the journey from a small development lab environment to a...
TRANSCRIPT

The Journey from a Small Development Lab Environment to a Production GPU Inference Datacenter
GTC 2018, Munich, Session S8150
Ryan Olson, Solution Architect
Markus Weber, Product Manager

2
NVIDIA DGX STATIONGroundbreaking AI – at your desk The Personal AI Supercomputer
for Researchers and Data Scientists
2
Key Features
1. 4 x NVIDIA Tesla V100 GPU (NOW 32 GB)
2. 2nd-gen NVLink (4-way)
3. Water-cooled design
4. 3 x DisplayPort (4K resolution)
5. Intel Xeon E5-2698 20-core
6. 256GB DDR4 RAM
2
1
5
4
3
6

3
DGX Station (with 4x Tesla V100 32 GB)
Spending more time training models and less time optimizing
The Largest GPU Memory Available In Any Workstation
MORE FLEXIBILITY
Faster training with optimized batch sizes
Same memory as the DGX-1 we announced last year
INCREASED CAPACITY
Up to 50% faster with larger deep learning model
UNCOMPROMISED PERFORMANCE
Spending more time training models and less time optimizing
Experiment with more models in parallel without
memory constraint

4
COMMON SOFTWARE STACK ACROSS DGX FAMILY
Cloud Service Provider
• Single, unified stack for deep learning frameworks
• Predictable execution across platforms
• Pervasive reach
DGX Station DGX-1
NVIDIAGPU
Cloud
DGX-2
4

5
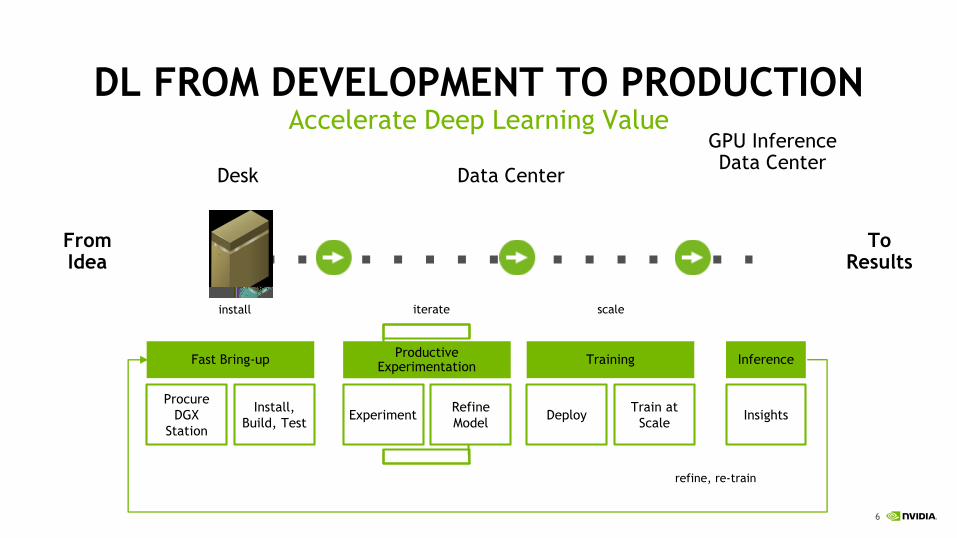
DL FROM DEVELOPMENT TO PRODUCTIONAccelerate Deep Learning Value
ExperimentRefine
ModelDeploy
Train at
ScaleInsights
Procure
DGX
Station
Install,
Build, Test
TrainingProductive
ExperimentationFast Bring-up
Data CenterDesk
FromIdea
install iterate
Inference
ToResults
refine, re-train
scale
Edge
6
DL FROM DEVELOPMENT TO PRODUCTIONAccelerate Deep Learning Value
ExperimentRefine
ModelDeploy
Train at
ScaleInsights
Procure
DGX
Station
Install,
Build, Test
TrainingProductive
ExperimentationFast Bring-up
Data CenterDesk
FromIdea
install iterate
Inference
ToResults
refine, re-train
scale
GPU InferenceData Center

The Tools
- Docker images hosted on NGC (TensorRT / TensorRT Server)
- Source and Examples: https://github.com/nvidia/yais
● NGC
● YAIS
● TensorRT
● TensorRT Server
● Kubernetes on
NVIDIA GPUs
➔ Cloud Registry of Docker Images
➔ C++ Microservice Library
➔ Inference Optimizing Compiler
➔ Inference Server (HTTP/gRPC)
➔ Hyperscale GPU Orchestration

Inference Characteristics
● Forward Pass of a DNN - no gradients (activations/weights)
● Activations can be discarded after they are no longer an input to a future layer
● Generally low batch, most often Batch1○ Reduced operational intensity - (# of compute ops / # of memory ops)
○ Tends to be Memory Bound
● Every Deployment is Different○ Optimize for Latency per Request
○ Relax Latency Criteria to Reduce Cost
○ Reduce Hardware Footprint to Save $$$

Inference Characteristics
● Input Data from Source
● Transform Input → Input Tensors (on CPU or GPU)
● Input Tensors → GPU memory
● Compute
● Output Tensors → Host memory
● Transform Output Tensors → consumable Output value
- ALL GPU Computing is Asynchronous!
- BEST Performance / Value = Keeping the Pipeline FULL

Where are the Bottlenecks?
- Ingest- Moving Input to Compute (gb/sec)
- Input → Input Tensors (reversed for Output)- What is the compression ratio for common problems?
- Computational Time to Transform?
- Ratio of Compute vs. Transfers- Goal: Evaluation of the DNN is the rate limiting condition
- Success = Proper choice of Hardware, Software and Tuning Parameters

Compute → Pre/Post → Serving → Metrics → Kubernetes
12
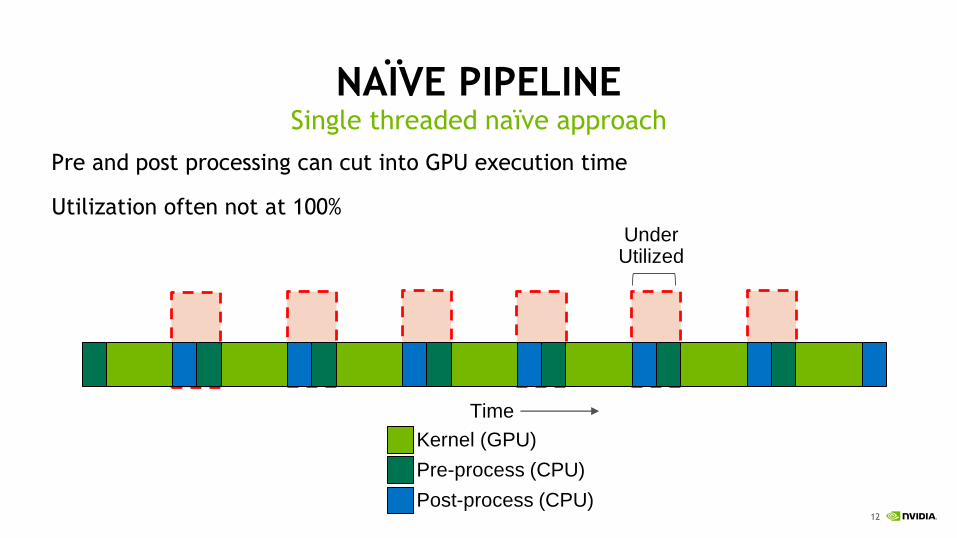
NAÏVE PIPELINE
Pre and post processing can cut into GPU execution time
Utilization often not at 100%
Single threaded naïve approach
Time
Under Utilized
Kernel (GPU)
Post-process (CPU)
Pre-process (CPU)
13
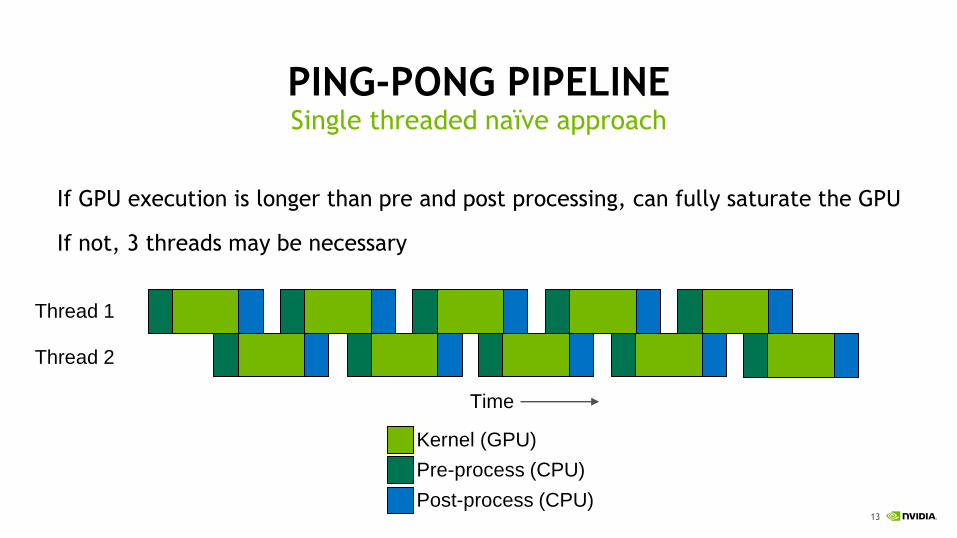
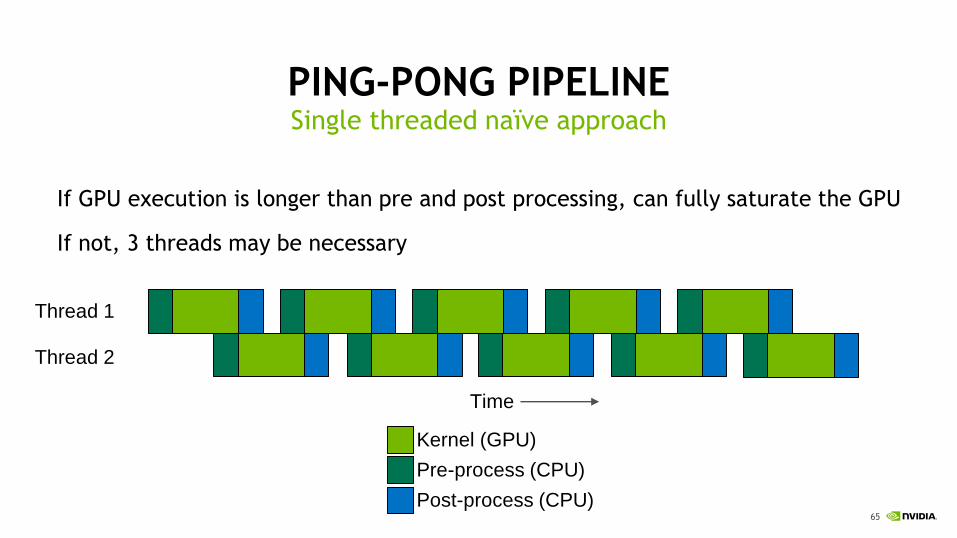
PING-PONG PIPELINE
If GPU execution is longer than pre and post processing, can fully saturate the GPU
If not, 3 threads may be necessary
Single threaded naïve approach
Time
Thread 1
Thread 2
Kernel (GPU)
Post-process (CPU)
Pre-process (CPU)

14
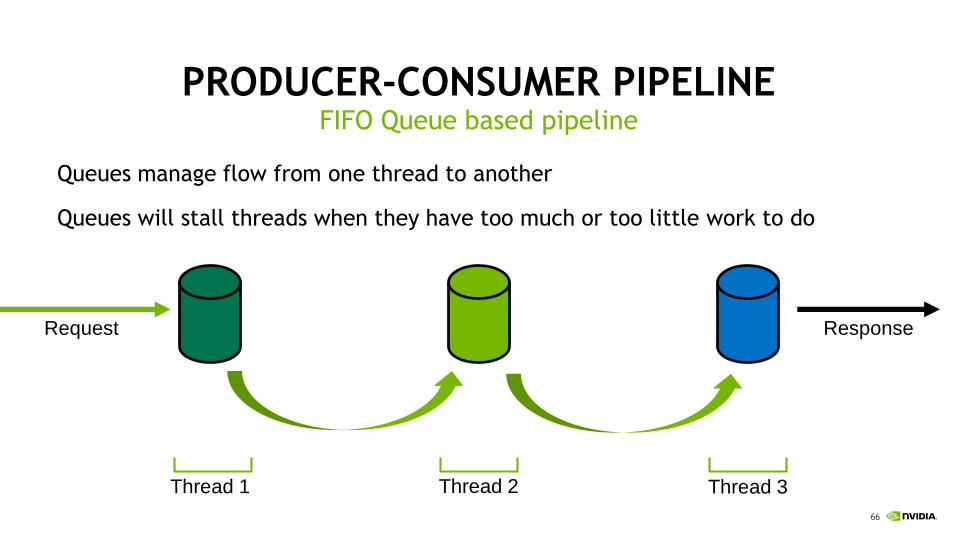
PRODUCER-CONSUMER PIPELINEFIFO Queue based pipeline
ResponseRequest
Thread 1 Thread 2 Thread 3
Queues manage flow from one thread to another (Beauty of the Async model!)
Queues will stall threads when their limited resource is exhausted.
Concurrency is limited by RESOURCES.

Compute → Pre/Post → Serving → Metrics → Kubernetes
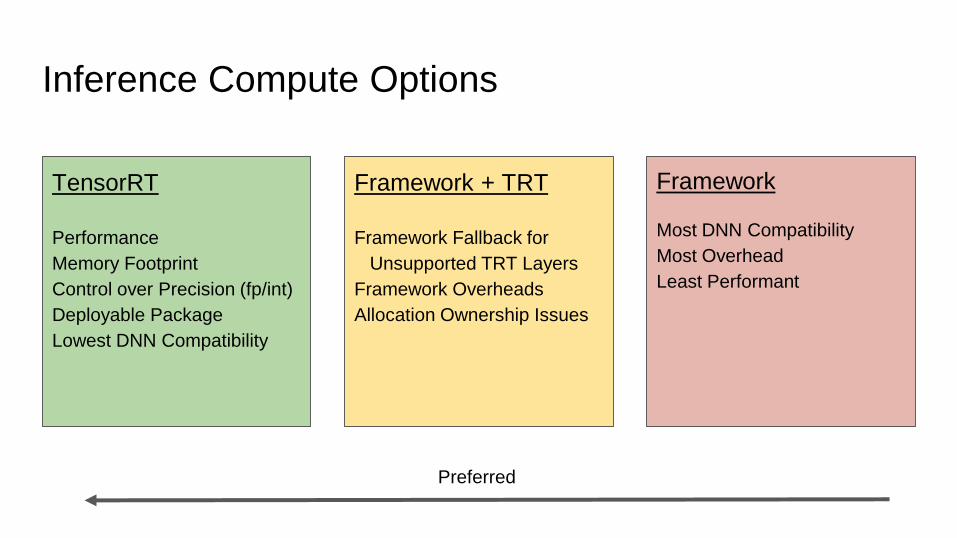
Inference Compute Options
TensorRT
Performance
Memory Footprint
Control over Precision (fp/int)
Deployable Package
Lowest DNN Compatibility
Framework + TRT
Framework Fallback for
Unsupported TRT Layers
Framework Overheads
Allocation Ownership Issues
Framework
Most DNN Compatibility
Most Overhead
Least Performant
Preferred

Starting with Trained Model(s)
● Freeze & Export Inference Graph○ TF = Freeze Graph → UFF or Direct → TensoRT
○ PyTorch, Chainer, MxNet, Caffe2 = ONNX → TensorRT
● Graph Surgery if needed○ Some operations need to be reformatted or re-expressed (identity ops) for TensorRT to
recognize
● These sets of tools are in constant flux. See latest documentation...

18
TENSOR RT
Designed to deliver maximum throughput and efficiency
Runs in two phases: build and deployment
The build phase optimizes the network for target hardware and serializes result
Deployment phase executes on batches of input without any deep learning framework
19
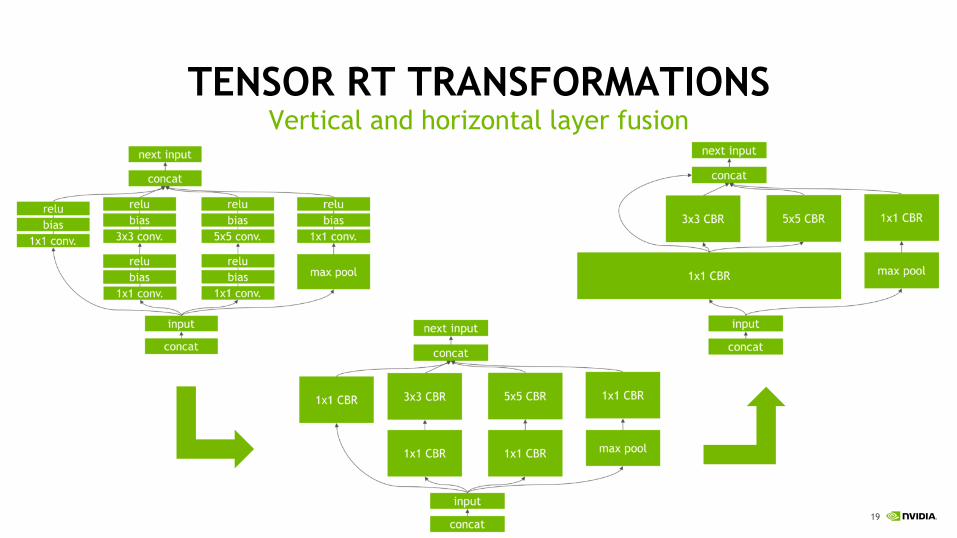
TENSOR RT TRANSFORMATIONSVertical and horizontal layer fusion

20
Sub graph is replaced by a
single TensorRT “op” in TensorFlow
This is the sub graph that can be
accelerated by TensorRT
The rest of the graph
runs in TensorFlow
as before.
Note: conv1 is a
format conversion

TensorRT in Action
- Build a .engine
- Evaluate:- Batch1 FP32, FP16, INT8
- What will we learn?- Precision matters
- FP16 is essentially free (if the GPU supports it)
- INT8 is worth exploring, but is not a drop-in. Extra calibration steps required.
- Building an engine requires a dedicated GPU
- Building an engine is a non-trivial in time (could limit the rate at which you spin up containers)
- General Profile of Input/Output sizes vs. Input/Output Tensors
- Source: https://github.com/NVIDIA/yais/tree/master/examples/00_TensorRT

TensorRT in Action
- V100 Evaluation Batch1- 1 Pipeline + `nvidia-smi dmon -i 0 -s put`
- N Pipelines
- ResNet-50 vs. Deep Recommender
- What will we learn?- Multiple Pipeline are needed to saturate larger GPUs
- Number of Concurrent Pipeline is both model and GPU dependent
- Concurrency
- Improves Throughput
- Increases Individual Compute Time on Device
- Source: https://github.com/NVIDIA/yais/tree/master/examples/00_TensorRT

TensorRT in Action
- V100 Evaluation with Batch8- 1 Pipeline + `nvidia-smi dmon -i 0 -s put`
- N Pipelines
- What will we learn?- Batching Increases Operational Intensity
- Enables Greater Throughput
- Concurrency > Batching for Light Load
- Batching + Concurrency for High Loads
- FP16 accels and excels batched workloads
- Source: https://github.com/NVIDIA/yais/tree/master/examples/00_TensorRT
External / Internal Batchers: https://github.com/NVIDIA/yais/pull/6

Compute → Pre/Post → Serving → Metrics → Kubernetes

Pre/Post Processing
● Problem Specific
● Requires the same level of attention as evaluating the DNN compute
● Questions○ CPU vs. GPU (video decode example)
○ Compute / Compression
■ IN-Process (same memory space)
■ IN-Pod (shared IPC spaces, i.e shared memory, /tmp
■ IN-Node (co-located on the same node via Pod Affinities)
● May need hacks to break down namespace barriers
● Scaled independently
■ Fully Independent
● Answer: Data Movement is Key
Coupled / scaled jointly
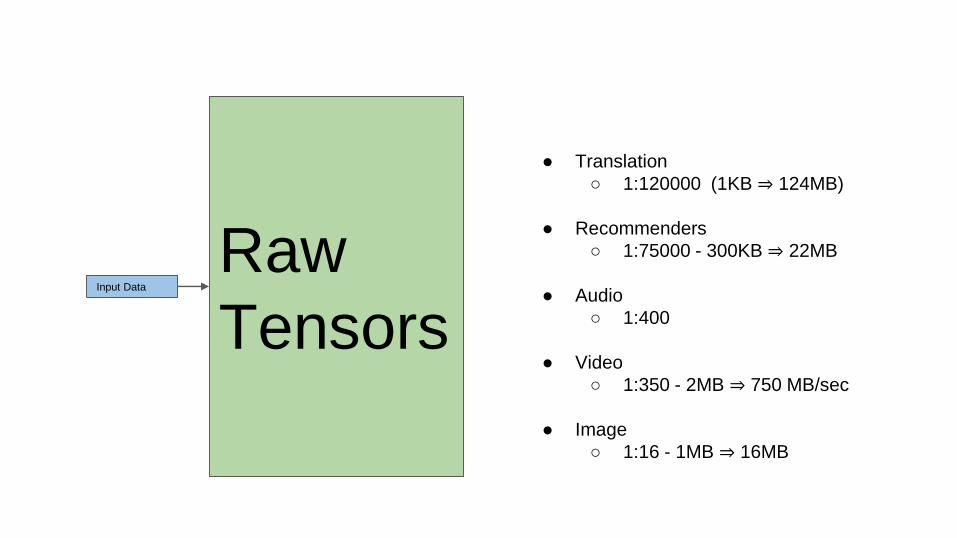
Input Data
Raw
Tensors
● Translation
○ 1:120000 (1KB ⇒ 124MB)
● Recommenders
○ 1:75000 - 300KB ⇒ 22MB
● Audio
○ 1:400
● Video
○ 1:350 - 2MB ⇒ 750 MB/sec
● Image
○ 1:16 - 1MB ⇒ 16MB

Compute → Pre/Post → Serving → Metrics → Kubernetes

Serving Options
TensorRT Inference Server
NGC Container
Ease of Use
TensorRT, TF+TRT, TF, Caffe2
HTTP/gRPC
Multiple Models
Multiple Frameworks
Dynamic Batching
YAIS
Open Source
Fully Featured Library
Async gRPC Simplified
Performance-First Design (Compute/Memory)
Maximum Flexibility
C++ required for customization
BYO-Extras (Frameworks)
Requires some Ninja skillz
Ease of Use, Support, Features Maximum Customization / Control

29
Metadata
Model
Labels
INFERENCE SERVER ARCH
Models supported:TensorFlow GraphDef and TensorRT models (including TensorRT/TensorFlow integrated models)ONNX / Caffe2 and ONNX / TensorRT
Multi-GPU and multi-tenancy
Server HTTP REST API
Python/C++ client library
Beta release available with monthly updates
CPU
Inference Server
GPU
…
HTTP/GRPC
Status Infer
Python/C++ Client Library
Client API
Model
Model Store

Messaging Queue
(Request/Response)
Model Store
Cassandra
(Logs)
TensorRT Server
(GPU)
Clients
NGC Inference App (CPU)
Clie
nt A
PI
Pre
Processing
Post
Processing
Inference
NGC Inference
Service
(hosted on Web
Servers)
Inference Storage
(Images/masks)
Frontend
NV Research Demo Site ATTIS Usage Workflow

YAIS for Custom Services
● TensorRT Server Pre/Postprocessing Service
● External Batcher / Middleman
● Non-Inference ML methods
● CUDA optimized applications: Monte-Carlo methods, Rendering
● In-Process pre/post-processing
● Sophisticated multi-model chaining

37
PRODUCER-CONSUMER PIPELINEFIFO Queue based pipeline
ResponseRequest
Thread 1 Thread 2 Thread 3
Queues manage flow from one thread to another (Beauty of the Async model!)
Queues will stall threads when their limited resource is exhausted.
Concurrency is limited by RESOURCES.

Compute → Pre/Post → Serving → Metrics → Kubernetes

Metrics
● Exposed via a Prometheus Library○ https://github.com/NVIDIA/yais/pull/2
● How to Evaluate your Service?○ Batches / second (counter/rate)
○ Inference / second (counter/rate)
○ GPU Power (gauge)
○ Queue Depth (gauge)
○ Request Time (summary quantile 50/90/99) [per model]
○ Compute Time (summary quantile 50/90/99) [per model]
○ Load Ratio [request time / compute_time]
(histogram: buckets [2, 4, 10, 100, 1000])

Compute → Pre/Post → Serving → Metrics → Kubernetes

Kubernetes Deployment
● KONG for GPU support○ DeepOps - Kubernetes + Slurm + Monitoring + Terraform + Ansible
https://github.com/nvidia/deepops
○ Minikube for Development
https://github.com/NVIDIA/yais/tree/master/examples/90_Kubernetes
● NGC TensorRT as Base Image
● Istio to manage Ingress, Routing and Load-Balancing
● Prometheus to Scrape Custom Metrics from Inference Services○ kube-prometheus + prometheus operator
● Grafana to visualize metrics
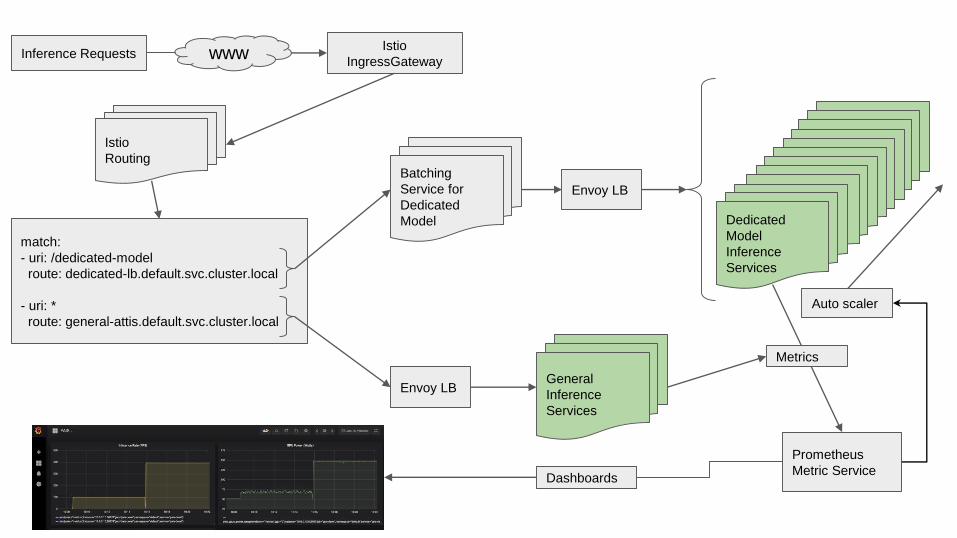
Istio
IngressGatewayInference Requests www
Istio
Routing
match:
- uri: /dedicated-model
route: dedicated-lb.default.svc.cluster.local
- uri: *
route: general-attis.default.svc.cluster.local
Batching
Service for
Dedicated
Model
Envoy LB
Dedicated
Model
Inference
Services
Envoy LBGeneral
Inference
Services
Prometheus
Metric Service
Auto scaler
Metrics
Dashboards

- Flow- Bootstrap
- Prometheus Metrics Stack
- Istio
- Launch TensorRT Server
- Start the Client
- Scale Service (manually)
- What will we learn?- Kubernetes is awesome!
- https://github.com/NVIDIA/yais/tree/master/examples/90_Kubernetes
Full Demo

Questions


50
Backup Slides

51
Building and Deploying an Inference Service
- Challenges
- Accelerating your Model
- Defining an Inference Service
- Deploying a Service
- Along the way
- Lessons Learned
- Best Practices
- … and a few funny moments...
Nothing -> Docker -> Kubernetes

52
DEMO: “INFERENCE ON FLOWERS”

53
COMMON TERMS AND METRICS
• Programmability
• Energy Efficiency
• Throughput
• Accuracy
• Latency
• Size
• Rate of Learning
PLASTER or (PETALS + R)
54
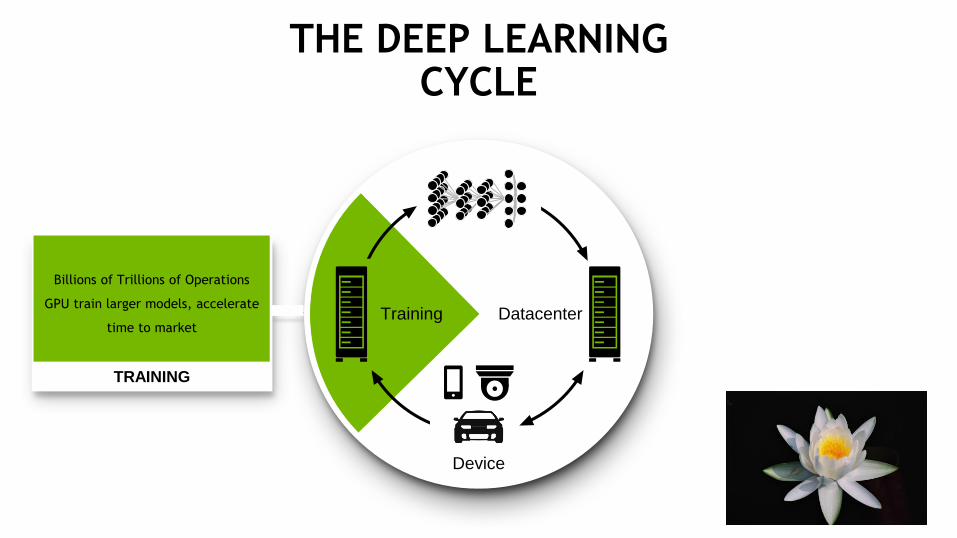
Training
Device
Datacenter
TRAINING
Billions of Trillions of Operations
GPU train larger models, accelerate
time to market
THE DEEP LEARNINGCYCLE

55
Training
Device
Datacenter
THE DEEP LEARNINGCYCLE
DATACENTER INFERENCING
10s of billions of image, voice, video
queries per day
GPU inference for fast response,
maximize datacenter throughput

56
INFERENCETRAINING
COMPARING TRAINING AND INFERENCE
▪ Calculates both forward and backwards propagation
▪ Large batch sizes to prevent overfitting
▪ More memory and computationally intensive
▪ Primary goal: Maximize total throughput
▪ Forward propagation only
▪ Small(er) batch sizes to minimize latency
▪ Requires less numerical precision
▪ Primary goal: balance maximum throughput with minimum latency

57
TENSOR RT
Designed to deliver maximum throughput and efficiency
Runs in two phases: build and deployment
The build phase optimizes the network for target hardware and serializes result
Deployment phase executes on batches of input without any deep learning framework

58
TENSOR RT TRANSFORMATIONSVertical and horizontal layer fusion

59
TENSOR RT RESULTSExample results
NETWORK LAYERSLAYERS AFTER
FUSION
VGG19 43 27
Inception V3 309 113
ResNet-152 670 159

60
INFERENCING COST SAVINGSThe More GPUs you buy...
INFERENCING
Video analytics
Translate
Search
VALUEDL INFERENCE TAM
INT8 (AI INFERENCE) EIOPs
Speak450 EIOPs
50 EIOPs
50K Inference/sec
12 RACKS
$2.3M
1 RACK
$240k
Source: NVIDIA, publicly available data, inference using Resnet-50.
$2M SAVINGS PER RACK$15B
FASTER REAL-TIME
INFERENCING10x

61
Design the Inference Service

62
DEMO ORGANIZATION
Client
Shared Memory
V100
V100V100V100V100
V100V100V100V100
Shared Memory
Shared Memory
Skylake
V100
DGX-1V

63
Design
- Rapid Prototype simple Python GRPC service
- Advanced Optimized C++ GPRC service
- Shared-Memory linkages
- Demo - Allows 1 client to simulate 1000s of Clients
- In Production - Allows for optimized separable services

64
NAÏVE PIPELINE
Pre and post processing can cut into GPU execution time
Utilization often not at 100%
Single threaded naïve approach
Time
Under Utilized
Kernel (GPU)
Post-process (CPU)
Pre-process (CPU)
65
PING-PONG PIPELINE
If GPU execution is longer than pre and post processing, can fully saturate the GPU
If not, 3 threads may be necessary
Single threaded naïve approach
Time
Thread 1
Thread 2
Kernel (GPU)
Post-process (CPU)
Pre-process (CPU)
66
PRODUCER-CONSUMER PIPELINEFIFO Queue based pipeline
ResponseRequest
Thread 1 Thread 2 Thread 3
Queues manage flow from one thread to another
Queues will stall threads when they have too much or too little work to do

67
INFERENCE IMPROVEMENTS OVER TIME
IMPLEMENTATION IMAGES/SEC LATENCY
CPU Only 5.5 ~200 ms
GPU ~45 ~20 ms
GPU + TensorRT ~500 9.9 ms
GPU + TensorRT + C++ Pipeline
~900 8.7 ms

68
Deployment

69
Deployment
- Develop on Docker
- The Magic of Base Images
- Docker-Compose is your Friend
- Deploy on Kubernetes
- Define in Software/Code the Applications requirements
- Let Kubernetes manage the lifecycle of the application
- Scheduling, Health Checking, etc.
Containers, Containers, Containers...

70
DEMO: “INFERENCE ON FLOWERS”