thread quantification for concurrent shape analysis josh berdinemsr cambridge tal lev-amitel aviv...
TRANSCRIPT

Thread Quantificationfor Concurrent Shape
Analysis
Josh Berdine MSR CambridgeTal Lev-Ami Tel Aviv UniversityRoman Manevich Tel Aviv UniversityMooly Sagiv Tel Aviv UniversityGanesan Ramalingam MSR India

2
Non-blocking stack [Treiber,‘86]
void push(Stack *S, data_type v) {[1] Node *x = alloc(sizeof(Node));[2] x->d = v;[3] do {[4] Node *t = S->Top;[5] x->n = t;[6] } while (!CAS(&S->Top,t,x));[7] }
data_type pop(Stack *S){[8] do {[9] Node *t = S->Top;[10] if (t == NULL)[11] return EMPTY;[12] Node *s = t->n;[13] data_type r = t->d;[14] } while (!CAS(&S->Top,t,s));[15] return r;[16] }
benign data races
unbounded number of
threads
x points to valid memory?does list remain acyclic?
stack linearizable?
Automatic proof of linearizabilityfor an unbounded number of threads

Linearizability [Herlihy and Wing, TOPLAS'90]
Linearizable data structure Sequential specification defines legal sequential executions Concurrent operations allowed to be interleaved Operations appear to execute atomically
External observer gets the illusion that each operation takes effect instantaneously at some point between its invocation and its response
time
push(4)
pop():4push(7)
push(4)
pop():4push(7)
Last In First Out
Concurrent LIFO stack
T1
T2
3

push2(4,5)
pop2():8,5push2(7,8)
4
Non-linearizable pairs stackvoid push2(Stack *S, data_type v1, data_type * v2) { push(s, v1); push(s, v2);}
void pop2(Stack *S, data_type * v1, data_type * v2) { *v2 = pop(s); *v1 = pop(s); }
time
push2(4,5)
pop2():8,5push2(7,8)
illegal sequential execution

push2(4,5)
pop2():8,5push2(7,8)
5
Non-linearizable pairs stackvoid push2(Stack *S, data_type v1, data_type * v2) { push(s, v1); push(s, v2);}
void pop2(Stack *S, data_type * v1, data_type * v2) { *v2 = pop(s); *v1 = pop(s); }
time
push2(4,5)
pop2():8,5push2(7,8)
illegal sequential execution

6
Main results New parametric shape analysis
Universally quantified shape abstractions Extra level of quantification over shape
abstraction Fine-grained concurrency Unbounded number of threads Thread-modular aspects
Sound transformers Application
Checking linearizability of concurrent data structures

7
Outline Motivation + what is linearizability Universally quantified shape
abstractions Checking linearizability via conjoined
execution and delta abstraction Experimental results

Universally QuantifiedShape Abstractions
8

9
Concurrent heaps [Yahav, POPL’01]
Heaps contain both threads and objects Logical structure, or Formula in subset of FOTC [Yorsh et al.,
TOCL‘07]
thread object with
program counter
thread-local variable
list field
list object
pc=6 pc=2
x
n
x
Topt

10
Heaps contain both threads and objects Logical structure, or Formula in subset of FOTC [Yorsh et al., TOCL‘07]
pc=6 pc=2
x
n
x
Topt
pc(tr1)=6 pc(tr2)=2 v1,v2,v3. Top(v1) x(tr1,v2) t(tr1,v1) x(tr2,v3) n(v2,v1) …
v1
v3
v2
tr1tr2
Concurrent heaps [Yahav, POPL’01]

Unbounded concurrent heaps
11
void push(Stack *S, data_type v) {[1] Node *x = alloc(sizeof(Node));[2] x->d = v;[3] do {[4] Node *t = S->Top;[5] x->n = t;[6] } while (!CAS(&S->Top,t,x));[7] }
x
n
x
Top
x x
t
x
t
x
n
t
t
Unbounded parallel composition:push(Top,?) || ... || push(Top,?)
n
n
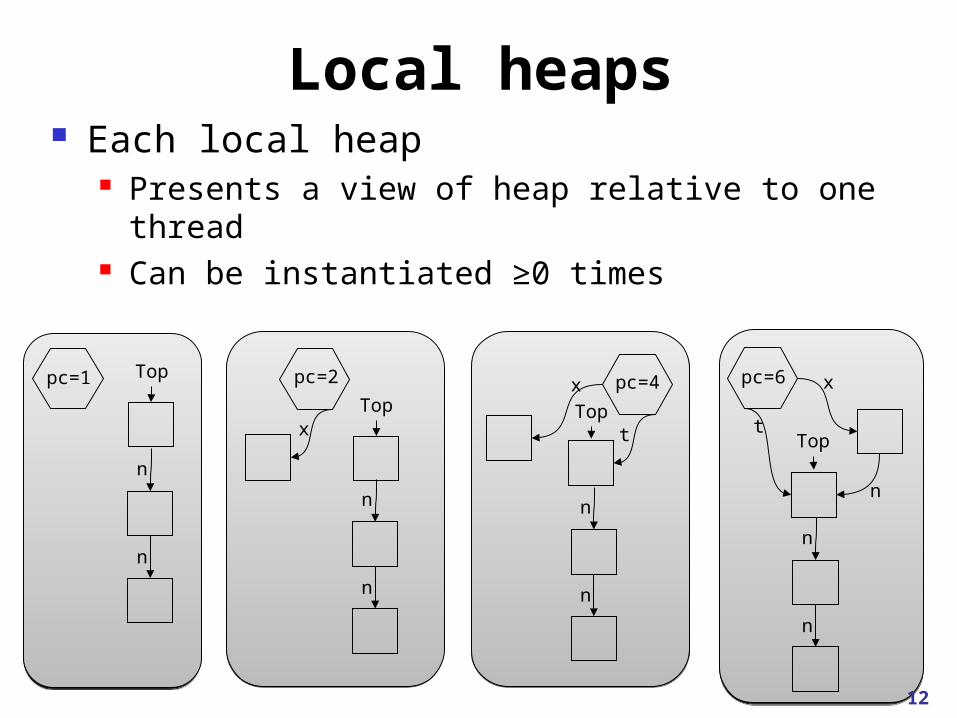
Local heaps Each local heap
Presents a view of heap relative to one thread Can be instantiated ≥0 times
12
pc=4
t
pc=2
x
xpc=1 Top
Top
pc=6
t
n
x
Top
Top
n
n
n
n
n
n
n
n

Bounded local heaps Each local heap
Presents a view of heap relative to one thread Can be instantiated ≥0 times Bounded by finitary abstraction (Canonical
Abstraction)
13
pc=4
t
pc=2
x
xpc=1 Top
Top
pc=6
t
n
x
Top
Top
n
n
n
n
n
n
n
n

14
pc(tr1)=6 pc(tr2)=2 v1,v2,v3. Top(v1) x(tr1,v2) t(tr1,v1) x(tr2,v3) n(v2,v1) …
Concurrent heap
pc=6 pc=2
x
n
x
Topt v1
v3
v2
tr1 tr2

pc=2
x
Top
pc(t)=6 v1,v2. Top(v1) x(t,v2) t(t,v1) n(v2,v1) …
t.pc(t)=2 v1,v3. Top(v1) x(t,v3) …
Universally quantifiedlocal heaps
pc=6
x
n
Topt
overlappinglocal heaps
15
t t
v1 v1
v2
v3
symbolicthread
symbolicthread

pc(t)=6 v1,v2. Top(v1) x(t,v2) t(t,v1) n(v2,v1) …
t.pc(t)=2 v1,v3. Top(v1) x(t,v3) …
Meaning of quantified invariant
pc=6
x
n
Topt
x
pc=1
pc=6
pc=2
t
Information maintained (dis)equalities between
local variables of each thread and global variables
Objects reachable from global variables
Information lost Number of threads (dis)equalities between
local variables of different threads
16
pc=2
x
Top
x
pc=1
pc=6
pc=3
t
pc=1
×m n×

Loss of non-aliasing information
pc(t)=6 v1,v2. Top(v1) x(t,v2) t(t,v1) n(v2,v1) …
t.
pc=6
x
n
Top
pc=6
x
n
t
t
pc=6
x
n
t
pc=6
x
t
unwanted aliasingconsider x->n=t
Remedy: record non-aliasing information explicitly
17
n
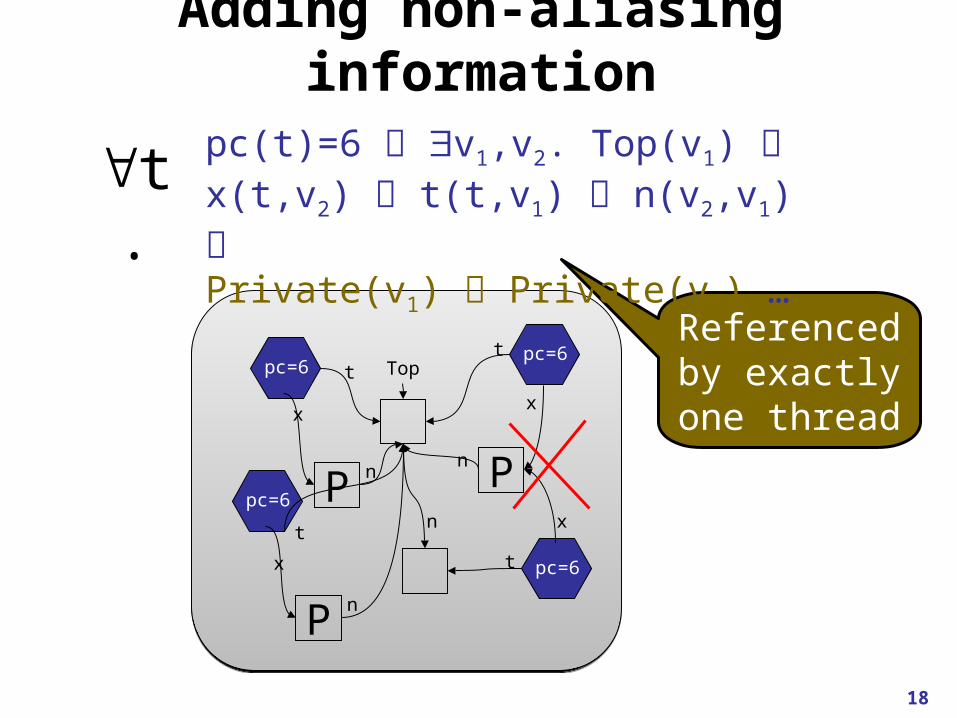
Adding non-aliasing information
pc=6
P
x
n
Top
pc=6
P
x
n
t
t
pc=6
x
n
t
pc=6
x
Referencedby exactlyone thread
pc(t)=6 v1,v2. Top(v1) x(t,v2) t(t,v1) n(v2,v1) Private(v1) Private(v2) …
t.
P
t
18
n

Adding non-aliasing information
pc(t)=6 v1,v2. Top(v1) x(t,v2) t(t,v1) n(v2,v1) Private(v1) Private(v2) …
t.
pc=6
P
x
n
Top
pc=6
P
x
n
t
t
pc=6
x
n
t
pc=6
Px
P
t
Operation on private objects
invisible to other threads
19
n

Recap Add universal quantification on top of
finitary heap abstractions Handle unbounded number of threads
Local heaps can overlap Handle fine-grained concurrency
Strengthen local heaps by Private predicate Private objects cannot be affected by
actions of other threads Missing: transformers (see paper)
20

Checking linearizabilityfor an unbounded number
of threads
21

Verification of fixed linearization points
[Amit et al., CAV’07] Compare each concurrent execution to a specific
sequential execution Show that every (terminating) concurrent
operation returns the same result as its sequential counterpart
linearizationpoint
operationConcurrent
Execution
Sequential
Execution
compare results
...
linearizationpoint
Conjoined
Execution
compare results
22

23
Linearization pointsfor Treiber’s stack
void push(Stack *S, data_type v) {[1] Node *x = alloc(sizeof(Node));[2] x->d = v;[3] do {[4] Node *t = S->Top;[5] x->n = t;[6] } while (!CAS(&S->Top,t,x)); // @LINEARIZE on CAS[7] }
data_type pop(Stack *S){[8] do {[9] Node *t = S->Top; // @LINEARIZE[10] if (t == NULL)[11] return EMPTY; [12] Node *s = t->n;[13] data_type r = t->d;[14] } while (!CAS(&S->Top,t,s)); // @LINEARIZE on CAS[15] return r;[16] }

Shape analysis with delta abstraction [Amit et al.,
CAV’07]
Tracks bounded differences between concurrent and sequential execution Abstracts two heaps together Limited to bounded number of threads
Tracks correlations between all threads Feasible up to 4 threads
24
What about an unboundednumber of threads?

25
Our approach Tracks bounded differences between
concurrent and sequential executionper thread Handles unbounded number of threads
Abstracts correlations between threads Thread-modular characteristics

Top
26
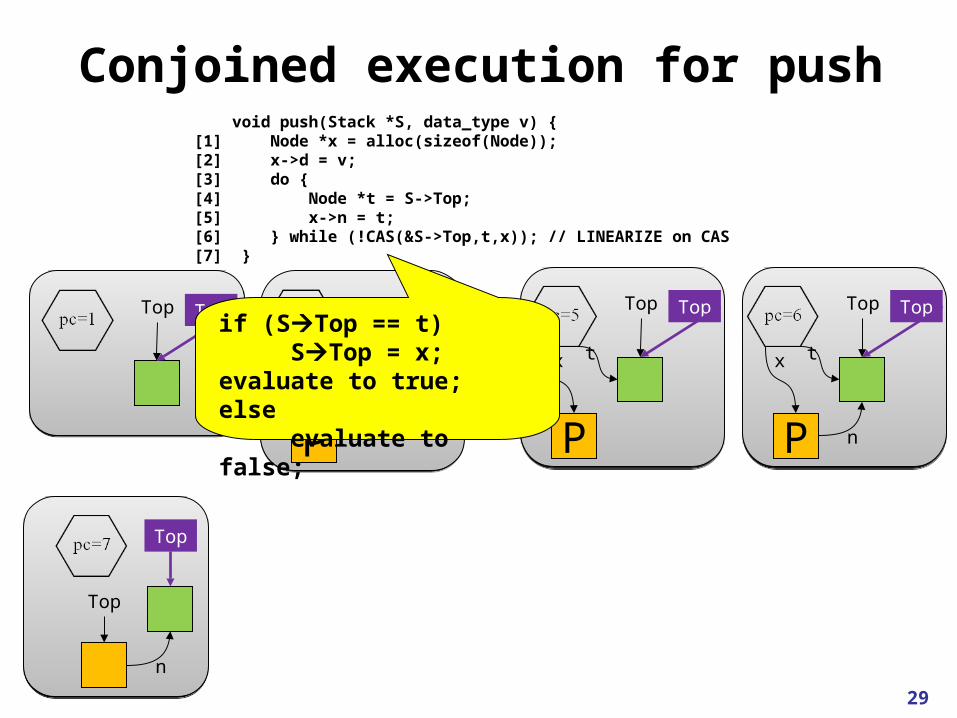
Conjoined execution for push
concurrent state
sequential view
isomorphismrelation
Top
void push(Stack *S, data_type v) {[1] Node *x = alloc(sizeof(Node));[2] x->d = v;[3] do {[4] Node *t = S->Top;[5] x->n = t;[6] } while (!CAS(&S->Top,t,x)); // LINEARIZE on CAS[7] }
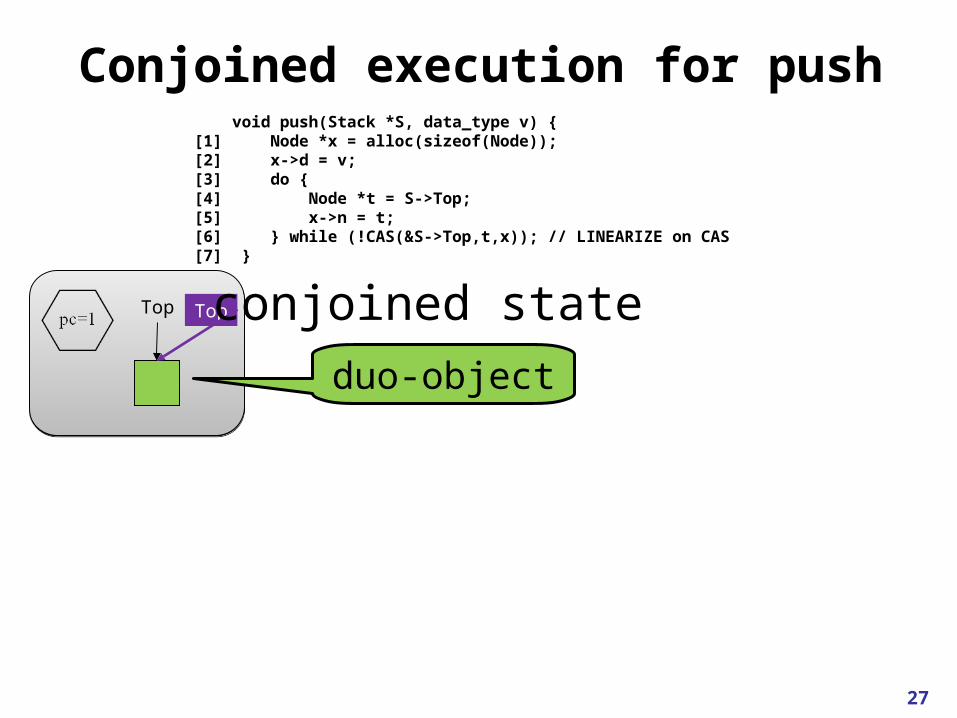
Top Top
27
Conjoined execution for push
conjoined state
duo-object
void push(Stack *S, data_type v) {[1] Node *x = alloc(sizeof(Node));[2] x->d = v;[3] do {[4] Node *t = S->Top;[5] x->n = t;[6] } while (!CAS(&S->Top,t,x)); // LINEARIZE on CAS[7] }
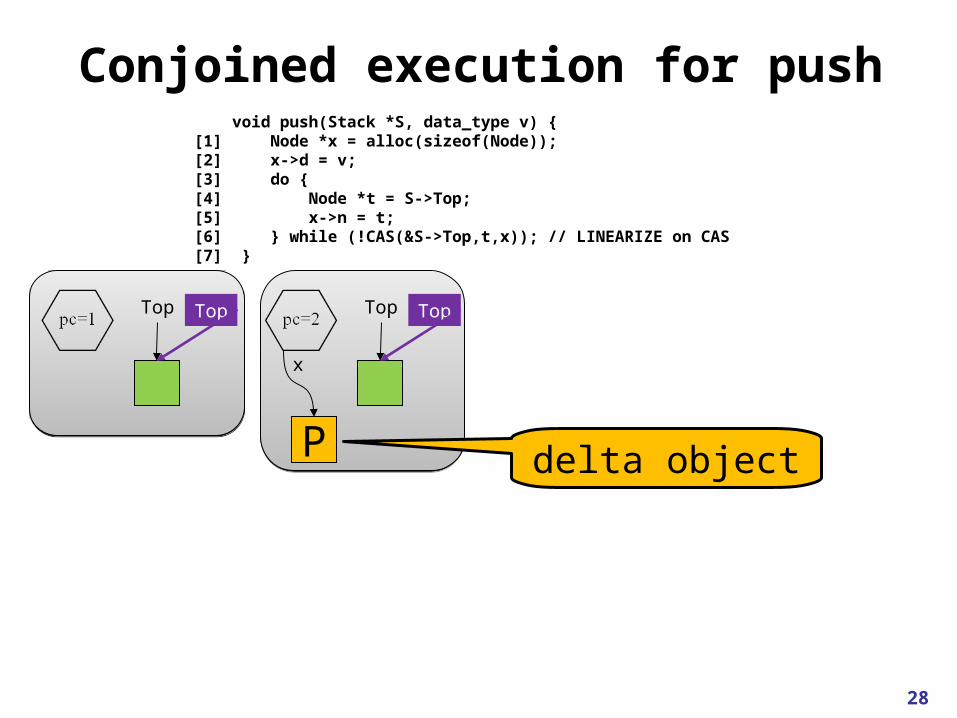
28
Conjoined execution for push
Top Top
P
x
delta object
Top Top
void push(Stack *S, data_type v) {[1] Node *x = alloc(sizeof(Node));[2] x->d = v;[3] do {[4] Node *t = S->Top;[5] x->n = t;[6] } while (!CAS(&S->Top,t,x)); // LINEARIZE on CAS[7] }
29
Conjoined execution for push void push(Stack *S, data_type v) {[1] Node *x = alloc(sizeof(Node));[2] x->d = v;[3] do {[4] Node *t = S->Top;[5] x->n = t;[6] } while (!CAS(&S->Top,t,x)); // LINEARIZE on CAS[7] }
Top Top
P
x
Top Top Top Top
P
x t…Top Top
P
x t
n
if (STop == t) STop = x; evaluate to true;else evaluate to false;
Top
Top
n

30
Run operation sequentially void push(Stack *S, data_type v) {[1] Node *x = alloc(sizeof(Node));[2] x->d = v;[3] do {[4] Node *t = S->Top;[5] x->n = t;[6] } while (!CAS(&S->Top,t,x)); // LINEARIZE on CAS[7] }
Top
Top
n
Top
Top
n
xTop
Top
n
x
t
Top
Top
n
x
t
n
Top Top
n n

31
Run operation sequentially
Top
Top
n
Top
Top
n
xTop
Top
n
x
t
Top
Top
n
x
t
n
TopTop
n
But how do you handleunboundedness due to
recursive data structures?
Employ CanonicalHeap Abstraction
void push(Stack *S, data_type v) {[1] Node *x = alloc(sizeof(Node));[2] x->d = v;[3] do {[4] Node *t = S->Top;[5] x->n = t;[6] } while (!CAS(&S->Top,t,x)); // LINEARIZE on CAS[7] }

32
An unbounded state void push(Stack *S, data_type v) {[1] Node *x = alloc(sizeof(Node));[2] x->d = v;[3] do {[4] Node *t = S->Top;[5] x->n = t;[6] } while (!CAS(&S->Top,t,x)); LINEARIZE on CAS[7] }
Px
n Px
Top
Px
Px
t
Px
t
P
x
n
t
t
unboundednumber of
delta objects
n
n

Top
n
n
Top
Px
n
n
Px
Topt
n
n
Px
n
Top
t
n
n
33
Bounded local states
number ofdelta objects
per local heapbounded

Observations used Unbounded number of heap objects
Number of delta objects created per thread is bounded
Objects in recursive data structures bounded by known shape abstractions
Delta objects always referenced bylocal variables + global variables Captured by local heaps
Threads mutate data structure near global access points
34
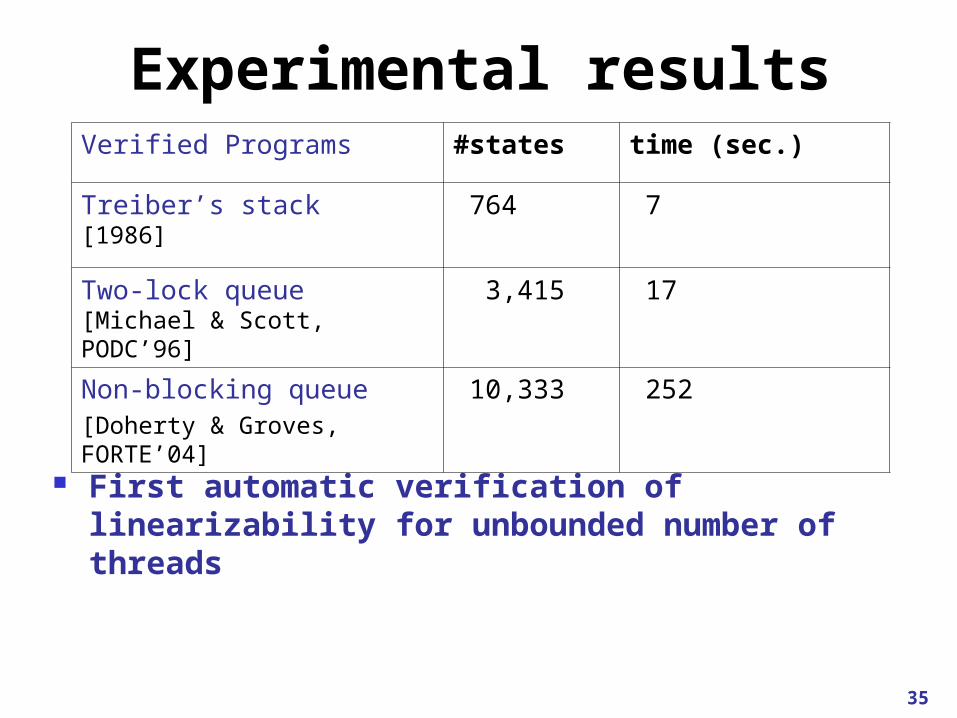
35
Verified Programs #states time (sec.)
Treiber’s stack[1986]
764 7
Two-lock queue[Michael & Scott, PODC’96]
3,415 17
Non-blocking queue[Doherty & Groves, FORTE’04]
10,333 252
Experimental results
First automatic verification of linearizability for unbounded number of threads

36
What’s missing from the talk?
Generic technique for lifting abstract domains with universal quantifiers
Abstract transformers Thread instantiation
Combining universal quantification with heap decomposition

37
Related work [Yahav, POPL’01]
Shape analysis with counter abstraction [Gotsman et al., PLDI’07]
Thread-modular shape analysis for coarse-grained concurrency
[Amit et al., CAV’07] Linearizability for a bounded number of threads
[Vafeiadis et al.,’06,’07,’08] Linearizability for an unbounded number of threads with
Rely-Guarantee reasoning w. separation logic Requires user annotations
[Gulwani et al., POPL’08] Lifting abstract interpreters to quantified logical domains
[Pnueli et al., TACAS’01] [Clarke et al., TACAS’08][Namjoshi, VMCAI’07]
Model checking concurrent systems
shape analysis model checking
concurrency
+

38
Conclusion Parametric shape abstraction for an
unbounded number of threads Fine-grained concurrency Thread-modular aspects Integrated into TVLA
Automatically proves linearizability offine-grained concurrent implementations

39
Thank You

Can you handle mutex? Yes with Canonical Abstraction
t1. { …. t2. … } Not with Boolean Heaps
Only one level of quantification
40

Requirements frombase domain
Support free variables (u,v,w) Support join and meet operations
41

42
Thread-modular analysis
Single global resource invariant[Flanagan & Qadeer, SPIN 03]
pc=1
pc=1
Separated resource invariants[Gotsman et al., PLDI 07]Coarse-grained concurrency
pc=1
pc=1
Non-disjoint resource invariants[this paper]Fine-grained concurrency
pc=1
pc=1

Constructing the correlation relation
Incrementally constructed during execution
Nodes allocated by matching push operations are correlated
Correlated nodes have equal data values Show that matching pops return data
values of correlated nodes

Fixed linearization points Every operation has (user-specified)
fixed linearization point Statement at which the operation appears
to take effect Show that these linearization points are
correct for every concurrent execution User may specify
Several (alternative) linearization points Certain types of conditional linearization
pointse.g., successful CAS operations
44

Stack's most-general client
void client (Stack S) {
do {
if (?)
push(S, rand());
else
pop(S);
} while ( 1 );
}