hong
Kong.
Moreira, J. E., M. M. Michael, D. da Silva, D. Shiloach, P. Dube, & L. Zhang (2007). Scalabil-
ity of the nutch search engine. In Proceedings of the 21st annual international conference
on Supercomputing, ICS ’07, New York, NY, USA, pp. 3–12. ACM.
Ng, K. (2008). Interactive feedbacks with visualisation and sonification for technology-

54 CHAPTER 6. CONCLUSION AND FUTURE WORK
enhanced learning for music performance. In Proceedings of the 26th annual ACM in-
ternational conference on Design of communication, SIGDOC ’08, New York, NY, USA,
pp. 281–282. ACM.
Okan, Z. Computing laboratory classes as language learning environments. Learning Environ-
ments Research 11, pp. 31–48.
Oliveira, H. G., D. Santos, P. Gomes, & N. Seco (2008). PAPEL: A dictionary-based lexical
ontology for portuguese. In Proceedings of the 8th International Conference on Compu-
tational Processing of the Portuguese Language, PROPOR ’08, Berlin, Heidelberg, pp.
31–40. Springer-Verlag.
O’Malley, J. M., A. U. Chamot, & L. Kupper (1989). Listening Comprehension Strategies in
Second Language Acquisition. Applied Linguistics 10 (4), pp. 418–437.
Paulo, S., L. Oliveira, C. Mendes, L. Figueira, R. Cassaca, C. Viana, & H. Moniz (2008). DIXI
- A Generic Text-to-Speech System for European Portuguese. In A. Teixeira, V. de Lima,
L. de Oliveira, & P. Quaresma (Eds.), Computational Processing of the Portuguese Lan-
guage, Volume 5190 of Lecture Notes in Computer Science, pp. 91–100. Springer Berlin /
Heidelberg.
Pulman, S. & J. Sukkarieh. Automatic short answer marking. In Proceedings of the Second
Workshop on Building Educational Applications Using NLP.
Rost, J. (2005). Software Engineering Theory in Practice. IEEE Softw. 22.
Santos, D. & P. Rocha (2001). Evaluating CETEMPublico, a free resource for Portuguese.
In Proceedings of the 39th Annual Meeting on Association for Computational Linguistics,
ACL ’01, Morristown, NJ, USA, pp. 450–457. Association for Computational Linguistics.
Seixas, M. & C. Castanheira (2010). Aprender em Portugues - Lıngua Portuguesa - 5.o Ano.
978-972-680-565-6. Lisboa Editora.
Siddiqi, R., C. Harrison, & R. Siddiqi (2010). Improving teaching and learning through auto-
mated short-answer marking. IEEE Transactions on Learning Technologies 3, pp. 237–249.
Stark, M. & R. Riesenfeld (1998). Wordnet: An electronic lexical database. In Proceedings of
11th Eurographics Workshop on Rendering. MIT Press.
Stern, H. Practical applications in second language learning. Interchange 6, pp. 57–58.

55
Sukkarieh, J., S. Pulman, & N. Raikes (2003). Auto-marking: using computational linguistics
to score short, free text responses. paper presented at the 29th annual conference. In of
the International Association for Educational Assessment (IAEA).
Tomas, A. & J. Leal (2003). A CLP-Based Tool for Computer Aided Generation and Solving
of Maths Exercises. In V. Dahl & P. Wadler (Eds.), Practical Aspects of Declarative Lan-
guages, Volume 2562 of Lecture Notes in Computer Science, pp. 223–240. Springer Berlin
/ Heidelberg.
Tomas, A., J. Leal, & M. Domingues. A web application for mathematics education. In
H. Leung, F. Li, R. Lau, & Q. Li (Eds.), Advances in Web Based Learning - ICWL
2007, Volume 4823 of Lecture Notes in Computer Science, pp. 380–391. Springer Berlin /
Heidelberg.

56 CHAPTER 6. CONCLUSION AND FUTURE WORK
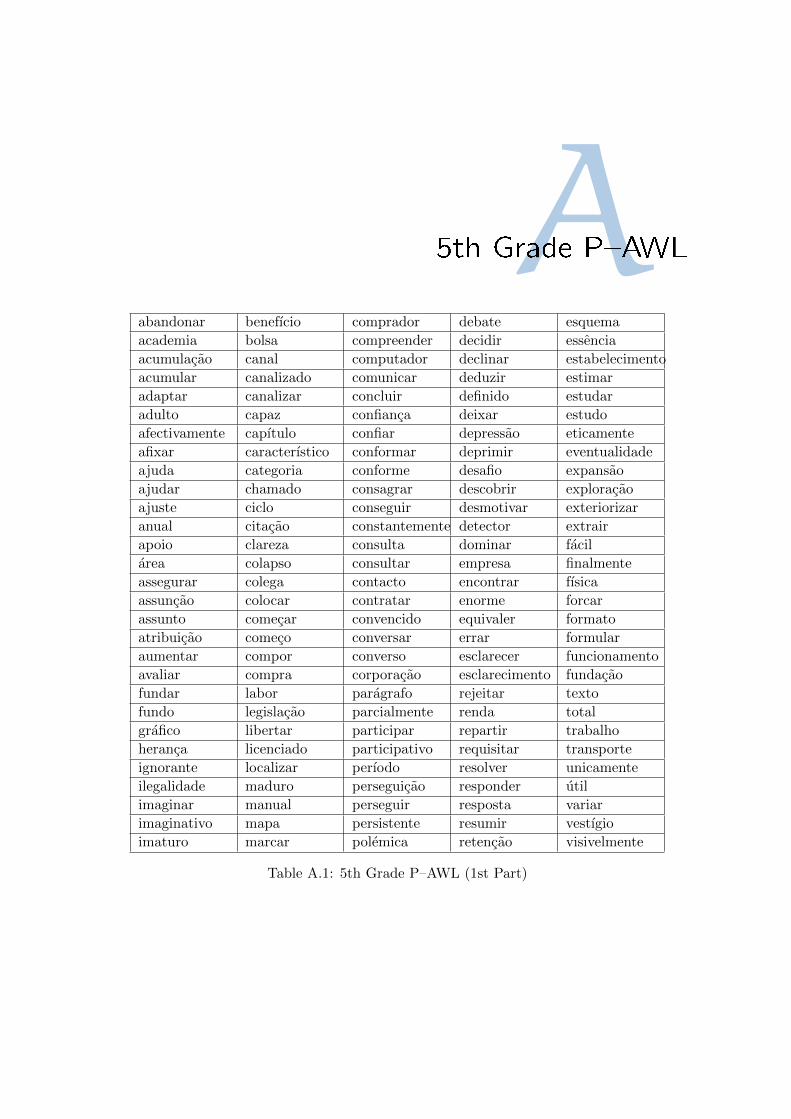
A5th Grade P{AWL
abandonar benefıcio comprador debate esquema
academia bolsa compreender decidir essencia
acumulacao canal computador declinar estabelecimento
acumular canalizado comunicar deduzir estimar
adaptar canalizar concluir definido estudar
adulto capaz confianca deixar estudo
afectivamente capıtulo confiar depressao eticamente
afixar caracterıstico conformar deprimir eventualidade
ajuda categoria conforme desafio expansao
ajudar chamado consagrar descobrir exploracao
ajuste ciclo conseguir desmotivar exteriorizar
anual citacao constantemente detector extrair
apoio clareza consulta dominar facil
area colapso consultar empresa finalmente
assegurar colega contacto encontrar fısica
assuncao colocar contratar enorme forcar
assunto comecar convencido equivaler formato
atribuicao comeco conversar errar formular
aumentar compor converso esclarecer funcionamento
avaliar compra corporacao esclarecimento fundacao
fundar labor paragrafo rejeitar texto
fundo legislacao parcialmente renda total
grafico libertar participar repartir trabalho
heranca licenciado participativo requisitar transporte
ignorante localizar perıodo resolver unicamente
ilegalidade maduro perseguicao responder util
imaginar manual perseguir resposta variar
imaginativo mapa persistente resumir vestıgio
imaturo marcar polemica retencao visivelmente
Table A.1: 5th Grade P–AWL (1st Part)

58 APPENDIX A. 5TH GRADE P–AWL
incessante margem posar revelacao inconformado
maximo preciso rever indiscreto medico
princıpio rota individualizar mental problema
salientar inevitavel meta procurar seccao
informacao ministro profissao seguranca informatico
modalidade profissional sexo insignificante monitor
projectar significado inspeccionar montar propriedade
somar instrutivo negar racional subsıdio
instrutor negativa rascunho sucesso inteligente
numero reaccao suposicao intensamente obter
realizar tabela intervalo ocupacao receita
tarefa inutil orientar recuperar tecnica
inutilmente origem recurso tecnico invalido
palestra rede tematica juntar par
regime terreno
Table A.2: 5th Grade P–AWL (2nd Part)
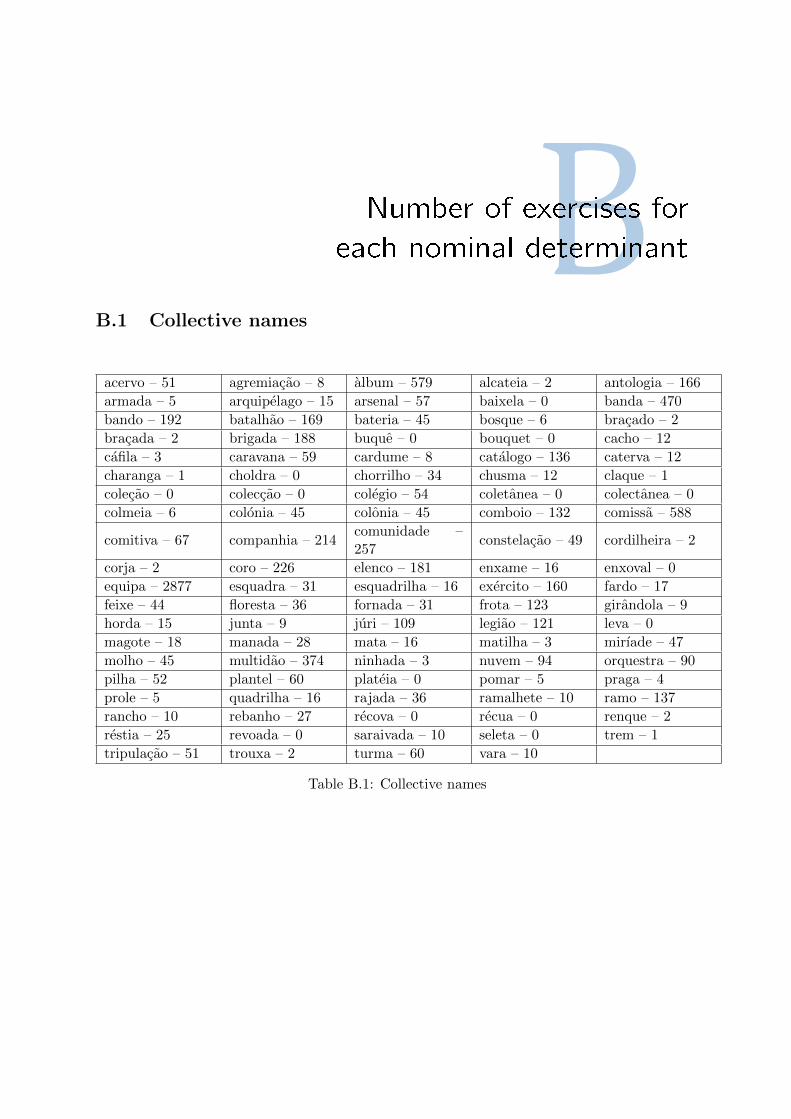
BNumber of exercises for
each nominal determinant
B.1 Collective names
acervo – 51 agremiacao – 8 album – 579 alcateia – 2 antologia – 166
armada – 5 arquipelago – 15 arsenal – 57 baixela – 0 banda – 470
bando – 192 batalhao – 169 bateria – 45 bosque – 6 bracado – 2
bracada – 2 brigada – 188 buque – 0 bouquet – 0 cacho – 12
cafila – 3 caravana – 59 cardume – 8 catalogo – 136 caterva – 12
charanga – 1 choldra – 0 chorrilho – 34 chusma – 12 claque – 1
colecao – 0 coleccao – 0 colegio – 54 coletanea – 0 colectanea – 0
colmeia – 6 colonia – 45 colonia – 45 comboio – 132 comissa – 588
comitiva – 67 companhia – 214comunidade –257
constelacao – 49 cordilheira – 2
corja – 2 coro – 226 elenco – 181 enxame – 16 enxoval – 0
equipa – 2877 esquadra – 31 esquadrilha – 16 exercito – 160 fardo – 17
feixe – 44 floresta – 36 fornada – 31 frota – 123 girandola – 9
horda – 15 junta – 9 juri – 109 legiao – 121 leva – 0
magote – 18 manada – 28 mata – 16 matilha – 3 mirıade – 47
molho – 45 multidao – 374 ninhada – 3 nuvem – 94 orquestra – 90
pilha – 52 plantel – 60 plateia – 0 pomar – 5 praga – 4
prole – 5 quadrilha – 16 rajada – 36 ramalhete – 10 ramo – 137
rancho – 10 rebanho – 27 recova – 0 recua – 0 renque – 2
restia – 25 revoada – 0 saraivada – 10 seleta – 0 trem – 1
tripulacao – 51 trouxa – 2 turma – 60 vara – 10
Table B.1: Collective names

60 APPENDIX B. NUMBER OF EXERCISES FOR EACH NOMINAL DETERMINANT
B.2 Nominal Determinants
alforge – 3 alguidar – 4 anfora – 1 arca – 9 bacia – 9
balde – 33 bilha – 3 bolsa – 132 bornal – 0 botija – 0
bureta – 0 cabaca – 0 cabaz – 24 cacarola – 2 caixa – 245
caixote – 20 caldeira – 4 caldeirao – 20 calice – 31 canastra – 0
caneca – 8 capsula – 19 carga – 147 carteira – 88 cartucho – 6
cesta – 5 cesto – 43 concha – 4 contentor – 22 copo – 139
cuba – 0 escudela – 0 estojo – 6 frasco – 33 gamela – 1
garrafa – 285 garrafao – 3 gaveta – 10 jarra – 10 jarro – 5
lata – 73 maco – 47 mala – 13 maleta – 0 malga – 6
marmita – 0 meada – 0 mesa – 78 molheira – 0 moringa – 0
pacote – 704 palete – 1 panela – 10 pasta – 34 pedaco – 345
pipa – 9 pires – 2 pitada – 33 prato – 123 recipiente – 10
restea – 20 saca – 5 saco – 105 sacola – 3 selha – 0
taca – 42 tacho – 11 tanque – 30 termo – 37 terrina – 2
tigela – 3 tina – 1 tonel – 3 urna – 5 vasilha – 3
vaso – 17 xıcara – 0chavena de cafe –0
chavena de cha –0
colher de cafe – 4
colher de cha – 14colher de so-bremesa – 6
colher de sopa –26
data – 178 imensidade – 13
montanha – 55 monte – 189 parte – 4768percentagem –577
porcao – 78
porradao – 0sem-numero –148
Table B.2: Nominal determinants

CInitial Form
Figure C.1: Initial Form

62 APPENDIX C. INITIAL FORM

DQuestionnaire
Figure D.1: Questionnaire - 1st Part

64 APPENDIX D. QUESTIONNAIRE
Figure D.2: Questionnaire - 2nd Part