texto de referencia sistemas operativos so.pdf · sistemas operativos ing. jorge orellana a. 5...
TRANSCRIPT

UNIVERSIDAD MAYOR DE SAN SIMON
FACULTAD DE CIENCIAS Y TECNOLOGIA DEPARTAMENTO INFORMATICA – SISTEMAS
TEXTO DE REFERENCIA
SISTEMAS OPERATIVOS
Jorge Walter Orellana Araoz
2016

Sistemas Operativos
Ing. Jorge Orellana A. 1
Tema I INTRODUCCIÓN A LOS SISTEMAS OPERATIVOS
1.1 SISTEMA OPERATIVO Una computador esta constituido de uno o más procesadores, memoria principal, discos, impresoras, teclado, pantalla y otros dispositivos de entrada/salida y la interrelación de sus componentes hace que el computador se torne en un sistema muy complejo. Se precisa escribir código de programas que controlen todos esos componentes y los utilicen de forma correcta, por esto, los computadores están equipados con una capa de software que se denomina sistema operativo.
Un sistema operativo es un programa que actúa como intermediario entre el usuario de un computador y el hardware del mismo. El propósito de un sistema operativo es crear un entorno en el que el usuario pueda ejecutar programas de forma cómoda y eficiente. A pesar de que se usa sistemas operativos casi a diario en dispositivos móviles, celulares, computadoras, etc.; es difícil definir qué es un sistema operativo ya que realizan dos funciones diferentes (complementarias): • Proveer una máquina virtual o extendida (interfaz), es decir, un ambiente en el cual el
usuario pueda ejecutar programas de manera conveniente, protegiéndolo de los detalles y complejidades del hardware.
• Administrar eficientemente (optimizar) los recursos del computador (componentes tanto físicos como lógicos: el procesador, memoria, discos, ratones o archivos) para soportar los requerimientos.
1.1.1 El sistema operativo como máquina virtual Escribir programas que hagan uso correcto de los componentes de una computadora no es una tarea trivial. Si cada programador tuviera que preocuparse de, por ejemplo, como funciona el disco duro del computador, teniendo además siempre presentes todas las posibles cosas que podrían fallar, entonces a la fecha se habría escrito una cantidad bastante reducida de programas. Es mucho más fácil decir “escriba adiós al final del archivo datos”, que
1. Poner en determinados registros del controlador de disco la dirección que se quiere escribir, el número de bytes que se desea escribir, la posición de memoria donde está la información a escribir, el sentido de la operación (lectura o escritura), además de otros parámetros;
2. Decir al controlador que efectué la operación. 3. Esperar. Decidir qué hacer si el controlador se demora más de lo esperado (¿cuánto es “lo
esperado”?). 4. Interpretar el resultado de la operación (una serie de bits). 5. Reintentar si algo anduvo mal. 6. etc.
Además, habría que reescribir el programa si se instala un disco diferente o se desea ejecutar el programa en otra máquina. Hace muchos años que quedó claro que era necesario encontrar algún medio para aislar a los programadores de las complejidades del hardware. Esa es precisamente una de las tareas del sistema operativo, que puede verse como una capa de software que maneja todas las partes del sistema, y hace de intermediario entre el hardware y los programas del usuario. El sistema operativo presenta, de esta manera, una interfaz o máquina virtual que es más fácil de entender y de programar que la máquina pura. Además, para una misma familia de máquinas, aunque tengan componentes diferentes (por ejemplo, monitores de distinta resolución o discos duros de diversos fabricantes), la máquina virtual puede ser idéntica: el programador ve exactamente la misma interfaz. Desde esta perspectiva, la función del sistema operativo es presentar al usuario el equivalente de una máquina extendida o máquina virtual que es más fácil de programar que el hardware subyacente.

Sistemas Operativos
Ing. Jorge Orellana A. 2
1.1.2 El sistema operativo como administrador de recursos La otra tarea de un sistema operativo consiste en administrar los recursos de un computador cuando hay dos o más programas que se ejecutan simultáneamente y requieren usar el mismo recurso (como tiempo de CPU, memoria o impresora). Además, en un sistema multiusuario, suele ser necesario o conveniente compartir, además de dispositivos físicos, información. Al mismo tiempo, debe tenerse en cuenta consideraciones de seguridad: por ejemplo, la información confidencial sólo debe ser accesada por usuarios autorizados, un usuario cualquiera no debiera ser capaz de sobrescribir áreas críticas del sistema, etc. (En este caso, un usuario puede ser una persona, un programa, u otro computador). En resumen, el sistema operativo debe llevar la cuenta acerca de quién está usando qué recursos; otorgar recursos a quienes los solicitan (siempre que el solicitante tenga derechos adecuados sobre el recurso); y arbitrar en caso de solicitudes conflictivas. 1.2 EVOLUCIÓN DE LOS SISTEMAS OPERATIVOS Los sistemas operativos y la arquitectura de computadores han evolucionado de manera interrelacionada: para facilitar el uso de los computadores, se desarrollaron los sistemas operativos. Al construir y usar los sistemas operativos, se hace obvio que ciertos cambios en la arquitectura los simplificaría. Por eso, es conveniente echar una mirada a la historia.
1.2.1. La primera generación (1945-1955): tubos de vacío y tableros de Conexiones
El primer computador digital fue diseñado por el matemático inglés Charles Babbage hace cerca de siglo y medio. Era un computador totalmente mecánico, que Babbage nunca pudo construir, principalmente debido a que la tecnología de la época no era capaz de producir las piezas con la precisión requerida.
Después de eso, poco se hizo hasta la segunda guerra, alrededor de 1940 se construyeron las primeras máquinas calculadoras usando tubos de vacío. Estas máquinas de varias toneladas de peso eran diseñadas, construidas, programadas y operadas por el mismo grupo de personas. No había ni lenguajes de programación, ni compiladores; mucho menos sistema operativo. Cada programa se escribía en lenguaje de máquina, usando tableros con enchufes e interruptores y tenía que manejar todo el sistema (lo que era factible gracias a que el programador era el mismo que diseñó y construyó la máquina). Con el tiempo se introdujeron las tarjetas perforadas, para reemplazar al tablero, pero el sistema era esencialmente el mismo.

Sistemas Operativos
Ing. Jorge Orellana A. 3
1.2.1 La segunda generación (1955-1965): transistores y procesamiento por lotes La introducción de los transistores permitió aumentar sustancialmente la confiabilidad de los computadores, lo que a su vez hizo factible construir máquinas comerciales. Por primera vez hubo una separación entre diseñadores, constructores, y programadores. La aparición de los primeros compiladores (FORTRAN) facilitó la programación, a costa de hacer mucho más compleja la operación de los computadores. Por ejemplo, para probar un programa en FORTRAN recién escrito, el programador debía esperar su turno, y:
1. Cargar el compilador de FORTRAN, típicamente desde una cinta magnética. 2. Poner el grupo de tarjetas perforadas correspondientes al programa FORTRAN y correr el
compilador. 3. El compilador genera código en assembler, así que hay que cargar ahora el ensamblador
para traducirlo a lenguaje de máquina. Este paso requiere poner otra cinta con el ensamblador. Ejecutar el ensamblador, para generar el programa ejecutable.
4. Ejecutar el programa. Si hay errores en cualquiera de estos pasos, el programador debía corregir el programa y comenzar todo de nuevo. Obviamente, mientras el programador ponía cintas y tarjetas, y mientras se devanaba los sesos para descubrir por qué el programa no funciona, la CPU de millones de dólares de costo se mantenía completamente ociosa. Se idearon mecanismos para mantener a la CPU siempre ocupada. El primero fue separar el rol de programador del rol de operador. Un operador profesional demoraba menos en montar y desmontar cintas, y podía acumular lotes de trabajos con requerimientos similares: por ejemplo, si se acumula la compilación de varios programas FORTRAN, entonces el compilador de FORTRAN se carga una sola vez para todos los trabajos.
Aún así, en la transición de un trabajo a otro la CPU se mantenía desocupada. Aparecieron entonces los monitores residentes, que fueron los precursores de los sistemas operativos. Un monitor residente es un pequeño programa que está siempre en la memoria del computador, desde que éste se enciende. Cuando un programa termina, se devuelve el control al monitor residente, quien inmediatamente selecciona otro programa para ejecutar. Ahora los programadores, en vez de decirle al operador qué programa cargar, debían informárselo al monitor (mediante tarjetas de control especiales): Esto se conoce como procesamiento por lotes: el programador deja su grupo de tarjetas, y después vuelve a retirar la salida que se emite por la impresora (y que puede ser nada más que la notificación de que el programa tenía un error de sintaxis).
1.2.2 La tercera generación (1965-1971): circuitos integrados y multiprogramación El procesamiento por lotes evitó que la CPU tenga que esperar tareas ejecutadas por lentos seres humanos. Pero ahora el cuello de botella se trasladó a los dispositivos mecánicos (impresoras, lectoras de tarjetas y de cinta), intrínsecamente más lentos que las CPUs electrónicas. Para resolver esto, aparece, dentro de la tercera generación de computadores, la multiprogramación: varios trabajos se mantienen permanentemente en memoria; cuando uno de ellos tiene que esperar que una operación (como grabar un registro en cinta) se complete, la CPU continúa con la

Sistemas Operativos
Ing. Jorge Orellana A. 4
ejecución de otro trabajo. Si se mantiene un número suficiente de trabajos en la memoria, entonces la CPU puede estar siempre ocupada.
Pero el sistema sigue siendo esencialmente un sistema de procesamiento por lotes; los programadores no interactúan en línea con el computador, los tiempos de respuesta desde que se deja un trabajo para ejecución hasta conocer el resultado son demasiado grandes. De ahí nace el concepto de tiempo compartido que es una variante de la multiprogramación en la cual una CPU atiende simultáneamente los requerimientos de varios usuarios conectados en línea a través de terminales.
Ya que los usuarios humanos demoran bastante entre la emisión de un comando y otro, una sola CPU es capaz de atender, literalmente, a cientos de ellos simultáneamente (bueno, en realidad, uno después de otro, pero los usuarios tienen la ilusión de la simultaneidad). Por otra parte, cuando no hay ningún comando que ejecutar proveniente de un usuario interactivo, la CPU puede cambiar a algún trabajo por lote. 1.2.3 La cuarta generación (1971-Presente): computadores personales Con el advenimiento de la integración a gran escala, que permitió concentrar en un solo chip miles, y luego millones de transistores, nació la era de la computación personal. Los conceptos utilizados para fabricar los sistemas operativos de la tercera generación de computadores siguen siendo, en general, adecuados para la cuarta generación. Algunas diferencias destacables: • Dado los decrecientes costos de las CPUs, ya no es nada de grave que un procesador esté
desocupado. • La creciente capacidad de las CPUs permite el desarrollo de interfaces gráficas; buena parte
del código de los sistemas operativos de hoy es para manejar la interfaz con el usuario. • Los sistemas paralelos (un computador con varias CPUs), requieren sistemas operativos
capaces de asignar trabajos a los distintos procesadores. • Las redes de computadores y sistemas distribuidos abren nuevas posibilidades e imponen
nuevas obligaciones a los sistemas operativos.
En 1974, Intel presentó el microprocesador 8080 de ocho bits y buscó un sistema operativo para ese procesador. Gary Kildall y un amigo construyeron primero un controlador para la unidad de disco flexible de ocho pulgadas recién salida de Shugart Associates, enganchando así el disquete al 8080, y dando lugar al primer microcomputador con disco. Luego Kildall escribió un sistema operativo basado en disco llamado CP/M (Control Program for Microcomputers). Intel no pensó que los microordenadores basados en disco fueran a tener mucho futuro, de manera que cuando Kildall pidió quedarse con los derechos del CP/M, Intel se lo concedió. Kildall formó entonces una compañía, Digital Research, para seguir desarrollando y vender el sistema operativo CP/M. En

Sistemas Operativos
Ing. Jorge Orellana A. 5
1977, Digital Research reescribió CP/M para que pudiera ejecutarse en los numerosos microcomputadores que utilizaban el 8080, el Zilog Z80 u otros microprocesadores. Se escribieron muchos programas de aplicación para ejecutarse sobre CP/M, lo que permitió a este sistema operativo dominar por completo el mundo de los microcomputadores durante unos cinco años.
A principios de la década de 1980, IBM diseñó el PC y buscó software que se ejecutara en él. Gente de IBM se puso en contacto con Bill Gates para utilizar bajo licencia su intérprete de BASIC. También le preguntaron si sabía de algún sistema operativo que funcionara sobre el PC. Gates sugirió a IBM que se pusiera en contacto con Digital Research, que entonces era la compañía de sistemas operativos dominante. Kildall rechazó reunirse con IBM. Consecuentemente, IBM fue de vuelta con Gates para preguntarle si podría ofrecerle un sistema operativo. Gates se percató de que un fabricante de computadores local, Seattle Computer Products, tenía un sistema operativo apropiado, DOS (Disk Operating System). Gates se reunió con el fabricante y se ofreció a comprarle el sistema (supuestamente por 50.000 dólares). Luego Gates ofreció a IBM un paquete DOS/BASIC, que IBM aceptó. IBM pidió que se hicieran ciertas modificaciones en el sistema, por lo que Gates contrató a la persona que había escrito DOS, Tim Paterson, como empleado de su naciente compañía, Microsoft, para que las llevara a cabo. El sistema revisado se rebautizó con el nombre de MS-DOS (Microsoft Disk Operating System) y pronto dominó el mercado del IBM PC.
Para cuando el PC/AT de IBM salió a la venta el 1983 con la CPU 80286 de Intel, MS- DOS estaba firmemente afianzado mientras que CP/M agonizaba. Más tarde se utilizó ampliamente MS-DOS en el 80386 y el 80486. Aunque la versión inicial de MS-DOS era más bien primitiva, sus versiones posteriores incluyeron funciones más avanzadas, incluyendo muchas procedentes de UNIX. (Microsoft tenía perfecto conocimiento de UNIX, e incluso vendió durante los primeros años de la compañía una versión para microordenador a la que llamó XENIX.)
CP/M, MS-DOS y otros sistemas operativos para los primeros microcomputadores obligaban al usuario a introducir comandos a través del teclado. En un momento dado la cosa cambió, gracias a las investigaciones hechas por Doug Engelbart en el Stanford Research Institute, en los años sesenta. Engelbart invento la GUI (Graphical User Interface; Interfaz Gráfica de Usuario), provista de ventanas, iconos, menús y ratón. Los investigadores de Xerox PARC adoptaron estas ideas, incorporándolas a las máquinas que fabricaban. Steve Jobs, coinventor de la computadora Apple en el garaje de su casa, visitó PARC, vio una GUI, y de inmediato se dio cuenta de su valor potencial, algo que, de forma asombrosa, no hizo la gerencia de Xerox (Smith y Alexander, 1988). Jobs se dedicó entonces a construir un Apple provisto de una GUI. Este proyecto condujo a la construcción del ordenador Lisa, que resultó demasiado caro y fracasó comercialmente. El segundo intento de Jobs, el Apple Macintosh, fue un enorme éxito, no sólo porque era mucho más económico que Lisa, sino también porque era amigable con el usuario (user friendly), lo que significa que iba dirigido a usuarios que no sólo carecían de conocimientos sobre computadores, sino que además no tenían ni la más mínima intención de aprender.
Microsoft decidió desarrollar un sucesor para MS-DOS y estuvo fuertemente influenciado por el éxito del Macintosh. La compañía produjo un sistema basado en una GUI al que llamó Windows, y que originalmente se ejecutaba por encima de MS-DOS (es decir, era más un shell que un verdadero sistema operativo). Durante cerca de 10 años, de 1985 a 1995, Windows no fue más que un entorno gráfico por encima de MS-DOS. Sin embargo, en 1995 salió a la circulación una versión autónoma de Windows, Windows 95, que incluía muchas funciones del sistema operativo y sólo utilizaba el sistema MS-DOS subyacente para arrancar y ejecutar programas antiguos de MS-DOS. En 1998 salió una versión ligeramente modificada de este sistema, llamada Windows 98. No obstante tanto Windows 95 como Windows 98 contienen todavía una buena cantidad de lenguaje ensamblador Intel de 16 bits. Otro sistema operativo de Microsoft es Windows NT (NT significa Nueva Tecnología), que es compatible hasta cierto punto con Windows 95, pero que internamente está reescrito desde cero. Se trata de un sistema completamente de 32 bits. El diseñador en jefe de Windows NT fue David Cutler, quien también fue uno de los diseñadores del sistema operativo VAX VMS, así que algunas de las ideas de VMS están presentes en NT. Microsoft confiaba en que la primera versión de NT exterminaría a MS-DOS y todas las demás versiones anteriores de

Sistemas Operativos
Ing. Jorge Orellana A. 6
Windows porque se trata de un sistema enormemente superior, pero no fue así. Sólo con Windows NT 4.0 comenzó a adoptarse ampliamente el sistema, sobre todo en redes corporativas. La versión 5 de Windows NT se rebautizó como Windows 2000 a principios de 1999, con la intención de que fuera el sucesor tanto de Windows 98 como de Windows NT 4.0. Eso tampoco funcionó como se pensaba, así que Microsoft sacó una versión más de Windows 98 llamada Windows Me (Millennium edition). Las versiones de Windows XP, Vista, 7 y 8 están basados en Windows NT.
El otro contendiente importante en el mundo de los computadores personales es UNIX (y sus diversos derivados). UNIX predomina en estaciones de trabajo y servidores de red. Es especialmente popular en máquinas basadas en chips RISC de alto rendimiento. Aunque muchos usuarios de UNIX, sobre todo programadores experimentados, prefieren un interfaz basado en comandos en vez de una GUI, casi todos los sistemas UNIX reconocen un sistema de ventanas llamado X Windows producido en el MIT. Linus Torvalds trabajó sobre Minix (una versión reducida de Unix creada por Andrew Tanembaum) llamandola Linux y liberó el código fuente en internet, de la cual se originaron infinidad de distribuciones y que también posee interfaces graficas en la actualidad (KDE, GNOME,etc).
1.3 COMPONENTES DEL SISTEMA Un sistema operativo crea el entorno en el que se ejecutan los programas. Podemos crear un sistema tan grande y complejo como un sistema operativo sólo si lo dividimos en porciones más pequeñas. Cada una de estas partes deberá ser un componente bien delineado del sistema, con entradas, salidas y funciones cuidadosamente definidas. La interfaz entre el S. O. y los programas del usuario se define como el conjunto de instrucciones ampliadas que proporciona el S. O. y son las “llamadas al sistema”. 1.3.1 Gestión de procesos Un programa no puede hacer nada si la CPU no ejecuta sus instrucciones. Podemos pensar en un proceso como una porción de un programa en ejecución o todo el programa. Un proceso necesita ciertos recursos, incluidos tiempo de CPU, memoria, archivos y dispositivos de E/S, para llevar a cabo su tarea. Estos recursos se otorgan al proceso en el momento en que se crea, o bien se le asignan durante su ejecución. Un proceso es la unidad de trabajo de un sistema. El sistema consiste en una colección de procesos, algunos de los cuales son procesos del sistema operativo (los que ejecutan código del sistema), siendo el resto procesos de usuario (los que ejecutan código de algún usuario). 1.3.2 Gestión de la memoria principal La memoria principal es crucial para el funcionamiento de un sistema de computación moderno. La memoria principal es una matriz grande de palabras o bytes, cuyo tamaño va desde cientos de miles hasta cientos de millones. Cada palabra o byte tiene su propia dirección. La memoria principal es un depósito de datos a los que se puede acceder rápidamente y que son compartidos por la CPU y los dispositivos de E/S. El procesador central lee instrucciones de la memoria principal durante el ciclo de obtención de instrucciones, y lee y escribe datos de la memoria principal durante el ciclo de obtención de datos. 1.3.3 Gestión de archivos Un archivo es una colección de información relacionada definida por su creador. Por lo regular, los archivos representan programas (en forma tanto fuente como objeto) y datos. Los archivos de datos pueden ser numéricos, alfabéticos o alfanuméricos. Los archivos pueden ser de forma libre, como los de texto, o tener un formato rígido. El sistema operativo posee un sistema de archivos que se encarga de estructurar, organizar, gestionar estos archivos. 1.3.4 Gestión del sistema de E/S Uno de los objetivos de un sistema operativo es ocultar las peculiaridades de dispositivos de hardware específicos de modo que el usuario no las perciba.

Sistemas Operativos
Ing. Jorge Orellana A. 7
1.3.5 Gestión de almacenamiento secundario El propósito principal de un sistema de computación es ejecutar programas. Estos programas, junto con los datos a los que acceden, deben estar alojados en la memoria principal (almacenamiento primario) durante la ejecución. Dado que la memoria principal es demasiado pequeña para dar cabida a todos los datos y programas, y que pierde su información cuando deja de recibir corriente eléctrica, el sistema de computación debe contar con algún almacenamiento secundario para respaldar la memoria principal. La mayor parte de los sistemas de computación modernos utiliza discos como principal medio de almacenamiento. El sistema operativo se encarga de las siguientes actividades relacionadas con la gestión de discos: Administración del espacio libre, Asignación del almacenamiento y Planificación del disco 1.3.6 Sistema de protección En los primeros computadores, el operador tenía el control completo del sistema. Con el tiempo, se fueron desarrollando los sistemas operativos, y parte del control se traspasó a ellos. Además, para mejorar la utilización del sistema, se comenzó primero a manejar varios programas en memoria en forma simultánea, y luego a atender simultáneamente a varios usuarios. Pero el remedio trajo su propia enfermedad, ya que un programa podía por error o por mala intención de su creador, modificar datos de otros programas, o peor aún, modificar el propio sistema operativo, lo que podía “colgar” todo el sistema. En general, un programa puede alterar el normal funcionamiento del sistema de las siguientes formas: • Ejecutando una instrucción de E/S ilegal (por ejemplo, que borre todos los archivos del disco). • Sobrescribiendo áreas de la memoria que pertenecen al sistema operativo. • No devolviendo el control de la CPU al sistema operativo. Para evitar esto, es indispensable el apoyo del hardware, a través de los siguientes mecanismos: 1.3.6.1 Operación dual Para asegurar una operación adecuada, se debe proteger al sistema operativo y todos los programas del malfuncionamiento de cualquier otro programa. Para eso, el hardware debe proveer al menos dos modos de operación. • Modo usuario. • Modo sistema (o privilegiado, protegido o supervisor). El bit de modo indica el modo de operación actual. Cuando se enciende el computador y se carga el sistema operativo, se comienza en modo sistema. El sistema operativo siempre cambia a modo usuario antes de pasar el control a un proceso de usuario. Cuando ocurre una interrupción, el hardware siempre cambia a modo sistema. De esta manera, el sistema operativo siempre ejecuta en modo sistema. Hay ciertas operaciones críticas que sólo pueden ser ejecutadas en modo sistema. 1.3.6.2 Protección de E/S Para prevenir que un usuario ejecute instrucciones de E/S que puedan provocar daño, la solución es simple: las instrucciones de E/S sólo pueden ejecutarse en modo sistema. Así los usuarios no pueden ejecutar E/S directamente, sino que deben hacerlo a través del sistema. Para que este mecanismo de protección sea completo, hay que asegurarse que los programas de usuario no puedan obtener acceso a la CPU en modo sistema. Por ejemplo, un programa de usuario podría poner una dirección que apunte a una rutina propia en el vector de interrupciones. Así, cuando se produzca la interrupción, el hardware cambiaría a modo sistema, y pasaría el control a la rutina del usuario. O, también, el programa de usuario podría reescribir el servidor de la interrupción. 1.3.6.3 Protección de memoria No sólo hay que proteger el vector de interrupciones y las rutinas servidoras, sino que, en general, queremos proteger las áreas de memoria utilizadas por el sistema operativo y por otros programas.

Sistemas Operativos
Ing. Jorge Orellana A. 8
Una forma es usando dos registros: base y límite, que establecen el rango de direcciones de memoria que el programa puede accesar legalmente. Para que esto funcione, hay que comparar cada dirección accesada por un programa en modo usuario con estos dos registros. Si la dirección está fuera del rango, se genera una interrupción que es atendida por el sistema operativo, quien aborta el programa (usualmente con un mensaje "segmentation fault"). Esta comparación puede parecer cara, pero teniendo presente que se hace en hardware, no lo es tanto. Obviamente, el programa usuario no debe poder modificar estos registros: las instrucciones que los modifican son instrucciones protegidas. 1.3.6.4 Protección de CPU Lo único que falta, es asegurarse que el sistema operativo mantenga el control del buque, o sea, hay que prevenir, por ejemplo, que un programa entre en un ciclo infinito y nunca devuelva el control al sistema operativo. Esto se logra con un timer (reloj). 1.3.7 Sistema de interpretación de órdenes Uno de los programas del sistema más importantes de un sistema operativo es el intérprete de órdenes o de comandos, que es la interfaz entre el usuario y el sistema operativo. Algunos sistemas operativos incluyen el intérprete de órdenes en el núcleo; otros, como MS-DOS y Unix, tratan el intérprete de órdenes como un programa especial que se está ejecutando cuando se inicia un trabajo, o cuando un usuario ingresa en un sistema de tiempo compartido. La función del intérprete de línea de comandos o shell es muy sencilla: obtener la siguiente orden y ejecutarla. 1.3.8 Llamadas al sistema Son la interfaz entre el sistema operativo y un programa en ejecución. Pueden ser instrucciones en lenguaje ensamblador (MSDOS) o pueden hacerse desde lenguajes de alto nivel como C (Unix, Linux, Windows). El control pasa al vector de interrupciones para que una rutina la atienda. El bit de modo se pone en modo monitor. El monitor analiza la instrucción que provocó la interrupción. Así se ejecuta la solicitud y vuelve el control a la instrucción siguiente a la llamada al sistema. Los parámetros asociados a las llamadas pueden pasarse de varias maneras: por registros, bloques o tablas en memoria o pilas. Hay varias categorías de llamadas al sistema:
• Control de procesos: finalizar, abortar, cargar, ejecutar, crear, terminar, establecer y obtener atributos del proceso, esperar un tiempo, señalar y esperar evento, asignar y liberar memoria.
• Manipulación de archivos: crear, eliminar, abrir, cerrar, leer, escribir, reposicionar, obtener y establecer atributos de archivo.
• Manipulación de dispositivos: solicitar, liberar, leer, escribir, reposicionar, obtener y establecer atributos de dispositivo.
• Mantenimiento de información: obtener fecha y hora, datos del sistema, atributos. • Comunicaciones: crear, eliminar conexión de comunicación, enviar y recibir mensajes,
transferir información de estado, etc. 1.4 ESTRUCTURA DE LOS SISTEMAS OPERATIVOS (ESTUDIO DE CASOS) 1.4.1 Estructura simple - Sistemas monolíticos. Una forma de organizar un sistema operativo, es con una estructura simple (o sin estructura). El sistema operativo se escribe como una colección de procedimientos, cada uno de los cuales llama a los otros cuando lo requiere. Lo único que está bien definido es la interfaz de estos procedimientos, en términos de parámetros y resultados. Para generar el sistema operativo (el binario), se compilan todos los procedimientos y se enlazan en un solo archivo (el kernel), que es el que se carga en la memoria cuando se enciende la máquina. El kernel es grande y cumple todas las funciones del sistema operativo. Es el caso de MS-DOS y de las primeras versiones de Unix.

Sistemas Operativos
Ing. Jorge Orellana A. 9
Incluso en los sistemas monolíticos es posible tener al menos un poco de estructura. Los servicios (llamadas al sistema) proporcionados por el sistema operativo se solicitan colocando los parámetros en lugares bien definidos, como en registros o en la pila, y ejecutando después una instrucción de trampa especial conocida como llamada al kernel o llamada al supervisor.
Esta instrucción conmuta la máquina del modo de usuario al modo de kernel y transfiere el control al sistema operativo, lo cual se muestra como evento (1) en la figura. (La mayor parte de las CPU tienen dos modos: modo de kernel, para el sistema operativo, en el que se permite todas las instrucciones; y modo de usuario, para programas de usuario, en el que no se permiten instrucciones de E/S y de ciertos otros tipos.) A continuación, el sistema operativo examina los parámetros de la llamada para determinar cuál llamada al sistema se ejecutará; esto se muestra como (2) en la figura. Acto seguido, el sistema operativo consulta una tabla que contiene en la ranura k un apuntador al procedimiento que lleva a cabo la llamada al sistema k. Esta operación, marcada con (3), identifica el procedimiento de servicio, mismo que entonces se invoca. Una vez que se ha completado el trabajo y la llamada al sistema ha terminado, se devuelve el control al programa de usuario (paso 4) a fin de que pueda continuar su ejecución con la instrucción que sigue a la llamada al sistema. Esta organización sugiere una estructura básica para el sistema operativo: 1. Un programa principal que invoca el procedimiento de servicio solicitado. 2. Un conjunto de procedimientos de servicio que llevan a cabo las llamadas al sistema. 3. Un conjunto de procedimientos de utilería que ayudan a los procedimientos de servicio. En este modelo, para cada llamada al sistema hay un procedimiento de servicio que se ocupa de ella. Los procedimientos de utilería hacen cosas que varios procedimientos de servicio necesitan, como obtener datos de los programas de usuario.
1.5.2 Sistemas Estructurados 1.5.2.1 Estructuración en capas Una generalización del modelo anterior es diseñar el sistema en capas. El primer exponente de esta categoría fue el sistema operativo THE (Technische Hogeschool Eindhoven , Holanda, 1968), un sistema de procesamiento por lotes. En el caso de THE, la estructuración en capas era más que nada para modularizar el diseño (igual se compilaba y enlazaba todo en un solo gran archivo).

Sistemas Operativos
Ing. Jorge Orellana A. 10
Cada capa encapsula datos y las operaciones que manipulan esos datos. Una capa puede usar los servicios sólo de capas inferiores.
La Capa 0 trabaja con la asignación del procesador, alterna entre los procesos cuando ocurren las interrupciones o expiran los cronómetros y proporciona la multiprogramación básica. La Capa 1 administra la memoria, asegura que las páginas (porciones de memoria) requeridas de los procesos lleguen a memoria cuando fueran necesarias. La Capa 2 administra la comunicación entre cada proceso y la consola del operador (Por sobre esta capa, cada proceso tiene su propia consola de operador). La Capa 3 controla los dispositivos de e / s y almacena en buffers los flujos de información entre ellos (Por sobre la capa 3 cada proceso puede trabajar con dispositivos abstractos de E/S en vez de con dispositivos reales). La Capa 4 aloja los programas del usuario, los programas. del usuario no tienen que preocuparse por el proceso, memoria, consola o control de e / s. La Capa 5 localiza el proceso operador del sistema. Como ventajas se pueden citar la modularización, ocultamiento de información, flexibilidad. Cada capa se desarrolla y depura "sin mirar hacia arriba". Nuevas funciones pueden añadirse, y la implementación de las existentes puede modificarse, mientras no se cambie su interfaz. Las desventajas son que requiere cuidadosa planificación, para decidir qué cosa va en qué capa. Por ejemplo, la capa que provee acceso al disco debe estar en una capa más baja que la que administra memoria virtual, pero encima del planificador de CPU, pues el driver probablemente se bloquea para esperar que una operación de E/S se complete. Sin embargo, en un sistema grande, el planificador podría llegar a necesitar manejar más información de los procesos que la que cabe en su memoria, requiriendo apoyarse en el disco. Otro potencial problema es la eficiencia, pues algunos servicios pasan por varias capas antes de llevarse a cabo. Una generalización mas avanzada del concepto de capas se presento con Multics (multiplexed information and computing service) MIT, Bell Labs y General Electric. Presenta una estructura en anillos concéntricos, siendo los interiores los privilegiados. Un procedimiento de un anillo exterior, para llamar a un procedimiento de un anillo interior, debe hacer el equivalente a una llamada al sistema. Otro ejemplo de sistema operativo diseñado por capas es el OS/2, descendiente de MS-DOS. 1.5.2.2 Máquinas virtuales Un sistema operativo de tiempo compartido cumple dos funciones: (1) multiprogramación, y (2) proveer una máquina extendida, con una interfaz más conveniente para los programas de usuario que la máquina pura. En la década del 70, a la IBM se le ocurrió separar completamente estas funciones en el sistema operativo VM/370. El núcleo del sistema, llamado monitor de la máquina virtual ejecuta directamente sobre el hardware, y su único objetivo es la multiprogramación, ofreciendo múltiples máquinas virtuales a la capa superior. Pero estas máquinas virtuales no son máquinas extendidas (con archivos y otras abstracciones), como es lo habitual, sino copias exactas de la máquina original. Cada máquina virtual puede ejecutar un sistema operativo diferente, construido para operar en la máquina original. La CPU se comparte con planificación de CPU, la memoria con memoria virtual, y el disco se particiona. No es simple de implementar. La máquina original tiene dos modos: monitor y usuario. El monitor de la máquina virtual opera en modo monitor, y cada máquina virtual puede operar sólo en modo usuario. En consecuencia se debe proveer un modo usuario virtual y un modo monitor virtual. Las

Sistemas Operativos
Ing. Jorge Orellana A. 11
acciones que en la máquina real causan el paso de modo usuario a modo monitor deben causar el paso de modo usuario virtual a modo monitor virtual. ¿Cómo? Cuando un proceso de usuario hace una llamada al sistema, el control se transfiere al monitor de la máquina virtual, quien devuelve el control a la máquina virtual, simulando una llamada al sistema. Si en esas condiciones (operando en modo monitor virtual, que en realidad no es más que modo usuario físico), se intenta accesar el hardware (por ejemplo, una operación de E/S), el control vuelve al monitor de la máquina virtual, quien efectúa, controladamente, la operación).
Las ventajas son que facilita el desarrollo de sistemas operativos (cuando la máquina es cara y no se puede entregar una a cada programador). Sin este esquema, es necesario bajar la máquina cada vez que quiere probar una modificación al sistema. También permite resolver problemas de compatibilidad. Por ejemplo, si queremos desarrollar un nuevo sistema operativo, pero queremos que los miles de programas DOS que existen sigan corriendo, podemos usar esta solución, asignando una máquina virtual a cada programa DOS que se ejecute. Se puede ir más lejos, y crear una máquina virtual distinta a la original. Así es como Windows para arquitectura Intel se puede ejecutar, por ejemplo en una Silicon Graphics. El problema es que, en este caso, hay que interpretar cada instrucción (en lugar de ejecutarla directamente).
1.5.2.3. Exokernel
Con el VM/370, cada proceso de usuario obtiene una copia exacta del ordenador real. Con el modo 8086 virtual del Pentium, cada proceso de usuario obtiene una copia exacta de un ordenador diferente. Yendo un paso más lejos, algunos investigadores del M.I.T. construyeron un sistema que proporciona a cada usuario un clon del ordenador real, pero con un subconjunto de los recursos (Engler y otros, 1995). Así, una máquina virtual podría obtener los bloques de disco del 0 al 1023, la siguiente podría recibir los bloques del 1024 al 2047, y así de forma sucesiva.
En la capa más baja, ejecutándose en modo núcleo, está un programa llamado exokernel. Su labor consiste en asignar recursos a las máquinas virtuales y luego comprobar cualquier intento de utilizarlos para garantizar que ninguna máquina trate de utilizar los recursos de cualquier otra. Cada máquina virtual a nivel de usuario puede ejecutar su propio sistema operativo, como sobre el VM/370 y los 8086 virtuales del Pentium, sólo que cada una está limitada a los recursos que solicitó y que le fueron asignados.
La ventaja del esquema de exokernel es que ahorra una capa de conversión. En los otros diseños, cada máquina virtual cree que tiene su propio disco, cuyos bloques van desde 0 hasta algún máximo, lo que obliga al monitor de la máquina virtual a mantener tablas para convertir las direcciones de disco (y todos los demás recursos). Con el exokernel no es necesario efectuar esa conversión, pues lo único que tiene que hacer es mantenerse al tanto de qué recursos se han asignado a qué máquinas virtuales. Este método sigue teniendo la ventaja de separar la multiprogramación (en el exokernel) y el código del sistema operativo del usuario (en el espacio del

Sistemas Operativos
Ing. Jorge Orellana A. 12
usuario), pero con menos sobrecarga porque la única tarea del exokernel es evitar que las máquinas virtuales se interfieran mutuamente.
1.5.2.3 MicroKernel (Modelo cliente – servidor) Una tendencia en los sistemas operativos modernos consiste en llevar más lejos aún la idea de subir código a las capas superiores y quitar tanto como sea posible del modo núcleo, dejando un microkernel mínimo. El enfoque usual es implementar la mayor parte del sistema operativo en procesos de usuario. Para solicitar un servicio, tal como la lectura de un bloque de un archivo, un proceso de usuario (que ahora se denomina proceso cliente) envía una solicitud a un proceso servidor, que realiza el trabajo y devuelve la repuesta. Para solicitar un servicio (por ej.: lectura de un bloque de cierto archivo) según el modelo cliente – servidor, el proceso del usuario (proceso cliente) envía la solicitud a un proceso servidor, realiza el trabajo y regresa la respuesta.
El núcleo controla la comunicación entre los clientes y los servidores. Se fracciona el S. O. en partes, cada una controlando una faceta, servicio a archivos, a procesos, a terminales, a memoria, etc., cada parte pequeña y más fácilmente controlable. Los servidores se ejecutan como procesos en modo usuario, no tienen acceso directo al hardware y se aíslan y acotan más fácilmente los problemas. Se adapta para su uso en los sistemas distribuidos, si un cliente se comunica con un servidor mediante mensajes, no necesita saber si el mensaje se atiende localmente o mediante un servidor remoto, situado en otra máquina conectada. Algunas funciones del S. O., ( por ej. el cargado de comandos en los registros físicos del dispositivo de e/s), presentan problemas especiales y distintas soluciones: • Ejecución en modo núcleo, con acceso total al hardware y comunicación con los demás
procesos mediante el mecanismo normal de mensajes. • Construcción de un mínimo de mecanismos dentro del núcleo manteniendo las decisiones de
política relativas a los usuarios dentro del espacio del usuario.
Minix [Tanenbaum, 1998], Mach [Accetta, 1986] y Amoeba [Mullender, 1990] son ejemplos de sistemas operativos que siguen este modelo. Windows NT también sigue esta filosofía de diseño, aunque muchos de los servidores (el gestor de procesos, gestor de E/S, gestor de memoria, etc.) se ejecutan en modo núcleo por razones de eficiencia.

Sistemas Operativos
Ing. Jorge Orellana A. 13
Tema II GESTIÓN DE PROCESOS
2.1. PROCESO. Todos los computadores pueden hacer varias cosas a la vez, mientras está ejecutando un programa de usuario puede perfectamente también estar leyendo de un disco e imprimiendo texto en una pantalla o una impresora. En un sistema multiprogramado la CPU (Unidad Central de Proceso) también conmuta de unos programas a otros, ejecutando cada uno de ellos durante decenas o cientos de milisegundos. Aunque, estrictamente hablando, en cualquier instante de tiempo la CPU sólo está ejecutando un programa, en el transcurso de 1 segundo ha podido estar trabajando sobre varios programas, dando entonces a los usuarios la impresión de un cierto paralelismo (pseudoparalelismo), en contraste con el auténtico paralelismo del hardware de los sistemas multiprocesador (que tienen dos o más CPUs compartiendo la misma memoria física). Seguir la pista de múltiples actividades paralelas resulta muy complicado, por ese motivo los diseñadores de los sistemas operativos han desarrollado un modelo conceptual evolucionado (el de los procesos secuenciales) que permite tratar el paralelismo de una forma más fácil.
En este modelo, todo el software ejecutable en el ordenador, incluyendo a veces al propio sistema operativo, se organiza en un número de procesos secuenciales, o simplemente procesos. Un proceso es justamente un programa en ejecución, incluyendo los valores actuales del contador de programa, registros y variables. Conceptualmente cada proceso tiene su propia CPU virtual. En realidad, la CPU real conmuta sucesivamente de un proceso a otro. Esta rápida conmutación de un proceso a otro en algún orden se denomina multiprogramación.
Debe hacerse una distinción entre un programa y un proceso. Un programa es una entidad estatica constituida por sentencias de programa que definen la conducta del proceso cuando se ejecutan utilizando un conjunto de datos. Un proceso es una entidad dinámica que ejecuta un programa sobre un conjunto de datos utilizando los recursos del sistema operativo. Dos o mas procesos podrían estar ejecutando el mismo programa, empleando sus propios datos y recursos, por ejemplo, si dos o más usuarios están usando simultáneamente el mismo editor de texto. El programa es el mismo, pero cada usuario tiene un proceso distinto (y con distintos datos). Por analogía al preparar una receta de una torta. El programa es la receta, el proceso es la actividad que consiste en leer la receta, mezclar los ingredientes y hornear la torta. 2.1.1. Creación de Procesos Los sistemas operativos necesitan asegurar de alguna forma que puedan existir todos los procesos requeridos, entonces es necesaria alguna manera de poder crear y destruir los procesos según sea necesario durante la operación del sistema. Los cuatro principales sucesos que provocan la creación de nuevos procesos son: • La inicialización del sistema • La ejecución por parte de un proceso (en ejecución) de una llamada al sistema de creación
de un nuevo proceso. • La petición por parte del usuario de la creación de un nuevo proceso. • El inicio de un trabajo en batch (lotes). Cuando un sistema operativo arranca, se crean típicamente varios procesos. Algunos de esos procesos son procesos foreground (en primer plano), esto es, procesos que interactúan con los usuarios y realizan trabajo para ellos. Otros son procesos background (en segundo plano), que no están asociados con usuarios particulares, sino que tienen alguna función específica. Los procesos que se ejecutan como procesos background para llevar a cabo alguna actividad tal como el correo electrónico, las páginas web, las news o la impresión de ficheros de salida, etc, se denominan demonios en Unix o servicios en Windows. Los sistemas grandes tienen comúnmente docenas de ellos. En UNIX, el programa ps puede utilizarse para listar los procesos que están en marcha. En Windows se utiliza el administrador de tareas.

Sistemas Operativos
Ing. Jorge Orellana A. 14
Adicionalmente a los procesos creados en el momento del arranque, también pueden crearse nuevos procesos después. A menudo un proceso en ejecución puede hacer llamadas al sistema para crear uno o más procesos nuevos para que le ayuden en su trabajo. En sistemas interactivos los usuarios pueden arrancar un programa tecleando un comando o haciendo clic (dos veces) con el ratón sobre un icono. Realizando cualquiera de esas acciones se consigue que comience un nuevo proceso y se ejecute el programa correspondiente. En sistemas UNIX basados en comandos y ejecutando X-Windows, el nuevo proceso creado se ejecuta sobre la ventana en la cual se le activó. En Windows, cuando un proceso comienza no tiene ninguna ventana asignada, aunque puede crear una o más. En ambos sistemas, los usuarios pueden tener múltiples ventanas abiertas a la vez, cada una de ellas ejecutando algún proceso. Utilizando el ratón, el usuario puede seleccionar una ventana e interactuar con el proceso, por ejemplo, proporcionando datos de entrada cuando sean necesarios. La última situación que provoca la creación de procesos se aplica sólo a los sistemas en batch que podemos encontrar en los grandes mainframes. En esos sistemas los usuarios pueden lanzar (submit) al sistema trabajos en batch (posiblemente de forma remota). Cuando el sistema operativo detecta que dispone de todos los recursos necesarios para poder ejecutar otro trabajo, crea un nuevo proceso y ejecuta sobre él el siguiente trabajo que haya en la cola de entrada. En UNIX sólo existe una llamada al sistema para crear un nuevo proceso: fork. Esta llamada crea un clon (una copia exacta) del proceso que hizo la llamada. Después del fork, los dos procesos, el padre y el hijo, tienen la misma imagen de memoria, las mismas variables de entorno y los mismos ficheros abiertos. Eso es todo lo que hay. Usualmente, a continuación el proceso hijo ejecuta execve o una llamada al sistema similar para cambiar su imagen de memoria y pasar a ejecutar un nuevo programa. En Windows, una única llamada al sistema de Win32, CreateProcess, realiza tanto la creación del proceso como la carga del programa correcto dentro del nuevo proceso. Tanto en UNIX como en Windows, después de crear un proceso, tanto el padre como el hijo cuentan con sus propios espacios de direcciones disjuntos. 2.1.2. Terminación de Procesos Tras la creación de un proceso comienza su ejecución realizando el trabajo que se le ha encomendado. Sin embargo pronto o tarde el nuevo proceso debe terminar, usualmente debido a una de las siguientes causas: • El proceso completa su trabajo y termina (voluntariamente). • El proceso detecta un error y termina (voluntariamente). • El sistema detecta un error fatal del proceso y fuerza su terminación. • Otro proceso fuerza la terminación del proceso (por ejemplo en UNIX mediante la llamada al
sistema kill). La mayoría de los procesos terminan debido a que han completado su trabajo. Cuando un compilador ha compilado el programa que se le ha dado, el compilador ejecuta una llamada al sistema para decirle al sistema operativo que ha finalizado. Esta llamada es exit en UNIX y ExitProcess en Windows. Los programas orientados a la pantalla soportan también la terminación voluntaria. Los procesadores de texto, navegadores y programas similares cuentan siempre con un icono o una opción de menú para que el usuario pueda elegir con el ratón indicándole al proceso que borre cualquier archivo temporal que esté abierto y a continuación termine. La segunda causa de terminación es que el proceso descubra un error fatal. Por ejemplo, si un usuario teclea un comando incorrecto. La tercera causa de terminación es la aparición de un error causado por el proceso, a menudo debido a un error de programación. Algunos ejemplos son: la ejecución de una instrucción ilegal, una referencia a una posición de memoria inexistente, o una división por cero. La cuarta razón por la cual un proceso puede terminar, es que un proceso ejecute una llamada al sistema diciéndole al sistema operativo que mate a algún otro proceso. En UNIX esta llamada al sistema es kill. La función Win32 correspondiente es TerminateProcess. En ambos casos el proceso asesino debe contar con la debida autorización.

Sistemas Operativos
Ing. Jorge Orellana A. 15
2.1.3. Estado de los procesos Durante su existencia un proceso pasa por una serie de estados discretos, siendo varias las circunstancias que pueden hacer que el mismo cambie de estado:
• Nuevo (new). • Ejecutándose (running). El proceso está siendo ejecutado en la CPU. Por lo tanto a lo
más un proceso puede estar en este estado en un computador uniprocesador. • Listo para ejecutar (ready). El proceso está en condiciones de ejecutarse, pero debe
esperar su turno de CPU. • Bloqueado o En espera (waiting) El proceso no está en condiciones de ejecutarse.
Está esperando que algún evento ocurra, como la finalización de una operación de E/S. También se dice que está suspendido o en espera.
• Terminado (terminated) Se puede establecer una cola de Listos para los procesos “listos” y una cola de Bloqueados para los “bloqueados”. La cola de Listos se mantiene en orden prioritario y la cola de Bloqueados está desordenada, ya que los procesos se desbloquean en el orden en que tienen lugar los eventos que están esperando. Al admitirse un trabajo en el sistema se crea un proceso equivalente y es insertado en la última parte de la cola de Listos. La asignación de la CPU al primer proceso de la cola de Listos se denomina “Despacho”, que es ejecutado por una entidad del Sistema Operativo llamada “Despachador” (dispatcher). El “Bloqueo” es la única transición de estado iniciada por el propio proceso del usuario, puesto que las otras transiciones son iniciadas por entidades ajenas al proceso.
2.1.4. Implementación de procesos El sistema operativo mantiene para cada proceso un bloque de control de proceso o process control block (PCB), donde se guarda para cada proceso la información necesaria para reanudarlo si es suspendido, y otros datos. • Estado: Puede ser nuevo, listo, en ejecución, en espera, detenido, etcétera • Contador de programa: El contador indica la dirección de la siguiente instrucción que se
ejecutará para este proceso. • Registros de CPU: El número y el tipo de los registros varía dependiendo de la arquitectura
del computador. Los registros incluyen acumuladores, registros índice, punteros de pila y registros de propósito general, así como cualquier información de códigos de condición que haya. Junto con el contador de programa, esta información de estado se debe guardar cuando ocurre una interrupción, para que el proceso pueda continuar correctamente después.
• Información para planificación: Esta información incluye una prioridad del proceso, punteros a colas de planificación y cualquier otro parámetro de planificación que haya.
• Información para administración de memoria: Esta información puede incluir datos tales como el valor de los registros de base y límite, las tablas de páginas o las tablas de segmentos, dependiendo del sistema de memoria empleado por el sistema operativo.

Sistemas Operativos
Ing. Jorge Orellana A. 16
• Información de estado de E/S: La información incluye la lista de dispositivos de E/S asignadas a este proceso, una lista de archivos abiertos, etcétera.
• Estadísticas y otros: tiempo real y tiempo de CPU usado, identificador del proceso, identificador del dueño, tiempo real consumido, límites de tiempo, números de cuenta, números de trabajo o proceso, y demás.
Cuando el Sistema Operativo cambia la atención de la CPU entre los procesos, utiliza las áreas de preservación del PCB para mantener la información que necesita para reiniciar el proceso cuando consiga de nuevo la CPU.
2.1.5. Cambios de contexto (context switch) Cuando el sistema operativo entrega la CPU a un nuevo proceso, debe guardar el estado del proceso que estaba ejecutando, y cargar el estado del nuevo proceso. El estado de un proceso comprende el PC (Contador del programa), y los registros de la CPU. Además, si se usan las técnicas de administración de memoria que veremos más adelante, hay más información involucrada. Este cambio, que demora de unos pocos a mil microsegundos, dependiendo del procesador, es puro overhead o sobrecosto, puesto que entretanto la CPU no hace trabajo útil (ningún proceso avanza). Considerando que la CPU hace varios cambios de contexto en un segundo, su costo es relativamente alto. Algunos procesadores tienen instrucciones especiales para guardar todos los registros de una vez. Otros tienen varios conjuntos de registros, de manera que un cambio de contexto se hace simplemente cambiando el puntero al conjunto actual de registros. El problema es que si hay más procesos que conjuntos de registros, igual hay que apoyarse en la memoria. Por ser un cuello de botella tan importante para el desempeño del sistema operativo se emplean estructuras nuevas (hilos) para evitarla hasta donde sea posible. 2.1.6. Jerarquia de procesos La secuencia de creación de procesos genera un árbol de procesos. Para referirse a las relaciones entre los procesos de la jerarquía se emplean los términos de padre, hermano o abuelo. Cuando el proceso A solicita al sistema operativo que cree el proceso B, se dice que A

Sistemas Operativos
Ing. Jorge Orellana A. 17
es padre de B y que B es hijo de A. Bajo esta óptica, la jerarquía de procesos puede considerarse como un árbol genealógico. Algunos sistemas operativos, como Unix, mantienen de forma explícita esta estructura jerárquica de procesos (un proceso sabe quién es su padre), mientras que otros sistemas operativos como el Windows NT no la mantienen. Por ejemplo, en Unix, cuando se carga el sistema operativo, se inicializa un proceso init. Este proceso lee un archivo que dice cuántos terminales hay, y crea un proceso login para cada terminal, que se encarga de solicitar nombre y contraseña. Cuando un usuario entra, login determina qué shell le corresponde al usuario, y crea otro proceso para ejecutar esa shell. A su vez, la shell crea más procesos según los comandos que ejecute el usuario, generándose así todo un árbol de procesos: cada proceso tiene cero o más hijos, y exactamente un padre (salvo init, que no tiene padre). Haciendo una analogia en Windows, aun cuando este sistema operativo no mantiene esta jerarquia y todos son iguales, unos de los primeros procesos seria System, luego Winlogon para crear una sesion y sobre ella crea su shell que es el Explorer, en el cual se ejecutaran todos los demas programas como hijos de este proceso. 2.2. PROCESOS LIVIANOS, HILOS, HEBRAS O THREADS En los sistemas operativos tradicionales, cada proceso tiene su propio espacio de direcciones y un único flujo (hilo) de control. Sin embargo, frecuentemente hay situaciones en las que es deseable contar con múltiples hilos de control (threads) en el mismo espacio de direcciones ejecutándose quasi-paralelamente, como si fueran procesos separados (excepto que comparten el mismo espacio de direcciones).
Una hebra (thread, hilo o proceso liviano) es un hilo de control dentro de un proceso. Un proceso tradicional tiene sólo una hebra de control. Si usamos threads, entonces podemos tener varias hebras dentro de un proceso. Cada hebra representa una actividad o unidad de computación dentro del proceso, es decir, tiene su propio PC, conjunto de registros y stack, pero comparte con las demás hebras el espacio de direccionamiento y los recursos asignados, como archivos abiertos y otros.
En muchos aspectos los procesos livianos son similares a los procesos pesados, comparten el tiempo de CPU, y a lo más un thread está activo (ejecutando) a la vez, en un monoprocesador. Los otros pueden estar listos o bloqueados. Pero los procesos pesados son independientes, y el sistema operativo debe proteger a unos de otros, lo que acarrea algunos costos. Los procesos livianos dentro de un mismo proceso pesado no son independientes, cualquiera puede acceder a

Sistemas Operativos
Ing. Jorge Orellana A. 18
toda la memoria correspondiente al proceso pesado. En ese sentido, no hay protección entre threads, nada impide que un thread pueda escribir, por ejemplo, sobre el stack de otro.
2.2.1. Comparando hebras con procesos • El cambio de contexto entre hebras de un mismo proceso es mucho más barato que el
cambio de contexto entre procesos; gracias a que comparten el espacio de direccionamiento, un cambio de contexto entre threads no incluye los registros y tablas asociados a la administración de memoria.
• La creación de threads también es mucho más barata, ya que la información que se requiere para mantener un thread es mucho menos que un PCB. La mayor parte de la información del PCB se comparte entre todos los threads del proceso.
• El espacio de direccionamiento compartido facilita la comunicación entre las hebras y el compartimiento de recursos.
2.2.2. Implementación de hebras Hay librerías de hebras que permiten implementar hebras dentro de procesos normales o pesados sin apoyo del sistema operativo. La planificación y manejo de las hebras se hace dentro del proceso. El sistema operativo no tiene idea de las hebras; sólo ve y maneja un proceso como cualquier otro. La alternativa es que el propio sistema operativo provea servicios de hebras; así como se pueden crear procesos, se pueden también crear nuevas hebras dentro de un proceso, y éstos son administrados por el sistema operativo. La ventaja del primer esquema respecto del segundo, es que los cambios de contexto entre hebras de un mismo proceso son extremadamente rápidos, porque ni siquiera hay una llamada al sistema de por medio. La desventaja es que si una de las hebras hace una llamada bloqueante (Ej., solicita E/S), el sistema operativo bloquea todo el proceso, aún cuando haya otras hebras listos para ejecutar. En el caso de sistemas operativos de servidores, cada hebra puede manejar una solicitud. El diseño es más sencillo y este esquema mejora la productividad, porque mientras unos hilos esperan, otros pueden hacer trabajo útil. Por ejemplo servidor de archivos, que recibe solicitudes para leer y escribir archivos en un disco. Para mejorar el rendimiento, el servidor mantiene un

Sistemas Operativos
Ing. Jorge Orellana A. 19
caché con los datos más recientemente usados, en la eventualidad que reciba algún requerimiento para leer esos datos, no es necesario acceder el disco. Cuando se recibe una solicitud, se le asigna a un thread para que la atienda. Si ese thread se bloquea porque tuvo que acceder el disco, otros threads pueden seguir atendiendo otras solicitudes. La clave es que el buffer debe ser compartido por todos los threads, lo que no podría hacerse si se usa un proceso pesado para cada solicitud. POSIX (Linux) especifica una serie de políticas de planificación, aplicables a procesos y procesos ligeros, que debe implementar cualquier sistema operativo que ofrezca esta interfaz. En Windows la unidad básica de ejecución es el proceso ligero y, por tanto, la planificación se realiza sobre este tipo de procesos. 2.3. PLANIFICACIÓN (SCHEDULING) DE PROCESOS En un ambiente de multiprogramación es frecuente que en un momento dado haya múltiples procesos compitiendo por el uso de la CPU al mismo tiempo. Esta situación se da siempre que dos o más procesos están simultánemente en el estado preparado. Si sólo hay una CPU disponible, es necesario hacer una elección para determinar cual de esos procesos será el siguiente que se ejecute. La parte del sistema operativo que realiza esa elección se denomina el planificador (scheduler), y el algoritmo que se utiliza para esa elección se denomina el algoritmo de planificación. Existen diferentes algoritmos de planificación que deben cumplir con criterios basicos, como: • Maximizar el uso de la CPU (que se mantenga ocupada el mayor tiempo posible). • Maximizar la Productividad (throughput), considerando que productividad (o rendimiento) es
el número de procesos que se ejecutan por unidad de tiempo. • Minimizar el Tiempo de retorno (turn around time), que es el tiempo transcurrido desde que
el proceso ingresa hasta que termina, sumando espera para entrar en memoria, en cola de procesos listos, ejecutándose en CPU y haciendo E/S.
• Minimizar el Tiempo de espera (waiting time), que es el tiempo que el proceso está en la cola de listos.
• Minimizar el Tiempo de respuesta (response time), que es el tiempo que transcurre desde que se presenta una solicitud hasta que se tiene respuesta. Es el tiempo que tarda en comenzar a responder, no incluyendo el tiempo de la respuesta en sí.
• La equidad (Justicia), que todos los procesos tienen que ser tratados de igual forma y a todos se les debe dar la oportunidad de ejecutarse.
• Recursos equilibrados, que la política de planificación que se elija debe mantener ocupados los recursos del sistema, favoreciendo a aquellos procesos que no abusen de los recursos asignados, sobrecargando el sistema y bajando la performance general.
En un sistema operativo los recursos compartidos exigen la organización en colas de las solicitudes pendientes. Tenemos colas para la planificación del uso de la CPU como también colas para el uso de dispositivos (device queues), que son utilizadas para ordenar los requerimientos que varios procesos pueden tener sobre un dispositivo específico. Al ser creados, los procesos se colocan en la cola de trabajos, formada por los procesos que aún no residen en la memoria principal, pero listos para su ejecución. La residencia en memoria es imprescindible para la ejecución de un proceso. La cola de trabajos listos (ready queue) es aquélla formada por los procesos que están listos para la ejecución, en memoria principal. Son los procesos que compiten directamente por CPU. Los elementos de cualquiera de estas colas no son los procesos en sí, sino sus PCB’s, que están en memoria. La cola de procesos listos (ready queue) se almacena como una lista enlazada donde la cabecera (header) de la ready queue tiene punteros al primer y al último PCB de los procesos de la lista. Cada PCB apunta al próximo en la lista.
2.3.1. Procesos orientados a la E/S y procesos orientados a la CPU En un sistema hay procesos con mayor proporción de ráfagas E/S (I/O bound process) y otros con mayor necesidad de CPU que de E/S (CPU bound process). Si cuando se seleccionan procesos para ejecutar se eligieran todos I/O bound, tendríamos las colas de dispositivo llenas

Sistemas Operativos
Ing. Jorge Orellana A. 20
de solicitudes y, probablemente, la CPU ociosa. Si se eligen muchos procesos limitados por CPU la cola de listos estará llena y las colas de dispositivo, vacías. Por eso es muy importante de qué manera se realiza la selección de trabajos para mantener el sistema en equilibrio. Esta selección la realizan los planificadores o schedulers.
El planificador (scheduler) forma parte del núcleo del sistema operativo. Entra en ejecución cada vez que se activa el sistema operativo y su misión es seleccionar el proceso que se ha de ejecutar a continuación. El activador (dispatcher) también forma parte del sistema operativo y su función es poner en ejecución el proceso seleccionado por el planificador. Debe ser muy rápido pues una de sus funciones es encargarse del cambio de contexto (context switch). Al tiempo entre detener un proceso y comenzar a correr otro se le llama dispatch latency. El dispatcher es también el que se encarga de pasar a modo usuario el proceso que esta activando y “saltar” a la dirección de la instrucción que comienza la ejecución del programa. 2.3.2. Temporizador de Intervalos o Reloj de Interrupción El proceso al cual está asignada la CPU se dice que está en ejecución y puede ser un proceso de Sistema Operativo o de usuario. El Sistema Operativo dispone de mecanismos para quitarle la CPU a un proceso de usuario para evitar que monopolice el sistema. El Sistema Operativo posee un “reloj de interrupción” o “temporizador de intervalos” para generar una interrupción, en algún tiempo futuro específico o después de un transcurso de tiempo en el futuro; la CPU es entonces despachada hacia el siguiente proceso. En cada interrupción del reloj el Sistema Operativo decide si el proceso que se está ejecutando continúa o si el proceso agotó su tiempo de CPU y debe suspenderse y ceder la CPU a otro proceso. Un proceso retiene el control de la CPU hasta que ocurra alguna de las siguientes situaciones:
• La libera voluntariamente. • El reloj la interrumpe. • Alguna otra interrupción atrae la atención de la CPU.
El reloj de interrupción ayuda a garantizar tiempos de respuesta razonables a usuarios interactivos, ya que evita que el sistema se “cuelgue” a un solo usuario en un ciclo infinito y permite que los procesos respondan a “eventos dependientes del tiempo”. 2.3.3. Niveles de Planificación del Procesador Se consideran tres niveles importantes de planificación: • Planificación de alto nivel (largo plazo o long term). Determina a qué trabajos se les va a
permitir competir activamente por los recursos del sistema, lo cual se denomina Planificación de admisión.

Sistemas Operativos
Ing. Jorge Orellana A. 21
• Planificación de nivel intermedio (mediano plazo o medium term). Determina a qué procesos se les puede permitir competir por la CPU. Responde a fluctuaciones a corto plazo en la carga del sistema y efectúa “suspensiones” y “activaciones” (reanudaciones) de procesos. Debe ayudar a alcanzar ciertas metas en el rendimiento total del sistema.
• Planificación de bajo nivel (corto plazo o short term). Determina a qué proceso listo se le asigna la CPU cuando esta queda disponible y asigna la CPU al mismo, es decir que “despacha” la CPU al proceso. La efectúa el Despachador del Sistema Operativo.
Los distintos Sistemas Operativos utilizan varias Políticas de Planificación, que se instrumentan mediante Mecanismos de Planificación.
2.4. ALGORITMOS DE PLANIFICACIÓN En entornos diferentes se necesitan algoritmos de planificación diferentes. Esto se debe a que cada área de aplicación (y cada tipo de sistema operativo) tiene objetivos diferentes. En otras palabras, lo que el planificador debe optimizar no es lo mismo en todos los sistemas. Es necesario distinguir aquí tres entornos:
• Batch (lotes) • Interactivo • Tiempo Real.
En los sistemas en batch, no existen usuarios que estén esperando impacientemente por una rápida respuesta ante sus terminales. En consecuencia, son aceptables los algoritmos no expulsores, o los algoritmos expulsores con largos periodos de tiempo para cada proceso. Con este enfoque se reduce el número de cambios de proceso, mejorando por tanto el rendimiento. En un entorno con usuarios interactivos es indispensable que haya expulsiones para impedir que un proceso acapare la CPU, negando cualquier servicio de la CPU a los demás. Incluso aunque ningún proceso tenga intención de ejecutarse eternamente, es posible que debido a un error en el programa un proceso mantenga parados a todos los demás indefinidamente. La expulsión es necesaria para impedir ese comportamiento. En los sistemas con restricciones de tiempo real, por extraño que parezca, la expulsión es algunas veces innecesaria debido a que los procesos saben que no pueden ejecutarse durante largos periodos de tiempo y usualmente hacen su trabajo y rápidamente se bloquean. La diferencia con los sistemas interactivos es que los sistemas en tiempo real sólo ejecutan programas pensados como parte de una misma aplicación. Los sistemas interactivos por el contrario son sistemas de propósito general y pueden ejecutar programas arbitrarios no cooperantes o incluso maliciosos. 2.4.1. Planificación en Sistemas en Batch 2.4.1.1. FCFS (first-come, first-served) Primero en llegar, primero en ser atendido.

Sistemas Operativos
Ing. Jorge Orellana A. 22
Se le asigna la CPU al proceso que la requirió primero. Se maneja a través de una cola FIFO (First In First Out), y cuando un proceso requiere CPU, su PCB se coloca la final de la cola. Cuando se debe elegir un proceso para asignarle CPU se elige el proceso cuya PCB esta primera en la cola. Es un algoritmo que no usa expropiación, y atiende a los procesos por estricto orden de llegada a la cola de listos (READY). Cada proceso se ejecuta hasta que termina, o hasta que hace una llamada bloqueante (de E/S), o sea, ejecuta su fase de CPU completa. El código para implementar este algoritmo es simple y comprensible. Pero el tiempo promedio de espera puede ser largo.
Considerando que los procesos P1, P2 y P3 están LISTOS para ejecutar su siguiente fase de CPU, cuya duración será de 24, 3 y 3 milisegundos, respectivamente. Si ejecutan en el orden P1, P2, P3, entonces los tiempos de espera son: 0 para P1, 24 para P2 y 27 para P3, o sea, en promedio, 17 ms. Pero si se ejecutan en orden P2, P3, P1, entonces el promedio es sólo 3 ms. En consecuencia, FCFS no asegura para nada que los tiempos de espera sean los mínimos posibles; peor aún, con un poco de mala suerte pueden llegar a ser los máximos posibles. Suponiendo que se tiene un proceso intensivo en CPU (CPU bound) y varios procesos intensivos en E/S (I/O bound). Entonces podría pasar lo siguiente: El proceso intensivo en CPU toma la CPU por un período largo, suficiente como para que todas las operaciones de E/S pendientes se completen. En esa situación, todos los procesos están LISTOS, y los dispositivos desocupados. En algún momento, el proceso intensivo en CPU va a solicitar E/S y va a liberar la CPU. Entonces van a ejecutar los otros procesos, pero como son intensivos en E/S, van a liberar la CPU muy rápidamente y se va a invertir la situación: todos los procesos van a estar BLOQUEADOS, y la CPU desocupada. Este fenómeno se conoce como efecto convoy, y se traduce en una baja utilización tanto de la CPU como de los dispositivos de E/S. Obviamente, el rendimiento mejora si se mantienen ocupados la CPU y los dispositivos (o sea, conviene que no haya colas vacías). 2.4.1.2. SJF (Shortest-job-first Scheduling). Primero el trabajo más corto. Este algoritmo elige entre los procesos de la cola de listos, aquel que tenga la próxima ráfaga de CPU mas corta. Para ello este dato debe ser conocido. Es un algoritmo que permite que el tiempo de espera promedio sea bajo. Se puede utilizar en planificadores de largo plazo, pero no en los de corto plazo pues no hay manera de conocer la medida de la próxima ráfaga. Se podría aproximar considerando el valor de la previa. Suponiendo que se tiene tres procesos cuyas próximas fases de CPU son de a, b y c milisegundos de duración. Si ejecutan en ese orden, el tiempo medio de espera es: (0 + a + (a + b))/3 = (2a+b)/3 El primer proceso que se ejecute es el que tiene mayor incidencia en el tiempo medio, y el último, tiene incidencia nula. En conclusión, el tiempo medio se minimiza si se ejecuta siempre el proceso con la menor próxima fase de CPU que esté LISTO. Además, es una buena manera de prevenir el efecto convoy. Lo malo es que para que esto funcione, hay que adivinar el futuro, pues se requiere conocer la duración de la próxima fase de CPU de cada proceso. Lo que se hace es predecir la próxima fase de CPU en base al comportamiento pasado del proceso, usando un promedio exponencial. Suponiendo que la predicción para la n-ésima fase es Tn, entonces, se actualiza el estimador para predecir Tn+1

Sistemas Operativos
Ing. Jorge Orellana A. 23
Tn+1= (1-alpha) Tn + alpha Tn El parámetro alpha, entre 0 y 1, controla el peso relativo de la última fase en relación a la historia pasada. Tn+1 = (1-alpha) Tn + alpha(1-alpha) Tn-1 + ... + alphaj(1-alpha) Tn-j + ... + alphan+1 T0 Mientras más antigua la fase menos incidencia tiene en el estimador. Un valor atractivo para alpha es 1/2, ya que en ese caso sólo hay que sumar los valores y dividir por dos. 2.4.2. Planificación en Sistemas Interactivos 2.4.2.1. Round-Robin Scheduling (RR). Planificación por turno circular o Carrousel. Se la asigna a cada proceso de la cola de listos un intervalo de tiempo de CPU. Ese intervalo es llamado time slice o quantum. Para implementar este algoritmo la cola de listos se mantiene como una cola FIFO, y la CPU se va asignando dándole un máximo de un quantum a cada proceso. Si el proceso no va a usar todo ese tiempo, usa lo necesario y libera la CPU. Se elige entonces otro proceso de la cola. Si excede el quantum, se produce una interrupción. En ambos casos al dejar la CPU hay un cambio de contexto. El tiempo promedio de espera puede ser largo. Su performance depende fuertemente de la elección del quantum. Y el tiempo gastado en el cambio de contexto es una variable que se debe tener muy en cuenta. Se debe determinar un quantum que sea mucho mayor que el tiempo de cambio de contexto. Se utiliza en los sistemas de tiempo compartido (time-sharing). El punto interesante es encontrar el quantum adecuado. Si es muy grande, se degenera en FCFS, pero tampoco puede ser demasiado pequeño, porque entonces el costo en cambios de contexto es preponderante. Por ejemplo, si un cambio de contexto toma 5 ms, y se fija el quantum en 20 ms, entonces 20% del tiempo de la CPU se perderá en sobrecosto. Un valor típico es 100 ms. Una regla que suele usarse es que el 80% de las fases de CPU deben ser de menor duración que un quantum. Con respecto a FCFS, se mejora el tiempo de respuesta y la utilización de la CPU, ya que se mantienen más balanceadas las colas listos (READY) y bloqueadas (BLOCKED). Pero RR tampoco asegura que los tiempos de espera sean los mínimos posibles. Usando el mismo ejemplo anterior, y considerando un quantum de 4ms, pero sin considerar costos de cambio de contexto, si el orden es P1, P2, P3 entonces el tiempo medio de espera es 5.66ms (P1 espera 6ms, P2 espera 4ms. y P3 espera 7ms.)
2.4.2.2. Planificación por prioridad Se le asocia un valor a cada proceso que representa la prioridad, y se le asigna la CPU al proceso de la cola de listos (ready) que tenga la mayor prioridad. Los valores asociados a la prioridad son un rango fijo de 0 a N, según cada sistema. También lo determina cada sistema si el número mas bajo es la más alta o la más baja prioridad. La prioridad puede ser fija o variable, externa o interna. Si es fija, ese valor no varia en el ciclo de vida del proceso. Si es variable, significa que ese valor puede cambiar dinámicamente de manera tal que haya factores, por ejemplo, el tiempo que lleva esperando en colas, que puedan ayudar a que haya un mejor nivel de competencia elevando la prioridad de procesos postergados

Sistemas Operativos
Ing. Jorge Orellana A. 24
y evitar una situación indeseable llamada starvation (inanición). A la técnica de elevar la prioridad a un proceso de acuerdo al tiempo que hace que esta en el sistema se le llama envejecimiento (aging). Si la prioridad es interna, es determinada en función del uso de los recursos (memoria, archivos abiertos, tiempos). Si es externa, puede decidirse darle alta prioridad a un proceso de importancia, a consideración del operador. POSIX (Linux) y Win32 (Windows) proporcionan planificación basada en prioridades. Hay muchos criterios para definir la prioridad, por ejemplo:
• Según categoría del usuario. • Según tipo de proceso: sistema, interactivo, o por lotes; o bien, intensivo en CPU o
intensivo en E/S. • Según cuanto hayan ocupado la CPU hasta el momento • Para evitar que un proceso de baja prioridad sea postergado en demasía, aumentar
prioridad mientras más tiempo lleve esperando: envejecimiento (aging). • Para evitar que un proceso de alta prioridad ejecute por demasiado tiempo, se le puede
ir bajando la prioridad. 2.4.2.3. Colas multinivel (Múltiples colas) En un sistema conviven procesos mixtos. Puede haber requerimientos de tiempo de respuesta distintos si conviven procesos interactivos con procesos batch (o para aquellos que provienen del Unix, procesos en foreground y procesos en background). Para complicar más la cosa, se puede agrupar los procesos en distintas clases, y usar distintos algoritmos de planificación intra-clase, más algún algoritmo inter-clases. Por ejemplo, los procesos interactivos y los procesos por lotes tienen distintos requerimientos en cuanto a tiempos de respuesta. Entonces, se puede planificar los procesos interactivos usando RR, y los procesos por lotes según FCFS, teniendo los primeros prioridad absoluta sobre los segundos. Existen algoritmos que contemplan esta situación dividiendo la cola de listos (ready) en distintas colas según el tipo de proceso, estableciendo una competencia entre las colas y entre los procesos del mismo tipo entre si. Por ejemplo, se puede tener una cola para
• Procesos de sistema. • Procesos interactivos. • Procesos de los alumnos. • Procesos por lotes.
Cada cola usa su propio algoritmo de planificación, pero se necesita un algoritmo de planificación entre las colas. Una posibilidad es prioridad absoluta con expropiación. Otra posibilidad: asignar tajadas de CPU a las colas. Por ejemplo, a la cola del sistema se le puede dar el 60% de la CPU para que haga RR, a la de procesos por lotes el 5% para que asigne a sus procesos según FCFS, y a las otras el resto.

Sistemas Operativos
Ing. Jorge Orellana A. 25
Por otra parte, se podría hacer que los procesos migren de una cola a otra. Por ejemplo: varias colas planificadas con RR, de prioridad decreciente y quantum creciente. La última se planifica con FCFS. Un proceso en la cola i que no termina su fase de CPU dentro del quantum asignado, se pasa al final de la siguiente cola de menor prioridad, pero con mayor quantum. Un proceso en la cola i que sí termina su fase de CPU dentro del quantum asignado, se pasa al final de la siguiente cola de mayor prioridad, pero con menor quantum. Ejemplo:
Cola 0: quantum=10 ms, 40% de CPU. Cola 1: quantum=20 ms, 30% de CPU. Cola 2: quantum=35 ms, 20% de CPU. Cola 3: FCFS, 10% de CPU.
En este modelo con retroalimentación, un proceso puede “moverse” entre colas, es decir, según convenga puede llegar a asignarse a otra cola. Los procesos se separan de acuerdo a la ráfaga de CPU que usan. Si esta usando mucha CPU se lo baja a una cola de menor prioridad. Se trata de mantener los procesos interactivos y de mucha E/S en las colas de mayor prioridad. Si además un proceso estuvo demasiado tiempo en una cola de baja prioridad puede moverse a una cola de mayor prioridad para prevenir inanición (starvation).
2.4.3. Planificación en Sistemas de Tiempo Real Un sistema de tiempo real es uno en el cual el tiempo juega un papel esencial. Típicamente, se tiene uno o más dispositivos físicos externos al ordenador que generan estímulos a los cuales debe reaccionar el ordenador de la manera apropiada y dentro de un plazo de tiempo prefijado. Por ejemplo, el computador interno de un reproductor de discos compactos recibe los bits tal y como salen de la unidad y debe convertirlos en música en un intervalo de tiempo muy ajustado. Si el cálculo tarda demasiado, la música sonará rara. Otros sistemas en tiempo real monitorizan pacientes en la unidad de cuidados intensivos de un hospital, controlan el piloto automático de

Sistemas Operativos
Ing. Jorge Orellana A. 26
un avión y controlan los robots en una fábrica automatizada. En todos estos casos, producir la respuesta correcta demasiado tarde es a menudo tan malo como no producir ninguna respuesta. Los sistemas en tiempo real se clasifican generalmente en sistemas de tiempo real estricto (hard real time) y sistemas de tiempo real moderado (soft real time). En los sistemas de tiempo real estricto hay plazos absolutos que deben cumplirse, pase lo que pase. En los sistemas de tiempo real moderado el incumplimiento ocasional de un plazo aunque es indeseable, es sin embargo tolerable. En ambos casos, el comportamiento en tiempo real se logra dividiendo el programa en varios procesos cuyo comportamiento es predecible y conocido por adelantado. Generalmente, tales procesos son cortos y pueden terminar su trabajo en mucho menos de un segundo. Cuando se detecta un suceso externo, el planificador debe planificar los procesos de tal modo que se cumplan todos los plazos. Los algoritmos de planificación para tiempo real pueden ser estáticos o dinámicos. Los primeros toman sus decisiones de planificación antes de que el sistema comience a ejecutarse. Los segundos toman las decisiones en tiempo de ejecución. La planificación estática sólo funciona si se está perfectamente informado por anticipado sobre el trabajo que debe realizarse y los plazos que deben cumplirse. Los algoritmos de planificación dinámica no tienen estas restricciones. 2.4.4. Planificación apropiativa, expropiativa o expulsiva (Preemptive Scheduling) Hay que considerar en el esquema de planificación en que momento se realiza la selección. Un algoritmo no apropiativo es aquel que una vez que le da la CPU a un proceso se ejecuta hasta que termina o hasta que se bloquea hasta la ocurrencia de determinado evento. En cambio, un algoritmo apropiativo es aquel en que un proceso que se esta ejecutando puede ser interrumpido y pasado a cola de listos (ready queue) por decisión del sistema operativo. Esta decisión puede ser porque llego un proceso de mayor prioridad, por ejemplo. Si bien los algoritmos apropiativos tienen un mayor costo que los no apropiativos, el sistema se ve beneficiado con un mejor servicio pues se evita que algún proceso pueda apropiarse de la CPU. No obstante si se utilizaran algoritmos apropiativos debe considerarse si el sistema operativo esta preparado para desplazar en cualquier momento un proceso. Por ejemplo, si ese proceso en ese momento, a causa de una llamada al sistema (system call) esta modificando estructuras de kernel y se lo interrumpe, esas estructuras pueden quedar en un estado inconsistente. O puede ocurrir con procesos que comparten datos y uno de ellos esta modificándolos al ser interrumpido. En Unix, por ejemplo se espera que se termine de ejecutar el system call para permitir apropiación.
Relacionemos la idea de apropiación con los diferentes algoritmos vistos.
• FCFS es no apropiativo. Cuando se le da la CPU a un proceso, este la mantiene hasta que decide liberarla, porque termino, o porque requiere I/O.
• SJF puede ser apropiativo o no. Si mientras se esta ejecutando un proceso llega uno cuya próxima ráfaga de CPU es mas corta que lo que queda de ejecutar del activo, puede existir la decisión de interrumpir el que se esta ejecutando o no. Al SJF apropiativo, se le llama shortest-remaining-time-first. (primero el de tiempo restante más corto).
• Prioridades puede ser apropiativo o no. Si mientras se esta ejecutando un proceso llega a la cola de ready un proceso de mayor prioridad que el que se esta ejecutando puede existir la decisión de interrumpir el que se esta ejecutando o no. Si es no apropiativo, en lugar de darle la CPU al nuevo proceso, lo pondrá primero en la cola de ready.
• RR es apropiativo pues si el proceso excede el tiempo asignado, hay una interrupción para asignarla la CPU a otro proceso.

Sistemas Operativos
Ing. Jorge Orellana A. 27
2.5. LA PLANIFICACIÓN DE PROCESOS EN AMBIENTES MULTIPROCESADOR Cuando hay varias CPUs (y una memoria común), la planificación también se hace más compleja. Se podría asignar una cola de listos (READY) a cada procesador, pero se corre el riesgo de que la carga quede desbalanceada; algunos procesadores pueden llegar a tener una cola muy larga de procesos para ejecutar, mientras otros están desocupados (con la cola vacía). Para prevenir esta situación se usa una cola común de procesos listos, para lo cual hay dos opciones: • Cada procesador es responsable de su planificación, y saca procesos de la cola listos
(READY) para ejecutar. El problema es que hay ineficiencia por la necesaria sincronización entre los procesadores para acceder la cola. En el caso en que los procesadores son idénticos, cualquier procesador disponible puede usarse para atender cualquier proceso en la cola. No obstante, debemos tener en cuenta que puede haber dispositivos asignados de manera privada o única a un procesador, y si un proceso quiere hacer uso de ese dispositivo deberá ejecutarse en ese procesador. Otra ventaja es implementar load sharing (carga compartida), permitiendo que si un procesador esta ocioso puedan pasarse procesos de la cola de otro procesador a este, o hacer una cola común, y la atención se realiza de acuerdo a la actividad de cada uno.
• Dejar que sólo uno de los procesadores planifique y decida qué procesos deben correr los demás: multiprocesamiento asimétrico. Se asume una estructura de procesadores master-slave que asigna a un procesador la toma de decisiones en cuanto a scheduling y otras actividades, dedicándose los otros procesadores a ejecutar código de usuario. La ventaja es que solo el procesador master accede a estructuras del kernel, evitando inconsistencias.
2.6. PLANIFICACIÓN EN WINDOWS (Win32) Y LINUX (POSIX) El kernel de Windows está diseñado utilizando POO. Posee una capa de abstracción de hardware (HAL), la cual es la única que se comunica directamente con el procesador; el resto del kernel está diseñado para utilizar la interfaz de la HAL. La unidad mínima de ejecución no es el proceso sino el hilo. Un hilo puede estar en alguno de estos seis estados: listo, standby (siguiente a ejecutar), en ejecución, en espera, en transición (un nuevo hilo) y terminado. Windows utiliza una planificación basada en colas múltiples de prioridades. Posee 32 niveles de colas, clasificadas en clase de Tiempo Real fija (16-31) y prioridad dinamica (0-15). Las colas se recorren de mayor a menor ejecutando los hilos asociados. Cada cola es manejada por medio de un algoritmo de RR, aun así, si un hilo de mayor prioridad llega, el procesador le es asignado a éste. La prioridades más altas son favorecidas. La prioridades de un thread no pueden ser reducidas. Los procesos en Linux pueden ser divididos en tres categorías, relacionadas con la prioridad: interactivos, por lotes y de tiempo real. Los procesos TR son manejados bien por un algoritmo FIFO o RR. Los demás procesos son despachados utilizando planificación RR con un sistema de envejecimiento basado en créditos, donde el siguiente proceso a ejecutar es aquel que más créditos posea. Los procesos TR son considerados prioritarios sobre cualquier otro proceso en el sistema, por lo que serán ejecutados antes que los demás. Algunos aspectos de la estructura interna del kernel que caben destacarse son: • La PCB está representada por la estructura task_struct. Ésta indica el tipo de planificación
(FIFO,RR) por medio del campo policy, la prioridad (priority), el contador del programa (counter), entre otros.
• La función goodness otorga una “calificación” al proceso pasado como parámetro. Dicha puntuación oscila entre -1000 (no elegible) y +1000 (TR). Los procesos que comparten una zona de memoria ganan una puntuación equivalente a su prioridad.
• El quantum varía según el proceso y su prioridad. La duración base es de aprox. 200ms. • La función switch_to es la encargada de salvar la información de un proceso y cargar el
siguiente.

Sistemas Operativos
Ing. Jorge Orellana A. 28
• Las funciones sched_{get/set}scheduler se refieren al mecanismo de planificación asociado a ese proceso.
• Una nueva copia del proceso actual es creada mediante la llamada al sistema fork. Para ejecutar un nuevo programa se utiliza la función execve.
• Las prioridades bajas son favorecidas. La mayoría de los procesos usan políticas de prioridad dinámica. El valor “nice” establece la prioridad base de un proceso. Los valores de nice van desde -20 a +20 (más grande = menor prioridad). Los usuarios no privilegiados sólo pueden especificar valores de nice positivos. Los procesos normales se ejecutan sólo cuando no quedan procesos de tiempo real (de prioridad fija) en la cola de listos.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
29
Tema III Comunicación y Sincronización de Procesos
Los procesos que se ejecutan de forma concurrente en un sistema se pueden clasificar como procesos independientes o cooperantes. Un proceso independiente es aquel que ejecuta sin requerir la ayuda o cooperación de otros procesos. Los procesos son cooperantes cuando están diseñados para trabajar conjuntamente en alguna actividad, para lo que deben ser capaces de comunicarse e interactuar entre ellos. Tanto si los procesos son independientes como cooperantes, pueden producirse una serie de interacciones entre ellos. Estas interacciones pueden ser de dos tipos: • Interacciones motivadas porque los procesos comparten o compiten por el acceso a
recursos físicos o lógicos. Por ejemplo, dos procesos totalmente independientes pueden competir por el acceso a disco, en este caso, el sistema operativo deberá encargarse de que los dos procesos accedan ordenadamente sin que se cree ningún conflicto.
• Interacción motivada porque los procesos se comunican y sincronizan entre sí para alcanzar un objetivo común. Por ejemplo, un compilador se puede construir mediante dos procesos: el compilador propiamente dicho, que se encarga de generar código ensamblador, y el proceso ensamblador, que obtiene código en lenguaje máquina a partir del ensamblador.
Estos dos tipos de interacciones obligan al sistema operativo a incluir mecanismos y servicios que permitan la comunicación y la sincronización entre procesos (IPC InterProcess Communication). 3.1 Condiciones de competencia. Muchos problemas se pueden resolver más fácilmente o más eficientemente si se usa procesos (o hebras) cooperativos, que se ejecutan concurrentemente, técnica que se conoce como programación concurrente. La programación concurrente es una herramienta poderosa, pero introduce algunos problemas que no existen en la programación secuencial (no concurrente). Suponiendo que se usan dos hebras concurrentes para determinar cuántos números primos hay en un intervalo dado.
Siendo numPrimos una variable global, podemos ejecutar primos(1,5000) en paralelo con primos(5001,10000) para saber cuántos números primos hay entre 1 y 10000. ¿El problema? numPrimos es una variable compartida que se accesa concurrentemente, y puede quedar mal actualizada si se dan determinadas intercalaciones de las operaciones de las dos hebras. Para ejecutar una operación como numPrimos=numPrimos+1 se suelen requerir varias instrucciones de máquina, como ser:
Suponiendo que, más o menos simultáneamente, las dos hebras encuentran su primer número primo. Podría darse el siguiente timing (inicialmente, numPrimos==0).

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
30
El resultado es que numPrimos queda en 1, pero lo correcto sería 2. El problema se produce porque las dos hebras o procesos tratan de actualizar una variable compartida al mismo tiempo; o mejor dicho, una hebra comienza a actualizarla cuando la otra no ha terminado. Esto se conoce como competencia por datos (data race, o también, race condition) cuando el resultado depende del orden particular en que se intercalan las operaciones de procesos concurrentes. La cosa se resuelve si se garantiza, de alguna manera, que sólo una hebra a la vez puede estar actualizando variables compartidas. 3.2 El problema de la sección crítica Éste es uno de los problemas que con mayor frecuencia aparece cuando se ejecutan procesos concurrentes tanto si son cooperantes como independientes. Si se considera un sistema compuesto por n procesos { P0, P1, ... , Pn }, en el que cada uno tiene un fragmento de código, que se denomina sección crítica, en el que se accesa a variables comunes, o en general, recursos compartidos. La característica más importante de este sistema es que cuando un proceso se encuentra ejecutando código de la sección crítica, ningún otro proceso puede ejecutar en su sección. Para resolver el problema de la sección crítica es necesario utilizar algún mecanismo de sincronización que permita a los procesos cooperar entre ellos sin problemas. Este mecanismo debe proteger el código de la sección crítica y su funcionamiento básico es el siguiente: • Cada proceso debe solicitar permiso para entrar en la sección crítica mediante algún
fragmento de código, que se denomina de forma genérica entrada en la sección crítica. • Cuando un proceso sale de la sección crítica debe indicarlo mediante otro fragmento de
código, que se denomina salida de la sección crítica. Este fragmento permitirá que otros procesos entren a ejecutar el código de la sección crítica. La estructura general, por tanto, de cualquier mecanismo que pretenda resolver el problema de la sección crítica es la siguiente:
Entrada en la sección crítica Código de la sección crítica
Salida de la sección crítica Cualquier solución que se utilice para resolver este problema debe cumplir los tres requisitos siguientes: • Exclusión mutua: si un proceso está ejecutando código de la sección crítica, ningún otro
proceso lo podrá hacer. • Progreso (Ausencia de postergación innecesaria): si ningún proceso está ejecutando
dentro de la sección crítica, la decisión de qué proceso entra en la sección se hará sobre los procesos que desean entrar. Los procesos que no quieren entrar no pueden formar parte de esta decisión. Además, esta decisión debe realizarse en tiempo finito.
• Espera acotada (Entrada garantizada -ausencia de inanición): debe haber un límite en el número de veces que se permite que los demás procesos entren a ejecutar código de la sección crítica después de que un proceso haya efectuado una solicitud de entrada y antes de que se conceda la suya.
A continuación se examinan varias propuestas de solucion, de manera que mientras un proceso esté ocupado actualizando la memoria compartida en su región crítica, ningún otro proceso pueda entrar en su región crítica y provocar algún problema.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
31
3.2.1 Primer intento (Inhabilitación de interrupciones) La solución más sencilla es hacer que cada proceso inhiba todas las interrupciones nada más entrar en su región crítica y que las rehabilite nada más salir de ella. Con las interrupciones inhibidas, no puede ocurrir ninguna interrupción del reloj. Después de todo, la CPU sólo se conmuta a otro proceso como resultado de una interrupción del reloj o de otro dispositivo, y con las interrupciones inhibidas la CPU no puede conmutarse a otro proceso. Entonces, una vez que un proceso ha inhibido las interrupciones, puede examinar y actualizar la memoria compartida sin temor a intromisiones de otros procesos. Se descarta por peligroso, un proceso de usuario con capacidad de deshabilitar interrupciones puede colgar el sistema. Además, no funcionaría en multiprocesadores.
3.2.2 Segundo intento (Variables de Bloqueo) Se considera una variable compartida (variable turno) cuyo valor es inicialmente 0. Cuando un proceso quiere entrar en su región crítica, primero examina la variable turno. Si el turno está a 0, el proceso lo pone a 1 y entra en la región crítica. Si el turno ya estaba a 1, el proceso espera hasta que vuelva a valer 0. Entonces, un 0 significa que ningún proceso está en la región crítica, y un 1 significa que algún proceso está en su región crítica.
Suponiendo que un proceso lee el turno y observa que vale 0. Antes de que pueda poner el turno a 1, se planifica otro proceso que pasa a ejecución y pone el turno a 1. Cuando el primer proceso se ejecute de nuevo, pondrá a 1 también el turno, y se tendrá a dos procesos en sus regiones críticas al mismo tiempo.
3.2.3 Tercer intento (Alternancia Estricta) Otro intento de solucion permite manejar más información, un arreglo para los procesos interesados en ingresar a la seccion critica, interesado[i] que está en verdadero si proceso i quiere entrar a la sección crítica y falso si no lo quiere.
Tampoco funciona ya que si ambos procesos ponen interesado[i] en TRUE al mismo tiempo, ambos quedan esperando para siempre. Se podría cambiar el orden, verificar primero y setear despúes la variable interesado, pero entonces se podría terminar con los dos procesos en la sección crítica. 3.2.4 Cuarto intento (Solución de Peterson) Combinando las dos ideas anteriores se puede obtener un algoritmo que sí funciona. Antes de utilizar las variables compartidas (es decir, antes de entrar en su región crítica), cada proceso invoca entrar_en_region con su propio número de proceso, 0 o 1, como parámetro. Esta llamada puede provocar su espera, si es necesario, hasta que sea seguro entrar. Cuando termine de utilizar las variables compartidas, el proceso invoca abandonar_region para indicar que ha terminado y para permitir a los demás procesos entrar, si así lo desean.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
32
Inicialmente no hay ningún proceso en su región crítica. Ahora el proceso 0 llama a entrar_en_region. Indica su interés poniendo a TRUE su componente del array interesado y pone el valor 0 en turno. Ya que el proceso 1 no está interesado, entrar_en_region retorna inmediatamente. Si el proceso 1 llama ahora a entrar_en_region, quedará atrapado en esa función hasta que interesado[0] pase a valer FALSE, algo que sólo ocurre cuando el proceso 0 llama a abandonar_region para salir de la región crítica. Si se considera el caso en que ambos procesos llaman a entrar_en_region casi simultáneamente. Ambos deben asignar su número de proceso a la variable turno. La asignación que va a prevalecer es la del último proceso que realice la asignación; siendo anulada la primera de las asignaciones por la sobreescritura. Supongamos que el proceso 1 es el último que hace la asignación, de manera que turno es 1. Cuando ambos procesos entran en la sentencia while, el proceso 0 la ejecuta cero veces y entra en su región crítica. El proceso 1 se pone a dar vueltas en el bucle y no entra en su región crítica hasta que el proceso 0 sale de su región crítica. 3.2.5 Solución con ayuda del hardware Muchos sistemas tienen instrucciones especiales que ayudan bastante a la hora de resolver el problema de la sección crítica. En general, son instrucciones que de alguna manera combinan dos o tres operaciones en una sola operación atómica. Por ejemplo, TEST-AND-SET (TS) lee el contenido de una dirección de memoria en un registro, y pone un 1 en la misma dirección, todo en una sola acción atómica o indivisible, en el sentido que ningún otro proceso puede accesar esa dirección de memoria hasta que la instrucción se complete. De cierto modo es equivalente a:
Con esto, una solución al problema de la sección crítica, en pseudoasssembler, sería:
Inicialmente, la variable lock está en 0. Este protocolo provee exclusión mutua sin postergación innecesaria, y sirve para n procesos, pero puede haber inanición.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
33
3.2.6 Semáforos Los inconvenientes de las soluciones anteriores, son que es difícil generalizarlas para problemas de sincronización más complejos, o simplemente distintos, de la sección crítica y derrochan CPU, ya que usan espera ocupada (busy waiting); cuando un proceso quiere entrar a la sección crítica, está permanentemente chequeando si puede hacerlo. Si el sistema operativo tuviera un mayor conocimiento de la situación, podría bloquear a un proceso que quiere entrar a la sección crítica, sin concederle oportunidad de ejecutar, mientras no pueda entrar. Una posibilidad es usar semáforos. Un semáforo S es un tipo abstracto de dato que puede manipularse mediante dos operaciones: P (o wait o down) y V (o signal o up), y cuyo efecto es equivalente a:
La operación wait sobre un semáforo comprueba si el valor es mayor que 0. Si lo es, simplemente decrementa el valor (es decir utiliza una de las señales guardadas). Si el valor es 0, el proceso procede a dormirse sin completar la operación bajar por el momento. La comprobación del valor del semáforo, su modificación y la posible acción de dormirse, se realizan como una única acción atómica indivisible. Está garantizado que una vez que comienza una operación sobre un semáforo, ningún otro proceso puede acceder al semáforo hasta que la operación se completa o hasta que el proceso se bloquea. Esta atomicidad es absolutamente esencial para resolver los problemas de sincronización y evitar que se produzcan condiciones de competencia. La operación signal incrementa el valor del semáforo al cual se aplica. Si uno o más procesos estuviesen dormidos sobre ese semáforo, incapaces de completar una anterior operación de wait, el sistema elige a uno de ellos (por ejemplo de forma aleatoria) y se le permite completar esa operación wait pendiente. Entonces, después de ejecutarse un signal sobre un semáforo con procesos dormidos en él, el semáforo sigue valiendo 0, pero habrá un proceso menos, dormido en él. La operación de incrementar el semáforo y despertar un proceso es también indivisible. La operación de signal nunca bloquea al proceso que la ejecuta. El problema de la sección crítica se puede resolver fácilmente con un semáforo S, con valor inicial 1.
A nivel de sincronizacion, si se quiere que un proceso P2 ejecute un trozo de código C2 pero sólo después que P1 haya completado otro trozo C1, se usa un semáforo para sincronizar con valor inicial 0.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
34
3.2.7. Monitores Los semáforos son una herramienta general y eficiente para sincronizar procesos, pero siguen siendo de bajo nivel. Las soluciones mediante semáforos no son ni muy limpias ni muy claras, y siempre están sujetas a errores como la omisión o mala ubicación de una operación wait o signal. Los monitores son una herramienta de sincronización más estructurada que encapsula variables compartidas en conjunto con los procedimientos para accesar esas variables.
Los monitores tienen una importante propiedad que los hace útiles para conseguir exclusión mutua: en cualquier instante solamente un proceso puede estar activo dentro del monitor. Los monitores son construcciones del lenguaje, por lo que el compilador sabe que son especiales, de manera que puede tratar las llamadas a los procedimientos del monitor de forma diferente que a otras llamadas a procedimientos normales. En la mayoría de los casos, cuando un proceso llama a un procedimiento de un monitor, las primeras instrucciones del procedimiento comprueban si cualquier otro proceso está actualmente activo dentro del monitor. En ese caso, el proceso que hizo la llamada debe suspenderse hasta que el otro proceso abandone el monitor. Si ningún otro proceso está utilizando el monitor, el proceso que hizo la llamada puede entrar inmediatamente. Corresponde al compilador implementar la exclusión mutua sobre las entradas al monitor. La forma más común de implementarla es utilizando una variable de exclusión mutua o un semáforo binario. Debido a que es el compilador y no el programador el que organiza las cosas para conseguir la exclusión mutua, resulta mucho más difícil que se produzcan errores. En cualquier caso, la persona que escribe el monitor no tiene que preocuparse de cómo consigue asegurar la exclusión mutua el compilador dentro del monitor. Es suficiente con que sepa que metiendo todas las regiones críticas en procedimientos del monitor, nunca habrá dos procesos que ejecuten sus regiones críticas a la vez. Un monitor es, en consecuencia, un tipo de dato abstracto, y por lo tanto: • Los procesos pueden llamar a los procedimientos del monitor en cualquier momento, pero
no pueden accesar directamente las variables encapsuladas por el monitor. • Los procedimientos dentro del monitor no pueden accesar variables externas al monitor: sólo
pueden accesar las variables permanentes del monitor (i y c en el ejemplo), las variables locales al procedimiento, y los argumentos del procedimiento (x en el ejemplo).
• Las variables permanentes del monitor deben estar inicializadas antes que ningún procedimiento sea ejecutado.
Para esperar eventos (sincronización por condición) se usan variables de condición. Una variable de condición c tiene asociada una cola de procesos, y soporta dos operaciones: • wait(c): suspende al proceso invocador, lo pone al final de la cola asociada a c, y libera el
monitor. O sea, aunque no se haya completado un procedimiento, el proceso deja de estar activo dentro del monitor, y por lo tanto otro proceso puede ejecutar dentro del monitor.
• signal(c): despierta al proceso al frente de la cola asociada a c, si es que existe. En monitores con semántica signal-and-continue, el proceso que hace signal continúa dentro

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
35
del monitor; el proceso despertado, si existe, debe esperar su oportunidad para volver a entrar al monitor y continuar después del wait. En monitores con semántica signal-and-wait, si es que el signal despierta a un proceso, entonces el proceso señalizador suspende su ejecución en favor del proceso señalizado; el señalizador debe esperar (posiblemente compitiendo con otros procesos) para poder volver al monitor.
Las variables de condición no son contadores, ya que no acumulan las señales para un uso posterior como hacen los semáforos. Entonces si una variable de condición recibe una señal sin que haya ningún proceso esperándola, la señal se pierde para siempre. En otras palabras el wait debe ocurrir antes que el signal. Esta regla simplifica mucho la implementación, y en la práctica no representa ningún problema ya que, si es necesario, es fácil seguir la pista del estado de cada proceso utilizando variables adicionales. Antes de llevar a cabo un signal, el proceso puede ver si esa operación es necesaria, o no, inspeccionando esas variables. Algunos lenguajes de programación reales soportan los monitores, aunque no siempre en la forma diseñada, por ejemplo Java. Java es un lenguaje orientado a objetos que soporta threads a nivel de usuario y que permite agrupar juntos varios métodos (procedimientos) formando clases. Añadiendo la palabra reservada synchronized a la declaración de un método, Java garantiza que una vez que un thread comienza a ejecutar ese método, no se le permite a ningún otro thread comenzar a ejecutar cualquier otro método synchronized de esa clase. Los métodos sincronizados de Java difieren de los monitores clásicos en un aspecto esencial: Java no dispone de variables de condición. En su lugar, ofrece dos procedimientos wait y notify que son los equivalentes de wait(c) y signal(c) salvo que cuando se utilizan dentro de métodos sincronizados no están expuestos a que se produzcan condiciones de competencia. 3.2.8. Paso de mensajes Las primitivas vistas hasta ahora sirven para sincronizar procesos, pero si se quiere que los procesos intercambien información se tiene que agregar variables compartidas a la solución. Se puede intercambiar información mediante paso de mensajes. Este método de comunicación entre procesos utiliza dos primitivas, enviar y recibir, que igual que los semáforos y de forma diferente a los monitores son llamadas al sistema en vez de construcciones del lenguaje de programación. Como tales, pueden incluirse fácilmente en librerías de procedimientos, tales como
enviar(destinatario, &mensaje); recibir(remitente, &mensaje);
La primera llamada envía un mensaje a un destinatario dado y la segunda recibe un mensaje de un remitente dado (o de cualquiera, si al receptor no le importa el remitente). Si no está disponible ningún mensaje, el receptor puede bloquearse hasta que llegue uno. De forma alternativa, puede retornar inmediatamente indicando un código de error. El paso de mensajes se utiliza comúnmente en sistemas de programación paralela. Un sistema de paso de mensajes bien conocido es MPI (Message-Passing Interface) que es una librería para lenguajes de programación como el C. 3.3. Problemas clásicos de sincronización 3.3.1. Productor-consumidor con buffer limitado El problema del productor consumidor (también conocido como el problema de buffer acotado) es un ejemplo clásico de un problema de multi- proceso de sincronización. En el problema se describen dos procesos, el productor y el consumidor, que comparten un común, búffer fijo utilizado como una cola. El trabajo del productor es generar un conjunto de productos y colocarlos en el buffer (almacen). Al mismo tiempo, el consumidor consume los productos (es decir, los retira del buffer) de una sola pieza a la vez. El problema es asegurarse de que el

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
36
productor no intente agregar productos en el búffer si está lleno y que el consumidor no va a tratar de consumir productos de un búffer vacío. La solución se puede alcanzar por medio de la comunicación entre procesos, usando semáforos. El problema también puede ser generalizado para tener múltiples productores y consumidores, como se muestra en el código siguiente:
int cantProductos = 0; // cantidad de productos que se encuentran en el buffer const int tamBuffer = 5; //tamaño buffer const int MAXPRODUCCION = 10; //numero de elementos a producir int estadoConsumo = 0; int estadoProduccion = 1; int ultimo = 0; int reciente = 0; int colaProduccion[tamBuffer]; semaphore semProductor = 1; // Si el buffer esta lleno, lo duerme semaphore semConsumidor = 0; // Si el buffer esta vacio, lo duerme semaphore semBuffer = 1; // controla la estricta alternancia, Si esta en 1 el consumidor consume // Si esta en 0, el productor produce y el consumidor deja de consumir void productor(int ID) { int producto = 1; while(producto <= MAXPRODUCCION) { wait(semProductor); wait(semBuffer); colaProduccion[reciente] = ID*100+producto; reciente = (reciente + 1) % tamBuffer; cantProductos = cantProductos + 1; cout << "Productor " << ID << " produce el producto " << ID*100+producto << endl; producto = producto + 1; cout << "...En la cola de produccion estan: " << cantProductos << " productos\n\n"; signal(semBuffer); if(cantProductos < tamBuffer) { signal(semProductor); estadoProduccion = 1; } else { estadoProduccion = 0; } if ((estadoConsumo == 0) && (estadoProduccion == 1)) { signal(semConsumidor); estadoConsumo = 1; } } } void consumidor(int ID) { int producto = 1; int p; while(producto <= MAXPRODUCCION) { wait(semConsumidor); wait(semBuffer); p = colaProduccion[ultimo]; ultimo = (ultimo + 1) % tamBuffer; cantProductos = cantProductos - 1; cout << "Consumidor " << ID << " consumio el producto " << p << endl; producto = producto + 1; cout << ".....en la cola de produccion estan: " << cantProductos << " productos\n\n"; signal(semBuffer); if(cantProductos > 0) { signal(semConsumidor); estadoConsumo = 1; } else { estadoConsumo = 0; } if((estadoProduccion == 0) && (estadoConsumo == 1)) { signal(semProductor); estadoProduccion = 1; } } } void main() { cobegin { productor(1); productor(2); consumidor(1); consumidor(2); } }

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
37
y su ejecucion sería:
3.3.2. Lector-Escritor Un objeto, tal como un archivo o un registro de una base de datos, es compartido por varios procesos concurrentes. Hay procesos escritores, que modifican el objeto, y procesos lectores, que sólo lo consultan. Puede haber múltiples procesos leyendo el objeto simultáneamente, pero cuando hay un proceso escribiendo, no puede haber ningún lector ni ningún otro escritor. La solución se puede alcanzar por medio de la comunicación entre procesos, usando monitores:
monitor LectorEscritor { int contadorLector; // lectores concurrentes int ocupado; condition OKleer, OKescribir; void EmpiezaLeer() { if (ocupado || !empty(OKescribir)) waitc(OKleer); contadorLector = contadorLector + 1; cout << "Numero lectores concurrentes " << contadorLector << '\n'; signalc(OKleer); } void FinLeer() { contadorLector = contadorLector - 1; if (contadorLector == 0) signalc(OKescribir); } void EmpiezaEscribir() { if (ocupado || (contadorLector != 0)) waitc(OKescribir); ocupado = 1; } void FinEscribir() { ocupado = 0; if (empty(OKleer)) signalc(OKescribir); else signalc(OKleer); } init { contadorLector = 0; ocupado = 0; //inicializacion } } // fin monitor void Lector(int N) { int I; for (I = 1; I < 2; I++) { EmpiezaLeer(); cout << N << " esta leyendo" << '\n'; FinLeer(); } } void Escritor(int N) { int I;

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
38
for (I = 1; I < 2; I++) { EmpiezaEscribir(); cout << N << " esta escribiendo" << '\n'; FinEscribir(); } } void main() { cobegin { Lector(1); Lector(2); Lector(3); Escritor(1); Escritor(2); } }
y su ejecucion sería:
3.3.3. Los filósofos comensales Cinco filósofos pasan la vida alternando entre comer y pensar, alrededor de una mesa redonda. Como son medio torpes, requieren dos tenedores para comer, pero como son pobres, sólo tienen 5 tenedores. Han acordado que cada uno usará sólo los tenedores a su izquierda y a su derecha. Entonces, de los 5 filósofos, sólo 2 pueden comer al mismo tiempo, y no pueden comer dos que son vecinos. La solución se puede alcanzar por medio de la comunicación entre procesos, usando monitores, con resultados gráficos también:
#include "gdefs.cm" const int PEN = 0; int HAM = 1; int COM = 2; int Mesa = 100; int pos[5][4]; int inc = 0; int i; monitor FilosofoComensal { int estFil[5];//estado de todos los filósofos condition libre[5];//condicion del cubierto de cada filósofo void comer(int fil){ if((estFil[fil]==HAM) && (estFil[(fil+4)%5]!=COM) && (estFil[(fil+1)%5]!=COM)){ estFil[fil] = COM; //Filósofo Comiendo cout << "Filosofo comiendo "<< fil <<endl; create(fil, TRIANGLE, RED, pos[fil][0], pos[fil][1], pos[fil][2], pos[fil][3]); signalc(libre[fil]); } } void mirar(int fil){ if(estFil[fil]==PEN){ estFil[fil] = HAM; comer(fil); if(estFil[fil] != COM){ //Filósofo Hambriento cout<< "Filosofo hambriento "<< fil <<endl; create(fil, TRIANGLE, YELLOW, pos[fil][0], pos[fil][1], pos[fil][2], pos[fil][3]); waitc(libre[fil]); } } } void pensar(int fil){ if(estFil[fil]!=PEN){ //Filósofo Pensando cout<< "Filosofo pensando "<< fil <<endl; create(fil, TRIANGLE, GREEN, pos[fil][0], pos[fil][1], pos[fil][2], pos[fil][3]); estFil[fil] = PEN; comer ((fil+4)%5); comer ((fil+1)%5); } } init{

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
39
for(i = 0; i<= 4; i++){ estFil[i]=PEN; //inicializacion } //Posiciones Graficas de los Filosofos pos[0][0] = 275; pos[0][1] = 160; pos[0][2] = 30; pos[0][3] = 30; pos[1][0] = 230; pos[1][1] = 230; pos[1][2] = -30; pos[1][3] = -30; pos[2][0] = 245; pos[2][1] = 245; pos[2][2] = 30; pos[2][3] = 30; pos[3][0] = 305; pos[3][1] = 245; pos[3][2] = 30; pos[3][3] = 30; pos[4][0] = 320; pos[4][1] = 230; pos[4][2] = -30; pos[4][3] = -30; } } void filosofo(int fil){ create(fil, TRIANGLE, GREEN, pos[fil][0], pos[fil][1], pos[fil][2], pos[fil][3]); while (inc < 100){// tiempo de vida de un filosofo if ((random(2))==PEN) pensar(fil); else mirar(fil); inc = inc + 1; } pensar(fil); //los filosofos se van create(fil, TRIANGLE, WHITE, pos[fil][0], pos[fil][1], pos[fil][2], pos[fil][3]); } void main(){ create(Mesa, CIRCLE, BLACK, 250, 200, 50, 50); cobegin{ filosofo(0); filosofo(1); filosofo(2); filosofo(3); filosofo(4); } }
y su ejecucion sería:

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
40
Tema IV Bloqueos Irreversibles
(Bloqueos mutuos, deadlocks, Interbloqueos o Abrazo mortal) La administración de los recursos es una de las principales tareas del sistema operativo, ya que tienen que ofrecer mecanismos que permitan a los procesos acceder de forma exclusiva a los recursos. Cuando un proceso solicita ciertos recursos y éstos no están disponibles en ese momento, entra en un estado de espera. Si se tienen muchos procesos que compiten por recursos finitos, puede darse una situación en la que un proceso está bloqueado esperando por un recurso que nunca se liberará, porque lo posee otro proceso también bloqueado. Una ley de principios de siglo, en Kansas, grafica esta situacion con el siguiente enunciado "cuando dos trenes se aproximan a un cruce, ambos deben detenerse completamente, y ninguno podrá continuar hasta que el otro se haya ido." Un sistema se compone de un número finito de recursos que son distribuidos entre un número de procesos que compiten por ellos. Los recursos pueden ser:
• Físicos: ciclos de CPU, espacio en memoria, dispositivos de E/S (impresoras, unidades de cinta, etc.).
• Lógicos: archivos, tablas del sistema, registro de bases de datos, semáforos. Los recursos son clasificados en diferentes tipos, cada uno de los cuales se compone de algún número de instancias iguales. Si un sistema tiene dos CPU’s, entonces el tipo CPU tiene dos instancias. Similarmente, el tipo IMPRESORAS puede tener cinco instancias. Si un proceso pide una instancia de un tipo de recurso, la asignación de cualquier instancia de ese tipo atenderá la petición. Si este no es el caso, entonces las instancias no son idénticas y las clases de tipos de recursos no están bien definidas. Un proceso debe solicitar un recurso antes de usarlo y liberarlo después de usarlo. Un proceso puede solicitar tantos recursos como sean necesarios para llevar a cabo la tarea para la cual ha sido diseñado. Obviamente el número de recursos solicitados no debe exceder el número de recursos disponibles en el sistema. En otras palabras, un proceso no debe pedir tres impresoras si en el sistema solo existen dos. Una computadora normalmente tendrá varios recursos que pueden ser otorgados. Algunos podrán tener varias referencias idénticas, como en el caso de las unidades de cinta. Si se tienen varias copias disponibles de un recurso, cualquiera de ellas se puede utilizar para satisfacer cualquier solicitud de recurso. Los recursos son de dos tipos:
• Apropiativos • No apropiativos
Recursos apropiativos. Los recursos apropiativos son aquellos que se pueden tomar del proceso que le posee sin efectos dañinos. La memoria es un ejemplo de recursos apropiativos. Por ejemplo considerar un sistema con 512 Kb de memoria de usuario, una impresora, y dos procesos de 512 Kb que se desean imprimir cada uno. • El proceso A solicita y obtiene la impresora, para entonces comienza a calcular los valores
que va a imprimir. Antes de terminar el cálculo excede su quantum de tiempo y se intercambia.
• El proceso B se empieza a ejecutar e intenta sin éxito adquirir la impresora. • Potencialmente se tendría una situación de bloqueo, puesto que A tiene la impresora y B la
memoria y ninguno puede continuar sin el recurso que posee el otro. • Por fortuna es posible apropiarse de la memoria de B y sacarlo de ella e intercambiarlo con
A. • A puede ejecutarse entonces, imprimir y liberar después la impresora. No ocurre un bloqueo.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
41
Recursos no apropiativos . Los recursos no apropiativos son aquellos que no se pueden tomar de su poseedor activo sin provocar un fallo de cálculo. Por ejemplo, si un proceso comienza a imprimir una salida, se toma la impresora y se le da otro proceso, el resultado será una salida incomprensible. Las impresoras no son apropiables. En general los bloqueos se relacionan con los recursos no apropiables.
La secuencia de eventos necesarios para utilizar un recurso es la siguiente:
1. Solicitar el recurso. 2. Utilizar el recurso. 3. Liberar el recurso.
• Petición. Si la petición no puede ser satisfecha inmediatamente (por ejemplo, el recurso esta
siendo utilizado por otro proceso), entonces el proceso solicitante debe esperar hasta que pueda adquirir el recurso.
• Uso. El proceso puede utilizar un recurso (por ejemplo, si el recurso es una impresora en línea, el proceso puede imprimir en la impresora).
• Liberación. El proceso libera el recurso. Si el recurso no esta disponible cuando es requerido, el proceso solicitante se ve forzado a esperar. En algunos sistemas operativos, el proceso se bloquea automáticamente cuando falla la solicitud el recurso y se desbloquea cuando esta disponible. En otros sistemas, la requisición falla en un código de error y corresponde al recurso solicitante esperar un poco y volverlo a intentar.
La petición y liberación del recurso son peticiones al sistema. Ejemplos de llamadas al sistema son: Petición/Liberación de dispositivos, Abrir/Cerrar archivos y Asignar/Desasignar memoria. El uso de recursos puede también hacerse sólo a través de llamadas al sistema. Por lo tanto, para cada uso, el sistema operativo chequea para asegurarse de que el proceso usuario ha pedido y se le han asignado los recursos. Una tabla del sistema registra cuando un recurso está libre o asignado, y si está asignado, a qué proceso. Si un proceso pide un recurso que está asignado en ese momento a otro proceso, éste puede ser agregado a una cola de procesos en espera de ese recurso. 4.1. Bloqueos Un conjunto de procesos se encuentra en estado de interbloqueo cuando cada uno de ellos espera un suceso que sólo puede originar otro proceso del mismo conjunto. Por ejemplo, si dos procesos desean imprimir cada uno un enorme archivo en cinta. • El proceso A solicita permiso para utilizar la impresora (recurso 1), el cual se le concede. • El proceso B solicita permiso para utilizar la unidad de cinta (recurso 2) y se le otorga. • El proceso A solicita entonces la unidad de cinta (recurso 2), pero la solicitud es denegada
hasta que B la libere. En este momento, en vez de liberar la unidad de cinta, el proceso B solicita la impresora (recurso 1).
Los procesos se bloquean en ese momento y permanecen así por siempre. A esta situación se le llama BLOQUEO.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
42
En ambientes de multiprogramación, varios procesos pueden competir por un número finito de recursos. Un proceso solicita recursos, y si los recursos no están disponibles en ese momento, el proceso entra en un estado de espera. Puede suceder que los procesos en espera nunca cambien de estado, debido a que los recursos que han solicitado están siendo detenidos por otros procesos en espera. Por ejemplo, esta situación ocurre en un sistema con cuatro unidades de disco y dos procesos. Si cada proceso tiene asignadas dos unidades de disco pero necesita tres, entonces cada proceso entrará a un estado de espera, en el cual estará hasta que el otro proceso libere las unidades de cinta que tiene asignadas. Esta situación es llamada Abrazo Mortal (Deadlock, interbloqueo o bloqueo mutuo). Para prevenir un abrazo mortal o recuperarse de alguno que ocurra, el sistema puede tomar alguna acción relativamente extrema, tal como el derecho de tomar los recursos (preemption of resources) de uno o más de los procesos que se encuentren en el abrazo mortal. 4.2. Condiciones para producir un interbloqueo Según Coffman (1971), existen cuatro condiciones que deben cumplirse para que haya bloqueo o interbloqueo. Una situación puede surgir sí y solo sí las siguientes cuatro condiciones ocurren simultáneamente en un sistema: • Exclusión mutua. Cada recurso se asigna por lo regular exactamente a un proceso o bien
esta disponible. Al menos un recurso es mantenido en un modo no-compartible; esto es, sólo un proceso a la vez puede usar el recurso. Si otro proceso solicita ese recurso, tiene que ser retardado hasta que el recurso haya sido liberado.
• Retener y esperar. Los procesos que regularmente contienen recursos otorgados antes pueden solicitar nuevos recursos. Debe existir un proceso que retenga al menos un recurso y esté esperando para adquirir recursos adicionales que están siendo retenidos por otros procesos.
• No existe el derecho de desasignar (No expropiación). Los recursos previamente otorgados no pueden extraerse por la fuerza de un proceso. Deben ser liberados explícitamente por el proceso que los contiene. Los recursos no pueden ser desasignados (preempted); esto es, un recurso sólo puede ser liberado voluntariamente por el proceso que lo retiene, después de que el proceso ha terminado su tarea.
• Espera circular. Debe haber una cadena de dos o más procesos, cada uno de los cuales esté esperando un recurso contenido en el siguiente miembro de la cadena. Debe existir un conjunto {p0, p1,...,pn} de procesos en espera tal que p0 esté esperando por un recurso que está siendo retenido por p1, p1 está esperando por un recurso que está siendo retenido por p2,..., pn-1 está esperando por un recurso que está siendo retenido por pn y pn está esperando por un recurso que está siendo retenido por p0.
4.3. Modelación de Interbloqueos Los interbloqueos pueden describirse utilizando un grafo dirigido y bipartito G(N,A) llamado grafo de asignación de recursos que consta en un conjunto de N nodos (vértices) y E arcos. Hay 2 tipos de nodos (Procesos y Recursos) y 2 tipos de arcos (Solicitud y Asignación). Los círculos representan procesos, los cuadrados recursos. Un arco desde un recurso a un proceso indica que el recurso ha sido asignado al proceso. Un arco desde un proceso a un recurso indica que el proceso ha solicitado el recurso, y está bloqueado esperándolo. Entonces, si hacemos el grafo con todos lo procesos y todos los recursos del sistema y encontramos un ciclo, los procesos en el ciclo están bajo bloqueo mutuo.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
43
4.4. Métodos para manejar el interbloqueo El punto de vista más simple es pretender que no existe el problema (El Algoritmo del Avestrúz o de Ostrich). Consiste en no hacer absolutamente nada (esconder la cabeza). Los S.O. que ignoran el problema de los bloqueos asumen la siguiente hipótesis: La mayoría de los usuarios preferiría un bloqueo ocasional, en vez de una regla que restringiera a todos los usuarios en el uso de los distintos tipos de recursos. El problema es que se debe pagar un cierto precio para encarar el problema del bloqueo: en restricciones para los procesos y en el uso de recursos. Se presenta una contradicción entre la conveniencia y lo que es correcto. Es muy difícil encontrar teóricamente soluciones prácticas de orden general aplicables a todos los tipos de S.O. Un criterio de orden general utilizado por los S.O. que no hacen tratamiento específico del bloqueo consiste en: • Intentar acceder al recurso compartido. • De no ser factible el acceso:
o Esperar un tiempo aleatorio. o Reintentar nuevamente.
Principalmente, existen cuatro métodos para manejar el interbloqueo. Podemos usar algún protocolo para asegurar que el sistema nunca entrará en un estado de abrazo mortal. Alternativamente, podemos permitir que el sistema entre en un estado de abrazo mortal (bloqueo) y después recuperarse. Pero el recuperarse puede ser muy difícil y muy caro. • Prevención del bloqueo (Deadlock Prevention). • Evitación del bloqueo (Deadlock Avoidance). • Detección del bloqueo. • Recuperación del bloqueo. 4.4.1. Prevención de Bloqueos La estrategia básica de la prevención del interbloqueo consiste, a grandes rasgos, en diseñar un sistema de manera que esté excluida, a priori, la posibilidad de interbloqueo. Los métodos para prevenir el interbloqueo consisten en impedir la aparición de alguna de las cuatro condiciones necesarias, antes mencionadas. Al asegurarnos de que por lo menos una de estas condiciones no se presente, podemos prevenir la ocurrencia de un bloqueo. Exclusión mutua. Si ningún recurso se puede asignar de forma exclusiva, no se produciría interbloqueo. Sin embargo, existen recursos para los que no es posible negar la condición de exclusión mutua, pues la propia naturaleza de los mismos obliga a que sean utilizados en exclusión mutua. No obstante, es posible eliminar esta condición en algunos recursos. Por ejemplo, una impresora es un recurso no compatible pues si se permite que dos procesos escriban en la impresora al mismo tiempo, la salida resultará caótica. Pero con el spooling de salida varios procesos pueden

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
44
generar salida al mismo tiempo. Puesto que el spooler nunca solicita otros recursos, se elimina el bloqueo originado por la impresora. El inconveniente es que no todos los recursos pueden usarse de esta forma (por ejemplo, la tabla de procesos no se presenta al spooling y, además, la implementación de esta técnica puede introducir nuevos motivos de interbloqueo, ya que el spooling emplea una zona de disco finita). Retener y esperar. Con el fin de asegurar que la condición de retener y esperar nunca ocurra en el sistema, se debe garantizar que siempre que un proceso solicite un recurso, éste no pueda retener otros recursos. Un protocolo que puede ser usado requiere que cada proceso solicite y le sean asignados todos los recursos antes de que empiece su ejecución. Esto puede ser implantado haciendo que las llamadas al sistema solicitando recursos se hagan antes que todas las otras llamadas al sistema. Un protocolo alternativo permite que un proceso solicite recursos cuando no tiene ningún recurso asignado. Un proceso puede solicitar algunos recursos y utilizarlos, pero, antes de que pueda volver a pedir recursos adicionales, debe liberar todos los recursos que tiene previamente asignados. Para ejemplificar la diferencia entre estos dos protocolos, consideremos un proceso que copia un archivo de una unidad de cinta(1) a una unidad de disco, ordena el archivo en disco, después imprime los resultados a una impresora en línea y finalmente copia el archivo de disco a la unidad de cinta(2). Si todos los recursos deben ser solicitados al inicio del proceso, entonces el proceso debe iniciar solicitando la unidad de cinta(1), la unidad de disco, la impresora en línea y la unidad de cinta(2). Este proceso mantendrá las unidades de cinta (1) y (2) durante la ejecución completa aunque sólo las utilice al principio y al final de su ejecución respectivamente. El segundo método permite al proceso el solicitar inicialmente solo la unidad de cinta(1) y la unidad de disco. Ahora puede copiar el archivo de la unidad de cinta (1) a la unidad de disco y ordenarlo, posteriormente debe liberar la unidad de cinta(1) y la unidad de disco. El proceso debe volver a solicitar la unidad de disco y la impresora en línea para hacer la impresión. Después de imprimir debe liberar la unidad de disco y la impresora. Ahora debe de volver a solicitar la unidad de disco y la unidad de cinta(2) para copiar el archivo a cinta, debe liberar ambos recursos y terminar. Existen dos desventajas principales en estos protocolos: • La primera, la utilización de los recursos puede ser muy baja, debido a que varios de los
recursos pueden estar asignados pero no son utilizados la mayor parte del tiempo. • Segundo, puede ocurrir Inanición (Starvation). Un proceso que necesite varios recursos que
sean muy solicitados puede tener que esperar indefinidamente mientras al menos uno de los recursos que necesita esté asignado siempre a algún otro proceso. En esta segunda condición, retener y esperar, si se puede impedir que los procesos que tienen los recursos esperen la llegada de más recursos podemos erradicar los estancamientos. La solución que exige que todos los procesos soliciten todos los recursos que necesiten a un mismo tiempo y bloqueando el proceso hasta que todos los recursos puedan concederse simultáneamente resulta ineficiente por dos factores:
o En primer lugar, un proceso puede estar suspendido durante mucho tiempo, esperando que concedan todas sus solicitudes de recursos, cuando de hecho podría haber avanzado con sólo algunos de los recursos.
o Y en segundo lugar, los recursos asignados a un proceso pueden permanecer sin usarse durante periodos considerables, tiempo durante el cual se priva del acceso a otros procesos.
No expropiación. La tercera condición necesaria es que no debe de existir el derecho de desasignar recursos que han sido previamente asignados. Con el fin de asegurar que esta condición no se cumpla, el siguiente protocolo puede ser usado: Si un proceso que está reteniendo algunos recursos solicita otro recurso que no puede ser asignado inmediatamente (es decir, el proceso tiene que esperar), entonces todos los recursos que tiene este proceso en espera son desasignados. Entonces, los recursos son liberados implícitamente. Los recursos

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
45
liberados son agregados a la lista de los recursos por los cuales está esperando el proceso. El proceso sólo puede volver a ser reinicializado cuando haya obtenido otra vez todos los recursos que tenía asignados, así como el nuevo recurso que estaba solicitando. Alternativamente si un proceso solicita algunos recursos, primero verificamos si estos están disponibles. Si es así, entonces se le asignan. De otro modo, se verifica si están asignados a alguno de los procesos que están en espera de recursos adicionales. Si es así, los recursos deseados son desasginados del proceso en espera y asignados al proceso solicitante. De otra manera (no están disponibles, ni asignados a procesos en espera) el proceso que hace la solicitud debe esperar. Pero, mientras esta esperando, algunos de sus recursos pueden ser desasignados solamente si estos son solicitados. Un proceso puede ser reinicializado cuando se le asigna el recurso que había solicitado y recupera cualquier recurso que haya sido desasignado mientras esperaba. Este protocolo es utilizado usualmente sobre recursos cuyo estado puede ser fácilmente salvado y restablecido posteriormente, ejemplo de ellos son los registros del CPU y el espacio en la memoria. Este no puede ser aplicado a recursos tales como impresoras. Esta tercera condición (llamada también sin prioridad) es aún menos premisoria que la segunda. Si a un proceso se le ha asignado la impresora y se encuentra a la mitad de la impresión, y tomamos a la fuerza la impresora porque no se dispone de una graficadora, se engendraría una confusión. Espera circular. Con el fin de asegurarse de que la condición de espera circular nunca se presente, se puede imponer un ordenamiento total sobre todos los tipos de recursos. Esto es, asignamos a cada tipo de recurso un número entero único, el cual permita comparar dos recursos y determinar cuándo uno precede al otro en el ordenamiento. Más formalmente, sea R = {r1, r2,..., rn} el conjunto de tipos de recursos. Puede definirse una función uno a uno F:R->N, donde N es el conjunto de números naturales. Por ejemplo, si el conjunto R de tipos de recursos incluye unidades de disco (UDD), unidades de cinta (UDC), lectoras ópticos (LO) e impresoras (I), entonces la función F puede ser definida como sigue: F(LO) =1 F(UDD) = 5 F(UDC) = 7 F(I) = 12 Se puede considerar el siguiente protocolo para prevenir interbloqueo: Cada proceso puede solicitar recursos solamente en un orden creciente de numeración. Esto es un proceso puede solicitar inicialmente cualquier número de instancias de un tipo de recurso, digamos ri. Después de esto, el proceso puede solicitar instancias de recursos del tipo rj si y solo si F(rj) > F(ri). Si varias instancias del mismo tipo de recurso son necesitadas, debe hacerse una sola petición para todas las instancias. Por ejemplo, usando la función definida anteriormente, un proceso que quiere usar el lector óptico (LO) y la impresora (I) debe solicitar primero el (LO) y después la (I). Alternativamente, se puede requerir simplemente que siempre que un proceso solicite una instancia del recurso tipo rj, éste tenga que liberar cualquier recurso del tipo ri tal que F(ri) >= F(rj). Debe notarse que la función F debe definirse de acuerdo al ordenamiento de uso normal de los recursos en el sistema. Por ejemplo, usualmente se utiliza primero una (UDD) antes que la (I), por lo cual es razonable definir F(UDD) < F(i). Esta última condición (espera circular) se puede eliminar en varias formas. Una manera consiste en simplemente tener una regla que afirme que un proceso sólo tiene derechos a un recurso único en cualquier momento. Si necesita un segundo recurso debe devolver el primero. Otra manera de evitar la espera circular es la de ofrecer una numeración global de todos los recursos. Ahora la regla es que los procesos pueden solicitar recursos siempre y cuando devuelva el recurso que tenga y el que solicite sea mayor que el que está utilizando. 4.4.2. Evasión de Bloqueos En vez de restringir la forma o el orden en que los procesos deben solicitar recursos, antes se chequea que sea seguro otorgar dichos recursos. Es decir, si se presentan las condiciones suficientes para un interbloqueo, todavía es posible evitarlos por medio de una restricción en la asignación de los procesos para tratar de buscar estados seguros. Estas restricciones aseguran que al menos una de las condiciones necesarias para el interbloqueo no pueda presentarse y por lo tanto, tampoco el interbloqueo. Otro método para evitar interbloqueo consiste en requerir información adicional sobre cómo se solicitarán los recursos. Esta información puede ser:

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
46
• La necesidad máxima de recursos de los procesos que se esta ejecutando. • La asignación actual de recursos a procesos. La cantidad actual de instancias libres de cada recurso. Con base a la información que ya se tiene de la forma y del orden en que se solicitarán los recursos, se puede tomar la decisión de ejecutar el proceso o si debe esperar. Por lo tanto, la evitación del interbloqueo sólo anticipa la posibilidad de interbloqueo y asegura que no exista nunca tal posibilidad. Estados seguros e inseguros • Un estado de asignación de recursos se considera seguro si en él no hay posibilidad de
interbloqueo. Para que un estado sea seguro, es necesario que los procesos formen una secuencia segura. Una secuencia segura es una ordenación de los procesos de modo que los recursos que aún pueden pedir cualquier proceso pueden ser otorgados con los recursos libres más los recursos retenidos por los demás procesos. Con base a ello, cuando un proceso realice una solicitud de recursos, el sistema se los concederá sólo en el caso de que la solicitud mantenga al sistema en un estado seguro.
• Un estado inseguro es aquel en el que puede presentarse un interbloqueo. Algoritmo del banquero para un sólo recurso Este algoritmo fue ideado por Dijkstra (1965). Se creó en la forma en que un banquero trata a un grupo de clientes, a quienes les otorga líneas de crédito. El banquero sabe que no todos los clientes (4) A, B, C y D necesitarán su limite de crédito máximo de inmediato, de manera que sólo ha reservado 10 unidades en lugar de 22 (total máximo disponible) para darles servicios (con este ejemplo asumiremos que los clientes son los procesos, las unidades de crédito son los recursos y el banquero es el sistema operativo). Los clientes emprenden sus respectivos negocios y solicitan préstamos de vez en cuando, es decir solicitan recursos. En cierto momento, la situación es como se muestra en el siguiente cuadro: Este estado es seguro, puesto que con dos unidades restantes, el banquero puede retrasar todas las solicitudes excepto la de C lo cual permite que C termine y libere sus cuatro recursos. Con cuatro unidades disponibles, el banquero puede permitir que B ó D tengan las unidades necesarias. Considerar lo que ocurriría si se otorgara una solicitud de B de una unidad adicional, analizando esto en el esquema anterior se tendría este nuevo esquema: Se tendría un estado inseguro, ya que si todos los clientes solicitaran de pronto su máximo préstamo, el banquero no podría satisfacerlas y se tendría un bloqueo. Un estado inseguro no tiene que llevar a un bloqueo, puesto que un cliente podría no necesitar toda su línea de crédito, pero el banquero no puede contar con ese comportamiento. El algoritmo del banquero consiste entonces en estudiar cada solicitud al ocurrir ésta y ver si su otorgamiento conduce a un estado seguro. En caso afirmativo, se otorga la solicitud; en caso contrario, se le pospone. Para ver si un estado es seguro, el banquero verifica si tiene los recursos suficientes para satisfacer a otro cliente. En caso afirmativo, se supone que estos préstamos se le volverán a pagar; entonces verifica al siguiente cliente cercano al límite y así sucesivamente. Si en cierto momento se vuelve a pagar todos los préstamos, el estado es seguro y la solicitud original debe ser aprobada.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
47
Algoritmo del banquero para varios recursos. El algoritmo del banquero de puede generalizar para el control de varios recursos. Por ejemplo, dado un sistema con cinco procesos, P1 a P5, y tres tipos de recursos, A, B y C, de los que existen 10, 5 y 7 ejemplares, respectivamente. Supongamos que en el instante actual tenemos la siguiente situación del sistema: Se calcula la matriz de necesidad, restando la matriz de Asignacion de la matriz Maximo requerido. Se compara el vector disponible con la matriz de necesidad y se cubre los requerimientos de un proceso, luego se recupera toda la asignacion maxima que junto al saldo se convierte en el nuevo disponible, como se ilustra a continuacion:
Disponible = (3 3 2) Se puede atender a P2 o P4, se elige P2 = - (1 2 2) Nuevo disponible después de la asignación =
(2 1 0)
Se recupera todos los recursos asignados a P2 = + (3 2 2) Nuevo disponible después de recuperar recursos =
(5 3 2)
Se puede atender a P4 o P5, se elige P4 = - (0 1 1) Nuevo disponible después de la asignación =
(5 2 1)
Se recupera todos los recursos asignados a P2 = + (2 2 2) Nuevo disponible después de recuperar recursos) =
(7 4 3)
Se puede atender a P3 o P5, se elige P5 = - (4 3 1) Nuevo disponible después de la asignación =
(3 1 2)
Se recupera todos los recursos asignados a P2 = + (4 3 3) Nuevo disponible después de recuperar recursos =
(7 4 5)
Se puede atender a P3 = - (6 0 0) Nuevo disponible después de la asignación =
(1 4 5)
Se recupera todos los recursos asignados a P2 = + (9 0 2) Nuevo disponible después de recuperar recursos =
(10 4 7)
Se puede atender a P1 = - (7 4 3) Nuevo disponible después de la asignación =
(3 0 4)
Se recupera todos los recursos asignados a P2 = + (7 5 3) Nuevo disponible después de recuperar recursos = (10 5 7)
El orden de atencion de los procesos es P2, P4, P5, P3 y P1; secuencia que permite un estado seguro de asignacion de recursos.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
48
Desventajas del algoritmo del Banquero El algoritmo del banquero es interesante debido a que proporciona un medio de asignar los recursos para evitar el interbloqueo. Permite proseguir a los trabajos que en una situación de prevención de interbloqueo tendría que esperar. Sin embargo el algoritmo contiene un número de desventajas importantes que pueden hacer que un diseñador escoja otro enfoque para el problema del estancamiento, las cuales se listan a continuación: • El algoritmo requiere que existan un número fijo de recursos asignables. Como los recursos
suelen requerir servicios, bien por avería o bien por mantenimiento preventivo, no podemos contar con que el número de recursos se mantenga siempre constante.
• El algoritmo requiere que la población de usuarios se mantenga constante. Esto también es irrazonable. En los sistemas multiprogramación actuales, la población de usuarios cambia constantemente.
• El algoritmo requiere que el banquero garantice que todas las peticiones serán concedidas dentro de un intervalo de tiempo finito. Está claro que, en sistemas reales, se necesitan garantías mucho mayores que ésta.
• El algoritmo requiere que los clientes (es decir, los trabajos) garanticen que los préstamos van a ser pagados (osea que los recursos van a ser devueltos) dentro de un intervalo de tiempo finito. También en este caso se necesitan garantías mucho mayores que ésta para sistemas reales.
• El algoritmo requiere que los usuarios indiquen sus necesidades máximas por adelantado. Al irse haciendo más dinámica la asignación de recursos resulta cada vez más difícil conocer las necesidades máximas de un usuario.
4.4.3. Detección de Bloqueos A diferencia de los algoritmos vistos, para evitar interbloqueos, que se deben ejecutar cada vez que existe una solicitud, el algoritmo utilizado para detectar circularidad se puede correr siempre que sea apropiado: cada hora, una vez al día, cuando el usuario note que el rendimiento se ha deteriorado o cuando se queje un usuario. Dicho algoritmo se puede explicar utilizando las gráficas de recursos dirigidos y “reduciéndolas”. Los pasos para reducir una gráfica son los siguientes: Se intenta ir terminando los procesos hasta que terminen todos
1. Si todos pueden ser terminados, se concluye que no hay interbloqueo 2. Sin no se pueden terminar todos los rpocesos, se concluye que los que no se han podido
terminar provocan interbloqueo. Para finalizar los procesos se busca un proceso que tenga todos los recursos que necesita. Para reducir se debe finalizar el proceso y liberara todos sus recursos. Por ejemplo, dada una situacion sin interbloqueo:
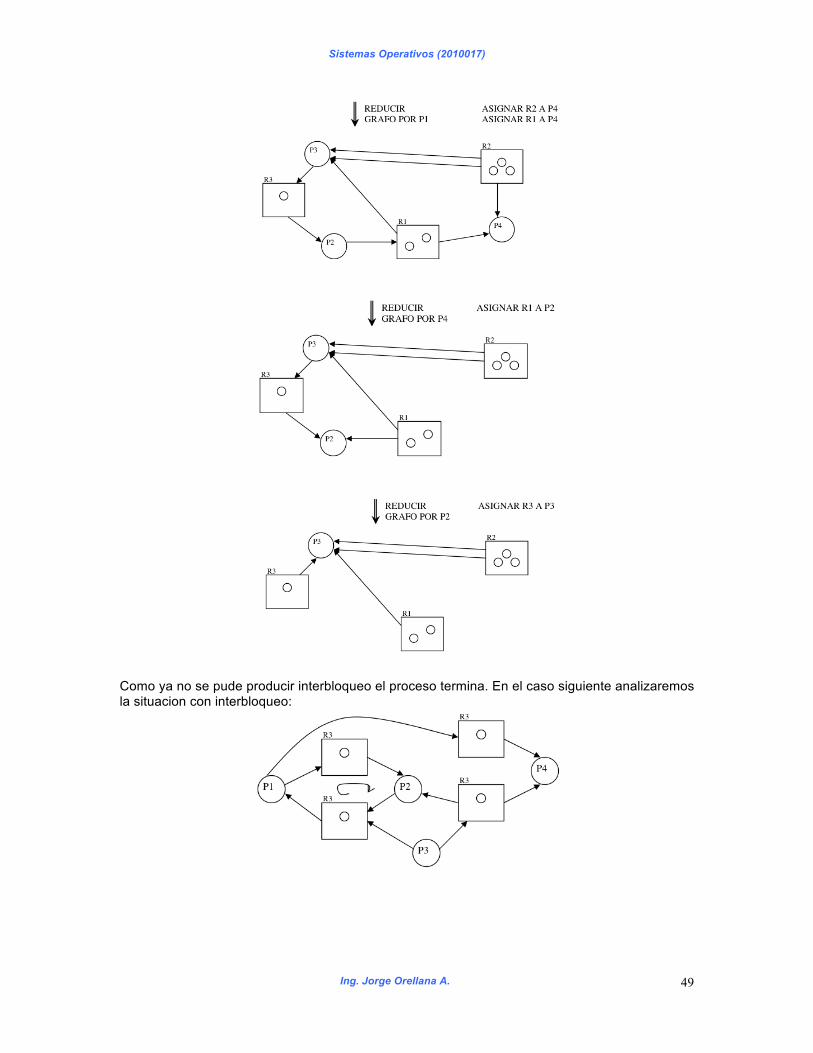
Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
49
Como ya no se pude producir interbloqueo el proceso termina. En el caso siguiente analizaremos la situacion con interbloqueo:

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
50
No se puede reducir mas, por lo que existe un interbloqueo. 4.4.4. Recuperación de Bloqueos Una vez que se detecta el interbloqueo hay que desarmarlo y devolver el sistema a la normalidad con tanta rapidez como sea posible. Existen varios algoritmos de recuperación, pero todos tienen una característica en común: requieren por lo menos una víctima, un trabajo consumible, mismo que, al ser eliminada del interbloqueo, liberará al sistema. Por desgracia, para eliminar la víctima generalmente hay que reiniciar el trabajo desde el principio o a partir de un punto medio conveniente. • El primer método y más simple de recuperación, y el más drástico es terminar los trabajos
que están activos en el sistema y volver a arrancarlos desde el principio. • El segundo método es terminar sólo los trabajos incluidos en el interbloqueo y solicitar a sus
usuarios que los vuelvan a enviar. • El tercero es identificar qué trabajos intervienen en el interbloqueo y terminarlos uno por uno
y comprobar la desaparición del bloqueo mutuo después de cada eliminación hasta resolverlo. Una vez liberado el sistema, se deja que los trabajos restantes terminen su procesamiento; luego, los trabajos detenidos se inician de nuevo desde el principio.
• El cuarto procedimiento se puede poner en efecto sólo si el trabajo mantiene un registro, una instantánea de su progreso, de manera que se pueda interrumpir y después continuar sin tener que reiniciar desde el principio. En general, este método es el preferido para trabajos de ejecución larga, a fin de ayudarlos a tener una recuperación rápida.
Hasta ahora los cuatro procedimientos anteriores comprenden los trabajos que se encuentran en interbloqueo. Los dos métodos siguientes se concentran en trabajos que no están en interbloqueo y los recursos que conservan. • Uno de ellos, el quinto método de la lista, selecciona un trabajo no bloqueado, retira los
recursos que contiene y los asigna a procesos bloqueados, de manera que pueda reanudarse la ejecución (esto deshace el interbloqueo).
• El sexto método detiene los trabajos nuevos e impide que entren al sistema, lo que permite que los que no estén bloqueados sigan hasta su terminación y liberen sus recursos. Con menos trabajos en el sistema, la competencia por los recursos se reduce, de suerte que los procesos bloqueados obtienen los recursos que necesitan para ejecutarse hasta su terminación. Este método es el único aquí listado que no necesita una víctima. No se garantiza que funcione, a menos que el número de recursos disponibles exceda los necesarios en por lo menos uno de los trabajos bloqueados para ejecutar (esto es posible con recursos múltiples).
Deben considerarse varios factores al elegir la víctima para que tengan el efecto menos negativo sobre el sistema. Los más comunes son:
• La prioridad del trabajo en consideración. Por lo general no se tocan los trabajos de alta prioridad.
• El tiempo de CPU utilizado por el trabajo. No suelen tocarse los trabajos que están a punto de terminar.
• La cantidad de tareas en que repercutiría la elección de la víctima.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
51
Además, los programas que trabajan con bases de datos también merecen un trato especial. Los trabajos que están modificando datos no se deben elegir para su terminación, ya que la consistencia y validez de la base de datos se pondría en peligro. Afortunadamente, los diseñadores de muchos sistemas de bases de datos han incluido mecanismos complejos de recuperación, por lo que se minimiza el daño a la base de datos si se interrumpe una transacción o se termina antes de completarse.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 52
Tema V Administración de Memoria
La memoria es un recurso escaso, y para aprovecharla bien hay que administrarla bien. A pesar de que la memoria es más barata cada día, los requerimientos de almacenamiento crecen en proporción similar. Parafraseando la ley de Parkinson, “Los programas se desarrollan para ocupar toda la memoria disponible para ellos”. La organización y administración de la memoria principal, memoria primaria, memoria real o almacenamiento de un sistema ha sido y es uno de los factores más importantes en el diseño de los S. O. [Deitel] y sus funciones son:
• Llevar un control de las partes de memoria que se están utilizando y de aquellas que no. • Asignar espacio en memoria a los procesos cuando estos la necesitan y liberarla cuando
estos finalicen. • Administrar el intercambio entre memoria principal y secundaria durante el swapping.
5.1. JERARQUÍA DE ALMACENAMIENTO Los programas y datos tienen que estar en la memoria principal para poder ejecutarse o ser referenciados [Deitel]. Los programas y datos que no son necesarios de inmediato pueden mantenerse en el almacenamiento secundario. El almacenamiento principal es más costoso y menor que el secundario pero de acceso más rápido. La mayor parte de las computadoras tienen una jerarquía de memoria, con una cantidad pequeña de memoria caché muy rápida, costosa y volátil, algunos megabytes de memoria principal (RAM) volátil de mediana velocidad y mediano precio, y cientos o miles de megabytes de almacenamiento en disco lento, económico y no volátil. Corresponde al sistema operativo coordinar el uso de estas memorias.
• Caché de nivel 1: 8 a 128 kb. empaquetados dentro del chip; por lo mismo, la velocidad de acceso es de unos pocos nanosegundos.
o L1 DC: (Level 1 date cache) se encarga de almacenar datos usados frecuentemente y cuando sea necesario volver a utilizarlos, inmediatamente los utiliza, por lo que se agilizan los procesos.
o L1 IC: (Level 1 instruction cache): se encarga de almacenar instrucciones usadas frecuentemente y cuando sea necesario volver a utilizarlas, inmediatamente las recupera, por lo que se agilizan los procesos.
• Caché de nivel 2: 256 Kb a 4Mb, 12-20 ns (L2 viene integrada en el microprocesador, se encarga de almacenar datos de uso frecuente y agilizar los procesos)
• Caché de nivel 3: hasta 6 Mb, 15-35 ns Con este nivel de memoria se agiliza el acceso a datos e instrucciones que no fueron localizadas en L1 ó L2. Si no se encuentra el dato en ninguna de las 3, entonces se accederá a buscarlo en la memoria RAM.
• Memoria RAM: hasta 32 Gb, 60-70ns • Disco duro. Para almacenamiento estable, y también para extender la RAM de manera
virtual, hasta 2 Tb, 8ms. • Cinta. 1 a 40 Gb.
La cahe L2 utiliza gran parte del dado del chip, ya que se necesitan millones de transistores para formar una memoria caché grande; ésta se crea tilizando SRAM (RAM estática) en oposición a la RAM normal, que es dinámica (DRAM). Mientras que la DRAM puede crearse utilizado un transistor por bit (además de un condensador), son necesarios 6 transistores (o más) para crear un bit de SRAM. Por lo tanto, 256 KB de memoria caché L2 necesitarían más de 12 millones de transistores. Tanto Intel como AMD no han incluido memoria caché L2 en algunas series para hacer productos más baratos. Sin embargo, no hay duda de que cuanto mayor es la memoria caché (tanto L1 como L2), más eficiente será la CPU y mayor será su rendimiento.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 53
5.2. ADMINISTRACIÓN DE MEMORIA Los sistemas de administración de memoria se pueden dividir en dos clases, los que trasladan procesos entre la memoria y el disco durante la ejecución (intercambio y paginación) y los que no lo hacen. Estudiaremos primero los segundos. 5.2.1. Monoprogramación sin intercambio ni paginación La forma más simple de administrar memoria es ejecutando sólo un programa a la vez, compartiendo la memoria con el sistema operativo. Por ejemplo, MS-DOS. Cuando un usuario digita un comando, el sistema operativo carga el programa correspondiente en la memoria, y lo ejecuta. Cuando el programa termina, el sistema operativo solicita un nuevo comando y carga el nuevo programa en la memoria, sobreescribiendo el anterior.
En la figura se muestran tres variaciones sobre este tema. El sistema operativo puede estar en la base de la memoria en RAM (memoria de acceso aleatorio), como se muestra en (a), o puede estar en ROM (memoria sólo de lectura) en la parte superior de la memoria, como en (b), o los controladores de dispositivos pueden estar en la parte superior de la memoria en una ROM con el resto del sistema en RAM hasta abajo, como se muestra en (c). Este último modelo es utilizado por los sistemas MS-DOS pequeños, por ejemplo. En las IBM PC, la porción del sistema que está en ROM se llama BIOS (Basic Input Output System, sistema básico de entrada salida). 5.2.2. Multiprogramación con particiones fijas Tener varios procesos en la memoria a la vez implica que cuando un proceso está bloqueado esperando que termine una E/S, otro puede usar la CPU. Así, la multiprogramación aumenta el

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 54
aprovechamiento de la CPU. Sin embargo, incluso en computadoras personales hay ocasiones en las que resulta útil poder ejecutar dos o más programas a la vez. La forma más fácil de lograr la multiprogramación consiste simplemente en dividir la memoria en n particiones, posiblemente desiguales, y asignar cada una de las partes a un proceso. Cuando llega un trabajo, se le puede colocar en la cola de entrada de la partición pequeña que puede contenerlo. Puesto que las particiones están fijas en este esquema, cualquier espacio de una partición que un trabajo no utilice se desperdiciará. En la siguiente figura se puede ver un sistema de particiones fijas y colas de entrada individuales. La desventaja de repartir los trabajos entrantes en colas distintas se hace evidente cuando la cola de una partición grande está vacía pero la cola de una partición pequeña está llena.
Particiones de memoria fijas con colas de entrada individuales para cada partición
Una organización alternativa sería mantener una sola cola. Cada vez que se libera una partición, se selecciona el trabajo más cercano al inicio de la cola que cabe en esa partición, se carga en dicha partición y ejecuta. Puesto que no es deseable desperdiciar una partición grande en un trabajo pequeño, una estrategia diferente consiste en examinar toda la cola de entrada cada vez que se libera una partición y escoger el trabajo más grande que cabe en ella. Este último algoritmo discrimina contra los trabajos pequeños, considerándolos indignos de recibir toda la partición, en tanto que usualmente es deseable dar el mejor servicio, y no el peor, a los trabajos más pequeños (que supuestamente son interactivos).
Particiones de memoria fija con una sola cola de entrada.
5.2.2.1. Relocalización (reubicación) y Protección Cuando se mantienen diversas tareas en diferentes particiones de memoria se presentan dos problemas esenciales que es preciso resolver: la reubicación y la protección. El termino reubicable se refiere a la posibilidad de cargar y ejecutar un programa dado en un lugar arbitrario de memoria. Si un mismo programa se ejecuta varias veces, no siempre va a quedar en la misma partición. Es evidente que diferentes trabajos se ejecutarán en diferentes direcciones. Cuando se enlaza (link) un programa o se lo vuelve ejecutable (es decir, cuando el programa principal, los procedimientos escritos por el usuario y los procedimientos de biblioteca se combinan en un solo espacio de direcciones), el enlazador necesita saber en qué dirección de la memoria va a comenzar el programa. Por ejemplo, supongamos que la primera instrucción es una llamada a un procedimiento que está en la dirección absoluta 100 dentro del archivo binario (ejecutable) producido por el enlazador. Si este programa se carga en la partición 1, esa instrucción saltará a la dirección absoluta 100, que está, dentro del sistema operativo. Lo que se necesita es una llamada a 100K + 100. Si el programa se le carga en la partición 2, deberá efectuarse como una llamada a 200K + 100, etc.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 55
Una posible solución es modificar realmente las instrucciones en el momento en que el programa se carga en la memoria. Se suma 100K a cada una de las direcciones de un programa que se carga en la partición 1, se suma 200K a las direcciones de los programas cargados en la partición 2, etc. A fin de efectuar la reubicación durante la carga, de esta manera el enlazador debe incluir en el programa binario una lista o mapa de bits que indique cuáles bytes del programa son direcciones que deben reubicarse y cuáles con códigos de operación, constantes u otros elementos que no deben reubicarse. La reubicación durante la carga no resuelve el problema de la protección. Un programa mal intencionado siempre puede construir una nueva instrucción y saltar a ella. Dado que los programas en este sistema usan direcciones de memoria absolutas en lugar de direcciones relativas a un registro, no hay forma de impedir que un programa construya una instrucción que lea o escriba cualquier byte de la memoria. En los sistemas multiusuario, no es conveniente permitir que los procesos lean y escriban en memoria que pertenece a otros usuarios. Una solución alternativa tanto al problema de reubicación como al de protección consiste en equipar la máquina con dos registros especiales en hardware, llamados registros de base y de límite. Cuando se planifica un proceso, el registro de base se carga con la dirección del principio de su partición, y el registro de límite se carga con la longitud de la partición. A cada dirección de memoria generada se le suma automáticamente el contenido del registro de base antes de enviarse a la memoria. De este modo, si el registro de base es de 100K, una instrucción CALL 100 se convierte efectivamente en una instrucción CALL 100K + 100, sin que la instrucción en sí se modifique. Además, las direcciones se cotejan con el registro de límite para asegurar que no intenten acceder a memoria fuera de la partición actual. El hardware protege los registros de base y de límite para evitar que los programas de usuario los modifiquen.
5.2.2.2. Fragmentación La mayor dificultad con las particiones fijas esta en encontrar una buena relación entre los tamaños de las particiones y la memoria requerida para los trabajos. La fragmentación de almacenamiento ocurre en todos los sistemas independientemente de su organización de memoria. Existen dos tipos de desaprovechamiento de memoria: a) La fragmentación interna, que consiste en aquella parte de la memoria que no se está
usando pero que es interna a una partición asignada a una tarea; por ejemplo si una tarea necesita m bytes de memoria para ejecutarse y se le asigna una partición de n bytes (con n>m), está desaprovechando n-m bytes.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 56
b) La fragmentación externa, que ocurre cuando una partición disponible no se emplea porque es muy pequeña para cualquiera de las tareas que esperan.
La selección de los tamaños de las particiones es una relación entre estos dos casos de fragmentación. Por ejemplo, 7 Mb asignados a los usuarios se reparten en 7 particiones de 1 Mb, y la cola de tareas contiene tareas con requerimientos de 400 Kb, 1600 Kb, 300 Kb, 900 Kb, 200 Kb, 500 Kb y 800 Kb. Se ve que hay un trabajo de 1600 Kb que no se podrá ejecutar nunca, los otros sin embargo si se ejecutaran pero en conjunto desperdiciaran 3044 Kb, casi la mitad de memoria disponible. Hay, pues en este caso 1024 Kb de fragmentación externa y 3044 Kb de fragmentación interna. Si se divide la memoria en cuatro particiones de 512 Kb, dos de 1 Mb y una de 3 Mb, todos los trabajos se ejecutarían sin fragmentación externa y con una pérdida de memoria en fragmentación interna de 2648 Kb. 5.2.3. Multiprogramación de Partición Variable Las particiones fijas tienen el inconveniente de que hay que determinar sus mejores tamaños con el fin de minimizar la fragmentación interna y externa. Pero si se ejecutan un conjunto dinámico de procesos, será difícil que se encuentre la partición correcta de la memoria. La solución de este problema está en permitir que los tamaños de las particiones varíen dinámicamente. Los procesos ocupan tanto espacio como necesitan, pero obviamente no deben superar el espacio disponible de memoria [Deitel].
No hay límites fijos de memoria, es decir que la partición de un trabajo es su propio tamaño. Se consideran “esquemas de asignación contigua”, dado que un programa debe ocupar posiciones adyacentes de almacenamiento. Los procesos que terminan dejan disponibles espacios de memoria principal llamados “agujeros” o áreas libres:
• Pueden ser usados por otros trabajos que cuando finalizan dejan otros agujeros menores.
• En sucesivos pasos los agujeros son cada vez más numerosos pero más pequeños, por lo que se genera un desperdicio de memoria principal.
La combinación de agujeros (áreas libres), consiste en fusionar agujeros adyacentes para formar uno sencillo más grande. Se puede hacer cuando un trabajo termina y el almacenamiento que libera tiene límites con otros agujeros. 5.2.3.1. Compresión o Compactación de Almacenamiento Puede ocurrir que los agujeros (áreas libres) separados distribuidos por todo el almacenamiento principal constituyan una cantidad importante de memoria:
• Podría ser suficiente (el total global disponible) para alojar a procesos encolados en espera de memoria.
• Podría no ser suficiente ningún área libre individual.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 57
La técnica de compresión de memoria implica pasar todas las áreas ocupadas del almacenamiento a uno de los extremos de la memoria principal:
• Deja un solo agujero grande de memoria libre contigua. • Esta técnica se denomina “recogida de residuos”.
Una de las principales desventajas de la compresión es que consume recursos del sistema.
El sistema debe detener todo mientras efectúa la compresión, lo que puede afectar los tiempos de respuesta. Implica la relocalización (reubicación) de los procesos que se encuentran en la memoria. La información de relocalización debe ser de accesibilidad inmediata. Una alta carga de trabajo significa mayor frecuencia de compresión que incrementa el uso de recursos. 5.2.3.2. Estrategias de Colocación del Almacenamiento (Selección de partición) Se utilizan para determinar el lugar de la memoria donde serán colocados los programas y datos que van llegando y se las clasifica de la siguiente manera:
• First Fit Estrategia de primer ajuste: El S.O. revisa en todas las secciones de memoria libre. Un proceso nuevo es colocado en el primer agujero disponible con tamaño suficiente para alojarlo. A menos que el tamaño del proceso coincida con el tamaño del agujero, este sigue existiendo, reducido por el tamaño del proceso.
• Next Fit Estrategia del próximo ajuste: En el primer ajuste, ya que todas las búsquedas empiezan al comienzo de la memoria, siempre se ocupan más frecuentemente los agujeros que están al comienzo que los que están al final de la memoria. Este algoritmo intenta mejorar el desempeño al distribuir sus búsquedas mas uniformemente sobre el espacio de memoria, manteniendo el registro de que agujero fue el ultimo en ser

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 58
asignado. La próxima búsqueda empieza en el último agujero asignado y no al comienzo de la memoria.
• Best Fit Estrategia de mejor ajuste: Este algoritmo revisa la lista completa de agujeros para encontrar el agujero más pequeño cuyo tamaño es mayor o igual que el tamaño del proceso.
• Worst Fit Estrategia de peor ajuste: Consiste en colocar un programa en el agujero en el que quepa de la peor manera, es decir en el más grande posible. El agujero restante es también grande para poder alojar a un nuevo programa relativamente grande.
5.2.3.3. Intercambio de Almacenamiento (Swapping) Si en un sistema interactivo no es posible mantener a todos los procesos en memoria, se puede usar el disco como apoyo para extender la capacidad de la memoria, pasando los procesos temporalmente a disco y traerlos dinámicamente para que se ejecuten. Podemos usar dos enfoques de administración de memoria generales, dependiendo (en parte) del hardware disponible. La estrategia más sencilla, llamada intercambio, consiste en traer a la memoria cada proceso en su totalidad, ejecutarlo durante un tiempo, y después colocarlo otra vez en el disco. La otra estrategia, llamada memoria virtual, permite a los programas ejecutarse aunque sólo estén parcialmente en la memoria principal. El sistema operativo mantiene una tabla que indica qué partes de la memoria están desocupadas, y cuáles en uso. Las partes desocupadas son agujeros en la memoria; inicialmente, toda la memoria es un solo gran agujero. Cuando se crea un proceso o se trae uno del disco, se busca un agujero capaz de contenerlo, y se pone el proceso allí. Las particiones ya no son fijas, sino que van cambiando dinámicamente, tanto en cantidad como en ubicación y tamaño. Además, cuando un proceso es pasado a disco, no hay ninguna garantía de que vuelva a quedar en la misma
El funcionamiento de un sistema con intercambio se ilustra en la figura. Inicialmente, sólo el proceso A está en la memoria. Luego se crean o se traen del disco los procesos B y C. A termina o se intercambia al disco. Luego llega D y B sale. Por último, entra E. 5.2.4. Paginación El que los procesos tengan que usar un espacio contiguo de la memoria es un impedimento serio para optimizar el uso de la memoria. Se podría considerar que las direcciones lógicas sean contiguas, pero que no necesariamente correspondan a direcciones físicas contiguas. Es decir, dividir la memoria física en bloques de tamaño fijo, llamados marcos (frames), y dividir la memoria lógica (la que los procesos ven) en bloques del mismo tamaño llamados páginas.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 59
Se usa una tabla de páginas para saber en qué marco se encuentra cada página. Obviamente, se requiere apoyo del hardware. Cada vez que la CPU intenta accesar una dirección, la dirección se divide en número de página p y desplazamiento d (offset). El número de página se transforma en el marco correspondiente, antes de accesar físicamente la memoria.
El tamaño de las páginas es una potencia de 2, entre 512 bytes y 8 kb. Si las direcciones son de m bits y el tamaño de página es 2n, entonces los primeros m-n bits de cada dirección forman p, y los restantes n forman d. Este esquema es parecido a tener varios pares de registros base y límite, uno para cada marco. Cada proceso tiene su propia tabla, cuando la CPU se concede a otro proceso, hay que cambiar la tabla de páginas a la del nuevo proceso. La paginación en general encarece los cambios de contexto. La seguridad sale gratis, ya que cada proceso sólo puede accesar las páginas que están en su tabla de páginas. Hay fragmentación interna, y de media página por proceso, en promedio. Esto sugeriría que conviene usar páginas chicas, pero eso aumentaría el sobrecosto de administrar las páginas. En general, el tamaño de página ha ido aumentando con el tamaño de la memoria física de una máquina típica. Por ejemplo, en la figura siguiente, el computador genera direcciones de 24 bits, lo que permite un espacio de direcciones de 16 Mb; se consideran marcos de páginas y páginas de 4 Kb. Un proceso de 14 kb necesita, pues, cuatro páginas numeradas de 0 a 3 y cada página se le asigna un marco de página de la memoria física. Para hacer esta asignación se usa una tabla de páginas, que se construye cuando se carga el proceso y que contiene tantas entradas como paginas tenga este.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 60
La tabla de páginas tiene cuatro entradas. Cada dirección lógica se divide en dos partes: el número de página, que se emplea como un índice en la tabla de páginas y un desplazamiento dentro de la página. La dirección lógica 002 0FF se descompone en dos campos: 002, que es el número de página y 0FF que es el desplazamiento relativo dentro de esta página. De la tabla de páginas se comprueba que a la pagina 002 le corresponde el marco de pagina 104, luego la dirección física se construye sustituyendo, en el primer campo en el que se divide la dirección, el numero de pagina por el marco de pagina correspondiente, resultando así la dirección física 104 0FF. 5.2.4.1. Tablas de páginas Si las direcciones son de m bits y el tamaño de página es 2n, la tabla de páginas puede llegar a contener 2m-n entradas. En una CPU moderna, m=32 (y ahora, incluso, 64), y n=12 o 13, lo que significa que se requerirían cientos de miles de entradas: ya no es posible tener la tabla en registros. En la mayor parte de los esquemas de paginación, las tablas de páginas se mantienen en la memoria, debido a su gran tamaño. Esto puede tener un impacto enorme sobre el rendimiento. Consideremos, por ejemplo, una instrucción que copia un registro en otro. Si no hay paginación, esta instrucción sólo hace referencia a la memoria una vez, para obtener la instrucción. Si hay paginación, se requieren referencias adicionales a la memoria para acceder a la tabla de páginas. Puesto que la velocidad de ejecución generalmente está limitada por la rapidez con que la CPU puede obtener instrucciones y datos de la memoria, tener que referirse dos veces a la tabla de páginas por cada referencia a la memoria reduce el rendimiento a una tercera parte. En estas condiciones, nadie usaría paginación. Los diseñadores de computadoras han estado al tanto de este problema desde hace años y han encontrado una solución. Su solución se basa en la observación de que muchos programas tienden a efectuar un gran número de referencias a un número pequeño de páginas, y no al revés. Así, sólo se lee mucho una fracción pequeña de las entradas de la tabla de páginas; el resto apenas si se usa.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 61
La solución típica es equipar las computadoras con un pequeño dispositivo de hardware para transformar las direcciones logicas en físicas sin pasar por la tabla de páginas. El dispositivo, llamado TLB (buffer de consulta para traducción, en inglés, Translation Lookaside Buffer) o también memoria asociativa. La memoria asociativa guarda pares (clave, valor), y cuando se le presenta la clave, busca simultáneamente en todos sus registros, y retorna, en pocos nanosegundos, el valor correspondiente. Obviamente, la memoria asociativa es cara; por eso, los TLBs rara vez contienen más de 64 registros. El TLB forma parte de la unidad de administración de memoria (MMU), y contiene los pares (página, marco) de las páginas más recientemente accesadas. Cuando la CPU genera una dirección lógica a la página p, la MMU busca una entrada (p,f) en el TLB. Si está, se usa marco f, sin acudir a la memoria. Sólo si no hay una entrada para p la MMU debe accesar la tabla de páginas en memoria (e incorporar una entrada para p en el TLB, posiblemente eliminando otra). Por pequeño que sea el TLB, la probabilidad de que la página esté en el TLB (tasa de aciertos) es alta, porque los programas suelen hacer muchas referencias a unas pocas páginas. Si la tasa de aciertos es el 90% y un acceso al TLB cuesta 10ns, entonces, en promedio, cada acceso a memoria costará 87ns. Es decir, sólo un 24% más que un acceso sin paginación. Una Intel 80486 tiene 32 entradas en el TLB; Intel asegura una tasa de aciertos del 98%. En cada cambio de contexto, hay que limpiar el TLB, lo que puede ser barato, pero hay que considerar un costo indirecto: si los cambios de contexto son muy frecuentes, la tasa de aciertos se puede reducir. 5.2.5. Segmentación Cuando se usa paginación, el sistema divide la memoria para poder administrarla, no para facilitarle la vida al programador. La vista lógica que el programador tiene de la memoria no tiene nada que ver con la vista física que el sistema tiene de ella. El sistema ve un sólo gran arreglo dividido en páginas, pero el programador piensa en términos de un conjunto de subrutinas y estructuras de datos, a las cuales se refiere por su nombre: la función coseno, el stack, la tabla de símbolos, sin importar la ubicación en memoria, y si acaso una está antes o después que la otra. La segmentación es una forma de administrar la memoria que permite que el usuario vea la memoria como una colección de segmentos, cada uno de los cuales tiene un nombre y un tamaño (que, además, puede variar dinámicamente). Las direcciones lógicas se especifican como un par (segmento, desplazamiento).

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 62
Las direcciones especifican el nombre del segmento y el desplazamiento dentro del segmento; por ello. El usuario debe especificar cada dirección mediante dos cantidades, el nombre del segmento y un desplazamiento. Por ejemplo: una dirección del segmento de la tabla de símbolos es:
[segmento s, elemento 4] y una dirección del segmento de la función coseno es:
[segmento cos, sentencia 7]
Como se ve, este esquema es conceptualmente muy diferente al de la paginación, donde el usuario especifica solo una única dirección, que mediante circuitería lógica se divide en un número de página y un desplazamiento y todo ello sin intervención directa por parte del programador. Un segmento es un objeto lógico, conocido por el programador y que lo utiliza como tal. Un segmento puede tener una determinada estructura de datos (pila, array, variables escalares, etc.) o un procedimiento o un modulo, pero normalmente no va a contener una mezcla de varios. 5.2.5.1. Implementación El programa de usuario se compila y el compilador construye automáticamente los segmentos de acuerdo a la estructura del programa. Por ejemplo, un compilador de Pascal creará segmentos separados para las variables globales, la pila de llamadas a los procedimientos (para almacenar parámetros y direcciones de retorno), el código de cada uno de los procedimientos y funciones. El cargador tomara todos los segmentos y le asignara números de segmento. Por propósito de reubicación cada uno de los segmentos se compila comenzando por su propia dirección lógica 0. Las direcciones lógicas, por tanto, constaran de un número de segmento y un desplazamiento dentro de él. Es este contexto, el espacio de direcciones es bidimensional, pero la memoria física mantiene su organización lineal unidimensional, luego es necesario disponer de un mecanismo que convierta las direcciones lógicas bidimensionales en su dirección física equivalente unidimensional. Esta asignación se efectúa mediante una tabla de segmentos.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 63
En la figura se puede observar el uso de la tabla de segmentos donde se mantienen registrados los descriptores de cada segmento: la base, correspondiente a la dirección física en que comienza el segmento (obtenida durante la creación de la partición) y el tamaño del mismo. El número de segmento, primer parámetro de la dirección lógica, se emplea como un índice dentro de la tabla de segmentos. La dirección física se obtiene añadiendo el desplazamiento a la base del segmento. Este desplazamiento no debe sobrepasar el tamaño máximo del segmento, si superara el tamaño máximo registrado en la tabla se producirá una error de direccionamiento. La realización de las tablas de segmentos es parecida a las tablas de páginas, teniendo en cuenta que los segmentos son de diferentes tamaños. Así, una tabla de segmentos que se mantiene en registros especiales puede ser referenciada muy rápidamente; la suma a la base y la comparación con el tamaño se puede hacer simultáneamente. Este método puede llevarse a cabo mientras el numero de segmentos no sea grande, pero cuando este crece la tabla de segmentos se deja en memoria; en este caso, un registro base de la tabla de segmentos apunta a la tabla de segmentos; además, como el numero de segmentos usados por un programa puede variar, también se emplea un registro de la longitud de la tabla de segmentos. Para una dirección lógica se procede de la siguiente manera:
1) Se comprueba que el numero de segmento es correcto (es decir, que es menor que el registro de la longitud de la tabla de segmentos)
2) Se suma el número de segmento al valor del registro base de la tabla de segmentos para obtener la dirección de memoria para la entrada de la tabla de segmentos.
3) Esta entrada se lee de memoria y se procede como antes, es decir, se comprueba que el desplazamiento no rebasa la longitud del segmento y se calcula la dirección física como la suma del registro base de la tabla de segmentos y del desplazamiento. Pero al igual que con la paginación, esto requiere dos referencias a memoria por dirección lógica, provocando así una disminución en la velocidad del computador.
La solución a este problema es disponer también de una memoria asociativa para retener las entradas de la tabla de segmentos usadas más recientemente (análogamente a como se hacía en las páginas) y conseguir rendimientos tan solo un poco peor que si tuviera acceso directo. La segmentación no produce fragmentación interna, pero si externa, la cual ocurre cuando todos los bloques de memoria libre son muy pequeños para acomodar a un segmento. En esta situación, el proceso solo puede esperar a disponer de más memoria, agujeros más grandes, o usar estrategias de compactación para crear huecos más grandes.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 64
Para el proceso de la figura, el espacio de direcciones lógicas está constituido por seis segmentos situados en memoria según se indica. La tabla de segmentos tiene una entrada para cada segmento, indicándose la dirección de comienzo del segmento en la memoria física (base) y la longitud del mismo (tamaño). El segmento 3 empieza en la dirección 1048576 y tiene un tamaño de 100 kb; si se hace una referencia a la dirección 115000 del segmento 3 se producirá un error de direccionamiento, puesto que esta dirección supera el tamaño del segmento. 5.2.5.2. Protección y compartición Una ventaja de la segmentación es la posibilidad de asociar la protección a los segmentos. Puesto que los segmentos son porciones diferentes del programa definidas semánticamente (unos segmentos contendrán solo instrucciones mientras que otros datos), todas las entradas al segmento se usan de la misma manera. De esta forma, los segmentos de código se pueden definir de solo lectura, mientras que un segmento de datos se puede definir de lectura/escritura. La segmentación también facilita la compartición de código o datos entre varios procesos. Un ejemplo usual es el de las librerías compartidas; así, en equipos con sistemas gráficos se suele tener librerías graficas muy grandes que se compilan casi en todos los programas; en un sistema segmentado, la librería grafica se puede situar en un segmento y compartirse entre varios procesos, sin necesidad de tenerla en el espacio de direcciones de cada proceso. Los segmentos son compartidos cuando la entrada a la tabla de segmentos de dos procesos apunta a la misma posición física. De esta forma, cualquier información se puede compartir si se define en un segmento. 5.2.6. Paginación - Segmentación La paginación y la segmentación son esquemas diferentes de gestión de la memoria cuyas principales características se pueden resumir en los siguientes puntos:
a) El programador no necesita saber que está utilizando la paginación; pero si se dispone de segmentación si necesita saberlo
b) Mientras que la paginación sigue un esquema lineal, con un único espacio de direcciones, la segmentación proporciona un espacio bidimensional con muchos espacios de direcciones.
c) En la paginación no se distingue el código de los datos. En cambio, en la segmentación si se distinguen (tienen segmentos diferentes), pudiéndose proteger de manera independiente.
d) La segmentación facilita la compartición de código y datos, así como el uso de estructuras de datos de tamaños fluctuantes.
e) Ambas tienen en común que el espacio total de direcciones puede exceder el tamaño de la memoria física.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 65
De forma absoluta no se puede decir que una técnica sea superior a otra, por ellos hay sistemas que combinan los dos métodos para recoger lo mejor de ambos. Una técnica muy extendida consiste en usar la segmentación desde el punto de vista del usuario pero dividiendo cada segmento en páginas de tamaño fijo para su ubicación. Esta técnica es adecuada en el caso de que los segmentos sean muy grandes y resuelve un grave inconveniente, o sea casi imposible mantenerlos en su totalidad dentro de la memoria.
El principio de la combinación de la segmentación con la paginación se muestra en la figura, bajo este esquema se elimina la fragmentación externa y se hace más fácil el problema de la ubicación ya que cualquier marco desocupado se puede asignar a una página. Se puede ver en la figura que la principal diferencia con la segmentación pura es que la entrada a la tabla de segmentos no contiene la dirección base del segmento, sino la dirección base de la tabla de páginas para este segmento. El desplazamiento del segmento se divide en un número de página y un desplazamiento dentro de ella. El número de página se usa como índice de la tabla de páginas para obtener el número del marco de página. Este último se combina con el desplazamiento de página para obtener la dirección física. Cada segmento tiene su propia tabla de páginas. Sin embargo, cada segmento tiene una longitud, dada en la tabla de segmentos, de forma que el tamaño de la tabla de páginas no tiene que ser el máximo, sino un tamaño en función de la longitud del segmento. De esta forma, en promedio, se tiene una fragmentación interna de media página por segmento. Consecuentemente, se ha eliminado la fragmentación externa, pero introduciendo fragmentación interna y aumentando el espacio de tablas. 5.3. Memoria Virtual Hace muchos años las personas enfrentaron por primera vez programas que eran demasiado grandes para caber en la memoria disponible. La solución que normalmente se adoptaba era dividir el programa en fragmentos, llamados superposiciones (overlay). Algunos sistemas de superposición eran muy complejos, pues permitían varias superposiciones en la memoria a la vez. Las superposiciones se mantenían en disco y el sistema operativo las intercambiaba con la memoria dinámicamente, según fuera necesario. Aunque el trabajo real de intercambiar las superposiciones corría por cuenta del sistema, la tarea de dividir el programa en fragmentos tenía que ser efectuada por el programador. La división de programas grandes en fragmentos modulares pequeños consumía tiempo y era tediosa. No pasó mucho tiempo antes de que a alguien se le ocurriera una forma de dejar todo el trabajo a la computadora.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 66
El método que se inventó (Fotheringham, 1961) se conoce ahora como memoria virtual. La idea en que se basa la memoria virtual es que el tamaño combinado del programa, los datos y la pila puede exceder la cantidad de memoria física disponible para él. El sistema operativo mantiene en la memoria principal las partes del programa que actualmente se están usando, y el resto en el disco. Por ejemplo, un programa de 16M puede ejecutarse en una máquina de 4M si se escogen con cuidado los 4M que se mantendrán en la memoria en cada instante, intercambiando segmentos del programa entre el disco y la memoria según se necesite [Tanembaum]. La memoria virtual también puede funcionar en un sistema de multiprogramación, manteniendo segmentos de muchos programas en la memoria a la vez. Mientras un programa está esperando que se traiga a la memoria una de sus partes, está esperando E/S y no puede ejecutarse, así que puede otorgarse la CPU a otro proceso, lo mismo que en cualquier otro sistema de multiprogramación. Mucho mejor sería poder extender la memoria de manera virtual, es decir, hacer que el proceso tenga la ilusión de que la memoria es mucho más grande que la memoria física (o que el trozo de memoria física que le corresponde, si tenemos multiprogramación). El sistema operativo se encarga de mantener en memoria física los trozos (páginas) que el proceso está usando, y el resto en disco. Ya que el disco es barato, podemos tener espacios de direccionamiento enormes. Los métodos más comunes de implementación son mediante:
o Técnicas de paginación. o Técnicas de segmentación. o Una combinación de ambas técnicas.
Las direcciones generadas por los programas en su ejecución no son, necesariamente, aquellas contenidas en el almacenamiento primario (memoria real), ya que las direcciones virtuales (lógicas) suelen seleccionarse dentro de un número mucho mayor de direcciones que las disponibles dentro del almacenamiento primario. Las estrategias para la administración de sistemas de memoria virtual condicionan la conducta de los sistemas de almacenamiento virtual que operan según esas estrategias. Se consideran las siguientes estrategias: o Estrategias de búsqueda: Tratan de los casos en que una página o segmento deben ser
traídos del almacenamiento secundario al primario. § Las estrategias de “búsqueda por demanda” esperan a que se haga referencia a una
página o segmento por un proceso antes de traerlos al almacenamiento primario. § Los esquemas de “búsqueda anticipada” intentan determinar por adelantado a qué
páginas o segmentos hará referencia un proceso para traerlos al almacenamiento primario antes de ser explícitamente referenciados.
o Estrategias de colocación: Tratan del lugar del almacenamiento primario donde se colocará una nueva página o segmento. Los sistemas toman las decisiones de colocación de una forma trivial ya que una nueva página puede ser colocada dentro de cualquier marco de página disponible.
o Estrategias de sustitución o reposición: Tratan de la decisión de cuál página o segmento desplazar para hacer sitio a una nueva página o segmento cuando el almacenamiento primario está completamente comprometido.
5.3.1. Estrategias de búsqueda (paginación) 5.3.1.1. Paginación por demanda. Las páginas son cargadas por demanda [Deitel]. No se llevan páginas del almacenamiento secundario al primario hasta que son referenciadas explícitamente por un proceso en ejecución. La memoria virtual se implementa con un poco de ayuda del hardware. Se agrega un bit a la tabla de páginas, que indica si la página en cuestión es válida o inválida. Válida significa que está en memoria (en el marco que indica la tabla), e inválida significa que no está.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 67
El acceso a las páginas válidas funciona igual que antes, pero si la CPU intenta accesar una página inválida, se produce una falta de página (page fault) que genera un trap al sistema operativo, quien debe encargarse de ir a buscar esa página al disco, ponerla en la memoria, y reanudar el proceso. El sistema operativo debe:
o Bloquear al proceso. o Ubicar un marco libre. Si no hay, tiene que liberar uno. o Ordenar al controlador de disco que lea la página (de alguna manera, el sistema
operativo debe saber dónde la guardó). o Cuando se completa la lectura, modificar la tabla de páginas para reflejar que ahora la
página si es válida. o Pasar el proceso a la cola READY. Cuando le toque ejecutar, no notará ninguna
diferencia entre esta falta de página y una simple expropiación de la CPU. Con este mecanismo, ya no se necesita superposiciones para ejecutar programas grandes, sólo se carga en memoria las partes del programa que se usan, reduciendo costos de lectura desde disco y ya que no es necesario tener el programa completo en memoria para poder ejecutarlo, se puede aumentar el nivel de multiprogramación. 5.3.1.2. Paginación Anticipada. El S. O. intenta predecir las páginas que un proceso va a necesitar y a continuación precarga estas páginas cuando hay espacio disponible [Deitel]. Mientras el proceso ejecuta sus páginas actuales, el sistema carga páginas nuevas que estarán disponibles cuando el proceso las pida, debido a ello, el tiempo de ejecución de un proceso se puede reducir. 5.3.1.3. Tablas de páginas. Ahora que la memoria lógica puede ser mucho más grande que la física, se acentúa el problema del tamaño de la tabla de páginas. Con direcciones de 32 bits, la memoria virtual puede alcanzar los 4GB. Con páginas de 4 KB, se necesita hasta 1M entradas. Si cada entrada usa 32 bits, entonces la tabla podría pesar 4 MB. Además, cada proceso tiene su tabla, y esta tabla debe estar siempre en memoria física mientras se ejecuta. La solución es usar tablas de varios niveles. El 386 usa dos niveles: una dirección lógica de 32 bits se divide en (p1, p2, d), de 10, 10 y 12 bits respectivamente. p1 es un índice a una tabla de tablas, metatabla, o tabla de primer nivel, que contiene 210=1024 entradas de 32 bits, o sea, exactamente una página. La entrada correspondiente a p1 en esta tabla indica el marco donde se encuentra otra tabla (de segundo nivel), donde hay que buscar indexando por p2, el marco donde está la página que finalmente se necesita.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 68
Es indispensable mantener en memoria la tabla de primer nivel. Las otras se tratan como páginas ordinarias, es decir, pueden estar en disco. Así, al utilizar la propia memoria virtual para estas páginas, se mantienen en memoria física sólo las más usadas. Sin embargo, se está agregando un acceso más a la memoria para convertir cada dirección lógica a una física, pero con un TLB con tasa de aciertos alta el impacto es mínimo. 5.3.1.4. Tablas de páginas invertidas. Las tablas de páginas tradicionales del tipo que hemos descrito hasta ahora requieren una entradas por cada página virtual, ya que están indizadas por número de página virtual. Si el espacio de direcciones consta de 232 bytes, con 4096 bytes por página, se necesitará más de un millón de entradas de tabla. Como mínimo, la tabla de páginas tendrá que ocupar 4 megabytes. En los sistemas grandes, este tamaño probablemente será manejable. Sin embargo, en computadoras de 64 bits, la situación cambia drásticamente. Si el espacio de direcciones ahora tiene 264 bytes, con páginas de 4K, se necesitara más de 1015 bytes para la tabla de páginas. Sacar de circulación un millón de gigabytes sólo para la tabla de páginas no es razonable. Por tanto, se requiere una solución distinta para los espacios de direcciones virtuales de 64 bits paginados. Una solución es la tabla de páginas invertida. En este diseño, hay una entrada por marco de página de la memoria real, no por cada página del espacio de direcciones virtual. Por ejemplo, con direcciones virtuales de 64 bits, páginas de 4K y 32MB de RAM, una tabla de páginas invertida sólo requiere 8192 entradas. La entrada indica cuál (proceso, página virtual) está en ese marco de página. Aunque las tablas de páginas invertidas ahorran enormes cantidades de espacio, al menos cuando el espacio de direcciones virtual es mucho más grande que la memoria física, tienen una desventaja importante: la traducción de virtual a física se vuelve mucho más difícil. Cuando el proceso n hace referencia a la página virtual p, el hardware ya no puede encontrar la página física usando p como índice de la tabla de páginas. En vez de ello, debe buscar en toda la tabla de páginas invertida una entrada (n, p). Además, esta búsqueda debe efectuarse en cada referencia a la memoria, no sólo cuando hay una falla de página. Examinar una tabla de 8K cada vez que se hace referencia a la memoria no es la forma de hacer que una máquina sea vertiginosamente rápida. La solución a este dilema es usar el TLB. Si el TLB puede contener todas las páginas de uso pesado, la traducción puede efectuarse con tanta rapidez como con las tablas de páginas normales. Sin embargo, si ocurre una falla de TLB, habrá que examinar la tabla de páginas

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 69
invertida. Si se usa una tabla de dispersión como índice de la tabla de páginas invertida, esta búsqueda puede hacerse razonablemente rápida. 5.3.2. Algoritmos de Sustitución (reposición) de Páginas Cuando ocurre una falla de página (si un proceso accesa una página inválida), el sistema operativo tiene que escoger la página que sacará de la memoria para que pueda entrar la nueva página. Si la página que se eliminará fue modificada mientras estaba en la memoria, se debe reescribir en el disco a fin de actualizar la copia del disco, pero si no fue así (si la página contenía texto de programa), la copia en disco ya estará actualizada y no será necesario reescribirla. La nueva página simplemente sobreescribe la que está siendo desalojada. Si bien sería posible escoger una página al azar para ser desalojada cuando ocurre una falla de página, el rendimiento del sistema es mucho mejor si se escoge una página que no se usa mucho. Si se elimina una página de mucho uso, probablemente tendrá que traerse pronto a la memoria otra vez, aumentando el gasto extra. Se ha trabajado mucho sobre el tema de los algoritmos de reemplazo de páginas, tanto teórica como experimentalmente. A continuación describimos algunos de los algoritmos más importantes. 5.3.2.1. Algoritmo de sustitución de páginas óptimo El mejor algoritmo de reemplazo de páginas posible es fácil de describir pero imposible de implementar. En el momento en que ocurre una falla de páginas, algún conjunto de páginas está en la memoria. A una de estas páginas se hará referencia en la siguiente instrucción (la página que contiene esa instrucción). Otras páginas podrían no necesitarse sino hasta 10, 100 o tal vez 1000 instrucciones después. Cada página puede rotularse con el número de instrucciones que se ejecutarán antes de que se haga referencia a esa página. El algoritmo de reemplazo de páginas óptimo simplemente dice que se debe eliminar la página que tenga el rótulo más alto. Si una página no se va a usar sino hasta después de 8 millones de instrucciones y otra página no se usará sino hasta después de 6 millones de instrucciones, el desalojo de la primera postergará la falla de página que la traerá de nuevo a la memoria lo más lejos hacia el futuro que es posible. Las computadoras, al igual que las personas, tratan de aplazar los sucesos desagradables el mayor tiempo que se puede. El único problema con este algoritmo es que no se puede poner en práctica. En el momento en que ocurre la falla de página, el sistema operativo no tiene manera de saber cuándo se hará referencia a cada una de las páginas. 5.3.2.2. Algoritmo de sustitución de páginas de primera que entra, primera que sale (FIFO) Consiste en reemplazar la página más vieja (la que lleva más tiempo en memoria física). Es simple, pero no es bueno, ya que la página más antigua no necesariamente es la menos usada. Además sufre de la Anomalía de FIFO (Belady, Nelson y Shedler descubrieron que con la reposición FIFO, ciertos patrones de referencias de páginas causan más fallos de páginas cuando se aumenta el número de marcos (celdas) de páginas asignados a un proceso). Para ilustrar su funcionamiento, consideremos un supermercado que tiene suficientes anaqueles para exhibir exactamente k productos distintos. Un día, alguna compañía introduce un nuevo alimento: yogurt orgánico liofilizado instantáneo que puede reconstituirse en un homo de microondas. Su éxito es inmediato, así que nuestro supermercado finito tiene que deshacerse de un producto viejo para poder tener el nuevo en exhibición. Una posibilidad consiste en encontrar el producto que el supermercado ha tenido en exhibición durante más tiempo (es decir, algo que comenzó a vender hace 120 años) y deshacerse de él bajo el supuesto de que a nadie le interesa ya. En efecto, el supermercado mantiene una lista enlazada de todos los productos que vende en el orden en que se introdujeron. El nuevo se coloca al final de la lista; el que está a la cabeza de la lista se elimina [Tanembaum]. Como algoritmo de reemplazo de páginas, puede aplicarse la misma idea. El sistema operativo mantiene una lista de todas las páginas que están en la memoria, siendo la página que está a la cabeza de la lista la más vieja, y la del final, la más reciente. Cuando hay una falla de página, se elimina la página que está a la cabeza de la lista y se agrega la nueva página al final. Cuando

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 70
FIFO se aplica a una tienda, el producto eliminado podría ser cera para el bigote, pero también podría ser harina, sal o mantequilla. En la siguiente figura, se considera la secuencia de acceso a las paginas (8, 1, 2, 3, 1, 4, 1, 5, 3, 4, 1, 4). Tiene 3 marcos de página. Si inicialmente la memoria esta vacía, las primeras tres transferencias causaran fallos de pagina, que provocaran que se traigan las tres paginas (8,1, 2) a la memoria. Para la siguiente referencia no se tiene espacio y se tendrá que elegir una pagina para sustituir, se elige la 8 que fue la primera que se cargo en memoria. Cuando se accede a la 1, esta ya esta en memoria y no hay que hacer nada, pero al referenciar la pagina 4, se sustituye la 1 y asi sucesivamente.
5.3.2.3. Algoritmo de sustitución de páginas Menos – Recientemente – Usada (LRU) Esta estrategia selecciona para ser reemplazada la página que no ha sido usada durante el mayor período de tiempo. Se basa en la heurística de que el pasado reciente es un buen indicador del futuro próximo. Requiere que cada página reciba un sello de tiempo cada vez que se referencia: Puede significar una sobrecarga adicional importante. No se implementa frecuentemente. La página seleccionada para reemplazo podría ser la próxima en ser requerida, por lo que habría que paginarla de nuevo al almacenamiento principal casi de inmediato.
5.3.2.4. Algoritmo de sustitución de páginas Menos - Frecuentemente - Usada (LFU) En este algoritmo interesa la intensidad de uso que haya tenido cada página. La página que será reemplazada es aquella que ha sido usada con menos frecuencia o que ha sido referida con menos intensidad. El inconveniente es que se puede seleccionar fácilmente para su reposición la página equivocada; por ejemplo la página de uso menos frecuente puede ser la página de entrada más reciente al almacenamiento principal, y por lo tanto existe una alta probabilidad de que sea usada de inmediato. 5.3.2.5. Algoritmo de sustitución de páginas No Usada - Recientemente (NUR) Presupone que las páginas que no han tenido uso reciente tienen poca probabilidad de ser usadas en el futuro próximo y pueden ser reemplazadas por otras nuevas. Es deseable reemplazar una página que no ha sido cambiada mientras estaba en el almacenamiento primario. La estrategia NUR se implementa con la adición de dos bits de hardware por página:

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 71
Bit referenciado: = 0 si la página no ha sido referenciada. = 1 si la página ha sido referenciada. Bit modificado (también llamado “bit sucio”): = 0 si la página no ha sido modificada. = 1 si la página ha sido modificada. La selección de la página que será reemplazada comienza buscando una página que no ha sido referenciada, pero si no la encuentra habrá que reemplazar una página que ha sido referenciada. Si una página ha sido referenciada se comprueba si ha sido modificada o no: Si no ha sido modificada se la reemplaza: Su reposición representa menos sobrecarga que la de una página modificada, ya que debería grabarse de nuevo en el almacenamiento secundario. Si no se encuentra una página que no ha sido modificada será reemplazada una página modificada. Con el transcurso del tiempo la mayoría de los bits referenciados serán activados: Se pierde la capacidad para distinguir las páginas más deseables para ser reemplazadas. Para evitarlo se ajustan periódicamente todos los bits referenciados a “0”: Se logra un nuevo inicio. Se vuelve vulnerable al reemplazo aún a las páginas activas, pero solo brevemente, mientras se reajustan los bits. Los “bits modificados” no se ajustan periódicamente según esta estrategia. 5.3.2.6. El algoritmo de sustitución de páginas de segunda oportunidad Una modificación sencilla de FIFO que evita el problema de desalojar una página muy utilizada consiste en inspeccionar el bit R de la página más vieja. Si es 0, sabremos que la página, además de ser vieja, no ha sido utilizada recientemente, así que la reemplazamos de inmediato. Si el bit R es 1, se apaga el bit, se coloca la página al final de la lista de páginas, y se actualiza su tiempo de carga como si acabara de ser traída a la memoria. Luego continúa la búsqueda.
El funcionamiento de este algoritmo, llamado de segunda oportunidad, se muestra en la figura donde se ve que se mantienen las páginas de la A a la H en una lista enlazada ordenadas según el momento en que se trajeron a la memoria. Supongamos que ocurre una falla de página en el tiempo 20. La página más antigua es A, que llegó en el tiempo 0, cuando se inició el proceso. Si A tiene el bit R apagado, es desalojada de la memoria, ya sea escribiéndose en el disco (si está sucia) o simplemente abandonándose (si está limpia). En cambio, si el bit R está encendido, A se coloca al final de la lista y su "tiempo de carga" se ajusta al tiempo actual (20).
También se apaga su bit R. La búsqueda de una página apropiada continúa con B. Lo que hace el algoritmo de segunda oportunidad es buscar una página vieja a la que no se, haya hecho referencia en el intervalo de reloj anterior. Si se ha hecho referencia a todas las páginas, este algoritmo pasa a ser FIFO puro. Específicamente, imaginemos que todas las páginas de la primera figura tienen su bit R encendido. Una por una, el sistema operativo pasará' páginas al final de la lista, apagando el bit R cada vez que anexa una página al final de la lista. Tarde o temprano, regresará a la página A, que ahora tiene su bit R apagado. En este punto, A será desalojada. Así, el algoritmo siempre termina. 5.3.2.7. El algoritmo de sustitución de páginas por reloj Aunque el algoritmo de segunda oportunidad es razonable, es innecesariamente eficiente porque constantemente cambia de lugar páginas dentro de su lista. Un enfoque mejor consiste en mantener todas las páginas en una lista circular con forma de reloj. Una manecilla apunta a la página más vieja.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A. 72
Cuando ocurre una falla de página, se inspecciona la página a la que apunta la manecilla. Si su bit R es 0, se desaloja la página, se inserta la nueva página en el reloj en su lugar, y la manecilla avanza una posición. Si R es 1, se pone en 0 y la manecilla se avanza a la siguiente página. Este proceso se repite hasta encontrar una página con R = 0. No resulta sorprendente que este algoritmo se llame de reloj. La única diferencia respecto al de segunda oportunidad es la implementación.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
73
Tema VI Sistema de Archivos
Todas las aplicaciones de computadora necesitan almacenar y recuperar información [Dietel], y las condiciones esenciales para el almacenamiento de información a largo plazo son: • Debe ser posible almacenar una cantidad muy grande de información. Mientras un proceso se
está ejecutando, puede almacenar una cantidad de información limitada dentro de su propio espacio de direcciones. Sin embargo, la capacidad de almacenamiento está restringida al tamaño del espacio de direcciones virtual. En el caso de algunas aplicaciones, este tamaño es adecuado, pero en el de otras, dicho tamaño resulta excesivamente pequeño.
• La información debe sobrevivir a la conclusión del proceso que la utiliza. Al mantener la información dentro del espacio de direcciones de un proceso, sucede que cuando el proceso termina la información se pierde. En muchas aplicaciones (como las bases de datos), la información debe retenerse durante semanas, meses, o incluso eternamente. No es aceptable que la información desaparezca cuando el proceso que la está usando termina. Además, la información no debe perderse cuando una caída de la computadora termina el proceso.
• Debe ser posible que varios procesos tengan acceso concurrente a la información. En muchos casos es necesario que múltiples procesos accedan a la información al mismo tiempo.
La solución es el almacenamiento de la información en discos y otros medios externos en unidades llamadas archivos. Los archivos deben ser persistentes, es decir, que no deben verse afectados por la creación o terminación de un proceso. El Sistema de Archivos es la parte del sistema de administración del almacenamiento responsable, principalmente, de la administración de los archivos del almacenamiento secundario. Es la parte del S. O. responsable de permitir compartir controladamente la información de los archivos. Sus funciones son:
• Los usuarios deben poder crear, modificar y borrar archivos. • Se deben poder compartir los archivos de una manera cuidadosamente controlada (acceso de
lectura, acceso de escritura, acceso de ejecución, etc.). • Se debe poder estructurar los archivos de la manera más apropiada a cada aplicación. • Los usuarios deben poder ordenar la transferencia de información entre archivos. • Se deben proporcionar posibilidades de respaldo y recuperación para prevenir contra pérdida
accidental y destrucción maliciosa de información. • Se debe poder referenciar a los archivos mediante Nombres Simbólicos, brindando
independencia de dispositivos. • En ambientes sensibles, el sistema de archivos debe proporcionar posibilidades de cifrado y
Descifrado. • Se debe brindar una interface favorable al usuario. Debe suministrar una visión lógica de los
datos y de las funciones que serán ejecutadas, en vez de una visión física. El usuario no debe tener que preocuparse por:
o Los dispositivos particulares. o Dónde serán almacenados los datos. o El formato de los datos en los dispositivos. o Los medios físicos de la transferencia de datos hacia y desde los dispositivos.
6.1. Archivos Es una colección o conjunto de datos relacionados lógicamente. Se considerará el punto de vista del usuario. Los archivos son un mecanismo de abstracción; proporcionan una forma de almacenar información en el disco y leerla después. Esto debe hacerse de tal manera que el usuario no tenga que ocuparse de los detalles de cómo y dónde se almacena la información, ni de cómo funcionan realmente los discos. 6.1.1. Nombre de los Archivos Cuando un proceso crea un archivo, le asigna un nombre y cuando termina, el archivo sigue existiendo y otros procesos pueden acceder a él utilizando su nombre. Las reglas exactas para nombrar archivos

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
74
varían un tanto de un sistema a otro, pero todos los sistemas operativos permiten cadenas de uno a ocho caracteres como nombres de archivo válidos. En muchos casos se permiten también dígitos y caracteres especiales. Muchos sistemas de archivos reconocen nombres de hasta 255 caracteres. Algunos sistemas de archivos distinguen entre las letras mayúsculas y minúsculas, y otros no. UNIX pertenece a la primera categoría; MS-DOS cae en la segunda. Muchos sistemas operativos reconocen nombres de archivo de dos partes, las cuales se separan con un punto. La parte que sigue al punto se denomina extensión de archivo y, por lo regular, indica algo acerca del archivo. En MS-DOS, por ejemplo, los nombres de archivo tienen de 1 a 8 caracteres, más una extensión opcional de 1 a 3 caracteres. En UNIX, el tamaño de la extensión, si la hay, es decisión del usuario, y un archivo incluso puede tener dos o más extensiones. En algunos casos, las extensiones de archivo no son más que convenciones y su uso no es obligatorio. Un archivo llamado archivo.txt con toda probabilidad es algún tipo de archivo de texto, pero ese nombre sirve más como recordatorio para el propietario que para comunicar alguna información específica a la computadora. Por otro lado, un compilador de C podría exigir que los archivos que va a compilar terminen con .c, y podría negarse a compilarlos si no es así. 6.1.2. Estructura de un Archivo Los archivos se pueden estructurar de varias maneras, las más comunes son [Tanenbaum]:
• Secuencia de bytes (a). El archivo es una serie no estructurada de bytes. El sistema operativo no
sabe (ni le importa) qué contiene el archivo; lo único que ve es bytes. Cualquier significado que tenga deberán imponerlo los programas en el nivel de usuario. Tanto UNIX como MS-DOS adoptan este enfoque. Windows usa básicamente el sistema de archivos de MS-DOS, agregándole un poco de azúcar sintáctica (nombres de archivo largos), así que casi todo lo que se diga acerca de MS-DOS también aplica a WINDOWS.
• Secuencia de registros (b). Un archivo es una secuencia de registros de longitud fija, cada uno con
cierta estructura interna. La idea de que un archivo es una secuencia de registros se apoya en el concepto de que la operación de lectura devuelve un registro y que la operación de escritura sobreescribe o anexa un registro. En el pasado, cuando existía la tarjeta perforada de 80 columnas, muchos sistemas operativos tenían archivos compuestos por registros de 80 caracteres, que eran imágenes de tarjetas. Estos sistemas también daban soporte a archivos con registros de 132 caracteres, pensados para la impresora de líneas. Los programas leían las entradas en unidades de 80 caracteres y las escribían en unidades de 132 caracteres Un sistema (antiguo) que consideraba los archivos como secuencias de registros de longitud fija era CP/M. Éste utilizaba registros de 128 caracteres. Hoy día, la idea de un archivo como una secuencia de registros de longitud fija es prácticamente cosa del pasado.
• Árbol (c). Un archivo consiste en un árbol de registros, no necesariamente todos de la misma
longitud, cada uno de los cuales contiene un campo de llave en una posición fija dentro del registro. El árbol está ordenado según el campo de llave, a fin de poder buscar rápidamente una llave en particular. La operación básica aquí no es obtener el siguiente registro, aunque eso también es posible, sino obtener el registro que tiene una llave dada. En el caso del archivo de zoológico de la figura (c), podríamos pedirle al sistema que obtenga el registro cuya llave es pony, por ejemplo, sin tener que preocuparnos por su posición exacta en el archivo. Además, es posible agregar nuevos

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
75
registros al archivo dejando que el sistema operativo, y no el usuario, decida dónde deben colocarse. Este tipo de archivo obviamente es muy distinto de los flujos de bytes no estructurados que se emplean en UNIX y MS-DOS, pero se utiliza ampliamente en las macrocomputadoras que todavía se usan en algunas aplicaciones comerciales de procesamiento de datos.
6.1.3. Tipos de Archivos Muchos sistemas operativos reconocen varios tipos de archivos. UNIX y MS-DOS, por ejemplo, tienen archivos normales y directorios (folders). UNIX también tiene archivos especiales por caracteres y por bloques. Los archivos regulares son los que contienen información del usuario. Los directorios son archivos de sistema que sirven para mantener la estructura del sistema de archivos. Los archivos especiales por caracteres están relacionados con entrada/salida y sirven para modelar dispositivos E/S en serie como las terminales, impresoras y redes. Los archivos especiales por bloques sirven para modelar discos. Los archivos normales generalmente son archivos ASCII o bien archivos binarios. Los archivos ASCII consisten en líneas de texto. En algunos sistemas cada línea termina con un carácter de retorno de carro; en otros se emplea el carácter de salto de línea. Ocasionalmente se requieren ambos. Las líneas no tienen que tener todas la misma longitud. La gran ventaja de los archivos ASCII es que pueden exhibirse e imprimirse tal como están, y se pueden editar con un editor de textos normal. Además, si una gran cantidad de programas usan archivos ASCII como entradas y salidas, es fácil conectar la salida de un programa a la entrada del otro, como en tuberías (pipes) de shell. Otros archivos son binarios, lo que simplemente significa que no son archivos ASCII. Si listamos estos archivos en una impresora, obtendremos un listado incomprensible lleno de lo que parece ser basura. Por lo regular, estos archivos tienen alguna estructura interna. 6.1.4. Atributos de un archivo Todo archivo tiene un nombre y ciertos datos. Además, todos los sistemas operativos asocian información adicional a cada archivo, por ejemplo, la fecha y hora de creación del archivo, y su tamaño. Llamamos a estos datos adicionales atributos del archivo. La lista de atributos varía considerablemente de un sistema a otro. Los atributos de un archivo son: el nombre, el tipo, la localización (donde se ubica), derechos de acceso, tiempo de creación/acceso/modificación, UID del creador, etc.
6.1.5. Operaciones con archivos Los archivos existen para almacenar información que posteriormente se pueda recuperar. Los diferentes sistemas ofrecen distintas operaciones de almacenamiento y recuperación. Podemos pensar en un archivo como en un tipo abstracto de datos, al que se pueden aplicar operaciones como: Abrir, Cerrar, Crear, Destruir, Copiar, Renombrar, Listar. A los ítems que forman el archivo (bytes, registros, etc.) se

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
76
pueden aplicar operaciones como: Leer, Modificar, Agregar (al final), Insertar, Borrar. Estas operaciones están implementadas a través de llamadas al sistema (systems calls). Las llamadas al sistema más comunes relacionadas con archivos son: CRÉATE. El archivo se crea sin datos. El propósito de la llamada es anunciar que va a haber un archivo y establecer algunos de los atributos. DELETE. Cuando el archivo ya no se necesita, es preciso eliminarlo para desocupar el espacio en disco. Siempre hay una llamada al sistema para este fin. OPEN. Antes de usar un archivo, un proceso debe abrirlo. El propósito de la llamada OPEN es permitir al sistema que obtenga los atributos y la lista de direcciones de disco y los coloque en la memoria principal a fin de agilizar el acceso en llamadas posteriores. CLOSE. Una vez concluidos todos los accesos, los atributos y las direcciones de disco ya no son necesarios, por lo que se debe cerrar el archivo para liberar el espacio correspondiente en las tablas internas. READ. Se leen datos del archivo. Por lo regular, los bytes provienen de la posición actual. El invocador debe especificar cuántos datos se necesitan y también debe suministrar un buffer para colocarlos. WRITE. Se escriben datos en el archivo, también, por lo regular, en la posición actual. Si dicha posición es el final del archivo, el tamaño del archivo aumenta. Si la posición actual está a la mitad del archivo, se sobreescribe en los datos existentes, que se pierden irremediablemente. APPEND. Esta llamada es una forma restringida de WRITE que sólo puede agregar datos al final del archivo. Los sistemas que ofrecen un juego mínimo de llamadas al sistema generalmente no cuentan con APPEND, pero muchos sistemas ofrecen varias formas de hacer una misma cosa, y a veces incluyen APPEND. SEEK. En el caso de archivos de acceso aleatorio, se requiere un método para especificar el lugar del que deben tomarse los datos. Un enfoque común es tener una llamada al sistema, SEEK, que ajuste el apuntador a la posición actual haciéndolo que apunte a un lugar específico del archivo. Una vez efectuada esta llamada, se pueden leer datos de esa posición o escribirlos en ella. GET ATTRIBUTES. Es frecuente que los procesos necesiten leer los atributos de un archivo para realizar su trabajo. SET ATTRIBUTES. Algunos de los atributos pueden ser establecidos por el usuario y modificarse después de que se creó el archivo. RENAME. Es común que un usuario necesite cambiar el nombre de un archivo existente. 6.2. Directorios Los sistemas de archivos casi siempre tienen directorios para organizar los archivos, En muchos sistemas, son también archivos. 6.2.1. Sistemas de directorio jerárquicos Un directorio contiene varias entradas (un conjunto de datos) por cada archivo. Por ejemplo cada entrada puede contener el nombre del archivo, los atributos del archivo, y la dirección de disco donde están almacenados los datos. Otra posibilidad es que cada entrada de directorio contenga el nombre del archivo y un apuntador a otra estructura de datos en la que pueden encontrarse los atributos y las direcciones en disco. Ambos sistemas son de uso generalizado. Cuando se abre un archivo, el sistema operativo examina su directorio hasta encontrar el nombre del archivo por abrir, y luego extrae los atributos y las direcciones en disco, ya sea directamente de la entrada de directorio o de la estructura de datos a la que ésta apunta, y los coloca en una tabla en la memoria principal. Todas las referencias subsecuentes al archivo utilizan la información que está en la memoria principal. El número de direcciones varía de un sistema a otro. • Directorio Único. El diseño más sencillo es aquel en el que el sistema mantiene un solo directorio
que contiene todos los archivos de todos los usuarios. Si hay muchos usuarios, y éstos escogen los mismos nombres de archivo (correo y juegos), los conflictos y la confusión resultante pronto harán inmanejable el sistema. Este modelo se utilizó en los primeros sistemas operativos de microcomputadoras, pero ya casi nunca se encuentra.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
77
• Un directorio por usuario. Este diseño elimina los conflictos de nombres entre usuarios pero no es
satisfactorio para quienes tienen un gran número de archivos. Es muy común que los usuarios quieran agrupar sus archivos atendiendo a patrones lógicos. Un profesor, por ejemplo, podría tener una colección de archivos que juntos constituyan un libro que está escribiendo para un curso, una segunda colección de archivos que contenga programas que los estudiantes de otro curso hayan presentado, un tercer grupo de archivos que contenga el código de un sistema avanzado de escritura de compiladores que él esté construyendo, un cuarto grupo de archivos que contenga propuestas para obtener subvenciones, así como otros archivos para correo electrónico, minutas de reuniones, artículos que esté escribiendo, juegos, etc.
Se requiere algún método para agrupar estos archivos en formas flexibles elegidas por el usuario. • Árbol de directorios. Cada usuario puede tener tantos directorios como necesite para poder
agrupar sus archivo) según patrones naturales. Los directorios contenidos en el directorio raíz, pertenecen cada uno a un usuario distinto.
6.2.2. Nombres de ruta de Accesos Cuando el sistema de archivos se organiza en forma de árbol de directorios, se necesita un método para determinar los nombres de los archivos. Los dos métodos principales son:

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
78
• Nombre de Ruta de Acceso Absoluta: Cada archivo tiene una ruta de acceso absoluta. Consta de la ruta de acceso desde el directorio raíz hasta el archivo. Los componentes de la ruta de acceso se separan mediante algún caracter llamado separador. Por ejemplo, la ruta /datos/joa/mailbox indica que el directorio raíz contiene un subdirectorio “datos”, que a su vez contiene un subdirectorio “joa”, el cual contiene el archivo “mailbox”. En UNIX los componentes de la ruta se separan con “/”. En MS-DOS y Windows el separador es “\”. Sea cual sea el carácter empleado, si el primer carácter del nombre de rutas es el separador, la ruta es absoluta. • Nombre de Ruta de Acceso Relativa: Se utiliza junto con el concepto de directorio de trabajo o directorio activo (directorio actual). Todos los nombres que no comiencen en el directorio raíz se toman en relación con el directorio de trabajo. El nombre absoluto de la ruta de acceso siempre funciona, sin importar cual sea el directorio de trabajo. Un usuario puede definir un directorio como directorio de trabajo actual, en cuyo caso todos los nombres de archivo que comiencen en el directorio raíz se tomarán en relación con el directorio con el trabajo. Por ejemplo si el directorio de trabajo actual es /datos/joa, entonces se podrá hacer referencia al archivo cuya ruta absoluta es /datos/joa/mailbox simplemente como mailbox. En otras palabras, el comando de UNIX
cp /datos/joa/mailbox /datos/joa/mailbox.bak y el comando
cp mailbox mailbox.bak harán exactamente lo mismo si el directorio de trabajo es /datos/joa. La forma relativa suele ser más cómoda, pero hace lo mismo que la forma absoluta. Algunos programas necesitan acceder a un archivo específico sin considerar el directorio de trabajo. En tal caso, siempre deben usar nombres de ruta absolutos. Por ejemplo, un revisor ortográfico podría necesitar leer /usr/lib/dictionary para efectuar su trabajo. En este caso, el programa deberá usar el nombre de ruta absoluto completo porque no sabe cuál será el directorio de trabajo cuando sea invocado. El nombre de ruta absoluta siempre funciona, sea cual sea el directorio de trabajo. La mayor parte de los sistemas operativos que manejan un sistema de directorios jerárquico tiene dos entradas especiales en cada directorio, "." y "..", generalmente pronunciados "punto" y "punto punto". Punto se refiere al directorio actual; punto punto se refiere a su padre. 6.2.3. Operaciones con directorios Las llamadas al sistema permitidas para administrar directorios muestran variaciones de un sistema a otro. A fin de dar una idea de la naturaleza modo de operar de esas llamadas, presentaremos una muestra (tomada de UNIX). • CRÉATE. Se crea un directorio, que está vacío con la excepción de punto y punto, punto, que el
sistema (o, en unos pocos casos, el programa mkdir) coloca ahí automáticamente. • DELETE. Se elimina un directorio. Sólo puede eliminarse un directorio vacío. Un directorio que sólo
contiene punto y punto punto se considera vacío, ya que éstos normalmente no pueden eliminarse. • OPENDIR. Los directorios pueden leerse. Por ejemplo, para listar todos los archivos de un directorio,
un programa para emitir listados abre el directorio y lee los nombres de los archivos que contiene. Antes de poder leer un directorio, es preciso abrirlo, de forma análoga a como se abren y leen los archivos.
• CLOSEDIR. Una vez que se ha leído un directorio, debe cerrarse para liberar espacio de tablas internas.
• READDIR. Esta llamada devuelve la siguiente entrada de un directorio abierto. Antes, era posible leer directorios empleando la llamada al sistema READ normal, pero ese enfoque tiene la desventaja de obligar al programador a conocer y manejar la estructura interna de los directorios. En contraste, READDIR siempre devuelve una entrada en un formato estándar, sin importar cuál de las posibles estructuras de directorio se esté usando.
• RENAME. En muchos sentidos, los directorios son iguales que los archivos y podemos cambiar su nombre tal como hacemos con los archivos.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
79
• LINK. El enlace (linking) es una técnica que permite a un archivo aparecer en más de un directorio. Esta llamada al sistema especifica un archivo existente y un nombre de ruta, y crea un enlace del archivo existente al nombre especificado por la ruta. De este modo, el mismo archivo puede aparecer en múltiples directorios.
• UNLINK. Se elimina una entrada de directorio. Si el archivo que está siendo desvinculado sólo está presente en un directorio (el caso normal), se eliminará del sistema de archivos. Si el archivo está presente en varios directorios, sólo se eliminará el nombre de ruta especificado; los demás seguirán existiendo. En UNIX, la llamada al sistema para eliminar archivos (que ya vimos antes) es, de hecho, UNLINK.
6.3. Implementación de Sistemas de Archivos A los usuarios les interesa la forma de nombrar los archivos, las operaciones que pueden efectuarse con ellos, el aspecto que tiene el árbol de directorios y cuestiones de interfaz por el estilo. A los implementadores les interesa cómo están almacenados los archivos y directorios, cómo se administra el espacio en disco y cómo puede hacerse que todo funcione de forma eficiente y confiable. Se deben tener presentes problemas tales como la fragmentación creciente del espacio en disco lo que ocasiona problemas de performance al hacer que los archivos se dispersen a través de bloques muy dispersos. Las técnicas para aliviar el problema de la fragmentación consiste en realizar periódicamente condensación (defragmentacion) donde se reorganizan los archivos expresamente o automáticamente según algún criterio predefinido y la recolección de basura o residuos, donde se puede hacer fuera de línea o en línea, con el sistema activo, según la implementación. 6.3.1. Implementación de archivos El aspecto clave de la implantación del almacenamiento de archivos es el registro de los bloques asociados a cada archivo [Deitel]. Podemos modelar el disco duro como una secuencia de bloques, de 0 a N-1, de tamaño fijo (usualmente de 512 bytes), a los cuales tenemos acceso directo, pero, por el movimiento del brazo es más caro leer dos bloques separados que dos bloques contiguos. El primer problema consiste en determinar cómo a almacenar los archivos en el disco. Algunos de los métodos utilizados son los siguientes: • Asignación contigua o adyacente. El esquema de asignación más sencillo es almacenar cada
archivo como un bloque contiguo de datos en el disco. Así, en un disco con bloques de 1K, a un archivo de 50K se le asignarían 50 bloques consecutivos. Las principales ventajas son que la implementación es sencilla porque para saber dónde están los bloques de un archivo basta con recordar un número( la dirección en disco del primer bloque) y que el rendimiento es excelente porque es posible leer todo el archivo del disco en una sola operación. Las desventajas son que se debe conocer el tamaño máximo del archivo al crearlo y que produce una gran fragmentación de los discos.
• Asignación por lista enlazada. Consiste en guardar cada archivo como una lista enlazada de
bloques de disco. La primera palabra de cada bloque se emplea como apuntador al siguiente. El

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
80
resto del bloque se destina a datos. Las ventajas son que es posible utilizar todos los bloques (No se pierde espacio por fragmentación del disco, excepto por fragmentación interna en el último bloque) y que el directorio sólo debe registrar el primer bloque de cada archivo (No es necesario declarar el máximo tamaño que puede llegar a tener un archivo, puesto que puede crecer sin problemas, mientras queden bloques libres). Las desventajas son que, aunque la lectura secuencial de un archivo es sencilla, el acceso aleatorio es extremadamente lento y que la cantidad de almacenamiento de datos en un bloque ya no es una potencia de dos porque el apuntador ocupa unos cuantos bytes.
• Asignación por lista enlazada empleando un índice. Para eliminar las desventajas del método
anterior, en vez de tener esparcidos los punteros en cada bloque, se pueden agrupar y poner todos juntos en una tabla o FAT (Tabla de asignación de archivos). En la siguiente figura se muestra un ejemplo de la tabla con dos archivos. El archivo A usa los bloques de disco 4,7,2,10 y 12, en ese orden, y el archivo B usa los bloques de disco 6, 3, 11 y 14, en ese orden. Se puede comenzar en el bloque 4 y seguir la cadena hasta el final. Lo mismo puede hacerse comenzando en el bloque 6. Si se emplea esta organización, todo el bloque está disponible para datos. Además, el acceso directo es mucho más fácil. Aunque todavía hay que seguir la cadena para encontrar una distancia dada dentro de un archivo, la cadena está por completo en la memoria, y puede seguirse sin tener que consultar el disco. Al igual que con el método anterior, basta con guardar un solo entero (el número del bloque inicial) en la entrada de directorio para poder localizar todos los bloques, por más grande que sea el archivo. MS-DOS emplea este método para la asignación en disco. La desventaja es que toda la tabla debe estar en la memoria todo el tiempo para que funcione. En el caso de un disco grande con, digamos, 500 000 bloques de 1K (500M), la tabla tendrá 500 000 entradas, cada una de las cuales tendrá que tener un mínimo de 3 bytes. Si se desea acelerar las búsquedas, se necesitarán 4 bytes. Así, la tabla ocupará de 1.5 a 2 megabytes todo el tiempo, dependiendo de si el sistema se optimiza en cuanto al espacio o en cuanto al tiempo. Aunque MS-DOS emplea este mecanismo, evita manejar tablas muy grandes empleando bloques grandes (de hasta 32K) en los discos de gran tamaño.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
81
• Nodos-I. Consiste en mantener juntos los punteros de cada archivo, en una tabla llamada nodo-i (nodo-índice), asociada al archivo, y que se guarda en un bloque como cualquiera (esta tabla es análoga a la tabla de páginas). Además, en ese bloque se puede guardar información de los otros atributos del archivo. El directorio sólo contiene un puntero al bloque que contiene la tabla.
Las primeras pocas direcciones de disco se almacenan en el nodo-i mismo, así que en el caso de archivos pequeños toda la información está contenida en el nodo-i, que se trae del disco a la memoria principal cuando se abre el archivo. En el caso de archivos más grandes, una de las direcciones del nodo-i es la dirección de un bloque de disco llamado bloque de indirección sencilla. Este bloque contiene direcciones de disco adicionales. Si esto todavía no es suficiente, otra dirección del nodo-i, llamada bloque de indirección doble, contiene la dirección de un bloque que contiene una lista de bloques de indirección sencilla. Cada uno de estos bloques de indirección sencilla apunta a unos cuantos cientos de bloques de datos. Si ni siquiera con esto basta, se puede usar también un bloque de dirección triple. UNIX emplea este esquema. Las ventajas son que lo único que hay que registrar en el directorio es un puntero al nodo-i, además que el acceso aleatorio es rápido para archivos pequeños y que el sobrecosto fijo es bajo (no hay FAT, entradas en directorios pequeñas). Las desventajas es que es relativamente complejo, además hay mayor sobrecosto variable (cada archivo, por pequeño que sea, necesita al menos dos bloques) y que el acceso aleatorio es más complicado para archivos grandes (en todo caso, los bloques con índices pueden guardarse en memoria para agilizar el acceso).
6.3.2. Implementación de directorios Para leer un archivo, hay que abrirlo. Cuando se abre un archivo, el sistema operativo usa el nombre de ruta proporcionado por el usuario para localizar la entrada de directorio. Esta entrada proporciona la

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
82
información necesaria para encontrar los bloques de disco. Dependiendo del sistema, esta información puede ser la dirección en disco de todo el archivo (asignación contigua), el número del primer bloque (ambos esquemas de lista enlazada) o el número del nodo-i. La función principal del sistema de directorios es transformar el nombre ASCII del archivo en la información necesaria para localizar los datos. Un aspecto íntimamente ligado con esto es la posición de almacenamiento de los atributos. Una posibilidad obvia es almacenarlos directamente en la entrada de directorio. Muchos sistemas hacen precisamente esto. En el caso de sistemas que usan nodos-i, otra posibilidad es almacenar los atributos en el nodo-i, en lugar de en la entrada de directorio. Como veremos más adelante, este método tiene ciertas ventajas respecto a la colocación de los atributos en la entrada de directorio. Directorios en MS-DOS La figura muestra una entrada de directorio de MS-DOS, la cual tiene 32 bytes de longitud y contiene el nombre de archivo, los atributos y el número del primer bloque de disco. El primer número de bloque se emplea como índice de una tabla del tipo FAT. Siguiendo la cadena, se pueden encontrar todos los bloques.
En MS-DOS, los directorios pueden contener otros directorios, dando lugar a un sistema de archivos jerárquico. En este sistema operativo es común que los diferentes programas de aplicación comiencen por crear un directorio en el directorio raíz y pongan ahí todos sus archivos, con objeto de que no haya conflictos entre las aplicaciones. Directorios en UNIX En la estructura de directorios UNIX, cada entrada contiene sólo un nombre de archivo y su número de nodo-i. Toda la información acerca del tipo, tamaño, tiempos, propietario y bloques de disco está contenida en el nodo-i. Algunos sistemas UNIX tienen una organización distinta, pero en todos los casos una entrada de directorio contiene en última instancia sólo una cadena ASCII y un número de nodo-i. Cuando se abre un archivo, el sistema de archivos debe tomar el nombre que se le proporciona y localizar sus bloques de disco. Consideremos cómo se busca el nombre de ruta /usr/ast/mbox. Lo primero que hace el sistema de archivos es localizar el directorio raíz. En UNIX su nodo-i está situado en un lugar fijo del disco. A continuación, el sistema de archivos busca el primer componente de la ruta, “usr”, en el directorio raíz para encontrar el número de nodo-i del archivo /usr. La localización de un nodo-i, una vez que se tiene su número es directa, ya que cada uno tiene una posición fija en el disco. Con la ayuda de este nodo-i, el sistema localiza el directorio correspondiente a /usr y busca el siguiente componente, “ast”, dentro de él. Una vez que el sistema encuentra la entrada para “ast”, obtiene el nodo-i del directorio /usr/ast. Con este nodo, el sistema puede encontrar el directorio mismo y buscar el archivo mbox.
Luego se trae a la memoria el nodo-i de este archivo y se mantiene ahí hasta que se cierra el archivo. El proceso de búsqueda se ilustra en la siguiente figura:

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
83
Los nombres de ruta relativos se buscan de la misma forma que los absolutos, sólo que el punto de partida es el directorio de trabajo en lugar del directorio raíz. Cada directorio tiene entradas para “.” y “..”, que se colocan ahí cuando se crea el directorio. La entrada “.” tiene el número de nodo-i del directorio actual, y la entrada “..” tiene el número de nodo-i del directorio padre. Así, un procedimiento que busque ../dick/prog.c simplemente buscará “..” en el directorio de trabajo, encontrará el número de nodo-i de su directorio padre y buscará dick en ese directorio. No se requiere ningún mecanismo especial para manejar estos nombres. En lo que al sistema de directorios concierne, se trata de cadenas ASCII ordinarias, lo mismo que los demás nombres. 6.3.3. Administración del espacio en disco Los archivos normalmente se almacenan en disco, así que la administración del espacio en disco es de interés primordial para los diseñadores de sistemas de archivos. Hay dos posibles estrategias para almacenar un archivo de n bytes: asignar n bytes consecutivos de espacio en disco, o dividir el archivo en varios bloques (no necesariamente) contiguos. Un trueque similar (entre segmentación pura y paginación) está presente en los sistemas de administración de memoria. El almacenamiento de un archivo como secuencia contigua de bytes tiene el problema obvio de que, si el archivo crece, probablemente tendrá que pasarse a otro lugar del disco. El mismo problema ocurre con los segmentos en la memoria, excepto que el traslado de un segmento en la memoria es una operación relativamente rápida comparada con el traslado de un archivo de una posición en el disco a otra. Por esta razón, casi todos los sistemas de archivos dividen los archivos en bloques de tamaño fijo que no necesitan estar adyacentes. Tamaño de bloque Una vez que se ha decidido almacenar archivos en bloques de tamaño fijo, surge la pregunta de qué tamaño deben tener los bloques. Dada la forma como están organizados los discos, el sector, la pista y el cilindro son candidatos obvios para utilizarse como unidad de asignación. En un sistema con paginación, el tamaño de página también es un contendiente importante. Tener una unidad de asignación grande, como un cilindro, implica que cada archivo, incluso un archivo de un byte, ocupará todo un cilindro. Estudios realizados (Mullender y Tanenbaum, 1984) han demostrado que la mediana del tamaño de los archivos en los entornos UNIX es de alrededor de 1K, así que asignar un cilindro de 32K a cada archivo implicaría un desperdicio de 31/32 = 97% del espacio en disco total. Por otro lado, el empleo de una unidad de asignación pequeña implica que cada archivo consistirá en muchos bloques. La lectura de cada bloque normalmente requiere una búsqueda y un retardo rotacional, así que la lectura de un archivo que consta de muchos bloques pequeños será lenta. Por ejemplo, consideremos un disco con 32 768 bytes por pista, tiempo de rotación de 16.67 ms y tiempo de búsqueda medio de 30 ms. El tiempo en milisegundos requerido para leer un bloque de k bytes es la suma de los tiempos de búsqueda, retardo rotacional y transferencia: 30 + 8.3 + (k/32768) x 16.67 La curva continua de la siguiente figura muestra la tasa de datos para un disco con estas características en función del tamaño de bloque. Si utilizamos el supuesto burdo de que todos los bloques son de 1K (la mediana de tamaño medida), la curva de guiones de la siguiente figura indicará la eficiencia de espacio

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
84
del disco. La mala noticia es que una buena utilización del espacio (tamaño de bloque < 2K) implica tasas de datos bajas y viceversa. La eficiencia de tiempo y la eficiencia de espacio están inherentemente en conflicto. El término medio usual es escoger un tamaño de bloque de 512, 1K o 2K bytes. Si se escoge un tamaño de bloque de 1K en un disco cuyos sectores son de 512 bytes, el sistema de archivos siempre leerá o escribirá dos sectores consecutivos y los tratará como una sola unidad, indivisible. Sea cual sea la decisión que se tome, probablemente convendrá reevaluarla periódicamente, ya que, al igual que sucede con todos los aspectos de la tecnología de computadoras, los usuarios aprovechan los recursos más abundantes exigiendo todavía más.
Administración de bloques libres Una vez que se ha escogido el tamaño de bloque, el siguiente problema es cómo seguir la pista a los bloques libres. Se utilizan ampliamente dos métodos, mismos que se ilustran en la siguiente figura. El primero (a) consiste en usar una lista enlazada de bloques de disco, en la que cada bloque contiene tantos números de bloques de disco libres como quepan en él. Con bloques de 1K y números de bloque de 32 bits, cada bloque de la lista libre contiene los números de 255 bloques libres. (Se requiere una ranura para el apuntador al siguiente bloque.) Un disco de 200M necesita una lista libre de, como máximo, 804 bloques para contener los 200K números de bloque. Es común que se usen bloques libres para contener la lista libre.
La otra técnica de administración del espacio libre es (b) el mapa de bits. Un disco con n bloques requiere un mapa de bits con n bits. Los bloques libres se representan con unos en el mapa, y los bloques asignados con ceros (o viceversa). Un disco de 200M requiere 200K bits para el mapa, mismos que ocupan sólo 25 bloques. No es sorprendente que el mapa de bits requiera menos espacio, ya que sólo usa un bit por bloque, en vez de 32 como en el modelo de lista enlazada. Sólo si el disco está casi lleno el esquema de lista enlazada requerirá menos bloques que el mapa de bits. Si hay suficiente memoria principal para contener el mapa de bits, este método generalmente es preferible. En cambio, si sólo se puede dedicar un bloque de memoria para seguir la pista a los bloques de disco libres, y el disco está casi lleno, la lista enlazada podría ser mejor. Con sólo un bloque del mapa de bits en la memoria, podría ser imposible encontrar bloques libres en él, causando accesos a disco para leer el resto del mapa de bits. Cuando un bloque nuevo de la lista enlazada se carga en la memoria, es posible asignar 255 bloques de disco antes de tener que traer del disco el siguiente bloque de la lista.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
85
6.3.4. Confiabilidad del sistema de archivos Es necesario proteger la información alojada en el sistema de archivos, efectuando los resguardos correspondientes [Tanenbaum]. De esta manera se evitan las consecuencias generalmente catastróficas de la pérdida de los sistemas de archivos. La destrucción de un sistema de archivos suele ser un desastre mucho peor que la destrucción una computadora. Las pérdidas se pueden deber a problemas de hardware, software, hechos externos, etc. Los discos pueden tener bloques defectuosos. Los discos flexibles normalmente son perfectos cuando salen de la fábrica, pero pueden adquirir defectos durante el uso. Para manejar bloques defectuosos se utilizan soluciones por hardware y por software.
• La solución en hardware consiste en dedicar un sector del disco a la lista de bloques defectuosos. Al inicializar el controlador de hardware por primera vez, este lee la “lista de bloques defectuosos” y elige un bloque (o pista) de repuesto para reemplazar los defectuosos, registrando la correspondencia en la lista de bloques defectuosos. A partir de entonces, todas las solicitudes que pidan el bloque defectuoso usarán el de repuesto. Cada vez que se descubren nuevos errores se actualiza esta lista como parte de un formato de bajo nivel.
• La solución en software requiere que el usuario o el sistema de archivos construyan un archivo con todos los bloques defectuosos. Se los elimina de la lista de bloques libres y se crea un “archivo de bloques defectuosos que está constituido por los bloques defectuosos que no debe ser leído ni escrito y no se debe intentar obtener copias de respaldo de este archivo.
Respaldos (copias de seguridad o de back-up) Es muy importante respaldar los archivos con frecuencia incluso teniendo una estrategia ingeniosa para manejar los bloques defectuosos. Los respaldos pueden consistir en efectuar copias completas del contenido de los discos flexibles o rígidos. Una estrategia de respaldo consiste en dividir los discos en áreas de datos y áreas de respaldo, utilizándolas de a pares, pero se desperdicia la mitad del almacenamiento de datos en disco para respaldo, donde cada noche (o en el momento que se establezca), la parte de datos de la unidad 0 se copia a la parte de respaldo de la unidad 1 y viceversa.
Otra estrategia es el vaciado por incrementos o respaldo incremental, donde se obtiene una copia de respaldo periódicamente (una vez por mes o por semana), llamada copia total. Se obtiene una copia diaria solo de aquellos archivos modificados desde la última copia total; en estrategias mejoradas, se copian solo aquellos archivos modificados desde la última vez que dichos archivos fueron copiados. Se debe mantener en el disco información de control como una lista de los tiempos de copiado de cada archivo, la que debe ser actualizada cada vez que se obtienen copias de los archivos y cada vez que los archivos son modificados. Puede requerir una gran cantidad de cintas de respaldo dedicadas a los respaldos diarios entre respaldos completos. También se puede usar métodos automáticos que emplean múltiples discos, como la creación de espejos que emplea dos discos. Las escrituras se efectúan en ambos discos, y las lecturas provienen de uno solo. La escritura en el disco espejo se retrasa un poco, efectuándose cuando el sistema está ocioso. Un sistema así puede seguir funcionando en "modo degradado" si un disco falla, y esto permite reemplazar el disco que falló y recuperar los datos sin tener que parar el sistema. Consistencia del sistema de archivos Muchos sistemas de archivos leen bloques, los modifican y escriben en ellos después. Si el sistema falla antes de escribir en los bloques modificados, el sistema de archivos puede quedar en un estado inconsistente. La inconsistencia es particularmente crítica si alguno de los bloques afectados son: • Bloques de nodos-i.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
86
• Bloques de directorios. • Bloques de la lista de bloques libres. La mayoría de los sistemas dispone de un programa utilitario que verifica la consistencia del sistema de archivos. Se pueden ejecutar al arrancar el sistema o a pedido, pueden actuar sobre todos o algunos de los discos y pueden efectuar verificaciones a nivel de bloques y a nivel de archivos. La consistencia del sistema de archivos no asegura la consistencia interna de cada archivo, respecto de su contenido. Generalmente pueden verificar también el sistema de directorios y / o de bibliotecas. Se pueden realizar dos tipos de verificaciones de consistencia: de bloques y de archivos. Para comprobar la consistencia de los bloques, el programa construye dos tablas, cada una de las cuales contiene un contador para cada bloque, que inicialmente vale 0. Los contadores de la primera tabla llevan la cuenta de cuántas veces un bloque está presente en un archivo; los contadores de la segunda tabla registran cuántas veces está presente cada bloque en la lista libre (o en el mapa de bits de bloques libres). A continuación, el programa lee todos los nodos-i. Partiendo de un nodo-i, es posible construir una lista de todos los números de bloque empleados en el archivo correspondiente. Al leerse cada número de bloque, su contador en la primera tabla se incrementa. Después, el programa examina la lista o mapa de bits de bloques libres, para encontrar todos los bloques que no están en uso. Cada ocurrencia de un bloque en la lista libre hace que su contador en la segunda tabla se incremente. Si el sistema de archivos es consistente, cada bloque tendrá un 1 ya sea en la primera tabla o en la segunda, como se ilustra en la figura (a). Sin embargo, después de una caída las tablas podrían tener el aspecto de la figura (b), en la que el bloque 2 no ocurre en ninguna de las dos tablas. Este bloque se informará como bloque fallante. Aunque los bloques fallantes no representan un daño real, desperdician espacio y, por tanto, reducen la capacidad del disco. La solución en el caso de haber bloques fallantes es directa: el verificador del sistema de archivos simplemente los agrega a la lista libre.
Otra situación que podría ocurrir es la de la figura (c). Aquí vemos un bloque, el número 4, que ocurre dos veces en la lista libre. (Sólo puede haber duplicados si la lista libre es realmente una lista; si es un mapa de bits esto es imposible.) La solución en este caso también es simple: reconstruir la lista libre. Lo peor que puede suceder es que el mismo bloque de datos esté presente en dos o más archivos, como se muestra en la figura (d) con el bloque 5. Si cualquiera de estos archivos se elimina, el bloque 5 se colocará en la lista libre, dando lugar a una situación en la que el mismo bloque está en uso y libre al mismo tiempo. Si se eliminan ambos archivos, el bloque se colocará en la lista libre dos veces. La acción apropiada para el verificador del sistema de archivos es asignar un bloque libre, copiar en él el contenido del bloque 5, e insertar la copia en uno de los archivos. De este modo, el contenido de información de los archivos no cambiará (aunque casi con toda seguridad estará revuelto), y la estructura del sistema de archivos al menos será consistente. Se deberá informar del error, para que el usuario pueda inspeccionar los daños. Además de verificar que cada bloque esté donde debe estar, el verificador del sistema de archivos también revisa el sistema de directorios. En este caso también se usa una tabla de contadores, pero ahora uno por cada archivo, no por cada bloque. El programa parte del directorio raíz y desciende recursivamente el árbol, inspeccionando cada directorio del sistema de archivo; Para cada archivo de cada directorio, el verificador incrementa el contador correspondiente í nodo-i de ese archivo. Una vez que termina la revisión, el verificador tiene una lista, indizada por número de nodo que indica cuántos directorios apuntan a ese nodo-i. Luego, el programa compara estos números con los conteos de enlace almacenados en los nodos-i mismos. En un sistema de archivos consistente, ambos conteos coinciden.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
87
Sin embargo, pueden ocurrir dos tipos de errores: el conteo de enlaces del nodo-i puede ser demasiado alto o demasiado bajo. Si el conteo de enlaces es mayor que el número de entradas de directorio, entonces aunque si borraran todos los archivos de todos los directorios el conteo seguiría siendo mayor que cero y el nodo-i no se eliminaría. Este error no es grave, pero desperdicia espacio en el disco con archivo: que no están en ningún directorio, así que debe corregirse asignando el valor correcto al conteo de enlaces del nodo-i. El otro error puede ser catastrófico. Si dos entradas de directorio están enlazadas a un archivo, pero el nodo-i dice que sólo hay una, cuando se elimine cualquiera de las entradas de directorio, el conteo del nodo-i se convertirá en cero. Cuando esto suceda, el sistema de archivos le marcará como desocupado y liberará todos sus bloques. El resultado de esta acción es que uno de los directorios ahora apunta a un nodo-i desocupado, cuyos bloques pronto pueden ser asignados a otros archivos. Una vez más, la solución es hacer que el conteo de enlaces del nodo-i sea igual al número real de entradas de directorio. Estas dos operaciones, verificar bloques y verificar directorios, a menudo se integran por razones de eficiencia (una sola pasada por los nodos-i). También pueden realizarse otras verificaciones heurísticas. Por ejemplo, los directorios tienen un formato definido, con números de nodo-i y nombres ASCII. Si un número de nodo-i es mayor que el número de nodos-i que hay en el disco, es señal de que el directorio ha sido dañado. Además, cada nodo-i tiene un modo, y algunos de estos modos son permitidos pero extraños, como el 0007, que no permite que el propietario ni su grupo tengan acceso, pero sí permite a terceros leer, escribir y ejecutar el archivo. Podría ser útil al menos informar de la existencia de archivos que dan más derechos a terceros que al propietario. Los directorios que tienen más de 1000 entradas también son sospechosos. Los archivos situados en directorios de usuarios, pero que son propiedad del superusuario y tienen habilitado el bit SETUID, implican posibles problemas de seguridad. 6.3.5. Desempeño del sistema de archivos El acceso a un disco es mucho más lento que el acceso a la memoria. La lectura de un byte de memoria por lo regular toma decenas de nanosegundos. La lectura de una palabra de un disco duro puede tardar 50 microsegundos, lo que implica que es cuatro veces más lenta por palabra de 32 bits, pero a esto deben sumarse de 10 a 20 milisegundos para mover la cabeza de lectura a la pista correcta y luego esperar a que el sector deseado se coloque debajo de la cabeza. Si sólo se necesita una palabra, el acceso a la memoria será del orden de 100 000 veces más rápido que al disco. En vista de esta diferencia en el tiempo de acceso, muchos sistemas de archivos se han diseñado pensando en reducir el número de accesos a disco requeridos. La técnica más común empleada para reducir los accesos a disco es el caché de bloques o el caché de buffer. En este contexto, un caché es una colección de bloques que lógicamente pertenecen al disco pero que se están manteniendo en la memoria por razones de rendimiento. Uno de los algoritmos más comunes para la administración del caché es el siguiente: • Verificar todas las solicitudes de lectura para saber si el bloque solicitado se encuentra en el caché. • En caso afirmativo, se satisface la solicitud sin un acceso a disco. • En caso negativo, se lee para que ingrese al caché y luego se copia al lugar donde se necesite. • Cuando hay que cargar un bloque en un caché totalmente ocupado:
— Hay que eliminar algún bloque y volverlo a escribir en el disco en caso de que haya sido modificado luego de haberlo traído del disco.
— Se plantea una situación muy parecida a la paginación y se resuelve con algoritmos similares. Se debe considerar la posibilidad de una falla total del sistema y su impacto en la consistencia del sistema de archivos, si un bloque crítico, como un bloque de un nodo-i, se lee en el caché y se modifica, sin volverse a escribir en el disco, una falla total del sistema dejará al sistema de archivos en un estado inconsistente. Se deben tener en cuenta los siguientes factores: • Los bloques que se vayan a utilizar muy pronto, como un bloque parcialmente ocupado que se está
escribiendo, deberían permanecer un largo tiempo. • Es esencial el bloque para la consistencia del sistema de archivos y si se ha modificado, debe
escribirse en el disco de inmediato, con lo que se reduce la probabilidad de que una falla total del sistema haga naufragar al sistema de archivos eligiendo con cuidado el orden de escritura de los bloques críticos.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
88
• No es recomendable mantener los bloques de datos en el caché durante mucho tiempo antes de reescribirlos.
La solución de algunos S. O. consiste en tener una llamada al sistema que fuerza una actualización general a intervalos regulares de algunos segundos. Una técnica importante para aumentar el rendimiento de un sistema de archivos es la reducción de la cantidad de movimientos del brazo del disco (mecanismo de acceso), se deben colocar los bloques que probablemente tengan un acceso secuencial, próximos entre sí, preferentemente en el mismo cilindro. Los nodos-i deben estar a mitad del disco y no al principio, reduciendo a la mitad el tiempo promedio de búsqueda entre el nodo-i y el primer bloque del archivo. 7.4. Ejemplos de Sistemas de Archivos
7.4.1. Sistemas de archivos Windows
7.4.1.1. FAT (File Allocation Table)
El sistema de archivos FAT es uno de los sistemas más simples que se implementan por los sistemas operativos. Esta sencillez viene dada por el reducido número de estructuras que lo conforman. FAT nació como una solución a la gestión de archivos y directorios para los sistemas DOS. Posteriormente su uso fue extendido a los sistemas operativos Windows en sus diferentes versiones, así como para sistemas UNIX. El nombre de FAT viene dado porque su principal estructura es precisamente una tabla de asignación de archivos (FAT, File Allocation Table). Dependiendo del tamaño de las entradas de esta tabla distinguiremos tres variantes de este sistema. Si las entradas son de 12 bits nos estaremos refiriendo a FAT12. Si las entradas son de 16 bits hablaremos de FAT16. Finalmente, si las entradas son de 32 bits (realmente se utilizan 28) nos dirigiremos a FAT32. La tabla de asignación de archivos (FAT), reside en la parte más "superior" del volumen. Para proteger el volumen, se guardan dos copias de la FAT por si una resultara dañada. Además, las tablas FAT y el directorio raíz deben almacenarse en una ubicación fija para que los archivos de arranque del sistema se puedan ubicar correctamente.
Las funciones que tienen las diferentes zonas son: • Sector de arranque: ésta zona contiene información acerca del código de arranque del sistema,
así como de características físicas y lógicas del sistema de archivos. • FAT: ésta zona no es más que la tabla que ya se ha citado anteriormente. Su función es
mantener la relación de los diferentes conjuntos de sectores o clústeres asignados a los archivos.
• Directorio raíz: estructura con entradas que mantienen la información de todos los archivos del sistema.
• Zona de datos: formada por clústeres que guardan la información contenida en los archivos. Un disco con formato FAT se asigna en clústeres, cuyo tamaño viene determinado por el tamaño del volumen. Cuando se crea un archivo, se crea una entrada en el directorio y se establece el primer número de clúster que contiene datos. Esta entrada de la tabla FAT indica que este es el último clúster del archivo o bien señala al clúster siguiente.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
89
FUNCIONAMIENTO DEL SISTEMA DE ARCHIVOS Para la grabación de un archivo o directorio, el sistema primero se fija cual es el primer cluster disponible para usar, luego genera una entrada en el directorio (lugar donde se inserta el nombre de archivo o directorio), luego determina el tamaño para ocupar un cluster o varios, si ocupa un solo cluster escribirá en el numero de cluster asignado la sentencia EOF indicando que el archivo termina en ese cluster, Si el archivo fuese mas grande que un cluster se informa sobre la ubicación del cluster inicial y luego se busca otro cluster (en lo posible consecutivo) para seguir almacenando el dato, colocando este numero en la posición inicial para indicar donde continuar la búsqueda al momento de recuperar el archivo y repitiendo este proceso hasta llegar al fin del archivo donde se colocara la sentencia EOF. En el área de directorio no solo se guardan el nombre de archivos sino también:
• Nombre del archivo (8 bytes con el formato 8.3) • Extensión (3 bytes) • Identificación (Si es archivo, directorio o entrada de nombre de archivo largo NFL) • Fecha y hora de creación (5 bytes) • Cluster de inicio (2 bytes) • Tamaño de archivo (4 bytes) • Atributos de archivo (A, R, S, H, D)

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
90
Convención de nomenclatura de FAT FAT utiliza la convención de nomenclatura tradicional 8.3 y todos los nombres de archivo deben crearse con el conjunto de caracteres ASCII. El nombre de un archivo o directorio puede tener ocho caracteres de longitud, después un separador de punto (.) y una extensión de hasta tres caracteres. El nombre debe empezar con una letra o un número y puede contener cualquier carácter excepto los siguientes: . " / \ [ ] : ; | = , Los nombres siguientes están reservados: CON, AUX, COM1, COM2, COM3, COM4, LPT1, LPT2, LPT3, PRN, NUL Todos los caracteres se convertirán a mayúsculas. Ventajas de FAT No es posible realizar una recuperación de archivos eliminados en Windows NT en ninguno de los sistemas de archivos compatibles. Las utilidades de recuperación de archivos eliminados intentan tener acceso directamente al hardware, lo que no se puede hacer en Windows NT. Sin embargo, si el archivo estuviera en una partición FAT y se reiniciara el sistema en MS-DOS, se podría recuperar el archivo. El sistema de archivos FAT es el más adecuado para las unidades y/o particiones de menos de 200 MB aproximadamente, ya que FAT se inicia con muy poca sobrecarga. Desventajas de FAT Cuando se utilicen unidades o particiones de más de 200 MB, es preferible no utilizar el sistema de archivos FAT. El motivo es que a medida que aumente el tamaño del volumen, el rendimiento con FAT disminuirá rápidamente. No es posible establecer permisos en archivos que estén en particiones FAT. Las particiones FAT tienen un tamaño limitado a un máximo de 4 Gigabytes (GB) en Windows NT y 2 GB en MS-DOS.
7.4.1.2. HPFS (sistemas de archivos de alto rendimiento)
El sistema de archivos HPFS se presentó por primera vez con OS/2 1.2 para permitir un mejor acceso a los discos duros de mayor tamaño que estaban apareciendo en el mercado. Además, era necesario que un nuevo sistema de archivos ampliara el sistema de nomenclatura, la organización y la seguridad para las crecientes demandas del mercado de servidores de red. HPFS mantiene la organización de directorio de FAT, pero agrega la ordenación automática del directorio basada en nombres de archivo. Los nombres de archivo se amplían hasta 254 caracteres de doble byte. HPFS también permite crear un archivo de "datos" y atributos especiales para permitir una mayor flexibilidad en términos de compatibilidad con otras convenciones de nomenclatura y seguridad. Además, la unidad de asignación cambia de clústeres a sectores físicos (512 bytes), lo que reduce el espacio perdido en el disco. En HPFS, las entradas de directorio contienen más información que en FAT. Además del archivo de atributos, esto incluye información sobre la fecha y la hora de modificación, de creación y de acceso. En lugar de señalar al primer clúster del archivo, en HPFS las entradas del directorio señalan a FNODE. FNODE puede contener los datos del archivo, o bien punteros que pueden señalar a datos del archivo o a otras estructuras que, a su vez, señalarán a datos del archivo. HPFS intenta asignar, en la medida de lo posible, la mayor cantidad de datos de un archivo en sectores contiguos. Esto se hace con el fin de aumentar la velocidad al realizar el procesamiento secuencial de un archivo. HPFS organiza una unidad en una serie de bandas de 8 MB y, siempre que sea posible, un archivo estará contenido dentro de una de estas bandas. Entre cada una de estas bandas hay mapas de bits de asignación de 2 KB, que hacen un seguimiento de los sectores dentro de una banda que se han asignado y que no se han asignado. La creación de bandas aumenta el rendimiento porque el cabezal de

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
91
la unidad no tiene que volver a la parte superior lógica (normalmente el cilindro 0) del disco, sino al mapa de bits de asignación de banda más cercano, para determinar dónde se almacenará un archivo.
Superbloque El superbloque se encuentra en el sector lógico 16 y contiene un puntero al FNODE del directorio raíz. Uno de los mayores peligros de utilizar HPFS es que si el superbloque se pierde o resulta dañado debido a un sector defectuoso, lo mismo ocurrirá con el contenido de la partición, incluso aunque el resto de la unidad esté bien. Sería posible recuperar los datos de la unidad copiando todo a otra unidad con un sector 16 en buen estado y volviendo a generar el superbloque. Sin embargo, es una tarea muy compleja. Bloque de reserva El bloque de reserva se encuentra en el sector lógico 17, y contiene una tabla de "revisiones" y el bloque de directorio de reserva. En HPFS, cuando se detecta un sector defectuoso, la entrada de las "revisiones" se utiliza para señalar lógicamente a un sector en buen estado existente en lugar de al sector defectuoso. Esta técnica para el tratamiento de errores de escritura se conoce como revisión. La revisión es una técnica en la que si se produce un error debido a un sector defectuoso, el sistema de archivos mueve la información a otro sector diferente y marca el sector original como no válido. Todo ello se realiza de forma transparente para cualquier aplicación que esté realizando operaciones de E/S de disco (es decir, la aplicación nunca sabe que hubo problemas con el disco duro). Al utilizar un sistema de archivos que admite revisiones, se eliminarán mensajes de error como el de FAT "¿Desea interrumpir, reintentar o cancelar?" que aparece cuando se encuentra un sector defectuoso. La versión de HPFS incluida con Windows NT no admite revisiones. Ventajas de HPFS
• HPFS es la mejor opción para las unidades comprendidas entre 200 y 400 MB. • Permite nombres de archivos de hasta 256 caracteres. • El volumen está estructurado en bandas. • La estructura de directorios es una estructura de árbol binario cuyos nodos se denominan
Fondees. Estas estructuras contienen un nombre de archivo, su longitud, atributos, ACL (Access Control List) y situación de los datos del archivo, es decir, el número de banda en el que se encuentran.
Desventajas de HPFS
• Debido a la sobrecarga que implica HPFS, no es una opción muy eficaz para un volumen de menos de unos 200 MB. Además, con volúmenes mayores de unos 400 MB, habrá una ligera degradación del rendimiento. No se puede establecer la seguridad en HPFS con Windows NT.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
92
• HPFS solo es compatible con las versiones 3.1, 3.5 y 3.51 de Windows NT. Windows NT 4.0 no puede tener acceso a particiones HPFS.
• Fragmentación externa. Depende del tamaño del archivo de los usuarios y de su disposición en las bandas.
7.4.1.3. NTFS (New Technology File System)
Está basado en el sistema de archivos HPFS de IBM/Microsoft usado en el sistema operativo OS/2, y también tiene ciertas influencias del formato de archivos HFS diseñado por Apple. Desde el punto de vista de un usuario, NTFS sigue organizando los archivos en directorios que, al igual que ocurre en HPFS, se ordenan. Sin embargo, a diferencia de FAT o de HPFS, no hay ningún objeto "especial" en el disco y no hay ninguna dependencia del hardware subyacente, como los sectores de 512 bytes. Además, no hay ninguna ubicación especial en el disco, como las tablas de FAT o los superbloques de HPFS. Los objetivos de NTFS son proporcionar lo siguiente:
• Confiabilidad, que es especialmente deseable para los sistemas avanzados y los servidores de archivos
• Una plataforma para tener mayor funcionalidad • Compatibilidad con los requisitos de POSIX • Eliminación de las limitaciones de los sistemas de archivos FAT y HPFS
Confiabilidad Para garantizar la confiabilidad de NTFS, se trataron tres áreas principales: posibilidad de recuperación, eliminación de errores graves de un único sector y revisiones. NTFS es un sistema de archivos recuperable porque hace un seguimiento de las transacciones con el sistema de archivos. Cuando se ejecuta un comando CHKDSK en FAT o HPFS, se comprueba la coherencia de los punteros dentro del directorio, la asignación y las tablas de archivos. En NTFS se mantiene un registro de transacciones con estos componentes de forma que CHKDSK solo tenga que deshacer las transacciones hasta el último punto de confirmación para recuperar la coherencia dentro del sistema de archivos. En FAT o en HPFS, si se produce un error en un sector que es la ubicación de uno de los objetos especiales del sistema de archivos, se producirá un error de un único sector. NTFS evita esto de dos maneras: en primer lugar, no utilizando objetos especiales en el disco, efectuando el seguimiento de todos los objetos del disco y protegiéndolos. En segundo lugar, en NTFS se mantienen varias copias (el número depende del tamaño del volumen) de la tabla maestra de archivos. De manera similar a las versiones OS/2 de HPFS, NTFS admite revisiones. Mayor funcionalidad Uno de los principales objetivos de diseño de Windows NT en cada nivel es proporcionar una plataforma a la que se pueda agregar e integrar funciones, y NTFS no es ninguna excepción. NTFS proporciona una plataforma enriquecida y flexible que pueden utilizar otros sistemas de archivos. Además, NTFS es totalmente compatible con el modelo de seguridad de Windows NT y admite varias secuencias de datos. Ya no es un archivo de datos en una única secuencia de datos. Por último, en NTFS un usuario puede agregar a un archivo sus propios atributos definidos por él mismo. Compatibilidad con POSIX NTFS es el sistema de archivos compatible que mejor se adhiere a POSIX, ya que cumple los requisitos siguientes de POSIX.:
• Nomenclatura con distinción entre mayúsculas y minúsculas (En POSIX, LÉAME.TXT, Léame.txt y léame.txt son todos archivos diferentes.)
• Marca de tiempo adicional (La marca de tiempo adicional proporciona la hora a la que se tuvo acceso al archivo por última vez)
• Vínculos físicos (Un vínculo físico se produce cuando dos nombres de archivo diferentes, que pueden estar en directorios diferentes, señalan a los mismos datos.)

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
93
Eliminación de limitaciones En primer lugar, NTFS ha aumentado considerablemente el tamaño de los archivos y los volúmenes, de forma que ahora pueden tener hasta 2^64 bytes (16 exabytes o 18.446.744.073.709.551.616 bytes). NTFS también ha vuelto al concepto de clústeres de FAT para evitar el problema de HPFS de un tamaño de sector fijo. Esto se hizo porque Windows NT es un sistema operativo portátil y es probable que se encuentre tecnología de disco diferente en algún lugar. Por tanto, se consideró que quizás 512 bytes por sector no fuera siempre un valor adecuado para la asignación. Para lograrlo, se permitió definir el clúster como múltiplos del tamaño de asignación natural del hardware. Por último, en NTFS todos los nombres de archivo se basan en Unicode, y los nombres de archivo 8.3 se conservan junto con los nombres de archivo largos.
Es un sistema adecuado para las particiones de gran tamaño requeridas en estaciones de trabajo de alto rendimiento y servidores puede manejar volúmenes de, teóricamente, hasta 264–1 clústeres. En la práctica, el máximo volumen NTFS soportado es de 232–1 clústeres (aproximadamente 16 TiB usando clústeres de 4 KiB).
Hay tres versiones de NTFS: v1.2 en NT 3.51, NT 4, v3.0 en Windows 2000 y v3.1 en Windows XP, Windows 2003 Server, Windows Vista y v5.1 en Windows 2008. Estas versiones reciben en ocasiones las denominaciones v4.0, v5.0, v5.1, v 5.2, y v 6.0 en relación con la versión de Windows en la que fueron incluidas
Una partición formateada con NTFS tiene la siguiente estructura:
• Sector de arranque. Esta zona no ocupa generalmente un único sector sino varios. Contiene información sobre la disposición del volumen así como de las diferentes estructuras que forman el sistema de archivos. También contiene información para el arranque del sistema.
• Master File Table (MFT). Se trata de una tabla, tal y como su nombre indica, que contiene información de todos los archivos y directorios del sistema.
• Archivos de sistema. Los archivos del sistema contienen estructuras útiles para la gestión del sistema de archivos, así como para la recuperación del mismo en caso de fallida.
• Zona de datos. Zona para la ubicación de los diferentes archivos de datos.
La estructura de directorios que implementa NTFS es la estructura de árbol. Para mejorar el rendimiento del sistema utiliza un árbol B, el cuál permite balanceo de carga
Master File Table (MFT) La tabla MFT está organizada en registros que contienen información de todos los archivos del volumen. El tamaño de un registro es de 1 KB. La tabla MFT se basa en el concepto de

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
94
tabla de una base de datos relacional. Cada registro contiene información de un archivo, incluyendo la tabla MFT que es tratada como un archivo más. De este modo se consigue que la tabla sea de tamaño variable.
Ventajas de NTFS • NTFS es la mejor opción para volúmenes de unos 400 MB o más. El motivo es que el
rendimiento no se degrada en NTFS, como ocurre en FAT, con tamaños de volumen mayores. • La posibilidad de recuperación está diseñada en NTFS de manera que un usuario nunca tenga
que ejecutar ningún tipo de utilidad de reparación de disco en una partición NTFS. Desventajas de NTFS
• No se recomienda utilizar NTFS en un volumen de menos de unos 400 MB, debido a la sobrecarga de espacio que implica. Esta sobrecarga de espacio se refiere a los archivos de sistema de NTFS que normalmente utilizan al menos 4 MB de espacio de unidad en una partición de 100 MB.
Convenciones de nomenclatura de NTFS Los nombres de archivo y de directorio pueden tener hasta 255 caracteres de longitud, incluyendo cualquier extensión. Los nombres conservan el modelo de mayúsculas y minúsculas, pero no distinguen mayúsculas de minúsculas. NTFS no realiza ninguna distinción de los nombres de archivo basándose en el modelo de mayúsculas y minúsculas. Los nombres pueden contener cualquier carácter excepto los siguientes: ? " / \ < > * | : En la actualidad, desde la línea de comandos solo se pueden crear nombres de archivo de un máximo de 253 caracteres.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
95
Límites
Máxima dimensión de archivo
16 TiB con la actual implementación
(16 EiB según su arquitectura)
Máximo número de archivos
4.294.967.295 (232–1)
Tamaño máximo del nombre de archivo
255 caracteres
Tamaño máximo del volumen
256 TiB con la actual implementación (16 EiBsegún su arquitectura)
Caracteres permitidos en
nombres de archivo
Cualquier carácter excepto '\0' (NULO) y '/'1
Windows también excluye el uso de \: * ? " < > |
Funcionamiento
Todo lo que tiene que ver con los archivos se almacena en forma de metadatos. Esto permitió una fácil ampliación de características durante el desarrollo de Windows NT. Un ejemplo lo hallamos en la inclusión de campos de indizado añadidos para posibilitar el funcionamiento de Active Directory.
Estructuras
Contenido del directorio
Árbol-B+
Localización de archivo
Mapa de bits/Extents
Bloques malos Mapa de bits/Extents
Los nombres de archivo son almacenados en Unicode (UTF-16), y la estructura de archivos en árboles-B, una estructura de datos compleja que acelera el acceso a los archivos y reduce la fragmentación, que era lo más criticado del sistema FAT. Se emplea un registro transaccional (journal) para garantizar la integridad del sistema de archivos (pero no la de cada archivo). Los sistemas que emplean NTFS han demostrado tener una estabilidad mejorada, que resultaba un requisito ineludible considerando la naturaleza inestable de las versiones más antiguas de Windows NT. Sin embargo, a pesar de lo descrito anteriormente, este sistema de archivos posee un funcionamiento prácticamente secreto, ya que Microsoft no ha liberado su código como hizo con FAT.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
96
Gracias a la ingeniería inversa, aplicada sobre el sistema de archivos, se desarrollaron controladores como el NTFS-3G que actualmente proveen a sistemas operativos GNU/Linux, Solaris, MacOS X o BSD, entre otros, de soporte completo de lectura y escritura en particiones NTFS. El procedimiento que lleva a cabo NTFS cuando se quiere almacenar un archivo o un directorio es el siguiente. Se pueden dar dos casos. • Si se quiere almacenar un archivo en el que sus atributos son de poco tamaño, se coloca
automáticamente en un registro MFT. Es importante recordar que los archivos tienen como atributo a su contenido. Los atributos que son guardados directamente en un registro MFT son denominados atributos residentes.
• Si, por el contrario, el tamaño de los atributos de un archivo supera la capacidad de un registro, los atributos son almacenados en clústeres de datos contiguos de la zona de datos. En este caso, el registro MFT contiene referencias a dichos clústeres. El registro también contiene un identificador denominado número de clúster virtual. Este identificador da información sobre el primer clúster que ocupa el archivo así como el número de clústeres que ocupa. Dado que los clústeres que están contiguos no tendremos que realizar consultas de la ubicación del siguiente clúster del archivo.
Se podría dar la posibilidad de que el número de referencias a los clústeres de un archivo también fuera elevado. Éstas serían almacenadas también en la zona de datos, y se mantendría en el registro MFT una referencia al bloque que las contiene. En general, los atributos que son guardados en la zona de datos se denominan atributos no residentes.
7.4.1.4. ReFS (Sistema de archivos resistente a errores)
ReFS (Resilient File System, originalmente con nombre en código «Protogon») es un nuevo sistema de archivos en Windows Server 2012 inicialmente previsto para servidores de archivos que mejora en NTFS. El sistema presenta limitaciones frente a su predecesor, como se detalla más adelante, pero también novedades en varios campos.
Los clientes de Windows desean disponer de una plataforma rentable que maximice la disponibilidad de los datos, que escale de manera eficiente a conjuntos de datos de gran tamaño en diversas cargas de trabajo y que garantice la integridad de los datos por medio de la resistencia a los daños (independientemente de los errores de software o hardware). ReFS es un nuevo sistema de archivos que está diseñado para satisfacer estas necesidades de los clientes y, al mismo tiempo, proporcionar una base para importantes innovaciones en el futuro. Mediante una pila de almacenamiento integrada que incluye ReFS y la nueva característica de Espacios de almacenamiento, los clientes ahora pueden implementar la plataforma más rentable para obtener un acceso a los datos escalable y disponible utilizando almacenamiento.
La característica Espacios de almacenamiento protege los datos contra errores de disco parciales y totales mediante la conservación de copias en varios discos. ReFS establece una interfaz con Espacios de almacenamiento para reparar los daños de manera automática.
Las siguientes son algunas de las características clave de ReFS:
• Mantiene los más altos niveles posibles de disponibilidad y confiabilidad del sistema, suponiendo que el almacenamiento subyacente puede ser, de forma inherente, poco confiable.
• Ofrece una arquitectura resistente a errores completa cuando se usa junto con Espacios de almacenamiento para que estas dos características amplíen las funcionalidades y la confiabilidad de la otra cuando se usan juntas.
• Mantiene la compatibilidad con las características de NTFS que se adoptan ampliamente y con resultados óptimos, además de reemplazar las características que aportan un valor limitado.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
97
Además, existe una nueva herramienta de línea de comandos Integrity.exe para administrar la integridad y las directivas de limpieza de discos.
Aplicaciones prácticas ReFS ofrece funcionalidades que ayudan a los clientes a almacenar y proteger los datos, independientemente de la confiabilidad de la pila subyacente de hardware y software. Esto minimiza el costo del almacenamiento y reduce los gastos de capital para las empresas. Las siguientes son algunas de las aplicaciones prácticas:
• Servidor de archivos de uso general. El cliente implementa un servidor de archivos conectado a una configuración de almacenamiento JBOD con unidades serie ATA (SATA) o SCSI conectado en serie (SAS).
• Almacenamiento remoto consolidado de datos de aplicaciones. El cliente implementa un clúster de servidor de archivos de dos nodos y escalabilidad horizontal con Espacios de almacenamiento, en el cual el clúster usa una configuración de almacenamiento JBOD con unidades SATA o SAS.
Funcionalidad importante La funcionalidad importante que se incluye con ReFS se describe a continuación:
• Integridad: ReFS almacena los datos de modo que los protege contra muchos de los errores comunes que normalmente ocasionan pérdida de datos. Cuando ReFS se usa junto con un Espacio de almacenamiento reflejado, los daños detectados (tanto en los metadatos como en los datos de usuario, cuando están habilitadas las secuencias de integridad) se pueden reparar de forma automática mediante la copia alternativa proporcionada por los Espacios de almacenamiento. En caso de que se produzca un error del sistema, ReFS se recupera rápidamente del error sin que haya pérdida de datos de usuario.
• Disponibilidad. ReFS prioriza la disponibilidad de los datos. Históricamente, los sistemas de archivos a menudo son susceptibles a daños en los datos que requieren que el sistema se desconecte para la reparación. Con ReFS, si se producen daños, el proceso de reparación se localiza en el área del daño y se ejecuta en línea, por lo que no se requiere tiempo de inactividad de los volúmenes. Pese a que no es algo habitual, si un volumen se daña, o si el usuario decide no usar Espacios de almacenamiento reflejados, ReFS implementa un rescate, una característica que elimina los datos dañados del espacio de nombres en un volumen activo sin que los datos en estado óptimo se vean afectados por los datos dañados que no se pueden reparar. Además, no hay chkdsk con ReFS.
• Escalabilidad. Dado que la cantidad y el tamaño de los datos que se almacenan en los equipos sigue aumentando con rapidez, ReFS está diseñado para funcionar correctamente con conjuntos de datos extremadamente grandes, petabytes y volúmenes aún mayores, sin afectar al rendimiento. No obstante, las preocupaciones prácticas en torno a las configuraciones del sistema (como la cantidad de memoria), los límites que imponen diversos componentes del sistema y el tiempo que se necesita para rellenar los conjuntos de datos o las horas de copia de seguridad pueden definir limitaciones prácticas. El formato en disco de ReFS está diseñado para admitir tamaños de volúmenes de hasta 2^78 bytes usando tamaños de clúster de 16 KB, mientras que el direccionamiento de la pila de Windows permite 2^64 bytes. Este formato también admite tamaños de archivo de 2^64-1 bytes, 2^64 archivos en un directorio y la misma cantidad de directorios en un volumen.
• Identificación proactiva de errores. Las funcionalidades de integridad de ReFS las aprovecha un escáner de integridad, cuyo proceso se conoce como limpieza. La utilidad de limpieza examina de forma periódica el volumen e intenta identificar los daños latentes y luego desencadena automáticamente una reparación de los datos dañados.
Principales novedades • Mejora de la fiabilidad de las estructuras en disco. ReFS utiliza árboles B+ para todas las
estructuras en disco incluyendo metadatos y los datos de los archivos. El tamaño de archivo, el tamaño total de volumen, el número de archivos en un directorio y el número de directorios en un volumen están limitados a números de 64 bits, lo que se traduce en un tamaño máximo de

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
98
archivo de 16 exbibytes, un tamaño máximo de volumen de 1 yobibyte (con clústeres de 64 KiB), que permite gran escalabilidad prácticamente sin límites en el tamaño de archivos y directorios (las restricciones de hardware siguen aplicando). Los metadatos y los archivos son organizados en tablas, de manera similar a una base de datos relacional. El espacio libre se cuenta mediante un asignador jerárquico que comprende tres tablas separadas para trozos grandes, medianos y pequeños. Los nombres de archivo y las rutas de acceso de archivo están limitados a una cadena de texto Unicode de 32 KiB.
• Capacidad de resiliencia incorporada. ReFS emplea estrategia de actualización de metadatos de asignación en escritura, que asigna los nuevos bloques para transacción de actualización y utiliza lotes grandes de entrada y salida (IO). Todos los metadatos de ReFS tienen sumas de verificación de 64 bits incorporadas, que son almacendas de forma independiente. Los datos de los archivos opcionalmente pueden tener una suma de verificación en una «corriente de integridad» separada, en cuyo caso la estrategia de actualización de archivo también implementa asignación en escritura; esto es controlado por un nuevo atributo «integridad» aplicable a archivos y directorios. Si los datos de archivo o los metadatos resultaran dañados, el archivo puede ser eliminado sin tener que desmontar el volumen por mantenimiento, y así restaurarlos desde una copia de seguridad. Con la resiliencia incorporada, los administradores no necesitan ejecutar periódicamente herramientas de comprobación de errores en el sistema de archivos (como CHKDSK) en los volúmenes con sistemas de archivos ReFS.
• Compatibilidad con las APIs y tecnologías existentes. ReFS no requiere de nuevas APIs de sistema y la mayoría de los filtros de sistema de archivos continuarán trabajando con volúmenes ReFS. ReFS soporta muchas características existentes de Windows y NTFS, como el cifrado BitLocker, Listas de Control de Acceso, diario USN, notificaciones de cambio, enlaces simbólicos, puntos de unión, puntos de montaje, puntos de reanálisis, instantáneas de volumen, IDs de archivo y oplock. ReFS se integra adecuadamente con los «espacios de almacenamiento», una capa de virtualización de almacenamiento que permite la realización de espejos de datos (mirroring), así como compartir las agrupaciones de almacenamiento entre máquinas. Las características de resiliencia de ReFS mejora la función de duplicación (mirroring) provista por los espacios de almacenamiento, y puede detectar si las copias espejo de los archivos llegan a corromperse usando un proceso de depuración de datos en segundo plano, que periódicamente lee todas las copias espejos y verifica sus sumas de verificación, luego remplaza las copias dañadas por copias en buen estado de los archivos implicados.
Limitaciones de ReFS frente a NTFS Algunas características de NTFS no son compatibles por ReFS, como los flujos de datos alternativos, identificadores de objetos, nombres cortos «8.3», compresión de archivos, cifrado a nivel de archivos, transacciones de datos de usuario, archivos dispersos, enlaces duros, atributos extendidos y cuotas de disco. ReFS no ofrece por sí mismo deduplicación de datos. Son remplazados los discos dinámicos con volúmenes espejos o en bandas, con agrupaciones de almacenamiento con bandas o espejos, provistas por espacios de almacenamiento. Sin embargo, en Windows Server 2012 solo es soportada la corrección automatizada de errores en los espacios reflejados, y tampoco es soportado el arranque desde un volumen con formato ReFS. 7.4.2. Sistemas de archivos UNIX
7.4.2.1. MINIX Minix fue el primer sistema de archivos de Linux. Se origino con el sistema operativo Minix de ahí su nombre. Fue escrito desde 0 por Andrew S. Tanenbaum en la década de los 80s, como un sistema operativo tipo UNIX, donde su código fuente puede ser usado libremente para la educación. El sistema de archivos MINIX fue diseñado para usarse en MINIX; copia la estructura básica del Sistema de archivos UNIX (UFS), pero evita características complejas para mantener el código fuente limpio, claro y simple, donde su objetivo total es ser de Minix una ayuda útil de enseñanza. Cuando Linus Torvalds comenzó a escribir el núcleo Linux en 1991, él trabajaba en una máquina corriendo MINIX, así el lanzamiento inicial estuvo basado en las funcionalides de éste último sistema operativo. Hasta que en abril de 1992 se realiza la introducción del Extended file system (sistema de

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
99
archivos extendido, conocido como ext). Este sistema de ficheros es aún usado por algunas distribuciones GNU/Linux para arrancar discos y en otras situaciones, donde se necesite un sistema de archivos simple y compacto. Un sistema de archivos MINIX tiene seis componentes: • El Bloque de arranque, el cual es el que se almacena en el primer bloque de un disco duro. Contiene
el cargador de Arranque, que carga y corre un sistema operativo dentro del sistema conocido como sistema de inicio.
• El segundo bloque es el Superblock, el cual almacena datos relacionados al sistema de archivos, que permite al sistema operativo localizar y entender otras arquitecturas de sistemas de archivos. Por ejemplo, el número de inodos y zonas, el tamaño de los dos bitmaps y el bloque de inicio de una área de datos.
• El inode bitmap, es el mapa simple de uno de los inodos que rastrea cuales están en uso y cuales están libres, representadolos con un 1 (para los en uso) y con un 0 (para los libres).
• El zone bitmap, trabaja de similar forma al inode bitmap, excepto que rastrea las zonas. • El área de inodos. Cada archivo o directorio es representado como un inodo, el cual graba
metadatos incluyendo los tipos (archivo, directorio, bloque, carácter, pipe), identidad (is) para el usuario y el grupo, tres registros de fecha y el tiempo de último acceso, la última modificación y el último cambio de estado. Un inodo también contiene una lista de las direcciones que indican las zonas en el àrea de datos donde el archivo o los datos de directorio están actualmente almacenados.
• El data area (área de datos), es el componente más largo de un sistema de archivos, que usa la mayor parte del espacio. Es donde los archivos y directorios de datos están almacenados.
7.4.2.2. Extended file system El sistema de archivos extendido más comúnmente conocido como ext o EXTFS. El sistema de archivos extendido (extended file system o ext), fue el primer sistema de archivos creado específicamente para el sistema operativo Linux. Fue diseñado para vencer las limitaciones del sistema de archivos MINIX. Fue reemplazado tanto por ext2 como xiafs, entre los cuales había una competencia, que finalmente ganó ext2, debido a su viabilidad a largo plazo.
ext
Nombre completo Extended file system
Introducción Abril de 1992 (Linux)
Estructuras
Localización de archivo bitmap (espacio libre), table (metadatos)
Bloques malos Tabla
7.4.2. 3. ext2 (second extended filesystem)
ext2 "segundo sistema de archivos extendido" es un sistema de archivos para el kernel Linux.. La principal desventaja de ext2 es que no implementa el registro por diario (en inglés Journaling) que sí

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
100
poseen sus posteriores versiones ext3 y ext4. ext2 fue el sistema de ficheros por defecto de las distribuciones de Linux Red Hat, Fedora y Debian.
El sistema de archivos tiene una tabla donde se almacenan los i-nodos. Un i-nodo almacena información del archivo (ruta o path, tamaño, ubicación física). En cuanto a la ubicación, es una referencia a un sector del disco donde están todas y cada una de las referencias a los bloques del archivo fragmentado. Estos bloques son de tamaño especificable cuando se crea el sistema de archivos, desde los 512 bytes hasta los 4 KiB, lo cual asegura un buen aprovechamiento del espacio libre con archivos pequeños. Los límites son un máximo de 2 terabytes de archivo, y de 4 para la partición.
ext2
Nombre completo Second extended file system
Sistemas operativos
compatibles Linux, BSD, Windows (mediante IFS), Mac OS X
Introducción Enero de 1993 (Linux)
Estructuras
Localización de archivo I-nodos
Límites
Máxima dimensión de archivo 2 TB
Máximo número de archivos 1018
Tamaño máximo del nombre de
archivo 255 caracteres
Tamaño máximo del volumen 16 TB
Caracteres permitidos en
nombres de archivo Cualquiera excepto NULL y '/'

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
101
7.4.2.4. ext3 (third extended filesystem) ext3 "tercer sistema de archivos extendido" es un sistema de archivos con registro por diario (journaling). Es el sistema de archivo más usado en distribuciones Linux. Es una extensión del sistema de ficheros ext2. Este sistema de archivos está incluido en los kernels 2.4.x.
La principal diferencia con ext2 es el registro por diario. Un sistema de archivos ext3 puede ser montado y usado como un sistema de archivos ext2. Otra diferencia importante es que ext3 utiliza un árbol binario balanceado (árbol AVL) e incorpora el asignador de bloques de disco Orlov.
Ventajas
Aunque su velocidad y escalabilidad es menor que sus competidores, como JFS, ReiserFS o XFS, tiene la ventaja de permitir actualizar de ext2 a ext3 sin perder los datos almacenados ni tener que formatear el disco. Tiene un menor consumo de CPU y está considerado más seguro que otros sistemas de ficheros en Linux dada su relativa sencillez y su mayor tiempo de prueba.
El sistema de archivo ext3 agrega a ext2 lo siguiente:
• Registro por diario. • Índices en árbol para directorios que ocupan múltiples bloques. • Crecimiento en línea.
Límites de tamaño
Ext3 tiene dos límites de tamaño distintos. Uno para archivos y otro para el tamaño del sistema de archivos entero. El límite del tamaño del sistema de archivos es de 232 bloques
Tamaño del bloque Tamaño máximo de los archivos Tamaño máximo del sistema de ficheros
1 KiB 16 GiB 2 TiB
2 KiB 256 GiB 8 TiB
4 KiB 2 TiB 16 TiB
8 KiB 2 TiB 32 TiB
Niveles del Journaling Hay tres niveles posibles de Journaling (registro por diario) Diario (riesgo bajo)
Los metadatos y los ficheros de contenido son copiados al diario antes de ser llevados al sistema de archivos principal. Como el diario está en el disco continuamente puede mejorar el rendimiento en ciertas ocasiones. En otras ocasiones el rendimiento es peor porque los datos deben ser escritos dos veces, una al diario y otra a la parte principal del sistema de archivos.
Pedido (riesgo medio) Solo los metadatos son registrados en el diario, los contenidos no, pero está asegurado que el contenido del archivo es escrito en el disco antes de que el metadato asociado se marque como

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
102
transcrito en el diario. Es el sistema por defecto en la mayoría de las distribuciones de Linux. Si hay un bajón de tensión o kernel Panic cuando el fichero se está escribiendo o está empezando, el diario indicará que el nuevo archivo o el intento no ha sido pasado, por lo que será purgado por el proceso de limpiado
Reescritura (riesgo alto) Solo los metadatos son registrados en el diario, el contenido de los archivos no. Los contenidos pueden estar escritos antes o después de que el diario se actualice. Como resultado, los archivos modificados correctamente antes de una ruptura pueden volverse corruptos. Por ejemplo, un archivo pendiente de ser marcado en el diario como mayor de lo que actualmente es, convirtiendo en basura al final de la comprobación. Las versiones antiguas de los archivos pueden aparecer inesperadamente después de una recuperación de diario. La carencia de sincronización entre los datos y el diario es rápidamente subsanada en muchos casos. JFS usa este nivel de journaling, pero se asegura de que cualquier basura es borrada al reiniciar
Desventajas Funcionalidad Como ext3 está hecho para ser compatible con ext2, la mayoría de las estructuras del archivación son similares a las del ext2. Por ello, ext3 carece de muchas características de los diseños más recientes como las extensiones, la localización dinámica de los inodos, y la sublocalización de los bloques. Hay un límite de 31998 subdirectorios por cada directorio, que se derivan de su límite de 32000 links por inodo. Ext3, como la mayoría de los sistemas de archivos actuales de Linux, no puede ser chequeado por el fsck mientras el sistema de archivos está montado para la escritura. Si se intenta chequear un sistema de ficheros que está montado puede detectar falsos errores donde los datos no han sido volcados al disco todavía, y corromper el sistema de archivos al intentar arreglar esos errores. Fragmentación No hay herramienta de desfragmentación online para ext3 que funcione en nivel del sistema de archivos. Existe un desfragmentador offline para ext2, e2defrag, pero requiere que el sistema de archivos ext3 sea reconvertido a ext2 antes de iniciarse. Además, dependiendo de los bits encendidos en el sistema, e2defrag puede destruir datos. Compresión El soporte para la compresión está disponible como un parche no oficial para ext3. Este parche es un aporte directo de e2compr pero necesita un mayor desarrollo ya que todavía no implementa el journaling. No hay comprobación en el diario Ext3 no hace la suma de verificación cuando está escribiendo en el diario.
ext3
Nombre completo Third extended file system
Sistemas operativos
compatibles Linux, BSD, Windows (a través de IFS)

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
103
Introducción Noviembre de 2001 (Linux 2.4.15)
Estructuras
Contenido del directorio Tabla, Árbol
Localización de archivo bitmap (espacio libre), tabla (metadatos)
Bloques malos Tabla
Límites
Máxima dimensión de
archivo 2 TB
Máximo número de archivos 1018
Tamaño máximo del nombre
de archivo 255 caracteres
Tamaño máximo del
volumen 32 TB
7.4.2.5. ext4 (fourth extended filesystem)
ext4 “cuarto sistema de archivos extendido” es un sistema de archivos transaccional (en inglés journaling). El 25 de diciembre de 2008 se publicó el kernel Linux 2.6.28, que elimina ya la etiqueta de "experimental" de código de ext4.
Las principales mejoras son: • Soporte de volúmenes de hasta 1024 PiB. • Soporte añadido de extent. • Menor uso del CPU. • Mejoras en la velocidad de lectura y escritura.
Mejoras Sistema de archivos de gran tamaño El sistema de archivos ext4 es capaz de trabajar con volúmenes de gran tamaño, hasta 1 exbibyte y archivos de tamaño de hasta 16 TiB. Extents

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
104
Los extents han sido introducidos para reemplazar al tradicional esquema de bloques usado por los sistemas de archivos ext2/3. Un extent es un conjunto de bloques físicos contiguos, mejorando el rendimiento al trabajar con ficheros de gran tamaño y reduciendo la fragmentación. Un extent simple en ext4 es capaz de mapear hasta 128 MiB de espacio contiguo con un tamaño de bloque igual a 4 KiB. Compatibilidad hacia adelante y hacia atrás Cualquier sistema ext3 existente puede ser montado como ext4 sin necesidad de cambios en el formato del disco. También es posible actualizar un sistema de archivos ext3 para conseguir las ventajas del ext4 ejecutando un par de comandos. Esto significa que se puede mejorar el rendimiento, los límites de almacenamiento y las características de sistemas de archivos ext3 sin reformatear y/o reinstalar el sistema operativo. Si se requiere de las ventajas de ext4 en un sistema de producción, se puede actualizar el sistema de archivos. Asignación persistente de espacio en el disco El sistema de archivos ext4 permite la reserva de espacio en disco para un archivo. Hasta ahora la metodología consistía en rellenar el fichero en el disco con ceros en el momento de su creación. Esta técnica no es ya necesaria con ext4, ya que una nueva llamada del sistema "preallocate()" ha sido añadida al kernel Linux para uso de los sistemas de archivos que permitan esta función. El espacio reservado para estos ficheros quedará garantizado y con mucha probabilidad será contiguo. Esta función tiene útiles aplicaciones en streaming y bases de datos. Asignación retrasada de espacio en el disco Ext4 hace uso de una técnica de mejora de rendimiento llamada Allocate-on-flush, también conocida como reserva de memoria retrasada. Consiste en retrasar la reserva de bloques de memoria hasta que la información esté a punto de ser escrita en el disco, a diferencia de otros sistemas de archivos, los cuales reservan los bloques necesarios antes de ese paso. Esto mejora el rendimiento y reduce la fragmentación al mejorar las decisiones de reserva de memoria basada en el tamaño real del fichero. Límite de 32000 subdirectorios superado En ext3 el nivel de profundidad en subdirectorios permitido estaba limitado a 32000. Este límite ha sido aumentado a 64000 en ext4. Journal checksumming ext4 usa checksums en el registro para mejorar la fiabilidad, puesto que el journal es uno de los ficheros más utilizados en el disco. Esta función tiene un efecto colateral beneficioso: permite de forma segura evitar una lectura/escritura de disco durante el proceso de registro en el journal, mejorando el rendimiento ligeramente. La técnica del journal checksumming está inspirada en la investigación de la Universidad de Wisconsin en sistemas de archivos IRON (Sección 6, bajo el nombre "checksums de transacciones"). Desfragmentación online Incluso haciendo uso de diversas técnicas para evitar la fragmentación, un sistema de larga duración tiende a fragmentarse con el tiempo. Ext4 dispondrá de una herramienta que permite desfragmentar ficheros individuales o sistemas de ficheros enteros sin desmontar el disco. En ext4, los grupos de bloques no asignados y secciones de la tabla de inodos están marcados como tales. Esto permite a e2fsck saltárselos completamente en los chequeos y en gran medida reduce el tiempo requerido para chequear un sistema de archivos del tamaño para el que ext4 está preparado. Esta función está implementada desde la versión 2.6.24 del kernel Linux. Asignador multibloque Ext4 asigna múltiples bloques para un fichero en una sola operación, lo cual reduce la fragmentación al intentar elegir bloques contiguos en el disco. El asignador multibloque está activo cuando se usa 0_DIRECT o si la asignación retrasada está activa. Esto permite al fichero tener diversos bloques "sucios" solicitados para escritura al mismo tiempo, a diferencia del actual mecanismo del kernel de solicitud de envío de cada bloque al sistema de archivos de manera separada para su asignación.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
105
Timestamps mejorados Puesto que los ordenadores se tornan en general cada vez más rápidos y que Linux está pasando a ser cada vez más usado en aplicaciones críticas, la granularidad de los timestamps basados en segundos se está volviendo insuficiente. Para resolver esto, ext4 tendrá timestamps medidos en nanosegundos. Ésta función está actualmente implementada en la versión 2.6.23 del kernel. Adicionalmente se han añadido 2 bits del timestamp extendido a los bits más significativos del campo de segundos de los timestamps para retrasar casi 500 años el problema del año 2038.
ext4
Nombre completo Fourth extended file system
Sistemas operativos
compatibles Linux
Introducción 10 de octubre de 2006 (Linux 2.6.19)
Estructuras
Contenido del directorio Tabla, Árbol
Localización de archivo bitmap (espacio libre), table (metadatos)
Bloques malos Tabla
Límites
Máxima dimensión de
archivo 16 TiB (usando bloques de 4k )
Máximo número de archivos 4 mil millones (4x10⁹) (especificado en el tiempo de
creación del sistema de archivos)
Tamaño máximo del nombre
de archivo 256 bytes
Tamaño máximo del volumen 1024 PiB = 1 EiB
Caracteres permitidos en
nombres de archivo Todos los bytes excepto NULL y '/'

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
106
7.4.3. Otros sistemas de archivos • ReiserFS: Este sistema de ficheros es un diseño completamente nuevo, que fue introducido en el
kernel de Linux 2.4.1. Se ha ganado una reputación de estabilidad y uso eficiente de espacio en disco, sobre todo cuando una partición tiene muchos archivos pequeños.
• XFS: Es de Silicon Graphics (SGI) del sistema de archivos de diario. Ha sido utilizado en la SGI de las estaciones de trabajo Unix y servidores, lo liberaron bajo la licencia GPL. Este sistema de ficheros es compatible con los tamaños máximos de hasta 16.384 peta bytes (1Pb es 1024Tb), y máximo de archivo de hasta 8192Pb. XFS no está integrado en el kernel de Linux, desde la versión 2.4.18.
• JFS: Se desarrollo originalmente para el sistema operativo AIX, sin embargo, IBM ha lanzado su sistema de archivos avanzado bajo la GPL y está apoyando activamente la migración a Linux. Soporta sistema de archivos de un tamaño máximo de 32Pb. Aun no se ha incluido en el kernel estándar, a partir de la versión 2.4.18.
• Apple - MFS: Fue utilizado por los 1ros. Macintosh. Este se utiliza en disquetes de 400Kb que son extremadamente raros en la actualidad. Linux no incluye compatibilidad con MFS.
• HFS: El sistema de archivos jerárquico (HFS) fue el reemplazo del MFS. Utilizado en más de 800Kb y los disquetes y discos duros de Macintosh hasta 1998; es muy común en el mundo Macintosh. Macintosh CD-ROM suelen utilizar HFS en lugar de la norma ISO-9660.
• HFS+: El seguimiento a HFS toma muchas características del estilo de sistemas de archivos Unix, pero no llega a la adición de un diario. Los nuevos Macintosh siempre vienen con discos con formato HFS+, pero este sistema de ficheros no se utiliza mucho en medios extraíbles. El soporte de Linux para HFS+ de encuentra en la fase alfa y todavía no se ha integrado en el kernel.
• FFS: MacOSX ofrece la opción de utilizar el sistema de archivos de Unix rápido (FFS). • BeFS: Utiliza un sistema de archivos de diario propio, conocido como BeFS. Este es un sistema
operativo mono usuarios, apoya archivo de propiedad y los permisos similares a los utilizados en Linux. Carece de soporte para acceso a archivos de marcas de tiempo, lo que puede dificultar su capacidad como sistema de archivos naticos de Linux.
• FFS/UFS: Sistema de ficheros rápido (FFS) o también conocido como sistema de archivos Unix (UFS) se desarrollo temprano en la historia de Unix. Es utilizado por muchos sistemas Unix y derivados, incluyendo FreeBSD y Solaris. El soporte de Linux de escritura para este sistema de archivos todavía se considera peligroso.
• NFS: Es el método preferido para el intercambio de archivos para redes de ordenadores Unix o Linux.
• Coda: Se trata de un sistema de archivos de red avanzada que soporta las características omitidas de NFS. Estas características incluyen una mayor seguridad (incluido el cifrado) y el almacenamiento en cache mejorada.
• SMB/CIFS El Server Message Block (SMB), es el medio habitual de intercambio de archivos en red entre los sistemas operativos de Microsoft. El kernel de Linux incluye SMB/CIFS cliente, para que pueda montar SMB/CIFS acciones.
• NCP El NetWare Core Protocol (NCP) es un protocolo de intercambio de archivos NetWare. Al igual que con SMB/CIFS, Linux incluye soporte básico de cliente NCP en el núcleo, y se puede añadir paquetes de servidor distintos para convertir Linux en un servidor NCP.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
82
Tema VIII
Sistemas de Entrada/Salida
Las aplicaciones utilizan los dispositivos (devices) para realizar la E/S (entrada-salida). Estos dispositivos son
variados y trabajan de manera diferente: secuencialmente, random; transfieren datos asincrónicamente o
sincrónicamente; pueden ser de sólo lectura ( read only) o lectura-escritura ( read-write), etc. El sistema operativo
debe permitir que las aplicaciones puedan utilizar esos dispositivos, proveyendo una interfaz que los presente de la
manera mas simple posible. Los dispositivos son una de las partes mas lentas de un sistema de computo. Por lo
tanto, el SO, debe manejar la situación como para salvar esa diferencia de velocidad.
Una de las funciones principales de un S. O. es el control de todos los dispositivos de E /S de la computadora
[Tanenbaum].
Las principales funciones relacionadas son:
• Enviar comandos a los dispositivos.
• Detectar las interrupciones.
• Controlar los errores.
• Proporcionar una interfaz entre los dispositivos y el resto del sistema.
8.1. Principios del Hardware de E / S
El enfoque que se considerará tiene que ver con la interfaz que desde el hardware se presenta al software:
[Tanenbaum]
• Comandos que acepta el hardware.
• Funciones que realiza.
• Errores que puede informar.
8.1.1. Dispositivos de E/S
Los dispositivos de E/S se pueden clasificar en dispositivos de almacenamiento, dispositivos de comunicación y
dispositivos de interfaz con humanos. Ortogonalmente, se pueden clasificar como dispositivos de bloques o de
caracteres.
• Dispositivos por bloques. Almacena información en bloques de tamaño fijo, cada uno con su propia dirección.
Los tamaños de bloque comunes van desde 512 bytes hasta 32768 bytes. La propiedad esencial de un
dispositivo por bloques es que es posible leer o escribir cada bloque con independencia de los demás. Los
discos son los dispositivos por bloques más comunes.
• Dispositivos por caracteres. Suministra o acepta una corriente de caracteres, sin contemplar ninguna estructura
de bloques; no es direccionable y no tiene una operación de búsqueda. Las impresoras, interfaces de red, ratones
y casi todos los demás dispositivos que no se parecen a los discos pueden considerarse como dispositivos por
caracteres.
Algunos dispositivos no se ajustan a este esquema de clasificación, por ejemplo los relojes, que no tienen
direcciones por medio de bloques y no generan o aceptan flujos de caracteres. El sistema de archivos solo trabaja
con dispositivos de bloque abstractos, por lo que encarga la parte dependiente del dispositivo a un software de
menor nivel, el software manejador del dispositivo.
8.1.2. Controladores de dispositivos
Las unidades de E/S consisten típicamente de una parte mecánica y una parte electrónica, conocida como
controlador de dispositivo. El sistema operativo sólo se comunica con el controlador. La parte del sistema operativo
encargada de ello es el manejador o driver del dispositivo. La interfaz entre el controlador y la parte mecánica es de
muy bajo nivel.
La tarjeta controladora casi siempre tiene un conector en el que puede insertarse un cable que conduce al dispositivo.
Muchos controladores pueden manejar dos, cuatro o incluso ocho dispositivos idénticos. Si la interfaz entre el
controlador y el dispositivo es de un tipo estándar, ya sea una norma oficial como ANSI, IEEE o ISO, o una norma
de facto, las compañías pueden fabricar controladores y dispositivos que se ajustan a esa interfaz. Por ejemplo,
muchas compañías producen unidades de disco que se ajustan a las interfaces de controlador de disco IDE
(Integrated Drive Electronics) o SCSI (Small Computer System Interface).
Los modelos más frecuentes de comunicación entre la cpu y los controladores son para la mayoría de las micro y
mini computadoras el modelo de bus del sistema y para la mayoría de los mainframes el modelo de varios buses y
computadoras especializadas en E/S llamadas canales de E/S.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
83
La interfaz entre el controlador y el dispositivo suele ser de nivel muy bajo. Un disco, por ejemplo, podría
formatearse con 16 sectores de 512 bytes en cada pista. Sin embargo, lo que realmente sale de la unidad es un flujo
de bits en serie que comienza con un preámbulo seguido de los 4096 bits del sector y por último una suma de
verificación, llamada también código para corrección de errores (ECC: error-correcting code). El preámbulo se
escribe cuando se da formato al disco y contiene el número de cilindro y de sector, el tamaño de sector y datos
similares, así como información de sincronización.
La función del controlador consiste en convertir un flujo de bits a un bloque de bytes y realizar las acciones de
corrección de errores necesarias. Generalmente, primero se arma el bloque de bytes, bit por bit, en un buffer dentro
del controlador. Una vez que se ha cotejado su suma de verificación y se le declara libre de errores, el bloque puede
copiarse en la memoria principal.
Cada controlador tiene unos cuantos registros que sirven para comunicarse con la CPU. En algunas computadoras
estos registros forman parte del espacio de direcciones de la memoria normal. Este esquema se denomina E/S
mapeada en memoria.
Además de los puertos de E/S, muchos controladores usan interrupciones para indicarle a la CPU cuándo están listos
para que sus registros sean leídos o escritos. Una interrupción es, en primera instancia, un suceso eléctrico. Una
línea de petición de interrupción (IRQ) de hardware es una entrada física del chip controlador de interrupciones. El
número de tales entradas es limitado; las PC de tipo Pentium sólo tienen 15 entradas disponibles para dispositivos de
E/S. Algunos controladores están alambrados físicamente en la tarjeta madre del sistema, como, por ejemplo, el
controlador del teclado en una PC. En el caso de un controlador que se enchufa en el plano posterior, a veces pueden
usarse interruptores o puentes de alambre en el controlador de dispositivo para seleccionar la IRQ que usará el
dispositivo, a fin de evitar conflictos (aunque en algunas tarjetas, como Plug „n Play, las IRQ pueden establecerse en
software). El chip controlador de interrupciones establece una correspondencia entre cada entrada IRQ y un vector
de interrupción, que localiza la rutina de servicio de interrupción correspondiente.
8.1.3. Acceso directo a memoria (DMA)
Muchos controladores, sobre todo los de dispositivos por bloques, manejan el acceso directo a memoria o DMA.
Analicemos cómo ocurren las lecturas de disco cuando no se usa DMA. Primero el controlador lee el bloque (uno o
más sectores) de la unidad en serie, bit por bit, hasta que todo el bloque está en el buffer interno del controlador. A
continuación, el controlador calcula la suma de verificación para comprobar que no ocurrieron errores de lectura, y
luego causa una interrupción. Cuando el sistema operativo comienza a ejecutarse, puede leer el bloque del disco del
buffer del controlador byte por byte o palabra por palabra, ejecutando un ciclo, leyéndose en cada iteración un byte o
una palabra de un registro del controlador y almacenándose en la memoria. Un ciclo de la CPU programado para
leer los bytes del controlador uno por uno desperdicia tiempo de CPU. Se inventó el DMA para liberar a la CPU de
este trabajo de bajo nivel.
Cuando se usa DMA, la CPU proporciona al controlador dos elementos de información, además de la dirección en
disco del bloque: la dirección de memoria donde debe colocarse el bloque y el número de bytes que deben
transferirse.
Una vez que el controlador ha leído todo el bloque del dispositivo, lo ha colocado en su buffer y ha calculado la
suma de verificación, copia el primer byte o palabra en la memoria principal en la dirección especificada por la

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
84
dirección de memoria de DMA. Luego, el controlador incrementa la dirección de DMA y decrementa la cuenta de
DMA en el número de bytes que se acaban de transferir. Este proceso se repite hasta que la cuenta de DMA es cero,
y en ese momento el controlador causa una interrupción. Cuando el sistema operativo inicia, no tiene que copiar el
bloque en la memoria; ya está ahí.
El proceso con almacenamiento intermedio de dos pasos tiene implicaciones importantes para el rendimiento de E/S.
Mientras los datos están siendo transferidos del controlador a la memoria, sea por la CPU o por el controlador, el
siguiente sector estará pasando bajo la cabeza del disco y los bits estarán llega al controlador. Los controladores
sencillos simplemente no pueden efectuar entrada y salida al mismo tiempo, de modo que mientras se está
realizando una transferencia a la memoria el sector/que pasa bajo la cabeza del disco se pierde.
En consecuencia, el controlador sólo puede leer bloques de manera intercalada, es decir, uno sí y uno no, de modo
que la lectura de toda una pista requiere dos rotaciones completas, una para los bloques pares y otra para los
impares. Si el tiempo que toma transferir un bloque del controlador a la memoria por el bus es más largo que el que
toma leer un bloque del disco, puede ser necesario leer un bloque y luego saltarse dos (o más) bloques. Saltarse
bloques para dar al controlador tiempo de transferir los datos a la memoria se denomina intercalación. Cuando se da
formato al disco, los bloques se numeran teniendo en cuenta el factor de intercalación. En la figura (a) hay un disco
con ocho bloques por pista y cero intercalación. En (b) el mismo disco con intercalación sencilla. En (c) la
intercalación doble.
El objetivo de numerar los bloques de este modo es permitir que el sistema operativo lea N bloques numerados
consecutivamente y aun así logre la máxima velocidad de que el hardware es capaz. Si los bloques se numeraran
como en (a) pero el controlador sólo pudiera leer bloques alternados, un sistema operativo que se encargara de
distribuir un archivo de ocho bloques en bloques de disco consecutivos requeriría ocho rotaciones de disco para leer
los bloques 0 al 7 en orden.
8.2. Principios del software de E/S
La idea básica es organizar el software como una serie de capas donde [Tanenbaum]:
• Las capas inferiores se encarguen de ocultar las peculiaridades del hardware a las capas superiores.
• Las capas superiores deben presentar una interfaz agradable, limpia y regular a los usuarios.
8.2.1. Objetivos del software de E/S
Un concepto clave del diseño de software de E/S se conoce como independencia del dispositivo, es decir, debe ser
posible escribir programas que puedan leer archivos de un disquete, un disco duro o un CD-ROM sin tener que
modificar los programas para cada tipo de dispositivo distinto. Es responsabilidad del sistema operativo resolver los
problemas causados por el hecho de que estos dispositivos en realidad son distintos y requieren controladores en
software muy distintos para escribir los datos en el dispositivo de salida.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
85
El nombre de un archivo o un dispositivo debe ser simplemente una cadena y un entero. El objetivo de lograr
nombres uniformes está muy relacionado con el de independencia del dispositivo. Todos los archivos y dispositivos
adquieren direcciones de la misma forma, es decir mediante el nombre de su ruta de acceso.
Otro aspecto importante del software de E/S es el manejo de errores. En general, los errores deben manejarse tan
cerca del hardware como sea posible. Si el controlador descubre un error de lectura, debe tratar de corregirlo él
mismo, si puede. Si no puede, el controlador en software debería manejarlo, tal vez tratando simplemente de leer el
bloque otra vez. Muchos errores son transitorios, como los errores de lectura causados por partículas de polvo en la
cabeza de lectura, y desaparecen si la operación se repite.
Sólo si las capas inferiores son incapaces de resolver el problema se deberá informar de él a las capas superiores. En
muchos casos, la recuperación de errores puede efectuarse de manera transparente en un nivel bajo sin que los
niveles superiores se enteren siquiera de que ocurrió un error.
Otro aspecto clave es si las transferencias son síncronas (por bloqueo) o asíncronas (controladas por interrupciones).
En general, la E/S física es asíncrona: la CPU inicia la transferencia y se dedica a otra cosa hasta que llega la
interrupción. Los programas de usuario son mucho más fáciles de escribir si las operaciones de E/S provocan
bloqueos. Le corresponde al sistema operativo hacer que las operaciones que en realidad son controladas por
interrupciones parezcan controladas por bloqueo a los programas de usuario.
El último concepto es el de dispositivos de uso exclusivo y no exclusivo. Algunos dispositivos de E/S, como los
discos, pueden ser utilizados por muchos usuarios al mismo tiempo. No hay problemas si varios usuarios tienen
archivos abiertos en el mismo disco al mismo tiempo. Otros dispositivos, como las unidades de cinta, tienen que
estar dedicados a un solo usuario hasta que éste haya terminado. Luego, otro usuario puede disponer de la unidad de
cinta. Si dos o más usuarios escriben bloques entremezclados al azar en la misma cinta, se generará el caos. La
introducción de dispositivos de uso exclusivo (no compartidos) da lugar a diversos problemas. Una vez más, el
sistema operativo debe poder manejar dispositivos tanto compartidos como de uso exclusivo de manera tal que se
eviten problemas.
Estos objetivos se pueden lograr de una forma lógica y eficiente estructurando el software de E/S en cuatro capas,
como se ve en el grafico anterior:
1. Manejadores de interrupciones (capa inferior)
2. Controladores de dispositivos en software.
3. Software del sistema operativo independiente del software.
4. Software de usuario (capa superior).
En la figura se resume el sistema de E/S, con todas las capas y las funciones principales de cada capa. Comenzando
por abajo, las capas son el hardware, los manejadores de interrupciones, los controladores de dispositivos, el
software independiente del dispositivo y por último los procesos de usuario. Las flechas indican el flujo de control.
Por ejemplo, cuando un proceso de usuario trata de leer un bloque de un archivo, se invoca el sistema operativo para
que ejecute la llamada. El software independiente del dispositivo busca, por ejemplo, en el caché de bloques. Si el
bloque que se necesita no está ahí, ese software invoca el controlador de dispositivo para que emita la petición al
hardware. A continuación el proceso se bloquea hasta que se lleva a cabo la operación de disco. Cuando el disco
termina, el hardware genera una interrupción. Se ejecuta el manejador de interrupciones para descubrir qué ha
sucedido, es decir, cuál dispositivo debe atenderse en este momento. El manejador extrae entonces el estado del
dispositivo y despierta al proceso dormido para que finalice la petición de E/S y permita al proceso de usuario
continuar.
8.2.2. Manejadores de interrupciones
Las interrupciones son desagradables pero inevitables, y deben ocultarse en las profundidades del sistema operativo,
con el fin de reducir al mínimo las partes del sistema que tienen conocimiento de ellas:
• Cada proceso que inicie una operación de E/S se bloquea hasta que termina la E/S y ocurra la interrupción.
• El procedimiento de interrupción realiza lo necesario para desbloquear el proceso que lo inicio.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
86
8.2.3. Controladores de dispositivos
Todo el código dependiente del dispositivo se coloca en los controladores de dispositivo. Cada controlador maneja
un tipo de dispositivo o, cuando más, una clase de dispositivos similares. Cada controlador tiene uno o más registros
de dispositivo que sirven para aceptar comandos. Los controladores en software emiten estos comandos y verifican
que se ejecuten correctamente. Así, el controlador de disco en software es la única parte del sistema operativo que
sabe cuántos registros tiene ese controlador de disco en hardware y para qué sirven. Sólo él sabe algo de sectores,
pistas, cilindros, cabezas, movimiento del brazo, factores de intercalación, motores, tiempos de asentamiento de la
cabeza y todos los demás aspectos mecánicos del funcionamiento correcto del disco.
La tarea de un controlador de dispositivo en software es aceptar peticiones abstractas del software independiente del
dispositivo que está arriba de él y ver que dichas peticiones sean atendidas.
El primer paso para atender realmente una petición de E/S, digamos para un disco, es traducirla de términos
abstractos a concretos. En el caso de un controlador de disco, esto implica calcular en qué parte del disco está
realmente el bloque solicitado, verificar si el motor de la unidad está funcionando, determinar si el brazo está
colocado en el cilindro apropiado, etc. En pocas palabras, el controlador en software debe decidir qué operaciones
del controlador son necesarias en el hardware y en qué orden. Una vez que el controlador en software ha decidido
qué comandos debe emitir al controlador en hardware, comenzará a emitirlos escribiendo en los registros de
dispositivo de este último. Algunos controladores en hardware sólo pueden manejar un comando a la vez; otros
están dispuestos a aceptar una lista enlazada de comandos, que luego ejecutan por su cuenta sin más ayuda del
sistema operativo.
Una vez que se ha emitido el comando o comandos, se presentará una de dos situaciones. En muchos casos el
controlador en software debe esperar hasta que el controlador en hardware realice cierto trabajo, así que se bloquea
hasta que llega la interrupción para desbloquearlo. En otros casos, sin embargo, la operación se lleva a cabo sin
dilación, y el controlador no necesita bloquearse. En el primer caso, el controlador bloqueado será despertado por la
interrupción; en el segundo, nunca se dormirá. De cualquier manera, una vez que se ha efectuado la operación el
controlador debe determinar si no ocurrieron errores. Si todo está bien, el controlador puede tener datos que pasar al
software independiente del dispositivo (el bloque que acaba de leerse). Por último, el controlador devuelve
información de estado para informar de errores a su invocador. Si hay otras peticiones en cola, puede seleccionarse e
inicia una de ellas. Si no hay nada en la cola, el controlador se bloquea esperando la siguiente petición.
8.2.4. Software de E/S independiente del dispositivo
Aunque una parte del software de E/S es específica para cada dispositivo, una fracción considerable es
independiente de él. La frontera exacta entre los controladores de dispositivos y el software independiente del
dispositivo depende del sistema, porque algunas funciones que podrían realizarse de forma independiente del
dispositivo podrían efectuarse realmente en los controladores en software, por razones de eficiencia o de otro tipo.
Las funciones generalmente realizadas por el software independiente del dispositivo son:
• Interfaz uniforme para los manejadores de dispositivos.
• Nombres de los dispositivos.
• Protección del dispositivo.
• Proporcionar un tamaño de bloque independiente del dispositivo.
• Uso de buffers.
• Asignación de espacio en los dispositivos por bloques.
• Asignación y liberación de los dispositivos de uso exclusivo.
• Informe de errores.
La función básica del software independiente del dispositivo es realizar las funciones de E/S comunes a todos los
dispositivos y presentar una interfaz uniforme al software de nivel de usuario.
Un aspecto importante de cualquier sistema operativo es cómo se nombran los objetos tales como archivos y
dispositivos de E/S. El software independiente del dispositivo se encarga de establecer la correspondencia entre los
nombres simbólicos de dispositivo y el controlador apropiado. En UNIX un nombre de dispositivo, como /dev/tty00,
especifica de manera única el nodo-i de un archivo especial, y este nodo-i contiene el número principal del
dispositivo, que sirve para localizar el controlador apropiado.
El nodo-i también contiene el número secundario del dispositivo, que se pasa como parámetro al controlador a fin de
especificar la unidad que se leerá o escribirá.
El software independiente del dispositivo debe ocultar a los niveles superiores los diferentes tamaños de sector de
los distintos discos y proporcionar un tamaño uniforme de los bloques, por ej.: considerar varios sectores físicos
como un solo bloque lógico.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
87
El almacenamiento intermedio también es una cuestión importante, tanto para los dispositivos por bloques como
para los de caracteres. En el primer caso, el hardware generalmente insiste en leer y escribir bloques completos a la
vez, pero los procesos de usuario están en libertad de leer y escribir en unidades arbitrarias. Si un proceso de usuario
escribe medio bloque, el sistema operativo normalmente guardará los datos internamente hasta que se escriba el
resto de los datos, y en ese momento se podrá grabar el bloque en el disco. En el caso de los dispositivos por
caracteres, los usuarios podrían escribir los datos al sistema con mayor velocidad que aquella a la que pueden salir,
lo que requeriría almacenamiento intermedio (buffers). De igual manera, la entrada del teclado que llega antes de
que sea necesaria también requiere buffers.
Cuando se crea un archivo y se llena con datos, es preciso asignar nuevos bloques de disco al archivo. Para poder
realizar esta asignación, el sistema operativo necesita una lista o un mapa de bits de los bloques libres del disco, pero
el algoritmo para localizar un bloque libre es independiente del dispositivo y se puede efectuar en un nivel más alto
que el del manejador.
El manejo de errores generalmente lo realizan los controladores. La mayor parte de los errores son altamente
dependientes del dispositivo, de modo que sólo el controlador sabe qué debe hacerse (p. ej., reintentar, ignorar,
situación de pánico). Un error típico es el causado por un bloque de disco que se dañó y ya no puede leerse. Después
de que el controlador ha tratado de leer el bloque cierto número de veces, se da por vencido e informa de ello al
software independiente del dispositivo. La forma como el error se trata de aquí en adelante es independiente del
dispositivo. Si el error ocurrió mientras se estaba leyendo un archivo de usuario, puede ser suficiente informar del
error al invocador. Sin embargo, si el error ocurrió durante la lectura de una estructura de datos crítica del sistema,
como el bloque que contiene el mapa de bits que indica cuáles bloques están libres, puede ser que el sistema
operativo no tenga más opción que imprimir un mensaje de error y terminar.
8.2.5. Software de E/S de espacio de usuario
Aunque la mayor parte del software de E/S está dentro del sistema operativo, una pequeña parte de él consiste en
bibliotecas enlazadas a los programas de usuario, e incluso en programas completos que se ejecutan fuera del kernel.
Si bien estos procedimientos no hacen mucho más que colocar sus parámetros en el lugar apropiado para la llamada
al sistema, hay otros procedimientos de E/S que sí realizan trabajo de verdad. En particular, el formateo de entradas
y salidas se realiza mediante procedimientos de biblioteca. Un ejemplo de C es printf, que toma una cadena de
formato y posiblemente algunas variables como entrada, construye una cadena ASCII y luego invoca WRITE para
enviar la cadena a la salida. Otro ejemplo para la entrada lo constituye scanf que lee entradas y las almacena en
variables descritas en una cadena de formato que tiene la misma sintaxis que prinlf. La biblioteca de E/S estándar
contiene varios procedimientos que implican E/S, y todos se ejecutan como parte de programas de usuario.
No todo el software de E/S de nivel de usuario consiste en procedimientos de biblioteca. Otra categoría importante
es el sistema de spool. El uso de spool es una forma de manejar los dispositivos de E/S de uso exclusivo en un
sistema multiprogramado. Consideremos un dispositivo spool típico: una impresora. Aunque desde el punto de vista
técnico sería fácil dejar que cualquier proceso de usuario abriera el archivo especial por caracteres de la impresora,
podría suceder que un proceso lo abriera y luego pasara horas sin hacer nada. Ningún otro proceso podría imprimir
nada. En vez de ello, lo que se hace es crear un proceso especial, llamado genéricamente demonio, y un directorio
especial, llamado directorio de spool. Si un proceso quiere imprimir un archivo, primero genera el archivo completo
que va a imprimir y lo coloca en el directorio de spool. Corresponde al demonio, que es el único proceso que tiene
permiso de usar el archivo especial de la impresora, escribir los archivos en el directorio. Al proteger el archivo
especial contra el uso directo por parte de los usuarios, se elimina el problema de que alguien lo mantenga abierto
durante un tiempo innecesariamente largo.
El spool no se usa sólo para impresoras; también se usa en otras situaciones. Por ejemplo, es común usar un
demonio de red para transferir archivos por una red. Si un usuario desea enviar un archivo a algún lado, lo coloca en
un directorio de spool de red. Más adelante, el demonio de red lo toma de ahí y lo transmite. Una aplicación especial
de la transmisión de archivos por spool es el sistema de correo electrónico de Internet. Esta red consiste en millones
de máquinas en todo el mundo que se comunican empleando muchas redes de computadoras. Si se desea enviar
correo a alguien, se invoca un programa como send, que acepta la carta que se desea enviar y la deposita en un
directorio de spool para ser transmitida posteriormente. Todo el sistema de correo se ejecuta fuera del sistema
operativo.
8.3 Discos
Las siguientes son las principales ventajas con respecto del uso de la memoria principal como almacenamiento
[Tanenbaum]:
• Mucha mayor capacidad de espacio de almacenamiento.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
88
• Menor precio por bit.
• La información no se pierde al apagar la computadora.
Un uso inapropiado de los discos puede generar ineficiencia, en especial en sistemas con multiprogramación.
8.3.1. Hardware de discos
Todos los discos reales están organizados en cilindros, cada uno de los cuales contiene tantas pistas como cabezas
hay apiladas verticalmente. Las pistas se dividen en sectores, de los cuales por lo regular hay entre 8 y 32 por pista
en los discos flexibles, llegando a varios cientos en algunos discos duros. Los diseños más sencillos tienen el mismo
número de sectores en todas las pistas. Todos los sectores tienen el mismo número de bytes aun cuando los sectores
cercanos al borde exterior del disco son físicamente más largos que los cercanos al centro. No obstante, el tiempo
que toma leer o escribir un sector es el mismo. La densidad de los datos obviamente es más alta en los cilindros más
interiores, y algunos diseños de disco requieren modificar la corriente de alimentación a las cabezas de lectura-
escritura para las pistas interiores. El controlador en hardware del disco se encarga de esto sin que lo vea el usuario
(o el implementador del sistema operativo). La diferencia en la densidad de los datos entre las pistas interiores y
exteriores implica un sacrificio de la capacidad, y existen sistemas más complejos. Se han probado diseños de disco
flexible que giran con mayor rapidez cuando las cabezas están sobre las pistas exteriores. Esto permite tener más
sectores en esas pistas, incrementando la capacidad del disco. Los discos duros modernos de gran capacidad también
tienen más sectores por pista en las pistas exteriores que en las interiores. Éstas son las unidades IDE (Integrated
Drive Electronics), y el complejo procesamiento que los circuitos incorporados en la unidad realizan enmascara los
detalles. Para el sistema operativo, estas unidades aparentan tener una geometría sencilla con un número constante
de sectores por pista. Los circuitos de la unidad y del controlador en hardware son tan importantes como el equipo
mecánico. El principal elemento de la tarjeta controladora que se instala en el plano posterior de la computadora es
un circuito integrado especializado, en realidad una microcomputadora pequeña. En el caso de un disco duro puede
ser que los circuitos de la tarjeta controladora sean más sencillos que para un disco flexible, pero esto es así porque
la unidad de disco duro en sí tiene un potente controlador electrónico incorporado. Una característica del dispositivo
que tiene implicaciones importantes para el controlador del disco en software es la posibilidad de que el controlador
en hardware realice búsquedas de sectores en dos o más unidades al mismo tiempo. Esto se conoce como búsquedas
traslapadas. Mientras el controlador en hardware y en software está esperando que se lleve a cabo una búsqueda en
una unidad, el controlador en hardware puede iniciar una búsqueda en otra unidad. También, muchos controladores
en hardware pueden leer o escribir en una unidad mientras buscan en otra u otras, pero un controlador de disco
flexible no puede leer o escribir en dos unidades al mismo tiempo. (La lectura o escritura requiere que el controlador
transfiera bits en una escala de tiempo de microsegundos, por lo que una transferencia ocupa casi toda su potencia
de cómputo.) La situación es diferente en el caso de los discos duros con controladores integrados en hardware, y en
un sistema provisto de más de uno de estos discos duros los controladores pueden operar simultáneamente, al menos
hasta el grado de transferir datos entre el disco y la memoria intermedia del controlador. Sin embargo, sólo es
posible una transferencia a la vez entre el controlador y la memoria del sistema. La capacidad para realizar dos o
más operaciones al mismo tiempo puede reducir considerablemente el tiempo de acceso medio.
8.3.1.1. Operación de Almacenamiento de Disco de Cabeza Móvil
Los datos se graban en una serie de discos magnéticos o platos [Deitel]. El eje común de los discos gira a una
velocidad del orden de las 7000 o más revoluciones por minuto. Se lee o escribe mediante una serie de cabezas de
lectura – escritura. Se dispone de una por cada superficie de disco y solo puede acceder a datos inmediatamente
adyacentes a ella. La parte de la superficie del disco de donde se leerá (o sobre la que se grabará) debe rotar hasta
situarse inmediatamente debajo (o arriba) de la cabeza de lectura - escritura. El tiempo de rotación desde la posición
actual hasta la adyacente al cabezal se llama tiempo de latencia. Todas las cabezas de lectura - escritura están

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
89
montadas sobre una barra o conjunto de brazo móvil. Puede moverse hacia adentro o hacia afuera, en lo que se
denomina operación de búsqueda. Para una posición dada, la serie de pistas accesibles forman un cilindro vertical.
A los tiempos de búsqueda y de latencia se debe agregar el tiempo de transmisión propiamente dicha. El tiempo total
de acceso a un registro particular involucra movimientos mecánicos y generalmente es del orden de centésimas de
segundo, aunque el tiempo de latencia sea de algunas milésimas de segundo (7 a 12 aproximadamente).
8.3.2. Software de discos
El tiempo requerido para leer o escribir un bloque de disco está determinado por tres factores:
1. El tiempo de búsqueda (el tiempo que toma mover el brazo al cilindro correcto).
2. El retraso rotacional (el tiempo que tarda el sector correcto en girar hasta quedar bajo la cabeza).
3. El tiempo real de transferencia de datos.
En casi todos los discos, el tiempo de búsqueda es mucho mayor que los otros dos, así que si reducimos el tiempo de
búsqueda mejoraremos sustancialmente el rendimiento del sistema.
Los dispositivos de disco son propensos a errores. Siempre se graba junto con los datos de cada sector de un disco
algún tipo de verificación de errores, una suma de verificación o una verificación de redundancia cíclica. Incluso las
direcciones registradas cuando se formatea un disco cuentan con datos de verificación. El controlador en hardware
de un disco flexible puede informar cuando se detecta un error, pero el software debe decidir qué se hará al respecto.
Los controladores en hardware de los discos duros con frecuencia asumen gran parte de esta carga. Sobre todo en el
caso de los discos duros, el tiempo de transferencia de sectores consecutivos dentro de la misma pista puede ser muy
rápido. Por ello, la lectura de más datos de los que se solicitan y su almacenamiento en un caché de la memoria
puede ser una estrategia muy eficaz para acelerar el acceso a disco.
8.3.2.1. Planificación de Discos
En los sistemas de multiprogramación muchos procesos pueden estar generando peticiones de E/S sobre discos
[Deitel]. La generación de peticiones puede ser mucho más rápida que la atención de las mismas, por lo que se
construyen líneas de espera o colas para cada dispositivo. Para reducir el tiempo de búsqueda de registros se ordena
la cola de peticiones: esto se denomina planificación de disco.
La planificación de disco implica:
• Un examen cuidadoso de las peticiones pendientes para determinar la forma más eficiente de servirlas.
• Un análisis de las relaciones posicionales entre las peticiones en espera.
• Un reordenamiento de la cola de peticiones para servirlas minimizando los movimientos mecánicos.
Los tipos más comunes de planificación son:
• Optimización de la búsqueda.
• Optimización rotacional (latencia).
Generalmente los tiempos de búsqueda superan a los de latencia, aunque la diferencia disminuye. Muchos
algoritmos de planificación se concentran en la reducción de los tiempos de búsqueda para un conjunto de
peticiones. La reducción de la latencia recién tiene efectos bajo cargas de trabajo muy pesadas.
Bajo condiciones de carga ligera (promedio bajo de longitud de la cola), es aceptable el desempeño del método
FCFS (primero en llegar, primero en ser servido). Bajo condiciones de carga media o pesada, es recomendable un
algoritmo de planificación de las colas de requerimientos.
Los principales criterios de categorización de las políticas de planificación son [Deitel]:
• Capacidad de ejecución.
• Media del tiempo de respuesta.
• Varianza de los tiempos de respuesta (predecibilidad).
Una política de planificación debe intentar maximizar la capacidad de ejecución, maximizando el número de
peticiones servidas por unidad de tiempo, minimizando la media del tiempo de respuesta y mejorando el rendimiento
global, quizás a costa de las peticiones individuales.
La planificación suele mejorar la imagen total al tiempo que reduce los niveles de servicio de ciertas peticiones. Se
mide utilizando la varianza de los tiempos de respuesta. La varianza es un término estadístico que indica hasta qué
punto tienden a desviarse del promedio de todos los elementos los elementos individuales. A menor varianza mayor
predecibilidad. Se desea una política de planificación que minimice la varianza, es decir que maximice la
predecibilidad. No debe haber peticiones que puedan experimentar niveles de servicio erráticos.
8.3.2.1.1. Optimización de la Búsqueda en Discos
En la mayoría de los discos, el tiempo de búsqueda supera al de retraso rotacional y al de transferencia, debido a
ello, la reducción del tiempo promedio de búsqueda puede mejorar en gran medida el rendimiento del sistema.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
90
Las estrategias más comunes de optimización de la búsqueda son las siguientes [Deitel]:
o FCFS.
o SSF.
o SCAN.
o SCAN de N - Pasos.
o C - SCAN.
o Esquema Eschenbach.
Planificación FCFS First come - first served (Primero en Llegar, Primero en Ser Servido)
Si el controlador en software del disco acepta peticiones una por una y las atiende en ese orden, es decir, el primero
que llega, el primero que se atiende, poco puede hacerse por optimar el tiempo de búsqueda. Sin embargo, cuando el
disco está sometido a una carga pesada puede usarse otra estrategia. Es probable que, mientras el brazo está
realizando una búsqueda para atender una petición, otros procesos generen otras peticiones de disco. Muchos
controladores de disco mantienen una tabla, indizada por número de cilindro, con todas las peticiones pendientes
para cada cilindro encadenadas en listas enlazadas cuyas cabezas son las entradas de la tabla. Dado este tipo de
estructura de datos, podemos utilizar un mejor algoritmo que el del primero que llega, primero que se atiende. Para
entender este algoritmo, consideremos un disco de 40 cilindros. Llega una petición para leer un bloque que está en el
cilindro 11. Mientras se está realizando la búsqueda del cilindro 11, llegan peticiones nuevas para los cilindros 1, 36,
16, 34, 9 y 12, en ese orden, y se introducen en la tabla de peticiones pendientes, con una lista enlazada individual
para cada cilindro.
Cuando se termina de atender la petición en curso (para el cilindro 11), el controlador de disco puede escoger la
petición que atenderá a continuación. Si el controlador usara FCFS, iría después al cilindro 1, luego al 36, y así
sucesivamente. Este algoritmo requeriría movimientos del brazo de 10, 35, 20, 18, 25 y 3, respectivamente, para un
total de 111 cilindros.
Planificación SSF shortest seekfirst (Menor Tiempo de Búsqueda Primero)
En este algoritmo el controlador podría atender a continuación la petición más cercana, a fin de minimizar el tiempo
de búsqueda. Dadas las peticiones anteriores, la secuencia es 12, 9, 16, 1, 34 y 36, como indica la línea punteada en
la parte inferior de la figura. Con esta secuencia, los movimientos del brazo son 1, 3, 7, 15, 33 y 2 para un total de 61
cilindros. Este algoritmo reduce el movimiento total del brazo casi a la mitad en comparación con FCFS. SSF tiene
un problema, si siguen llegando más peticiones mientras se están procesando las peticiones anteriores. Por ejemplo,
si, después de ir al cilindro 16 está presente una nueva petición para el cilindro 8, ésta tendrá prioridad sobre el
cilindro 1. Si luego llega una petición para el cilindro 13, el brazo irá después a ese cilindro, en lugar de al 1. Si la
carga del disco es elevada, el brazo tenderá a permanecer en la parte media del disco la mayor parte del tiempo, y las
peticiones en los extremos tendrán que esperar hasta que una fluctuación estadística en la carga haga que no se
presenten peticiones cerca de la parte media. Las peticiones alejadas de la parte media podrían recibir un servicio
deficiente. Los objetivos de tiempo de respuesta mínimo y equitatividad están en conflicto aquí.
Planificación SCAN
Los edificios altos también tienen que enfrentar el trueque del algoritmo anterior. El problema de planificar un
elevador de un edificio alto es similar al de planificar un brazo de disco. Continuamente llegan llamadas que
reclaman al elevador que se dirija a otros pisos al azar. El microprocesador que controla el elevador fácilmente
podría usar FCFS para seguir la pista a la secuencia en que los clientes oprimen el botón de llamada y atenderlos;
también podría usar SSF. Sin embargo, la mayor parte de los elevadores usan un algoritmo distinto para conciliar los
objetivos en conflicto de eficiencia y equitatividad: continúan desplazándose en la misma dirección hasta que no hay
más peticiones pendientes en esa dirección, y luego se mueven en la dirección opuesta.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
91
El algoritmo, conocido como algoritmo del elevador, requiere que el software mantenga un bit: el bit de dirección
actual, UP o DOWN. Cuando termina de atenderse una petición el controlador del disco o del elevador examina el
bit. Si éste es UP, el brazo o el elevador se mueve a la petición pendiente más cercana hacia arriba. Si no hay
peticiones pendientes en posiciones más altas, se invierte el bit de dirección. Si el bit está en DOWN, el movimiento
es hacia la siguiente posición solicitada hacia abajo, si la hay. La siguiente figura muestra el algoritmo del elevador
usando las mismas siete peticiones anteriores, suponiendo que el bit de dirección inicialmente estaba en UP. El
orden en que se atienden los cilindros es 12, 16, 34, 36, 9 y 1, que produce movimientos del brazo de 1, 4, 18, 2, 27
y 8, para un total de 60 cilindros. En este caso el algoritmo del elevador es un poco mejor que SSF, aunque
usualmente es peor.
Una propiedad agradable del algoritmo del elevador es que, dada cualquier colección de peticiones, el límite
superior del movimiento total está fijo: no puede ser mayor que dos veces el número de cilindros.
Planificación SCAN de N - Pasos
La estrategia de movimiento del brazo es como en SCAN; solo da servicio a las peticiones que se encuentran en
espera cuando comienza un recorrido particular. Las peticiones que llegan durante un recorrido son agrupadas y
ordenadas y serán atendidas durante el recorrido de regreso. Posee menor varianza de los tiempos de respuesta si se
compara con las planificaciones SSTF y SCAN convencionales.
Planificación C - SCAN (Búsqueda Circular)
El brazo se mueve del cilindro exterior al interior, sirviendo a las peticiones sobre una base de búsqueda más corta.
Finalizado el recorrido hacia el interior, salta a la petición más cercana al cilindro exterior y reanuda su
desplazamiento hacia el interior. No discrimina a los cilindros exterior e interior. La varianza de los tiempos de
respuesta es muy pequeña.
Esquema Eschenbach
El brazo del disco se mueve como en C - SCAN, pero las peticiones se reordenan para ser servidas dentro de un
cilindro para tomar ventaja de la posición rotacional y si dos peticiones trasladan posiciones de sectores dentro de un
cilindro, solo se sirve una en el movimiento actual del brazo del disco. Esta estrategia tiene en cuenta el retraso
rotacional.
Mediante trabajos de simulación y de laboratorio se demostró que la estrategia SCAN es la mejor con carga baja, la
estrategia C - SCAN es la mejor con cargas medias y pesadas y que la estrategia C - SCAN con optimización
rotacional es la mejor para cargas muy pesadas (mejor que la estrategia Eschenbach inclusive).
Generalmente, las mejoras tecnológicas de los discos, acortan los tiempos de búsqueda (seek), pero no acortan los
tiempos de demora rotacional (search). En algunos discos, el tiempo promedio de búsqueda ya es menor que el
retraso rotacional. El factor dominante será el retraso rotacional, por lo tanto, los algoritmos que optimizan los
tiempos de búsqueda (como el algoritmo del elevador) perderán importancia frente a los algoritmos que optimicen el
retraso rotacional. Una tecnología importante es la que permite el trabajo conjunto de varios discos. Una
configuración interesante es la de treinta y ocho (38) unidades ejecutándose en paralelo. Cuando se realiza una
operación de lectura, ingresan a la cpu 38 bit a la vez, uno por cada unidad. Los 38 bits conforman una palabra de 32
bits junto con 6 bits para verificación. Los bits 1, 2, 4, 8, 16 y 32 se utilizan como bits de paridad. La palabra de 38
bits se puede codificar mediante el código Hamming, que es un código corrector de errores. Si una unidad sale de
servicio, se pierde un bit de cada palabra y el sistema puede continuar trabajando; se debe a que los códigos
Hamming se pueden recuperar de un bit perdido. Este diseño se conoce como RAID; siglas en inglés de “arreglo
redundante de discos no costosos”.

Sistemas Operativos (2010017)
Ing. Jorge Orellana A.
92
8.3.2.1.2. Optimización Rotacional en Discos
En condiciones de carga pesada, las probabilidades de que ocurran referencias al mismo cilindro aumentan, por ello
resulta útil considerar la optimización rotacional además de la optimización de búsqueda [Deitel]. La optimización
rotacional es de uso común en dispositivos de cabezas fijas. La estrategia utilizada es la SLTF (tiempo de latencia
más corto primero). Situado el brazo del disco en un cilindro, examina todas las peticiones sobre el cilindro y sirve
primero a la que tiene el retraso rotacional más corto.
8.3.2.2. Manejo de Errores en Discos
Algunos de los errores más comunes en discos son [Tanenbaum]:
• Error de programación. (Ej.: Solicitar un sector no existente)
• Error temporal en la suma de verificación. (Ej.: Provocado por polvo en la cabeza).
• Error permanente en la suma de verificación. (Ej.: Un bloque del disco dañado físicamente).
• Error de búsqueda. (Ej.: El brazo se envía al cilindro 6 pero va al 7).
• Error del controlador. (Ej.: El controlador no acepta los comandos).
El manejador del disco debe controlar los errores de la mejor manera posible. La mayoría de los controladores,
verifican los parámetros que se les proporcionan e informan si no son válidos.
Respecto de los errores temporales en la suma de verificación, generalmente se eliminan al repetir la operación. Si
persisten, el bloque debe ser marcado como un bloque defectuoso, para que el software lo evite.
Otra posibilidad es que controladores “inteligentes” reserven cierta cantidad de pistas que serán asignadas en
reemplazo de pistas defectuosas. Una tabla asocia las pistas defectuosas con las pistas de repuesto. Está alojada en la
memoria interna del controlador y en el disco. La sustitución es transparente para el manejador. Puede afectarse el
desempeño de los algoritmos de búsqueda, como el del elevador, ya que el controlador utiliza pistas físicamente
distintas de las solicitadas.