theo ungerer systems and networking university of augsburg [email protected] ...
Post on 21-Dec-2015
215 views
TRANSCRIPT

Theo Ungerer
Systems and Networking
University of [email protected]
http://www.informatik.uni-augsburg.de/sik/
Opportunities for Hardware Multithreading in Microprocessors and Microcontrollers

2
Basic Principle of Multithreading
Register set 1
Register set 2
Register set 3
Register set 4
PC PSR 1
PC PSR 2
PC PSR 3
PC PSR 4
Thread pointer
thread 1:
thread 2:
thread 3:
thread 4:
... ... ...

3
Multithreadingin High Performance Processors
Multithreading in high-performance microprocessors IBM RS64 IV (SStar) Sun UltraSPARC V Intel Xeon TM
Hardware multithreading is the ability to pursue more than one thread within a processor pipeline.
Typically features: multiple register sets, fast context switching
Main objective: performance gain by latency hiding for multithreaded workloads

4
Motivation State-of-the-art Multithreading
• Multithreading for throughput increase• Multithreading for power reduction• Multithreading for embedded real-time systems
Conclusions & Research Opportunities
Outline of the Presentation

5
Todays Multiple-issue Processors
Utilization of instruction level parallelism
by a long instruction pipeline and
by the superscalar or the VLIW-/EPIC-technique.

6
Problem: Low Resource Utilization by Sequential Programs
processor cycles
issue slots
vertical loss (= 4)
vertical loss (= 4)
horizontal loss = 2
horizontal loss = 1
horizontal loss = 3
Losses by empty issue slots

7
Outline of the Presentation
Motivation State-of-the-art Multithreading
• Multithreading for throughput increase• Multithreading for power reduction• Multithreading for embedded real-time systems
Conclusions & Research Opportunities

8
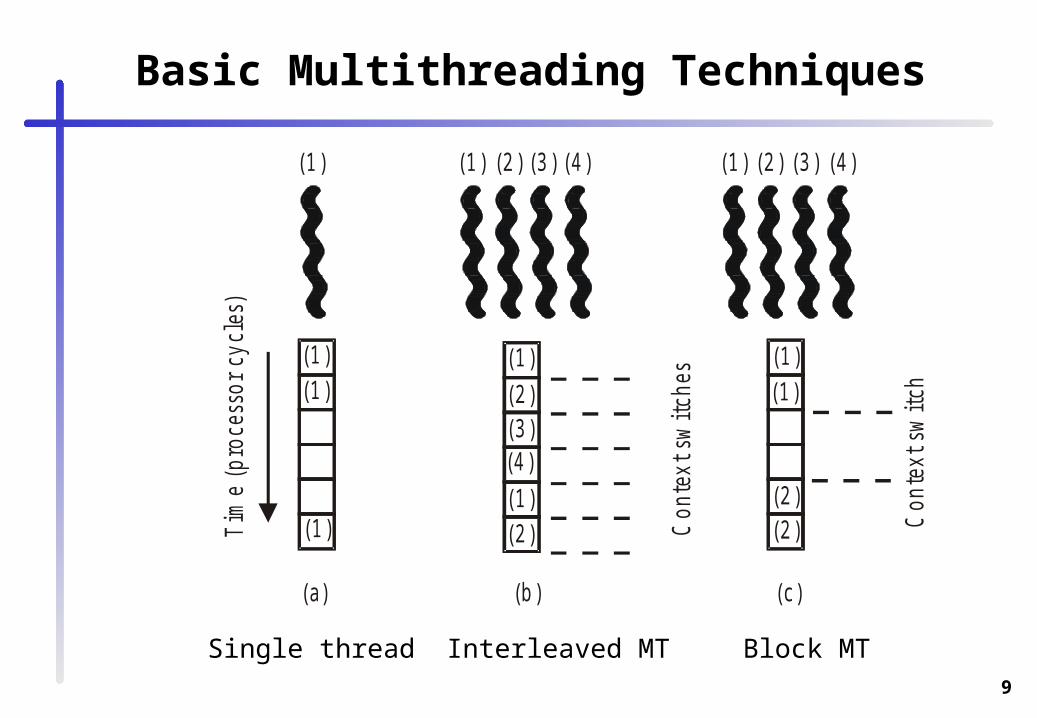
Multithreading
Two basic multithreading techniques• Interleaved Multithreading • Block Multithreading
Simultaneous multithreading (SMT)• combines wide issue superscalar with multithreading,• issues instructions from several threads simultaneously.
9
Basic Multithreading Techniques
Single thread Interleaved MT Block MT
(a )
Tim
e (p
roce
ssor
cyc
les)
(c )
Con
text
sw
itch
(b )
Con
text
sw
itche
s
(1 )
(1 )
(1 )
(1 )
(1 )
(1 )
(1 )
(1 )
(1 )
(1 )
(2 )
(2 )
(2 )
(2 )
(2 ) (2 )
(3 )(4 )(3 )
(3 )
(4 )
(4 )

10
SMT vs. CMP
SMT CMP
(a )
Tim
e (p
roce
ssor
cyc
les)
(b )
(1 ) (2 )
(4 ) (4 )
(4 )
(1 ) (2 ) (4 )(3 )
(1 )
(1 )
(1 )(1 )
(1 )
(4 ) (4 ) (4 )
(4 )
(2 ) (4 )
(4 ) (4 ) (1 )
(1 )
(1 )
(2 ) (2 ) (4 )
(2 ) (3 )
(1 ) (2 )
(4 )
(4 )
(2 )
(1 )
(2 )
(1 ) (1 ) (2 )
(1 )
(1 ) (1 )
(1 ) (1 ) (1 )
(2 ) (2 )
(3 )
(4 ) (4 ) (4 )
(2 ) (2 )
(2 )
(1 ) (2 ) (4 )(3 )
(1 )
(1 ) (2 )
(1 ) (1 )
(2 ) (2 )(1 )
(4 )
(4 )
(3 )
(3 )
(3 )(2 )
(4 )(3 )
(3 ) (4 ) (4 )
(4 )
(3 ) (4 )
(1 )(1 )

11
Characteristics of Multithreading
Latency Utilization • The latencies that arise in the computation of a single
instruction stream are filled by computations of another thread.
Throughput of multithreaded workloads is increased Power Reduction
• Using less speculation Rapid Context Switching
• appropriate for real-time applications

12
Outline of the Presentation
Motivation State-of-the-art Multithreading
Multithreading for throughput increase• Multithreading for power reduction• Multithreading for embedded real-time systems
Conclusions & Research Opportunities

13
Multithreading for Throughput Increase
Lots of research results with simulated SMT since 1995
Some of our own research results• Performance estimation of SMT multimedia• Regard transistor count and chip-space estimation of the
models.

14
Relevant Attributes for Rating Microprocessors
Performance Resource Requirement
Clock Speed Power Consumption
Two tools
• Performance estimation tool
• Transistor count and chip-space estimation tool

15
Transistor Count and Chip-space Estimator
Vision:• The resources of the baseline model should be adjusted such that the same
chip space or the same transistor count is covered as in the new microachitecture models.
We use an analytical method for memory-based structures like register files or internal queues and
an empirical method for logic blocks like control logic and functional units.
half-feature size as measure of length of basic cell
Estimator tool is available (also for SimpleScalar) at:
http://www.informatik.uni-augsburg.de/lehrstuehle/info3/research/complexity/
16
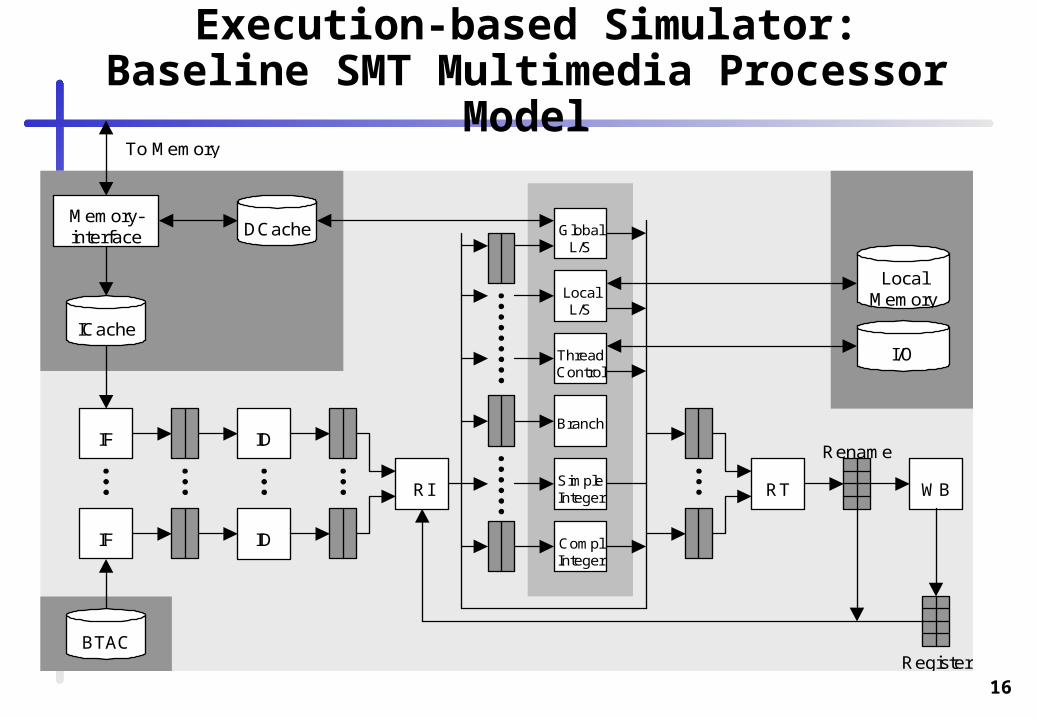
Execution-based Simulator:Baseline SMT Multimedia Processor Model
Branch
ComplInteger
RT WBRI
IDIF
GlobalL/S
LocalL/S
ThreadControl
SimpleInteger
LocalMemory
I/O
Memory-interface DCache
BTAC
ICache
Rename
Register
IDIF
To Memory

17
Results of Performance and Hardware Cost Estimation
Demonstrated by two set of models:
„Maximum“ processor models with an abundance of resources
Small processor models
Workload is a MPEG-2 decoder made multithreaded
11
22

18
Simulation Parameters
Fixed parameters:• 1024-entry BTAC, gshare branch predictor (2 K 2-bit counters, 8 bit history,
mispred. pen. 5 cycles)• 4-way set-associative D- and I-caches with 32 byte cache lines• 32 KB local on-chip RAM • 64-bit system bus, 4 MB main memory
Varied parameters:• 8-12 execution units• 256- and 32-entry reservation stations • 10 to 4 result buses• different D-cache sizes, D- and I-caches of 4 MB and 64 KB
Parameters Varied with Number of Threads: • 32 32-bit general-purpose registers and 40 rename registers (per thread),• 32- and 16-entry issue and retirement buffers (per thread)• Fetch and decode bandwidth is scaled with issue bandwidth and number of
threads: 1x1 – 8x8

1912
46
8
1
2
4
68
6,39
5,57
3,91
1,99
1
6,38
5,57
3,91
1,99
1
5,58
5,23
3,89
1,99
1
3,283,26
3,07
1,96
1
1,681,68
1,65
1,43
0,930
1
2
3
4
5
6
7
IPC
Issue
Threads
Performance vs. Hardware Cost Estimation:Maximum Processor Models
4 MB I- and D-caches,6 integer/mm units2 local load/store units
11

Transistor Count and Chip Space Estimation of Maximum Processor Models
86
42
1
8
4
297505
293124
288983
285178
283360
294584
291150
287794
284608
283038275000
280000
285000
290000
295000
300000
Threads
Issue
K Transistors
86
42
18
4
140366
123618
112461
105463
102947
123314
115208
108944
104283102357
80000
90000
100000
110000
120000
130000
140000
150000
Threads
Issue
Size in M ²
11

21
Small Processor Models
12 4 6 8
12
46
8
3,63,6
3,09
1,9
0,98
3,513,51
3,08
1,91
0,97
3,23,2
2,91
1,89
0,99
2,172,17
2,1
1,72
0,98
1,231,23
1,231,17
0,88 0
1
2
3
4
IPC
Issue
Threads
64 KB I- and D-caches,3 integer/mm units1 local load/store unit32-enty reserv. stations16-entry issue andretirement buffers4 result buses2x4 fetch and decode bandwidth fixed
22
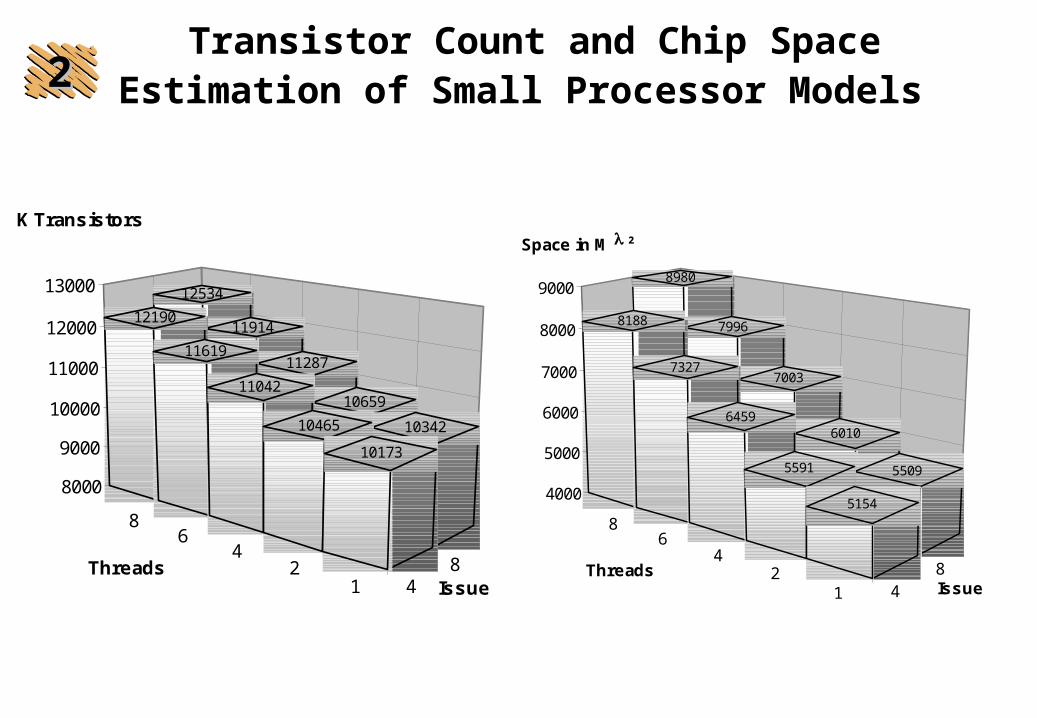
Transistor Count and Chip Space Estimation of Small Processor Models
86
42
18
4
12534
11914
11287
10659
10342
12190
11619
11042
10465
10173
8000
9000
10000
11000
12000
13000
ThreadsIssue
K Transistors
86
42
1
84
8980
7996
7003
6010
5509
8188
7327
6459
5591
51544000
5000
6000
7000
8000
9000
ThreadsIssue
Space in M ²
22

23
Results
4-threaded 8-issue SMT over a single-threaded 8-issue:
Commercial Multithreaded Processors:• Tera, MAJC, Alpha 21464, IBM Blue Gene, Sun UltraSPARC V• Network processors (Intel IXP, IBM PowerNP, Vitesse IQ2x00, Lextra,..)• IBM RS64 IV: two-threaded block MT, reported 5% overhead• Intel Xeon TM (hyperthreading): two-threaded SMT, reported 5% overhead
Speedup Transistor Chip Space Increase Increase
maximum model: 3 2% 9%
small model: 1.5 9% 27%

24
Outline of the Presentation
Motivation State-of-the-art Multithreading
• Multithreading for throughput increase Multithreading for power reduction• Multithreading for embedded real-time systems
Conclusions & Research Opportunities

25
SMT for Reduction of Power Consumption
Observation: Mispredictions cost energy
Todays superscalars: ~ 60% of the fetched and ~ 30% of the executed instructions are squashed
Idea: fill issue slots by less speculative instructions of other threads
Simulations of Seng et al. 2000 show that ~ 22% less energy is consumed by using a power-aware scheduler

26
Outline of the Presentation
Motivation State-of-the-art Multithreading
• Multithreading for throughput increase• Multithreading for power reduction Multithreading for embedded real-time systems
Conclusions & Research Opportunities

27
Multithreading in Embedded Real-time Systems– The Komodo Approach
Observation: multithreading allows a context switching overhead of zero cycles
Idea: harness multithreading for embedded real-time systems
Komodo Project: Real-time Java Based on a Multithreaded Java-microcontroller
http://www.informatik.uni-augsburg.de/lehrstuehle/info3/research/
komodo/indexEng.html

28
Real-time Requirements
• run-time predictability• isolation of the threads• programmability• real-time scheduling support• fast context switching
Hard real-time: a deadline may never be missed
Soft real-time: a deadline may occasionally be missed

29
Komodo Solutions
Extremely fast context switching by hardware multithreading Real-time scheduling in hardware Based on a Java processor core Predictability of all instruction executions by a careful
hardware design
30
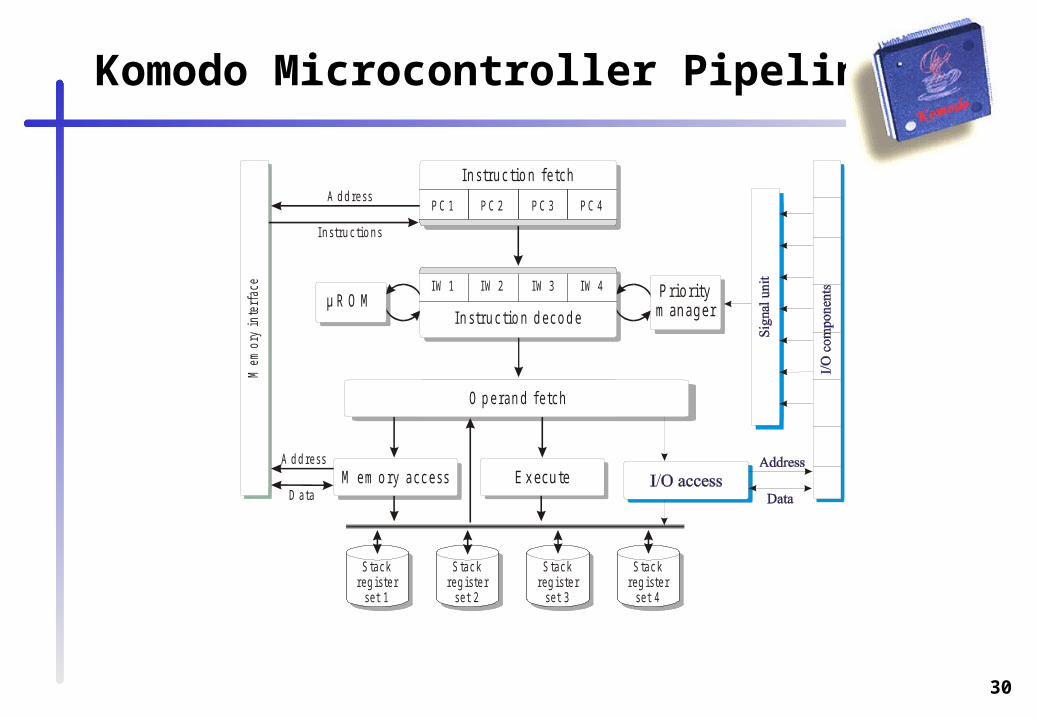
Komodo Microcontroller Pipeline
µ R O M P rio r itym a n a g e r
S ta c kreg iste r
s e t 1
S ta c kreg iste r
s e t 2
S ta c kreg iste r
s e t 3
S ta c kreg iste r
s e t 4
E xecu te
In s t ru c tio n fe tc h
P C 1 P C 2 P C 3 P C 4
IW 1 IW 2 IW 3 IW 4
In s t ru c tio n d e c o d e
P rio ritym anage r
µ R O M
O p e ra n d f e tc h
M e m o ry a c c e s s
O p e ra n d f e tc h
S ta c kreg iste r
s e t 2
S ta c kreg iste r
s e t 1
S ta c kreg iste r
s e t 3
S ta c kreg iste r
s e t 4
A d d re s s
In s tru c tio n s
Mem
ory
inte
rfac
e
A d d re s s
D a ta

31
Komodo Microcontroller Design
c a p ture /c o m p a re
se ria linte rfa c e
I Cinte rfa c e
2
tim e r/c o unte r
p a ra lle lI/O
m ic ro -c o ntro lle r-
ke rne l
e xte rna lI/O -b us
m e m o ryb us
C AN-Businte rfa c e
se ria linte rfa c e
sig na l-unit

32
Hardware Real-time Scheduling
Real-time scheduler is realized in hardware (by the priority manager)
Scheduling decision every clock cycle Four different scheduling algorithms implemented:
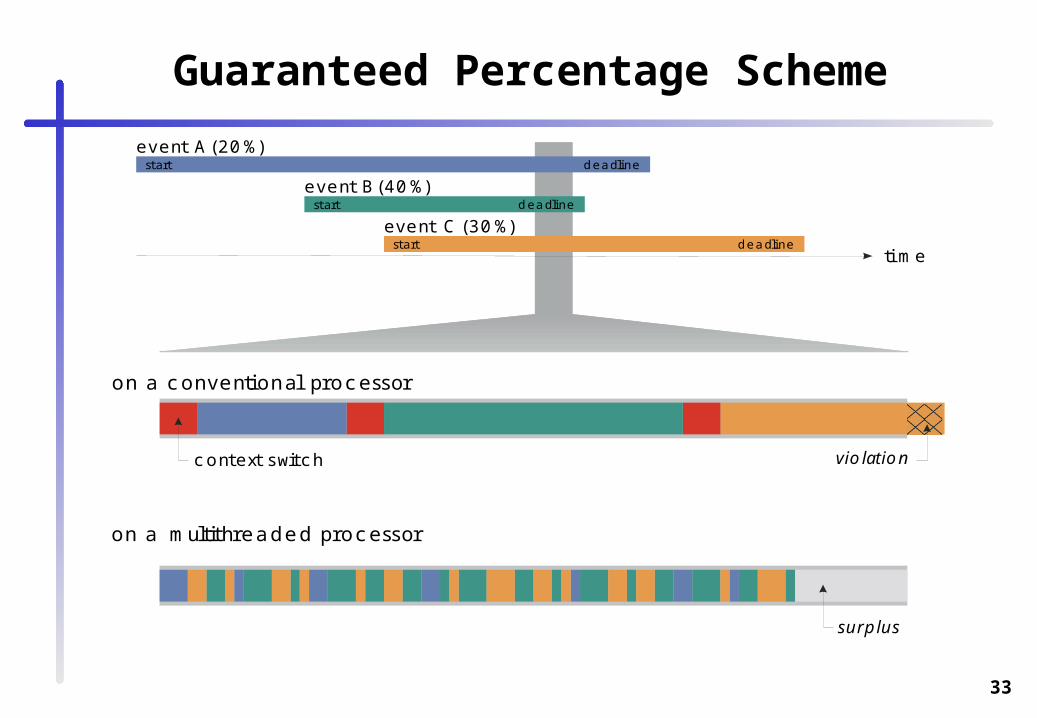
• Fixed Priority Preemptive (FPP)• Earliest Deadline First (EDF)• Least Laxity First (LLF)• Guaranteed Percentage (GP)
33
Guaranteed Percentage Scheme
event A (20%)
tim e
event B (40%)
event C (30%)
start deadline
start
start
deadline
deadline
on a conventional processor
on a multithreaded processor
context switch
surplus
tionviola
34
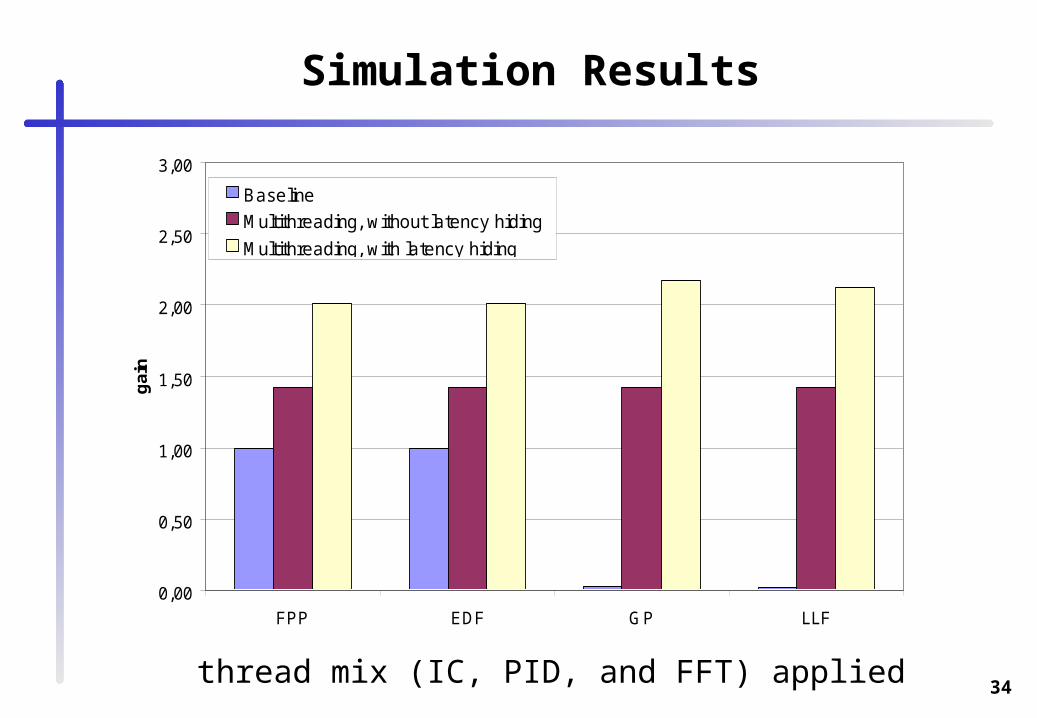
Simulation Results
0,00
0,50
1,00
1,50
2,00
2,50
3,00
FPP EDF GP LLF
gai
n
Baseline
Multithreading, without latency hiding
Multithreading, with latency hiding
thread mix (IC, PID, and FFT) applied

35
Technical Data of the Komodo Prototype
Implementation of Komodo core pipeline on a Xilinx XCV800 with 800k gates
ASIC synthesis of whole microcontroller (0.18 m technology): 340 MHz, 3 mm2 chip
data bit widthaddress spacenumber of threadsinstruction window sizestack sizeexternal frequencyinternal frequencyCLBsnumber of gates
32 bit19 bit
48 bytes
128 entries33 MHz
8.25 MHz9 200
133 000

36
Chip-Space of Komodo Core Pipeline
0
50000
100000
150000
200000
250000
300000
350000
400000
450000
1 2 4 8 16threads
gat
e co
un
t
OF/MEM
BMIU
SMU
WBU
EXE
MRU
IWDU
IFU

37
Reducing Power Consumption Using Real-time Scheduling in Hardware
Current work: Idea: Use information about the thread states and configurations available within the priority manager for a „fine-grained“ adaption of power consumption and performance.
Frequency and voltage adjustments in short time intervals done by hardware
38
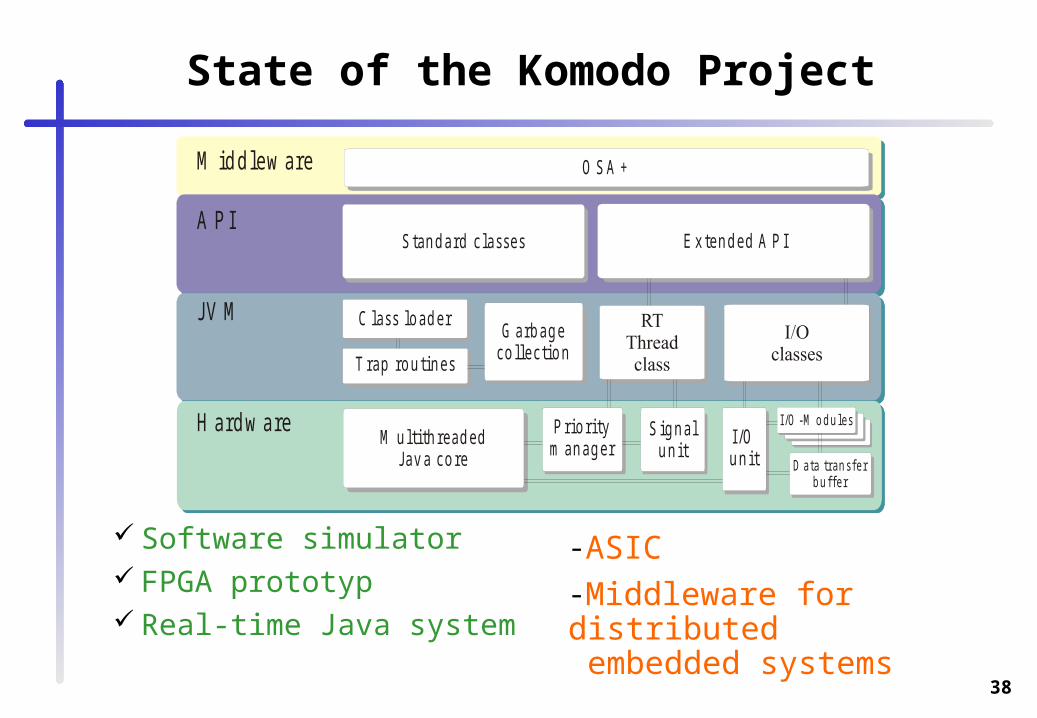
State of the Komodo Project
Software simulator FPGA prototyp Real-time Java system
M u ltith rea d edJav a co re
S ig n a lu n it
P rio ritym an a g er
H ard w a re
JV M
T rap ro u tin es
G a rb a g eco lle c tio n
S tan d a rd c la ssesA P I
O S A +M id d lew are
E x te n d ed A P I
C lass lo ad e r
IO -M o d u le sI /O -M o d u le sI/Ou n it D a ta tra n s fe r
b u ffe r
-ASIC-Middleware for distributed embedded systems

39
Conclusions onMultithreading in Real-time Environments
Multithreaded processor cores: Performance gain due to fast context switching (for hard real-
time) and latency hiding (for soft and non real-time) More efficient event handling by ISTs Helper threads possible (garbage collection, debugging)
Real-time scheduling in hardware: Software overhead for real-time scheduling removed more efficient power saving mechanisms possible better predictablility by isolation of threads (GP scheduling)

40
Conclusions & Research Opportunities
Multithreading proves advantageous:• Latency hiding: speed-ups of 2-3 for SMT,
lots of research done, next generation of microprocessors• Power reduction: 22% savings reported,
not much research up to now• Fast context switching utilized by microcontroller for real-time systems,
not much research up to now
Research opportunities:• Scheduling in SMT, network processors and multithreaded real-time systems• Thread-speculation: how to speed-up single-threaded programs?• Multithreading and power consumption• Multithreading in other communities: microcontrollers, SoCs• System software based on helper threads

41
Acknowledgements
SMT Multimedia research group • Uli Sigmund and Heiko Oehring
Complexity estimation group• Marc Steinhaus, Reiner Kolla, Josep L. Larriba-Pey, Mateo
Valero
Komodo project group• Jochen Kreuzinger, Matthias Pfeffer, Sascha Uhrig,
Uwe Brinkschulte, Florentin Picioroaga, Etienne Schneider
42
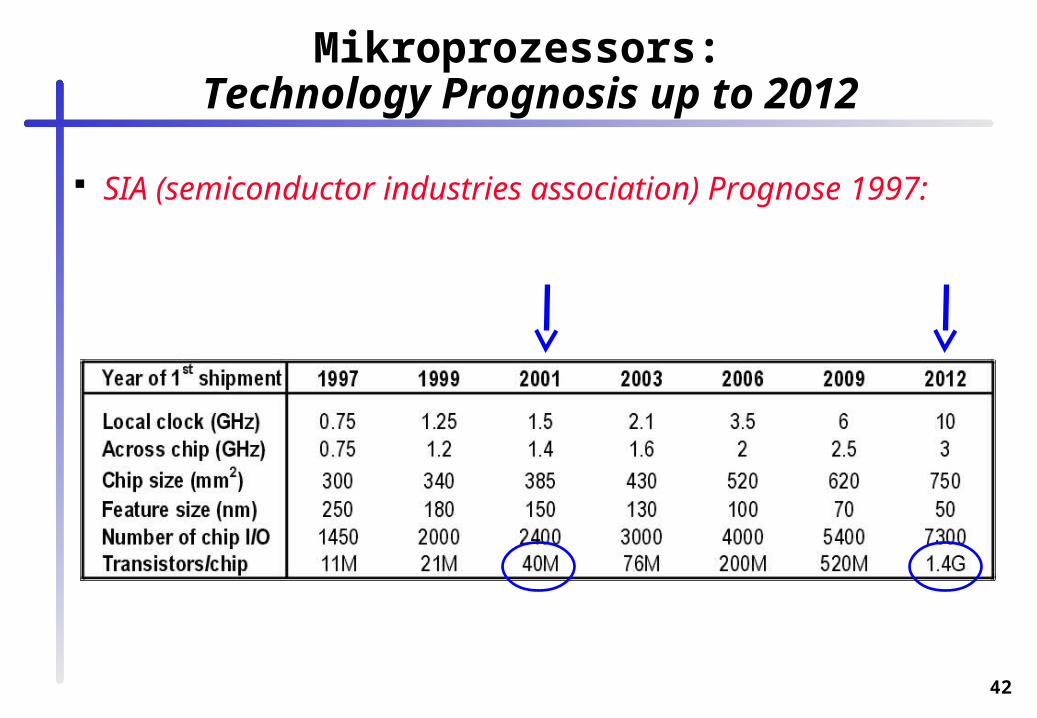
Mikroprozessors: Technology Prognosis up to 2012
SIA (semiconductor industries association) Prognose 1997:

43
Research Directions?
Increase performance of a single thread of control by• more instruction-level speculation
- Better branch prediction, - Trace cache and next trace prediction,- Data dependence and value prediction
Increase throughput of a workload of multiple threads• Utilize thread-level and instruction-level parallelism
- Chip-Multiprocessors- Multithreading (hardware thread = thread or process)
Thread speculation