the dev-admin chimera: customising connections (with gab davis)
DESCRIPTION
IBM Connections customisation comes in many flavours, from modifying branding, adding languages and customising menu items to developing and adding your own widgets. Some of it is as simple as changing XML files or style sheets, some take us into the dark world of JSPs and ear files. We'll take you through the highlights of what can be customised and what skills you need to achieve different effects. Some are simple enough for even an administrator to manage and all of them need the work of an administrator to deploy. If you're a Administrator who fancies making a few simple Connections changes or a Developer who fancies deploying your own changes onto a server, Mark and Gab will explain why it's better to work together to build a customised maintainable system with little of no bloodshed and the minimum of ritual sacrifice.TRANSCRIPT

W I T H A L I TT L E B I T O F D O M I N O T H R O W N I N
THE DEV-ADMIN CHIMERA: CUSTOMISING CONNECTIONS

WHAT WE’RE HERE TO TALK ABOUT
• The what , how and where of Connections• Admin for administrators• Making Changes• Customizations Within the Framework• Working with applications• Customizations Outside the Framework• Security

WHY?
• IBM connections requires far more interaction and Trust between Developers and Administrators than nearly any other major platform • It lacks the security granularity of Domino.• It lacks delegation as you would see in a cloud service
such as Amazon web service’s.• To get nearly any customization working, both Developers
and Admins have to work together.• Developers can break environments and have their code
broken by Administrators in a wide variety of ways• Administrators have to know the details of any non IBM code
running on their servers and • Developers have to seriously adhere to architecture standards.

WHO ARE WE? – MARK MYERS
• A Member of the London Developer Co-op (londc.com) A group of UK based developers • Ben Poole• Julian Woodward• Mark Myers (me)• Robin Willis• Matt White
• Developer from a support background
• 12+ years on Domino, 15+ years in IT
• Speaker at 3x Lotuspheres, 4x UKLUGs, 1x ILUG, 1x BLUG
• Contact• Email: [email protected] , Twitter: @stickfight , Skype:
Stickfight , Blog: stickfight.co.uk

WHO ARE WE – GAB DAVIS
• An Administrator, first of ccMail, then Notes and Domino, Sametime, Connections, WebSphere, DB2, TDI ..running to keep up with an ever expanding range of software
• Co-founder of The Turtle Partnership in 1996 along with Tim Davis (development) and Mike Smith
• Co-Author the Sametime Administrators’s Guide, the IBM Connections Enterprise Redwiki and Connections101.net
• Speaker at Lotusphere, The View, UKLUG, BLUG, AUSLUG, IAMLUG, NLUG, DANNOTES, ISBUG etc – loves an excuse to write a new presentation
• Nerd Girl
• Travels a lot (most my bio photos are taken on planes)

CONNECTIONS IN ALL ITS GUISES

A INTRODUCTION TO CONNECTIONS
• IBM Connections can be used as a descriptor in two ways• The name of a group of WebSphere applications that install
under the product name of “IBM Connections”• The name of a collection of servers, services and applications
that deliver the IBM Connections experience the user sees
• When people talk about “customising Connections” 90% of the time they mean the WebSphere J2EE applications
• When people talk about “administering Connections” they could mean work across any of 20+ different systems and applications

• A Connections Administrator is knowledgeable about many different products and tools that have a wider application than just IBM Connections
• A Connections developer can use development tools from CSS to OpenSocial gadgets to Java and more, all have a much wider application than just IBM Connections

PRODUCTS THAT MAKE UP CONNECTIONS - REQUIRED
• Operating System• LDAP • Databases • Tivoli Directory Integrator • WebSphere Application Server • IBM Connections

PRODUCTS THAT MAKE UP CONNECTIONS - OPTIONAL
• IBM HTTP Server (optional’ish)• IBM Filenet • Connections Content Manager. • IBM Cognos • WebSphere Edge Server

ARCHITECTURE
ARCHITECTURE

DATA SOURCES – WHERE THINGS ARE
• WebSphere has no database itself and your information has to be stored somewhere. • We need a database server, either DB2 , SQL or Oracle• Most of the applications have their own dedicated
database for storing the tables and data they need
• As administrators we don’t mess with the design or structure of the Connections databases• These are created by IBM supplied scripts and
occasionally updated during fixpacks by new scripts• If you touch it, you break it.

DATA SOURCES – THE DEVELOPER’S DILEMMA
• Your developer may want access to the databases• That’s fine. They can have read access• BUT not using your standard db2admin credentials, create
them their own• BUT if they ask for write access your first answer is “no”.
• Your second answer is “let’s talk about what you’re trying to do”
• Remember if you touch the design of the databases or the data, you’ve broken it• Even if it works, you’re now so far outside what IBM will
support you’re entirely on your own

IS THAT ALL?
• Well no, there’s data in other places too• File attachments uploaded into files or activities
or forums etc aren’t kept in the databases• Only pointers to those files are kept in the databases• The files themselves are stored on the file system
• If you have multiple WebSphere servers those files can’t stay in sync, this isn’t Domino• So there needs to be a file share location (NFS) that all
servers can see and access• Don’t worry the files aren’t easily readable as content or
even a file structure
• This is called Connections Shared Data

SHARED DATA - ADMINISTRATOR
• Back up your Connections shared data location• Make sure that shared data is on a fast accessible
disk that isn’t fragmenting• Make sure you move the data if you move the servers• The location of the share is determined by an
environment variable set in WebSphere so it’s easy to change the value of that variable or even where that path points to, at a later date if you need more capacity
• Handling shared data is part of your upgrade strategy• If your shared store is broken you may not notice until
someone tries to look at, download or upload a file attachment

SHARED DATA - DEVELOPER
• The files you want to access may be on the data share but how to find them will be in a table in the application’s database e.g.• Opnact for “activities”• Files for “files”
• The files will be secured on the file system with a local user account that WebSphere runs under• You will need an account created for you that can access that part of
the file system
• Connections maintains internal indexes to determine where to place a new file and what to call it• If you are going to attempt to create your own data you must update
both the application database and the file system
• IBM do not publish the structure of the Connections databases• Basically they don’t want you doing any direct writing of data

IS THAT ALL?
• No. There’s also local data stores for Connections applications• Some information needs to be local to the server
running each application and is exclusively used by that application on that server• Another server with a cluster of the application
will have a different local data store and its own locally created information• A good example of this is the search index• The search index is created by the search application on
each server that application runs on

LOCAL DATA - ADMINISTRATOR
• You can copy a search index between servers but that’s a point in time copy, it won’t stay in sync• Don’t copy any local data whilst your destination server
is running
• Local data in general will be re-created by the applications if removed• Whereas the shared data is a single location to
backup, the local data is different on every server• Losing your local data shouldn’t be fatal for your
environment but I don’t recommend it

LOCAL DATA - DEVELOPER
• The local data is the least likely place you would want to retrieve data from• I can’t think of a circumstance when you would want to
write local data
• Since local data is specific to a server, each instance of an application will generate different local data• If you are writing to local data (again why?) you
would have to write to each server that contains an instance of the application you are working with

ANYTHING ELSE?
• Many customisations are in a specific customisation directory in the shared data store• This protects them from being overwritten during upgrades• More on this later
• Communities are a special case• A community contains data from many other applications like
forums, blogs, files, activities• Community content is written out directly to those applications
and cross referenced in a Community
• If you delete a Community you create holes in the databases of those applications, restoring a backup of your Community won’t fill in those holes again• Deleting a Community is “crossing the beams” bad.

LDAP - AUTHENTICATION
• LDAP is used In Connections for authenticating users access to the system• Multiple different LDAP servers can be specified
to operate like Directory Assistance in Domino• If you want to use failover LDAP servers set those
up in WebSphere rather than point WebSphere at a load balancer for LDAP• WebSphere will be more consistently reliable and stable
• If your LDAP server (or even DNS) is slow to respond, your users will experience slow server access

LDAP – POPULATING PROFILES
• Profiles in Connections are populated from your LDAP directory• Connections uses Tivoli Directory Integrator to
move the data from your LDAP source to the PEOPLEDB database• It’s possible to populate bi-directionally and to
populate from multiple sources• IBM supply all the scripts, batch files and
assemblylines needed to manage profiles• Use the IBM supplied files as templates, do not create
your own – you won’t have support

ADMINISTRATOR –POPULATING PROFILES
• There are three methods to populate profiles• The population wizard that provides a GUI to import LDAP
source to PeopleDB destination
• Manually modifying the XML and properties files supplied by IBM and running the batch files such as collect_dns and sync_all dns to populate the data either LDAPtoPEOPLEDB or LDAPtoPEOPLEDBtoLDAP (bi directionally)
• Create an assemblyline using TDI’s configuration editor interface and using IBM supplied ProfileConnector• As assemblyline can connect to nearly any data source• Assemblylines can run very quickly and custom populate data
to and from multiple data sources

DEVELOPER – WORKING WITH PROFILES
• Registration and User management is not exactly built in to connections it is mainly catered to existing directories.• If you want to allow users to register them selves you are
going to have to write your own registration app or customize the one used with your User directory
• If you are using an external directory, beg and plead not to have the email field turned off as it makes the integration with atom feeds far harder

DEVELOPER – WORKING WITH PROFILES
• The main internal connection user table has 7 (yes 7!) user identification fields• Even so your main issue will be uniquely identifying a
user if you are authenticating via your LDAP non-Connections directory and then calling or modifying items within the Connections environment
• The most useful field from a developers perspective is the “profGuid” field in the “EMPLOYEE” table in the “jdbc/profiles” datasource almost certainly called PEOPLEDB

IBM HTTP SERVER
• The IBM HTTP Server routes URL queries to and from users to the back end WebSphere applications• Since this is the route through which all traffic
travels we can secure SSL through IHS intead of WebSphere• IHS is cluster aware when added to WebSphere
and will dynamically route requests across the cluster• Multiple IHS servers can be used via a load
balancer to route Connections traffic

IBM HTTP SERVER - ADMINISTRATOR
• Configuration for IHS happens in three main places• Httpd.conf file , a complex text file held on the file
system• This can easily be ovewritten and a simple change can
break Connections completely
• Plugin-cfg.xml – the WebSphere plugin file that informs IHS what URLs need to be redirected to the back end servers and not resolved locally• This is generated from within WebSphere and distributed
via the ISC
• Plugin-key.kdb / plugin-key.sth used to store the SSL certificates

IBM HTTP SERVER - DEVELOPER
• When you add a new application or URL, it wont show up when you start the application as the HTTP server wont know about it.• You have to go ask your administrator to update the HTTP
server configuration.• Generate Plugin – Populate Plugin
• You can in addition get the direct port to the http stack on the websphere server so you can do your testing straight away without pestering your admin all the time• Direct ports are usually 9081, 9082, 9083 etc insecure and
9443, 9445, 9445 secure depending on how many clusters you have o one server

CONNECTIONS CONTENT MANAGER
• CCM uses FileNet as a document library which itself needs to store file data and references
• We have additional databases that are created either during install or via the DBWizard to be used exclusively by Filenet
• There is also a Filenet Administration Interface called the Administering Console for Content Engine where the Filenet specific configuration settings are held including how to map Filenet to Connections applications and behaviour

COGNOS
• Cognos is used for creating and reporting Metrics, it uses WebShere to deliver HTML reports that are built into the Metrics application in Connections• Data is held in three places• Metrics and Cognos databases created by the
Connections DBWizard• Cognos configuration interface• Transformer Cubes on the Cognos file system
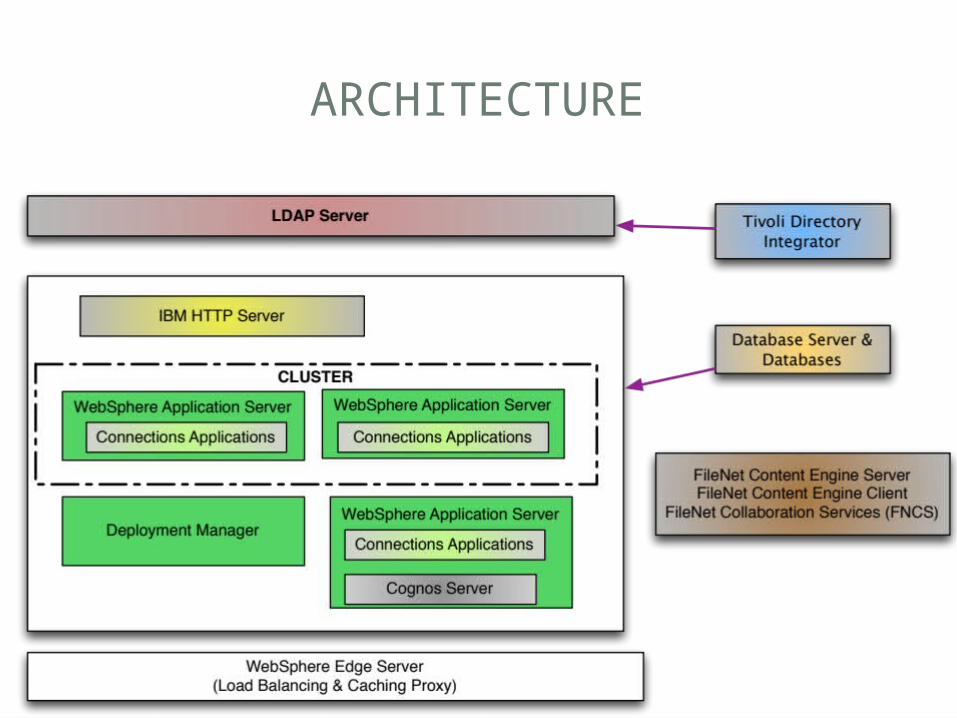
ARCHITECTURE

ADMINISTRATION

WEBSPHERE ADMINISTRATION
• Once IBM Connections is installed there are two places where we would perform day to day administration
• Application security - the rights users have to applications• Application security isn’t very granular “one size fits all”• New roles that change behaviour aren’t something you can add
• Wsadmin• WebSphere’s command line administration tool for sending
instructions to applications• Wsadmin is also used to make changes to application
configuration settings

APPLICATION SECURITY
• For every application there are pre-defined roles that that determine the scope of the user’s behaviour• Many of the roles such as “admin” or “global-
moderator” apply across multiple applications• But do different specific things in each application• And must be set separately
• There are also pre-defined special “categories” you can assigned to applications such as• all authenticated users in application’s realm• Everyone (includes anonymous users)
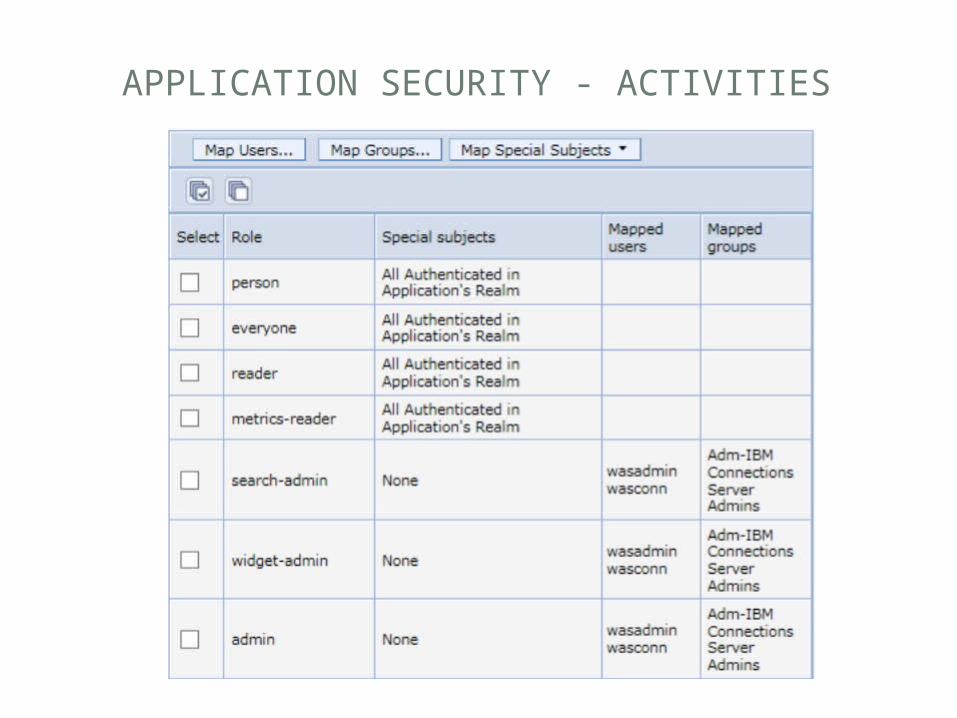
APPLICATION SECURITY - ACTIVITIES

WSADMIN – SENDING COMMANDS
To run any wsadmin command always start from the bin directory of the deployment manager e.g
• C:\IBM\WebSphere\AppServer\profiles\Dmgr01\bin
• Call wsadmin by typing
wsadmin(.sh) –lang jython –username [name] –password [password]
then choose which application you want to work with
execfile(“profilesAdmin.py”)
• Any changes you make here will be pushed out to all the nodes• Wsadmin commands are case sensitive regardless of your
platform

WSADMIN – MODIFYING CONNECTIONS CONFIGURATION
• wsadmin –lang jython –username [name] –password [password]
• execfile(“connectionsConfig.py”)• LCConfigService.checkOutConfig(“[filepath]”,AdminContr
ol.getCell())
• The LotusConnections-config.xml file will be in your filepath where it can be edited then checked back in and validated
• LCConfigService.checkInConfig()

JAAS AUTHENTICATION
• To connect each application to its data source there is a J2C authentication resource created during install• If you need to change the account name or
password you will need to edit the details for the JAAS Alias• Global Security – JAAS – J2C authentication data

REORG SCRIPTS
• To handle database fragmentation you should regularly run the supplied IBM reorg.sql scripts• The scripts are located in the connections.sql
directory of the installer• The reorg scripts traverse each table in the
database clearing up whitespace and optimising the remaining data

BACKING UP CONFIGURATION
• Always backup before making configuration changes• From the deployment manager bin directory run
the backupconfig(.sh) • Backupconfig c:\backups\gdbackup.zip –nostop• The backup will be a zip file,• The –nostop command prevents backupconfig from stopping
the deployment manager before running
• Restoreconfig c:\backups\gdbackup.zip• Restore once you have stopped the server

CUSTOMIZATIONS WITHIN THE FRAMEWORK
• These are Customizations that use IBM APIs to integrate with Connections (nearly always via ATOM feed), normally broken down into 2 types• XML: These involve changes to the XML configuration
documents for connections.• None XML: where you don’t need to touch the undying
connections files (such as Iwidgets)
• The Basic Premise for this type of customization is that IBM will support it from One version to the Next• Not to be underestimated, when a client updates their
connections environment, you don’t want people pointing at your changes and blaming them for project slippage.

CUSTOMIZATIONS WITHIN THE FRAMEWORK
• Connections is not a RAD environment but it is a very updateable environment with a lot of feeds.• You get far more bang for your buck by writing truly
external apps, via either domino or native java apps, then feeding back into the connections environment.
• Such applications need SSO and / or service accounts, check that these will be available BEFORE writing your code
• Before committing to an in-framework customization, confirm that it is do able, all things are possible but the level of hacking needed my render the solution unviable to your administrator and / or client.

XML FILE UPDATES
• Nearly everything serious requires a restart of the effected application (Profiles/Commons etc)• Treat it as an architectural area.• Don’t store any setting or configuration that might ever
change (there are lots of other areas to do that)

XML FILE UPDATES
• Documentation is a bit thin on the ground• http://www-10.lotus.com/ldd/appdevwiki.nsf/ (that’s your lot)
• If something is not implicitly mentioned in the documentation it might be tolerated/support in a given release but not for future release even on the adopted platforms• E.g. dojo.i18n.getLocalization solution not supported
between 3 and 4.5

CUSTOMIZATIONS OUTSIDE THE FRAMEWORK
• When your customizations go outside the functions provided by IBM. • Basically this only happens when the ATOM APIs do not
do the job for you, and you end up with a native app reading / writing to the Connections DB2 data bases
• IBM will not support this type of customization, but on the plus side you can deliver exceptional solutions to clients.• Eg. Editing activity stream.• Expanding data accessibility.

CUSTOMIZATIONS OUTSIDE THE FRAMEWORK
• An .Ear (Enterprise ARchive) is Basically a normal War file (Web application ARchive) wrapped in a configuration wrapper.• It contains Lots and lots of very cool features,
very few of which you should use on connections without full buy in from your administrator• Remember you are on a shared server and you can not
make any assumptions as to what is happening• Far Better to write detailed installation instructions that
allow your admin to balance the system.• Make No Assumptions on your application regarding
available resources, give detailed errors on the sys log.

CUSTOMIZATIONS OUTSIDE THE FRAMEWORK
• Do not use the full functionality provided by .ear

CUSTOMIZATIONS OUTSIDE THE FRAMEWORK
• JDBC connections• It has already been mentioned, but resist the urge to use
the Integrated JDBC connections.• If a developer is not 100% trusted i.e. external. the lack
of security on the system JDBC connections is reason enough for a code audit.
• Their Presence is a bonus point for all external application to be written on a Domino server.

LOGS
• Any application problems will be found in the SystemOut.log of the server where the application is running• If you are using a cluster then you will need to
check the SystemOut for each server in the cluster• Modify the LOG_ROOT WebSphere variable for log
location• Configure each server log for rollover and retention

LOGS - DEVELOPER
• Remember which application server your stuff is on (check Web modules on the application properties if you are unsure) • It’s best if you can agree on a server for all your
customization work with your admin (where applicable)• It’s a total face palm moment if you complain to your
admin and you have been looking at the wrong servers log.
• Be responsible with your Logging, remember you have to share it so don’t stuff it with pages and pages of entries when you are not actively debugging.

LOGS - ADMINISTRATOR
• Don’t give your developer rights to do any of the things Mark just mentioned• No logging into the ISC to apply their own applications,
review servers or modify logs
• No. Bad Mark.

DO’S & DO NOTS
• Admin:• Backup your configuration using backupconfig before making
changes to the configuration• Never manually edit an XML configuration file, always use
wsadmin which verifies the XML structure as it’s checked back in• Schedule the database reorg maintenance scripts to run
regularly, • Set up specific credentials for developers to use to access the
Connections data, don’t re-use administration credentials• Ensure you have a test / staging server to test customisations
and developments on
• Never let your developer have ISC access or wsadmin access to a production environment!

DO’S & DO NOTS
• Developer:• Never underestimate the fragility of the connections environment.• Never forget to document as you go as there are far more ‘fiddly
bits’ in connections than a lot of other environments (and its really embarrassing to ask an admin to deploy to a PT or UAT environment and the darn thing doesn't work)
• Consider Connections as basically ‘Beta’ software and code accordingly in every aspect (logging, error handling).
• Don’t be tempted to access areas via data sources and other back doors stick to API’s or stand alone code.
• Remember “A miss is as good as a mile” with IBM support, you might regard it as inventive and only a tiny bit off documentation standards, they regard it as “Not supported”• If you need to do that kind of thing then separate you code completely
and integrate via approved API’s

WHO ARE WE AGAIN?