tale of two stream processing frameworks - india's no.1 ... · tale of two stream processing...
TRANSCRIPT

1
Tale of two stream processing frameworks
Apache Storm & Apache Flink
Karthik Deivasigamani
@WalmartLabs

2
Streaming
• Stream
– Continuous flow
• Streaming Data
– Streaming data is data that is continuously
generated by different sources.
– Unbounded data
• Stream Processing
– processing of data in motion, or in other
words, computing on data directly as it is
produced or received
– data processing engine that is designed with
infinite data sets in mind

3
Retail Data
• Catalog Data
• Pricing Data
• Clickstream logs
• Payments
• Order Data
• Inventory
• Delivery Logistics

4
Not so long ago..
• Data submitted as feeds
• Periodic Data Collection
• Data Processed In Batches
• Runs offline
• Delay between actual time &
processing time
• Failures
5
Need For Speed – Fast Data
• Catalog Updates
• Price Updates
• Fraud Detection
• Out of stock
• Delivery alerts
• Personalization

6

7
Catalog Use Case
8
Catalog Functions
• Normalization
• Classification
• Product Matching
• Shelving
• Attribute Extraction
• Grouping
• Image

9
Characteristics of ingestion pipeline
• Zero message loss
• Fault Tolerance
• Source based priority queue
• Scale to millions of product updates/hour
• Near Real Time Updates
• Checkpoint at various stages

10
Apache Storm
• Created by Nathan Marz
• Stream Abstraction
• Spouts, Bolts, Topology
• Trident
• Kafka Integration
• Message processing
guarantees

11
Storm Cluster
• Nimbus
– distributing code
– assigning tasks to machines
– monitoring for failures
• Supervisor
– communicates with Nimbus
through Zookeeper
– starts and stops workers
according to signals from Nimbus
• Zookeeper
– Coordinates the storm cluster
12
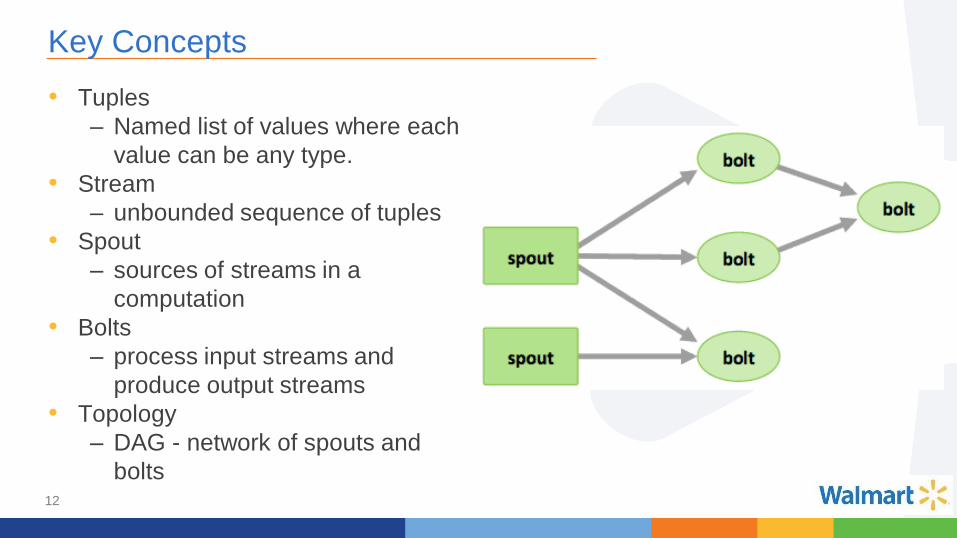
Key Concepts
• Tuples
– Named list of values where each
value can be any type.
• Stream
– unbounded sequence of tuples
• Spout
– sources of streams in a
computation
• Bolts
– process input streams and
produce output streams
• Topology
– DAG - network of spouts and
bolts
13
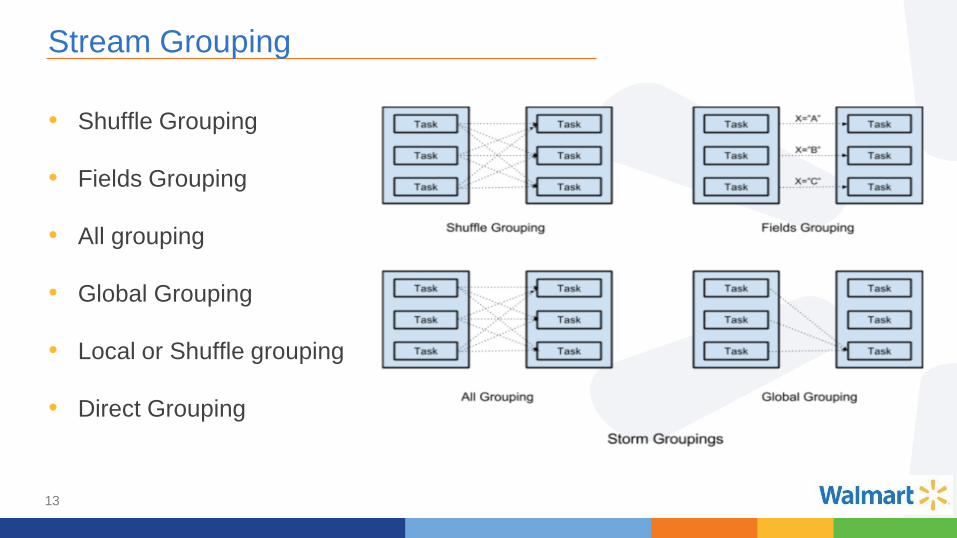
Stream Grouping
• Shuffle Grouping
• Fields Grouping
• All grouping
• Global Grouping
• Local or Shuffle grouping
• Direct Grouping

14
Parallelism of a Storm Topology
• Worker processes
– Executes a subset of a topology
• Executors (Threads)
– Is a thread that is spawned by a
worker process.
– It may run one or more tasks for
the same component (spout or
bolt).
• Tasks
– performs the actual data processing
— each spout or bolt that you
implement in your code executes as
many tasks across the cluster

15
Guaranteeing Message Processing

16
Micro Service vs Bolt
• Choice of language
• Teams operate independently
• Platform with pluggable services
Bolt

17
Catalog Pipeline

18
Challenges
• Validations at various stages
• Async IO using RxJava, Hystrix
• Hystrix Circuit Breaker
• Failing Tuples
• Fetch-size, increase workers,
increase bolt parallelism
• Data Errors
• Services taking longer
• Service outage
• Fatal Errors
• Spike in traffic

19
Lessons Learnt
• Things will fail
• Monitor everything
• Automation
• Scale is not a feature
• Logs don’t lie

20

21
Pricing Use Case
• Competitive pricing (EDLP)
• Seller price updates
• Handle spike during holidays
• Promotions
• Anomaly Detection
• Accuracy

22
Characteristics of ingestion pipeline
• Exactly Once
• Order Guarantee
• Stateful
• Handle tens of millions of
updates/hour
• NRT price update on website
• Traceability

23
Apache Flink
• Project Stratosphere in
Universities around Berlin
• data Artisans founded in 2014
• Process Unbounded and
Bounded Data
• Exactly Once
• Stateful & Flexible API
• Alibaba was using it at scale
24
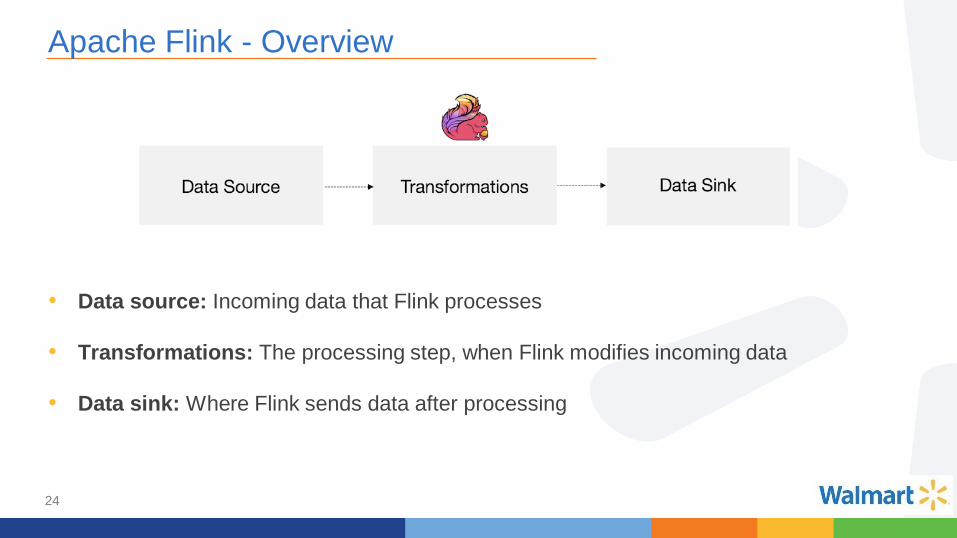
Apache Flink - Overview
• Data source: Incoming data that Flink processes
• Transformations: The processing step, when Flink modifies incoming data
• Data sink: Where Flink sends data after processing

25
Apache Flink - Runtime
Footer
26
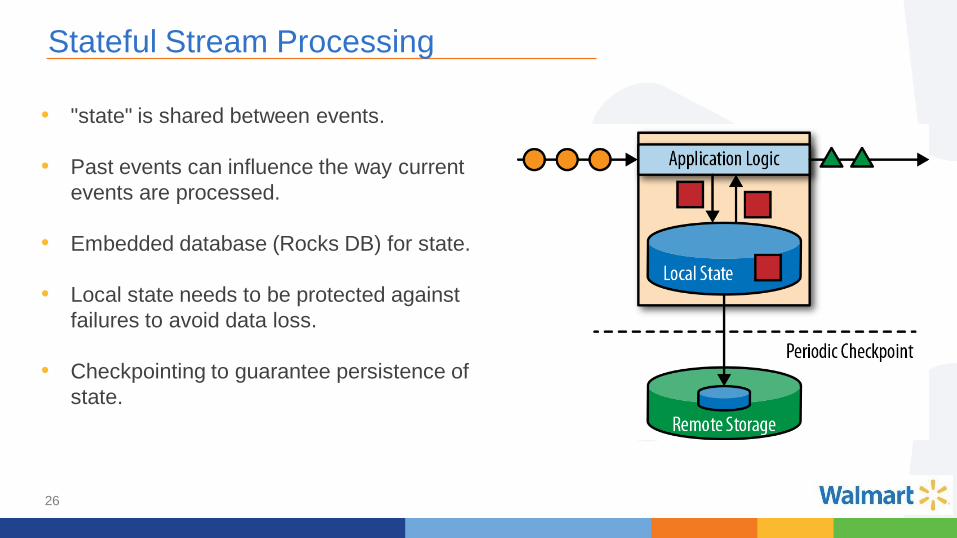
Stateful Stream Processing
• "state" is shared between events.
• Past events can influence the way current
events are processed.
• Embedded database (Rocks DB) for state.
• Local state needs to be protected against
failures to avoid data loss.
• Checkpointing to guarantee persistence of
state.

27
Flink Checkpointing (Chandy-Lamport Algorithm)

28
Exactly Once - Explained
• The label ―exactly-once‖ is misleading in
describing what is done exactly once.
• No Stream Processing can guarantee
exactly-once event processing.
• Flink guarantees exactly-once state
updates.
• Flink uses Chandy and Lamport Algorithm,
to draw consistent snapshots of current
state to create a checkpoint.
• Flink restarts an application using the most
recently completed checkpoint as a starting
point.

29
Duplicate Events
30
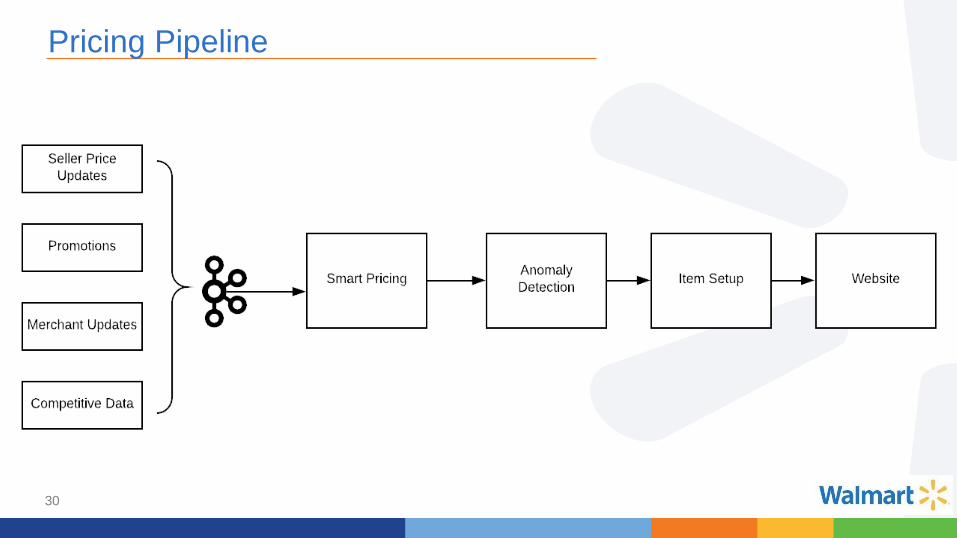
Pricing Pipeline

31
Challenges
• HTTP/DB lookup calls
• Huge payload choking network
• Isolation
• Buffer bloat
• Async I/O Operator
• Operator Chaining
• Mesos / YARN
• taskmanager.memory.segment-size

32
What we learnt • Flink is fast, APIs are super easy to use.
• Avoid network shuffle and use forward / operator
chaining.
• Use accumulators to monitor the progress of your
application.
• Checkpoint failures indicate that your application is
running slow.
• Monitor everything – lag, checkpoints, latency etc
• For application inherently slow configure your
buffers to accommodate for buffer bloat, so that
checkpoints don’t fail.
• Join the flink users mailing list and ask questions!
33
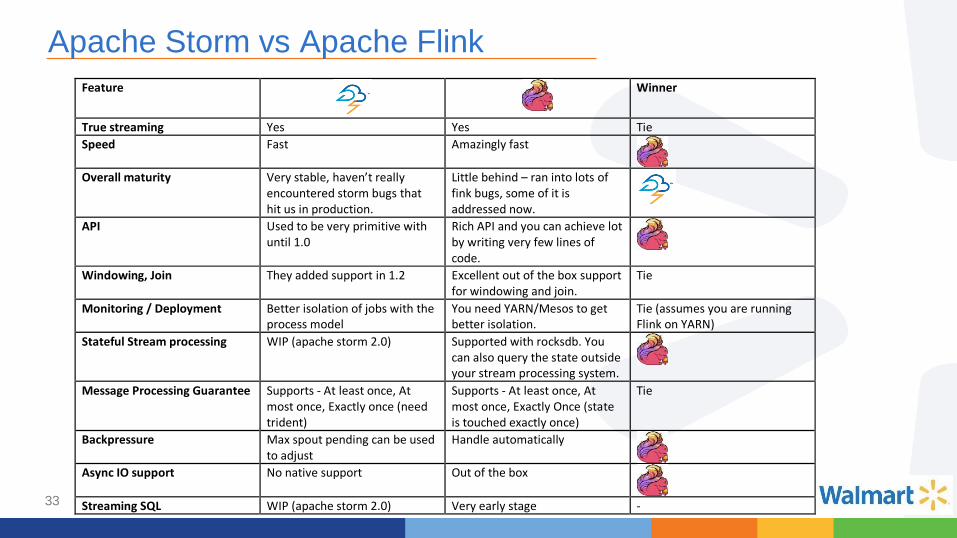
Apache Storm vs Apache Flink
Feature
Winner
True streaming Yes Yes Tie
Speed Fast Amazingly fast
Overall maturity Very stable, haven’t really encountered storm bugs that hit us in production.
Little behind – ran into lots of fink bugs, some of it is addressed now.
API Used to be very primitive with until 1.0
Rich API and you can achieve lot by writing very few lines of code.
Windowing, Join They added support in 1.2 Excellent out of the box support for windowing and join.
Tie
Monitoring / Deployment Better isolation of jobs with the process model
You need YARN/Mesos to get better isolation.
Tie (assumes you are running Flink on YARN)
Stateful Stream processing WIP (apache storm 2.0) Supported with rocksdb. You can also query the state outside your stream processing system.
Message Processing Guarantee Supports - At least once, At most once, Exactly once (need trident)
Supports - At least once, At most once, Exactly Once (state is touched exactly once)
Tie
Backpressure Max spout pending can be used to adjust
Handle automatically
Async IO support No native support Out of the box
Streaming SQL WIP (apache storm 2.0) Very early stage -
34
What should I pick
35
Future of streaming - Cloud
Amazon Kinesis Streams
Functions as stream processors
Cloud Flow
Confluent Cloud
Event Hub – Kafka Compatible

36
Thank You!
Yes, we are hiring!
https://indiacareers.walmartlabs.com/
