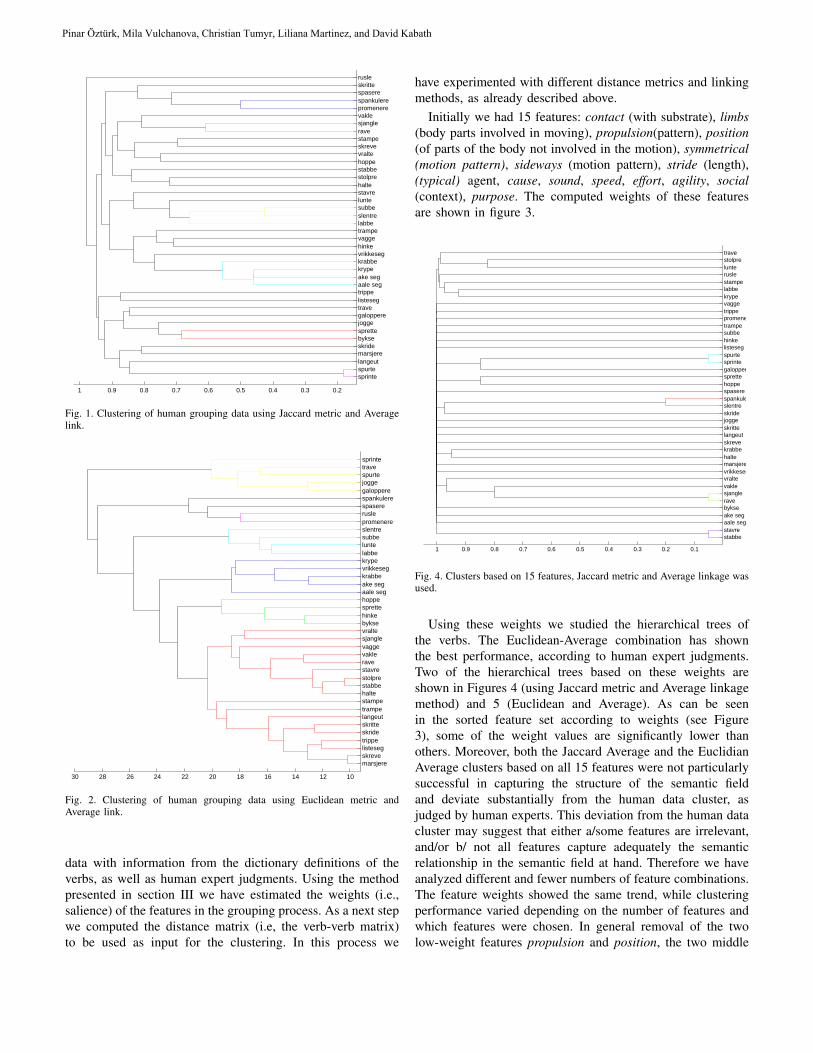
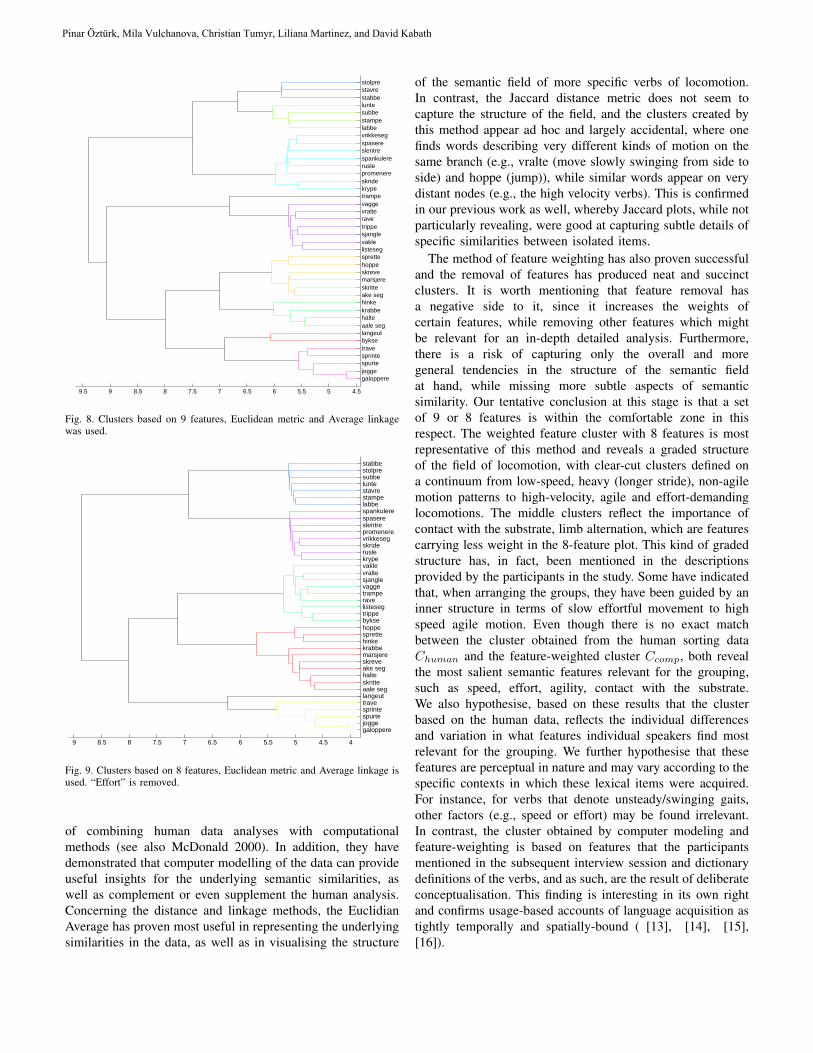
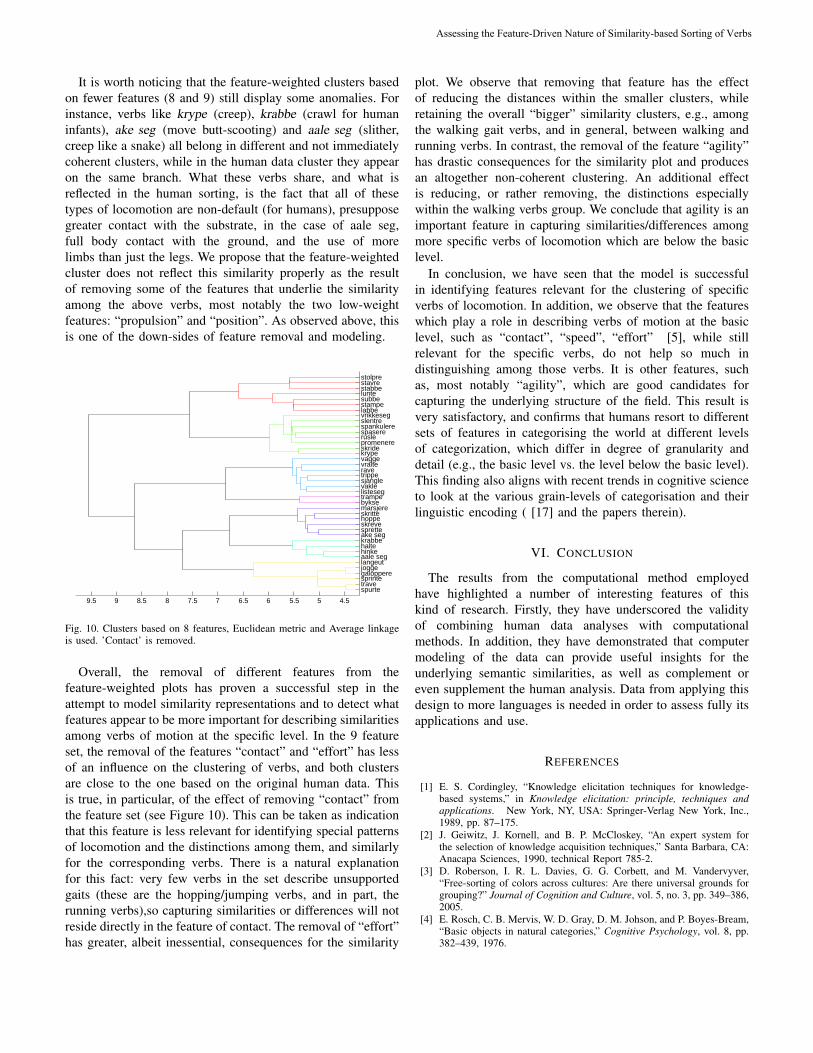
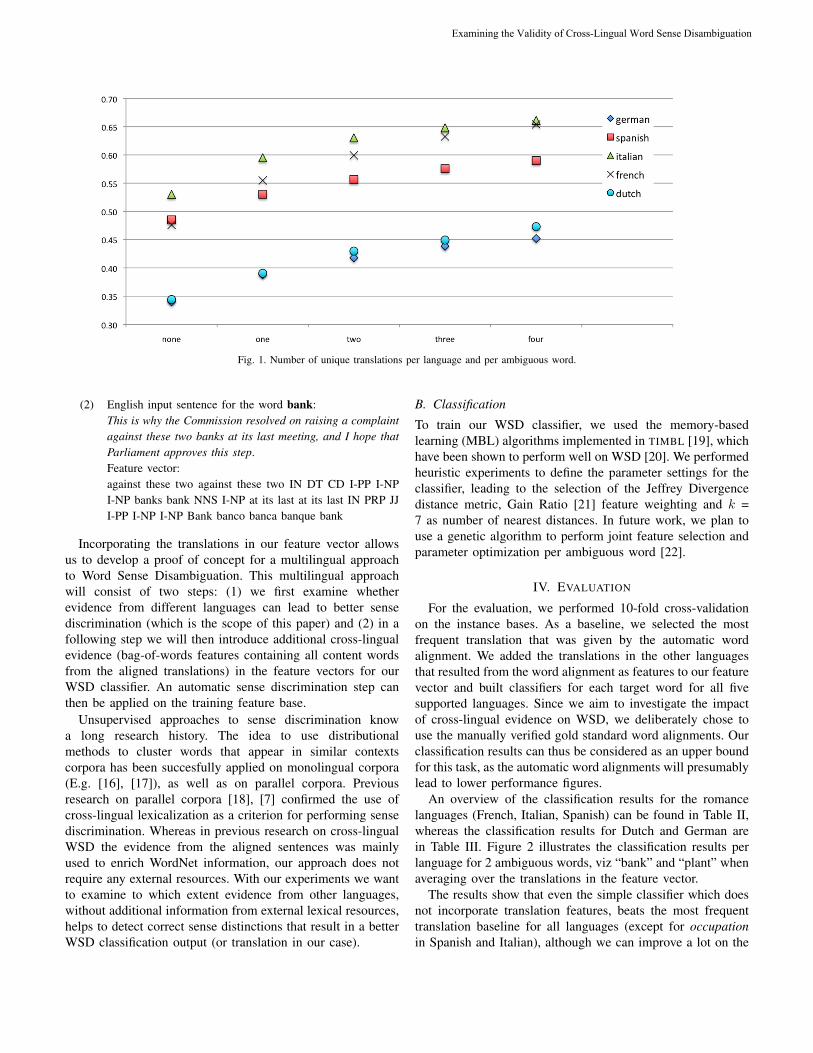
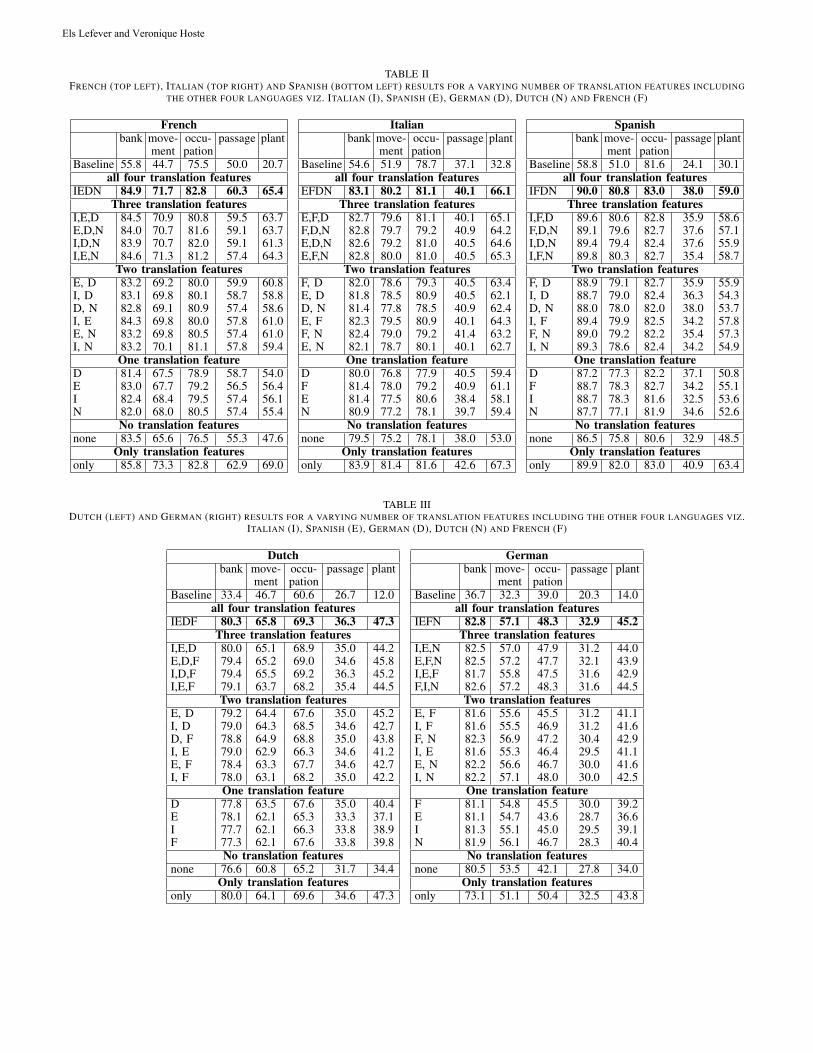
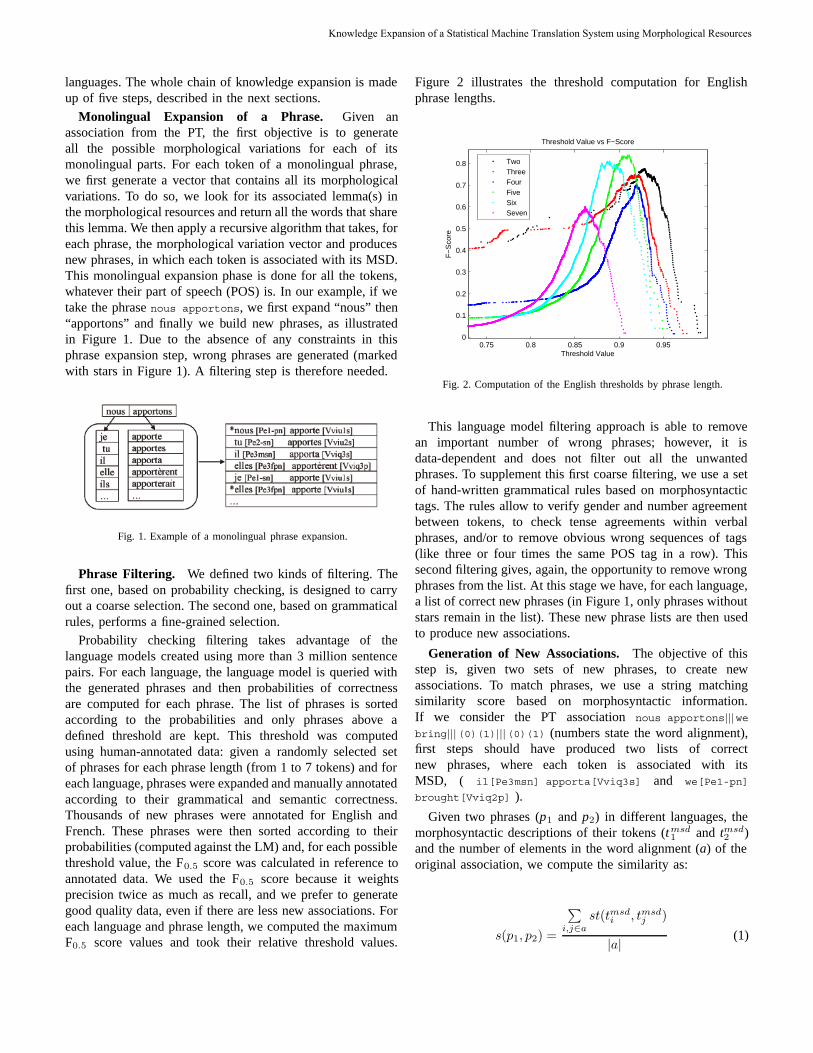
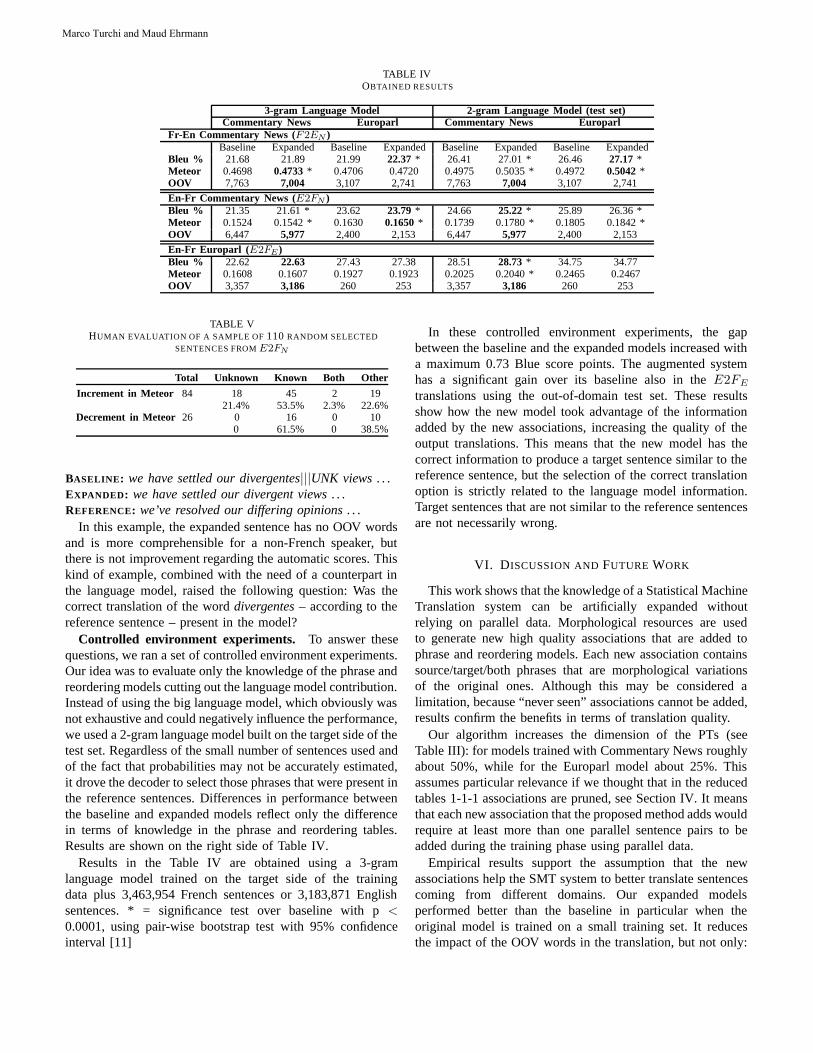
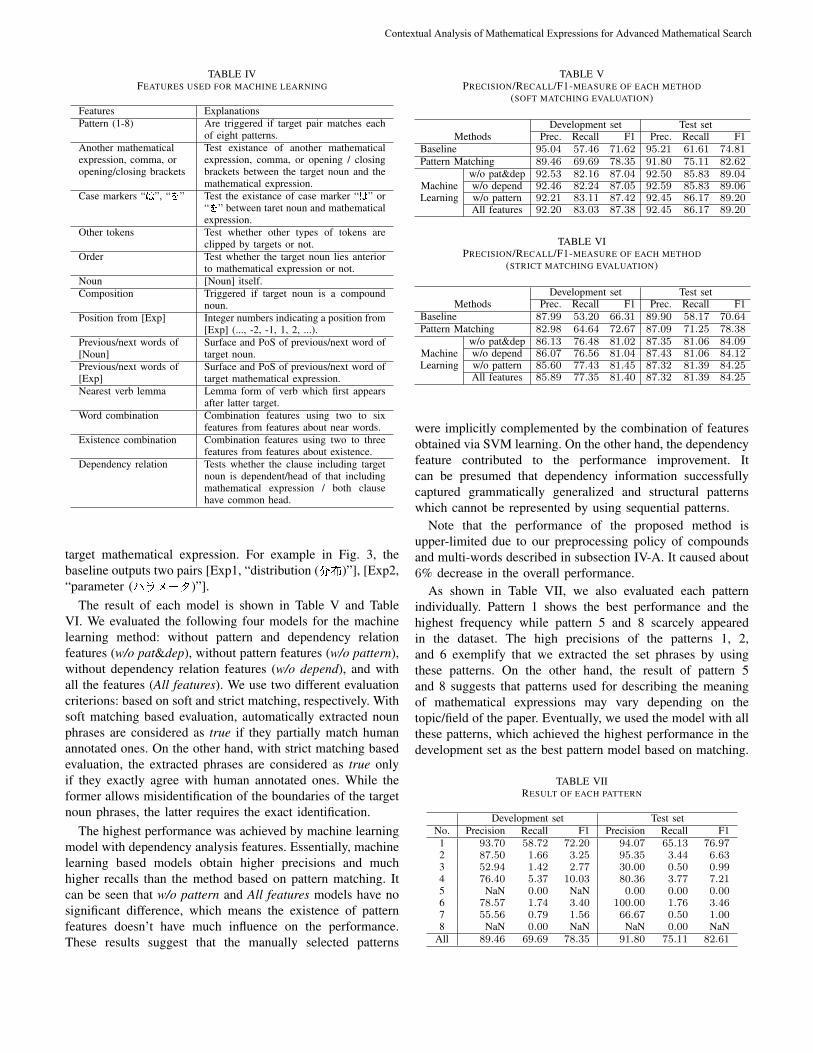
THEMATIC ISSUE: COMPUTATIONAL LINGUISTICS AND INTELLIGENT TEXT
117
T IS my great pleasure to congratulate the readers of the journal and the members of its Editorial Board with a long- awaited success—the inclusion of the journal in the Index of Mexican research journals maintained by the National Council of Science and Technology (CONACYT) of Mexico—the country where this journal is published—in “recognition of the quality and editorial excellence” of the journal, according to the CONACYT. This opens a new page in the 22-year-long history of the journal. This thematic issue is devoted to computational linguistics and intelligent text processing, a rapidly growing and dynamic field that lays at the intersection of linguistics, artificial intelligence, and computer science. It embraces a variety of technological developments that enable computers to meaningfully process human language—the language that we use both for our everyday communication and to record all human knowledge—in its written form as far as text processing is concerned. Its main applications include search and information retrieval, machine translation, and human- computer interaction, among others. The first four papers included in this thematic issue deal with semantics of natural language. The paper “Detecting derivatives using specific and Invariant descriptors” by F. Poulard et al. from France suggests a faster and simpler method to detect semantic similarity between textual documents that can indicate plagiarism or copying. This task is very important in many application areas, from education to law and forensics. The authors have built a French corpus based on Wikinews revisions in order to facilitate the evaluation of plagiarism detection algorithms for French. Both the corpus and the implementation of their algorithm has been made freely available to the community—an excellent example most research papers that seeks verifiability and the reproducibility of its results should certainly follow. The paper “Assessing the feature-driven nature of similarity-based sorting of verbs” by P. Öztürk et al. from Norway presents a computational analysis of the results from a sorting task with motion verbs in Norwegian, which is a contribution to both computational linguistics and psycholinguistics. The authors argue for that when sorting words, humans first compare the words by their similarity, which, in turn, involves comparison of some features of words. The authors investigate the set of these features and show that some of these features are more important than others for human judgments. What is more, they model these features computationally by finding a set of features that give automatic clustering similar to the clustering made by human annotators. The paper “Semantic textual entailment recognition using UNL” by P. Pakray et al. from India and Japan describes a system for recognizing textual entailment, i.e., a semantic relation between two phrases consisting in that one of them logically imply the other, e.g.: John’s assassinator was caught by police ⇒ John is dead. This task is crucial in information retrieval, machine translation, text understanding, text summarization and many other tasks and applications of natural language processing. To compare the semantics of the two phrases, the authors use a particular semantic representation originally introduced for machine translation and having its roots in the Meaning ⇔ Text theory: Universal Networking Language (UNL). The next paper, still continuing the topic of semantics, starts the series of four papers that deal with multilingualism and machine translation. The last paper of the issue can also be included in this group. The paper “Examining the validity of cross-lingual word sense disambiguation” by E. Lefever and V. Hoste from Belgium is devoted to word sense disambiguation, which is the task of automatically determining the intended meaning of a word from the context, e.g.: a saving account in the bank vs. a low wooden bank vs. a high bank of the river. The authors introduce a multilingual approach to the word sense disambiguation task. Instead of using a predefined monolingual sense-inventory such as WordNet, the authors’ language-independent framework includes a manually constructed gold standard corpus with word senses made up by their translations in other languages. Experiments with five European languages are reported. The paper “Knowledge expansion of a statistical machine translation system using morphological resources” by M. Turchi and M. Ehrmann et al. from Italy shows how to efficiently expand the existing knowledge of a phrase-based statistical machine translation system with limited training parallel data by using external morphological resources. This is a move to a long-awaited combination of statistical and knowledge-based techniques in computational linguistics and machine translation. The authors suggest that their knowledge expansion framework is generic and could be used to add other types of information to the model. The paper “Low cost construction of a multilingual lexicon from bilingual lists” by L. T. Lim et al. from Malaysia suggests a low cost method for constructing a multilingual lexicon using only simple lists of bilingual translation mappings. Their method is especially suitable for under- resourced language pairs—which is still the majority of world’s languages—because such bilingual resources are often freely available and easily obtainable from the Internet or Editorial I