the nmr fingerprints of proteins: what you can see in simple spectra typical chemical shifts...
TRANSCRIPT

The NMR Fingerprints of Proteins:What you can see in simple spectra
• typical chemical shifts observed in proteins• interpreting simple 1D spectra• interpreting 15N-1H 2D correlation (HSQC) spectra• using changes in HSQC spectra to measure binding events

a reference frequency of0 ppm is defined by the signalfrom an internal standardsuch as DSS or TMSP
chemical shift dispersion is very small (~12 ppm) compared to the B0 field strength (like ripples on an ocean surface). At 500 MHz, 12 ppm is a 6 KHz range. This makes it easy to pulse in the center of the 1H spectrum, around 4.5-5 ppm, and excite all resonances nearly evenly.
x axis is the chemicalshift , in units ofparts per million (ppm)of the B0 field strength
not all nuclei in a protein will have the same resonance frequency (the spectrum would be pretty uninformative if they did!)
so why don’tall the nucleihave thesame frequency?
Chemical shift
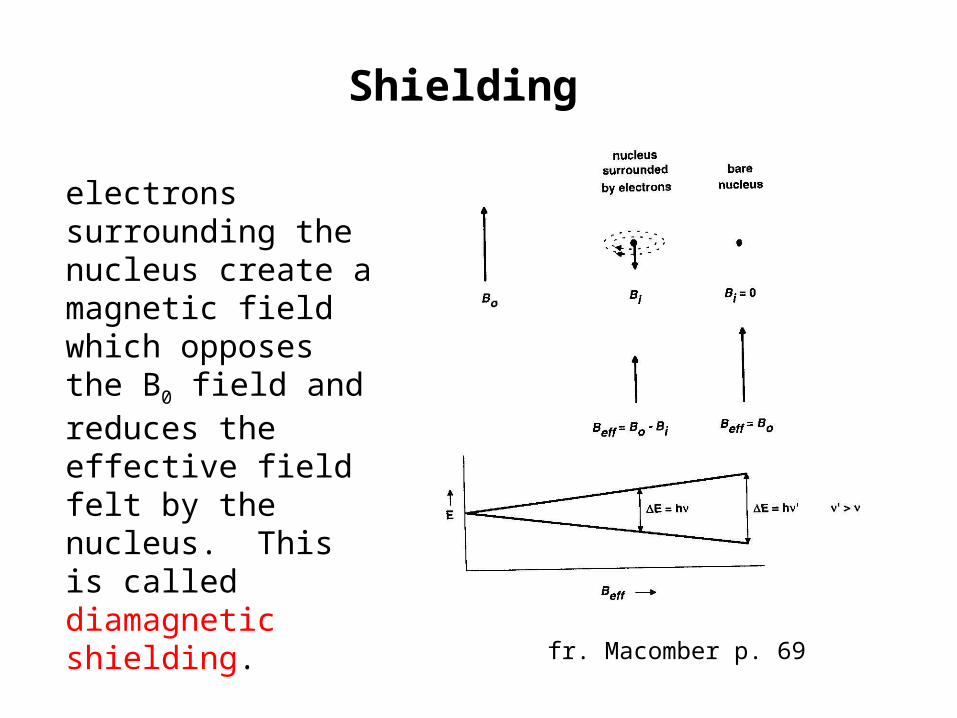
Shielding
electrons surrounding the nucleus create a magnetic field which opposes the B0 field and reduces the effective field felt by the nucleus. This is called diamagnetic shielding.
fr. Macomber p. 69

The amount of shielding the nucleus experiences will vary with the density of the surrounding electron cloud If a 1H nucleus is bound to a more electronegative atome.g. N or O as opposed to C, the density of the electron cloud will be lower and it will be less shielded or “deshielded”. These considerations extend beyond what is directly bonded to the H atom as well.
Simple shielding effects--electronegativity
N
H
C
H
more electronwithdrawing--less shielded
less electronwithdrawing--more shielded
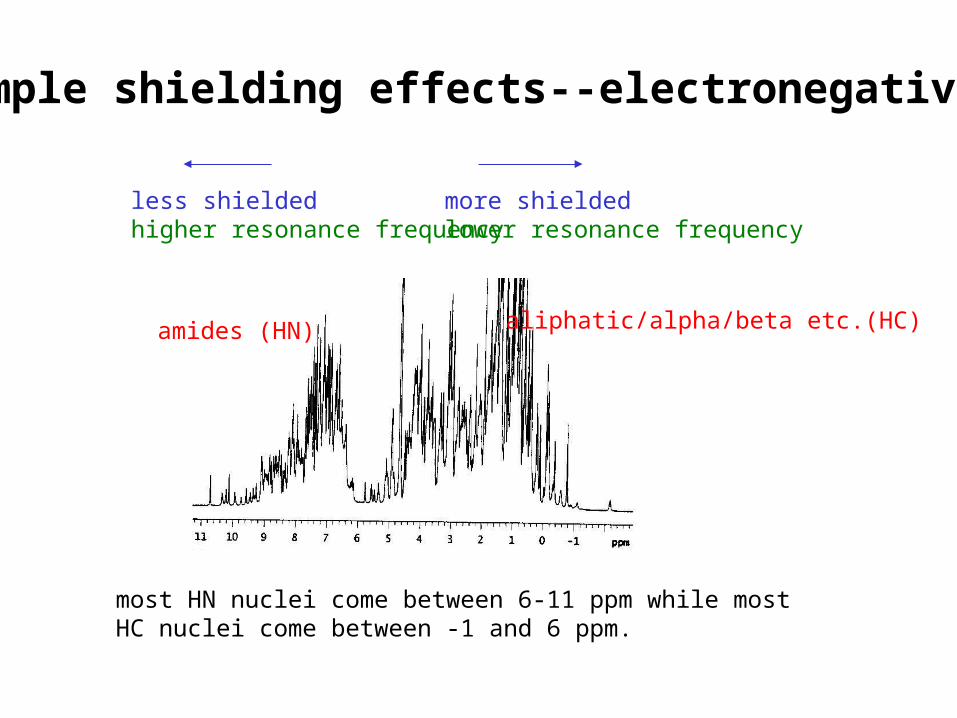
less shielded higher resonance frequency
more shielded lower resonance frequency
amides (HN) aliphatic/alpha/beta etc.(HC)
most HN nuclei come between 6-11 ppm while mostHC nuclei come between -1 and 6 ppm.
Simple shielding effects--electronegativity
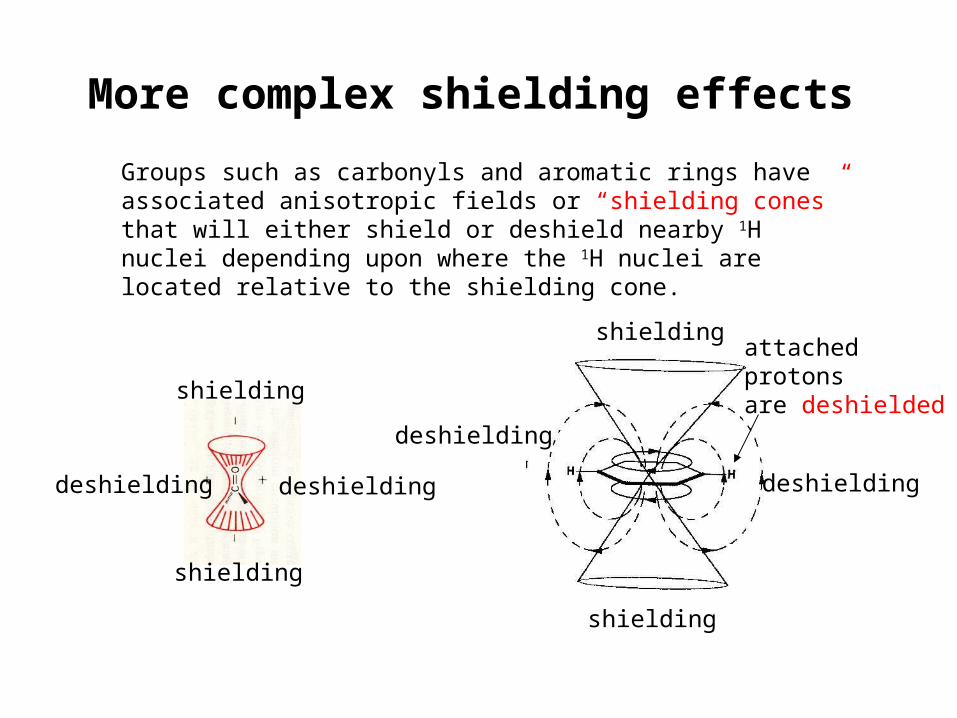
More complex shielding effects
Groups such as carbonyls and aromatic rings have associated anisotropic fields or “shielding cones” that will either shield or deshield nearby 1H nuclei depending upon where the 1H nuclei are located relative to the shielding cone.
shielding
shielding
deshieldingdeshielding
shielding
shielding
deshielding
deshielding
attached protonsare deshielded
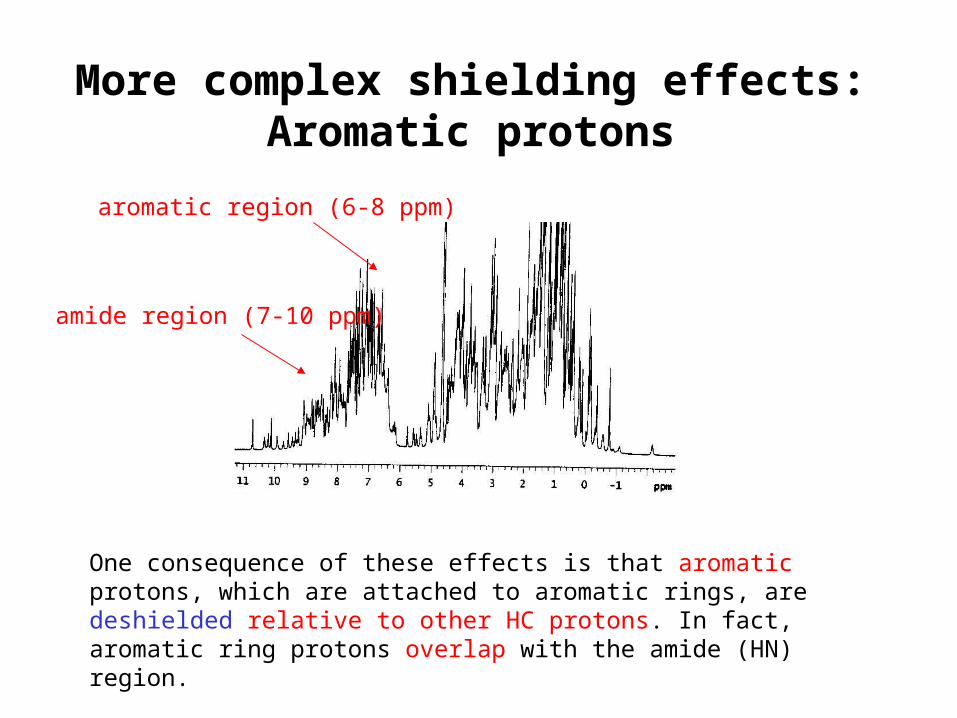
One consequence of these effects is that aromatic protons, which are attached to aromatic rings, are deshielded relative to other HC protons. In fact, aromatic ring protons overlap with the amide (HN) region.
aromatic region (6-8 ppm)
amide region (7-10 ppm)
More complex shielding effects:Aromatic protons
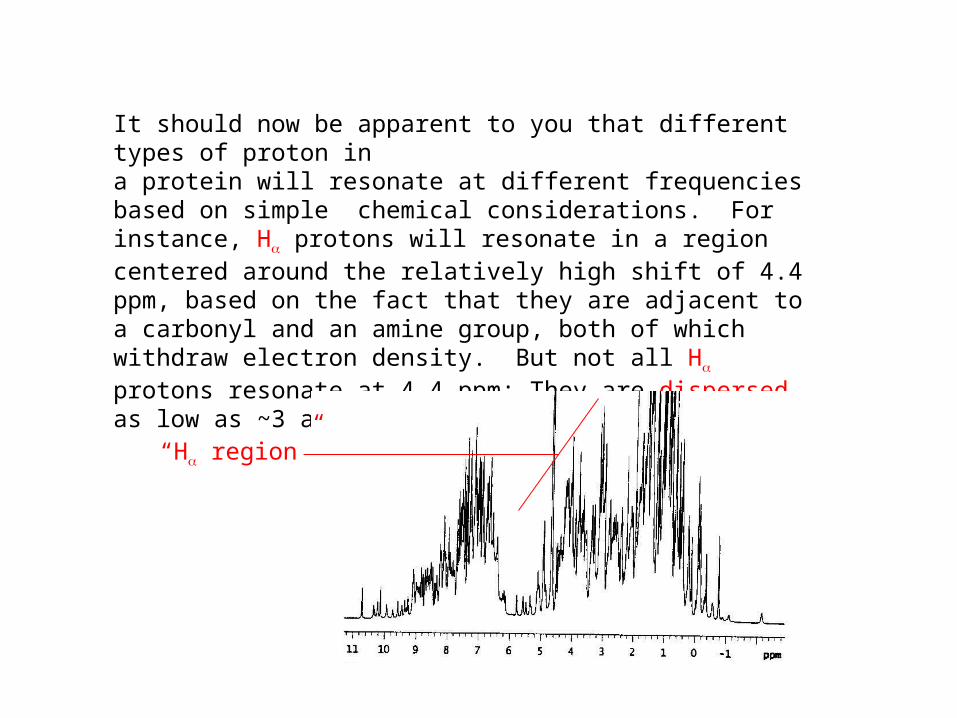
It should now be apparent to you that different types of proton ina protein will resonate at different frequencies based on simple chemical considerations. For instance, H protons will resonate in a region centered around the relatively high shift of 4.4 ppm, based on the fact that they are adjacent to a carbonyl and an amine group, both of which withdraw electron density. But not all H protons resonate at 4.4 ppm: They are dispersed as low as ~3 and as high as ~5.5. Why?
“H region”
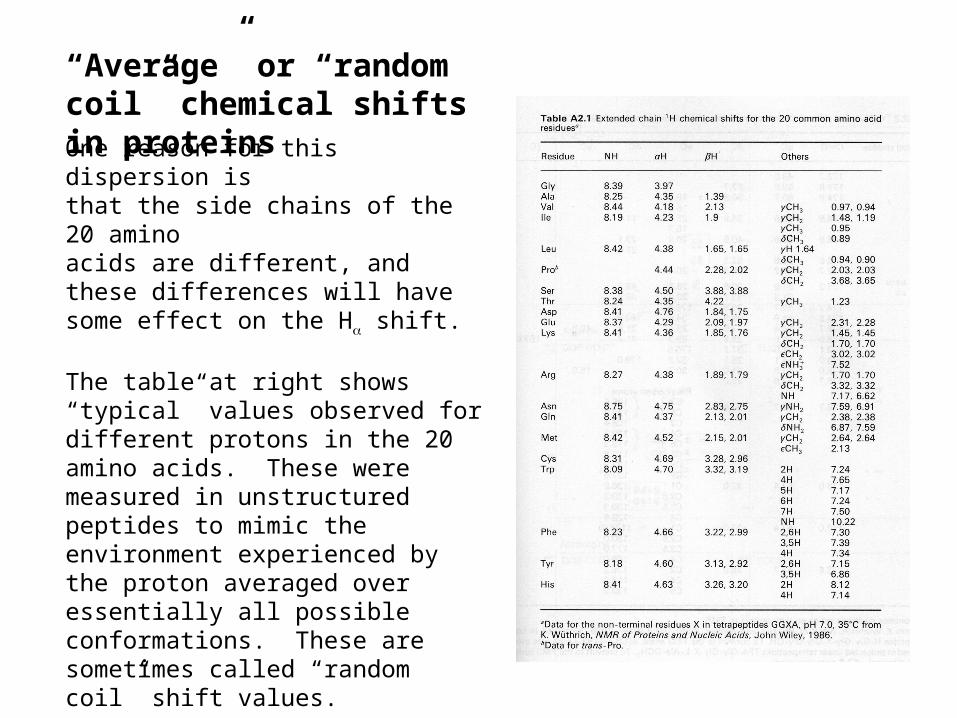
“Average” or “random coil” chemical shifts in proteinsOne reason for this dispersion isthat the side chains of the 20 aminoacids are different, and these differences will have some effect on the H shift.
The table at right shows “typical” values observed for different protons in the 20 amino acids. These were measured in unstructured peptides to mimic the environment experienced by the proton averaged over essentially all possible conformations. These are sometimes called “random coil” shift values.
Note that the Hshifts range from ~4-4.8, but Hshifts in proteins range from ~3 to 5.5. So this cannot entirely explain the observed dispersion.
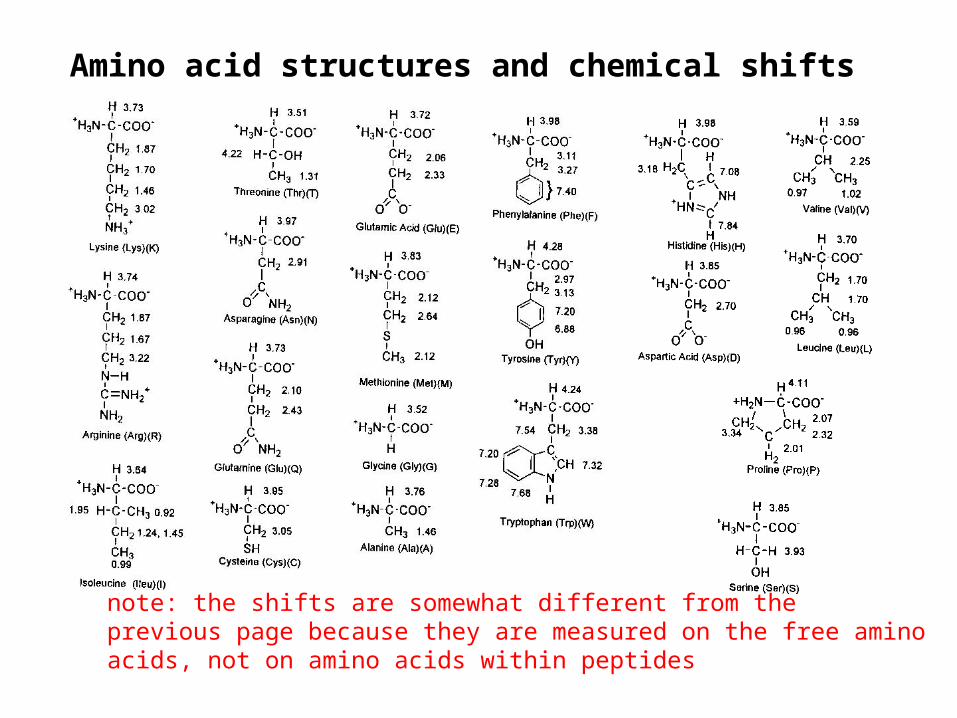
Amino acid structures and chemical shifts
note: the shifts are somewhat different from theprevious page because they are measured on the free aminoacids, not on amino acids within peptides

A simple reason for the increased shift dispersion is that the environment experienced by 1H nuclei in a folded protein (B) is not the same as in a unfolded, extended protein or “random coil” (A).
shift of particular proton in folded protein influenced by groups nearby in space, conformation of the backbone, etc. Not averaged among many structures because there is only one folded structure.
So, some protons in folded proteins will experience very particular environments and will stray far from the average.
shift of particular proton in unfolded protein is averaged over many fluctuating structures
will be nearrandom coilvalue
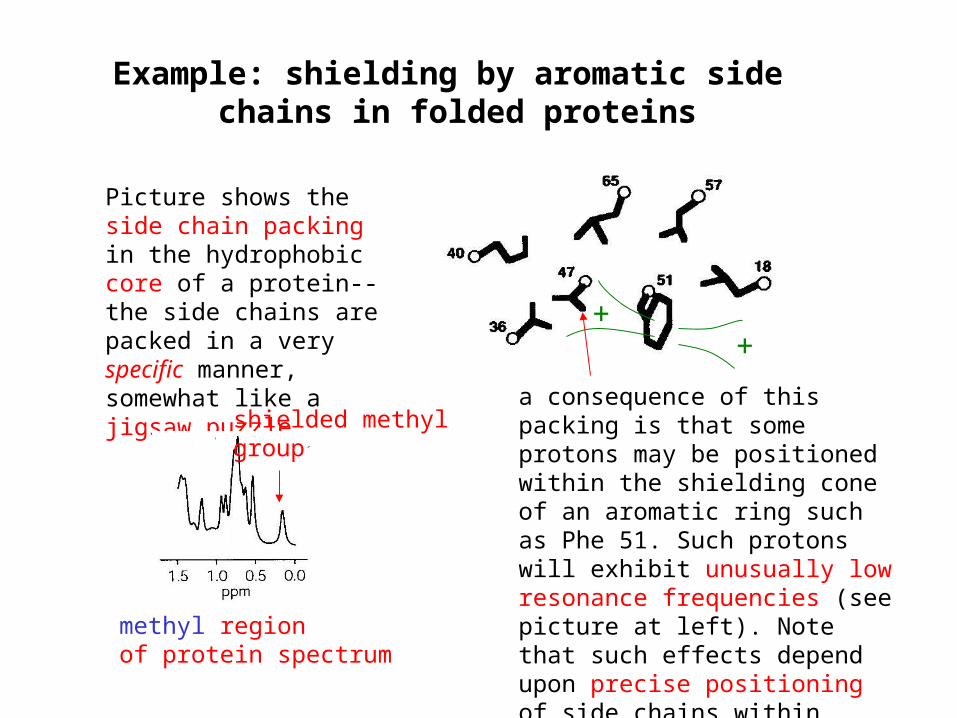
Example: shielding by aromatic side chains in folded proteins
Picture shows the side chain packing in the hydrophobic core of a protein--the side chains are packed in a very specific manner, somewhat like a jigsaw puzzle
a consequence of this packing is that some protons may be positioned within the shielding cone of an aromatic ring such as Phe 51. Such protons will exhibit unusually low resonance frequencies (see picture at left). Note that such effects depend upon precise positioning of side chains within folded proteins
++
shielded methylgroup
methyl regionof protein spectrum
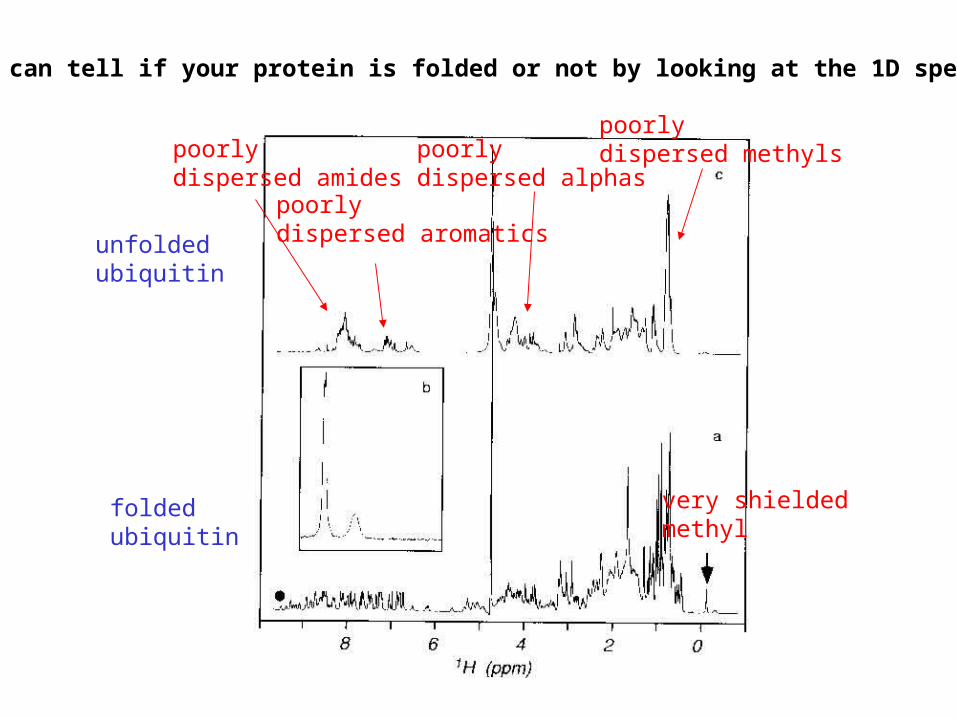
poorlydispersed amides
poorlydispersed aromatics
poorlydispersed alphas
poorlydispersed methyls
very shielded methyl
unfoldedubiquitin
foldedubiquitin
so you can tell if your protein is folded or not by looking at the 1D spectrum...
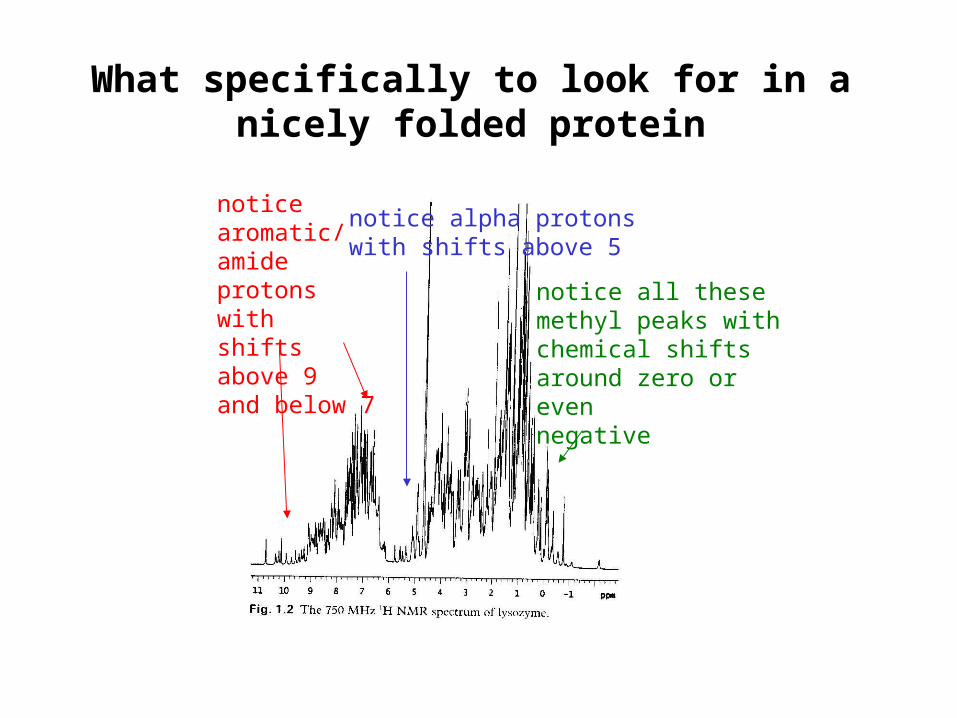
What specifically to look for in a nicely folded protein
noticearomatic/amideprotons withshifts above 9and below 7
notice alpha protonswith shifts above 5
notice all these methyl peaks withchemical shifts around zero or evennegative

Linewidths in 1D spectra: aggregation andconformational flexibility
Linewidths get broader with larger particle size, due to faster transverse relaxation rates. We’ll learn the physical basis for the faster relaxation later. Broader than expected linewidths can indicate that the protein is aggregated. It can also indicate that the protein has conformational flexibility, i.e. that its structure is fluctuating between several slightly different forms. We’ll learn why this is when we cover the effect of protein dynamics on NMR spectra. Conformational flexibility also tends to reduce dispersion by averaging the environment experienced by a nucleus.

An example of analyzing linewidths and dispersion:
Hill & DeGrado used measurements of chemical shift dispersion and line broadening in the methyl region of 1D spectra to gauge the effect of mutations at position 7 on the conformational flexibility of 2D protein
leucine and valine mutants have poordispersion and broad lines, despite being very stably foldedand not aggregated (circular dichroism and analytical ultra- centrifugation measurements). These mutants are folded but flexible.
Hill & DeGrado (2000) Structure 8: 471-9.

In general, 1D NMR provides only qualitative information about your protein:
Does it have a stable, specific folded structure under the NMR conditions?
Does it seem to be aggregated?
Spectra of even small proteins (e.g. 6 kD), unlike the spectra of small organic molecules and short peptides, are just too complex to be studied by 1D methods.
Limitations of 1D NMR

Adding a second dimension: Isotopic labelling
There are many overlapping resonances in 1D protein spectra. One way to remove this overlap is to label your protein with 15N and/or 13C and correlate the chemical shift of each 1H nucleus with the chemical shift of the 15N or 13C atom to which it is directly attached.
This is done by transferring the magnetization between the two atoms using the large one-bond 13C-1H or 15N-1H scalar coupling
15N---1H
J = ~89-95 Hz
13C---1H
J = ~110-160 Hz
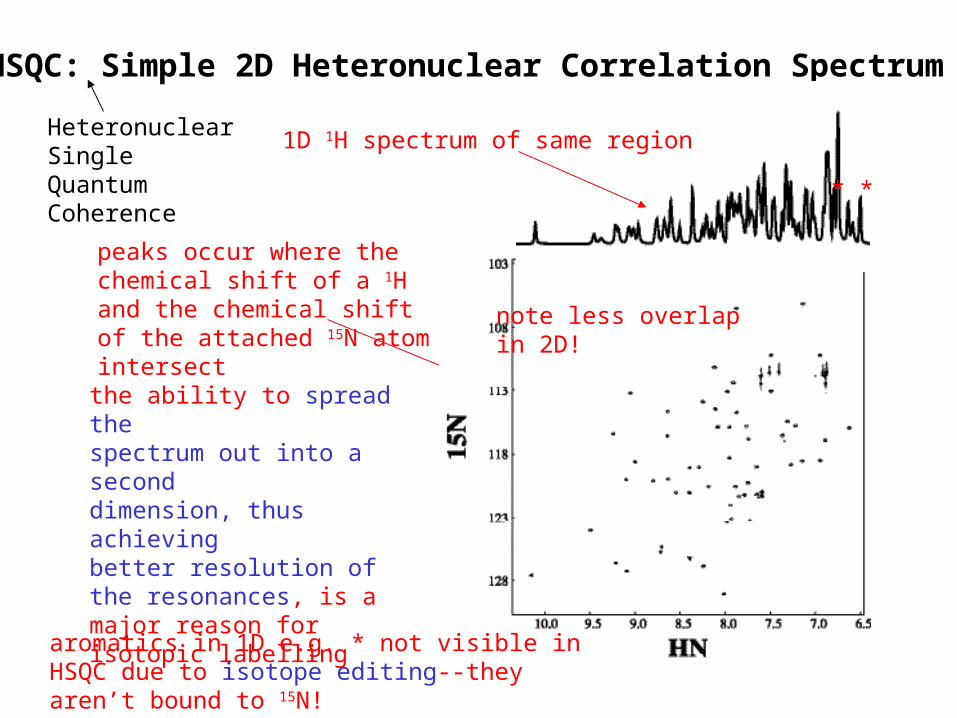
HSQC: Simple 2D Heteronuclear Correlation Spectrum
the ability to spread thespectrum out into a seconddimension, thus achievingbetter resolution of the resonances, is a major reason for isotopic labelling
peaks occur where the chemical shift of a 1H and the chemical shift of the attached 15N atom intersect
1D 1H spectrum of same region
aromatics in 1D e.g. * not visible in HSQC due to isotope editing--they aren’t bound to 15N!
* *
HeteronuclearSingleQuantumCoherence
note less overlapin 2D!
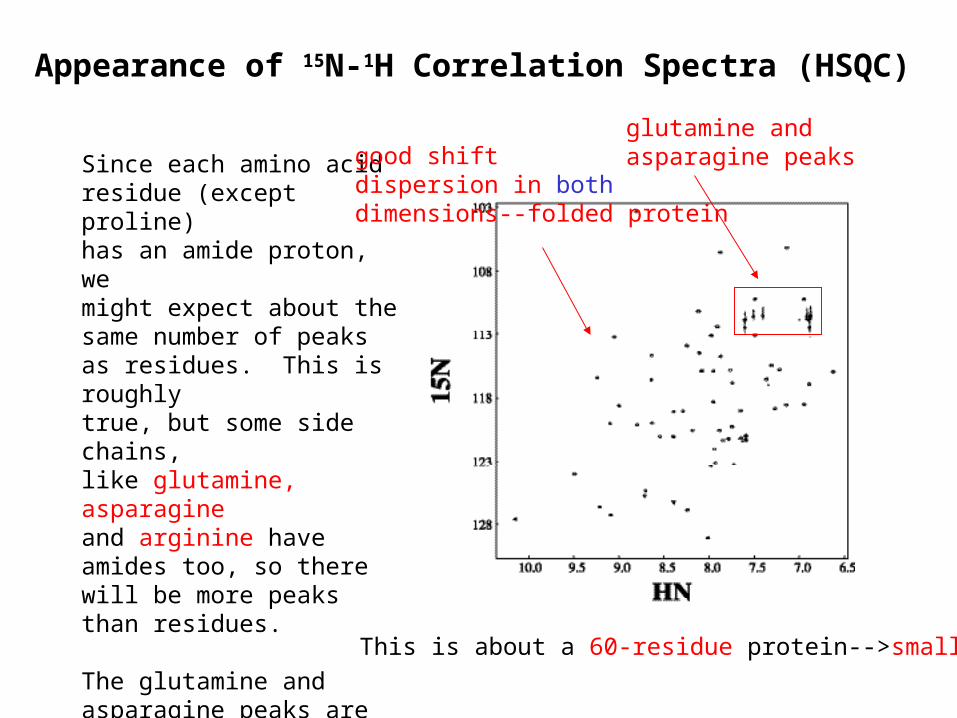
Since each amino acidresidue (except proline)has an amide proton, wemight expect about thesame number of peaksas residues. This is roughlytrue, but some side chains,like glutamine, asparagineand arginine have amides too, so there will be more peaks than residues.
The glutamine and asparagine peaks are especially recognizable--they are pairs of 1H shifts correlated to a single nitrogen in the upper right portion of the spectrum
glutamine andasparagine peaks
This is about a 60-residue protein-->small
Appearance of 15N-1H Correlation Spectra (HSQC)
good shiftdispersion in bothdimensions--folded protein
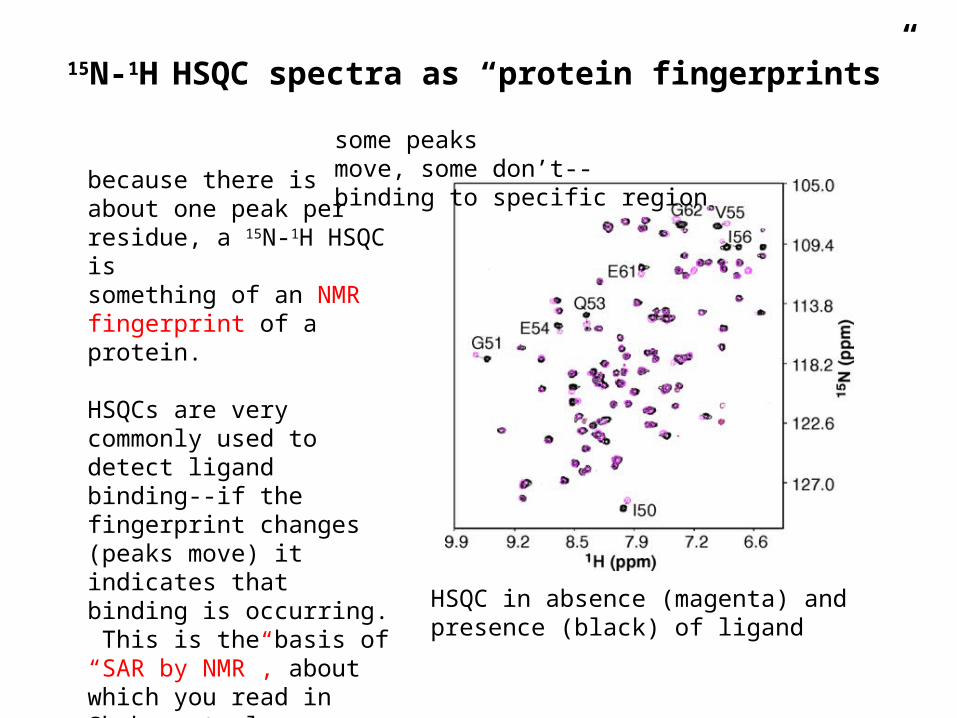
15N-1H HSQC spectra as “protein fingerprints”
because there isabout one peak perresidue, a 15N-1H HSQC issomething of an NMR fingerprint of a protein.
HSQCs are very commonly used to detect ligand binding--if the fingerprint changes (peaks move) it indicates that binding is occurring. This is the basis of “SAR by NMR”, about which you read in Shuker et al.
HSQC in absence (magenta) andpresence (black) of ligand
some peaksmove, some don’t--binding to specific region

Notice that SAR by NMR uses an approach whereby two ligands are sought which bind to two different places with micromolar affinity. They are then linked together to produce a single ligand with nanomolar/picomolar affinity. One can tell that the two ligands bind in different places because different peaks move, or because one will bind in the presence of the other (no competitive inhibition).
Why don’t they just screen for a single ligand with nanomolar/picomolar affinity in the first place?
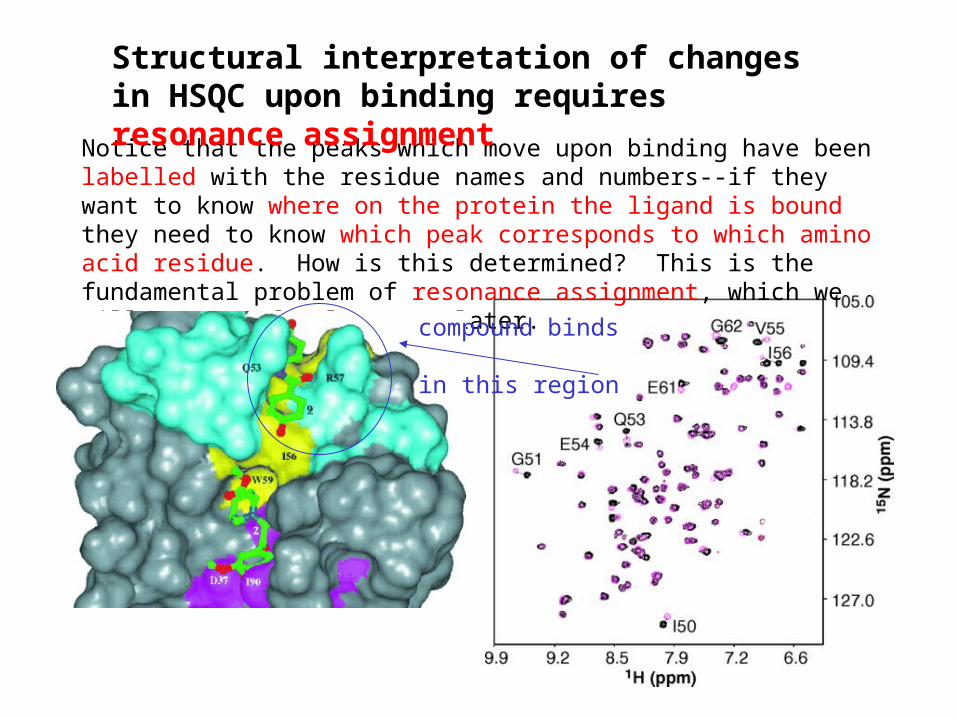
Notice that the peaks which move upon binding have been labelled with the residue names and numbers--if they want to know where on the protein the ligand is bound they need to know which peak corresponds to which amino acid residue. How is this determined? This is the fundamental problem of resonance assignment, which we will cover a few lectures later.
Structural interpretation of changes in HSQC upon binding requires resonance assignment
compound binds
in this region