trisma & instagrammatics:framing & balancing big data for humanities research
TRANSCRIPT

TrISMA & Instagrammatics:Framing & Balancing Big Data for
Humanities ResearchDr Tama Leaver, Curtin University (@tamaleaver)
Department of Internet StudiesCentre for Culture and Technology (CCAT)
(& Dr Tim Highfield, QUT (@timhighfield)
Social Media Research Group)
The Social Life of Big Data 2015 SymposiumPerth Zoo Convention Centre 2 June, 2015

Overview
1. TrISMA.
2. Instagrammatics: A Method for Collecting Media from Instagram
3. Project Context: The Ends of Identity
4. Breaking down #ultrasound

[1] TrISMA

Tracking Infrastructure for Social Media Analytics [TrISMA]
• ARC-funded infrastructure cooperatively developed by QUT (lead), Curtin, Swinburne & Deakin universities.
• Twitter: full snapshot of all Australian Twitter use• Facebook pages: ongoing scraping.• Instagram: tag scraping, and attempt to ‘map’
Australian use (via geotags).• Backed by Google BigQuery (for speed, breadth).• Bespoke tools for ease of queries and analysis.
Ready to go tools and data, to facilitate Australian-centric research.

[2] Instagrammatics: A Method for Collecting Media from Instagram

Building from studies using Twitter
• To map and track social media use, we start with established methods for studying Twitter.
• Topical datasets, using similar methods around varied subjects, including:– Breaking news– Politics– Crises– Popular culture– Sports

Twitter data
User name
TweetHashtag
Link
Date and time@mention

#hashtags on Twitter
• “… a way of indicating textually keywords or phrases especially worth indexing… by using the # character to mark particular keywords, Twitter users communicate a desire to share particular keywords folksonomically.” (Halavais, 2013, p. 36)
• Hashtag use has evolved over time to serve additional, less organisational functions: humour, meta-commentary, emotion…

Tags and social media
• Tagging did not originate with Twitter, although a prominent aspect of how users tweet.
• Tags and hashtags used on other social media, although functionality, adoption, and intentions vary.– Instagram vs. Pinterest vs. Facebook…

The Twitter dilemma
• Does the comparative ease of access to data and the use of common methods mean that Twitter is over-represented in research?
• There are methodological challenges of comparing Twitter – as a series of (predominantly) fixed data points – with Instagram and other more dynamic social media data, as well as comparing text and image/video/sound content.

Twitter vs. Instagram
• Advantages of Twitter:– Established capture and analytics methods;– Public data;– Consistent data (140 character limit);– Primarily textual data (processing and analysis).
• Methods for large-scale tracking and analysis of Twitter are well-established, but not yet for other social media, including Instagram.

Instagram data
Creator user name
Image/ video Caption
Likes
Comments
Tag
@mention
Date/time

Tracking Instagram activity
• Our initial approach builds on Twitter-specific work and tools, which allows for comparative analysis (methods and content).
• The starting focus is on #tags – practices, functions, coverage of the same topic/tag, including across different platforms.
• See Highfield and Leaver, 2015.

Prototype Instagram methods
• Following the Twitter analytics model of querying for specified keywords/hashtags, query Instagram API for similar tag-specific results.
• The tag search query retrieves data including: media id, media type, user id, user name, caption, image/video links, time and date, location data, tags, comments (count and content), likes (count).

Changing data• Unlike Twitter, content posted on Instagram is not
static.• A photo or video posted can be added to by the
original user and others viewing the file.– Liking, adding comments, replying to previous comments.
• Rather than creating standalone data, comments are additions to the existing image – attached to this specific data point, not in isolation.
• Additional contributions may be made to these files hours, days, months after the fact.
• When should we ‘capture’ the data? (How long until comments typically finish, for example?)

Authorship and intentions
• Comments also impact upon what is being tracked and captured.
• Tracking specific tags through the Instagram API returns media where the creator has, in the process of publishing the content, included these tags in their caption.
• However, it also includes media where a follow-up comment includes these tags (although this can later be filtered out).

NB: Privacy isn’t a binary …Individual and cultural definitions and expectations of privacy are ambiguous, contested, and changing. People may operate in public spaces but maintain strong perceptions or expectations of privacy. Or, they may acknowledge that the substance of their communication is public, but that the specific context in which it appears implies restrictions on how that information is -- or ought to be -- used by other parties. Data aggregators or search tools make information accessible to a wider public than what might have been originally intended.
(Markham & Buchanan, 2012, p. 6)

Contextual Integrity in Ethics• Instagram may be experienced as private or partially
private in everyday use (contextually), despite being public at a technical level (via the API).
• The shift from an iPhone only app to Android and Windows phone, plus web profiles makes Instagram photos more and more public.
• Researchers have to weigh intentionality in sharing, not just technical publicness (“it’s freely available online”).
• We need to move from ‘public vs private’ to questions of surfacing and amplification.
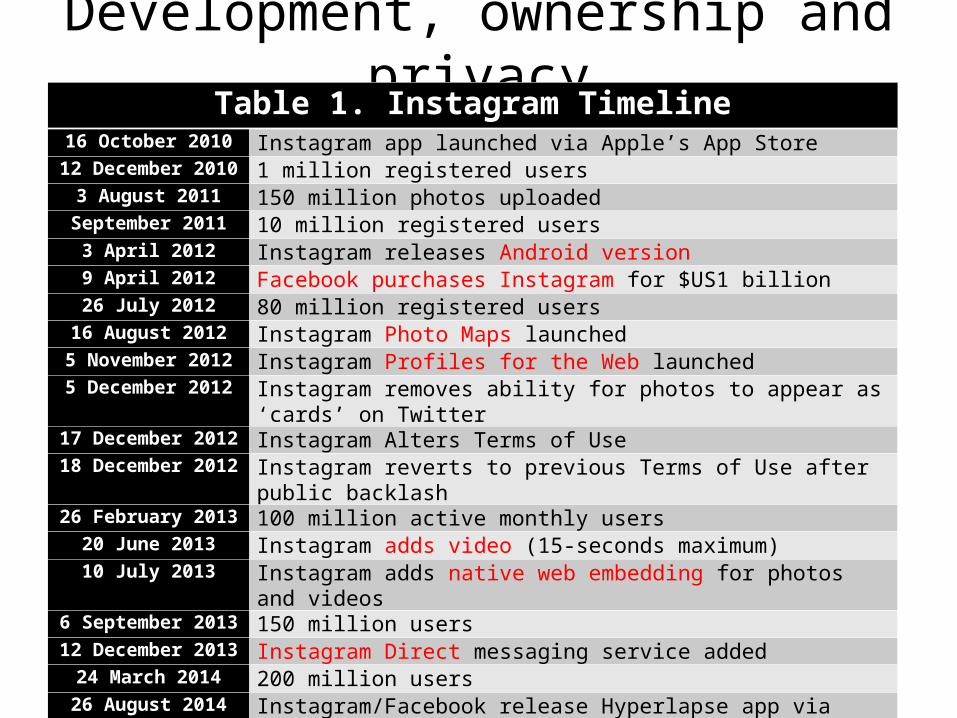
Development, ownership and privacyTable 1. Instagram Timeline
16 October 2010 Instagram app launched via Apple’s App Store12 December 2010 1 million registered users
3 August 2011 150 million photos uploadedSeptember 2011 10 million registered users
3 April 2012 Instagram releases Android version9 April 2012 Facebook purchases Instagram for $US1 billion26 July 2012 80 million registered users
16 August 2012 Instagram Photo Maps launched5 November 2012 Instagram Profiles for the Web launched5 December 2012 Instagram removes ability for photos to appear as ‘cards’ on Twitter
17 December 2012 Instagram Alters Terms of Use 18 December 2012 Instagram reverts to previous Terms of Use after public backlash26 February 2013 100 million active monthly users
20 June 2013 Instagram adds video (15-seconds maximum)10 July 2013 Instagram adds native web embedding for photos and videos
6 September 2013 150 million users12 December 2013 Instagram Direct messaging service added
24 March 2014 200 million users26 August 2014 Instagram/Facebook release Hyperlapse app via Apple App Store
10 November 2014 Instagram enables photo caption editing after posting10 December 2014 300 million users, 70 million photos & videos shared per day

Limitations of platforms …
• Even with 300 million users, Instagram is far from representative of users in any particular location or demographic.
• Analysing use of any platform is necessarily limited, and these limits need to be kept in mind when making any claims about the representativeness of the findings.

[3] Project Context: the Ends of Identity

Identity Online: The Networked Self / Networked Publics
• Persistence• Replicability• Scalability• Searchability (boyd, 2010)• + Ownership (Aufderheide, 2010)

Shared assumptions of ‘Identity 2.0’, the ‘Networked Self’, and ‘Web Presence’
• Individual agency is central.• Presumption that identity should be
controlled, curated and managed by the ‘self’ being presented.
• When agency is not the controlling influence, this is seen as an issue to be overcome (eg better privacy settings, clearer Terms of Use).

What about the Ends of Identity?
• Following Erving Goffman (1959) if frontstage is self performed, and backstage is the more essential self, who builds the stage, and who remembers the performance(s)?
Before (online) agency: before birth, until the ‘reigns’ of online identity tools and performances are inherited?
After (online) agency: who looks after online traces of self once the self they refer to dies?

At one end: parents as initial identity curators/creators online …
• Parents/guardians set the initial parameters of online identity.
• From ultrasounds photos to cute toddler pics, losing that first tooth etc …
• How do and should young people ‘inherit’ online identities?

“The emergence of such social media platforms as Facebook, Flickr, Instagram, Twitter, Bundlr and YouTube facilitating the sharing of images has allowed the wide dissemination of imagery and information about the unborn in public forums. Indeed, sharing of the first ultrasound photograph on social media has become a rite of pregnancy for many women.”
(Lupton, 2013, p. 42)

NB: The ‘Real Name’ Web"Nowadays, however, the anonymity of the [early] internet and the construction of online personas that do not reflect offline identities have been reconstructed as 'risk factors' of internet use … Governments, schools, parents and other concerned parties now routinely warn against online imposters, bullying and identity theft, and social network sites like Facebook or Google+ have policies requiring users to register with their real names and data, and prevent them from having more than one account.”
(Zoonen, 2013: 45)

At the other end: Memorializing Performed Digital Selves?
• What happens to profiles, accounts, photos, videos and other social traces after someone dies?
• Do we have the right to delete it all?
• Should it be memorialized?• Who decides? (very few laws
address social media inheritance).

[4] Breaking down #ultrasound

On Instagram alone, every month thousands of foetal images are shared and publicly tagged as ultrasounds. Often these images capture the metadata visible on the ultrasound screen, which might include the mother’s name, the current date, the location of the scan, the expected delivery date, and other personal information. For many young people, this type of sharing will be their first mention on social media, the beginning of a long and likely loving record published by their parents, guardians and loved ones.
(Leaver, 2015)

#ultrasound Table 1. #ultrasound tagged media on Instagram,
2014
Images Videos Overall Media
March 3468 151 3619
April 3847 128 3975
May 3575 151 3726
3-Month Totals: 10890 430 11320

#ultrasound 48hr snapshot (focused on first Monday of each month)
• March: 289 images / 7 videos• April: 331 images / 14 videos• May: 373 images / 11 videos
Now to drill down further into the March #ultrasound images …
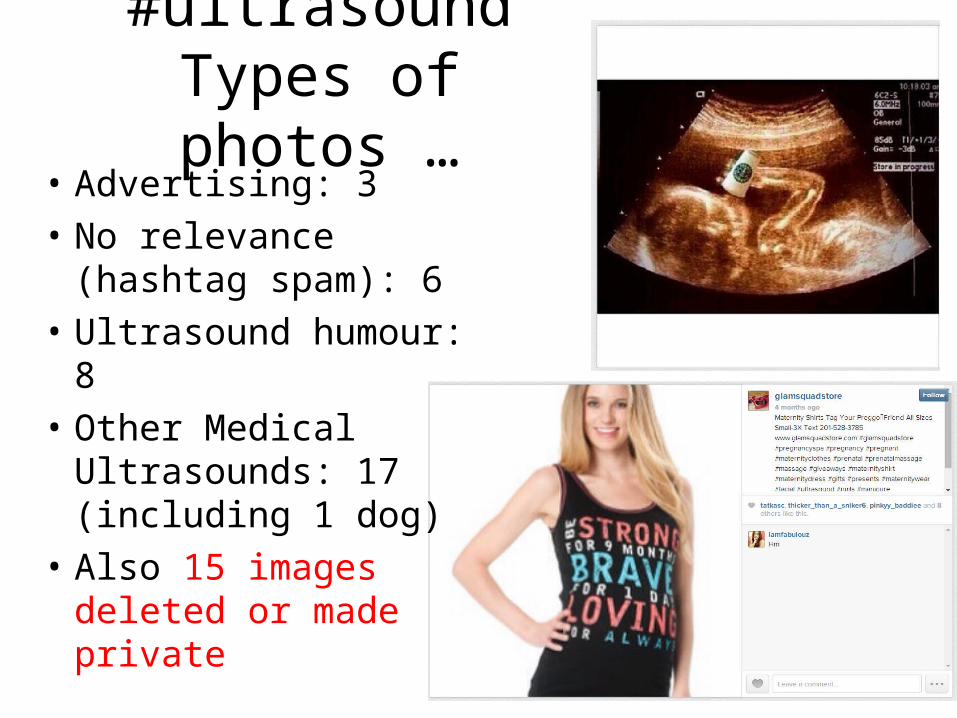
#ultrasoundTypes of photos …
• Advertising: 3• No relevance (hashtag
spam): 6• Ultrasound humour: 8• Other Medical
Ultrasounds: 17 (including 1 dog)
• Also 15 images deleted or made private

Social Experiences of #Ultrasounds
• 32 photos depicting social experiences centred on prenatal ultrasounds
• EG parent(s) travelling to/from the ultrasound
• EG selfie and caption expression nervousness or excitement prior to ultrasound

Collages/Professional Photos incl. #ultrasounds
• 32 photos either deliberate collages or professional photographs incorporating ultrasound photos
• EG professional posed shot or ultrasound on screen or printed
• EG collage showing ultrasound, parent(s) plus celebratory details (eg champagne glass or ‘it’s a boy/girl’ or planned baby name).
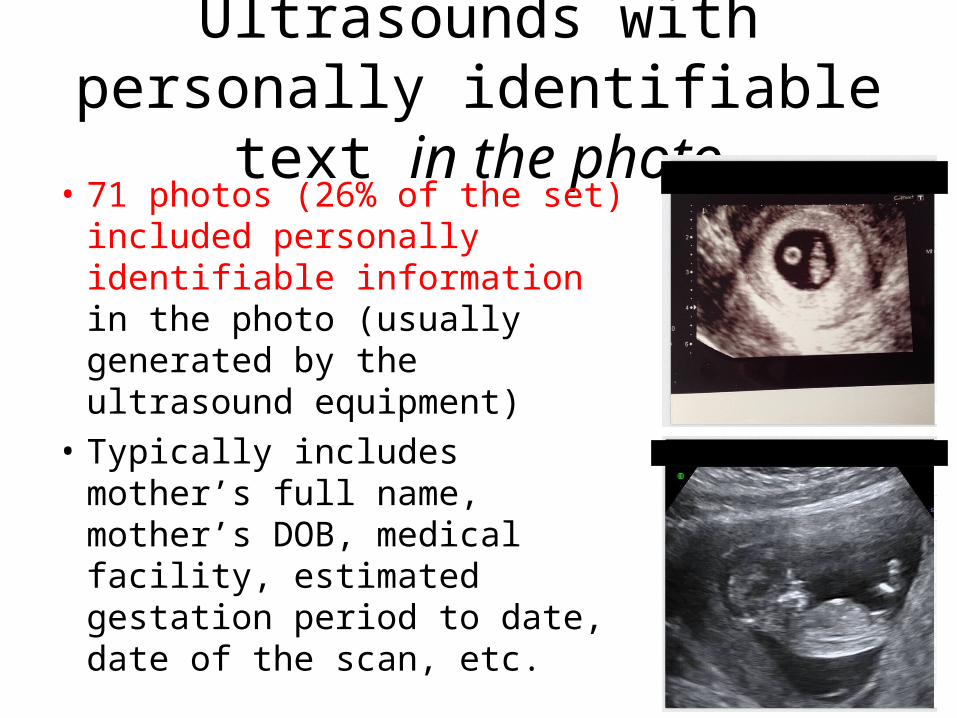
Ultrasounds with personally identifiable text in the photo
• 71 photos (26% of the set) included personally identifiable information in the photo (usually generated by the ultrasound equipment)
• Typically includes mother’s full name, mother’s DOB, medical facility, estimated gestation period to date, date of the scan, etc.

Ultrasounds without personally identifiable text in the photo
• 105 photos (38% of the set) do not include personally identifiable information in the photograph
• Some deliberately obscured, some out of focus, most zoomed to avoid those details (either consciously or simply to take a better photograph)

Instagram Videos …
• 7 videos in data collected• 1 not relevant (hashtag spam)• 1 other medical ultrasound• 2 videos included personally
identifiable information• 3 videos did not contain
personally identifiable information

Not visible …• December 2013 Instagram Direct
messaging introduced: photos sent only to specified Instagram contacts: no way of identifying how many are ultrasound photos (or tagged as such).
• Also, no way to track #ultrasound from private Instagram accounts

Tentative Conclusions: Privacy
• 15 images deleted/hidden in first fortnight is significant (potentially rethinking sharing publicly).
• 71 images with personally identifiable information = the initial (named) social media footprint preceding birth.
• Whether conscious choice (informed) or not, very hard to tell.

Tentative Conclusions: Ultrasounds part of the social experience of pregnancy
• Social experience (selfies, journey to/from) and collages/professional photos demonstrate the mainstream sociality of sharing ultrasound photos.
• Collages show explicit choices about framing the ’story’ of the ultrasound; often a form of visual digital storytelling.

Tentative conclusions: identity/presence forming
• All shared #ultrasound photos are indicative of a growing culture of sharing photos of young people by parents/guardians/etc.
• Literacies regarding the persistence of this data are haphazard, rarely informed by the apps/platforms, showing a cultural need for widespread embedding of mobile media literacies.
• Social norms about sharing these images are evolving because of affordances, as much as driving them

Bigger Picture …
• Instagram can provide both big data (quantitative) and also the richness of granular data (qualitative).
• Asking social questions of big data must take account of the insights available at the granular level.
• Balancing big data and granularity allows the humanities researchers, with all their tools for interpreting granularity, to enhance their research with contextualised big data.

References• Aufderheide, P. (2010). Copyright, Fair Use, and Social Networks. In Z. Papacharissi (Ed.), A Networked
Self: Identity, Community, and Culture on Social Network Sites (pp. 274-303). Routledge.• boyd, danah. (2010). Social Network Sites and Networked Publics: Affordances, Dymanics and
Implications. In Z. Papacharissi (Ed.), A Networked Self: Identity, Community, and Culture on Social Network Sites (pp. 39-58). Routledge.
• boyd, d., & Crawford, K. (2012). Critical Questions for Big Data. Information, Communication & Society, 15(5), 662-679.
• Bruns, A., & Burgess, J. (2011). Mapping Online Publics. http://mappingonlinepublics.net/• Halavais, A. (2013). Structure of Twitter: Social and Technical. In K. Weller, A. Bruns, J. Burgess, M.
Mahrt, & C. Puschmann (Eds.), Twitter and Society. New York: Peter Lang.• Highfield, T., & Leaver, T. (2015). A methodology for mapping Instagram hashtags. First Monday, 20(1).
http://doi.org/10.5210/fm.v20i1.5563 • Goffman, E. (1959). The Presentation of Self in Everyday Life. New York: Anchor Book.• Lupton, D. (2013). The Social Worlds of the Unborn. Basingstoke: Palgrave MacMillan.• Leaver, T. (2015). Researching the Ends of Identity: Birth and Death on Social Media. Social Media +
Society, 1(1). http://doi.org/10.1177/2056305115578877 • Markham, A., & Buchanan, E. (2012). Ethical Decision-Making and Internet Research Recommendations
from the AoIR Ethics Working Committee (Version 2.0). Retrieved from http://aoir.org/reports/ethics2.pdf
• Zoonen, L. van. (2013). From identity to identification: fixating the fragmented self. Media, Culture & Society, 35(1), 44–51. doi:10.1177/0163443712464557

Questions or Comments?
Or find me later …
www.tamaleaver.net@tamaleaver