trc-mc: decentralized software transactional memory for multi-multicore computers
TRANSCRIPT

TrC-MC: Decentralized SoftwareTransactional Memory forMulti-Multicore Computers
Kinson Chan, Cho-Li WangICPADS 2011, Tainan

Multicore Processors
• Multicore processors‣ a.k.a. chip multiprocessing‣ multiple cores on a processor‣ cores share a common cache‣ faster information
sharing among threads‣ more threads per cabinet
• Chip Multithreading‣ e.g. hyperthreading,
coolthreads, ...‣ ≥ 2 threads per core‣ hide the data load latency
2
L2 L2 L2 L2
ALU ALU ALU ALU
QPIDDR3
L1 L1 L1 L1
L3
QPI
DD
R3-1066 x3
25.6 GB/sec
Host ProcessorHost Memory

Multi-Multicore Computers
• Multiple multicore processors in a computer• Shared cache is not really global
• Accessing others’ cache content is slow...‣ Write back, remote memory access (through QPI), ...‣ About the speed of previous-generation SMP
3
L2 L2 L2 L2
ALU ALU ALU ALU
QPIDDR3
L1 L1 L1 L1
L3
QPI
L2L2L2L2
ALUALUALUALU
QPI DDR3
L1L1L1L1
L3
QPI
DD
R3-1066 x3
25.6 GB/sec
DD
R3-
1066
x3
25.6
GB/
sec
Host Processor 1 Host Processor 2Host Memory Host Memory

Processor Clockspeed Intra-Die Inter-Die
Core 2 Quad Q6600
Dual Xeon E5540
Dual Xeon E5550
Dual Xeon X5670
Quad Xeon X7750
2.40 GHz 1.6 • 107 trips/s 3.9 • 106 trips/s
2.53 GHz 1.3 • 107 trips/s 5.4 • 106 trips/s
2.66 GHz 1.5 • 107 trips/s 6.3 • 106 trips/s
2.93 GHz 1.4 • 107 trips/s 6.2 • 106 trips/s
2.00 GHz 5.4 • 106 trips/s 9.0 • 105 trips/s
Ping-pong trips per second
4

Processor Clockspeed Intra-Die Inter-Die
Core 2 Quad Q6600
Dual Xeon E5540
Dual Xeon E5550
Dual Xeon X5670
Quad Xeon X7750
2.40 GHz 63 ns/trip 256 ns/trip
2.53 GHz 77 ns/trip 158 ns/trip
2.66 GHz 66 ns/trip 158 ns/trip
2.93 GHz 71 ns/trip 161 ns/trip
2.00 GHz 185 ns/trip 1111 ns/trip
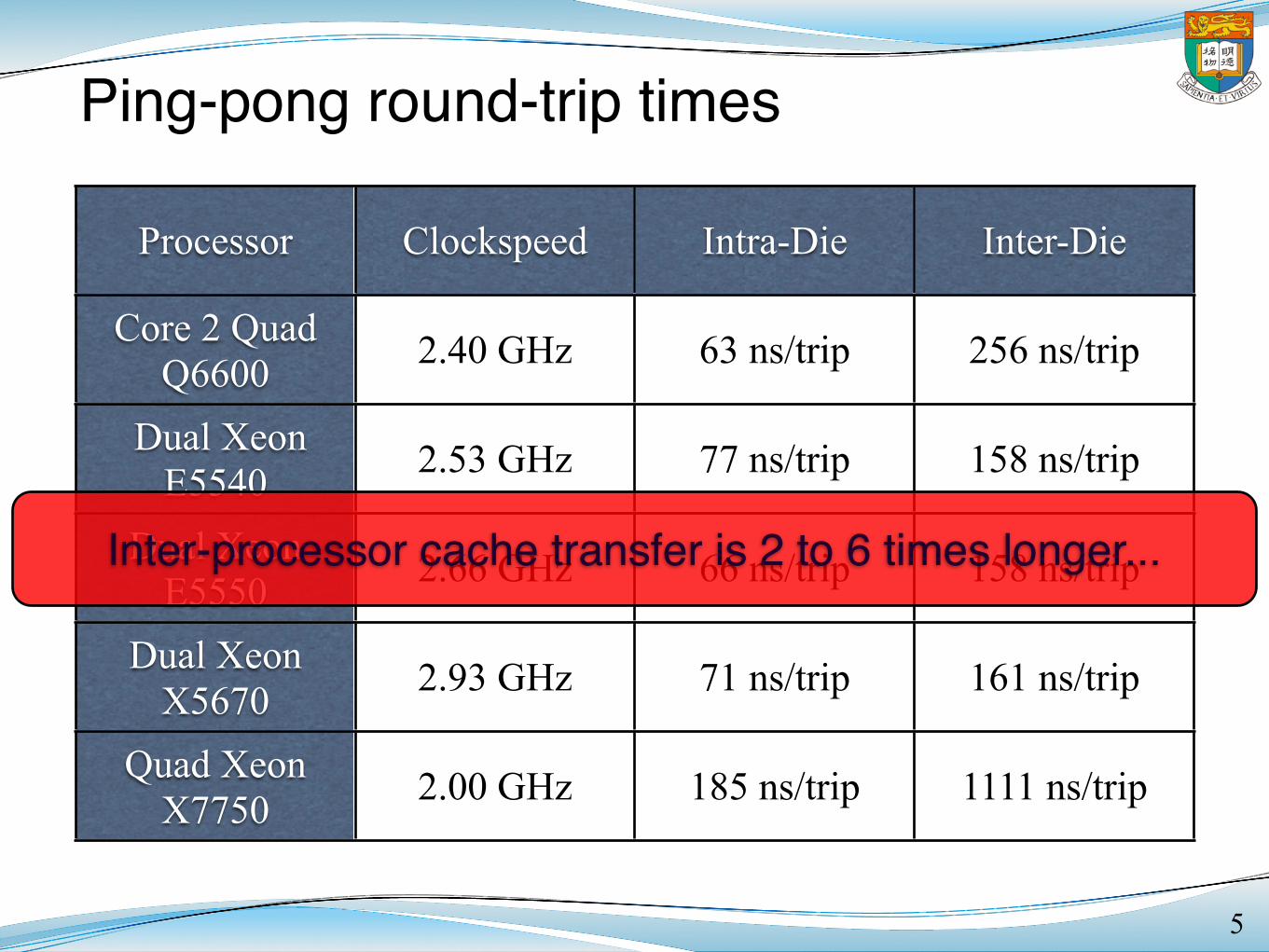
Ping-pong round-trip times
5
Processor Clockspeed Intra-Die Inter-Die
Core 2 Quad Q6600
Dual Xeon E5540
Dual Xeon E5550
Dual Xeon X5670
Quad Xeon X7750
2.40 GHz 63 ns/trip 256 ns/trip
2.53 GHz 77 ns/trip 158 ns/trip
2.66 GHz 66 ns/trip 158 ns/trip
2.93 GHz 71 ns/trip 161 ns/trip
2.00 GHz 185 ns/trip 1111 ns/trip
Ping-pong round-trip times
5
Inter-processor cache transfer is 2 to 6 times longer...

Now and future multicores
6
Micro-architecture Clock rate Cores Threads per
coreThreads per
package Shared cache Memory arrangement
IBM Power 7 ~ 3 GHz 4 ~ 8 4 32 Max 4 MBshared L3 NUMA
Sun Niagara2 1.2 ~ 1.6 GHz 4 ~ 8 8 64 Max 4 MBshared L2 NUMA
Intel Westmere ~ 2 GHz 4 ~ 8 2 16 Max 12 ~ 24 MB
shared L3 NUMA
Intel Harpertown ~ 3 GHz 2 x 2 2 8 2 x 6 MB
shared L3 UMA
AMD Bulldozer ~ 2 GHz 2 x 6 ~ 2 x 8 1 16 Max 8 MB
shared L3 NUMA
AMD Magny-Cours ~ 3 GHz 8 modules 2 per module 16 Max 8 MB
shared L3 NUMA
Intel Terascale ~ 4 GHz 80? 1? 80? 80 x 2 KBdist. cache NUCA

Now and future multicores
6
Micro-architecture Clock rate Cores Threads per
coreThreads per
package Shared cache Memory arrangement
IBM Power 7 ~ 3 GHz 4 ~ 8 4 32 Max 4 MBshared L3 NUMA
Sun Niagara2 1.2 ~ 1.6 GHz 4 ~ 8 8 64 Max 4 MBshared L2 NUMA
Intel Westmere ~ 2 GHz 4 ~ 8 2 16 Max 12 ~ 24 MB
shared L3 NUMA
Intel Harpertown ~ 3 GHz 2 x 2 2 8 2 x 6 MB
shared L3 UMA
AMD Bulldozer ~ 2 GHz 2 x 6 ~ 2 x 8 1 16 Max 8 MB
shared L3 NUMA
AMD Magny-Cours ~ 3 GHz 8 modules 2 per module 16 Max 8 MB
shared L3 NUMA
Intel Terascale ~ 4 GHz 80? 1? 80? 80 x 2 KBdist. cache NUCA
How to exploit parallelism for better performance?

Multi-threading and synchronization
7

Multi-threading and synchronization
7
Coarse grain locking
Easy / Correct(few locks, predictable)
Difficult to scale(excessive mutual
exclusion)

Multi-threading and synchronization
7
Coarse grain locking
Easy / Correct(few locks, predictable)
Difficult to scale(excessive mutual
exclusion)
Fine-grain locking
Error prone(deadlock, forget to
lock, ...)
Scales better(allows more parallelism)

Multi-threading and synchronization
7
Coarse grain locking
Easy / Correct(few locks, predictable)
Difficult to scale(excessive mutual
exclusion)
Fine-grain locking
Error prone(deadlock, forget to
lock, ...)
Scales better(allows more parallelism)
Do we have anything in between?
Easy / Correct
Scales good

C. J. Rossbach, O. S. Hofmann and Emmett Witchel, Is transactional programming actually easier, In Proceedings of the 15th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 45–56, 2010.
STM is easy
• In the University of Texas at Austin, 237 students taking Operating System courses were instructed to program the same problem with coarse locks, fine-grained locks, monitors and transactions...
8
DevelopmentTime
Errors
CodeComplexity

C. J. Rossbach, O. S. Hofmann and Emmett Witchel, Is transactional programming actually easier, In Proceedings of the 15th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 45–56, 2010.
STM is easy
• In the University of Texas at Austin, 237 students taking Operating System courses were instructed to program the same problem with coarse locks, fine-grained locks, monitors and transactions...
8
DevelopmentTime
Errors
CodeComplexity
LongShort
TMCoarse Fine

C. J. Rossbach, O. S. Hofmann and Emmett Witchel, Is transactional programming actually easier, In Proceedings of the 15th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 45–56, 2010.
STM is easy
• In the University of Texas at Austin, 237 students taking Operating System courses were instructed to program the same problem with coarse locks, fine-grained locks, monitors and transactions...
8
DevelopmentTime
Errors
CodeComplexity
LongShort
TMCoarse Fine
Simple Complex
TMCoarse Fine

C. J. Rossbach, O. S. Hofmann and Emmett Witchel, Is transactional programming actually easier, In Proceedings of the 15th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 45–56, 2010.
STM is easy
• In the University of Texas at Austin, 237 students taking Operating System courses were instructed to program the same problem with coarse locks, fine-grained locks, monitors and transactions...
8
DevelopmentTime
Errors
CodeComplexity
LongShort
TMCoarse Fine
Simple Complex
TMCoarse Fine
Less More
TM Coarse Fine

STM optimistic execution
9
Begin Begin
Proceed Proceed
Commit Commit
Retry
Commit
x=x+4
y=y-4
x=x+2
y=y-2
Begin
Proceed Begin
Proceed
Commit
Commit
x=x+4
y=y-4
w=w+5
z=w
Thread 1 Thread 2 Thread 3 Thread 1 Thread 2 Thread 3
x=x+2
y=y-2
Success
Success
Success
Success
conflict detection
conflict detection
begin; x=x+4; y=y-4; commit;
begin; x=x+2; y=y-2; commit;
begin; x=x+4; y=y-4; commit;
begin; w=w+5; z=w; commit;
begin;x = x + 4;y = y - 4;commit;

STM optimistic execution
9
Begin Begin
Proceed Proceed
Commit Commit
Retry
Commit
x=x+4
y=y-4
x=x+2
y=y-2
Begin
Proceed Begin
Proceed
Commit
Commit
x=x+4
y=y-4
w=w+5
z=w
Thread 1 Thread 2 Thread 3 Thread 1 Thread 2 Thread 3
x=x+2
y=y-2
Success
Success
Success
Success
conflict detection
conflict detection
begin; x=x+4; y=y-4; commit;
begin; x=x+2; y=y-2; commit;
begin; x=x+4; y=y-4; commit;
begin; w=w+5; z=w; commit;

STM optimistic execution
9
Begin Begin
Proceed Proceed
Commit Commit
Retry
Commit
x=x+4
y=y-4
x=x+2
y=y-2
Begin
Proceed Begin
Proceed
Commit
Commit
x=x+4
y=y-4
w=w+5
z=w
Thread 1 Thread 2 Thread 3 Thread 1 Thread 2 Thread 3
x=x+2
y=y-2
Success
Success
Success
Success
conflict detection
conflict detection
begin; x=x+4; y=y-4; commit;
begin; x=x+2; y=y-2; commit;
begin; x=x+4; y=y-4; commit;
begin; w=w+5; z=w; commit;
case 1: two transactions conflicts:rollback and retry one of them.

STM optimistic execution
9
Begin Begin
Proceed Proceed
Commit Commit
Retry
Commit
x=x+4
y=y-4
x=x+2
y=y-2
Begin
Proceed Begin
Proceed
Commit
Commit
x=x+4
y=y-4
w=w+5
z=w
Thread 1 Thread 2 Thread 3 Thread 1 Thread 2 Thread 3
x=x+2
y=y-2
Success
Success
Success
Success
conflict detection
conflict detection
begin; x=x+4; y=y-4; commit;
begin; x=x+2; y=y-2; commit;
begin; x=x+4; y=y-4; commit;
begin; w=w+5; z=w; commit;
case 1: two transactions conflicts:rollback and retry one of them.
case 2: two transactions do not conflict: they execute together,
achieving better parallelism.

Timestamp-based detection
10
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
IDLE IDLE
234
232
229
230

Timestamp-based detection
11
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
ACTIVE ACTIVE
234
232
229
230
234 234

Running
Timestamp-based detection
12
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
ACTIVE ACTIVE
234
232
229
230
234 234 write
read
read

Running
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
Timestamp-based detection
13
ACTIVE ACTIVE
234
232
229
230
234 234
write
read

Running
Timestamp-based detection
14
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
COMMIT ACTIVE
234
232
229
230
234 234

Running
Timestamp-based detection
15
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
COMMIT ACTIVE
234
LOCKED
229
230
234 234

Running
Timestamp-based detection
16
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
COMMIT ACTIVE
235
LOCKED
229
230
234 234
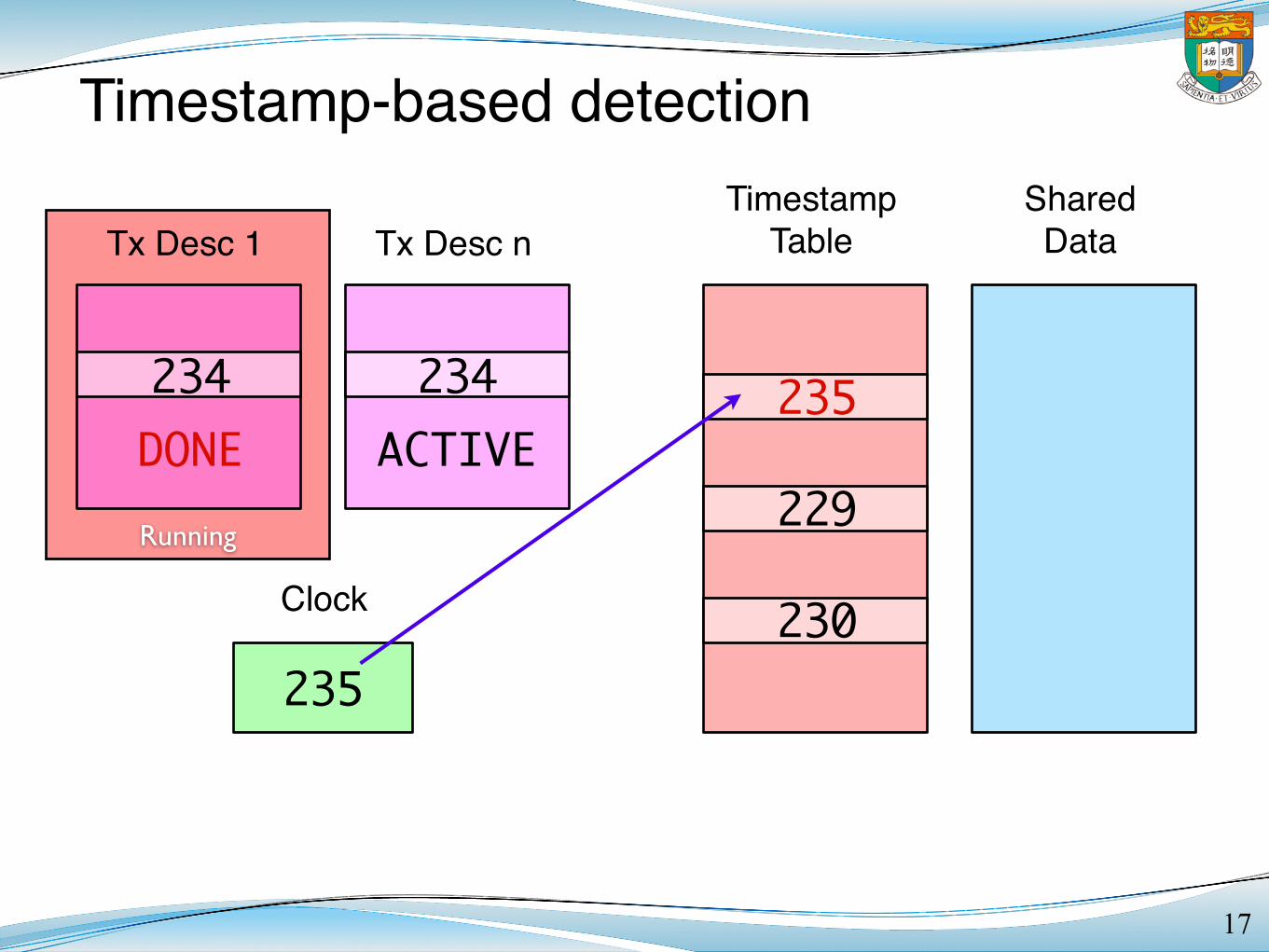
Running
Timestamp-based detection
17
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
DONE ACTIVE
235
235
229
230
234 234
Running
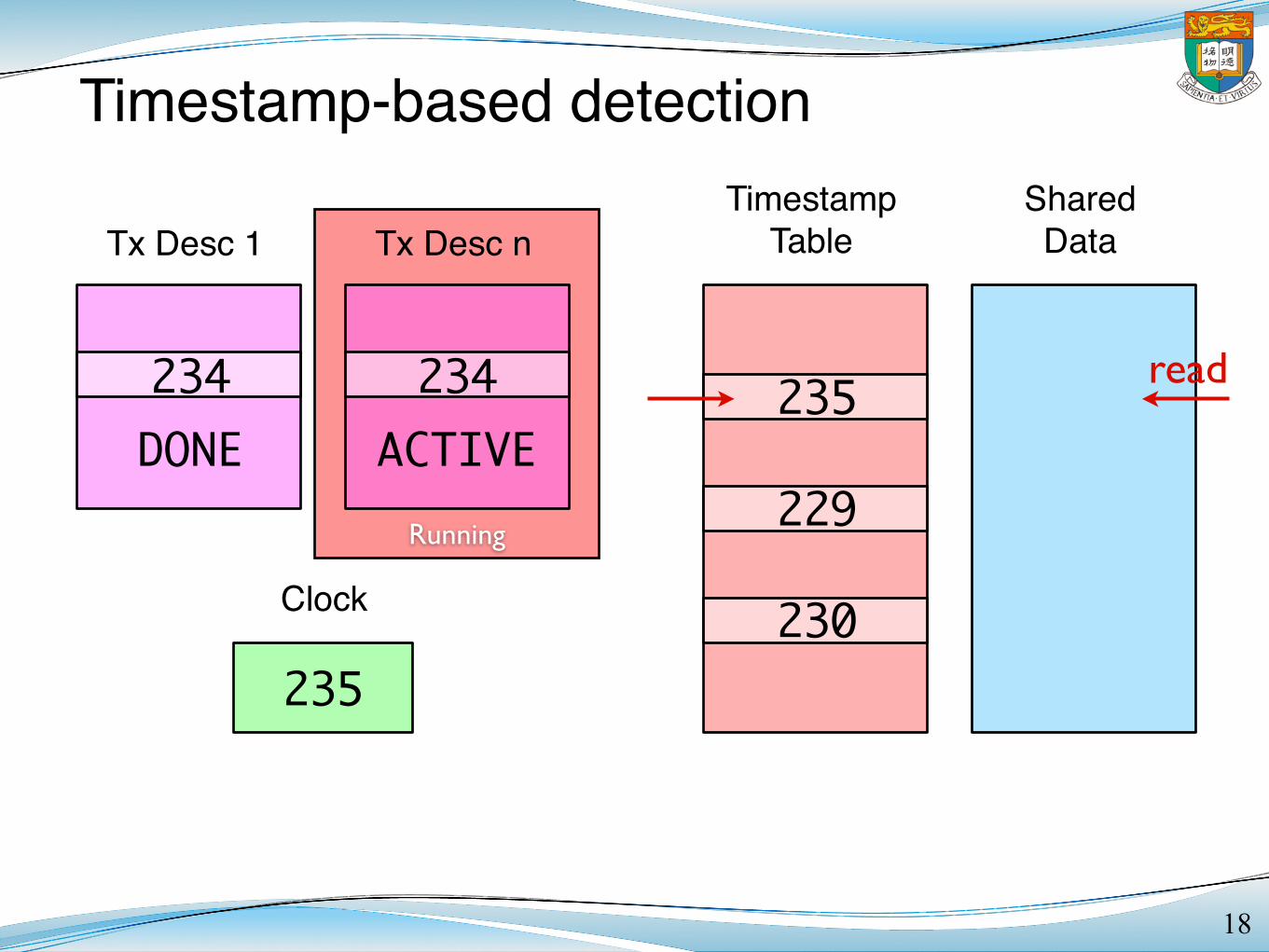
Timestamp-based detection
18
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
DONE ACTIVE
235
235
229
230
234 234 read
Running
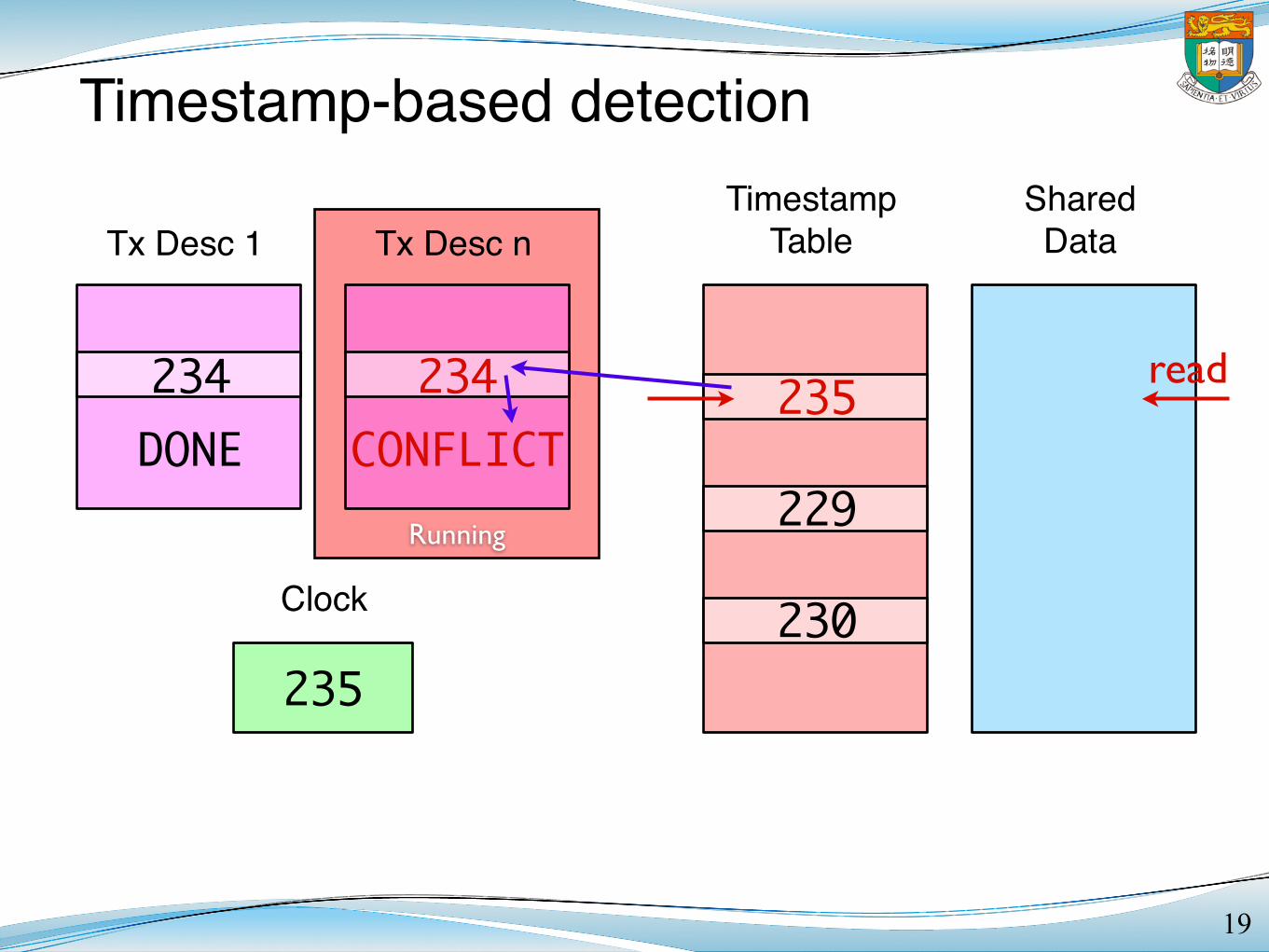
Timestamp-based detection
19
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
DONE CONFLICT
235
235
229
230
234 234 read

Timestamp-based detection
20
Tx Desc 1 Tx Desc nTimestamp
TableShared
Data
Clock
DONE CONFLICT
235
235
229
230
234 234
CommonAccessVariable

Centralized Data Structure
• All transactions touch the same clock...• Even if they do not overlap.
• Serious contention among the processors.
• Lots of time spent on cache coherence.
• Example: ssca2‣ Very high commit ratio (> 95%, green dots)‣ Very high commit rate (M/sec, red dashes)‣ Not scalable on word-based STM (black)
21
1 2 4 8 16 32 64 1 2 4 8 16 32 64
100%
0%
100%
0%
100%
0%
100%
0%
100%
0%
900
0
0
0
0
0
0
0
0
0
0
1.5M
1.2M
80M
20M
100
2.5M
1.2M
1M
250K
8
8
3
4
2 2
12
12
2
10
Com
mit
Rat
io (G
reen
Dot
ted
Line
s)
Com
mit
Rat
e (P
er S
econ
d, R
ed D
ashe
d Li
nes)
Spee
dup
Rat
io (B
lack
Sol
id L
ines
)
Com
mit
Rat
e (P
er S
econ
d, R
ed D
ashe
d Li
nes)
Spee
dup
Rat
io (B
lack
Sol
id L
ines
)
0
0
0
0
0
0
0
0
0
0
bayes
genome
intruder
kmeans-1
kmeans-2
labyrinth
ssca2
vacation-1
vacation-2
yada
Number of Threads
50%
50%
50%
50%
50%
450
750K
600K
40M
10M
50
1.25M
600K
500K
125K
4
4
1.5
2
1
5
1
6
6
1
Figure 1. Commit Ratios, Commit Rates and Speedup Ratios ofSTAMP Benchmark on TinySTM
Time
Com
mit
Rat
e(P
er S
econ
d,R
ed D
ashe
d Li
ne)
Com
mit
Rat
io(G
reen
Dot
ted
Line
) 100%
0%
200K
0
100K50%
Figure 2. Instantaneous Commit Ratios and Commit Rates of va-cation with 64 Threads
is completed. These engaged data locks obstruct other trans-actions to proceed and they cause a cascading effect in whichfurther more transactions are obstructed and aborted.
• Optimal concurrencies are application-dependent: Differentapplications have different optimal concurrencies (sweet spot).For instance, genome scales the best at 32 threads while yadascales the best at 8. While kmeans-1 and kmeans-2 are essen-tially the same application program, they have different speedupcurves as they have different input data.
• Transactional nature changes in runtime: As a program maytake multiple stages of data processing, the nature of the trans-actions may change along the timeline. Figure 2 shows the in-stantaneous commit rates and ratios while vacation-2 is run-
Processor Clockspeed Intra-Die Inter-DieCore 2 Quad Q6600 2.40 GHz 63 ns 256 ns
2⇥ Xeon E5540 2.53 GHz 77 ns 185 ns2⇥ Xeon E5550 2.66 GHz 66 ns 158 ns2⇥ Xeon X5670 2.93 GHz 71 ns 161 ns4⇥ Xeon X7550 2.00 GHz 185 ns 1111 ns
Table 1. Cache Ping-Pong Round-Trip Times of some Processors
ning. Although the work nature is uniform, the commit rate andratio are constantly changing through time.
• Programs with low commit ratio may still be scalable: Althoughyada has commit ratio as low as 5% when there are 2 threads,doubling number of threads to 4 yields around 30% perfor-mance gain. If an ACC policy watches on the commit ratio only,it may over-react and stall more threads than necessary.
• Lower commit ratio does not imply worse performance: Despiteof a lot of coincidences, there are also a few cases where thesystem performs better with lower commit ratio. When numberof threads is increased from 8 to 32, labyrinth’s commit ratiodrops by around 15%. Meanwhile the speedup ratio increasesby 2.
• Commit rate acts as better performance index: Generally,higher commit rate on the graphs also implies higher speedupratio. This assumption holds on all of the benchmarks we havetested on this paper.
An adaptive concurrency control policy is required to guidea STM to have optimal concurrency and the best performance.To be a reasonable policy, it should make decisions based on theinstantaneous commit rates, not ratios.
2.3 Modern Computer Cache HierarchyModern computers are equipped with multicore (CMP) processors.A multicore processor features a shared cache and several compu-tation cores, on which at least one thread can execute. With chipmultithreading (CMT) technology, a core makes use of the cachelatency and runs more than one thread. Threads within the samecore share the L1 cache while threads on different cores (but sameprocessor) share L2 or L3 cache. To pursue high performance, high-end computers are equipped with multiple multicore processors.This complicates the cache-sharing situation as threads on differ-ent processors do not share any common cache.
We run ping-pong tests on several systems equipped with multi-ple multicore processors, as shown on Table 1.3 Our aim is to eval-uate how fast data sharing can be. Inter-thread data sharing speedmay give us some inspiration for how STM policies and protocolscan be designed.
We notice it takes tens of nanoseconds to transfer a cache linefrom a processor to another. From another view point, if a cacheline (e.g., a commit counter) has to be uniformly updated by threadson different processors, there can be only millions of cache transferper second. When there are more transactions than this capacity,threads slow down as they contend for the cache line ownership.
For instance, Chan, et al [4] were puzzled why ssca2 cannotgain benefit from their adaptive concurrency policies. The systemperformance drops by 26% when their ACC policy is activated.We can repeat the same observation by running similar softwareset on our computers. With millions of transactional commits persecond, the commit counter in their solution is saturated and causes
3 Although Q6600 comes in a single quad-core package, it features two setsof shared L2 cache, each to be shared by two cores only. According to ourdefinition in Section 1, we treat it as two processors.
3 2011/8/20
1 2 4 8 16 32 64 1 2 4 8 16 32 64
100%
0%
100%
0%
100%
0%
100%
0%
100%
0%
900
0
0
0
0
0
0
0
0
0
0
1.5M
1.2M
80M
20M
100
2.5M
1.2M
1M
250K
8
8
3
4
2 2
12
12
2
10
Com
mit
Ratio
(Gre
en D
otte
d Li
nes)
Com
mit
Rate
(Per
Sec
ond,
Red
Das
hed
Line
s)
Spee
dup
Ratio
(Bla
ck S
olid
Lin
es)
Com
mit
Rate
(Per
Sec
ond,
Red
Das
hed
Line
s)
Spee
dup
Ratio
(Bla
ck S
olid
Lin
es)
0
0
0
0
0
0
0
0
0
0
bayes
genome
intruder
kmeans-1
kmeans-2
labyrinth
ssca2
vacation-1
vacation-2
yada
Number of Threads
50%
50%
50%
50%
50%
450
750K
600K
40M
10M
50
1.25M
600K
500K
125K
4
4
1.5
2
1
5
1
6
6
1
Figure 1. Commit Ratios, Commit Rates and Speedup Ratios ofSTAMP Benchmark on TinySTM
Time
Com
mit
Rate
(Per
Sec
ond,
Red
Dash
ed L
ine)
Com
mit
Ratio
(Gre
en D
otte
d Li
ne) 100%
0%
200K
0
100K50%
Figure 2. Instantaneous Commit Ratios and Commit Rates of va-cation with 64 Threads
is completed. These engaged data locks obstruct other trans-actions to proceed and they cause a cascading effect in whichfurther more transactions are obstructed and aborted.
• Optimal concurrencies are application-dependent: Differentapplications have different optimal concurrencies (sweet spot).For instance, genome scales the best at 32 threads while yadascales the best at 8. While kmeans-1 and kmeans-2 are essen-tially the same application program, they have different speedupcurves as they have different input data.
• Transactional nature changes in runtime: As a program maytake multiple stages of data processing, the nature of the trans-actions may change along the timeline. Figure 2 shows the in-stantaneous commit rates and ratios while vacation-2 is run-
Processor Clockspeed Intra-Die Inter-DieCore 2 Quad Q6600 2.40 GHz 63 ns 256 ns
2⇥ Xeon E5540 2.53 GHz 77 ns 185 ns2⇥ Xeon E5550 2.66 GHz 66 ns 158 ns2⇥ Xeon X5670 2.93 GHz 71 ns 161 ns4⇥ Xeon X7550 2.00 GHz 185 ns 1111 ns
Table 1. Cache Ping-Pong Round-Trip Times of some Processors
ning. Although the work nature is uniform, the commit rate andratio are constantly changing through time.
• Programs with low commit ratio may still be scalable: Althoughyada has commit ratio as low as 5% when there are 2 threads,doubling number of threads to 4 yields around 30% perfor-mance gain. If an ACC policy watches on the commit ratio only,it may over-react and stall more threads than necessary.
• Lower commit ratio does not imply worse performance: Despiteof a lot of coincidences, there are also a few cases where thesystem performs better with lower commit ratio. When numberof threads is increased from 8 to 32, labyrinth’s commit ratiodrops by around 15%. Meanwhile the speedup ratio increasesby 2.
• Commit rate acts as better performance index: Generally,higher commit rate on the graphs also implies higher speedupratio. This assumption holds on all of the benchmarks we havetested on this paper.
An adaptive concurrency control policy is required to guidea STM to have optimal concurrency and the best performance.To be a reasonable policy, it should make decisions based on theinstantaneous commit rates, not ratios.
2.3 Modern Computer Cache HierarchyModern computers are equipped with multicore (CMP) processors.A multicore processor features a shared cache and several compu-tation cores, on which at least one thread can execute. With chipmultithreading (CMT) technology, a core makes use of the cachelatency and runs more than one thread. Threads within the samecore share the L1 cache while threads on different cores (but sameprocessor) share L2 or L3 cache. To pursue high performance, high-end computers are equipped with multiple multicore processors.This complicates the cache-sharing situation as threads on differ-ent processors do not share any common cache.
We run ping-pong tests on several systems equipped with multi-ple multicore processors, as shown on Table 1.3 Our aim is to eval-uate how fast data sharing can be. Inter-thread data sharing speedmay give us some inspiration for how STM policies and protocolscan be designed.
We notice it takes tens of nanoseconds to transfer a cache linefrom a processor to another. From another view point, if a cacheline (e.g., a commit counter) has to be uniformly updated by threadson different processors, there can be only millions of cache transferper second. When there are more transactions than this capacity,threads slow down as they contend for the cache line ownership.
For instance, Chan, et al [4] were puzzled why ssca2 cannotgain benefit from their adaptive concurrency policies. The systemperformance drops by 26% when their ACC policy is activated.We can repeat the same observation by running similar softwareset on our computers. With millions of transactional commits persecond, the commit counter in their solution is saturated and causes
3 Although Q6600 comes in a single quad-core package, it features two setsof shared L2 cache, each to be shared by two cores only. According to ourdefinition in Section 1, we treat it as two processors.
3 2011/8/20
threads
ssca2

Solutions?
• Abandon timestamp-based detection?‣ We are still retaining some global data... e.g.,‣ A single clock (TML, NOrec)‣ A ring (RingSTM)‣ We are just having cache contention on some other things.
• Copy ideas from STM for cluster?‣ Usually involves network messages, esp. broadcasts.‣ Network messages can be taken as remote-memory operations.
• Finally, TL2C by Anvi?
22

Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
23
IDLE IDLE
2…232
2…220
3…125IDLE
1…1232…2343…124
1…1202…2303…124
1…1232…2333…126

Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
24
IDLE IDLE
2…232
2…220
3…125IDLE
1…1232…2343…124
1…1202…2303…124
1…1232…2333…126
Separated Clocks

Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
25
IDLE IDLE
2…232
2…220
3…125IDLE
1…1232…2343…124
1…1202…2303…124
1…1232…2333…126
Cache Clocks

Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
26
IDLE IDLE
2…232
2…220
3…125IDLE
1…1232…2343…124
1…1202…2303…124
1…1232…2333…126
Timestamp = Node ID + Clock
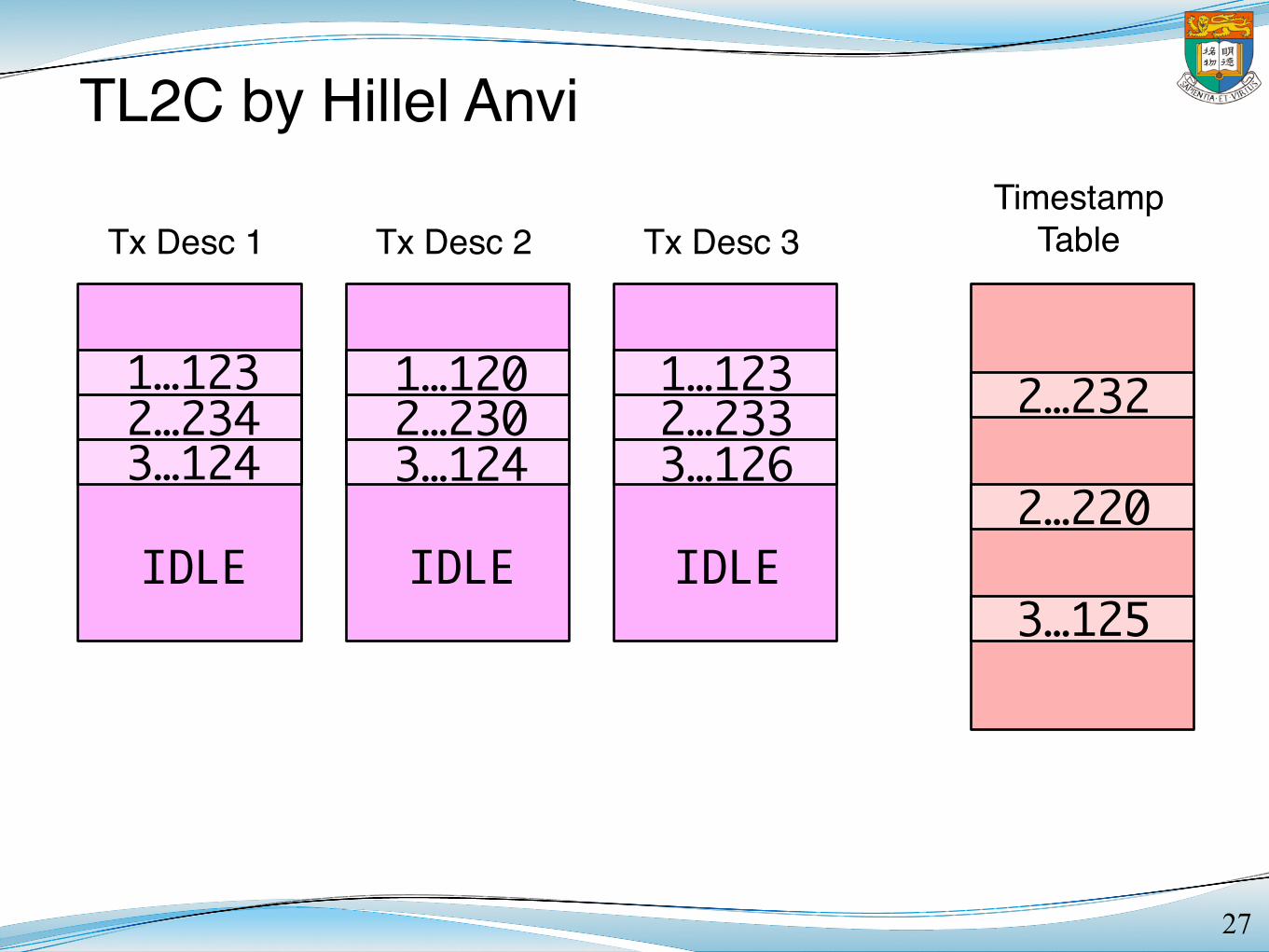
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
27
IDLE IDLE
2…232
2…220
3…125IDLE
1…1232…2343…124
1…1202…2303…124
1…1232…2333…126

Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
28
ACTIVE IDLE
2…232
2…220
3…125ACTIVE
1…1232…2343…124
1…1202…2303…124
1…1232…2333…126
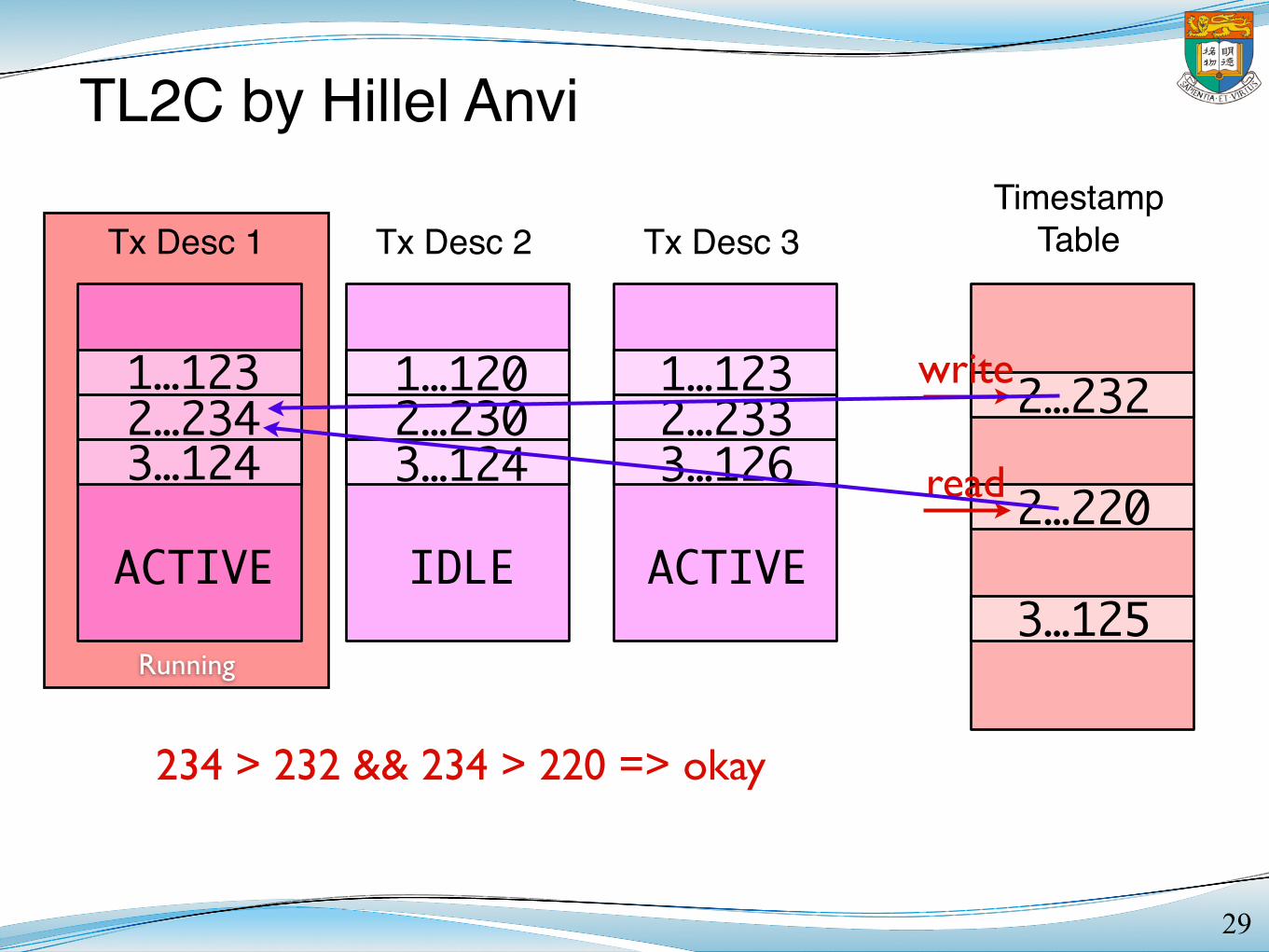
Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
29
ACTIVE IDLE
2…232
2…220
3…125ACTIVE
1…1232…2343…124
1…1202…2303…124
1…1232…2333…126
write
read
234 > 232 && 234 > 220 => okay

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
30
ACTIVE IDLE
2…232
2…220
3…125ACTIVE
1…1232…2343…124
1…1202…2303…124
1…1232…2333…126
read
write
233 > 232 && 233 > 220 => okay

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
31
COMMIT IDLE
2…232
2…220
3…125ACTIVE
1…1232…2343…124
1…1202…2303…124
1…1232…2333…126

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
32
COMMIT IDLE
LOCKED
2…220
3…125ACTIVE
1…1232…2343…124
1…1202…2303…124
1…1232…2333…126

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
33
COMMIT IDLE
LOCKED
2…220
3…125ACTIVE
1…1242…2343…124
1…1202…2303…124
1…1232…2333…126

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
34
DONE IDLE
1…124
2…220
3…125ACTIVE
1…1242…2343…124
1…1202…2303…124
1…1232…2333…126

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
35
DONE IDLE
1…124
2…220
3…125ACTIVE
1…1242…2343…124
1…1202…2303…124
1…1232…2333…126
read

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
36
DONE IDLE
1…124
2…220
3…125CONFLICT
1…1242…2343…124
1…1202…2303…124
1…1232…2333…126
read
123 < 124 => not okay

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
37
DONE ACTIVE
1…124
2…220
3…125ABORT
1…1242…2343…124
1…1202…2303…124
1…1242…2333…126

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
38
DONE ACTIVE
1…124
2…220
3…125ABORT
1…1242…2343…124
1…1202…2303…124
1…1242…2333…126
read

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
39
DONE CONFLICT
1…124
2…220
3…125ABORT
1…1242…2343…124
1…1202…2303…124
1…1232…2333…126
120 < 124 => not okay

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
40
DONE CONFLICT
1…124
2…220
3…125ABORT
1…1242…2343…124
1…1242…2303…124
1…1242…2333…126

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
41
DONE RETRY
1…124
2…220
3…125ABORT
1…1242…2343…124
1…1242…2303…124
1…1242…2333…126
read
read

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
42
DONE CONFLICT
1…124
2…220
3…125ABORT
1…1242…2343…124
1…1242…2303…124
1…1242…2333…126
read
124 < 125 => not okay

Running
Tx Desc 1 Tx Desc 2Timestamp
TableTx Desc 3
TL2C by Hillel Anvi
43
DONE CONFLICT
1…124
2…220
3…125ABORT
1…1242…2343…124
1…1242…2303…125
1…1242…2333…126

H. Avni and N. Shavit, “Maintaining consistent transactional states without a global clock,” in Proceedings of the 15th international colloquium on Structural Information and Communication Complexity. Berlin, Heidelberg: Springer-Verlag, 2008, pp. 131–140.
Disadvantages
• Acknowledge new clocks by conflicts only‣ No more global clock to inform the newest timestamp value‣ New timestamp, Conflict, and then Abort Inevitable
• An update generates at most (n-1) unnecessary “conflicts”when there are n threads. Thus high resultant abort rate.
• “The hope is that in the future, on larger distributed machines, the cost of the higher abort rate will be offset by the reduction in the cost that would have been incurred by using a shared global clock.” — Hillel Anvi and Nir Shavit, SIROCCO, 2008
44

Improving the design...
1. How do we reduce the chance a transaction encountering a timestamp that is “too new” like transaction 2?Find some other mechanisms to copy the clock values.
2. Can we copy the clock values directly from other transactions?No. This would cause cache invalidation on important data.
3. Would leveraging on the multicore’s shared cache help?
TrC-MC: Transactional Consistency for Multicore... Zone + Timestamp Extension
45

Zones
• We allocate transactions into zones.
• Ideally, threads in the same zone are in the same processor.• Thus, we have fast sharing among the same zone.
• Threads within a zone share a group of cache clocks.• A thread copies the cache clocks before it starts a transaction.
• A thread updates the zone cache encountering new timestamps.
• So, once a thread encounters a conflict, other threads in the zone no longer suffers from the timestamp.
46

Zones
47
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…1242…180
1…1182…225 2…225
1…118
1…124 2…220 1…119 2…225
1…118
2…219
2…210
IDLE IDLE IDLE

Zones
48
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…1242…220
1…1182…225 2…225
1…119
1…124 2…220 1…119 2…225
1…118
2…219
2…210
ACTIVE IDLE ACTIVE

Running
Zones
49
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…1242…220
1…1182…225 2…225
1…119
1…124 2…220 1…119 2…225
1…118
2…219
LOCKED
COMMIT IDLE ACTIVE

Running
Zones
50
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…1252…220
1…1182…225 2…225
1…119
1…125 2…220 1…119 2…225
1…118
2…219
LOCKED
COMMIT IDLE ACTIVE

Running
Zones
51
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…1252…220
1…1182…225 2…225
1…119
1…125 2…220 1…119 2…225
1…118
2…219
1…125
DONE IDLE ACTIVE

Running
Zones
52
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…1252…220
1…1182…225 2…225
1…119
1…125 2…220 1…119 2…225
1…118
2…219
1…125
DONE IDLE CONFLICT
read

Running
Zones
53
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…1252…220
1…1182…225 2…225
1…125
1…125 2…220 1…125 2…225
1…118
2…219
1…125
DONE IDLE CONFLICT

Running
Zones
54
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…1252…220
1…1252…225 2…225
1…125
1…125 2…220 1…125 2…225
1…118
2…219
1…125
DONE ACTIVE CONFLICT

Running
Zones
55
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…1252…220
1…1252…225 2…225
1…125
1…125 2…220 1…125 2…225
1…118
2…219
1…125
DONE ACTIVE CONFLICT
read

Torvald Riegel, Pascal Felber, and Christof Fetzer. A Lazy Snapshot Algorithm with Eager Validation. In Proceedings of the 20th International Symposium on Distributed Computing (DISC), pages 284–298, September 2006.
P. Felber, C. Fetzer, and T. Riegel, “Dynamic performance tuning of word-based software transactional memory,” in Proceedings of the 13th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 2008, pp. 237–246.
Timestamp extension
• Originally done by T. Riegel et al.‣ LSA: “Lazy Snapshot Algorithm with Eager Detection”‣ State-of-the-art example: TinySTM
• Effect: fewer aborts as some transactions are rescued.
• When a new timestamp is encountered...1. Update the new clock into the cache clock.2. Re-execute the read set, check for inconsistencies.3. If consistent, the transaction can proceed with new clock.4. Otherwise, the transaction has to abort.
56

Proof
57
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…124 1…118 1…119
1…124 1…119
1…119IDLE IDLE IDLECache clocks intransaction descriptorsare under-estimation
of those in zone.

Proof
58
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…124 1…118 1…119
1…124 1…119
1…119IDLE IDLE IDLE
Cache clocks in zones areunderestimations of the largest
values in timestamp table.

Proof
59
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…124 1…118 1…119
1…124 1…119
1…119IDLE IDLE IDLEThe largest value is in the actualclock in the corresponding zone.

Proof
60
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…124 1…118 1…119
1…124 1…119
1…119IDLE IDLE IDLETherefore, cache clocks intransaction descriptorsare underestimation of
the actual clocks.

Proof
61
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…124 1…124 1…124
1…124 1…124
1…124IDLE IDLE IDLEOr, at extreme case,
all these numbers wouldbe equal...

Proof
62
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…125 1…124 1…124
1…125 1…124
1…124COMMIT IDLE IDLE
1…125
In commit procedure,the clock in the zoneis incremented by 1.

Proof
63
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…124 1…124 1…124
1…125 1…124
1…124IDLE IDLE IDLE
1…125
After increment, all thesecache clocks would be
absolutely smaller.

Proof
64
Tx Desc 1 Tx Desc 3 TimestampTable
Tx Desc 4
Zone 1 Zone 2
1…124 1…124 1…124
1…125 1…124
1…124IDLE IDLE IDLE
1…125
Therefore, it would generatea conflict / extension whennewly written values are
encountered.

Performance: ssca2
65
Tran
sact
ions
per
sec
ond
Number of threads

TSTM / CommitsTSTM / AbortsTSTM / Extension
TRC-MC / CommitsTRC-MC / AbortsTRC-MC / Extension
TL2C / CommitsTL2C / AbortsSEQUENTIAL
Performance: ssca2
65
0
3750000
7500000
11250000
15000000
1 2 4 8 16 32 64
Tran
sact
ions
per
sec
ond
Number of threads

TSTM / CommitsTSTM / AbortsTSTM / Extension
TRC-MC / CommitsTRC-MC / AbortsTRC-MC / Extension
TL2C / CommitsTL2C / AbortsSEQUENTIAL
Performance: ssca2
65
0
3750000
7500000
11250000
15000000
1 2 4 8 16 32 64
Tran
sact
ions
per
sec
ond
Number of threads
Less Aborts

Performance: vacation
66
Tran
sact
ions
per
sec
ond
Number of threads

TSTM / CommitsTSTM / AbortsTSTM / Extension
TRC-MC / CommitsTRC-MC / AbortsTRC-MC / Extension
TL2C / CommitsTL2C / AbortsSEQUENTIAL
Performance: vacation
66
0
375000
750000
1125000
1500000
1 2 4 8 16 32 64
Tran
sact
ions
per
sec
ond
Number of threads

TSTM / CommitsTSTM / AbortsTSTM / Extension
TRC-MC / CommitsTRC-MC / AbortsTRC-MC / Extension
TL2C / CommitsTL2C / AbortsSEQUENTIAL
Performance: vacation
66
0
375000
750000
1125000
1500000
1 2 4 8 16 32 64
Tran
sact
ions
per
sec
ond
Number of threads
Less Aborts

TSTM / CommitsTSTM / AbortsTSTM / Extension
TRC-MC / CommitsTRC-MC / AbortsTRC-MC / Extension
TL2C / CommitsTL2C / AbortsSEQUENTIAL
Performance: vacation
66
0
375000
750000
1125000
1500000
1 2 4 8 16 32 64
Tran
sact
ions
per
sec
ond
Number of threads
Less Aborts
Slightly more extensions

Conclusions
• Cache contention over the global structure in STM.• Especially serious on a computer with multiple multicores.
• Our solution: Zone + Timestamp Extension‣ Compared with single-clock STM (like TinySTM):
✴ Much better performance (with less cache contention)‣ Compared with distributed-clock STM (like TL2C):
✴ Less aborts (at cost of some timestamp extensions)✴ Similar or better performance
• Future work:‣ Having multiple timestamp tables as well for better scalability‣ Experiment similar protocols on cluster STM
67

Contact Us
• Kinson Chan‣ [email protected]‣ http://i.cs.hku.hk/~kchan
• Cho-Li Wang‣ [email protected]‣ http://i.cs.hku.hk/~clwang
• System Research Group‣ http://www.srg.cs.hku.hk/
• Department of Computer Science, University of Hong Kong‣ http://www.cs.hku.hk/
68

Questions?