text classification the naïve bayes algorithm ip notice: most slides from: chris manning, plus some...
TRANSCRIPT

Text ClassificationText Classification
The Naïve Bayes algorithmThe Naïve Bayes algorithm
IP notice: most slides from: Chris Manning, plus some from William Cohen, Chien Chin Chen, Jason Eisner, David Yarowsky, Dan Jurafsky, P. Nakov, Marti Hearst, Barbara Rosario

OutlineOutline
Introduction to Text ClassificationIntroduction to Text Classification Also called “text categorization”
Naïve Bayes text classificationNaïve Bayes text classification
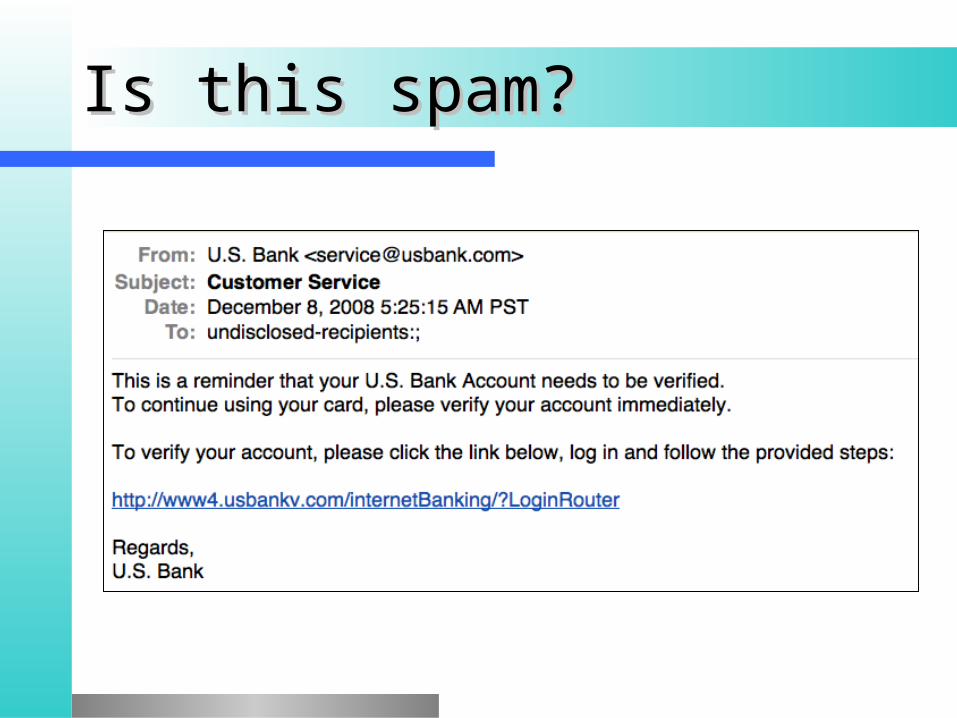
Is this spam?Is this spam?

More Applications of Text More Applications of Text ClassificationClassification Authorship identificationAuthorship identification Age/gender identificationAge/gender identification Language IdentificationLanguage Identification Assigning topics such as Yahoo-categoriesAssigning topics such as Yahoo-categories
e.g., "finance," "sports," "news>world>asia>business"e.g., "finance," "sports," "news>world>asia>business" Genre-detectionGenre-detection
e.g., "editorials" "movie-reviews" "news“e.g., "editorials" "movie-reviews" "news“ Opinion/sentiment analysis on a person/productOpinion/sentiment analysis on a person/product
e.g., “like”, “hate”, “neutral”e.g., “like”, “hate”, “neutral” Labels may be domain-specificLabels may be domain-specific
e.g., “contains adult language” : “doesn’t”e.g., “contains adult language” : “doesn’t”

Text Classification: Text Classification: definitiondefinition The classifier: The classifier:
Input: a document d Output: a predicted class c from some fixed set of
labels c1,...,cK
The learner:The learner: Input: a set of m hand-labeled documents (d1,c1),....,
(dm,cm) Output: a learned classifier f:d → c
Slide from William Cohen
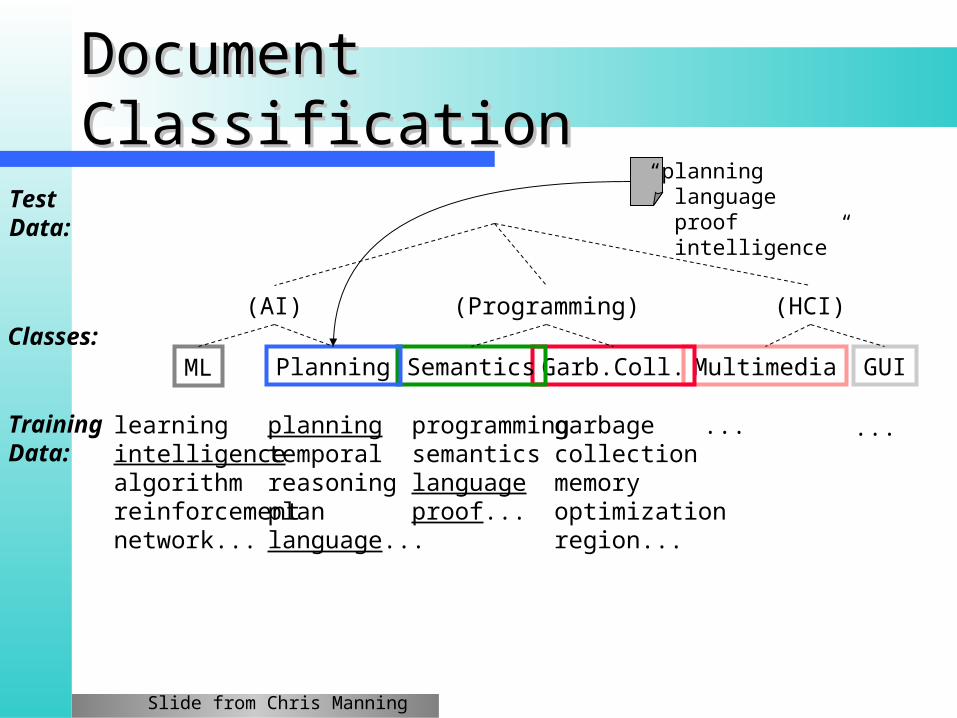
Multimedia GUIGarb.Coll.SemanticsML Planning
planningtemporalreasoningplanlanguage...
programmingsemanticslanguageproof...
learningintelligencealgorithmreinforcementnetwork...
garbagecollectionmemoryoptimizationregion...
“planning language proof intelligence”
TrainingData:
TestData:
Classes:(AI)
Document ClassificationDocument Classification
Slide from Chris Manning
(Programming) (HCI)
... ...

Classification Methods: Classification Methods: Hand-coded rulesHand-coded rules Some spam/email filters, etc. Some spam/email filters, etc. E.g., assign category if document contains a given E.g., assign category if document contains a given
boolean combination of wordsboolean combination of words Accuracy is often very high if a rule has been Accuracy is often very high if a rule has been
carefully refined over time by a subject expertcarefully refined over time by a subject expert Building and maintaining these rules is expensiveBuilding and maintaining these rules is expensive
Slide from Chris Manning

Classification Methods: Classification Methods: Machine LearningMachine Learning Supervised Machine LearningSupervised Machine Learning To learn a function from documents (or To learn a function from documents (or
sentences) to labelssentences) to labels Naive Bayes (simple, common method) Others
• k-Nearest Neighbors (simple, powerful)• Support-vector machines (new, more powerful)• … plus many other methods
No free lunch: requires hand-classified training data• But data can be built up (and refined) by amateurs
Slide from Chris Manning

Naïve Bayes IntuitionNaïve Bayes Intuition

Representing text for Representing text for classificationclassification
Slide from William Cohen
ARGENTINE 1986/87 GRAIN/OILSEED REGISTRATIONSBUENOS AIRES, Feb 26Argentine grain board figures show crop registrations of grains, oilseeds and their
products to February 11, in thousands of tonnes, showing those for future shipments month, 1986/87 total and 1985/86 total to February 12, 1986, in brackets:
• Bread wheat prev 1,655.8, Feb 872.0, March 164.6, total 2,692.4 (4,161.0).• Maize Mar 48.0, total 48.0 (nil).• Sorghum nil (nil)• Oilseed export registrations were:• Sunflowerseed total 15.0 (7.9)• Soybean May 20.0, total 20.0 (nil)
The board also detailed export registrations for subproducts, as follows....
f( )=c
? What is the best representation for the document d being classified?
simplest useful

Bag of words Bag of words representationrepresentation
Slide from William Cohen
ARGENTINE 1986/87 GRAIN/OILSEED REGISTRATIONSBUENOS AIRES, Feb 26Argentine grain board figures show crop registrations of grains, oilseeds and their
products to February 11, in thousands of tonnes, showing those for future shipments month, 1986/87 total and 1985/86 total to February 12, 1986, in brackets:
• Bread wheat prev 1,655.8, Feb 872.0, March 164.6, total 2,692.4 (4,161.0).• Maize Mar 48.0, total 48.0 (nil).• Sorghum nil (nil)• Oilseed export registrations were:• Sunflowerseed total 15.0 (7.9)• Soybean May 20.0, total 20.0 (nil)The board also detailed export registrations for subproducts, as follows....
Categories: grain, wheat

Bag of words Bag of words representationrepresentation
xxxxxxxxxxxxxxxxxxx GRAIN/OILSEED xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx grain xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx grains, oilseeds xxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxx tonnes, xxxxxxxxxxxxxxxxx shipments xxxxxxxxxxxx total xxxxxxxxx total xxxxxxxx xxxxxxxxxxxxxxxxxxxx:
• Xxxxx wheat xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx, total xxxxxxxxxxxxxxxx• Maize xxxxxxxxxxxxxxxxx• Sorghum xxxxxxxxxx• Oilseed xxxxxxxxxxxxxxxxxxxxx• Sunflowerseed xxxxxxxxxxxxxx• Soybean xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx....
Categories: grain, wheat
Slide from William Cohen

Bag of words Bag of words representationrepresentation
xxxxxxxxxxxxxxxxxxx GRAIN/OILSEED xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx grain xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx grains, oilseeds
xxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxx tonnes, xxxxxxxxxxxxxxxxx shipments xxxxxxxxxxxx total xxxxxxxxx total xxxxxxxx xxxxxxxxxxxxxxxxxxxx:
• Xxxxx wheat xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx, total xxxxxxxxxxxxxxxx
• Maize xxxxxxxxxxxxxxxxx• Sorghum xxxxxxxxxx• Oilseed xxxxxxxxxxxxxxxxxxxxx• Sunflowerseed xxxxxxxxxxxxxx• Soybean xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx....
Categories: grain, wheat
grain(s) 3
oilseed(s) 2
total 3
wheat 1
maize 1
soybean 1
tonnes 1
... ...
word freq
Slide from William Cohen

Formalizing Naïve Formalizing Naïve BayesBayes

Bayes’ RuleBayes’ Rule
)(
)()|()|(
AP
BPBAPABP
•Allows us to swap the conditioning
•Sometimes easier to estimate one kind of dependence than the other

S
Conditional ProbabilityConditional Probability
let let AA and and BB be events be events PP(B|A)(B|A) = the = the probabilityprobability of event of event BB occurring givenoccurring given event event
AA occursoccurs definition:definition: PP(B|A) = (B|A) = PP(A (A B) / B) / PP(A)(A)

Deriving Bayes’ RuleDeriving Bayes’ Rule
P(B | A) P(A B)P(A)
P(B | A) P(A B)P(A))(
)()|(
BPBAP
BAP
)()(
)|(BP
BAPBAP
P(B | A)P(A) P(A B)
P(B | A)P(A) P(A B))()()|( BAPBPBAP )()()|( BAPBPBAP
P(A | B)P(B) P(B | A)P(A)
P(A | B)P(B) P(B | A)P(A)
P(A | B) P(B | A)P(A)
P(B)
P(A | B) P(B | A)P(A)
P(B)

Bayes’ Rule Applied to Bayes’ Rule Applied to Documents and ClassesDocuments and Classes
Slide from Chris Manning
P (C , D) P (C | D)P (D) P (D | C )P (C )
P(C | D) P(D | C)P(C)
P(D)
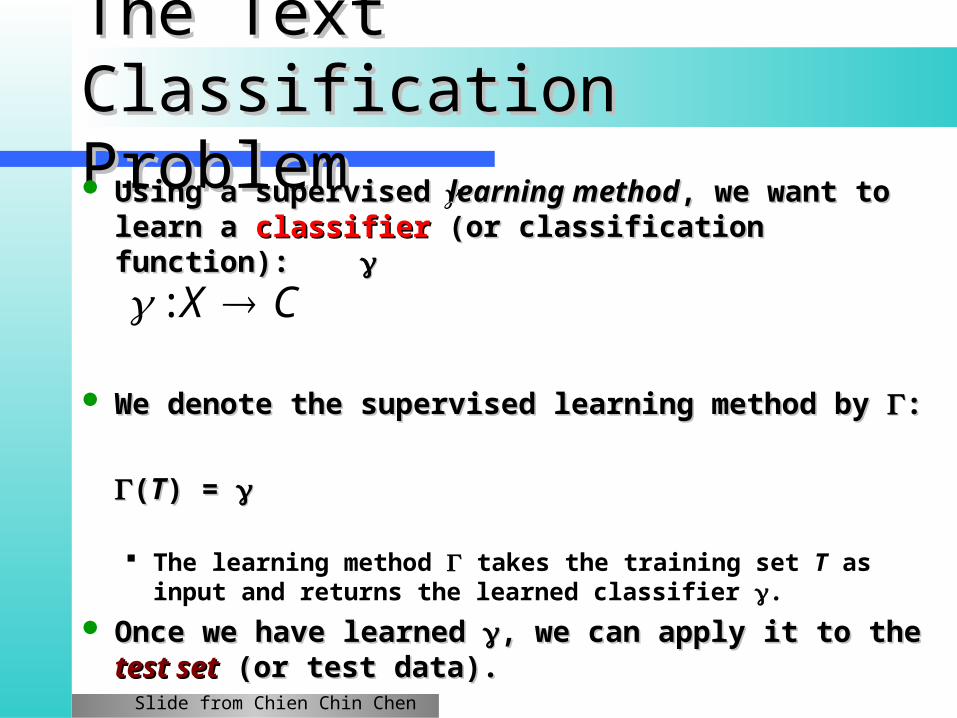
The Text Classification The Text Classification ProblemProblem
Using a supervised Using a supervised learning methodlearning method, we want to learn a , we want to learn a classifierclassifier (or classification function): (or classification function):
We denote the supervised learning method by We denote the supervised learning method by ::
((TT) =) =
The learning method takes the training set T as input and returns the learned classifier .
Once we have learned Once we have learned , we can apply it to the , we can apply it to the test settest set (or (or test data).test data).
Slide from Chien Chin Chen
CX :

Naïve Bayes Text Naïve Bayes Text ClassificationClassification TheThe Multinomial Naïve Bayes modelMultinomial Naïve Bayes model (NB) is a (NB) is a
probabilistic learning method.probabilistic learning method.
In text classification, our goal is to find the “In text classification, our goal is to find the “bestbest” ” class for the document:class for the document:
Slide from Chien Chin Chen
)|(maxarg dcPcCc
map
)(
)|()(maxarg
dP
cdPcP
Cc
)|()(maxarg cdPcPCc
The probability of a document d being in class c.
The probability of a document d being in class c.
Bayes’ RuleBayes’ Rule
We can ignore the denominator
We can ignore the denominator

Naive Bayes ClassifiersNaive Bayes ClassifiersWe represent an instance We represent an instance DD based on some attributes. based on some attributes.
Task: Classify a new instance Task: Classify a new instance DD based on a tuple of attribute values based on a tuple of attribute values into one of the classes into one of the classes ccjj CC
Slide from Chris Manning
nxxxD ,,, 21
),,,|(argmax 21 njCc
MAP xxxcPcj
),,,(
)()|,,,(argmax
21
21
n
jjn
Cc xxxP
cPcxxxP
j
)()|,,,(argmax 21 jjnCc
cPcxxxPj
The probability of a document d being in class c.
The probability of a document d being in class c.
Bayes’ RuleBayes’ Rule
We can ignore the denominator
We can ignore the denominator

Naïve Bayes Classifier: Naïve Naïve Bayes Classifier: Naïve Bayes AssumptionBayes Assumption PP((ccjj))
Can be estimated from the frequency of classes in the training examples.
PP((xx11,x,x22,…,x,…,xnn|c|cjj) ) O(|X|n•|C|) parameters Could only be estimated if a very, very large number of
training examples was available.Naïve Bayes Conditional Independence Assumption:Naïve Bayes Conditional Independence Assumption: Assume that the probability of observing the conjunction Assume that the probability of observing the conjunction
of attributes is equal to the product of the individual of attributes is equal to the product of the individual probabilities probabilities PP((xxii||ccjj))..
Slide from Chris Manning
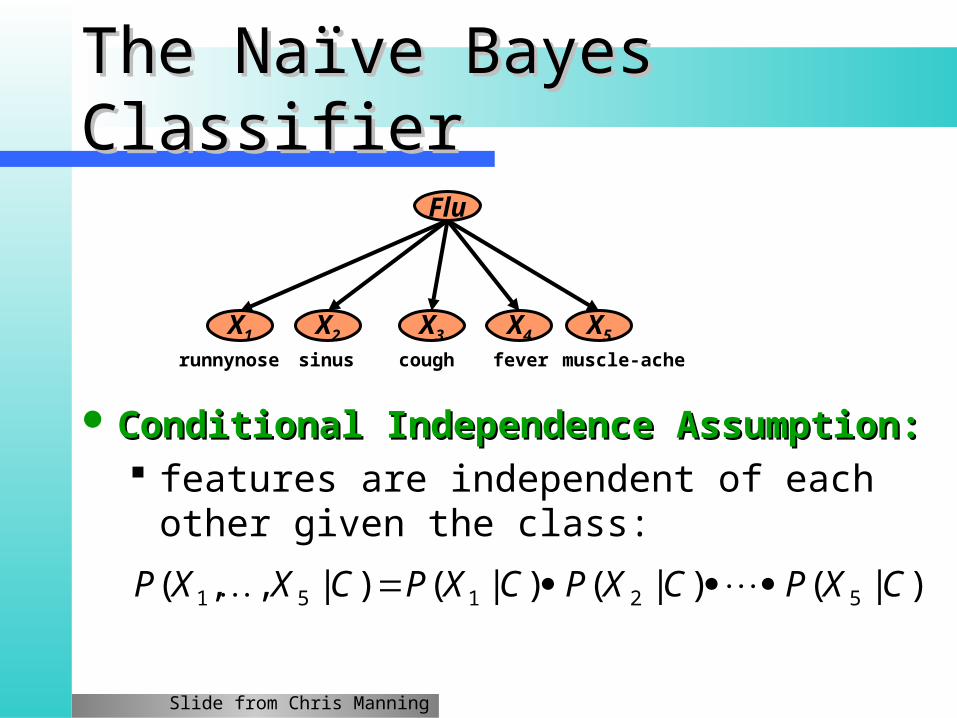
Flu
X1 X2 X5X3 X4
feversinus coughrunnynose muscle-ache
The Naïve Bayes The Naïve Bayes ClassifierClassifier
Conditional Independence Assumption:Conditional Independence Assumption: features are independent of each other given the
class:
)|()|()|()|,,( 52151 CXPCXPCXPCXXP
Slide from Chris Manning

Using Multinomial Naive Bayes Using Multinomial Naive Bayes Classifiers to Classify TextClassifiers to Classify Text Attributes are text positions, values are words.Attributes are text positions, values are words.
Still too many possibilities Assume that classification is independent of the
positions of the words Use same parameters for each position Result is bag of words model (over tokens not types)
)|text""()|our""()(argmax
)|()(argmax
1j
j
jnjjCc
ijij
CcNB
cxPcxPcP
cxPcPc
Slide from Chris Manning
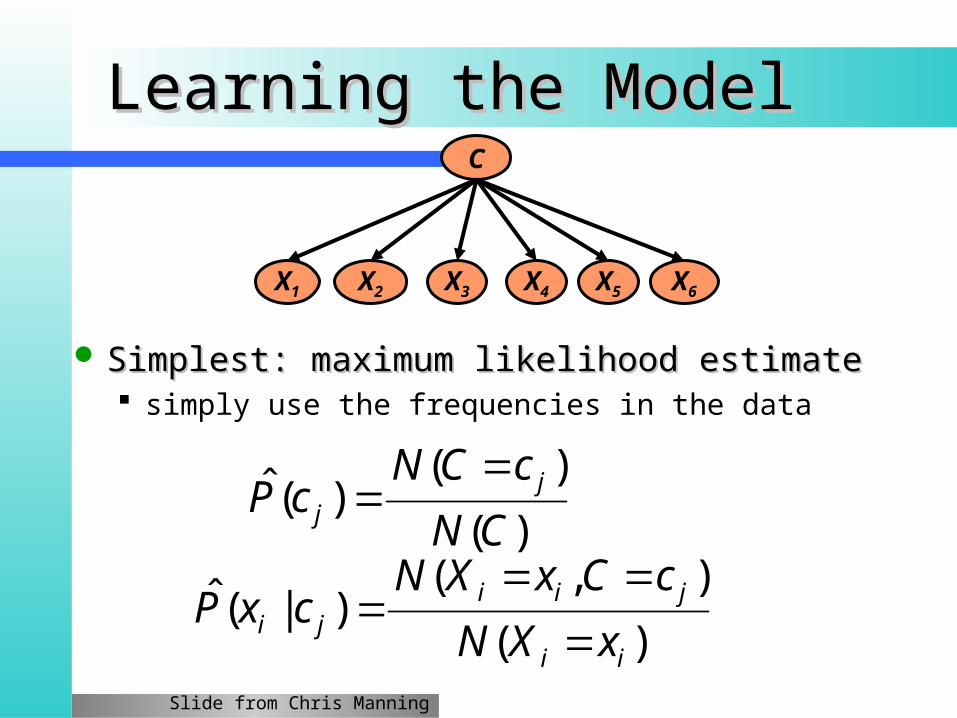
Learning the ModelLearning the Model
Simplest: maximum likelihood estimateSimplest: maximum likelihood estimate simply use the frequencies in the data
)(
),()|(ˆ
ii
jiiji xXN
cCxXNcxP
C
X1 X2 X5X3 X4 X6
)(
)()(ˆ
CN
cCNcP j
j
Slide from Chris Manning

Problem with Max Problem with Max LikelihoodLikelihood
0)(
),()|(ˆ 5
5
nfCN
nfCtXNnfCtXP
What if we have seen no training cases where patient had no flu and What if we have seen no training cases where patient had no flu and muscle aches?muscle aches?
Zero probabilities cannot be conditioned away, no matter the other Zero probabilities cannot be conditioned away, no matter the other evidence!evidence!
i ic cxPcP )|(ˆ)(ˆmaxarg
Flu
X1 X2 X5X3 X4
feversinus coughrunnynose muscle-ache
)|()|()|()|,,( 52151 CXPCXPCXPCXXP
Slide from Chris Manning

Smoothing to Avoid Smoothing to Avoid OverfittingOverfitting
kcCN
cCxXNcxP
j
jiiji
)(
1),()|(ˆ
Bayesian Unigram Prior:Bayesian Unigram Prior:
Slide from Chris Manning
# of values of Xi
mcCN
mpcCxXNcxP
j
kijkiijki
)(
),()|(ˆ ,,
,
overall fraction in data where Xi=xi,k
extent of“smoothing”
• Laplace:

• Textj single document containing all docsj
• for each word wk in Vocabulary
nkj number of occurrences of wk in Textj
nk number of occurrences of wk in all docs
Naïve Bayes: LearningNaïve Bayes: Learning
From training corpus, extract From training corpus, extract VocabularyVocabulary Calculate required Calculate required PP((ccjj)) and and PP((wwkk | c | cjj)) termsterms
For each cj in C do• docsj subset of documents for which the target class is cj
||)|(
Vocabularyn
ncwP
k
kjjk
documents # total
||)( j
j
docscP
Slide from Chris Manning

Naïve Bayes: ClassifyingNaïve Bayes: Classifying
positions positions all word positions in current document all word positions in current document which contain tokens found in which contain tokens found in
VocabularyVocabulary
Return Return ccNBNB, where, where
positionsi
jijCc
NB cwPcPc )|()(argmaxj
Slide from Chris Manning

Underflow Prevention: log Underflow Prevention: log spacespace Multiplying lots of probabilities, which are between 0 and Multiplying lots of probabilities, which are between 0 and
1 by definition, can result in floating-point underflow.1 by definition, can result in floating-point underflow. Since Since log(log(xyxy) = log() = log(xx) + log() + log(yy)), it is better to perform all , it is better to perform all
computations by summing logs of probabilities rather computations by summing logs of probabilities rather than multiplying probabilities.than multiplying probabilities.
Class with highest final un-normalized log probability Class with highest final un-normalized log probability score is still the most probable.score is still the most probable.
Note that model is now just max of sum of weights…Note that model is now just max of sum of weights…
positionsi
jijCc
NB cxPcPc )|(log)(logargmaxj
Slide from Chris Manning
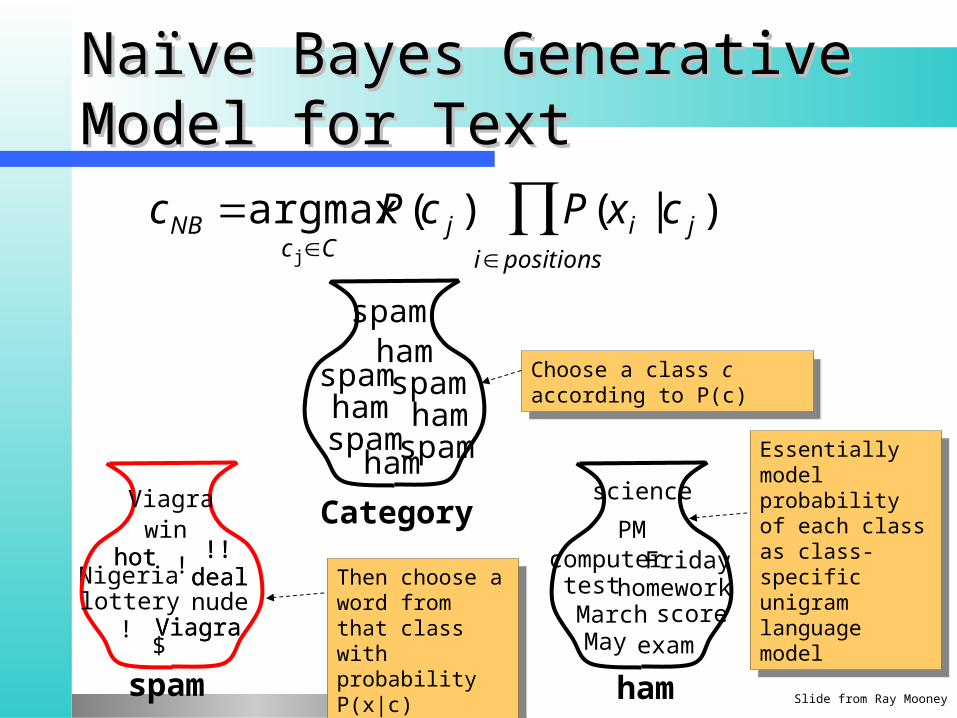
Naïve Bayes Generative Naïve Bayes Generative Model for TextModel for Text
nudedealNigeria
spam ham
hot
$Viagra
lottery
!!!
winFriday
exam
computer
May
PM
testMarch
scienceViagra
homeworkscore
!
spamhamspam
spamham
spam
ham
hamspam
Category
Viagra
dealhot !!
Slide from Ray Mooney
cNB argmaxcj C
P(c j ) P(x i | c j )ipositions
Choose a class c according to P(c)
Choose a class c according to P(c)
Then choose a word from that class with probability P(x|c)
Then choose a word from that class with probability P(x|c)
Essentially model probability of each class as class-specific unigram language model
Essentially model probability of each class as class-specific unigram language model
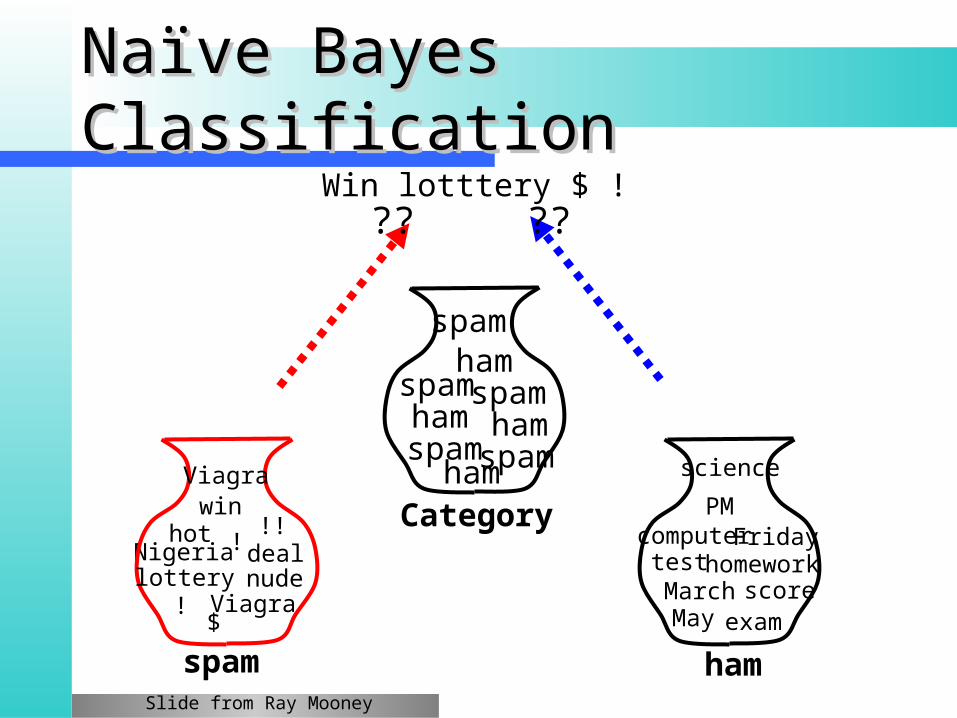
Naïve Bayes Naïve Bayes Classification Classification
nudedealNigeria
spam ham
hot
$Viagra
lottery
!!!
winFriday
exam
computer
May
PM
testMarch
scienceViagra
homeworkscore
!
spamhamspam
spamham
spam
ham
hamspam
Category
Win lotttery $ !?? ??
Slide from Ray Mooney

Naïve Bayes Text Classification Naïve Bayes Text Classification ExampleExample
Training: Training: Vocabulary V = {Chinese, Beijing, Shanghai,
Macao, Tokyo, Japan} and |V | = 6.
P(c) = 3/4 and P(~c) = 1/4.
P(Chinese|c) = (5+1) / (8+6) = 6/14 = 3/7
P(Chinese|~c) = (1+1) / (3+6) = 2/9 P(Tokyo|c) = P(Japan|c) = (0+1)/(8+6)=1/14 P(Chinese|~c) = (1+1)/(3+6)=2/9 P(Tokyo|~c)=p(Japan|~c)=(1+1/)3+6)=2/9
Testing:Testing: P(c|d) 3/4 * (3/7)3 * 1/14 * 1/14
≈ 0.0003
P(~c|d) 1/4 * (2/9)3 * 2/9 * 2/9 ≈ 0.0001
Slide from Chien Chin Chen

Naïve Bayes Text Naïve Bayes Text ClassificationClassification Naïve Bayes algorithm – training phase.Naïve Bayes algorithm – training phase.
Slide from Chien Chin Chen
TrainMultinomialNB(C, D)V ExtractVocabulary(D)N CountDocs(D)
for each c in C Nc CountDocsInClass(D, c) prior[c] Nc / Count(C) textc TextOfAllDocsInClass(D, c) for each t in V Ftc CountOccurrencesOfTerm(t, textc) for each t in V condprob[t][c] (Ftc+1) / ∑(Ft’c+1)
return V, prior, condprob
TrainMultinomialNB(C, D)V ExtractVocabulary(D)N CountDocs(D)
for each c in C Nc CountDocsInClass(D, c) prior[c] Nc / Count(C) textc TextOfAllDocsInClass(D, c) for each t in V Ftc CountOccurrencesOfTerm(t, textc) for each t in V condprob[t][c] (Ftc+1) / ∑(Ft’c+1)
return V, prior, condprob

Naïve Bayes Text Naïve Bayes Text ClassificationClassification Naïve Bayes algorithm – testing phase.Naïve Bayes algorithm – testing phase.
Slide from Chien Chin Chen
ApplyMultinomialNB(C, V, prior, condProb, d)W ExtractTokensFromDoc(V, d)for each c in C score[c] log prior[c] for each t in W score[c] += log condprob[t][c]
return argmaxcscore[c]
ApplyMultinomialNB(C, V, prior, condProb, d)W ExtractTokensFromDoc(V, d)for each c in C score[c] log prior[c] for each t in W score[c] += log condprob[t][c]
return argmaxcscore[c]

Evaluating CategorizationEvaluating Categorization
Evaluation must be done on test data that are Evaluation must be done on test data that are independentindependent of the training data of the training data usually a disjoint set of instances
Classification accuracyClassification accuracy: : cc//nn where where nn is the total is the total number of test instances and number of test instances and cc is the number of is the number of test instances correctly classified by the system.test instances correctly classified by the system. Adequate if one class per document
Results can vary based on sampling error due to Results can vary based on sampling error due to different training and test sets.different training and test sets. Average results over multiple training and test sets
(splits of the overall data) for the best results.
Slide from Chris Manning
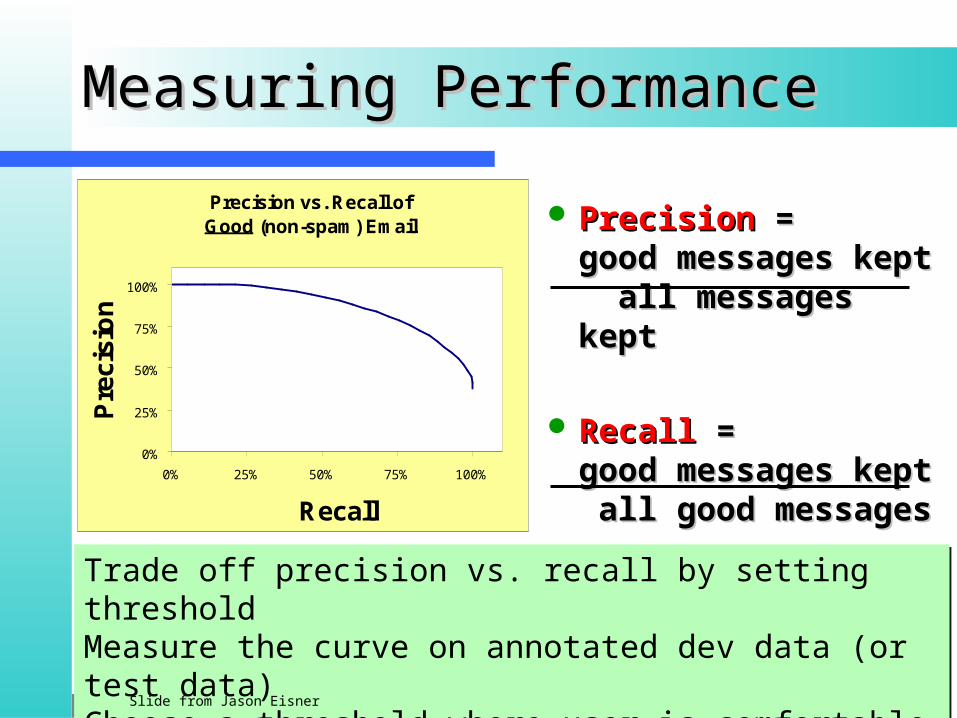
Measuring PerformanceMeasuring Performance
PrecisionPrecision = = good messages keptgood messages kept all messages kept all messages kept
RecallRecall = =good messages keptgood messages kept all good messages all good messages
Trade off precision vs. recall by setting thresholdMeasure the curve on annotated dev data (or test data)Choose a threshold where user is comfortable
Trade off precision vs. recall by setting thresholdMeasure the curve on annotated dev data (or test data)Choose a threshold where user is comfortable
Precision vs. Recall of Good (non-spam) Email
0%
25%
50%
75%
100%
0% 25% 50% 75% 100%
Recall
Pre
cisi
on
Slide from Jason Eisner

Measuring PerformanceMeasuring Performance
Slide from Jason Eisner
Precision vs. Recall of Good (non-spam) Email
0%
25%
50%
75%
100%
0% 25% 50% 75% 100%
Recall
Pre
cisi
on
low threshold:keep all the good stuff,but a lot of the bad too
high threshold:all we keep is good,but we don’t keep much
OK for spam filtering and legal search
OK for search engines (maybe)
would prefer to be here!
point whereprecision=recall(often reported)

More Complicated Cases of More Complicated Cases of Measuring PerformanceMeasuring Performance For multi-way classifiers:For multi-way classifiers:
Average accuracy (or precision or recall) of 2-way distinctions: Sports or not, News or not, etc.
Better, estimate the cost of different kinds of errors• e.g., how bad is each of the following?
– putting Sports articles in the News section– putting Fashion articles in the News section– putting News articles in the Fashion section
• Now tune system to minimize total cost
For ranking systems:For ranking systems: Correlate with human rankings? Get active feedback from user? Measure user’s wasted time by tracking clicks?
Slide from Jason Eisner
Which articles are most Sports-like?Which articles / webpages most relevant?

Training sizeTraining size The more the better! (usually)The more the better! (usually) Results for text classificationResults for text classification**
*From: Improving the Performance of Naive Bayes for Text Classification, Shen and Yang, Slide from Nakov/Hearst/Rosario
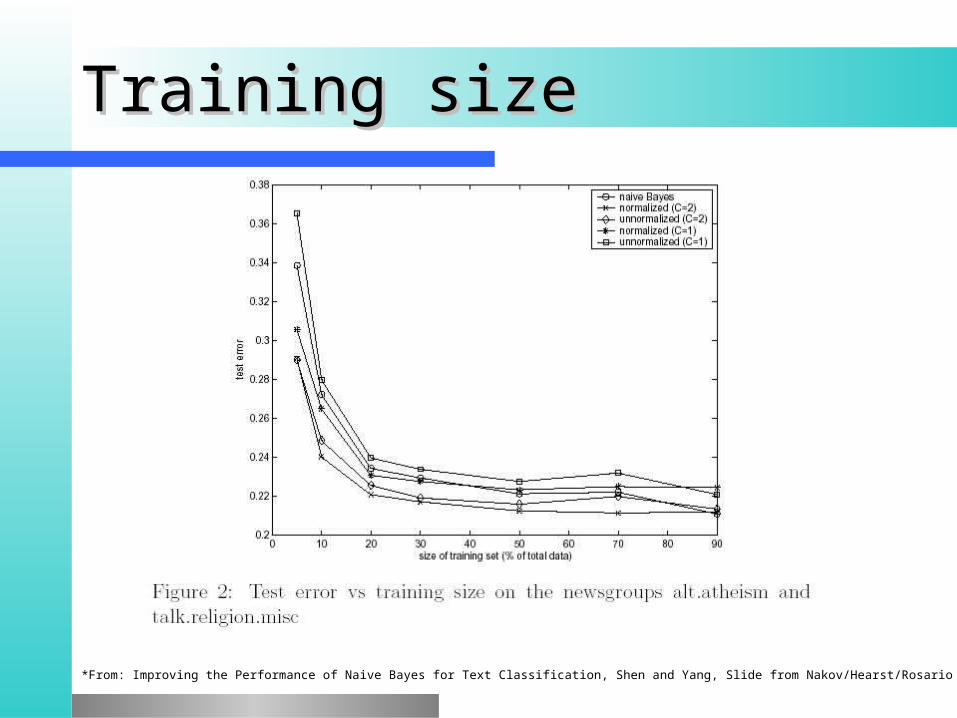
Training sizeTraining size
*From: Improving the Performance of Naive Bayes for Text Classification, Shen and Yang, Slide from Nakov/Hearst/Rosario
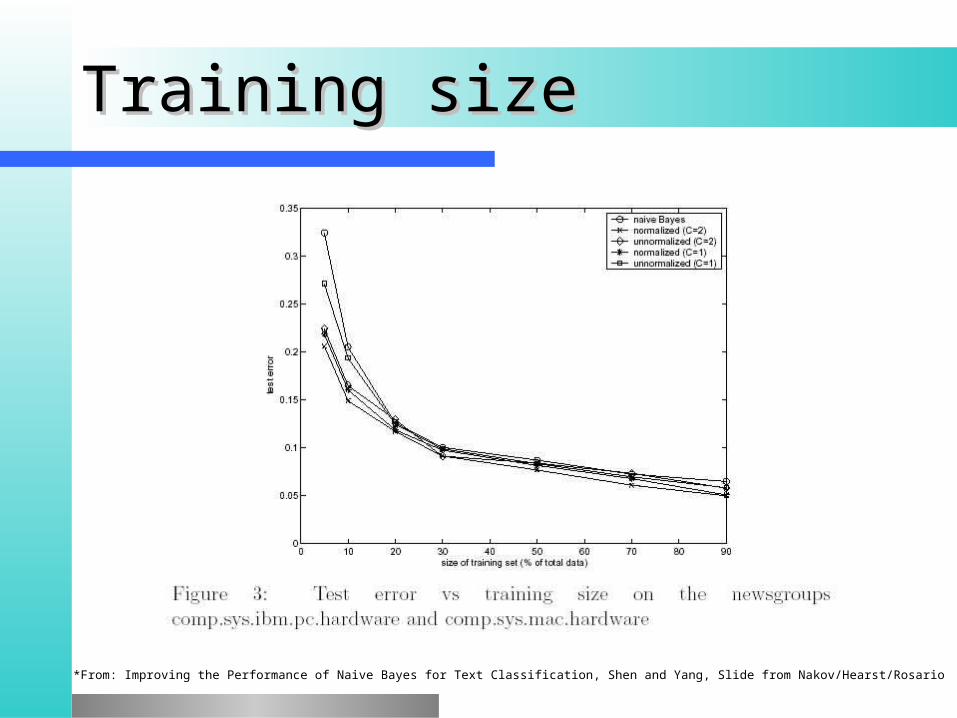
Training sizeTraining size
*From: Improving the Performance of Naive Bayes for Text Classification, Shen and Yang, Slide from Nakov/Hearst/Rosario
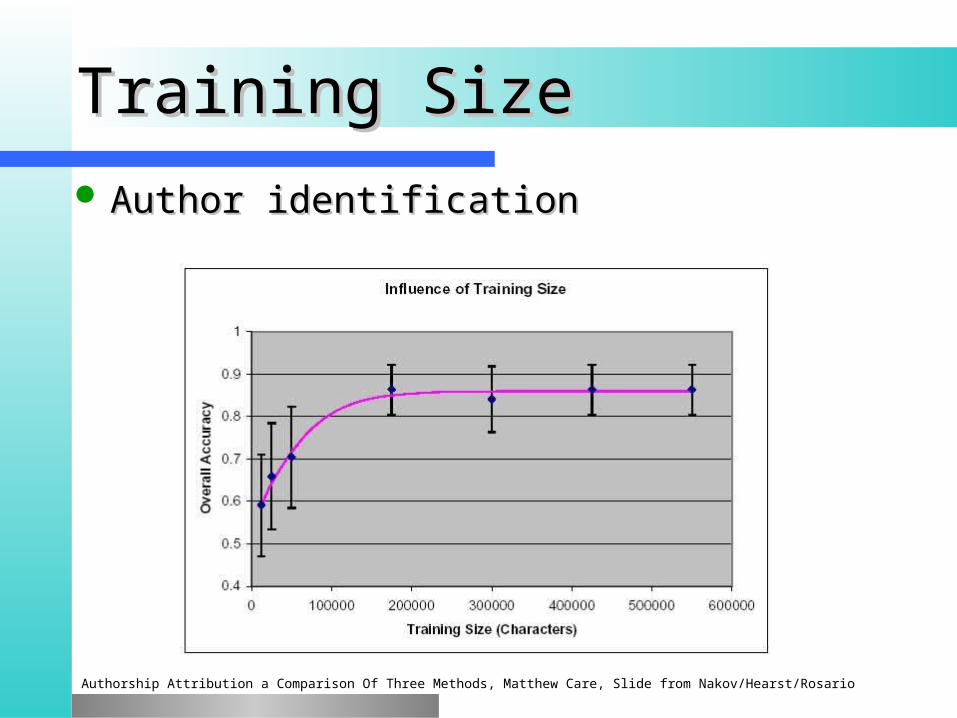
Training SizeTraining Size Author identificationAuthor identification
Authorship Attribution a Comparison Of Three Methods, Matthew Care, Slide from Nakov/Hearst/Rosario

Violation of NB Violation of NB AssumptionsAssumptions Conditional independenceConditional independence ““Positional independence”Positional independence” Examples?Examples?
Slide from Chris Manning

Naïve Bayes is Not So Naïve Bayes is Not So NaïveNaïve Naïve Bayes: first and second place in KDD-CUP 97 Naïve Bayes: first and second place in KDD-CUP 97
competition, among 16 (then) state of the art algorithmscompetition, among 16 (then) state of the art algorithmsGoal: Financial services industry direct mail response prediction model: Predict if the recipient of mail will actually respond to the advertisement – 750,000 records.
Robust to Irrelevant FeaturesRobust to Irrelevant FeaturesIrrelevant Features cancel each other without affecting resultsInstead Decision Trees can heavily suffer from this.
Very good in domains with many Very good in domains with many equally importantequally important features featuresDecision Trees suffer from fragmentation in such cases – especially if little data
A good dependable baseline for text classification (but not the A good dependable baseline for text classification (but not the best)!best)!
Slide from Chris Manning

Naïve Bayes is Not So Naïve Bayes is Not So NaïveNaïve Optimal if the Independence Assumptions Optimal if the Independence Assumptions
hold:hold:If assumed independence is correct, then it is the Bayes Optimal If assumed independence is correct, then it is the Bayes Optimal Classifier for problemClassifier for problem
Very Fast:Very Fast:Learning with one pass of counting over the data; testing linear in Learning with one pass of counting over the data; testing linear in the number of attributes, and document collection sizethe number of attributes, and document collection size
Low Storage requirementsLow Storage requirements Online Learning AlgorithmOnline Learning Algorithm
Can be trained incrementally, on new examplesCan be trained incrementally, on new examples

SpamAssassinSpamAssassin
Naïve Bayes widely used in spam filteringNaïve Bayes widely used in spam filtering Paul Graham’s A Plan for Spam
• A mutant with more mutant offspring... Naive Bayes-like classifier with weird parameter
estimation But also many other things: black hole lists, etc.
Many email topic filters also use NB classifiersMany email topic filters also use NB classifiers
Slide from Chris Manning

SpamAssassin TestsSpamAssassin Tests Mentions Generic ViagraMentions Generic Viagra Online PharmacyOnline Pharmacy No prescription neededNo prescription needed Mentions millions of (dollar) ((dollar) NN,NNN,NNN.NN)Mentions millions of (dollar) ((dollar) NN,NNN,NNN.NN) Talks about Oprah with an exclamation!Talks about Oprah with an exclamation! Phrase: impress ... girlPhrase: impress ... girl From: starts with many numbersFrom: starts with many numbers Subject contains "Your Family”Subject contains "Your Family” Subject is all capitalsSubject is all capitals HTML has a low ratio of text to image areaHTML has a low ratio of text to image area One hundred percent guaranteedOne hundred percent guaranteed Claims you can be removed from the listClaims you can be removed from the list 'Prestigious Non-Accredited Universities''Prestigious Non-Accredited Universities' http://spamassassin.apache.org/tests_3_3_x.html

Naïve Bayes: Word Naïve Bayes: Word Sense DisambiguationSense Disambiguation ww an ambiguous wordan ambiguous word ss11, …, s, …, sKK senses for word senses for word ww v1, …, vJ words in the context of words in the context of ww PP((ssjj)) prior probability of sense prior probability of sense ssjj PP((vvjj||sskk)) probability that word probability that word vvjj occurs in context of sense occurs in context of sense sskk
)(
),()|(
k
kjkj sC
svCsvP
)(
)()(
wC
sCsP k
k
jk v
kjks
svPsPs )|()(argmax