the role of libraries in data management and curation
DESCRIPTION
The Role of Libraries in Data Management and Curation, presented at the American Library Association conference in Las Vegas, NV, 07/29/14. Abstract: As increasing amounts of data are being generated, applying best practices in handling data is important, and librarians are well poised to assist users. During this session, we will discuss the role of libraries in assisting with data management, application of metadata, ontologies, data standards, and the publication of data in repositories and on the Semantic Web. This talk will describe best data practices and engage the attendees in interactive activities to demonstrate these principles.TRANSCRIPT

The Role of Libraries in Data Management and
CurationNicole Vasilevsky
Oregon Health & Science University@n_vasilevsky

Fellow
BioinformatacistCell Biologist
OntologistBiocurator
Data Wrangler
NeuroscientistScholarly Communications Librarian
Molecular Biologist
www.ohsu.edu/library/ontologyOntology Development Group
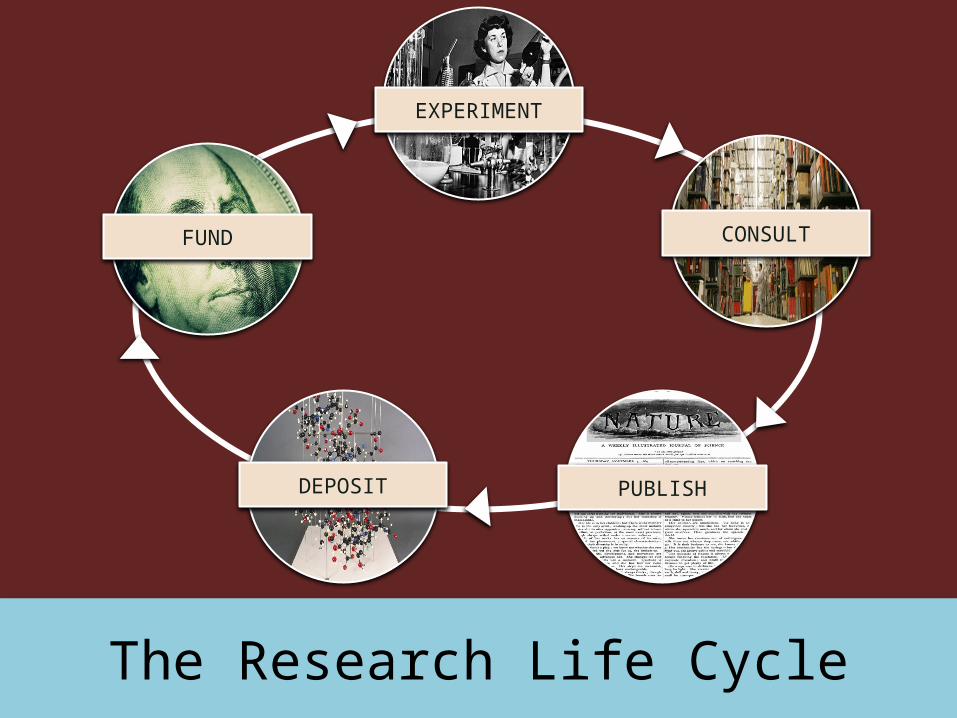
The Research Life Cycle
EXPERIMENT
CONSULT
PUBLISHDEPOSIT
FUND
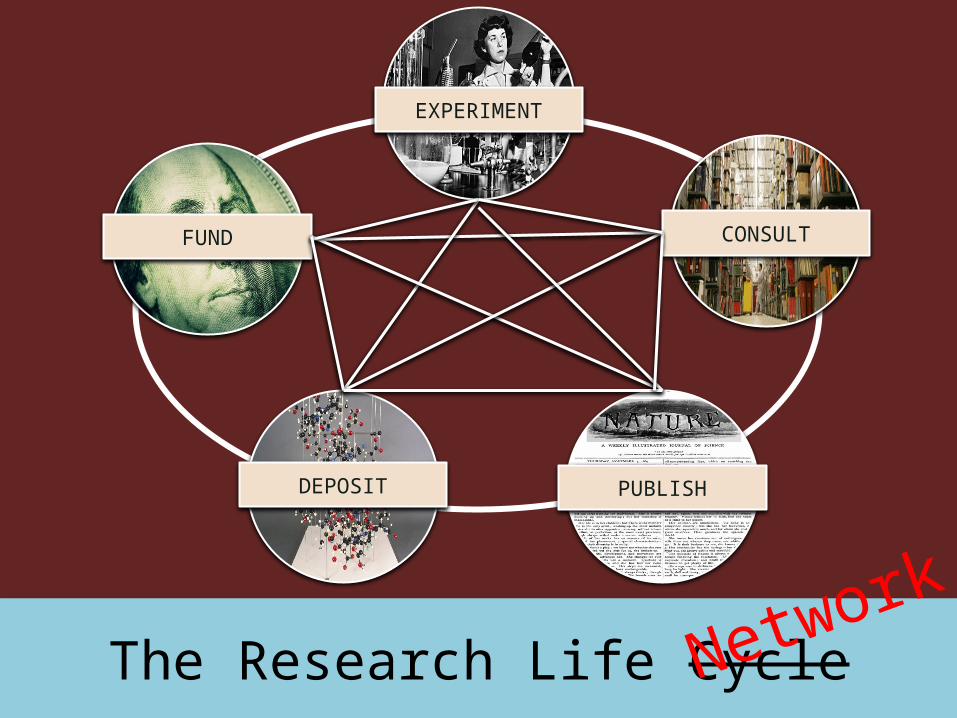
The Research Life Cycle
EXPERIMENT
CONSULT
PUBLISHDEPOSIT
FUND
Network
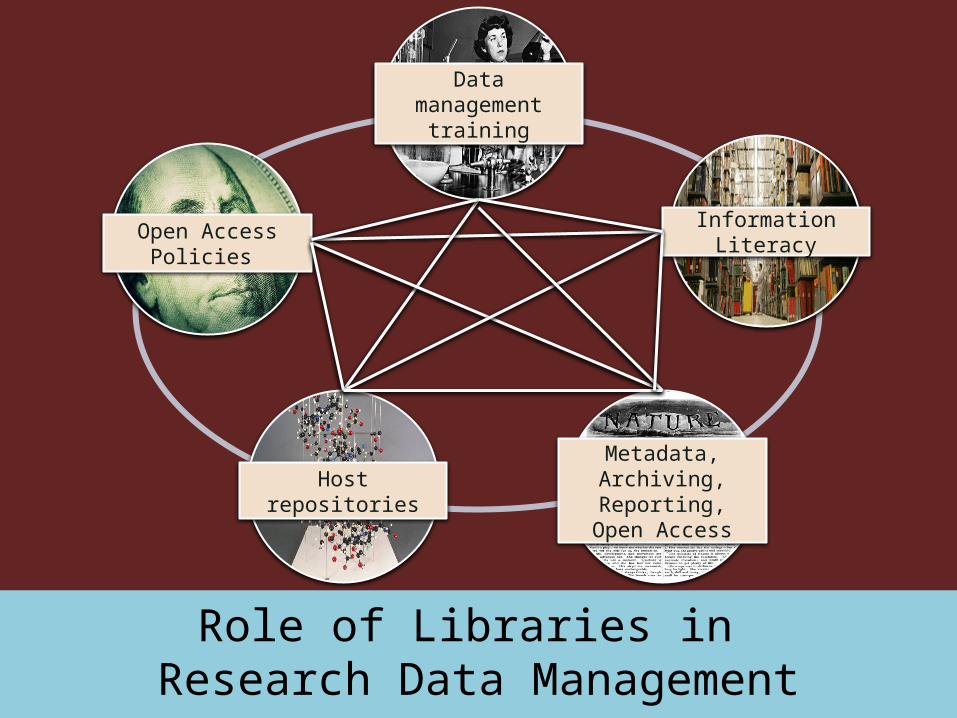
Role of Libraries in Research Data Management
Data management
training
Information Literacy
Metadata, Archiving,
Reporting, Open Access
Host repositories
Open AccessPolicies

1 | How can we make science more reproducible?
2 | How can we educate researchers to make their data reusable and research reproducible?
3 | How can we use data to generate new hypotheses and make new connections?

Ontologies: The foundation of our projects

Definition: Any closed, prescribed list of terms used for classifying data
Wine Chardonnay Pinot Noir Bordeaux Red Reisling
Controlled vocabulary
Key Features:• List of terms• Terms are
defined• Relationships
between terms are defined
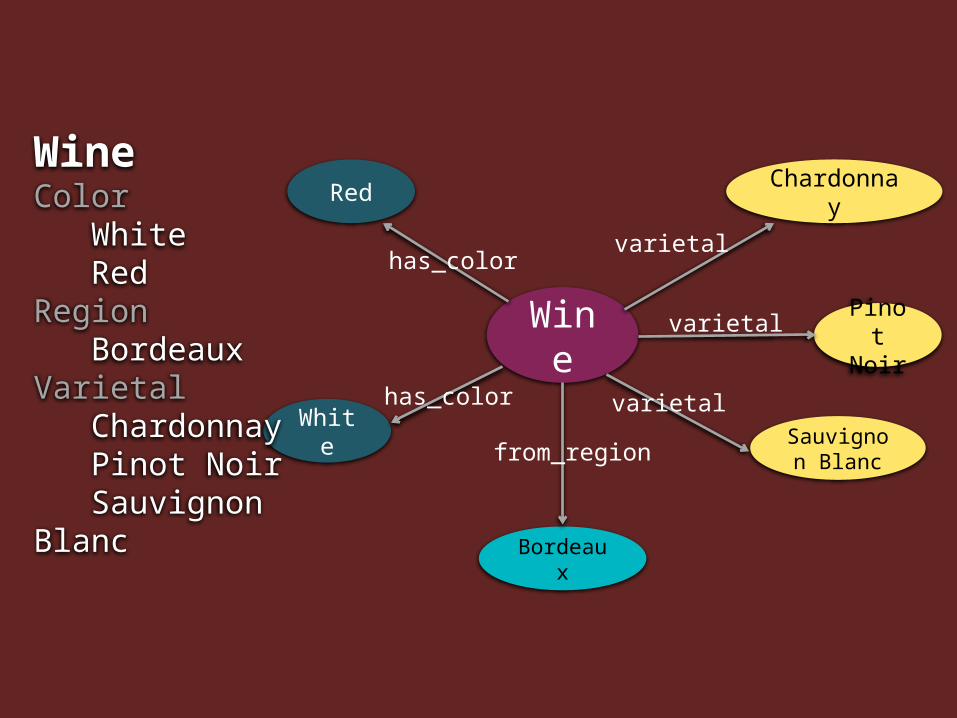
Wine
White
has_color
Red
has_color
Pinot Noir
varietal
Chardonnay
varietal
Sauvignon Blanc
varietal
Bordeaux
from_region
WineColor White RedRegion BordeauxVarietal Chardonnay Pinot Noir Sauvignon Blanc
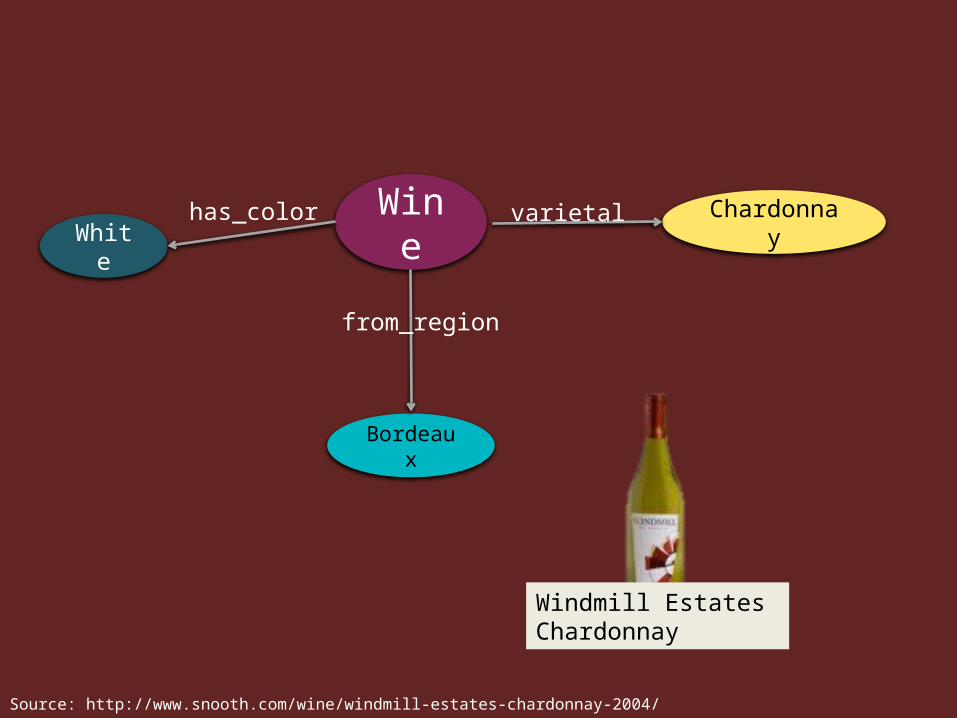
WineWhite
has_color Chardonnayvarietal
Bordeaux
from_region
Windmill Estates Chardonnay
Source: http://www.snooth.com/wine/windmill-estates-chardonnay-2004/

A formal conceptualization of a specified domain of interest
What is an Ontology?
Roz Chast 8/4/1986
1. Hierarchical terms are defined textually and logically
2. Relationships between the terms are defined
3. Expressed in a language that can be reasoned across by computers
4. Data can be reused and can be easily linked together

Well known ontologies

The Ontology Spectrum
Strong semantics
Weaksemantics
http://www.mkbergman.com/?m=20070516

1| How can we make science more reproducible?
Source: http://storify.com/BeckiePort/overlyhonestmethods

How identifiable are resources in the published literature?

An experiment in reproducibility
Domains:ImmunologyCell biologyNeuroscienceDevelopmental biology
General biology
Impact factors:HighMediumLow
84 Journals
248 papers
707 antibodies
104 cell lines
258 constructs
210 knockdown reagents
437 model organisms
http://biosharing.org/bsg-000532
Reporting Guidelines:StringentSatisfactoryLoose
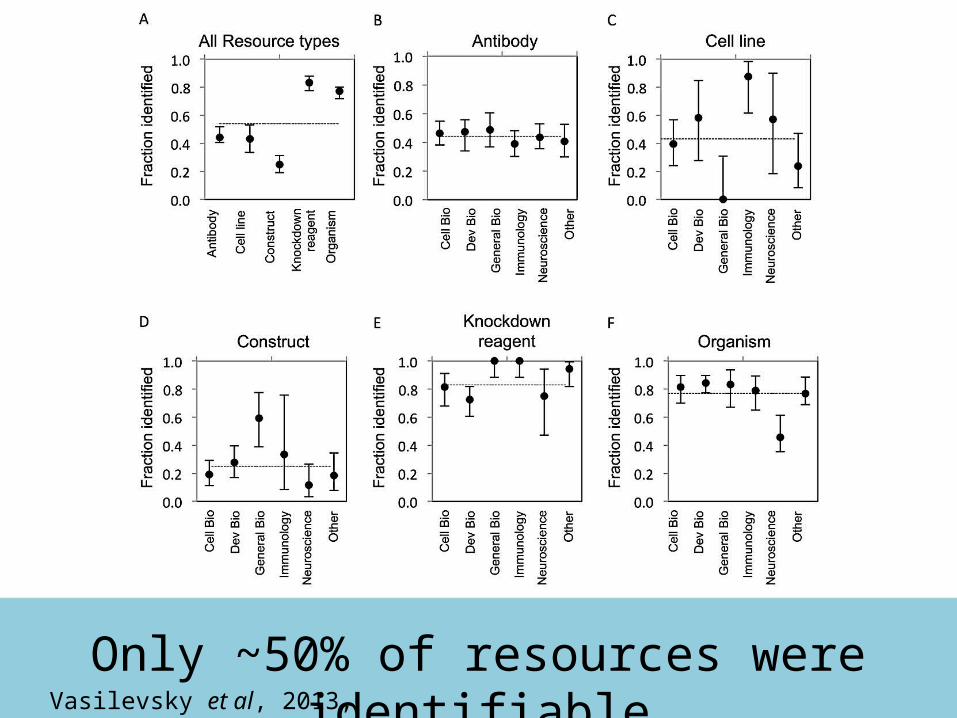
Only ~50% of resources were identifiableVasilevsky et al, 2013, PeerJ
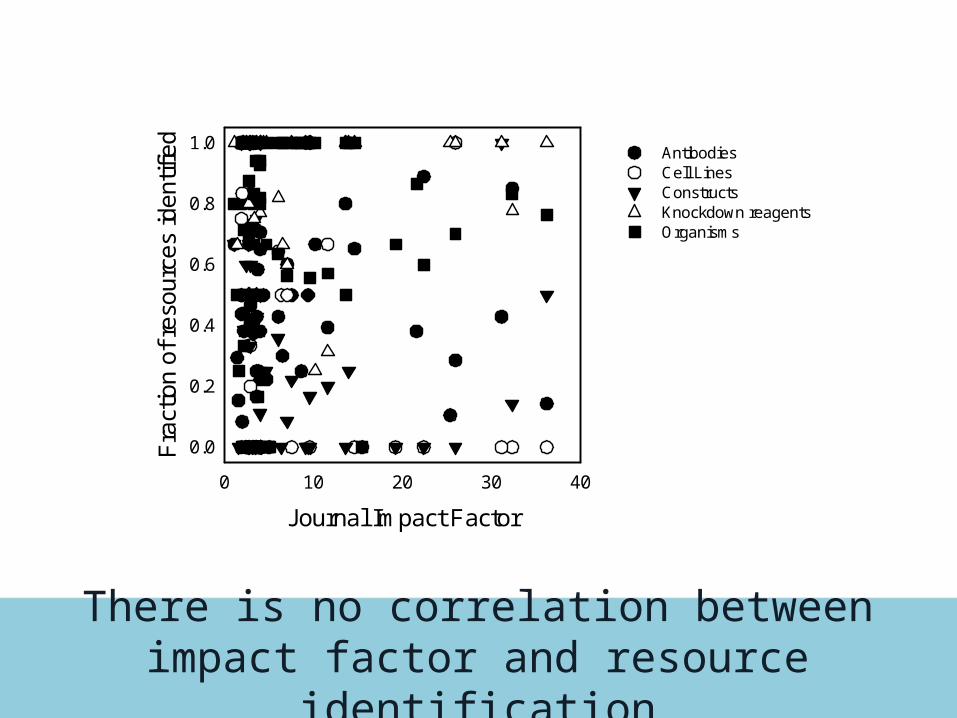
There is no correlation between impact factor and resource identification
Journal Impact Factor
0 10 20 30 40
Fra
ctio
n of
res
ourc
es id
entif
ied
0.0
0.2
0.4
0.6
0.8
1.0AntibodiesCell LinesConstructsKnockdown reagentsOrganisms

Resources are not more identifiable in journals with stricter reporting requirements

How can we fix this?

Vendor names/Catalog numbers
Stable, unique identifiers
Data Standards
Cell signaling, Cat #35763
Antibody Registry ID:AB_823460
Use of unique identifiers for resources

Resource Identification InitiativePromoting use of Research Resource IDs (RRIDs) in the published literature
Antibodies
Software & Tools
Model Organisms
Pilot project ongoing through 2014
RRIDs should be: Machine Readable
Consistent across publishers and journals
Free to generate and access
Resources:

Resource
Identification
Portal
Sample citation: Polyclonal rabbit anti-MAPK3 antibody, Abgent, Cat# AP7251E, RRID:AB_2140114
1. Researcher submits a manuscript for publication
2. Editor or Publisher asks for inclusion of RRID
3. Author goes to Research Identification Portal to locate RRID
4. RRID is included in Methods section and as Keyword
Workflow

Outcomes Demonstrate the need for …
better reporting of materials and methods
a cultural shift in the way we write and structure papers
a cultural shift in the way we view the literature

What does it mean to be reproducible anyway?

Attempting to independently replicate research in 50 major cancer studies
https://osf.io/e81xl/wiki/home/Reproducibility Project: Cancer Biology

On average, approximately 15% of the resources are unidentifiable
Resources reported in the 50 Reproducibility Initiative studies show similar results
Vasilevsky et al., 2013, PeerJ
Reproducibility Initiative
Treatment with peptide X and two of its isomers inhibits leishmania growth
http://pt.wikipedia.org/wiki/Leishmania_infantum

Tried to replicate the primary finding, not the other experiments (funding constraints)
Experiment showed similar dose response, but at 10X concentration
There was no negative control
The Leshmania strain turned out to be a different one
The peptides turned out to be amidated but this was not described in the original publication
The Reproducibility Initiative attempted to reproduce this study

What does it mean to be reproducible?
• Compare study results statistically • What is primary conclusion being tested?• Which experiments need to be
reproduced?• Is there an experimental effect?
a lab effect?– A synergy between the two?

2 | How can we educate researchers to make their data reusable and reproducible?

What would you do with $1k today to make research communication better that doesn’t involve building another tool?

1| Workshops with the library
2| Individual consultations



Gummy Bear: the Groundbreaking Paper

Your Data: Gummy Bear Raw Data
Bounces
Amplitude Color
15 4 blue43 3 red58 9 green75 82 purple
Materials:• Haribo Gummi
Bears Sugar Free, 5 lb bag
• SpringOMatic 3000
http://laughingsquid.com/the-anatomy-of-a-gummy-bear-by-jason-freeny/

Fig. 1Belly button ofHaribo Sugar FreeGummi Bear
Group 1 Group 2
Group 3 Group 4
Results from each groups varied

GUMMY BEARS TAUGHT US…• People see the same data very
differently• “Detailed” means different things…• Metadata?!?• File Management is Difficult• Workflow

CONSULTATIONSResearcher + 2-3 from Data Stewardship Team

Initial findings…
• Researchers need assistance:• Finding and choosing the best standard
for their data• File versioning• Applying metadata to facilitate data
sharing• Lack of awareness of services and
expertise offered by the library

3 | How can we use data to generate new hypotheses and make new connections?

Research Resources as Scholarly Products
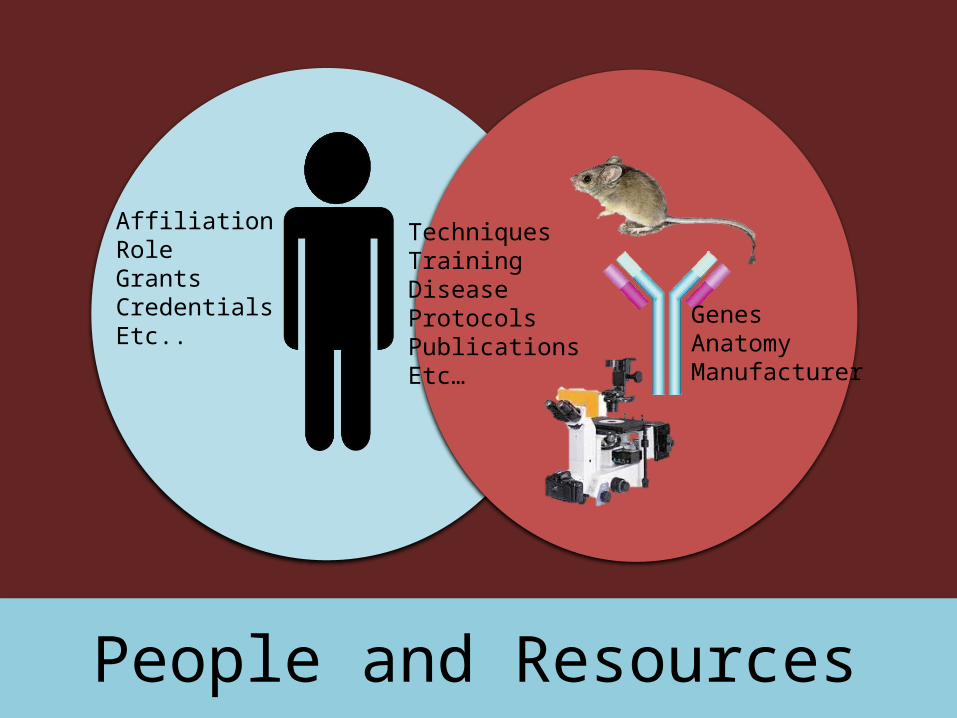
AffiliationRoleGrantsCredentialsEtc..
TechniquesTrainingDiseaseProtocolsPublicationsEtc…
GenesAnatomyManufacturer
People and Resources

CTSAconnect ProjectConnecting people and resources
MeansGoal is to create a semantic representation researcher expertise
Publish linked data
vivoweb.org

VIVO Integrated Semantic Framework (VIVO-ISF) Ontology Suite
Merge the eagle-i and VIVO ontologies into one single ontology suite (the VIVO-ISF)
Extend their coverage to include representation of clinical encounter
Modularize the VIVO-ISF such that it can be made available in a set of files that can be reused independently
eagle-i
Resources
VIVO
People
Coordinationeagle-i
VIVO
Inte
grat
ed
Framew
ork
Semantic
Clinical activities
vivoweb.org

How the VIVO-ISF can help

Hooking up the VIVO-ISF
ISF
vivoweb.org

The Challenge:Interpretation of Disease Candidates

The undiagnosed patient
Is it a known disorder that we are not recognizing?
Is it a new disorder?

Genotype vs Phenotype
Phenotype = genotype + environment + life history + epigenetics
Genotype: genetic code of an organism
Phenotype: Observable characteristics of an organism
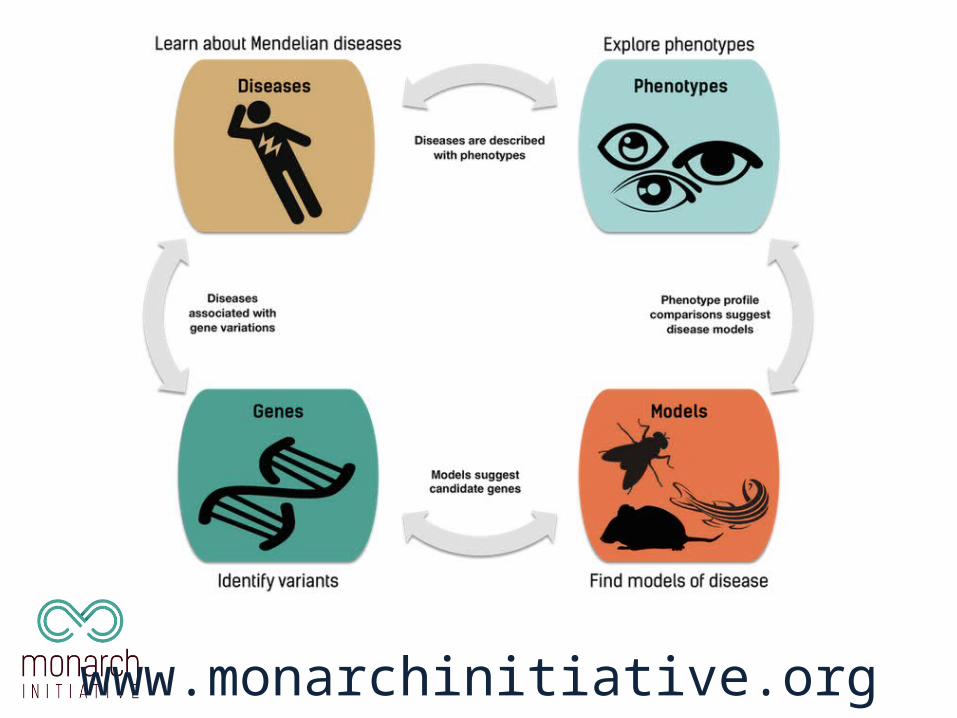
www.monarchinitiative.org

1 | How can we make science more reproducible?
2 | How can we educate researchers to make their data reusable and reproducible?
3 | How can we use data to generate new hypotheses and make new connections?

AcknowledgementsODG• Melissa Haendel• Robin Champieux• Matthew Brush• Shahim Essaid• Bryan Laraway• Eric Segerdell• Jeff Emch• Mike Grove
Monarch InitiativeParticipating institutions:• OHSU• LBNL• UC San Diego• University of
Pittsburg• Sanger Institute• Charité -
Universitätsmedizin Berlin
• NIH UDP
Resource Identification InitiativeParticipating institutions:• OHSU• University of
California, San Diego
• International Neuroscience Coordinating Facility
• National Institute of Health
• Publishers and Journals
CTSAconnectParticipating institutions:• OHSU• Cornell University• Stony Brook
University• University of Florida• Harvard University• University at Buffalo
Collaborators• Urban Lab, Carnegie
Mellon• Science Exchange• Anita de Waard,
Elsevier• Michael Lauruhn,
Elsevier
OHSU Library• Chris Shaffer• Jackie Wirz• Todd Hannon• Kyle Banerjee
