towards publishing recommendation data with predictive anonymization
DESCRIPTION
Towards Publishing Recommendation Data With Predictive Anonymization. Chih-Cheng Chang † , Brian Thompson † , Hui Wang ‡ , Danfeng Yao †. †. ‡. ACM Symposium on Information, Computer, and Communications Security (ASIACCS 2010). Outline. Introduction Privacy in recommender systems - PowerPoint PPT PresentationTRANSCRIPT

April 13, 2010
Towards Publishing Recommendation Data With Predictive Anonymization
Chih-Cheng Chang†, Brian Thompson†, Hui Wang‡, Danfeng Yao†
† ‡
ACM Symposium on Information, Computer, and Communications Security (ASIACCS 2010)

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Outline
• Introduction
• Privacy in recommender systems
• Predictive Anonymization
• Experimental results
• Conclusions and future work

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
• Inevitable trend towards data sharing– Medical records
– Social networks
– Web search data
– Online shopping, ads
• Databases contain sensitive information
• Growing need to protect privacy
Motivation
Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
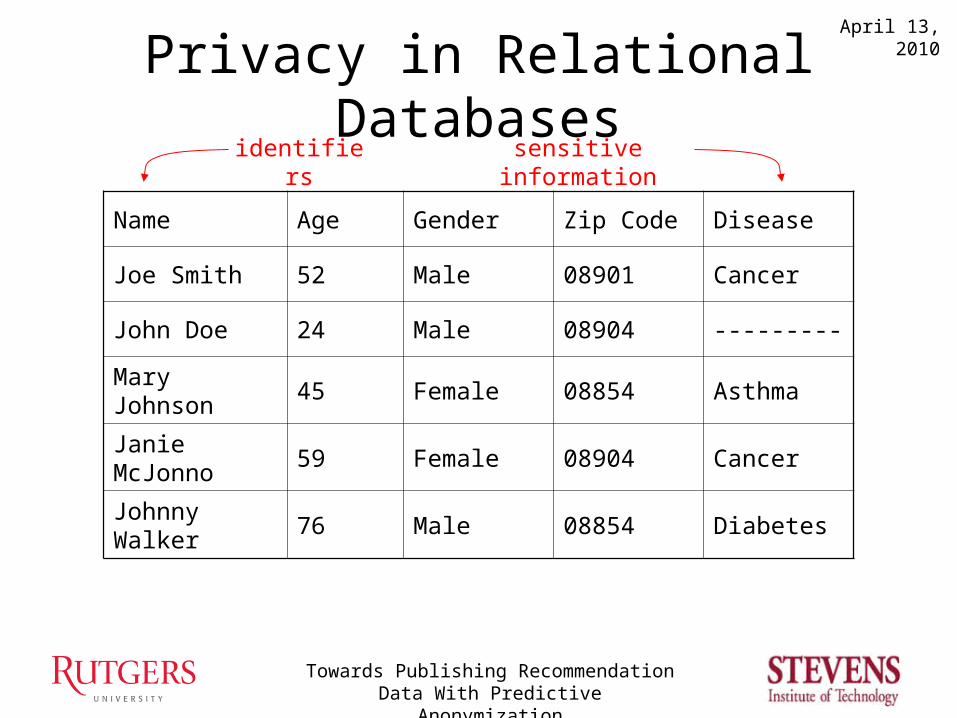
Privacy in Relational Databases
Name Age Gender Zip Code Disease
Joe Smith 52 Male 08901 Cancer
John Doe 24 Male 08904 ---------
Mary Johnson 45 Female 08854 Asthma
Janie McJonno 59 Female 08904 Cancer
Johnny Walker 76 Male 08854 Diabetes
identifiers sensitive information
Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
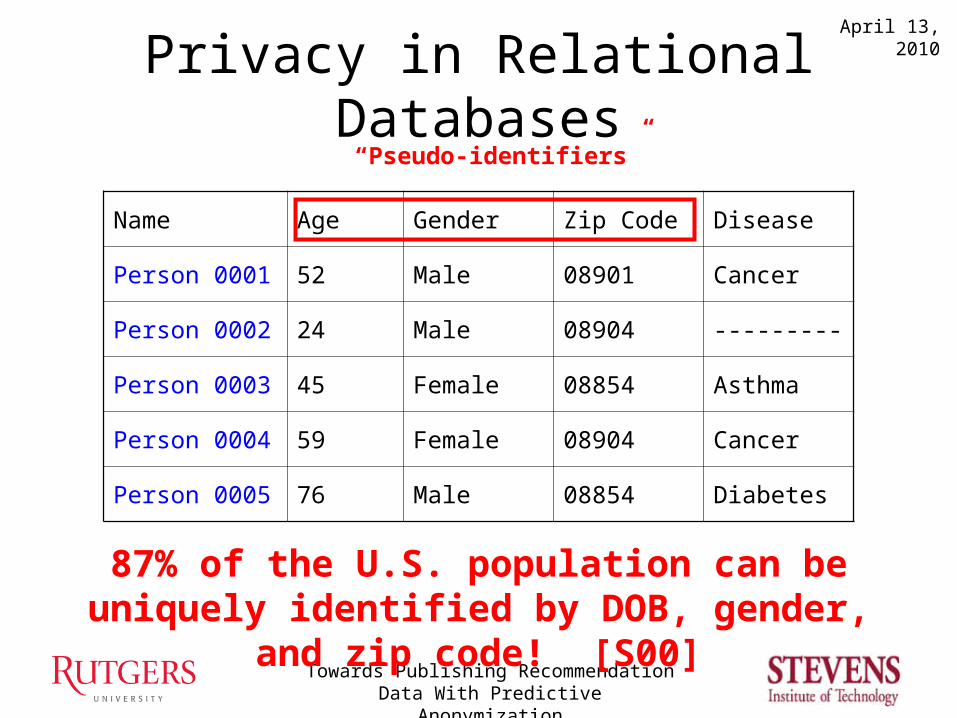
Privacy in Relational Databases
Name Age Gender Zip Code Disease
Person 0001 52 Male 08901 Cancer
Person 0002 24 Male 08904 ---------
Person 0003 45 Female 08854 Asthma
Person 0004 59 Female 08904 Cancer
Person 0005 76 Male 08854 Diabetes
“Pseudo-identifiers”
87% of the U.S. population can be uniquely identified by DOB, gender, and zip code! [S00]

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Approaches to Achieving Privacy
1. Statistical databases• Only aggregate queries: What is average salary?
• Differential Privacy [Dinur-Nissim ‘03, Dwork ‘06]Adaptively add random noise to output so querier can not determine if a user is in the database
• Quality decreases over multiple queries
2. Publishing of anonymized databases• No restriction on how data is utilized, good for
complex data mining applications
• How to address privacy concerns?

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Anonymization of Databases
Techniques:
• PerturbationName Age
Joe Smith
John Doe
Mary Johnson
52 53
24 26
45 42

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Anonymization of Databases
Techniques:
• Perturbation
• Swapping
Name Age
Joe Smith
John Doe 24
Mary Johnson
52
45

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Anonymization of Databases
Techniques:
• Perturbation
• Swapping
• Generalization
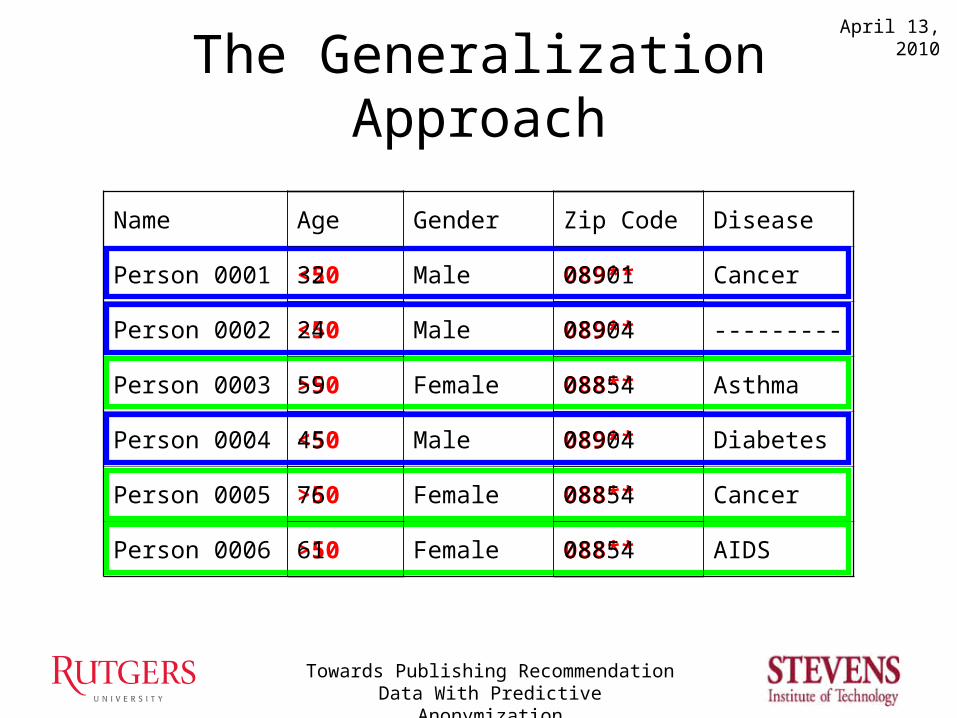
Def. A database entry is k-anonymousif ≥ k-1 other entries match identically on the insensitive attributes. [SS98]
Name Age
Joe Smith
John Doe
Mary Johnson
52 50s
24 20s
45 40s
Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
The Generalization Approach
Name Age Gender Zip Code Disease
Person 0001 Male Cancer
Person 0002 Male ---------
Person 0003 Female Asthma
Person 0004 Male Diabetes
Person 0005 Female Cancer
Person 0006 Female AIDS
<50
<50
>50
<50
>50
>50
089**
089**
088**
089**
088**
088**
32
24
59
45
76
61
08901
08904
08854
08904
08854
08854

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Outline
• Introduction
• Privacy in recommender systems
• Predictive Anonymization
• Experimental results
• Conclusions and future work
Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Recommender Systems
• Users register for service
• After buying a good, they submit a rating for it
• Get recommendations based on yours and others’ ratings

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Recommender Systems
NETFLIX Alien Batman Closer Dogma Evita X-rated Gladiator
4 2
3 3 5
2 5 3
3 2
?
?
?Joe Smith
John Doe
Mary Johnson
Janie McDonno
User 0001
User 0002
User 0003
User 0004
Question: Is privacy really protected?
The Netflix Challenge:
“Anonymized” Netflix data is released to the public.
$1 million prize for best movie prediction algorithm.

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Privacy in Recommender Systems
NETFLIX Alien Batman Closer Dogma Evita X-rated Gladiator
User 0001 4 2
User 0002 3 3 5
User 0003 2 5 3
User 0004 3 2
Narayanan and Shmatikov [NS08] exploited external information to re-identify users in the released Netflix Challenge dataset.
Privacy breach!

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
News Timeline
Oct. 2006 Netflix Challenge announced
May 2008 N&S publish attack
Aug. 2009 Plans announced for Challenge 2
Dec. 2009 Netflix users file lawsuits
Mar. 2010NC2 plans canceled due to privacy concerns (and FTC investigation)
How can we enable sharing of recommendation data without compromising users’ privacy?

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
• All data may be considered “sensitive” by users.
• All data could be used as quasi-identifiers.
• Data sparsity helps re-identification attacks, and makes anonymization difficult. [NS08]
• Scalability – Netflix matrix has 8.5 billion cells!
Challenges in Anonymization of Recommender Systems
Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
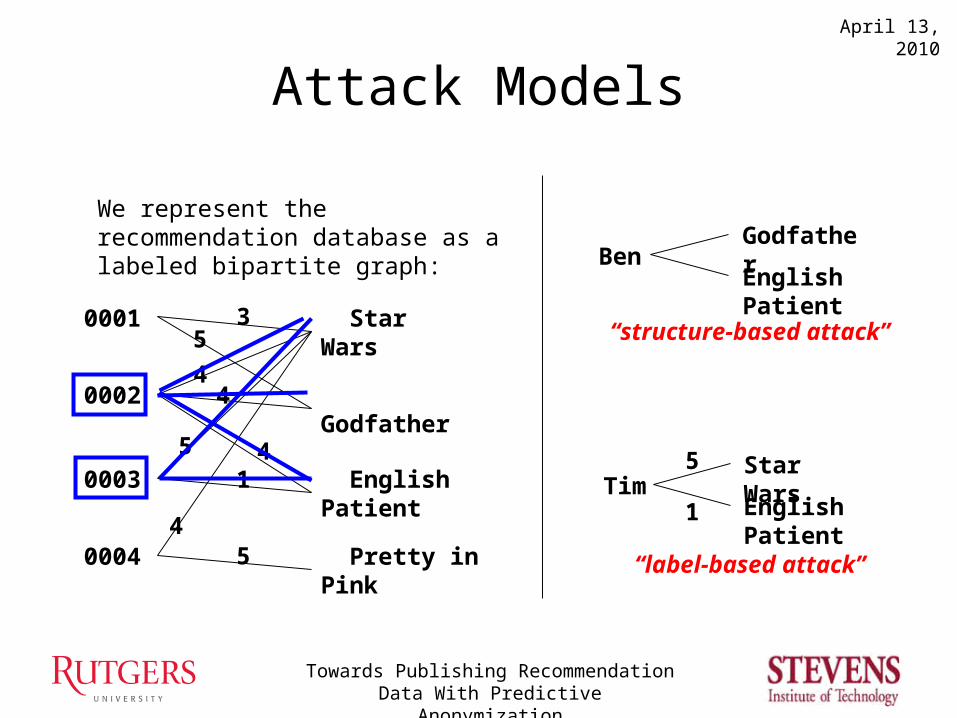
Attack Models
0001
0002
0003
0004
Star Wars
Godfather
English Patient
Pretty in Pink
3
1
54
5
44
4
5
Godfather
English PatientBen
Star Wars
English PatientTim
5
1
We represent the recommendation database as a labeled bipartite graph:
“structure-based attack”
“label-based attack”

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Privacy Models
• Node re-identification privacy:Should not be possible to re-identify individuals.
• Link existence privacy:Should not be possible to infer whether a user has seen a particular movie.
Our approach, Predictive Anonymization, provides these notions of privacy against both the structure-based and label-based attacks.

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Outline
• Introduction
• Privacy in recommender systems
• Predictive Anonymization
• Experimental results
• Conclusions and future work

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Predictive Anonymization
Our solution takes a 3-step approach:
1. Use predictive padding to reduce sparsity.
2. Cluster users into groups of size k.
3. Perform homogenization by assigning users in each group to have the same ratings.
Achieves k-anonymity!

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Predictive Anonymization
Alien Batman Closer Dogma Evita X-rated Gladiator
User 0001 4 2
User 0002 3 3 5
User 0003 2 5 3
User 0004 3 2
• Want to cluster users, but there is not enough information due to data sparsity.
• Solution: Fill empty cells with predicted values.
• Cluster users based on similar tastes, not necessarily similar lists of movies rated.
3 5 3 1 4
5 2 3 1
2 3 2 3
3 2 4 1 3

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
1. Use predictive padding to reduce sparsity.
2. Cluster users into groups of size k.
3. Perform homogenization by assigning users in each group to have the same ratings.
Predictive Anonymization
The final step, homogenization, can be done in one of several ways. We describe two methods, “padded” and “pure” homogenization.

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
0001
0002
0003
0004
Star Wars
Godfather
English Patient
Pretty in Pink
“Padded Homogenization”
3.5
4.5
4.5
4.5
4.5
4.5 3.5
4.5
3.53.5
1.52.5
2.5
1.5
3
1
5
4
5
44
4
5
Predictive Anonymization
• All edges are added to the recommendation graph.• Each cluster is averaged using the padded data.

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
0001
0002
0003
0004
Star Wars
Godfather
English Patient
Pretty in Pink
3
1
5
4
5
4
4
5 43.5
1
5
4.5
4.5
4.5
4
4.5 3.5
4
15
Predictive Anonymization
“Pure Homogenization”
• Only necessary edges are added to the graph.• Each cluster is averaged using the original data.

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Outline
• Introduction
• Privacy in recommender systems
• Predictive Anonymization
• Experimental results
• Conclusions and future work

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Experiments
• Performed on the Netflix Challenge dataset:– 480,189 users and 17,770 movies– more than 100 million ratings
• Singular value decomposition (SVD) is used for padding and prediction.
• We compute the root mean squared error (RMSE) for a test set of 1 million ratings on the original and anonymized data.
RMSE = nactualpredicted 2

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Analysis: Prediction Accuracy
• Padded Anonymization preserves prediction accuracy.
• However, sparsity is eliminated, which affects the utility of the published dataset for data mining applications.
Experiment Series RMSE
Original Data 0.95185
Padded Anonymization (k=5) 0.95970
Padded Anonymization (k=50) 0.95871
Pure Anonymization (k=5) 2.36947
Pure Anonymization (k=50) 2.37710
Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
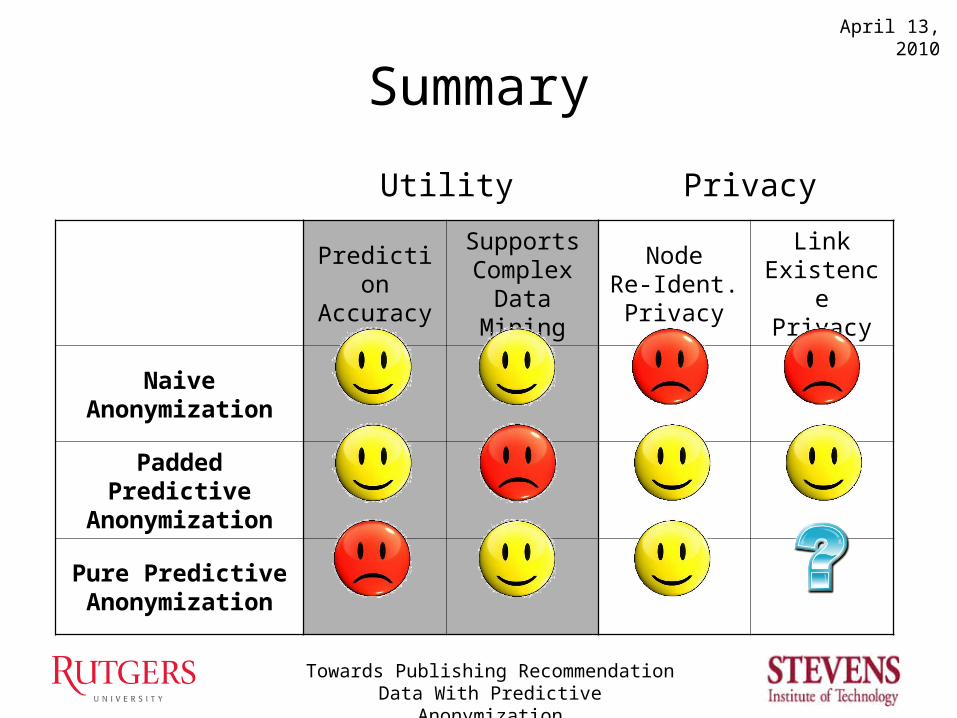
Summary
Prediction Accuracy
Supports Complex
Data Mining
NodeRe-Ident. Privacy
Link Existence Privacy
Naive Anonymization
Padded Predictive Anonymization
Pure Predictive Anonymization
Utility Privacy

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Outline
• Introduction
• Privacy in recommender systems
• Predictive Anonymization
• Experimental results
• Conclusions and future work

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Conclusions
• We have formalized privacy and attack models for recommender systems.
• Our solutions show that privacy-preserving publishing of anonymized recommendation data is feasible.
• More work is required to find a practical solution that satisfies real-world privacy and utility goals.

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Future Work
• Investigate the use of differential privacy-like guarantees for recommendation databases
• Analyze how to protect against more complex attacks with greater background knowledge
• Evaluate the utility of anonymized recommendation data for advanced data mining applications

Towards Publishing Recommendation Data With Predictive Anonymization
April 13, 2010
Thank you!