thesis
TRANSCRIPT

National College of Ireland
Project Submission Sheet – 2014/2015
School of Computing
Student Name:
Karan Chhabra Student ID:
14111322
Programme:
MSc Cloud Computing
Year:
2015
Module:
Research & Development 2 Lecturer:
21/04/2015
Submission Due Date:
Project Title:
Can we design an efficient Byzantine Fault Tolerant mechanism for a
cloud computing environment?
Word Count: 6475
I hereby certify that the information contained in this (my submission) is information pertaining to research I conducted for this project. All information
other than my own contribution will be fully referenced and listed in the relevant bibliography section at the rear of the project. ALL internet material must be referenced in the bibliography section. Students are encouraged to use the Harvard Referencing Standard supplied by the Library. To use other author's written or electronic work is illegal (plagiarism) and may result in disciplinary action. Students may be required to undergo a viva (oral
examination) if there is suspicion about the validity of their submitted work. Signature:
Karan Chhabra
Date:
………………………………………………………………………………………………………………
PLEASE READ THE FOLLOWING INSTRUCTIONS: 1. Please attach a completed copy of this sheet to each project (including multiple
copies). 2. You must ensure that you retain a HARD COPY of ALL projects, both for
your own reference and in case a project is lost or mislaid. It is not sufficient to keep a copy on computer. Please do not bind projects or place in covers unless specifically requested.
3 Assignments that are submitted to the Programme Coordinator office must be placed into the assignment box located outside the office.
Office Use Only
Signature:
Date:
Penalty Applied (if applicable):

Can we design an efficient ByzantineFault Tolerant mechanism for acloud computing environment?
Karan Chhabra
Submitted as part of the requirements for the degree
of MSc in Cloud Computing
at the School of Computing,
National College of Ireland
Dublin, Ireland.
April 2015
Supervisor Dr. Adriana Chis

Can we design an efficient ByzantineFault Tolerant mechanism for acloud computing environment?
Karan Chhabra
Submitted as part of the requirements for the degree
of MSc in Cloud Computing
at the School of Computing,
National College of Ireland
Dublin, Ireland.
April 2015
Supervisor Dr. Adriana Chis

Abstract
The substantial advancements in Information Technology (IT) over the last century,
have triggered a perceived vision of computing being a 5th utility one day after wa-
ter, gas, electricity and telephony. In order to deliver this vision various computing
paradigm are proposed out which Cloud computing is the latest paradigm. Cloud com-
puting has benefits of its own including on-demand service, pay-per-use etc. but along
with benefits there are various challenges associated with it.
One of the major research challenges in Cloud Computing is to ensure reliability and
availability of resources provided by it which is only possible if the cloud computing
environment is not prone to faults and if there is a proper fault tolerant system/mech-
anism to prevent these faults. This concept becomes even stronger after introduction
of federated computing i.e. a type of computing in which customers using cloud ser-
vices are allowed to scale various applications over many domains but building such
reliable clouds is an area of concern due faults like byzantine faults which are arbitrary
in nature.
This research work is focused on testing the effectiveness of Byzantine Fault Tolerance in
a hybrid cloud environment by proposing a framework called BFS-HC (Byzantine Fault
Solution – Hybrid Cloud) for a hybrid cloud environment by creating a vigorous Fault
Tolerant (FT) system in order to test the effectiveness of the proposed framework by
injecting byzantine faults into the application layer of the cloud application installed
in the hybrid cloud environment. This research problem is essential because these
arbitrary faults or byzantine faults can occur in any running process within any cloud
computing environment at any point of time and a proper fault tolerant mechanism is
required to prevent or overcome these faults.
Keywords: Cloud computing, Fault tolerance, Byzantine faults, Byzantine fault tol-
erance.
ii

Contents
Abstract ii
1 Introduction 1
2 Background 3
2.1 Cloud Computing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Fault Tolerance: A challenge in cloud computing . . . . . . . . . . . . . 4
2.3 Byzantine Fault Tolerance . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.4 Current Byzantine Fault Tolerance (BFT) work in cloud . . . . . . . . . 7
2.5 Hypothesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.6 Expected Contribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3 Specifications 10
3.1 The Byzantine Fault Tolerance (BFT) experiment . . . . . . . . . . . . 10
3.1.1 Hybrid Cloud environment . . . . . . . . . . . . . . . . . . . . . 11
3.1.2 Byzantine Fault Solution - Hybrid Cloud (BFS - HC) . . . . . . 11
3.1.3 A cloud application . . . . . . . . . . . . . . . . . . . . . . . . . 12
4 Design and Implementation 13
4.1 The Experimental Design . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.2 Steps of Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.3 Implementation tools and technologies . . . . . . . . . . . . . . . . . . . 16
4.3.1 Openstack . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4.3.2 AWS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.3.3 MySQL server - A judgement result database . . . . . . . . . . . 18
4.3.4 Monitoring Tool . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.3.5 Fault injection tool . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5 Evaluation 20
5.1 Evaluation Process . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
iii

5.2 Metrics for evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.3 Expected Result . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
6 Dissertation Plan 25
Bibliography 27
iv

List of Figures
4.1 Experimental Setup using BFS-HC Framework . . . . . . . . . . . . . . 14
4.2 Flow diagram of experimental setup . . . . . . . . . . . . . . . . . . . . 16
4.3 Openstack conceptual diagram . . . . . . . . . . . . . . . . . . . . . . . 17
4.4 AWS architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5.1 Evaluation Process . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.2 Differing failure rate clouds . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.3 Efficiency comparison of experiment . . . . . . . . . . . . . . . . . . . . 22
6.1 Dissertation Plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
v

Chapter 1
Introduction
Cloud computing is a term used to describe a category of on-demand computing ser-
vices (pay as you go) which were first offered by providers, such as Google, Amazon and
Microsoft. Cloud computing acts as a model on which the infrastructure of computing
is viewed as a “cloud,” through which individuals access applications on demand. Cloud
computing is considered as utility computing which has enabled computing infrastruc-
ture which are highly scaled and flexible in nature. The computing infrastructure
empowered by cloud computing has provided capital saving for both consumers and
service providers. Such highly scalable compute resources has led to a tremendous
amount of cost saving.
Before we proceed further to the research problem, it is important to understand the
concepts of cloud computing along with the different areas of cloud computing related
to the research problem.
In Cloud computing major emphasis is laid on providing computing as a service i.e.
“on demand” and is achieved by providing a virtualized infrastructure consisting of
data centers which are maintained and monitored by content providers. The services
offered by cloud computing vendors are based on the fundamental models of cloud
computing such as IaaS (Infrastructure as a Service), SaaS (Software as a Service)
and PaaS (Platform as a Service). Cloud computing stands tall over other computing
paradigms such as grid computing, utility computing, mainframe computers and peer-
to-peer computers due to its characteristics such as agility, Application Programming
Interface (API), cost, device and location independency, maintenance, multitenancy,
performance, productivity, reliability, scalability, elasticity and security.
Cloud Computing provides benefits like cost efficiency, on-demand services and multi-
tenancy but with some risks associated to it. One of the major research challenges
1

in Cloud Computing is to ensure reliability and availability of resources provided by
it which is only possible if the cloud computing environment is not prone to faults
and if there is a proper fault tolerant system/mechanism to prevent these faults. So
there is a requirement for a vigorous Fault Tolerant (FT) system in Cloud Computing.
These faults can be of many types but this research problem focuses on byzantine
faults, which occur at any time and destroy an ongoing process completely in a cloud
computing environment. This document also focuses on the measures to overcome this
problem in order to provide good quality of service. There is a requirement for a robust
fault tolerance mechanism in order to prevent these byzantine faults.
(Duan, Levitt, Meling, Peisert & Zhang 2014) say that the fundamental problem
occurring in distributed systems is constructing robust network services that can with-
stand a wide range of failure types. In order to mask arbitrary failures the most general
approach used is byzantine fault tolerance but it is considered too exorbitant to install
in practice and many solutions are not resilient to performance attacks. According
to (AlZain, Soh & Pardede 2013), the major requirement for the clients dealing with
clouds is data security as clouds may fail due to the faults occurring in the software
or hardware, or attacks from malicious insiders. Hence, the construction of a highly
reliable or consistent cloud system has become a vital research requirement.
According to (Zhang, Zheng & Lyu 2011) cloud computing is becoming a highly
popular and efficient solution for constructing dependable applications on dispersed
resources. However, it is a perilous challenge to assure the dependability of applica-
tions within the system due to the very dynamic environment. This document de-
bates the problems faced due to byzantine faults occurring in cloud computing en-
vironments along-with the different approaches to overcome these faults by applying
different byzantine fault tolerant mechanisms in a cloud environment. The structure of
this document is laid as follows:
Chapter 2 discusses the related work done in domain of the research problem along-with
hypothesis and expected contribution.
2

Chapter 2
Background
This chapter discusses the background of Cloud computing along-with a glimpse of
domain of the research problem, Fault tolerance: A challenge in cloud computing,
Byzantine Fault Tolerance (BFT), Current Byzantine Fault Tolerance (BFT) work in
cloud, Hypothesis and Contribution.
2.1 Cloud Computing
This section discusses the background of cloud computing and the main issues that
occur in a cloud computing environment. The first paragraph discusses the background
of cloud computing while the second paragraph discusses the main issues in a cloud
computing environment.
(Armbrust, Fox, Griffith, Joseph, Katz, Konwinski, Lee, Patterson, Rabkin, Stoica &
Zaharia 2010) define cloud computing as referring to both the applications delivered as
services over the internet and the hardware and systems software in the data centers
that provide those services. The services themselves have long been referred to as
Software as a Service (SaaS). Some vendors use terms such as IaaS (Infrastructure as a
Service) and PaaS (Platform as a Service) to describe their products, but eschew with
these because accepted definitions for them still vary widely.
(Armbrust et al. 2010) and (Cloud computing and emerging {IT} platforms: Vision,
hype, and reality for delivering computing as the 5th utility 2009) describe cloud com-
puting as a computing rebellion that has the capability to change a huge part of the
IT industry by making software eye-catching and changing the way IT hardware is
purchased and designed. They have also compared cloud computing with several other
3

computing paradigms that have promised to deliver utility computing, Grid computing
and Cluster computing. According to NIST, “Cloud Computing is a model for enabling
ubiquitous convenient, on-demand network access to a shared pool of configurable com-
puting resources (e.g., networks, servers, storage, applications, and services) that can
be rapidly provisioned and released with minimal management effort or service provider
interaction.” (Mell & Grance 2010)
The advent of Cloud Computing has conveyed a new dimension to the domain of (IT)
Information Technology but with many benefits there are some issues related to it.
One of the major research challenges in Cloud Computing is to make sure that the
resources are reliable and continuously available. (Ganesh, Sandhya & Shankar 2014)
recommend the need for a vigorous Fault Tolerant (FT) system in Cloud Computing.
However building vigorous fault tolerant systems is itself a big challenge but it plays
an important role in the improvement of quality of service (QOS) in cloud computing.
In the next section we will discuss Fault Tolerance in more detail.
2.2 Fault Tolerance: A challenge in cloud computing
This section discusses fault tolerance, its resilience and management in cloud computing
along with some fault tolerant techniques applied in a cloud computing environment in
order to build a fault tolerant environment and also demonstrates the perception of the
number, nature and kind of faults that appear in cloud computing infrastructures, and
the impact of these faults on a user’s applications along with the measures to handle
these faults in a cost-effective and efficient manner. The first paragraph discusses
fault tolerance and how different journals and conferences describe fault tolerance in
cloud computing while the second paragraph discusses the different approaches of fault
tolerance in different computing environments.
(Jhawar & Piuri 2014) discuss and classify the type of faults that appear as failures
to the end users as Crash faults that stop the functioning of the system components
completely or remain inactive at the time of failures and Byzantine faults that force
the components of a system to act arbitrarily at the time of failure, triggering the
system to behave randomly incorrect. (Ganesh et al. 2014) say that “a single Cloud
consists of different layers which can be affected with various types of faults. So these
layers requires different levels of fault tolerant techniques in order to provide seamless
service.” The argument of both sets of authors share a common ground on providing a
robust fault tolerance in order to overcome faults. (Jhawar & Piuri 2014) discuss fault
tolerance as the capability of the system to achieve its purpose even in the existence of
4

failures. They describe fault tolerance as one of the mechanisms to improve the overall
dependability of the system.
Fault tolerance serves as a key factor in achieving good quality of service in a computing
environment because if a system is prone to faults it cannot provide good service quality
so a tough fault tolerance mechanism is required to prevent faults. Since fault tolerance
is required in a cloud computing environment to prevent faults, different people have
proposed different approaches of fault tolerance in order to achieve quality of service
in a cloud computing environment. (Jhawar, Piuri & Santambrogio 2013) discuss an
inventive and integrated perception for creation and management of fault tolerance in
Clouds. They present an intangible framework called Fault Tolerance Manager (FTM)
which provides a base for the service provider to propose fault tolerance as a service, and
propose an inclusive approach to cover execution details of fault tolerance techniques
to developers and users by virtue of a committed service layer. (Zheng, Zhou, Lyu
& King 2010) discuss reliable cloud applications as a critical research problem and
propose a FTCloud framework to build cloud applications which can tolerate faults
and hence improve reliability. (Ganesh et al. 2014) agree with (Jhawar et al. 2013)
on a requirement for a vigorous fault tolerance framework in order to prevent faults.
(Ganesh et al. 2014) discuss the elementary concepts of fault tolerance by thoughtful
consideration of different Fault Tolerance policies like Reactive Fault tolerance policy
and Proactive Fault Tolerance policy and the related Fault Tolerance techniques applied
on diverse types of faults. (Kurt & Agrawal 2012) debate the major problems arising in
data sets due to the continuous increase in the size of data sets and the requirement for
data management in order to meet the processing needs by means of added parallelism
(by including a greater number of nodes and/or cores into the system) but this exposes
the system to frequent failures during processing. In order to recover from this problem
they present a possible design and implementation of a fault-tolerant environment for
processing large queries on huge datasets.
To conclude, Fault tolerance is becoming a crucial area of research as faults occurring
during processing highly affect the performance of a system which in turn affects the
service quality offered by the system. (Duan, Peisert & Levitt 2015) discuss the
importance of fault tolerance in a cloud computing environment to prevent faults like
byzantine faults and develop an efficient fault tolerance model to prevent these kind of
faults.
In the next section we will be discussing Byzantine fault tolerance in further detail.
5

2.3 Byzantine Fault Tolerance
This section discusses Byzantine Fault Tolerance (BFT), a fault tolerant mechanism
required to prevent byzantine faults in a cloud computing environment. The first para-
graph discusses byzantine fault tolerance and how different journals and conferences
describe byzantine fault tolerance in a cloud computing environment while the second
paragraph provides a conclusion to byzantine fault tolerance with a glimpse of different
approaches for byzantine fault tolerance in a cloud computing environment.
(Zhang et al. 2011) confer byzantine faults as arbitrary faults which when they occur
in a cloud computing environment may damage a process or an entire application and
in order to build dependable cloud applications on a cloud infrastructure, it is vital
to design a fault tolerance structure for handling these type of faults. Normally, the
dependability of cloud applications in a cloud computing environment is effected due to
different types of faults such as network faults (disconnection), node faults (crashing),
byzantine faults (arbitrary faults) and the research problem is focused on one of these
faults i.e. byzantine faults, application of a byzantine fault tolerant mechanism in a
cloud computing environment. (Castro & Liskov 2002) discuss the arbitrary behavior
caused by byzantine faults due to malicious attacks, software error and mistake of op-
erator and suggest the requirement of highly available systems for the growing online
services in order to provide these services without interruptions. (Duan et al. 2015)
discuss the need of a byzantine fault tolerant mechanism in order to overcome hard-
ware and software errors, arbitrary/byzantine failures which are generated by malicious
attacks in modern distributed systems. Byzantine faults make a huge impact on qual-
ity of service in a cloud computing environment as these faults send an inconsistent
response to a request, forcing a process to crash. (Duan et al. 2014) agree with
(Zhang et al. 2011) on byzantine fault tolerance, a necessary framework to overcome
byzantine faults. Both sets of authors confer that regardless of significant improvement
in making byzantine fault tolerance practical, it is still not adopted widely because
of high overheads and complex techniques involved building such structures. (Duan
et al. 2014) say “despite significant progress in making BFT practical, it has not been
widely adopted, mainly because of the complexity of the techniques involved and high
overheads. In addition, BFT is not a panacea, since there are a variety of attacks,
such as various performance attacks that BFT does not handle well.” (Vukolic 2010)
describes byzantine faults as malicious behavior or arbitrary faults which have become
an important issue in a cloud computing environment, an efficient fault tolerant struc-
ture to prevent byzantine faults is required. (Guerraoui & Yabandeh 2010) agrees
with (Duan et al. 2015) on the requirement of a robust fault tolerant mechanism in a
cloud computing environment. (Guerraoui & Yabandeh 2010) discuss the requirement
6

of byzantine fault tolerant protocols in order to tolerate arbitrary/byzantine failures
of hardware and software components. Hence byzantine fault tolerance attracts lots of
researchers ever since byzantine faults were introduced but despite being a big research
area byzantine fault tolerance suffers from a limited practical adoption in real-time
systems such as the aerospace industry.
To conclude, Byzantine fault tolerance is an approach for overcoming the effects of
byzantine faults or arbitrary faults in a cloud computing environment to enhance qual-
ity of service. Since byzantine fault tolerance serves as an area of concern therefore so
many attempts have been made to use byzantine fault tolerance in cloud computing
environments in order to enhance quality of service provided. Byzantine fault tolerance
is serving as a big issue in cloud computing and makes the research problem even more
important because of the amount of impact it causes to a cloud computing environ-
ment and in this review we will be discussing more about the different approaches of
application of byzantine fault tolerance in a cloud computing environment.
In the next section we will analyze the different approaches of Byzantine fault tolerance
in detail.
2.4 Current Byzantine Fault Tolerance (BFT) work in
cloud
This section discusses the current work done in the domain byzantine fault tolerance
(BFT) in a cloud computing environment. This section provides an analysis on the
different methods adopted by different people in order to provide byzantine fault tol-
erance in cloud computing. The first paragraph analyses the diverse approaches for
byzantine fault tolerance by different people in a cloud computing environment while
the second paragraph provides a conclusion to different methodologies for byzantine
fault tolerance.
(AlZain et al. 2013) consider data security, a significant requirement in clouds be-
cause a cloud may fail due to faults occurring in the hardware or software making it
a critical research problem. They propose a practical model, BFT-MCDB (Byzantine
Fault Tolerance Multi-Clouds Database) with byzantine fault tolerance in a multi-cloud
environment which depend on an approach which combines Shamir’s secret sharing ap-
proach (to detect Byzantine failure) along with Byzantine Agreement protocols in a
multi-cloud computing environment ensuring the security of stowed data inside the
cloud. (Zhang et al. 2011) agree with (AlZain et al. 2013) in context to byzantine
fault tolerance being an important research area in a cloud computing environment.
7

(Zhang et al. 2011) discuss the importance of building highly dependent applications in
a cloud computing environment. They say building such applications is a big challenge
in order to guarantee dependability of the applications mostly in voluntary-resource
cloud because of the highly dynamic environment, so they propose a Byzantine fault
tolerance structure for constructing vigorous systems in voluntary-resource cloud en-
vironment, BFTCloud (Byzantine Fault Tolerant Cloud) which guarantees heftiness
of systems when up to f out of 3f +1 resource providers incur fault which may in-
clude arbitrary faults. (Castro & Liskov 2002) propose a new replication algorithm
to tolerate byzantine faults and produce highly available systems. (Zhang et al. 2011)
also say that “BFTCloud guarantees high reliability of systems built on the top of
voluntary-resource cloud infrastructure and ensures good performance of these sys-
tems.” (Garraghan, Townend & Xu 2011) support (Zhang et al. 2011) and (AlZain
et al. 2013) on proposing a fault tolerant system that can overcome arbitrary faults or
byzantine faults and also discuss strengthening this concept with the rise of federated
computing clouds which help to meet Quality of Service targets by allowing users to
scale the applications across various domains. They analyze the application of byzan-
tine fault tolerance to federated clouds in detail by an experiment under which a cloud
framework called FT-FC is built which allows them to create diversity based byzantine
fault tolerant systems and apply them to federated Clouds in order to examine the
efficiency of byzantine fault tolerance in federated Clouds. (Celesti, Tusa, Villari &
Puliafito 2010) describe about how to build an interoperable heterogeneous cloud milieu
inside a horizontally federated configuration, where clouds cooperate with each other in
order to build trust and provide new opportunities for business including power saving,
reduced cost assets and on-demand provisioning of resources. Costa et al (2011) talk
about the importance of MapReduce to run scientific data analysis and how result of
these MapReduce jobs get effected by arbitrary faults. They say “MapReduce run-
times like Hadoop tolerate crash faults, but not arbitrary or Byzantine faults”. So they
propose a MapReduce algorithm to tolerate these type of faults. Both (Costa, Pasin,
Bessani & Correia 2013) and (Correia, Costa, Pasin, Bessani, Ramos & Verissimo 2012)
agrees with (Costa, Pasin, Bessani & Correia 2011) and describe byzantine faults in a
cloud and propose a MapReduce runtime which can tolerate these faults and run at a
low cost in terms of execution time.
To conclude, byzantine fault tolerance is considered a large domain and a lot of work
is done on it, there are various other approaches for application of byzantine fault
tolerance in cloud computing environment along with the approaches discussed above
making byzantine fault tolerance a wide area for research.
8

2.5 Hypothesis
This document focuses on the following research problem:-
“Can we design an efficient Byzantine Fault Tolerant mechanism for a cloud
computing environment?”
This research problem is important because these arbitrary faults or byzantine faults
can occur in any running process within any cloud computing environment at any
point of time and a proper fault tolerant mechanism is required to prevent or overcome
these faults. In this research work, we propose an efficient byzantine fault tolerant
framework named BFS - HC (Byzantine Fault Solution – Hybrid Cloud) in order to
test the effectiveness of Byzantine Fault Tolerance in a hybrid cloud environment.
2.6 Expected Contribution
This paper carefully addresses the byzantine/arbitrary faults and continues the novel
approach of (Garraghan et al. 2011) and proposes a fault tolerant framework, Byzan-
tine Fault Solution – Hybrid Cloud (BFS - HC) in order to test the effectiveness of
Byzantine Fault Tolerance in a hybrid cloud environment by injecting byzantine faults
into the application layer, hardware level and find the reasons of failing due to byzan-
tine/arbitrary faults, trying to increase the cloud dynamicity, record results for the
framework and compare Byzantine Fault Solution – Hybrid Cloud (BFS - HC) with
the framework proposed by (Garraghan et al. 2011).
9

Chapter 3
Specifications
In this section we will discuss about the specifications of our research. This section
discusses the Byzantine Fault Tolerance (BFT) experiment and the cloud application
to be used in the experiment.
3.1 The Byzantine Fault Tolerance (BFT) experiment
The byzantine faults have been a big area of concern in cloud computing because of
the highly dynamic cloud environment, the application of Byzantine Fault Tolerance is
equally difficult and expensive in a cloud environment but along-with being expensive
and difficult to implement it also ensures strong failure independence between nodes
within the system. Therefore an experiment is projected in order to analyze the applica-
tion of Byzantine Fault Tolerance in a cloud computing environment and an experiment
is carried out to analyze the effectiveness of Byzantine Fault Tolerance in a cloud com-
puting environment. This experiment is focused on projecting a framework “Byzantine
Fault Solution-Hybrid Cloud” (BFS-HC) which allows to create variety-based Byzan-
tine Fault Tolerant system and apply in a Hybrid Cloud environment. The proposed
framework will test the effectiveness of Byzantine Fault Tolerance in a Hybrid Cloud
environment.
The experiment encompasses of development of a Hybrid Cloud environment, appli-
cation of the proposed framework (BFS-HC) in the Hybrid Cloud environment. The
hybrid cloud environment is discussed in the subsequent section.
10

3.1.1 Hybrid Cloud environment
The hybrid cloud environment in the experiment is set up using Openstack, Private
Cloud and Amazon Web Services (AWS), Public Cloud. Openstack is a private cloud
platform and is set up locally by installing all the services on the system locally whereas
AWS is a public cloud platform and its services are directly used from its management
console. Once the private cloud, Openstack is set up locally on the system and the
public cloud AWS is up and running a connection is set up between both the clouds
resulting in a hybrid cloud environment.
On successful implementation of the hybrid cloud environment the proposed framework
BFS-HC is applied to the created cloud environment. The proposed framework is
discussed in the subsequent section.
3.1.2 Byzantine Fault Solution - Hybrid Cloud (BFS - HC)
The proposed framework Byzantine Fault Solution-Hybrid Cloud is created in order to
explore the efficiency of Byzantine Fault Tolerance in a hybrid cloud environment. The
projected framework BFS-HC features following components in order to promote the
use Byzantine Fault Tolerance in a Hybrid Cloud environment:
Job scheduling tool
A job scheduling tool is used to automatically submit cloud applications to both clouds
i.e. Openstack and AWS. This tool submits multiple copies of the cloud application on
different virtual machines set up on both the cloud platforms. The subsequent section
confers the communication system used in the experimental setup.
Communication system
A communication system is set up in between the clouds and the virtual machines resid-
ing over the clouds. This communication set up allows the virtual machines over both
clouds to communicate with each other using a messaging system. The communication
is based on Secure Shell protocol.
The subsequent section describes the judgement system used in the experimental setup.
11

A Judgement system
A judgement system is set up in the experiment which is fault tolerant by nature.
This judgement system features in sending and receiving communication from several
clouds. This sending and receiving communication is featured for the judgement system
in order to come to an agreement on the results returned from different clouds.
The subsequent section includes the specifications of the cloud application created and
tested for Byzantine Fault Tolerance in the hybrid cloud environment.
3.1.3 A cloud application
A cloud application is created and deployed on each virtual machine residing on the
two cloud platforms, Openstack and AWS. The cloud application is designed in such
a way that it allows us to inject byzantine/arbitrary faults into the processing of the
cloud application. The faults injected into each application residing on each virtual
machine on the respective clouds.
The code of BFS-HC framework is added to the cloud application in a way that it
sends the results to the judgement system. The application is installed on six virtual
machines, three on each Openstack and AWS respectively. The following sections confer
the design of the experimental setup followed by the evaluations and dissertation plan.
The subsequent section describes the design of the experimentation performed.
12

Chapter 4
Design and Implementation
The experimental design includes the development of a framework Byzantine Fault
Tolerance-Hybrid Cloud (BFT-HC). The framework is then applied to a hybrid cloud
environment in order to test the effectiveness of Byzantine Fault Tolerance in the hybrid
cloud environment. The design section discusses about the creation of a framework
which when applied in the hybrid cloud environment tests its effectiveness. The design
section also confers the effectiveness of Byzantine Fault Tolerance in a hybrid cloud
environment by checking its efficiency using a cloud application which is replicated on
six virtual machines residing on the chosen cloud platforms, Openstack and AWS.
The design section is structured as follows: The Experimental Design, Steps of imple-
mentation and Implementation tools and technologies.
4.1 The Experimental Design
This section discusses about the design of the proposed experiment followed by the
steps of implementation and the key tools and technologies used.
At present Byzantine Fault Tolerance and its application in a hybrid cloud environment
is an area where not much research has been done. Although our experiment is primar-
ily focused on testing the effectiveness of Byzantine Fault Tolerance in a hybrid cloud
environment. We advise a framework BFS-HC which is used to test the effectiveness
of Byzantine Fault Tolerance in a hybrid cloud environment. The experimental design
comprises of following: Openstack (Private Cloud), AWS (Public Cloud), 6 virtual ma-
chines (3 on each Openstack and AWS respectively), Job scheduling tool, a judgement
system and a judgement result database.
13

The framework BFS-HC agrees to create different redundant fault tolerant algorithms.
Some initial work is done in order to assess the effectiveness of including Byzantine
Fault Tolerance inside a hybrid cloud environment. In order to perform a series of ex-
periment which involved the submission of real cloud application into a hybrid cloud the
framework BFS-HC is used. The cloud application which is used includes a program
which helps to generate a virtual representation for a population. Once the virtual
representation is generated various analysis are performed on the population. On care-
ful analysis a series of values is returned back to the user. The cloud application is
designed in a way that it allows us to inject byzantine faults into the processing of the
application, also the code of the framework BFS-HC is added to allow the cloud appli-
cation send the results back to the judgement system. The two clouds Openstack and
AWS are used in a hybrid environment. Openstack is an open-source cloud computing
environment which allows to create, deploy and manage virtual computing resources
over it. Openstack uses KVM hypervisor and the virtual images used are ubuntu desk-
top edition. AWS is a public cloud environment which is managed by Amazon. AWS
uses KVM hypervisor and Ubuntu Debian operating system images over it.
A diversity mechanism is used to achieve the effectiveness of Byzantine Fault Tolerance
based on the idea of failure independence. We have opted N Copy system as the
diversity mechanism. N Copy system works as the N design system but it gears data
diversity instead of design diversity. We have used N Copy system in our experiment as
the purpose of our experiment is to explore the viability of Byzantine Fault Tolerance
in a hybrid cloud environment. The experimental design is described in figure 4.1.
Figure 4.1: Experimental Setup using BFS-HC Framework
14

4.2 Steps of Implementation
This section discusses the steps included during the implementation of the experiment.
The steps included in the setup of the experiment are as follows:
Step 1: Install and run VMware workstation on the host operating system. Step 2:
Create a virtual machine (Ubuntu desktop edition) over VMware workstation. Step 3:
Install all the services of Openstack on the virtual machine created on VMware work-
station. Step 4: When all the services of Openstack are installed open the dashboard of
Openstack and create three virtual machines with KVM hypervisor and ubuntu desktop
edition over it. Step 5: Similarly created three virtual machines using KVM hypervisor
and ubuntu desktop edition over AWS. Step 6: Install the e-science cloud application
over all three virtual machines residing over Openstack and AWS respectively. Step
7: In the experiment it is assumed that the job scheduling tool and judgement system
don’t consist faults. Three different types of faults are inserted into all the services of
experiment. The faults inserted are late timing faults, omission faults and late timing
faults. Step 8: The entire experiment runs for all three types of faults for 1000 times
at the failure rate of 1Step 9: The entire experiment works as shown in figure 4.2. Step
10: Firstly, the application is automatically submitted to both the clouds using a job
scheduling tool. Step 11: Secondly, the application is submitted to the N Copy service
in both the clouds i.e. Openstack and AWS. Step 12: Thirdly, Each virtual machine
executes the e-science application and faults are inserted. Step 13: Fourthly, The result
is submitted to the judgement system in form of structured data by each service. Step
14: Fifthly, The judgement system decides about the results returned being acceptable
or not in a given time frame. Step 15: The result obtained from the judgement system
is casted as a failure or a success and is stored in the judgement result database either
ways.
The BFS-HC framework is responsible for keeping the records of the results obtained
from the judgement system. The framework also records the information including the
success state of the judgement system, the total time for job submission, the flagging
for the detected failure and the reason/reasons for failing.
15

Figure 4.2: Flow diagram of experimental setup
4.3 Implementation tools and technologies
This section deals with the tools and technologies required for the implementation of
the experiment are as follows:
4.3.1 Openstack
Openstack is an open-source cloud platform used as a private cloud for our experiment.
It resides on Kernel-based Virtual Machine. It uses Ubuntu virtual machine images
which reside over the hypervisor. It includes three virtual machines on which the
e-science application is installed and faults are inserted. The conceptual diagram of
Openstack is shown in figure 4.3.
Why Openstack: 1. Openstack is used as the private cloud in our experimental setup.
2. Openstack includes different key projects which can be installed separately but can
work together according to cloud needs of the user. 3. Openstack provides services
16

such as Networking, Block Storage, Database, Telemetry, Compute, Orchestration,
Image Service and Object Storage. All the above stated services can be installed and
configured separately. 4. It is an open-source cloud platform, making it easier to obtain
all its services as per the need for the experiment. 5. Most of the services will be used
during the experimentation.
Figure 4.3: Openstack conceptual diagram
4.3.2 AWS
AWS is a public cloud platform used as a public cloud for our experiment. The virtual
machines required for the experimental setup are created and deployed on AWS. Three
virtual machines are created on AWS and e-science cloud application is installed on
every single virtual machine. The architecture of AWS is explained in figure 4.4.
17

Figure 4.4: AWS architecture
Why AWS:
1. AWS is used as the public cloud platform in our experimental setup. 2. AWS is
used in our experimental setup due to the various services made available by this public
cloud. 3. It provides a low cost infrastructure platform which is highly scalable and
reliable. 4. We have used AWS as our public cloud platform in our experimental setup
due to easy availability of the services required for the experiment. 5. Some of the
services which will be used are EC2 for compute and S3 for data storage.
4.3.3 MySQL server - A judgement result database
The above proposed framework BFS-HC records the results of from the judgement
system including the success state, total job submission time and the reasons for failing
and stores the result in the judgement result database. The database used to store the
result of the judgement is MySQL server.
18

Why MySQL server:
1. In our experimental setup MySQL is used to store results obtained after the judge-
ment system. 2. MySQL server is an open-source available database. 3. It is easily
available database which is highly secure and reliable.
4.3.4 Monitoring Tool
The Openstack and AWS consoles provide individual monitoring of both cloud plat-
forms.
Why Openstack and AWS console:
1. The consoles for both the cloud platforms provide monitoring of applications in
real-time. 2. The consoles monitor the CPU load, memory usage, latency (average),
I/O processing load and few more. 3. The consoles of both Openstack and AWS also
provide real time monitoring of network traffic.
4.3.5 Fault injection tool
The fault injection tool used to insert faults in the cloud application is FERRARI.
Why FERRARI:
1. FERRARI is a software based error and fault injection tool. 2. It uses the techniques
to emulate permanent faults and transient errors. 3. It is a real time injector of errors
and faults.
The evaluation for the experimental setup is explained in the next section.
19

Chapter 5
Evaluation
5.1 Evaluation Process
The experimental design includes the development of a framework Byzantine Fault
Tolerance-Hybrid Cloud (BFT-HC). It includes the valuation of the different scenarios
of different configuration, the comparison is also done for the different configuration for
same configurations. The evaluation process is explained in figure 5.1.
20

Figure 5.1: Evaluation Process
The evaluation criteria includes the gathering of information for scenarios and input
data. Under evaluation criteria it is ensured that the cloud application and the re-
sources associated with it are available. The input data is gathered for each scenario
simultaneously the metrics are initiated for each scenario. After the evaluation criteria
is set the configuration and methodologies are evaluated. After the configuration and
methodologies the results of the run experiment provides detailed outputs for different
parameters. The monitoring of the scenarios is done by the monitoring tool in order to
obtain detailed analysis.
5.2 Metrics for evaluation
The table for the comparison of the judgement success rate in performed experiment
is shown in Table 5.2.1. The failure percentage for Openstack and AWS is the second
column and contains numerical values. For instance: 10-5 represent the 10 percent
failure rate of services in Openstack and 5 percent failure rate of services in AWS. The
table is used in order represent the effectiveness of the N Copy scheme in the presence
or absence of failure.
21
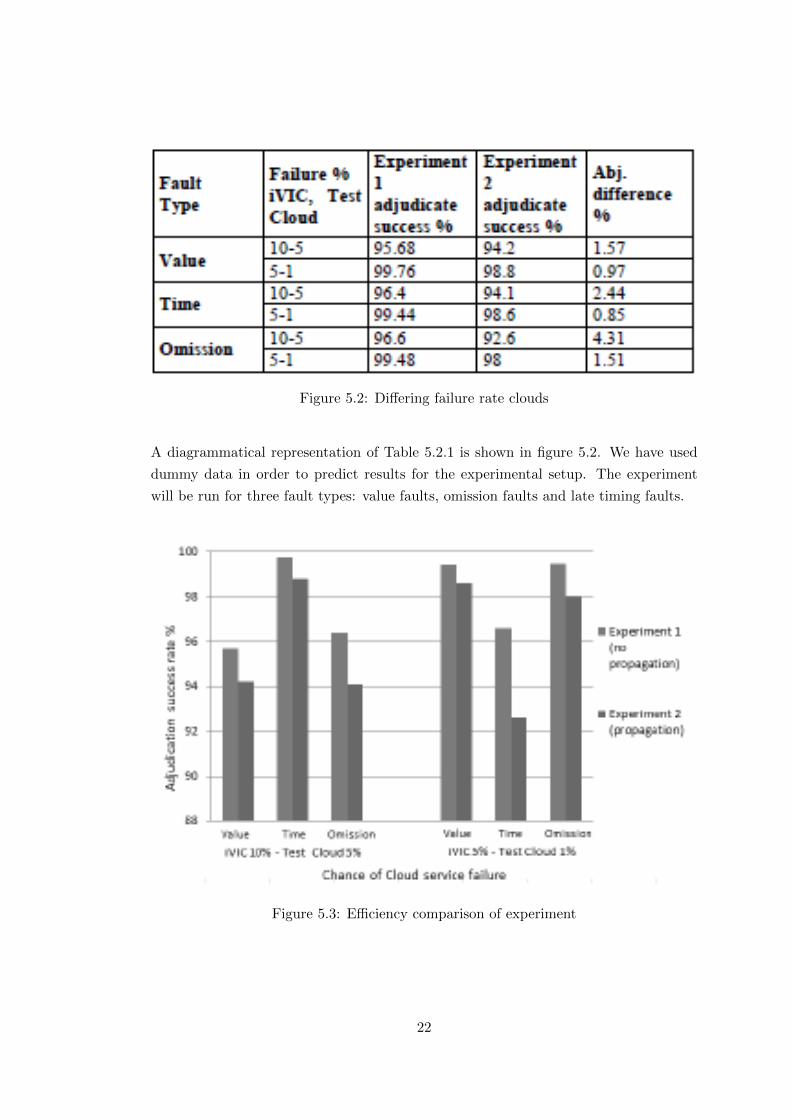
Figure 5.2: Differing failure rate clouds
A diagrammatical representation of Table 5.2.1 is shown in figure 5.2. We have used
dummy data in order to predict results for the experimental setup. The experiment
will be run for three fault types: value faults, omission faults and late timing faults.
Figure 5.3: Efficiency comparison of experiment
22

5.3 Expected Result
The results from the experimentation will help us to validate issues concerning cloud
agreement about the high probability of propagation of failure within a single cloud
infrastructure. Also the results from the experiment will help us test the effectiveness
of Byzantine Fault Tolerance in a hybrid cloud environment i.e. whether it is efficient
in a hybrid cloud environment.
It is expected that the problem of byzantine faults can be tolerated better in a hybrid
cloud environment by using BFS-HC framework.
5.4 Conclusion
The background for the research has measured cloud computing, fault tolerance: a chal-
lenge in cloud computing, byzantine fault tolerance, current byzantine fault tolerance
work in cloud. In brief cloud computing has rose as popular paradigm which allows the
establishment of flexible computing infrastructures which can offer major cost savings
for both the consumers and businesses by letting compute resources to be scaled vig-
orously in order to deal with current or expected usage but along with the increase in
the popularity of cloud computing number of failures and faults have also increased in
which byzantine faults have gained a lot of consideration as these faults hinder the pop-
ularity of cloud computing. So a good fault tolerance mechanism is required to prevent
byzantine faults in order to provide good quality of service. The background for the re-
search has discovered that different approaches for byzantine fault tolerance have been
suggested for application to a cloud environment in order to enhance quality of service
but with a common motive to prevent these arbitrary faults/byzantine faults. Many
authors discuss the importance of the application of byzantine fault tolerance in differ-
ent cloud computing environments but some of them say that even though byzantine
fault tolerance is an important step to implement in a cloud computing environment
but still many big data centers haven’t adopted byzantine fault tolerance because of
the high cost associated with it.
Few authors have suggested some improvement measures to enhance quality of ser-
vice in a cloud computing environment by application of the byzantine fault tolerance
framework proposed by them. The research thesis has identified different approaches
of different authors working in the domain of byzantine fault tolerance in a cloud com-
puting environment. All the authors have suggested their own approaches and have
23

shown confidence on their proposed frameworks for byzantine fault tolerance. How-
ever, further research is highly recommended because till date big cloud vendors are
not using byzantine fault tolerance in their data centers due to cost related issues, also
an efficient approach is required to create a framework that can tolerate or overcome
byzantine faults which in turn leads to enhanced quality of service.
24

Chapter 6
Dissertation Plan
In this research waterfall model is entire development lifecycle. We have selected the
Software Development Life Cycle model because of the input based dependent compo-
nents. The dissertation is shown in figure 6.1
25

Figure 6.1: Dissertation Plan
26

Bibliography
AlZain, M., Soh, B. & Pardede, E. (2013), A byzantine fault tolerance model for a multi-cloud comput-
ing, in ‘Computational Science and Engineering (CSE), 2013 IEEE 16th International Conference
on’, pp. 130–137.
Armbrust, M., Fox, A., Griffith, R., Joseph, A. D., Katz, R., Konwinski, A., Lee, G., Patterson,
D., Rabkin, A., Stoica, I. & Zaharia, M. (2010), ‘A view of cloud computing’, Commun. ACM
53(4), 50–58.
Castro, M. & Liskov, B. (2002), ‘Practical byzantine fault tolerance and proactive recovery’, ACM
Trans. Comput. Syst. 20(4), 398–461.
Celesti, A., Tusa, F., Villari, M. & Puliafito, A. (2010), Three-phase cross-cloud federation model:
The cloud sso authentication, in ‘Advances in Future Internet (AFIN), 2010 Second International
Conference on’, pp. 94–101.
Cloud computing and emerging {IT} platforms: Vision, hype, and reality for delivering computing as
the 5th utility (2009), Future Generation Computer Systems 25(6), 599 – 616.
Correia, M., Costa, P., Pasin, M., Bessani, A., Ramos, F. & Verissimo, P. (2012), On the feasibility of
byzantine fault-tolerant mapreduce in clouds-of-clouds, in ‘Reliable Distributed Systems (SRDS),
2012 IEEE 31st Symposium on’, pp. 448–453.
Costa, P., Pasin, M., Bessani, A. & Correia, M. (2011), Byzantine fault-tolerant mapreduce: Faults are
not just crashes, in ‘Cloud Computing Technology and Science (CloudCom), 2011 IEEE Third
International Conference on’, pp. 32–39.
Costa, P., Pasin, M., Bessani, A. & Correia, M. (2013), ‘On the performance of byzantine fault-tolerant
mapreduce’, Dependable and Secure Computing, IEEE Transactions on 10(5), 301–313.
Duan, S., Levitt, K., Meling, H., Peisert, S. & Zhang, H. (2014), Byzid: Byzantine fault tolerance
from intrusion detection, in ‘Reliable Distributed Systems (SRDS), 2014 IEEE 33rd International
Symposium on’, pp. 253–264.
Duan, S., Peisert, S. & Levitt, K. (2015), ‘hbft: Speculative byzantine fault tolerance with minimum
cost’, Dependable and Secure Computing, IEEE Transactions on 12(1), 58–70.
Ganesh, A., Sandhya, M. & Shankar, S. (2014), A study on fault tolerance methods in cloud computing,
in ‘Advance Computing Conference (IACC), 2014 IEEE International’, pp. 844–849.
Garraghan, P., Townend, P. & Xu, J. (2011), Byzantine fault-tolerance in federated cloud computing,
in ‘Service Oriented System Engineering (SOSE), 2011 IEEE 6th International Symposium on’,
pp. 280–285.
Guerraoui, R. & Yabandeh, M. (2010), Independent faults in the cloud, in ‘Proceedings of the 4th
International Workshop on Large Scale Distributed Systems and Middleware’, LADIS ’10, pp. 12–
17.
27

Jhawar, R. & Piuri (2014), ‘Fault tolerance and resillience in cloud computing environments’, In Vacca,
J.R. (ed.) Cyber Security and IT infrastructure Protection .
Jhawar, R., Piuri, V. & Santambrogio, M. (2013), ‘Fault tolerance management in cloud computing:
A system-level perspective’, Systems Journal, IEEE 7(2), 288–297.
Kanawati, G., Kanawati, N. & Abraham, J. (1995), ‘Ferrari: a flexible software-based fault and error
injection system’, Computers, IEEE Transactions on 44(2), 248–260.
Kurt, M. & Agrawal, G. (2012), A fault-tolerant environment for large-scale query processing, in ‘High
Performance Computing (HiPC), 2012 19th International Conference on’, pp. 1–10.
Mell, P. & Grance, T. (2010), ‘The nist definition of cloud computing.’, Communications of the ACM
53(6), 50.
Vukolic, M. (2010), ‘The byzantine empire in the intercloud’, SIGACT News 41(3), 105–111.
Zhang, Y., Zheng, Z. & Lyu, M. (2011), Bftcloud: A byzantine fault tolerance framework for voluntary-
resource cloud computing, in ‘Cloud Computing (CLOUD), 2011 IEEE International Conference
on’, pp. 444–451.
Zheng, Z., Zhou, T., Lyu, M. & King, I. (2010), Ftcloud: A component ranking framework for fault-
tolerant cloud applications, in ‘Software Reliability Engineering (ISSRE), 2010 IEEE 21st Inter-
national Symposium on’, pp. 398–407.
28