tutorial: algorithm engineering for big data - kit
TRANSCRIPT

Tutorial: Algorithm Engineering for Big DataPeter Sanders, Karlsruhe Institute of Technology
Efficient algorithms are at the heart of any nontrivial computer application. But how can weobtain innovative algorithmic solutions for demanding application problems with exploding inputsizes using complex modern hardware and advanced algorithmic techniques?
This tutorial proposes algorithm engineering as a methodology for taking all these issues intoaccount. Algorithm engineering tightly integrates modeling, algorithm design, analysis, imple-mentation and experimental evaluation into a cycle resembling the scientific method used in thenatural sciences. Reusable, robust, flexible, and efficientimplementations are put into algorithmlibraries. Benchmark instances provide further coupling to applications.
appl. engin.
realisticmodels
design
implementation
librariesalgorithm−
perf.−guarantees
app
lication
s
falsifiable
inductionhypothesesanalysis experiments
algorithmengineering real
Inputs
deduction
We begin with examples representing fundamental algorithms and data structures with a par-ticular emphasis on large data sets. We first look atsorting in detail. Then we will have shorterexamples forfull text indices, priority queue data structures,route planning, graph partition-ing, andminimum spanning trees. We will also give examples of future challenges centeredon particular big data applications likegenome sequencing and phylogenetic tree reconstruction,particle tracking at the CERN LHC, and the SAP-HANAdata base,
Further Information
Duration: half-day
Intended Audience: Practitioners with some basic background in algorithms (2nd semester com-puter science in most German universities)
Slides are attached. Some images with unclear copyright are removed

0 Peter Sanders:Algorithm Engineering for Big Data
Institute of Theoretical InformaticsAlgorithmics
.
.
..
appl. engin.
realisticmodels
design
implementation
librariesalgorithm−
perf.−
guarantees
applic
atio
ns
falsifiable
induction
hypothesesanalysis experiments
algorithmengineering real
Inputs
deductionread buffers
.
.
..
k+O(D)overlap buffers
merging
−ping
1
k
merg
e
2D
write b
uffers
D blocks
merg
e buffers
overlap−disk scheduling
O(D
) prefetch
buffers
16 GB
RAM
240
GBInfiniband switch400 MB / s node all−all
XeonXeon
Institute of Theoretical Informatics - Algorithmics
Algorithm Engineering for Big DataPeter Sanders
KIT – University of the State of Baden-Wuerttemberg andNational Laboratory of the Helmholtz Association www.kit.edu

Sanders: Algorithm Engineering / Big Data 2
Overview� A detailed explanation of algorithm engineering
with sorting for (more or less) big inputs
as a throughgoing example
� More Big Data examples from my group
[with: David Bader, Veit Batz, Andreas Beckmann, Timo Bingmann, Stefan
Burkhardt, Jonathan Dees, Daniel Delling, Roman Dementiev, Daniel Funke,
Robert Geisberger, David Hutchinson, Juha Kärkkäinen, Lutz Kettner, Moritz
Kobitzsch, Nicolai Leischner, Dennis Luxen, Kurt Mehlhorn, Ulrich Meyer,
Henning Meyerhenke, Rolf Möhring, Ingo Müller, Petra Mutzel, Vitaly Osipov,
Felix Putze, Günther Quast, Mirko Rahn, Dennis Schieferdecker, Sebastian
Schlag, Dominik Schultes, Christian Schulz, Jop Sibeyn, Johannes Singler,
Jeff Vitter, Dorothea Wagner, Jan Wassenberg, Martin Weidner, Sebastian
Winkel, Emmanuel Ziegler]

Sanders: Algorithm Engineering / Big Data 3
Algorithmics
= the systematic design of efficient software and hardware
computer science
logics correct
efficient
soft− & hardware
the
ore
tic
al p
rac
tica
l
algorithmics

Sanders: Algorithm Engineering / Big Data 4
(Caricatured) Traditional View: Algorithm Theory
models
design
analysis
perf. guarantees applications
implementation
deduction
Theory Practice

Sanders: Algorithm Engineering / Big Data 5
Gaps Between Theory & Practice
Theory ←→ Practice
simple appl. model complex
simple machine model real
complex algorithms FOR simple
advanced data structures arrays,. . .
worst case max complexity measure inputs
asympt. O(·) efficiency 42% constant factors

Sanders: Algorithm Engineering / Big Data 6
Algorithmics as Algorithm Engineering
models
design
perf.−guarantees
deduction
analysis experiments
algorithmengineering
??
?
[1]

Sanders: Algorithm Engineering / Big Data 7
Algorithmics as Algorithm Engineering
models
design
implementationperf.−guarantees
deduction
falsifiable
inductionhypothesesanalysis experiments
algorithmengineering
[1]

Sanders: Algorithm Engineering / Big Data 8
Algorithmics as Algorithm Engineering
realisticmodels
implementationperf.−guarantees
deduction
falsifiable
inductionhypotheses experiments
algorithmengineering
design
analysis
real.
real.
[1]

Sanders: Algorithm Engineering / Big Data 9
Algorithmics as Algorithm Engineering
realisticmodels
design
implementation
librariesalgorithm−
perf.−guarantees
deduction
falsifiable
inductionhypothesesanalysis experiments
algorithmengineering real
Inputs
[1]

Sanders: Algorithm Engineering / Big Data 10
Algorithmics as Algorithm Engineering
appl. engin.
realisticmodels
design
implementation
librariesalgorithm−
perf.−guarantees
applications
falsifiable
inductionhypothesesanalysis experiments
algorithmengineering real
Inputs
deduction
[1]

Sanders: Algorithm Engineering / Big Data 11
Goals
� bridge gaps between theory and practice
� accelerate transfer of algorithmic results into applications
� keep the advantages of theoretical treatment:
generality of solutions and
reliabiltiy, predictabilty from performance guarantees
appl. engin.
realisticmodels
design
implementation
librariesalgorithm−
perf.−guarantees
applications
falsifiable
inductionhypothesesanalysis experiments
algorithmengineering real
Inputs
deduction

Sanders: Algorithm Engineering / Big Data 12
Bits of History1843– Algorithms in theory and practice
1950s,1960s Still infancy
1970s,1980s Paper and pencil algorithm theory.
Exceptions exist, e.g., [D. Johnson]
1986 Term used by [T. Beth],
lecture “Algorithmentechnik” in Karlsruhe.
1988– Library of Efficient Data Types and Algorithms
(LEDA) [2]
1997– Workshop on Algorithm Engineering
ESA applied track [G. Italiano]
1997 Term used in US policy paper [Aho, Johnson, Karp, et. al]
1998 Alex workshop in Italy ALENEX

Sanders: Algorithm Engineering / Big Data 13
Realistic Models
Theory ←→ Practice
simple appl. model complex
simple machine model real
� Careful refinements
� Try to preserve (partial) analyzability / simple results

Sanders: Algorithm Engineering / Big Data 14
Sorting – Model
basedComparison
<e.g. integer
arbitrary
full informationtrue/false

Sanders: Algorithm Engineering / Big Data 15
Advanced Machine Models [3]
registersALU
freely programmable
fast memorycapacity Mfreely programmable
ALUregisters
(also) count (block) I/Oscount instructions
B
RAM / von Neumann External
large memory
[3]

Sanders: Algorithm Engineering / Big Data 16
Distributed Memory [4]
...
...P
(also) determine communication volume
21

Sanders: Algorithm Engineering / Big Data 17
Parallel Disks [5]
MM
B...
B
D1 2

Sanders: Algorithm Engineering / Big Data 18
Set Associative Caches [6]
MB
...cache lines of the memory
cache setsa=2
B cache
main memory
...

Sanders: Algorithm Engineering / Big Data 19
Branch Prediction [7]

Sanders: Algorithm Engineering / Big Data 20
Hierarchical Parallel External Memory [8]
multicore
disks...
MPI

Sanders: Algorithm Engineering / Big Data 21
Graphics Processing Units [9]

Sanders: Algorithm Engineering / Big Data 22
Combininig Models?
� design / analyze one aspect at a time
� hierarchical combination
� autotuning ?
...cache lines of the memory
cache setsa=2
B cache
main memory
...
M
basedComparison
<
true/false
e.g. integerarbitrary
full information......
P
B...
21
D1 2

Sanders: Algorithm Engineering / Big Data 23
Design
of algorithms that work well in practice
� simplicity
� reuse
� constant factors
� exploit easy instances

Sanders: Algorithm Engineering / Big Data 24
Design – Sorting
� simplicity
...
...
...
...
...
...
...
...
...
...
...
...
merge distribute
� reuse disk scheduling, prefetching,
load balancing, sequence partitioning [10, 5, 11, 8]
� constant factors detailed machine model·
(caches, TLBs, registers, branch prediction, ILP) [3, 7]
� instances randomization for difficult instances [5, 8]

Sanders: Algorithm Engineering / Big Data 25
Example: External Sorting [12]
n: input size
M : internal memory size
B: block size
large memory
fast memorycapacity Mfreely programmable
ALUregisters
B

Sanders: Algorithm Engineering / Big Data 26
Procedure externalMerge(a, b, c :File of Element)
x := a.readElement // Assume emptyFile.readElement=∞
y := b.readElement
for j := 1 to |a|+ |b| do
if x ≤ y then c.writeElement(x); x := a.readElement
else c.writeElement(y); y := b.readElement
xac
b y
Sanders: Algorithm Engineering / Big Data 27
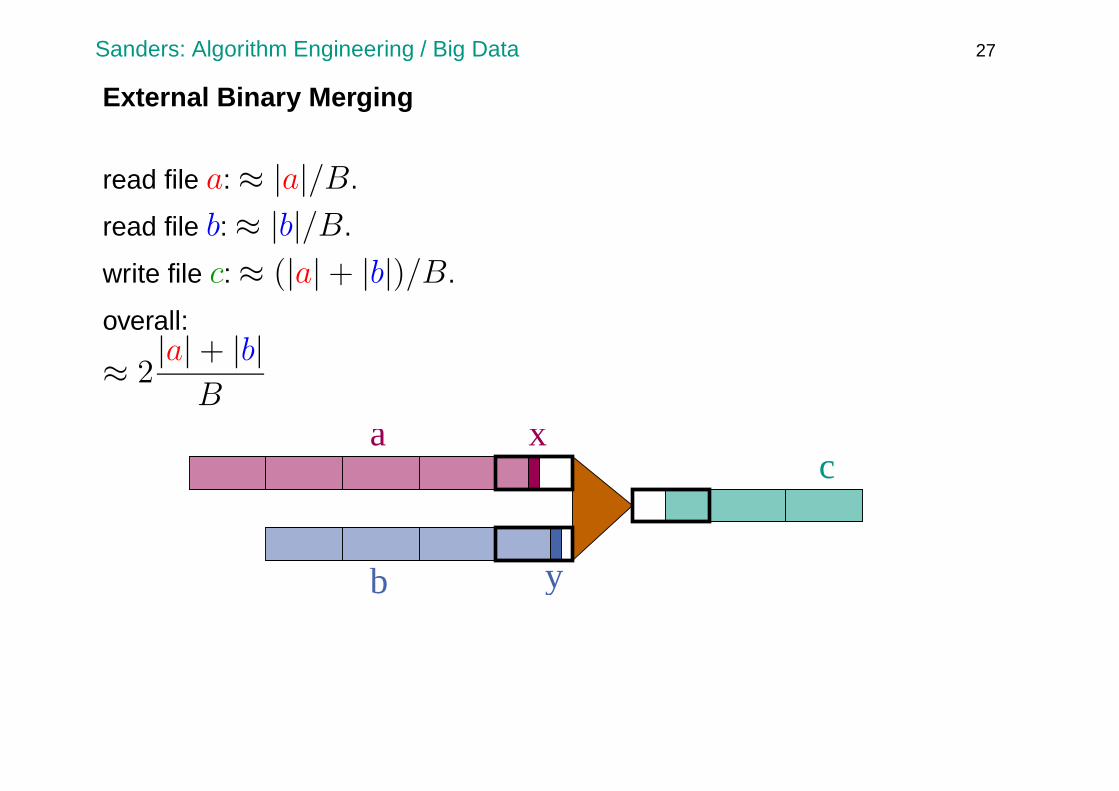
External Binary Merging
read file a:≈ |a|/B.
read file b:≈ |b|/B.
write file c:≈ (|a|+ |b|)/B.
overall:
≈ 2|a|+ |b|
Bxa
c
b y

Sanders: Algorithm Engineering / Big Data 28
Run Formation
Sort input pieces of size M
i=0 i=M i=2M
i=2Mi=0 i=M
internalsort
f
t
run
M
I/Os:≈ 2n
B

Sanders: Algorithm Engineering / Big Data 29
Sorting by External Binary Merging
formRuns formRuns formRuns formRuns
merge merge
make_things_
__aeghikmnst
as_simple_as
__aaeilmpsss
_possible_bu
__aaeilmpsss
t_no_simpler
__eilmnoprst
____aaaeeghiiklmmnpsssst ____bbeeiillmnoopprssstu
merge
________aaabbeeeeghiiiiklllmmmnnooppprsssssssttu
Procedure externalBinaryMergeSort // I/Os:≈
run formation // 2n/B
while more than one run left do //⌈log n
M
⌉×
merge pairs of runs // 2n/B
output remaining run //∑
: 2n
B
(
1 +⌈
logn
M
⌉)

Sanders: Algorithm Engineering / Big Data 30
Example Numbers: PC 2013
n = 240 Byte (1 TB)
M = 233 Byte (8 GB)
B = 222 Byte (4 MB)
one I/O needs 2−5 s (31.25 ms)
time =2n
B
(
1 +⌈
logn
M
⌉)
· 2−5s
=2 · 218 · (1 + 7) · 2−5s = 217s ≈ 36h
Idea: 8 passes 2 passes

Sanders: Algorithm Engineering / Big Data 31
Multiway Merging
Procedure multiwayMerge(a1, . . . , ak, c :File of Element)
for i := 1 to k do xi:= ai.readElement
for j := 1 to∑k
i=1|ai| do
find i ∈ 1..k that minimizes xi // no I/Os!,O(log k) time
c.writeElement(xi)
xi := ai.readElement
...
...
...
...
...
internal buffers
...

Sanders: Algorithm Engineering / Big Data 32
Mulitway Merging – Analysis
...
...
...
...
...
interne puffer
...
I/Os: read file ai:≈ |ai|/B.
write file c:≈∑k
i=1|ai|/B
overall:
≤≈ 2
∑ki=1|ai|
B
constraint: We need k + 1 buffer blocks, i.e., k + 1 < M/B

Sanders: Algorithm Engineering / Big Data 33
Sorting by Multiway-Merging� sort ⌈n/M⌉ runs with M elements each 2n/B I/Os
� merge M/B runs at a time 2n/B I/Os
� unit a single run remains ×⌈logM/B
nM
⌉merging phases
————————————————-
overall sort(n) :=2n
B
(
1 +⌈
logM/B
n
M
⌉)
I/Os
formRuns formRuns formRuns formRuns
make_things_
__aeghikmnst
as_simple_as
__aaeilmpsss
_possible_bu
__aaeilmpsss
t_no_simpler
__eilmnoprst
________aaabbeeeeghiiiiklllmmmnnooppprsssssssttu
multi merge

Sanders: Algorithm Engineering / Big Data 34
External Sorting by Multiway-Merging
More than one merging phase?:
Not for the hierarchy main memory, hard disk.
reason:
>2000︷︸︸︷
M
B>
≈200︷ ︸︸ ︷
RAM Euro/bit
Platte Euro/bit

Sanders: Algorithm Engineering / Big Data 35
More on Multiway Mergesort – Parallel Disks
� Randomized Striping [5]
� Optimal Prefetching [5]
� Overlapping of I/O and Computation [10]
.
.
..
read buffers
.
.
..
k+O(D)overlap buffers
merging
−ping
1
k
merge
2D w
rite buffers
D blocks
merge buffers
overlap−disk schedulingO
(D) prefetch buffers

Sanders: Algorithm Engineering / Big Data 36
Shared Memory Multiway Mergesort [11]

Sanders: Algorithm Engineering / Big Data 37
Combinations
parallel disk + shared memory: [13]
+ distributed memory: [8] stay tuned
load balancing, randomization, collective communication
+ energy: [14] stay tuned
multicore
disks...
MPI

Sanders: Algorithm Engineering / Big Data 38
Analysis
� Constant factors matter
� Beyond worst case analysis
� Practical algorithms might be difficult to analyze
(randomization, meta heuristics,. . . )

Sanders: Algorithm Engineering / Big Data 39
Analysis – Sorting
.
.
......
merge
write
prefetch
overlap
merge
� Constant factors matter (1 + o(1))×lower bound
[5, 8] I/Os for parallel (disk) external sorting
� Beyond worst case analysis
� Practical algorithms might be difficult to analyze Open Problem:
[5] greedy algorithm for parallel disk prefetching [Knuth@48]

Sanders: Algorithm Engineering / Big Data 40
Implementation
sanity check for algorithms !
Challenges
Semantic gaps:
Abstract algorithm
↔
C++. . .
↔
hardware
Small constant factors:
compare highly tuned competitors
.
.
......
merge
write
prefetch
overlap
merge

Sanders: Algorithm Engineering / Big Data 41
Example: Inner Loops Sample Sort [7]
template <class T>
void findOraclesAndCount(const T* const a,
const int n, const int k, const T* const s,
Oracle* const oracle, int* const bucket) {
{ for (int i = 0; i < n; i++)
int j = 1;
while (j < k) {
j = j*2 + (a[i] > s[j]);
}
int b = j-k;
bucket[b]++;
oracle[i] = b;
}
}
6s
splitter array index
3s
<
< <
<<<< 1s 5s 7s6 7
buckets
4
3s 2 2
1 4s
5
decisions
decisions
decisions
> >
>>>>
*2
*2 *2
>+1
+1 +1

Sanders: Algorithm Engineering / Big Data 42
Example: Inner Loops Sample Sort [7]
template <class T>
void findOraclesAndCountUnrolled([...]){
for (int i = 0; i < n; i++)
int j = 1;
j = j*2 + (a[i] > s[j]);
j = j*2 + (a[i] > s[j]);
j = j*2 + (a[i] > s[j]);
j = j*2 + (a[i] > s[j]);
int b = j-k;
bucket[b]++;
oracle[i] = b;
} }
6s
splitter array index
3s
<
< <
<<<< 1s 5s 7s6 7
buckets
4
3s 2 2
1 4s
5
decisions
decisions
decisions
> >
>>>>
*2
*2 *2
>+1
+1 +1

Sanders: Algorithm Engineering / Big Data 43
Example: Inner Loops Sample Sort [7]
template <class T>
void findOraclesAndCountUnrolled2([...]){
for (int i = n & 1; i < n; i+=2) {\
int j0 = 1; int j1 = 1;
T ai0 = a[i]; T ai1 = a[i+1];
j0=j0*2+(ai0>s[j0]); j1=j1*2+(ai1>s[j1]);
j0=j0*2+(ai0>s[j0]); j1=j1*2+(ai1>s[j1]);
j0=j0*2+(ai0>s[j0]); j1=j1*2+(ai1>s[j1]);
j0=j0*2+(ai0>s[j0]); j1=j1*2+(ai1>s[j1]);
int b0 = j0-k; int b1 = j1-k;
bucket[b0]++; bucket[b1]++;
oracle[i] = b0; oracle[i+1] = b1;
} }

Sanders: Algorithm Engineering / Big Data 44
Experiments
� sometimes a good surrogate for analysis
� too much rather than too little output data
� reproducibility (10 years!)
� software engineering

Sanders: Algorithm Engineering / Big Data 45
Example, Parallel External Sorting [10]
0
1000
2000
3000
4000
1 2 4 8 16 32 64
sec
nodes
sort 100GiB per node
worst case inputworst case input, randomized
random inputrandom input, randomized

Sanders: Algorithm Engineering / Big Data 46
Algorithm Libraries — Challenges
� software engineering , e.g. CGAL [www.cgal.org]
� standardization, e.g. java.util, C++ STL and BOOST
� performance ↔ generality ↔ simplicity
� applications are a priori unknown
� result checking, verification
MC
ST
L
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
TX
XL
S
files, I/O requests, disk queues,
block prefetcher, buffered block writer
completion handlers
Asynchronous I/O primitives layer
Block management layertyped block, block manager, buffered streams,
Containers:
STL−user layervector, stack, set
priority_queue, mapsort, for_each, merge
Pipelined sorting,zero−I/O scanning
Streaming layer
Algorithms:
Operating System
Applications

Sanders: Algorithm Engineering / Big Data 47
Example: External Sorting [10, 15]
������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������
TX
XL
S
LinuxWindowsMac, ...
files, I/O requests, disk queues,
block prefetcher, buffered block writer
completion handlers
Asynchronous I/O primitives layer
Block management layertyped block, block manager, buffered streams,
Containers:
STL−user layervector, stack, set
priority_queue, mapsort
Pipelined sorting,zero−I/O scanning
Streaming layer
Algorithms:
Operating System
Applications
for_each, merge

Sanders: Algorithm Engineering / Big Data 48
Example: Shared Memory Sorting [11, 16]
MC
ST
L
STL-alike≪ STL-integrated

Sanders: Algorithm Engineering / Big Data 49
Problem Instances
Benchmark instances for NP-hard problems
� TSP
� Steiner-Tree
� SAT
� set covering
� graph partitioning [17]
� . . .
have proved essential for development of practical algorithms
Strange: much less real world instances for polynomial problems
(MST, shortest path, max flow, matching. . . )

Sanders: Algorithm Engineering / Big Data 50
Example: Sorting Benchmark (Indy) [8, 14]
100 byte records, 10 byte random keys, with file I/O
Category data volume performance improvement
GraySort 100 TB 564 GB / min 17×
MinuteSort 955 GB 955 GB / min > 10×
JouleSort 1 000 GB 13 400 Recs/Joule 4×
JouleSort 100 GB 35 500 Recs/Joule 3×
JouleSort 10 GB 34 300 Recs/Joule 3×
Also: PennySort

Sanders: Algorithm Engineering / Big Data 51
GraySort: inplace multiway mergesort, exact splitting [8]
16 GBRAM
240GB
Infiniband switch400 MB / s node all−all
XeonXeon

Sanders: Algorithm Engineering / Big Data 52
JouleSort [14]
� Intel Atom N330
� 4 GB RAM
� 4×256 GB
SSD (SuperTalent)
Algorithm similar to
GraySort

Sanders: Algorithm Engineering / Big Data 53
Applications that “Change the World”
Algorithmics has the potential to SHAPE applications
(not just the other way round) [G. Myers]
Bioinformatics: sequencing, proteomics, phylogenetic trees,. . .
Information Retrieval: Searching, ranking,
Traffic Planning: navigation, flow optimization,
adaptive toll, disruption management
Geographic Information Systems: agriculture, environmental protection,
disaster management, tourism,. . .
Communication Networks: mobile, P2P, grid, selfish users,. . .

Sanders: Algorithm Engineering / Big Data 54
AE for Big Data
experiencePS
Applicationssensor datagenomesdata baseswwwGISmobile...
data structuresgraphsgeometrystringscoding theory
Techniques
...
parallelismmemory hierarchiescommunicationfault toleranceenergy
Technology
AE

Sanders: Algorithm Engineering / Big Data 55
Larger Sorting Problems
� millions of processors
multipass algorithms
� fault tolerance
� still energy ∼ time?
Higly related to MapReduce, index construction,. . .

Sanders: Algorithm Engineering / Big Data 56
More Big Data Examples From my Group
� Suffix Sorting and its applications
� Main Memory Data Bases
� Graph Partitioning
� Track Reconstruction at CERN
� Route Planning
� Genome Sequencing
� Image Processing
� Priority Queues

Sanders: Algorithm Engineering / Big Data 57
Suffix Sorting
"to be or not to be"
WWW
banana
aanaananabananananana
sort suffixes si · · · sn of string
S = s1 · · · sn, si ∈ {1..n}.
Applications: full text search,
Burrows-Wheeler text compression, bioinformatics,. . .
E.g. phrase search in time logarithmic
or even independent of input size.
particularly interesting for large data

Sanders: Algorithm Engineering / Big Data 58
Linear Work Suffix Sorting [18]
simple: Radix-Sort + linear recursion + merging.
trivial external [19], parallel [20] adaptation
I’
anananas.012345678
nananas.0 sort .00
I
325241
lexicographic triple names
anaananannass.0
1 2 2 5432
42
3 5
1 ananas.00

Sanders: Algorithm Engineering / Big Data 59
Current Work
� distributed memory (external) query
� parallel distributed construction of query data structure
(longest common prefixes,. . . )

Sanders: Algorithm Engineering / Big Data 60
Data Bases – Our Approach [21, 22]
[with SAP HANA team, PhD students Dees, Müller]
� main memory based
� column based
� many-core machines
� NUMA-aware
� no precomputed aggregates
� aggressive indexing
� generate C++ code close to tuned manual implementation
forwardindexinverted
index

Sanders: Algorithm Engineering / Big Data 61
TPC-H Decision Support Benchmark
� 22 realistic queries of varying complexity
� pseudorealistic random data
� F GByte space
LINEITEM
=attribute
1.5M*F
150K*F
25
5
800K*F
10K*F
200K*F
6M*F
F = scale factor
NATIONPART
ORDERSPARTSUPP
SUPPLIER CUSTOMER
REGION
TPC−H Scheme

Sanders: Algorithm Engineering / Big Data 62
Typical TPC-H Queries
Q1: Revenue etc. of all shipped LINEITEMs
(aggregated into 6 categories)
plain flat scan of all LINEITEMs
Q9: Sum profit for all LINEITEMs with a given color
for each nation and order year.
scan PARTs,
use inverted index
to access matching LINEITEMs
Go down from there
using forward indices (≈pointers).
LINEITEM
NATIONPART
ORDERSPARTSUPP
SUPPLIER CUSTOMER
REGION
name
price...date
nation
cost
color

Sanders: Algorithm Engineering / Big Data 63
First Results [21]
� ≈ 30× faster than current record in 300GB category
(manual implementation)
� Compiler: seems to be largely orthogonal to algorithmic and
parallelization issues
LINEITEM
=attribute
1.5M*F
150K*F
25
5
800K*F
10K*F
200K*F
6M*F
F = scale factor
NATIONPART
ORDERSPARTSUPP
SUPPLIER CUSTOMER
REGION
TPC−H Scheme

Sanders: Algorithm Engineering / Big Data 64
Larger Inputs
� Already needed by some
large customers of SAP
� Move to clusters
Master thesis Martin Weidner
seems to give positive results
(5 TPC-H queries) [22]
� fault tolerance
beyond recovery?
� energy efficiency using many small nodes (ARM)?
Algorithmic Meat: Randomization, collective communication,
communication complexity, sorting, data structures, multi-level memory
hierarchies, coding theory
1 TB RAM
256 GB RAM 256 GB RAM 256 GB RAM
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
16 GB
Sanders: Algorithm Engineering / Big Data 65
Graph Partitionierung [23, 24]
Input: Graph (V,E) (possibly with node and edge weights), ǫ, k
Output: V1
·
∪ · · ··
∪ Vk mit |Vi| ≤ (1 + ǫ)
⌈|V |
k
⌉
Objective Function: minimize cut
Applications: finite element simulations, VLSI-design, route planning,. . .
Variants : hypergraphs, clustering, different objective functions,. . .

Sanders: Algorithm Engineering / Big Data 66
Multilevel Graph Partitioning
input graph
OutputPartition
contract
... ...
partitioning
initial
local improvement
uncontract

Sanders: Algorithm Engineering / Big Data 67
Reengineering Multilevel Graph Partitioning
input graph
[ESA10] [ESA11]
OutputPartition
contract
... ...
match
distr.evol. Alg.
partitioning
initial
local improvement
uncontract
[IPDPS10]
[ESA11] Cycles a la multigridW−F−V−
[Alenex12]
[IPDPS10]
[SEA12] [SEA13]
n−levelflows etc.
todo
+
edge ratings
parallel
augm. paths

Sanders: Algorithm Engineering / Big Data 68
Our Contribution
� scalable parallelization KaPPa
(matching, edge coloring, evolutionary)
� thorough reengineering of multilevel approch
(use flows, SCCs, BFS, matching, edge coloring,
negative cycle detection, . . . )
high quality (e.g. 90–99%
entries in Walshaw’s benchmark)

Sanders: Algorithm Engineering / Big Data 69
Large Data Graph Partitioning
� difficult inputs: social networks, WWW, 3D/4D models, VLSI,
knowledge graph?
� more difficult parallelization

Sanders: Algorithm Engineering / Big Data 70
Future Work
� parallel external
� other variants
� fault tolerant
� component of a graph processing framework

Sanders: Algorithm Engineering / Big Data 71
Track reconstruction [25]
Input: clouds of≈ 104 3D points
Output: < 103 spiral tracks of high energy particles
Also cluster tracks by emergence point
Large Data???
� up to 105 instances / s
� cost of processors / energy
� memory constrained
� exploit SIMD/GPU parallelism?
Algorithmic Meat:
Geometric data structures, parallelization, clustering
Sanders: Algorithm Engineering / Big Data 72
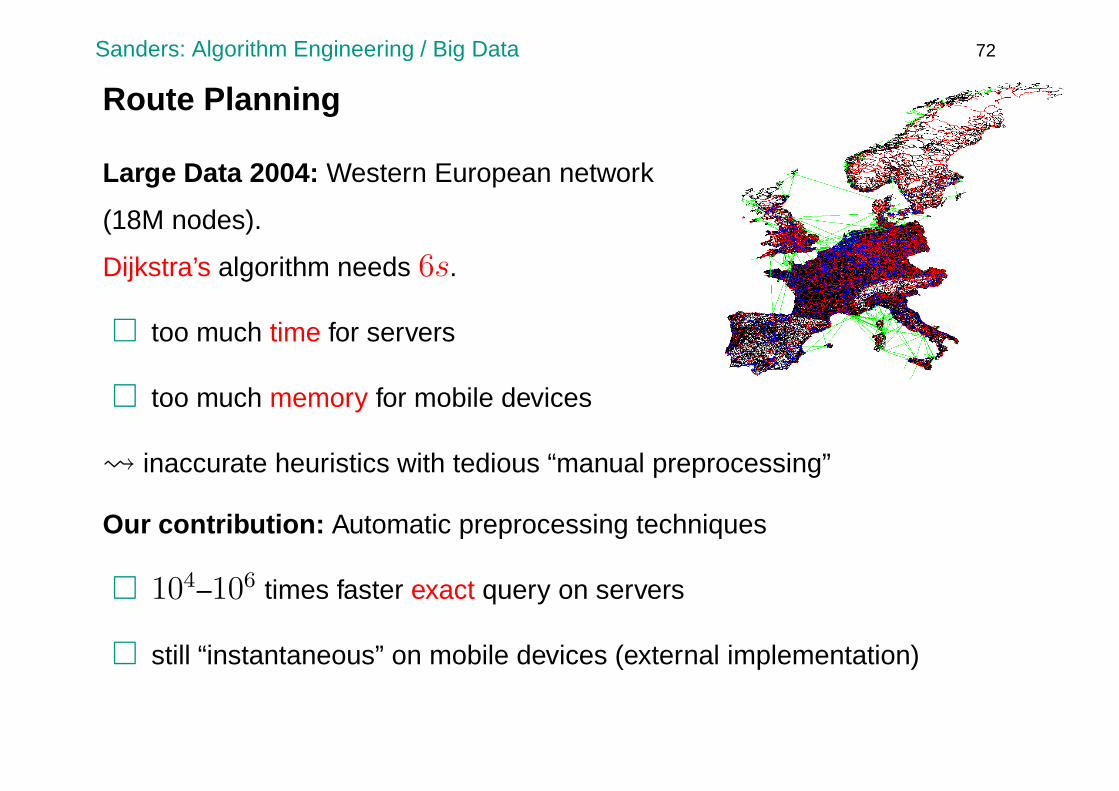
Route Planning [26]
Large Data 2004: Western European network
(18M nodes).
Dijkstra’s algorithm needs 6s.
� too much time for servers
� too much memory for mobile devices
inaccurate heuristics with tedious “manual preprocessing”
Our contribution: Automatic preprocessing techniques
� 104–106 times faster exact query on servers
� still “instantaneous” on mobile devices (external implementation)

Sanders: Algorithm Engineering / Big Data 73
Large Data 2013
� 1.6G nodes OpenStreetMap routing graph (edge based)
� billions of GPS traces
(+ road based sensors + elevation data)
� public transportation
Potential use:
� time-dependent edge weights [27]
� detailed traffic jam detection Google, TomTom,. . .
� multi-modal route planning [28]
� probabilistic route planning attempts
� really useful detours around traffic jams ???
use real time traffic simulation??

Sanders: Algorithm Engineering / Big Data 74
Genome Sequencing
[29]: 20 000 CPU hours for shotgun sequencing of the human genome
(3 · 109 base pairs, 5–10 times oversampling.
Prototypical large data problem?
Today: a few minutes on a work station [ZieglerDFMS work in progr.]
(use template, modern hardware, AE + cheap sequencing)
routine use for personal medicine
New Challenge:
processing many sequences

Sanders: Algorithm Engineering / Big Data 75
Phylogenetic Tree Reconstruction

Sanders: Algorithm Engineering / Big Data 76
Image Processing [30]
Gigapixel aerial images.
Filters, Segmentation, Change detection
Algorithmic meat: Graph algorithms, parallelization, memory
hierarchies, range minimum data structures,. . .

Sanders: Algorithm Engineering / Big Data 77
External Priority Queues
Problem: Binary heaps need
Θ(
logn
M
)
I/Os per deleteMin
We would rather have:
Θ
(1
BlogM/B
n
M
)
I/Os (amortized)

Sanders: Algorithm Engineering / Big Data 78
Medium Size PQs – km≪M 2/B Insertions
minsertionbuffer PQ
sortedsequences
PQ
...1 2 k
k−merge
mB
Insert: Initially into insertion buffer.
Overflow−→
sort; flush; smallest key is now in merge PQ
Delete-Min: deleteMin from the PQ with smaller min

Sanders: Algorithm Engineering / Big Data 79
Large Queues
≈2n
B
(
1 +⌈
logM/B
n
M
⌉)
I/Os for n insertiosn
O(n log n) Arbeit.
[31].
deleteMin:
“amortisiert umsonst”.
group− group− group−buffer bufferbuffer 1 2 3
cached
externalswapped
group 1
group 2
group 3Sequence Heap Priority Queues
k k
k
m
m m
2T 3T
...1 2 k ...1 2 k ...1 2 k
k−merge k−merge k−merge
R−merge
m
m’
m
1T
deletion buffer
m
insertion bufferm

Sanders: Algorithm Engineering / Big Data 80
Experiments
Keys: random 32 bit integers
Associated information: 32 dummy bits
Deletion buffer size: 32 Near optimal
Group buffer size: 256 : performance on
Merging degree k: 128 all machines tried!
Compiler flags: Highly optimizing, nothing advanced
Operation Sequence:
(Insert-DeleteMin-Insert)N(DeleteMin-Insert-DeleteMin)N
Near optimal performance on all machines tried!
Sanders: Algorithm Engineering / Big Data 81
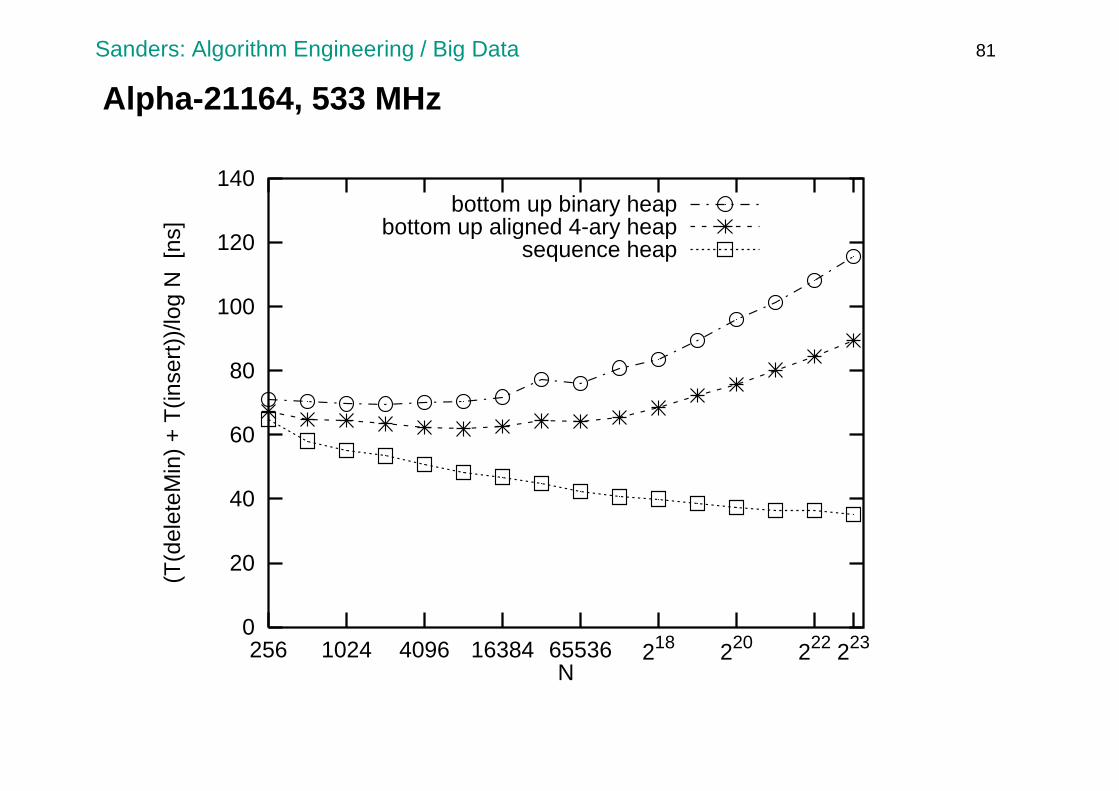
Alpha-21164, 533 MHz
0
20
40
60
80
100
120
140
256 1024 4096 16384 65536 218 220 222 223
(T(d
elet
eMin
) +
T(in
sert
))/lo
g N
[ns
]
N
bottom up binary heapbottom up aligned 4-ary heap
sequence heap

Sanders: Algorithm Engineering / Big Data 82
Core2 Duo Notebook, 1.??? GHz
0
5
10
15
20
25
1024 4096 16384 65536 218 220 222 223
(T(d
elet
eMin
) +
T(in
sert
))/lo
g N
[ns
]
N
bottom up binary heapsequence heap

Sanders: Algorithm Engineering / Big Data 83
Future Work
� see above
� find more algorithmic application problems
� algorithmic cores of application independent libraries and tools
data structures, MapReduce, graphs, data bases,. . .
� distributed memory external algorithms
� back to massive parallelism including exascale
� fault tolerance

Sanders: Algorithm Engineering / Big Data 84
Commercial Break
I am hiringPhD students, Postdocs in algorithm engineering.
Desirable Skills:
� Desire to bridge gaps between theory and practice
� Algorithmics
� Performance oriented C++ programming
� Parallelization, e.g., MPI, OpenMP,. . .

Sanders: Algorithm Engineering / Big Data 85
Literatur[1] P. Sanders. Algorithm engineering – an attempt at a definition. In Efficient Algorithms, volume 5760 of LNCS, pages 321–340. Springer,
2009.
[2] K. Mehlhorn and S. Näher. The LEDA Platform of Combinatorial and Geometric Computing. Cambridge University Press, 1999.
[3] U. Meyer, P. Sanders, and J. Sibeyn, editors. Algorithms for Memory Hierarchies, volume 2625 of LNCS Tutorial. Springer, 2003.
[4] Peter Sanders, Sebastian Schlag, and Ingo Müller. Communication efficient algorithms for fundamental big data problems. In IEEE Int.
Conf. on Big Data, 2013.
[5] D. A. Hutchinson, P. Sanders, and J. S. Vitter. Duality between prefetching and queued writing with parallel disks. SIAM Journal on
Computing, 34(6):1443–1463, 2005.
[6] K. Mehlhorn and P. Sanders. Scanning multiple sequences via cache memory. Algorithmica, 35(1):75–93, 2003.
[7] P. Sanders and S. Winkel. Super scalar sample sort. In 12th European Symposium on Algorithms, volume 3221 of LNCS, pages
784–796. Springer, 2004.
[8] M. Rahn, P. Sanders, and J. Singler. Scalable distributed-memory external sorting. In 26th IEEE International Conference on Data
Engineering, pages 685–688, 2010.
[9] N. Leischner, V. Osipov, and P. Sanders. GPU sample sort. CoRR, abs/0909.5649, 2009. submitted for publication.
[10] R. Dementiev and P. Sanders. Asynchronous parallel disk sorting. In 15th ACM Symposium on Parallelism in Algorithms and
Architectures, pages 138–148, San Diego, 2003.
[11] J. Singler, P. Sanders, and F. Putze. MCSTL: The multi-core standard template library. In 13th International Euro-Par Conference,
volume 4641 of LNCS, pages 682–694. Springer, 2007.
[12] K. Mehlhorn and P. Sanders. Algorithms and Data Structures — The Basic Toolbox. Springer, 2008.
[13] A. Beckmann, R. Dementiev, and J. Singler. Building a parallel pipelined external memory algorithm library. In 23rd IEEE International
Symposium on Parallel and Distributed Processing, pages 1–10, 2009.

Sanders: Algorithm Engineering / Big Data 86
[14] A. Beckmann, U. Meyer, P. Sanders, and J. Singler. Energy-efficient sorting using solid state disks. In 1st International Green
Computing Conference, pages 191–202. IEEE, 2010.
[15] R. Dementiev, L. Kettner, and P. Sanders. STXXL: Standard Template Library for XXL data sets. Software Practice & Experience,
38(6):589–637, 2008.
[16] J. Singler and B. Kosnik. The libstdc++ parallel mode: Software engineering considerations. In International Workshop on Multicore
Software Engineering (IWMSE), 2008.
[17] David A. Bader, Henning Meyerhenke, Peter Sanders, and Dorothea Wagner, editors. Graph Partitioning and Graph Clustering – 10th
DIMACS Implementation Challenge Workshop, volume 588 of Contemporary Mathematics. American Mathematical Society, 2013.
[18] J. Kärkkäinen, P. Sanders, and S. Burkhardt. Linear work suffix array construction. Journal of the ACM, 53(6):1–19, 2006.
[19] R. Dementiev, J. Kärkkäinen, J. Mehnert, and P. Sanders. Better external memory suffix array construction. ACM Journal of
Experimental Algorithmics, 12, 2008. Special issue on Alenex 2005.
[20] F. Kulla and P. Sanders. Scalable parallel suffix array construction. Parallel Computing, 33:605–612, 2007. Special issue on Euro
PVM/MPI 2006, distinguished paper.
[21] Jonathan Dees and Peter Sanders. Efficient many-core query execution in main memory column-stores. In 29th IEEE Conference on
Data Engineering, 2013.
[22] Martin Weidner, Jonathan Dees, and Peter Sanders. Fast olap query execution in main memory on large data in a cluster. In IEEE Int.
Conf. on Big Data, 2013.
[23] Vitaly Osipov, Peter Sanders, and Christian Schulz. Engineering graph partitioning algorithms. In 11th International Symposium on
Experimental Algorithms (SEA), volume 7276 of LNCS, pages 18–26. Springer, 2012.
[24] Christian Schulz. High Quality Graph Partitioning. PhD thesis, Karlsruhe Institute of Technology, 2013.
[25] Daniel Funke. Parallel triplet finding for particle track reconstruction. Master’s thesis, Karlsruhe Institute of Technology, 2013.
[26] D. Delling, P. Sanders, D. Schultes, and D. Wagner. Engineering route planning algorithms. In Algorithmics of Large and Complex
Networks, volume 5515 of LNCS State-of-the-Art Survey, pages 117–139. Springer, 2009.

Sanders: Algorithm Engineering / Big Data 87
[27] Gernot Veit Batz and Peter Sanders. Time-dependent route planning with generalized objective functions. In 20th European Symposium
on Algorithme (ESA), volume 7501 of LNCS, pages 169–180. Springer, 2012.
[28] Hannah Bast, Erik Carlsson, Arno Eigenwillig, Robert Geisberger, Chris Harrelson, Veselin Raychev, and Fabien Viger. Fast routing in
very large public transportation networks using transfer patterns. In 18th European Symposium on Algorithms, volume 6346 of LNCS,
pages 290–301, 2010.
[29] J Craig Venter. Sequencing the human genome. In Proceedings of the sixth annual international conference on Computational biology,
pages 309–309. ACM, 2002.
[30] Jan Wassenberg. Efficient Algorithms for Large-Scale Image Analysis. PhD thesis, Karlsruhe Institute of Technology, 2011.
[31] P. Sanders. Fast priority queues for cached memory. ACM Journal of Experimental Algorithmics, 5, 2000.