ttic 31190: natural language processing -...
TRANSCRIPT

TTIC31190:NaturalLanguageProcessing
KevinGimpelWinter2016
Lecture11:RecurrentandConvolutionalNeuralNetworksinNLP
1

Announcements• Assignment3assignedyesterday,dueFeb.29
• projectproposaldueTuesday,Feb.16
• midtermonThursday,Feb.18
2
Roadmap• classification• words• lexicalsemantics• languagemodeling• sequencelabeling• neuralnetworkmethodsinNLP• syntaxandsyntacticparsing• semanticcompositionality• semanticparsing• unsupervisedlearning• machinetranslationandotherapplications
3
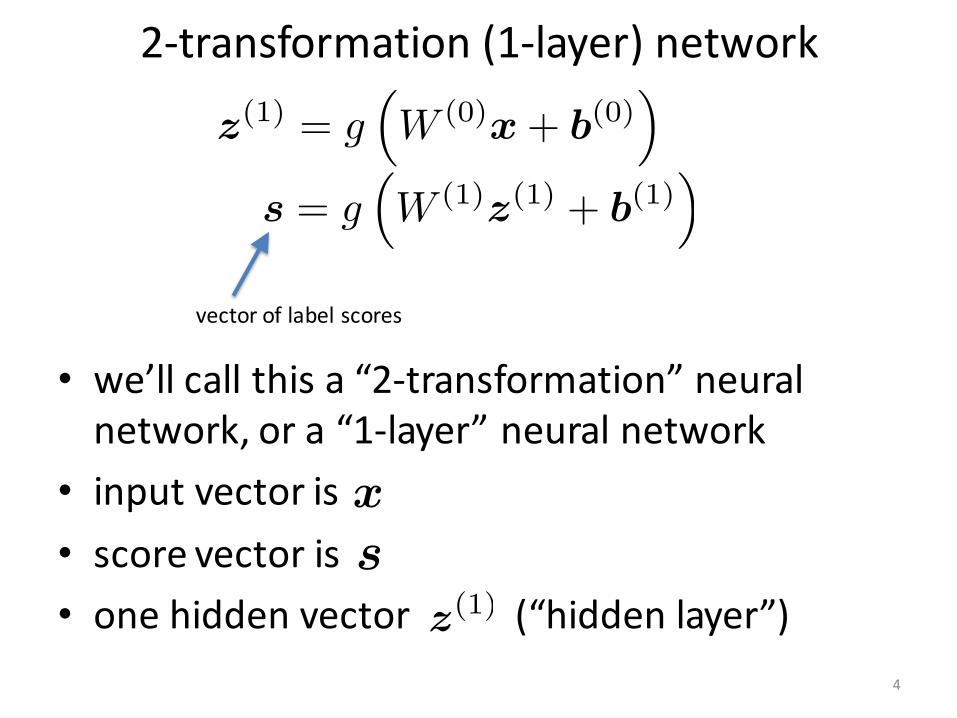
2-transformation(1-layer)network
• we’llcallthisa“2-transformation”neuralnetwork,ora“1-layer”neuralnetwork
• inputvectoris• scorevectoris• onehiddenvector(“hiddenlayer”)
4
vectoroflabelscores

1-layerneuralnetworkforsentimentclassification
5

Usesoftmax functiontoconvertscoresintoprobabilities
6

ikr smh heaskedfiryo lastnamesohecanadduonfb lololol
7
intj pronoun prepadj prep verbotherverb det noun pronoun
pronoun propernoun
verbprep intj
NeuralNetworksforTwitterPart-of-SpeechTagging
adj =adjectiveprep=prepositionintj =interjection
• inAssignment3,you’llbuildaneuralnetworkclassifiertopredictaword’sPOStagbasedonitscontext

ikr smh heaskedfiryo lastnamesohecan
8
intj pronoun prepadj prep verbotherverbdet noun pronoun
NeuralNetworksforTwitterPart-of-SpeechTagging
• e.g.,predicttagofyo givencontext• whatshouldtheinputxbe?– ithastobeindependentofthelabel– ithastobeafixed-lengthvector

ikr smh heaskedfiryo lastnamesohecan
9
intj pronoun prepadj prep verbotherverbdet noun pronoun
NeuralNetworksforTwitterPart-of-SpeechTagging
• e.g.,predicttagofyo givencontext• whatshouldtheinputxbe?
wordvectorforyo

ikr smh heaskedfiryo lastnamesohecan
10
intj pronoun prepadj prep verbotherverbdet noun pronoun
NeuralNetworksforTwitterPart-of-SpeechTagging
• e.g.,predicttagofyo givencontext• whatshouldtheinputxbe?
wordvectorforyowordvectorforfir

ikr smh heaskedfiryo lastnamesohecan
11
intj pronoun prepadj prep verbotherverbdet noun pronoun
NeuralNetworksforTwitterPart-of-SpeechTagging
wordvectorforyowordvectorforfir
• whenusingwordvectorsaspartofinput,wecanalsotreatthemasmoreparameterstobelearned!
• thisiscalled“updating”or“fine-tuning”thevectors(sincetheyareinitializedusingsomethinglikeword2vec)

ikr smh heaskedfiryo lastnamesohecan
12
intj pronoun prepadj prep verbotherverbdet noun pronoun
NeuralNetworksforTwitterPart-of-SpeechTagging
vectorforlastvectorforyo
• let’susethecenterword+twowordstotheright:
vectorforname
• ifname istotherightofyo,thenyo isprobablyaformofyour• butourx aboveusesseparatedimensionsforeachposition!
– i.e.,nameistwowordstotheright– whatifnameisonewordtotheright?

FeaturesandFilters• wecoulduseafeaturethatreturns1ifnameistotherightofthecenterword,butthatdoesnotusetheword’sembedding
• howdoweincludeafeaturelike“awordsimilartoname appearssomewheretotherightofthecenterword”?
• ratherthanalwaysspecifyrelativepositionandembedding,wewanttoaddfilters thatlookforwordslikenameanywhereinthewindow(orsentence!)
13

Filters• fornow,thinkofafilterasavectorinthewordvectorspace
• thefiltermatchesaparticularregionofthespace• “match”=“hashighdotproductwith”
14

Convolution• convolutionalneuralnetworksuseabunchofsuchfilters
• eachfilterismatchedagainst(dotproductcomputedwith)eachwordintheentirecontextwindoworsentence
• e.g.,asinglefilterisavectorofsamelengthaswordvectors
15

Convolution
16
vectorforlastvectorforyo vectorforname

Convolution
17
vectorforlastvectorforyo vectorforname
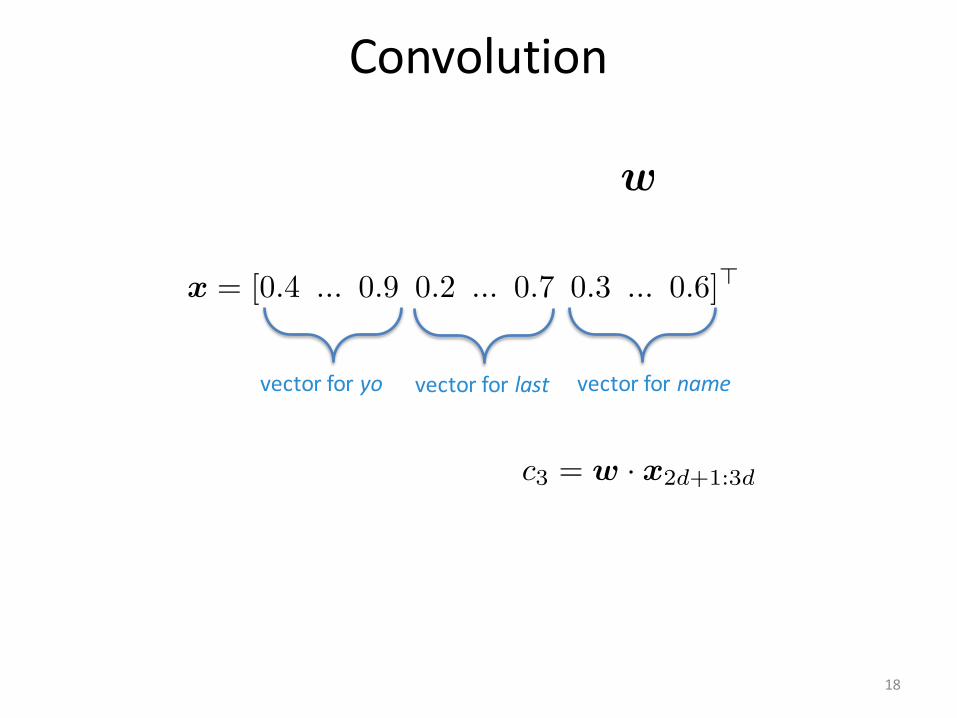
Convolution
18
vectorforlastvectorforyo vectorforname

Convolution
19
vectorforlastvectorforyo vectorforname
=“featuremap”,hasanentryforeachwordposition incontextwindow/sentence

Pooling
20
vectorforlastvectorforyo vectorforname
=“featuremap”,hasanentryforeachwordposition incontextwindow/sentence
howdoweconvertthisintoafixed-lengthvector?usepooling:
max-pooling:returnsmaximumvalueinaverage pooling:returnsaverageofvaluesin

Pooling
21
vectorforlastvectorforyo vectorforname
=“featuremap”,hasanentryforeachwordposition incontextwindow/sentence
howdoweconvertthisintoafixed-lengthvector?usepooling:
max-pooling:returnsmaximumvalueinaverage pooling:returnsaverageofvaluesin
then,thissinglefilterproducesasinglefeaturevalue(theoutputofsomekindofpooling).inpractice,weusemanyfiltersofmanydifferentlengths(e.g.,n-gramsratherthanwords).

ConvolutionalNeuralNetworks• convolutionalneuralnetworks(convnets orCNNs)usefiltersthatare“convolvedwith”(matchedagainstallpositionsof)theinput
• informally,thinkofconvolutionas“performthesameoperationeverywhereontheinputinsomesystematicorder”
• “convolutionallayer”=setoffiltersthatareconvolvedwiththeinputvector(whetherx orhiddenvector)
• couldbefollowedbymoreconvolutionallayers,orbyatypeofpooling
• oftenusedinNLPtoconvertasentenceintoafeaturevector
22
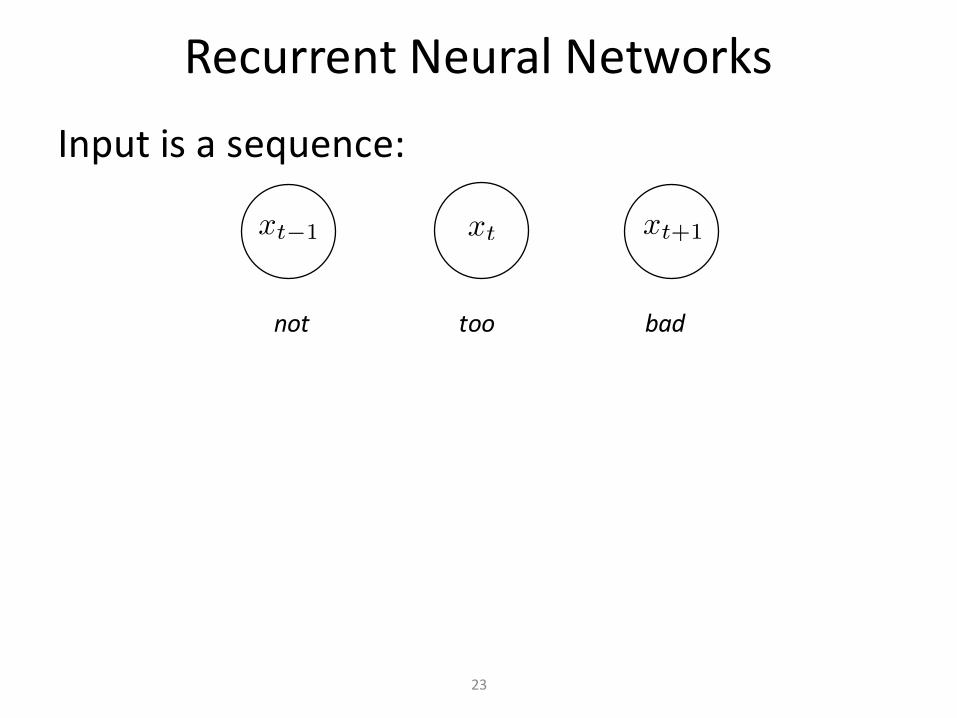
RecurrentNeuralNetworksInputisasequence:
23
nottoobad
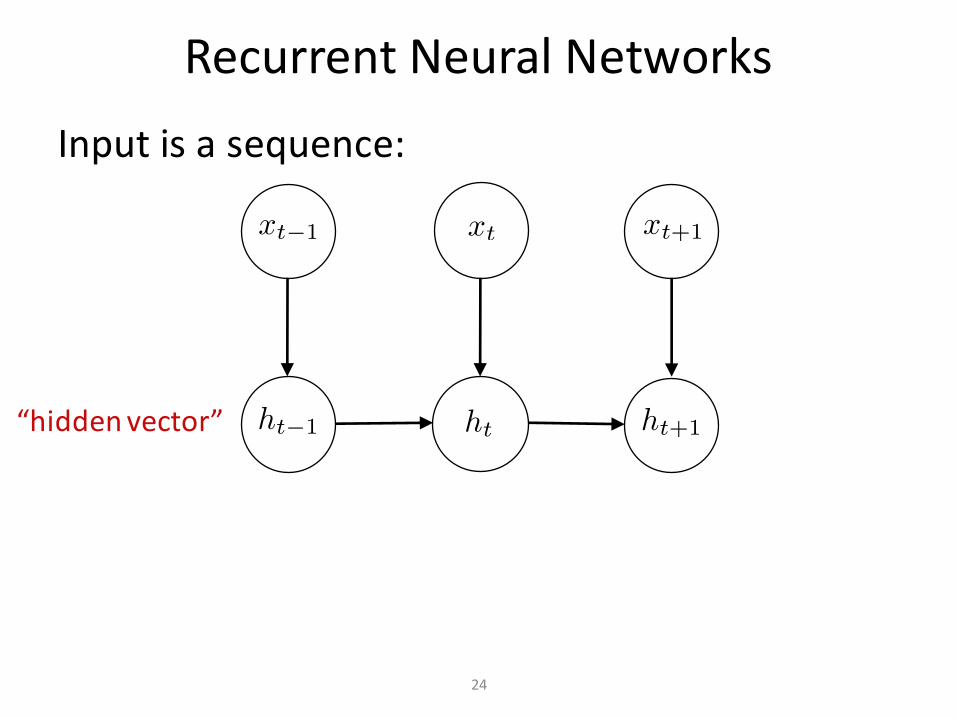
RecurrentNeuralNetworksInputisasequence:
24
“hiddenvector”

RecurrentNeuralNetworks
25
“hiddenvector”

Disclaimer• thesediagramsareoftenusefulforhelpingusunderstandandcommunicateneuralnetworkarchitectures
• buttheyrarelyhaveanysortofformalsemantics(unlikegraphicalmodels)
• theyaremorelikecartoons
26

LongShort-TermMemoryRNNs(gateless)
27
“memorycell”
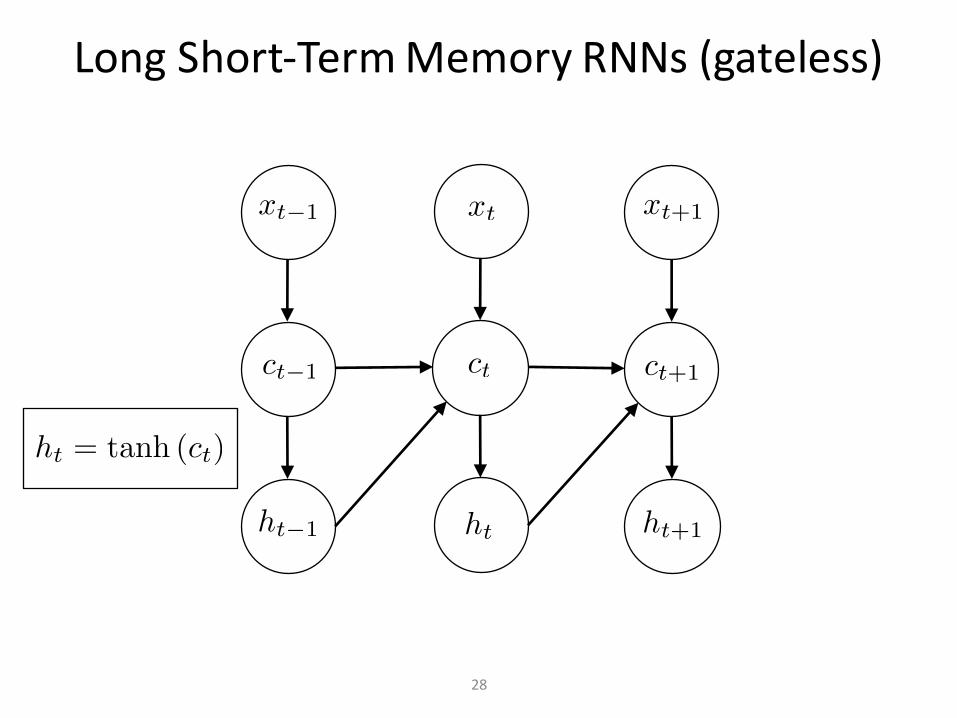
LongShort-TermMemoryRNNs(gateless)
28
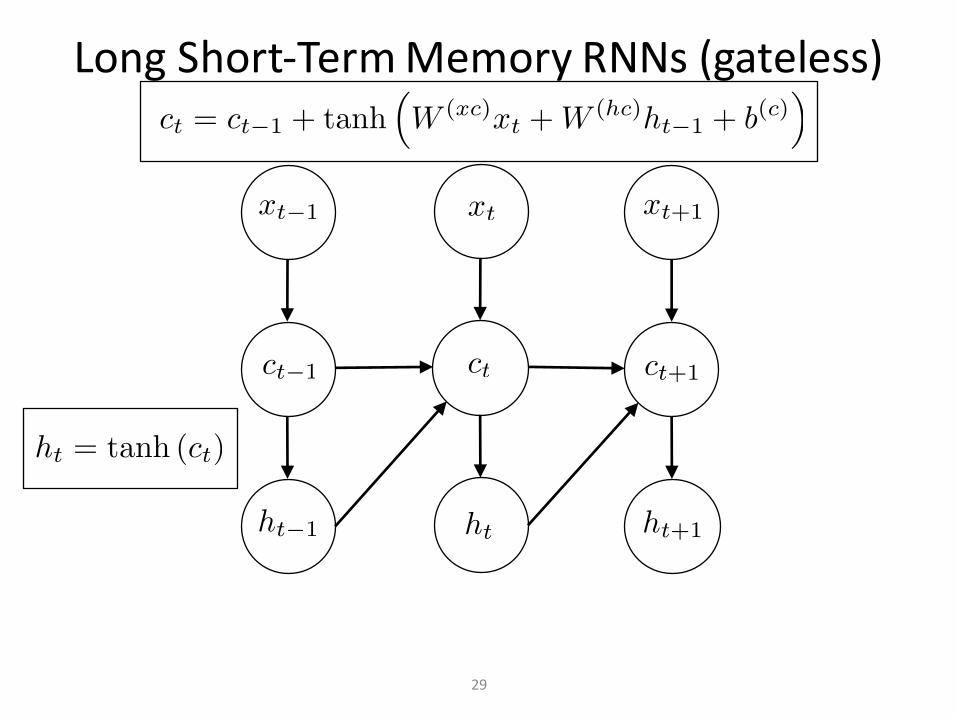
LongShort-TermMemoryRNNs(gateless)
29

LongShort-TermMemoryRNNs(gateless)
30
Experiment:textclassification• StanfordSentimentTreebank• binaryclassification(positive/negative)
• 25-dimwordvectors• 50-dimcell/hiddenvectors• classificationlayeronfinal hiddenvector• AdaGrad,10epochs,mini-batchsize10• earlystoppingondev set
accuracy
80.6
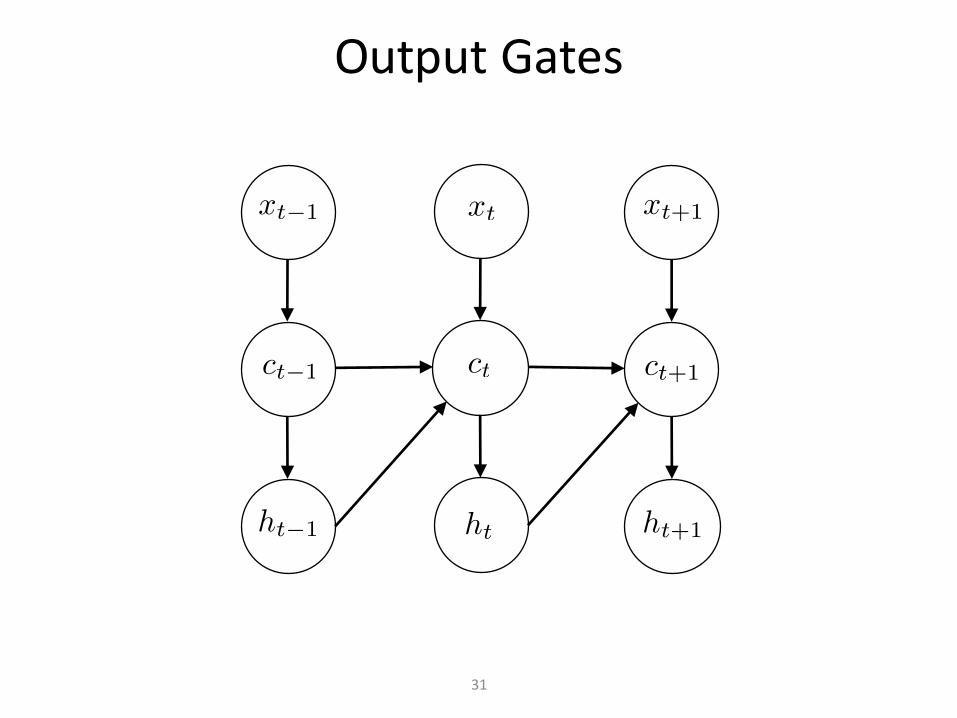
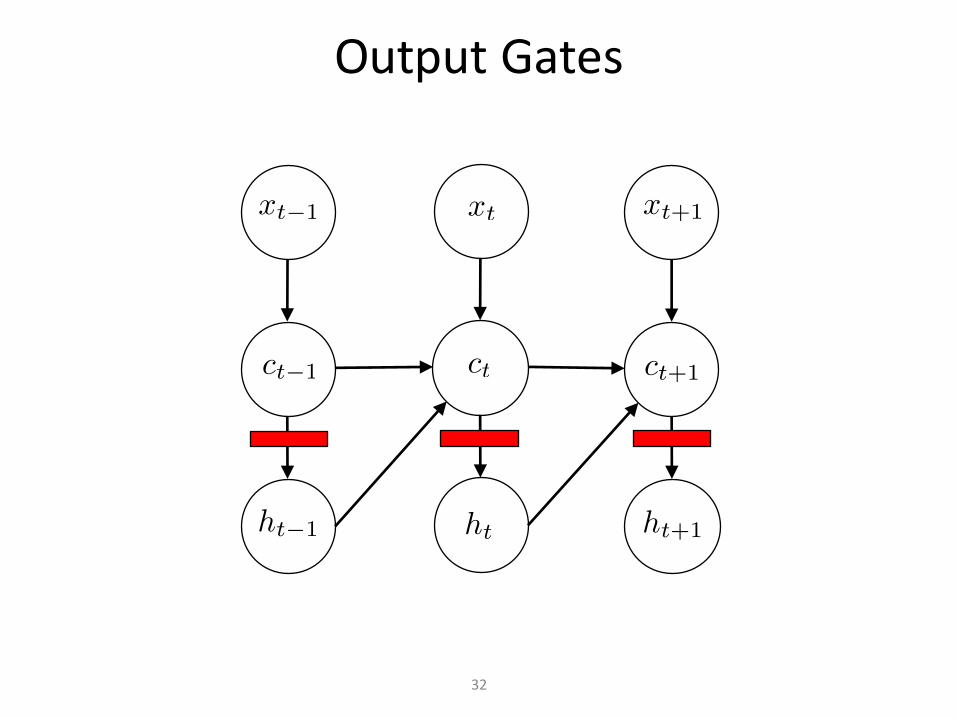
OutputGates
31
OutputGates
32
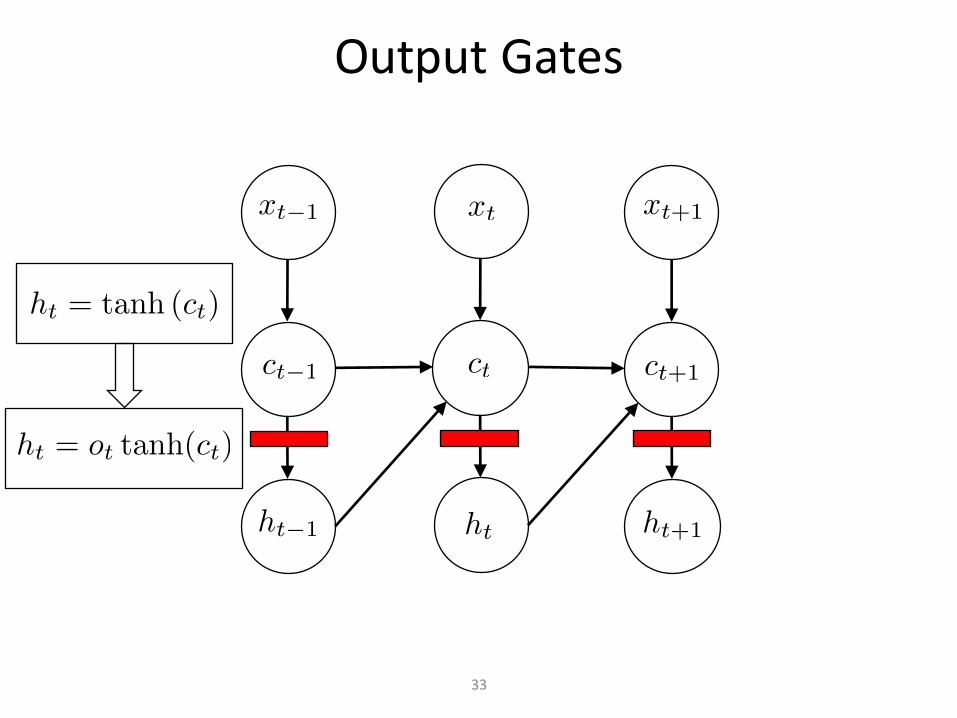
OutputGates
33
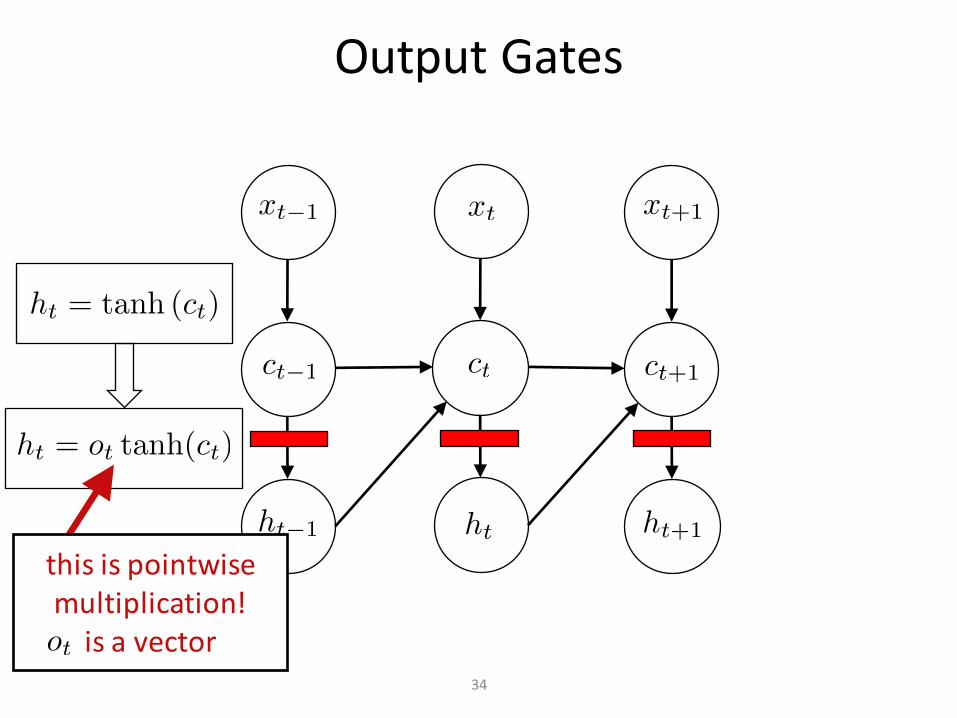
OutputGates
34
thisispointwisemultiplication!isavector
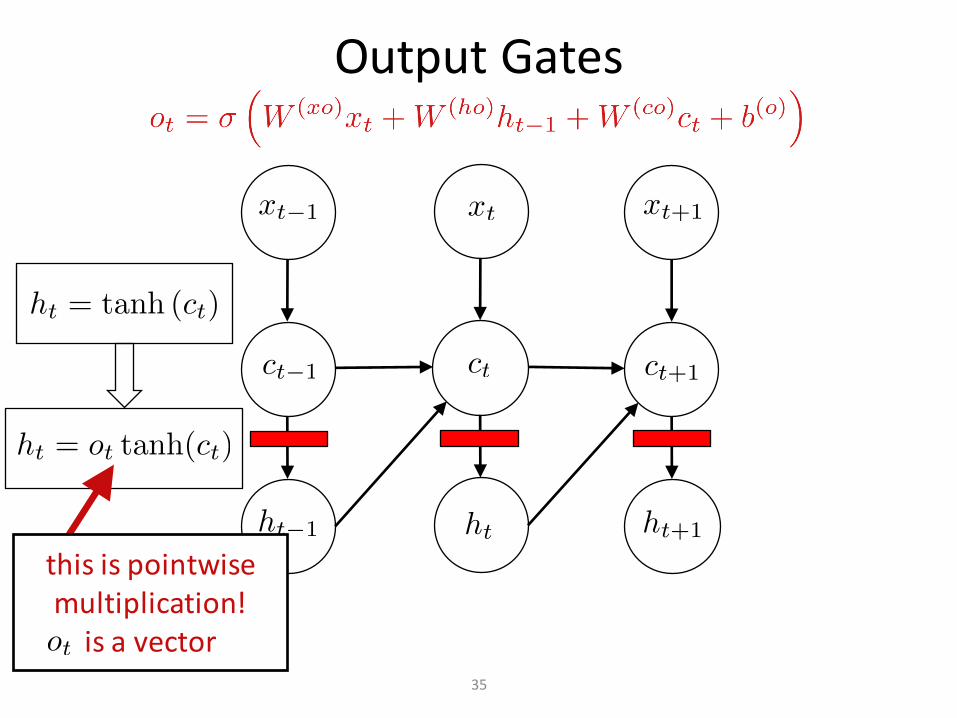
OutputGates
35
thisispointwisemultiplication!isavector
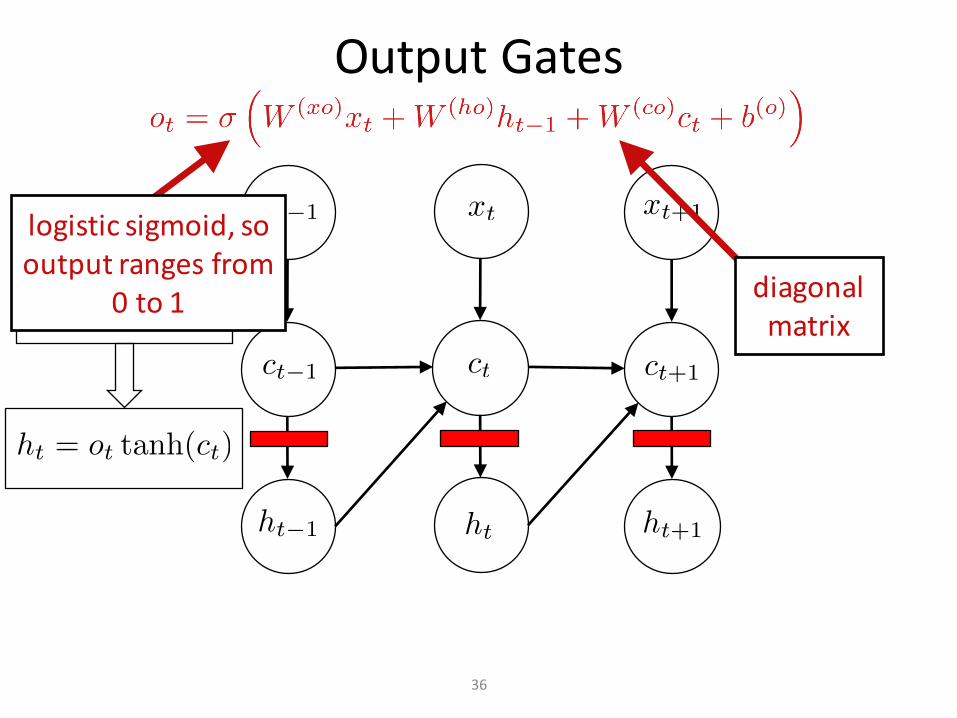
OutputGates
36
diagonalmatrix
logisticsigmoid,sooutputrangesfrom
0to1
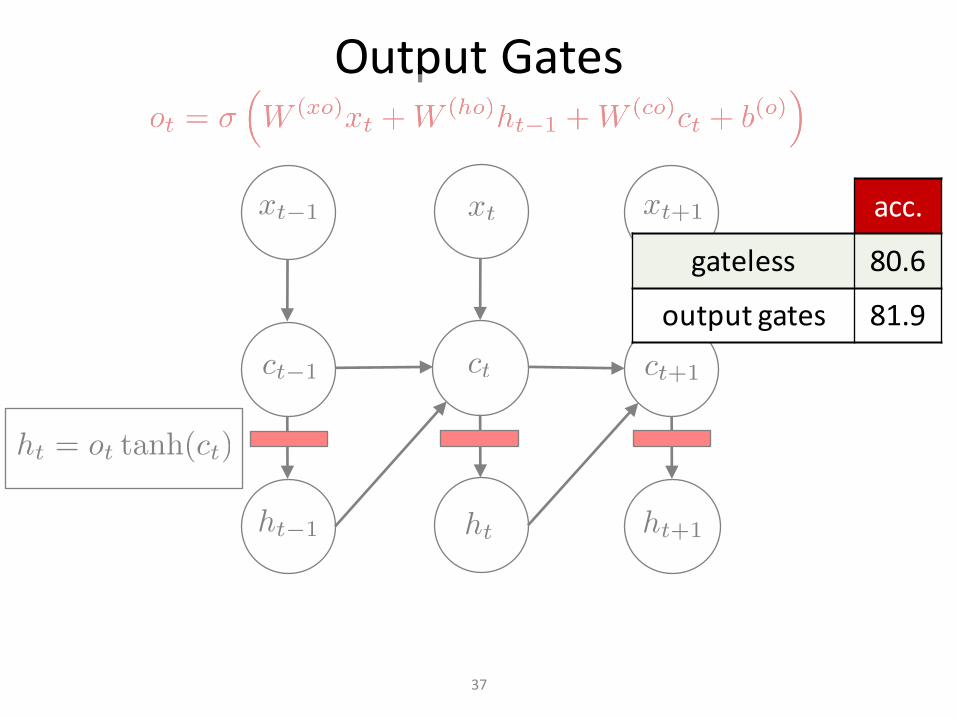
OutputGates
37
acc.
gateless 80.6
outputgates 81.9
OutputGates
38
acc.
gateless 80.6
outputgates 81.9
What’sbeinglearned?(demo)
InputGates
39

InputGates
40
again,thisispointwise
multiplication
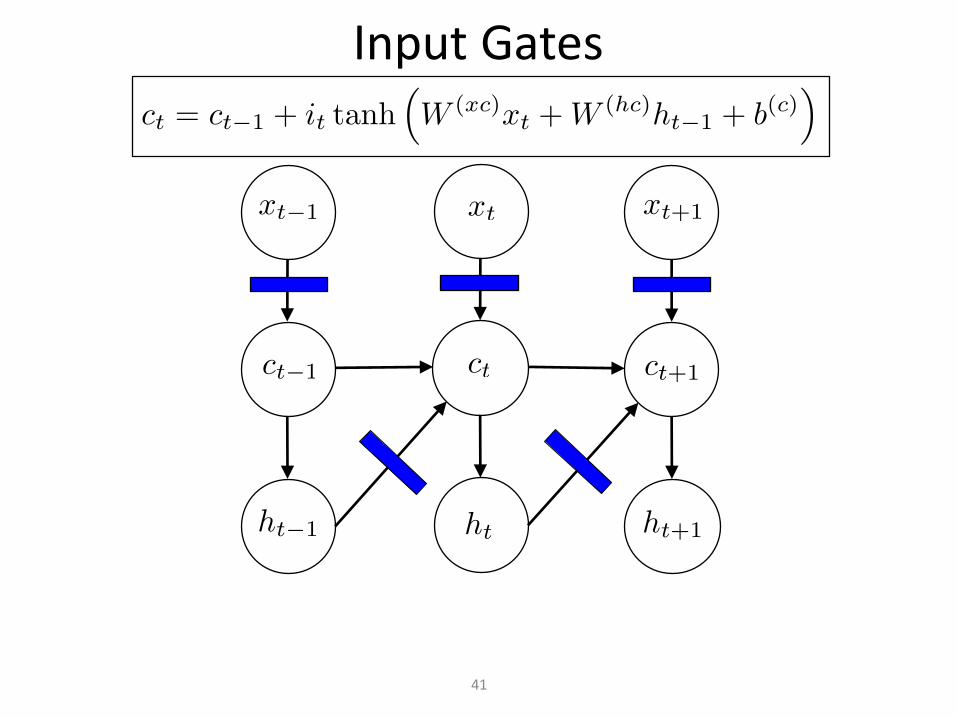
InputGates
41
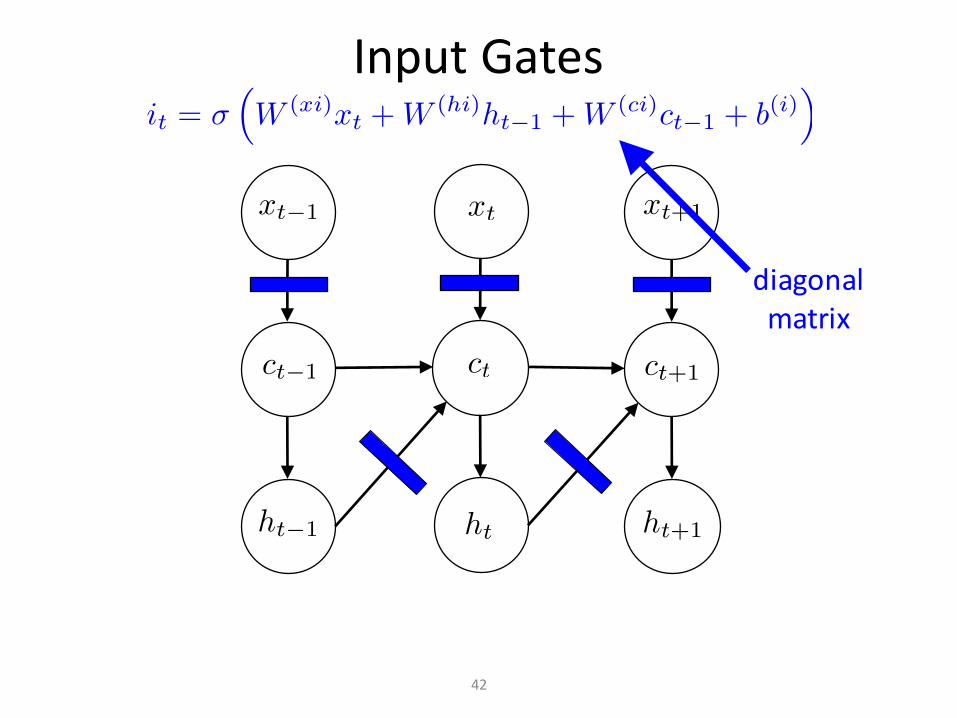
InputGates
42
diagonalmatrix
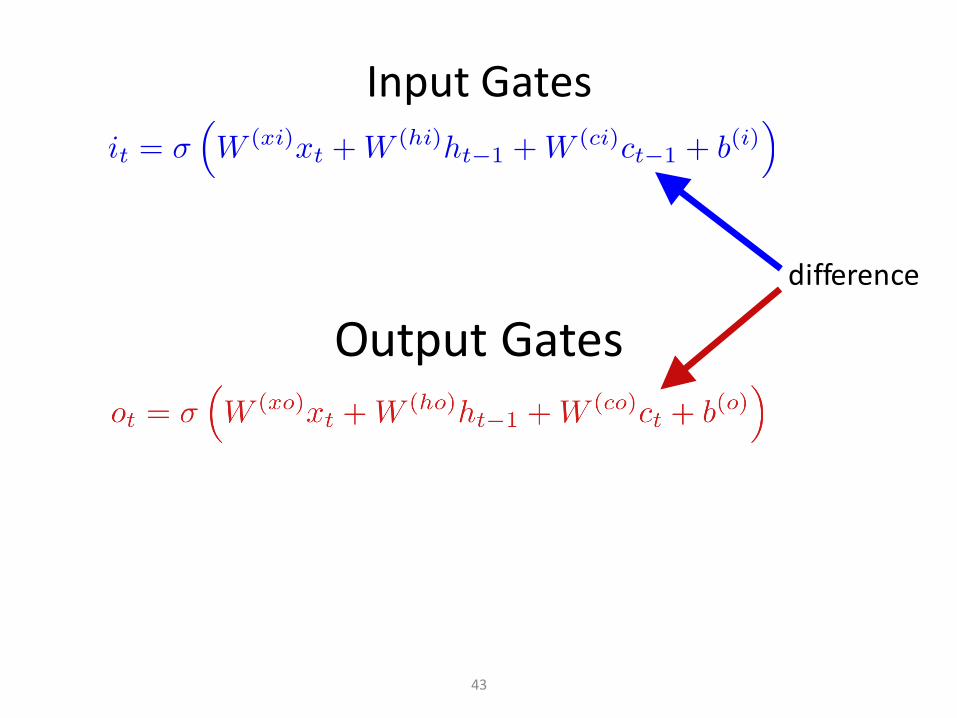
OutputGates
43
InputGates
difference
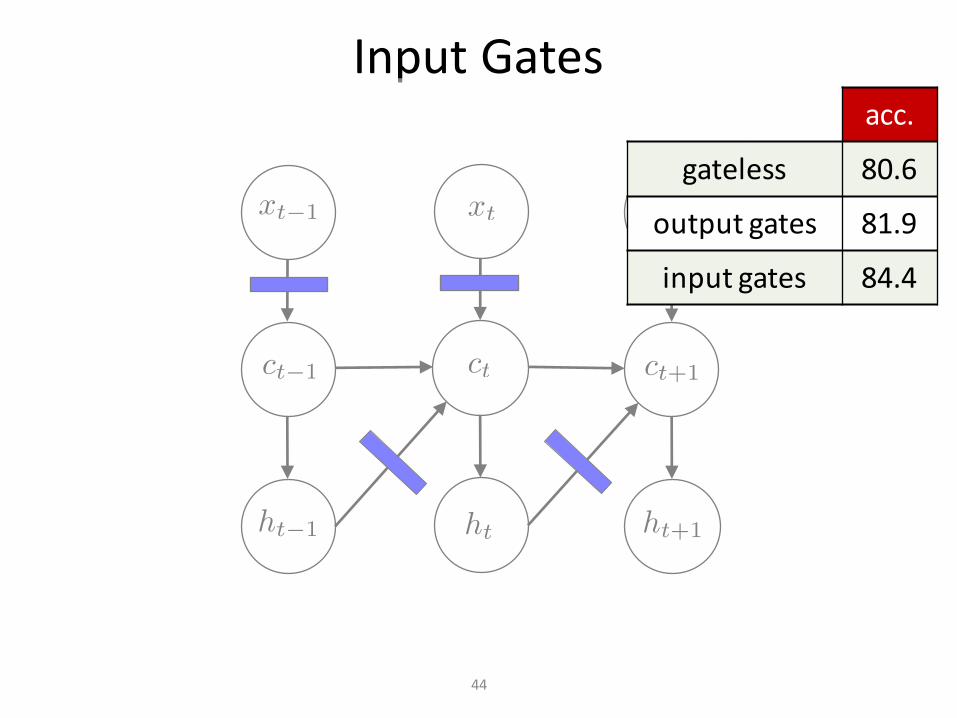
InputGates
44
acc.
gateless 80.6
outputgates 81.9
inputgates 84.4
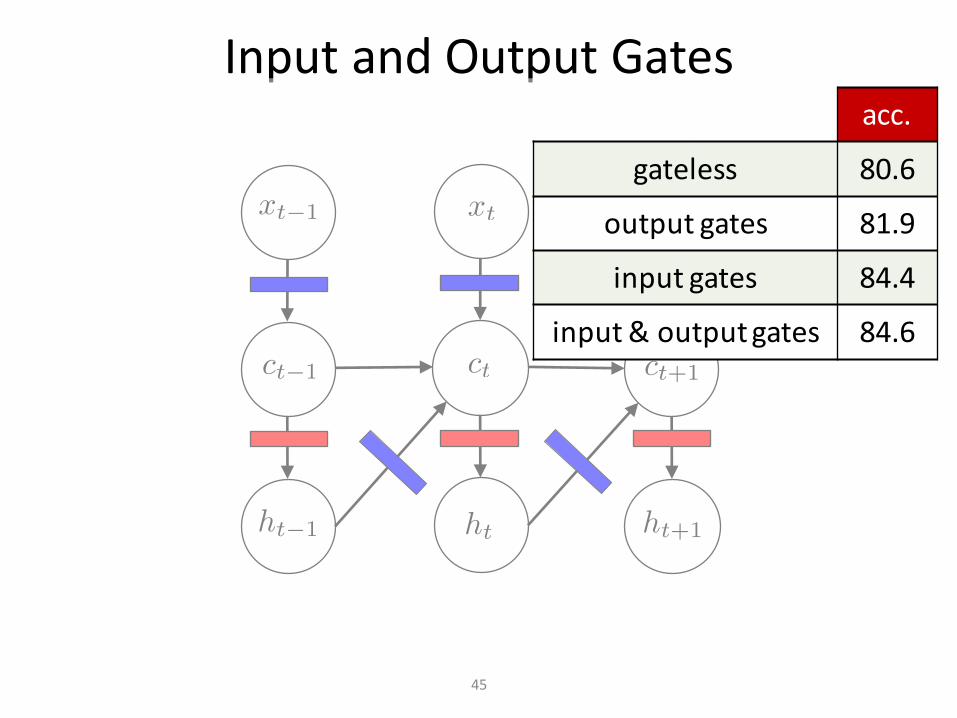
InputandOutputGates
45
acc.
gateless 80.6
outputgates 81.9
inputgates 84.4
input&outputgates 84.6
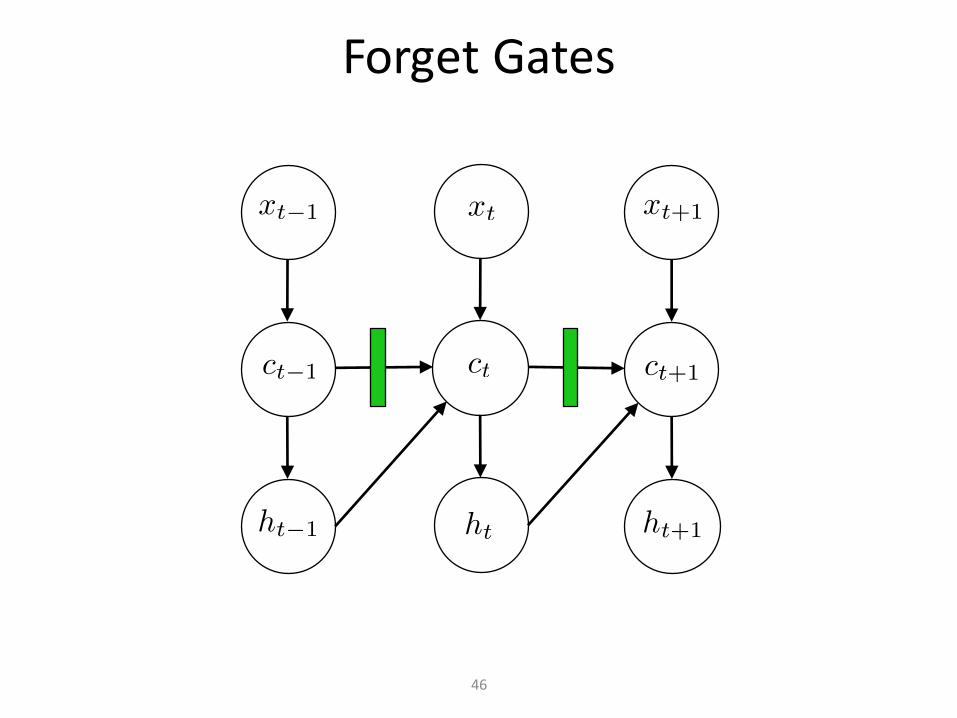
ForgetGates
46
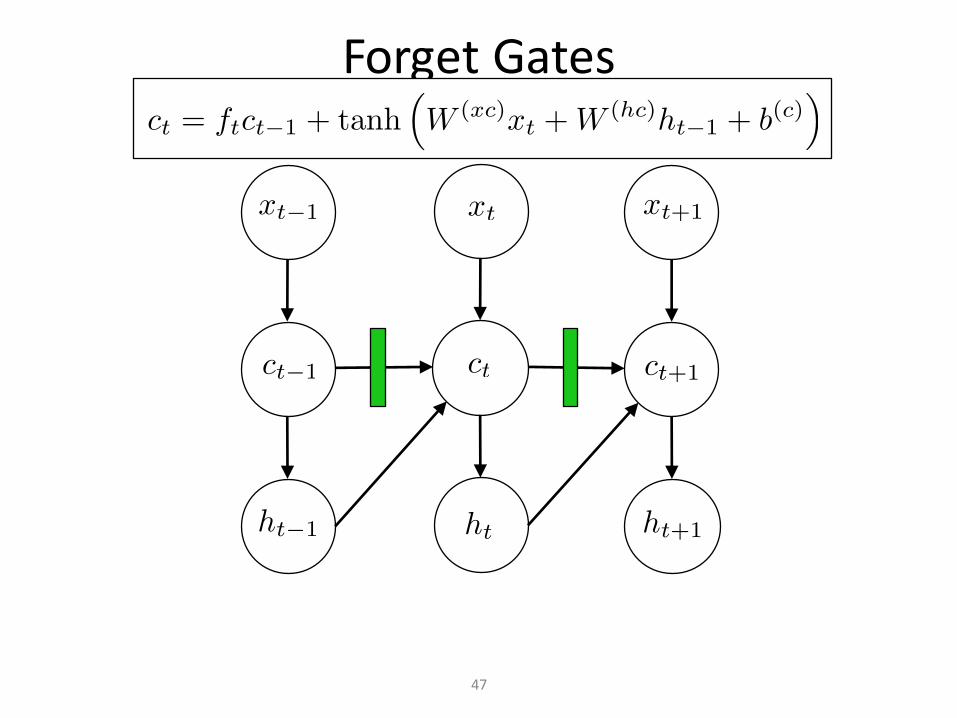
ForgetGates
47
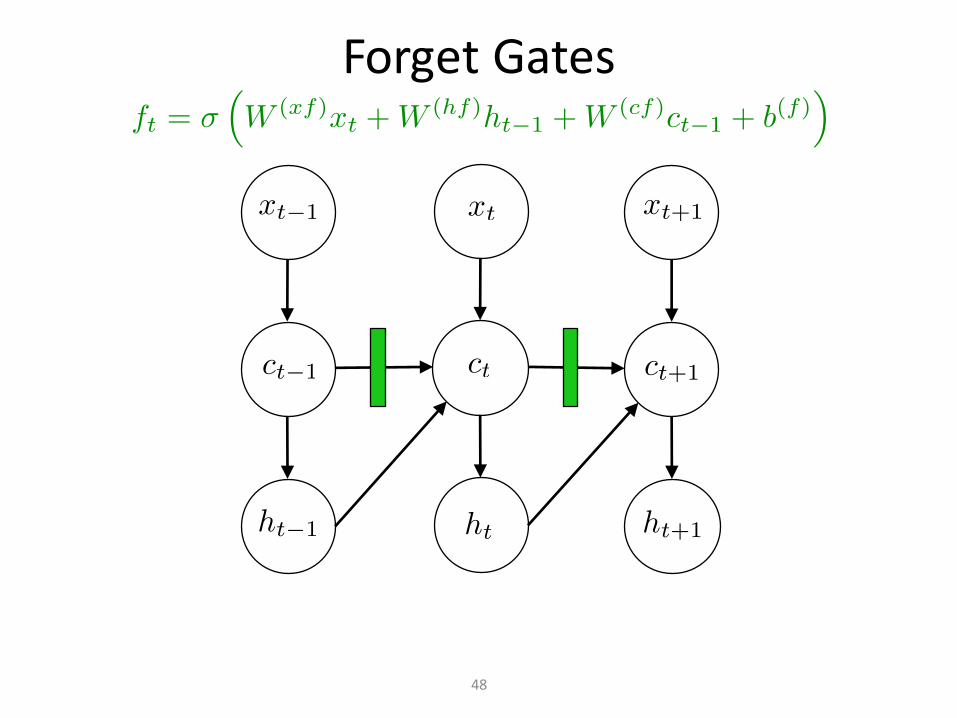
ForgetGates
48
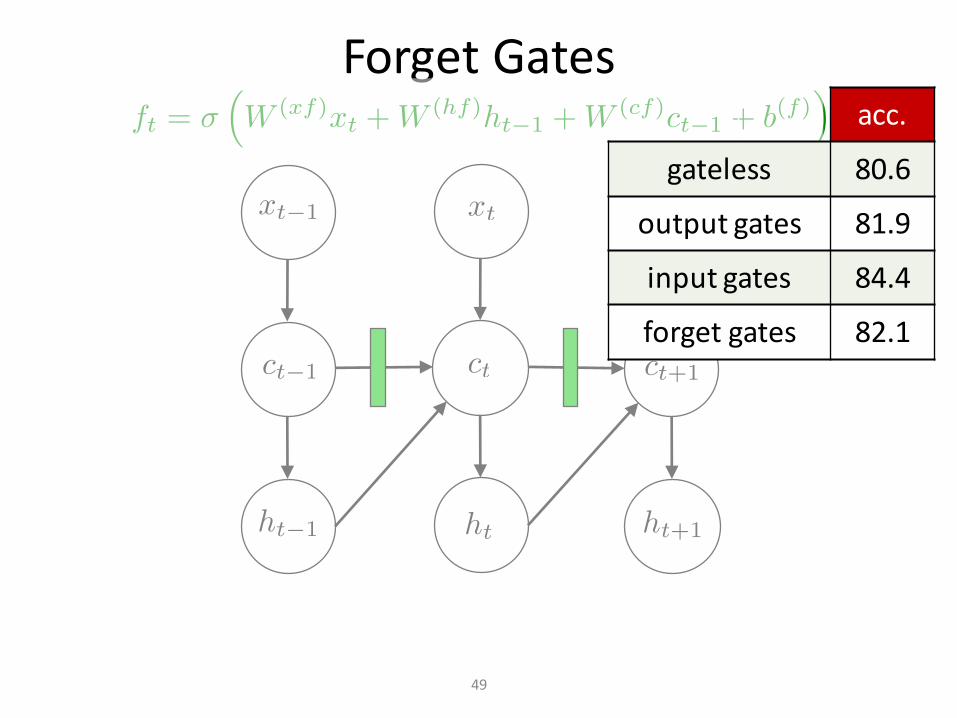
ForgetGates
49
acc.
gateless 80.6
outputgates 81.9
inputgates 84.4
forgetgates 82.1

AllGates
50
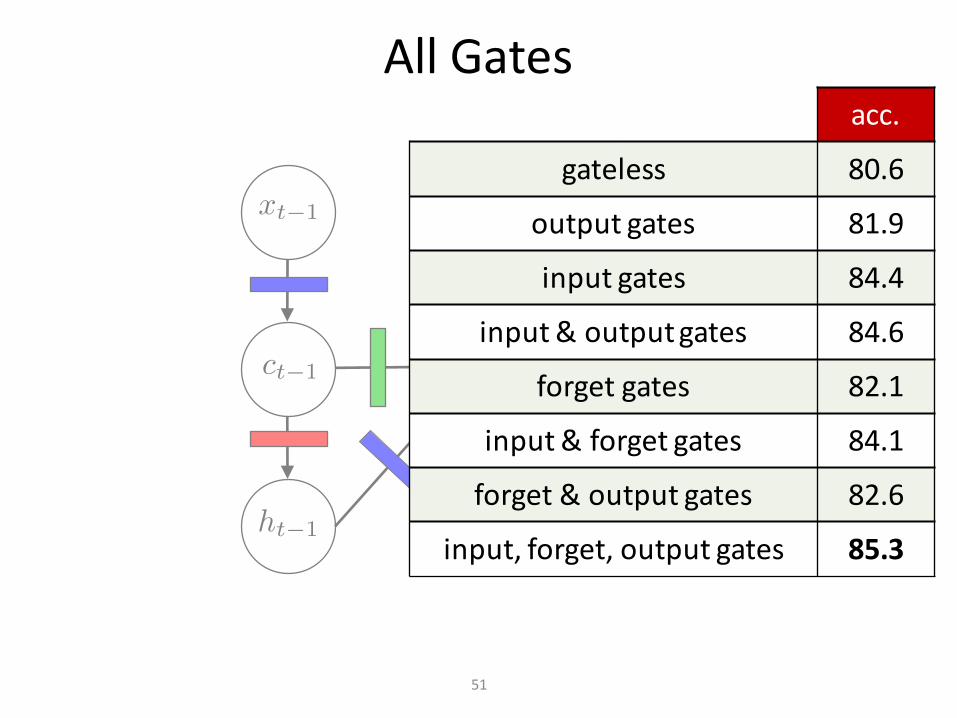
AllGates
51
acc.
gateless 80.6
outputgates 81.9
inputgates 84.4
input&outputgates 84.6
forgetgates 82.1
input&forget gates 84.1
forget& outputgates 82.6
input,forget,outputgates 85.3
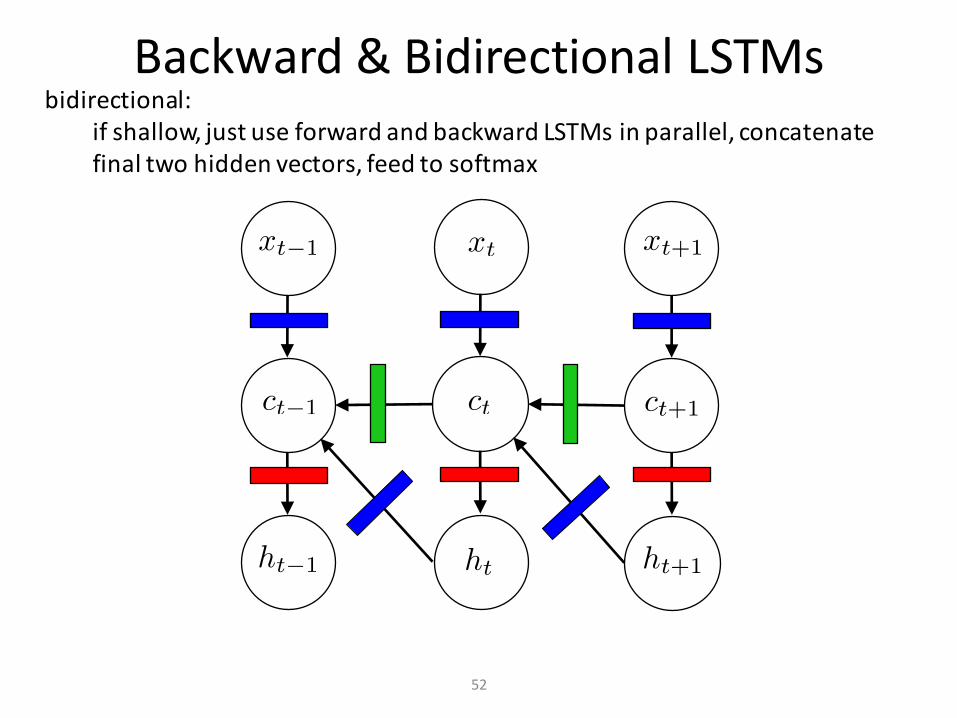
Backward&BidirectionalLSTMs
52
bidirectional:ifshallow,justuseforwardandbackwardLSTMsinparallel,concatenatefinaltwohiddenvectors,feedtosoftmax

Backward&BidirectionalLSTMs
53
bidirectional:ifshallow,justuseforwardandbackwardLSTMsinparallel,concatenatefinaltwohiddenvectors,feedtosoftmax
forward backward
gateless 80.6 80.3
outputgates 81.9 83.7
inputgates 84.4 82.9
forgetgates 82.1 83.4
input,forget,outputgates 85.3 85.9

Backward&BidirectionalLSTMs
54
bidirectional:ifshallow,justuseforwardandbackwardLSTMsinparallel,concatenatefinaltwohiddenvectors,feedtosoftmax
forward backward bidirectional
gateless 80.6 80.3 81.5
outputgates 81.9 83.7 82.6
inputgates 84.4 82.9 83.9
forgetgates 82.1 83.4 83.1
input,forget,outputgates 85.3 85.9 85.1
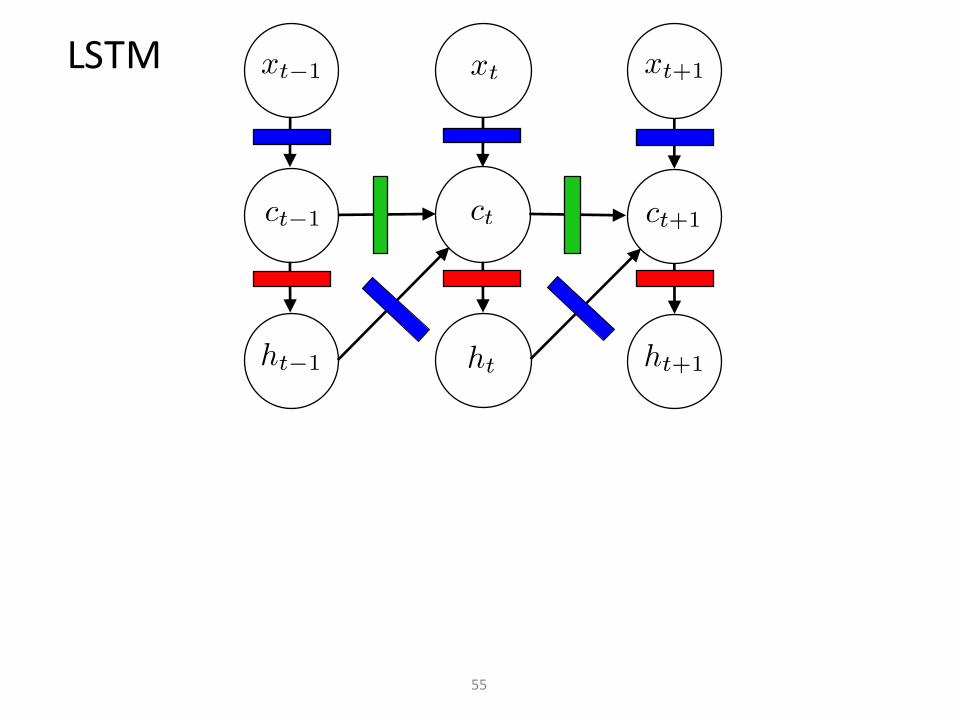
LSTM
55
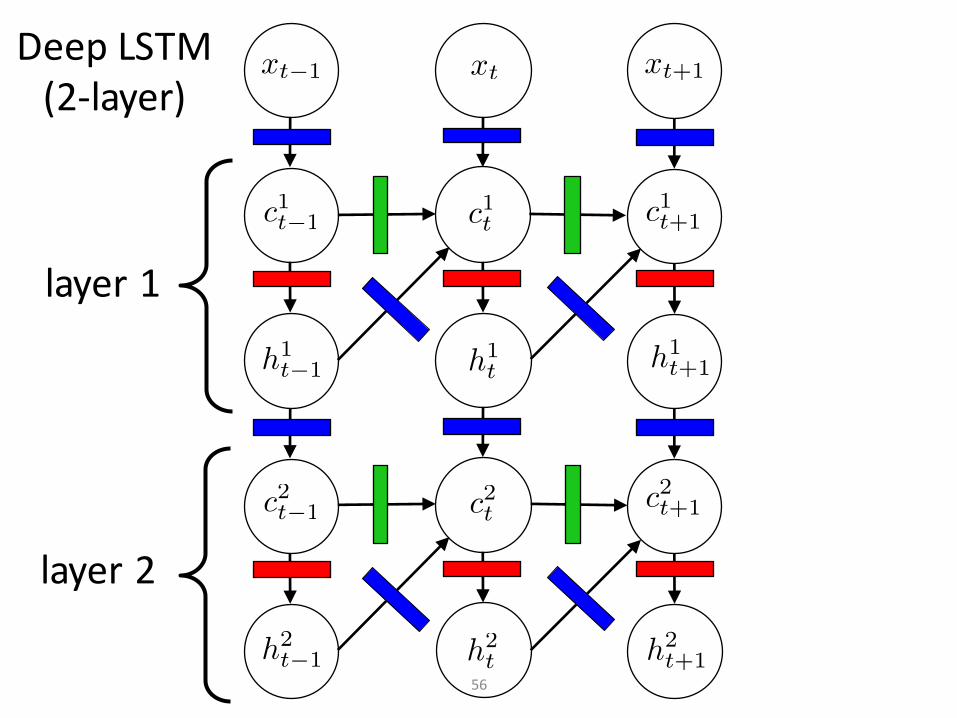
DeepLSTM(2-layer)
56
layer1
layer2
DeepLSTM(2-layer)
57
layer1
layer2
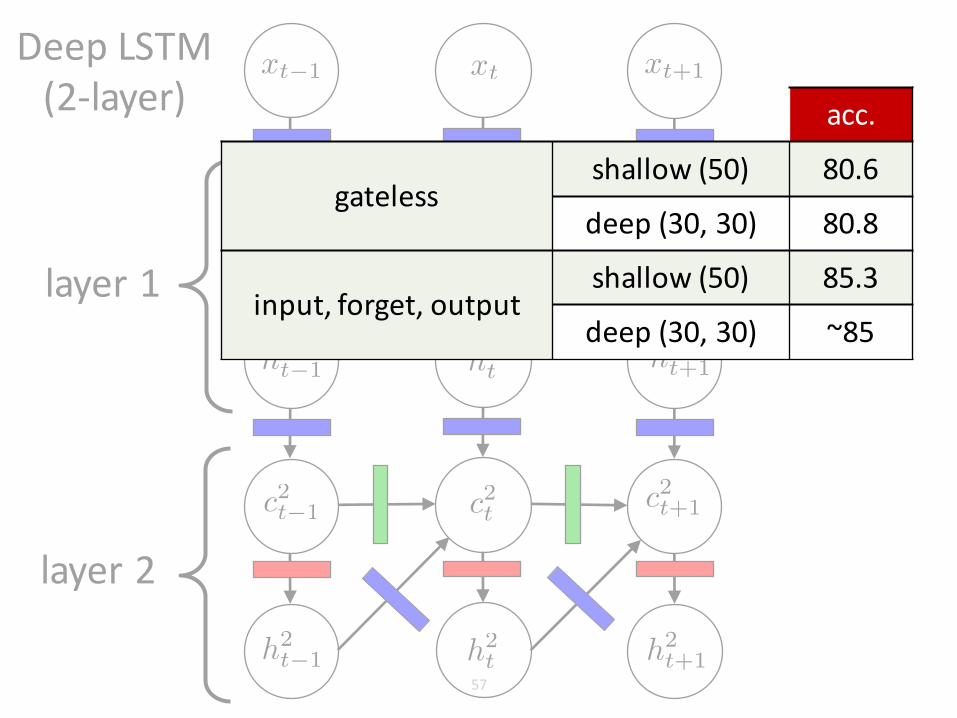
acc.
gatelessshallow(50) 80.6
deep(30,30) 80.8
input,forget,outputshallow(50) 85.3
deep(30,30) ~85
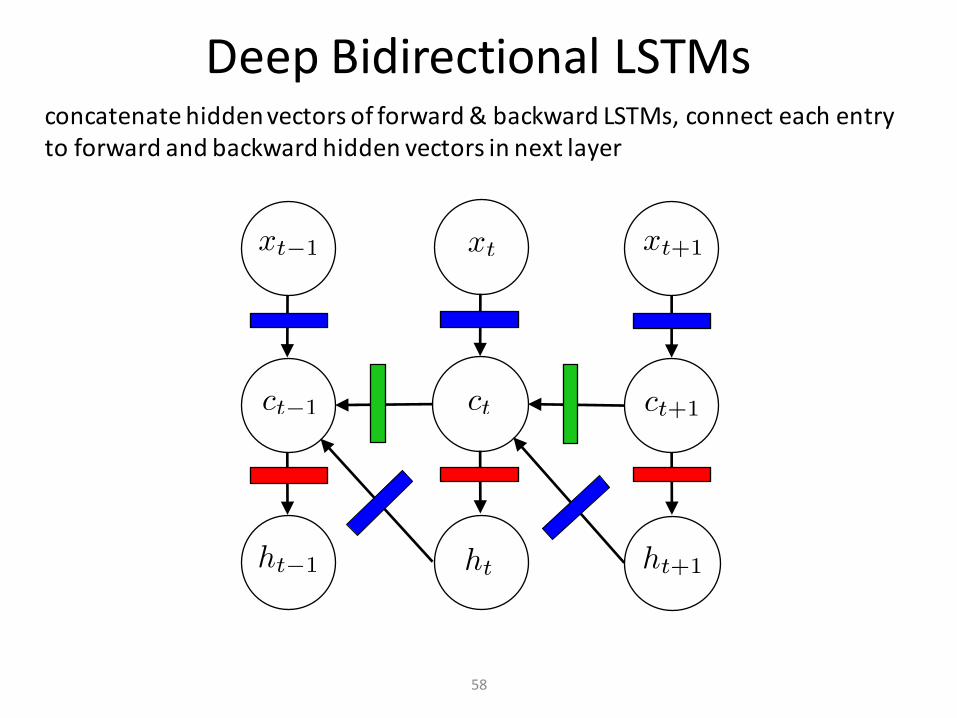
DeepBidirectionalLSTMs
58
concatenatehiddenvectorsofforward&backwardLSTMs,connecteachentrytoforwardandbackwardhiddenvectorsinnextlayer

59
(logistic)sigmoid: