tolerating dependences between large speculative threads via sub-threads chris colohan 1,2,...
Post on 21-Dec-2015
222 views
TRANSCRIPT

Tolerating Dependences Between Large Speculative Threads Via Sub-Threads
Chris Colohan1,2, Anastassia Ailamaki2,
J. Gregory Steffan3 and Todd C. Mowry2,4
1Google, Inc.2Carnegie Mellon University
3University of Toronto4Intel Research Pittsburgh

Copyright 2006 Chris Colohan 2
Thread Level Speculation (TLS)
*p=
*q=
=*p
=*q
Sequential
Tim
e
Parallel
*p=
*q=
=*p
=*q
=*p
=*q
Thread 1 Thread 2

Copyright 2006 Chris Colohan 3
Thread Level Speculation (TLS)
*p=
*q=
=*p
=*q
Sequential
Tim
e
*p=
*q=
=*p
R2
Violation!
=*p
=*q
Parallel
Use threads
Detect violations
Restart to recover
Buffer state
Worst case: Sequential
Best case: Fully parallel
Data dependences limit performance.Data dependences limit performance.
Thread 1 Thread 2

Copyright 2006 Chris Colohan 4
Violations as a Feedback Signal
*p=
*q=
=*p
=*q
Sequential
Tim
e
*p=
*q=
=*p
R2
Violation!
=*p
=*q
Parallel
0x0FD80xFD200x0FC00xFC18
Must…Make…Faster
Must…Make…Faster
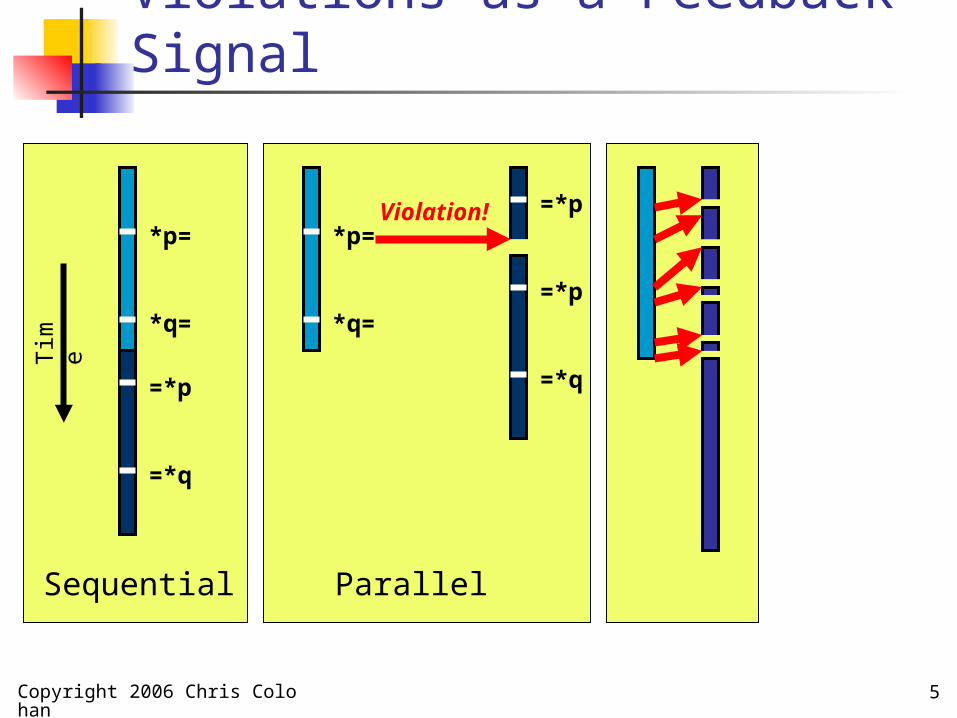
Copyright 2006 Chris Colohan 5
Violations as a Feedback Signal
*p=
*q=
=*p
=*q
Sequential
Tim
e
*p=
*q=
=*p
R2
Violation!
=*p
=*q
Parallel

Copyright 2006 Chris Colohan 6
Eliminating Violations
*p=
*q=
=*p
R2
Violation!
=*p
=*q
Parallel
*q==*q
=*q
Violation!
Eliminate *p Dep.
Tim
e
0x0FD80xFD200x0FC00xFC18
Optimization maymake slower?
All-or-nothing execution makes optimization harder
All-or-nothing execution makes optimization harder

Copyright 2006 Chris Colohan 7
Tolerating Violations: Sub-threads
Tim
e
*q=Violation!
Sub-threads
=*q
=*q
*q==*q
=*q
Violation!
Eliminate *p Dep.

Copyright 2006 Chris Colohan 8
Sub-threads
Periodic checkpoints of a speculative thread
Makes TLS work well with: Large speculative
threads Unpredictable frequent
dependences
*q=Violation!
Sub-threads
=*q
=*q
Speed up database transactionresponse time by a factor of
1.9 to 2.9.
Speed up database transactionresponse time by a factor of
1.9 to 2.9.

Copyright 2006 Chris Colohan 9
Overview
TLS and database transactions Buffering large speculative threads Hardware support for sub-threads Results

Copyright 2006 Chris Colohan 10
Case Study: New Order (TPC-C)
Only dependence is the quantity field Very unlikely to occur (1/100,000)
GET cust_info FROM customer;UPDATE district WITH order_id; INSERT order_id INTO new_order;foreach(item) { GET quantity FROM stock WHERE i_id=item; UPDATE stock WITH quantity-1 WHERE i_id=item; INSERT item INTO order_line;}
78% of transactionexecution time

Copyright 2006 Chris Colohan 11
Case Study: New Order (TPC-C)GET cust_info FROM customer;UPDATE district WITH order_id; INSERT order_id INTO new_order;
foreach(item) { GET quantity FROM stock WHERE i_id=item; UPDATE stock WITH quantity-1 WHERE i_id=item; INSERT item INTO order_line;}
GET cust_info FROM customer;UPDATE district WITH order_id; INSERT order_id INTO new_order;
TLS_foreach(item) { GET quantity FROM stock WHERE i_id=item; UPDATE stock WITH quantity-1 WHERE i_id=item; INSERT item INTO order_line;}
GET cust_info FROM customer;UPDATE district WITH order_id; INSERT order_id INTO new_order;
TLS_foreach(item) { GET quantity FROM stock WHERE i_id=item; UPDATE stock WITH quantity-1 WHERE i_id=item; INSERT item INTO order_line;}

Copyright 2006 Chris Colohan 12
Optimizing the DBMS: New Order
0
0.25
0.5
0.75
1
1.25
Seque
ntial
No Opt
imiza
tions
Latch
es
Lock
s
Mall
oc/F
ree
Buffe
r Poo
l
Curso
r Que
ue
Error C
heck
s
False
Sharin
g
B-Tre
e
Logg
ing
Tim
e (n
orm
aliz
ed)
Idle CPU
FailedCache Miss
Busy
This process took me 30 days and <1200 lines of code.
This process took me 30 days and <1200 lines of code.
Results from Colohan, Ailamaki, Steffan and Mowry VLDB2005

Copyright 2006 Chris Colohan 13
Overview
TLS and database transactions Buffering large speculative
threads Hardware support for sub-threads Results

Copyright 2006 Chris Colohan 14
Threads from Transactions
Thread Size (Dyn.
Instrs.)
Dependent loads
New Order 62k 75
New Order 150
61k 75
Delivery 33k 20
Delivery Outer
490k 34
Stock Level 17k 29Challenge: buffering large threadsChallenge: buffering large threads

Copyright 2006 Chris Colohan 15
Buffering Large Threads
Prior work: Cintra et. al. [ISCA’00]
Oldest thread in each chip can store state in L2 Prvulovic et. al. [ISCA’01]
Speculative state can overflow into RAM What we need:
Fast Deals well with many forward
dependences Easy to add sub-epoch support
Buffer speculative state in shared L2Buffer speculative state in shared L2

Copyright 2006 Chris Colohan 16
L1 cache changes
Add Speculatively Modified bit per line Line modified by current thread or an
older thread On violation invalidate all SM lines
dataS

Copyright 2006 Chris Colohan 17
L2 cache changes
Add Speculatively Modified and Speculatively Loaded bit per line, one pair per speculative thread
If two threads modify a line, replicate Within the associative set
Add a small speculative victim cache Catch over-replicated lines
dataSMSLSMSL
T1 T2

Copyright 2006 Chris Colohan 18
Overview
TLS and database transactions Buffering large speculative threads Hardware support for sub-threads Results

Copyright 2006 Chris Colohan 19
data
Sub-thread support
Add one thread contexts per sub-thread
No dependence tracking between sub-threads
SMSLSMSL
T1a
SMSL
T1 T2T1b
dataSMSL
T2bT2a

Copyright 2006 Chris Colohan 20
When to start new sub-threads?
Right before “high-risk” loads?
Results show that starting periodically works well
*q==*q
=*q
Violation!
=*q

Copyright 2006 Chris Colohan 21
Secondary Violations
Sub-thread start table: How far to rewind on a secondary violation?
*q=Violation! =*q
=*q

Copyright 2006 Chris Colohan 22
Secondary Violations
Sub-thread start table: How far to rewind on a secondary violation?
*q=Violation! =*q
=*q

Copyright 2006 Chris Colohan 23
Overview
TLS and database transactions Buffering large speculative threads Hardware support for sub-threads Results
Copyright 2006 Chris Colohan 24
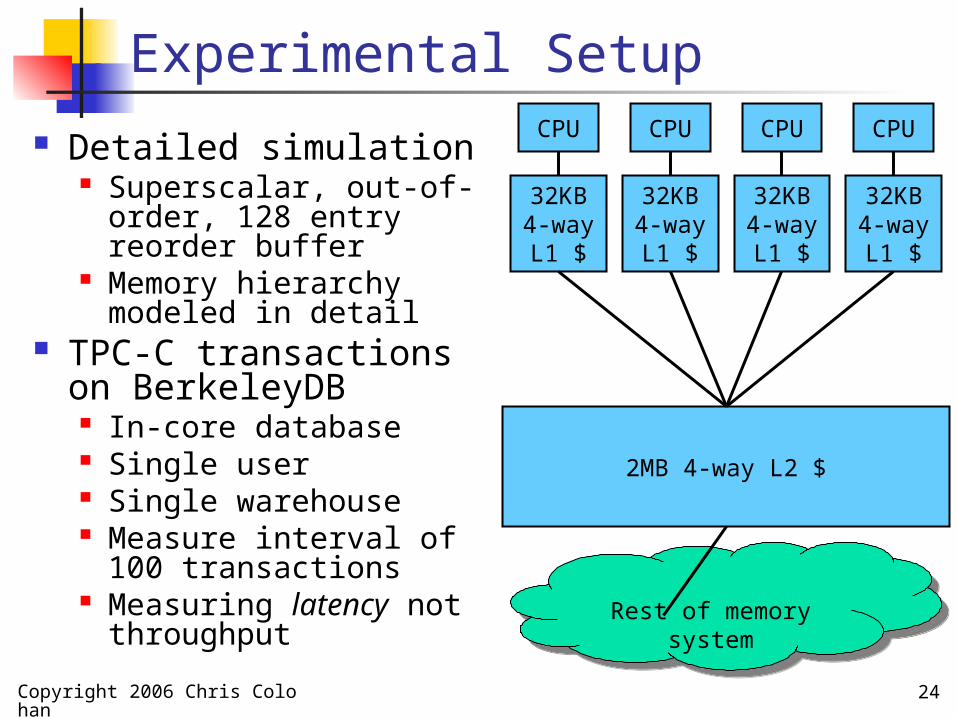
Experimental Setup
Detailed simulation Superscalar, out-of-
order, 128 entry reorder buffer
Memory hierarchy modeled in detail
TPC-C transactions on BerkeleyDB In-core database Single user Single warehouse Measure interval of 100
transactions Measuring latency not
throughput
CPU
32KB4-wayL1 $
Rest of memory system
Rest of memory system
CPU
32KB4-wayL1 $
CPU
32KB4-wayL1 $
CPU
32KB4-wayL1 $
2MB 4-way L2 $

Copyright 2006 Chris Colohan 25
Tim
e (n
orm
aliz
ed)
TPC-C on 4 CPUs
0
0.2
0.4
0.6
0.8
1
1.2
New O
rder
New O
rder
150
Deliv
ery
Deliv
ery
Outer
Stock
Lev
el
Paym
ent
Order
Sta
tus
Without sub-thread
support
Without sub-thread
supportWith sub-
threads
With sub-
threads
Ignore violations (Amdahl’s Law
limit)
Ignore violations (Amdahl’s Law
limit)
Idle CPU
Failed
Cache Miss
Busy
N S L N S L N S L N S L N S L N S L N S L
N = no sub-threads S = with sub-threads L = limit, ignoring violations

Copyright 2006 Chris Colohan 26
TPC-C on 4 CPUs
0
0.2
0.4
0.6
0.8
1
1.2
Idle CPU
Failed
Cache Miss
Busy
Tim
e (n
orm
aliz
ed)
New O
rder
New O
rder
150
Deliv
ery
Deliv
ery
Outer
Stock
Lev
el
Paym
ent
Order
Sta
tus
N S L N S L N S L N S L N S L N S L N S L
N = no sub-threads S = with sub-threads L = limit, ignoring violations
Sub-threads improve performance bylimiting the impact of failed speculationSub-threads improve performance by
limiting the impact of failed speculation
Copyright 2006 Chris Colohan 27
TPC-C on 4 CPUs
0
0.2
0.4
0.6
0.8
1
1.2
Idle CPU
Failed
Cache Miss
Busy
Tim
e (n
orm
aliz
ed)
New O
rder
New O
rder
150
Deliv
ery
Deliv
ery
Outer
Stock
Lev
el
Paym
ent
Order
Sta
tus
N S L N S L N S L N S L N S L N S L N S L
N = no sub-threads S = with sub-threads L = limit, ignoring violations
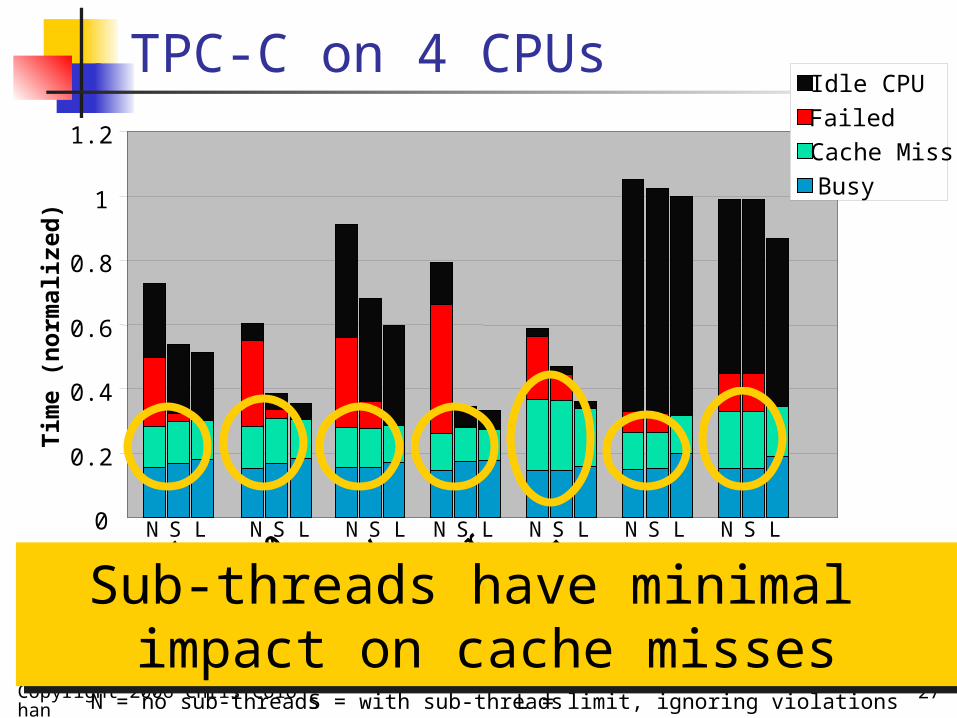
Sub-threads have minimal impact on cache misses
Sub-threads have minimal impact on cache misses

Copyright 2006 Chris Colohan 28
Victim Cache Usage
4-way 8-way16-way
New Order 54 4 0
New Order 150
64 39 0
Delivery 14 0 0
Delivery Outer
62 4 0
Stock Level 40 0 0
L2 cache associativity
Small victim cache is sufficientSmall victim cache is sufficient

Copyright 2006 Chris Colohan 29
Sub-thread sizeT
ime
(no
rmal
ized
)
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
250
500
1000
2500
5000
1000
025
000
250
500
1000
2500
5000
1000
025
000
250
500
1000
2500
5000
1000
025
000
New Order
Idle CPU
Failed
Cache Miss
Busy
2 Sub-threads4 Sub-threads8 Sub-threads

Copyright 2006 Chris Colohan 30
Sub-thread sizeT
ime
(no
rmal
ized
)
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
250
500
1000
2500
5000
1000
025
000
250
500
1000
2500
5000
1000
025
000
250
500
1000
2500
5000
1000
025
000
New Order
Idle CPU
Failed
Cache Miss
Busy
2 Sub-threads4 Sub-threads8 Sub-threads
Periodically starting sub-threads works surprisingly well
Periodically starting sub-threads works surprisingly well

Copyright 2006 Chris Colohan 31
Related Work
Checkpointing Use cache to simulate larger reorder buffer
[Martínez02] Tolerating dependences
Selective re-execution [Sarangi05] Predicting and synchronizing dependences
[many papers] Using speculation for manual parallelization
As applied to SPEC [Prabhu03] TCC [Hammond04]
TLS and Transactional Memory: Multiscalar, IACOMA, Hydra, RAW

Copyright 2006 Chris Colohan 32
Conclusion
Sub-threads let TLS tolerate unpredictable dependences
Makes incremental feedback-directed parallelization possible
Makes TLS with large threads practical Can now parallelize database transactions
Hardware: simple extensions to previous TLS schemes
Speeds up 3 of 5 TPC-C transactions: By a factor of 1.9 to 2.9

Any questions?

BACKUP SLIDES FOLLOW

Copyright 2006 Chris Colohan 35
Why Parallelize Transactions?
Do not use if you have no idle CPUs Database people only care about
throughput! Some transactions are latency sensitive
e.g., financial transactions Lock bound workloads
Free up locks faster == more throughput!

Copyright 2006 Chris Colohan 36
Buffering Large Threadsstore X, 0x00
L1$
0x00:
0x01:
L2$
X
0x00:
0x01:
L1$
0x00:
0x01:
XS1
Store and load bit per thread
Store and load bit per thread

Copyright 2006 Chris Colohan 37
Buffering Large Threadsstore X, 0x00store A, 0x01
L1$
0x00:
0x01:
L2$
X
A
0x00:
L1$
0x00:
0x01:
X
A
S1
S10x01:

Copyright 2006 Chris Colohan 38
Buffering Large Threadsstore X, 0x00store A, 0x01 load 0x00
L1$
0x00:
0x01:
L2$
X
A
0x00:
0x01:
L1$
0x00:
0x01:
X
X
A
S1
S1
L2

Copyright 2006 Chris Colohan 39
XL2 XS1
Buffering Large Threadsstore X, 0x00store A, 0x01 load 0x00
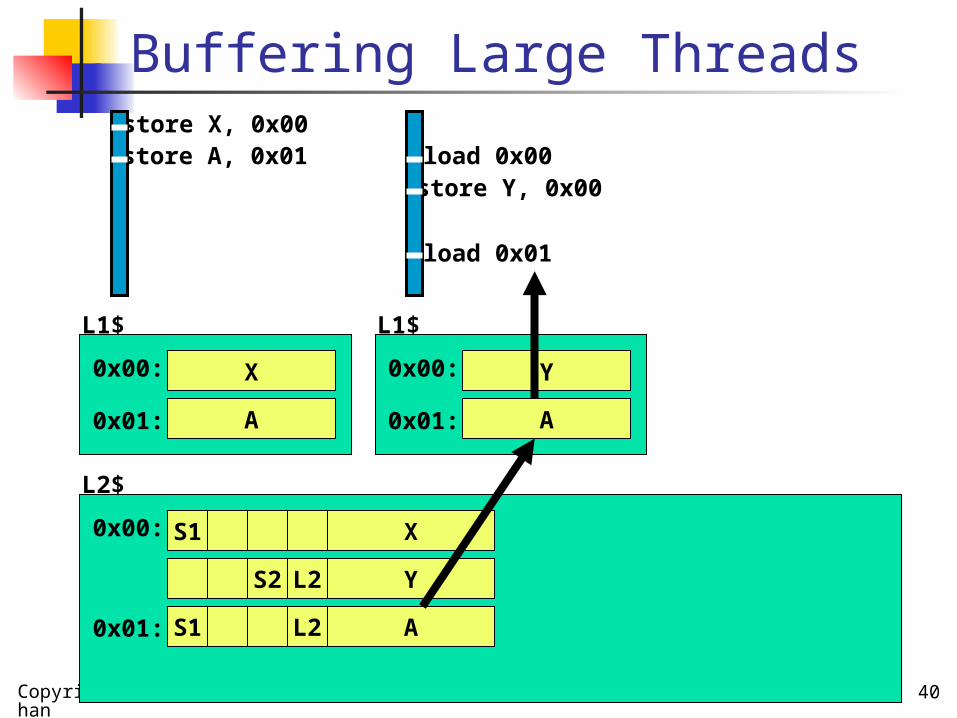
store Y, 0x00
L1$
0x00:
0x01:
L2$
X
A
0x00:
0x01:
L1$
0x00:
0x01:
XY
AS1
YS2 L2 Replicate line – one version per
thread
Replicate line – one version per
thread
Copyright 2006 Chris Colohan 40
Buffering Large Threadsstore X, 0x00store A, 0x01 load 0x00
load 0x01
store Y, 0x00
L1$
0x00:
0x01:
L2$
X
A
0x00:
0x01:
X
A
Y
L1$
0x00:
0x01:
Y
A
S1
S2 L2
S1 L2

Copyright 2006 Chris Colohan 41
Buffering Large Threadsstore X, 0x00store A, 0x01 load 0x00
load 0x01
store Y, 0x00
store B, 0x01
L1$
0x00:
0x01:
L2$
X
A
0x00:
0x01:
X
A
L1$
0x00:
0x01:
Y
A
S1
YS2 L2
S1 L2
B
B

Copyright 2006 Chris Colohan 42
Sub-thread Supportstore X, 0x00store A, 0x01 load 0x00
load 0x01
store Y, 0x00
store B, 0x01
L1$
0x00:
0x01:
L2$
X
A
0x00:
0x01:
X
A
L1$
0x00:
0x01:
S1
S1 L2
B
B
Y
YS2 L2
a{b{
Divide into two sub-threads
Only roll backviolated sub-thread

Copyright 2006 Chris Colohan 43
Sub-thread Supportstore X, 0x00store A, 0x01 load 0x00
load 0x01
store Y, 0x00
L1$
0x00:
0x01:
L2$
X
A
0x00:
0x01:
X
A
Y
L1$
0x00:
0x01: A
S1a
S1a
A
A
S2aL2a
L2b
Y
a{b{
Store and load bit per sub-
thread
Store and load bit per sub-
thread
store B, 0x01
B

Copyright 2006 Chris Colohan 44
AAAL2bS1a
Sub-thread Supportstore X, 0x00store A, 0x01 load 0x00
load 0x01
store Y, 0x00
L1$
0x00:
0x01:
L2$
X
A
0x00:
0x01:
X
Y
L1$
0x00:
0x01:
Y
S1a
A
S2aL2a
B
store B, 0x01
S1b
AB
a{b{
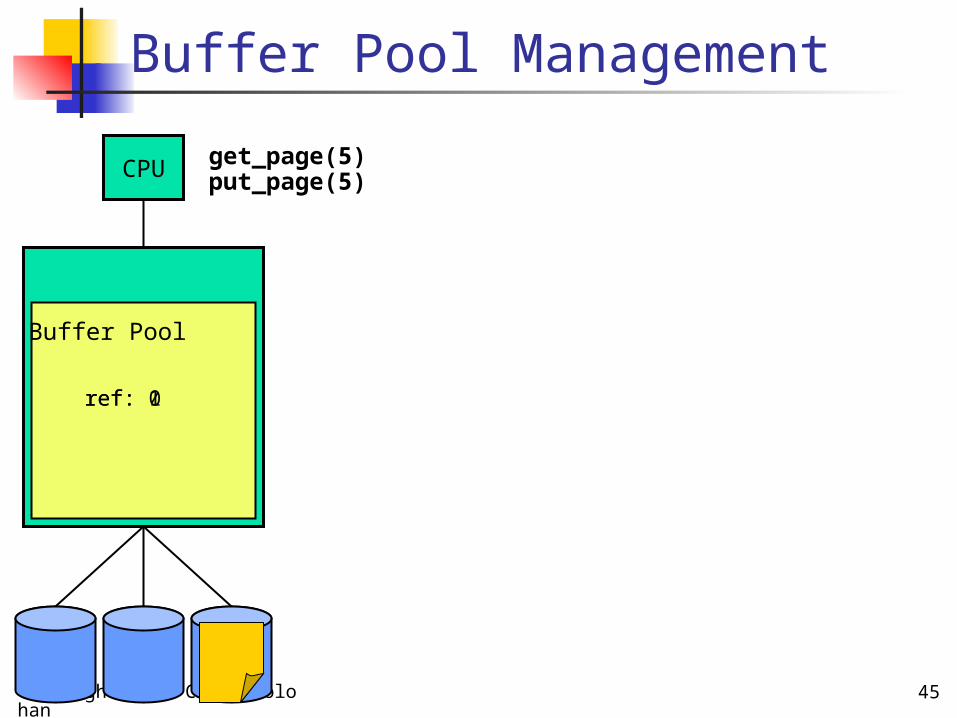
Copyright 2006 Chris Colohan 45
Buffer Pool Management
CPU
Buffer Pool
get_page(5)
ref: 1
put_page(5)
ref: 0

Copyright 2006 Chris Colohan 46
get_page(5)put_page(5)
Buffer Pool Management
CPU
Buffer Pool
get_page(5)
ref: 0
put_page(5)
Tim
e
get_page(5)
put_page(5)
TLS ensures first thread gets page
first.Who cares?
TLS ensures first thread gets page
first.Who cares?
get_page(5)put_page(5)

Copyright 2006 Chris Colohan 47
Buffer Pool Management
CPU
Buffer Pool
get_page(5)
ref: 0
put_page(5)
Tim
e
get_page(5)
put_page(5)
= Escape Speculation
• Escape speculation• Invoke operation• Store undo function• Resume speculation
• Escape speculation• Invoke operation• Store undo function• Resume speculation
get_page(5)put_page(5)
put_page(5)get_page(5)

Copyright 2006 Chris Colohan 48
Buffer Pool Management
CPU
Buffer Pool
get_page(5)
ref: 0
put_page(5)
Tim
e
get_page(5)
put_page(5)
get_page(5)put_page(5)
Not undoable!
Not undoable!
get_page(5)put_page(5)
= Escape Speculation

Copyright 2006 Chris Colohan 49
Buffer Pool Management
CPU
Buffer Pool
get_page(5)
ref: 0
put_page(5)
Tim
e
get_page(5)
put_page(5)
get_page(5)
put_page(5)
Delay put_page until end of thread Avoid dependence
= Escape Speculation
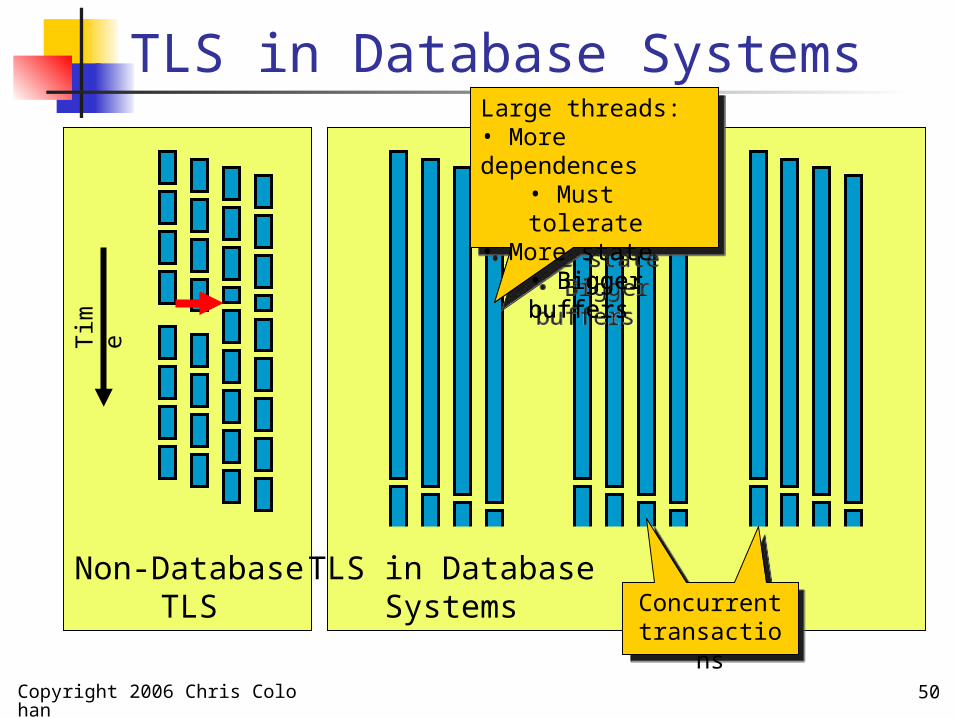
Copyright 2006 Chris Colohan 50
TLS in Database Systems
Non-DatabaseTLS
Tim
e
TLS in DatabaseSystems Concurrent
transactions
Large threads:• More dependences
• Must tolerate
• More state• Bigger buffers
Large threads:• More dependences
• Must tolerate
• More state• Bigger buffers
Large threads:• More dependences
• Must tolerate
• More state• Bigger buffers
Large threads:• More dependences
• Must tolerate
• More state• Bigger buffers

Copyright 2006 Chris Colohan 51
Feedback Loop I know this is
parallel!
for() { do_work();}
par_for() { do_work();}
Must…Make…Faster
think
feed back feed back feed back feed back feed back feed back feed back feed back feed back feed back feed

LATCHES

Copyright 2006 Chris Colohan 53
Latches
Mutual exclusion between transactions Cause violations between threads
Read-test-write cycle RAW Not needed between threads
TLS already provides mutual exclusion!

Copyright 2006 Chris Colohan 54
Latches: Aggressive Acquire
Acquirelatch_cnt++…work…latch_cnt--
Homefree
latch_cnt++…work…(enqueue release)
Commit worklatch_cnt--
Homefree
latch_cnt++…work…(enqueue release)
Commit worklatch_cnt--Release
Larg
e c
riti
cal secti
on
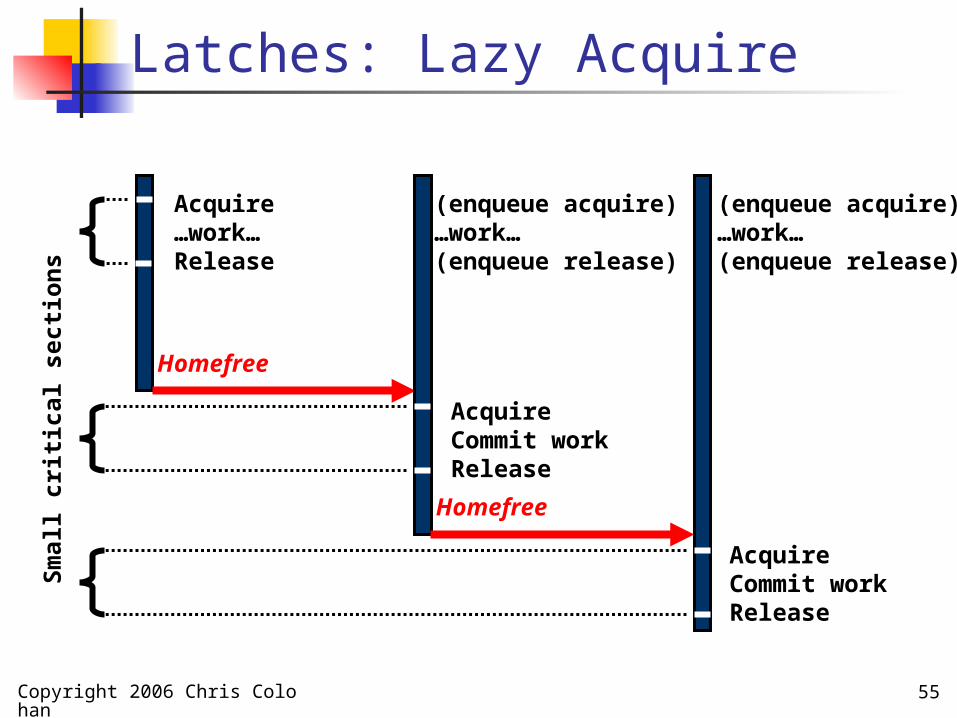
Copyright 2006 Chris Colohan 55
Latches: Lazy Acquire
Acquire…work…Release
Homefree
(enqueue acquire) …work…(enqueue release)
AcquireCommit workRelease
Homefree
(enqueue acquire)…work…(enqueue release)
AcquireCommit workRelease
Sm
all c
riti
cal secti
on
s

Copyright 2006 Chris Colohan 56
Applying TLS
1. Parallelize loop2. Run benchmark3. Remove bottleneck4. Go to 2 T
ime