t41 s:@=/1> -90 c:9>1 :2 ?41 f7@19? p=:/1>>593 :2 n
TRANSCRIPT

Journal of Marketing ResearchVol. XLVIII (April 2011), 327 –341
*Dan King is Assistant Professor of Marketing, NUS Business School,National University of Singapore ([email protected]). ChrisJaniszewski is the JCPenney Professor of Marketing, Warrington Collegeof Business Administration, University of Florida ([email protected]). The authors gratefully acknowledge the helpful comments ofLyle Brenner and three anonymous JMR reviewers. Both authors con-tributed equally to this work. Geeta Menon served as associate editor forthis article.
Dan King and Chris JaniszewsKi*
Consumers often like fluently processed stimuli. The authors find thatone source of fluency for numerical stimuli is the generation of a numberthrough common addition (e.g., 1 + 1 through 10 + 10) and commonmultiplication (2 ¥ 2 through 10 ¥ 10) problems (study 1). Commonaddition and multiplication problems (arithmetic), or their operands, canbe used to prime a number and increase its fluency (study 3). Thebenefits of arithmetic and operand primes are limited to single primes(i.e., more primes are not necessarily better) (study 5). number fluencyis relevant to creating numeric brand names (study 2), enhancing theliking of numeric brand names through advertising (study 4), andexecuting price promotions (study 6).
Keywords: advertising, branding, choice, consumer behavior, processingfluency
The sources and Consequences of theFluent Processing of numbers
© 2011, American Marketing AssociationISSN: 0022-2437 (print), 1547-7193 (electronic) 327
Numbers are used in a variety of marketing contexts.They can be used in brand names (e.g., Miller Beer’s MGD64, Doritos X-13, X-14 Cleaner, Heinz 57, Maybach 57,Intel Core 2 Duo, Toyota MR2 Spyder, K2 skis), to labellevels of a product line (e.g., Nikon D40, D50, D70, D80;Canon PowerShot A430, A530, A630), to indicate attributelevels (e.g., credit card annual percentage rates of 5.9%,7.9%, and 9.9%; automobiles with 2.3, 2.5, and 3.0 literengines), and to facilitate brand trademark recognition (e.g.,Levi’s 501). In some of these situations, the numbers arefunctional. For example, BMW brands its product line witha series of ascending odd numbers: The 3 Series, 5 Series,and 7 Series identify entry-level, midlevel, and premium-level automobiles, respectively. In other situations, numbersare part of a brand label. Examples of numeric brand namesinclude Adidas’s 5ive clothing, X-14 cleanser, 310 footwear,Levi’s 501 jeans, and 2000 Flushes.Number liking can be a relevant consideration when
employing numbers in marketing applications (Boyd 1985;Pavia and Costa 1993). One source of number liking is the
fluency experienced when processing the number. We positthat the fluent processing of numbers is a consequence ofthe prior generation of the number and the activation ofinformation that supports the generation of the number. Forexample, the results of common arithmetic problems (e.g.,sums of 1 + 1 through 10 + 10, products of 2 ¥ 2 through 10 ¥10) should be more fluently processed than numbers that arenot regularly computed (Study 1).1 This makes these resultsbetter candidates for inclusion in brand names (Study 2).Moreover, if prior computation is a source of fluency, anassociation should exist between arithmetic problems (e.g.,2 ¥ 6) and their results (e.g., 12). The implication is thatsolving arithmetic problems (e.g., A ¥ B = D), or the expo-sure to operands from arithmetic problems (e.g., A ¥ B in A ¥B = D), should lead to more fluent processing of the result(e.g., D) (Study 3). As a consequence, we should be able toincrease the fluency of numeric brand names by includingrelevant operands in promotional materials (Study 4). Addi-tional support for the importance of prior computation innumber fluency can be illustrated by patterns of interferencecreated by solving multiple arithmetic problems with thesame result. Speeded responses to common arithmetic prob-lems are made possible by the suppression of competingresponses (Phenix and Campbell 2004). As a consequence,multiple primes (e.g., 2 ¥ 6, 3 ¥ 4) of the same result (e.g.,12) create less fluency than a single prime (Study 5), owing
1N + 0 sums and n ¥ 1 products do not require computation.

to mutual inhibition. Study 6 illustrates the consequences ofthis interference in price promotion materials.
THEORETICAL BACKGROUND
Processing Fluency
“Processing fluency” refers to the ease of executing acognitive activity, whether it is the generation of a perception(i.e., perceptual fluency), the retrieval of information frommemory (i.e., retrieval fluency), or the assignment of meaningto an event (i.e., conceptual fluency). When a cognitive activ-ity is more fluent than expected, people make attributionsabout the reasons for this fluency (Bornstein and D’Agostino1994; Whittlesea and Williams 2000). For example, if a situation requires a person to assess liking for a stimulusand experience has taught the person that liked stimuli aremore easily processed, the person can misattribute process-ing fluency as evidence of liking. Processing fluency influ-ences judgments about brand evaluation (Lee and Labroo2004), expensiveness (Janiszewski and Meyvis 2001), pricediscounts (Thomas and Morwitz 2009), consideration setformation (Shapiro 1999), choice (Novemsky et al. 2007),and confidence (Ülkümen, Thomas, and Morwitz 2008).Processing fluency effects typically occur because the
target concept, or a processing act involving the target con-cept, is more fluent than expected (Whittlesea and Williams2000). For example, a previously seen logo is more fluentlyprocessed than a novel logo (Janiszewski and Meyvis 2001),and an easy-to-compute price discount is more fluently cal-culated than a difficult-to-compute price discount (Thomasand Morwitz 2009). In these cases, people use processingfluency to make misattributions or an errant inference.However, there are situations in which processing fluency isused as a diagnostic cue to support judgments. When this isthe case, fluency-based misattributions may be constrainedby the operations supporting their typical use. Number pro-cessing is one context in which misattributions should beconstrained.
Arithmetic Problems, Number Representation, and Fluency
Arithmetic problem solving is a part of daily life. There-fore, elementary school education includes training in com-mon addition (e.g., 1 + 1 through 10 + 10) and multiplica-tion (e.g., 1 ¥ 1 through 10 ¥ 10) problems. Studies onarithmetic problem solving have identified two classes ofprocesses that support problem solving (Baroody 1985):reconstructive and reproductive processes. Reconstructiveprocesses rely on rules, procedures, and principles to calcu-late the answer to a problem. This process is slow and rea-soned; it is frequently used when children are learning howto solve problems or when adults are attempting a difficultcalculation. Reproductive processes rely on rapid factretrieval to generate responses. Over time, children aredrilled on simple problems so that an association developsbetween operands (e.g., 2 ¥ 6) and results (e.g., 12). Thesestored associations are called “number facts” (Baroody1985). Stored number facts enable a child, and later anadult, to respond effortlessly to simple arithmetic problems.Most models of numerical representation assume that bothprocesses are active in an adult but that the reproductiveprocess is more active when simple arithmetic operationsare required (Baroody 1985).
A person’s associative network of number facts is exten-sive; thus, processing fluency can be used as an importantdiagnostic tool for selecting the correct response to a mathe-matical problem. The associative network supporting num-ber representation includes associations between operands(e.g., 2 ¥ 6) and correct responses (e.g., 12) in addition toassociations between an operand (e.g., 6) and its multiples(e.g., 12, 18, 24). Thus, errors in speeded problem solvingare typically adjacent multiples of one of the operands in thearithmetic problem (e.g., responding “18” to “2 ¥ 6 = __”),an effect that has been attributed to insufficient differencesin the relative accessibility of the correct response and otherpotential responses (Campbell and Graham 1985). In sup-port of this conclusion, evidence shows that speededresponses to arithmetic problems depend on the differentialaccessibility of the potential response, through inhibition ofcompeting responses, to the problem (Campbell and Graham1985; Manly and Spoehr 1999; Phenix and Campbell 2004).
Hypotheses
The associative network that supports arithmetic problemsolving should allow for two sources of fluent processing.First, consistent with the observation that frequentlyprocessed concepts are more fluent, commonly producednumbers should be more fluent. Sums from common addi-tion problems (e.g., 1 + 1 through 10 + 10) and productsfrom common multiplication problems (e.g., 2 ¥ 2 through10 ¥ 10) should be more accessible, more fluently processed,and liked to a greater degree.
H1: Consumers like sum numbers (e.g., 1 + 1 through 10 + 10)and product numbers (e.g., 2 ¥ 2 through 10 ¥ 10) morethan other numbers under 101.
Second, we should be able to alter the fluency of a num-ber by priming, but only indirectly. Typical demonstrationsof fluency misattribution rely on direct priming of the stimu-lus percept to enhance fluency (e.g., prior exposure to a per-cept makes it more fluent at a later time; e.g., Lee andLabroo 2004). In the case of sum or product numbers, directpriming (e.g., exposure to a potential answer) would bedetrimental to using fluency to solve problems (i.e., it couldinduce the selection of incorrect answers). Given that arith-metic problem solving is an integral part of the representa-tion of sum and product numbers, this fluency from directpriming should be nondiagnostic. Thus, we expect that sumand product numbers will only benefit from indirect prim-ing that relies on relevant operands to make the numbermore accessible and fluent. Stated another way, we shouldbe able to influence the accessibility of a number (e.g., 12)by having people solve a common problem (e.g., 2 ¥ 6 = __)that would generate the number as the result or by provid-ing the associated set of operands (e.g., 2, 6) for the result.In contrast, solving uncommon problems (e.g., 67 – 55 =__) should not increase liking for the result (e.g., 12),because uncommon problems, which do not have an estab-lished memory trace, should not influence the accessibilityof the result. In summary, the accessibility of sum and prod-uct numbers is inherently linked to the arithmetic problems(and operands) used to generate these numbers.
H2: (a) Solving a common mathematical problem makes theresult of the problem more fluent and thus influences theconsumer’s liking of the result. (b) Solving an uncommon
328 Journal oF MarKeTing researCh, aPril 2011
Fluent Processing of numbers 329
mathematical problem does not make the result of the prob-lem more fluent and thus does not influence the consumer’sliking of the result. (c) Exposure to a pair of operandsmakes the associated result more fluent and thus influencesthe consumer’s liking of the result.
STUDY 1
H1 predicts that sum and product numbers will be evalu-ated more positively than the remaining numbers under 101.To investigate this prediction, participants were presentedwith numbers from 1 to 100, one number at a time, in ran-domized order. Each number was presented in 2.5 cm ¥ 2cm black Times New Roman font on a white backgroundusing a 14-inch computer screen. Participants were instructedto place their left-hand index finger over the letter D andtheir right-hand index finger over the letter L. When a num-ber was displayed, they were asked to indicate their likingfor the number by pressing d for “dislike,” l for “like,” or thespace bar for “neither like or dislike.” We controlled thepresentation and timing of stimulus images using Macro-media’s Authorware program (Version 7). Reaction timeswere recorded for each response. Three hundred six under-graduate students participated in the study for course credit.
Results
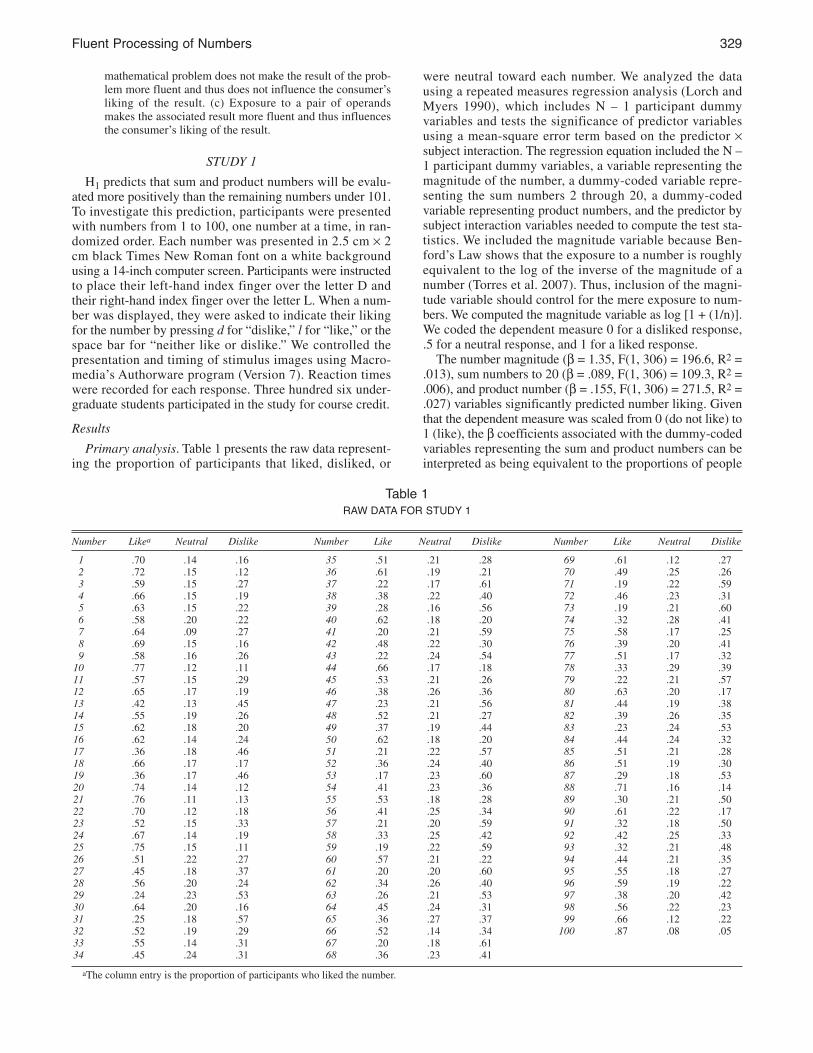
Primary analysis. Table 1 presents the raw data represent-ing the proportion of participants that liked, disliked, or
were neutral toward each number. We analyzed the datausing a repeated measures regression analysis (Lorch andMyers 1990), which includes N – 1 participant dummyvariables and tests the significance of predictor variablesusing a mean-square error term based on the predictor ¥subject interaction. The regression equation included the N –1 participant dummy variables, a variable representing themagnitude of the number, a dummy-coded variable repre-senting the sum numbers 2 through 20, a dummy-codedvariable representing product numbers, and the predictor bysubject interaction variables needed to compute the test sta-tistics. We included the magnitude variable because Ben-ford’s Law shows that the exposure to a number is roughlyequivalent to the log of the inverse of the magnitude of anumber (Torres et al. 2007). Thus, inclusion of the magni-tude variable should control for the mere exposure to num-bers. We computed the magnitude variable as log [1 + (1/n)].We coded the dependent measure 0 for a disliked response,.5 for a neutral response, and 1 for a liked response.The number magnitude (b = 1.35, F(1, 306) = 196.6, R2 =
.013), sum numbers to 20 (b = .089, F(1, 306) = 109.3, R2 =
.006), and product number (b = .155, F(1, 306) = 271.5, R2 =
.027) variables significantly predicted number liking. Giventhat the dependent measure was scaled from 0 (do not like) to1 (like), the b coefficients associated with the dummy-codedvariables representing the sum and product numbers can beinterpreted as being equivalent to the proportions of people
Table 1raw DaTa For sTuDY 1
Number Likea Neutral Dislike Number Like Neutral Dislike Number Like Neutral Dislike
1 .70 .14 .16 35 .51 .21 .28 69 .61 .12 .272 .72 .15 .12 36 .61 .19 .21 70 .49 .25 .263 .59 .15 .27 37 .22 .17 .61 71 .19 .22 .594 .66 .15 .19 38 .38 .22 .40 72 .46 .23 .315 .63 .15 .22 39 .28 .16 .56 73 .19 .21 .606 .58 .20 .22 40 .62 .18 .20 74 .32 .28 .417 .64 .09 .27 41 .20 .21 .59 75 .58 .17 .258 .69 .15 .16 42 .48 .22 .30 76 .39 .20 .419 .58 .16 .26 43 .22 .24 .54 77 .51 .17 .3210 .77 .12 .11 44 .66 .17 .18 78 .33 .29 .3911 .57 .15 .29 45 .53 .21 .26 79 .22 .21 .5712 .65 .17 .19 46 .38 .26 .36 80 .63 .20 .1713 .42 .13 .45 47 .23 .21 .56 81 .44 .19 .3814 .55 .19 .26 48 .52 .21 .27 82 .39 .26 .3515 .62 .18 .20 49 .37 .19 .44 83 .23 .24 .5316 .62 .14 .24 50 .62 .18 .20 84 .44 .24 .3217 .36 .18 .46 51 .21 .22 .57 85 .51 .21 .2818 .66 .17 .17 52 .36 .24 .40 86 .51 .19 .3019 .36 .17 .46 53 .17 .23 .60 87 .29 .18 .5320 .74 .14 .12 54 .41 .23 .36 88 .71 .16 .1421 .76 .11 .13 55 .53 .18 .28 89 .30 .21 .5022 .70 .12 .18 56 .41 .25 .34 90 .61 .22 .1723 .52 .15 .33 57 .21 .20 .59 91 .32 .18 .5024 .67 .14 .19 58 .33 .25 .42 92 .42 .25 .3325 .75 .15 .11 59 .19 .22 .59 93 .32 .21 .4826 .51 .22 .27 60 .57 .21 .22 94 .44 .21 .3527 .45 .18 .37 61 .20 .20 .60 95 .55 .18 .2728 .56 .20 .24 62 .34 .26 .40 96 .59 .19 .2229 .24 .23 .53 63 .26 .21 .53 97 .38 .20 .4230 .64 .20 .16 64 .45 .24 .31 98 .56 .22 .2331 .25 .18 .57 65 .36 .27 .37 99 .66 .12 .2232 .52 .19 .29 66 .52 .14 .34 100 .87 .08 .0533 .55 .14 .31 67 .20 .18 .6134 .45 .24 .31 68 .36 .23 .41
aThe column entry is the proportion of participants who liked the number.

that liked the class of numbers relative to the remainingnumbers (assuming a stable base of neutral ratings). Thus,the numbers 1–20 were liked by 8.9% more people than theremaining numbers. Similarly, the product numbers wereliked by 15.5% more people than the remaining numbers.Process analysis.We investigated the response time data
to provide support for the fluency explanation of numberliking. If fluency contributes to number liking, responses tonumbers that were liked should be faster than responses tonumbers that were disliked. The response times for the threetypes of ratings, controlling for outliers, were 1.09 secondsfor the disliked numbers, 1.53 seconds for the neutral num-bers, and 1.01 seconds for the liked numbers. The responsetimes for the numbers that were judged neutral were signifi-cantly longer because neutral responses required respondentsto press the space bar, whereas like and dislike judgmentsrequired respondents to press a key with the their index fin-gers, which were already positioned over the letter keys. Arepeated measures regression that controlled for numbermagnitude (b = .001, F(1, 306) = 1.48, R2 = 0) showed thatwhen a person liked a number more, the person respondedto the number more quickly (b = –.089, F(1, 306) = 61.29,R2 = .005).
Discussion
Study 1 indicates that respondents liked that sum andproduct numbers more than the remaining numbers under100. This is particularly interesting because this liking wasbeyond the number-magnitude-based mere exposure effect(i.e., the idea that lower numbers have been experiencedmore often than larger numbers). We believe that the likingfor sum and product numbers is a consequence of the flu-ency that resulted from practicing and performing arith-metic problems.
STUDY 2
Study 1 provides evidence that sum and product numbersare more liked than other numbers. If this is so, we shouldbe able to observe the influence of this number liking onjudgments about numeric brand names. In Study 2, we usedSawtooth’s Conjoint-Based Choice software to test theinfluence of numbers on choice. We anticipated that brandnames that included a product number would be more likedand thus more likely to be chosen than brand names thatincluded a nonproduct number or no number at all.
Design and Procedure
Two hundred thirty-six undergraduate students partici-pated in the study for course credit. The study used abetween-subjects manipulation of the type of brand name(brand name, brand name with a product number, brandname with a nonproduct number) with two between-subjectsproduct category replicates (anti-itch cream, shampoo).Each replicate had three attributes: brand name, key benefit,and price. In the anti-itch cream category, the brand nameswere Resorcinol or Itch-Away; the primary benefit was“relieves itching and redness” or “cools and repairs theskin”; the price was $4.25 or $6.97; and the manipulationwas “Resorcinol,” “Resorcinol 25,” or “Resorcinol 29.” Inthe shampoo category, the brand names were Zinc and Fol-liculex; the primary benefit was “restores damaged roots”or “relieves itchy scalp”; the price was $5.19 or $7.99; and
the manipulation was “Zinc,” “Zinc 24,” or “Zinc 31.”The Sawtooth program presented each participant with 28
choices between two product profiles (e.g., two anti-itchcreams), with each product profile containing one level ofeach attribute (brand name, benefit, and price). Each partici-pant provided a response by clicking the mouse on the prod-uct that he or she preferred.
Results
We performed the analysis on aggregate choice sharesand on individual partworths for each replicate. We gener-ated the individual partworths using hierarchical Bayes esti-mation in Sawtooth’s Conjoint Value Analysis/HierarchicalBayes module.Anti-itch replicate. Choice shares differed across condi-
tions (Wald c2 = 6.49). As we predicted, respondents choseResorcinol more often when it was accompanied by a prod-uct number (MResorcinol 25 = .529) than a nonproduct number(MResorcinol 29 = .477; Wald c2 = 4.95, p < .05) or no numberat all (MResorcinol = .476; Wald c2 = 4.97, p < .05). Compar-ing the size of the brand name trade-off (.529 – .477) withthe average size of the price trade-off (.664 – .338) suggeststhat the product number added $.43 of value to the brandname. The individual-level partworth analysis confirmedthat the brand name trade-off was more important when itinvolved a product number (M = .26) than a nonproductnumber (M = .18; F(1, 97) = 3.83, p = .05) or no number atall (M = .16; F(1, 97) = 5.82, p < .05).Shampoo replicate. Choice shares differed across condi-
tions (Wald c2 = 11.75). As we predicted, respondents choseZinc more often when it was accompanied by a productnumber (MZinc 24 = .554) than when it was accompanied bya nonproduct number (MZinc 31 = .489; Wald c2 = 10.74, p <.05) or no number at all (MZinc = .501; Wald c2 = 6.94, p <.05). Comparing the size of the brand name trade-off (.554 –.501) with the average size of the price trade-off (.669–.334)suggests that the product number added approximately $.44of value to the brand name. The individual-level partworthanalysis confirmed that the brand name trade-off was moreimportant when it involved a product number (M = .19) thana nonproduct number (M = .14; F(1, 133) = 4.94, p < .05) orno number at all (M = .13; F(1, 133) = 6.88, p < .05).
STUDIES 3A AND 3B
The goal of Study 3 is to illustrate that solving commonarithmetic problems enhances the fluency of the associatedresults (H2a) but solving uncommon arithmetic problemsdoes not (H2b). In an effort to show robustness, in Study 3a,we investigate results that could be generated by addition(e.g., 4 + 5 = 9) and multiplication (e.g., 3 ¥ 3 = 9) prob-lems. Study 3b investigates results that could be generatedby multiplication (e.g., 6 ¥ 6 = 36) problems. Both studiesalso provide an opportunity for a more direct test of themediating role of fluency on the liking of numbers.
Design and Procedure
Study 3a used numbers associated with common additionand multiplication problems (4, 6, 8, 9, 12, and 16), andStudy 3b used numbers associated with common multipli-cation problems (36, 42, 48, 49, 56, and 64). The manipu-lated factor was the type of priming. In Study 3a, there werecommon addition problem primes, common multiplication
330 Journal oF MarKeTing researCh, aPril 2011
Fluent Processing of numbers 331
problem primes, uncommon addition problem primes, unre-lated problem primes (a form of control group), and a no-prime control (see Appendix A). In Study 3b, there werecommon multiplication problem primes (solved andunsolved), uncommon multiplication problem primes, unre-lated problem primes (a form of control group), and a no-prime control (see Appendix B). Study 3b included unsolvedproblems to assess whether operand primes were sufficientto facilitate the fluent processing of results (H2c). We choseunrelated problem primes so that the results were not nearthe target numbers. One hundred fifty-one and 143 studentsfrom an undergraduate business subject pool participated inStudies 3a and 3b, respectively, for course credit.Participants entered a lab and were told that they would
participate in three studies assessing their number aptitude.The first study was a priming or control task, depending onthe condition. Participants were told that the experimenterswere interested in how people print and solve mathematicalproblems. They were asked to rewrite and solve six mathe-matical problems listed on a piece of paper. Each problemwas listed (e.g., “1 + 3”), and then a space was provided torewrite and solve the problem (e.g., “______ = __”). Partici-pants in the unsolved common multiplication problem con-dition of Study 3b were asked to rewrite the problem. Par-ticipants in the no-prime control group circled all the e’s ina text passage. The control task took 90 seconds, approxi-mately the same time it took to complete the problem-solvingtask.The second study collected the participants’ evaluations
of the target numbers. Participants were told that a secondstudy would measure their liking for numbers. They satdown at a computer and indicated their liking of the 12 testnumbers on a five-point scale with endpoints labeled “dis-like” and “like.” The numbers were the 6 target numbersplus 6 filler numbers (11, 17, 19, 23, 31, and 47). The targetand filler numbers were presented in random order. Theresponse task involved a Likert scale response and thus wasnot appropriate for response time recording.The third study was a verification time task that assessed
the accessibility of number facts (e.g., 1 + 3 = 4). The pro-cedure was modeled after those commonly used to assessresponse accessibility in speeded problem-solving studies(for an illustration, see Phenix and Campbell 2004). Partici-pants were told that we wanted to assess how quickly theycould verify the mathematical truth of an equation. Theinstructions stated that they would see 48 arithmetic equa-tions and that half would be true and half would be false.They were told to indicate whether each equation was trueor false by pressing the y key (true) or the n key (false). Par-ticipants were told to respond as quickly and accurately aspossible. We interpreted the speed of the response as anindication of the accessibility of the number fact and, byextension, the fluency of the result represented in the num-ber fact (Phenix and Campbell 2004). In Study 3a, the 24true equations were the 6 common addition primes, 6 com-mon multiplication primes, 6 uncommon addition primes,and 6 unrelated primes (see Appendix A). The 24 falseequations had the same operands and operators as the trueequations, but an incorrect answer. In Study 3b, the 24 trueequations were the 6 common multiplication primes, 6uncommon multiplication primes, 6 unrelated primes, and 6novel equations (see Appendix B). The 24 false equations
had the same operands and operators as the true equationsbut an incorrect answer.
Results of Study 3a
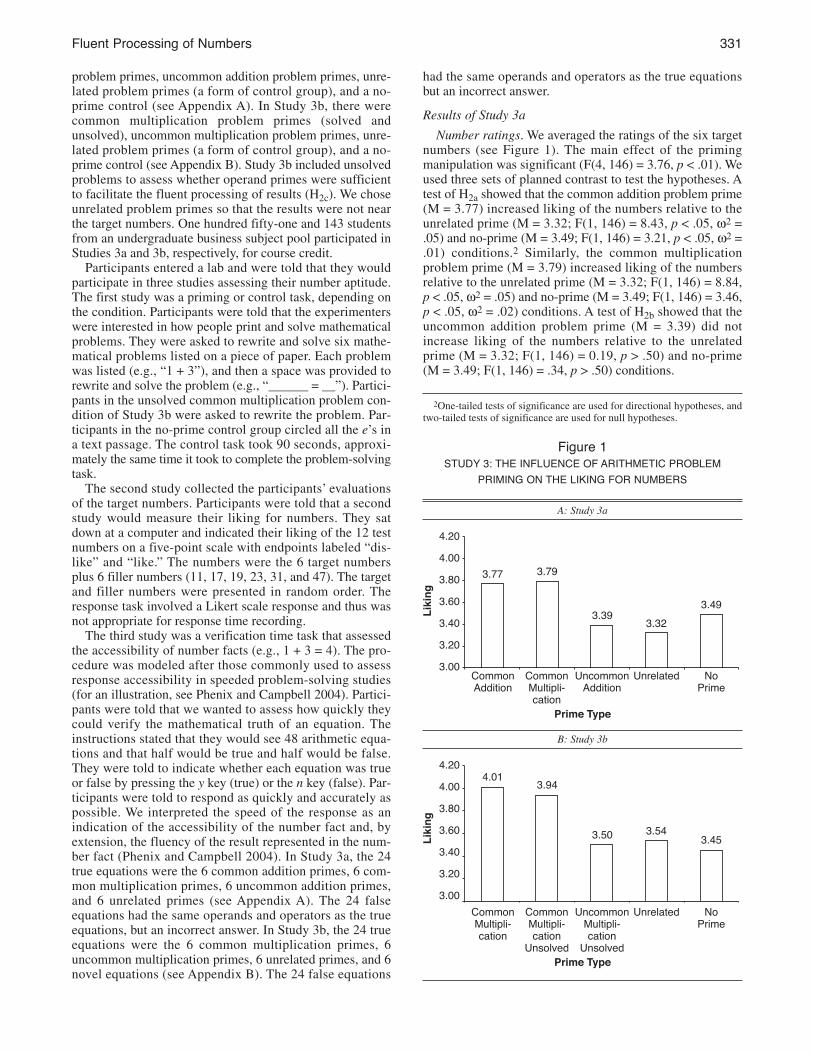
Number ratings. We averaged the ratings of the six targetnumbers (see Figure 1). The main effect of the primingmanipulation was significant (F(4, 146) = 3.76, p < .01). Weused three sets of planned contrast to test the hypotheses. Atest of H2a showed that the common addition problem prime(M = 3.77) increased liking of the numbers relative to theunrelated prime (M = 3.32; F(1, 146) = 8.43, p < .05, w2 =.05) and no-prime (M = 3.49; F(1, 146) = 3.21, p < .05, w2 =.01) conditions.2 Similarly, the common multiplicationproblem prime (M = 3.79) increased liking of the numbersrelative to the unrelated prime (M = 3.32; F(1, 146) = 8.84,p < .05, w2 = .05) and no-prime (M = 3.49; F(1, 146) = 3.46,p < .05, w2 = .02) conditions. A test of H2b showed that theuncommon addition problem prime (M = 3.39) did notincrease liking of the numbers relative to the unrelatedprime (M = 3.32; F(1, 146) = 0.19, p > .50) and no-prime(M = 3.49; F(1, 146) = .34, p > .50) conditions.
2One-tailed tests of significance are used for directional hypotheses, andtwo-tailed tests of significance are used for null hypotheses.
Figure 1sTuDY 3: The inFluenCe oF ariThMeTiC ProBleM
PriMing on The liKing For nuMBers
A: Study 3a
B: Study 3b
4.20
4.00
3.80
3.60
3.40
3.20
3.00
Lik
ing
Prime Type
Commonaddition
CommonMultipli-cation
3.77 3.79
3.393.32
3.49
uncommonaddition
unrelated no Prime
4.20
4.00
3.80
3.60
3.40
3.20
3.00
Lik
ing
Prime Type
CommonMultipli-cation
CommonMultipli-cation
unsolved
4.013.94
3.50 3.543.45
uncommonMultipli-cation
unsolved
unrelated no Prime

Verification times. We prepared responses from the verifi-cation task for analysis by removing incorrect responses(2.3%) and times that exceeded three standard deviationsfrom their cell mean (.2%) (Fazio 1990). We averaged veri-fication times to generate one score per participant for eachof the eight classes of verification problems (see Table 2).We used three sets of planned contrasts to confirm the
assumption that commonly practiced problems benefitedfrom priming. First, verification times for true commonaddition problems varied by condition (F(4, 146) = 4.76, p <.05). Verification was faster in the common addition prob-lem prime condition (M = 1.21) than in the unrelated prime(M = 1.67; F(1, 146) = 18.34, p < .05, w2 = .10) and no-prime (M = 1.39; F(1, 146) = 2.60, p < .05, w2 = .01) condi-tions. Second, verification times for true common multipli-cation problems varied by condition (F(4, 146) = 4.33, p <.05). Verification was faster in the common multiplicationproblem prime condition (M = 1.11) than in the unrelatedprime (M = 1.35; F(1, 146) = 7.27, p < .05, w2 = .04) andno-prime (M = 1.31; F(1, 146) = 4.86, p < .05, w2 = .02)conditions. Third, verification times for true uncommonaddition problems did not vary by condition (F(4, 146) =1.53, p > .10).
Mediation analysis. Verification times varied widely byrespondent, so we used a ratio of the average verificationtime on the primed information to the average verificationtime on the unrelated targets as an indicator of the relativefluency in generating the response. In the unrelated controland no-prime control conditions, we used verification timesfor the common addition and multiplication times as thenumerator in the ratio because these participants had notseen a relevant prime. We dummy-coded the primingvariable as 1 in the common prime conditions and 2 in theremaining three conditions.We used four tests to assess mediation, and their results
are as follows: First, priming was a significant predictor ofthe number liking (b = –.38, SE = .10; t(149) = –3.76, p <.01); second, priming was a significant predictor of fluency(b = .08, SE = .02; t(149) = 3.40, p < .01); third, fluency wasa significant predictor of number liking (b = –.96, SE = .34;t(149) = –2.83, p < .01); and fourth, when number likingwas regressed on priming and fluency, priming became lesssignificant (b = –.33, SE = .10; t(148) = –3.12, p < .01), andfluency remained significant (b = –.67, SE = .34; t(148) =–1.97, p < .05; Sobel z = –2.18, p = .03). These results indi-cate partial mediation. Iacobucci, Saldanha, and Deng
332 Journal oF MarKeTing researCh, aPril 2011
Table 2sTuDies 3a, 3B, anD 5: VeriFiCaTion TiMes For eQuaTions
A: Study 3a
Common Common UncommonAddition Multiplication Addition Unrelated No Prime
True targets common addition 1.21a 1.46b 1.45b 1.67b 1.39bTrue targets common multiplication 1.17a,c 1.11a 1.44b 1.35b 1.31b,cTrue targets uncommon 3.50 3.30 3.45 3.81 3.10True targets unrelated 2.47 2.35 2.62 2.65 2.15False targets common addition 1.42 1.59 1.67 1.74 1.55False targets common multiplication 1.34 1.39 1.35 1.48 1.51False targets uncommon 3.42 3.44 3.58 3.87 3.35False targets unrelated 2.73 3.13 3.08 3.02 2.65
B: Study 3b
Common Common UncommonMultiplication Multiplication Multiplication
Solved Unsolved Solved Unrelated No Prime
True targets common multiplication 1.26a 1.43a 1.85b 2.08b 1.93bTrue targets uncommon 2.85 2.89 2.87 3.23 2.85True targets unrelated 2.49 2.46 2.53 2.54 2.55True targets extra 3.46 3.31 3.52 4.30 3.52False targets common multiplication 1.80 1.93 1.96 1.97 2.06False targets uncommon 2.73 2.81 3.15 3.45 3.07False targets unrelated 2.89 2.68 2.74 3.25 2.89False targets extra 3.22 3.22 3.08 3.85 3.57
C: Study 5
Common Common CombinedMultiplication 1 Multiplication 2 Multiplication Unrelated No Prime
True targets common 1 1.29a 1.78b 1.65b 1.73b 1.69bTrue targets common 2 1.47b 1.28a 1.39 1.42 1.45True targets unrelated 2.13 2.40 2.33 2.11 2.29True targets extra 3.02 3.21 2.95 3.03 3.14False targets common 1 1.56 1.97 1.62 1.77 1.69False targets common 2 1.51 1.59 1.54 1.61 1.46False targets unrelated 2.63 2.82 2.65 2.52 2.62False targets extra 2.99 3.10 3.10 2.98 3.05
Notes: Row means with different superscripts are significantly different at p < .05. Given that common multiplication sets 1 and 2 described in text arereplicates, it is appropriate to collapse the means of these conditions.
Fluent Processing of numbers 333
(2007) find that partial mediation was observed in 67.4% ofconsumer behavior studies that report Sobel statistics.
Results of Study 3b
Number ratings. We averaged the ratings of the six prod-uct numbers and (see Figure 2). The main effect of the prim-ing manipulation was significant (F(4, 138) = 8.18, p < .05).We used two sets of planned contrasts to test the hypothe-ses. A test of H2a showed that the solved common multipli-cation prime (M = 4.01) increased liking of the numbersrelative to the solved uncommon multiplication prime (M =3.50; F(1, 138) = 14.68, p < .05, w2 = .08), unrelated prime(M = 3.54; F(1, 138) = 12.37, p < .05, w2 = .07), and no-prime (M = 3.45; F(1, 138) = 18.51, p < .05, w2 = .10) con-ditions. A test of H2c showed that the unsolved commonmultiplication prime (M = 3.94) increased liking of thenumbers relative to the solved uncommon multiplicationprime (M = 3.50; F(1, 138) = 11.23, p < .05, w2 = .06), unre-lated prime (M = 3.54; F(1, 138) = 9.27, p < .05, w2 = .05),and no-prime (M = 3.45; F(1, 138) = 14.71, p < .05, w2 =.08) conditions. A test of H2b showed that the solveduncommon multiplication prime (M = 3.50) did not increaseliking of the numbers relative to the unrelated prime (M =3.54; F(1, 138) = .10, p > .50) and no-prime (M = 3.45; F(1,138) = .14, p > .50) conditions.Verification times. We prepared the verification times as in
Study 3a (see Table 2). Verification times for true commonmultiplication problems varied by condition F(4, 138) =4.77, p < .05). Verification times for true common multipli-cation problems were faster in the solved common multipli-cation prime condition (M = 1.26) than in the solveduncommon multiplication prime (M = 1.85; F(1, 138) =6.47, p < .05, w2 = .03), unrelated prime (M = 2.08; F(1,138) = 12.86, p < .05, w2 = .07), and no-prime (M = 1.93;F(1, 138) = 9.03, p < .05, w2 = .05) conditions. Verificationtimes for true common multiplication problems were fasterin the unsolved common multiplication prime condition (M= 1.43) than in the solved uncommon multiplication prime(M = 1.85; F(1, 138) = 3.51, p = .06, w2 = .02), unrelatedprime (M = 2.08; F(1, 138) = 8.61, p < .05, w2 = .05), andno-prime (M = 1.93; F(1, 138) = 5.41, p < .05, w2 = .03)conditions. Verification times for the remaining types ofproblems did not vary.Mediation analysis. We used four tests to assess media-
tion. We obtained the following results: First, priming was asignificant predictor of the number liking (b = –.474, SE =.083; t(141) = –5.70, p < .01); second, priming was a sig-nificant predictor of fluency (b = .186, SE = .05; t(141) =3.75, p < .01); third, fluency was a significant predictor ofnumber liking (b = –.597, SE = .141; t(141) = –4.24, p <.01); and fourth, when number liking was regressed onpriming and fluency, priming became less significant (b =–.399, SE = .085; t(141) = –4.70, p < .01), and fluencyremained significant (b = –.40, SE = .138; t(141) = –2.92, p <.05; Sobel z = –2.79, p < .01). These results indicate partialmediation.
Discussion
The results of Studies 3a and 3b provide insight into howto enhance the fluency of numbers. Increasing the accessi-bility of a number fact led to an increase in liking for theassociated result, consistent with H2a. In contrast, increas-
ing the accessibility of a number itself, through solving anuncommon number problem, did not influence the liking ofa number, consistent with H2b. Solving arithmetic problemslowered the verification times for these problems but onlywhen these problems were common. In support of the pro-posed process, verification times, an indicator of fluency,partially mediated the influence of arithmetic problem prim-ing on number liking.The results of Studies 3a and 3b are inconsistent with two
alternative hypotheses. First, the results do not seem todepend on demand effects. An example of a demandhypothesis is “The experimenter wants me to rate theanswers of the math problems more positively.” However,there was no influence of the uncommon problem prime onthe liking of the numbers. This result is inconsistent with ademand awareness hypothesis. Second, the results do notseem to be a consequence of mood or self-efficacy. If suc-cessful problem solving made people happier, this happi-ness should have increased the evaluation of the filler num-bers in the common addition and multiplication primeconditions. Participants in the common prime conditionsrated the filler numbers lower than control participants inStudy 3a (F(1, 146) = 10.26, p < .05) and no differentlyfrom control participants in Study 3b (F(1, 138) = .96, p >.05).
STUDY 4
We designed Study 4 to (1) demonstrate that consumerslike brand names that include product numbers more thanthey like brand names that include nonproduct or nonsumnumbers and (2) show that the liking of the brand namesthat include product numbers can be enhanced by includingrelevant operand primes in the advertisement (H2c). Wedeveloped three versions of three print advertisements toillustrate these effects. For example, we modified a Volvoprint advertisement for its S-series car to be an “S12” (prod-uct number) or an “S29” (nonproduct number). We furthermodified these two advertisements to include the operands(e.g., [6, 2] in the priming conditions). We anticipated that participants would like brand names with product num-bers more than brand names with nonproduct numbers and
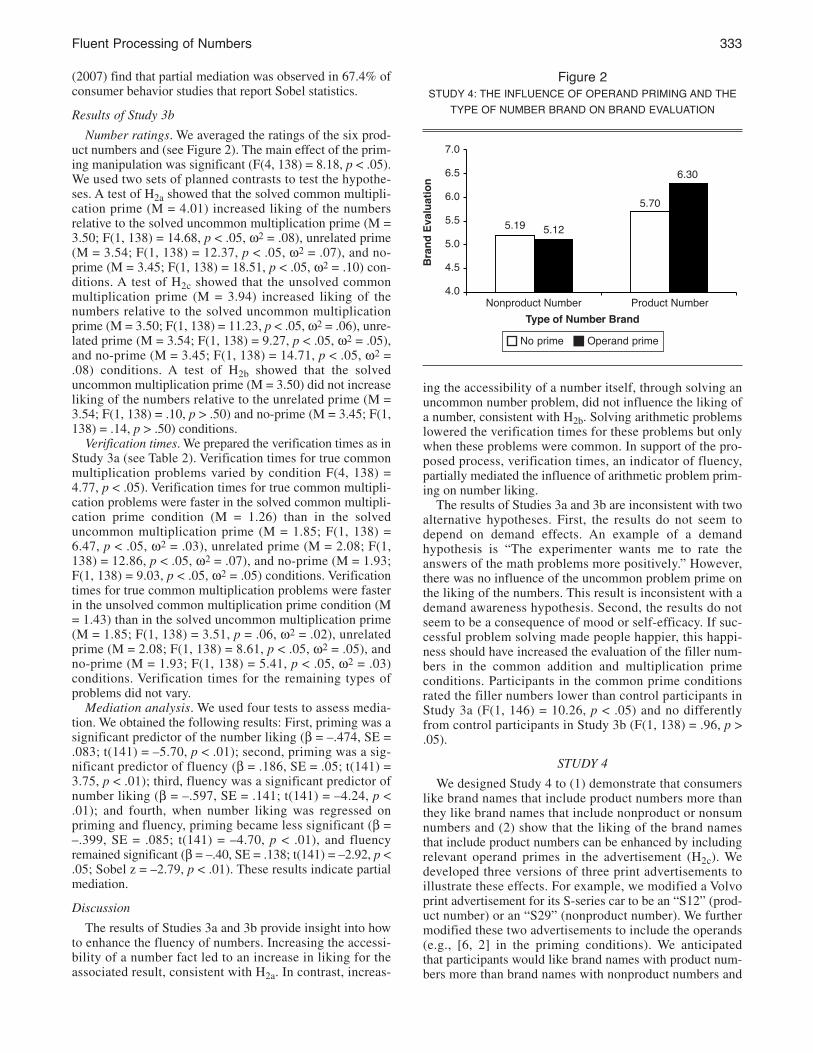
Figure 2sTuDY 4: The inFluenCe oF oPeranD PriMing anD The
TYPe oF nuMBer BranD on BranD eValuaTion
7.0
6.5
6.0
5.5
5.0
4.5
4.0
Bra
nd
Evalu
ati
on
Type of Number Brand
nonproduct number
5.19 5.12
5.70
6.30
Product number
no prime operand prime

that this liking would be stronger when there was operandpriming.
Design and Procedure
One hundred eighty-five undergraduate students partici-pated in the study for extra credit. The study used a type ofnumber (product number, nonproduct/nonsum number) ¥operand priming (priming, no priming) ¥ replicate (Volvo,Axe body spray, Solus contact lens) design. The type ofnumber and priming factors were between-subjects manipu-lations, and the replicate factor was a within-subjectmanipulation. Participants remained in the same between-subjects condition for each of the three advertisement repli-cates. We counterbalanced the order of the advertisements.Participants viewed and evaluated each print advertise-
ment before moving on to the next one, with filler andexperimental advertisements presented in alternating order(filler, experimental, filler, experimental, filler, experimen-tal, filler). Three dependent measures were recorded usingthree nine-point scales: (1) liking for the brand (endpointslabeled “dislike” and “like”), (2) liking for the advertise-ment (endpoints labeled “dislike” and “like”), and (3) pur-chase intentions (endpoints labeled “low” and “high”).
Stimuli
Appendix C shows the stimuli. The Volvo advertisementwas for an S12 or S29 and included the operands [6, 2] onthe rear license plate in the priming condition. The no-primingcondition had a blank license plate. The Axe body sprayadvertisement was labeled “Axe 16” or “Axe 17” andincluded the operand [4] on an apartment door in the prim-ing condition. The no-priming condition had no number onthe apartment door. The Solus contact lens advertisementwas labeled “Solus 36” or “Solus 37” and included theoperand [6, 6] in a headline that read “6 colors. 6 fits.” in thepriming condition. The no-priming condition did notinclude this headline.
Results
We combined the ad liking, brand liking, and purchaseintention measures to create a brand evaluation measure(Cronbach’s a = .85). Figure 2 shows the aggregate results.Three results are particularly noteworthy. First, the type ofnumber ¥ priming interaction was significant (F(1, 181) =3.93, p < .05). Second, operand priming led to a more favor-able evaluation of the brand when the product number wasin the brand name (MNo prime = 5.70, MPrime = 6.30; F(1,181) = 6.15, p < .01, w2 = .04) but not when a nonproduct/nonsum number was in the brand name (MNo prime = 5.19,MPrime = 5.12; F(1, 181) = .10, p > .05). Third, the ad repli-cate factor did not interact with the interaction or the simplemain effect tests (all Fs < 2).
Ancillary Study
We conducted an additional study to determine whetheroperand priming could influence product choice. The studyused an operand prime (present, absent) ¥ prime relevance(potentially relevant, irrelevant) between-subjects design.The procedure involved viewing an advertisement and thenmaking a choice between V8 and Campbell’s tomato juice.The prime present/relevant advertisement showed a pictureof a 12 oz. bottle of V8 juice on a green background with
the heading “Get a full day’s supply of 4 essential vitaminsand 2 minerals with a bottle of V8.” The heading in theprime absent advertisement read “Get a full day’s supply ofessential vitamins and minerals with a bottle of V8.” Thetwo prime irrelevant advertisements replaced the bottle ofV8 with a bottle of Campbell’s tomato juice. After readingthe advertisement, 79 participants were invited to take asingle serving of V8 (6 oz. can) or Campbell’s (6 oz, can)from a location in the upper-left-hand corner of their carrel.(Carrels were private, so participants’ choice would not beinfluenced by others in the room.) Prime presence and rele-vance significantly influenced choice shares (b = –2.86,Wald c2 = 4.75, p < .05). The operand prime increased thechoice of V8 juice in the prime relevant condition (present =94.7%, absent = 60%; z = 2.57, p < .05). The operand primehad no influence on the choice of Campbell’s juice in theprime irrelevant condition (present = 63.2%, absent =71.4%; z = –1.47, p > .05).
Discussion
The results of Study 4 show that there are practical waysfor a brand manager to increase liking for a number brand.First, the brand manager can use a product number ratherthan a nonproduct/nonsum number in a brand name. Thisreflects the findings of Study 2. Second, the brand managercan incorporate operands into an advertisement that con-tains the corresponding sum or product in the brand name.The operands make the result more fluent, which in turnincreases liking for the result and the associated brandname. This reflects the findings of Study 3.Thus far, we have argued that results are represented as a
part of number facts. Next, we show that number fact repre-sentations should create some noteworthy response patternsof facilitation and inhibition. More specifically, priming anumber fact should facilitate the processing of a result rep-resented in that fact (as Study 3 shows), but priming twonumber facts that share the same result should not facilitateprocessing of the result. Recall that storing number facts isuseful because operands can facilitate access to a resultwhile inhibiting access to competing results (Phenix andCampbell 2004). In this system, each number fact is unique.Thus, two number facts that share the same result will com-pete for access to the result, negating the opportunity forfluent processing. This prediction is consistent with thefinding that increasing the number of related primes fromone to two reduces a person’s ability to recognize a relatedword (Balota and Paul 1996; Neely, VerWys, and Kahan1998). We summarize this prediction in the followinghypothesis:
H3: Solving multiple common arithmetic problems that gener-ate the same result does not make the result of the problemmore fluent and thus dies not influence the liking of theresult.
STUDY 5
The goal of Study 5 was to investigate whether increas-ing the number of arithmetic problem primes from one totwo would decrease the liking of the number that is theresult in the problems. To illustrate, consider the productnumber 16. Priming the number fact 8 ¥ 2 = 16 or 4 ¥ 4 =16 should increase the processing fluency, and liking, of the
334 Journal oF MarKeTing researCh, aPril 2011

Fluent Processing of numbers 335
product number 16 (H2a). In contrast, priming both numberfacts should not increase processing fluency (H3). Themathematical problem primes should conflict because theyrelate to two unique number facts, even though their resultsare equivalent.
Design and Procedure
Study 5’s procedure was identical to Studies 3a and 3b,with the exception of different target numbers, differentmathematical problem primes, and different verificationequations. For Study 5, we used numbers (12, 16, 18, 24,and 36) associated with two common multiplication prob-lems. The mathematical problem priming manipulation wasset 1 of common multiplication problem primes, set 2 ofcommon multiplication problem primes, both sets of com-mon multiplication problem primes, unrelated primes (aform of control group), and a no-prime control group (seeAppendix D). The 20 true verification equations were the 10 common multiplication primes, 5 uncommon additionprimes, and 5 unrelated primes. The 20 false equations hadthe same operands and operators as the true equations butan incorrect answer. One hundred seventy-four studentsfrom an undergraduate subject pool received extra credit fortheir participation in the study.
Results
Number ratings. We averaged the ratings of the five prod-uct numbers (see Figure 3). The main effect of the primingmanipulation was significant (F(4, 169) = 2.42, p < .05).Given that common multiplication sets 1 and 2 were repli-cates and members of the set were arbitrarily determined, itis appropriate to collapse the means of these conditions(MSet 1 = 3.80, MSet 2 = 3.92; F(1, 169) = .49). A test of H2ashowed that the sole common multiplication problem prime(M = 3.86) increased liking of the numbers relative to thecombined common multiplication problem prime (M =3.59; F(1, 169) = 3.61, p < .05, w2 = .01), unrelated prime(M = 3.50; F(1, 169) = 7.01, p < .05, w2 = .03), and no-prime (M = 3.57; F(1, 169) = 4.36, p < .05, w2 = .02) condi-tions. A test of H3 showed that the combined common mul-tiplication problem prime (M = 3.59) did not increase likingof the numbers relative to the unrelated prime (M = 3.50;F(1, 169) = .33, p > .5) and no-prime (M = 3.57; F(1, 169) =.02, p > .5) conditions.Verification times. We prepared responses from the verifi-
cation task for analysis by removing incorrect responses(2.1%) and times that exceeded three standard deviationsfrom their cell mean (.1%) (Fazio 1990). Table 2 presentsthe verification times. Again, given that common multipli-cation sets 1 and 2 were replicates, it is appropriate to col-lapse the means of these conditions (MSet 1 = 1.29, MSet 2 =1.28; F(1, 169) = .01, p = .92). We used the first set ofplanned contrasts to confirm the assumption that commonlypracticed problems would benefit from priming but onlywhen the set of primes was limited to a single set. The veri-fication time for true common addition problems was fasterin the common multiplication problem prime condition(MSet 1 = 1.29, MSet 2 = 1.28, MCollapsed = 1.29) than in theunprimed common multiplication problems (MSet 1 = 1.78,MSet 2 = 1.47, MCollapsed = 1.62; F(1, 68) = 24.72, p < .05,w2 = .24), combined common multiplication problem prime(MSet 1 = 1.65, MSet 2 = 1.39, MCollapsed = 1.52; F(1, 169) =
10.23, p < .05, w2 = .05), unrelated prime (MSet 1 = 1.73,MSet 2 = 1.42, MCollapsed = 1.57; F(1, 169) = 7.89, p < .05,w2 = .04), and no-prime (MSet 1 = 1.69, MSet 2 = 1.45, MCol-
lapsed = 1.54; F(1, 169) = 5.78, p < .05, w2 = .03) conditions.The second set of planned contrasts confirmed that the veri-fication times in the combined multiplication problem primecondition (MSet 1 = 1.65, MSet 2 = 1.39, MCollapsed = 1.52)were the same as the times in the unrelated prime (MSet 1 =1.73, MSet 2 = 1.42, MCollapsed = 1.57; F(1, 169) = .28, p >.10) and no-prime (MSet 1 = 1.69, MSet 2 = 1.45, MCollapsed =1.54; F(1, 169) = .07, p > .10) conditions.Mediation analysis. We used four tests to assess mediation
and found the following results: First, priming was a signifi-cant predictor of the number liking (b = –.306, SE = .10;t(172) = –2.99, p < .01); second, the priming was a signifi-cant predictor of fluency (b = .11, SE = .03; t(172) = 4.41, p <.01); third, the fluency was a significant predictor of num-ber liking (b = –.91, SE = .29; t(172) = –3.18, p < .01); andfourth, when we regressed number liking on priming andfluency, priming became less significant (b = –.23, SE =.11; t(171) = –2.11, p = .04), and fluency remained signifi-cant (b = –.71, SE = .30; t(171) = –2.37, p < .05; Sobel z =–2.57, p = .01). These results indicate partial mediation.
Discussion
The results of Study 5 are consistent with the claim thatnumber facts are fundamental in number representations.When a single number fact was primed, liking for the resultincreased. When two number facts with the same resultwere primed, liking for the number fact did not increase.The verification times for the primed number facts followedthis same response pattern: A single-number-fact primereduced verification time, but dual-number-fact primes hadno influence on verification time. Apparently, the represen-tation of declarative knowledge in a number fact formatallows number facts to inhibit the activation of other facts,even when these number facts share the same result. Thisresult is also consistent with the response competition thathas been observed in the naming of category members(Roediger 1973) and the recognition of picture and wordassociations (Balota and Paul 1996; Neely, VerWys, andKahan 1998).
Figure 3sTuDY 5: The inFluenCe oF one or Two ariThMeTiC
ProBleM PriMes on liKing For nuMBers
4.20
4.00
3.80
3.60
3.40
3.20
3.00
Lik
ing
Prime Type
CommonMultipli-cation 1
CommonMultipli-cation 2
3.803.92
3.593.50
3.57
CommonMultipli-cation
1 and 2
unrelated no Prime
STUDY 6
Study 5 shows that when two number facts with the sameresult are primed, liking for the result does not increase.Although there are few situations in which two sets ofoperand primes accompany a brand name, there are situa-tions in which one or two sets of operand primes accompanya price. For example, consider the newspaper inserts that areused to announce price deals. As Appendix E illustrates,pizza businesses often advertise multiple deals in the sameflyer. We designed Study 6 to show that advertising appealscan use operand primes to influence the liking of a resultthat is expressed as a price and, by extension, the appeal ofthe offer.
Design and Procedure
One hundred forty-one undergraduate students partici-pated in the study for extra credit. The study used a type ofprime (relevant, irrelevant) ¥ prime set (prime set 1, primeset 2, two prime sets) between-subjects design. Participantsviewed and evaluated each advertisement before moving onto the next one. The experimental advertisement was thesecond of the three advertisements. Similar to Study 4, thethree dependent measures were brand liking, ad liking, andpurchase intentions.
Stimuli
Appendix E shows the stimuli. The advertisement was fora price deal on pizza. In the relevant single set of primesconditions, the advertisement promoted “3 medium pizzas,up to 8 toppings” or “4 small pizzas, up to 6 toppings” for$24. In the irrelevant single set of primes conditions, theadvertisement promoted “3 medium pizzas, unlimited top-pings” or “4 small pizzas, unlimited toppings” for $24. Inthe two sets of primes conditions, both the small andmedium pizza deals were included in the same advertise-ment. Note that the irrelevant primes stimuli offer a betterdeal than the relevant primes (i.e., unlimited toppings arebetter than up to 6 or up to 8 toppings).
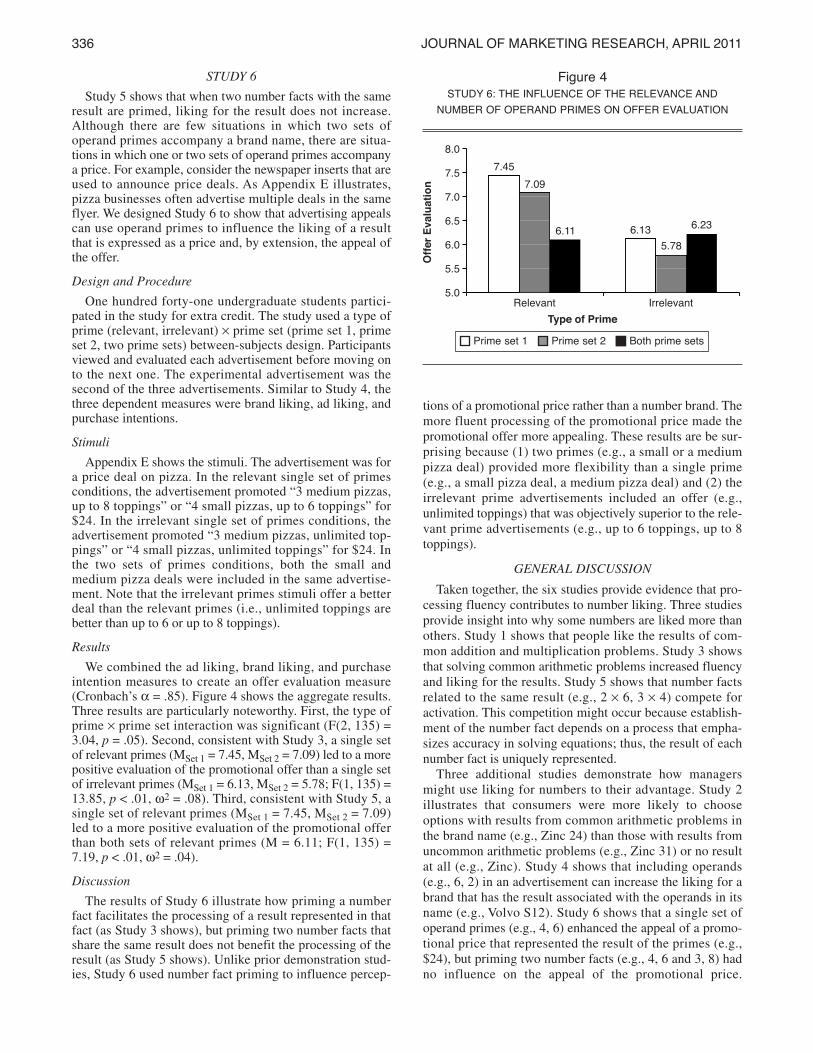
Results
We combined the ad liking, brand liking, and purchaseintention measures to create an offer evaluation measure(Cronbach’s a = .85). Figure 4 shows the aggregate results.Three results are particularly noteworthy. First, the type ofprime ¥ prime set interaction was significant (F(2, 135) =3.04, p = .05). Second, consistent with Study 3, a single setof relevant primes (MSet 1 = 7.45, MSet 2 = 7.09) led to a morepositive evaluation of the promotional offer than a single setof irrelevant primes (MSet 1 = 6.13, MSet 2 = 5.78; F(1, 135) =13.85, p < .01, w2 = .08). Third, consistent with Study 5, asingle set of relevant primes (MSet 1 = 7.45, MSet 2 = 7.09)led to a more positive evaluation of the promotional offerthan both sets of relevant primes (M = 6.11; F(1, 135) =7.19, p < .01, w2 = .04).
Discussion
The results of Study 6 illustrate how priming a numberfact facilitates the processing of a result represented in thatfact (as Study 3 shows), but priming two number facts thatshare the same result does not benefit the processing of theresult (as Study 5 shows). Unlike prior demonstration stud-ies, Study 6 used number fact priming to influence percep-
tions of a promotional price rather than a number brand. Themore fluent processing of the promotional price made thepromotional offer more appealing. These results are be sur-prising because (1) two primes (e.g., a small or a mediumpizza deal) provided more flexibility than a single prime(e.g., a small pizza deal, a medium pizza deal) and (2) theirrelevant prime advertisements included an offer (e.g.,unlimited toppings) that was objectively superior to the rele-vant prime advertisements (e.g., up to 6 toppings, up to 8toppings).
GENERAL DISCUSSION
Taken together, the six studies provide evidence that pro-cessing fluency contributes to number liking. Three studiesprovide insight into why some numbers are liked more thanothers. Study 1 shows that people like the results of com-mon addition and multiplication problems. Study 3 showsthat solving common arithmetic problems increased fluencyand liking for the results. Study 5 shows that number factsrelated to the same result (e.g., 2 ¥ 6, 3 ¥ 4) compete foractivation. This competition might occur because establish-ment of the number fact depends on a process that empha-sizes accuracy in solving equations; thus, the result of eachnumber fact is uniquely represented.Three additional studies demonstrate how managers
might use liking for numbers to their advantage. Study 2illustrates that consumers were more likely to chooseoptions with results from common arithmetic problems inthe brand name (e.g., Zinc 24) than those with results fromuncommon arithmetic problems (e.g., Zinc 31) or no resultat all (e.g., Zinc). Study 4 shows that including operands(e.g., 6, 2) in an advertisement can increase the liking for abrand that has the result associated with the operands in itsname (e.g., Volvo S12). Study 6 shows that a single set ofoperand primes (e.g., 4, 6) enhanced the appeal of a promo-tional price that represented the result of the primes (e.g.,$24), but priming two number facts (e.g., 4, 6 and 3, 8) hadno influence on the appeal of the promotional price.
336 Journal oF MarKeTing researCh, aPril 2011
Figure 4sTuDY 6: The inFluenCe oF The releVanCe anD
nuMBer oF oPeranD PriMes on oFFer eValuaTion
8.0
7.5
7.0
6.5
6.0
5.5
5.0
Off
er
Evalu
ati
on
Type of Prime
relevant
7.45
7.09
6.11 6.13
5.78
6.23
irrelevant
Prime set 1 Prime set 2 Both prime sets

Fluent Processing of numbers 337
Together, these three studies show that numerical stimulihave the potential to influence consumer behavior.
Managerial Issues
The results of the six studies suggest that numbers caninfluence decisions. On average, sum and product numbersare more appealing than other numbers under 100. Thisappeal makes these numbers better candidates for inclusionin brand names or prices. However, this appeal is likely toinfluence preference and choice only when the fluency ofthe number is diagnostic given other available information.We anticipate that number fluency will be most diagnosticin product categories in which there is limited knowledgeabout the benefits that differentiate products (e.g., infre-quent purchase, homogeneous products). People are alsomore likely to rely on the fluency of processing when deci-sions are fast (e.g., Whittlesea and Williams 2000), process-ing resources are constrained (e.g., Menon and Raghubir2003), need for cognition is limited (Gunasti and Ross2010), and involvement is low (e.g., Janiszewski and Chan-don 2007). Fluency has more influence on decision makingwhen people are not being strategic or reasoned.To the extent that a product category is conducive to num-
ber fluency effects, the benefits of fluent number processingmust be considered in concert with the many other factorsthat influence the choice of a number. Other factors thatinfluence the choice of a brand number include phoneticconsiderations (e.g., Core 2 Duo), semantic associations(Fiber One), and information considerations (e.g., 7-Elevenconvenience stores). We contend that the coconsideration ofthese criteria may lead to a more effective brand name. Toillustrate, consider the acne medication benzoyl peroxide.The topical medication is sold over the counter undernumerous brand names, including Benzac, Benzagel-10,and Oxy-10. All these formulations of the medicationinclude 10% of the active ingredient, but only some of thebrand names include the informational number 10. Includ-ing this number has both informational consequences (i.e.,consumers need to differentiate 10% solutions and 5% solu-tions) and fluency consequences (i.e., consumers mustchoose from equivalent 10% solution products, some ofwhich have numeric brand names). Marketers who includenumbers in their brands not only enhance consumers’ under-standing of product content but, in light of our results, alsoseem to enhance consumers’ liking for their brand.
Conceptual Implications
This article explores declarative knowledge representa-tions that originally depended on procedural representations.When a child solves an arithmetic problem (e.g., 2 ¥ 8 = __)using informal counting algorithms, heuristics, and rules,procedural knowledge is encoded in memory networks.When a child solves an arithmetic problem by directlyretrieving the result (e.g., 16) from a stored number fact(e.g., 2 ¥ 8 = 16), declarative knowledge is encoded. Devel-opmentally, common number sentences (e.g., common addi-tion and multiplication problems) are initially representedas procedural knowledge (during initial learning) and sub-sequently as declarative knowledge (after rote practice)(Ashcraft 1982; Baroody 1985). This sequence of learningcreates a representation in which fluency depends on the
association between a mental operation (or representationthereof) and the outcome.It might be worthwhile to consider other representations
in which there is an association between operations and out-comes. For example, consider the development of anyknowledge base that depends on using operations or proce-dures to classify exemplars (e.g., medicine). These knowl-edge bases rely on classification by functions rather than themore typical classification by feature similarity (Rehder andHastie 2001). Initially, classification by functions mightdepend on computation processes and, thus, be slow. Thisprocess can be hastened if relationships between functionsand classes can be established (e.g., declarative knowledge).As a consequence of these operations, frequent classifica-tion categories could be more fluent and preferred. Forexample, analgesics, anti-inflammatories, antihistamines,corticosteroids, and so on are classes of drugs that achievebeneficial outcomes. Understanding their occasions (symp-toms) and benefits (outcomes) of use contribute to theirclassification (e.g., symptom A + symptom B + context C =drug class X). As declarative knowledge about these cate-gories develops, the classifications become more fluent.This fluency could contribute to the liking of the drug, thelikelihood of using the drug, the frequency of use, and themisuse of the drug if only a subset of the operands primesthe drug class.
Limitations
Our results suggest conditions under which a managershould consider adding a number to a brand name. How-ever, some limitations are noteworthy. First, it is plausiblethat the positive influence of adding a fluent number tobrand name is obtained only when perceived technicalexpertise is desirable in the product category, such as inanti-itch creams and dandruff shampoos. Appending a flu-ent number to the brand name may increase the perceivedquality of the technical properties of the brand becausenumbers seem to indicate an active ingredient or some othertechnical property. Second, it is also possible that the posi-tive influence of a fluent number is maximal only when thebrand name is relatively simple (e.g., Zinc) or unfamiliar(e.g., Resorcinol). Appending a fluent number might addcomplexity (from the addition of a number) or familiarity(from the processing fluency of the number) to the brandname and increase liking for the brand. Thus, the conditionsthat make it profitable for the brand manager to use a fluentnumber in a brand name might depend on the product cate-gory in which he or she operates and other factors that alterthe weights assigned to different inputs in evaluating thebrands (see Gunasti and Ross 2010).Third, noted that number fluency effects were more pro-
nounced for product numbers than sum numbers. This maybe a function of how the number representations develop.Addition problems are often solved using counting rules, aprocess that can become automatic without the use of rotememorization. For simple addition problems, rote memo-rization, and the fluency that supports the process, is rele-vant but not critical. In contrast, multiplication problems areoften learned through rote memorization, and the fluencythat supports the process is critical. The implication is thatproduct numbers are likely to be better candidates for mar-keting applications than sum numbers.
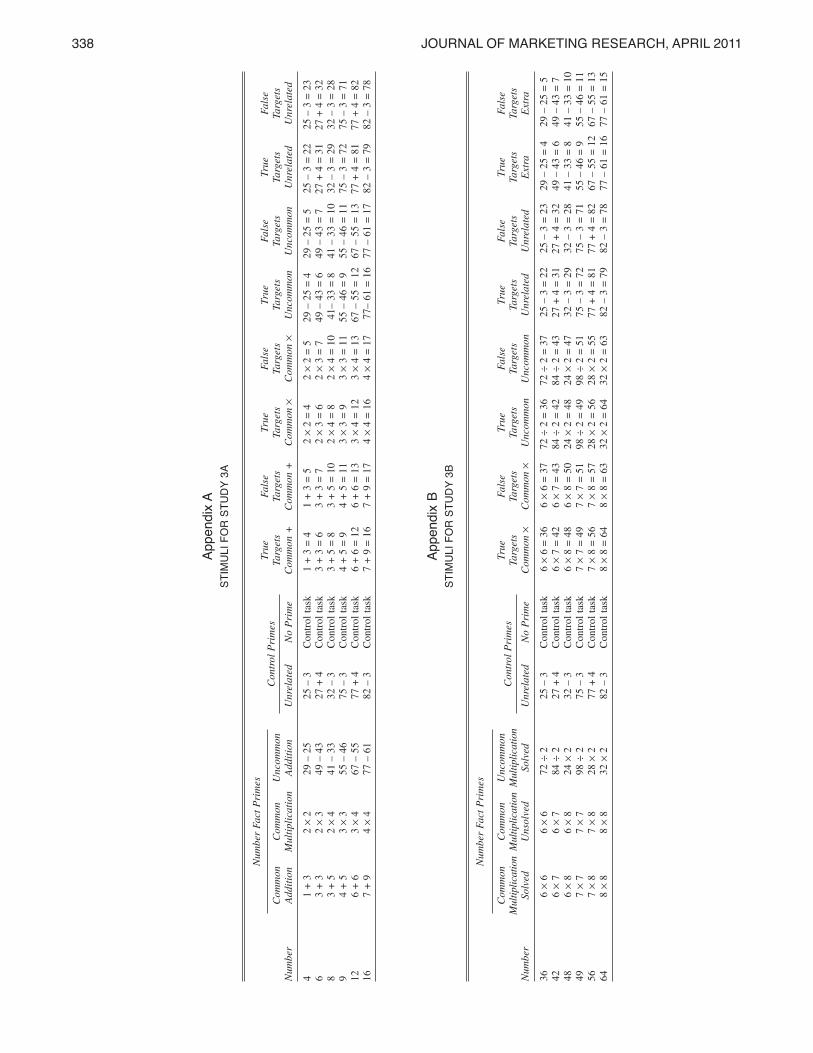
338 Journal oF MarKeTing researCh, aPril 2011
appendix
as
TiM
uli
Fo
r s
Tu
DY
3a
Control Primes
Number Fact Primes
True
False
True
False
True
False
True
False
Common
Common
Uncommon
Targets
Targets
Targets
Targets
Targets
Targets
Targets
Targets
Number
Addition
Multiplication
Addition
Unrelated
No Prime
Common +
Common +
Common ¥
Common ¥
Uncommon
Uncommon
Unrelated
Unrelated
41 + 3
2 ¥2
29 – 25
25 – 3
Control task
1 + 3 = 4
1 + 3 = 5
2 ¥2 = 4
2 ¥2 = 5
29 – 25 = 4
29 – 25 = 5
25 – 3 = 22
25 – 3 = 23
63 + 3
2 ¥3
49 – 43
27 + 4
Control task
3 + 3 = 6
3 + 3 = 7
2 ¥3 = 6
2 ¥3 = 7
49 – 43 = 6
49 – 43 = 7
27 + 4 = 31
27 + 4 = 32
83 + 5
2 ¥4
41 – 33
32 – 3
Control task
3 + 5 = 8
3 + 5 = 10
2 ¥4 = 8
2 ¥4 = 10
41– 33 = 8
41 – 33 = 10
32 – 3 = 29
32 – 3 = 28
94 + 5
3 ¥3
55 – 46
75 – 3
Control task
4 + 5 = 9
4 + 5 = 11
3 ¥3 = 9
3 ¥3 = 11
55 – 46 = 9
55 – 46 = 11
75 – 3 = 72
75 – 3 = 71
126 + 6
3 ¥4
67 – 55
77 + 4
Control task
6 + 6 = 12
6 + 6 = 13
3 ¥4 = 12
3 ¥4 = 13
67 – 55 = 1267 – 55 = 1377 + 4 = 81
77 + 4 = 82
167 + 9
4 ¥4
77 – 61
82 – 3
Control task
7 + 9 = 16
7 + 9 = 17
4 ¥4 = 16
4 ¥4 = 17
77– 61 = 1677 – 61 = 17
82 – 3 = 79
82 – 3 = 78
appendix
Bs
TiM
uli
Fo
r s
Tu
DY
3B
Number Fact Primes
Control Primes
Common
Common
Uncommon
True
False
True
False
True
False
True
False
MultiplicationMultiplicationMultiplication
Targets
Targets
Targets
Targets
Targets
Targets
Targets
Targets
Number
Solved
Unsolved
Solved
Unrelated
No Prime
Common ¥
Common ¥
Uncommon
Uncommon
Unrelated
Unrelated
Extra
Extra
366 ¥6
6 ¥6
72 ÷ 2
25 – 3
Control task
6 ¥6 = 36
6 ¥6 = 37
72 ÷ 2 = 36
72 ÷ 2 = 37
25 – 3 = 22
25 – 3 = 23
29 – 25 = 4
29 – 25 = 5
426 ¥7
6 ¥7
84 ÷ 2
27 + 4
Control task
6 ¥7 = 42
6 ¥7 = 43
84 ÷ 2 = 42
84 ÷ 2 = 43
27 + 4 = 31
27 + 4 = 32
49 – 43 = 6
49 – 43 = 7
486 ¥8
6 ¥8
24 ¥2
32 – 3
Control task
6 ¥8 = 48
6 ¥8 = 50
24 ¥2 = 48
24 ¥2 = 47
32 – 3 = 29
32 – 3 = 28
41 – 33 = 8
41 – 33 = 10
497 ¥7
7 ¥7
98 ÷ 2
75 – 3
Control task
7 ¥7 = 49
7 ¥7 = 51
98 ÷ 2 = 49
98 ÷ 2 = 51
75 – 3 = 72
75 – 3 = 71
55 – 46 = 9
55 – 46 = 11
567 ¥8
7 ¥8
28 ¥2
77 + 4
Control task
7 ¥8 = 56
7 ¥8 = 57
28 ¥2 = 56
28 ¥2 = 55
77 + 4 = 81
77 + 4 = 82
67 – 55 = 1267 – 55 = 13
648 ¥8
8 ¥8
32 ¥2
82 – 3
Control task
8 ¥8 = 64
8 ¥8 = 63
32 ¥2 = 64
32 ¥2 = 63
82 – 3 = 79
82 – 3 = 78
77 – 61 = 1677 – 61 = 15

Fluent Processing of numbers 339
REFERENCES
Ashcraft, Mark H. (1982), “The Development of Mental Arith-metic: A Chronometric Approach,” Developmental Review, 2(3), 213–36.
Balota, David A. and Stephen T. Paul (1996), “Summation of Activa-tion: Evidence from Multiple Primes that Converge and DivergeWithin Semantic Memory,” Journal of Experimental Psychol-ogy: Learning, Memory, and Cognition, 22 (July), 827–45.
Baroody, Arthur J. (1985), “Mastery of Basic Number Combina-tions: Internalization of Relationships or Facts?” Journal forResearch in Mathematics Education, 16 (March), 83–98.
Bornstein, Robert F. and Paul R. D’Agostino (1994), “The Attribu-tion and Discounting of Perceptual Fluency: Preliminary Testsof a Perceptual Fluency/Attributional Model of the Mere Expo-sure Effect,” Social Cognition, 12 (Summer), 103–128.
Boyd, Colin D. (1985), “Point of View: Alpha Numeric BrandNames,” Journal of Advertising Research, 25 (October/Novem-ber), 48–52.
Campbell, Jamie I.D. and David J. Graham (1985), “Mental Multi-plication Skill: Structure, Process, and Acquisition,” CanadianJournal of Psychology, 39 (June), 338–66.
Fazio, Russell H. (1990), “A Practical Guide to the Use ofResponse Latencies in Social Psychological Research,” inReview of Personality and Social Psychology, Vol. 11, Clyde A.Hendrick and Margaret S. Clark, eds. Newbury Park, CA: SagePublications, 74–97.
Gunasti, Kunter and William T. Ross Jr. (2010), “How and WhenAlphanumeric Brand Names Affect Consumer Preferences,”Journal of Marketing Research, 47 (December), 1177–92.
Iacobucci, Dawn, Neela Saldanha, and Xiaoyan Deng (2007), “AMeditation on Mediation: Evidence that Structural Equations
appendix CsTiMuli For sTuDY 4
A: Volvo Replicate
B: Solus Replicate
C: Axe Replicate
nonproduct number/no operands
Product number/no operands
nonproduct number/operand prime
Product number/operand prime
nonproduct number/no operands
Product number/no operands
nonproduct number/operand prime
Product number/operand prime
nonproduct number/no operands
Product number/no operands
nonproduct number/operand prime
Product number/operand prime

340 Journal oF MarKeTing researCh, aPril 2011
appendix
Ds
TiM
uli
Fo
r s
Tu
DY
5
Number Fact Primes
Control Primes
Common
Common
Common
True
False
True
False
True
False
True
False
MultiplicationMultiplicationMultiplication
Targets
Targets
Targets
Targets
Targets
Targets
Targets
Targets
Number
12
1 and 2
Unrelated
No Prime
Common 1
Common 1
Common 2
Common 2
Unrelated
Unrelated
Extra
Extra
122 ¥6
3 ¥4
2 ¥6, 3 ¥4
25 – 3
Control task
2 ¥6 = 12
2 ¥6 = 13
3 ¥4 = 12
3 ¥4 = 11
25 – 3 = 22
25 – 3 = 23
29 – 25 = 4
29 – 25 = 5
162 ¥8
4 ¥4
2 ¥8, 4 ¥4
27 + 4
Control task
2 ¥8 = 16
2 ¥8 = 17
4 ¥4 = 16
4 ¥4 = 15
27 + 4 = 31
27 + 4 = 32
49 – 43 = 6
49 – 43 = 7
182 ¥9
3 ¥6
2 ¥9, 3 ¥6
32 – 3
Control task
2 ¥9 = 18
2 ¥9 = 20
3 ¥6 = 18
3 ¥6 = 19
32 – 3 = 29
32 – 3 = 28
41 – 33 = 8
41 – 33 = 10
243 ¥8
4 ¥6
3 ¥8, 4 ¥6
75 – 3
Control task
3 ¥8 = 24
3 ¥8 = 26
4 ¥6 = 24
4 ¥6 = 22
75 – 3 = 72
75 – 3 = 71
55 – 46 = 9
55 – 46 = 11
364 ¥9
6 ¥6
4 ¥9, 6 ¥6
77 + 4
Control task
4 ¥9 = 36
4 ¥9 = 37
6 ¥6 = 36
6 ¥6 = 35
77 + 4 = 81
77 + 4 = 82
67 – 55 = 1267 – 55 = 13

Fluent Processing of numbers 341
Models Perform Better than Regressions,” Journal of ConsumerPsychology, 17 (2), 139–53.
Janiszewski, Chris and Elise Chandon (2007), “Transfer Appropri-ate Processing, Response Fluency, and the Mere MeasurementEffect,” Journal of Marketing Research, 44 (May) 309–323.
——— and Tom Meyvis (2001), “Effects of Brand Logo Com-plexity, Repetition, and Spacing on Processing Fluency andJudgment,” Journal of Consumer Research, 28 (June), 18–32.
Lee, Angela Y. and Aparna A. Labroo (2004), “The Effect of Con-ceptual and Perceptual Fluency on Brand Evaluation,” Journalof Marketing Research, 41 (May), 151–65.
Lorch, Robert F., Jr., and Jerome L. Myers (1990), “RegressionAnalyses of Repeated Measures Data in Cognitive Research,”Journal of Experimental Psychology: Learning, Memory, andCognition, 16 (January), 149–57.
Manly, Charlotte F. and Kathryn T. Spoehr (1999), “Mental Multi-plication: Nothing but the Facts?” Memory and Cognition, 27(November), 1087–96.
Menon, Geeta and Priya Raghubir (2003), “Ease-of-Retrieval asan Automatic Input in Judgments: A Mere-Accessibility Frame-work?” Journal of Consumer Research, 30 (September), 230–43.
Neely, James H., Christopher A. VerWys, and Todd A. Kahan (1998),“Reading ‘Glasses’ Will Prime ‘Vision,’ but Reading a Pair of‘Glasses’ Will Not,” Memory and Cognition, 26 (January), 34–39.
Novemsky, Nathan, Ravi Dhar, Norbert Schwarz, and ItamarSimonson (2007), “Preference Fluency in Choice,” Journal ofMarketing Research, 44 (August), 347–56.
Pavia, Teresa M. and Janeen A. Costa (1993), “The Winning Num-ber: Consumer Perceptions of Alpha-Numeric Brand Names,”Journal of Marketing, 57 (July), 85–98.
Phenix, Thomas L. and Jamie I.D. Campbell (2004), “Effects ofMultiplication Practice on Product Verification: IntegratedStructures Model or Retrieval Induced Forgetting,” Memory andCognition, 32 (March), 324–35.
Rehder, Bob and Reid Hastie (2001), “Causal Knowledge andCategories: The Effects of Causal Beliefs on Categorization,Induction, and Similarity,” Journal of Experimental Psychology:General, 130 (September), 323–60.
Roediger, Henry L. (1973), “Inhibition in Recall from Cueing withRecall Targets,” Journal of Verbal Learning and Verbal Behav-ior, 12 (December), 644–57.
Shapiro, Stewart (1999), “When an Ad’s Influence Is Beyond OurConscious Control: Perceptual and Conceptual Fluency EffectsCaused by Incidental Ad Exposure,” Journal of ConsumerResearch, 26 (June), 16–36.
Thomas, Manoj and Vicki G. Morwitz (2009), “The Ease-of-Computation Effect: The Interplay of Metacognitive Experi-ences and Naive Theories in Judgments of Price Differences,”Journal of Marketing Research, 46 (February), 81–91.
Torres, Jose, Santiago Fernández, Antonio Gamero, and AntonioSola (2007), “How Do Numbers Begin? (The First Digit Law),”European Journal of Physics, 28 (3), L17–L25.
Ülkümen, Gülden, Manoj Thomas, and Vicki G. Morwitz (2008),“Will I Spend More in 12 Months or a Year? The Effect of Easeof Estimation and Confidence on Budget Estimates,” Journal ofConsumer Research, 35 (August), 245–56.
Whittlesea, Bruce W.A. and Lisa D. Williams (2000), “The Sourceof Feelings of Familiarity: The Discrepancy-AttributionHypothesis,” Journal of Experimental Psychology: Learning,Memory, and Cognition, 26 (May), 547–65.
appendix esTiMuli For sTuDY 6