tree-pattern queries on a lightweight xml processor mirella m. moro zografoula vagena vassilis j....
TRANSCRIPT

Tree-Pattern Queries on a Lightweight XML Processor
MIRELLA M. MORO
Zografoula Vagena
Vassilis J. Tsotras
Research partially supported by CAPES, NSF grant IIS 0339032, UC Micro, and Lotus Interworks

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 2
Outline
Motivation and Contributions Background Method Categorization Experimental Evaluation Conclusions

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 3
Motivation
XML query languages: selection on both value and structure “Tree-pattern” queries (TPQ) very common in XML
Many promising holistic solutions
None in lightweight XML engines Without optimization module (e.g. eXist, Galax) Effective, robust processing method
Reasons: No systematic comparison of query methods under a common
storage model No integration of all methods under such storage model
Context: XPath semantics, stored data (indexed at will)

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 4
Contributions
TPQ methods over unified environment Method Categorization: data access patterns and
matching algorithm Common storage model + integration of all methods
Capture the access features Permit clustering data with off-the-shelf access methods
(e.g. B+tree) Novel variations of methods using index structures +
Handle TPQ Extensive comparative study
Synthetic, benchmark and real datasets Decision in the applicability, robustness and efficiency
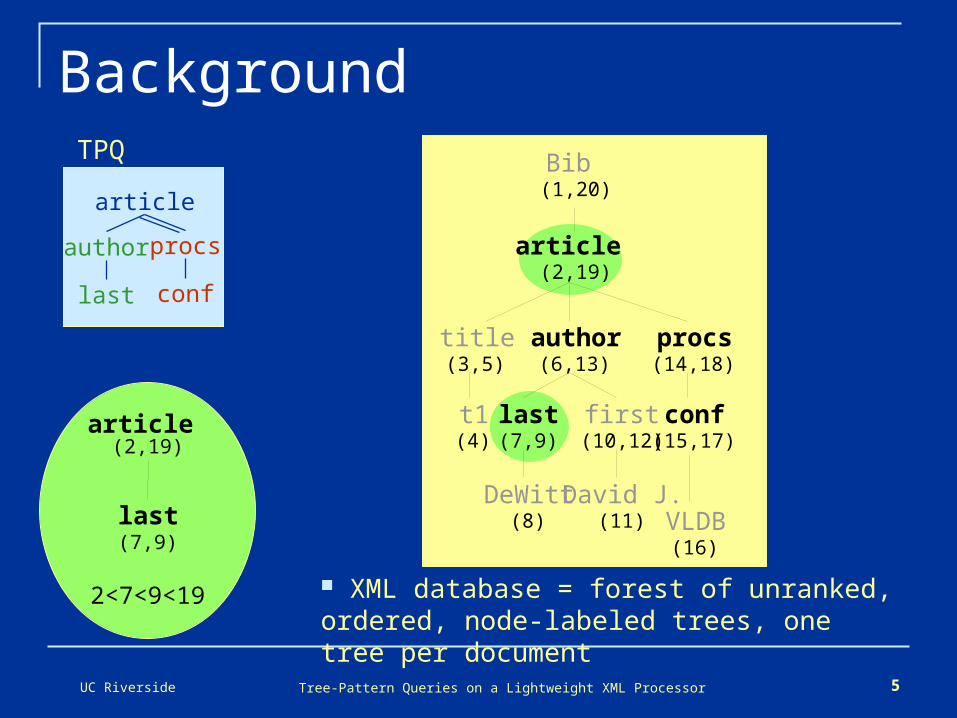
UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 5
article
author
last
procs
conf
Background
article (2,19)
last(7,9)
2<7<9<19
Bib (1,20)
article (2,19)
title(3,5)
procs(14,18)
author(6,13)
last(7,9)
first(10,12)
David J.(11)
DeWitt(8)
conf(15,17)
t1(4)
VLDB(16)
XML database = forest of unranked, ordered, node-labeled trees, one tree per document
TPQ

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 6
Common Storage Model
B+ Tree on ( tag, initial )
bib (1,16)
book (2,9) (10,17)
author (3,8) (11,16) (19,24)
name (4,5) (12,13) (20,21)
paper (18,25)
address (6,7) (14,15) (22,23)
bib(1,26)
book (2,9) paper (18,25)
author (3,8) author (19,24)
name(4,5)
address(6,7)
name(20,21)
address(22,23)
book (10,17)
author(11,16)
name(12,13)
address(14,15)
Input = sequence (list) of elements One list per document tag = element list
Node clustering by index structures Numbering scheme

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 7
Method Categorization
Parameters: access pattern and matching algorithm
(1) set based techniques
(2) query driven
(3) input driven
(4) structural summaries

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 8
Cat 1: Set-based Techniques
Access Pattern Matching Process
Sorted/indexedJoin sets,
merge individual paths
Input: sequences of elements, one list per query node element, possibly indexed (set-based)
Major representative: TwigStack Optimal XML pattern matching algorithm (ancestor/descendant)
Stack-based processing Set of stacks = compact encoding of partial and total results in
linear space (possibly exponential number of answers)

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 9
TwigStack + Indexes
B+tree, built on the left attribute From ancestor: probe descendants: skip initial nodes Ancestor skipping not effective (up to 1st element that follows)
XB-tree: on (left,right) bounding segment XR-tree: on (left,right), B+tree with complex index key + stab lists
A comparative study* shows that Skipping ancestors: XBTree better (XBTree size is smaller) Recursive level of ancestors: XBTree better again
Searching on stab lists of XR-tree is less efficient Plain B+tree: skips descendants, BUT not ancestors XBTwigStack is our choice
* H.Li et al. “An Evaluation of XML Indexes for Structural Joins”. Sigmod Record, 33(3), Sept 04

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 10
Cat 2: Query Driven Techniques
Processing: the query defines the way input is probed
Major representatives: ViST and PRIX Specific details: significantly different Same strategy
Convert both document and query to sequences Processing query = subsequence matching
Access Pattern Matching Process
Indexed/random Incremental construction of each result instance

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 11
ViST and PRIX
Recursively identify matches = quadratic time Optimize the naïve solution:
Identify candidate nodes for each matching step Index structures to cluster those candidates
Subsequence matching process = a plan consisting of INLJ among relations, each of which groups document nodes with the same label
For a given query, joins sequence statically defined by the sequencing of the query
INLJ plans are a superset of the static plans that PRIX and VIST use
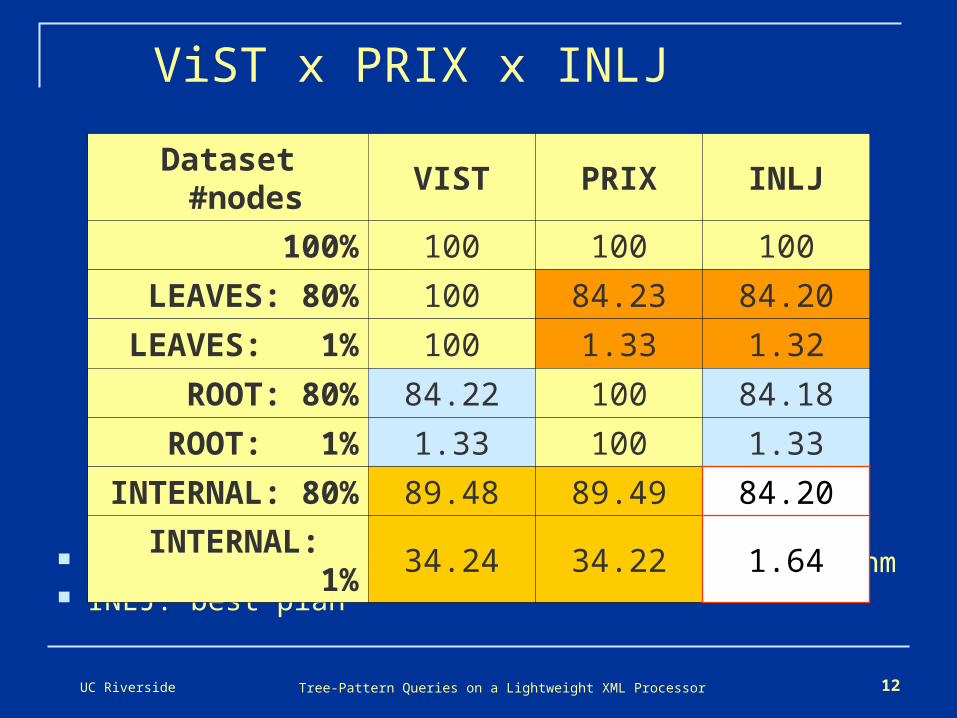
UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 12
ViST x PRIX x INLJ
Percentage of nodes processed by each algorithm INLJ: best plan
Dataset #nodes VIST PRIX INLJ
100% 100 100 100
LEAVES: 80% 100 84.23 84.20
LEAVES: 1% 100 1.33 1.32
ROOT: 80% 84.22 100 84.18
ROOT: 1% 1.33 100 1.33
INTERNAL: 80% 89.48 89.49 84.20
INTERNAL: 1% 34.24 34.22 1.64
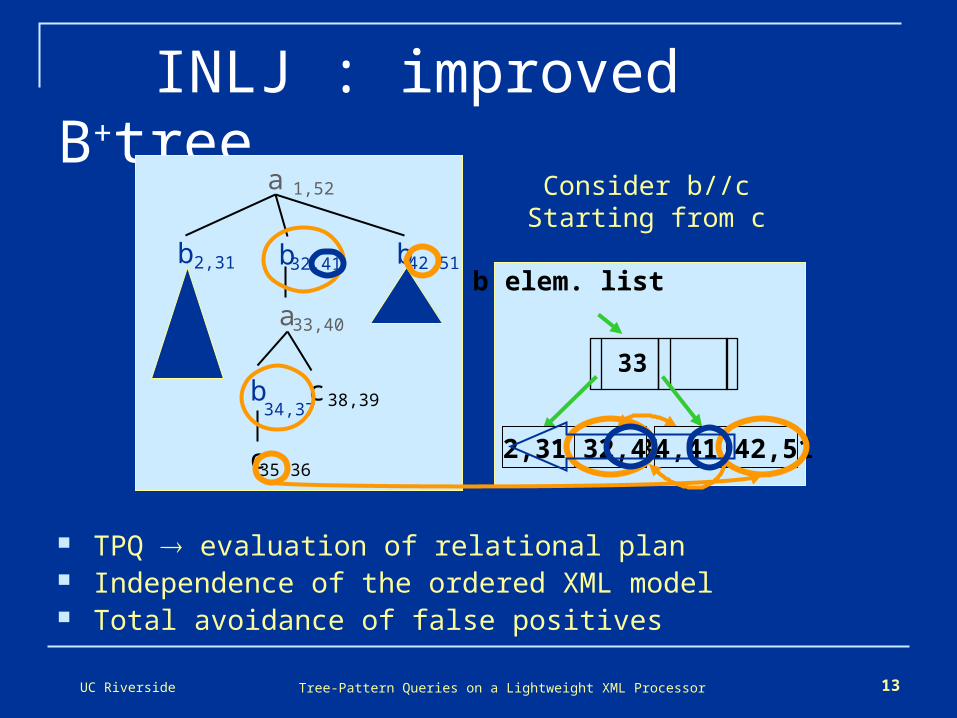
UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 13
INLJ : improved B+tree
TPQ evaluation of relational plan Independence of the ordered XML model Total avoidance of false positives
a 1,52
b32,41
b34,37
a33,40
c 38,39
c35,36
b 2,31 b42,51b elem. list
33
34,41 42,51 2,31 32,41
Consider b//cStarting from c

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 14
Cat 3: Input Driven Techniques
Processing: at each point, the flow of computation is guided entirely by the input through a Finite State Machine (DFA/NFA)
Advantages Each node processed only once Simplicity, sequential access pattern
Problem: skipping elements
Access Pattern Matching Process
Sequential Input drives computation, merge individual paths

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 15
SingleDFA and IdxDFA
SingleDFA <element> triggers the DFA, choosing next state </element>: execution backtracks to when start processed TPQ matching: intermediate results compacted on stacks
Experiments show reading whole input = not enough
Speeding up navigation: IdxDFA Instead of reading sequentially: use indexes and
skip descendants
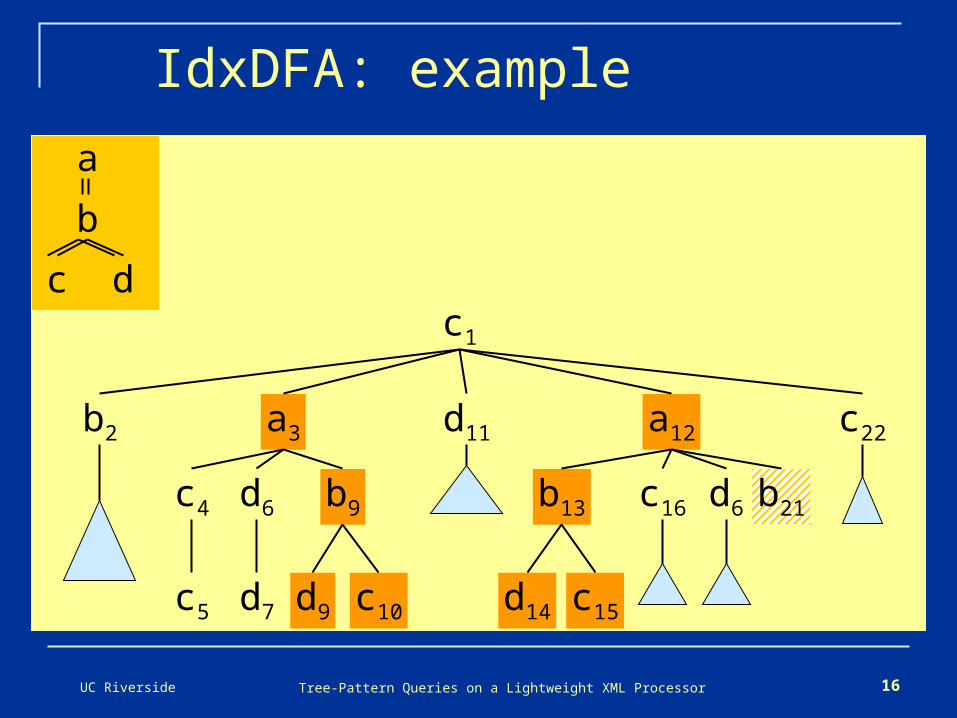
UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 16
IdxDFA: example
c1
b2 a3
c4 d6
c5 d7
b9
d9 c10
d11 a12
c16 d6b13
d14 c15
b21
c22
a
b
c d

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 17
IdxDFA: example
c1
b2 a3
c4 d6
c5 d7
b9
d9 c10
d11 a12
c16 d6b13
d14 c15
b21
c22
b9c4 d6
c5 d7
a
b
c d
d9 c10
d11 a12
b13
d14 c15
c16 d6 b21
c22

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 18
Cat 4: Graph Summary Evaluation
Structural summary: index node identifies a group of nodes in the document
Processing: identify index nodes that satisfy the query + post processing filtering
Beneficial: when there is a reasonable structural index, much smaller than document
Problem: graph size comparable/larger than original document
Access Pattern Matching Process
Indexed/Random Merge-join partitioned input,merge individual paths

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 19
Categories Summary
Access Pattern
Matching Process Methods
Set Based Sorted/Indexed
Join sets, merge individual paths
Twigstack /XB, B+tree, XR-tree
Query Driven
Indexed/random
Incremental construction of each result instance
(ViST, PRIX)INLJ
Input Driven
Sequential Input drives computation, merge individual paths
SingleDFA, IdxDFA
Structural Summary
Indexed/random
Merge-join partitioned input, merge individual paths
Structural indexes

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 20
Experimental Evaluation
1. Experiments with real datasets
2. Experiments with synthetic datasets Further analyze each method Characterize the methods according to specific
features available in each custom dataset
3. More sets of experiments Closely verify XBTWIGSTACK versus INLJ

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 21
Algorithms using the same API Analysis varying structure and selectivity Performance measure = total time required to
compute a query Number of nodes as secondary information
Intel Pentium 4 2.6GHz, 1Gb ram Berkeley DB: 100 buffers, page size 8Kb, B+ tree Real/benchmark datasets
XMark (Internet auction, 1.4 GB raw data, ± 17 million nodes), Protein Sequence Database
Setup
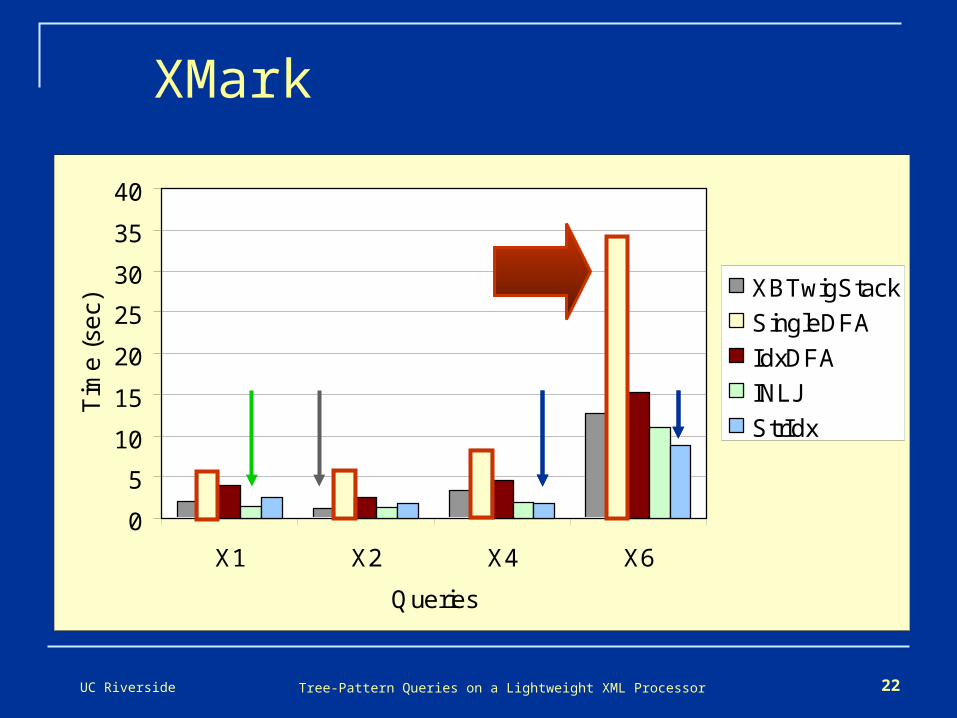
UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 22
XMark
0
5
10
15
20
25
30
35
40
X1 X2 X4 X6
Queries
Tim
e (
sec)
XBTwigStack
SingleDFA
IdxDFA
INLJ
StrIdx

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 23
Custom Data
Goal: isolate important features Query //a//b[.//c]//d
Simple enough for detailed investigation Complex enough to provide large number of
different data access possibilities Vary selectivity of each element separately Add recursion to key elements (root, leaf)
a
b
c d
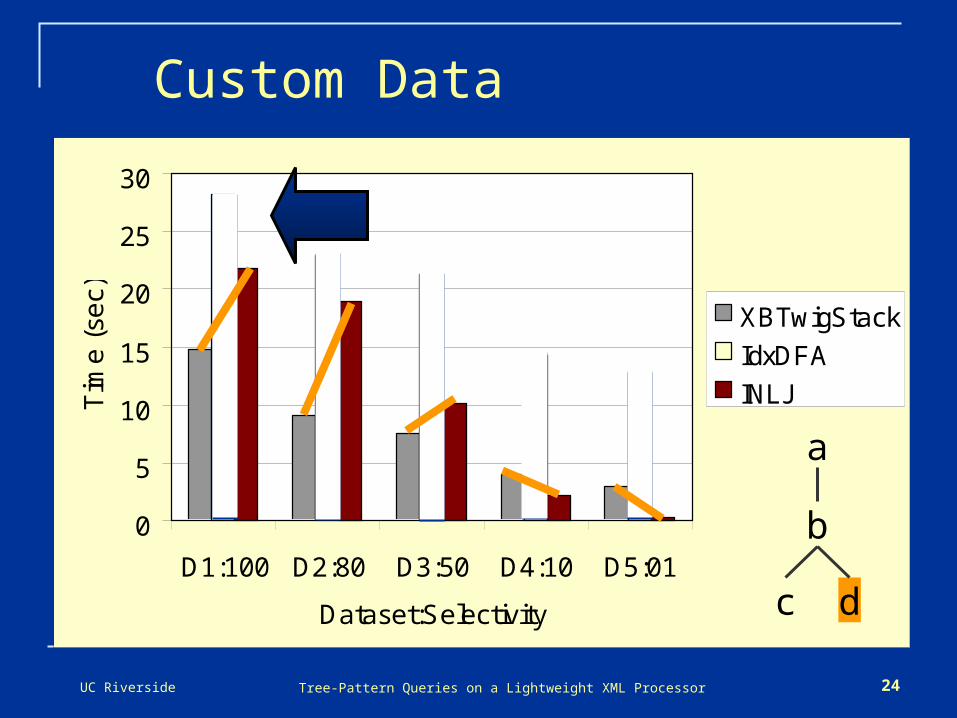
UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 24
Custom Data
0
5
10
15
20
25
30
D1:100 D2:80 D3:50 D4:10 D5:01
Dataset:Selectivity
Tim
e (
sec)
XBTwigStack
IdxDFA
INLJ
a
b
c d
UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 25
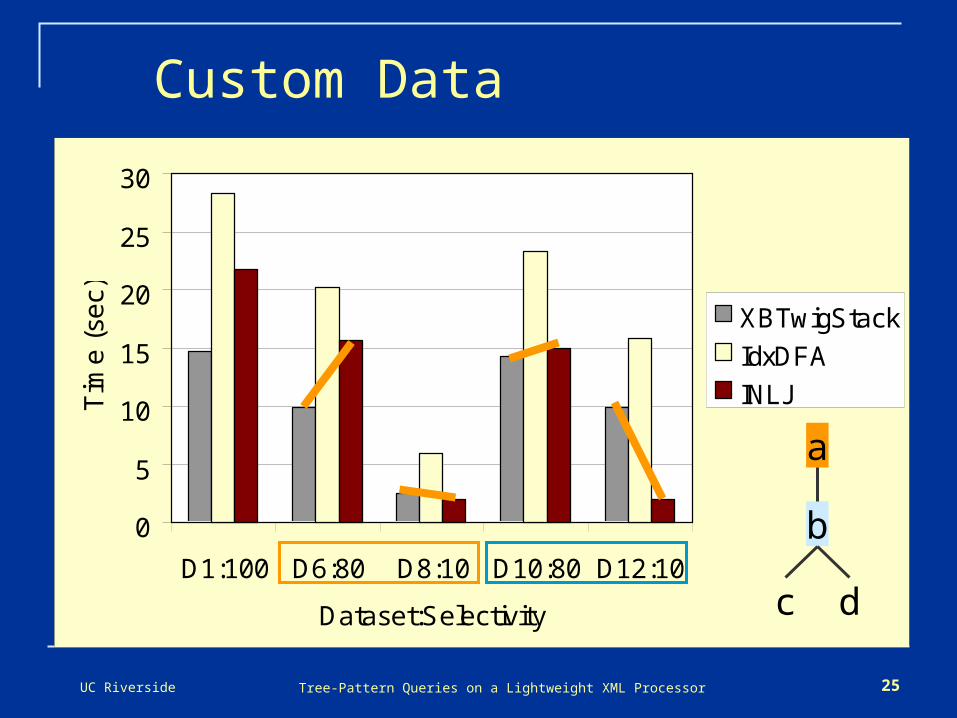
Custom Data
0
5
10
15
20
25
30
D1:100 D6:80 D8:10 D10:80 D12:10
Dataset:Selectivity
Tim
e (
sec)
XBTwigStack
IdxDFA
INLJ
a
b
c d
UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 26
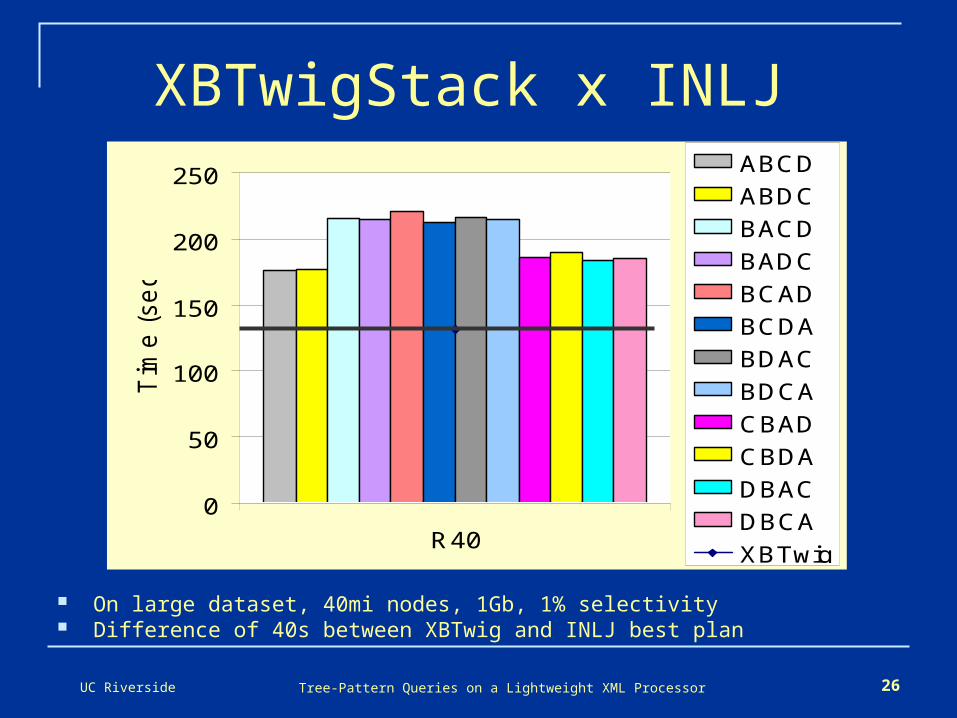
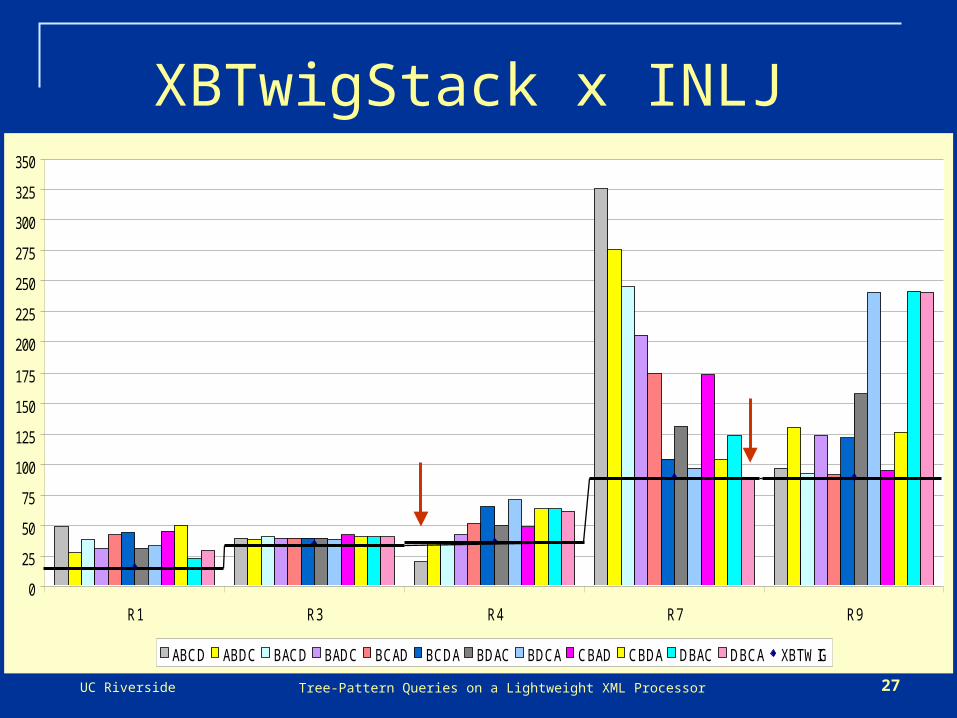
XBTwigStack x INLJ
On large dataset, 40mi nodes, 1Gb, 1% selectivity Difference of 40s between XBTwig and INLJ best plan
0
50
100
150
200
250
R40
Tim
e (
se
c)
ABCD
ABDC
BACD
BADC
BCAD
BCDA
BDAC
BDCA
CBAD
CBDA
DBAC
DBCA
XBTwig
UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 27
0
25
50
75
100
125
150
175
200
225
250
275
300
325
350
R1 R3 R4 R7 R9
ABCD ABDC BACD BADC BCAD BCDA BDAC BDCA CBAD CBDA DBAC DBCA XBTWIG
XBTwigStack x INLJ

UC Riverside Tree-Pattern Queries on a Lightweight XML Processor 28
Conclusions
Categorization of TPQ processing algorithms Adaptations for processing TPQ
DFA + accessing nodes from B+tree INLJ + ancestor skipping
DFA-based improved, IdxDFA, not enough Structural summary available and smaller than
document: StrIdx XBTwigStack: most robust and predictable
INLJ when high selectivity: no guarantee about chosen plan without optimizer module

Questions?