the practical value of statistics for sentence generation: the perspective of the nitrogen system
DESCRIPTION
The Practical Value of Statistics for Sentence Generation: The Perspective of the Nitrogen System. Irene Langkilde-Geary. How well do statistical n-grams make linguistic decisions?. Subject-Verb Agreement Article-Noun Agreement - PowerPoint PPT PresentationTRANSCRIPT

The Practical Value of Statistics for Sentence Generation:
The Perspective of the Nitrogen System
Irene Langkilde-Geary

How well do statistical n-grams make linguistic decisions?
Subject-Verb Agreement Article-Noun Agreement
I am 2797 a trust 394 an trust 0 the trust 1355I are 47 a trusts 2 an trusts 0 the trusts 115I is 14
Singular vs Plural Word Choice
their trust 28 reliance 567 trust 6100their trusts 8 reliances 0 trusts 1083

More ExamplesRelative pronoun Prepositionvisitor who 9 visitors who 20 in Japan 5413 to Japan 1196visitor which 0 visitors which 0visitor that 9 visitors that 14 came to 2443 arrived in 544 came in 1498 arrived to 35Singular vs Plural came into 244 arrived into 0visitor 575 visitors 1083 came to Japan 7 arrived to Japan 0Verb Tense came into Jap 1 arrived into Japan 0admire 212 admired 211 came in Japan 0 arrived in Japan 4admires 107

How can we get a computer to learn by “reading”?

Nitrogen takes a two-step approach
1. Enumerate all possible expressions2. Rank them in order of probabilistic
likelihood
Why two steps? They are independent.

Assigning probabilities
• Ngram modelFormula for bigrams: P(S) = P(w1|START) * P(w2|w1) * … * P(w n|w n-2)
• Probabilistic syntax (current work)– A variant of probabilistic parsing models

Sample Results of Bigram model
Random path: (out of a set of 11,664,000 semantically-related sentences)Visitant which came into the place where it will be Japanese has admired that there
was Mount Fuji.
Top three:Visitors who came in Japan admire Mount Fuji .Visitors who came in Japan admires Mount Fuji .Visitors who arrived in Japan admire Mount Fuji .
Strengths• Reflects reality that 55% (Stolke et al. 1997) of dependencies are
binary, and between adjacent words• Embeds linear ordering constraints

Limitations of Bigram model
Example Reason
Visitors come in Japan. A three-way dependencyHe planned increase in sales. Part-of-speech ambiguityA tourist who admire Mt. Fuji... Long-distance dependencyA dog eat/eats bone. Previously unseen ngramsI cannot sell their trust. Nonsensical head-arg
relationshipThe methods must be modified to Improper subcat structure
the circumstances.

Representation of enumerated possibilities
(Easily on the order of 1015 to 1032 or more)
• List• Lattice• Forest
Issues• space/time constraints
• redundancy
• localization of dependencies
• non-uniform weights of dependencies




Number of phrases versus size (in bytes) for 15 sample inputs
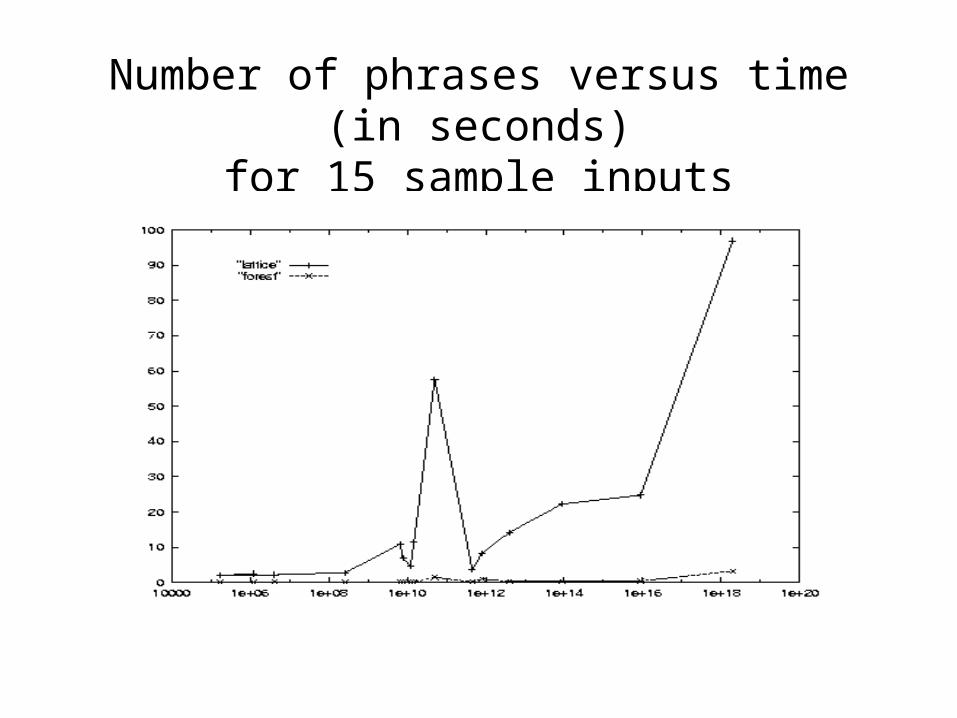
Number of phrases versus time (in seconds)for 15 sample inputs

Generating from Templates and Meaning-based Inputs
INPUT ( <label> <feature> VALUE )VALUE INPUT -OR--OR- <label>
Labels are defined in: 1. input 2. user-defined lexicon3. WordNet-based lexicon
(~ 100,000 concepts)
Example Input:(a1 :template (a2 / “eat”
:agent YOU
:patient a3):filler (a3 / |poulet| ))


Mapping Rules1. Recast one input to another
– (implicitly providing varying levels of abstraction)2. Assign linear order to constituents3. Add missing info to under-specified inputs
Matching Algorithm• Rule order determines priority. Generally:
– Recasting < linear ordering < under-specification– High (more semantic) level of abstraction < low (more syntactic)– Distant position (adjuncts) from head < near (complements)– Basic properties < specialized

Recasting(a1 :venue <venue>
:cusine <cuisine> )
(a2 / |serve| :agent <venue> :patient <cuisine> )
(a2 / |have the quality of being| :domain (a3 / “food type”
:possessed-by <venue>) :range (b1 / |cuisine|))

Recasting (a1 :venue <venue>
:region <region> )
(a2 / |serve| :agent <venue> :patient <cuisine>
(a3 / |serve| :voice active :subject <venue> :object <cuisine> )
(a3 / |serve| :voice passive :subject <cuisine> :adjunct (b1 / <venue>
:anchor |BY| ))

Linear ordering
(a3 / |serve| :voice active :subject <venue> :object <cuisine> )
<venue> (a4 / |serve| :voice active :object <cuisine> )

Under-specification
(a4 / |serve|)
(a5 / |serve|
:cat verb)
(a6 / |serve|
:cat noun)

Under-specification
(a4 / |serve|)
(a5 / |serve|
:cat verb)
(a5 / |serve|
:cat verb
:tense past)(a5 / |serve|
:cat verb
:tense present)

Core features currently recognized by Nitrogen
Syntactic relations
:subject :object :dative :compl :pred :adjunct :anchor :pronoun :op :modal :taxis :aspect :voice :article
Functional relations:logical-sbj :logical-obj :logical-dat :obliq1 :obliq2 :obliq3 :obliq2-of :obliq3-of :obliq1-of :attr :generalized-possesion :generalized-possesion-inverse
Semantic/Systemic Relations :agent :patient :domain :domain-of :condition :consequence :reason :compared-to :quant :purpose :exemplifier :spatial-locating :temporal-locating :temporal-locating-of :during :destination :means :manner :role :role-of-agent :source :role-of-patient :inclusive :accompanier :sans :time :name :ord
Dependency relations :arg1 :arg2 :arg3 :arg1-of :arg2-of :arg3-of

Properties used by Nitrogen
:cat [nn, vv, jj, rb, etc.]
:polarity [+, -]
:number [sing, plural]
:tense [past, present]
:person [1s 2s 3s 1p 2p 3p s p all]
:mood [indicative, pres-part, past-part, infinitive, to-inf, imper]

How many grammar rules needed for English?
Sentence Constituent+Constituent Constituent+ OR LeafLeaf Punc* FunctionWord* ContentWord
FunctionWord* Punc*FunctionWord ``and'' OR ``or'' OR ``to'' OR ``on'' OR
``is'' OR ``been'' OR ``the'' OR ….ContentWord Inflection(RootWord,Morph) RootWord ``dog'' OR ``eat'' OR ``red'' OR ....
Morph none OR plural OR third-person-singular ...

Computational Complexity(x2/A2) + (y2/B2) = 1
X
Y
???

Advantages of a statistical approachfor symbolic generation module
• Shifts focus from “grammatical” to “possible”• Significantly simplifies knowledge bases• Broadens coverage• Potentially improves quality of output• Dramatically reduces information demands on
client• Greatly increases robustness
