towards declarative stream processing using apache flink · stream processing with apache flink •...
TRANSCRIPT

1 © DIMA 2016© 2013 Berlin Big Data Center • All Rights Reserved1 © DIMA 2016
Towards Declarative Stream Processing using Apache Flink
Tilmann RablBerlin Big Data Center
www.dima.tu-berlin.de | bbdc.berlin | [email protected]

2 © DIMA 20162
2 © DIMA 2016
Agenda

3 © DIMA 20163
3 © DIMA 2016
AgendaApache Flink Primer• Architecture• Execution Engine• Some key features• Some demo (!)
Stream Processing with Apache Flink• Flexible Windows/Stream Discretization• Exactly-once Processing & Fault Tolerance
Apache Flink Use Cases• How companies use Flink (if we have time)
With slides from Data Artisans, Volker Markl, Asterios Katsifodimos, Juan Soto

4 © DIMA 20164 © DIMA 2016
Flink Primer
5 © DIMA 20165
5 © DIMA 2016
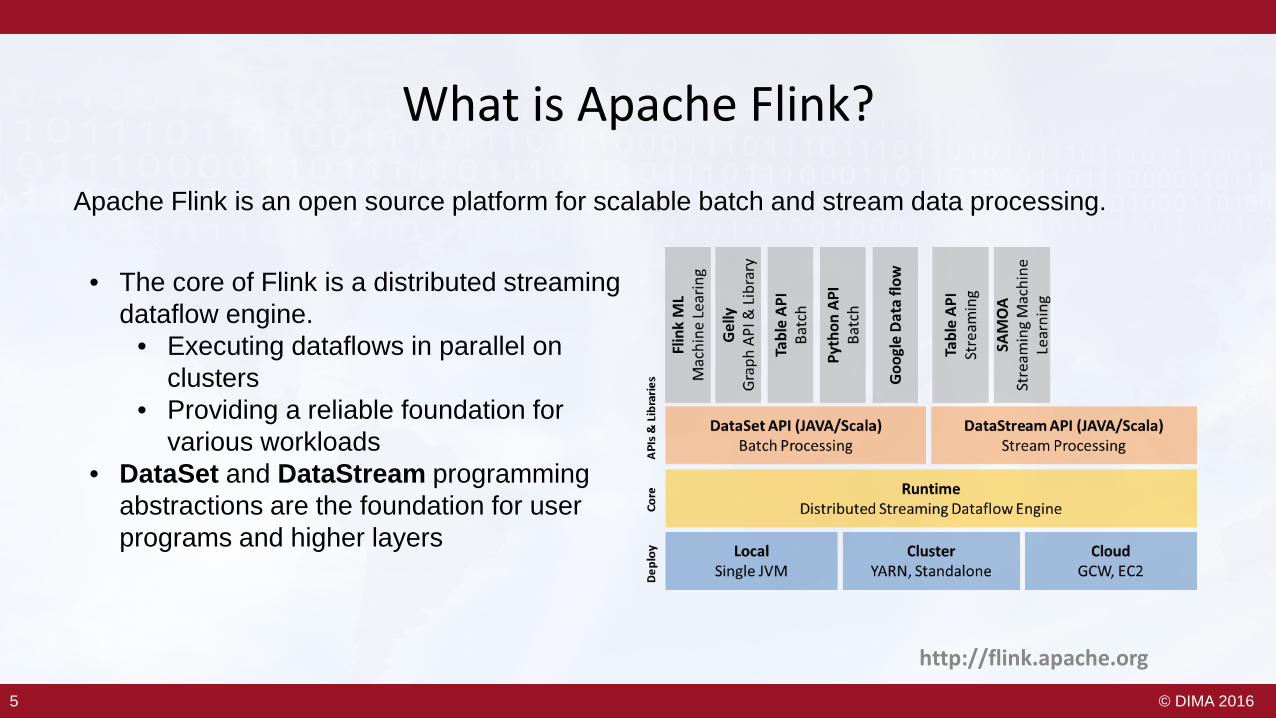
What is Apache Flink?
Apache Flink is an open source platform for scalable batch and stream data processing.
http://flink.apache.org
• The core of Flink is a distributed streaming dataflow engine.
• Executing dataflows in parallel on clusters
• Providing a reliable foundation for various workloads
• DataSet and DataStream programming abstractions are the foundation for user programs and higher layers
6 © DIMA 20166 © 2013 Berlin Big Data Center • All Rights Reserved
6 © DIMA 2016
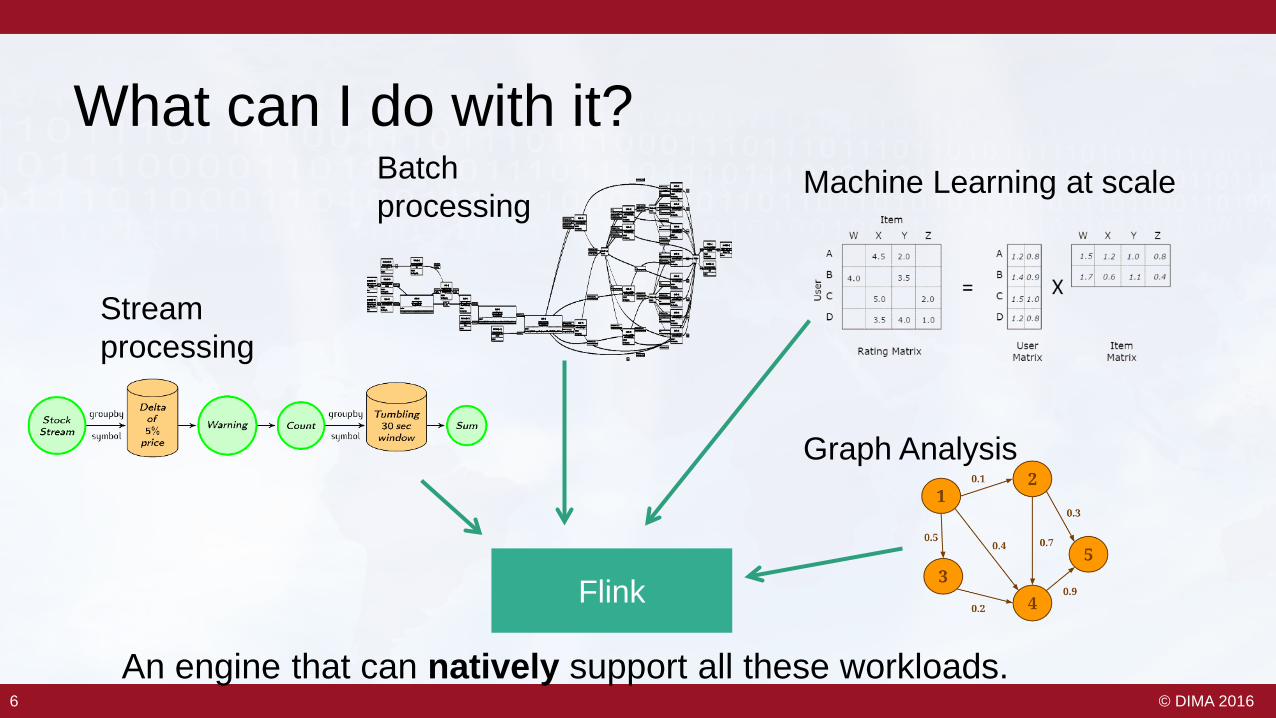
What can I do with it?
An engine that can natively support all these workloads.
Flink
Stream processing
Batchprocessing
Machine Learning at scale
Graph Analysis
7 © DIMA 20167 © 2013 Berlin Big Data Center • All Rights Reserved
7 © DIMA 2016
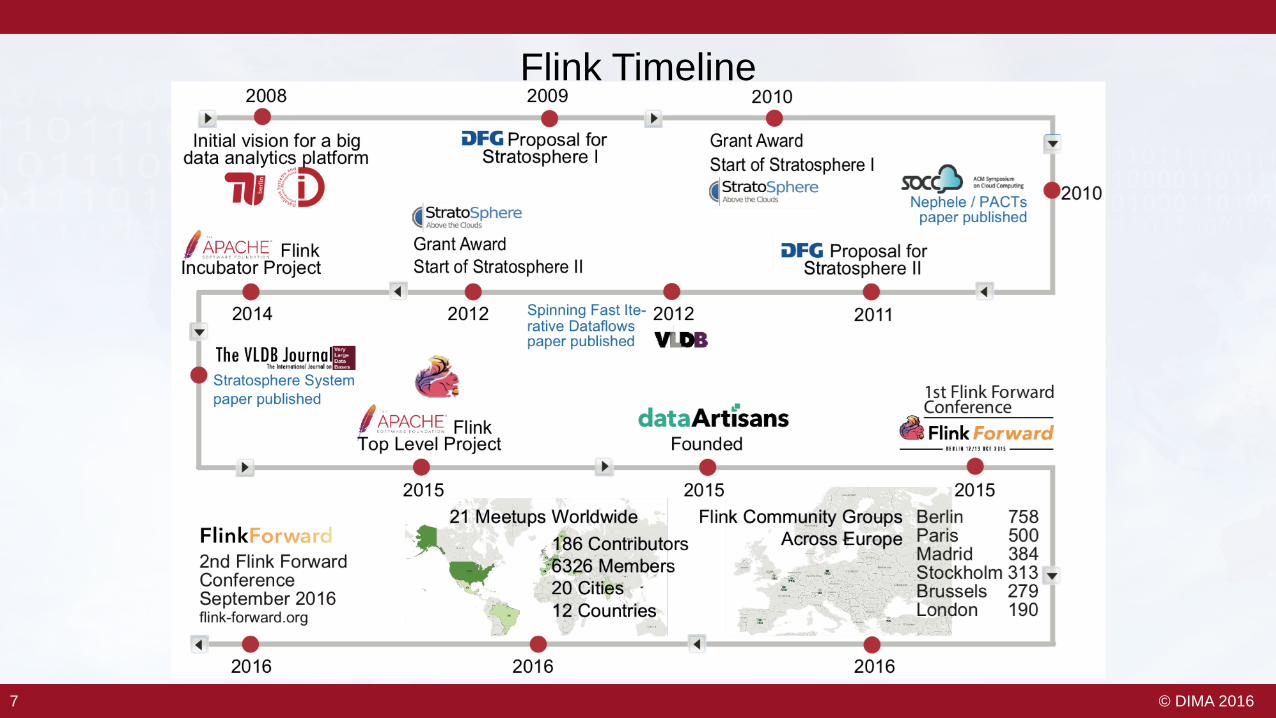
Flink Timeline
8 © DIMA 2016
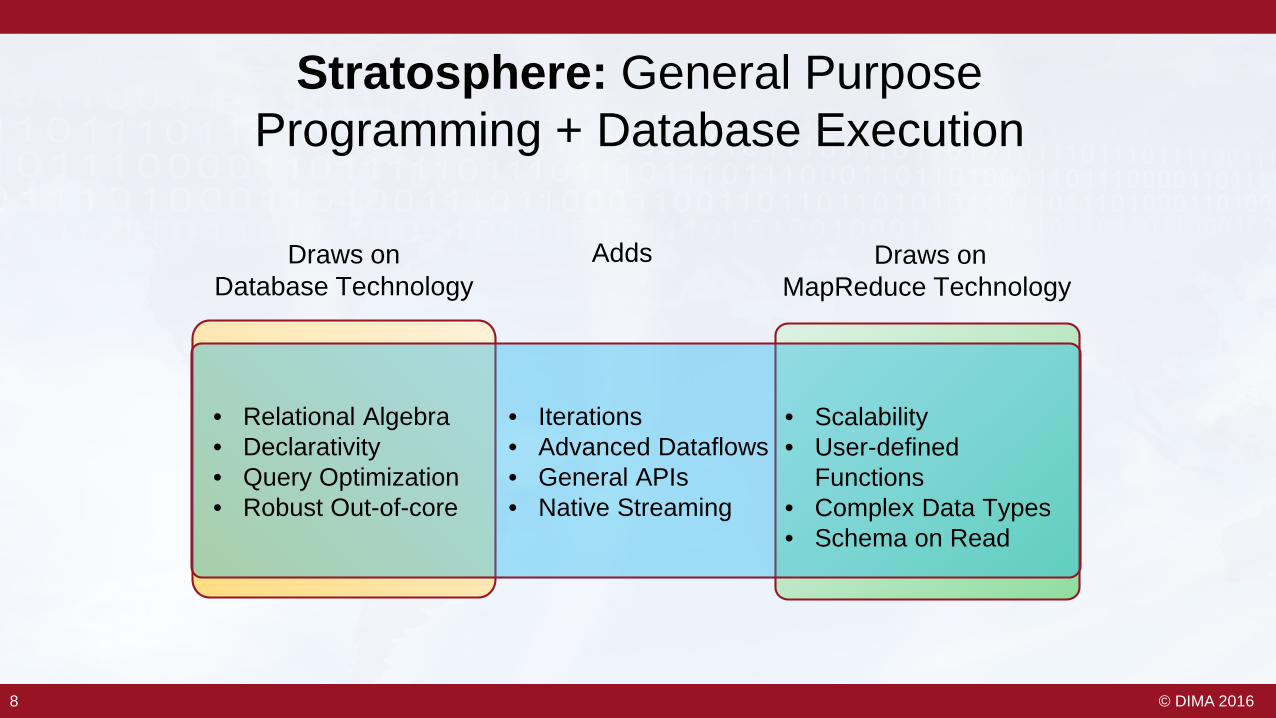
• Relational Algebra• Declarativity• Query Optimization• Robust Out-of-core
• Scalability• User-defined
Functions • Complex Data Types• Schema on Read
• Iterations• Advanced Dataflows• General APIs• Native Streaming
Draws onDatabase Technology
Draws onMapReduce Technology
Adds
Stratosphere: General Purpose Programming + Database Execution
9 © DIMA 20169 © 2013 Berlin Big Data Center • All Rights Reserved
9 © DIMA 2016
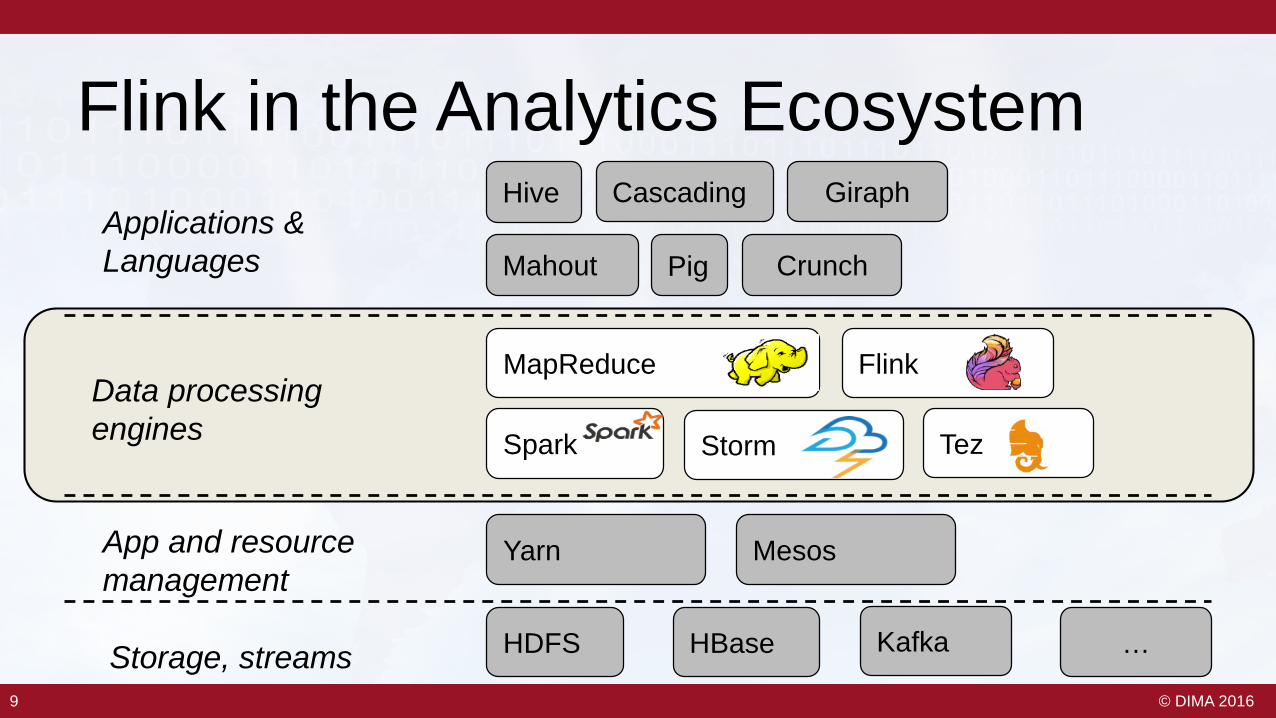
Flink in the Analytics Ecosystem
9
MapReduce
Hive
Flink
Spark Storm
Yarn Mesos
HDFS
Mahout
Cascading
Tez
Pig
Data processing engines
App and resource management
Applications &Languages
Storage, streams KafkaHBase
Crunch
…
Giraph
10 © DIMA 2016
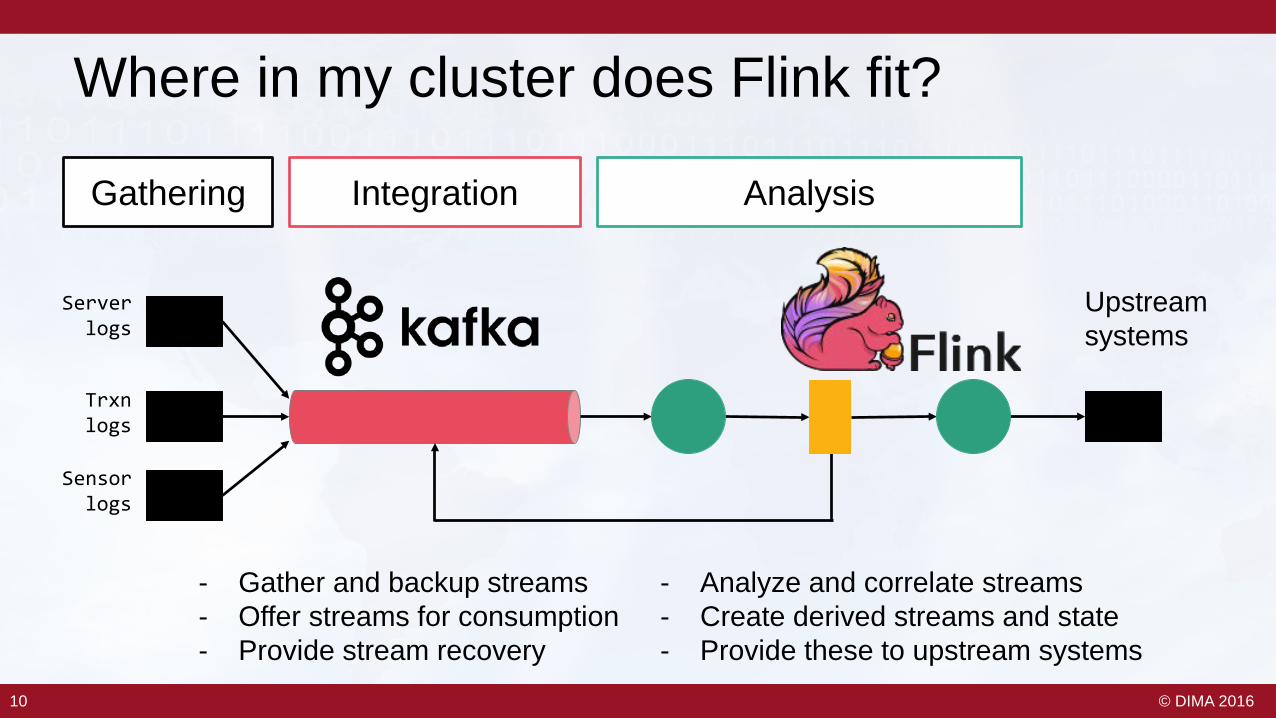
Where in my cluster does Flink fit?
- Gather and backup streams- Offer streams for consumption- Provide stream recovery
- Analyze and correlate streams- Create derived streams and state- Provide these to upstream systems
Serverlogs
Trxnlogs
Sensorlogs
Upstreamsystems
Gathering Integration Analysis
11 © DIMA 201611
11 © DIMA 2016
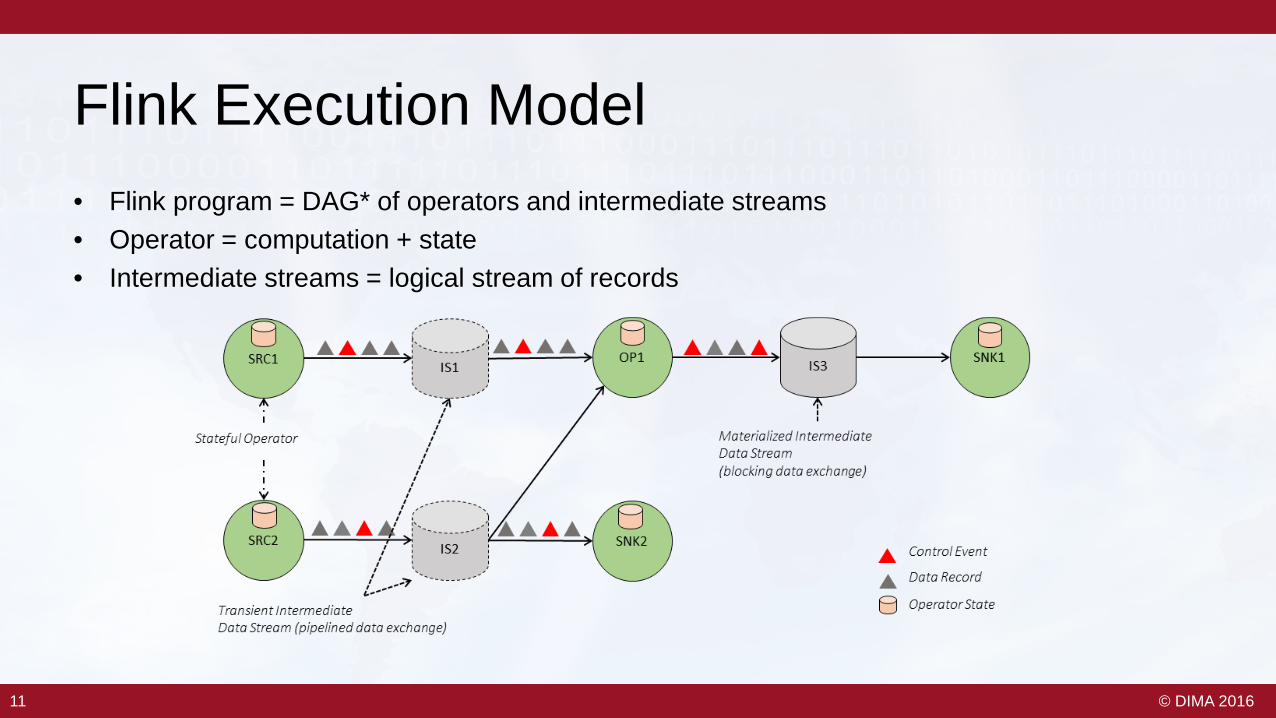
Flink Execution Model• Flink program = DAG* of operators and intermediate streams• Operator = computation + state• Intermediate streams = logical stream of records
12 © DIMA 201612
12 © DIMA 2016
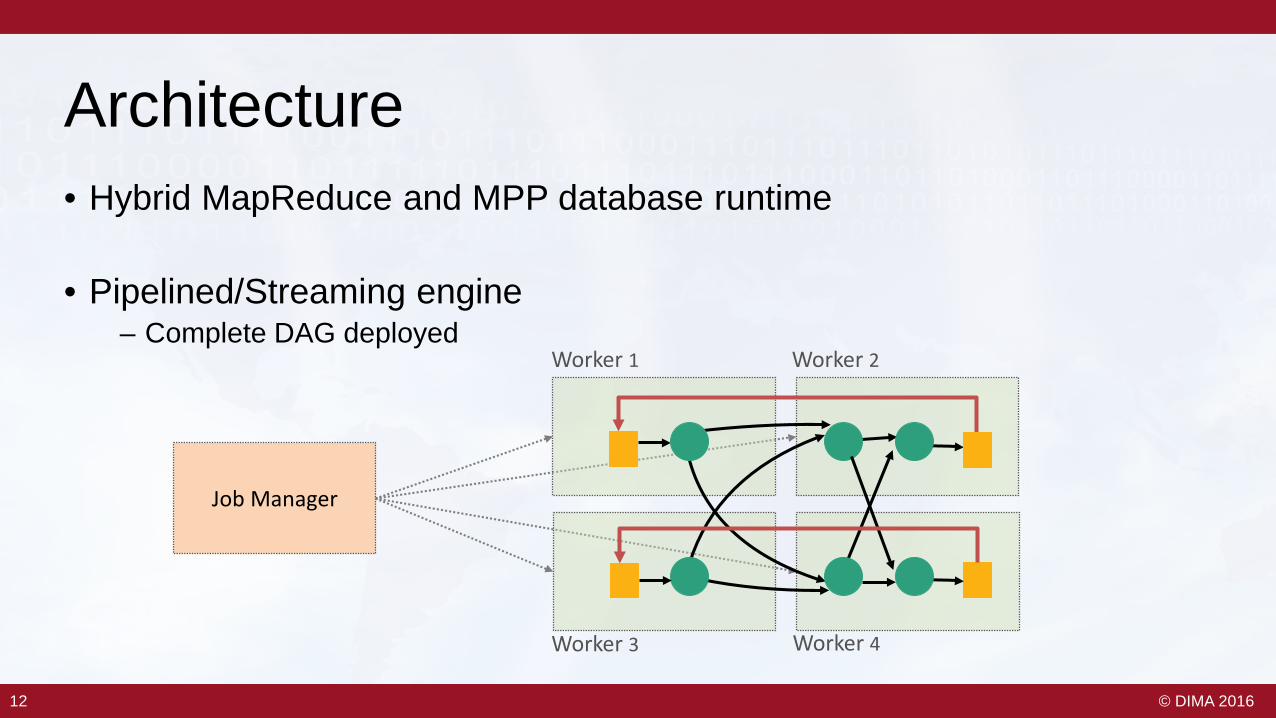
Architecture• Hybrid MapReduce and MPP database runtime
• Pipelined/Streaming engine– Complete DAG deployed
Worker 1
Worker 3 Worker 4
Worker 2
Job Manager
13 © DIMA 201613 © 2013 Berlin Big Data Center • All Rights Reserved
13 © DIMA 2016
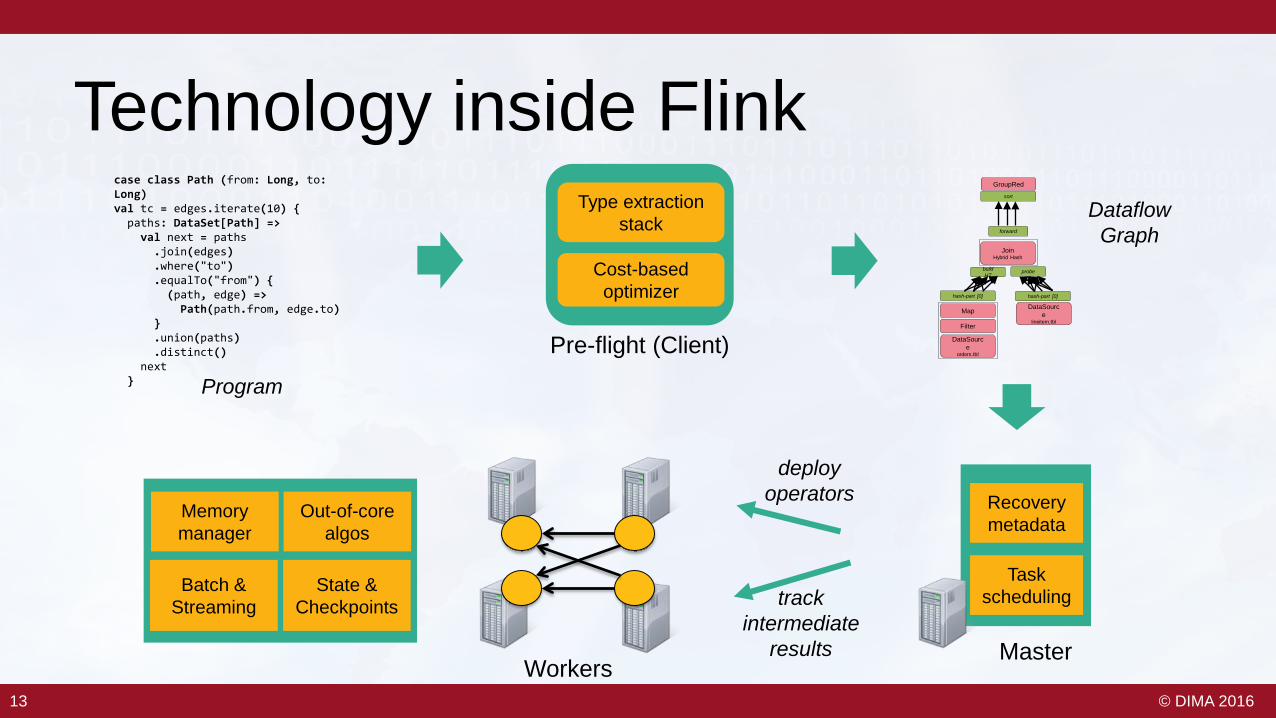
Technology inside Flinkcase class Path (from: Long, to:Long)val tc = edges.iterate(10) {
paths: DataSet[Path] =>val next = paths
.join(edges)
.where("to")
.equalTo("from") {(path, edge) =>
Path(path.from, edge.to)}.union(paths).distinct()
next}
Cost-based optimizer
Type extraction stack
Task scheduling
Recoverymetadata
Pre-flight (Client)
MasterWorkers
DataSource
orders.tbl
Filter
Map DataSource
lineitem.tbl
JoinHybrid Hash
buildHT
probe
hash-part [0] hash-part [0]
GroupRed
sort
forward
Program
DataflowGraph
Memory manager
Out-of-core algos
Batch & Streaming
State & Checkpoints
deployoperators
trackintermediate
results
14 © DIMA 201614
14 © DIMA 2016
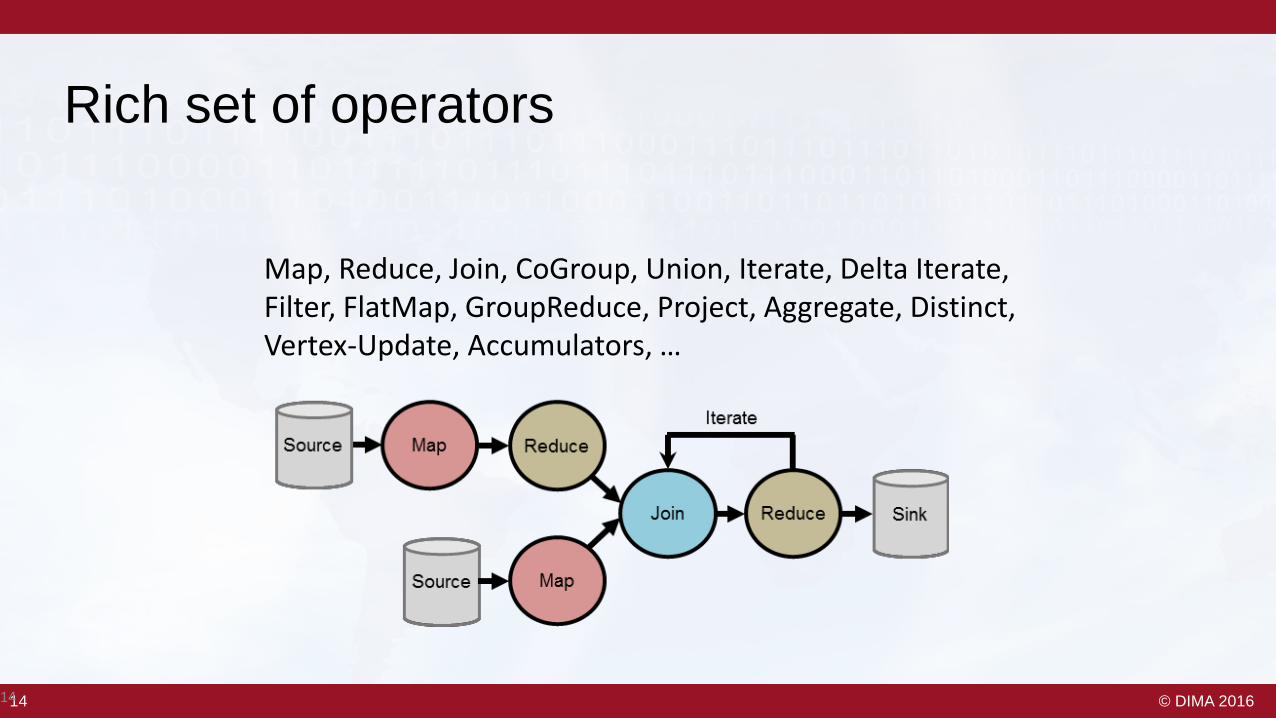
Rich set of operators
14
Map, Reduce, Join, CoGroup, Union, Iterate, Delta Iterate, Filter, FlatMap, GroupReduce, Project, Aggregate, Distinct, Vertex-Update, Accumulators, …
15 © DIMA 201615
15 © DIMA 2016
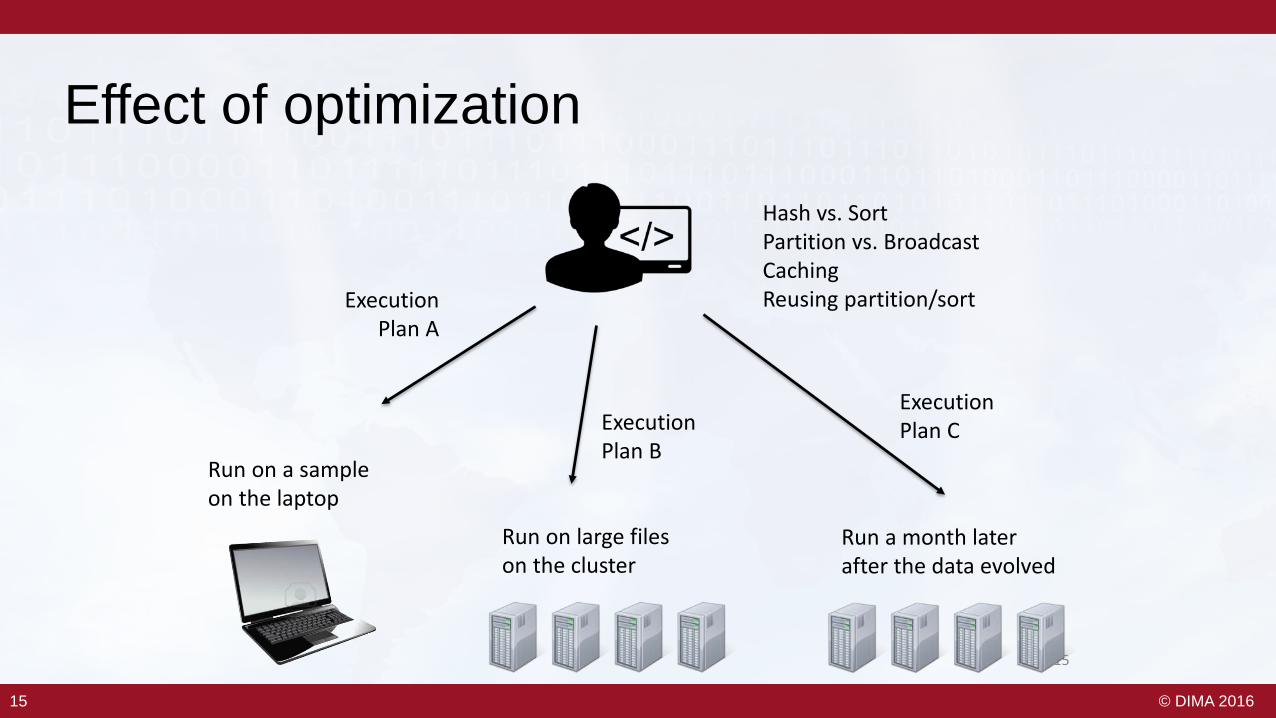
Effect of optimization
15
Run on a sampleon the laptop
Run a month laterafter the data evolved
Hash vs. SortPartition vs. BroadcastCachingReusing partition/sortExecution
Plan A
ExecutionPlan B
Run on large fileson the cluster
ExecutionPlan C
16 © DIMA 201616
16 © DIMA 2016
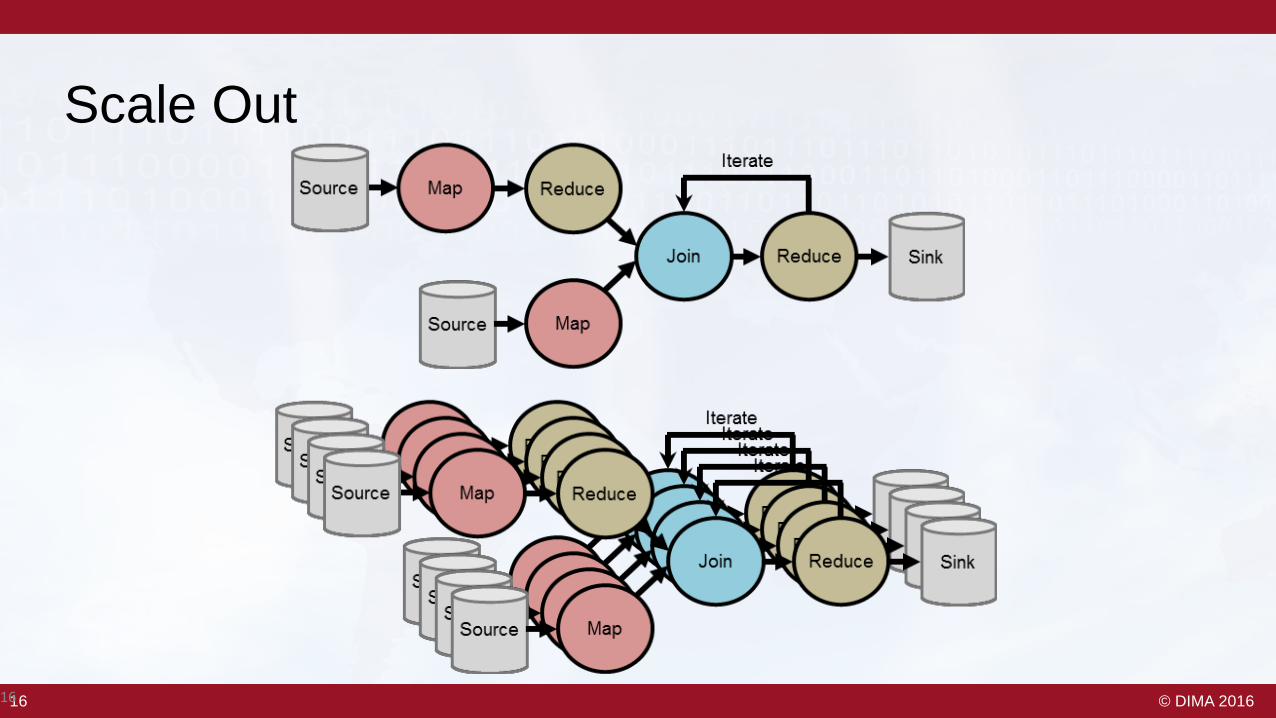
Scale Out
16

17 © DIMA 201617
17 © DIMA 2016
Flink Optimizer Transitive Closure
HDFS
newPaths
paths
Join Union Distinct
Step function
IterateIteratereplace
• What you write is not what is executed• No need to hardcode execution strategies
• Flink Optimizer decides:– Pipelines and dam/barrier placement– Sort- vs. hash- based execution– Data exchange (partition vs. broadcast)– Data partitioning steps– In-memory caching
Hash Partition on [0]Hash Partition on [1]
Hybrid Hash Join
Loop-invariant data cached in memory
Group Reduce (Sorted (on [0]))
Co-locate JOIN + UNIONHash Partition on [1]
ForwardCo-locate DISTINCT + JOIN
18 © DIMA 201618 © 2013 Berlin Big Data Center • All Rights Reserved
18 © DIMA 2016
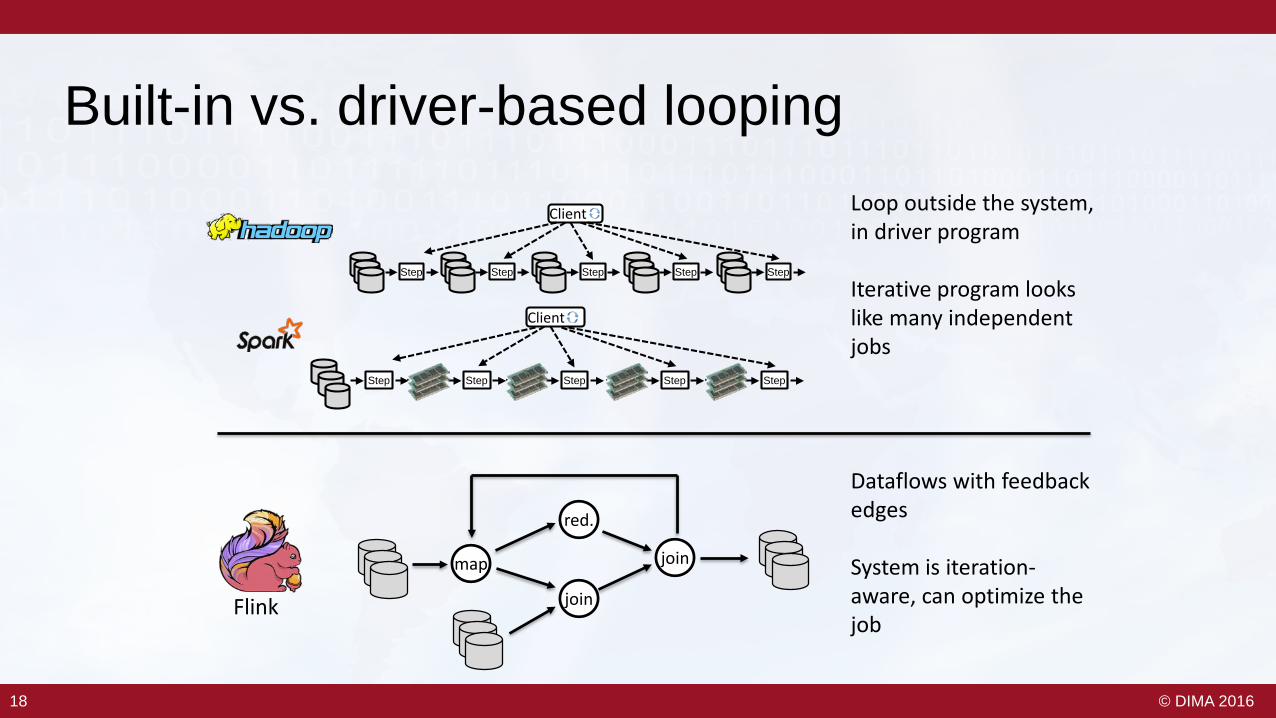
Built-in vs. driver-based looping
Step Step Step Step Step
Client
Step Step Step Step Step
Client
map
join
red.
join
Loop outside the system, in driver program
Iterative program looks like many independent jobs
Dataflows with feedback edges
System is iteration-aware, can optimize the job
Flink
19 © DIMA 201619
19 © DIMA 2016
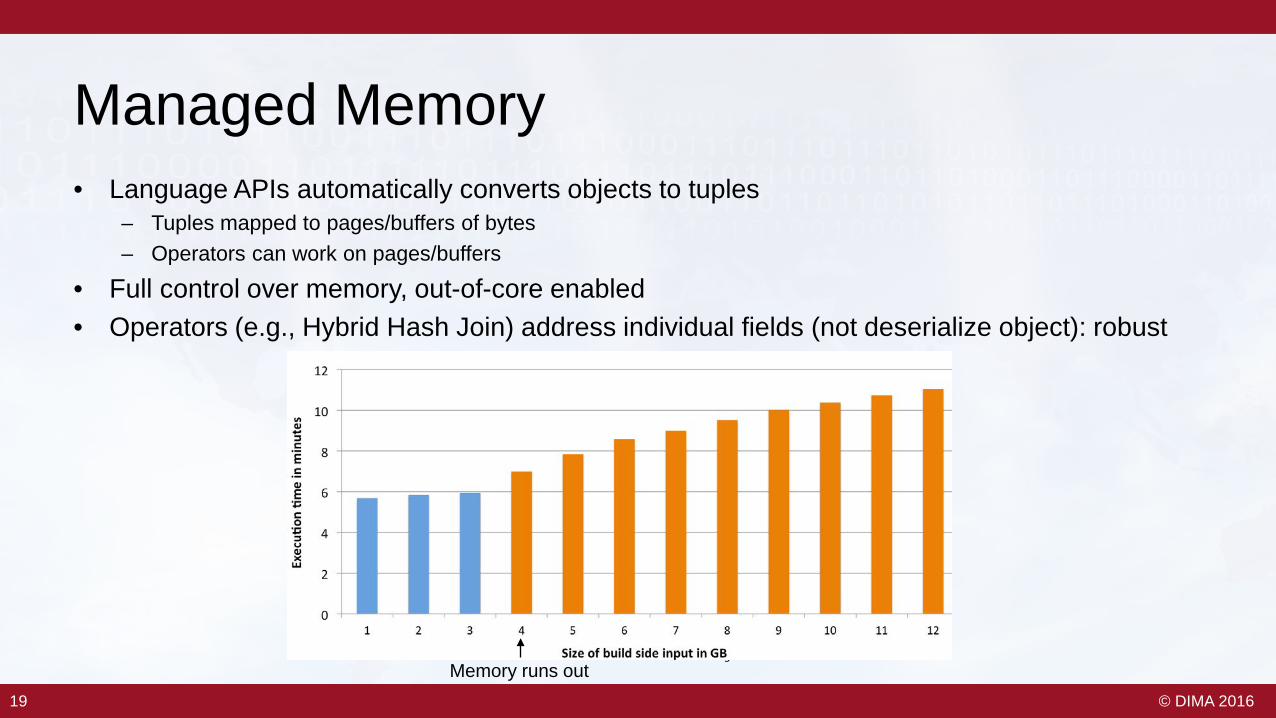
Managed Memory• Language APIs automatically converts objects to tuples
– Tuples mapped to pages/buffers of bytes– Operators can work on pages/buffers
• Full control over memory, out-of-core enabled• Operators (e.g., Hybrid Hash Join) address individual fields (not deserialize object): robust
4b 8b 1b 4b Variable Length
Tuple3<Integer, Double, Person>
F0: int
F1: double
Person
Id: int
Name: String
public class Person {int id; String name;}
Pojo (header)
IntSerialized
DoubleSerialized
IntSerialized
StringSerialized
Memory runs out

20 © DIMA 201620
20 © DIMA 2016
Sneak peak: Two of Flink’s APIs
20
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ").map(word => Word(word,1))}
.keyBy("word")
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.sum("frequency”)
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ").map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):

21 © DIMA 201621 © 2013 Berlin Big Data Center • All Rights Reserved
21 © DIMA 2016
DEMO – BATCH
„Inspired“ byhttp://dataartisans.github.io/flink-training/index.html

22 © DIMA 201622 © DIMA 2016
Stream Processing with Flink

23 © DIMA 201623
23 © DIMA 2016
Ingredients of a Streaming System• Streaming Execution Engine• Windowing (a.k.a Discretization)• Fault Tolerance• High Level Programming API (or language)
23
24 © DIMA 201624
24 © DIMA 2016
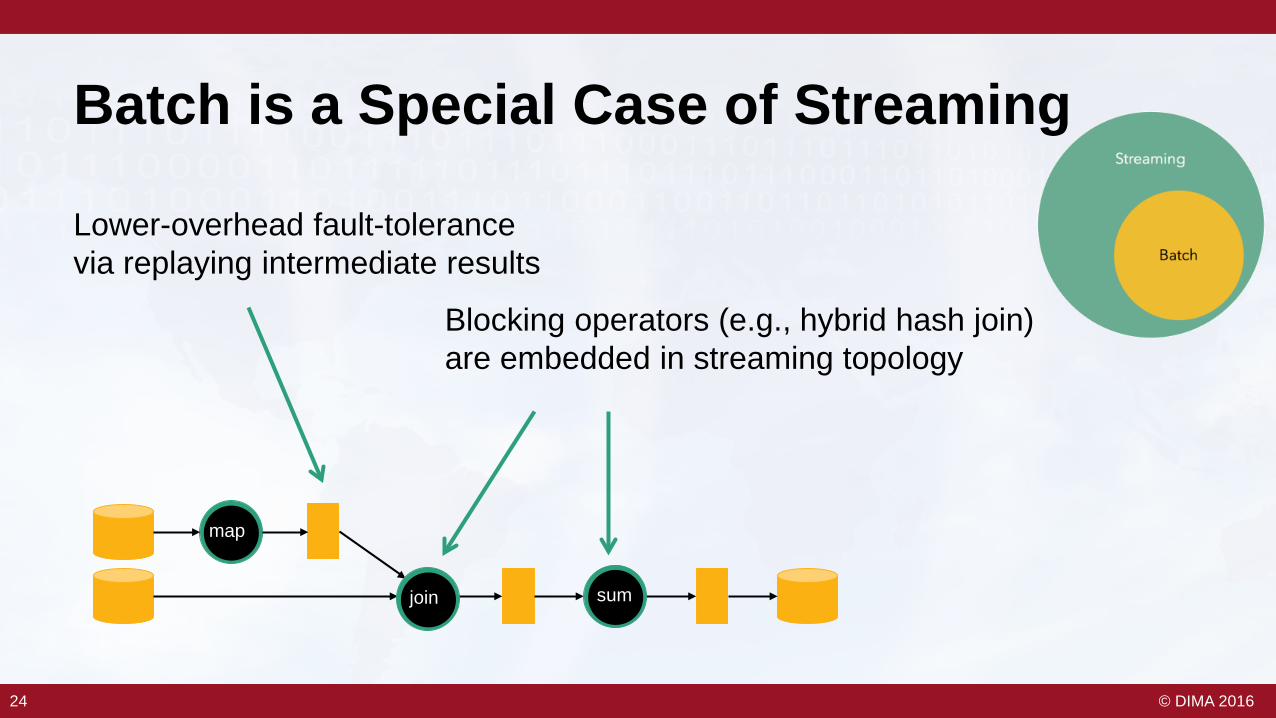
Batch is a Special Case of Streaming
map
Blocking operators (e.g., hybrid hash join) are embedded in streaming topology
Lower-overhead fault-tolerance via replaying intermediate results
join sum
25 © DIMA 201625
25 © DIMA 2016
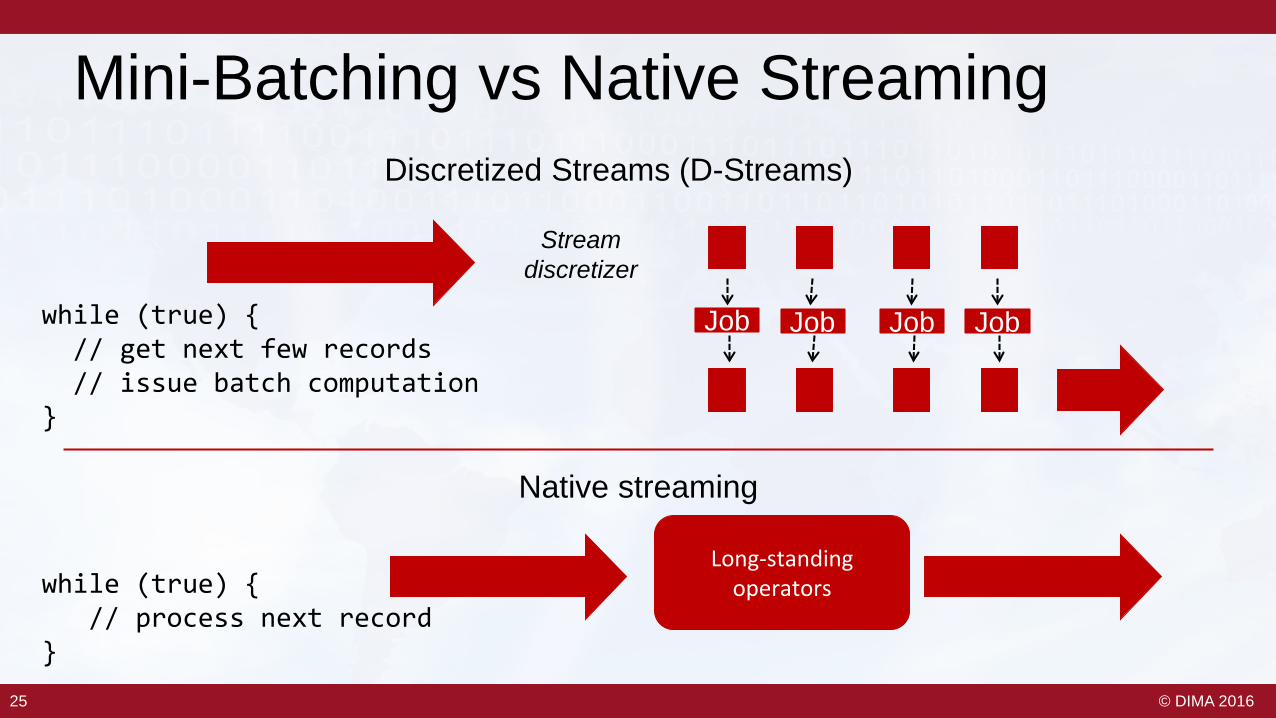
Mini-Batching vs Native Streaming
Streamdiscretizer
Job Job Job Jobwhile (true) {// get next few records// issue batch computation
}
while (true) {// process next record
}
Long-standing operators
Discretized Streams (D-Streams)
Native streaming

26 © DIMA 201626
26 © DIMA 2016
Problems of Mini-Batch• Latency
– Each mini-batch schedules a new job, loads user libraries, establishes DB connections, etc
• Programming model– Does not separate business logic from recovery – changing the mini-batch size changes
query results
• Power– Keeping and updating state across mini-batches only possible by immutable
computations
26

27 © DIMA 201627
27 © DIMA 2016
Stream Discretization• Data is unbounded
– Interested in a (recent) part of it e.g. last 10 days
• Most common windows around: time, and count– Mostly in sliding, fixed, and tumbling forms
• Need for data-driven window definitions– e.g., user sessions (periods of user activity followed by inactivity), price changes, etc.
27
The world beyond batch: Streaming 101, Tyler Akidauhttps://beta.oreilly.com/ideas/the-world-beyond-batch-streaming-101Great read!

28 © DIMA 201628
28 © DIMA 2016
Flink’s Discretization
• Allows very flexible windowing
• Borrows ideas (and extends) from IBM’s SPL– SLIDE = Trigger = When to emit a window– RANGE = Eviction = What the window contains
• Allows for lots of optimization– Not part of this talk
28

29 © DIMA 201629
29 © DIMA 2016
Flink’s Windowing• Windows can be any combination of (multiple) triggers & evictions
– Arbitrary tumbling, sliding, session, etc. windows can be constructed.
• Common triggers/evictions part of the API– Time (processing vs. event time), Count
• Even more flexibility: define your own UDF trigger/eviction
• Examples:dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)));
30 © DIMA 2016
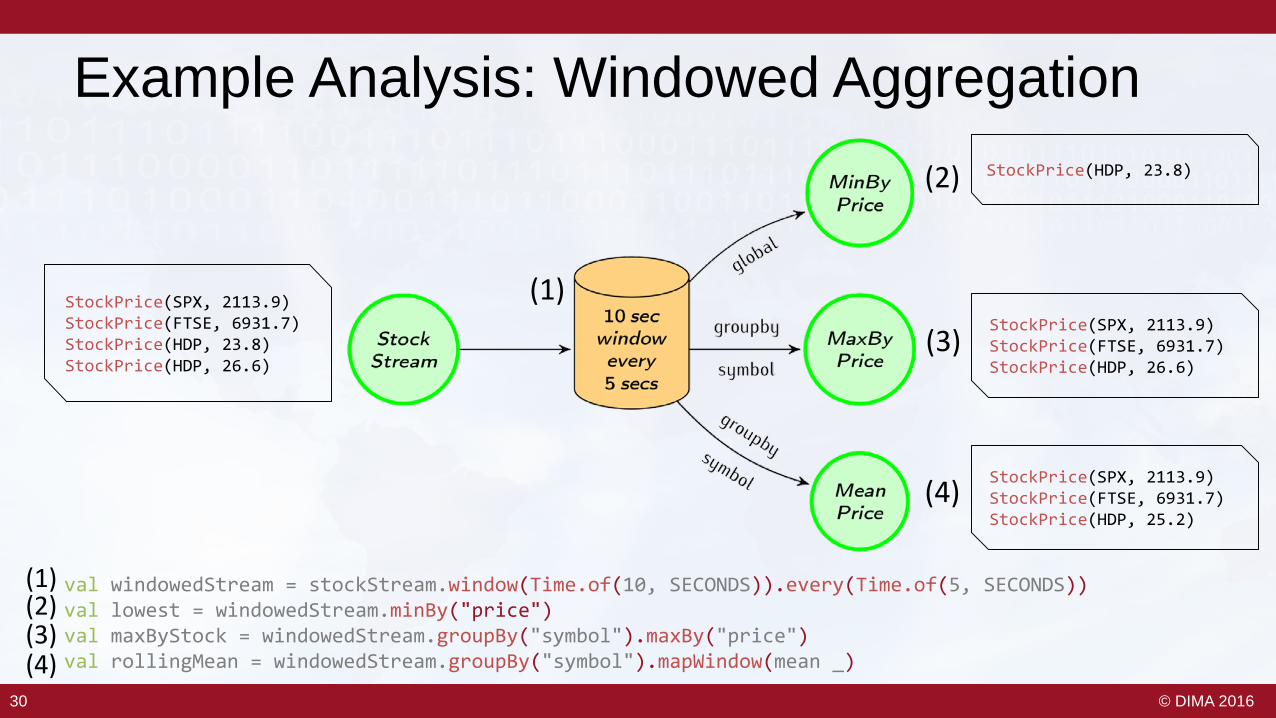
Example Analysis: Windowed Aggregation
val windowedStream = stockStream.window(Time.of(10, SECONDS)).every(Time.of(5, SECONDS))val lowest = windowedStream.minBy("price")val maxByStock = windowedStream.groupBy("symbol").maxBy("price")val rollingMean = windowedStream.groupBy("symbol").mapWindow(mean _)
(1)
(2)
(4)
(3)
(1)(2)
(4)(3)
StockPrice(SPX, 2113.9)StockPrice(FTSE, 6931.7)StockPrice(HDP, 23.8)StockPrice(HDP, 26.6)
StockPrice(HDP, 23.8)
StockPrice(SPX, 2113.9)StockPrice(FTSE, 6931.7)StockPrice(HDP, 26.6)
StockPrice(SPX, 2113.9)StockPrice(FTSE, 6931.7)StockPrice(HDP, 25.2)
31 © DIMA 201631 © 2013 Berlin Big Data Center • All Rights Reserved
31 © DIMA 2016
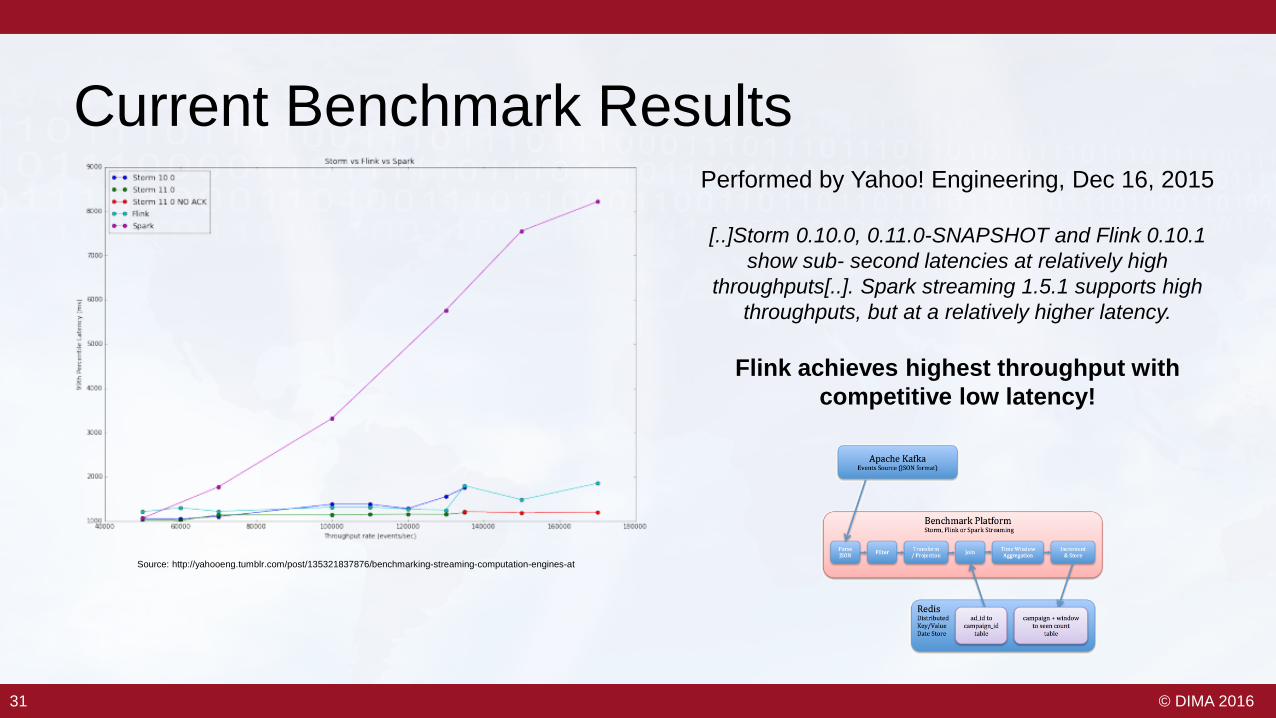
Current Benchmark ResultsPerformed by Yahoo! Engineering, Dec 16, 2015
[..]Storm 0.10.0, 0.11.0-SNAPSHOT and Flink 0.10.1 show sub- second latencies at relatively high
throughputs[..]. Spark streaming 1.5.1 supports high throughputs, but at a relatively higher latency.
Flink achieves highest throughput with competitive low latency!
Source: http://yahooeng.tumblr.com/post/135321837876/benchmarking-streaming-computation-engines-at
32 © DIMA 201632 © 2013 Berlin Big Data Center • All Rights Reserved
32 © DIMA 2016
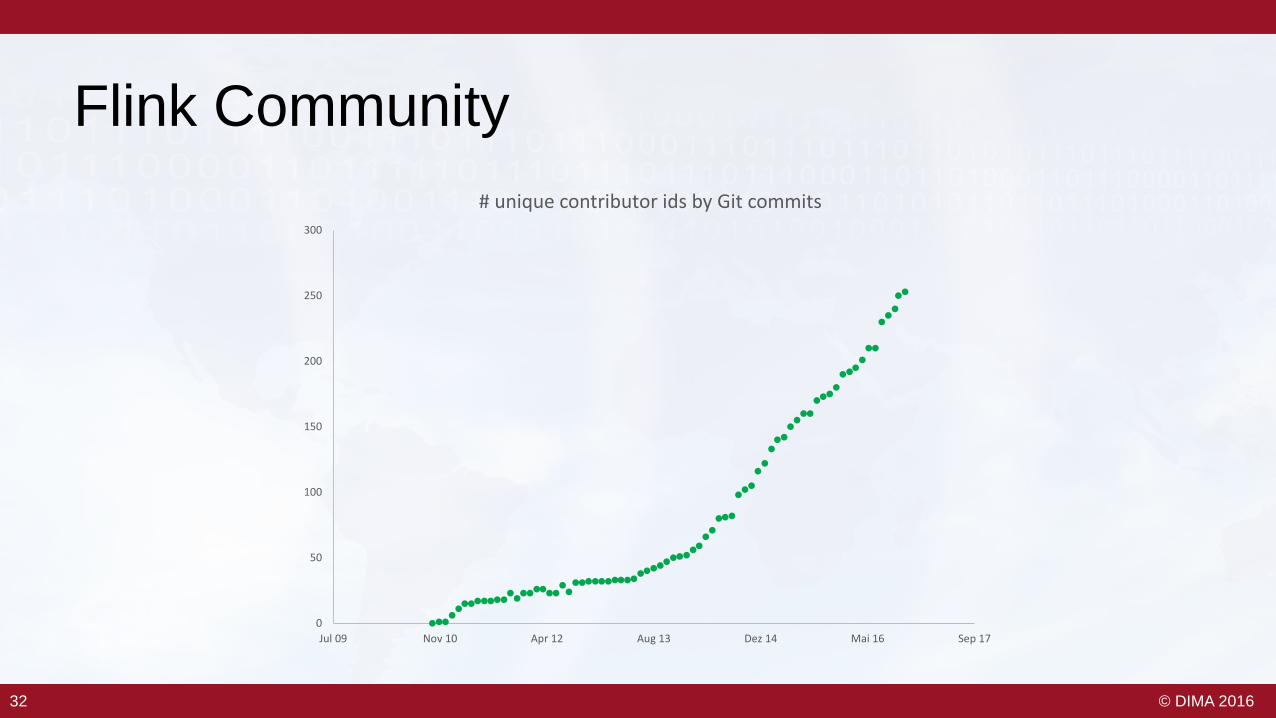
Flink Community
0
50
100
150
200
250
300
Jul 09 Nov 10 Apr 12 Aug 13 Dez 14 Mai 16 Sep 17
# unique contributor ids by Git commits

33 © DIMA 201633
33 © DIMA 2016
ConclusionThe case for Flink as a stream processor
– Proper streaming engine foundation– Flexible Windowing– Fault Tolerance with exactly once guarantees– Integration with batch– Large (and growing!) community

34 © DIMA 2016© 2013 Berlin Big Data Center • All Rights Reserved34 © DIMA 2016
Thank You
Contact:Tilmann [email protected]