team 13 - jay kothari - apr 25 2014 457 pm - group 13 final capstone paper
TRANSCRIPT

Page | 1
Incorporating Congestion Control in BGP considering its
Economic and Policy Effects
Dhaval Malnika
Jay Kothari
Kishan Parekh
Vinita Shah
TLEN 5700: Research Methods
April 25, 2014
Advisors:
Prof. Jose Santos
Prof. Mark Dehus
Special Thanks:
Jay Robertson
Senior Manager, IP/CDN Software Engineering
Internap

Page | 2
ABSTRACT
The Internet can be visualized as an interconnection of Autonomous Systems (ASes), which use
the Border Gateway Protocol (BGP) as the standard for exchanging network information among
each other. The growth of the Internet has made it possible to access information with ease, but
on the other hand, it has given rise to the problem of congestion. BGP does not have an inherent
mechanism to avoid or detect congested areas and routes packets through paths that are often
congested. The AS_PATH attribute in BGP is an indicator for selecting the best path to reach a
certain Internet destination. Current congestion control practice involves manual network
configuration changes by network engineers. Our proposal is to amend the BGP protocol to
incorporate congestion control mechanism. Thus, we have developed a tool that continuously
monitors a link for congestion and automatically carries out AS path prepending to re-route the
traffic from a congested link onto another, thereby improving network reachability and reducing
packet loss. A new model discussing the related economic and policy consequences is also
discussed in the paper.

Page | 3
Table of Contents
Serial No. Introduction Page No.
I.
i.
ii.
Introduction
Statement of the problem
Research Question
5
5
6
II. Literature Review 9
III. Research Methodology 10
IV. Research Results 19
V. Discussion of Results 22
VI. Conclusion and Future Research 24
VII. References 25
List of Figures
Serial No. Name of Figures Page No.
Fig. 1.2.1 ISP 2 incurs cost for ISP 1’s traffic 8
Fig. 3.1 Congested BGP topology 11
Fig. 3.2 Congestion Detection algorithm 13
Fig. 3.3 Congestion Recovery algorithm 14
Fig. 3.4 Congestion-controlled BGP 15
Fig. 3.5 Co-ordination between Tier 1 ISPs 16
Fig. 3.6 Multihomed customer 17
Fig 3.7 Economic incentives for Tier 2 ISPs to form a full-mesh 18

Page | 4
Serial No. Name of Figures Page No.
Fig 4.1 Bandwidth vs. % Loss due to congestion 20
Fig 4.2 Comparison of Bandwidth vs. % Loss 20
Fig. 4.3 Graph of transmit load on interfaces 21
Fig. 4.4 Flow analysis graph 22
Fig 4.5 % Loss with a congested alternate path 22

Page | 5
I. Introduction
i. Statement of the problem
The Internet is comprised of a large number of ASes and exchanging routing information
between two or more ASes is achieved using BGP. BGP is a vector distributed routing protocol
and uses TCP as its underlying mechanism, making it reliable [1]. It is not only important for the
BGP sessions to be reliable, but also scalable to provide inter-domain Internet connectivity.
However, in case of link congestion, the BGP router still forwards packets along the same path,
increasing packet loss and degrading network reachability. It not only leads to the packets being
dropped and re-sent repeatedly, but also affects cost, performance, and adds delay which
eventually affects the customer.
Current solutions to cope with congestion majorly focus more on increasing the available
bandwidth by adding more links between routers [2]. It is not economical for ISPs to meet traffic
requirements by incrementing bandwidth at Layer-1 as traffic is irregular and not always at
maximum capacity. Service Providers rely on mechanisms such as Multi-Protocol Label
Switching – Traffic Engineering (MPLS-TE) and route manipulations that can control
congestion to a certain extent by redirecting traffic through suboptimal paths within an AS, but
for inter-AS congestion-control, there is no clear technique. Thus, a multi-provider congestion
control mechanism needs to be implemented by enhancing BGP, to reduce overall packet loss
and improve reachability.
Considering the previous reasons, there is a need to incorporate an intelligent BGP
implementation that will choose a path considering the network utilization and traffic patterns at
some point in time. We propose the use of AS Path Prepending as a method to reduce congestion
in BGP. By prepending AS_PATH to the destination prefix, we deflect all traffic flows for that

Page | 6
destination onto another suboptimal link, which helps solving delay, packet loss, and throughput
problems.
Along with BGP, there come certain types of relationships between different ASes. They
are commonly referred to as peer, transit, and customer relationships. These three types have
traffic agreements between them, what is more commonly known as Service Level
Assurances/Agreements (SLAs). These SLAs in customer-transit relationships have monetary
arrangements. Generally, peer-peer relationships are settlement-free or require certain financial
agreements depending upon the shared number of routes between both the ASes. For example,
Century Link and Verizon have settlement-free peering, since both have equal number of routes
to share, while Verizon and Cogent have paid-peering since the number of routes shared from
both ISPs have a significant difference. Tier-I ISPs have more number of Internet routes as
compared to Tier-2 ISPs. Tier-I ISPs offer transit services to Tier-2 ISPs and Tier-2 ISPs offer
transit services to its customers.
Alternate links to a destination might not have the same financial agreements. Deflecting
traffic onto these alternate links, which are not congested, could be a concern to the customer-
transit and peer-peer relationships. This traffic deflection could cause problems in the SLAs.
ii. Research Question:
How will integrating a congestion-control mechanism in BGP make it a network efficient
protocol and what will be the economic and policy implications as well as feasibility from an
industry standpoint?
The rest of the paper is organized as follows: The following sub-section provides the sub-
problems associated with BGP congestion. Section II highlights the literature review and the
research done so far regarding BGP congestion. Section III discusses the research methodology.

Page | 7
Section IV provides the results we achieved after running tests on a congested network topology.
In Section V, we discuss on the results achieved. Section VI proposes the future scope for this
research and conclusion.
Research Sub-problems:
This section will discuss critical issues and challenges to the possible adoption of
congestion control mechanism in BGP.
• When diverting traffic onto an alternate link, if the alternate path to a destination
becomes congested as well, there is a possibility of path flapping or ‘bouncing effect’.
The traffic will flap between the best path and the alternate path until all the data is sent
to the destination. This behavior has to be avoided to prevent packets arriving out of
order or packets not arriving at all at the destination. Packet losses will cause
retransmission requests through the flapping paths, which will degrade network
performance further. Bouncing effect can be eliminated by the router having the best path
to the destination by refusing to divert traffic again if it receives the traffic back from the
alternate link.
• An ISP implementing congestion control mechanism may divert traffic to some other
ISP. However, some of the ISPs may restrict such traffic flow and as a result the traffic
will be black holed. For example, if ISP 2 has implemented congestion control
mechanism and if it experiences congestion, then the BGP packet sent by ISP 1 towards
ISP 2 will now have a different path towards the destination. Assuming the traffic is now
flowing through ISP 3, and if ISP 3 has implemented policies for the traffic to be
blocked, all the traffic being diverted to ISP 3 will be dropped. As a result, we might have
to implement this mechanism globally and SLAs between the ISPs will have to be

Page | 8
modified. Traffic could be offloaded between the ISPs on an equivalent basis. This also
highlights the importance for the ISPs to collaborate among one another for such a
congestion control mechanism.
The inclusion of these modifications into BGP can lead to economic and policy challenges.
• Economic: As shown in Fig 1.2.1, congestion occurs on the link between ISP 1 and
Transit Provider. In order for ISP 1 to reach its destination, sending data over ISP 2’s link
may not seem a plausible solution for ISP 2 because it may not want traffic of a customer
on its own link from which it does not obtain profits. This can be a problem when the
available alternate paths of ISP 2 are via the transit provider. ISP 2 might have to pay the
transit provider, which can result into an overall increase in their costs, which will
eventually be borne by the customers or certain financial arrangements will have to be
made between the ISPs. Also, such methods may not be acceptable to ISP 2, which are
having their bills increased due to diversion of traffic.
Fig. 1.2.1 ISP 2 incurs cost for ISP 1’s traffic
• Policy: By default, ISPs give highest priority to traffic from their customers, followed by
peers, and then transit. The alternate or suboptimal path might be via either peer or transit
and if congestion control in BGP will be implemented, the peering and traffic
arrangements rules will change to a certain extent. Currently, certain ISPs block traffic of

Page | 9
other ISPs from entering their domain unless they are explicitly permitted. This
restriction needs to be changed in order to successfully implement congestion control
mechanism in BGP. In addition, ISPs may be required to share internal topological
information and/or their available routes with other ISPs, which can lead to ISPs losing
their competitive edge [3]. As a result, ISPs might become hesitant to adopt this idea into
BGP.
II. Literature Review
When BGP was invented in 1989, there was no support for traffic congestion based on
network load, cost and performance which led to numerous instances of Internet outages. Also,
during congestion, BGP still prefers the “congested best-path route” to a given destination.
Experts have done extensive research to overcome this frailty in BGP. The key research ideas
related to our research are listed below.
Gupta et al., MacKie-Mason and Varian proposed a new Internet model with users being
the customers, and providers as suppliers of services like videos, stock quotes, etc. Their model
deals with priority pricing mechanisms, where the users decide how much priority they want to
give to their own traffic, before sending it towards the destination. In this way, when congestion
occurs, lower priority traffic can be dropped and the users with higher priority traffic can pay a
higher amount than usual [4]. This research gave us the idea of enabling BGP to prioritize traffic
based on its distance (maximum AS path length) from the congested area.
Fujinoki, Wang and Gao proposed ideas to include multiple paths in the BGP routing
table. They devised methods like Multi-Path BGP, D-BGP, and B-BGP, which added suboptimal
paths into BGP for a given destination without creating routing loops [5] [6]. This increased overall
network efficiency and throughput in case of congestion.

Page | 10
Sebakor et al. proposed a unique method of introducing a control system for each AS,
which controls the inter-domain traffic. This method reserves capacity on a link for certain IP
traffic and allocates bandwidth to other traffic automatically. The results obtained from this
research showed that the control system could achieve efficiency in link utilization, avoid
possible link congestion, and decrease the packet loss rate [7]. The concept of a ‘BGP Path
Announcer’ in our research stems from this idea.
According to statistics from the AT&T backbone, about 30% of routes are AS prepended
which indicates the significant impact of the attribute on the entire Internet domain [8].
Prepending an AS path does not compromise the BGP routing resilience or increase the BGP
routing table size. Rocky K.C. Change et.al proposed various advantages of AS path prepending
approach for means of traffic engineering [9]. We incorporated such an approach into our
algorithm to reduce manual network configuration and enable predictable control over change in
traffic flow.
Agarwal et al. proposed an Overlay Policy Control Architecture (OPCA), which runs as
an overlay network on top of BGP in the Internet. OPCA allows an AS to make route changes to
other remote ASs and achieve quicker fail-over. It also provides an AS the capability to control
the inbound traffic, and thereby help in avoiding congestion [10]. This idea cannot be
implemented in real world because traffic of one AS is being manipulated by another AS, which
would violate current norms in the Internet. To overcome this limitation, we created a model
where each AS is independent but requires collaboration with other ASes.
III. Research Methodology
We adopted the following methodology for our research:
Step 1: Proving that BGP cannot handle congestion

Page | 11
We simulated a non-congestion-controlled BGP topology in a multi-AS environment.
The topology consisting of five ASes had all the possible paths from the source to the destination
and selected the best path using the BGP decision process. Thereafter, we simulated a congested
BGP scenario by continuously flooding stream of data using Iperf, thereby congesting a
particular link between two ASes.
Fig. 3.1 Congested BGP topology
Iperf is a free Linux based network performance tool used to measure various TCP and
UDP parameters such as bandwidth, delay, jitter, packet loss [11]. Here, client is the sender and
server is the receiver. All ASes in Fig. 3.1 have external BGP (eBGP) running between them. We
created data streams of different bandwidths ranging from 1 Mbps to 100 Mbps and streamed the
data from Ubuntu client to Ubuntu server. Also, we observed the % packet loss and % transmit
load on the outgoing interface of AS 2 for different bandwidths.
Step 2: Logging and analyzing the data
We logged the data from the results and analyzed various performance parameters like
average end-to-end delay, average packet loss rate, and average load. Then we processed the

Page | 12
logged data to plot the graph of Bandwidth vs. % Loss and Bandwidth vs. % Load to compare
them with the results of congestion-controlled BGP scenario.
Step 3: Developing the algorithm
We developed a tool to achieve congestion control and route optimization using AS Path
Prepending approach. The tool is basically divided into two components.
1. The Initial Setup: Simple Network Management Protocol (SNMP) is extensively used
to poll the router for various information regarding the interface index, IP addresses, the
next hop addresses, routing table attributes and information about the BGP routes, and
the AS path lengths. A link object is created that maps the link index to its directly
connected neighbors and possible routable network destinations. A dictionary mapping of
IP addresses to their AS path lengths is also stored during the initial setup.
2. Active Continuous Measurement: The tool actively monitors all the links of the router
for its utilization values. The formula used for calculation link utilization is: [12]
Input Utilization = ∆𝑖𝑓𝐼𝑛𝑂𝑐𝑡𝑒𝑡𝑠 × 8 × 100
(𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑠𝑒𝑐𝑜𝑛𝑑𝑠 𝑖𝑛 ∆) × 𝑖𝑓𝑆𝑝𝑒𝑒𝑑
Output Utilization = ∆𝑖𝑓𝑂𝑢𝑡𝑂𝑐𝑡𝑒𝑡𝑠 × 8 × 100
(𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑠𝑒𝑐𝑜𝑛𝑑𝑠 𝑖𝑛 ∆) × 𝑖𝑓𝑆𝑝𝑒𝑒𝑑
where ∆𝑖𝑓𝐼𝑛𝑂𝑐𝑡𝑒𝑡𝑠 and ∆𝑖𝑓𝑂𝑢𝑡𝑂𝑐𝑡𝑒𝑡𝑠 represents the count of inbound and outbound
octets of traffic respectively.
A variable threshold value is defined to identify congestion on the link. When the
link utilization value exceeds the threshold value, the tool starts its congestion control
mechanism.

Page | 13
Fig 3.2 Congestion Detection algorithm
• From the link object, the interface index, IP addresses along with their AS path lengths,
and it’s directly connected interfaces are retrieved. In case the link has never faced
congestion, a subset list of IP addresses having AS path length equal to the maximum AS
path length is obtained.

Page | 14
• Route-maps to prepend the AS path are entered into the router, which triggers in its
immediate neighbors a BGP decision process to choose an alternate best path for the
concerned IP addresses. Route maps can also be entered on the basis of Netflow statistics
to prepend the largest traffic flow through the router. Such a decision is left onto the ISP.
• The program then returns to monitoring link utilization. In case the link utilization value
still persists above the threshold value, the router again starts the congestion control
mechanism. Since, it has already prepended the AS value for the maximum possible AS
path lengths, it now prepends the AS path for IP addresses with the next maximum AS
path length.
Fig 3.3 Congestion Recovery algorithm

Page | 15
If the link utilization value decreases beyond a minimum threshold value, the link is no
longer congested. At this point, the ISP will try to restore its previous best forwarding path. The
tool identifies from the link object, the minimum of the AS path value for which route maps were
entered along with the corresponding IP addresses. The tool then continues to monitor the link
utilization.
Fig 3.2 also takes care of the bouncing effect or “flapping” of routes. After diversion of
traffic, in case no peers have the required capacity to allow the traffic, the traffic is routed back
to ISP, which initially prepended the path. At this stage the ISP can drop/allow the traffic.
Step 4: Implementing the algorithm
We implemented the mechanism explained in Fig. 3.2 and Fig. 3.3 in the following BGP
scenario, where the link between AS 1 and Switch 0 is 10 Mbps and the link between AS 2 and
AS 3 is 100 Mbps. Thereafter, we analyzed the traffic patterns to compare average end-to-end
delay, average packet loss rate, and average load between traditional BGP and congestion-
controlled BGP.
Fig. 3.4 Congestion-controlled BGP

Page | 16
Step 5: Interviews
As per our topology and obtained results; we conducted interviews with experts from
ISPs to know their viewpoints over a possible integration of congestion-control mechanism into
BGP. The interviews helped us analyze the industry standpoint on the possible integration of this
new concept in BGP. The interviews mainly focused on these major domains:
• Awareness: How far the industry experts were aware about the BGP congestion problem
and any existing mechanism that could solve the issue
• Feasibility: The feasibility of incorporating the algorithm in regards to technical and
commercial viability
• Prospective clientele: Based on the current market scenario, who among Tier 1 ISPs, Tier
2 ISPs, and customers, would have an interest in implementing such automatic
congestion control mechanism
Step 6: Proposed Model
Considering the current business relationships among the ASes, we propose a modified
Internet model to address the economic and policy sub-problems mentioned previously. The
model is divided into the following scenarios:
Fig. 3.5 Co-ordination between Tier 1 ISPs

Page | 17
Scenario 1: Explicit Co-ordination among the Tier 1 ISPs
As addressed in the economic and policy sub-problem, diversion of traffic onto another
link will not be acceptable to an ISP due to increase in costs and trust issues. However, we
suggest that all Tier-1 ISPs engage in coordinated inter-domain routing and traffic engineering as
shown in Fig. 3.5. As of today, ISPs take independent decisions to carry out its own network
engineering, which can impact another ISP's traffic. Coordinated routing on the other hand,
requires exchange of policies and routing decisions allowing predictable incoming and outgoing
traffic engineering control. Rahul et al, further explain how ISPs can end in a win-win situation
while maintaining limited information disclosure among the ISPs. We support the idea of ISPs
engaging themselves in a two-way exchange of information and route negotiation between the
upstream and the downstream routers as it provides a strong base for global deployment of our
tool. With the ability to predict traffic changes, ISPs can divert traffic without worrying about
local resource policies and system instability, thus optimizing cost and network performance [13].
Fig. 3.6 Multihomed customer
Scenario 2: Mutihomed ASes and Customers
"Mutihomed" means connected to more than one Internet service provider as shown in
Fig. 3.6. Over the past few years, there has been an increase in the growth of multihomed ASes

Page | 18
and customers to improve network connectivity and performance. We propose the use of our tool
for all such enterprise networks that have more than one connection to the Internet. The tool will
allow automated traffic engineering control by varying the AS's traffic among the different
service providers it is connected to, thus providing better network utilization. Such automated
load balancing abilities allow the AS to support more users connecting to the Internet leading to
increased revenues.
Fig. 3.7 Economic incentives for Tier 2 ISPs to form a full-mesh
Scenario 3: Economic arrangements between full-meshed Tier 2 ISPs
According to the current Internet model, the interconnection between Tier 2 ISPs is sparse as
compared to the interconnection between the Tier 1 ISPs [14]. Tier 2 ISPs purchase transit from
the Tier 1 ISPs in order to access the Internet. Congestion on the Tier 2 transit link results in
more costs for the Tier 2 ISP in order to allow the additional traffic. We suggest in our model
that all the Tier 2 ISPs in a specific region have full mesh connectivity between themselves. Such
complete peering benefits the Tier 2 ISPs by reducing the overall transit cost. Considering the
transit cost between Tier 1 and Tier 2 is $1/Mbps, the Tier 2 ISP facing congestion can offload

Page | 19
the additional traffic through another Tier 2 peer for the duration of congestion. The costs of the
additional traffic can be billed:
• At the same cost as it would have been to a Tier 1 ISP or,
• Based upon specific peering and traffic load balancing agreements among the Tier 2 ISPs
• Based upon pay-per-use of network resources.
Such model allows support for inflow and outflow of money among the Tier 2 ISPs as against
the current unidirectional outflow of money from a Tier 2 ISP to a Tier 1 ISP. Another additional
benefit is that the Tier 2 ISP has a virtual link capacity equal to the entire Tier 2 full mesh
bandwidth, thus allowing support for more customers and traffic generating income for the Tier
2 ISP.
IV. Research Results
After implementing the BGP topology as shown in Fig 3.1, the first step was to prove that
BGP cannot handle congestion. We performed the following steps:
1. Injected a stream of data packets on a serial link for the bandwidths ranging from 1 Mbps
to 100 Mbps from the Ubuntu client to the Ubuntu server
2. There was no packet loss from 1 Mbps to 1.544 Mbps. For various link bandwidths from
1.544 Mbps to 100 Mbps, we observed that the packet loss increased exponentially and
remained constant (97%) after 70 Mbps as shown in Fig. 4.1.

Page | 20
Fig. 4.1 Bandwidth vs. % Loss due to congestion
3. Fig. 4.2 shows the comparison graph of Bandwidth (BW) vs. % Loss before and after
implementing the congestion-control algorithm. The blue curve represents a flow of
traffic within the link capacity of Fa0/0 (AS1). Thus, when the BW was between 1 and 10
Mbps the corresponding loss was 0%. As we increased the bandwidth beyond 10 Mbps,
the % loss increased exponentially, as shown by the red curve. At 60 Mbps, we started
our congestion control mechanism and as seen, the traffic gets diverted onto the Fa0/1,
AS2 link and the flow does not suffer from loss of packets and reaches the destination.
Fig. 4.2 Comparison of Bandwidth vs. % Loss

Page | 21
4. Fig. 4.3 shows the comparison graph of % transmit load on outgoing interfaces Fa0/0 and
Fa0/1 for routers AS1 and AS2 in Fig. 3.4 respectively. The values are plotted before
congestion as well as before and after implementing the congestion-control algorithm.
The bar graph shows that the transmit load was 1% before congestion. After congestion
on the Fa0/0 interface of AS1, the transmit load rises to 63% i.e. the interface is using
around 63% of the available transmit bandwidth. The red portion in the bar graph
represents % packet loss on the Fa0/0 interface. Once the algorithm diverts the traffic via
an alternate path, the transmit load gradually decreases to 19% on Fa0/0 of AS1 and
increases to 30% on the interface Fa0/1 of AS2.
Fig. 4.3 Graph of transmit load on interfaces
5. Fig. 4.4 compares the % Loss for 3 flows, which have the same best path to reach the
destination, ultimately leading to congestion of the link. Referring Fig. 3.4, flow 1 is
traffic from customer connected to AS 1, while flow 2 and flow 3 represent external
traffic passing through AS 1. Due to congestion there is a 70-80% loss for flow 1 and
flow 2. Since the link is completely congested, there is 100% packet loss for flow 3. We
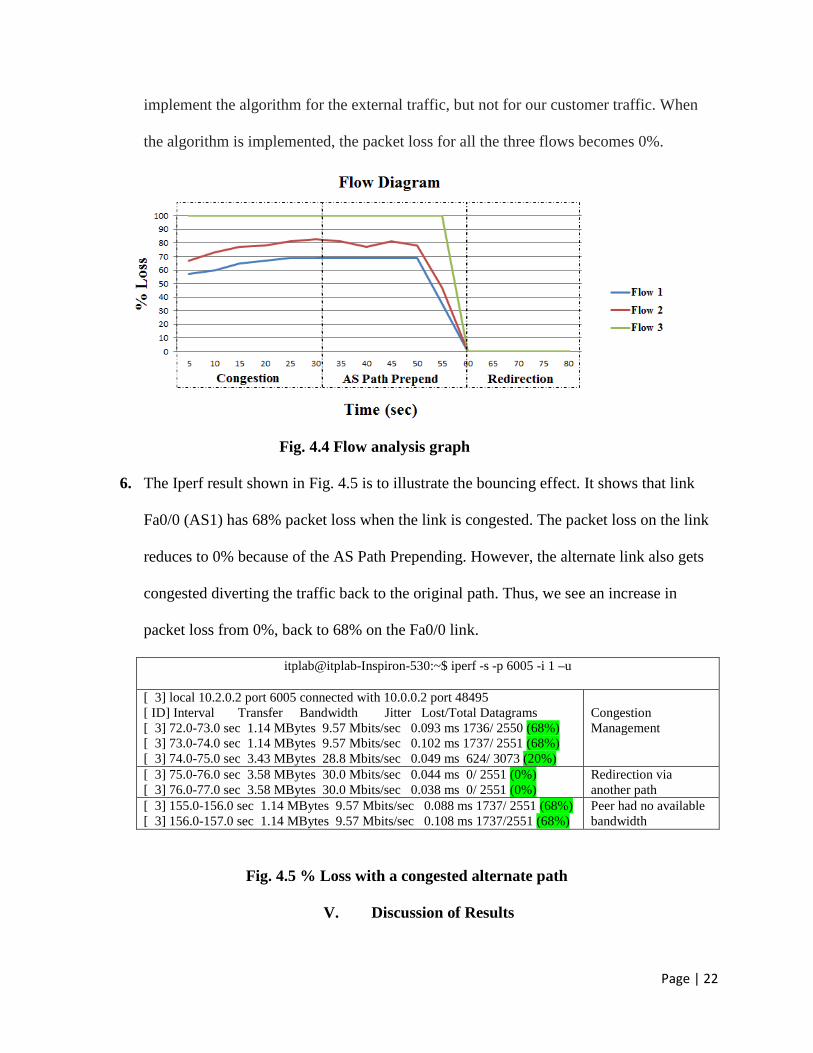
Page | 22
implement the algorithm for the external traffic, but not for our customer traffic. When
the algorithm is implemented, the packet loss for all the three flows becomes 0%.
Fig. 4.4 Flow analysis graph
6. The Iperf result shown in Fig. 4.5 is to illustrate the bouncing effect. It shows that link
Fa0/0 (AS1) has 68% packet loss when the link is congested. The packet loss on the link
reduces to 0% because of the AS Path Prepending. However, the alternate link also gets
congested diverting the traffic back to the original path. Thus, we see an increase in
packet loss from 0%, back to 68% on the Fa0/0 link.
itplab@itplab-Inspiron-530:~$ iperf -s -p 6005 -i 1 –u
[ 3] local 10.2.0.2 port 6005 connected with 10.0.0.2 port 48495 [ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams [ 3] 72.0-73.0 sec 1.14 MBytes 9.57 Mbits/sec 0.093 ms 1736/ 2550 (68%) [ 3] 73.0-74.0 sec 1.14 MBytes 9.57 Mbits/sec 0.102 ms 1737/ 2551 (68%) [ 3] 74.0-75.0 sec 3.43 MBytes 28.8 Mbits/sec 0.049 ms 624/ 3073 (20%)
Congestion Management
[ 3] 75.0-76.0 sec 3.58 MBytes 30.0 Mbits/sec 0.044 ms 0/ 2551 (0%) [ 3] 76.0-77.0 sec 3.58 MBytes 30.0 Mbits/sec 0.038 ms 0/ 2551 (0%)
Redirection via another path
[ 3] 155.0-156.0 sec 1.14 MBytes 9.57 Mbits/sec 0.088 ms 1737/ 2551 (68%) [ 3] 156.0-157.0 sec 1.14 MBytes 9.57 Mbits/sec 0.108 ms 1737/2551 (68%)
Peer had no available bandwidth
Fig. 4.5 % Loss with a congested alternate path
V. Discussion of Results

Page | 23
1. As per Fig. 4.1, the rate at which the data is being sent is much higher as compared to the
actual capacity of the link resulting in packet loss. The BGP protocol continues to send
traffic over the congested link even though there are alternate paths to reach the
destination. This shows that BGP has no inherent congestion control mechanism.
2. From Fig. 4.2, we see that link bandwidth was insufficient to handle the incoming traffic
resulting in packet loss. As the link utilization increased above the threshold value, the
algorithm diverted the additional traffic via an alternate link, which had enough capacity
to forward the incoming traffic towards the destination at 0% loss.
3. Fig. 4.3 shows that the link congestion results in packet loss and a high transmit load on
the interface. Since the algorithm diverts traffic via an alternate link, the loads get shared
among the interfaces.
4. The Iperf result in the fig. 4.5 shows that our algorithm takes care of situation when the
alternate path to the destination is also congested. Diverting the traffic causes congestion
on the alternate link which then sends the traffic back through the original path. Even
though the traffic bounces back with no reduction in packet loss, the traffic is not
completely dropped or black holed. However, if such a scenario occurs the ISPs can
decide whether to allow/block the traffic.
5. To understand the industry standpoint and the feasibility of the tool, we interviewed
industry experts from Tier 1 and Tier 2 ISPs. We asked them about their awareness of the
BGP congestion problem, deployment feasibility and viability, and potential customers
who could buy our solution. The experts from CenturyLink suggested that the
effectiveness of the tool depends on the acceptance of the Open Internet model by other
ISPs. They suggested making the tool capable of recognizing multiple links between two

Page | 24
Tier 1 ISPs and pass traffic through those links. They also agreed that such automatic
congestion control tool can be readily deployed for multihomed ASes and customers.
Tier 2 ISPs supported the idea as this solution not only solves their congestion problem,
but also benefits them and their customers economically. They also have an added
advantage in the form of inflow and outflow on money, and an increased customer base.
VI. Conclusion and Future Research
In this paper, we have proposed a novel approach for controlling congestion by diverting
traffic onto another link by means of AS Path Prepending traffic engineering approach. Initially,
our tool creates a database of all the necessary information, actively probes the links to detect
utilization, and then undertakes necessary steps to control congestion. The entire process is
automated as opposed to the current ad-hoc engineering methods and does not have any
additional dedicated hardware or software requirements. The paper also proposes a model that
supports an Open Internet system and explains various scenarios for which the tool can be
readily deployed. From the results obtained, we conclude that such automated tools are the future
for network operations management and troubleshooting.
Our current BGP congestion control mechanism tool works on three simple principles of
link utilization monitoring, BGP AS Path Prepending attribute, and co-ordination among the
ISPs. The future scope of the tool is based on the decision of the ISPs and their willingness to
adopt the Open Internet model. The Open Internet architecture provides the ability to monitor
links of different ASes and divert traffic based on least link utilization. The ISPs can choose to
develop additional complex features to increase the tool’s efficiency to measure delay and
throughput characteristics and also take into consideration Netflow statistics before diverting
onto an alternate path.

Page | 25
VII. References
[1] G. Siganos and M. Faloutsos, “Analyzing BGP policies: Methodology and tool,” in
INFOCOM 2004. Twenty-third AnnualJoint Conference of the IEEE Computer and
Communications Societies, 2004, vol. 3, pp. 1640–1651.
[2] I. van Beijnum, “BGP: Chapter 6: Traffic Engineering,” Building Reliable Networks with the
Border Gateway Protocol, Sep-2002. [Online]. Available:
http://oreilly.com/catalog/bgp/chapter/ch06.html. [Accessed: 06-Dec-2013].
[3] N. Hu, P. Zhu, H. Cao, and K. Chen, “Routing Policy Conflict Detection without Violating
ISP’s Privacy,” in Computational Science and Engineering, 2009. CSE’09. International
Conference on, 2009, vol. 3, pp. 337–342.
[4] A. Gupta, D. O. Stahl, and A. B. Whinston, “A stochastic equilibrium model of internet
pricing,” May-1997. [Online]. Available:
http://www.sciencedirect.com/science/article/pii/S0165188996000036. [Accessed: 23-Apr-
2014].
[5] H. Fujinoki, “Multi-path BGP (MBGP): A solution for improving network bandwidth
utilization and defense against link failures in inter-domain routing,” in Networks, 2008.
ICON 2008. 16th IEEE International Conference on, 2008, pp. 1–6.
[6] F. Wang and L. Gao, “Path diversity aware interdomain routing,” in INFOCOM 2009, IEEE,
2009, pp. 307–315.
[7] M. Sebakor, N. Theera-Umpon, and S. Auephanwiriyakul, “Centralized control system in
interdomain routing environments,” in International Symposium on Intelligent Signal
Processing and Communications Systems, 2008. ISPACS 2008, 2009, pp. 1–4.

Page | 26
[8] H. Wang, R. Chang, D.-M. Chiu, and J. C. Lui, “Characterizing the performance and
stability issues of the AS path prepending method: taxonomy, measurement study and
analysis,” in Proceedings of ACM SIGCOMM Asia Workshop, 2005.
[9] R. K. C. Chang and M. Lo, “Inbound traffic engineering for multihomed ASs using AS path
prepending,” IEEE Netw., vol. 19, no. 2, pp. 18–25, Mar. 2005.
[10] S. Agarwal, C.-N. Chuah, and R. H. Katz, “OPCA: robust interdomain policy routing and
traffic control,” in 2003 IEEE Conference on Open Architectures and Network
Programming, 2003, pp. 55–64.
[11] “Iperf - The TCP/UDP Bandwidth Measurement Tool.” [Online]. Available:
http://iperf.fr/. [Accessed: 23-Apr-2014].
[12] “How To Calculate Bandwidth Utilization Using SNMP - Cisco,” 26-Oct-2005. [Online].
Available: http://www.cisco.com/c/en/us/support/docs/ip/simple-network-management-
protocol-snmp/8141-calculate-bandwidth-snmp.html. [Accessed: 23-Apr-2014].
[13] R. Mahajan, D. Wetherall, and T. Anderson, “Towards coordinated interdomain traffic
engineering,” in Proceedings of Third Workshop on Hot Topics in Networks (HotNets-III),
2004.
[14] “The Global Internet Peering Ecosystem.” [Online]. Available:
http://drpeering.net/AskDrPeering/blog/articles/The_Internet_Peering_Ecosystem__The_Tie
r_2_ISP.html. [Accessed: 23-Apr-2014].