thread criticality predictors for dynamic performance, power, and resource management in chip...
Post on 19-Dec-2015
216 views
TRANSCRIPT

Thread Criticality Predictors for Dynamic Performance, Power,
and Resource Management in Chip Multiprocessors
Abhishek Bhattacharjee
Margaret Martonosi
Princeton University

Why Thread Criticality Prediction?
D-Cache Miss
I-Cache Miss
Stall Stall
T0 T1 T2T3 • Threads 1 & 3 are critical
Performance degradation, energy inefficiency
• Sources of variability: algorithm, process variations, thermal emergencies etc.
• With thread criticality prediction:1.Task stealing for performance2.DVFS for energy efficiency3.Many others …
Insts Exec

Related Work
Instruction criticality [Fields et al., Tune et al. 2001 etc.]
Thrifty barrier [Li et al. 2005] Faster cores transitioned into low-power mode based on prediction of
barrier stall time
DVFS for energy-efficiency at barriers [Liu et al. 2005]
Meeting points [Cai et al. 2008] DVFS non-critical threads by tracking loop iterations completion rate
across cores (parallel loops)
Our Approach:1.Also handles non-barrier code2.Works on constant or variable loop iteration size3.Predicts criticality at any point in time, not just barriers

Thread Criticality Prediction GoalsDesign Goals
1. Accuracy• Absolute TCP accuracy• Relative TCP accuracy
2. Low-overhead implementation• Simple HW (allow SW policies to be built on top)
3. One predictor, many uses
Design Decisions
1. Find suitable arch. metric
2. History-based local approach versus thread-comparative approach
3. This paper: TBB, DVFS Other uses: Shared LLC management, SMT and memory priority, …

Outline of this Talk
Thread Criticality Predictor Design Methodology Identify µarchitectural events impacting thread criticality Introduce basic TCP hardware
Thread Criticality Predictor Uses Apply to Intel’s Threading Building Blocks (TBB) Apply for energy-efficiency in barrier-based programs

Methodology Evaluations on a range of architectures: high-performance and embedded domains
Full-system including OS
Detailed power/energy studies using FPGA emulatorInfrastructure
Domain
System
Cores
Caches
GEMS Simulator
High-performance, wide-issue, out-of-order
16 core CMP with Solaris 10
4-issue SPARC
32KB L1 , 4MB L2
ARM Simulator
Embedded, in-order
4-32 core CMP
2-issue ARM
32KB L1, 4MB L2
FPGA Emulator
Embedded, in-order
4-core CMP with Linux 2.6
1-issue SPARC
4KB I-Cache, 8KB D-Cache

Why not History-Based TCPs?
+ Info local to core: no communication
-- Requires repetitive barrier behavior
-- Problem for in-order pipelines: variant IPCs
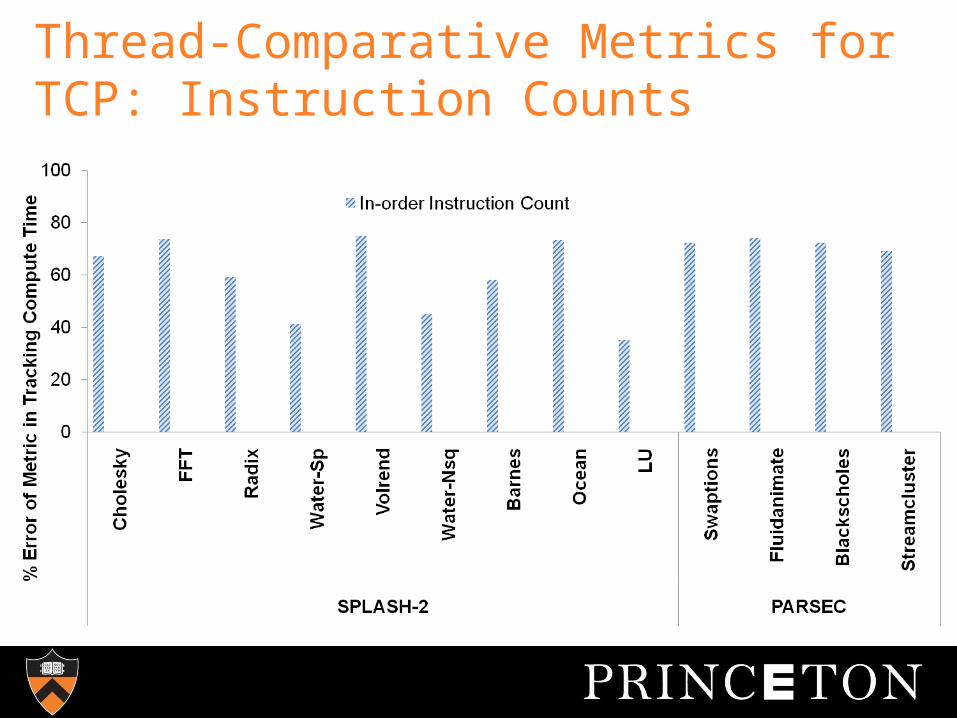
Thread-Comparative Metrics for TCP: Instruction Counts

Thread-Comparative Metrics for TCP: L1 D Cache Misses

Thread-Comparative Metrics for TCP: L1 I & D Cache Misses

Thread-Comparative Metrics for TCP: All L1 and L2 Cache Misses

Thread-Comparative Metrics for TCP: All L1 and L2 Cache Misses

Outline of this Talk
Thread Criticality Predictor Design Methodology Identify µarchitectural events impacting thread criticality Introduce basic TCP hardware
Thread Criticality Predictor Uses Apply to Intel’s Threading Building Blocks (TBB) Apply for energy-efficiency in barrier-based programs
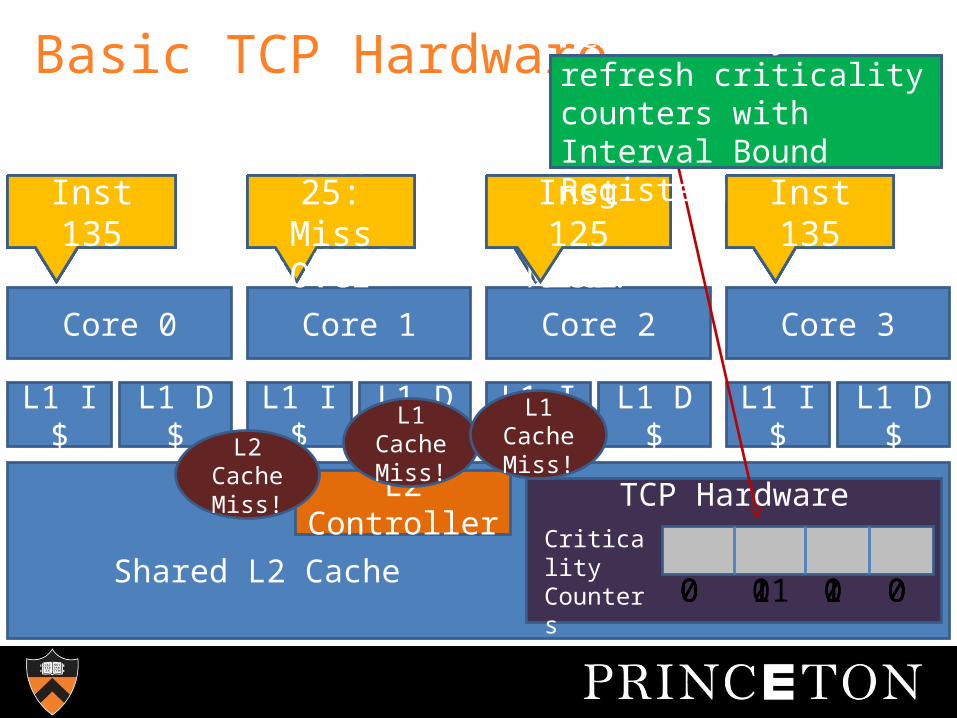
Basic TCP Hardware
Core 0 Core 1 Core 2
L1 I $
L1 D $
L1 I $
L1 D $
L1 I $
L1 D $
Core 3
L1 I $
L1 D $
Shared L2 Cache
L2 Controller
TCP Hardware
Inst 1 Inst 1 Inst 1 Inst 1Inst 2 Inst 2 Inst 2 Inst 2Inst 5Inst 5: L1 D$ Miss!
Inst 5 Inst 5
Criticality Counters 0 0 0 0
L1 Cache Miss!
0 1 0 0
Inst 15Inst 5: Miss Over
Inst 15 Inst 15Inst 20 Inst 10Inst 20:
L1 I$ Miss!
Inst 20
L1 Cache Miss!
0 1 1 0
Inst 30 Inst 20Inst 20:
Miss Over
Inst 30Inst 35Inst 25:
L2 $ Miss
Inst 25 Inst 35
L2 Cache Miss!
0 11 1 0
Per-core Criticality Counters track poorly cached, slow threads
Inst 135Inst 25:
Miss Over
Inst 125 Inst 135
Periodically refresh criticality counters with Interval Bound Register

Outline of this Talk
Thread Criticality Predictor (TCP) Design Methodology Identify µarchitectural events impacting thread criticality Introduce basic TCP hardware
Thread Criticality Predictor Uses Apply to Intel’s Threading Building Blocks (TBB) Apply for energy-efficiency in barrier-based programs

TBB Task Stealing & Thread Criticality
TBB dynamic scheduler distributes tasks Each thread maintains software queue filled with tasks
Empty queue – thread “steals” task from another thread’s queue
Approach 1: Default TBB uses random task stealing More failed steals at higher core counts poor performance
Approach 2: Occupancy-based task stealing [Contreras, Martonosi, 2008] Steal based on number of items in SW queue Must track and compare max. occupancy counts

TCP-Guided TBB Task StealingCore 0
SW Q0
Shared L2 Cache
Core 1
SW Q1
Core 2
SW Q2
Core 3
SW Q3
Criticality Counters
Interval Bound Register
Task 1
TCP Control Logic
Task 0
Task 2
Task 3
Task 4 Task 5 Task 6
Task 7
Clock: 0Clock: 100 0 0 01
Core 3: L2 Miss
11Clock: 30
Clock: 100
None
14 5 2 21
Core 2:
Steal Req.
Scan for
max val.
Steal from
Core 3
Task 7
• TCP initiates steals from critical thread• Modest message overhead: L2 access latency• Scalable: 14-bit criticality counters 114 bytes of storage @ 64 cores
Core 3: L1 Miss

TCP-Guided TBB Performance
• TCP access penalized with L2 latency
% Perf. Improvement versus Random Task Stealing
Avg. Improvement over Random (32 cores) = 21.6 %
Avg. Improvement over Occupancy (32 cores) = 13.8 %

Outline of this Talk
Thread Criticality Predictor Design Methodology Identify µarchitectural events impacting thread criticality Introduce basic TCP hardware
Thread Criticality Predictor Uses Apply to Intel’s Threading Building Blocks (TBB) Apply for energy-efficiency in barrier-based programs

Adapting TCP for Energy Efficiency in Barrier-Based Programs
T0 T1 T2 T3Insts Exec
L2 D$
Miss
L2 D$
OverT1 critical, => DVFS T0, T2, T3
Approach: DVFS non-critical threads to eliminate barrier stall time
Challenges:• Relative criticalities• Misprediction costs• DVFS overheads
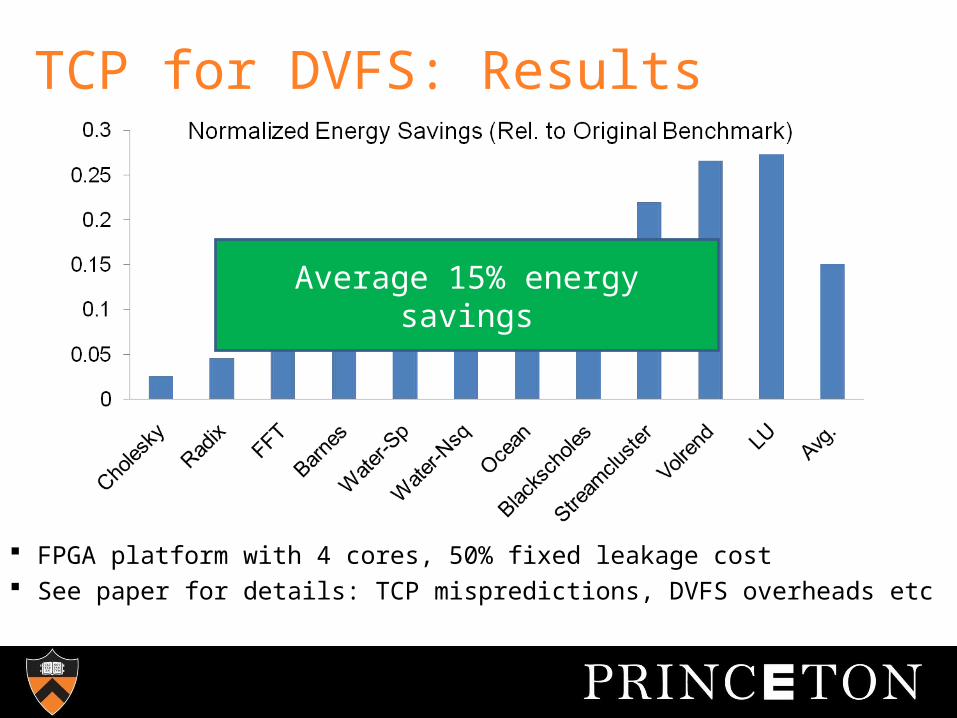
TCP for DVFS: Results
FPGA platform with 4 cores, 50% fixed leakage cost See paper for details: TCP mispredictions, DVFS overheads etc
Average 15% energy savings

Conclusions
Goal 1: Accuracy Accurate TCPs based on simple cache statistics
Goal 2: Low-overhead hardware Scalable per-core criticality counters used TCP in central location where cache info. is already available
Goal 3: Versatility TBB improved by 13.8% over best known approach @ 32 cores DVFS used to achieve 15% energy savings Two uses shown, many others possible…

Thread Criticality Predictors for Dynamic Performance, Power,
and Resource Management in Chip Multiprocessors
Abhishek Bhattacharjee
Margaret Martonosi
Princeton University

Backup
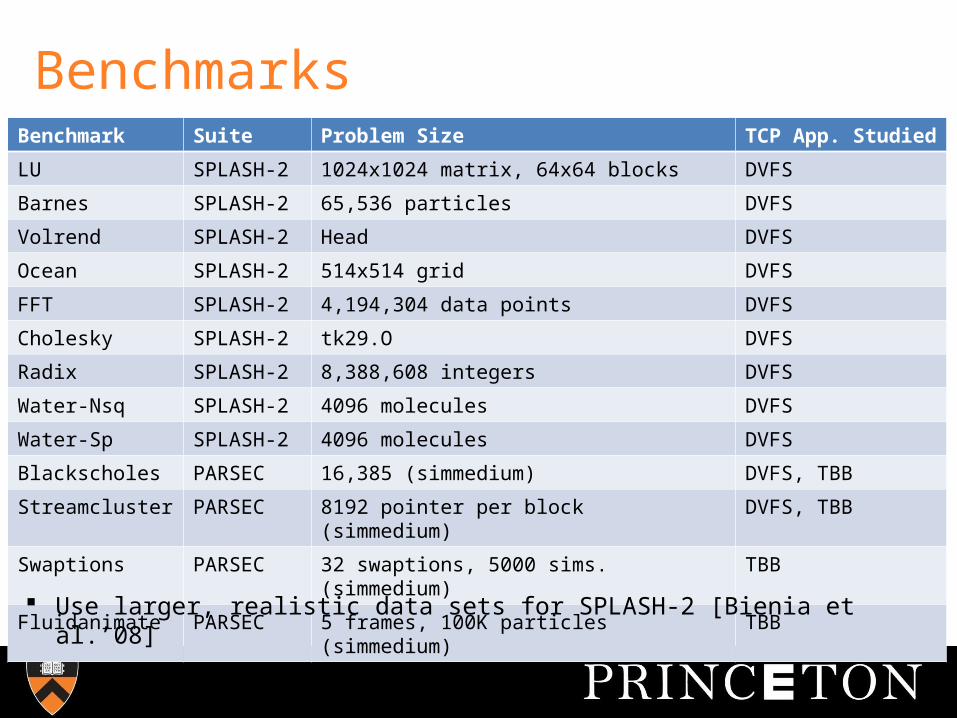
BenchmarksBenchmark Suite Problem Size TCP App.
Studied
LU SPLASH-2 1024x1024 matrix, 64x64 blocks DVFS
Barnes SPLASH-2 65,536 particles DVFS
Volrend SPLASH-2 Head DVFS
Ocean SPLASH-2 514x514 grid DVFS
FFT SPLASH-2 4,194,304 data points DVFS
Cholesky SPLASH-2 tk29.O DVFS
Radix SPLASH-2 8,388,608 integers DVFS
Water-Nsq SPLASH-2 4096 molecules DVFS
Water-Sp SPLASH-2 4096 molecules DVFS
Blackscholes PARSEC 16,385 (simmedium) DVFS, TBB
Streamcluster PARSEC 8192 pointer per block (simmedium) DVFS, TBB
Swaptions PARSEC 32 swaptions, 5000 sims. (simmedium) TBB
Fluidanimate PARSEC 5 frames, 100K particles (simmedium) TBB Use larger, realistic data sets for SPLASH-2 [Bienia et al.’08]

How is %Error of Metric Calculated?
For one barrier iteration or 10% execution snapshotTrack the following info per thread:1.Num Instructions = Ii2.Num Cache Misses per Inst = Cmi
3.Compute time per thread = CTiThread 0I0, CM0 , CT0
Thread 1I1, CM1, , CT1
Thread 2I2, CM2, , CT2
Thread 3I3, CM3, , CT3
Suppose Thread 1 is criticalThread 0Get I0 / I1 ,CM0 / CM1
Compare withCT0 / CT1
Thread 1I1, CM1, , CT1
Thread 2Get I2 / I1 ,CM2 / CM1
Compare withCT2 / CT1
Thread 3Get I3 / I1 ,CM3 / CM1
Compare withCT3 / CT1
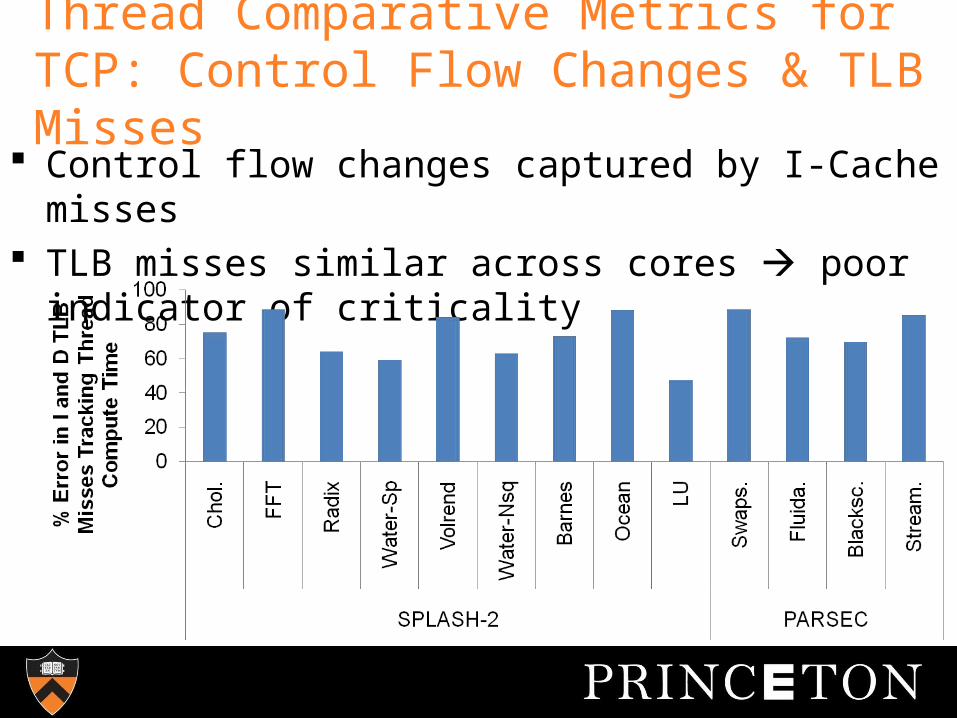
Thread Comparative Metrics for TCP: Control Flow Changes & TLB Misses
Control flow changes captured by I-Cache misses
TLB misses similar across cores poor indicator of criticality

TBB Random Stealer
TBB dynamic scheduler distributes tasks
Thread 0
Task 0
SW Q0
Task 2
Task 3
Thread 1
Task 4
SW Q1
Thread 2
Task 5
SW Q2
Thread 3
Task 6
SW Q3
Task 7
Clock: 0Clock: 100
None
Steal Task!
Random Stealing: SW Q1
False Negative!Backoff…Clock: 150
Retry Steal:SW Q0
Successful!
Task 1
Task 1
Critical Thread (ideal steal
victim)
Poor performance at higher core
counts and load imbalance

TBB Stealing with Occupancy-Approach
Occupancy-based approach [Contreras, Martonosi 2008]
Thread 0
Task 0
SW Q0
Task 2
Task 3
Thread 1
Task 4
SW Q1
Thread 2
SW Q2
Thread 3
Task 6
SW Q3
Task 7
Clock: 0
Occ: 3 Occ: 0 Occ: 0 Occ: 1
Task 5
Clock: 100 Occ. Steal: SW Q0
None
Task 1
Task 1
Steal successful
False negatives eliminated but still not stealing from
critical thread

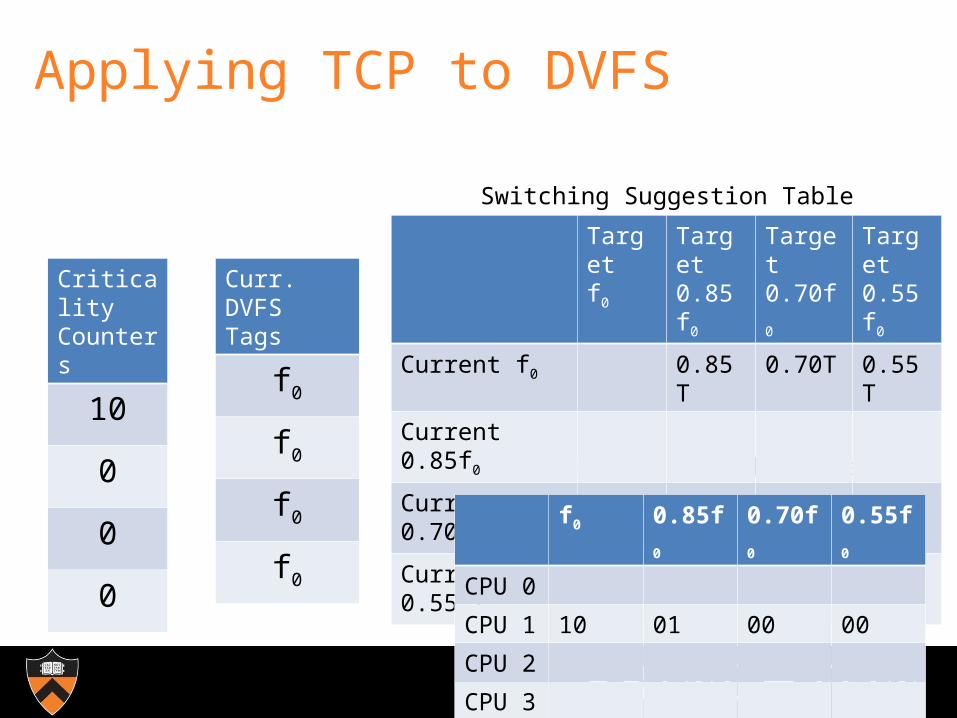
Applying TCP to DVFS
Assume available frequencies are f0 , 0.85f0, 0.70f0, 0.55f0
Switching Suggestion Table
Switching Confidence Table
Targetf0
Target0.85f0
Target0.70f0
Target0.55f0
Current f0 0.85T 0.70T 0.55T
Current 0.85f0
Current 0.70f0
Current 0.55 f0
f0 0.85f0
0.70f0
0.55f0
CPU 0
CPU 1 10 01 00 00
CPU 2
CPU 3
Criticality Counters
0
0
0
0
Curr. DVFS Tags
f0
f0
f0
f0
Applying TCP to DVFS
Switching Suggestion Table
Switching Confidence Table
Targetf0
Target0.85f0
Target0.70f0
Target0.55f0
Current f0 0.85T 0.70T 0.55T
Current 0.85f0
Current 0.70f0
Current 0.55 f0
f0 0.85f0
0.70f0
0.55f0
CPU 0
CPU 1 10 01 00 00
CPU 2
CPU 3
Criticality Counters
10
0
0
0
Curr. DVFS Tags
f0
f0
f0
f0
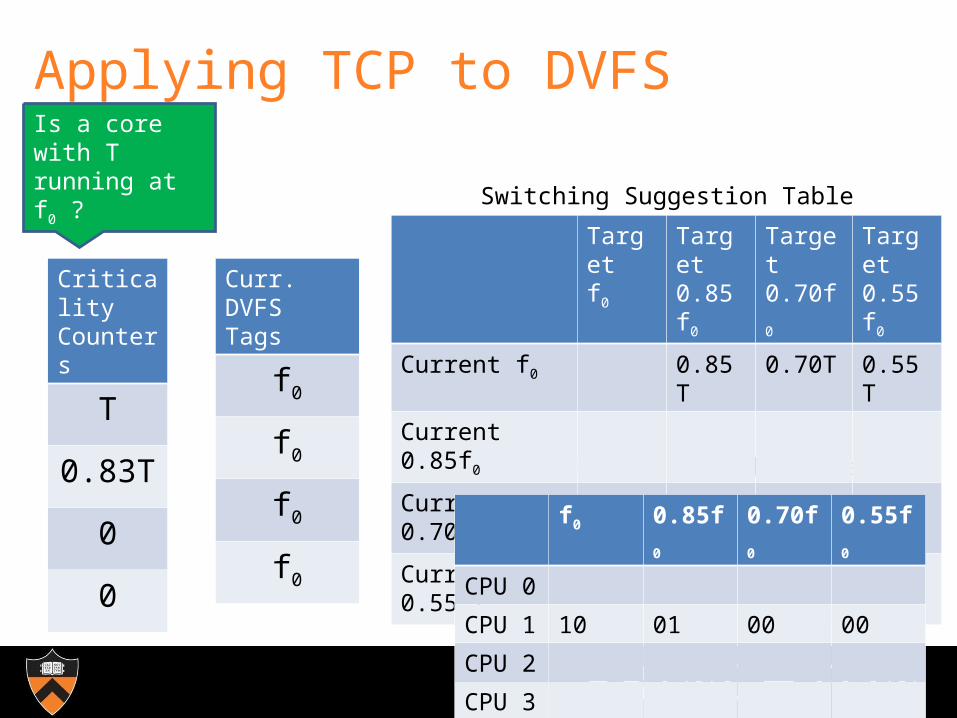
Applying TCP to DVFS
Switching Suggestion Table
Switching Confidence Table
Targetf0
Target0.85f0
Target0.70f0
Target0.55f0
Current f0 0.85T 0.70T 0.55T
Current 0.85f0
Current 0.70f0
Current 0.55 f0
f0 0.85f0
0.70f0
0.55f0
CPU 0
CPU 1 10 01 00 00
CPU 2
CPU 3
Criticality Counters
T
0.83T
0
0
Curr. DVFS Tags
f0
f0
f0
f0
Is a core with T running at f0 ?

Applying TCP to DVFS
Switching Suggestion Table
Switching Confidence Table
Targetf0
Target0.85f0
Target0.70f0
Target0.55f0
Current f0 0.85T 0.70T 0.55T
Current 0.85f0
Current 0.70f0
Current 0.55 f0
f0 0.85f0
0.70f0
0.55f0
CPU 0
CPU 1 10 01 00 00
CPU 2
CPU 3
Criticality Counters
T
0.83T
0
0
Curr. DVFS Tags
f0
f0
f0
f0
For all cores, find closest SST match to Criticality Counter. SST suggests DVFS for core 1.
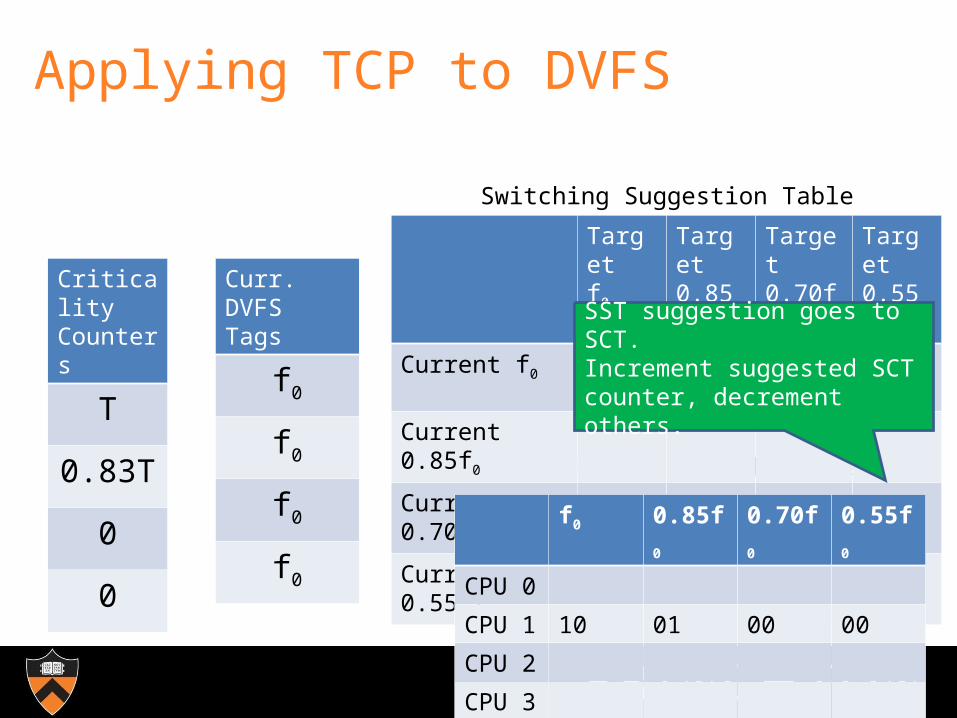
Applying TCP to DVFS
Switching Suggestion Table
Switching Confidence Table
Targetf0
Target0.85f0
Target0.70f0
Target0.55f0
Current f0 0.85T 0.70T 0.55T
Current 0.85f0
Current 0.70f0
Current 0.55 f0
f0 0.85f0
0.70f0
0.55f0
CPU 0
CPU 1 10 01 00 00
CPU 2
CPU 3
Criticality Counters
T
0.83T
0
0
Curr. DVFS Tags
f0
f0
f0
f0
SST suggestion goes to SCT.Increment suggested SCT counter, decrement others.

Applying TCP to DVFS
Switching Suggestion Table
Switching Confidence Table
Targetf0
Target0.85f0
Target0.70f0
Target0.55f0
Current f0 0.85T 0.70T 0.55T
Current 0.85f0
Current 0.70f0
Current 0.55 f0
f0 0.85f0
0.70f0
0.55f0
CPU 0
CPU 1 01 10 00 00
CPU 2
CPU 3
Criticality Counters
T
0.83T
0
0
Curr. DVFS Tags
f0
f0
f0
f0
Scan for max. counter. Is this corresponding to DVFS?

Applying TCP to DVFS
Switching Suggestion Table
Switching Confidence Table
Targetf0
Target0.85f0
Target0.70f0
Target0.55f0
Current f0 0.85T 0.70T 0.55T
Current 0.85f0
Current 0.70f0
Current 0.55 f0
f0 0.85f0
0.70f0
0.55f0
CPU 0
CPU 1 01 10 00 00
CPU 2
CPU 3
Criticality Counters
0
0
0
0
Curr. DVFS Tags
f0
0.85f0
f0
f0
Initiate DVFS on core 1 and refresh criticality counters

TCP Parameters for DVFS
Carried out a number of experiments to gauge T and bits per SCT counter T = 1024 78.19% accuracy 2 bits SCT 92.68 % accuracy Refer to paper for details…
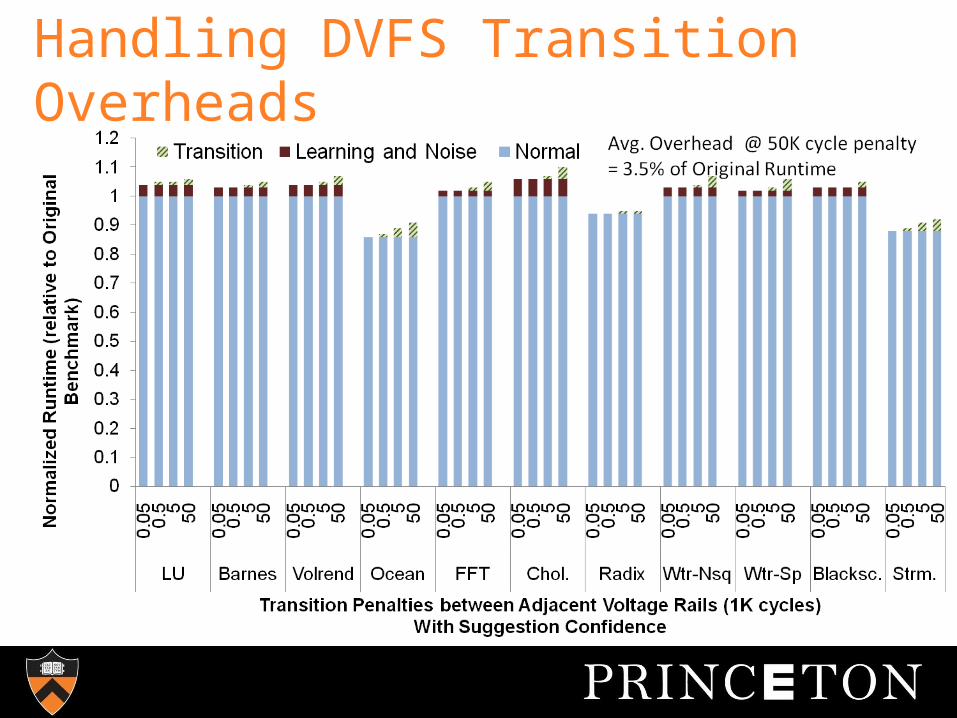
Handling DVFS Transition Overheads

TCP vs Meeting Points
Meeting points unsuitable for extremely irregular parallel program behavior
Example: LU from Splash 2
Akk
Pseudocode for a thread
for all k from 0 to N-1 if I own Akk , factorize it
BARRIER for all my blocks Akj in pivot row Akj Akj * Akk
-1
BARRIER for all my blocks Aij in active interior of matrix
Aij Aij -- Aik * Akj
end for

TCP vs Meeting Point ctd…
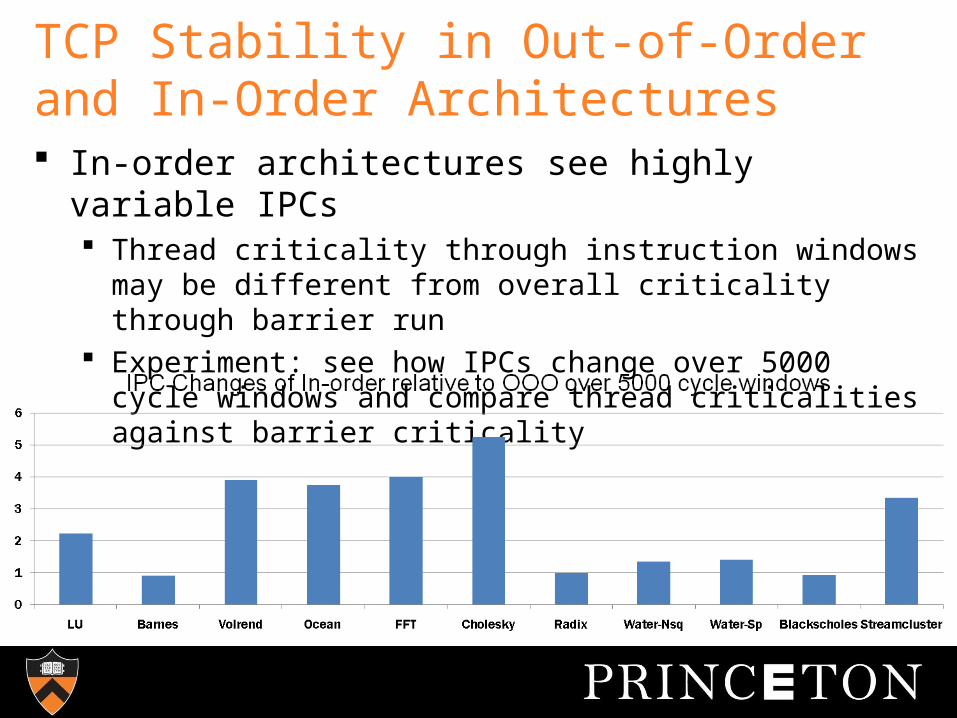
TCP Stability in Out-of-Order and In-Order Architectures In-order architectures see highly variable IPCs
Thread criticality through instruction windows may be different from overall criticality through barrier run
Experiment: see how IPCs change over 5000 cycle windows and compare thread criticalities against barrier criticality

Comparison to Other Works
Thread Motion Could use TCP to trigger TM instead of using DVFS
for energy-efficiency in barrier-based programs TM already shown to successfully use a last-level
cache miss-driven approach
Temperature-constrained Power Control TCP can be used as performance proxy instead of
MIPS to guide power allocation of controller Could be used to guide DVFS of programs under
temperature constraints