tomographic mammography parallelization juemin zhang (nu) tao wu (mgh) waleed meleis (nu)
DESCRIPTION
Tomographic mammography parallelization Juemin Zhang (NU) Tao Wu (MGH) Waleed Meleis (NU) David Kaeli (NU). Parallelization of SSI Applications. - PowerPoint PPT PresentationTRANSCRIPT

Tomographic mammography parallelization
Juemin Zhang (NU)
Tao Wu (MGH)
Waleed Meleis (NU)
David Kaeli (NU)

Parallelization of SSI Applications
• We have developed profile-guided parallelization techniques to rapidly characterize program control flow and data flow, and use this information to guide parallelization• We have already sped up a number of CenSSIS applications, including:
– finite-difference time domain – steepest descent fast multi-pole method– photo simulation– ellipsoid algorithm
• We target Beowulf clusters running Linux• We utilize MPICH as our middleware

Tomographic mammography
• 3D image reconstruction from x-ray projections– Used to detect and diagnose breast cancer– Based on well-developed mammography techniques– Exposes tissue structure using multiple projections from different angles
• Advantages Accuracy: provides at least as much useful information than x-ray film Flexibility: digital image manipulation, digital storage Provides structural information: using layered images Safe: low-dose x-ray Lower cost: compared to MRI

Image acquisition and reconstruction process
• Acquisition: 11 uniform angular samples along Y-axis• X-ray projection: breast tissue density absorption radiograph• Algorithm: constrained non-linear convergence and iterative process
detector
X-ray sourceY
Set 3D volume
Compute projections
Correct 3D volume
3D volume
NoYes
Exit
Initialization
Forward
Backward
Satisfied? XY
Zx-ray
projections

Reconstruction and Parallelization
• Reconstruction algorithm: Maximum likelihood expectation maximization (ML-EM)
High resolution image Computationally intensive: 3 hours serial execution
on 2.2GHz Pentium 4 workstation, using 2GB memory• The need for speed:
– Large number of medical cases– Execution time increases as a function of breast size– Real-time application: computer-guided needle biopsy breast surgery
• Research motivation– Computation vs. communication– Platforms vs. parallelization methods

Parallelization approaches
• Reduce communication data– Segmentation along Y-axis– Using redundant computation to replace communication– Segmenting along x-ray beam
First approach:No inter-node communication(more computation, nocommunication)
Second approach:Overlap with inter-node communication
Third approach:Non-overlapped with inter-node communication(no redundant computation, more communication)
exchange dataOverlap area

Implementation and tests
• Serial code provided by T. Wu at MGH
• Programming model– C++ and message passing interface (MPI)
– Globus tool kits: MPICH-G2 over NPACI Grid, in progress
•Test input data set– Phantom data set: 1600x2034x45
– A large patient data set: 1040x2034x70
• Test platforms
Processor Interconnection
MGH cluster 2.5GHz Pentium 4 100Mb interconnect switch
UIUC NCSA Titan cluster 800MHz Itanium 1
dual-processor
1Gb Myrinet,
Shared L3 cache
UIUC NCSA
IBM p690 server
1.3GHz Power4 1Gb Ethernet
Shared memory system
SGI Altix 3300 system 1.3GHz Itanium 2
dual-processor
NUMAlink interconnect,
Shared memory system
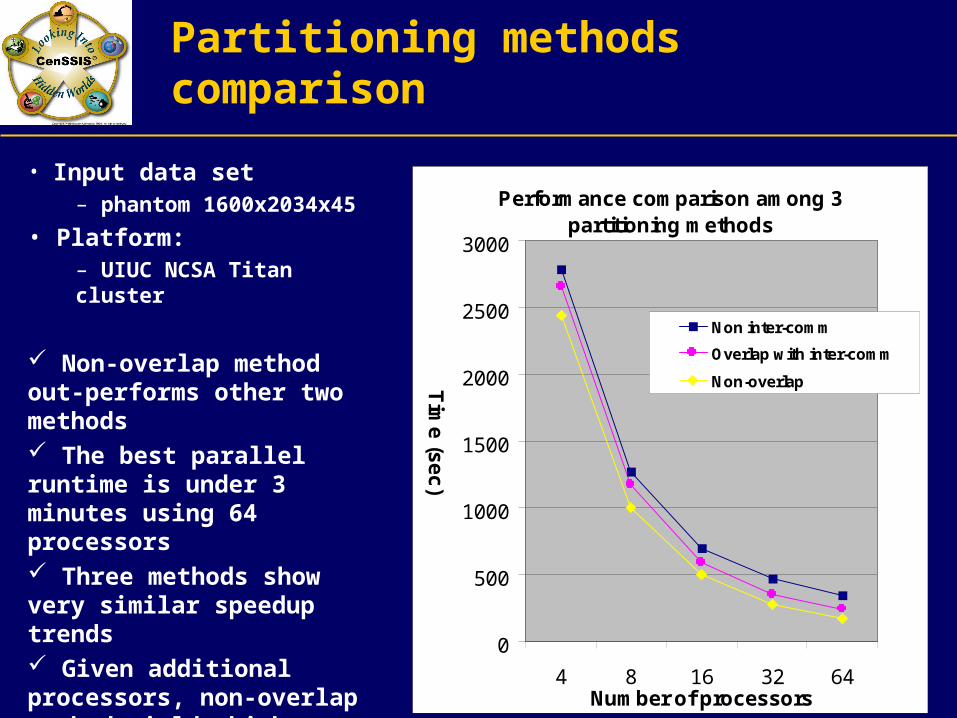
Partitioning methods comparison
• Input data set– phantom 1600x2034x45
• Platform: – UIUC NCSA Titan cluster
Non-overlap method out-performs other two methods The best parallel runtime is under 3 minutes using 64 processors Three methods show very similar speedup trends Given additional processors, non-overlap method yields higher performance increase than other methods
Performance comparison among 3 partitioning methods
0
500
1000
1500
2000
2500
3000
4 8 16 32 64Number of processors
Tim
e (s
ec
)
Non inter-comm
Overlap with inter-comm
Non-overlap

Platform performance comparisonusing non-overlap method
• Input data set: phantom 1600x2034x45• Platforms:
– SGI Altix system – UIUC NCSA Titan cluster– UIUC NCSA IBM p690– Pentium 4 cluster at MGH
• Number of processors: 32• Algorithm: Non-overlap with inter-node communication partition method
Computation: SGI Altix with Itanium 2 processor outperforms the other CPUs Communication: shared memory platforms have very low communication overhead Over 2 times performance difference between SGI Altix and Pentium IV cluster
Profiling non-overlap method on different platforms
0
50
100
150
200
250
300
350
SGI Altix TitanCluster
IBM p690 P4 cluster
Tim
e (s
ec
)
Forward Backward Sync
Inter-comm Collect File IO
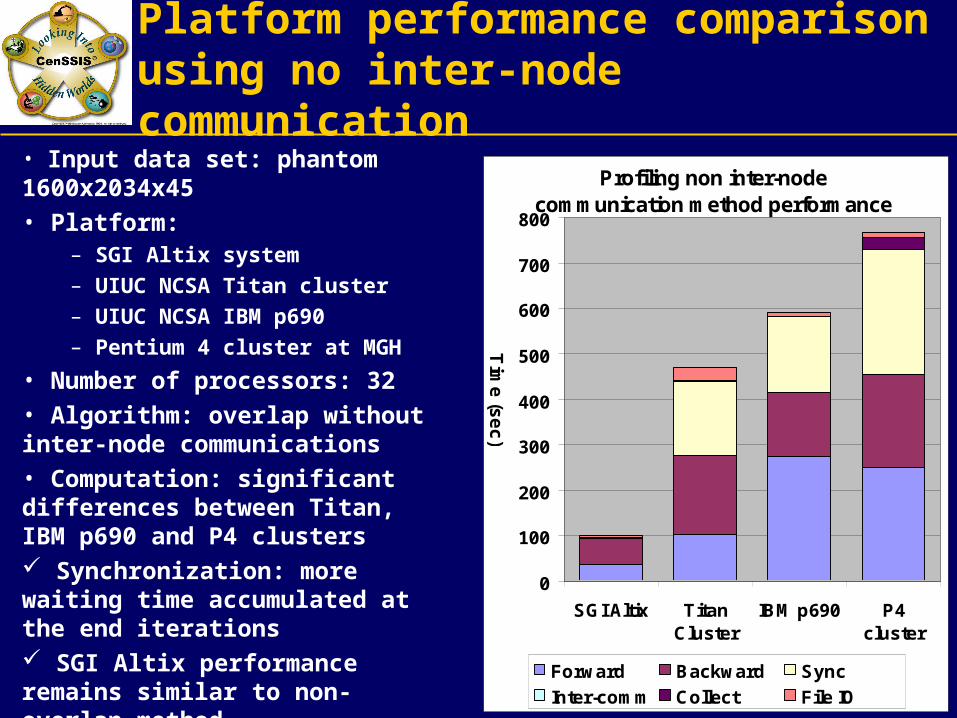
Platform performance comparison using no inter-node communication
• Input data set: phantom 1600x2034x45
• Platform:– SGI Altix system– UIUC NCSA Titan cluster – UIUC NCSA IBM p690 – Pentium 4 cluster at MGH
• Number of processors: 32
• Algorithm: overlap without inter-node communications
• Computation: significant differences between Titan, IBM p690 and P4 clusters Synchronization: more waiting time accumulated at the end iterations SGI Altix performance remains similar to non-overlap method
Profiling non inter-node communication method performance
0
100
200
300
400
500
600
700
800
SGI Altix TitanCluster
IBM p690 P4cluster
Tim
e (s
ec
)
Forward Backward Sync
Inter-comm Collect File IO

Platform and parallel partitioning method performance comparison
• Input data set:–phantom 1600x2034x45
• Platform:
– Pentium 4 cluster at MGH– UIUC NCSA IBM p690 – UIUC NCSA Titan cluster– SGI Altix
• Number of processors: 32
Computation power dominant performances Inter-node communication and non-overlap methods lead to higher performance on some platforms
0
100
200
300
400
500
600
700
800
Tim
e (s
ec
)
MGH P4cluster
IBMp690
TitanCluster
SGI Altix
N o n -o v e rla p
O v e rla p w ith in te r-c o mm
N o n -in te rc o mm
Parallel test results on 32 processors
Non-overlap Overlap with inter-comm Non-intercomm

Summary and future work
• Over 180X speedup vs. serial implementation 1. Phantom data set: 1600x2034x45
– 1 minute using 64 processors on SGI Altix2. A large patient data set: 1040x2034x70
– 1.5 minutes using 64 processors on SGI Altix
• Joint SPIE paper with T. Wu at MGH: “A parallel reconstruction method for digital tomosynthesis mammography,” 2004 SPIE Workshop on Medical Imaging
• Future work:– Real-time application: computer-guided needle biopsy
• Goal: 5~10 seconds delay or less• Evaluation of computation reduction effects on image quality
– Move code to a Grid environment (underway)