travel time estimation of a path using sparse trajectories dr. yu zheng [email protected] lead...
TRANSCRIPT

Travel Time Estimation of a Path using Sparse Trajectories
Dr. Yu Zheng [email protected]
Lead Researcher, Microsoft Research Chair Professor at Shanghai Jiao Tong University
r1 r2 r3
r4r5 r6
r7Tr1
Tr2
Tr3
Tr4
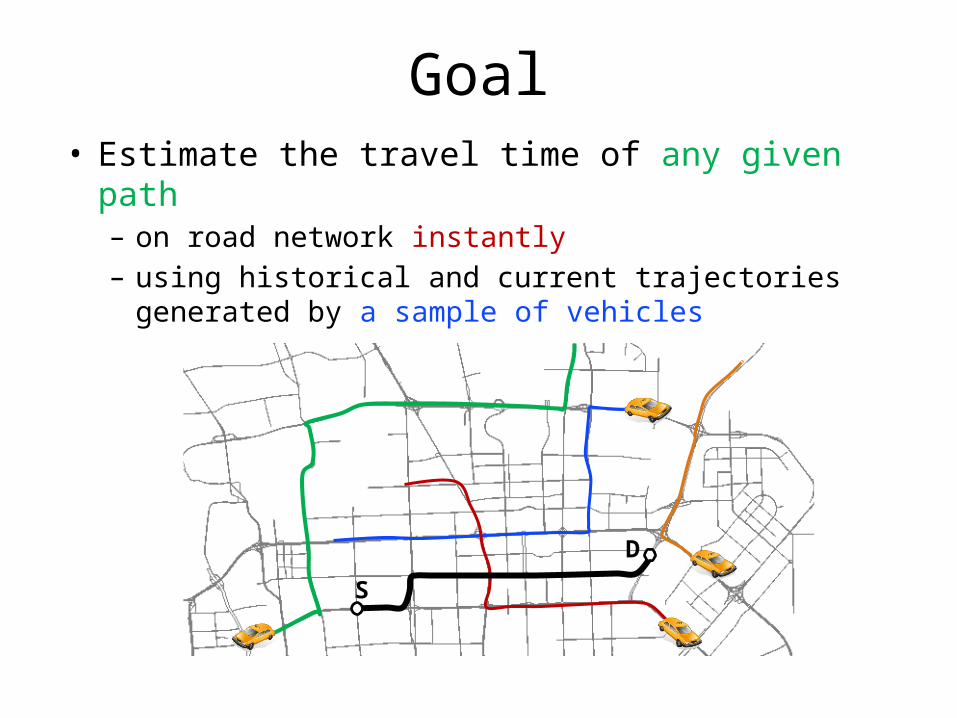
Goal• Estimate the travel time of any given path
– on road network instantly– using historical and current trajectories generated by a
sample of vehicles
S
D

Challenges• Data sparsity• Trajectory concatenation
– Multiple ways to combine sub-trajectories– Length of a sub-trajectory and its support
• Scalability and efficiency– A citywide estimation– E.g. Beijing has over 100,000 road segments
r1 r2 r3
r4r5 r6
r7Tr1
Tr2
Tr3
Tr4
𝑟1 →𝑟 2→𝑟3 →𝑟 4S
D
𝑟1+𝑟 2+𝑟3
(𝑟1+(𝑟2 →𝑟 3)
Methodology
• Framework– Context-Aware Tensor Decomposition (CATD)– Optimal Concatenation (OC)
Map-Matching
Tensor Construction
Tensor Decomposition
Road Networks
Trajectory Database
Frequent Trajectory Pattern Mining
Optimal Concatenation
Features
Path
Context Feature Extraction
Trajectories
Patterns cost
Arec
Ar

Methodology• Supplementing missing values
r2
Tr1
r3
r1
p1 p2
r4
p3
r2
r3
r1
v1 v2
r4
v3
v4 v4
v6 v5
v7
Tr2 Tr3
r1: (v1, v2, v4) r2: (v4, v5, v6) r3: (v5, v7) r4: (v2, v3)
v5
r1 r2 rN
u1
u2
uM
tj
tkAr
r1 r2 rN
t'j
t'k
r1
d1 r2
r3
r4
r6
r5
r1r2
rN
f1 f2 fq
fr fp
Y
g1 g2 g3 g16titi+1
219
42
00 0 0
6 17
0 0 0tj 0
014g1 g2 g3
g16
g4
g5 g6 g7 g8
g9 R10 g11 g12
g13 g14 g15
g1 g2 g3 g16t1 22
0420
35
110
00 0 0
16 8
0 00 15
0 31
0
tn
0
0
00
27
tj
ti
t2
0 0 0 7 0
MG=
=M¶G
g1 g16tj
tkXh
Xr
g2
t'j
t'k

Methodology• Supplementing missing values
t'j
t'k
r1 r2 rN
u1
u2
uM
tj
tkg1 g16tj
tkXh r1
r2
rN
f1 f2 fq
X
Xrfr fp
Yg2
t'j
t'k
A = Ar || Ah
Ar
Ah

Methodology
• Framework
Map-Matching
Tensor Construction
Tensor Decomposition
Road Networks
Trajectory Database
Frequent Trajectory Pattern Mining
Optimal Concatenation
Features
Path
Context Feature Extraction
Trajectories
Patterns cost
Arec
Ar

Methodology
,
estimated travel time:true travel time: .
Suppose is decomposed as
• Optimal Concatenation
S D
𝑃1 𝑃2 𝑃𝑘
𝑡𝑃1𝑡𝑃2
𝑡𝑃𝑘
𝜇𝑷

Methodology• Optimal Concatenation
assuming and are independent
=0

Methodology
• Support vs. Variance – The bigger the support is, the smaller the error is– The bigger the variance the bigger the error
• Solved by dynamic programming– Denote
.
𝑜𝑝𝑡𝑛=min1≤𝑖<𝑛
(𝑜𝑝𝑡 𝑖+𝑔(𝑃𝑟 𝑖+1∨¿ 𝑟𝑖 +2⋯ ¿∨𝑟𝑛))

Methodology
• Make optimal concatenation more efficient• Frequent trajectory pattern mining
– Not necessary to check every combination– Using suffix-tree-based method
r1 r2 r3
r4r5 r6
r7Tr1
Tr2
Tr3
Tr4 r2
r3
r3 r5
r7
r6
r1
r2
r3
Root
r2 r6 r72
11
2
1
1
1
1 133
1
r3 r6
12
r2ė r3, r3ė r4
(u2, u3, u4)
P: r1ė r2ė r3ė r4
(1)
(3)
(3)
r1 r2 rN
u1
u2
uM
tj
tk
Arec
(1)
, ,
Tr2,Tr3,Tr4
tr4,u2,k tr4,u3,k tr4,u4,k
tr3ė r4,u2,k = tr3,u2,k+t r4,u2,k
A) An example of suffix-tree B) Filling in the missing time for a pattern
Patterns:

Methodology• Combining the suffix tree with tensors
– Searching for frequent trajectory pattern from the suffix tree– Find the travel time of a particular user from the tensor
r2
r3
r3 r5
r7
r6
r1
r2
r3
Root
r2 r6 r72
11
2
1
1
1
1 133
1
r3 r6
12
r2ė r3, r3ė r4
(u2, u3, u4)
P: r1ė r2ė r3ė r4
(1)
(3)
(3)
r1 r2 rN
u1
u2
uM
tj
tk
Arec
(1)
, ,
Tr2,Tr3,Tr4
tr4,u2,k tr4,u3,k tr4,u4,k
tr3ė r4,u2,k = tr3,u2,k+t r4,u2,k
A) An example of suffix-tree B) Filling in the missing time for a pattern
Patterns:
r1 r2 r3
r4r5 r6
r7Tr1
Tr2
Tr3
Tr4

Methodology• Deal with efficiency and scalability
– data-driven space partition – an element-wise optimization algorithm– Use trajectory patterns as concatenation candidates– Indexing recent trajectories for a fast online retrieval
r1 r2 rN
u1
u2
uM
tj
tk
g1 g2
g3g4
g1 g2
g3g4
r2
r3
r6
r6
r1
Root
Tr2 Tr1
Tr2
Tr1
Tr2
tr1ė r2
Tr1
tr1ė r2
tr1ė r2ė r3 tr1ė r2ė r6
tr1
t r1
Tr1 tr2ė r6
r2
r3
Tr2
Tr2
Tr2
tr2
tr2
t r2ė r3
r3 r6
Tr1tr3 Tr1 tr6

Experiments• Datasets
– Taxi Trajectories: • Generated by 32,670 taxicabs in Beijing • From Sept. 1 to Oct. 31, 2013. • 673+ million GPS points • Total length: over 26 million km. • Sampling rate: 96 seconds per point.
– Road networks: • 148,110 nodes and 196,307 edges. • Covers a 4050km spatial range• Total length of road segments: 21,985km.
– POIs: • Th273,165 POIs of Beijing• 195 tier two categories. • Chose the top 10 categories that occur around road
segments
Download data here

Experiments
MAE (min) RMSE
0.747 1.646
0.732 1.629 0.714 1.613
2 3 4 50.70
0.71
0.72
0.73
0.74
MAE Time Cost
Number of time slices L
MA
E (m
in)
0
50
100
150
200
250
300
Tim
e C
ost (
min
ute)
1 2 3 4 50.5
0.6
0.7
0.8
0.9
1.0
MAE (min) Time cost (min)
The number of partitions (hxh)
MA
E (m
in)
0
20
40
60
80
100
120
140
160
180
Tim
e co
st (m
in)
r1 r2 rN
u1
u2
uM
tj
tk
g1 g2
g3g4
g1 g2
g3g4
Metrics
• Performance of CATD– /(5×5): 4,736×12,674×4– 0.09%

Experiments• Query paths
– From taxi trajectories • 12,384 queries, 50 paths per hour/day• Traveled by at least two drivers• Total length 76,412.6km • Effective time span: 2,734 hours
A) Geographical distribution
B) Distribution of the length
C) Distribution of time length
– In the field study • 114 queries • from Sept. 1 to Oct. 30, 2013• Total length 999km • Effective time span: 62 hours
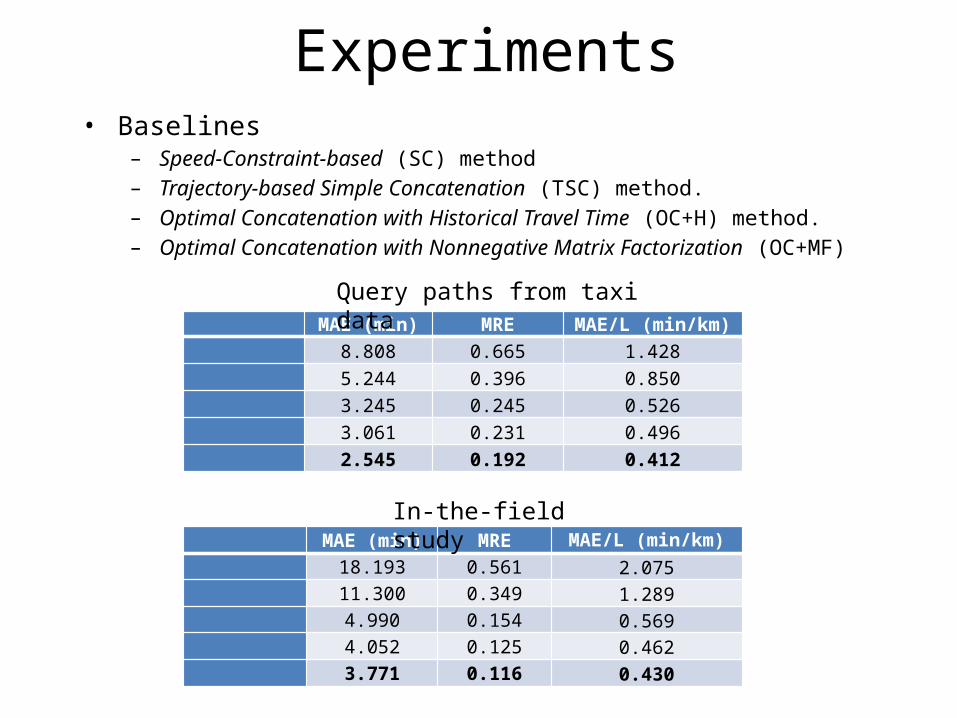
Experiments• Baselines
– Speed-Constraint-based (SC) method– Trajectory-based Simple Concatenation (TSC) method. – Optimal Concatenation with Historical Travel Time (OC+H) method.– Optimal Concatenation with Nonnegative Matrix Factorization (OC+MF)
MAE (min) MRE MAE/L (min/km)8.808 0.665 1.4285.244 0.396 0.8503.245 0.245 0.5263.061 0.231 0.4962.545 0.192 0.412
MAE (min) MRE MAE/L (min/km)
18.193 0.561 2.07511.300 0.349 1.2894.990 0.154 0.5694.052 0.125 0.4623.771 0.116 0.430
In-the-field study
Query paths from taxi data

Experiments
Components Time Memory (MB)
Deal with missing values ()
Building matrix 34ms 9
Tensor construction
44ms 4.4233ms 14.6
Decomposition 5×5 6.31min 116Total 6.4min 144
Optimal Concatenation (OC)
Best OC 2.3ms 995
w/o trajectory patterns 8.6ms 877
w/o index 12.2s 714
• Efficiency
0 200 400 600 800 10001
2
3
4
5
6
7
8
9
Time/Query (ms) MAE
Support
Tim
e/Q
uery
(ms)
2.0
2.2
2.4
2.6
2.8
3.0
MA
E
0 200 400 600 800 1000
0
100
200
300
400
500
600
700
800
Siz
e of
Inde
x (M
B)
Support
r2
r3
r3 r5
r7
r6
r1
r2
r3
Root
r2 r6 r72
11
2
1
1
1
1 133
1
r3 r6
12
r2ė r3, r3ė r4
(u2, u3, u4)
P: r1ė r2ė r3ė r4
(1)
(3)
(3)
r1 r2 rN
u1
u2
uM
tj
tk
Arec
(1)
, ,
Tr2,Tr3,Tr4
tr4,u2,k tr4,u3,k tr4,u4,k
tr3ė r4,u2,k = tr3,u2,k+t r4,u2,k
A) An example of suffix-tree B) Filling in the missing time for a pattern
Patterns:

Conclusion
• A very fundamental but challenging task– Data sparsity– Trade off between length of a path and support of trajectories– Efficiency and scalability
• Our method– Context-Aware Tensor Decomposition– Optimal Concatenation
• Results– Effectiveness
• 12,384 query paths and 114 in the field study• Relative error ratio: 19% and 11.6%
– Efficiency• Partition a city into grids• Suffix-tree-based pattern mining and index• Infer the travel time of a path in 2.3ms
Download data and codes

Search for “Urban Computing”
Thanks!
Homepage

Experiments• Datasets
– Taxi Trajectories: • Generated by 32,670 taxicabs in Beijing • From Sept. 1 to Oct. 31, 2013. • 673+ million GPS points • Total length: over 26 million km. • Sampling rate: 96 seconds per point.
– Road networks: • 148,110 nodes and 196,307 edges. • Covers a 4050km spatial range• Total length of road segments: 21,985km.
– POIs: • Th273,165 POIs of Beijing• 195 tier two categories. • Chose the top 10 categories that occur around road
segments
0 10 20 30 40 50
0.0
2.0k
4.0k
6.0k
8.0k
10.0k
Max
. Num
. of T
raje
ctor
ies
(Sup
port)
Length of a Path
0 4 8 12 16 200
10k
20k
30k
40k
50k
Num
. of R
oad
Segm
ents
Time of Day
1-2 3-4 5-6 7-8 >8
Download data here