towards information retrieval with more inferential power jian-yun nie department of computer...
TRANSCRIPT

Towards Information Retrieval with More Inferential Power
Jian-Yun Nie
Department of Computer ScienceUniversity of [email protected]

2
Background IR Goal:
Retrieve relevant information from a large collection of documents to satisfy user’s information need
Traditional relevance: Query Q and document D in a given corpus: Score (Q,D)
User-independent Knowledge independent Independent of all contextual factors
Expected relevance: Also depends on users (U) and contexts (C): Score (Q,D,U,C) Reasoning with contextual information
Several approaches in IR can be viewed as simple inference
We have to consider more complex inference

3
Overview
Introduction: Current Approaches to IR
Inference using terms relations
A General Model to Integrate Contextual Factors
Constructing and Using Domain Models
Conclusion and Future Work

4
Traditional Methods in IR
Each query term t matches a list of documents t: {…, D, …}
Final answer list = combining all the lists of query terms
e.g. Vector space model:
Language model:
2 implicit assumptions: Information need is only specified by the query terms Query terms are independent
Qt
ii
i
DtwQtwQDsim ),(),(),(
Qt
ii
i
DtPQttfDQP )|(log),()|(log

5
Reality A term is only one of the possible
expression of a meaning Synonyms, related terms
Query is only a partial specification of user’s information need Many words can be omitted in the query: e.g. “Java hotel”: hotel booking in Java island, …
How to make the query more complete?

6
Dealing with relations between terms
Previous methods try to enhance the query: Query expansion (add some related terms)
Thesauri: Wordnet, Hownet Statistical co-occurrence: 2 terms that often co-
occur together in the same context Pseudo relevance feedback: top-ranked
documents retrieved with original query
User profile, background, preference… (a set of background terms)
Used to re-rank the documents Equivalent to a query expansion

7
Question
Are these related to inference? How to perform inference in
general in IR?
LM as a tool for implementing logical IR

8
Overview
Introduction: Current Approaches to IR
Inference using terms relations
A General Model to Integrate Contextual Factors
Constructing and Using Domain Models
Conclusion and Future Work

9
What is logical IR?
Key: inference – infer query from document D: Tsunami Q: natural disaster DQ?

10
Using knowledge to make inference in IR K | D Q
K: general knowledge No knowledge Thesauri Co-occurrence …
K: user knowledge Characterizes the knowledge of a
particular user

11
Simple inference – the core of logical IR Logical deduction
(A B) (B C) A C In IR:
(D Q’) (Q’ Q) D Q
(D D’) (D’ Q) D Q
Doc. matching Inference on query
Inference on doc. Doc. matching

12
Is language modeling a reasonable framework? 1. Basic generative model: P(Q|D) ~ P(DQ)
Current Smoothing:
E.g. D=Tsunami, PML(natural disaster|D)=0 change to P(natural disaster|D)>0
Not inference P(computer|D)>0 ~ P(natural disaster|D)>0
)|()1()|()|( CtPDtPDtP iMLiMLi
0)|( tochange
0)|(:
DtP
DtPDt
i
iMLi
Qt
i
i
DtPDQP )|()|(

13
Effect of smoothing? Doc: Tsunami, ocean, Asia, …
Smoothing inference Redistribution uniformly/according to
collection (also to unrelated terms)
Tsunami ocean Asia computer nat.disaster …

14
Expected effect
Using Tsunami natural disaster Knowledge-based smoothing
Tsunami ocean Asia computer nat.disaster …

15
Inference: Translation model (Berger & Lafferty 99)
i j
j
qj
dji
jd
jii
DdPdqPDQP
DdPdqPDqP
)|()|()|(
)|()|()|(
D
dj’ dj’’ dj’’’ ... qi
Inference
Traditional LM

16
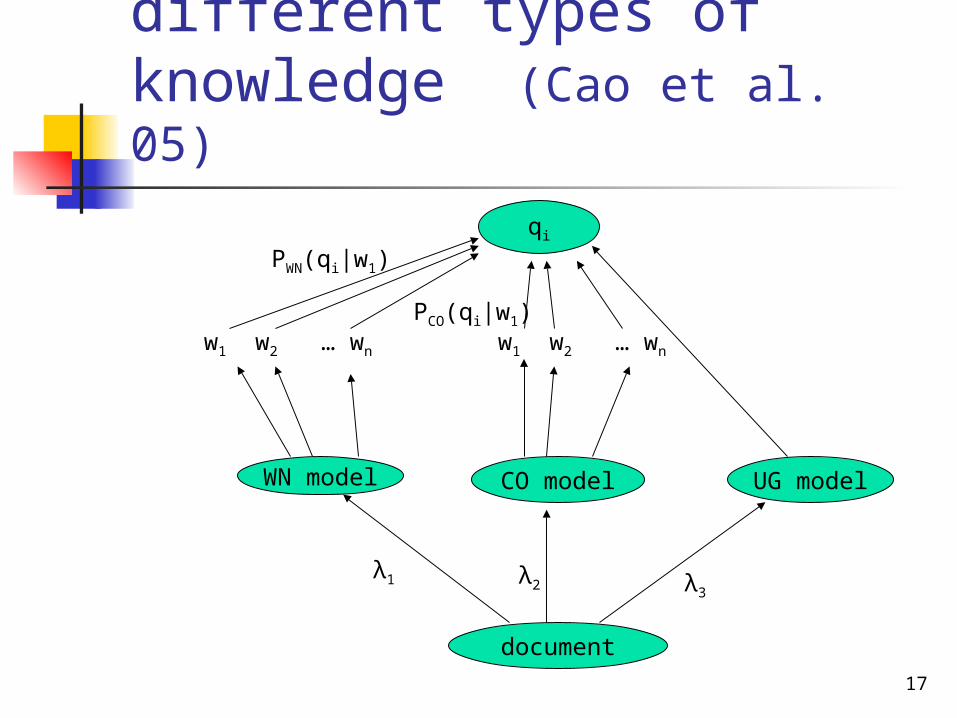
Using more types of knowledge for document expansion (Cao et al. 05)
Different ways to satisfy a query (term) Directly though unigram model Indirectly (by inference) through
Wordnet relations Indirectly trough Co-occurrence relations …
Dti if DUG ti or DWN ti or DCO ti )|()|()|()|()|()|( 321 CtPDtPttPDtPttPDtP iUGj
jjiCOj
jjiWNi
17
Inference using different types of knowledge (Cao et al. 05)
qi
w1 w2 … wn w1 w2 … wn
WN model CO model UG model
document
λ1 λ2 λ3
PWN(qi|w1)
PCO(qi|w1)

18
Experiments (Cao et al. 05)
Different combinations of unigram model, link model and co-occurrence model
Model
WSJ AP SJM
AvgP Rec. AvgP Rec. AvgP Rec.
UM 0.2466 1659/2172 0.1925 3289/6101 0.2045 1417/2322
CM 0.2205 1700/2172 0.2033 3530/6101 0.1863 1515/2322
LM 0.2202 1502/2172 0.1795 3275/6101 0.1661 1309/2322
UM+CM 0.2527 1700/2172 0.2085 3533/6101 0.2111 1521/2322
UM+LM 0.2542 1690/2172 0.1939 3342/6101 0.2103 1558/2332
UM+CM+LM 0.2597 1706/2172 0.2128 3523/6101 0.2142 1572/2322
Integrating more types of relation is useful

19
Query expansion in LM KL-div:
With no query expansion, equivalent to generative model
Qt
ii
i
DtPQtPQDscore )|(log)|(),(
Smoothed doc. model
Query model
)|(~
)|(log)|(log),(~
)|(log)|(~)||(
),(
DQP
DtPDtPQttf
DtPQtPDQKL
Qttf
Qti
Qtii
Qtii
i
ii
i

20
Expanding query model
VqiiR
QqiiML
VqiiRiML
Vqii
iR
jML
iRiMLi
ii
i
i
DqPQqPDqPQqP
DqPQqPQqP
DqPQqPDQScore
QtP
QtP
QqPQqPQqP
)|(log)|()1()|(log)|(
)|(log)]|()1()|([
)|(log)|(),(
model l Relationa:)|(
smoothed)(not model unigram hoodMax.Likeli:)|(
)|()1()|()|(
Classical LM Relation model

21
?)|( estimate toHow QtP iR
Using co-occurrence information Using an external knowledge base
(e.g. Wordnet) Pseudo-rel. feedback Other term relationships …

22
Using co-occurrence relation
Use term co-occurrence relationship Terms that often co-occur in the same windows are
related Window size: 10 words
Unigram relationship (wj wi )
Query expansion
lwjl
jijiR
wwc
wwcwwP
),(
),()|(
jMLEjiRVq
jiRiR
jj
QqPqwPQqwPQwP )|()|()|,()|(

23
Problem co-occurrence relations
Ambiguity
Term relationship between two single words e.g. “Java programming”
No information to determine the appropriate context
e.g. “Java travel” by “programming”
Solution: add some context information into term relationship

24
Overview
Introduction: Current Approaches to IR
Inference using terms relations Extracting context-dependent term relations
A General Model to Integrate Contextual Factors
Constructing and Using Domain Models
Conclusion and Future Work

25
General Idea (Bai et al. 06) Use (t1, t2, t3, …) t instead of t1 t
e.g. “(Java, computer, language) programming”
Problem with arbitrary number of terms in condition: Complexity with many words in condition part Difficult to obtain reliable relations
Our solution: Limit condition part to 2 words e.g. “(Java, computer) programming”
“(Java, travel) island” One word specifies the context to the other

26
Hypotheses Hypothesis 1: most words can be disambiguated with
one useful context word e.g. “Java + computer, Java + travel, Java + taste”
Hypothesis 2: users often choose useful related words to form their queries
A word in query provides useful information to disambiguate another word
Possible queries: e.g. “windows version” “doors and windows”
Seldom case: users do not express their need clearly e.g. “windows installation” ?

27
Context-dependent co-occurrences (Bai et al. 06)
wiwj wk
New relation model
lwkjl
kjikjiR
wwwc
wwwcwwwP
),,(
),,()|(
uniform :)|(
)|()|()|()|()|(,,
QqqP
QqqPqqwPQqqPqqwPQwP
kj
QqqkjkjiR
VqqkjkjiRiR
kjkj
28
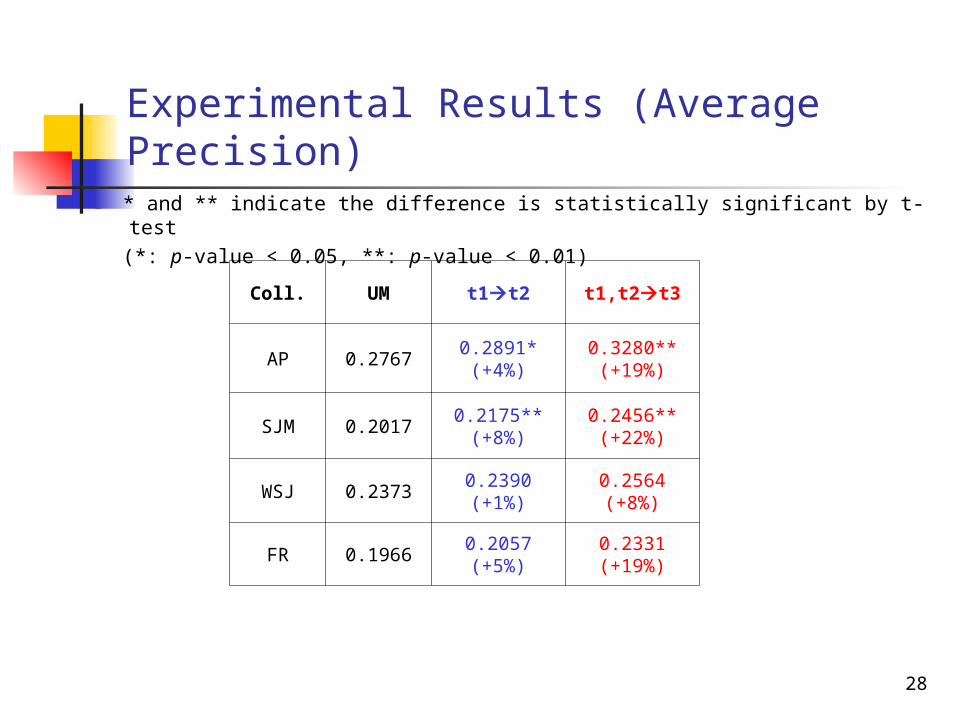
Experimental Results (Average Precision)
Coll. UM t1t2 t1,t2t3
AP 0.27670.2891*(+4%)
0.3280**(+19%)
SJM 0.20170.2175**
(+8%)0.2456**(+22%)
WSJ 0.23730.2390(+1%)
0.2564(+8%)
FR 0.19660.2057(+5%)
0.2331(+19%)
* and ** indicate the difference is statistically significant by t-test (*: p-value < 0.05, **: p-value < 0.01)

29
Experimental Analysis (example) Query #55: “Insider trading”
Unigram relationships: P(*|insider) or P(*|trading)stock:0.014177 market:0.0113156 US:0.0112784 year:0.010224exchang:0.0101797 trade:0.00922486 report:0.00825644 price:0.00764028dollar:0.00714267 1:0.00691906 govern:0.00669295 state:0.00659957futur:0.00619518 million:0.00614666 dai:0.00605674 offici:0.00597034peopl:0.0059315 york:0.00579298 issu:0.00571347 nation:0.00563911
Bi-term relationships: P(*|insider, trading)secur:0.0161779 charg:0.0158751 stock:0.0137123
scandal:0.0128471boeski:0.0125011 inform:0.011982 street:0.0113332 wall:0.0112034case:0.0106411 year:0.00908383 million:0.00869452
investig:0.00826196exchang:0.00804568 govern:0.00778614 sec:0.00778614 drexel:0.00756986fraud:0.00718055 law:0.00631543 ivan:0.00609914 profit:0.00566658
=> Expansion terms determined by BQE are more relevant than UQE

30
Logical point of view of the extensions
)| )'()'( :expansionQuery
form particulara expansionDocument
)| )'()'( then
)| )()(: if
)()()(
)|()|()|(
Q (DQQQD
Q (DQDDD
t (DtttDQt
tDPttPtDP
DtPttPDtP
iijji
tjijWNiWN
tjjiWNiWN
j
j
D
tj …
ti

31
Overview
Introduction: Current Approaches to IR
Inference using terms relations
A General Model to Integrate Contextual Factors
Constructing and Using Domain Models
Conclusion and Future Work

32
LM for context-dependent IR? Context (X) = background knowledge of the user, the
domain of interest, … Document model smoothed by context model
X | DQ = | X+D Q Similar to doc. Expansion approaches
Query smoothed by context model X | DQ = | DQ+X
Similar to (Lau et al. 04) and query expansion approaches Utilizations of context:
domain knowledge (e.g. javaprogramming only in computer science)
Specification of the area of interest (e.g. science): background terms
Characteristics of the collection

33
Contexts and Utilization (1) General term relations (Knowledge)
Traditional term relations are context-independent : e.g. “Java programming”, Prob(programming|Java)
Context-dependent term relations: add some context words in term relations
e.g. “{Java, computer} programming” (“programming” only derived to expand a query containing both “Java” and “computer”)
“{Java, computer}” identifies a better context than “Java ” to determine expansion terms

34
Contexts and Utilization (2)
Topic domains of the query (Domain background)
Consider topic domain as specifying a set of background terms frequently used in the domain
However, these terms are often omitted in the queries e.g. in Computer Science domain, term “computer” is often implied by queries in this domain, but usually omitted
e.g. Computer Science domain: any query “computer”, …

35
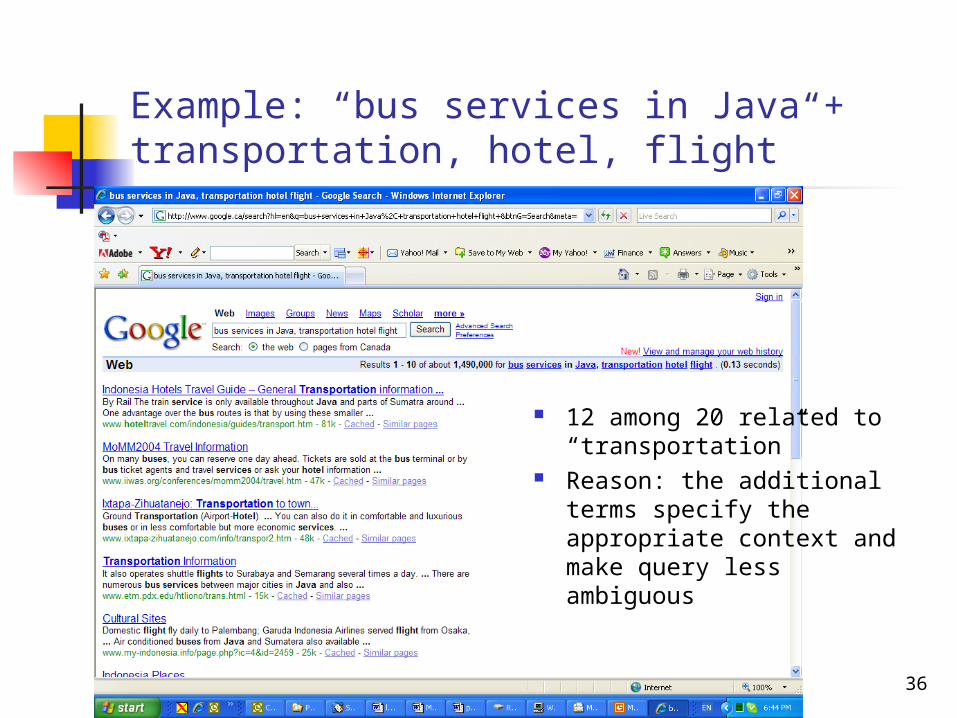
Example: “bus services in Java”
99 concern “Java language”, only one related to “transportation” (but irrelevant to the query)
Reason: do not consider the retrieval context - the user is preparing a travel
36
Example: “bus services in Java + transportation, hotel, flight”
12 among 20 related to “transportation”
Reason: the additional terms specify the appropriate context and make query less ambiguous

37
Contexts and Utilization (3)
Query-specific collection characteristics (Feedback model)
What terms are useful to retrieve relevant documents in a particular corpus?
~ What other topics are often described together with the query topic in the corpus? e.g. in a corpus, “terrorism” can be described often with “9-11, air hijacking, world trade center, …”
Expand query with related terms
Feedback model: capture query-related collection context

38
Enhanced Query Model Basic idea for query expansion:
Combine original query model with the expansion model
Generalized model: 3 expansion models from 3 contextual factors:
: original query model : knowledge model : domain model : feedback model
where X = {0, K, Dom, FB} is the set of all component models
is the mixture weight
)|()1()|()|( QwPQwPQwP iRiMLEi
Expansion modelOriginal query model
i

39
Illustration: Expanded Query Model
t
)|( 0QtP … … )|( FB
QtP
0Q K
Q DomQ FB
Q
0 K Dom FB
Q
Xiii
Xi VtD
iQi
Vt XiD
iQi
DQscoretPtP
tPtPDQScore
),()|(log)|(
)|(log)|(,
Term t can be derived from query model by several inference paths
Once a path is selected, the corresponding LM is to generate term t

40
Overview
Introduction: Current Approaches to IR
Inference using terms relations
A General Model to Integrate Contextual Factors
Constructing and Using Domain Models
Conclusion and Future Work

41
Creating Domain Models
Assumption: each topic domain contains a set of example (in-domain) documents
Extract domain-specific terms from them
Use EM algorithm: extract only the specific terms Assume each in-domain document is generated from:
(Dom=0.5)
Domain model is extracted by EM so as to maximize P(Dom|θ’Dom):
Dt
DttfCDomDomDomDom tPtPDP ,|)1(|'|
DomD Dt
DttfCDomDomDom
DomDom
tPtP
DomP
Dom
Dom
,|)1(|maxarg
'|maxarg

42
Effect of EM Process
Term probabilities in domain “Environment” before/after EM (12 iterations)
=> Extract domain-specific terms while filtering out common words
Term Initial Final change Term Initial Final change
air 0.00358 0.00558 + 56% year 0.00357 0.00052 - 86%
environment 0.00213 0.00340 + 60% system 0.00212 7.13*e-6 - 99%
rain 0.00197 0.00336 + 71% program 0.00189 0.00040 - 79%
pollution 0.00177 0.00301 + 70% million 0.00131 5.80*e-6 - 99%
storm 0.00176 0.00302 + 72% make 0.00108 5.79*e-5 - 95%
flood 0.00164 0.00281 + 71% company 0.00099 8.52*e-8 - 99%
tornado 0.00072 0.00125 + 74% president 0.00077 2.71*e-6 - 99%
greenhouse 0.00034 0.00058 + 72% month 0.00073 3.88*e-5 - 95%

43
How to Gather in-domain Documents
Existing directories: ODP, Yahoo! directory
We assume that user defines his own domains, and assigns a domain to each of his queries (during the training phase)
Gather relevant documents of the queries (by user’s relevance judgments) (C1)
Simply collect the top-ranked documents (without user’s relevance judgments) (C2)
(This strategy is used in order to test on TREC data)

44
How to Determine the Domain of a New Query
2 strategies to assign domain to the query: Manually (U1) Automatically (U2)
Automatic query classification by LM: Similar to text classification, but query is much shorter
than text document Select domain with the lowest KL-divergence score of the
query:
This is an extension to Naïve Bayes classification [Peng et al. 2003]
)|(log)|(maxarg 0
DomQt
Q
Dom
Q tPtPDom

45
Overview
Introduction: Current Approaches to IR
Inference using terms relations
A General Model to Integrate Contextual Factors
Constructing and Using Domain Models Experiments
Conclusion and Future Work

46
Experimental Setting
Text collection statistics: TREC
Coll. DescriptionSize (GB)
Vocab.# of Doc.
Query
Training Disk 2 0.86 350,085 231,219 1-50
Disks 1-3 Disks 1-3 3.10 785,932 1,078,166 51-150
TREC7 Disks 4-5 1.85 630,383 528,155 351-400
TREC8 Disks 4-5 1.85 630,383 528,155 401-450
Training collection: to determine the parameter values (mixture weights)

47
An Example: Query with Manually Assigned Domain
<top><head> Tipster Topic Description<num> Number: 055 <dom> Domain: International Economics<title> Topic: Insider Trading (only use title as Query)<desc> Description:
Document discusses an insider-trading case. …
Figure: Distribution of the queries among 13 domains in TREC
05
101520253035
Query 1-50
Query 51-150
48
Baseline Methods
Document model: Jelinek-Mercer smoothing
Collection MeasureUnigram Model
Without FB With FB
Disks 1-3
AvgP 0.1570 0.2344 (+49.30%)**
Recall / 48 355 15 711 19 513
P@10 0.4050 0.5010
TREC7
AvgP 0.1656 0.2176 (+31.40%)**
Recall / 4 674 2 237 2 777
P@10 0.3420 0.3860
TREC8
AvgP 0.2387 0.2909 (+21.87%)**
Recall / 4 728 2 764 3 237
P@10 0.4340 0.4860

49
Constructing and Using Domain Models
2 Strategies to create domain models: (current test query is excluded from domain model construction)
with the relevant documents for in-domain queries (C1) User judges which documents relevant to the domain Similar to manual construction of directories
with the top-100 documents retrieved by in-domain queries (C2)
User specifies a domain for queries without judging relevant documents
System gathers in-domain documents from user’s search history
Once constructed domain models, 2 Strategies to use them: Domain can be assigned to a new query by user manually (U1) Domain is determined by the system automatically using query
classification (U2)

50
Creating Domain ModelsC1 (constructed with relevant documents) vs. C2 (with top-100):
Collection MeasureRel. Doc. for training (C1) Top-100 doc. (C2)
Without FB With FB Without FB With FB
Disks 1-3(U1)
AvgP0.1700
(+8.28%)++0.2454
(+4.69%)**0.1718
(+9.43%)++0.2456
(+4.78%)**
Recall / 48 355 16 517 20 141 16 558 20 131
P@10 0.4370 0.5130 0.4300 0.5140
TREC7(U2)
AvgP0.1715
(+3.56%)++0.2389
(+9.79%)*0.1765
(+6.58%)++0.2395
(+10.06%)**
Recall / 4 674 2 270 2 965 2 319 2 969
P@10 0.3720 0.3740 0.3780 0.3820
TREC8(U2)
AvgP0.2442
(+2.30%)0.2957
(+1.65%)0.2434
(+1.97%)0.2949
(+1.38%)
Recall / 4 728 2 796 3 308 2 772 3 318
P@10 0.4420 0.5000 0.4380 0.4960

51
Determine Query Domain Automatically U2 (automatic domain assignment) vs. U1 (manual domain assignment):
Coll. MeasureDomain with relevant doc. (C1) Domain with top-100 doc. (C2)
Without FB With FB Without FB With FB
Disks 1-3(U1)
AvgP0.1700
(+8.28%)++0.2454
(+4.69%)**0.1718
(+9.43%)++0.2456
(+4.78%)**
Recall / 48 355
16 517 20 141 16 558 20 131
P@10 0.4370 0.5130 0.4300 0.5140
Disks 1-3(U2)
AvgP0.1650
(+5.10%)++0.2444
(+4.27%)**0.1670
(+6.37%)++0.2449
(+4.48%)**
Recall / 48 355
16 343 20 061 16 414 20 090
P@10 0.4270 0.5100 0.4090 0.5140

52
Complete Models Integrate original query domain, knowledge model, domain model and FB model:
Collection MeasureAll Documents Domain
Manual domain Id. (U1) Automatic domain Id. (U2)
Disks 1-3
AvgP0.2501 (+59.30%)++
(+6.70%)**0.2489 (+58.54%)++
(+6.19%)**
Recall /48 355 20 514 20 367
P@10 0.5200 0.5230
TREC7
AvgP
N/A
0.2462 (+48.67%)++ (+13.14%)**
Recall /4 674 3 014
P@10 0.3960
TREC8
AvgP
N/A
0.3029 (+26.90)++ (+4.13%)**
Recall /4 728 3 321
P@10 0.5020

53
Overview
Introduction: Current Approaches to IR
Inference using terms relations
A General Model to Integrate Contextual Factors
Constructing and Using Domain Models
Conclusion and Future Work

54
Conclusions Document/Query expansion is useful for IR
They can be considered as an inference process: deduce if a document is related to a query, DQ
Useful to consider several types of context during the inference Relations between terms (expansion terms) Query context: domain Collection characteristics: feedback model Context | DQ
Good experimental results: Different contextual factors are complementary Complete query model that integrates all contextual factors performs
the best
Language modeling can be extended for this purpose
Future users will not be content with word-matching. They will require some inference: determining the intent, suggested related words, select appropriate vertical search engines, …

55
Future Work Integrate other contextual factors (user preference)
How to extract them ? Query logs?
Other ways to extract term relations than co-occ. (association rules)
Term independence in final model: relax term independence assumption
Create a model which integrates compound terms [Bai, Nie and Cao, Web Intelligence’05] Dependence language model [Gao et al, SIGIR’04]
Do different contextual factors act independently? Can we use simple smoothing to combine them?
Is there a better formalism than language modeling for inference? Inference network (Turtle&Croft 1990)? Non-classical logic?

56
Thanks!