the beowulf cluster at the center for computational...
TRANSCRIPT

The Beowulf Cluster at the Center for Computational Mathematics, CU-Denver
Jan Mandel, CCM DirectorRuss Boice, System Administrator
CLUE North
September 18, 2003
Supported by
National Science Foundation Grant DMS-0079719
www-math.cudenver.edu/ccm/beowulf

Overview• Why a Beowulf cluster?• Parallel programming• Some really big clusters• Design constraints and objectives• System hardware and software• System administration• Development tools• The burn-in experience• Lessons learned

Why a Beowulf Cluster?
• Parallel supercomputer on the cheap• Take advantage of bulk datacenter pricing• Open source software tools available• Uniform system administration• Looks like one computer from the outside• Better than a network of workstation

Why parallel programming
• Speed: Divide problem into parts that can run on different CPUs– Communication between the parts is necessary, and– the art of efficient parallel programming is to minimize
the communication • Memory: On a cluster, the memory needed for
the problem is distributed between the nodes• But parallel programming is hard!

Numerical parallel programming software layers
Interconnect hardware drivers(ethernet, SCI, Myrinet…)
Message passing libraries
(MPI, PVM)
Shared memory
(hardware, virtual)
Distributed parallel object
libraries(PetSC, HYPRE,…)
OpenMPHigh
Performance Fortran (HPF)

Top 500 list
• Maintained by www.top500.org• Speed measured in floating point
operations per second (FLOPs) • LINPACK benchmark = solving dense
square linear systems of algebraic equations by Gaussian elimination www.netlib.org
• Published twice a year at the International Supercomputing Conference

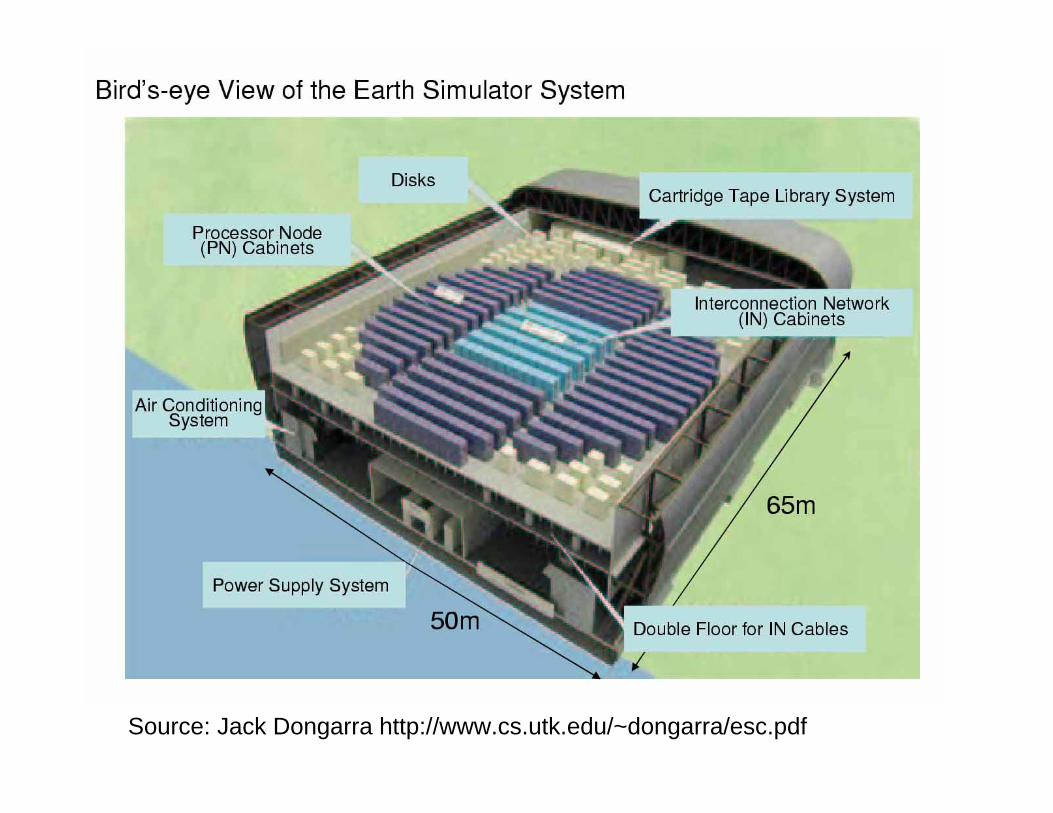
Source: Jack Dongarra http://www.cs.utk.edu/~dongarra/esc.pdf

Source: Jack Dongarra http://www.cs.utk.edu/~dongarra/esc.pdf

Source: www.top500.org

Design objectives and constraints
• Budget $200,000, including 3 year warranty• Maximize computing power in GFLOPs• Maximize communication speed• Maximize memory per node• Run standard MPI codes• Nodes useful as computers in themselves• Use existing application software licenses• Run existing software, porting, development• Remote control of everything, including power• System administration over low bandwidth links

Basic choices• Linux, because
– It is free and we have been using it on the whole network already for years
– Cluster software runs on Linux– Our applications run on Linux
• Thick nodes, with disks and complete Linux, because– Nodes need to be useful for classical computations– Local disks are faster than over network– Tested Scyld (global process space across the
cluster), which did not work well at the time– At least we know how to make them run

Interconnects available in early 2001
• 100Mb/s ethernet: slow, high latency• 1Gb/s ethernet: expensive (fibre only), high latency• Myrinet: nominal 2Gb/s duplex, star topology, needs
expensive switch• SCI (Dolphin): nominal 10Gb/s, actual 1.6Gb/s duplex,
torus topology, no switch, best latency and best price per node. Also promised serial consoles and remote power cycling of individual nodes.
• Dolphin and Myrinet avoid TCP/IP stack• Speed limited by the PCI bus - 64bit 66MHz required to
get fast communication• Decision: SCI Dolphin Wulfkit with Scali cluster software

x86 CPUs available in early 2001
• Intel PIII: 1GHz, cca 0.8 GFLOPs– Dual CPUs = best GFLOPs/$– 64bit 66MHz PCI bus available on server class motherboards– 1U 2CPU possible– Cheap DRAM
• Intel P4 1.5GHz– SSE2 = double precision floating point vector processor– Theoretically fast, but no experience with SSE2 at the time– No 64bit 66MHz PCI bus, no dual processors– Rambus memory only, expensive
• AMD Athlon– Not available with dual processors– No experience in house
• Decision: Dual PIII, server class motherboard, 1U

Disks available in early 2001• ATA100
– Internal only, 2 devices/bus, no RAID– Simple drives, less expensive
• Ultra160 SCSI– Internal/external, RAID– 16bit bus, up to 160MB/s– Up to 16 devices/channel– More intelligence on drive, more expensive– Disk operation interleaving– High-end server class motherboards have SCSI
• Decision: Ultra160 SCSI

Remote console management• Goal: manage the cluster from off campus• Considered KVM switches• Solutions exist to convert KVM to a graphics session, but
– Required a windoze client– And lots of bandwith, even DSL may not be enough (bad
experience with sluggish VNC even over 10Mb/s)– Would the client run through a firewall?
• All we wanted was to convert KVM to a telnet session when the display is in green screen text mode – when we are up and run X we do not need a console… but found no such gadget on the market
• Decision: console through serial port and reverse telnet via terminal servers

Purchasing
• Bids at internet prices + few % for integration, delivery, installation, tech support, and 3 year warranty
• Vendor acts as a single point for all warranties and tech support (usual in the cluster business)
• Worked out detailed specs with vendors– DCG, became ATIPA in the process– Paralogic– Finally bought from Western Scientific

The Beowulf Cluster at CCM

Cluster hardware• 36 nodes (Master + 35 slaves)
– Dual PIII-933MHz, 2GB memory– Slaves have 18GB IBM Ultrastar Ultra160 SCSI disk, floppy
• Master node– mirrored 36GB IBM Ultrastar Ultra160 SCSI disk, CDROM– External enclosure 8*160GB Seagate Barracuda Ultra160 SCSI,
PCI RAID card with dual SCSI channels, mirrored & striped– Dual gigabit fiber ethernet– VXA 30 AIT tape library
• SCI Dolphin interconnect• Cluster infrastructure
– 100Mb/s switch with gigabit fiber uplink to master– 4 APC UPS 2200 with temperature sensors and ethernet– 3 Perle IOLAN+ terminal servers for the serial consoles– 10Mb/s hub for the utility subnet (UPS, terminal servers)

Performance
• CPU theoretical ~60 GFLOPs• Actual 38 GFLOPs LINPACK benchmark• Disk array: 4 striped disks@40MB/s on
160MB/s channel=160MB/s theoretical, 100MB/s actual disk array bandwidth
• SCI interconnect: 10Gb/s between cards, card to node 528MB/s theoretical (PCI), 220MB/s actual bandwidth, <5µs latency

SCI
MasterNode 1
Node 10
Node 20
Node 30
Node 35
100Mb/s Switch
36 Nodes 2 CPU 2GB RAM Each
Three Terminal
Controllers
RS 232 100 MB Ethernet
SC
I Cable Interconnect
Fiber Gaga bit to Internet
Fiber Giga Bit Link
10 MB Hub
UPS Power
UPS Power
UPS Power
UPS Power
To Four 30 Amp 115 VAC Circuits
Each UPS Supplies two power strips which then Supply Nodes and other equipment
To Internet

1
3
5
4
2
M
13
15
17
16
14
12
25
27
29
28
26
24
31
33
35
34
32
30
19
21
23
22
20
18
7
9
11
10
8
6
SCI Dolphin interconnect topology 6 x 6 2D torus

Eight 160 GBSCSI Drives
(with RAID leaves 698 GB actual capacity) Master node
Two VXA Tape Drives With30 Tape Auto Load Library
(Recording Rate: 4000 kB/s)(70 GB Typical Compressed
Capacity Per Tape)
18 GB Internal SCSI Drives
Node 1
Node 2
Node 3
Node 35
Mass storageTwo 160MB/s
SCSI Channels
One SCSI Channel
Internal 36GB mirrored drives on 160MB/s SCSI

WARNINGEXPLICIT PICTURES
OF BIG HARD DRIVESNEXT

The master
The master node

The slaves
The slave nodes

The back
SCI Dolphin cables
Keyboard, monitor, and mouse plugged into a slave node
Serial console cables
Ethernet cables

The uninterruptible power supplies (UPS), utility hub, two UPS network interface boxes, and temperature sensor on top

Disk array 8*160GB
Tape library
An extra fan to blow in the beast’s face

The beast eats lots of power

Perfectly useless doors that came with the beast but just inhibit air flow. Note the shiny surface of the left door, holes only on the sides.

Ethernet switch
Terminal servers for serial consoles

The disk array and the tape library

The 10Gb/s SCI Dolphin cables are a bit too long.

Office power strips were commandeered to distribute the load between the outlets on the uninterruptible power supplies to avoid tripping the circuits breakers.

The backplane in gory detail

Cluster software• Redhat Linux 7.2• Scali cluster software
– SCI Dolphin accessible through MPI library only– Management tools, Portable Batch System (PBS)
• Portland group compilers– C, C++, Fortran 90– High Performance Fortran (HPF) is
the easiest way to program the cluster• Totalview debugger by Etnus
– Switch between group of processes in an MPI job, control all processes at once
– Alternative: one gdb per process in an xterm window…

Networking• All slaves and one master fiber interface run a local
network with NAT• Master is the gateway, only node visible from the outside• Disk array on master shared by NFS with slaves• Utility hub (power supplies, serial consoles) is accessible
from the outside• Master runs ntp server – important to keep time in sync• All other protocols pass through master to the outside• FlexLM license server for apps is outside of cluster

System administration
• All slave nodes kept in sync– Moving files etc done by Scali commands
(basically just loops over the nodes)– Slave disks are cloned (boot Linux, run dd on
the raw device) when a disk is replaced• Software on master and nodes kept in
sync by duplicating /opt• Few custom cron scripts

System administration cron scripts
• From cron on another box, log periodically into UPSes and turn everything off if room temperature is too high
• Check periodically if Dolphin cards work and take nodes that failed offline so that PBS will not assign jobs to them
• Export status report to the web• Start and stop PBS queues from cron depending
on if jobs are waiting; the built-in scheduler is not smart enough and cannot be changed easily

Common libraries and application software
• Optimized BLAS (Basic Linear Algebra Subroutines)
• Parallel distributed object libraries:– PetSC (Argonne National Lab)– HYPRE (Lawrence Livermore Nat. Lab.)
• Matlab– Single processor only

The burn-in: Software
• Vendor technicians struggled with serial consoles• SCI drivers conflict with RAID drivers on master, Scali
developers had to compile custom kernel.• Scali management tools never fully worked.• Arkeia tape library software never worked.• The PBS (batch system) did not work properly• Etc… it took about 8 months and upgrade to Redhat 7.2
and new Scali 4.0 for things to start working reasonably well.
• The PGI compilers, the Totalview debugger, the ScaliSCI drivers, and Redhat version never worked together well: everybody supports fully only the previous version of the other people’s software!

The burn-in: Power and heat• Too few UPSes, vendor had to buy 2 more• Did not have enough power outlets, had to steal power
from all over the floor• The UPSes did not support automatic shutoff at high
temperature as promised, had to buy network boxes for all UPSes and write a shutoff script
• Running the benchmark overheated 1U slave nodes• Vendor replaced front plates and added internal fans• Running the benchmark for few minutes tripped the
circuit breakers on the UPSes• Redistributed the load between outlets on the UPSes
using office power strips• After running the benchmark for few hours the machine
room air-conditioning compressor failed• After 6 months finally the benchmark goes through!

The burn-in:Disks, CPUs, and motherboards
• When all nodes are opened, at least one of them would not work again
• A node disk, motherboard, or Dolphin card occasionally dies (less often now)
• Probably caused by more heat in the 1U enclosures, master had no problems

Cluster use
• Numerical mathematics: research of iterative solvers for large scale systems of equations, eigenvalue solvers
• Discrete mathematics: search for graphs with special properties
• Massive experiments: run large number of copies of the same code on different data (also for tables and graphs)
• Computational chemistry: runs existing codes for molecular simulation
• Student training

Node usage
• Master: compilation, light load only• Node1 and node2: interactive work,
debugging• Nodes 3 to 36: jobs submitted through
PBS (Portable Batch System) only– each job gets assigned full nodes to run on
• No enforcement, relies on user cooperation

Lessons learned
• You get what you pay for• Refuse any hardware not supported by the
stock kernel right out of the CD• Air must stream through the nodes like in
a jet engine, anything less will overheat• Using the cluster is hard• Avoid inconveniencing users

What we would buy now• Dual P4, of course• Memory depending on usage; we would go for
2GB or 4GB so that the nodes are useful as computers on their own in what we do
• Interconnect by twisted pair gigabit– Motherboards now have dual gigabit ports– Switches are reasonably priced– Reasonably fast– High latency, but well written parallel programs do not
use that much communication– One port for MPI subnet, one for all else, esp. NFS
• Make sure of good air flow: 2U or blower fans

What we would buy now (cont.)• Use ATA disks, they are now fast enough and
much cheaper than SCSI• Networked power strips to powercycle over the
network each node individually• Basic KVM but no remote consoles – if you have
a problem that requires console, you probably have to go in the machine room anyway
• A cheap slow huge disk array offsite at a friendly machine room for disk to disk backups, no tape library, just one tape drive on master for system